Co to są pipelines w sci-kit learn i jak je wykorzystać? Czyli bardziej efektywne szukanie najlepszego modelu.

Jeśli zajmujesz się tworzeniem modeli na przykład klasyfikujących jakieś dane to pewnie wielokrotnie powtarzasz te same kroki:
- wczytanie danych
- oczyszczenie danych
- uzupełnienie braków
- przygotowanie dodatkowych cech (feature engineering)
- podział danych na treningowe i testowe
- dobór hyperparametrów modelu
- trenowanie modelu
- testowanie modelu (sprawdzenie skuteczności działania)
I tak w kółko, z każdym nowy modelem.
Jest to dość nudne i dość powtarzalne. Szczególnie jak trzeba wykonać różne kroki transformacji danych w różnej kolejności – upierdliwe staje się zmienianie kolejności w kodzie.
Dlatego wymyślono pipelines.
Dlatego w tym i kolejnych postach zajmiemy się tym mechanizmem.
Zaczniemy od podstaw data science, czyli…
|
1 2 3 4 5 6 7 8 |
# bez tego nie ma data science! ;) import pandas as pd # być może coś narysujemy import matplotlib.pyplot as plt import seaborn as sns import time |
Wszystkie elementy jakich będziemy używać znajdują się w ramach biblioteki scikit-learn. Zaimportujemy co trzeba plus kilka modeli z oddzielnych bibliotek.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
from sklearn.model_selection import train_test_split # modele from sklearn.dummy import DummyClassifier from sklearn.linear_model import LogisticRegression from sklearn.tree import ExtraTreeClassifier from sklearn.ensemble import RandomForestClassifier from sklearn.svm import SVC from sklearn.neighbors import KNeighborsClassifier # preprocessing ## zmienne ciągłe from sklearn.preprocessing import StandardScaler, MinMaxScaler, Normalizer ## zmienne kategoryczne from sklearn.preprocessing import OrdinalEncoder, OneHotEncoder # Pipeline from sklearn.pipeline import Pipeline from sklearn.compose import ColumnTransformer # dodatkowe modele spoza sklearn from xgboost import XGBClassifier from catboost import CatBoostClassifier from lightgbm import LGBMClassifier |
Skąd wziąć dane? Można użyć wbudowanych w sklearna irysów czy boston housing ale mi zależało na znalezieniu takiego datasetu, który będzie zawierał cechy zarówno ciągłe jak i kategoryczne. Takim zestawem jest Adult znany też jako Census Income, a ściągnąć go można z UCI (studenci i absolwenci AGH mogą mylić z UCI w budynku C-1).
Pobieramy (potrzebne nam będą pliki adult.data oraz adult.test) dane, wrzucamy surowe pliki do katalogu data/ i wczytujemy.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
# dane nie mają nagłówka - samo sobie nadamy nazwy kolumn col_names= ['age', 'work_class', 'final_weight', 'education', 'education_num', 'marital_status', 'occupation', 'relationship', 'race', 'sex', 'capital_gain', 'capital_loss', 'hours_per_week', 'native_country', 'year_income'] # wczytujemy dane adult_dataset = pd.read_csv("data/adult.data", engine='python', sep=', ', # tu jest przeciek i spacja! header=None, names=col_names, na_values="?") # kolumna 'final_weight' do niczego się nie przyda, więc od razu ją usuwamy # wiadomo to z EDA, które tutaj pomijamy adult_dataset.drop('final_weight', axis=1, inplace=True) # usuwamy braki, żeby uprościć przykład adult_dataset.dropna(inplace=True) |
Zobaczmy jakie mamy typy danych w kolumnach:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
adult_dataset.dtypes ## age int64 ## work_class object ## education object ## education_num int64 ## marital_status object ## occupation object ## relationship object ## race object ## sex object ## capital_gain int64 ## capital_loss int64 ## hours_per_week int64 ## native_country object ## year_income object ## dtype: object |
A teraz standardowo – dzielimy dane na zbiór treningowy i testowy. Przy okazji z całej ramki danych wyciągamy kolumnę year_income jako Y, a resztę jako X. Szalenie wygodnym jest nazywanie cech zmienną X a targetów y – przy Ctrl-C + Ctrl-V ze StackOverflow niczego właściwie nie trzeba robić ;)
|
1 2 3 4 |
X_train, X_test, y_train, y_test = train_test_split(adult_dataset.drop('year_income', axis=1), adult_dataset['year_income'], test_size=0.3, random_state=42) |
Sporą część wstępnej analizy pomijam w tym wpisie, ale jeśli nie wiesz dlaczego wybieram takie a nie inne kolumny to zrób samodzielnie analizę danych w tym zbiorze.
Czas na trochę informacji o rurociągach.
W dużym uproszczeniu są to połączone sekwencyjnie (jedna za drugą, wyjście pierwszej trafia na wejście drugiej i tak dalej do końca) operacje. Operacje czyli klasy, które posiadają metody .fit() i .transform().
Rurociąg może składać się z kilku rurociągów połączonych jeden za drugim – taki model zastosujemy za chwilę.
