Jak zmusić R do korzystania z (dowolnego) API? Jak przygotować atrakcyjne tabelki w raportach?
Nie tak dawno na Dane i analizy wrzuciłem post z informacją, że Feedly ma API. Źródłem inspiracji był post z bardzo fajnego bloga, którego autor chyba pracuje nad biblioteką do R obsługującą API Feedly (tak to wygląda po opublikowanych przez niego fragmentach kodu).
Niby nic szczególnego, ale od czasu śmierci Google Readera brakuje mi w czytnikach RSS jednej rzeczy: informacji o tym, których kanałów nie czytam. Google Reader miał to niejako wbudowane (był wskaźnik liczby przeczytanych postów do wszystkich opublikowanych w kanale), Feedly niestety tej informacji nie ma.
Spróbujemy to samo uzyskać w Feedly, najpopularniejszym chyba czytniku RSS. Może na początek słówko wyjaśnienia co to jest czytnik RSS?
Większość z nas korzysta z internetu podobnie: przeglądamy wiadomości, Facebooka i Twittera (też jako źródło wiadomości), jakiegoś Instagrama czy Snapchata (to już magia dla mnie, zapewne w związku z wiekiem…). Jeśli coś nas zainteresuje w feedzie na Facebooku to przechodzimy na odpowiednią stronę, czytamy i wracamy. Podobnie jest z Twitterem. Do wiadomości najczęściej używamy jednego portalu. Problem pojawia się kiedy czytamy jakieś ulubione blogi i nie pamiętamy aby na nie wejść (a Facebook skutecznie usuwa nam z walla posty z odpowiednich stron). Albo jak potrzebujemy porównać wiadomości prezentowane przez Wyborczą, TVN z tym co pisze TVPInfo, Niezależna czy TV Republika. Poza tym nie ma czasu na czytanie nawet leadów, opinię o tekście można sobie wyrobić na podstawie samego tytułu, a jakże!
Co zrobić? Z pomocą przychodzą właśnie czytniki RSS.
Kanał RSS to takie pliczki XML na serwerach (najczęściej generowane automatycznie) z najnowszymi wpisami (lub ich skrótami) albo czymkolwiek innym (np. z najnowszymi ogłoszeniami z Allegro czy OLX – przydatna opcja jeśli śledzimy ogłoszenia z jakiejś kategorii, na przykład polujemy na aukcje z poszukiwanym winylem). Feedly to jeden z czytników tych kanałów. Cały myk polega na tym, że serwis co jakiś czas (jak często dowiemy się na przykładzie za chwilę) sprawdza kolejne kanały i zapisuje sobie nowości. A potem na jednej stronie widzimy skróty i linki do wszystkich kanałów. Ja mam jakieś 170 kanałów zapisanych w Feedly – nie dałbym rady codziennie ogarnąć tylu stron. Wystarczy za to 15 minut z Feedly i przegląd nowości mam z głowy.
Dodatkowy plus czytnika jest taki, że nie musimy pamiętać co czytaliśmy – czytnik sam to oznacza. Ja robię tak, że przeglądam całość, czytam to co mnie interesuje (albo zaznaczam do przeczytania później – ta lista stale rośnie…), a resztę oznaczam jako przeczytane. I przy kolejnej sesji z Feedly nie miesza mi się to co nowe z tym co już czytałem (albo tylko tak oznaczyłem).
Rozumiecie już ideę? Wszystkie serwisy (na które się zapiszemy) w jednym miejscu, w wygodnej aplikacji. Idealna sprawa.
Ale przy większej liczbie obserwowanych kanałów rośnie liczba treści jaka wpada do czytnika. A części kanałów nie czytamy. Ja na przykład mam kategorię Wiadomości – zagranica, gdzie pojawia się dużo treści (bo są tam najnowsze z CNN i BBC), a których czytam kilka… tytułów. Resztę oznaczam jako przeczytane.
Wracając do celu całego ćwiczenia: chciałbym wiedzieć które kanały usunąć, żeby mi nie zaśmiecały feedu – po co ma pojawiać się coś, czego i tak nie czytam?
Zajmiemy się dzisiaj w związku z tym próbą rozwiązania tego problemu. Początek standardowy:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
# standardowy zestaw :) library(tidyverse) library(lubridate) library(glue) # wygodniejsze sklejanie ciągów # biblioteki do obsługi zapytań i JSONa library(httr) library(jsonlite) # biblioteki do formatowania danych i tabelek library(knitr) library(kableExtra) library(formattable) |
Aby korzystać z API najczęściej potrzebujemy jakiegoś klucza autoryzującego. A przypadku Feedly logujemy się na stronie dla developerów, klikamy co trzeba i mailem przychodzi link do strony, na której dostaniemy access token (taki długi ciąg znaków):
|
1 |
feedly_access_token <- "TU_WKLEJ_SWÓJ_TOKEN" |
Ważna informacja – token wygasa (na stronie z access tokenem jest informacja kiedy, z tego co widzę to po miesiącu – może to inaczej wyglądać w wersji Pro). Obowiązują też ograniczenia liczby zapytań: 250 zapytań na dzień, 500 dla posiadaczy konta w wersji Pro. Informacje o tym znajdziecie w dokumentacji API. Tam też jest cała dokumentacja, o którą się opieramy.
Przykładowe zapytanie wyglądają tak (to jest linuxowa komenda):
curl -H “Authorization: Bearer TU_WKLEJ_SWÓJ_TOKEN” http://cloud.feedly.com/v3/profile
Czyli zapytanie polega na otwarciu (tak jak w przeglądarce) odpowiedniego adresu, ale z nagłówkiem zapytania zawierającym informacje o autoryzacji (-H nam to mówi).
Aby ułatwić pracę zapiszmy sobie początek adresu do API, później będziemy posługiwać się konkretnymi funkcjami, a ten początek dokleimy. Bo gdyby się zmienił serwer z API wystarczy jedna zmiana:
|
1 |
api_base_url <- "http://cloud.feedly.com/v3" |
Skorzystajmy z przykładowego zapytania i zbudujmy je w R – pobierzemy informacje o profilu:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
query <- "/profile" # profil # tutaj wywołujemy API response <- GET(url = paste0(api_base_url, query), # konkretne zapytanie add_headers(Authorization = paste0("Bearer " , feedly_access_token)) # token przekazany w nagłówku ) # co dostajemy w odpowiedzi? Listę, a przykładowe pola to: content(response)$givenName ## [1] "Łukasz" content(response)$familyName ## [1] "Prokulski" content(response)$gender ## [1] "male" |
Oczywiście nie ujawnię Wam wszystkiego co widać w moim profilu.
Najprościej mówiąc: aby pobrać coś z API (jakiegokolwiek) potrzebujemy wysłać stosowne zapytanie pod określony adres. Inaczej mówiąc – wejść na konkretną stronę, tylko nie osobiście a maszynowo. Najczęściej jest tak, że adres zawiera wszystkie parametry.
W odpowiedzi dostajemy kilka informacji, m.in. o ewentualnym kodzie błędu czy też konkretną odpowiedź. Najczęściej odpowiedź przychodzi upakowana w JSON (ale to już zależy od API):
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
# lista subskrypcji query <- "/subscriptions" # wysyłamy zapytanie response <- GET(url = paste0(api_base_url, query), add_headers(Authorization = paste0("Bearer " , feedly_access_token))) # odpowiedź z JSONa przekształcamy na data frame feedy <- fromJSON(content(response, type="text", encoding = "UTF-8")) %>% # niektóre kolumny to listy - rozpłaszczamy je unnest(categories) %>% # zostawiając sobie tylko potrzebne dane select(id, title, website, updated, subscribers, velocity, label) %>% # i zmieniając format kolumn z datami mutate(updated = as.POSIXct(updated/1000, origin = "1970-01-01", tz = "Europe/Warsaw")) |
Pisząc kolejne skrypty warto przeanalizować odpowiedzi z API – zobaczyć jak wygląda to co zwraca GET() (w naszym przypadku zmienna response).
Dobrze. Mamy trochę danych to – jak zwykle – przeanalizujmy je i może znajdziemy jakieś ciekawostki?
Feedly posiada kilka ciekawych miar: velocity, engagement i engagementRate. Oczywiście różne API zwracają różne informacje. Nawet w ramach Feedly nie wszystkie kanały zwrócą nam takie same dane (np. informacje o autorze tekstu) – jeśli nie ma ich w RSSie to Feedly też ich nie posiada.
