Każdego dnia pojawia się nowa muzyka, w wielu różnych gatunkach. Jak wybrać to, czemu warto poświęcić czas?
Dodatkowo dowiemy się jakie znaczenie ma uczciwe przygotowanie danych.

Zdjęcie na okładce: Franck V. on Unsplash
Gdybym miał powiedzieć co lubię najbardziej bez wątpienia byłaby to muzyka. Słucham dużo, nie wyobrażam sobie życia w ciszy. Ale mimo dostępu do nieskończonych (powiedzmy) zasobów muzycznych chociażby poprzez Spotify zauważyłem, że zamykam się w bańce już znanych wykonawców i utworów. A ja lubię odkrywać nowe dźwięki, tylko nie mam czasu (trochę też zbyt na to jestem leniwy) na szukanie nieznanych utworów czy wykonawców. Po co mam poświęcać kupę czasu na szukanie czegoś co mi się nie spodoba?
Mechanizmy Spotify budujące co tydzień listy może ci się spodoba po jakimś czasie przestały podrzucać nowe rzeczy i na 30 utworów na liście mam na przykład 20 oznaczonych jako ulubione. Co to za odkrywanie? Może więc trzeba zabrać się za to samodzielnie?
Cel: automat, który z użyciem metod machine learning zbuduje dla nas w Spotify listę utworów, które powinny nam się spodobać.
Wykorzystamy do tego API Spotify, Pythona i pakiet spotipy.
|
1 2 3 4 |
import spotipy from spotipy import util import pandas as pd |
W pierwszej kolejności potrzebujemy klucza API (jak to zwykle bywa). Zdobywamy go budując odpowiednią aplikację. Cały proces jest dobrze opisany w dokumentacji pakietu Spotipy, a wynikiem są dwa ciągi znaków:
- client_id
- client_secret
które w poniższym kodzie wstawiamy do zmiennych SpotifyClientID oraz SpotifyClientSecret.
Przydatne będzie też ID użytkownika – najprościej je uzyskać szerując swój profil. Dostajemy wtedy adres URL, w którym po ciągu http://open.spotify.com/user/ będzie nasze ID. To z kolei wpisujemy (jako string) do zmiennej username poniżej. Komplet powinien wyglądać tak:
|
1 2 3 4 |
SpotifyClientID='xxxxxxxxxxxxxxxxxxxxxxxx' SpotifyClientSecret='xxxxxxxxxxxxxxxxxxxxxxxx' username = 'xxxxxxxxxxxxxxxxxxxxx' |
Kolejna sprawa to zakres uprawnień na jakie użytkownik musi się zgodzić. Podajemy listę tych uprawnień, których potrzebujemy. Poniżej mamy przykładowe, razem z dostępem do modyfikacji publicznych playlist użytkownika i odczytem list prywatnych. Dość grube to uprawnienia…
|
1 |
scope = 'user-library-read,playlist-read-private,user-read-recently-played,playlist-modify-public,user-top-read' |
Ostatni krok to pozyskanie tokenu i autoryzacja użytkownika:
|
1 2 3 4 5 |
token = util.prompt_for_user_token(username, scope, client_id=SpotifyClientID, client_secret=SpotifyClientSecret, redirect_uri='http://localhost/') |
Mając proces autoryzacji za sobą możemy stworzyć obiekt Spotipy na którego metodach będziemy dalej pracować:
|
1 |
sp = spotipy.Spotify(auth=token) |
Znowu Python… Pisałem kiedyś o tym samym z poziomu R!
Zacznijmy od sprawdzenia czy to w ogóle działa, na przykład próbując wydobyć informacje o użytkowniku:
|
1 2 3 |
sp.current_user() ## {'country': 'PL', 'display_name': 'Łukasz Prokulski', 'explicit_content': {'filter_enabled': False, 'filter_locked': False}, 'external_urls': {'spotify': 'https://open.spotify.com/user/1166639346'}, 'followers': {'href': None, 'total': 11}, 'href': 'https://api.spotify.com/v1/users/1166639346', 'id': '1166639346', 'images': [{'height': None, 'url': 'https://scontent.xx.fbcdn.net/v/t1.0-1/p320x320/72530210_10157567070828864_2506969271054106624_o.jpg?_nc_cat=101&_nc_sid=0c64ff&_nc_ohc=tOl_U1v3KMQAX_kD1P9&_nc_ht=scontent.xx&_nc_tp=6&oh=92cdcafca7a1ceaed0ef466723bf4711&oe=5E9FE65B', 'width': None}], 'product': 'premium', 'type': 'user', 'uri': 'spotify:user:1166639346'} |
albo liście najpopularniejszych piosenek przez niego słuchanych:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 |
for i, track in enumerate(sp.current_user_top_tracks(limit=50, time_range='short_term')['items']): print(f"{i+1}. {track['id']} \"{track['name']}\" - {track['artists'][0]['name']} (LP \"{track['album']['name']}\")") ## 1. 0z1b34WikhOH9ZxU8QDWcv "One Headlight" - The Wallflowers (LP "Bringing Down The Horse") ## 2. 2EC9IJj7g0mN1Q5VrZkiYY "Rebel Rebel - 2016 Remaster" - David Bowie (LP "Diamond Dogs (2016 Remastered Version)") ## 3. 4pGqFOfzvfe6avb9kbZicC "Sweater Weather" - The Neighbourhood (LP "I'm Sorry...") ## 4. 60wxK3idlzc3lykP8cYZ2l "My Mistake" - Gabrielle Aplin (LP "Dear Happy") ## 5. 0uppYCG86ajpV2hSR3dJJ0 "Give It Away" - Red Hot Chili Peppers (LP "Blood Sugar Sex Magik (Deluxe Edition)") ## 6. 2aoo2jlRnM3A0NyLQqMN2f "All Along the Watchtower" - Jimi Hendrix (LP "Electric Ladyland") ## 7. 4ReyTz0y3TGkX48wO3Llot "Epic" - Faith No More (LP "The Real Thing") ## 8. 02acUMylPHMjJ9miDc9b38 "Ever the Same" - Rob Thomas (LP "Something To Be") ## 9. 05NYcsjJwOYq4jIiKPVj9p "Hard To Handle" - The Black Crowes (LP "Shake Your Money Maker") ## 10. 09nEPqqMCJ5gNioi7M2dth "New Soul" - Yael Naim (LP "Yael Naim") ## 11. 0leJYiYyZE6jjXCEVYUQAm "Heroin" - Badflower (LP "OK, I'M SICK") ## 12. 0tZ3mElWcr74OOhKEiNz1x "Bulls On Parade" - Rage Against The Machine (LP "Evil Empire") ## 13. 1TF8mSG5YHyaS4o3NeBSAo "Munich" - Editors (LP "The Back Room") ## 14. 2EaWqg4KUDVx6gVbgQ4Lyw "Przebój nocy" - PRO8L3M (LP "Art Brut 2") ## 15. 2fICdpdRotwfmGYzvs8Ngf "Rock You Like a Hurricane - 2015 - Remaster" - Scorpions (LP "Love At First Sting (Deluxe Edition)") ## 16. 4QbvmYYVLl8LNUsOXstLft "Take This Waltz - Paris Version" - Leonard Cohen (LP "I'm Your Man") ## 17. 4qO03RMQm88DdpTJcxlglY "Call Me" - Blondie (LP "Atomic/Atomix") ## 18. 52cfCOnS2x2TFuM0pFLl8x "Pigs on the Wing, Pt. 1 - Live" - Roger Waters (LP "In the Flesh - Live") ## 19. 5MMnwYs0hIxkENRsbkWJ2G "Smoke On The Water - Remastered 2012" - Deep Purple (LP "Machine Head (Remastered)") ## 20. 