Kto uważany jest za gwiazdę rozrywki 100-lecia niepodległej Polski?
Takie pytanie pojawiło się w poniedziałek 15 października na fanpage’u Karoliny Korwin-Piotrowskiej. Pani Karolina poprosiła o wpisywanie nazwisk w komentarzach. Oczywiście obudził się we mnie umysł pragmatyczny i zapytał (siebie): ciekawe jak ona to ręcznie sobie policzy?. Ludzie przecież będą wpisywać nazwiska jak leci a nie w jakiejś uporządkowanej formie.
Bo ankietę można zrobić tak jak ta majonezowo-ketchupowa do której wypełnienia serdecznie namawiam! Jak będzie dużo głosów to będzie sensowny wynik. I opowieść jak to wszystko zostało zbudowane. Zajmie Ci to góra dwie minuty.
Nie po to człowiek siedzi w internecie i analizie danych, żeby z takim problemem sobie nie poradził. A że w R jest dostępny pakiet Rfacebook to zadanie policzenia głosów jest banalnie proste.
Poza Rfacebook przyda nam się kilka innych pakietów (w sumie standard):
|
1 2 3 4 |
library(Rfacebook) library(tidyverse) library(lubridate) library(glue) |
Na początek jednak potrzebujemy aplikacji zbudowanej na Facebooku. Idziemy zatem na stronę dla developerów i odpowiednią aplikację budujemy.
I teraz uwaga – ja mam aplikację zbudowaną pewnie z rok albo i dwa lata temu. Nie ma wielkich uprawnień, ale do poniższych (i innych) zastosowań wystarczy. Po aferze z Cambridge Analytica Facebook wprowadził sporo zmian i obostrzeń do swojego API, więc nie ma lekko. Nie wiem też czy da się zbudować aplikację bez jej weryfikacji przez FB (a to jest pain in the ass). Koniec końców potrzebujemy ID aplikacji (poniżej wstawiony jako parametr app_id) i jej sekretnego klucza (parametr app_secret).
Mając te dwa ciągi znaków prosimy Facebooka o token:
|
1 2 |
fb_oauth <- fbOAuth(app_id = "xxxxxxxxxxx", app_secret = "yyyyyyyyyyyyyyyy") |
i możemy korzystać z niego (oraz API). Ja tak przygotowany token zapisałem sobie do pliku fb_oauth.rda poprzez:
|
1 |
save(fb_oauth, file = "fb_oauth.rda") |
zatem mogę go teraz wczytać:
|
1 |
load("fb_oauth.rda") |
To wygodne, bo pliczek jest mały, a autentykacja na serwerze unixowym może być problemem – podczas tworzenia tokenu powinna otworzyć się przeglądarka, w której logujemy się do Facebooka. Jeśli system nie ma przeglądarki to co wtedy? Ano wtedy odpalamy R na Windowsie, tworzymy token (bez problemów z brakiem przeglądarki) i gotowy plik wrzucamy gdzie trzeba na serwer. Tak samo obejść da się problem z tokenem od Twittera czy Google.
No dobrze, co dalej? Przygotujmy dwie funkcje, które z API będą korzystać.
Pierwsza pobierze nam zadaną liczbę postów z podanego fanpage’a:
|
1 2 3 4 5 6 7 8 9 10 11 |
getFPPosts <- function(page_name, n_posts = 50) { # pobieramy posty z fanpage'a fb_page <- getPage(page = page_name, token = fb_oauth, n = n_posts) # zostawiamy sobie tylko potrzebne informacje fb_page <- fb_page %>% select(id, created_time, message, likes_count, comments_count) %>% mutate(created_time = ymd_hms(created_time)) return(fb_page) } |
Druga funkcja pobierze nam wszystkie komentarze do konkretnego postu:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
getPostComments <- function(post_id, post_coments = 100) { # pobieramy komentarze z wybranego postu, max 100 sztuk fb_post <- getPost(post_id, token = fb_oauth, n = max(post_coments, 1000), comments = TRUE) # tabela z komciami - tylko potrzebne dane comments <- fb_post$comments %>% select(created_time, message, likes_count) %>% mutate(created_time = ymd_hms(created_time)) %>% arrange(created_time) return(comments) } |
Uwaga – nie bierzemy tutaj pod uwagę komentarzy zagłębionych (komentarzy do komentarzy) – do tego trzeba zaprząc dodatkowo getCommentReplies() z pakietu Rfacebook. Najprościej na już pobranych komentarzach sprawdzić czy jakieś mają komentarze i dla nich wywołać odpowiednio getCommentReplies(). Doczytajcie w dokumentacji pakietu.