|
1 2 3 4 5 6 7 8 9 10 |
feedy %>% top_n(20, velocity) %>% arrange(velocity) %>% mutate(title = fct_inorder(title)) %>% ggplot() + geom_col(aes(title, velocity), fill = "#31a354") + coord_flip() + labs(title = "Najczęściej aktualizowane kanały RSS", subtitle = "Dane z Feedly.com (z mojego konta)", x = "", y = "velocity (liczba wpisów w tygodniu)") |
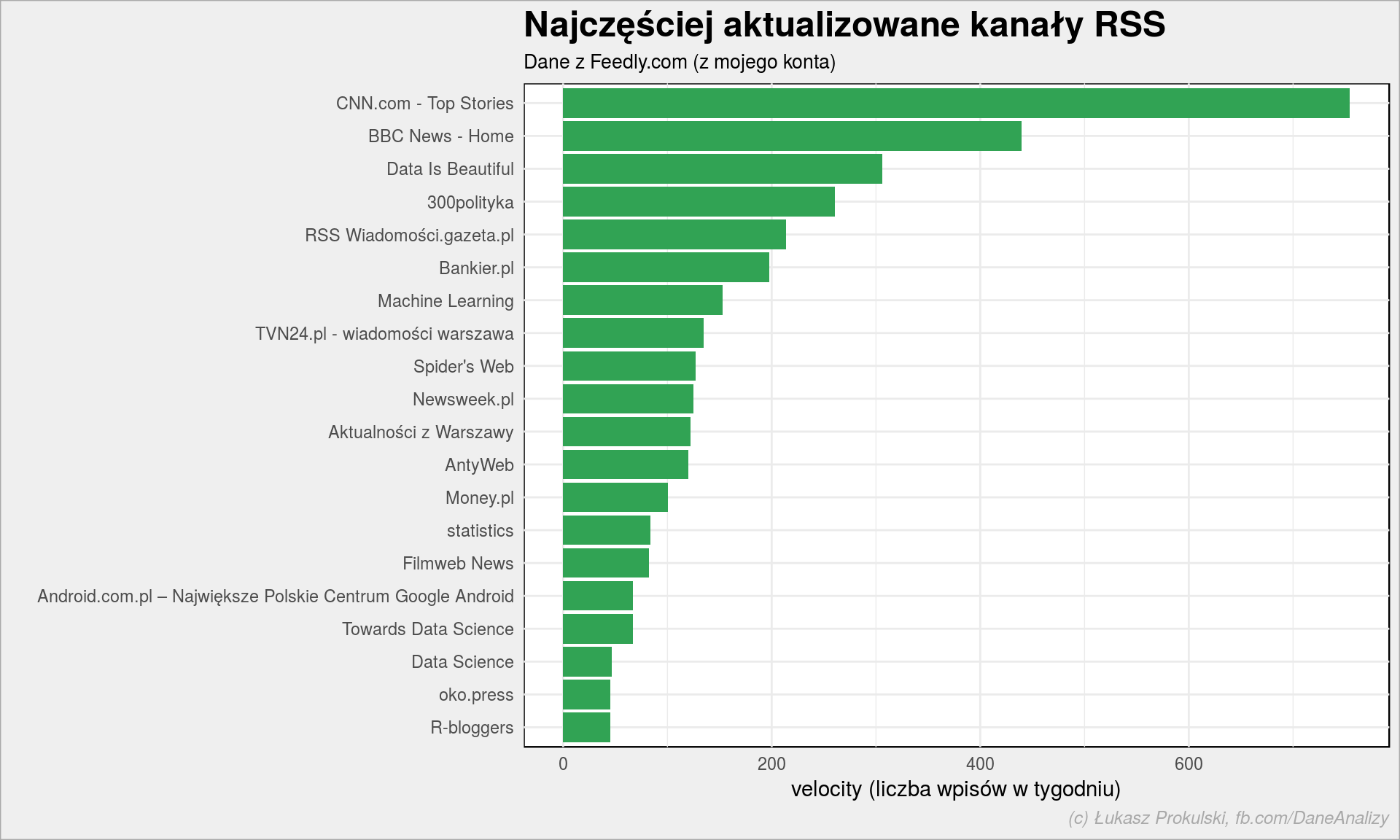
Widzimy, że najwięcej treści produkują serwisy informacyjne (CNN, BBC, 300polityka, Gazeta.pl, TVN24). W moich feedach mam też najnowsze posty z Reddita (to właśnie widoczne wyżej Data Is Beautiful czy Machine Learning).
Naszym celem jest usunięcie feedów, których nie czytamy. Sprawdźmy jeszcze kiedy pojawiły się ostatnie wpisy w feedach. Wybiorę tylko te, które nic nie opublikowały w 2018 roku:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
feedy %>% filter(!is.na(updated)) %>% # aktualizowane przez początkiem bieżącego roku filter(updated < floor_date(now(), unit = "year")) %>% arrange(desc(updated)) %>% mutate(title = fct_inorder(title)) %>% ggplot() + geom_point(aes(title, updated)) + coord_flip() + labs(title = "Daty najnowszych wpisów w kanałach RSS\n(tych dawno nie aktualizowanych)", subtitle = "Dane z Feedly.com (z mojego konta)", x = "", y = "Data ostatniej aktualizacji") + theme(legend.position = "bottom") |
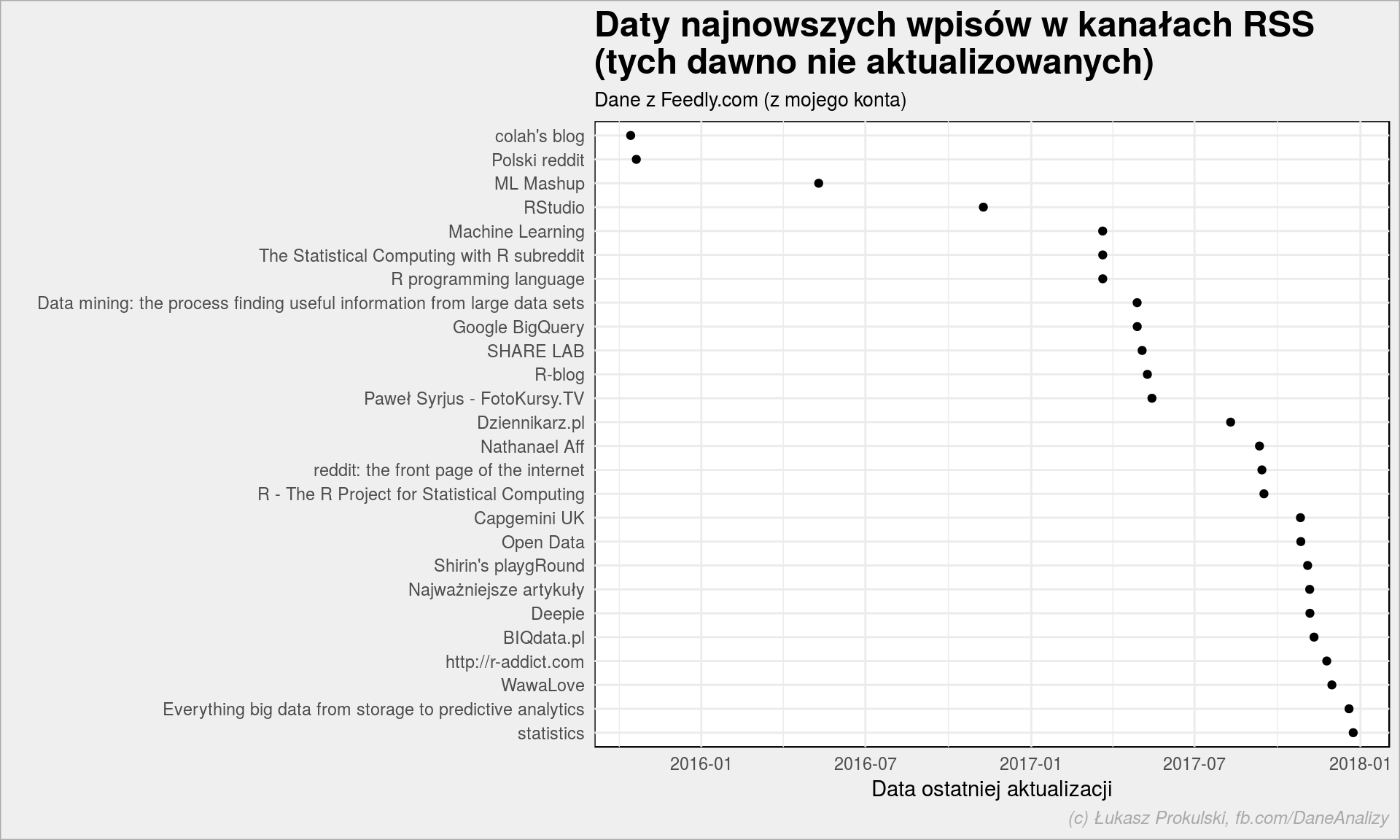
Jest kilku kandydatów do usunięcia. Ale jeśli nie piszą niczego to w sumie nie zaśmiecają listy – czy jest sens usuwać? Można sprawdzić te źródła czy w ogóle działają (może serwisy zmieniły adres – o ile nie przeniosły się na inną domenę to może zmieniły adres pliku RSS? Tak jest w przypadku Polski reddit i innymi feedami z Reddita – popierniczyłem coś z adresami). Trzeba wejść na każdą z tych stron i sprawdzić. Albo sobie odpuścić.
Sprawdźmy teraz najwięcej publikujący feed – czyli ten, który ma największe velocity.
|
1 |
feed_id <- feedy[feedy$velocity == max(feedy$velocity, na.rm = TRUE), "id"] |
Pobierzmy z niego 1000 najnowszych wpisów:
|
1 2 3 4 5 6 |
# parametry zakodowane w URLu: query <- paste0("/streams/", URLencode(feed_id, reserved = TRUE), "/contents?count=1000") # wykonanie zapytania: response <- GET(url = paste0(api_base_url, query), add_headers(Authorization = paste0("Bearer ", feedly_access_token))) |
To jeden ze sposobów – wszystkie parametry zapytania zakodować w adresie URL.
Można też nieco inaczej, wygodniej i bardziej czytelnie:
|
1 2 3 4 5 6 7 |
response <- GET(url = paste0(api_base_url, "/streams/contents"), # parametry zapytania: query = list( streamId = feed_id, count = 1000 ), add_headers(Authorization = paste0("Bearer ", feedly_access_token))) |
W tej drugiej wersji GET() odpowiednio buduje URL zapytania. Bo koniec końców zapytanie to odwiedzenie konkretnego adresu. Odpowiedź API w obu przypadkach jest taka sama.
Pobraliśmy JSONa (czytaj: odpowiedź z API), wyciągnijmy z niego co trzeba. Zwróć uwagę, że bierzemy tylko JSON-ową tablicę items a nie całego JSONa jak w przypadku listy subskrypcji – właśnie dlatego warto zrobić czasem str(response) lub coś analogicznego. Robiłem to przed publikacją posta, tutaj macie gotowe rozwiązania.
|
1 2 3 4 5 |
entries <- fromJSON(content(response, type="text", encoding = "UTF-8"), flatten = TRUE)$items %>% # bierzemy tylko potrzebne dane select(id, title, summary = summary.content, picture = visual.url, canonicalUrl, published, crawled, engagement, engagementRate) %>% mutate(published = as.POSIXct(published/1000, origin = "1970-01-01", tz = "Europe/Warsaw"), crawled = as.POSIXct(crawled/1000, origin = "1970-01-01", tz = "Europe/Warsaw")) |
W powyższym kodzie wybieramy tylko kilka kolumn, które przydadzą się za chwilę. Między innymi opuszczam (nie biorę jej) kolumnę unread, która mówi o tym czy dany post w konkretnym feedzie był przeczytany czy nie. Niestety nie jest to informacja czy otworzyłem (w Feedly lub przechodząc na stronę) konkretny element. Feedly ma bardzo fajny przycisk Mark all as read. I wszystko potraktowane w ten sposób dostaje unread = FALSE. Niestety nie dowiemy się ile postów z feedu czytam a ile oznaczam jako przeczytane bez czytania. Zaplanowane zadanie jest niewykonalne w ten sposób, cały misterny plan w p…iach. No szkoda.