5OpDM7JORZzXPo0YIN3vYq "Tower of Song" - Leonard Cohen (LP "I'm Your Man") ## 21. 5Z8EDau8uNcP1E8JvmfkZe "School's Out" - Alice Cooper (LP "School's Out") ## 22. 5aT3i3rdNH74QWbA1o6qwl "Język Wszechświata" - Fisz (LP "Polepione Dźwięki") ## 23. 5anZi6BM5SWn6u6wrVYsgy "5 O'clock (K-Def Remix) [feat. Nonchalant] [Bonus Track]" - Pete Rock, Marley Marl (LP "Future Flavas Mixtape") ## 24. 5arVt2Wg0zbiWwAOZef2Nl "Higher Ground - Remastered" - Red Hot Chili Peppers (LP "Mother's Milk") ## 25. 5fztgDIt1Nq32VHJrAHq0Y "Big Yellow Taxi" - Counting Crows (LP "Hard Candy") ## 26. 6EPRKhUOdiFSQwGBRBbvsZ "Ace of Spades" - Motörhead (LP "Ace of Spades (Expanded Edition)") ## 27. 6MB1W09LUZCYrXTA0JdW3M "Red Wind" - Jan Garbarek (LP "Visible World") ## 28. 6QewNVIDKdSl8Y3ycuHIei "Even Flow" - Pearl Jam (LP "Ten") ## 29. 6dxfn2W3dN7MXWvnOJI3qS "Pygmy Lullaby" - Jan Garbarek (LP "Visible World") ## 30. 6hnkM0k52jzX3OLP9cgbuV "Ballad for Bernt" - Robert Majewski (LP "Plays Komeda") ## 31. 6y20BV5L33R8YXM0YuI38N "No One Knows" - Queens of the Stone Age (LP "Songs For The Deaf") ## 32. 7KPTwEENcZ5r4KJ6FHmhLP "Home" - Daughtry (LP "It's Not Over....The Hits So Far") ## 33. 14sAMwqbuFDSlLKmVBD9MI "Girls Chase Boys" - Ingrid Michaelson (LP "Lights Out") ## 34. 1yC4zXWJuywuVp5Hm5nobQ "You Shouldn't Do That - 1996 Remaster" - Hawkwind (LP "In Search Of Space") ## 35. 2aBxt229cbLDOvtL7Xbb9x "Always Be My Baby" - Mariah Carey (LP "Daydream") ## 36. 4m0q0xQ2BNl9SCAGKyfiGZ "Somebody Else" - The 1975 (LP "I like it when you sleep, for you are so beautiful yet so unaware of it") ## 37. 3pSJtP2BOA9zxU7r6bPPkH "In A Hand Or A Face" - The Who (LP "The Who By Numbers") ## 38. 2E5vl5eF4M4QbaADGegVDP "The Partisan" - Leonard Cohen (LP "Songs From A Room") ## 39. 2espysVKOqumSCzevPfdSa "Your Possible Pasts - 2011 Remastered Version" - Pink Floyd (LP "The Final Cut (2011 Remastered Version)") ## 40. 2hQADwe4Ve0ZHwBDrBEuTF "Pierwszy raz" - Dezerter (LP "Blasfemia") ## 41. 3ix6K4wZY29bCujrSznwFZ "Let's Dance - 2018 Remaster" - David Bowie (LP "Let's Dance (2018 Remaster)") ## 42. 3q4hJtKfWjpJrEFtSFmqAf "Master of the Universe - 1996 Remaster" - Hawkwind (LP "In Search Of Space") ## 43. 45Ia1U4KtIjAPPU7Wv1Sea "Are You Gonna Go My Way" - Lenny Kravitz (LP "Are You Gonna Go My Way") ## 44. 4NirsDE9nOl4HnwlZOIwR1 "Polepiony" - Fisz (LP "Polepione Dźwięki") ## 45. 56xbGPjb5lWowId6TzWYDP "One Of The Few - 2011 Remastered Version" - Pink Floyd (LP "The Final Cut (2011 Remastered Version)") ## 46. 5atFAXIgMXP378op4FaxBm "I'm Your Man" - Leonard Cohen (LP "I'm Your Man") ## 47. 5uF3hldjpeDjlSPhUYa1Ob "The Post War Dream - 2011 Remastered Version" - Pink Floyd (LP "The Final Cut (2011 Remastered Version)") ## 48. 6GtX0jaNL8IjVQfrDBx81z "Bullet With Butterfly Wings - Remastered 2012" - The Smashing Pumpkins (LP "Mellon Collie And The Infinite Sadness (Deluxe Edition)") ## 49. 6UEzGV76d96lYTA68iBO0B "First We Take Manhattan" - Leonard Cohen (LP "I'm Your Man") ## 50. 6d0LXn0CWYufMF3G6iJn14 "I Can't Forget" - Leonard Cohen (LP "I'm Your Man") |
Co do tej listy mam pewne wątpliwości – niektóre z utworów tutaj jak najbardziej pasują, bo było grane w ostatnim czasie częściej (na przykład te z płyty “The Final Cut” Floydów), ale część tylko raz. Można również sprawdzić inny zakres czasowy (parametr time_range) ale też wychodzą mi dziwactwa. Może być tak, że Spotify przelicza te dane raz na jakiś czas – pryz tej liczbie użytkowników miałoby to sens.
Przy okazji: jeśli masz ochotę dodać mnie do znajomych czy obserwować – śmiało, nie mam nic przeciwko. A może muzyka której słucham spodoba się też Tobie?
To co w Spotify jest najciekawsze z punktu widzenia analityka danych to cechy utworów. Spotify w jakiś znany sobie sposób analizuje każdy utwór i podsumowuje w postaci kilku liczb określających właśnie te cechy. Oczywiście API pozwala na zapytanie o takie cechy. Weźmy przykładowy utwór o ID 5mc6EyF1OIEOhAkD0Gg9Lc i zobaczmy co dla niego mamy:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 |
def get_track_info(track_id): # próbujemy pobrać informacje o konkretnym track id try: track_info = sp.track(track_id) except: return pd.DataFrame() # pobieramy cechy dla tego track id audio_features = sp.audio_features(track_id) # uwaga - czasem tych cech nie ma if audio_features[0] is not None: # jeśli wszystko udało się zgromadzić pakujemy w wiersz pandasowej tabeli tracks_df = pd.DataFrame({'track_id': track_info['id'], 'track_title': track_info['name'], 'track_artist': track_info['artists'][0]['name'], 'album_id': track_info['album']['id'], 'album_title': track_info['album']['name'], 'album_artist': track_info['album']['artists'][0]['name'], 'album_release_date': track_info['album']['release_date'], 'track_popularity': track_info['popularity'], 'explict': track_info['explicit'], 'danceability': audio_features[0]['danceability'], 'energy': audio_features[0]['energy'], 'key': audio_features[0]['key'], 'loudness': audio_features[0]['loudness'], 'mode': audio_features[0]['mode'], 'speechiness': audio_features[0]['speechiness'], 'acousticness': audio_features[0]['acousticness'], 'instrumentalness': audio_features[0]['instrumentalness'], 'liveness': audio_features[0]['liveness'], 'valence': audio_features[0]['valence'], 'tempo': audio_features[0]['tempo'], 'duration_ms': audio_features[0]['duration_ms'], 'time_signature': audio_features[0]['time_signature']}, index=[0]) # wydzielamy dodatkowo rok wydania z daty tracks_df['album_release_year'] = tracks_df['album_release_date'].apply(lambda d: pd.to_datetime(d).year) else: return pd.DataFrame() return(tracks_df) |
Pamiętamy jaki jest cel? Zrobić automat, który z użyciem metod machine learning zbuduje dla nas listę utworów, które powinny nam się spodobać.
