Pytanie tytułowe jest nieco przewrotne. Sprawdzimy czy wystąpienia są do siebie podobne, a przede wszystkim dowiemy się jak to zrobić. Nazwisk autorów wystąpień nie podam…
Niniejszy tekst to fragment (ale rozbudowany i zmodyfikowany) mojej prezentacji z konferencji “Machine Learning @ Enterprise”. Całość prezentacji z odpowiednimi skryptami znajdziecie na GitHubie.
Dzisiaj skorzystamy z bibliotek:
|
1 2 3 4 5 6 7 8 9 10 |
library(tidyverse) # wykresy i manipulacja danymi library(data.table) # dla fread - szybkie wczytywanie plików CSV library(lsa) # dla cosine() library(Rtsne) # implementacja t-SNE w R library(plotly) # interaktywne wykresy library(tidytext) # do manipulacji tekstem library(wordcloud) # chmurki słów library(lubridate) # manipulacja datami library(rvest) # do pobierania danych z www library(glue) # wygodne sklejanie ciągów znaków |
W pierwszym kroku potrzebujemy wypowiedzi Andrzeja Dudy. Na szczęście wszystko jest podane na tacy na oficjalnej stronie prezydenta, a jedyne czego potrzebujemy to wyłuskać teksty. Do tego celu przygotujemy kawałek kodu:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 |
#### pobranie listy linków do wypowiedzi # ile stron ma lista wypowiedzi? max_page_no <- 64 # tu będziemy zbierać linki links_all <- vector() # dla każdej ze stron: for(i in 1:max_page_no) { # budujemy URL tej strony url <- glue("http://www.prezydent.pl/aktualnosci/wypowiedzi-prezydenta-rp/wystapienia/page,{i}.html") # pobieramy zawartość strony page <- read_html(url) # pobieramy wszystki linki w konkretnym DIVie links <- page %>% html_nodes("div.news-list") %>% html_node("a") %>% html_attr("href") %>% paste0("http://www.prezydent.pl", .) # i te linki dodajemy do już zebranych z poprzednich stron links_all <- c(links_all, links) } # pozostawiamy tylko linki do wypowiedzi (są też inne) links_all <- links_all[str_detect(links_all, "http://www.prezydent.pl/aktualnosci/wypowiedzi-prezydenta-rp/wystapienia/art,")] # i tylko unikalne links_all <- unique(links_all) #### funkcja pomocnicza # zwracajaca datę z polskiego ciągu typu "2 lutego 2018" parse_pl_date <- function(f_data) { # slownik miesiecy miesiace <- c("stycznia", "lutego", "marca", "kwietnia", "maja", "czerwca", "lipca", "sierpnia", "września", "października", "listopada", "grudnia") # rozbicie daty na dzien - miesiac - rok data_tab <- f_data %>% str_split(",") %>% unlist() %>% .[[2]] %>% trimws() %>% str_split(" ") %>% unlist() # budujemy obiekt typu dttm return(make_date(year = data_tab[3], # rok month = which(miesiace == data_tab[2]), # numer miesiąca day = data_tab[1])) # dzień } #### pobranie wypowiedzi # pusta tabelka, do której będziemy dodawać wypowiedzi wypowiedzi <- tibble() # dla każdego kolejnego linku do strony z wypowiedzią for(i in 1:length(links_all)) { # wczytaj stronę page <- read_html(links_all[[i]]) # znajdź treść wystapienia speech <- page %>% html_node("div.description") %>% html_text() %>% str_replace_all("\\s+", " ") # data wystapienia data <- page %>% html_node("div.webreader") %>% html_node("div.date") %>% html_text() %>% trimws() %>% parse_pl_date() # dodaj wystąpienie do pełnej tabeli jako nowy wiersz wypowiedzi <- bind_rows(wypowiedzi, tibble(text = speech, # treść date = data, # data url = links_all[[i]])) # link } # sortujemy wypowiedzi po dacie i numerujemy kolejno wypowiedzi <- wypowiedzi %>% arrange(date) %>% mutate(id = row_number(), text = trimws(text)) # zapisujemy zgromadzone dane na później saveRDS(wypowiedzi, "wypowiedzi_Duda.RDS") |
Dane mamy zebrane i zapisane. Ja zapuściłem powyższy skrypt 20 września rano i w dalszej części będę korzystał z zapisany danych.
O czym mówi Andrzej Duda?
Zobaczmy jakich słów najczęściej w swoich wypowiedziach używa Andrzej Duda. Da nam to bardzo zgrubny obraz tego o czym mówi. Bardzo zgrubny.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
duda <- readRDS("wypowiedzi_Duda.RDS") # zapisane dane zebrane ze strony pl_stop_words <- read_lines("polish_stopwords.txt") # słownik polskich stop-words # dzielimy wszystkie wypowiedzi na słowa duda_words <- duda %>% unnest_tokens(word, text, token = "words") # zliczamy ile razy występuje każde ze słów # w każdej z wypowiedzi (ten podział przyda się później) duda_words_cnt <- duda_words %>% count(id, word) %>% # usuwamy stop words filter(!word %in% pl_stop_words) #### chmurka słów # sumujemy liczbę wystąpień słów, # tak aby uniezależnić się od wystąpienia duda_words_cnt_cloud <- duda_words_cnt %>% group_by(word) %>% summarise(n = sum(n)) %>% ungroup() # budujemy chmurkę 150 najpopularniejszych słów wordcloud(duda_words_cnt_cloud$word, duda_words_cnt_cloud$n, max.words = 150, scale = c(1.8, 0.4), colors = colorRampPalette(c("#313695", "#a50026"))(15)) |
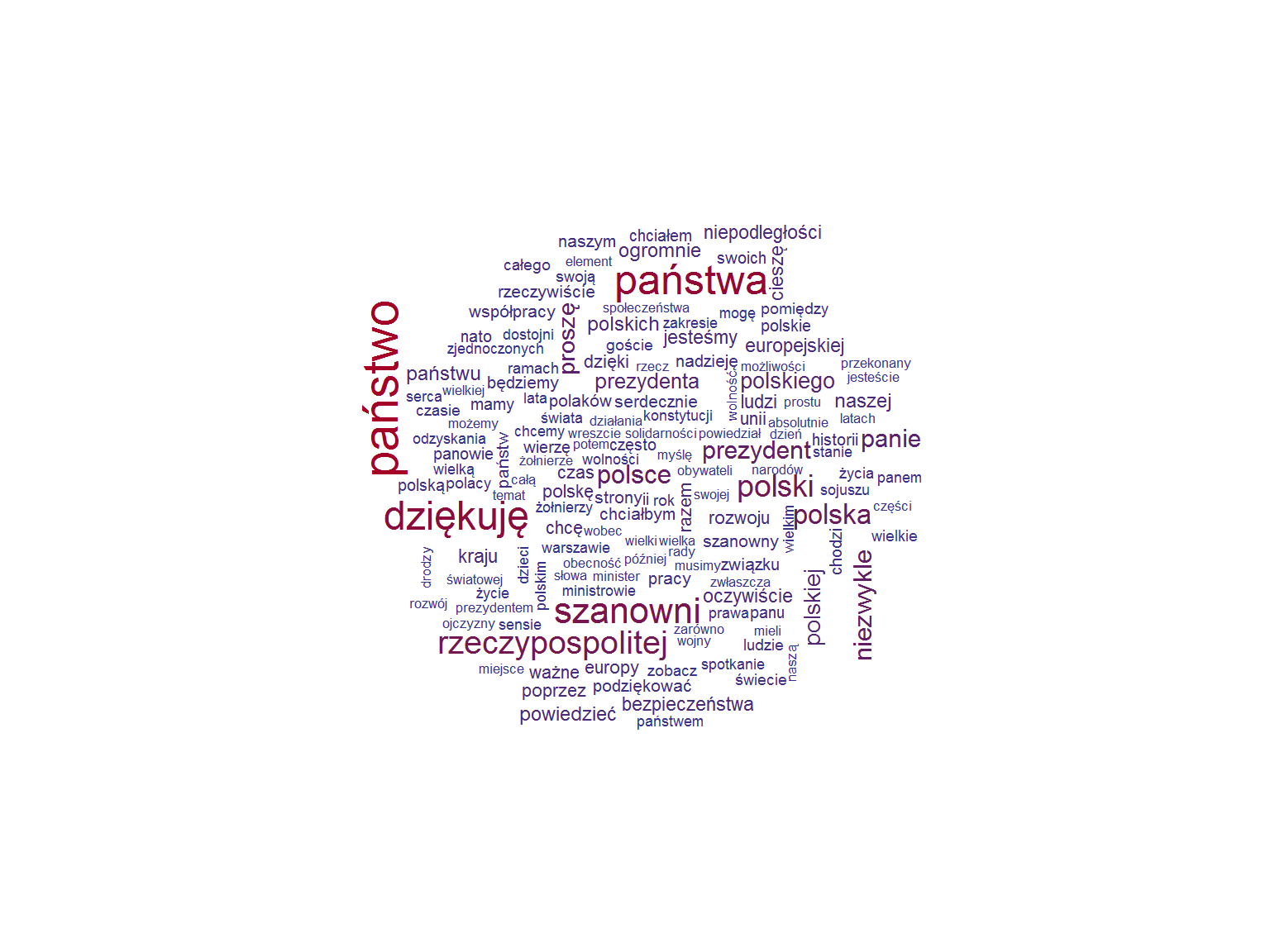
Prezydent mówi głównie o Polsce, wita szanownych słuchaczy, dziękuje im itd.
