W tym artykule zaprezentujemy koncepcję stworzenia systemu generującego rekomendacje na stronie produktu w sklepie internetowym. Omówimy dwa modele wykorzystywane do budowania silnika rekomendacji produktowych, przyjrzymy się ich wadom i zaletom. W drugiej części zastanowimy się nad tym, w jaki sposób optymalizować system rekomendacji, aby zwiększyć współczynnik konwersji na stronie sklepu internetowego.
To wpis gościnny, autorem jest Michał Kosztołowicz, Senior AI Developer w Recostream.
Zakładamy, że znajdujemy się na stronie konkretnego produktu (w dalszej części tekstu będziemy nazywać go „produktem wyjściowym”). Naszym celem będzie wybranie spośród pozostałej oferty sklepu zbioru produktów, które mogą leżeć w kręgu zainteresowania użytkownika przeglądającego produkt wyjściowy i wyświetlenia ich jako rekomendacji na stronie tego produktu. Te wybrane produkty będziemy nazywać „rekomendacjami” lub „rekomendowanymi produktami”.

Zdjęcie: Lucrezia Carnelos @ Unsplash
Nasz system rekomendacji produktów zbudujemy w dwóch krokach. W pierwszym zaprezentujemy dwa modele, za pomocą których ze zbioru produktów w sklepie będziemy w stanie wybrać te, które mogą stanowić rekomendacje na stronie z danym produktem wyjściowym. W drugim kroku zaprezentujemy koncepcję, która pozwoli zoptymalizować kolejność, w jakiej rekomendacje te będą wyświetlane oraz usunąć ewentualne błędne wskazania modeli.
1. Modele rekomendacji produktowych
1.1. Model rekomendacji oparty na atrybutach produktu
Pierwszy model, który rozważymy, będzie opierał się na cechach produktów. Przez cechy produktów rozumiemy takie atrybuty jak: nazwa, opis, kategoria, zdjęcie czy cena.
Oprzemy się na założeniu, że produkty o zbliżonych atrybutach są do siebie podobne i że użytkownik przeglądający produkt wyjściowy będzie zainteresowany rekomendacjami produktów do niego podobnymi. Oczywiście dla różnych atrybutów w różny sposób będziemy definiować relację podobieństwa. Nie będziemy wnikać w szczegóły algorytmów, które tę relację wyznaczają (to osobna działka wiedzy) ale przyjrzymy się, jakie możliwości i ograniczenia generują one w naszym zastosowaniu:
Nazwa, opis
Obydwa atrybuty są tekstowe, więc potraktujmy je łącznie. Przenoszą one główną charakterystykę produktu i dlatego powinny stanowić główny punkt odniesienia. Mała bowiem jest szansa, aby produkty o zupełnie niepodobnych nazwach i opisach miały ze sobą coś wspólnego.
Dziedzina algorytmów porównujących teksty jest bardzo obszerna i wciąż rozwija się dynamicznie, szczególnie w zakresie zastosowania uczenia maszynowego. Zanim jednak wybierzemy najbardziej skomplikowany i wyrafinowany z nich, warto się zastanowić, czy faktycznie potrzebujemy takiego stopnia złożoności. Nie da się bowiem ukryć, że opisy i nazwy produktów to nie są wielostronicowe dzieła o złożonej składni i wielowarstwowych znaczeniach, lecz raczej proste i treściwe komunikaty (a przynajmniej powinny takie być). Wystarczy być może więc jakiś prosty algorytm oparty na porównywaniu częstości występowania słów kluczowych aby skutecznie wydobyć produkty podobne.
Pamiętajmy też, że w drugiej części opiszemy mechanizm, który umożliwi usuwanie błędnych wskazań modeli. Możliwe więc, że lepiej zastosować prosty, niewymagający algorytm i ewentualnie usunąć później błędne wskazania niż inwestować w znacznie bardziej złożony i ostatecznie dostać takie same rezultaty.