Powiedzieliśmy sobie wyżej, że pierwszy krok to przygotowanie danych – odpowiednie transformacje danych źródłowych i ewentualnie uzupełnienie danych brakujących. W dzisiejszym przekładzie brakujące dane (około 7% całości) po prostu wyrzuciliśmy przez dropna(), więc uzupełnieniem braków się nie zajmujemy. Ale może w kolejnej części już tak.
Drugim krokiem jest przesłanie danych odpowiednio obrobionych do modelu i jego wytrenowanie.
No to do dzieła, już konkretnie – transformacja danych
Zatem na początek przygotujemy sobie fragmenty całego rurociągu odpowiedzialnego za transformacje kolumn. Mamy dwa typy kolumn, zatem zbudujemy dwa małe rurociągi.
Pierwszy będzie odpowiedzialny za kolumny z wartościami liczbowymi. Nie wiemy czy są to wartości ciągłe (jak na przykład wiek) czy dyskretne (tutaj taką kolumną jest education_num mówiąca o poziome edukacji) i poniżej bierzemy wszystkie jak leci. Znowu: porządna EDA wskaże nam odpowiednie kolumny.
Najpierw wybieramy wszystkie kolumny o typie numerycznym, a potem budujemy mini-rurociąg transformer_numerical, którego jedynym krokiem będzie wywołanie StandardScaler() zapisane pod nazwą num_trans (to musi być unikalne w całym procesie). Kolejny krok łatwo dodać – po prostu dodajemy kolejnego tupla w takim samym schemacie.
Co nam to daje? Ano daje to tyle, że mamy konkretną nazwę dla konkretnego kroku. Później możemy się do niej dostać i na przykład zmienić: zarówno metodę wywoływaną w tym konkretnym kroku jak i parametry tej metody.
|
1 2 3 4 5 6 7 |
# lista kolumn numerycznych cols_numerical = X_train.select_dtypes(include=['int64', 'float64']).columns # transformer dla kolumn numerycznych transformer_numerical = Pipeline(steps = [ ('num_trans', StandardScaler()) ]) |
To samo robimy dla kolumn z wartościami kategorycznymi – budujemy mini-rurociąg transformer_categorical, który w kroku cat_trans wywołuje OneHotEncoder().
|
1 2 3 4 5 6 7 8 |
# lista kolmn kategorycznych cols_categorical = ['work_class', 'education', 'marital_status', 'occupation', 'relationship', 'race', 'sex', 'native_country'] # transformer dla kolumn numerycznych transformer_categorical = Pipeline(steps = [ ('cat_trans', OneHotEncoder()) ]) |
Co dalej? Z tych dwóch małych rurociągów zbudujemy większy – preprocessor. Właściwie to będzie to swego rodzaju rozgałęzienie – ColumnTransformer który jedne kolumny puści jednym mini-rurociągiem, a drugie – drugim. I znowu: tutaj może być kilka elementów, oddzielne przepływy dla konkretnych kolumn (bo może jedne ciągłe chcemy skalować w jeden sposób, a inne w inny? A może jedne zmienne chcemy uzupełnić średnią a inne medianą?) – mamy pełną swobodę.
|
1 2 3 4 5 |
# preprocesor danych preprocessor = ColumnTransformer(transformers = [ ('numerical', transformer_numerical, cols_numerical), ('categorical', transformer_categorical, cols_categorical) ]) |
Cała rura to złożenie odpowiednich elementów w całość – robiliśmy to już wyżej:
|
1 2 3 4 |
pipe = Pipeline(steps = [ ('preprocessor', preprocessor), ('classifier', RandomForestClassifier()) ]) |
Teraz cały proces wygląda następująco:
- najpierw preprocessing:
- dla kolumn liczbowych wykonywany jest
StandardScaler() - dla kolumn kategorycznych –
OneHotEncoder()
- dla kolumn liczbowych wykonywany jest
- złożone dane przekazywane są do
RandomForestClassifier()
Proces trenuje się dokładne tak samo jak model – poprzez wywołanie metody .fit():
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
pipe.fit(X_train, y_train) ## Pipeline(memory=None, ## steps=[('preprocessor', ## ColumnTransformer(n_jobs=None, remainder='drop', ## sparse_threshold=0.3, ## transformer_weights=None, ## transformers=[('numerical', ## Pipeline(memory=None, ## steps=[('num_trans', ## StandardScaler(copy=True, ## with_mean=True, ## with_std=True))], ## verbose=False), ## Index(['age', 'education_num', 'capital_gain', 'capital_loss', ## 'hours_per_wee... ## RandomForestClassifier(bootstrap=True, ccp_alpha=0.0, ## class_weight=None, criterion='gini', ## max_depth=None, max_features='auto', ## max_leaf_nodes=None, max_samples=None, ## min_impurity_decrease=0.0, ## min_impurity_split=None, ## min_samples_leaf=1, min_samples_split=2, ## min_weight_fraction_leaf=0.0, ## n_estimators=100, n_jobs=None, ## oob_score=False, random_state=None, ## verbose=0, warm_start=False))], ## verbose=False) |
Oczywiście predykcja działa tak samo jak zawsze:
|
1 2 3 4 |
pipe.predict(X_test) ## array(['<=50K', '<=50K', '<=50K', ..., '>50K', '<=50K', '<=50K'], ## dtype=object) |
Są też metody zwracające prawdopodobieństwo przypisania do każdej z klas .predict_proba() oraz jego logarytm .predict_log_proba().
