Początek roku to dobry czas na podsumowanie roku poprzedniego. Wykorzystajmy więc ten moment i podsumujmy 2018. Oczywiście z użyciem R.
W zeszłym roku dokonałem analogicznego podsumowania opartego jedynie o dane z Google Analytics. Tym razem skorzystamy bezpośrednio z danych zawartych w postach (ale uzupełnimy je o dane z Google Analytics), dla ułatwienia wyciągniętych z bazy danych.
Chciałbym dowiedzieć się kilku rzeczy o moim pisaniu w 2018 roku:
- Jakich słów używałem najczęściej?
- Czy da się podzielić posty na tematy?
- Jak długo żyją posty (ile dni po publikacji są czytane)?
- Czy istnieje korelacja pomiędzy liczbą wizyt a liczbą komentarzy?
Ja to wszystko wiem na bieżąco, ale pokażę Wam jak to zrobić. A nuż przyjdzie komuś przeprowadzić podobną analizę? Antyweb, Spider’s Web, Niebezpiecznik – Was przeanalizowałbym najchętniej pod tym kątem :) Grzesiek, Przemek, Piotrek – piszcie na maila! Potrale nawet chętniej…
Ale jedźmy (“…nikt nie woła”). Kilka bibliotek nam się przyda:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
# operacje na danych, datach i wygodne łączenie tekstów library(tidyverse) library(lubridate) library(glue) # operacje na bazie danych library(RMySQL) # operacje na tekstach, chmurka słów, LDA library(tidytext) library(wordcloud) library(topicmodels) # ładne tabelki library(knitr) library(kableExtra) # pobranie danych z Google Analytics library(RGoogleAnalytics) |
Mój blog stoi na WordPressie. Miałem ochotę na przesiadkę na coś statycznego (są gotowe narzędzia do renderowania całych stron wprost z plików napisanych w markdown), ale szkoda mi komentarzy. Poza tym WordPress to wygodny CMS, chociaż update edytora w wersji 5.0 jest irytujący (i tak wklejam gotowego HTMLa wygenerowanego z RStudio).
W każdym razie – skoro WordPress to cała zawartość (oraz konfiguracja) leży w SQLowej bazie danych (MySQL konkretnie). Baza jest dość prosta w konstrukcji, a nas interesować będzie tabela wp_posts w której znajdziemy wszystkie podstawowe informacje o postach (a także stronach czy elementach nawigacji) oraz tabela wp_postmeta gdzie są dodatkowe meta-dane (interesują nas skróty artykułów dla social media, które zapisuje plugin All in One SEO).
Aby sięgnąć do bazy trzeba znać namiary na nią – serwer, nazwę bazy, login i hasło użytkownika. Oto one:
|
1 2 3 4 5 |
# baza wordpress dbname = "***" user = "***" password = "***" host = "***" |
;-) Oczywiście, że ich nie podam.
Ponieważ będziemy analizować teksty to standardowo przyda się słownik polskich (bo i teksty polskie) stop words, o którym było już nie raz. U mnie leży on sobie w specjalnym miejscu na dane słownikowe i zapisany jest w postaci pliku tekstowego (każde słowo w oddzielnej linii):
|
1 |
pl_stop_words <- read_lines("~/RProjects/!polimorfologik/polish_stopwords.txt") |
Uzbrojeni w potrzebne parametry możemy połączyć się z bazą:
|
1 2 3 4 5 6 7 8 |
# łączymy się z bazą danych db_drv <- dbDriver("MySQL") db_conn <- dbConnect(db_drv, dbname = dbname, user = user, password = password, host = host) # aby pozbyć się problemu polskich liter dbSendQuery(db_conn, "SET NAMES utf8;") dbSendQuery(db_conn, "SET CHARACTER SET utf8;") dbSendQuery(db_conn, "SET character_set_connection=utf8;") |
Trzy ostatnie linie to poinformowanie bazy w jakim formacie ma obsługiwać znaki narodowe. Nie wiem dlaczego tak jest, ale sięgając do bazy z poziomu R (czy to czytając czy zapisując dane) mam krzaki zamiast polskich znaków, mimo że wszystko ustawione jest na UTF8. Ważne, że powyższe linie robią porządek.
Zacznijmy od pobrania danych z bazy.
Potrzebujemy informacji o postach (tutaj tylko tych utworzonych po 1.01.2018) – ze wspomnianej tabeli wp_posts. Weźmiemy tylko potrzebne informacje:
- ID – ID postu w bazie WordPressa
- post_date – data (i czas) utworzenia postu
- post_title – tytuł postu
- post_content – treść postu, w formie HTML
- post_name – nazwa postu użyta w jego URLu
- comment_count – liczba komentarzy
Z drugiej tabeli (wp_postmeta) weźmiemy wszystkie kolumny, ale tylko dla postów już pobranych (wyławiając je po ID) i tylko taki meta_key który nas interesuje (tutaj: _aioseop_description).
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
# pobieramy treści postów wp_posts <- dbGetQuery(db_conn, 'SELECT ID, post_date, post_title, post_content, post_name, comment_count FROM wp_posts WHERE post_date >= "2018-01-01" AND post_status = "publish" AND post_type = "post";') # pobieramy metadane dla postów (konkretne opis z pluginu All in One SEO) wp_postmeta <- dbGetQuery(db_conn, paste0('SELECT * FROM wp_postmeta WHERE post_id IN (', paste0(wp_posts$ID, collapse = ', '), ') AND meta_key = "_aioseop_description";')) # odpinamy się od bazy dbDisconnect(db_conn) |
Na koniec odpięliśmy się od bazy.
Teraz zbudujemy sobie adres (fragment) postu – to będzie potrzebne do złączenia danych z informacjami z Google Analytics oraz do linkowania do postów w tabelce (poniżej będzie taka tabela ze spisem treści 2018 roku). U mnie adres postów zawiera datę, więc odpowiednio trzeba przygotować link:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
# budujemy urla do postu wp_posts <- wp_posts %>% mutate(post_url = sprintf("/index.php/%04d/%02d/%02d/%s/", year(post_date), month(post_date), day(post_date), post_name)) # łączymy opis z postami wp_posts <- left_join(wp_posts, wp_postmeta %>% select(post_id, post_description = meta_value), by = c("ID" = "post_id")) %>% filter(!is.na(post_description)) |
W drugiej operacji dodałem kolumnę z opisem (takim niby leadem dla social mediów) wziętym z wp_postmeta.
Przystępujemy do analizowania tekstów z całego roku. Jakich słów używałem najczęściej? Czy da się podzielić posty na tematy? Analiza treści ma odpowiedzieć na te pytania.
W moich postach dużą cześć treści zajmują kody źródłowe – te nie powinny podlegać analizie (no, chyba że chciałbym dowiedzieć się z jakich bibliotek korzystam albo jak nazywam zmienne), więc trzeba ich się pozbyć z treści. Trzeba też pozbyć się znaczników HTML (to może zrobić za nas pakiet tidytext w momencie podzielnia tekstu na słowa, ale dla celów edukacyjnych zrobimy to ręcznie). Kody źródłowe mam pomiędzy znacznikami <pre> i </pre> więc zadanie będzie łatwe. To samo można zrobić dla tabelek, ale to nie tym razem.
|
1 2 3 4 5 6 7 8 9 10 11 |
# usuwamy kod z treści postów wp_posts <- wp_posts %>% mutate(post_content_stripped = post_content %>% # usuwamy kod z postów - wszystko pomiędzy "<pre" a "</pre>" usuwamy str_replace_all("<pre(.|\\n|\\r)*?<\\/pre>", "") %>% # usuwamy znaczniki html z treści str_replace_all("<.*?>", "") %>% # zamienamy kropki i przecinki na spacje str_replace_all("(\\.|\\,)", " ") %>% # usuwamy podwójne spacje itd, chociaż to po nic :) str_squish()) |
Jedno wyjaśnienie – dlaczego zamieniam kropki na spacje, skoro użyta funkcja unnest_tokens uważa kropkę za znak podziału między słowami? Ano dlatego, że owszem używa, ale w przypadku adresów internetowych pozostają one w całości. Bo nie ma po kropce spacji. No tak jest.
