Jak nauczyć się analizy danych? Robiąc małe i duże projekty.
Kiedyś napisałem post o tym jak się przemieszczam w którym odsłoniłem dość dużo swojej prywatności, dzisiaj ciąg dalszy.
Postanowiłem, że mocniej wezmę się za Pythona i to co potrafię dość szybko zrobić w R będę robił w Pythonie. To najlepszy sposób na naukę – zmuszać się w pewnym sensie do przełamywania własnych oporów. Z drugiej strony – od dawna chodził za mną tekst związany z analizą własnych wydatków.
Połączmy więc to razem i przeanalizujmy w Pythonie (dość prostym) moje wydatki z karty kredytowej.
Karty używam od wielu lat i z reguły płacę kartą kredytową za wszystko (za co płacę kartą). A potem hurtem spłacam cały miesiąc i mam z głowy. W tym czasie gotówka na koncie może pracować w inny sposób (o ile jakaś jest).
Kartę mam w mBanku i co miesiąc dostaję ma maila podsumowanie ruchu na karcie. Przychodzi to w pliku HTML, od zawsze w jednym formacie. Zaczynajmy więc!
Na początek jak zawsze potrzebujemy jakichś pakietów, dość standardowych (seaborn bo wydaje mi się przyjaźniejszy i ładniejszy niż goły matplotlib):
|
1 2 3 4 5 6 7 8 |
import os import math import pandas as pd import numpy as np import seaborn as sns import matplotlib.pyplot as plt |
Tak jak wspomniałem – każdy wyciąg jest w jednym pliku. Przygotujemy więc funkcję, która przeczyta konkretny plik i zwróci nam data frame z interesującymi nas elementami wyciągu:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
def read_file(file_name): # wczytujemy plik i odpowienią z niego tabelkę df = pd.read_html(file_name)[8] # wywalamy ostatni wiersz df = df.iloc[:-1] # zmieniamy nazwy kolumn df.columns = ['id_operacji', 'data_operacji', 'rodzaj_operacji', 'szczegoly_operacji', 'kwota_org', 'kwota_pln'] # tylko te wiersze, które w dacie mają na pewno datę df = df[df.data_operacji.str.contains("20")] # data zawiera datę operacji i księgowania - zostawiamy tą pierwszą df.data_operacji = df.data_operacji.map(lambda x: x[:10]) # datę zmieniamy na datę :) df.data_operacji = pd.to_datetime(df.data_operacji) # kwotę pln zmieniamy na liczbę, zmieniamy znak, żeby była wartość wydatku df['kwota_pln_float'] = df.kwota_pln.map(lambda x: -1*float(x.replace(" ", "").replace(",", "."))) # dodajemy nazwę pliku z wyciągiem (na potrzeby sprawdzania niezgodności - będzie wiadomo w którym oryginalnym pliku szukać) df['wyciag'] = file_name # odrzucamy spłaty df = df[~df.rodzaj_operacji.str.contains("SPŁATA")] # odrzucamy zwroty df = df[~df.rodzaj_operacji.str.contains("ZWROT")] return df |
Jak widzicie (po kodzie, albo komentarzach) trochę się tutaj dzieje, wiele niepotrzebnego. Można to posprzątać (właściwie powinno się) i zostawić to co konieczne:
- datę operacji
- kwotę operacji
- szczegóły operacji
Jeśli nie macie wyciągów comiesięcznych to możecie wykorzystać eksport listy operacji z Waszego banku do jakiegoś CSV (każdy to powinien mieć, jeśli nie ma to proponuję zmienić bank) zamiast przechodzenia plik po pliku, o tak:
|
1 2 3 4 5 6 7 8 |
# lista plików w folderze files = os.listdir("kk") wyciag = pd.DataFrame() for f in files: # print(os.path.join("kk", f)) tmp_df = read_file(os.path.join("kk", f)) wyciag = wyciag.append(tmp_df) |
…po prostu wciągnąć cały CSV do data frame wyciag. Wystarczy zapewne jakieś:
|
1 |
wyciag = pd.read_csv("plik_z_historią.csv") |
i odpowiednie nazwanie kolumn. Reszta kodu z tego postu powinna zadziałać.
Każdego dnia kartą można zapłacić wiele razy. Jeśli będziemy chcieli policzyć średnie dzienne wydatki (a będziemy chcieli) to napotkamy na problem typu pięć zakupów po 20 zł w ciągu dnia. Uśredniając to wyjdzie nam, że średni dzienny wydatek to 20 zł. A przecież wydaliśmy stówę! Dlatego policzymy sumę wydaną każdego kolejnego dnia (zagregujemy dane do dni):
|
1 2 |
# łączne wydatki dzień po dniu wyciag_day = wyciag[['data_operacji', 'kwota_pln_float']].groupby('data_operacji').sum().reset_index() |
Mamy zebrane surowe dane, czas trochę je przygotować. Chociażby posortować zgodnie z czasem i rozbić datę na poszczególne składowe (feature engineering mocno ;-) – wyciągamy rok, miesiąc i dzień tygodnia):
|
1 2 3 4 5 6 7 8 |
# posortowanie po datach wyciag_day = wyciag_day.sort_values('data_operacji').reset_index(drop=True) # dodajemy składowe daty wyciag_day['data_operacji_year'] = wyciag_day.data_operacji.dt.year wyciag_day['data_operacji_month'] = wyciag_day.data_operacji.dt.month wyciag_day['data_operacji_day'] = wyciag_day.data_operacji.dt.day wyciag_day['data_operacji_wday'] = wyciag_day.data_operacji.dt.dayofweek + 1 # dni numerowane od 0 |
Teraz już możemy przejść do analizy.