Przydałoby się więc pobrać listę ulubionych utworów. To da nam muzyczny profil użytkownika i kawałek zbioru treningowego – będą to nasze jedynki, utwory które użytkownik lubi. Oczywiście jest na to metoda w API current_user_saved_tracks(). Zbierzemy więc wszystkie utwory, razem z ich cechami i zapakujemy do jednego pandasowego data frame’a:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
tracks_df = pd.DataFrame() tracks = sp.current_user_saved_tracks() while tracks: for tr in tracks['items']: tracks_df = tracks_df.append(get_track_info(tr['track']['id'])) tracks = sp.next(tracks) print(tracks_df.head(10)) |
| idx | track_id | track_title | track_artist | album_id | album_title | album_artist | album_release_date | track_popularity | explict | danceability | energy | key | loudness | mode | speechiness | acousticness | instrumentalness | liveness | valence | tempo | duration_ms | time_signature | album_release_year |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 3q4hJtKfWjpJrEFtSFmqAf | Master of the Universe – 1996 Remaster | Hawkwind | 1cgsYqtDTMTetu7FjEsIhI | In Search Of Space | Hawkwind | 1971 | 39 | False | 0.403 | 0.603 | 8 | -10.523 | 1 | 0.0392 | 0.239 | 0.0389 | 0.127 | 0.657 | 150.017 | 377520 | 4 | 1971 |
| 1 | 73HSIWZlSCfs4tqVkrGv7H | Silver Machine – Live at the Roundhouse London; 1996 Remaster | Hawkwind | 1cgsYqtDTMTetu7FjEsIhI | In Search Of Space | Hawkwind | 1971 | 56 | False | 0.31 | 0.874 | 1 | -11.889 | 1 | 0.152 | 0.000416 | 0.712 | 0.0695 | 0.096 | 131.717 | 279973 | 4 | 1971 |
| 2 | 3gv4AhWWneEu2oh1Egz652 | Personal Jesus – 2006 Remaster | Depeche Mode | 3PIszA6UT9iI99izK60AdV | The Best Of Depeche Mode Volume 1 | Depeche Mode | 2006-11-14 | 48 | False | 0.689 | 0.844 | 10 | -5.519 | 0 | 0.0348 | 0.0963 | 0.00852 | 0.0621 | 0.772 | 129.973 | 225040 | 4 | 2006 |
| 3 | 0z1b34WikhOH9ZxU8QDWcv | One Headlight | The Wallflowers | 2BOlaNQt6WJ1HO5pQcKHGh | Bringing Down The Horse | The Wallflowers | 1996-01-01 | 69 | False | 0.701 | 0.539 | 2 | -8.968 | 1 | 0.0277 | 0.000655 | 0.005 | 0.0589 | 0.752 | 107.531 | 312627 | 4 | 1996 |
| 4 | 74drJLr20XF1f4yqyNPRSZ | Heroin | Badflower | 05AOz993WTdQcAox3vPcjv | Heroin | Badflower | 2018-11-30 | 0 | False | 0.503 | 0.709 | 11 | -5.809 | 1 | 0.0431 | 0.204 | 0.00438 | 0.0675 | 0.12 | 143.113 | 281227 | 4 | 2018 |
| 5 | 5anZi6BM5SWn6u6wrVYsgy | 5 O’clock (K-Def Remix) [feat. Nonchalant] [Bonus Track] | Pete Rock, Marley Marl | 4UuOh5u2YvngPjrxiKzQPx | Future Flavas Mixtape | Marley Marl | 1999-02-09 | 36 | True | 0.759 | 0.803 | 10 | -6.152 | 0 | 0.233 | 0.143 | 0.0235 | 0.111 | 0.789 | 172.043 | 263221 | 4 | 1999 |
| 6 | 0brCwVt3kQES8K9qpJorQo | The Fletcher Memorial Home – 2011 Remaster | Pink Floyd | 5ChHkKb5VhZe0pgQRsvpek | The Final Cut (2011 Remastered Version) | Pink Floyd | 1983-03-21 | 39 | False | 0.248 | 0.3 | 7 | -10.69 | 1 | 0.0389 | 0.64 | 0.000508 | 0.231 | 0.0511 | 173.366 | 249442 | 4 | 1983 |
| 7 | 2oXzhMnWAeSHbkCQVgvkqg | Breadfan | Budgie | 5Vhc4qqnuizoAPYgUHBy1s | Metal Mania | Various Artists | 2018-02-02 | 37 | False | 0.304 | 0.739 | 1 | -9.532 | 1 | 0.0779 | 0.0167 | 0.117 | 0.376 | 0.41 | 102.416 | 364800 | 4 | 2018 |
| 8 | 2PzU4IB8Dr6mxV3lHuaG34 | (I Can’t Get No) Satisfaction – Mono Version | The Rolling Stones | 2Q5MwpTmtjscaS34mJFXQQ | Out Of Our Heads | The Rolling Stones | 1965-07-30 | 75 | False | 0.723 | 0.863 | 2 | -7.89 | 1 | 0.0338 | 0.0383 | 0.0317 | 0.128 | 0.931 | 136.302 | 222813 | 4 | 1965 |
| 9 | 75ARkUKb54dQ86YezuoNhn | Hate To Say I Told You So | The Hives | 4LIKns3pN21w48Yf4dA6eL | Veni Vidi Vicious | The Hives | 2000 | 11 | False | 0.447 | 0.9 | 5 | -6.741 | 1 | 0.0578 | 0.00114 | 0.00596 | 0.47 | 0.39 | 135.861 | 199733 | 4 | 2000 |
Dla pewności zapiszemy sobie nasze zebrane dane, na przykład do pliku CSV:
|
1 |