|
1 2 3 4 5 6 7 8 9 |
pipe.predict_proba(X_test) ## array([[0.97 , 0.03 ], ## [0.73061905, 0.26938095], ## [0.7625 , 0.2375 ], ## ..., ## [0.31388997, 0.68611003], ## [1. , 0. ], ## [0.99888889, 0.00111111]]) |
Po wytrenowaniu na danych treningowych (cechy X_train, target y_train) możemy zobaczyć ocenę modelu na danych testowych (odpowiednio X_test i y_test):
|
1 2 3 |
pipe.score(X_test, y_test) ## 0.8457288098132391 |
Świetnie, świetne, ale to samo można bez tych pipelinów, nie raz na Kaggle tak robili i działało. Więc po co to wszystko?
Ano po to, co nastąpi za chwilę.
Mamy cały proces, każdy jego krok ma swoją nazwę, prawda? A może zamiast StandardScaler() lepszy będzie MinMaxScaler()? A może inna klasa modeli (zamiast lasów losowych np. XGBoost?). A gdyby sprawdzić każdy model z każdą transformacją? No to się robi sporo kodu… A nazwane kroki w procesie pozwalają na prostą podmiankę!
Zdefiniujmy sobie przestrzeń poszukiwań najlepszego modelu i najlepszych transformacji:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
# klasyfikatory classifiers = [ DummyClassifier(strategy='stratified'), LogisticRegression(max_iter=500), # można tutaj podać hiperparametry KNeighborsClassifier(2), # 2 bo mamy dwie klasy ExtraTreeClassifier(), RandomForestClassifier(), SVC(), XGBClassifier(), CatBoostClassifier(silent=True), LGBMClassifier(verbose=-1) ] # transformatory dla kolumn liczbowych scalers = [StandardScaler(), MinMaxScaler(), Normalizer()] # transformatory dla kolumn kategorycznych cat_transformers = [OrdinalEncoder(), OneHotEncoder()] |
Teraz w zagnieżdżonych pętlach możemy sprawdzić każdy z każdym podmieniając klasyfikatory i transformatory (cała pętla trochę się kręci):
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 |
# miejsce na zebranie wyników models_df = pd.DataFrame() # przygotowujemy pipeline pipe = Pipeline(steps = [ ('preprocessor', preprocessor), # mniejszy pipeline ('classifier', None) # to ustalimy za moment ]) # dla każdego typu modelu zmieniamy kolejne transformatory kolumn for model in classifiers: for num_tr in scalers: for cat_tr in cat_transformers: # odpowiednio zmieniamy jego paramety - dobieramy transformatory pipe_params = { 'preprocessor__numerical__num_trans': num_tr, 'preprocessor__categorical__cat_trans': cat_tr, 'classifier': model } pipe.set_params(**pipe_params) # trenujemy tak przygotowany model (cały pipeline) mierząc ile to trwa start_time = time.time() pipe.fit(X_train, y_train) end_time = time.time() # sprawdzamy jak wyszło score = pipe.score(X_test, y_test) # zbieramy w dict parametry dla Pipeline i wyniki param_dict = { 'model': model.__class__.__name__, 'num_trans': num_tr.__class__.__name__, 'cat_trans': cat_tr.__class__.__name__, 'score': score, 'time_elapsed': end_time - start_time } models_df = models_df.append(pd.DataFrame(param_dict, index=[0])) models_df.reset_index(drop=True, inplace=True) |
Teraz w jednej tabeli mamy wszystkie interesujące dane, które mogą posłużyć nam chociażby do znalezienia najlepszego modelu:
|
1 |
models_df.sort_values('score', ascending=False) |
| model | num_trans | cat_trans | score | time_elapsed |
|---|---|---|---|---|
| CatBoostClassifier | StandardScaler | OrdinalEncoder | 0.871 | 50.595 |
| CatBoostClassifier | MinMaxScaler | OrdinalEncoder | 0.871 | 55.328 |
| CatBoostClassifier | StandardScaler | OneHotEncoder | 0.871 | 46.503 |
| CatBoostClassifier | MinMaxScaler | OneHotEncoder | 0.871 | 65.044 |
| XGBClassifier | StandardScaler | OneHotEncoder | 0.871 | 4.458 |
| LGBMClassifier | StandardScaler | OneHotEncoder | 0.871 | 3.736 |
| LGBMClassifier | MinMaxScaler | OneHotEncoder | 0.871 | 2.319 |
| XGBClassifier | StandardScaler | OrdinalEncoder | 0.870 | 1.435 |
| XGBClassifier | MinMaxScaler | OrdinalEncoder | 0.870 | 5.215 |
| XGBClassifier | MinMaxScaler | OneHotEncoder | 0.869 | 3.056 |
| LGBMClassifier | StandardScaler | OrdinalEncoder | 0.869 | 2.620 |
| LGBMClassifier | MinMaxScaler | OrdinalEncoder | 0.869 | 2.999 |
| XGBClassifier | Normalizer | OneHotEncoder | 0.862 | 8.008 |
| CatBoostClassifier | Normalizer | OneHotEncoder | 0.859 | 57.878 |
| LGBMClassifier | Normalizer | OneHotEncoder | 0.859 | 2.356 |
| LGBMClassifier | Normalizer | OrdinalEncoder | 0.859 | 0.893 |