Zobaczmy zatem jak wyglądał ponad rok na fanpage’u Dane i Analizy. Pobieramy maksymalnie tysiąc najnowszych postów:
|
1 2 3 |
page_name <- "daneanalizy" fb_page_table <- getFPPosts(page_name, 1000) |
Prosiliśmy o tysiąc, ale wszystkich jest 558.
Jeśli obserwujecie uważnie mojego fanpage’a to wiecie kiedy pojawia się coś nowego. Sprawdźmy to empirycznie:
|
1 2 3 4 5 6 7 8 9 10 |
fb_page_table %>% mutate(h = hour(created_time), d = wday(created_time, week_start = 1, label = TRUE, locale = "pl_PL.UTF8")) %>% count(d, h) %>% ggplot() + geom_tile(aes(d, h, fill = n), color = "gray60") + scale_y_reverse() + scale_fill_distiller(palette = "Reds", direction = 1) + labs(title = "Kiedy publikowane są posty na fanpage'u Dane i Analizy?", x = "", y = "Godzina") |
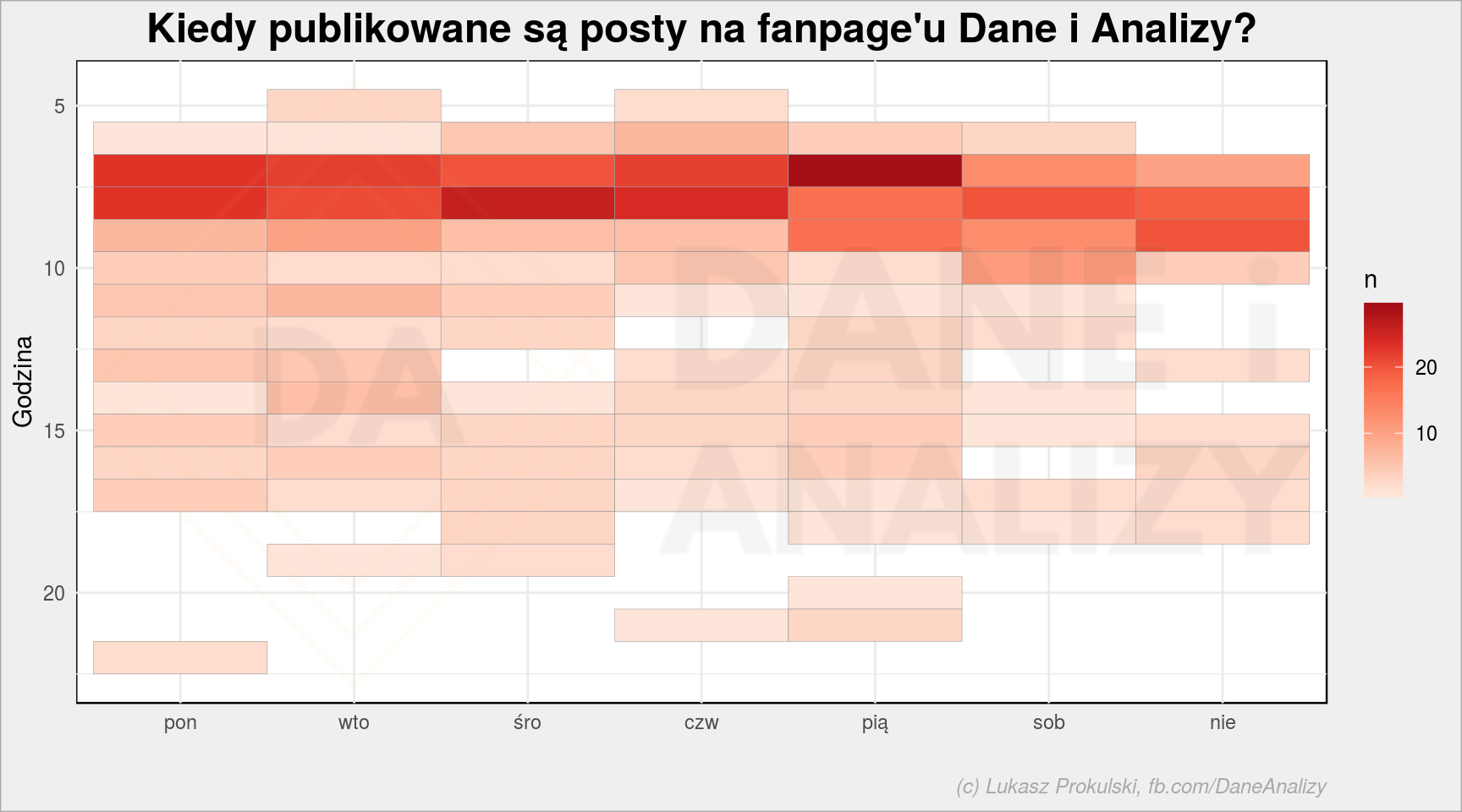
Dla mnie jako zarządzającego stroną ciekawe jest to czy rośnie Wasza aktywność. Zgrupujmy dane po miesiącu (zwróć uwagę na floor_date()) i narysujmy wykres liczby postów, like’ów i komentarzy do postów z danego miesiąca:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
fb_page_table %>% mutate(date = floor_date(created_time, unit = "months")) %>% group_by(date) %>% summarise(n = n(), l = sum(likes_count), c = sum(comments_count)) %>% ungroup() %>% ggplot() + geom_line(aes(date, n), color = "blue") + # posts geom_line(aes(date, l), color = "red") + # likes geom_line(aes(date, c), color = "green") + # comments annotate(geom = "label", x = min(fb_page_table$created_time), y = 400, label = "Liczba like'ów", fill = "red", color = "black", hjust = 0) + annotate(geom = "label", x = min(fb_page_table$created_time), y = 350, label = "Liczba postów", fill = "blue", color = "white", hjust = 0) + annotate(geom = "label", x = min(fb_page_table$created_time), y = 300, label = "Liczba komentarzy", fill = "green", color = "black", hjust = 0) + labs(title = "Liczba postów, like'ów i komentarzy na fanpage'u Dane i Analizy", x = "", y = "") |
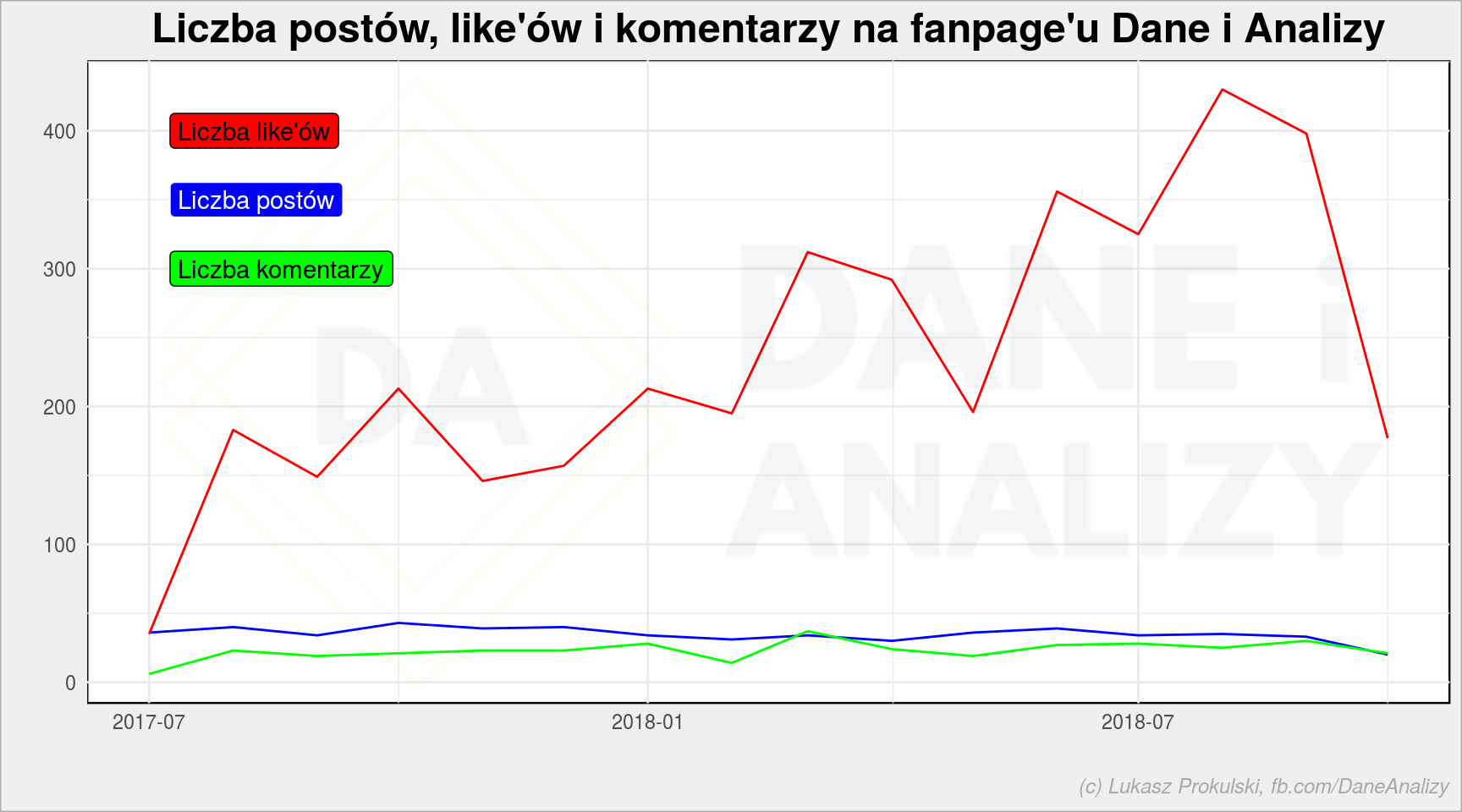
Moglibyście więcej komentować… Taką mam prośbę ;) Chociaż liczba like’ów na post…
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
fb_page_table %>% mutate(date = floor_date(created_time, unit = "weeks")) %>% group_by(date) %>% summarise(n = n(), l = sum(likes_count), c = sum(comments_count)) %>% ungroup() %>% ggplot() + geom_smooth(aes(date, l/n), color = "blue") + # likes/post geom_smooth(aes(date, c/n), color = "green") + # comments/post annotate(geom = "label", x = min(fb_page_table$created_time), y = 12, label = "Liczba like'ów/post", fill = "blue", color = "white", hjust = 0) + annotate(geom = "label", x = min(fb_page_table$created_time), y = 10, label = "Liczba komentarzy/post", fill = "green", color = "black", hjust = 0) + labs(title = "Liczba like'ów i komentarzy na post - na fanpage'u Dane i Analizy", x = "", y = "") |
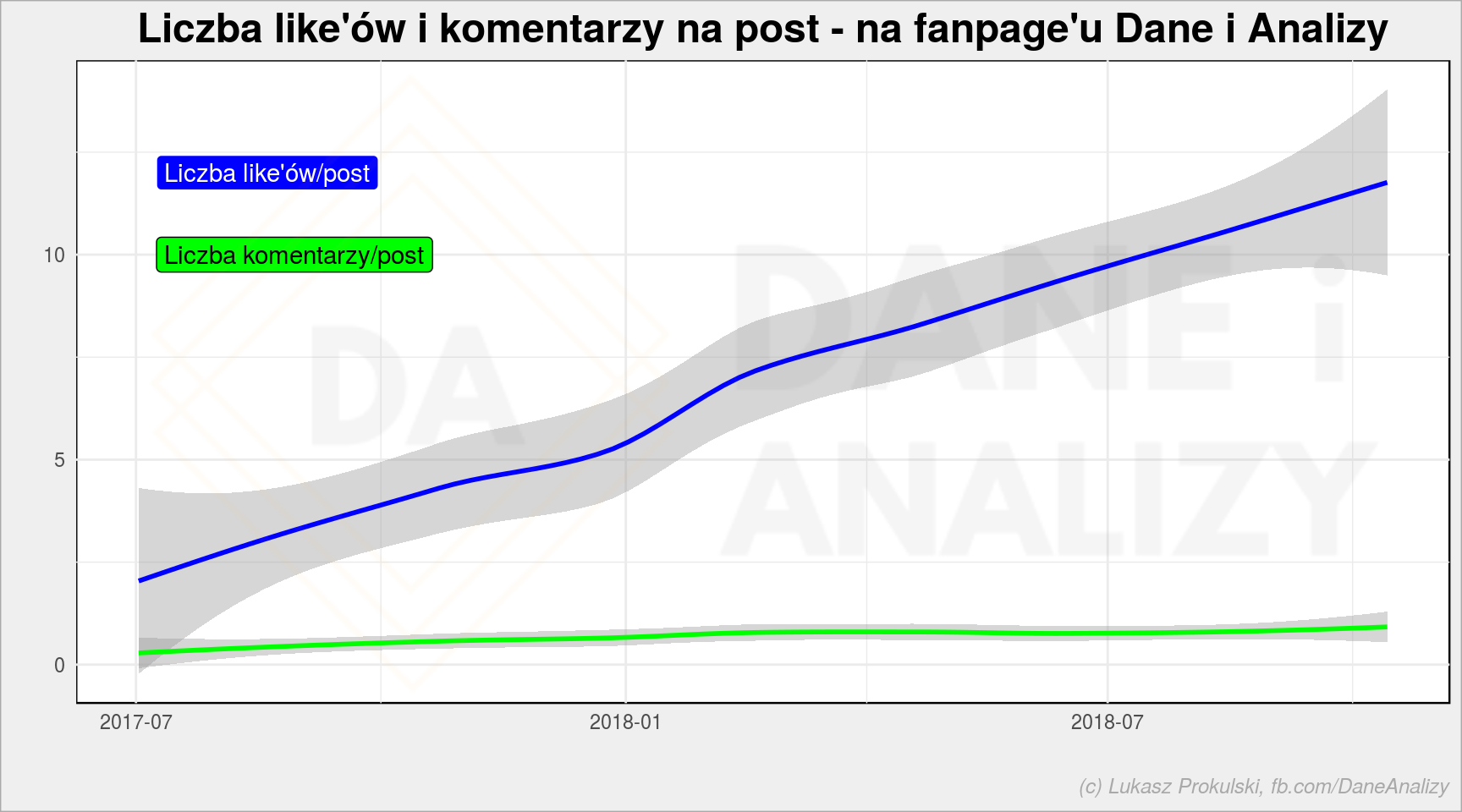
rośnie, co cieszy. Wynikiem jest oczywiście rosnąca liczba fanów strony (no i zajebisty kontent, ale to rozumie się samo przez się).
No dobrze, ale trochę odbiegamy od postawionego problemu (przypomnę: jak z komentarzy wyciągnąć najczęściej wymieniane nazwiska) chociaż jest ciekawie. Mam nadzieję.