Podzielmy więc oczyszczone teksty na pojedyncze słowa i oczyśćmy je z stop words (czy jest jakiś polski odpowiednik tego sformułowania?), usuńmy to co jest liczbą (jeśli konwersja na liczbę się uda to coś jest liczbą) oraz słowa krótsze niż 2 znaki (bo to śmieci są).
|
1 2 3 4 5 6 7 8 9 10 11 |
# podział tekstów na słowa words <- wp_posts %>% select(post_title, post_content_stripped) %>% unnest_tokens(words, post_content_stripped) %>% count(post_title, words) %>% # usuwamy stop words filter(!words %in% pl_stop_words) %>% # usuwamy liczby filter(is.na(as.numeric(words))) %>% # zostawiamy słowa dłuższe niz 2 znaki filter(nchar(words) > 2) |
Mamy podział na słowa dla każdego postu osobno (taki przyda się za chwilę, do analizy tematów postów), a do znalezienia najpopularniejszych słów potrzebujemy policzyć je globalnie. No to agregujemy globalnie:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
# najpopularniesze słowa w postach words_cnt <- words %>% group_by(words) %>% summarise(n = sum(n)) %>% ungroup() plot <- words_cnt %>% top_n(50, n) %>% mutate(words = reorder(words, n)) %>% ggplot() + geom_col(aes(words, n), fill = "lightgreen") + coord_flip() + labs(title = "Najpopularniejsze słowa użyte w postach", y = "Liczba wystąpień", x = "") da_plot(plot) |
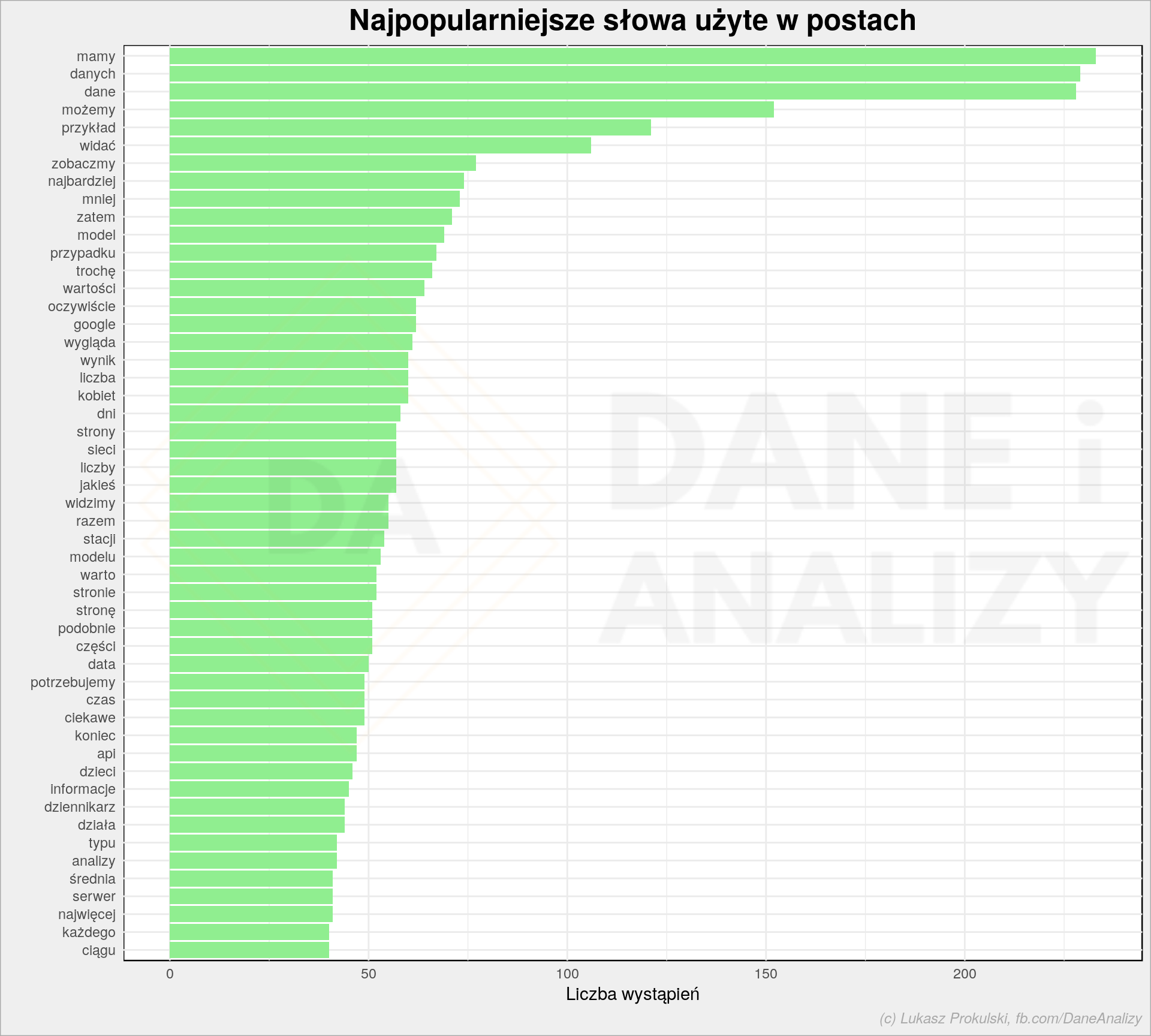
Nie ma (nie powinno być) zaskoczenia, że najpopularniejsze słowa to dane i okolice oraz możemy czy zobaczmy – w takim stylu piszę posty (zobaczmy na przykładzie jak to zrobić). Cała reszta ma związek z treścią postów.
Wykresy wymagają jakiegoś dodatniego IQ, gawiedź lubi chmurki słów. Proszę bardzo:
|
1 2 3 4 |
wordcloud(words_cnt$words, words_cnt$n, max.words = 100, scale = c(2.8, 0.8), colors = RColorBrewer::brewer.pal(9, "Reds")[5:9]) |

Przy analizie tematów te bardzo popularne słowa (największe na powyższej chmurce) zrobią nam problem – są za mało unikalne dla poszczególnych postów. Rozszerzymy więc słownik stop words o 20 najpopularniejszych słów z postów (zgodnie z prawem Zipfa to powinno się sprawdzić; 20 jest liczbą dobraną, że tak powiem, z dupy).