| XGBClassifier | Normalizer | OrdinalEncoder | 0.857 | 17.738 |
| CatBoostClassifier | Normalizer | OrdinalEncoder | 0.857 | 66.315 |
| SVC | StandardScaler | OneHotEncoder | 0.853 | 36.520 |
| LogisticRegression | StandardScaler | OneHotEncoder | 0.850 | 1.581 |
| LogisticRegression | MinMaxScaler | OneHotEncoder | 0.849 | 1.079 |
| RandomForestClassifier | StandardScaler | OrdinalEncoder | 0.847 | 3.022 |
| RandomForestClassifier | MinMaxScaler | OrdinalEncoder | 0.846 | 2.647 |
| RandomForestClassifier | StandardScaler | OneHotEncoder | 0.843 | 21.878 |
| RandomForestClassifier | Normalizer | OneHotEncoder | 0.843 | 19.976 |
| LogisticRegression | Normalizer | OneHotEncoder | 0.842 | 1.440 |
| RandomForestClassifier | MinMaxScaler | OneHotEncoder | 0.842 | 18.986 |
| RandomForestClassifier | Normalizer | OrdinalEncoder | 0.840 | 3.454 |
| SVC | Normalizer | OneHotEncoder | 0.836 | 36.707 |
| SVC | MinMaxScaler | OneHotEncoder | 0.834 | 39.465 |
| LogisticRegression | StandardScaler | OrdinalEncoder | 0.818 | 1.284 |
| LogisticRegression | MinMaxScaler | OrdinalEncoder | 0.816 | 4.131 |
| KNeighborsClassifier | StandardScaler | OneHotEncoder | 0.812 | 0.143 |
| KNeighborsClassifier | StandardScaler | OrdinalEncoder | 0.810 | 0.883 |
| KNeighborsClassifier | Normalizer | OneHotEncoder | 0.810 | 0.125 |
| KNeighborsClassifier | Normalizer | OrdinalEncoder | 0.807 | 0.690 |
| ExtraTreeClassifier | Normalizer | OneHotEncoder | 0.805 | 0.833 |
| ExtraTreeClassifier | StandardScaler | OneHotEncoder | 0.803 | 0.666 |
| KNeighborsClassifier | MinMaxScaler | OneHotEncoder | 0.801 | 0.147 |
| ExtraTreeClassifier | MinMaxScaler | OrdinalEncoder | 0.800 | 0.187 |
| KNeighborsClassifier | MinMaxScaler | OrdinalEncoder | 0.799 | 0.652 |
| SVC | StandardScaler | OrdinalEncoder | 0.798 | 17.911 |
| ExtraTreeClassifier | StandardScaler | OrdinalEncoder | 0.798 | 0.203 |
| ExtraTreeClassifier | MinMaxScaler | OneHotEncoder | 0.797 | 0.541 |
| ExtraTreeClassifier | Normalizer | OrdinalEncoder | 0.794 | 0.221 |
| LogisticRegression | Normalizer | OrdinalEncoder | 0.784 | 13.174 |
| SVC | Normalizer | OrdinalEncoder | 0.769 | 22.420 |
| SVC | MinMaxScaler | OrdinalEncoder | 0.748 | 19.661 |
| DummyClassifier | MinMaxScaler | OneHotEncoder | 0.630 | 0.114 |
| DummyClassifier | Normalizer | OrdinalEncoder | 0.627 | 0.105 |
| DummyClassifier | Normalizer | OneHotEncoder | 0.626 | 0.131 |
| DummyClassifier | StandardScaler | OrdinalEncoder | 0.623 | 0.097 |
| DummyClassifier | StandardScaler | OneHotEncoder | 0.623 | 0.113 |
| DummyClassifier | MinMaxScaler | OrdinalEncoder | 0.617 | 0.096 |
Ale najlepszy może być w różnych kategoriach – nie tylko skuteczności, ale też na przykład czasu uczenia czy też stabilności wyniku. Zobaczmy podstawowe statystyki dla typów modeli:
|
1 2 3 4 5 6 7 8 |
models_df[['model', 'score', 'time_elapsed']] \ .groupby('model') \ .aggregate({ 'score': ['mean','std', 'min', 'max'], 'time_elapsed': ['mean','std', 'min', 'max'] }) \ .reset_index() \ .sort_values(('score', 'mean'), ascending=False) |
| model | mean | std | min | max | mean | std | min | max |
|---|---|---|---|---|---|---|---|---|
| CatBoostClassifier | 0.867 | 0.007 | 0.857 | 0.871 | 56.944 | 7.826 | 46.503 | 66.315 |
| XGBClassifier | 0.867 | 0.006 | 0.857 | 0.871 | 6.652 | 5.861 | 1.435 | 17.738 |
| LGBMClassifier | 0.866 | 0.006 | 0.859 | 0.871 | 2.487 | 0.941 | 0.893 | 3.736 |
| RandomForestClassifier | 0.843 | 0.003 | 0.840 | 0.847 | 11.661 | 9.491 | 2.647 | 21.878 |
| LogisticRegression | 0.826 | 0.026 | 0.784 | 0.850 | 3.782 | 4.737 | 1.079 | 13.174 |
| KNeighborsClassifier | 0.806 | 0.005 | 0.799 | 0.812 | 0.440 | 0.340 | 0.125 | 0.883 |
| SVC | 0.806 | 0.042 | 0.748 | 0.853 | 28.781 | 9.784 | 17.911 | 39.465 |
| ExtraTreeClassifier | 0.800 | 0.004 | 0.794 | 0.805 | 0.442 | 0.277 | 0.187 | 0.833 |
| DummyClassifier | 0.624 | 0.004 | 0.617 | 0.630 | 0.109 | 0.013 | 0.096 | 0.131 |
Tutaj tak na prawdę nie mierzymy stabilności modelu – podajemy różnie przetworzone dane do tego samego modelu. Stabilność można zmierzyć puszczając na model fragmentaryczne dane, co można zautomatyzować poprzez KFold/RepeatedKFold (z sklearn.model_selection), ale dzisiaj nie o tym.