Znajdźmy coś, na czym będzie można potrenować dalej – najbardziej komentowany post:
|
1 2 3 4 5 |
# najbradziej komentowany post post_id <- fb_page_table %>% filter(comments_count == max(comments_count)) %>% pull(id) %>% .[[1]] # weźmy wszystko co o nim powie Facebook: post_details <- getPost(post_id, token = fb_oauth) |
Co my tutaj mamy? W odpowiedzi funkcja getPost() (z Rfacebook) zwraca listę zawierającą dwie tabele (zazwyczaj).
Pierwsza to informacje o samym poście:
|
1 2 |
post_details$post %>% kable() %>% kable_styling(bootstrap_options = c("striped", "hover", "condensed")) |
| from_id | from_name | message | created_time | type | link | id | likes_count | comments_count | shares_count |
|---|---|---|---|---|---|---|---|---|---|
| 1775448726078953 | Dane i analizy | Zrobiłem czytanie maili z Gmaila w #R. Chcecie czy wolicie próbę podejścia do klasyfikacji użytkowników na podstawie Google Analytics? | 2018-09-25T14:45:27+0000 | status | NA | 1775448726078953_1993305864293237 | 19 | 10 | 1 |
oraz o komentarzach do niego:
|
1 2 |
post_details$comments %>% kable() %>% kable_styling(bootstrap_options = c("striped", "hover", "condensed")) |
| from_id | from_name | message | created_time | likes_count | comments_count | id |
|---|---|---|---|---|---|---|
| NA | NA | Chcemy :)) | 2018-09-25T14:50:21+0000 | 3 | 3 | 1993305864293237_1993307890959701 |
| NA | NA | A ja bym popatrzył na analizę z google analytics :) | 2018-09-25T15:04:33+0000 | 1 | 1 | 1993305864293237_1993312367625920 |
| NA | NA | Poczta z Gmaila | 2018-09-25T15:12:15+0000 | 0 | 0 | 1993305864293237_1993315130958977 |