|
1 2 3 4 5 |
# górne 20 słów traktujemy jako stopwords dedicated_stop_words <- words_cnt %>% top_n(20, n) %>% pull(words) # dodajmy jeszcze jakieś śmieci dedicated_stop_words <- c(dedicated_stop_words, "http", "https", "the", "and") |
Teraz możemy narysować chmurkę słów bez tych dodatkowych stop words:
|
1 2 3 4 5 6 7 8 |
# usuwamy dedykowane stop words words_cnt <- words_cnt %>% filter(!words %in% dedicated_stop_words) # ponownie rysujemy chmurkę wordcloud(words_cnt$words, words_cnt$n, max.words = 100, scale = c(1.8, 0.4), colors = RColorBrewer::brewer.pal(9, "Reds")[5:9]) |
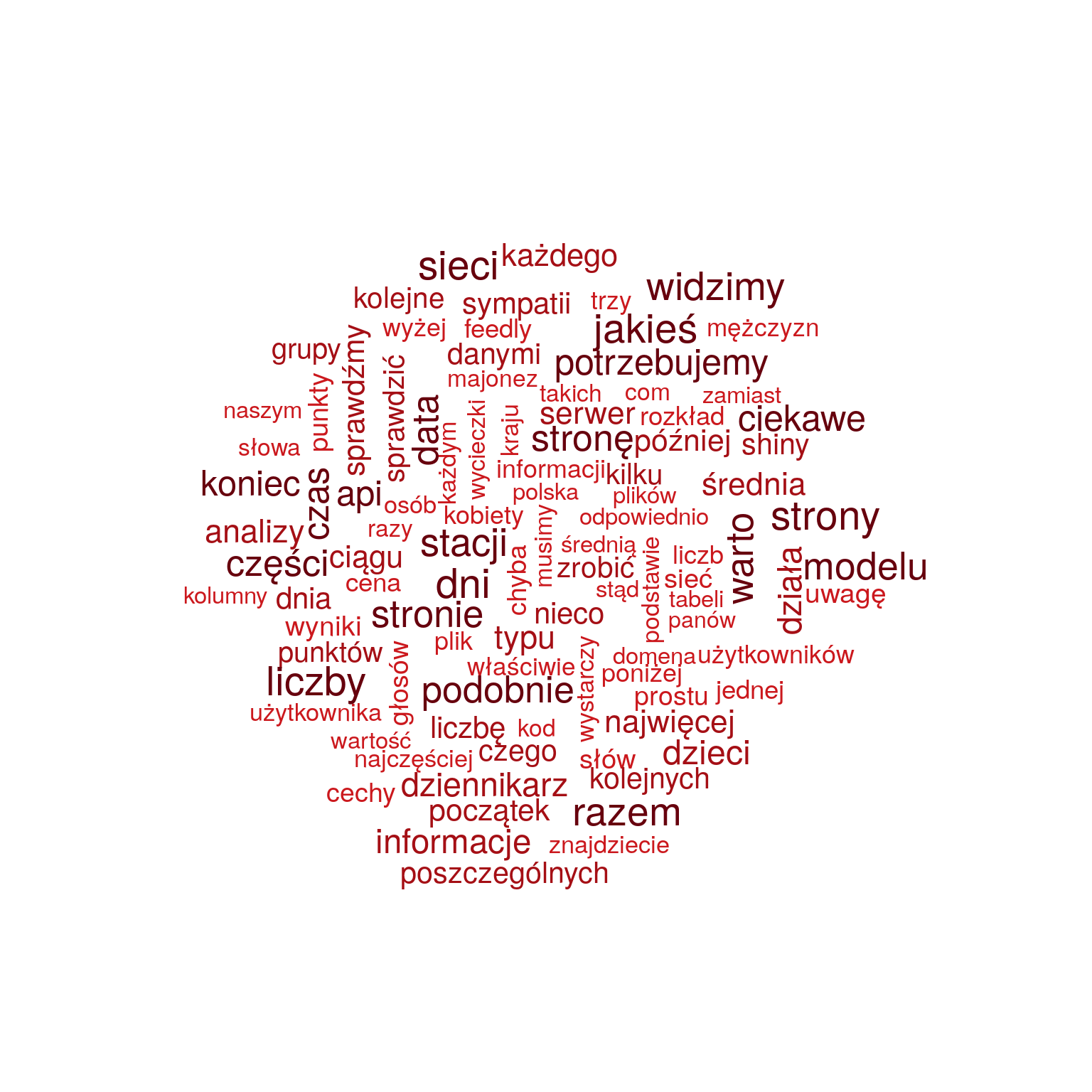
Prawda, że lepiej widać o czym jest ten blog? Liczby, sieci, API, serwer. Za mało predykcja czy model – to moje plany na 2019.
Zgodnie ze sztuką analizy tekstu spróbujmy poszukać tematów opisujących poszczególne teksty. Zgodnie ze sztuką skorzystamy z algorymtu LDA. Powiedzmy, że skoro było 12 miesięcy to może jest 12 tematów (parametr k = 12)?
|
1 2 3 4 5 6 7 8 9 10 |
# LDA # najpierw Document Term Matrix dtm <- words %>% filter(!words %in% dedicated_stop_words) %>% cast_dtm(post_title, words, n) # potem LDA lda <- LDA(dtm, k = 12, control = list(seed = 12345)) |
LDA daje nam dwa widoki – przypisanie słów do tematów oraz przypisanie tematów do dokumentów. Zajmijmy się na początek tym pierwszym:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
# słowa opisujące tematy posts_beta <- tidy(lda, matrix = "beta") plot <- posts_beta %>% group_by(topic) %>% top_n(10, beta) %>% ungroup() %>% mutate(term = reorder(term, beta)) %>% ggplot(aes(term, beta, fill = factor(topic))) + geom_col(show.legend = FALSE) + facet_wrap(~topic, scales = "free") + coord_flip() + labs(title = "Słowa określające tematy postów", subtitle = "Na podstawie LDA", y = "beta", x = "") da_plot(plot) |
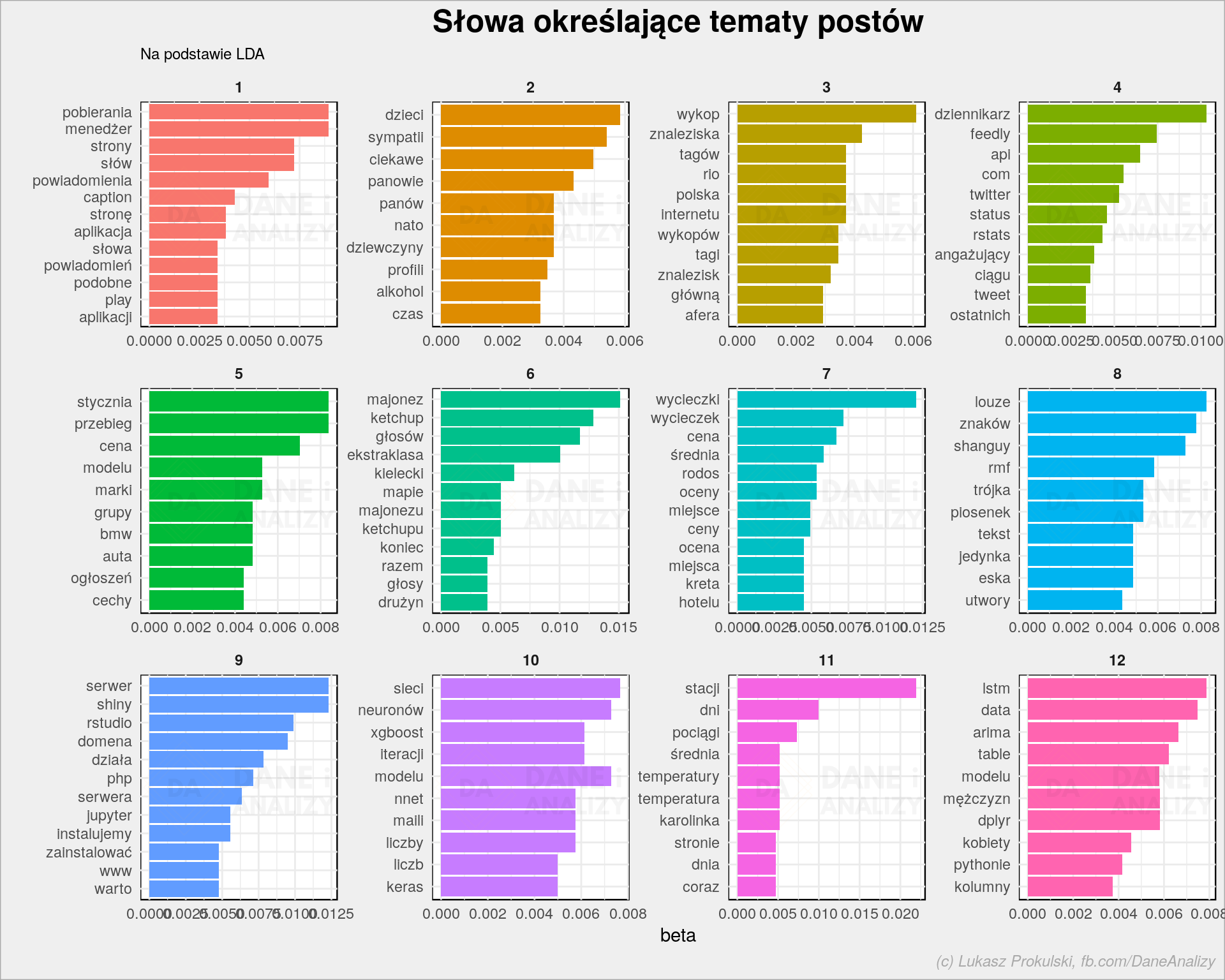
Analizując poszczególne małe wykresiki (głównie słowa na nich wypisane) można dojść do wniosku, że słowa się powtarzają więc tematów jest za dużo. Albo są to kolejne stop words. Pozostańmy przy tym co jest.