O kim mówi Andrzej Duda?
Kto jest częściej wspominany w wystąpieniach prezydenta? Premier, prezes partii czy szef MON (pamiętacie konflikt z Macierewiczem?), a może ktoś z opozycji?
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
duda_words_cnt %>% # wybieramy słowa zawierające jeden z ciągów filter(str_detect(word, "^kaczyńsk|^szydło|^morawieck|^macierewicz|^schetyn|^petru|^wałęs|^kwaśniewsk|^komorowsk|^tusk|^błaszczak")) %>% # na podstawie pierwszych pięciu znaków słowa przypisujemy kolor mutate(kolor = str_sub(word, 1, 4)) %>% # zliczemy ile razy łącznie wystąpiło dane słowo group_by(kolor) %>% summarise(n = sum(n)) %>% ungroup() %>% # układamy paski w odpowiedniej kolejności mutate(kolor = reorder(kolor, n)) %>% # rysujemmy wykres słupkowy ggplot() + geom_col(aes(kolor, n, fill = kolor), show.legend = FALSE) + coord_flip() + scale_x_discrete(labels = c("szyd" = "Szydło", "mora" = "Morawiecki", "maci" = "Macierewicz", "błas" = "Błaszczak", "kacz" = "Kaczyński", "sche" = "Schetyna", "petr" = "Petru", "tusk" = "Tusk", "wałę" = "Wałęsa", "kwaś" = "Kwaśniewski", "komo" = "Komorowski")) |
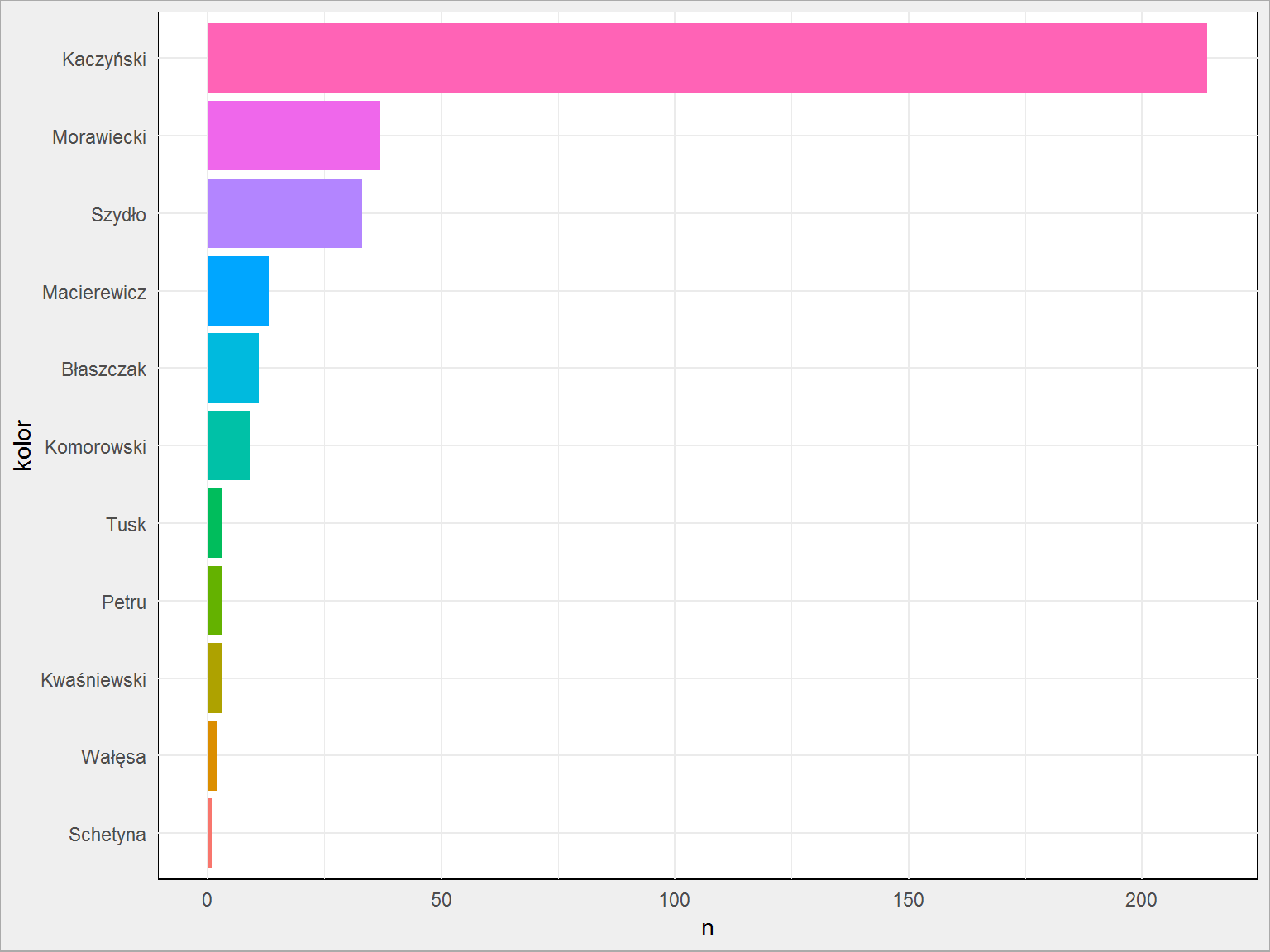
Widzimy, że najważniejszy (czytaj: najczęściej wymieniany) w przemówieniach prezydenta jest prezes partii, do której prezydent nie należy (bo prezydent jest bezpartyjny). Albo jego brat – jeden z poprzednich prezydentów. O poprzednich prezydentach (innych) Duda mówi niewiele. Co ciekawe więcej mówił o Petru niż Schetynie.