Można by to wyciągnąć z pola actionTimestamp (według dokumentacji) tyle, że zawiera ono informację o akcji typu otagowanie. Każdy przeczytany artykuł musiałbym tagować… Przydałoby się pole informujące co i kiedy stało się z danym entry – czy był przeczytany (w ramach Feedly), kliknięty (i użytkownik przeszedł na stronę), zapisany na później, udostępniony (i jaką metodą – tego Feedly ma multum). Pewnie to zbierają, ale nie pokazują. Ja bym przynajmniej zbierał.
Ale jak już dobraliśmy się do danych to pooglądajmy je sobie (tak, znowu będą jakieś bzdurne wykresiki). Na początek zobaczmy rozkład w kolumnach liczbowych (dla feedu z CNN):
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
summary(entries[6:9]) ## published crawled ## Min. :2018-03-23 05:01:32 Min. :2018-04-10 09:50:47 ## 1st Qu.:2018-04-12 03:54:00 1st Qu.:2018-04-12 08:03:42 ## Median :2018-04-14 02:01:29 Median :2018-04-14 03:48:26 ## Mean :2018-04-14 15:38:04 Mean :2018-04-14 19:06:47 ## 3rd Qu.:2018-04-17 05:10:04 3rd Qu.:2018-04-17 07:05:55 ## Max. :2018-04-19 13:02:20 Max. :2018-04-19 13:06:22 ## ## engagement engagementRate ## Min. : 0 Min. : 0.0000 ## 1st Qu.: 189 1st Qu.: 0.0225 ## Median : 913 Median : 0.1200 ## Mean : 6358 Mean : 0.7484 ## 3rd Qu.: 3925 3rd Qu.: 0.4500 ## Max. :330574 Max. :34.5200 ## NA's :1 NA's :394 |
Co tutaj mamy? Zgodnie z logiką i dokumentacją API:
- published – data (i czas) publikacji postu
- crawled – data (i czas) zaciągnięcia postu przez mechanizmy Feedly
- engagement i enagagementRate – wskaźniki zaangażowania (popularności) dla postu liczone przez Feedly
Znając datę publikacji i datę crawlowania możemy sprawdzić jak szybko informacje z RSSa przechodzą do Feedly.
|
1 2 3 4 5 |
entries %>% ggplot() + geom_point(aes(published, crawled), alpha = 0.5, size = 0.7) + labs(title = "Publikacja a pobranie wpisu przez Feedly", x = "Czas publikacji wpisu", y = "Czas pobrania wpisu") |
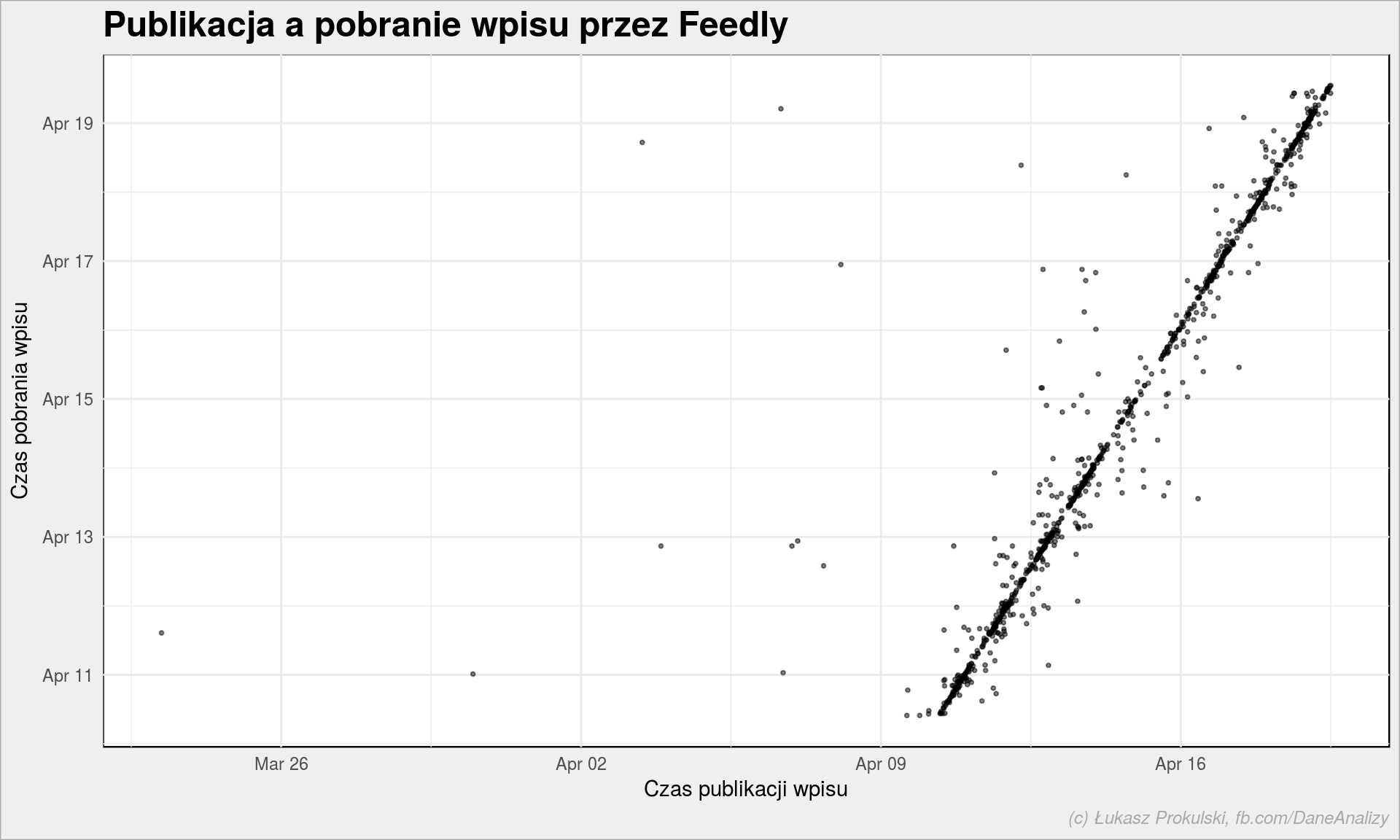
Wygląda liniowo, więc pewnie od razu. Czy na pewno? W końcu są odchyłki… Zobaczmy jak dokładnie wygląda rozkład różnic w czasie pomiędzy momentem published a crawled:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
# liczymy różnicę w czasie, w minutach entries_tdiffs <- entries %>% mutate(t_diff = as.numeric(difftime(crawled, published, units = "mins"))) %>% # zostawiamy tylko takie +/- godzinę, bez długiego ogona filter(t_diff > -60 & t_diff < 60) entries_tdiffs %>% ggplot() + geom_density(aes(t_diff), color = "#31a354", fill = "#a1d99b") + geom_vline(xintercept = mean(entries_tdiffs$t_diff), color = "darkred") + annotate("text", x = mean(entries_tdiffs$t_diff), y = 0, label = sprintf("Średnia = %.1f minut", mean(entries_tdiffs$t_diff)), color = "darkred", hjust = -0.1, vjust = -1) + labs(title = "Rozkład opóźnienia pobrania wpisu w porównaniu do jego publikacji", subtitle = paste0("Na podstawie danych z Feedly.com za okres ", as_date(min(entries$published)), " - ", as_date(max(entries$published)), " dla kanału CNN.com - Top Stories"), x = "Różnica w minutach", y = "Gęstość prawdopodobieństwa") |
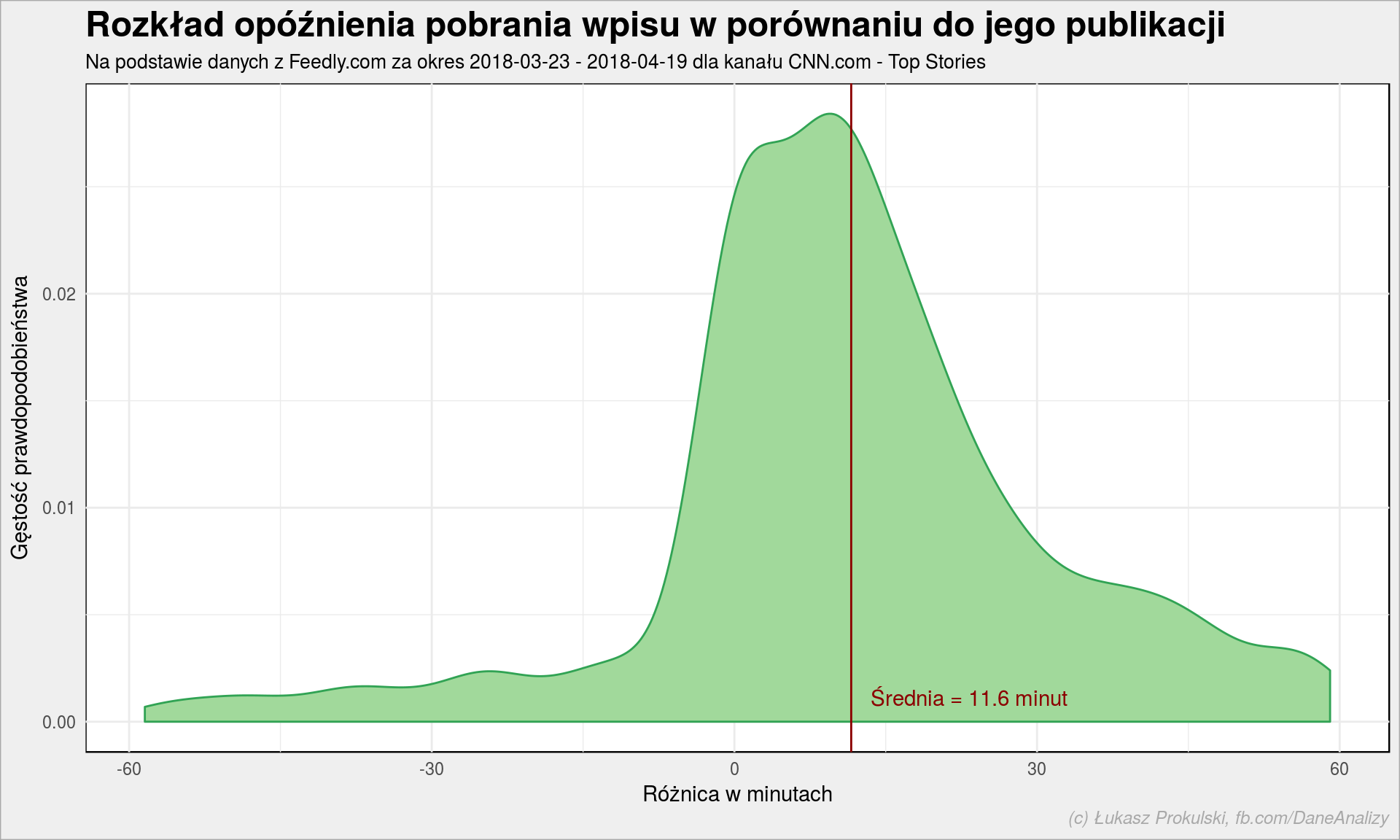
Dla tego konkretnego feedu potrzebne jest prawie 12 minut od publikacji tekstu na stronie CNN do jego pojawienia się w czytniku. Nie jest to co prawda natychmiast (Twitter do odkrywania super-szybko najnowszych wiadomości jest lepszy, bo szybszy), ale opóźnienie jest niewielkie, można mieć wrażenie bycia na bieżąco.