Ewidentnie widać kilak tematów:
- serwer, shiny, php, domena, jupyter – to post o przygotowaniu serwera na potrzeby data science
- majonez, ketchup, ekstraklasa – to podsumowanie ankiety majonezowo-ketchupowej
- powiadomienia, menedżer, aplikacja, play – był post o powiadomieniach jakie pokazuje mój telefon komórkowy
- wycieczki, rodos, cena – to analiza cen wycieczek do Grecji
- RMF, Shanguy czy Trójka – to post o tym co znajduje się na playlistach stacji radiowych
- wykop, tagi, afera – niedawny post o Wykop.pl
- przebieg, auta, ogłoszeń – pierwszy ubiegłoroczny hit na Wykopie, czyli analiza ogłoszeń sprzedaży aut używanych
- xgboost, nnet, keras – coś o sieciach neuronowych i modelach wszelakich
Podobnie da się rozpoznać inne tematy. Zresztą całe zestawienie za chwilę. Przygotujmy listę dokumentów z największym gamma dla tematu – to da nam pojęcie o tym który dokument (post) pasuje najbardziej do danego tematu:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
# przypisanie postów do tematów posts_gamma <- tidy(lda, matrix = "gamma") # lista postów z 2018 roku wraz z pisaniem ich do tematów posts_gamma %>% # dla każdego postu wybieramy najbardziej znaczący temat group_by(document) %>% top_n(1, gamma) %>% ungroup() %>% # dodajemy opisy postów i linki do nich left_join(wp_posts %>% select(post_url, post_title, post_description), by = c("document" = "post_title")) %>% mutate(link = glue('<a href="{post_url}">{document}</a>')) %>% arrange(topic, document) %>% select(topic, link, post_description) %>% set_names(c("ID tematu", "Tytuł posta", "Opis")) %>% kable(escape = FALSE) %>% kable_styling(bootstrap_options = c("striped", "hover", "condensed", "responsive")) |
| ID tematu | Tytuł posta | Opis |
|---|---|---|
| 1 | Kto pisze teksty przemówień prezydenta Dudy? | Czy wystąpienia Prezydenta Andrzeja Dudy są do siebie podobne? Jak to sprawdzić korzystając z R i FastText? |
| 1 | Powiadomienia z telefonu i IFTTT.com | Jak przygotować sobie dane o sobie? Jak dostać się do Google Drive z poziomu języka R? |
| 1 | Webscrapping w R | Jak pobrać dane ze strony WWW w R? |
| 2 | Chłopaki z Sympatii | Średnio jest to niebieskooki ciemny blondyn, 180 cm z Mazowsza, w 90% katolik o normalnej budowie ciała. Czuły, dowcipny, spokojny. Szuka… – właśnie, czego? |
| 2 | Dziewczyny z Sympatii | Ponad 1/3 kobiet na Sympatii szuka miłości. Chce się zakochać, wyjść za mąż i mieć dzieci. Jest czuła i towarzyska. Ich partner powinien być… Właśnie – JAKI? |
| 2 | Facebook w R | Kto uważany jest za gwiazdę rozrywki 100-lecia niepodległej Polski? |
| 2 | Zmiany w Polsce a głosowanie w ONZ | Jak wygląda sytuacja geopolityczna Polski na podstawie głosowania w Zgromadzeniu Ogólnym Organizacji Narodów Zjednoczonych? |
| 3 | Analiza wykopalisk z głównej strony Wykop.pl | Czy Wykop to obraz całego świata czy tylko specyficzny dla społeczności wycinek? Co cieszy się największym powodzeniem? |
| 3 | Mapy hipsometryczne | Rozdzielenie danych punktowych na gminy, powiaty i województwa. Wskazówki jak pokazywać takie dane na mapie. Na przykładzie danych o wysokości terenu |
| 4 | API, Feedly i R | Jak zmusić R do korzystania z (dowolnego) API? Jak przygotować atrakcyjne tabelki w raportach? |
| 4 | Google Analytics w R | Jak pobrać dane z Google Analytics do R? Jak z nich korzystać? |
| 4 | Jak zrobić twitterowego bota? | Automaty rządzą naszym życiem, szczególnie w sieciach społecznościowych. Spróbujmy samodzielnie przygotować taki automat działający w social mediach. |
| 4 | MNIST dataset – sieci neuronowe, część 3 (sieć CNN) | Rozpoznawanie liczb ze zbioru MNIST przy pomocy sieci konwolucyjnej CNN w R oraz Keras – 99.35% skuteczności! |
| 5 | Kategoryzacja użytkowników strony www | Jak podzielić klientów na grupy? Na przykładzie użytkowników strony internetowej |
| 5 | Sprzedam Opla | Auta na sprzedaż – czego można dowiedzieć się z ogłoszeń? Jak ustrzelić okazję? Analiza danych z ogłoszeń Otomoto.pl |
| 6 | Wielka bitwa majonezów! Ketchupów też | Dwie najpopularniejsze marki majonezu zagarniają łącznie prawie 2/3 rynku, Najpopularniejszy ketchup zgarnia nieco ponad 1/4. |
| 7 | Gdzie Polacy jadą na wakacje? | Gdzie Polak jedzie na urlop? W ile osób jedzie? Ile to kosztuje? |
| 7 | Wycieczki do Grecji | Ile kosztuje wycieczka do Grecji? Czy last minute jest opłacalne i kiedy cena zaczyna spadać? |
| 8 | Co grało radio? | Jakie są najpopularniejsze stacje radiowe w Polsce i jaką grają muzykę? |
| 8 | LSTM – przewidywanie tekstu (sieci neuronowe, część 4) | Czy da się napisać tekst za pomocą sieci neuronowych? Wykorzystanie Keras w R do zbudowania sieci Long Short Term Memory |
| 8 | MNIST dataset – sieci neuronowe, część 0 (przygotowanie) | Zaczynamy cykl związany z sieciami neuronowymi. Zaczniemy od przygotowania danych. |
| 9 | Gdzie są sklepy, drogi czy cokolwiek innego? | Gdzie są sklepy, drogi czy cokolwiek innego? Jak wykorzystać Open Street Map w R (i mapach leaflet)? |
| 9 | Stawiamy własny serwer | Budujemy własny serwer do programowania w R i Pythonie, razem z serwerem WWW, PHP oraz bazami danych MySQL i PostgreSQL. |
| 10 | Dziewczyny z Sympatii – co widać na zdjęciach? | Jakie cechy można rozpoznać na zdjęciach? Czy dziewczyny w okularach czytają więcej książek? Jakiej muzyki należy słuchać, żeby się uśmiechać? |
| 10 | Jak odczytać maile z Gmaila w R? | Jak stworzyć mechanizm informujący, że w skrzynce odbiorczej wzrasta liczba maili dotyczących określonego tematu? |
| 10 | MNIST dataset – sieci neuronowe, część 1 (xgboost i nnet) | Budujemy pierwszą sieć neuronową oraz porównujemy jej wyniki z XGBoost. |
| 10 | MNIST dataset – sieci neuronowe, część 2 (Keras) | Sieci neuronowe w R – Keras |
| 10 | Shiny – punkty z mapki | Użytkownik klika w mapę – jak pobrać współrzędne klikniętego miejsca? |
| 11 | A lato było cieplejsze… | Czy w Boże Narodzenie zawsze brakowało śniegu? Czy klimat się ociepla? Jak ciepło przepływa przez Polskę? |
| 11 | Spark, czyli opóźnienia pociągów | Czy polskie pociągi są punktualne? To pytanie jest tylko przyczynkiem do poznania Apache Sparka |
| 12 | Przewidywanie pogody | Prognozowanie szeregów czasowych i weryfikacja modeli, na przykładzie prognozowania temperatury. |
| 12 | R-base, R-dplyr, R-data.table i Python | Podstawy manipulacji danymi w tabelkach. W R (trzy wersje) oraz w Pythonie. |
| 12 | Sympatia – porównanie pań i panów | Czy kobiety z Sympatii oczekują tego co mogą dać im panowie? A czy panowie lubią ten sam sport co panie? |
To spis treści całego 2018 roku na moim blogu. Niektóre połączenia postów w ramach jednego tematu są dość zaskakujące.
Przy okazji zobaczyliście jak łatwo za pomocą pakietu kableExtra zrobić ładną tabelkę w dokumentach generowanych z Markdown.
Dodajmy dane o ruchu z Google Analytics. Znowu – nie pokażę odpowiednich tokenów czy ID stron. Jak je zdobyć? Zerknij do stosownego postu.
|
1 2 3 4 5 |
# token do GA oauth_token <- Auth(client.id = "***", client.secret = "***") # ID strony w GA ga_page_id <- "ga:xxxx" |
Sprawdzamy token i pobieramy dane. Tutaj tylko liczbę odsłon (page views) i użytkowników (users) dla każdego dnia i każdego adresu odwiedzonego w ramach witryny.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
ValidateToken(oauth_token) # dane z ostatniego roku query_list <- Init(start.date = "2018-01-01", end.date = "2018-12-31", dimensions = "ga:date,ga:pagePath", metrics = "ga:pageviews,ga:users", max.results = 50000, table.id = ga_page_id) ga_query <- QueryBuilder(query_list) view_ga_data <- GetReportData(ga_query, oauth_token) # wyciągamy url strony zgodnie z tym jak wyglądają urle do postów view_ga_data <- view_ga_data %>% mutate(post_page_path = str_extract(pagePath, "(\\/\\d+\\/\\d+\\/\\d+\\/[a-z\\-\\_0-9]*\\/)")) %>% mutate(post_page_path = paste0("/index.php", str_trim(post_page_path))) %>% # agregujemy do tak przygotowanych urli group_by(post_page_path, date) %>% summarise(pageviews = sum(pageviews), users = sum(users)) %>% ungroup() |
Które posty cieszyły się największą popularnością?