Sprwadźmy czy to ile razy dana osoba jest wspominana zależy od momentu w czasie:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
duda_words_cnt %>% # wybieramy słowa zawierające jeden z ciągów filter(str_detect(word, "^kaczyńsk|^szydło|^morawieck|^macierewicz|^schetyn|^petru|^wałęs|^kwaśniewsk|^komorowsk|^tusk|^błaszczak")) %>% # na podstawie pierwszych czterech znaków słowa przypisujemy kolor (i później nazwisko polityka) mutate(kolor = str_sub(word, 1, 4)) %>% # łączymy numery przemówień z datami inner_join(duda %>% select(date, id), by = "id") %>% # liczymy ile razy danego dnia dana osoba była wspomniana group_by(date, kolor) %>% summarise(n = sum(n)) %>% ungroup() %>% # rysujemy wykresik ggplot() + geom_point(aes(date, kolor, size = n, color = kolor), alpha = 0.8, show.legend = FALSE) + scale_size(range = c(3,10)) + # linie oznaczające istotne zmiany w rządzie geom_vline(xintercept = as_date(c("2015-11-16", # początek rządu Szydło "2017-12-11", # koniec rządu Szydło "2018-01-09"))) + # Maciarewicz przestaje być szefem MON scale_y_discrete(labels = c("szyd" = "Szydło", "mora" = "Morawiecki", "maci" = "Macierewicz", "błas" = "Błaszczak", "kacz" = "Kaczyński", "sche" = "Schetyna", "petr" = "Petru", "tusk" = "Tusk", "wałę" = "Wałęsa", "kwaś" = "Kwaśniewski", "komo" = "Komorowski")) |
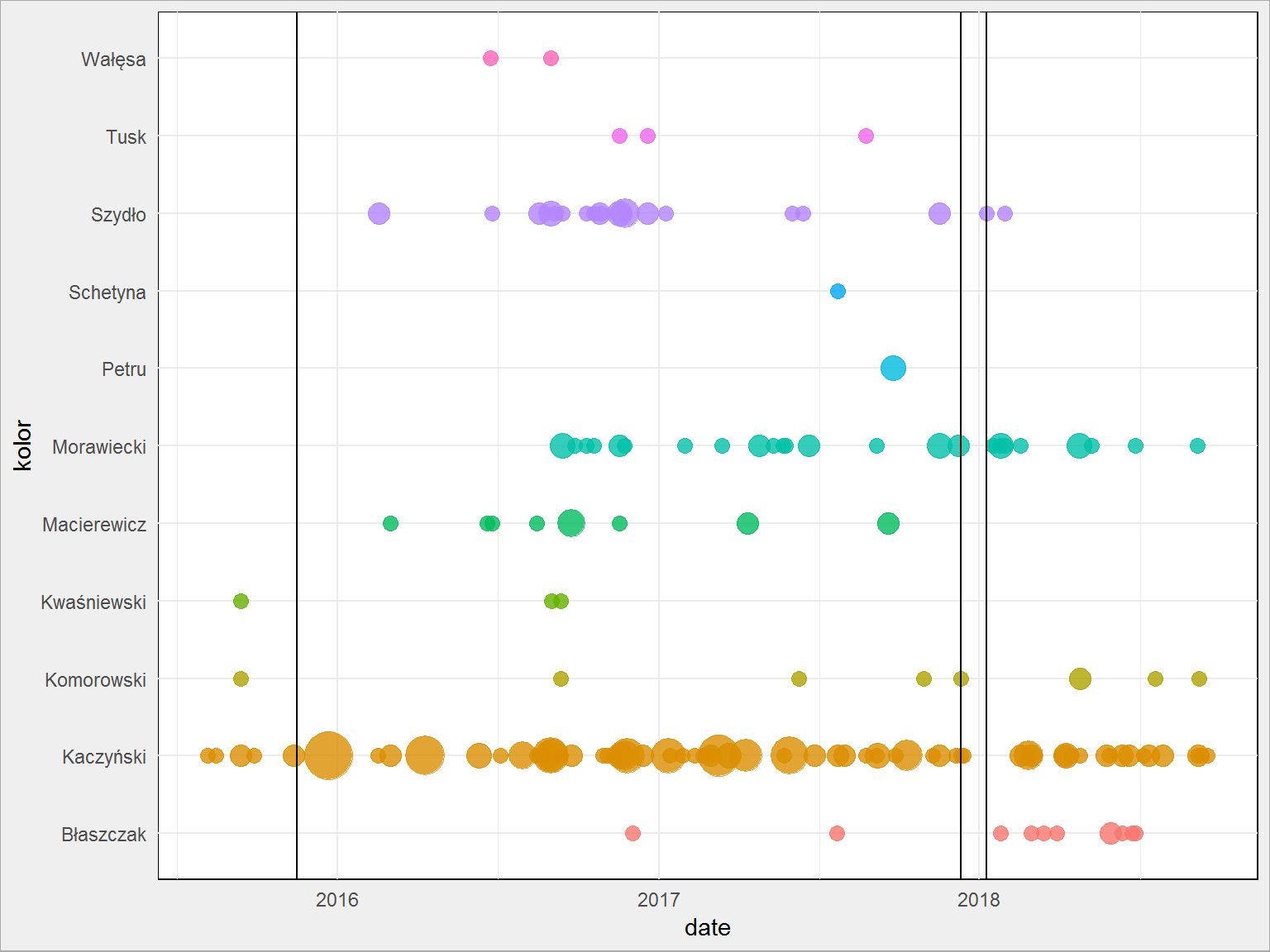
Pionowe linie oznaczają kolejno od lewej: początek rządu Beaty Szydło, zmianę premiera na Mateusza Morawieckiego i przebudowanie rządu (m.in. zmianę na stanowisku szefa MON). Wielkość bąbelka to liczba wystąpień danego nazwiska w wystąpieniach prezydenta z danego dnia.
To jest ciekawsze – Szydło po zakończeniu misji premiera rządu przestała być wymieniana, podobnie Macierewicz (w jego miejsce zaczął pojawiać się Błaszczak częściej niż wcześniej). Petru i Schetyna pojawili się po jednym razie – pewnie przy konkretnej okazji (trzeba by sprawdzić konkretne wystąpienia). O Wałęsie się nie mówi.
To Lech czy Jarosław?
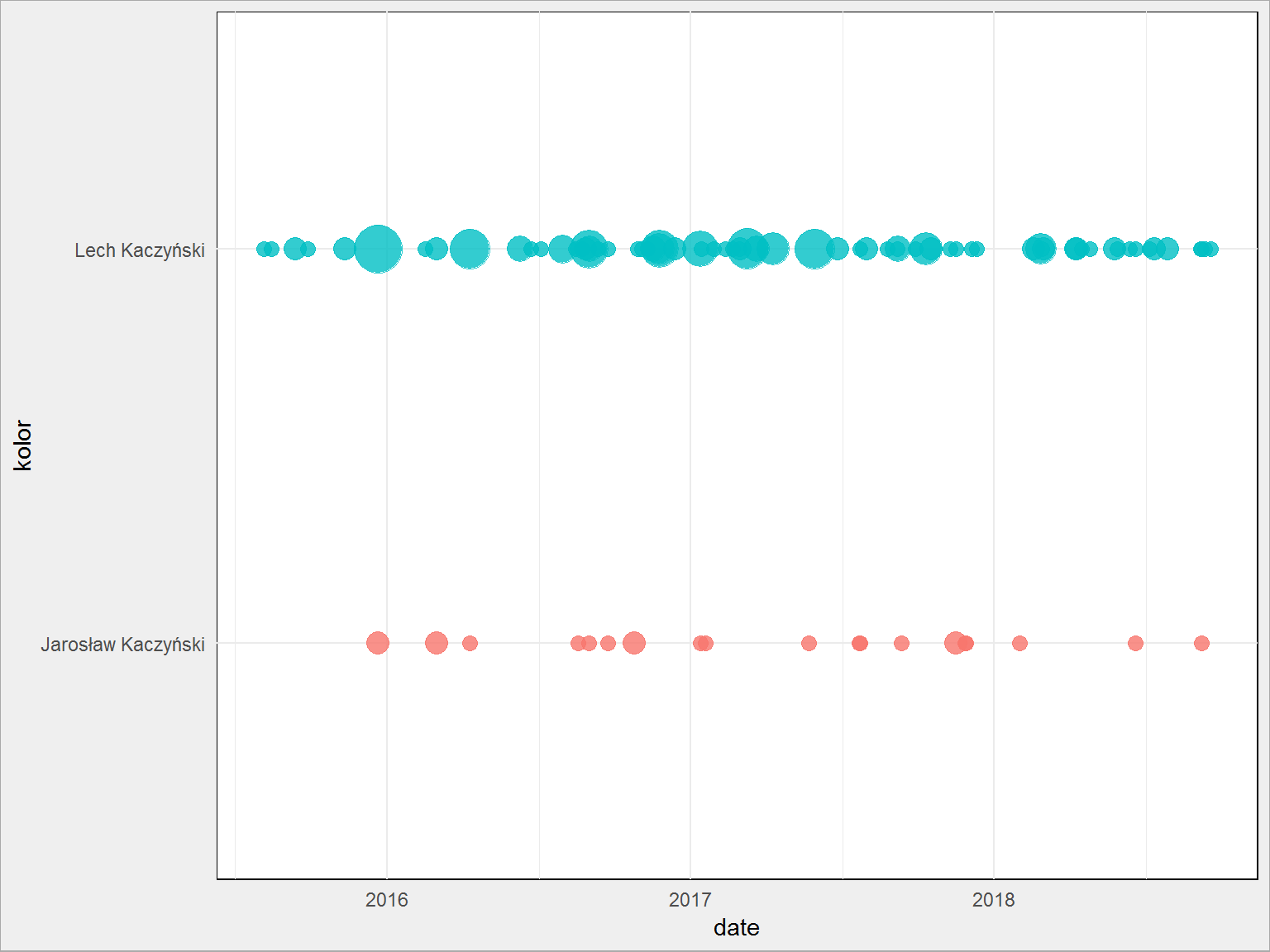
Jednak Lech. Ale i tak Jarosław pojawia się często – sumarycznie Jarosława jest tyle, że wypada pomiędzy Szydło a Macierewiczem (Lech bierze 88% wymienionych Kaczyńskich).