Kategoria
Zastosowanie tego atrybutu do porównywania produktów mocno zależy od sklepu. Jeśli ma on bardzo zróżnicowany asortyment podzielony na bardzo się od siebie różniące kategorie, na pewno sens będzie miało szukanie produktu podobnego jedynie wśród produktów o tej samej kategorii. Odwrotnie, jeśli sklep sprzedaje produkty zasadniczo tego samego typu, być może podział na kategorie nie powinien być brany w ogóle pod uwagę.
Zdjęcie
Do zastosowania tylko w szczególnych przypadkach. Istnieją algorytmy, które są w stanie zdefiniować podobieństwo między obrazkami. Mogłyby być przydatne w naszych zastosowaniach, gdybyśmy mieli do czynienia ze sklepem, w którym faktycznie produkt jest adekwatnie reprezentowany przez swoje zdjęcie i jego wygląd stanowi główną charakterystykę produktu – jak na przykład w branży odzieżowej lub jubilerskiej.
Cena
To atrybut pomocniczy, nie można oczywiście zakładać, że dwa produkty są do siebie podobne tylko dlatego, że obydwa kosztują 30 zł. Może być jednak użyty do zwiększania wartości koszyka za pomocą rekomendacji – zaproponujemy użytkownikowi produkt podobny do wyjściowego, ale odrobinę droższy.
Wady i zalety modelu rekomendacji produktowych opartego na atrybutach
Ustalanie podobieństwa za pomocą atrybutów produktu ma jedną, niezaprzeczalną zaletę: relacje podobieństwa są dostępne od razu po wdrożeniu systemu rekomendacyjnego, bo wszystkie dane, jakich potrzebujemy, są już na stronie, więc wystarczy je zebrać. To pozwala ominąć tzw. cold start problem, który oznacza występujący w początkowej fazie działania systemu rekomendacyjnego problem związany z brakiem danych, na podstawie których nasz system ma działać. To problem z jakim będzie zmagał się drugi model.
Podejście oparte na atrybutach ma oczywiście również swoje wady. Jedną z nich jest istotna zależność od jakości charakterystyki produktów w danym sklepie. Jeśli opisy są bardzo lakoniczne, chaotyczne lub nawet nie ma ich wcale, wskazania modelu będą odpowiednio gorsze. Z drugiej strony, opisy mogą być też przesadnie rozbudowane, pełne marketingowych fraz mających na celu raczej skłonienie użytkownika do zakupu niż przekazanie informacji na temat produktu. Wówczas słowa kluczowe mogą gubić się w natłoku tekstu i wskazania modelu mogą na tym mocno ucierpieć.
Kolejną wadą podejścia opartego na atrybutach jest „sztywność” modelu. Powiązania między produktami są ustalone raz na zawsze (o ile atrybuty produktów nie zostaną zaktualizowane) i nie zmieniają się, gdy zdobywamy więcej informacji na temat faktycznej aktywności użytkowników. Inaczej mówiąc, model ten nie uczy się i nie ulepsza swoich wskazań wraz z upływem czasu.
1.2. Model rekomendacji produktowych oparty o zależność statystyczną
Drugi model, który rozważymy, będzie oparty o dane związane z ruchem użytkowników na stronie.
Nasz system rekomendacyjny będzie zbierał dane o tym, które produkty przeglądane są przez użytkowników. Będziemy przy tym posługiwać się pojęciem sesji przeglądania: mamy tu na myśli zbiór produktów, które użytkownik przeglądał w czasie jednego posiedzenia. Historia przeglądania, jaką nasz system będzie dysponował, będzie więc po prostu zbiorem sesji wszystkich użytkowników, natomiast każda sesja to po prostu zbiór produktów. Każdy użytkownik może mieć dowolną liczbę sesji – jeśli przegląda ofertę sklepu i po kilku dniach przerwy znów do niego powróci, w naszej historii przeglądania utworzą się dwie osobne sesje. W naszych rozważaniach nie będzie istotne, do którego użytkownika należy dana sesja.