tracks_df.to_csv("spotify_loved_tracks.csv", index=False) |
Teraz przydałby się cały przegląd tego jakie cechy mamy, jak się rozkładają i co z nich można wykorzystać. Zobaczymy tylko rozkład wartości dla cech i korelację między nimi:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
import matplotlib.pyplot as plt import seaborn as sns fig = plt.figure(figsize=(15,15)) sns.pairplot(tracks_df[['danceability', 'energy', 'key','loudness', 'mode', 'speechiness', 'acousticness', 'instrumentalness', 'liveness', 'valence', 'tempo', 'duration_ms', 'time_signature', 'album_release_year']], kind="reg") plt.show() |
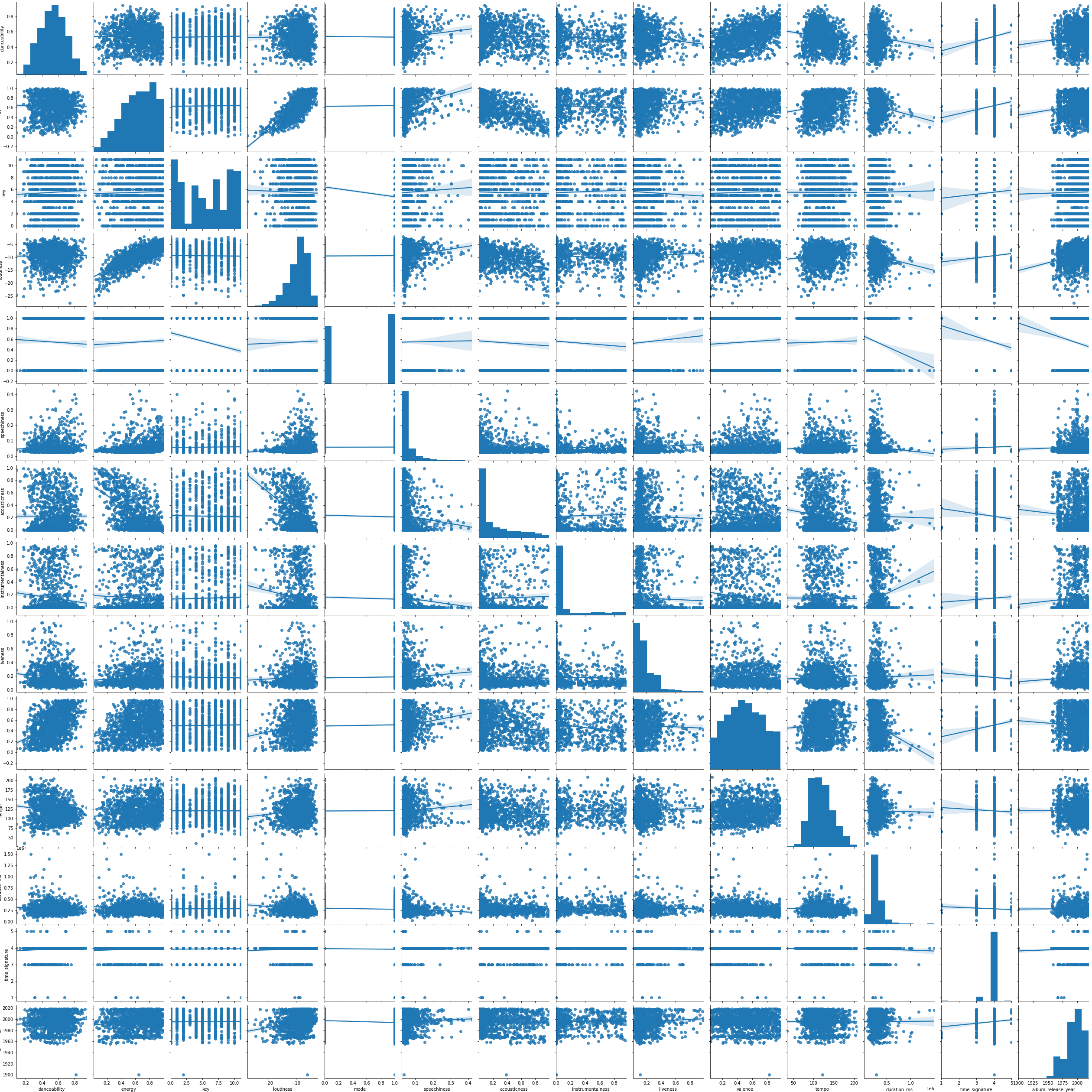
Kliknij w obrazek, aby powiększyć
Wszędzie (prawie) właściwie nie widać korelacji pomiędzy cechami, a po tym można sądzić że wszystkie cechy przydadzą się w modelu. Co więcej – większość z nich jest znormalizowana (w przedziale 0-1), część wygląda na wartości dyskretne (mimo że są liczbami – key, mode) a część jest ciągła i nie ma właściwie limitu – chociażby długość utworu (durration_ms).
Mamy piosenki, które lubię, mamy ich cechy – to są nasze jedynki. Tylko, żeby wytrenować model potrzebujemy też zer – czegoś czego nie lubię. Skąd wytrzasnąć takie dane? Kilka propozycji padło pod stosownym postem na fanpage’u Dane i Analizy:
Aby się nie męczyć za wiele wykorzystam listy przygotowane przez Spotify – wybierając te, które wyglądają że nie są z moim guście.
Wziąłem wszystkie jakie użytkownik spotify przygotował, wylistowałem ich zawartość i ręcznie wybrałem ID playlist, które wyglądają że nie są dla mnie. Stosowny kod:
|
1 2 3 4 5 6 7 |
spotify_playlist = sp.user_playlists('spotify') for playlist in spotify_playlist['items']: print(f"\n{playlist['id']}: {playlist['name']} ({playlist['description']}) - {playlist['tracks']['total']} tracks:") for i, track in enumerate(sp.playlist(playlist['id'])['tracks']['items']): if track['track'] is not None: print(f"\t{i}\t{track['track']['id']} {track['track']['name']} - {track['track']['artists'][0]['name']}") |
Wynik jest dłuuugi, więc go sobie oszczędzimy.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 |
# lista ID playlist, z utworami które mi się nie podobają bad_playlists = ['37i9dQZF1DXcBWIGoYBM5M', '37i9dQZF1DX0XUsuxWHRQd', '37i9dQZF1DX1lVhptIYRda', '37i9dQZF1DX10zKzsJ2jva', '37i9dQZF1DX4JAvHpjipBk', '37i9dQZF1DX4dyzvuaRJ0n', '37i9dQZF1DX4SBhb3fqCJd', '37i9dQZF1DX4sWSpwq3LiO', '37i9dQZF1DWXJfnUiYjUKT', '37i9dQZF1DXcRXFNfZr7Tp', '37i9dQZF1DWTwnEm1IYyoj', '37i9dQZF1DX2A29LI7xHn1', '37i9dQZF1DX2RxBh64BHjQ', '37i9dQZF1DWVA1Gq4XHa6U', '37i9dQZF1DWY4xHQp97fN6', '37i9dQZF1DWX3387IZmjNa', '37i9dQZF1DWYkaDif7Ztbp', '37i9dQZF1DX5hR0J49CmXC', '37i9dQZF1DXan38dNVDdl4', '37i9dQZF1DWSvKsRPPnv5o', '37i9dQZF1DWUVpAXiEPK8P', '37i9dQZF1DX0Tkc6ltcBfU', '37i9dQZF1DX1YPTAhwehsC', '37i9dQZF1DXaKctwWdt4be', '37i9dQZF1DWTggY0yqBxES', '37i9dQZF1DX0HRj9P7NxeE', '37i9dQZF1DWT6SJaitNDax', '37i9dQZF1DWZkHEX2YHpDV'] # tutaj będziemy zbierać wszystkie informacje o utworach bad_tracks_df = pd.DataFrame() # dla każdej ze "złych" playlist: for i, one_playlist in enumerate(bad_playlists): print(i, len(bad_playlists), one_playlist) # pobieramy listę utworów track_list = sp.playlist(one_playlist) # dla każdego utworu for trid in track_list['tracks']['items']: # pobieramy cechy if trid['track']: bad_tracks_df = bad_tracks_df.append(get_track_info(trid['track']['id'])) # usuwamy duplikaty bad_tracks_df.drop_duplicates(inplace=False) #usuwamy te utwory, których wykonwcy są w ulubionych bad_tracks_df = bad_tracks_df[~bad_tracks_df['album_artist'].isin(tracks_df['album_artist'].unique())] # zapisujemy do pliku bad_tracks_df.to_csv("spotify_heted_tracks.csv", index=False) |
Co nam się pozbierało i zostało po drobnych manipulacjach (usunięcie duplikatów i utworów wykonywanych przez artystów z listy lubianych)?