Zanim przejdziemy dalej kilka słów o sposobie mierzenia podobieństwa tekstów.
Rozważmy podobieństwo słów: kiedy słowa są do siebie podobne? W rozumieniu języka możemy przyjąć, że wtedy, kiedy mają podobne znaczenie czy też sens, albo należą do jakiejś podobnej grupy (np. nazwy, liczebniki). W sensie matematycznym możemy mierzyć podobieństwo różnymi miarami, najczęstszą jest odległość kosinusowa między wektorami zdefiniowana wzorem:
![\[podobienstwo = cos(\theta) = \frac{A \cdot B}{|A| |B|} = \frac{\sum \limits _{i=1}^{n}{A_{i}B_{i}}}{{\sqrt {\sum \limits _{i=1}^{n}{A_{i}^{2}}}}{\sqrt {\sum \limits _{i=1}^{n}{B_{i}^{2}}}}}\]](https://quicklatex.com/cache3/4a/ql_5530c89314bd73f4e1f3f7634389844a_l3.png "Rendered by QuickLaTeX.com")
Zatem potrzebujemy słów zapisanych jako wektory. Popularnym sposobem reprezentacji słów w przestrzeni wektorowej jest word2vec i słowniki typu GloVe lub zyskujący na popularności FastText. Mechanizm przygotowania reprezentacji wektorowej słów polega mniej więcej na przebadaniu ogromnej liczby dokumentów, określeniu popularności słów w każdym z dokumentów i całości korpusu (czyli wszystkich dokumentach razem), a także szukaniu częstotliwości wystąpienia każdego ze słów w przesuwającym się po dokumentach oknie określonej szerokości (liczby słów wpadających do okna). Warto doczytać, jest o tym sporo (z przykładami w Pythonie, ale też w R) – googlaj word2vec.
Przygotowanie takiego słownika słowo – wektor wymga dużo tekstu, dużo czasu. Są gotowe słowniki i z nich skorzystamy. Tutaj kłania się FastText gdzie znajdziemy słowniki dla 157 języków, w tym dla polskiego. Słownik w wersji tekstowej (plik csv) to ponad 4 GB – pobieramy go z odpowiedniej strony i rozpakowujemy. Zobaczmy co siedzi w środku.
Weźmy tylko kilkadziesiąt (N_VEC) pierwszych składowych wektora – dla ograniczenia konsumpcji pamięci. Po wczytaniu całego słownika i pierszych 100 składowych w pamięci słownik zajął 1.6GB.
|
1 2 3 4 5 6 7 8 9 10 11 |
N_WORDS <- 2000 N_VEC <- 100 word2vec <- fread("cc.pl.300.vec", # ścieżka do rozpakowanego pliku z FastText.cc sep = " ", skip = 1, header = FALSE, stringsAsFactors = FALSE, select = 1:(N_VEC+1), # tylko początkowe kolumny quote = "", encoding = "UTF-8") |
Weźmy losowe N_WORDS słów z tego słownika i zredukujmy przestrzeń N_VEC wymiarową do dwóch wymiarów, aby dało się to pokazać na obrazku. Do redukcji użyjemy algorytmu t-SNE (może być PCA, ale t-SNE stara się trzymać bliskie wektory blisko po przeskalowaniu).
|
1 2 3 4 5 6 |
word2vec_sample <- word2vec[sample(1:nrow(word2vec), N_WORDS), ] tsne <- Rtsne(word2vec_sample, dims = 2, initial_dims = N_VEC) tsne_df <- as.data.frame(tsne$Y) %>% mutate(word = word2vec_sample$V1) |
Teraz możemu już to narysować:
|
1 2 3 4 5 6 7 |
plot_ly(tsne_df, type="scatter", mode = "markers", x = ~V1, y = ~V2, alpha = 0.75, text = ~word, hoverinfo = "text") |
Spróbujcie pojeździć myszą po powyższym wykresie – punkty, które są blisko siebie to słowa w jakiś sposób podobne. Na przykład zgrupowane są różne liczby, różne sposoby zapisu dat, mogą się trafić ciągi wyglądające jak internetowe nicki. Zawartość słów zależy od korpusu (zbioru dokumentów) na którym słownik był trenowany. Na MLForum Joanna Misztal-Radecka pokazała slajd z słowami podobnymi do słowa gwiazda – korpus onetowy zwrócił synonimy typu aktorka, modelka zaś korpus wikipedia – planeta, galaktyka. Nie wiem na czym był trenowany FastText, ale widać nawet na powyższym wykresie, że wiele tam jest śmieci, zbitek wyrazów itp. Ewidentnie pochodzi to z procesu sczytywania jakichś stron internetowych, ale nie bardzo przyłożono się do oczyszczenia tekstu (ma to swoje wady i zalety).
Wszystko to słowa, ale jak zmierzyć podobieństwo dokumentów? Zamiast word2vec przydałby się jakiś doc2vec. No to zróbmy sobie! Niech wektor opisujący dokument będzie średnią z wektorów opisujących poszczególne słowa w dokumencie. Genialne w swojej prostocie! Potrzebujemy rozbić dokument na słowa, wypisać wektory kolejnych słów i całość uśrednić. Odpowiednie funkcje:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 |
# funkcja zwraca wektor dla słowa word_vector <- function(f_word, f_word2vec = word2vec) { return(f_word2vec[f_word2vec$V1 == f_word, 2:N_VEC] %>% as.numeric()) } # funkcja dzieli zdanie na pojedyncze słowa split_phrase <- function(f_phrase) { str_split(f_phrase, pattern = "[ .,!?:;]") %>% unlist() %>% .[nchar(.) >= 1] } # funkcja liczy uśreniony wektor zdania mean_doc_vec <- function(f_phrase, f_word2vec = word2vec) { # podział zdania na słowa word_list <- split_phrase(f_phrase) phrase <- tibble() # dla każdego słowa for(i in seq_along(word_list)) { # szukamy jego wektora i dodajemy jako kolejny wiersz phrase <- bind_rows(phrase, f_word2vec %>% filter(V1 == word_list[[i]])) } # zwracamy uśreniony wektor return(phrase %>% summarise_at(.vars = 2:(ncol(phrase)-1), .funs = mean, na.rm = TRUE) %>% as.numeric()) } # funkcja liczy odległość kosinusową dwóch zdań two_phrase_sim <- function(f_phrase_A, f_phrase_B, f_word2vec = word2vec) { cosine(mean_doc_vec(f_phrase_A, f_word2vec), mean_doc_vec(f_phrase_B, f_word2vec)) } # z całego słownika wydzielamy słowa z wypowiedzi Dudy word2vec_duda <- word2vec %>% filter(V1 %in% unique(duda_words$word)) %>% # usuwamy też stopwords filter(!V1 %in% pl_stop_words) |
Zwróćcie uwagę, że nie korzystamy z całego słownika, a jedynie wybraliśmy z niego te słowa, które występują w wypowiedziach Dudy. Usunęliśmy też polskie stop words, chociaż nie trzeba tego robić. Będzie po prostu szybciej. Chociaż wcale nie tak szybko – całość trochę się przeliczała.