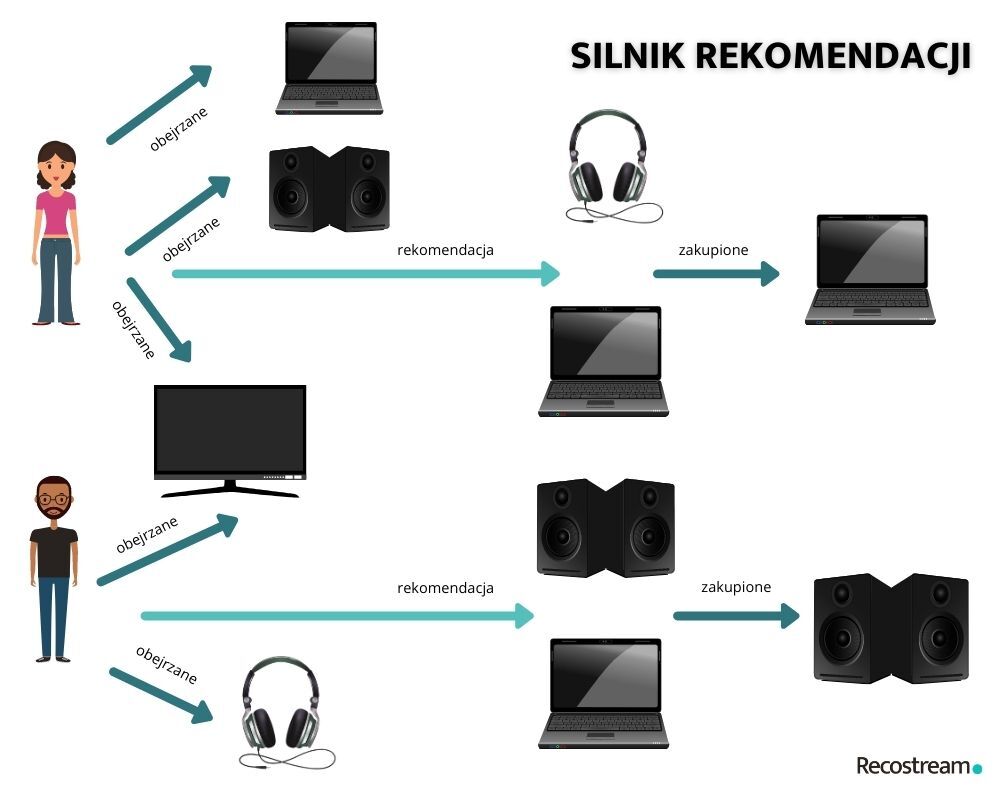
Źródło: System rekomendacji produktowych w pigułce, Recostream
W dalszym ciągu oprzemy się na prostym założeniu, które najlepiej wyjaśnić przykładem. Jeśli użytkownik szuka w sklepie czarnej bluzki to możemy założyć, że zanim dokona wyboru, przejrzy kilka innych ofert czarnych bluzek. Możemy też założyć, że istotna część użytkowników szukających czarnej bluzki postąpi w ten właśnie sposób. Oznacza to, że czarne bluzki będą występowały razem w obrębie jednej sesji istotnie częściej niż z innymi produktami. Naszym celem będzie znalezienie właśnie takich produktów, które w obrębie jednej sesji występują wyjątkowo często z naszym produktem wyjściowym. Uznajemy, że są to właśnie te „inne oferty”, które użytkownik przeglądał, uznając je za alternatywną opcję do produktu wyjściowego. Właśnie ze względu na to podobieństwo będziemy wyświetlać je jako polecane rekomendacje.
Jak zatem znaleźć te produkty, które wyjątkowo często pojawiają się w obrębie jednej sesji z naszym produktem wyjściowym? Do tego posłuży nam pojęcie zależności statystycznej pomiędzy produktami A i B. Określa ono, na ile większe jest prawdopodobieństwo znalezienia produktu A wśród sesji zawierających produkt B w porównaniu z prawdopodobieństwem znalezienia produktu A wśród wszystkich sesji w sklepie.