| NA | NA | Analytics! :) | 2018-09-25T15:35:16+0000 | 1 | 0 | 1993305864293237_1993322067624950 |
| NA | NA | Analyticsy :) | 2018-09-25T16:08:35+0000 | 1 | 0 | 1993305864293237_1993332204290603 |
| 1775448726078953 | Dane i analizy | O GA pisałem tutaj http://blog.prokulski.science/index.php/2017/08/10/animowany-wykres-kolowy/ – do wyciągania danych powinno wystarczyć. W planach mam kategoryzację użytkowników, a dane z GA mogłyby być równie dobrze zastąpione czymś innym, na przykład parami id_usera i timestamp jakiejś jego akcji | 2018-09-25T16:15:46+0000 | 0 | 0 | 1993305864293237_1993334244290399 |
| NA | NA | Analytics!:) | 2018-09-25T16:27:24+0000 | 0 | 0 | 1993305864293237_1993338787623278 |
| NA | NA | Analytics ale żeby user_id zbierać to trzeba mieć dobrze skonfigurowane konto i zestaw danych wysłanych do Analytics. | 2018-09-25T20:47:19+0000 | 0 | 0 | 1993305864293237_1993424510948039 |
| NA | NA | dej ;) (poczta w gmail) | 2018-09-26T08:24:15+0000 | 0 | 0 | 1993305864293237_1993588984264925 |
| NA | NA | Poczta z Gmaila! | 2018-09-26T10:16:39+0000 | 0 | 0 | 1993305864293237_1993617047595452 |
Zwróćcie uwagę, że nie ma informacji o ID czy nazwie użytkownika, który pozostawił komentarz. A kiedyś jeszcze było… co dawało duuużo ciekawych możliwości. Wykorzystałem je chociażby w poście o zwolennikach partii politycznych, zapewne to jeden z początków ścieżki jaką szli ludzie z Cambridge Analytica. Osobiście uważam, że wzięli to co leżało i odpowiednio tym zamieszali – nie ma tutaj żadnego przestępstwa. Proceder jest szemrany moralnie, Facebook pokazywał za dużo itd.