|
1 |
print(bad_tracks_df.head(10)) |
| idx | track_id | track_title | track_artist | album_id | album_title | album_artist | album_release_date | track_popularity | explict | danceability | energy | key | loudness | mode | speechiness | acousticness | instrumentalness | liveness | valence | tempo | duration_ms | time_signature | album_release_year |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0sf12qNH5qcw8qpgymFOqD | Blinding Lights | The Weeknd | 2ZfHkwHuoAZrlz7RMj0PDz | Blinding Lights | The Weeknd | 2019-11-29 | 100 | False | 0.513 | 0.796 | 1 | -4.075 | 1 | 0.0629 | 0.00147 | 0.000209 | 0.0938 | 0.345 | 171.017 | 201573 | 4 | 2019 |
| 1 | 364dI1bYnvamSnBJ8JcNzN | Intentions | Justin Bieber | 55zg331p7m1EFA4uRggkwt | Intentions | Justin Bieber | 2020-02-07 | 92 | False | 0.811 | 0.553 | 9 | -6.644 | 1 | 0.0552 | 0.317 | 0 | 0.105 | 0.86 | 148.014 | 212869 | 4 | 2020 |
| 2 | 3Dv1eDb0MEgF93GpLXlucZ | Say So | Doja Cat | 1MmVkhiwTH0BkNOU3nw5d3 | Hot Pink | Doja Cat | 2019-11-07 | 95 | True | 0.787 | 0.673 | 11 | -4.577 | 0 | 0.158 | 0.256 | 3.57e-06 | 0.0904 | 0.786 | 110.962 | 237893 | 4 | 2019 |
| 3 | 6WrI0LAC5M1Rw2MnX2ZvEg | Don’t Start Now | Dua Lipa | 0ix3XtPV1LwmZADsprKxcp | Don’t Start Now | Dua Lipa | 2019-10-31 | 97 | False | 0.794 | 0.793 | 11 | -4.521 | 0 | 0.0842 | 0.0125 | 0 | 0.0952 | 0.677 | 123.941 | 183290 | 4 | 2019 |
| 4 | 0nbXyq5TXYPCO7pr3N8S4I | The Box | Roddy Ricch | 52u4anZbHd6UInnmHRFzba | Please Excuse Me For Being Antisocial | Roddy Ricch | 2019-12-06 | 99 | True | 0.896 | 0.586 | 10 | -6.687 | 0 | 0.0559 | 0.104 | 0 | 0.79 | 0.642 | 116.971 | 196653 | 4 | 2019 |
| 5 | 1Cv1YLb4q0RzL6pybtaMLo | Sunday Best | Surfaces | 3mMWlBGocBwsS1Q0o9wvlc | Where the Light Is | Surfaces | 2019-01-06 | 93 | False | 0.878 | 0.525 | 5 | -6.832 | 1 | 0.0578 | 0.183 | 0 | 0.0714 | 0.694 | 112.022 | 158571 | 4 | 2019 |
| 6 | 7eJMfftS33KTjuF7lTsMCx | death bed (coffee for your head) (feat. beabadoobee) | Powfu | 2p9gK2BcdrloHNJwarc9gc | death bed (coffee for your head) (feat. beabadoobee) | Powfu | 2020-02-08 | 93 | False | 0.726 | 0.431 | 8 | -8.765 | 0 | 0.135 | 0.731 | 0 | 0.696 | 0.348 | 144.026 | 173333 | 4 | 2020 |
| 7 | 6wJYhPfqk3KGhHRG76WzOh | Blueberry Faygo | Lil Mosey | 6rBennOYWR1OZQnsU39PKL | Blueberry Faygo | Lil Mosey | 2020-02-07 | 91 | True | 0.774 | 0.554 | 0 | -7.909 | 1 | 0.0383 | 0.207 | 0 | 0.132 | 0.349 | 99.034 | 162547 | 4 | 2020 |
| 8 | 4TnjEaWOeW0eKTKIEvJyCa | Falling | Trevor Daniel | 1Czfd5tEby3DbdYNdqzrCa | Falling | Trevor Daniel | 2018-10-05 | 96 | False | 0.784 | 0.43 | 10 | -8.756 | 0 | 0.0364 | 0.123 | 0 | 0.0887 | 0.236 | 127.087 | 159382 | 4 | 2018 |
| 9 | 7szuecWAPwGoV1e5vGu8tl | In Your Eyes | The Weeknd | 4yP0hdKOZPNshxUOjY0cZj | After Hours | The Weeknd | 2020-03-20 | 81 | True | 0.665 | 0.718 | 7 | -5.385 | 0 | 0.0335 | 0.00356 | 7.18e-05 | 0.074 | 0.72 | 100.033 | 237520 | 4 | 2020 |
Możemy przejrzeć jak wyglądają cechy tych złych utworów i na oko porównać czy jakoś różnią się od lubianych. Nie będę tego analizował, ale mając te obrazki możecie uczynić to sami.
|
1 2 3 4 5 6 7 8 9 |
fig = plt.figure(figsize=(15,15)) sns.pairplot(bad_tracks_df[['danceability', 'energy', 'key','loudness', 'mode', 'speechiness', 'acousticness', 'instrumentalness', 'liveness', 'valence', 'tempo', 'duration_ms', 'time_signature', 'album_release_year']], kind="reg") plt.show() |

Kliknij w obrazek, aby powiększyć
Czas na przygotowanie zbiorów uczących. Weźmiemy na początek taką samą liczbę utworów nielubianych co lubianych (dzięki temu nie powinno być problemu niezbalansowanych klas). Później dla każdego ze zbiorów:
- 80% na trening
- 20% na test
Z pomocą przyjdzie nam scikit-learn.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
from sklearn.model_selection import train_test_split # oznaczamy ulubione piosenki klasą "1" tracks_df['liked'] = 1 # a nielubiane klasą "0" bad_tracks_df['liked'] = 0 # z nielubianych bierzemy tyle ile jest lubianych (bo akurat wiemy że nielubianych jest więcej) disliked_df = bad_tracks_df.sample(n=tracks_df.shape[0]) # cały zbiór all_tracks_full = tracks_df.append(disliked_df).drop_duplicates() # przemieszajmy go dla pewności all_tracks_full = all_tracks_full.sample(frac=1).reset_index(drop=True) # i tylko numeryczne kolumny all_tracks = all_tracks_full[['track_id', 'track_popularity', 'danceability', 'energy', 'key', 'loudness', 'mode', 'speechiness', 'acousticness', 'instrumentalness', 'liveness', 'valence', 'tempo', 'duration_ms', 'time_signature', 'album_release_year', 'liked']] # podział na trening i test X_train, X_test, y_train, y_test = train_test_split(all_tracks.drop('liked', axis=1), all_tracks['liked'], test_size=0.2) |
Mając przygotowany zbiór uczący (X_train to cechy, y_train to odpowiedzi) oraz testowy (odpowiednio X_test i y_test) możemy przystąpić do budowania i weryfikowania modelu. Nie będziemy jednak tym razem w to zbytnio się zagłębiać – weźmiemy po prostu random forest z domyślnymi parametrami. Chodzi mi tutaj o pokazanie procesu (i tego co i dlaczego wyjdzie) a nie szykowanie idealnego rozwiązania..
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
from sklearn.ensemble import RandomForestClassifier from sklearn.metrics import classification_report, confusion_matrix # budujemy model i uczymy go model = RandomForestClassifier() model.fit(X_train.drop('track_id', axis=1), y_train) # obliczamy predykcje dla danych testowych y_pred = model.predict(X_test.drop('track_id', axis=1)) # jaki mamy wynik? print(classification_report(y_test, y_pred)) ## precision recall f1-score support ## ## 0 0.96 0.98 0.97 223 ## 1 0.98 0.97 0.97 276 ## ## accuracy 0.97 499 ## macro avg 0.97 0.97 0.97 499 ## weighted avg 0.97 0.97 0.97 499 |
Wygląda dobrze – wszystkie wskaźniki na poziomie w okolicach 97%.