Skąd ujemne wartości? Weźmy przykładowy artykuł CIA chief met secretly with Kim Jong Un, gdzie w źródle strony mamy (na moment pisania tego tekstu):
<meta content=“2018-04-18T00:17:55Z” name=“pubdate”>
<meta content=“2018-04-18T09:10:55Z” name=“lastmod”>
co zapewne oznacza, że tekst został opublikowany (o 00:17), zaczytany przez Feedly, zmieniony (po raz ostatni o 09:10) i ponownie zaczytany przez Feedly. Zapewnie w RSSie pozostaje data ostatniej publikacji (czyli lastmod a nie pubdate) i jest ona w tym przypadku późniejsza niż data pierwszego zaczytania do Feedly. Bo w wyniku otrzymanym z API jest też data recrwaled, czego nie powiedziałem (z premedytacją).
Wiemy już, że engagement i engagementRate to miary popularności wpisów (według dokumentacji liczonej jako liczbę przeczytań, zapisań na później czy też przesłanych dalej). Ale czy są ze sobą powiązane?
|
1 2 3 4 5 6 7 8 9 10 11 12 |
entries %>% filter(!is.na(engagement), !is.na(engagementRate)) %>% ggplot() + geom_point(aes(engagement, engagementRate)) + geom_smooth(aes(engagement, engagementRate), method = "lm", se = FALSE, color = "red") + labs(title = "Engagement versus EngagementRate", subtitle = paste0("Na podstawie danych z Feedly.com za okres ", as_date(min(entries$published)), " - ", as_date(max(entries$published)), " dla kanału CNN.com - Top Stories"), x = "Engagement", y = "EngagementRate") |
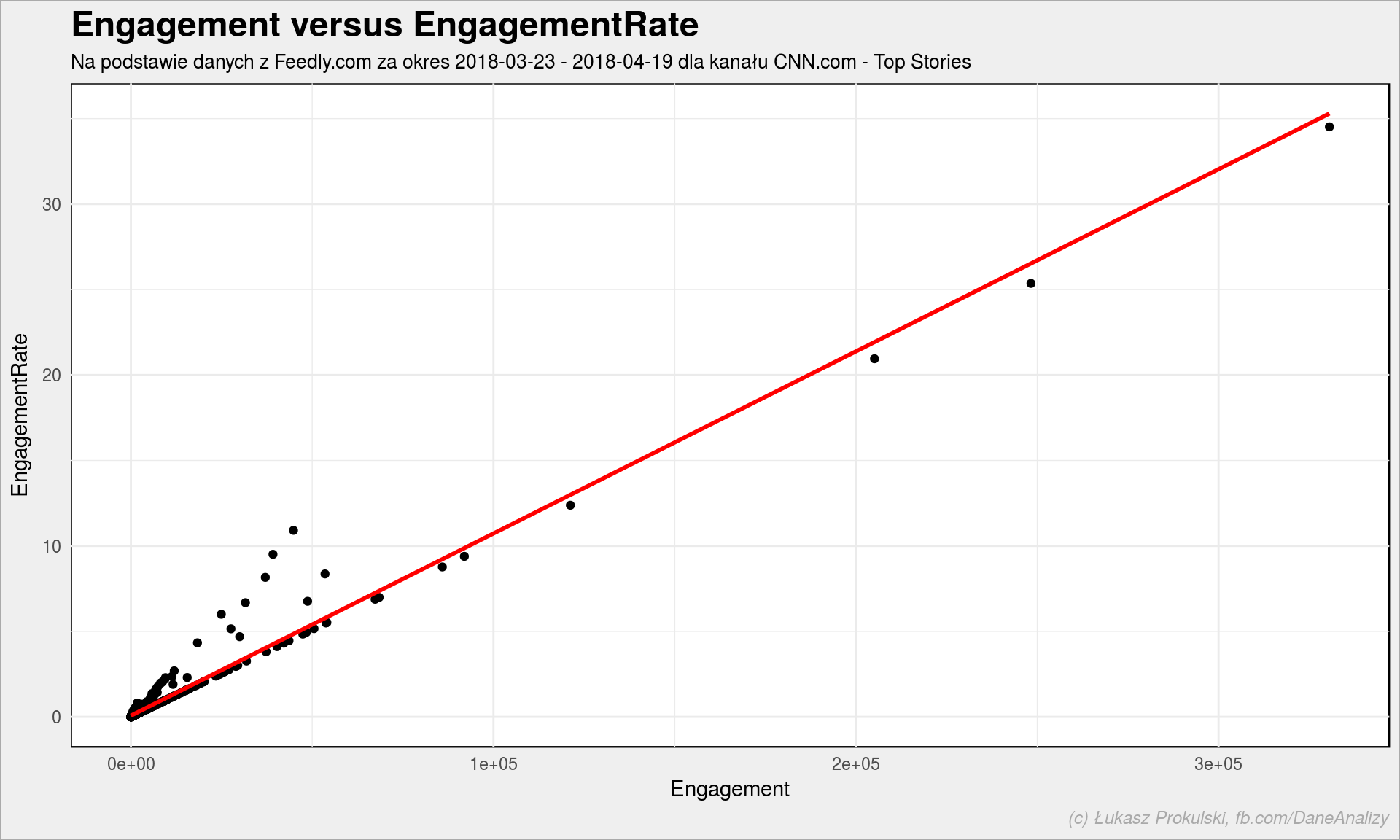
No są, są – liniowo. Wystarczy nam więc engagement (engagementRate częściej brakuje). Rozkład engagement dla CNN.com – Top Stories wygląda następująco:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
entries %>% filter(!is.na(engagement), engagement > 0) %>% ggplot() + geom_density(aes(engagement), color = "#31a354", fill = "#a1d99b") + geom_vline(xintercept = quantile(entries$engagement, c(0.25, 0.5, 0.75), na.rm = TRUE), color = "darkred") + annotate("text", x = quantile(entries$engagement, c(0.25, 0.5, 0.75), na.rm = TRUE), y = 0, label = sprintf("%s=%.0f", c("1kw", "2kw", "3kw"), quantile(entries$engagement, c(0.25, 0.5, 0.75), na.rm = TRUE)), color = "darkred", hjust = -0.1, vjust = -1) + scale_x_log10() + labs(title = "Rozkład wskaźnika engagement", subtitle = paste0("Na podstawie danych z Feedly.com za okres ", as_date(min(entries$published)), " - ", as_date(max(entries$published)), " dla kanału CNN.com - Top Stories"), x = "Engagement (skala logarytmiczna)", y = "Gęstość prawdopodobieństwa") |
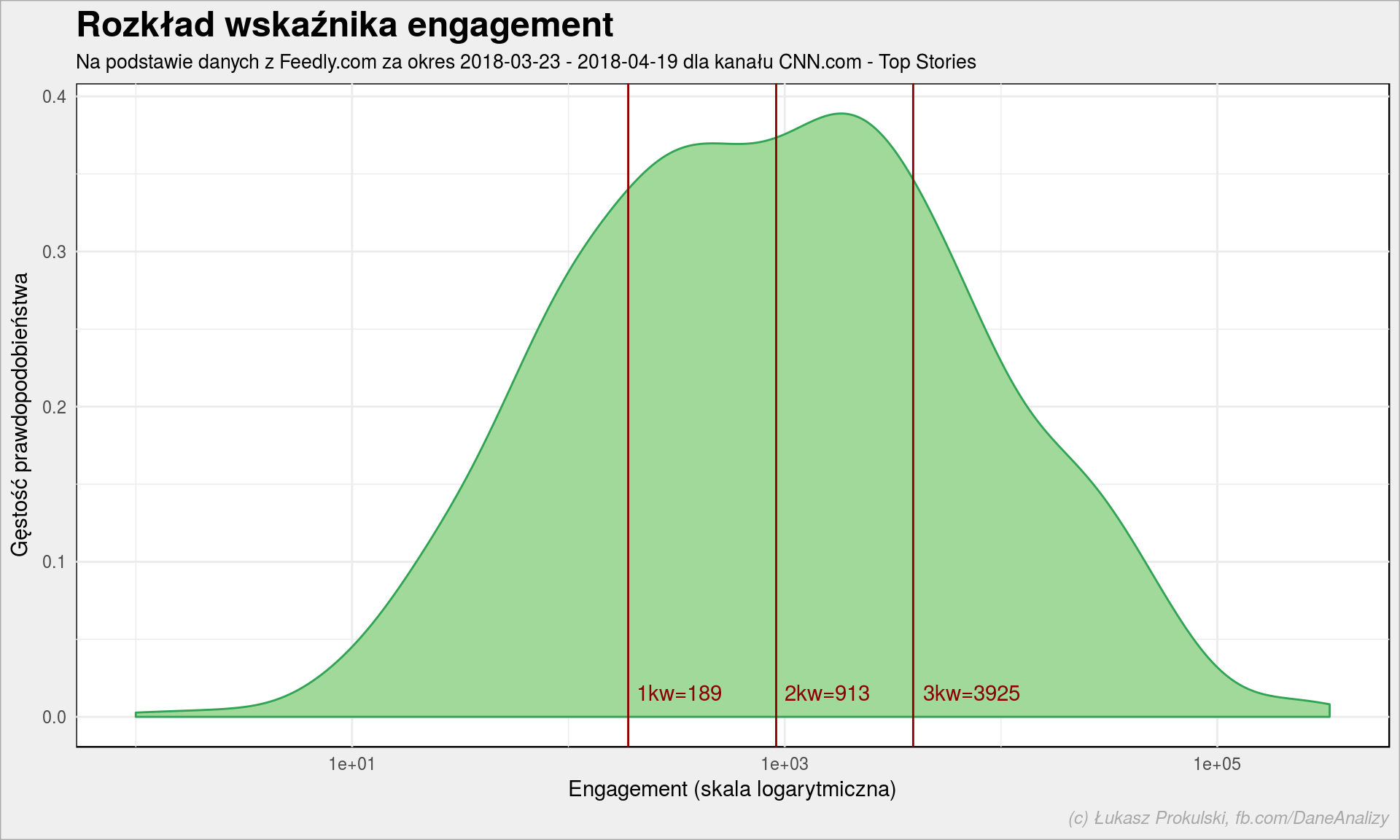
Połowa (2 kwartyl) tekstów zdobywa engagement na poziomie bliskim tysiąca. Nie wiem czy to dużo czy nie… Ale można to zestawić z liczbą subskrbentów danego kanału (mamy to w tabelce feedy, w kolumnie subscribers – dla naszego kanału CNN.com – Top Stories jest to 662936) co da nam medianę zaangażowania na poziomie 0.138 procent.