Równie dobrze możemy wykorzystać naszą funkcję:
|
1 |
comments_table <- getPostComments(post_id) |
która trochę nam porządkuje dane i pozostawia to co ma sens:
|
1 2 3 |
comments_table %>% kable() %>% kable_styling(bootstrap_options = c("striped", "hover", "condensed")) |
| created_time | message | likes_count |
|---|---|---|
| 2018-09-25 14:50:21 | Chcemy :)) | 3 |
| 2018-09-25 15:04:33 | A ja bym popatrzył na analizę z google analytics :) | 1 |
| 2018-09-25 15:12:15 | Poczta z Gmaila | 0 |
| 2018-09-25 15:35:16 | Analytics! :) | 1 |
| 2018-09-25 16:08:35 | Analyticsy :) | 1 |
| 2018-09-25 16:15:46 | O GA pisałem tutaj http://blog.prokulski.science/index.php/2017/08/10/animowany-wykres-kolowy/ – do wyciągania danych powinno wystarczyć. W planach mam kategoryzację użytkowników, a dane z GA mogłyby być równie dobrze zastąpione czymś innym, na przykład parami id_usera i timestamp jakiejś jego akcji | 0 |
| 2018-09-25 16:27:24 | Analytics!:) | 0 |
| 2018-09-25 20:47:19 | Analytics ale żeby user_id zbierać to trzeba mieć dobrze skonfigurowane konto i zestaw danych wysłanych do Analytics. | 0 |
| 2018-09-26 08:24:15 | dej ;) (poczta w gmail) | 0 |
| 2018-09-26 10:16:39 | Poczta z Gmaila! | 0 |
Mechanizmy mamy gotowe, możemy wrócić do naszego zadania związanego z postem Korwin-Piotrowskiej:
Mając ID postu pobieramy wszystkie komentarze:
|
1 |
comments <- getPostComments("180340042008871_2128002970575892") |
I teraz zaczyna się zabawa! Jak policzyć nazwiska? Bardzo prosto! Wszystko to są słowa, zatem komentarze rozbijamy na pojedyncze słowa i liczymy które jest najpopularniejsze:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
library(tidytext) ludzie <- comments %>% select(message) %>% mutate(message = str_replace_all(message, "\\.", " ")) %>% unnest_tokens(word, message, token = "words") %>% mutate(word = case_when( # czasem ludzie wpisują jedno lub drugie - ujednolicamy word == "jackowska" ~ "kora", word == "kazik" ~ "staszewski", word == "muniek" ~ "staszczyk", TRUE ~ word)) %>% count(word, sort = T) %>% filter(nchar(word) > 2) |