Dodajmy do danych testowych informację o tym co zwrócił model, a następnie wybieramy z tego zbioru utwory:
- których do tej pory nie lubiłem (w teście są zarówno piosenki lubiane jak i nie lubiane)
- ale według modelu powinienem polubić:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
X_test['predicted_like'] = y_pred # z przewidzianych wyników zostawiamy tylko to, co ma się potencjalnie podobać new_tracks = X_test[X_test['predicted_like'] == 1][['track_id']] # dodajemy info o wykonawcy i tym czy już było lajkowane new_tracks = new_tracks.merge(all_tracks_full, how='inner', on='track_id') # i usuwamy to co już miało lajka new_tracks = new_tracks[new_tracks['liked'] == 0] # zostawiamy tylko potrzebne kolumny new_tracks = new_tracks[['track_id', 'track_title', 'track_artist']] # wynik: print(new_tracks) |
| idx | track_id | track_title | track_artist |
|---|---|---|---|
| 161 | 4qug3gWrzeTNm0GhOkugJV | Love Yourself | Justin Bieber |
| 181 | 10Oin6yhBlz0BF5XASDczp | Dark Pools | Circa Survive |
| 201 | 0KpfYajJVVGgQ32Dby7e9i | Hey, Soul Sister | Train |
| 229 | 6uP0XLqjRqFx8HAfesdcAg | X Gon’ Give It To Ya | DMX |
| 250 | 3VmVapCFKcU9d3CJsoSUm8 | Feels So Good | Remy Ma |
Wyniki…. jak wyniki. Nie znam żadnego z tych utworów, wykonawcy gdzieś majaczą. Przesłuchajmy je.
Najprościej będzie dodać je do nowej playlisty i taką playlistę przesłuchać w dowolnym momencie.
|
1 2 3 4 5 6 7 |
import time # tworzymy nową playlistę - nazwa z czasem utworzenia new_playlist = sp.user_playlist_create(username, f"Lista z #ML {time.strftime('%Y-%m-%d %H:%M')}", public=True) # dodajemy do niej piosneczki res = sp.user_playlist_add_tracks(username, new_playlist['id'], new_tracks.track_id.values) |
I to właściwie koniec naszego procesu. W wyniku całej drogi, czyli:
- zebrania listu utowrów lubianych
- dodania do nich informacji o cechach audio
- zebrania informacji (razem z cechami) o utowrach potencjalnie nielubianych
- wytrenowaniu modelu klasyfikującego nieznane utwory na lubiane lub nie
- dodaniu potencjalnie lubianych do nowej playlisty
możemy przesłuchać zdecydowanie mniejszą liczbę utworów i zweryfikować organoleptycznie czy nasz model się sprawdza.
Do tej pory działaliśmy na utworach z playlist – to je scorowaliśmy w modelu. To samo możemy zrobić dla całego albumu. Weźmy na przykład “The Wall” Pink Floyd, którą uważam za najlepszą płytę jaką słyszałem w życiu. A przynajmniej taką w pierwszej piątce, bo najlepszych płyt na świecie to pewnie mam z 10, może 20. I wszystkie równorzędne.
Na początek musimy znaleźć ID albumu. Wyszukamy wszystkich albumów odpowiadających zapytaniu the wall pink floyd i zobaczymy jaki będzie efekt:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
for i, a in enumerate(sp.search("The Wall Pink Floyd", type='album')['albums']['items']): print(i+1, a['id'], a['artists'][0]['name'], a['name'], a['release_date'], a['total_tracks']) ## 1 6WaIQHxEHtZL0RZ62AuY0g Pink Floyd The Wall (Remastered) 1979-11-30 26 ## 2 4Y8K5Cfs0vdi5M2RZSF1Pp Vitamin String Quartet VSQ Performs Pink Floyd's The Wall: More Bricks 2006-02-21 12 ## 3 2ZQXrdTaiUvgbr22cvgy6D Gustavo Zavala The Wall for Babies: The Complete Pink Floyd-The Wall Album for Babies 2012-12-03 26 ## 4 5ISax6a3D5kBQKY1zeFsYA Atom Pink Floyd Tribute Tearing Down the Wall: Live 2015 2016-12-05 10 ## 5 6273GngZvwpRWgg99GsESp Various Artists Re-Building The Wall - A Tribute To Pink Floyd 2007-01-01 26 ## 6 42s70vpGM4iOk0BWhhpsVe Various Artists Back Against the Wall - A Tribute to Pink Floyd (Bonus Track Version) 2015-01-20 31 ## 7 1aHDf1VsnUKbMPJX6RtwLH Various Artists Back Against The Wall – A Tribute To Pink Floyd 2005-11-15 26 ## 8 6mntef7MKxZKqEL2Aw3RXb Done Again Another Brick in the Wall (Part II) [In the Style of Pink Floyd] {Performance Track with Demonstration Vocals} - Single 2012-06-13 1 ## 9 12WlibQIazyVIlduAqBB15 Solo Sounds Solo Cello: Pink Floyd's the Wall 2017-04-14 27 ## 10 6ijyx2AhwsHASUIJjdOu6L Rockopera Tribute to Pink Floyd: The Wall Live Orchestra 2013-04-20 25 |
Jak widać jest 10 potencjalnych kandydatów. Oczywiście pierwszy jest najbardziej pasującym, ale wyniki te pokazuję dlatego, że w Spotify mamy bardzo często pełno różnych wersji remastered, deluxe edition, bonus trakcs, tribute to i tym podobnych. To jest problem. Najczęściej pierwszy zwracany wynik pasuje najlepiej, ale mimo wszystko trzeba być ostrożnym (prezydent Kwaśniewski o tym kiedyś mówił, #pdk mordeczki ;-).
Weźmy więc ten pierwszy album i sprawdźmy jakie utwory na nim znajdziemy:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
for i, t in enumerate(sp.album_tracks('6WaIQHxEHtZL0RZ62AuY0g')['items']): print(i+1, t['id'], t['name']) ## 1 1KaIRTf1YEWt54V3IW34qV In The Flesh? - 2011 Remastered Version ## 2 3dHzjlxUULSWDsTHFc2zM7 The Thin Ice - 2011 Remastered Version ## 3 4j2bQkwIEO7QzAdjJ4txVm Another Brick In The Wall, Pt. 1 - 2011 Remastered Version ## 4 6ASehhdN08JbXzDJmMrogn The Happiest Days Of Our Lives - 2011 Remastered Version ## 5 7rPzEczIS574IgPaiPieS3 Another Brick In The Wall, Pt. 2 - 2011 Remastered Version ## 6 5xdySZ8v0lEOKblcwXWT3M Mother - 2011 Remastered Version ## 7 4Y1Ra2qfmTYOugWzBfocAX Goodbye Blue Sky - 2011 Remastered Version ## 8 6tsfGbVHWirffWWUUmtalg Empty Spaces - 2011 Remastered Version ## 9 4ZhPXTpqp3NojMWsNHGnSd Young Lust - 2011 Remastered Version ## 10 0MW7g3oFkdmZIiomSGC4x4 One Of My Turns - 2011 Remastered Version ## 11 3wm0FEw4BhPvCnSK8L0vGP Don't Leave Me Now - 2011 Remastered Version ## 12 22IiK3b7NSBfmUrnhj7rSr Another Brick In The Wall, Pt. 3 - 2011 Remastered Version ## 13 3mPeMKup50f1llqTciEfLJ Goodbye Cruel World - 2011 Remastered Version ## 14 5UJmwdqGP7RONuVzYnHjUp Hey You - 2011 Remastered Version ## 15 2rKcC5vlTsDM94RWTPoyHV Is There Anybody Out There? - 2011 Remastered Version ## 16 3kM50GD76NgPWaTfKKKTz3 Nobody Home - 2011 Remastered Version ## 17 2rzHK6y5GTxaz8104rp2cA Vera - 2011 Remastered Version ## 18 4rvDQAW3boZffZIzaYqnAc Bring The Boys Back Home - 2011 Remastered Version ## 19 7Fg4jpwpkdkGCvq1rrXnvx Comfortably Numb - 2011 Remastered Version ## 20 7myPwy9eGrRv9jNAoeTh2s The Show Must Go On - 2011 Remastered Version ## 21 0B545eDyCppapUQ1ujrTmg In The Flesh - 2011 Remaster ## 22 7CLHw352I29cIRf944RQnO Run Like Hell - 2011 Remastered Version ## 23 7s9MWRmBH5fbohw3Tqikyb Waiting For The Worms - 2011 Remastered Version ## 24 6X9k4QxABkn8luC8P93OZf Stop - 2011 Remastered Version ## 25 7p8QuQC5aIRY3q9wWE2f6T The Trial - 2011 Remastered Version ## 26 1zeyA74WeKOpYH6wtXQwkp Outside The Wall - 2011 Remastered Version |
Zgadza się – po tytułach i liczbie utworów to jest ta płyta.