Sprawdźmy który rodzaj modelu daje najlepszą skuteczność:
|
1 |
sns.boxplot(data=models_df, x='score', y='model') |
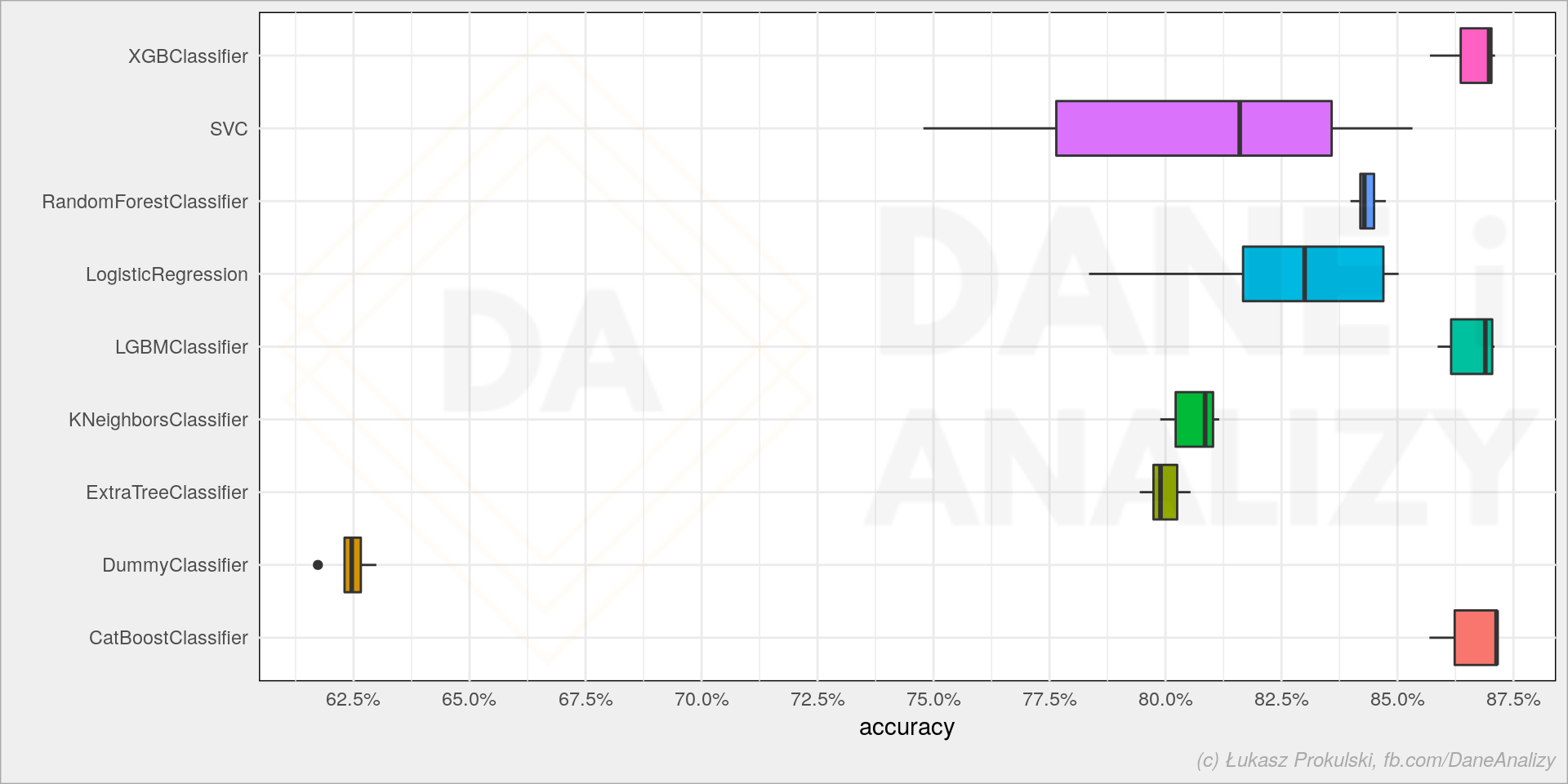
Ostatnie trzy (XGBoost, LigthGBM i CatBoost) dają najlepsze wyniki i pewnie warto je brać pod uwagę w przyszłości.