Zobaczmy teraz jakie posty z CNN wzbudziły największe zaangażowanie? Na początek tylko tabelka, a później wrócimy do tego jak ją przygotować (w wersji bardziej skomplikowanej):
| engagement | title | summary | published |
|---|---|---|---|
| 330574 | Dynasty’s matriarch elevated the cause of literacy | Barbara Bush, the matriarch of a Republican political dynasty and a first lady who elevated the cause of literacy, died Tuesday, according to a statement from her husband’s office. She was 92. | 2018-04-18 |
| 258608 | First black woman nominated to be Marine brigadier general | Marine Corps Col. Lorna Mahlock has been nominated to serve as the first black female brigadier general, the Marine Corps media office said. | 2018-04-12 |
| 248255 | Starbucks closing US stores for racial-bias training | 2018-04-17 | |
| 214049 | House Speaker: ‘I like to think I’ve done my part’ | House Speaker Paul Ryan has told confidantes he is not seeking re-election and will soon announce his decision, two sources with direct knowledge of the matter told CNN Wednesday. | 2018-04-11 |
| 205098 | US, UK and France target Assad’s chemical weapons | The US, UK and France launched strikes against targets at three sites in Syria in the early hours of Saturday morning, following a week of threats of retaliation for an alleged chemical weapons attack on civilians in the Damascus enclave of Douma. | 2018-04-14 |
| 121212 | Judge to decide who vets what investigators can see in docs | Donald Trump’s personal attorney had at least 10 clients between 2017 and 2018, including the President, the former GOP fundraiser Elliot Broidy who acknowledged paying $1.6 million to a Playboy model he had an affair with, and one client who asked not to be identified, lawyers for Michael Cohen said in a filing Monday. | 2018-04-17 |
| 91971 | Ailing Barbara Bush won’t seek further treatment | Former first lady Barbara Bush is in failing health, a source close to the Bush family tells CNN. | 2018-04-16 |
| 91643 | A beached sperm whale in Spain had 64 pounds of plastic and waste in its stomach | When a young sperm whale washed up on a beach in southern Spain, scientists wanted to know what killed it. They now know: waste – 64 pounds of it. Most of it plastic, but also ropes, pieces of net and other debris lodged in its stomach. | 2018-04-11 |
| 85896 | Boy with autism builds world’s largest Lego Titanic replica | The world’s largest Lego replica of the doomed Titanic liner was built over 700 hours – 11 months – by a 10-year-old boy from Reykjavik, Iceland, who is on the autism spectrum. | 2018-04-16 |
| 80555 | Analysis: Senate fails its Facebook test | 2018-04-11 |
Zostawmy CNN i przejdźmy na polskie podwórko – przeanalizujmy jeden z najpopularniejszych polskich serwisów technologicznych – AntyWeb. Mógłby być też Spiders Web, ale wybrałem akurat AntyWeb.
Weźmy dane o 1000 najnowszych postach z Feedly
|
1 2 3 4 5 6 7 8 9 10 11 12 |