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
# ktory post był najpopularniejszy? wp_posts <- left_join(wp_posts, view_ga_data %>% group_by(post_page_path) %>% summarise(pageviews = sum(pageviews), users = sum(users)) %>% ungroup(), by = c("post_url" = "post_page_path")) plot <- wp_posts %>% mutate(post_title = reorder(post_title, pageviews)) %>% ggplot() + geom_col(aes(post_title, pageviews), fill = "lightgreen") + coord_flip() + labs(title = "Najpopularniejsze posty według liczby odsłon", y = "Liczba odsłon (page views)", x = "") da_plot(plot) |
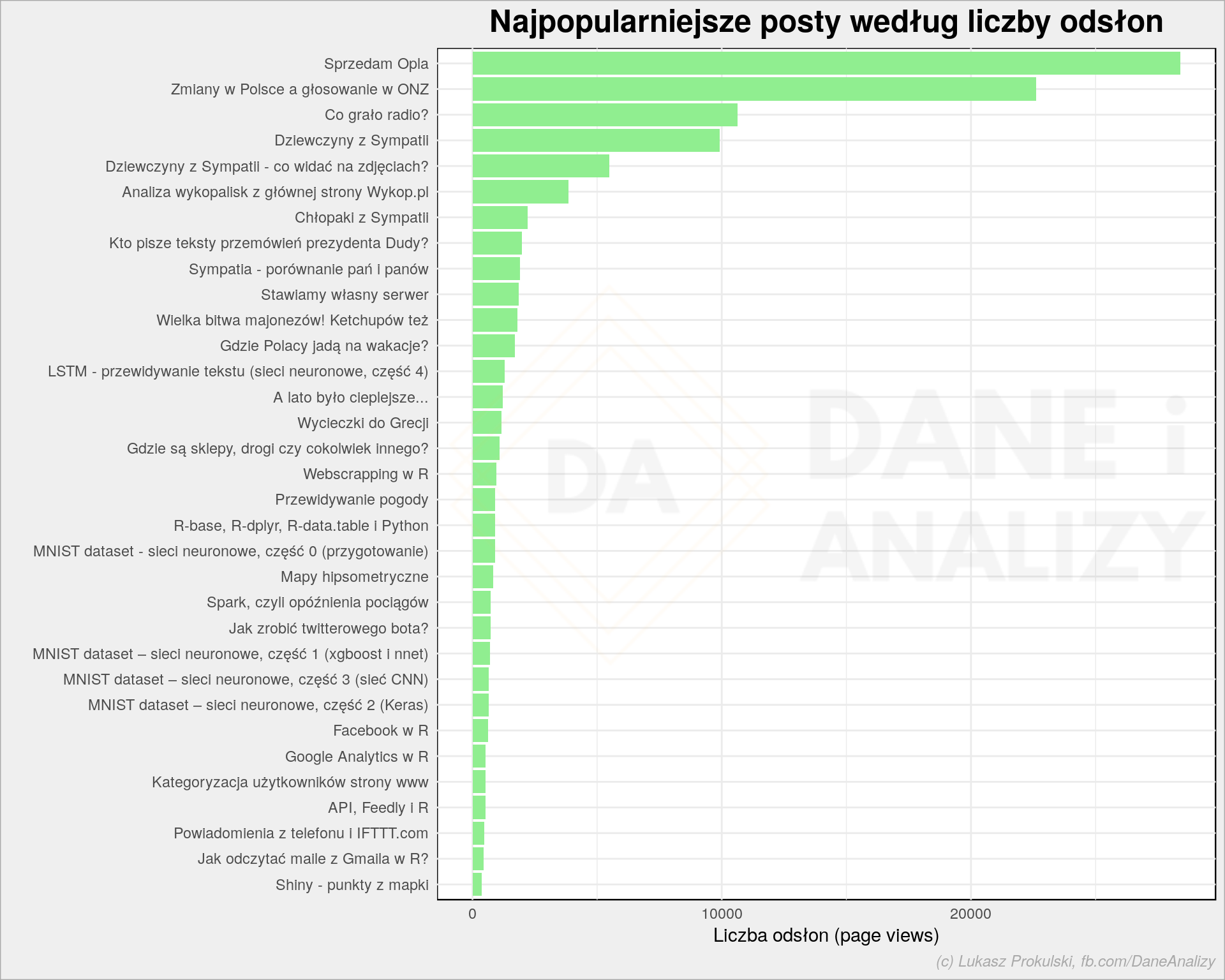
Ano te, które były na Wykopie. Wykop to dostarczyciel ruchu. Niestety raz widać w refferalu Wykop a raz wejście (direct) (czyli takie samo jak wpisanie adresu ręcznie w przeglądarce) i trudno odfiltrować ruch w Wykopu. Ciekawe jest (dla mnie to), że post w pewnym sensie autotematyczny na Wykopie nie zrobił oszałamiającej kariery. Widocznie #motoryzacja i #polityka są ciekawsze. Dziewczyny (i panowie) z Sympatii też.
Czy liczba odsłon jest związana z liczbą odwiedzających użytkowników (liczone dzień po dniu – to ważne)? Narysujmy to na wykresie (chociaż można zrobić prostą regresję liniową):
|
1 2 3 4 5 6 7 8 9 10 11 12 |
# czy liczba PV jest skorelowana z liczbą Userów? plot <- wp_posts %>% ggplot() + geom_smooth(aes(pageviews, users)) + geom_point(aes(pageviews, users), size = 0.5) + scale_x_log10() + scale_y_log10() + labs(title = "Liczba odsłon a liczba użytkowników", x = "Liczba odsłon (page views, skala logarytmiczna)", y = "Liczba użytkowników (skala logarytmiczna)") da_plot(plot) |
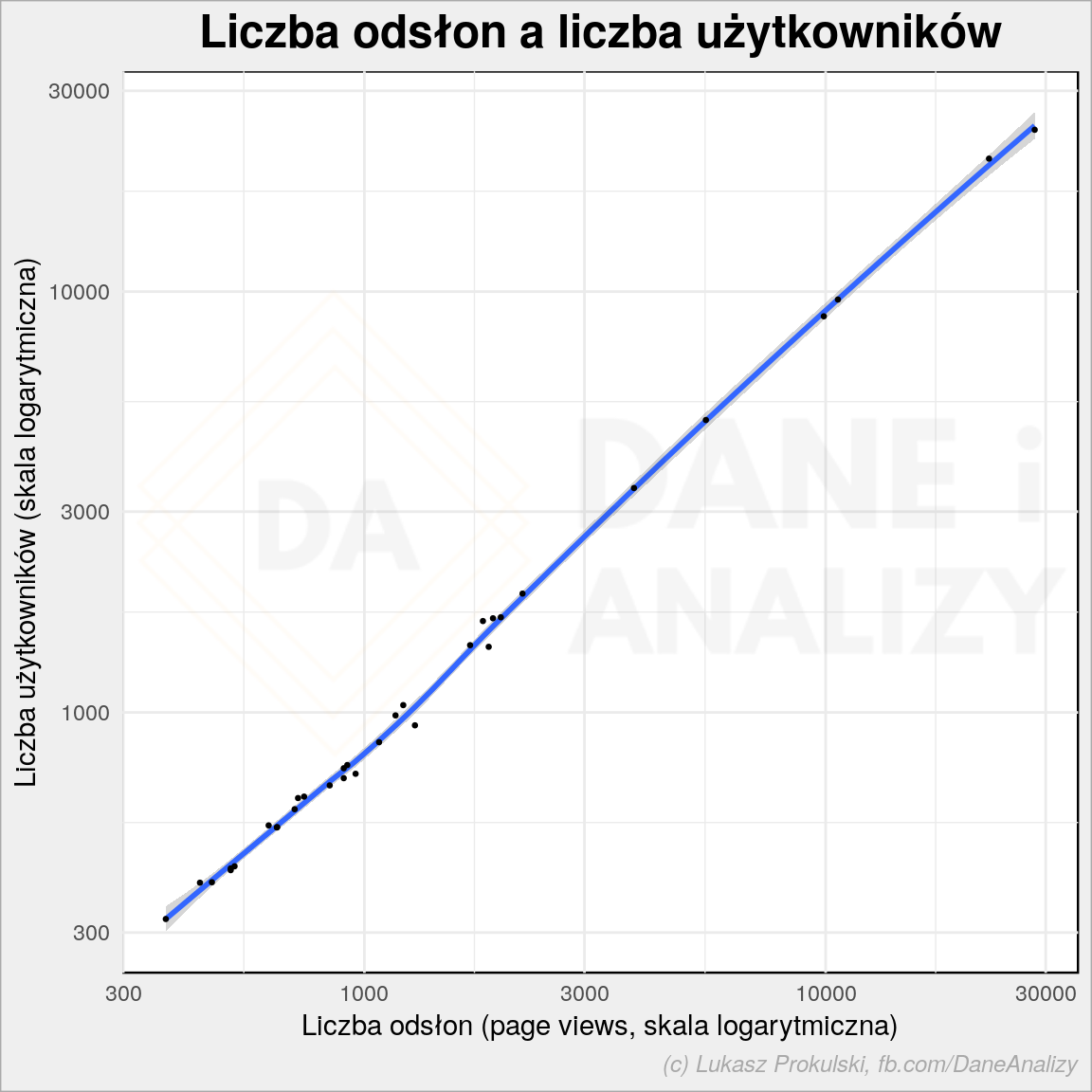
No jak najbardziej – wprost liniowa zależność (a osie w skali logarytmicznej dla ładniejszego wykresu, i niczego więcej). No to ile odsłon robi jeden użytkownik? Jak wygląda rozkład?