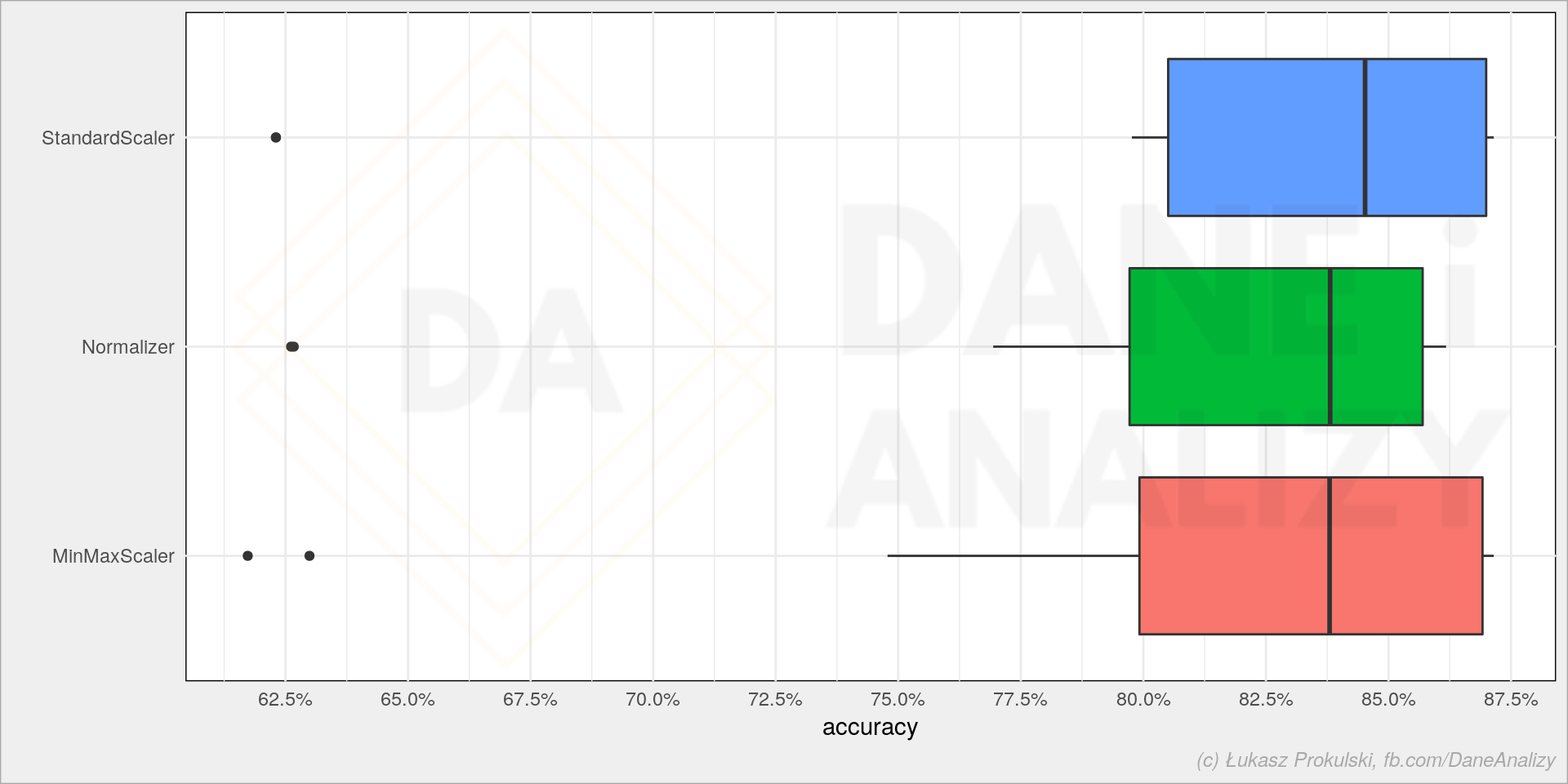
A czy są różnice pomiędzy transformatorami?