Mamy trzy możliwości:
- Jeśli większe jest prawdopodobieństwo znalezienia produktu A wśród sesji zawierających produkt B niż wśród wszystkich sesji w sklepie, mówimy, że pomiędzy tymi produktami istnieje dodatnia zależność statystyczna.
- Jeśli prawdopodobieństwo znalezienia produktu A wśród sesji zawierających produkt B jest takie samo co wśród wszystkich sesji w sklepie, mówimy, że pomiędzy tymi produktami nie ma zależności statystycznej.
- Jeśli mniejsze jest prawdopodobieństwo znalezienia produktu A wśród sesji zawierających produkt B niż wśród wszystkich sesji w sklepie, mówimy, że pomiędzy tymi produktami istnieje ujemna zależność statystyczna.
Opcja numer dwa oznacza, że między produktami nie ma żadnej szczególnej zależności. Mówiąc inaczej, są one ze sobą równie niepowiązane co dwa dowolne, losowo wybrane produkty z oferty sklepu.
Scenariusz numer trzy oznacza, że między produktami istnieje zależność, ale jest ona dla nas nieinteresująca. Oznacza bowiem, że oba te produkty „nie lubią” się i wręcz możemy mieć pewność, że osoba przeglądając jeden produkt będzie wyjątkowo niezainteresowana drugim produktem. Sytuacja taka może mieć miejsce na przykład w momencie, gdy jeden produkt to kostium kąpielowy, a drugi to rękawiczki zimowe. Możemy zakładać, że prawie nikt nie przegląda obu tych produktów w czasie jednej sesji.
Jedynym interesującym nas scenariuszem będzie scenariusz numer jeden, czyli sytuacja, w której zależność statystyczna jest dodatnia. Właśnie w ten sposób będzie działał nasz model rekomendacji: dla produktu wyjściowego będzie wybierał te produkty, których dodatnia zależność statystyczna z nim jest największa.
Wady i zalety modelu rekomendacji produktowych opartego o zależność statystyczną
Model oparty o zależność statystyczną potrafi bardzo trafnie wskazać produkty podobne do produktu wyjściowego. Jego wielką zaletą jest to, że uczy się wraz z dostępnością coraz dłuższej historii sesji użytkowników. Jego wskazania są więc coraz lepsze. Wadą natomiast jest to, że nie generuje żadnych rekomendacji w początkowej fazie działania systemu rekomendacyjnego, gdyż potrzebne do ich wygenerowania dane nie są jeszcze dostępne. To jest cold start problem o którym wspominaliśmy, gdy rozważaliśmy poprzedni model. Widzimy więc, że wybranie akurat tych dwóch rodzajów modeli nie jest bezpodstawne, gdyż w pewien sposób uzupełniają się nawzajem. Model oparty o atrybuty generuje w ogólności nieco słabsze rekomendacje produktowe, które są jednak dostępne od razu, natomiast model oparty o zależność statystyczną ma lepsze wskazania, jednak trzeba na nie nieco poczekać.
Powyższe rozważania to szczególny, najprostszy przypadek tzw. reguł asocjacyjnych. Mając do dyspozycji dane o historii przeglądania wszystkich użytkowników w sklepie, możemy za pomocą specjalnych algorytmów wydobyć zestaw interesujących zależności między produktami. Takie zależności są ujęte w postaci reguł. Są one w ogólności bardziej złożone niż w naszych rozważaniach i są postaci „użytkownicy przeglądający produkty A, B i C przeglądali również produkty D i E”. Oczywiście liczba produktów po obu stronach reguły może się zmieniać. Podobne rozumowanie można zastosować do zbioru wszystkich transakcji. Wówczas otrzymamy reguły postaci „użytkownicy którzy kupili produkty A, B i C kupili również produkty D i E”. Jest to bardzo wydajne narzędzie tworzenia rekomendacji cross-sellingowych.