response <- GET(url = paste0(api_base_url, "/streams/contents"), query = list( streamId = "feed/http://feeds2.feedburner.com/Antyweb-full", count = 1000 ), add_headers(Authorization = paste0("Bearer ", feedly_access_token))) # data frame z wpisami antyweb_entries <- fromJSON(content(response, type="text", encoding = "UTF-8"), flatten = TRUE)$items %>% # bierzemy tylko potrzebne dane select(originId, title, author, summary = summary.content, picture = visual.url, published, engagement) %>% mutate(published = as.POSIXct(published/1000, origin = "1970-01-01", tz = "Europe/Warsaw")) |
i policzmy ile tekstów było publikowanych w kolejnych dniach:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
antyweb_entries %>% mutate(date = as_date(published)) %>% group_by(date) %>% summarise(n = n()) %>% ungroup() %>% mutate(weekend = wday(date, week_start = 1) %in% c(6, 7)) %>% ggplot() + geom_col(aes(date, n, fill = weekend), show.legend = FALSE) + scale_fill_manual(values = c("TRUE" = "red", "FALSE" = "gray50")) + labs(title = "Kiedy Antyweb publikuje teksty?", subtitle = paste0("Na podstawie danych z Feedly.com za okres ", as_date(min(antyweb_entries$published)), " - ", as_date(max(antyweb_entries$published))), x = "", y = "Liczba opublikowanych tekstów") |
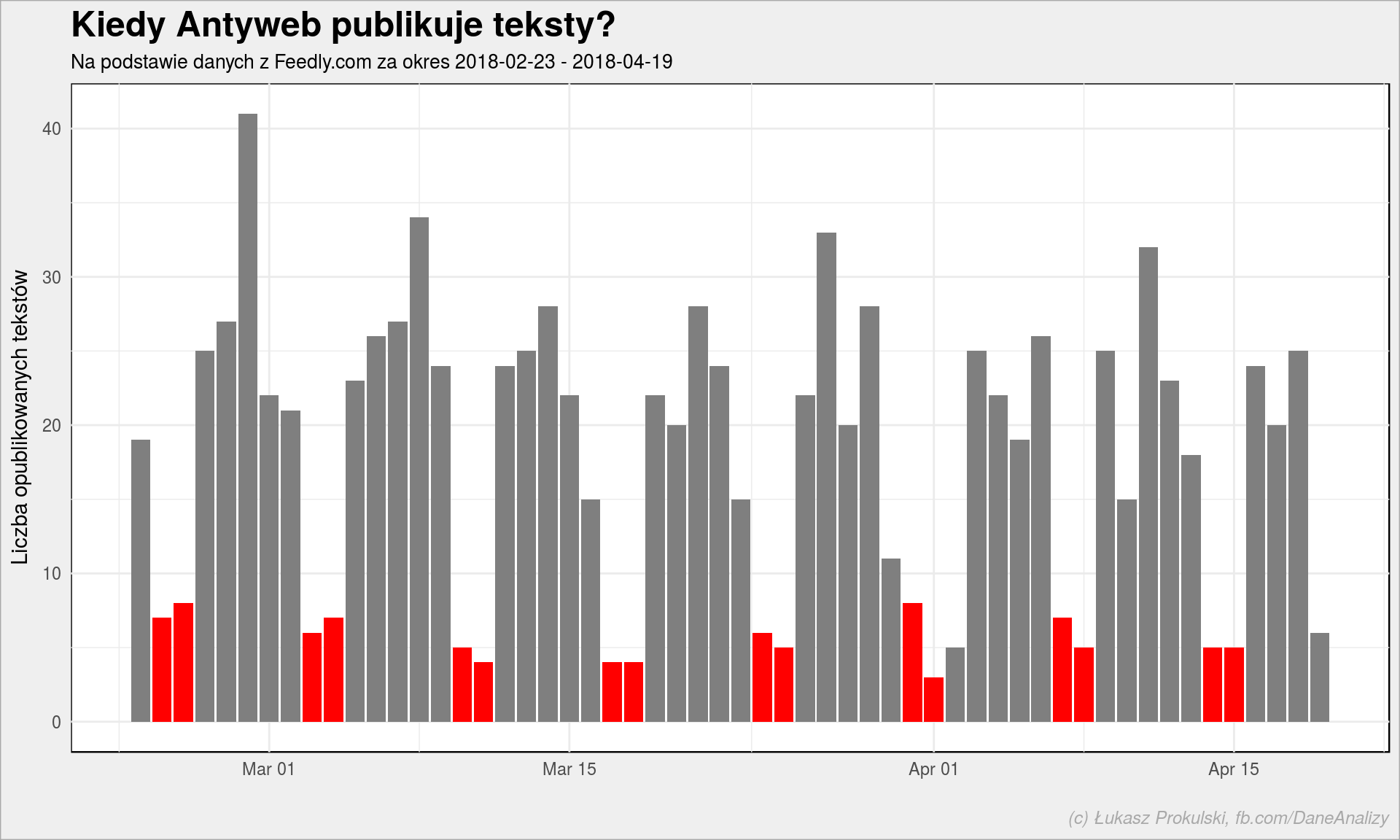
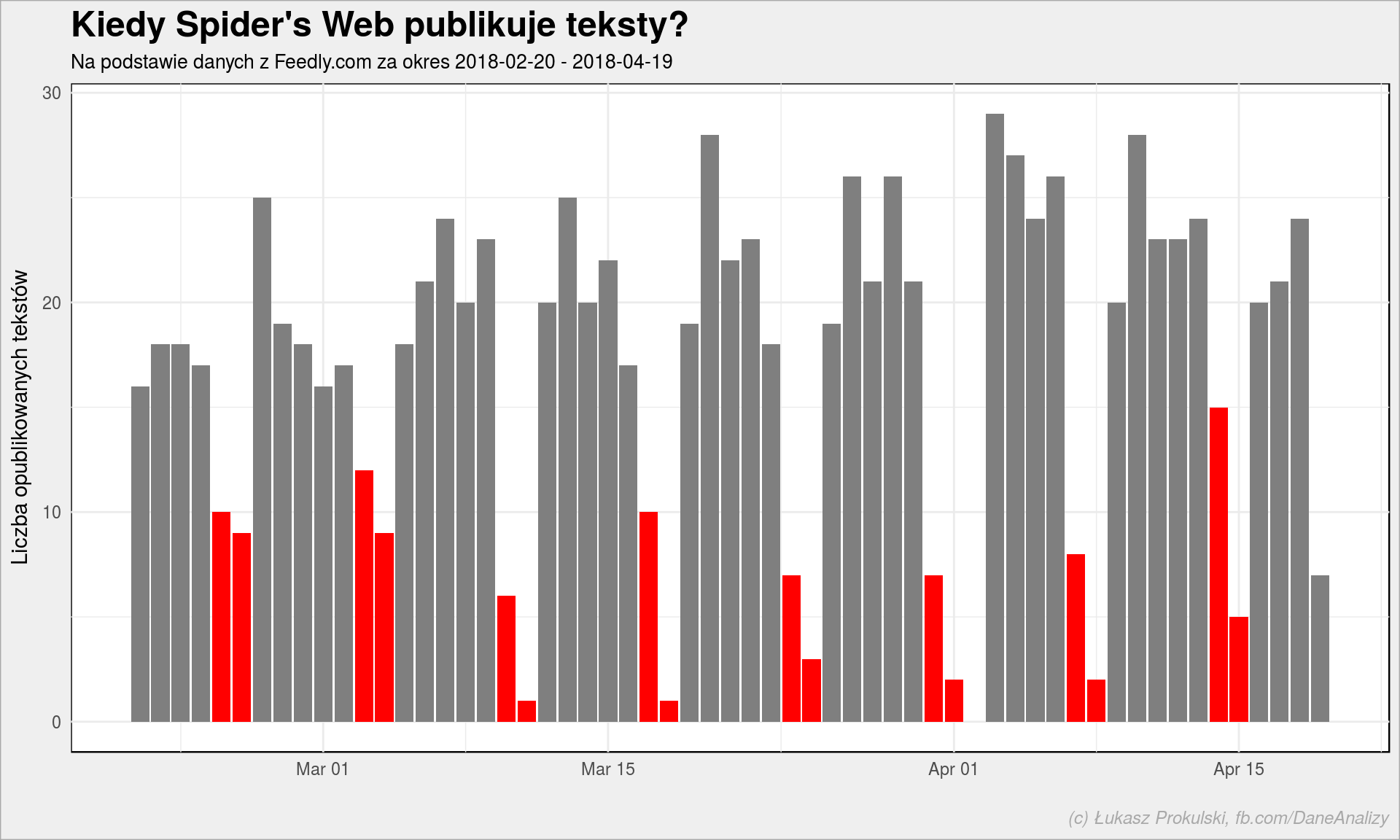
Czerwone słupki to soboty i niedziele. Jest też jeden ciekawy słupek (dla ułatwienia – szary), który odbiega od normy. Kto wie który to? Trochę lepiej to widać na danych dla Spider’s Web:
No dobra, ale kiedy pojawiają się nowe teksty? Bo ich liczba w poszczególnych dniach jest średnio interesująca (jak dla mnie) – ot produkują średnio jakieś 20-25 tekstów dziennie. Ciekawszy jest rozkład pracy redakcji: w jakich godzinach i w jakich dniach tygodnia publikowane jest najwięcej tekstów?
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
antyweb_entries %>% # rozdzielamy odpowiednio datę publikacji mutate(weeknum = week(published), wday = as.factor(wday(published, week_start = 1, label = TRUE)), hour = hour(published)) %>% # liczymy ile tesktów było w poszczególne dni o konkretnej godzinie w kolejnych tygodniach count(weeknum, wday, hour) %>% # uśredniamy liczby po tygodniach group_by(wday, hour) %>% summarise(n = mean(n)) %>% ungroup() %>% ggplot() + geom_tile(aes(wday, hour, fill = n), color = "gray50") + scale_y_reverse() + scale_fill_distiller(palette = "YlOrRd", direction = 1) + labs(title = "Kiedy Antyweb publikuje teksty?", subtitle = paste0("W podziale na dni tygodnia i godziny. Dane uśrednione po tygodniach.\n", "Na podstawie danych z Feedly.com za okres ", as_date(min(antyweb_entries$published)), " - ", as_date(max(antyweb_entries$published))), x = "", y = "Godzina", fill = "Średnia liczba opublikowanych tekstów") + theme(legend.position = "bottom") |
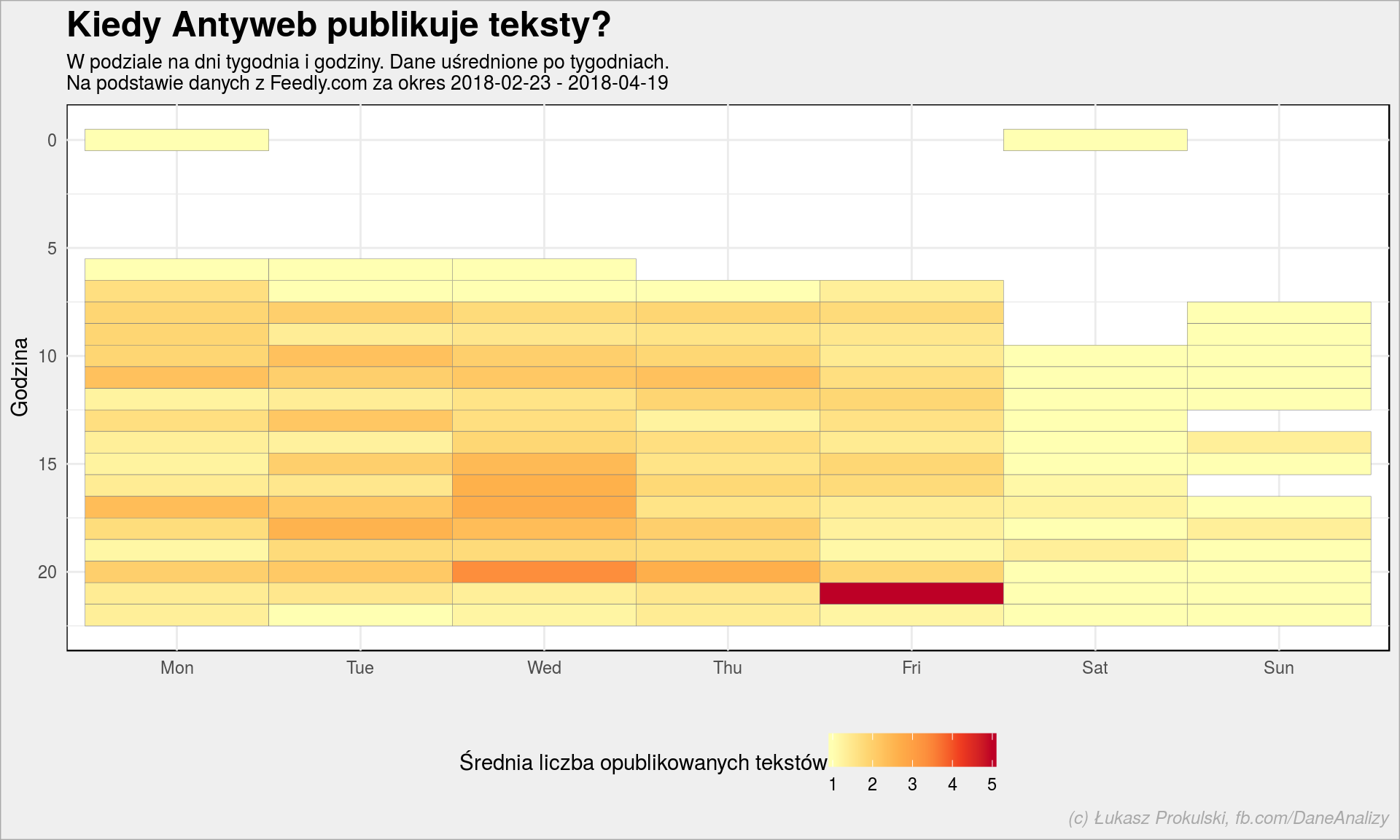
W nocy się nie publikuje, bo nie ma dla kogo. Ciekawy jest piątkowy wieczór – wtedy wypychanych jest najwięcej tekstów. Ciekawe z czego to wynika?
Porównajmy to ze Spider’s Web:
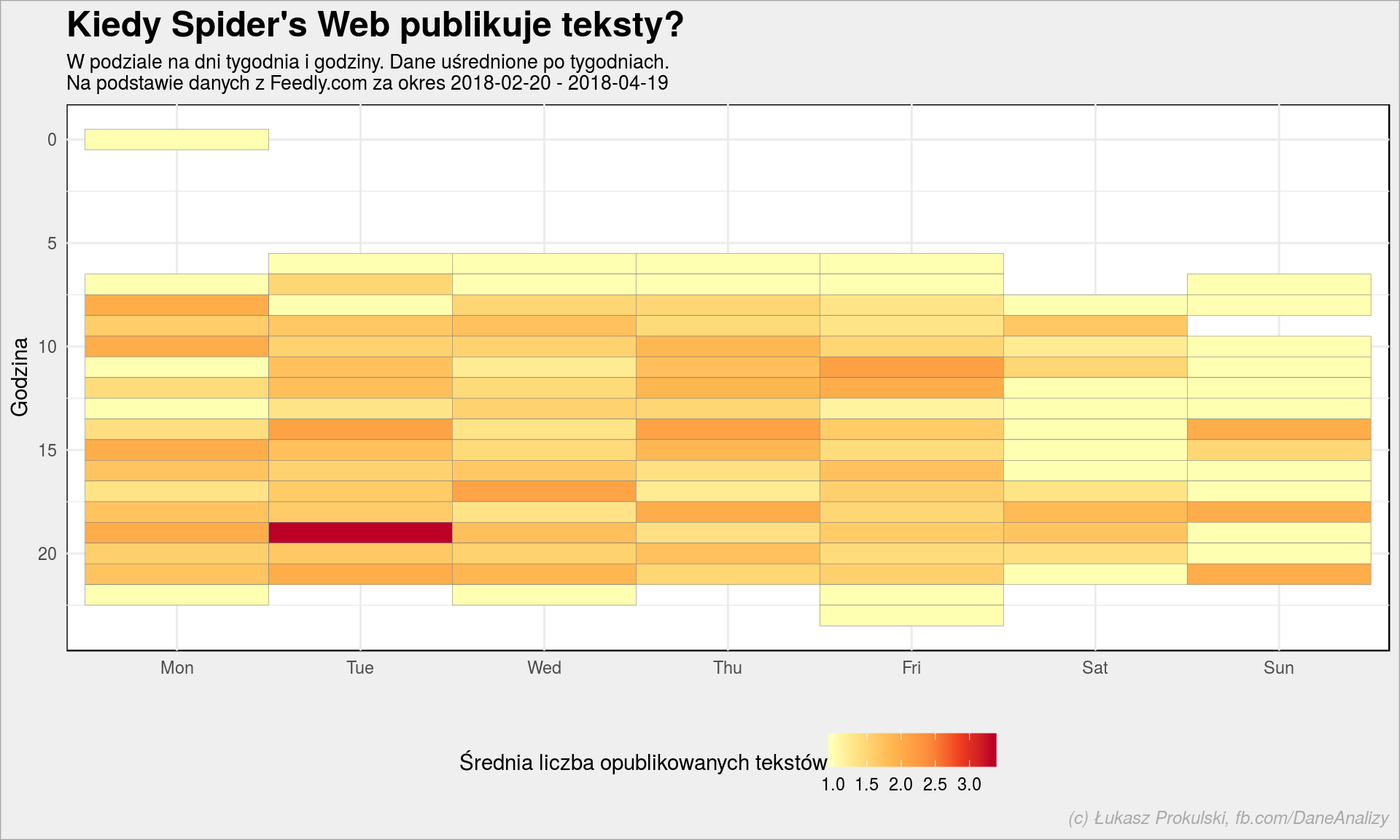
Powyżej rozdzieliliśmy dane na poszczególne tygodnie i po tych tygodniach uśredniliśmy dane. To powoduje, że mamy obraz średniego tygodnia. Bez podzielenia na tygodnie a jedynie na dni i godziny informacja jest nieco zaburzona – mogą być jakieś specjalne okazje (typu konrefencja Apple, a której powstaje kilka materiałów w ciągu jednego dnia).