Przy okazji usunęliśmy te, które składają się z jednego lub dwóch znaków. 60 najpopularniejszych to:
|
1 2 3 4 5 |
ludzie %>% as.data.frame() %>% head(60) %>% kable() %>% kable_styling(bootstrap_options = c("striped", "hover", "condensed")) |
| word | n |
|---|---|
| kora | 111 |
| janda | 101 |
| gajos | 69 |
| wajda | 68 |
| niemen | 63 |
| krystyna | 60 |
| osiecka | 58 |
| wodecki | 55 |
| irena | 46 |
| jerzy | 44 |
| wojciech | 44 |
| anna | 42 |
| nosowska | 41 |
| andrzej | 40 |
| młynarski | 40 |
| agnieszka | 36 |
| janusz | 36 |
| stuhr | 36 |
| zbigniew | 35 |
| kieślowski | 31 |
| polański | 29 |
| ciechowski | 28 |
| czesław | 28 |
| grechuta | 28 |
| krzysztof | 28 |
| bodo | 27 |
| jan | 27 |
| santor | 27 |
| demarczyk | 26 |
| kulig | 26 |
| rodowicz | 26 |
| olbrychski | 25 |
| szaflarska | 25 |
| dymna | 24 |
| hanka | 24 |
| marek | 24 |
| nie | 24 |
| holland | 21 |
| tyszkiewicz | 21 |
| kulesza | 20 |
| kwiatkowska | 20 |
| owsiak | 19 |
| ewa | 18 |
| holoubek | 18 |
| negri | 18 |
| penderecki | 18 |
| pieczka | 18 |
| pola | 18 |
| szymborska | 18 |
| beata | 17 |
| bielicka | 17 |
| fogg | 17 |
| maryla | 17 |
| tomasz | 17 |
| danuta | 16 |
| grzegorz | 16 |
| joanna | 16 |
| roman | 16 |
| tadeusz | 16 |
| daniel | 15 |
Mamy nie tylko nazwiska, ale też imiona inne słowa. Zbudujmy słownik słów niepotrzebnych:
|
1 2 3 4 5 6 7 8 9 |
stop_w <- c("krystyna", "anna", "janusz", "jerzy", "zbigniew", "hanka", "irena", "jan", "czesław", "nie", "artur", "ale", "beata", "danuta", "eugeniusz", "krzysztof", "franciszek", "marek", "piotr", "pola", "tomasz", "andrzej", "wojciech", "joanna", "agnieszka", "daniel", "roman", "ewa", "grzegorz", "gustaw", "katarzyna", "się", "maryla", "jeszcze", "aktorzy", "kalina", "panowie","maria", "mieczysław", "jest", "adolf", "edyta", "urszula", "jacek", "kabaret", "tadeusz", "tylko", "może", "pan", "pani", "tak", "agata", "violetta") |
i usuńmy je z tabelki słów występujących w komentarzach
|
1 |
ludzie <- filter(ludzie, !word %in% stop_w) |