2. Optymalizacja wyświetlania rekomendacji produktowych
W poprzedniej sekcji poznaliśmy dwa modele rekomendacji produktowych, które generują produkty powiązane w jakiś sposób z produktem wyjściowym. Właściwie na tym etapie moglibyśmy zakończyć i uznać, że wygenerowane produkty to ostateczne rekomendacje, które wyświetlimy na stronie przeglądanego produktu. Niewątpliwie podejście takie pozwala uzyskać znacznie sensowniejsze rezultaty niż wyświetlanie najpopularniejszych lub przypadkowych propozycji z tej samej kategorii, co często jeszcze można zobaczyć w sklepach internetowych. My pójdziemy jednak o krok dalej i zaproponujemy podejście, które pozwoli wykrzesać więcej z wygenerowanych przez modele rekomendacji produktowych.
W dalszym rozumowaniu wyjdziemy od prostej obserwacji: jeśli użytkownikom zaprezentujemy listę rekomendowanych produktów, w ogólności najchętniej będą wybierać produkt prezentowany jako pierwszy, następnie drugi, potem trzeci itd. Jest kilka powodów takiej sytuacji.
- Po pierwsze, produkty z listy będą przeglądane po kolei i w momencie, gdy użytkownik znajdzie coś dla siebie, dokonuje wyboru i przestaje przeglądać listę.
- Po drugie, większość użytkowników rzuci jedynie okiem na kilka pierwszych produktów i albo dokona wyboru, albo się zniecierpliwi i przestanie przeglądać listę.
- Po trzecie wreszcie, jeśli lista rekomendowanych produktów jest długa, na ekranie wyświetlimy tylko kilka początkowych pozycji, natomiast zobaczenie pozostałych będzie wymagać jakiejś akcji od użytkownika: przewinięcia slajdu, zeskrolowania w dół lub kliknięcia guzika.
Wszystkie te trzy przesłanki świadczą o jednym: produkty pojawiające się niżej na liście w olbrzymiej części przypadków nie zostaną przez użytkownika w ogóle zauważone. Jest więc jasne, że powinniśmy wyświetlać rekomendowane produkty od najlepszego do najgorszego, aby zmaksymalizować liczbę użytkowników, którzy widzieli najlepsze oferty.
 Przykład modelu opartego o zależność statystyczną, źródło: domowanie.pl
Przykład modelu opartego o zależność statystyczną, źródło: domowanie.pl
Naturalne staje się pytanie: jak wyznaczyć kolejność od najlepszej do najgorszej rekomendacji? Omówione wcześniej modele generują nam rekomendowane produkty wraz z kolejnością wyznaczoną przez ranking danego modelu. Jest to jednak kolejność czysto teoretyczna i w praktyce może okazać się, że produkt, któremu ranking przyznał miejsce pierwsze sprawdza się gorzej niż produkt z miejsca na przykład szóstego. Pomysł naszego podejścia polega więc na tym, aby wśród produktów wygenerowanych przez model wprowadzić kolejność opartą na rzeczywistej, a nie tylko teoretycznej, skuteczności danego produktu jako rekomendacji. Dalszy ciąg tekstu będzie więc poświęcony temu w jaki sposób taką rzeczywistą kolejność ustalić.
Reakcje użytkowników na rekomendacje produktowe
Jak dotąd, przy definicji modeli w poprzedniej sekcji, wykorzystywaliśmy dwa rodzaje danych: te dotyczące cech produktów oraz te związane z ruchem na stronie. Teraz zrobimy użytek z trzeciego rodzaju danych: reakcji użytkowników na prezentowane im rekomendacje. Ściśle rzecz biorąc, będzie nas interesował jeden scenariusz: sytuacja, w której użytkownik kliknie w rekomendowany produkt, a następnie dokona zakupu tego produktu. Taką sytuację będziemy nazywać „konwersją”.
Konwersję mierzy się powszechnie prostym współczynnikiem równym liczbie konwersji podzielonej przez liczbę wyświetleń danego produktu jako rekomendacji. Tą wartość wygodnie ująć w procentach. Jeśli wyświetlimy dany produkt jako rekomendację 1000 razy z czego 7 razy produkt ten zostanie zakupiony, to mówimy, że konwersja dla tego rekomendowanego produktu ma wartość 0.7%. Ten współczynnik liczbowy posłuży nam jako nowy ranking ustalający kolejność od najlepszego do najgorszego wśród produktów wygenerowanych przez model. W takiej właśnie kolejności będziemy starali się prezentować rekomendacje, aby maksymalizować liczbę użytkowników, którzy zobaczą najlepsze propozycje.