Teraz część ciekawsza – które teksty Antyweb były najpopularniejsze (według użytkowników Feedly)? Plus przygotowanie atrakcyjnej tabelki (szczegóły już w kodzie) z kolumnami zbijanymi w jeden wiersz i innymi zabiegami. Zaprawdę powiadam Wam, kableExtra to potężne narzędzie (zarówno do tabel w HTMLu jak tutaj jak i w Latexie, a którego tworzymy później PDFy)!
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
antyweb_entries %>% top_n(10, engagement) %>% arrange(desc(engagement)) %>% select(picture, title, author, summary, engagement, originId) %>% # usuwamy HTML z summary mutate(summary = gsub("<[^>]*>", "", summary)) %>% # usuwamy dopisywany standardowy tekst z końca leadu mutate(summary = gsub("The post .* appeared first on AntyWeb\\.", "", summary)) %>% # trochę formatujemy tabelkę: mutate( # zbijamy dwa pola w jedną kolumnę (w rozumieniu data frame) - wyboldowany autor i lead summary = glue("<strong>{author}</strong><br/><br/>{summary}"), # zbijamy dwa pola w jedną kolumnę (zdjęcie, niżej podlinkowany tytuł) picture = glue("<img src = \"{picture}\", width = \"200px\" /><br/><a href=\"{originId}\">{title}</a>"), # engagement jako liczba i zielony pasek stosownej długości engagement = color_bar("lightgreen")(engagement)) %>% # zostawiamy potrzebne nam kolumny select(picture, summary, engagement) %>% kable("html", # produkujemy tabelę w HTMLu # traktuj tagi HTML jak HTML escape = FALSE, # bez nazw kolumn col.names = NULL, # kolumny wyrównane do lewej align = "l", # tytuł tabeli caption = "<strong>10 tekstów z Antyweb z największym engagement</strong>") %>% kable_styling(bootstrap_options = c("striped", "condensed", "hover")) %>% # dostosowujemy szerokość kolumn column_spec(1, width = "200px") %>% column_spec(3, width = "8em") |
 Wiktor „TaZ” Wojtas dla Antyweb : Team Kinguin będzie moją ostatnią profesjonalną drużyną |
Grzegorz Marczak
Wiktor “TaZ” Wojtas to legenda Counter Strike. Legenda, która ostatnio przechodziła dość burzliwy okres kiedy to najpierw został przez Virtus Pro odesłany na ławkę rezerwowych po to aby za chwilę przejąć dowodzenie w nowym składzie Team Kinguin. Miałem przyjemność porozmawiać z Wiktorem już po tym jak wszystkie zmiany się dokonały. Jest to też chyba jego pierwszy wywiad po przejściu do nowego zespołu. |
1855 |
 Nie żyje Stephen Hawking. Odeszła ikona współczesnej nauki |
Jakub Szczęsny
Nawet ci, którzy nie są na bieżąco z najnowszymi informacjami ze świata nauki znają Stephena Hawkinga. Być może dzięki mocnym i kultowym wręcz wypowiedziom, albo… charakterystycznej aparycji, która była efektem śmiertelnej choroby, której ostatecznemu wyrokowi Hawking zdołał się wymknąć. Wybitny naukowiec, mimo stwardnienia zanikowego bocznego dożył 76 lat. |
546 |
 Waldemar Ariel Gala – bezczelność dłużnika z jaką się nigdy nie spotkałem |
Grzegorz Marczak
Prowadzi firmę wartą według niego dziesiątki milionów złotych tymczasem nie płaci ludziom i podwykonawcom. Swoich wierzycieli straszy prawnikami i konsekwencjami finansowymi. Przesyła potwierdzenia przelewów, które nigdy nie dotarły do odbiorców. Mówi o sobie, że jest startupowcem i inwestorem. |
518 |
 Zapytałem X-kom czy na sklepie z elektroniką da się jeszcze zarobić? Zobaczcie co odpowiedzieli |
Grzegorz Marczak
X-kom to jednaj z najbardziej rozpoznawalnych marek w sieci jeśli chodzi o elektronikę. Miałem okazję porozmawiać z nimi o biznesie, o tym co się sprzedaje, czy pojawią się u nich grille i jak radzą sobie z marżą na elektronice itp. |
304 |
 Przestańmy mówić o Informatykach |
Grzegorz Marczak
Określenie zawodu czy też grupy zawodowej hasłem “informatyk” jest dziś nie tylko zbyt ogólne, nieprecyzyjne i błędne na wielu polach. Dziś już nie ma informatyków. Dawno, dawno temu, tym mianem określano tego pana, co się zna na komputerach, co instalował aplikacje na komputerze czy potrafił skonfigurować sieć w biurze. |
269 |
 Pierwsza polska firma hostingowa udostępnia swoje usługi w USA |
Grzegorz Ułan
O planach dhosting.pl na podbicie rynku amerykańskiego pisaliśmy Wam rok temu, po roku przygotowań w końcu się udało, wczoraj zadebiutowali w USA ze swoimi usługami pod domeną dhosting.com |
177 |
 Oto Chmura Faktur. Dokumenty księgowe nigdy nie były prostsze |
Redakcja Antyweb
Każdy przedsiębiorca wie o tym, że wystawianie, przechowywanie i przekazywanie dokumentów księgowych może być niezwykle żmudne. W polskich firmach króluje papier, który wcale nie jest wygodny. Nic więc dziwnego, że coraz więcej osób prowadzących firmy szuka prostszych i pewniejszych sposobów na ogarnięcie firmowych rozliczeń. – Chmura Faktur jest odpowiedzią na te potrzeby. |
176 |
 Oto jak może radzić sobie pisarz w czasach, gdy mało ludzi czyta książki |
Redakcja Antyweb
Jeszcze nie wszyscy zdają sobie z tego sprawę, lecz wkrótce przestrzeń oplatającej nas internetowej sieci zaroi się od debiutantów, którzy nawet nie pomyślą, by swój rękopis wysyłać do wydawców. Co więcej, wielu z nich w nieodległej przyszłości odniesie sukces. |
167 |
 To osiągnięcie Google jest niesamowite i… przerażające jednocześnie |
Jakub Szczęsny
Sztuczna inteligencja Google potrafi coś, do czego wcześniej potrzeba było profesjonalnych dźwiękowców. Czy to zalążek nowej metody inwigilacji? |
161 |
 Jedna z najbardziej wciągających planszówek teraz dostępna za darmo na Androida! |
Kamil Świtalski
Myślę że nie przesadzę uogólniając i twierdząc, że wszyscy kochamy dobre promocje i rozdawane za darmo gry wideo. Ostatnie lata nas w tej kwestii niezwykle rozpieszczają: co rusz dostajemy wspaniałe tytuły za grosze w paczkach (np. trwające wlaśnie Humble Strategy Bundle, ale co jakiś czas możemy też liczyć na tytuły za darmo. Przez najbliższych kilka dni będziemy mogli za darmo pobrać jedną z najbardziej kultowych gier planszowych, które doczekały się wspaniałej wersji mobilnej: Talisman! |
159 |
Piękne, prawda? :) Opakowując zapytania API i ich wyniki w aplikację Shiny można przygotować ładny czytnik RSSów. Tylko po co, skoro jest Feedly? Można zamiast korzystać z Feedly pobierać RSSy (pliki XML) bezpośrednio z serwerów i osiągnąć to samo – czyli napisać swój czytnik RSS.