To ćwiczenie trzeba powtórzyć kilka razy, aby wyłapać wszystkie słowa nie będące nazwiskami. Oczywiście nie chcemy wszystkich – wystarczy, aby w pierwszej na przykład pięćdziesiątce pozostały same nazwiska (stąd head(60) wyżej – 50 z lekkim marginesem).
Teraz odetnijmy listę słów (w tym momencie to już głównie nazwisk) na 50 pozycji:
|
1 2 3 4 5 |
# ile razy występuje 50 najpopularniejsze słowo? n_limit <- ludzie %>% arrange(desc(n)) %>% pull(n) %>% .[[50]] # zostawmy tylko te, które wystąpują więcej razy ludzie <- ludzie %>% filter(n >= n_limit) |
Ostatni krok to odpowiednio narysowany wykres (czy co tam jest nam potrzebne):
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
# ile mamy wszystkich komentarzy? n_comm <- nrow(comments) # rysujemy wykres słupkowy z wynikiem ankiety ludzie %>% arrange(n, word) %>% mutate(word = fct_inorder(str_to_title(word))) %>% ggplot() + geom_col(aes(word, n), color = "gray40", fill = "lightgreen") + coord_flip() + labs(title = "Kto Waszym zdaniem powinien znaleźć się w pierwszej dwudziestce\ngwiazd polskiej rozrywki na 100-lecie niepodległości Polski?", subtitle = glue("Zestawienie na podstawie {n_comm} komentarzy pod postem Karoliny Korwin-Piotrowskiej"), x = "", y = "Ile razy nazwisko padło w komentarzu?") |
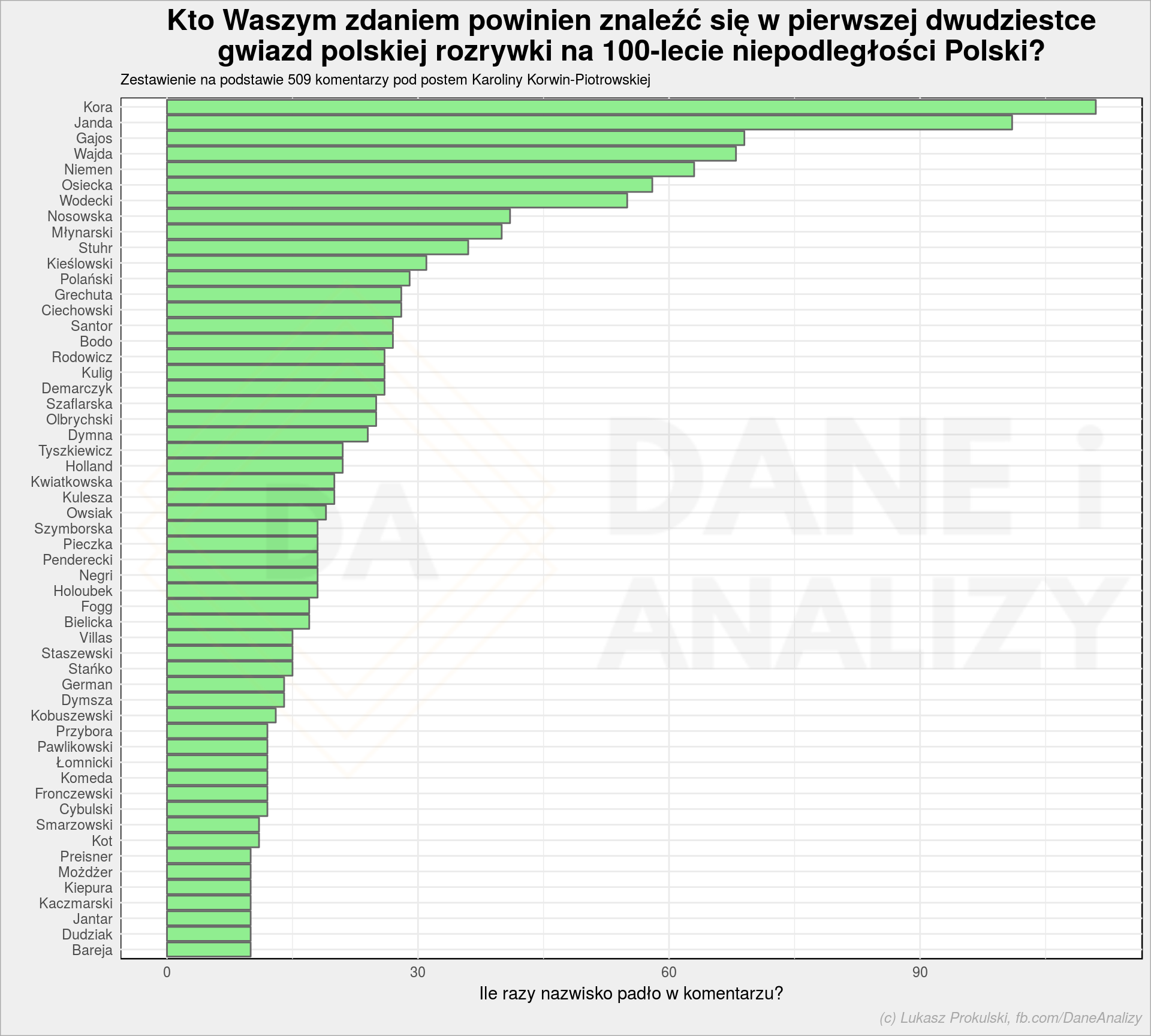
Prawda, że proste? Po przycięciu całego kodu z dzisiejszego postu można zamknąć się w góra 40-50 liniach (czytelnego) kodu dającego ładnie przygotowany wynik. A wszystko w czasie krótszym niż picie jednej kawy (właśnie, kończy mi się – może chcesz postawić kolejną?).
Oczywiście zapraszam do śledzenia fanpage’a Dane i Analizy i (koniecznie!) udzielania się na nim. Bo skąd ja wezmę dane do kolejnych wpisów? :)
Pamiętajcie też o ankiecie majonezowo-ketchupowej.
Widzę jeden problem: nazwiska nie są unikalne i to może zaburzać wyniki, bo taki Stuhr to mogą być przecież dwie osoby, a nie jedna.
To prawda. Ale nie należy ufać maszynie, trzeba też pooglądać dane samodzielnie. Maciej pojawia się sporadycznie.
Inna opcja to podział na bigramy i weryfikacja. Ale wtedy pojawiają się nowe problemy – imiona w różnych wersjach, albo tylko skrócone do jednej, albo w ogóle bez imion…
Super sprawa, bardzo ciekawy wpis. Dziękuję :-)