Porównajmy dwa przykładowe wystąpienie:
|
1 2 3 4 |
two_phrase_sim(duda$text[[1]], duda$text[[2]], word2vec_duda) ## [,1] ## [1,] 0.9370738 |
Jest to jakaś wartość – czy podobne są te teksty? Jak wiemy z matematyki wektory identyczne będą miały odległość kosinusową równą jeden. Policzymy więc odległości kosinusowe pomiędzy wszystkimi wystąpieniami (każdy z każdym):
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
#### najpierw średnie wektory dla każdego z tekstów duda_vec <- tibble() # dla wszystkich wystąpień for(i in 1:nrow(duda)) { cat(paste("\ri = ", i, " / ", nrow(duda))) # progress bar dla ubogich ;-) # do zebranych przeliczonych danych duda_vec <- bind_rows(duda_vec, # dodaj średni wektor wystąpienia mean_doc_vec(duda$text[[i]], word2vec_duda) %>% t() %>% as.data.frame() %>% mutate(n_duda = i)) } #### i policz odległość kosinusową każdy z każdym duda_sim <- cosine(duda_vec %>% select(-n_duda) %>% t()) |
Narysujmy całą macierz (właściwie tylko jej połowę – to jest macierz symetryczna względem przekątnej, nie musimy rysować całości):
|
1 2 3 4 5 6 7 8 9 10 11 12 |
# wybieramy połowę macierzy przy okazji przekształcając dane z szerokich na długie duda_sim_df <- duda_sim %>% as_data_frame() %>% mutate(speechA = sprintf("V%d", row_number())) %>% gather(speechB, sim, -speechA) %>% mutate(speechA = gsub("V", "", speechA) %>% as.numeric(), speechB = gsub("V", "", speechB) %>% as.numeric()) %>% filter(speechA < speechB) # rysujemy ggplot(duda_sim_df, aes(speechA, speechB, color = sim, fill = sim)) + geom_tile() |
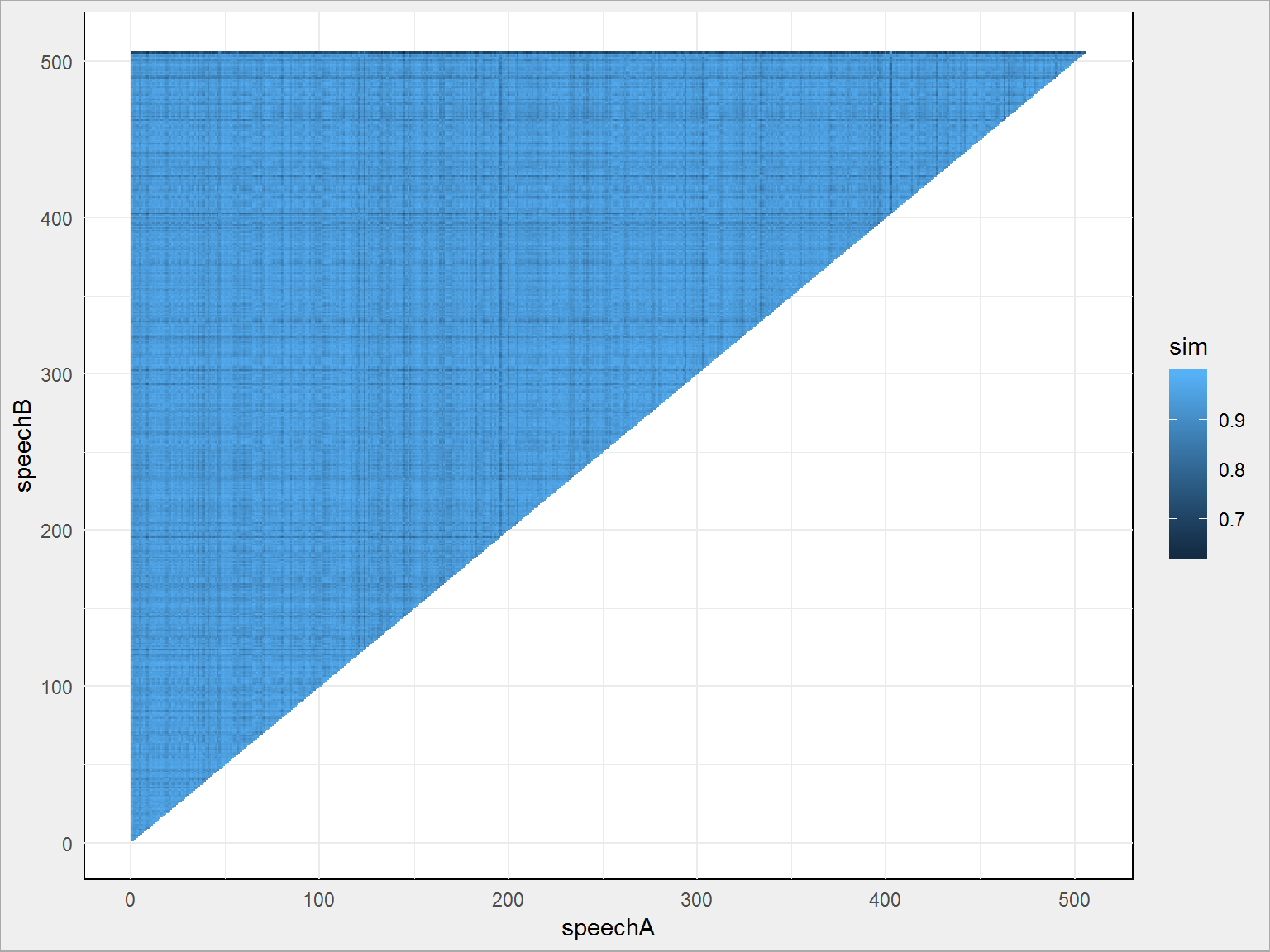
albo interaktywnie, jeśli wykorzystamy Plot.ly (ale to wielkie, więc nie zamieszczam):
|
1 2 3 4 5 6 7 8 9 |
plot_ly(duda_sim_df, type="scatter", mode = "markers", x = ~speechA, y = ~speechB, color = ~sim, text = ~paste0("Wystąpienie nr ", speechA, " jest podobne<br>do wystąpienia ", speechB, " w ", sim), hoverinfo = "text") |
Możemy też zobaczyć rozkład podobieństw tekstów między sobą:
|
1 |
ggplot(duda_sim_df, aes(sim)) + geom_density(fill = "lightgreen") |
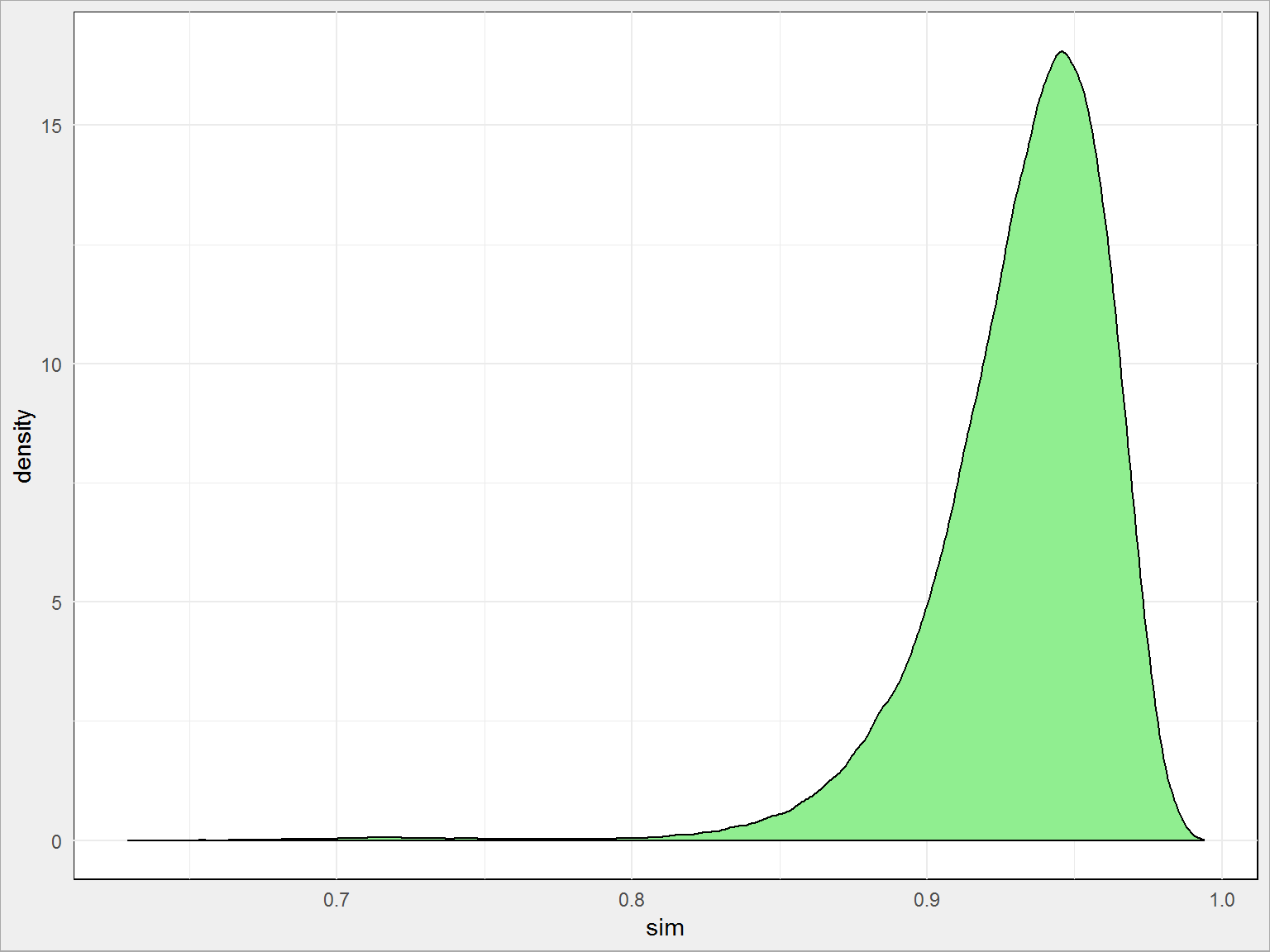
Rozkład mówi nam, że teksty są mniej więcej jednakowo podobne do siebie – nie ma wysp czy oddzielnych górek na wykresie. Możemy pokusić się o tezę, że skoro tak jest to autor jest potencjalnie jeden (albo kilku i wszyscy dobrze się maskują pisząc w podobnym stylu).