|
1 |
sns.boxplot(data=models_df, x='score', y='num_trans') |
|
1 |
sns.boxplot(data=models_df, x='score', y='cat_trans') |
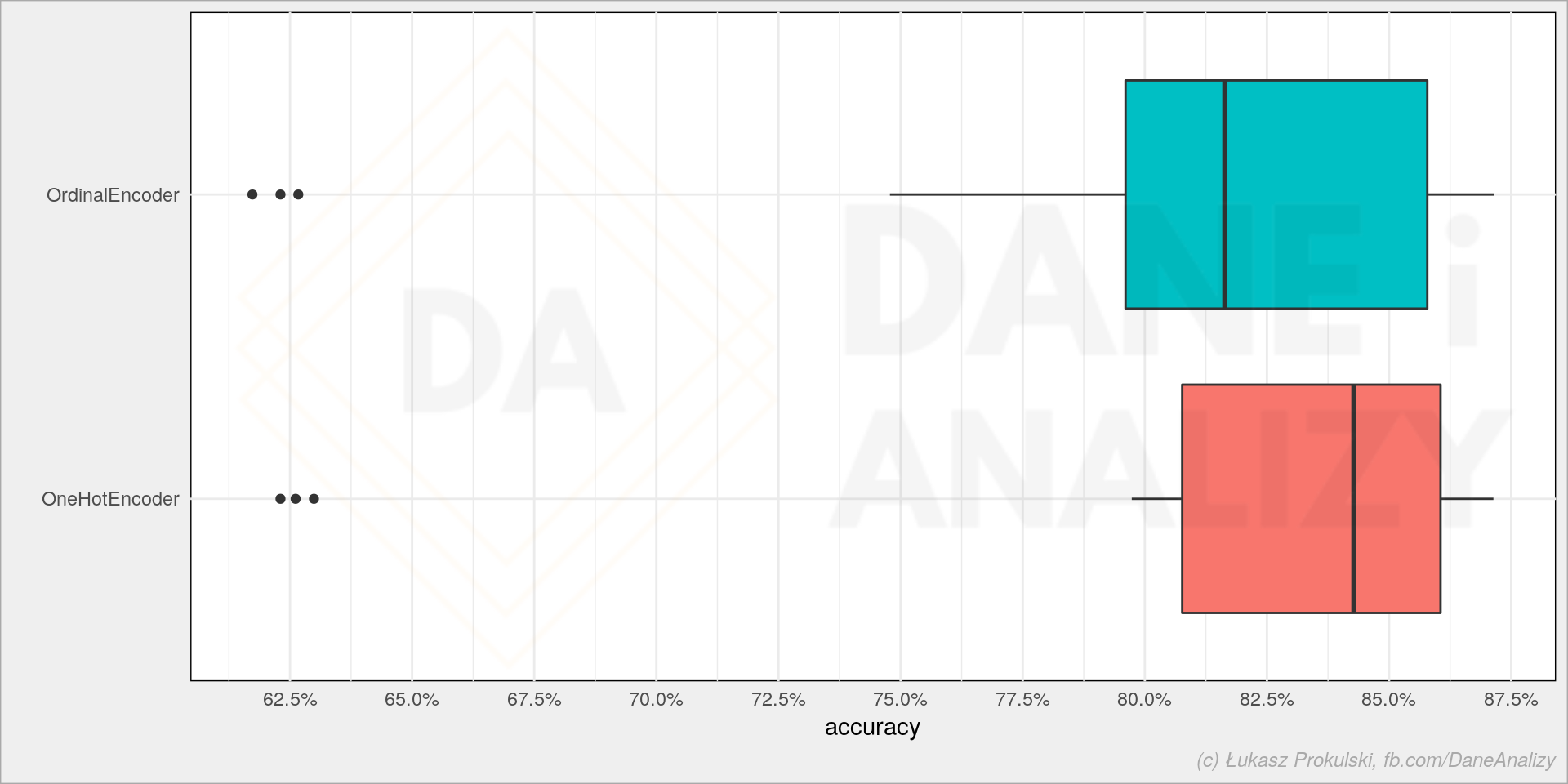
Przy tych danych wygląda, że właściwie nie ma większej różnicy (nie bijemy się tutaj o 0.01 punktu procentowego poprawy accuracy modelu). Może więc czas treningu jest istotny?