Do dalszej pracy potrzebujemy ramki danych takiej samej jak wcześniej. Bo dalsza praca to sprawdzenie czy ten album mi się spodoba (uwaga – kilka z tych piosenek ma już moje lajki).
|
1 2 3 4 5 6 7 8 |
# bierzemy listę ID utworów tracks_to_score_ids = [trid['id'] for trid in sp.album_tracks('6WaIQHxEHtZL0RZ62AuY0g')['items']] tracks_to_score = pd.DataFrame() # dla każdego utworu podobieramy o nim info for track in tracks_to_score_ids: tracks_to_score = tracks_to_score.append(get_track_info(track)) |
Dodajmy info o tym czy dany ID utworu znajduje się na liście ulubionych:
|
1 |
tracks_to_score['liked'] = [True if tid in list(tracks_df['track_id']) else False for tid in tracks_to_score['track_id'] ] |
i zobaczmy proste podsumowanie:
|
1 |
print(tracks_to_score[['track_title', 'track_popularity', 'liked']]) |
| idx | track_title | track_popularity | liked |
|---|---|---|---|
| 0 | In The Flesh? – 2011 Remastered Version | 52 | False |
| 0 | The Thin Ice – 2011 Remastered Version | 49 | False |
| 0 | Another Brick In The Wall, Pt. 1 – 2011 Remastered Version | 54 | False |
| 0 | The Happiest Days Of Our Lives – 2011 Remastered Version | 53 | False |
| 0 | Another Brick In The Wall, Pt. 2 – 2011 Remastered Version | 71 | False |
| 0 | Mother – 2011 Remastered Version | 55 | True |
| 0 | Goodbye Blue Sky – 2011 Remastered Version | 53 | False |
| 0 | Empty Spaces – 2011 Remastered Version | 48 | False |
| 0 | Young Lust – 2011 Remastered Version | 52 | False |
| 0 | One Of My Turns – 2011 Remastered Version | 48 | False |
| 0 | Don’t Leave Me Now – 2011 Remastered Version | 47 | False |
| 0 | Another Brick In The Wall, Pt. 3 – 2011 Remastered Version | 49 | False |
| 0 | Goodbye Cruel World – 2011 Remastered Version | 49 | False |
| 0 | Hey You – 2011 Remastered Version | 61 | False |
| 0 | Is There Anybody Out There? – 2011 Remastered Version | 49 | False |
| 0 | Nobody Home – 2011 Remastered Version | 48 | True |
| 0 | Vera – 2011 Remastered Version | 47 | True |
| 0 | Bring The Boys Back Home – 2011 Remastered Version | 46 | False |
| 0 | Comfortably Numb – 2011 Remastered Version | 68 | True |
| 0 | The Show Must Go On – 2011 Remastered Version | 47 | False |
| 0 | In The Flesh – 2011 Remaster | 47 | False |
| 0 | Run Like Hell – 2011 Remastered Version | 51 | False |
| 0 | Waiting For The Worms – 2011 Remastered Version | 46 | False |
| 0 | Stop – 2011 Remastered Version | 43 | False |
| 0 | The Trial – 2011 Remastered Version | 48 | False |
| 0 | Outside The Wall – 2011 Remastered Version | 43 | False |
Teraz puszczamy wszystkie utwory przez model i sprawdzamy jakie jest prawdopodobieństwo jedynki (że się spodoba):
|
1 2 3 4 5 6 7 8 9 10 11 |
# nie wszystkie kolumny są używane w modelu X_tracks_to_score = tracks_to_score[['track_popularity', 'danceability', 'energy', 'key', 'loudness', 'mode', 'speechiness', 'acousticness', 'instrumentalness', 'liveness', 'valence', 'tempo', 'duration_ms', 'time_signature', 'album_release_year']] # uwaga - potrzebujemy tutaj prawdopodobieństwo przynależności do klasy (i bierzemy tylko to, które dotyczy "jedynki") a nie samą klasę tracks_to_score['like_prob'] = model.predict_proba(X_tracks_to_score)[:, 1] # jaki mamy wynik? z jakim prawdopodobieństwem piosenka mi się spodoba? print(tracks_to_score[['track_title', 'liked', 'like_prob']]) |
| idx | track_title | liked | like_prob |
|---|---|---|---|
| 0 | In The Flesh? – 2011 Remastered Version | False | 0.99 |
| 0 | The Thin Ice – 2011 Remastered Version | False | 0.93 |
| 0 | Another Brick In The Wall, Pt. 1 – 2011 Remastered Version | False | 0.75 |
| 0 | The Happiest Days Of Our Lives – 2011 Remastered Version | False | 0.95 |
| 0 | Another Brick In The Wall, Pt. 2 – 2011 Remastered Version | False | 0.97 |
| 0 | Mother – 2011 Remastered Version | True | 1 |
| 0 | Goodbye Blue Sky – 2011 Remastered Version | False | 0.88 |
| 0 | Empty Spaces – 2011 Remastered Version | False | 0.89 |
| 0 | Young Lust – 2011 Remastered Version | False | 0.96 |
| 0 | One Of My Turns – 2011 Remastered Version | False | 0.99 |
| 0 | Don’t Leave Me Now – 2011 Remastered Version | False | 0.98 |
| 0 | Another Brick In The Wall, Pt. 3 – 2011 Remastered Version | False | 0.91 |
| 0 | Goodbye Cruel World – 2011 Remastered Version | False | 0.73 |
| 0 | Hey You – 2011 Remastered Version | False | 1 |
| 0 | Is There Anybody Out There? – 2011 Remastered Version | False | 0.85 |
| 0 | Nobody Home – 2011 Remastered Version | True | 0.96 |
| 0 | Vera – 2011 Remastered Version | True | 0.93 |
| 0 | Bring The Boys Back Home – 2011 Remastered Version | False | 0.98 |
| 0 | Comfortably Numb – 2011 Remastered Version | True | 1 |
| 0 | The Show Must Go On – 2011 Remastered Version | False | 0.99 |
| 0 | In The Flesh – 2011 Remaster | False | 0.99 |
| 0 | Run Like Hell – 2011 Remastered Version | False | 0.98 |
| 0 | Waiting For The Worms – 2011 Remastered Version | False | 0.99 |
| 0 | Stop – 2011 Remastered Version | False | 0.86 |
| 0 | The Trial – 2011 Remastered Version | False | 1 |
| 0 | Outside The Wall – 2011 Remastered Version | False | 0.87 |
Zdecydowanie wszystkie utwory dostałyby jako klasę jedynkę, niektóre mniej inne bardziej. Można powiedzieć, że na (nie tak do końca) losowo wybranym przykładzie model empirycznie się sprawdza. “Goodbye Cruel World” został oceniony najniżej a jest jednym z moich ulubionych tracków na tej płycie. Zwróć uwagę, że nie był oserduszkowany.