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
# PV/User dla każdego postu - w osobnej tabeli, bo później liczymy średnią i medianę pv_per_user_df <- wp_posts %>% select(pageviews, users) %>% mutate(pv_per_user = pageviews/users) # rozkład PV/User plot <- ggplot() + geom_density(data = pv_per_user_df, aes(pv_per_user), fill = "lightgreen", color = "green") + geom_vline(xintercept = mean(pv_per_user_df$pv_per_user), color = "red") + geom_vline(xintercept = median(pv_per_user_df$pv_per_user), color = "black") + labs(title = "Rozkład liczy odsłon na użytkownika", x = "Liczba odsłon na użytkownika (PV/users)", y = "Gęstość prawdopodobieństwa") da_plot(plot) |
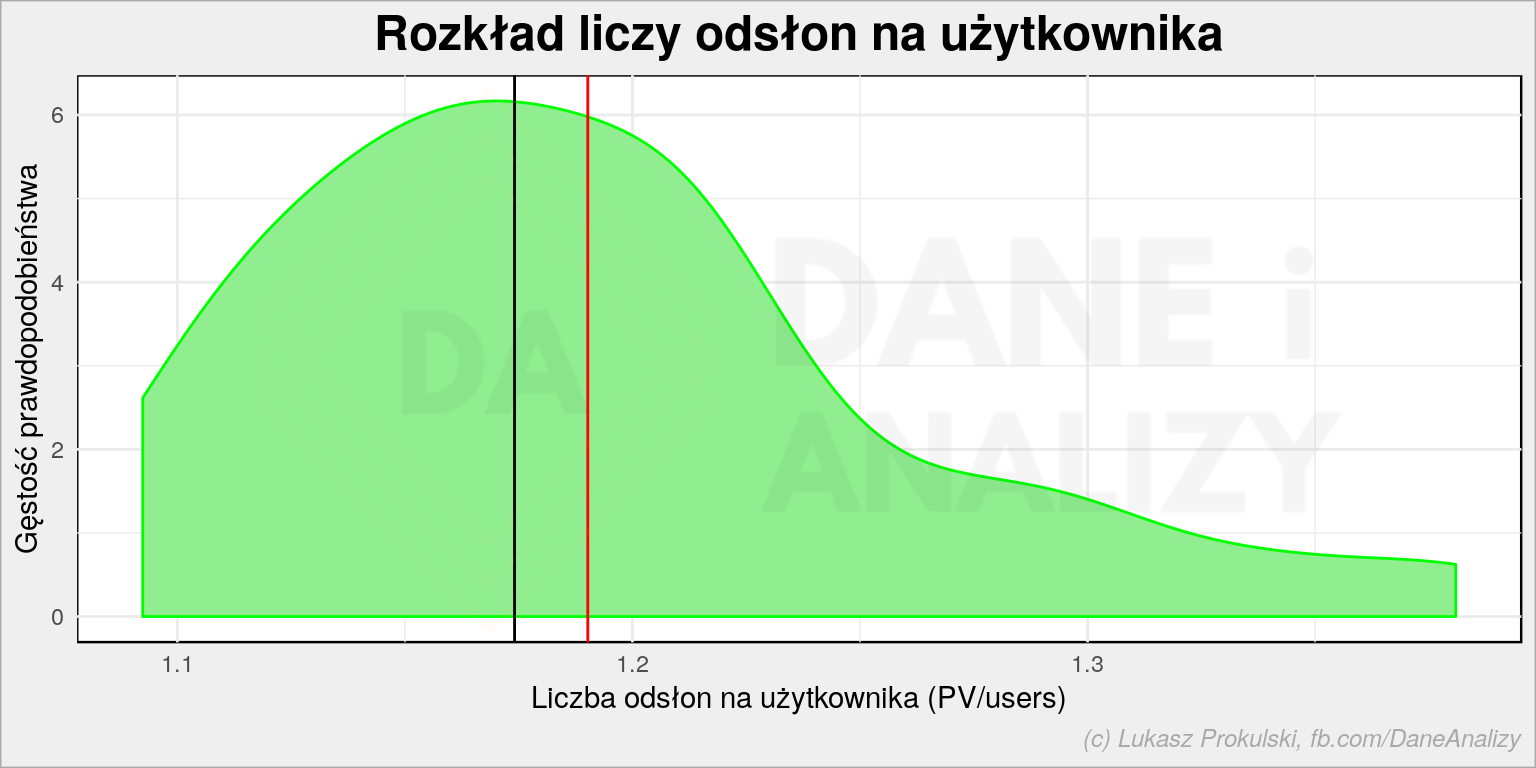
Czerwona linia to średnia (równa 1.19), czarna – mediana (równa 1.17). Szaleństwa nie ma. Powracający, lojalni użytkownicy to procent, może i promil. Weźcie dodajcie sobie do RSSów mój blog, albo chociaż zalajkujcie Dane i Analizy, żeby być na bieżąco! Wiele tracicie…
Czy liczba wizyt (odsłon) przekłada się na liczbę komentarzy pod postami? Intuicyjnie tak, ale jak bardzo?