Ciekawe są wypowiedzi o numerach ponad 500 (konkretnie jest to numer 506), bo wyglądają na inne. Trzeba przeczytać tekst wystąpienia, wówczas okaże się że jego część (ściągniętego tekstu ze strony) jest po angielsku – stąd właśnie różnica.
Aby z większym prawdopodobieństwem stwierdzić czy jest jeden autor czy jest ich wielu możemy:
- wziąć przede wszystkim większy słownik – pamiętacie, że na początku ograniczyliśmy się do 100 składowych wektora? A w słowniku jest ich 300
- dodać dodatkowe cechy do porównania: liczbę znaków przestankowych, średnią długość słów (w znakach) oraz zdania (w słowach)
- nie usuwać stop-words
- policzyć ile słów w wypowiedzi (albo średnio w zdaniu) to stop words
To tylko kilka z pierwszych pomysłów. Czasem logarytm jakiejś wartości (szczególnie tej obliczonej) pomaga.
Poszukajmy jeszcze dwóch najbardziej podobnych wystąpień:
|
1 2 3 4 5 6 |
duda_sim_df %>% filter(sim == max(sim)) ## # A tibble: 1 x 3 ## speechA speechB sim ## <dbl> <dbl> <dbl> ## 1 282 284 0.994 |
|
1 2 |
simA <- 284 simB <- 282 |
Są to (treść pod linkami):
|
1 2 3 4 5 6 7 8 |
duda$url[[simA]] ## [1] "http://www.prezydent.pl/aktualnosci/wypowiedzi-prezydenta-rp/wystapienia/art,288,wystapienie-prezydenta-podczas-inauguracji-roku-akademickiego-w-kolegium-europejskim-w-natolinie.html" duda$url[[simB]] ## [1] "http://www.prezydent.pl/aktualnosci/wypowiedzi-prezydenta-rp/wystapienia/art,286,wystapienie-prezydenta-rp-podczas-uroczystego-otwarcia-ii-ogolnopolskiego-kongresu-europeistyki-w-szczecinie.html" |
a najczęściej występujące w nich słowa to:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
par(mfrow = c(1,2)) wordcloud(duda_words_cnt %>% filter(id == simA) %>% pull(word), duda_words_cnt %>% filter(id == simA) %>% pull(n), max.words = 150, scale = c(1.8, 0.4), colors = colorRampPalette(c("#313695", "#a50026"))(15)) wordcloud(duda_words_cnt %>% filter(id == simB) %>% pull(word), duda_words_cnt %>% filter(id == simB) %>% pull(n), max.words = 150, scale = c(1.8, 0.4), colors = colorRampPalette(c("#313695", "#a50026"))(15)) par(mfrow = c(1,1)) |
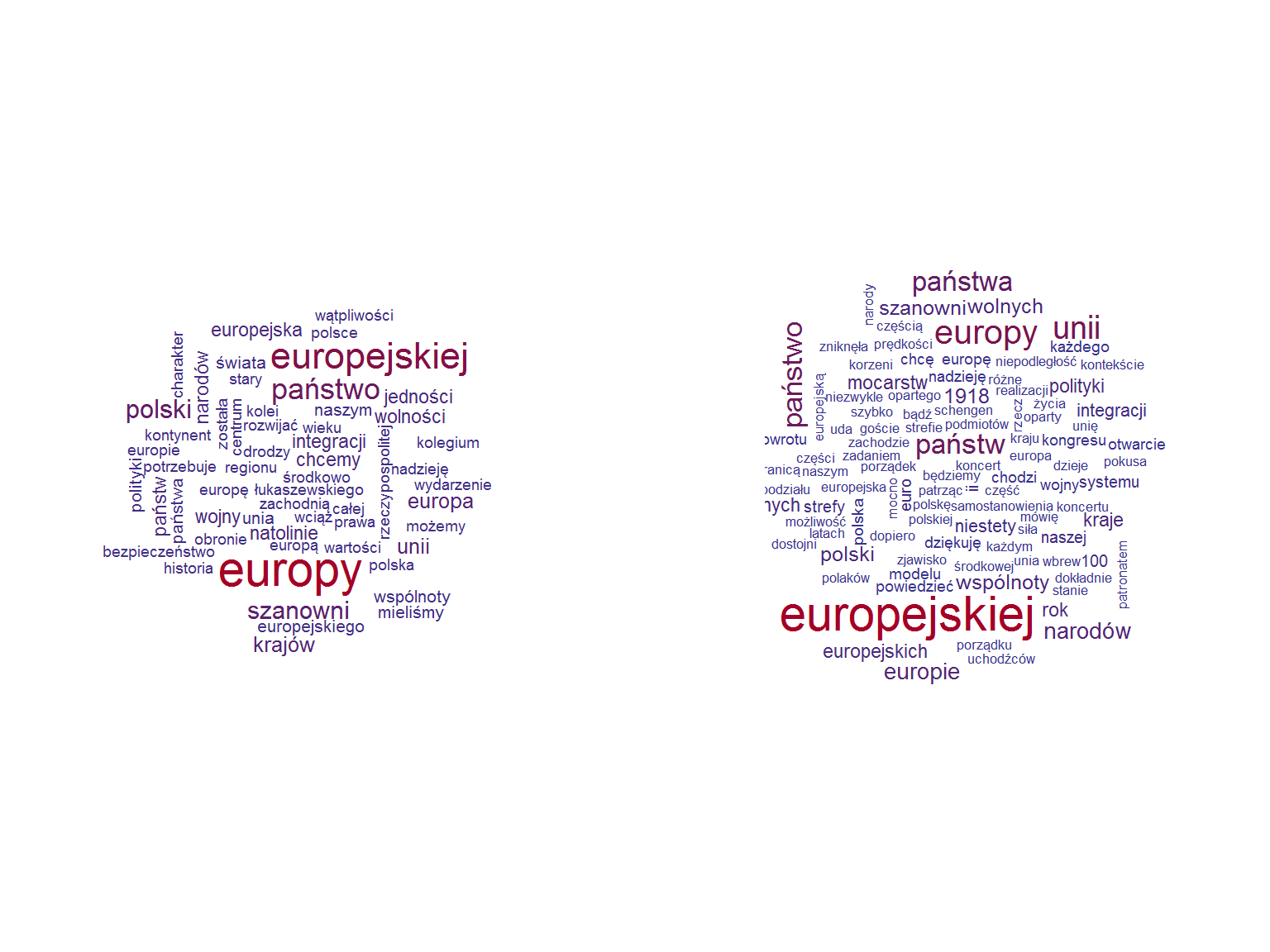
Możemy pokusić się o rzutowanie wszystkich wektorów wystąpień na przestrzeń dwuwymiarową (identycznie jak dla pojedynczych słów wcześniej – korzystając z t-SNE).