|
1 |
sns.boxplot(data=models_df, x='time_elapsed', y='model') |
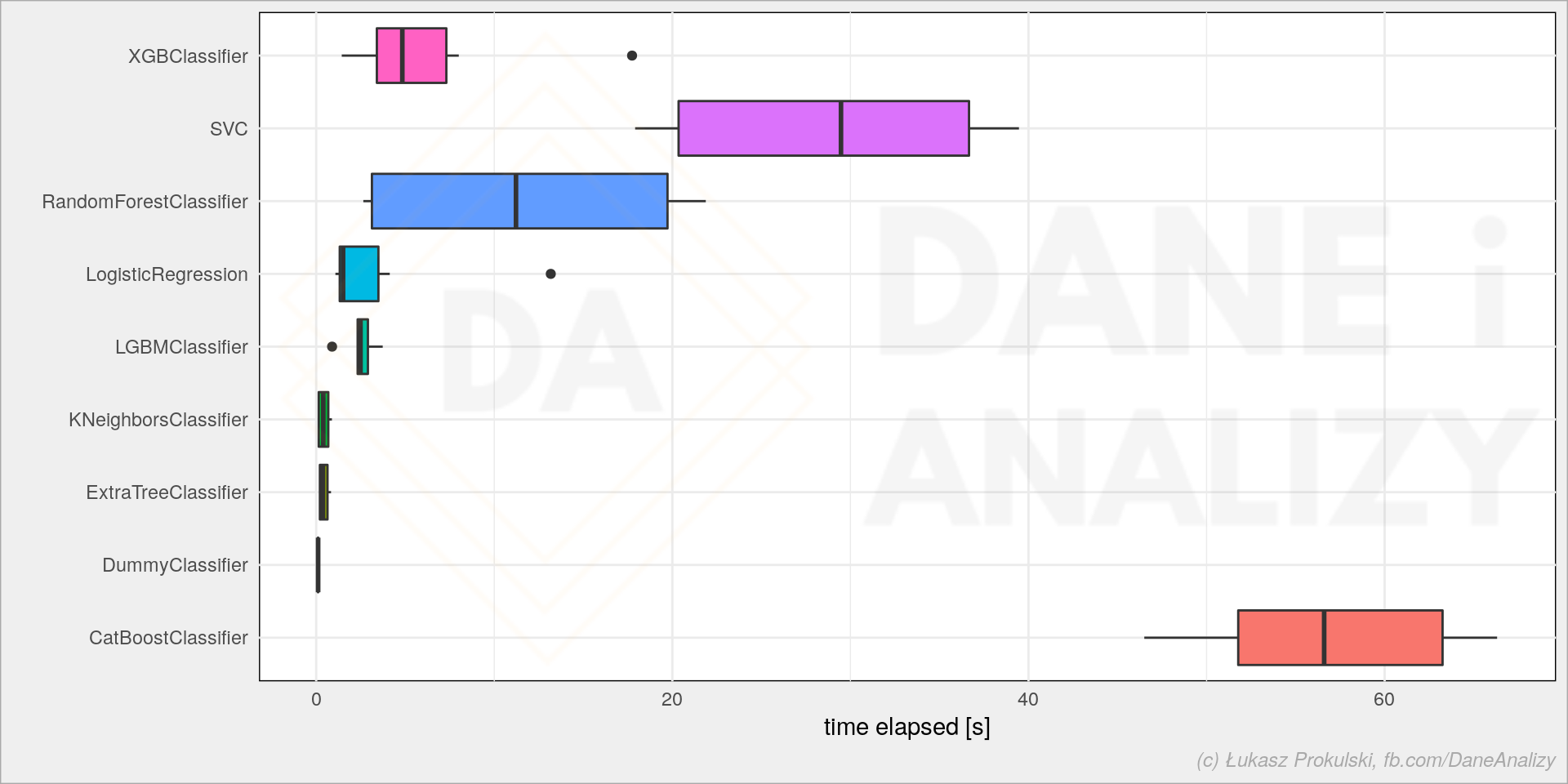
Mamy kilku liderów, ale z tych które dawały najlepsze wyniki warto wziąć pod uwagę XGBoosta i LightGBM.
Dzięki przećwiczeniu kilku modeli mamy dwóch najbardziej efektywnych (czasowo) i efektownych (z najlepszym accuracy) kandydatów do dalszych prac. Wyszukanie ich to kilka linii kodu. Jeśli przyjdzie nam do głowy nowy model – dodajemy go do listy classifiers. Jeśli znajdziemy inny transformator – dopisujemy do listy scalers lub cat_transformers. Nie trzeba kopiować dużych kawałków kodu, nie trzeba właściwie pisać nowego kodu.
Dokładnie tym samym sposobem możemy poszukać hyperparametrów dla konkretnego modelu i zestawu transformacji w pipeline. Ale to już w następnym odcinku.
Bardzo dobry i przydatny poradnik. Kompletnie nie znam Azure i zastanawiam się czy tak samo łatwe będzie uruchomienie projektu Javovego? Z tego co wyczytałem, chyba jest możliwość na Azure DevOps zdefiniować pipeliny dla projektów napisanych w Javie.
Cześć, powiem tak… to co tu jest to jakaś poezja!!! Żałuję, że jak zacząłem robić mgr to dopiero teraz po kilku miesiącach to odkryłem. Część modeli już postawiłem… Mam pytanie. Czy potem można wywoływać:
cm2 = confusion_matrix(target_test, predykcja modelu)
cm2_display = ConfusionMatrixDisplay(cm2).plot()
Bo jak tak na razie patrzę to krzywą ROC można wyrysować dla modeli za pomocą:
import matplotlib.pyplot as plt
from sklearn.metrics import RocCurveDisplay
fig, ax = plt.subplots()
models = [
(„Regresja logistyczna -> RL”, model),
(„Las losowy -> LS”, model2)
]
model_displays = {}
for name, pipeline in models:
model_displays[name] = RocCurveDisplay.from_estimator(
pipeline, data_test, target_test, ax=ax, name=name
)
_ = ax.set_title(„ROC curve”)
I pod nazwy modeli podkładamy no właśnie co? :/
Edit do confusion matrix* chodzi mi o to czy można w jakiś sposób podpiąć jeszcze predykcję modelu w pętli tak, żeby potem móc wyświetlić wszystko na wykresach.