Nic dziwnego, że wszystko z “The Wall” według modelu mi się powinno podobać, skoro trenowany jest głównie na tego typu muzyce. Ale zróbmy inny eksperyment. Lubię Bjork, chociaż ostatnio jakoś mniej jej słucham, najbardziej lubię płytę “Post”. Jedziemy zatem z tym samym kodem co wyżej dla ID albumu 3p7WXDBxhC5KS9IFXnwae7 (powyższy kod ubrałem w zgrabną funkcję)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
def score_album_trakcs(album_id): tracks_to_score_ids = [trid['id'] for trid in sp.album_tracks(album_id)['items']] tracks_to_score = pd.DataFrame() for track in tracks_to_score_ids: tracks_to_score = tracks_to_score.append(get_track_info(track)) # to w sumie niczego nie wnosi, ale będzie widać, że nie było żadnego lajka na tej płycie tracks_to_score['liked'] = [True if tid in list(tracks_df['track_id']) else False for tid in tracks_to_score['track_id'] ] X_tracks_to_score = tracks_to_score[['track_popularity', 'danceability', 'energy', 'key', 'loudness', 'mode', 'speechiness', 'acousticness', 'instrumentalness', 'liveness', 'valence', 'tempo', 'duration_ms', 'time_signature', 'album_release_year']] tracks_to_score['like_prob'] = model.predict_proba(X_tracks_to_score)[:, 1] return tracks_to_score[['track_title', 'liked', 'like_prob']] print(score_album_trakcs('3p7WXDBxhC5KS9IFXnwae7')) |
| idx | track_title | liked | like_prob |
|---|---|---|---|
| 0 | Army Of Me | False | 0.98 |
| 0 | Hyper-ballad | False | 1 |
| 0 | The Modern Things | False | 0.93 |
| 0 | It’s Oh So Quiet | False | 0.94 |
| 0 | Enjoy | False | 0.99 |
| 0 | You’ve Been Flirting Again | False | 0.83 |
| 0 | Isobel | False | 1 |
| 0 | Possibly Maybe | False | 1 |
| 0 | I Miss You | False | 0.93 |
| 0 | Cover Me | False | 0.98 |
| 0 | Headphones | False | 0.84 |
Tutaj też wszystkie utwory dostałyby lajka! Ciekawe jest to, że “Isobel” większego niż “It’s oh so quiet”, a lubię odwrotnie.
To są przykłady pozytywne – wiem, że mi się podoba i model mówi to samo. A jak wiem, że mi się nie podoba to co powie model? O, na przykład o płycie 5C0YLr4OoRGFDaqdMQmkeH?
|
1 |
print(score_album_trakcs('5C0YLr4OoRGFDaqdMQmkeH')) |
| idx | track_title | liked | like_prob |
|---|---|---|---|
| 0 | Sola | False | 0.03 |
| 0 | Apaga La Luz | False | 0.02 |
| 0 | Le Pido Al Cielo | False | 0.17 |
| 0 | Imposible | False | 0.13 |
| 0 | Poco A Poco | False | 0 |
| 0 | Dime Que No Te Iras | False | 0.23 |
| 0 | Échame La Culpa | False | 0.06 |
| 0 | Tanto Para Nada | False | 0.13 |
| 0 | Despacito | False | 0.03 |
| 0 | Más Fuerte Que Yo | False | 0.06 |
| 0 | Calypso | False | 0.2 |
| 0 | Ahí Estas Tú | False | 0.02 |
| 0 | Despacito – Remix | False | 0.03 |
| 0 | Calypso – Remix | False | 0.05 |
| 0 | Sola – English Version | False | 0.02 |
Sprawdza się.
Ale są też błędy. Na przykład model mówi, że nie, a ja po przesłuchaniu mówię że całkiem ok. Płyta 6R8ir7mqaqV3vrtv5pmvID wypada wg modelu bardzo słabo (Fonsi wygląda na lepszy, ale jak?):
|
1 |
print(score_album_trakcs('6R8ir7mqaqV3vrtv5pmvID')) |
| idx | track_title | liked | like_prob |
|---|---|---|---|
| 0 | Koło fortuny | False | 0.06 |
| 0 | W domach z betonu | False | 0.01 |
| 0 | Matchboxy | False | 0.01 |
| 0 | Na rympał | False | 0.02 |
| 0 | Piekło jest w nas | False | 0 |
| 0 | Przebój nocy | False | 0 |
| 0 | Noc | False | 0.03 |
| 0 | Street Fighter | False | 0.01 |
| 0 | Zadzwoń do mnie | False | 0.01 |
| 0 | BMK | False | 0.02 |
| 0 | Mistrz ping-ponga | False | 0.01 |
| 0 | Szansa na sukces | False | 0 |
| 0 | Dym | False | 0.01 |
| 0 | Bagaże | False | 0.03 |
| 0 | Skrable | False | 0.01 |
| 0 | Outro | False | 0.05 |
Płyta ta jest całkiem zgrabnym kawałkiem polskiego HH, którego nie lubię (z 20 lat temu napisałem o tym tekst do jakiegoś fun zina, ależ mnie zjechali! Nie umiem znaleźć tekstu niestety) i się na nim nie znam. Kudosy dla Pana Huberta z Warszawy za przedstawienie tej płyty.
Zauważyliście, że specjalnie nie podaję nazw tych płyt i liczę na to, że klikniecie albo rozpoznacie po tytułach utworów? Post edukacyjny zarówno z Pythona, prostego machine learning jak i muzyki. W czasach kwarantanny za darmo takie rzeczy… No chyba że kawkę postawisz.
Panu Maciejowi (również z Warszawy) obiecałem jeszcze płytę 7xV2TzoaVc0ycW7fwBwAml:
|
1 |
print(score_album_trakcs('7xV2TzoaVc0ycW7fwBwAml')) |
| idx | track_title | liked | like_prob |
|---|---|---|---|
| 0 | Golden | False | 0.08 |
| 0 | Watermelon Sugar | False | 0.03 |
| 0 | Adore You | False | 0 |
| 0 | Lights Up | False | 0.04 |
| 0 | Cherry | False | 0.2 |
| 0 | Falling | False | 0.05 |
| 0 | To Be So Lonely | False | 0.07 |
| 0 | She | False | 0.4 |
| 0 | Sunflower, Vol. 6 | False | 0.2 |
| 0 | Canyon Moon | False | 0.15 |
| 0 | Treat People With Kindness | False | 0.11 |
| 0 | Fine Line | False | 0.3 |
Normalnie bym palcem nie kiwnął i nie zapuścił się w te rejony patrząc na cyferki. Ale włączyłem (pan Maciej z Warszawy podrzucał i podrzucał kolejnych wykonawców) i ta muzyka przypadła mi do gustu (ale nie mogłem zaserduszkować jeszcze, żeby test był fair).
Dlaczego więc model się myli?
Wytłumaczenie jest stosunkowo proste:
- jedynki są pewne. Sam musiałem wykonać akcję polegającą na kliknięciu w serduszko.
- ale z zerami poszliśmy na łatwiznę (oceniając trochę po okładce)
- dodatkowo nie było zer dla wykonawców, którzy mieli chociaż jedną jedynkę, a to duże uproszczenie
Przy poprawnym labelkowaniu trzeba pracę wykonać samodzielnie, niestety. Bo inaczej shit in, shit out.
Druga sprawa – sam model jest dość prosty, bez dobierania żadnych hiperparametrów, bez szukania cech dodatkowych (np. totalnie oderwanych od muzyki – średnia liczba znaków w tytule utworu na płycie z której utwór pochodzi ;) Może więc sieć nieuronowa? Może. Ale przede wszystkim uczciwy sposób oznaczania nielubianych.
Ciekawy tekst na ten sam temat na pisał też Grzesiek Zembrowski – polecam uwadze, bo Grzegorz skupił się na większej liczbie cech i poszedł nieco dalej z modelem (jakieś PCA po drodze).
Ja pisałem kiedyś o tym samym z poziomu R.