|
1 2 3 4 5 |
duda_sim_tsne <- duda_vec %>% select(-n_duda) %>% Rtsne() %>% .$Y %>% as.data.frame() |
Teraz zaznaczmy oddzielnymi kolorami punkty opisujące te dwa wystąpienia:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
# jednakowy ID koloru dla wszystkich kolor <- rep(1, nrow(duda)) # z wyjątkiem wybranych dwóch kolor[simA] <- simA kolor[simB] <- simB duda_sim_tsne %>% mutate(kolor = kolor) %>% ggplot() + geom_point(aes(V1, V2, color = as.factor(kolor), size = kolor, shape = as.factor(kolor)), alpha = 0.7) |
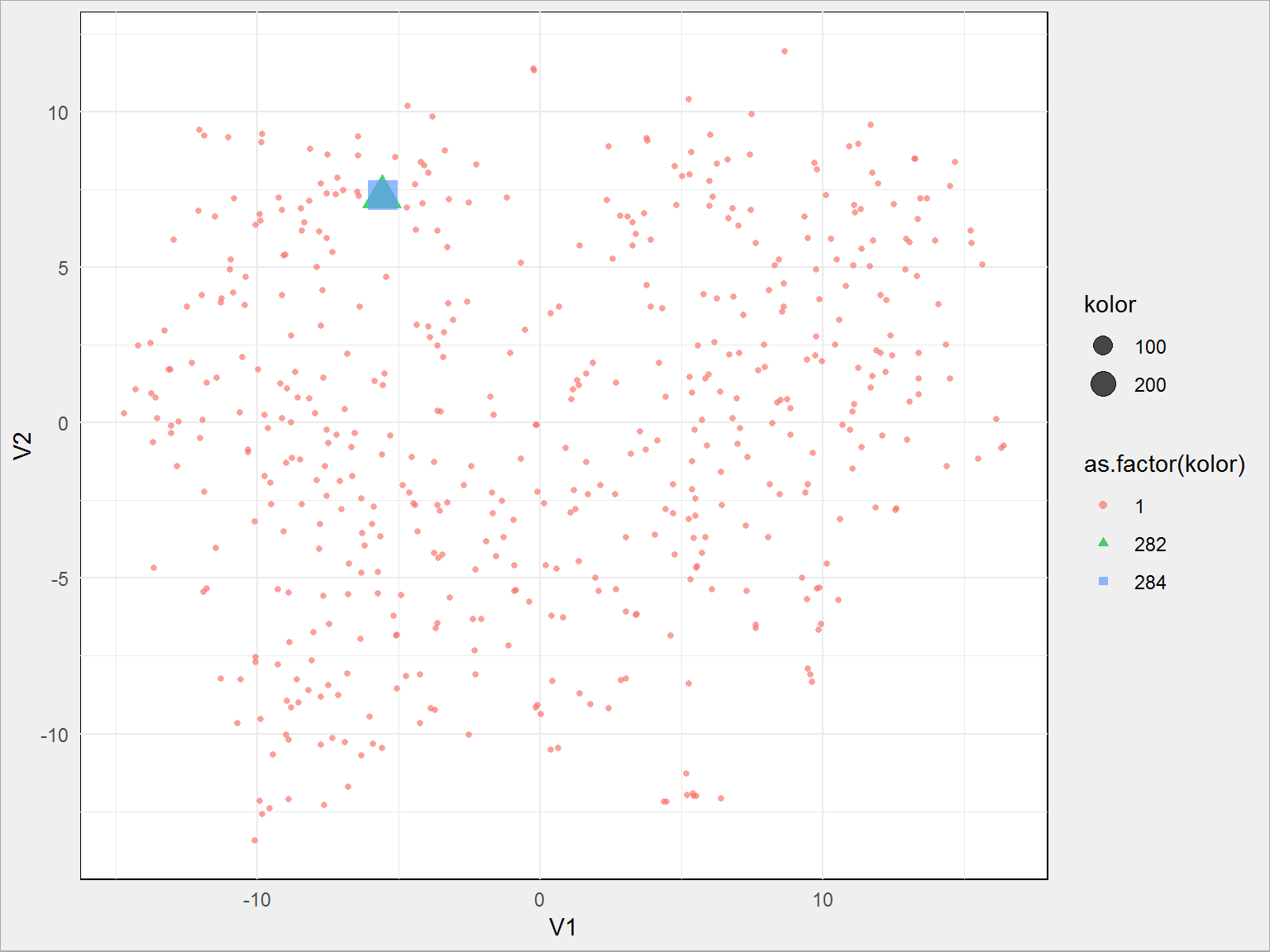
Widzimy, że dwa najbardziej podobne wystąpienia (to te powiększone: trójkąt i kwadrat) leżą blisko siebie, wręcz na sobie.
Co jeszcze można zrobić? Można próbować klasteryzacji (podziału na grupy) poszczególnych wystąpień prezydenta (np. poprzez kmeans na tabeli duda_sim_tsne), co w przypadku podziału na 6 grup da nam:
|
1 2 3 4 5 6 7 8 9 |
duda_kmeans <- kmeans(duda_sim_tsne, 6) duda_sim_tsne$cluster <- duda_kmeans$cluster duda_sim_tsne %>% ggplot() + geom_point(aes(V1, V2, color = as.factor(cluster), shape = as.factor(cluster))) |
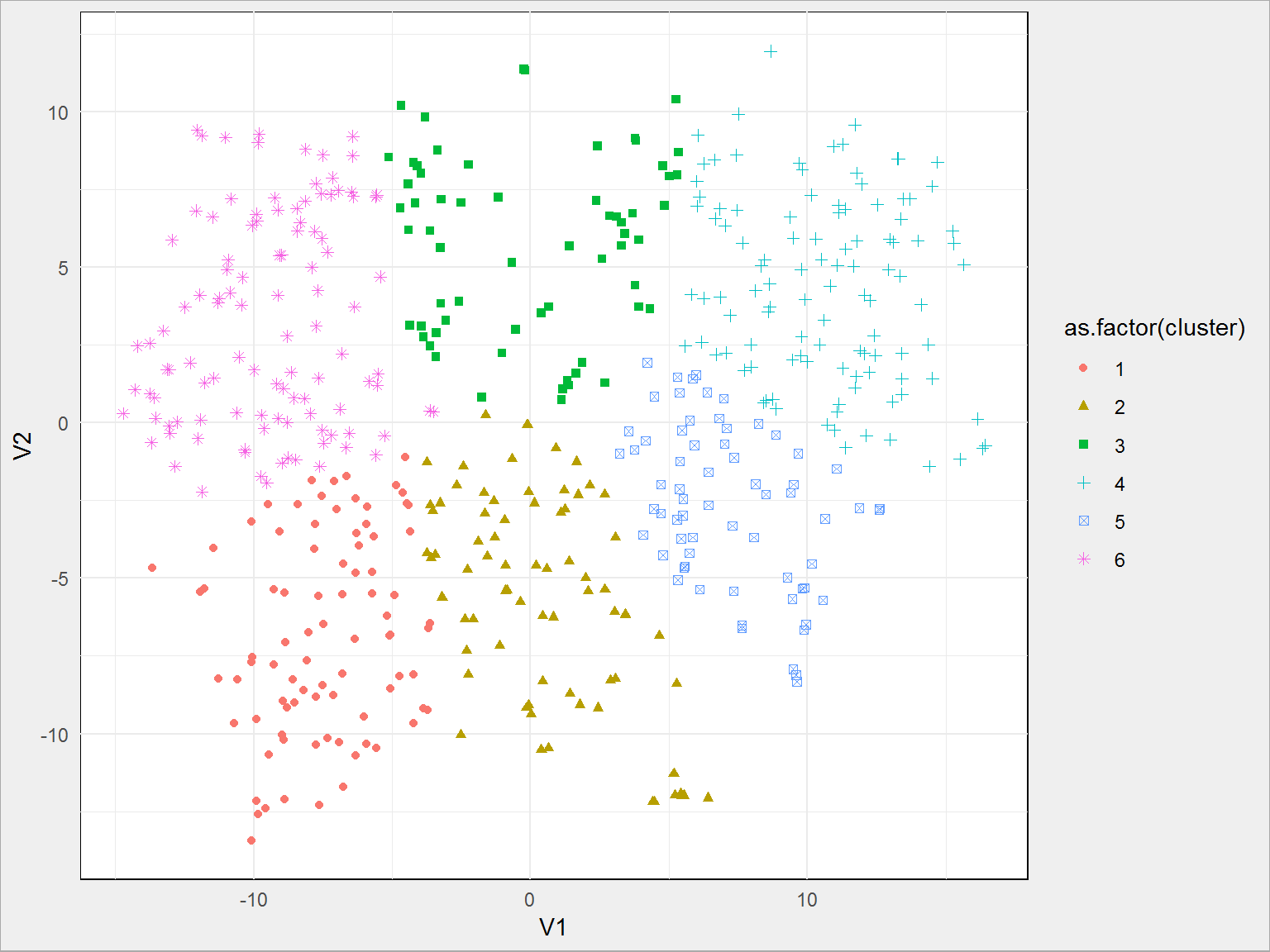
Klasteryzację można też przeprowadzić na wektorach przed t-SNE (co wydaje się mieć większy sens).