Pomysł ten jest praktyczną realizacją jednego z nurtów uczenia maszynowego, mianowicie uczenia przez wzmocnienie (ang. reinforcement learning). Mówiąc obrazowo, produkty, w które użytkownicy chętniej klikają (i następnie kupują) idą „w górę” na liście wyświetlanych rekomendacji, natomiast te klikane rzadziej, idą „w dół”. Efektywnie wygląda to tak, jakby nasz system uczył się, jakie preferencje mają użytkownicy i następnie dostosowywał kolejność rekomendacji do tych preferencji.
Jak zbierać reakcje użytkowników?
Skoro już wiemy, co chcemy osiągnąć, pora zastanowić się, jak to zrobić. Pierwszym krokiem będzie zebranie statystycznie możliwie wiarygodnych danych dotyczących reakcji użytkowników na prezentowane rekomendacje. Zaczynamy ze zbiorem rekomendacji wygenerowanych przez model o których nic nie wiemy, jeśli chodzi o ich zdolność do generowania konwersji. Wiemy za to, że miejsce na liście rekomendacji samo w sobie istotnie wpływa na skłonność użytkowników do klikania w prezentowany tam produkt.
Rozsądne wydaje się więc, aby w pierwszej fazie wyświetlać rekomendowane produkty w losowej kolejności – w przeciwnym wypadku, przy wyświetlaniu ich w jakimś ustalonym porządku, produkt z pierwszego miejsca otrzyma (dużą) premię w stosunku do produktów z niższych miejsc z samego tylko faktu, że jest pierwszy. Dopiero potem, dysponując już niezniekształconą wiedzą na temat zdolności konwersji poszczególnych rekomendacji, moglibyśmy przejść do drugiej fazy, w której rekomendowane produkty będą wyświetlane już w ustalonej kolejności wyznaczonej przez współczynnik konwersji.
Ogólnie rzecz biorąc, w idealnym świecie, plan działania mógłby wyglądać następująco: wyświetlamy rekomendowane produkty w losowej kolejności przez, powiedzmy, 10 000 pierwszych odsłon strony wyjściowego produktu, zbieramy reakcje na prezentowane rekomendacje, a następnie, mając już do dyspozycji po kilkadziesiąt konwersji na produkt, sortujemy rekomendowane produkty po współczynniku konwersji i w takiej kolejności wyświetlamy użytkownikom.
Problemy w praktyce
W tym momencie przychodzi jednak czas, aby zastanowić się, jak te teoretyczne rozważania mają się do praktycznych realiów. Za przykład niech posłużą nam tu realne dane z prawdziwego sklepu z damską odzieżą: mamy w ofercie 1500 produktów oraz łącznie około 100 000 odsłon stron z produktami miesięcznie. Zwróćmy uwagę na to istotne rozróżnienie: mamy tu na myśli ŁĄCZNĄ liczbę wyświetleń WSZYSTKICH stron produktów w sklepie, niezależnie od tego, jaki to produkt. W naszym dotychczasowym rozumowaniu rozważaliśmy stronę konkretnego produktu i mówiąc o odsłonach strony w poprzednim paragrafie rozumieliśmy jedynie liczbę odsłon strony z tym konkretnym produktem. Ile w takim razie taki pojedynczy produkt może mieć miesięcznie odsłon w naszym sklepie internetowym? To oczywiście zależy.
Można przyjąć, że dla liczby odsłon w sklepie zastosowanie znajduje zasada Pareto, a więc 20% produktów generuje 80% odsłon. Konkretne liczby oczywiście różnią się w zależności od sklepu, ale chodzi o zasadę, że większość odsłon jest generowana przez stosunkowo nieduży zbiór produktów. Wynika z tego, że rozkład ten nie jest równomierny i że większość produktów jest mało popularna. W naszym sklepie produkt o miesięcznej liczbie odsłon równej 500 jest jednym z dwudziestu najpopularniejszych produktów, natomiast połowa produktów jest odwiedzana rzadziej niż raz dziennie.