|
1 2 3 4 5 6 7 8 9 10 |
# liczba komentarzy w zależności od liczby wyświetleń plot <- wp_posts %>% ggplot() + geom_smooth(aes(pageviews, comment_count)) + geom_point(aes(pageviews, comment_count), size = 0.5) + labs(title = "Liczba komentarzy a liczba odsłon", x = "Liczba odsłon postu (page views, skala logarytmiczna)", y = "Liczba komentarzy") da_plot(plot) |
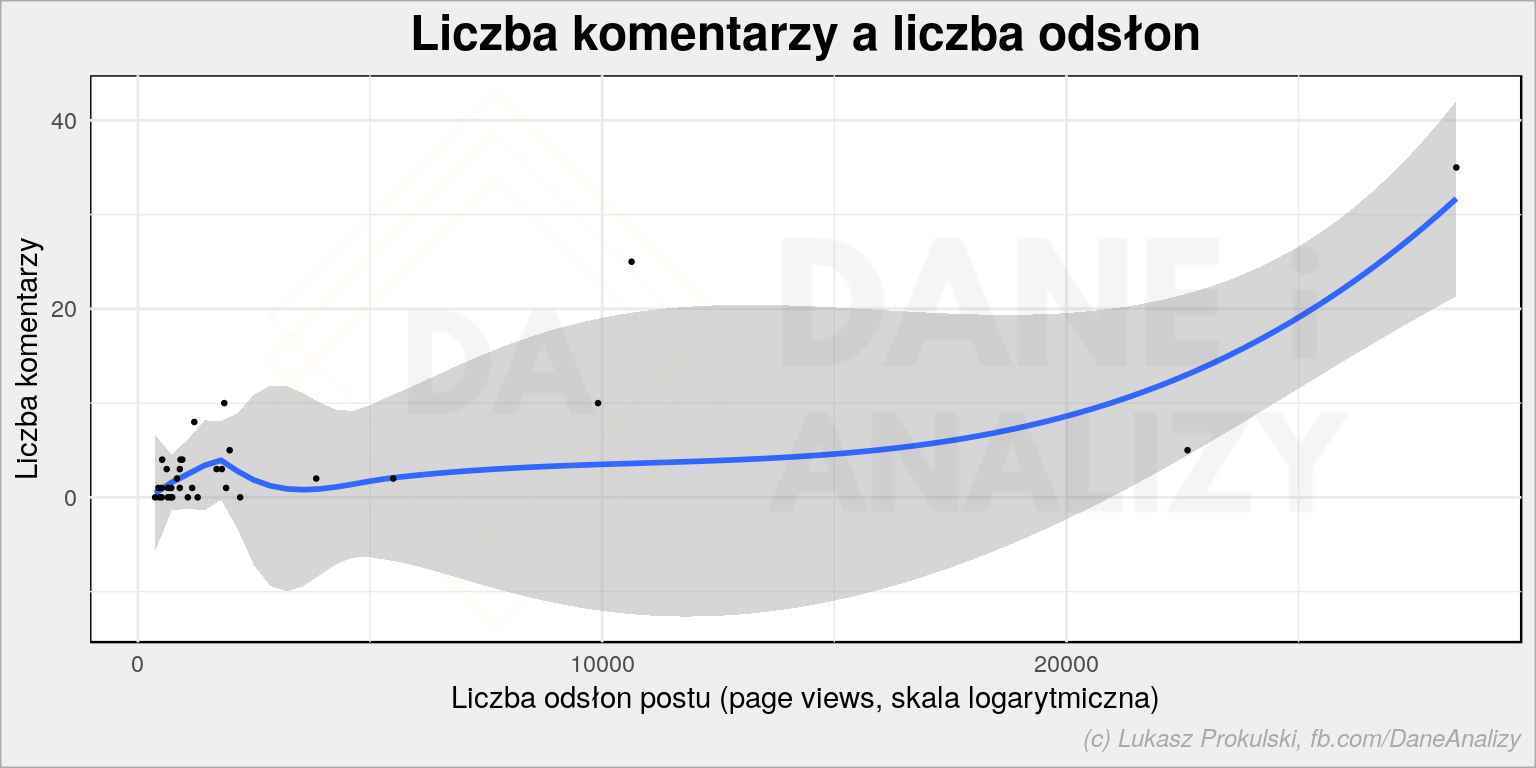
Średnio rzecz biorąc mamy około 804 odsłon na jeden komentarz. Czyli komentuje 0.1% użytkowników (no, odsłon, żeby być precyzyjnym). Ale tutaj nie ma ploteczek, nie ma polityki – nic więc dziwnego, że dyskusje nie są ożywione.
Zobaczmy na koniec jak wyglądają odwiedziny poszczególnych postów w zależności od czasu jaki minął od jego publikacji. Czyli: czy czytacie tylko nowe posty, czy też wracacie do starszych?
W pierwszej kolejności informacje o postach (pobrane z wp_posts) połączymy z danymi o liczbie wizyt w poszczególnych dniach (dzień po dniu). Kluczem łączącym jest adres URL posta – to po to były te wcześniejsze zabawy ze zbudowaniem adresu czy odpowiednim jego rozpoznaniem w danych z GA.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
post_view_age <- wp_posts %>% # potrzebne informacje o postach select(post_date, post_url, post_title) %>% # wystarczy nam data, bez godziny utworzenia mutate(post_date = as_date(post_date)) %>% # dodajemy dane z Google Analytics left_join(view_ga_data %>% # ale też tylko ich fragment select(post_page_path, view_date = date, pageviews), # łącząc po adresie URL by = c("post_url" = "post_page_path")) %>% mutate(view_date = ymd(view_date)) %>% # liczymy wiek postu - różnicę pomiędzy info o wyświetleniach a datą publikacji mutate(post_age = view_date - post_date) |
W pierwszej kolejności sprawdźmy to na uśrednionych danych: liczymy średnią liczbę odsłon dla kolejnych dni od publikacji, dla wszystkich postów.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
plot <- post_view_age %>% group_by(post_age) %>% summarise(pv_mean = mean(pageviews)) %>% ungroup() %>% ggplot() + geom_line(aes(as.numeric(post_age)+1, pv_mean), size = 0.5, color = "gray80") + geom_smooth(aes(as.numeric(post_age)+1, pv_mean)) + geom_point(aes(as.numeric(post_age)+1, pv_mean), size = 0.5) + scale_x_log10() + scale_y_log10() + labs(title = "Średnia liczba odsłon a czas życia postu", subtitle = "Skala log-log", x = "Liczba dni od publikacji postu", y = "Średnia liczba odsłon") da_plot(plot) |
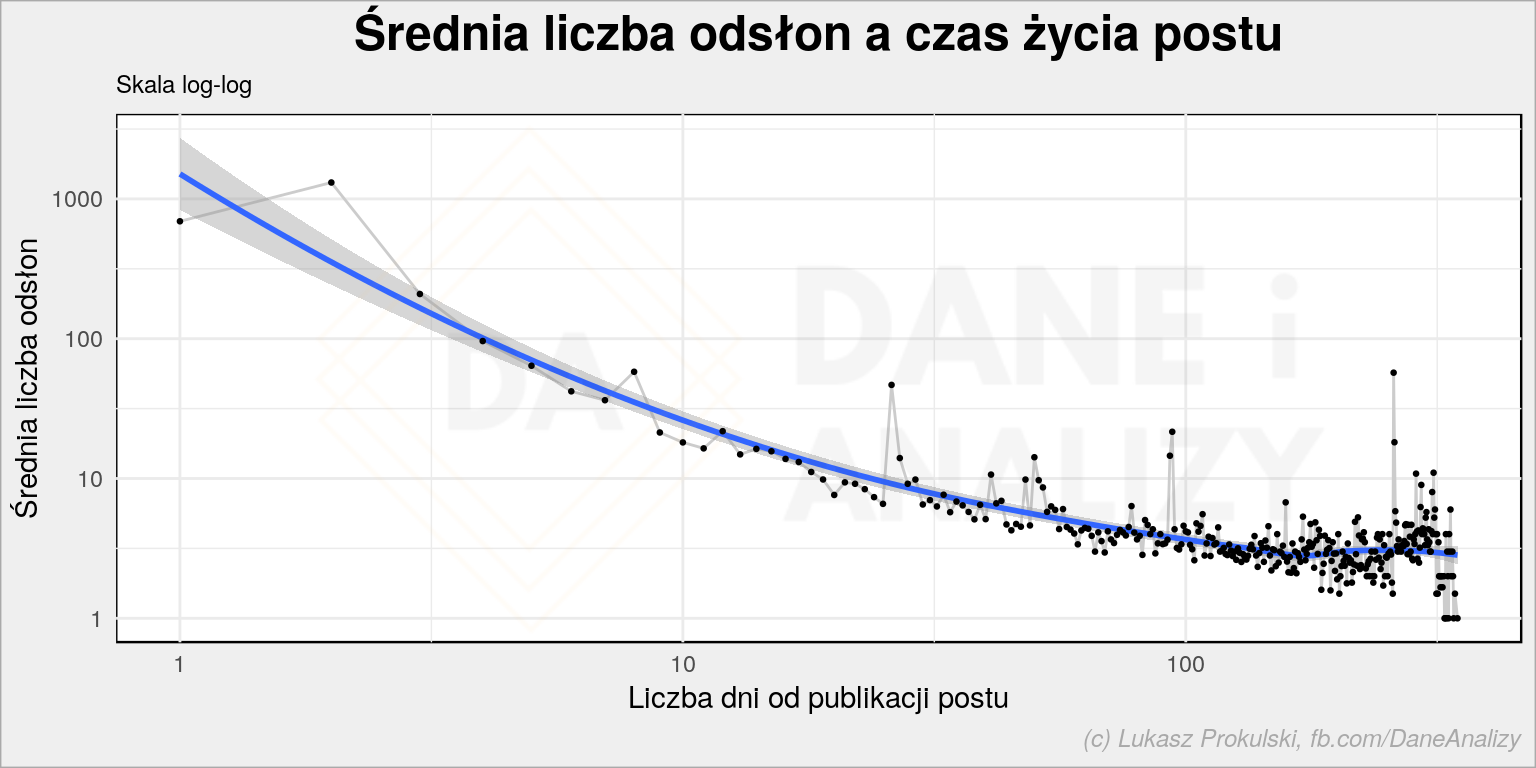
Skala logarytmiczna dla obu osi kompresuje wykres nie zmieniając kształtu wynikowej krzywej. Widać coś, co chyba nie zaskakuje – posty są czytane wtedy kiedy są nowe. To naturalne i zgodne z moimi działaniami wokół bloga:
- publikuję post
- automatycznie trafia on do RSSów (kilka osób w ten sposób tutaj dociera)
- ręcznie publikuję zajawkę na Dane i analizy oraz u siebie na Twitterze
- automatycznie publikuje się ona na twitterowym koncie @rstatspl
- czasem dorzucam linki na LinkedIn czy grupy facebookowe tematycznie związane z data science, machine learning czy R albo analizą danych
Wszystko to dzieje się z reguły w ciągu jednego lub dwóch dni. Jeśli temat uznam za ciekawy (i potencjalnie żrący) – wrzucam link dodatkowo na Wykop. Też w sumie w ciągu pierwszych dwóch dni.