Co ciekawe – według danych Feedly RSS Antywebu ma 740 subskrybentów. Skąd więc liczba ponad 1800 w engagement? Trzeba zapytać Feedly jak dokładnie liczą ten wskaźnik…
W tym konkretnym feedzie mamy dostęp do pola z nazwiskiem autora danego wpisu. Wykorzystajmy to i sprawdźmy czyje teksty są najbardziej popularne:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
# ta tabela nam sie przyda za chwilę antyweb_authors <- antyweb_entries %>% group_by(author) %>% summarise(eng = mean(engagement, na.rm = TRUE), n = n()) %>% ungroup() antyweb_authors %>% arrange(eng) %>% mutate(author = fct_inorder(author)) %>% ggplot() + geom_col(aes(author, eng), fill = "#31a354") + geom_text(aes(author, eng, label = sprintf("%.1f (%d)", eng, n)), hjust = -0.2, vjust = 0.5) + scale_y_continuous(limits = c(0, 230)) + coord_flip() + labs(title = "Który autor Antyweb budzi największe zaangażowanie?", subtitle = paste0("Na podstawie danych z Feedly.com za okres ", as_date(min(antyweb_entries$published)), # tutaj przydaje się tabela przejściowa " - ", as_date(max(antyweb_entries$published))), # i tutaj :) x = "", y = "Średnie zaangażowanie, w nawiasie liczba opublikowanych tekstów") |
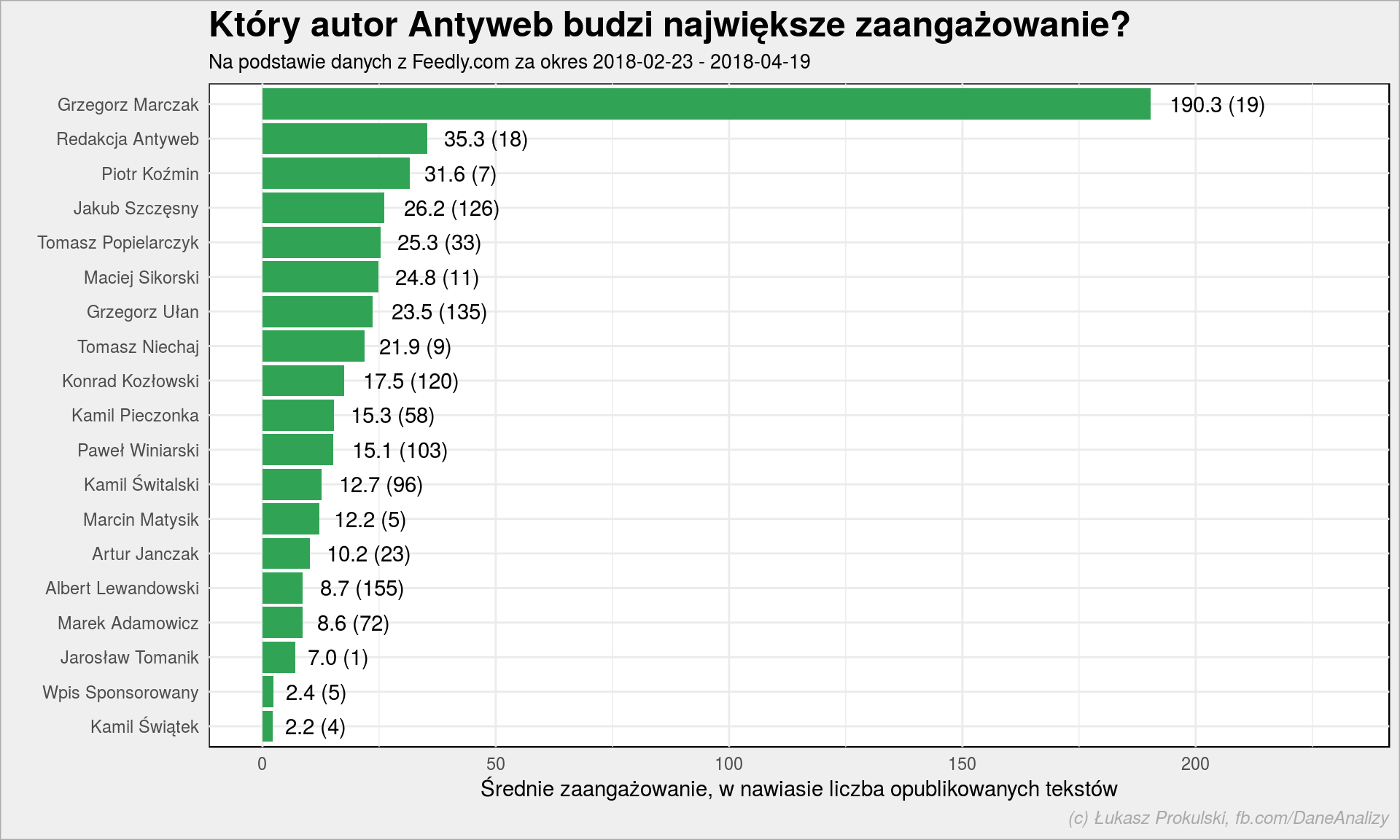
Nie wiem czy Grzegorz Marczak zechce coś zrobić z tymi informacjami :) Dane z Feedly to tylko ułamek wszystkich informacji – dajcie mi (Wy = Antyweb) dostęp do:
- bazy WordPressa – dla listy postów i ich autorów i tagów
- Google Analytics – dla informacji o odsłonach
- dane z fanpage’a sam sobie wezmę :-P
to coś policzymy. Można te trzy źródła zestawić ze sobą i policzyć średnie liczby odsłon na autora, liczbę like’ów i komentarzy na FB. Dodając do tego informacje o dolarach i klikach (CTR) wpadających za reklamy można ciekawie ustawić dobór tematów, o których warto pisać. I jak wynagradzać autorów… System motywacyjny taki, a co!
Jeden wykres może jednak wprowadzić w błąd – a co jeśli popularność autora (średni engagement) jest powiązana z liczą napisanych przez niego tekstów? Być może tak jest, ale raczej nie jest, bo współczynnik korelacji tych dwóch wartości
|
1 |
cor(antyweb_authors$eng, antyweb_authors$n) |
jest równy -0.141 czyli mówimy o słabej (nawet bardzo) korelacji ujemnej. Pisanie więcej nie oznacza pisania ciekawiej (z korelacji jest wręcz odwrotnie, ale delikatnie). Albert Lewandowski napisał dwa razy więcej tekstów niż Marek Adamowicz, a popularność (wg Feedly) mają podobną. Podobnie Winiarski i Pieczonka, a w przypadku par Ułan i Sikorski oraz Szczęsny i Popielarczyk widać to najbardziej dobitnie.
Zobaczmy to samo dla Spider’s Web:
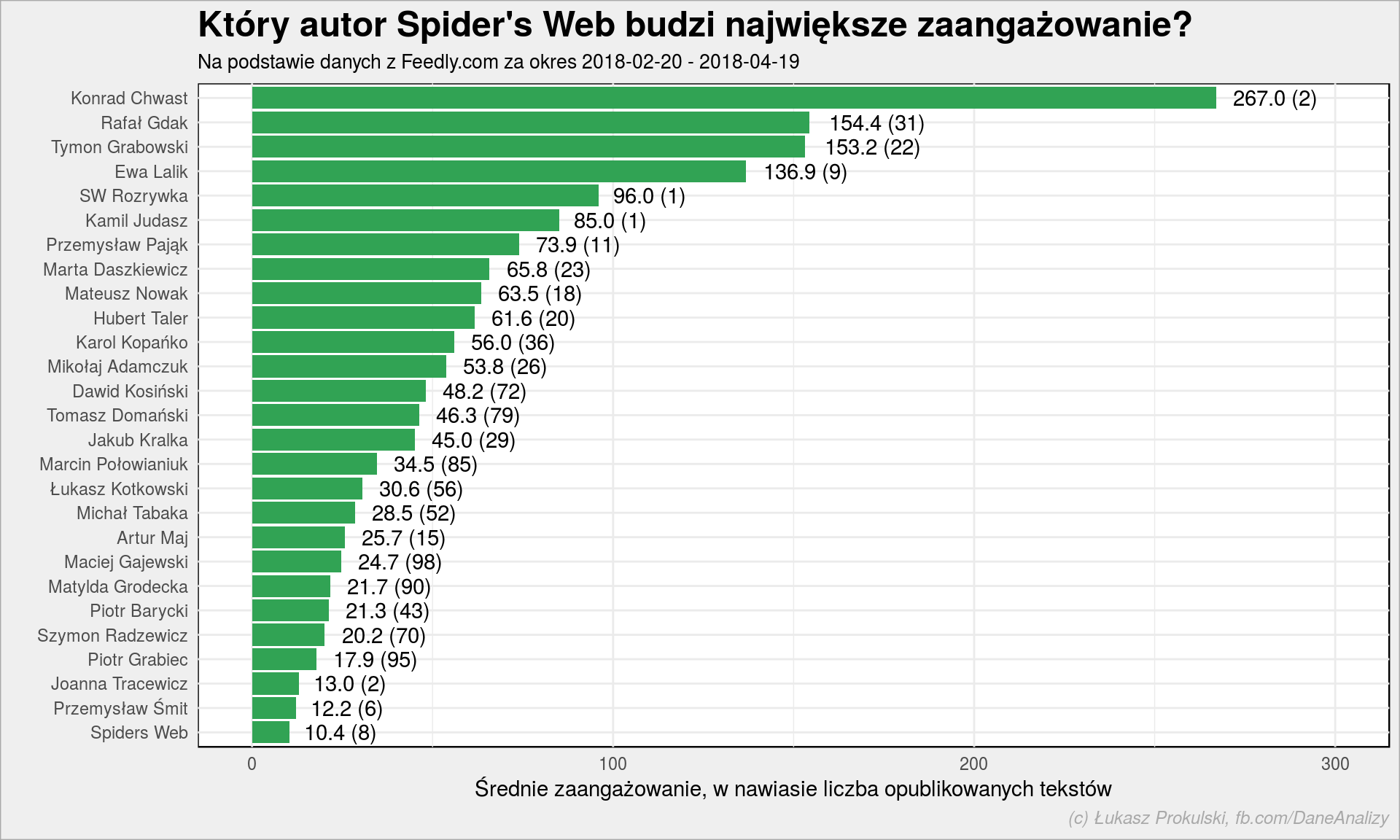
Dla Spider’s Web współczynnik korelacji to -0.412 – ciągle słaba korelacja, ale już mniej delikatnie.
Oczywiście oddzielną sprawą jest popularność RSSów w Polsce (i w ogóle w internecie) – wiele osób nie ma o nich pojęcia i nie wie jak bardzo ułatwiają życie. Do czego mam nadzieję, Was przekonałem w pierwszej części tego tekstu.
W drugiej zobaczyliśmy jak pytać API (dowolne) i radzić sobie z odpowiedziami. W części trzeciej – przy okazji analizy pracy redakcji Antyweb – nauczyliśmy się odrobinę o przygotowywaniu atrakcyjnych tabelek.
Jeśli podobało Ci się – rzuć piątaka, tu obok masz link do PayPala. Wskocz też na Dane i Analizy na Facebooku i polub stronę. Przecież nie wszystko jestem w stanie napisać sam, uzupełniam to linkami na fanpage’u!