Jakie konsekwencje dla naszego planu sortowania rekomendacji po konwersjach mają te liczby? Jak za chwilę zobaczymy, dość poważne. W pierwszej fazie chcieliśmy wyświetlać rekomendacje w losowej kolejności przez pierwszych 10 000 odsłon wyjściowego produktu, aby zebrać dane na temat reakcji użytkowników. Jak łatwo policzyć, nawet w przypadku jednego z najpopularniejszych produktów w sklepie (500 odsłon miesięcznie) pierwsza faza musiałaby trwać prawie dwa lata. W przypadku produktów mniej popularnych czas ten wydłużałby się do absurdalnie długich okresów. Widać więc, że takie podejście nie ma większego sensu.
Co można więc zrobić? Liczba 10 000 odsłon, po której chcieliśmy zakończyć fazę zbierania danych o reakcjach użytkowników, jest oczywiście wybrana arbitralnie – chodziło o uzyskanie możliwie wiarygodnej próby statystycznej. Można oczywiście rozważyć jej zmniejszenie do wartości, która spowoduje, że faza zbierania danych potrwa miesiąc a nie dwa lata – mając jednak w pamięci, że zbyt mała próba spowoduje taką przypadkowość wyników, że jest spora szansa, że nie będą miały one żadnego sensu.
Można też pójść na jeszcze większy kompromis – który dla najmniej popularnych produktów będzie koniecznością – i uznać, że mechanizmu uczenia przez wzmocnienie użyjemy tylko do poprawienia rażących błędów w kolejności wyznaczonej przez teoretyczne rankingi modeli, a nie do definiowania jej od podstaw.
Mamy tu na myśli następujący scenariusz: domyślnie wyświetlamy rekomendacje produktowe w kolejności wyznaczonej przez modele, a po zebraniu pierwszych reakcji użytkowników zaczynamy sortować po konwersjach. Oczywiście taki mechanizm jest obarczony błędem, o którym wspominaliśmy wcześniej: produkty wyświetlane wyżej na liście dostają premię z samego faktu, że pojawiają się na tej a nie innej pozycji. Pozwala on jednak wyeliminować rażące błędy modeli: jeśli rekomendowany produkt wyświetlany wciąż na pierwszej pozycji ma gorszy współczynnik konwersji niż rekomendowane produkty pojawiające się za nim, widać, że w rzeczywistości jest on tak istotnie od nich gorszy, że nawet premia za pierwsze miejsce nie pomaga. W takiej sytuacji jesteśmy w stanie usunąć pomyłki modeli z pierwszych miejsc na liście rekomendacji.
O ile napotkane trudności faktycznie są dość poważne i mogą podważać sensowność całego przedsięwzięcia związanego z wykorzystaniem mechanizmu uczenia przez wzmocnienie, gra jest jednak wart świeczki. Praktyka pokazuje bowiem, że posortowanie rekomendacji po współczynniku konwersji pozwala zwiększyć średnią konwersję na stronie z produktami nawet o połowę.
Słowo na koniec
Mam nadzieję, że udało mi się przybliżyć działanie silnika rekomendacji produktowych w sklepach internetowych. Omówione modele posiłkują się danymi na temat produktów i sesji przeglądania, przynosząc tym samym różne efekty. Ich optymalizacja zdaje się być niezbędna do jak najtrafniejszego generowania rekomendacji przez system. Zapraszam do dyskusji, a w razie pytań do kontaktu z zespołem budującym silnik rekomendacji produktowych Recostream pisząc na adres team@recostream.com.
Ciekawy artykuł. Myślę, że częściowo wykorzystam informacje w nim zawarte przy rozwoju sklepu internetowego. Takie modele statystyczne wyglądają na skomplikowane, ale w praktyce nie są, a korzyści z nich płynące są ogromne. Pozdrawiam.