Skąd zatem te piki w okolicach 25, 90 czy 260 dnia (tak, te liczby trudno wyłowić z logarytmicznej osi X – narysowałem sobie wykres bez scale_x_log10())? Nie mam pewności, ale możemy to sprawdzić rozdzielając powyższy obraz na poszczególne posty:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
plot <- post_view_age %>% group_by(post_title, post_age) %>% summarise(pv_mean = mean(pageviews)) %>% ungroup() %>% ggplot() + geom_line(aes(as.numeric(post_age)+1, pv_mean, color = post_title), show.legend = FALSE) + geom_point(aes(as.numeric(post_age)+1, pv_mean, color = post_title), show.legend = FALSE, size = 0.5) + scale_x_log10() + facet_wrap(~post_title, scales = "free_y", ncol = 4) + labs(title = "Średnia liczba odsłon a czas życia postu w podziale na posty", x = "Liczba dni od publikacji postu (skala logarytmiczna)", y = "Liczba odsłon postu") da_plot(plot) |
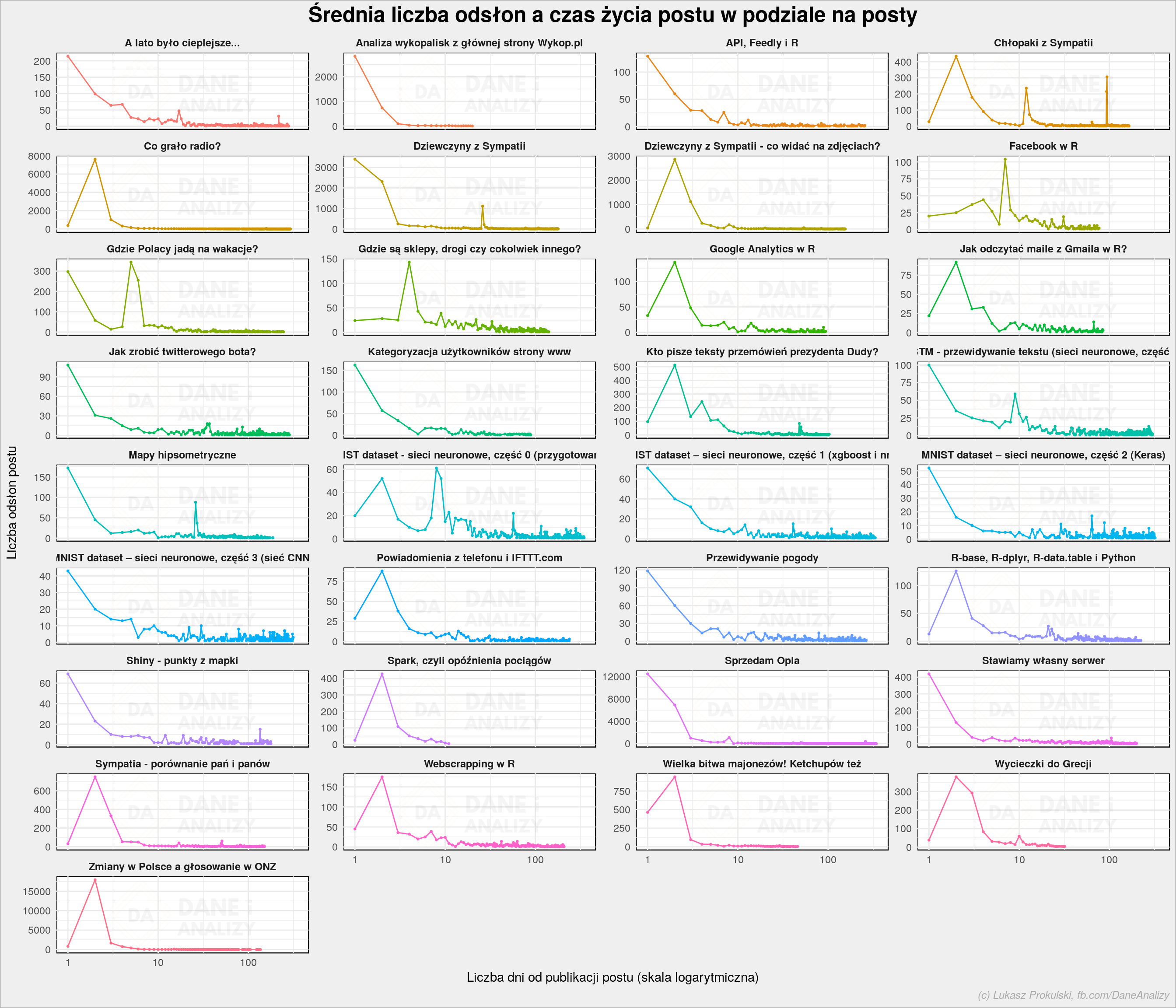
Tutaj logarytmiczna jest tylko skala na osi czasu (X). Z tego co pamiętam poszczególne piki to wynik Wykopów, Redditów lub podania linku w komentarzu na jakimś Facebooku (na ruchliwych stronach) albo pod postami na innych blogach.
Rok 2018 podsumowany i zamknięty. Na grubych liczbach:
- napisałem 33 posty
- łącznie mające 400 tysiąca znaków, nie licząc kodu źródłowego czy znaczników HTML
- wygenerowały one około 177 tysięcy odsłon
Chyba należy się kawa, i czas na realizację kolejnych zadań w 2019.
Hej,
Super podsumowanie, miło się czytało.
Tak samo sama idea strony i jej zawartość. Odkryłem dopiero niedawno, ale czytam z ciekawością.
Masa przydatnych informacji, oby tak dalej!
Pozdrawiam!
Cześć,
Ciekawy wpis. Gdybyś sprowadził słowa do rdzeni (polimorfologik stwarza taką możliwość), to zmienią się statystyki. W chmurze masz np. słowa „danych” i „dane”, które można potraktować jako jedno słowo.
Pozdrawiam
Tak, wiem. To szybka analiza. Poszukaj innych wpisów i analizie tekstów, tam wykorzystuję właśnie polimofologik
Dzień dobry!
Wymienił Pan tu przede wszystkim sukcesy statystyczne strony. Jednak muszę w tym momencie wspomnieć, że link do Pana publikacji ,,Przewidywanie pogody” znalazł miejsce w mojej pracy magisterskiej (a tym samym nazwisko:)). Wykorzystałam w jednym z krótkich rozdziałów przedstawiony przez Pana pakiet forecast, w tym funkcje: ets() auto.arima() i forecast() – do potrzebnych mi obliczeń. Artykuł (przewidywanie pogody) był wielką inspiracją i pomocą.
Co prawda było to w czerwcu, jednak dopiero post podsumowujący przypomniał mi o tym. Dziękuję.
Miło mi. Możesz zdradzić o czym jest praca i podesłać na priv do przejrzenia (tylko z ciekawości)?