Zostańmy jednak przy naszych grupach ustalonych po t-SNE. Możemy przypisać numery grup do oryginalnych wystąpień i sprawdzić czy dwa teksty z jednej grupy dotyczą podobnych spraw, na przykład szukając najpopularniejszych słów w grupie::
|
1 2 3 4 5 6 7 8 9 10 11 12 |
inner_join(duda_words_cnt, tibble(id = 1:length(duda_kmeans$cluster), cluster = duda_kmeans$cluster), by = "id") %>% group_by(cluster) %>% top_n(10, n) %>% ungroup() %>% ggplot() + geom_col(aes(word, n, fill = as.factor(cluster)), show.legend = FALSE) + coord_flip() + facet_wrap(~cluster, scales = "free") |
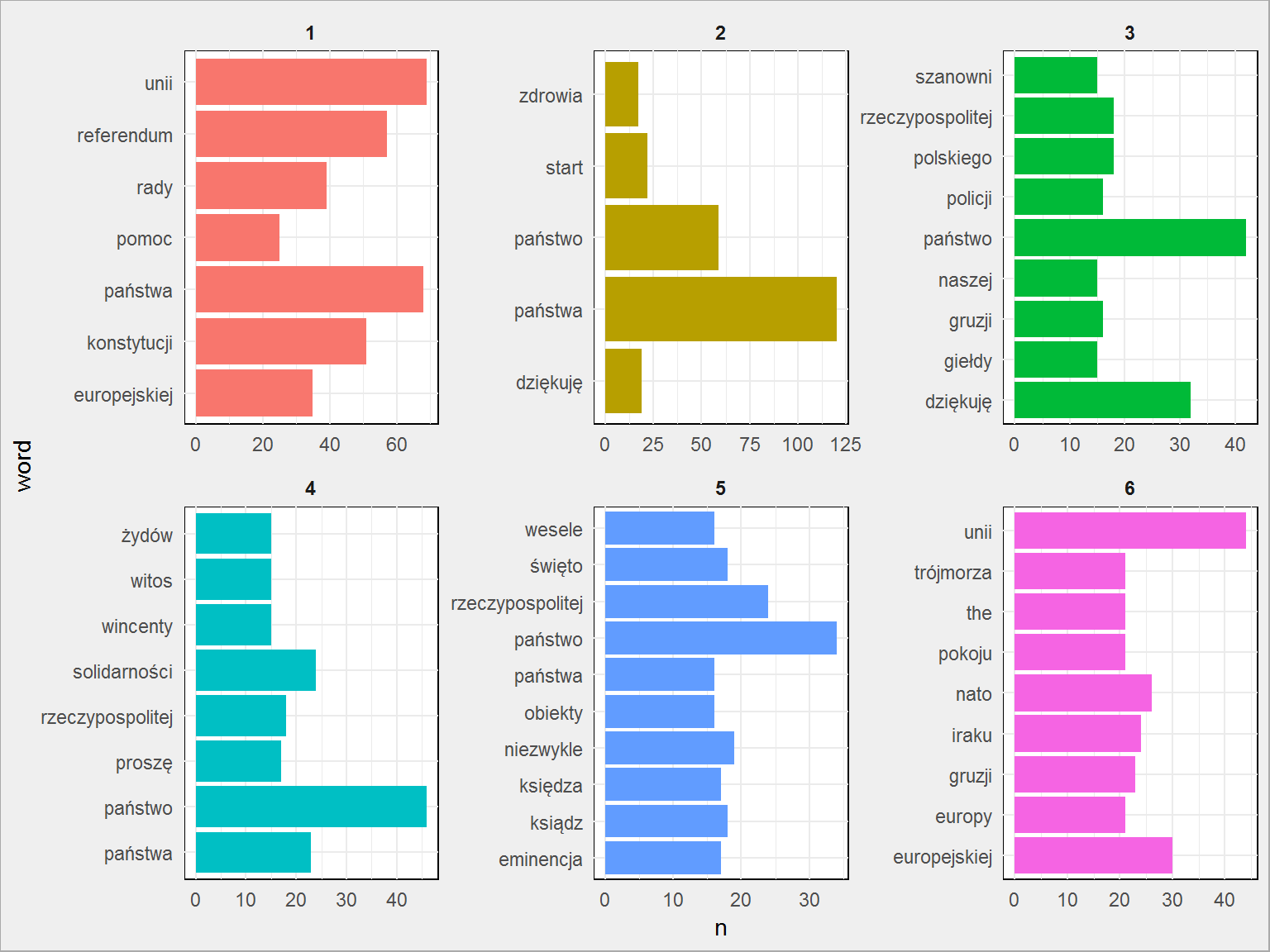
Podobnie możemy przeprowadzić analizę tematów (poprzez LDA – też np. wybierając 6 tematów) i porównać czy klasteryzacja na wyniku t-SNE daje podobne przypisania do grup co LDA przypisania do tematów. Pozwólcie jednak, że na tym zakończymy :)
Analiza tekstu to bardzo rozległy temat – im więcej się w nim siedzi tym więcej przychodzi do głowy. Ale na tym to polega. Szczególnie, jeśli bawisz się danymi a nie budujesz coś (model, narzędzie), co ma rozwiązać określony cel.
Jeżeli zabawa (ale i nauka) danymi to Twój konik – koniecznie zostań fanem Dane i Analizy na Facebooku – tam więcej takich smaczków, mniej więcej raz na dzień coś nowego.
Mi z kolei miło będzie jeśli docenisz mój trud i poświęcony czas stawiając dużą kawę (albo po prostu dobre piwo z marketu).
Jestem też do wynajęcia o ile jest taka potrzeba, tutaj więcej info.
Czyli nie przeczytałeś nawet leadu: „Pytanie tytułowe jest nieco przewrotne. Sprawdzimy czy wystąpienia są do siebie podobne, a przede wszystkim dowiemy się jak to zrobić. Nazwisk autorów wystąpień nie podam…”
O jak kwikłem XD
Łukasz, kiedyś trafiłem na bloga z wykopu (albo tylko tak mi się wydaje). Parę razy Cię szukałem w czeluściach internetu. Fajnie, że znowu dzięki wykopowi tu trafiłem. Może w niedługim czasie będę miał dla Ciebie małe zlecenie. Albo może raczej – pomożesz mi sprzedać swoje usługi dalej. Pozdrawiam!
napisz maila z konkretami :)
Dobra robota, jedna literówka się trafiła, piszę się Wehrmacht* ;)