Na początku zobaczmy ile wydawałem każdego kolejnego dnia. Uwaga – żeby chronić nieco swoją prywatność na obrazkach liczby będą zamazane albo zafałszowane.
|
1 2 3 4 5 6 7 8 |
# wydatki dzień po dniu f, ax = plt.subplots(figsize=(15, 6)) sns.scatterplot(data=wyciag_day, x='data_operacji', y='kwota_pln_float', ax=ax) plt.title("Wydatki dzień po dniu") plt.xlabel("Data") plt.ylabel("Suma wydatków") ax.set(xlim = (np.min(wyciag_day.data_operacji), np.max(wyciag_day.data_operacji))) plt.show() |
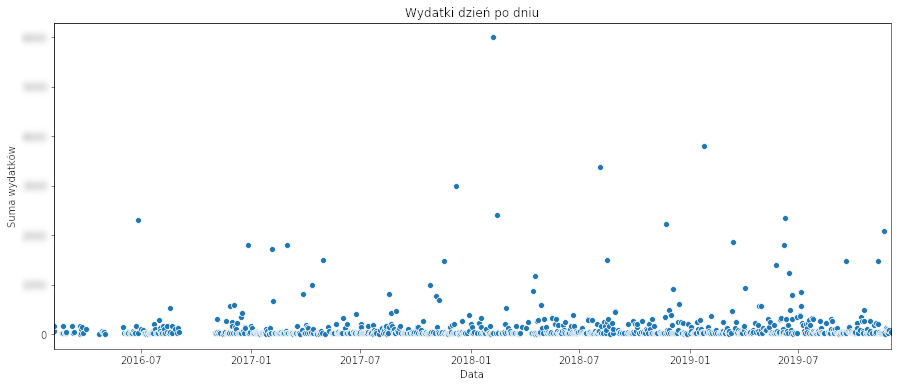
Jak widać z reguły wydaję mniej więcej tyle samo. Są oczywiście jakieś pojedyncze większe wydatki (zakupy sprzętu, wakacje).
Widać też jedną dziurę pod koniec 2016 roku. Okazuje się, że brakuje w tym miejscu wyciągów (i nie mam pojęcia dlaczego).
Zobaczmy skumulowane wydatki, czyli ile w sumie wydałem od początku.
|
1 2 3 4 5 6 7 8 9 |
# wydatki skumulowane wyciag_day['kwota_pln_float_cumsum'] = wyciag_day.kwota_pln_float.cumsum() f, ax = plt.subplots(figsize=(15, 6)) sns.lineplot(data=wyciag_day, x='data_operacji', y='kwota_pln_float_cumsum', ax=ax) plt.title("Wydatki dzień po dniu - narastająco") plt.xlabel("Data") plt.ylabel("Suma wydatków narastająco") plt.show() |
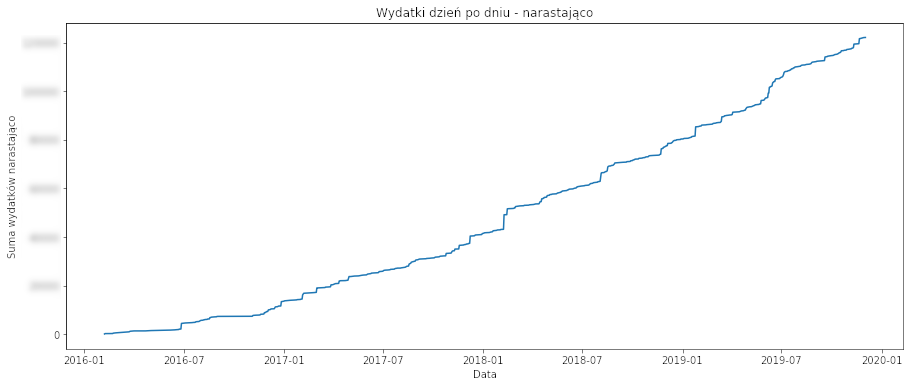
Linia rośnie, bo podczas wczytywania kolejnych wyciągów usunąłem wszystkie spłaty karty. A z takich danych można by przeprowadzić prostą regresję liniową. Ale to nie tym razem.
Czy jest jakiś pattern mówiący o tym, że w danym okresie wydaję więcej? Na przykład w podziale na dni tygodnia? Uśrednijmy więc dane według dni tygodnia i zobaczmy wynik na wykresie słupkowym:
|
1 2 3 4 5 6 7 8 9 |
# średnie wydatki wg dnia tygodnia wydatki_wday = wyciag_day[['data_operacji_wday', 'kwota_pln_float']].groupby('data_operacji_wday').mean().reset_index() f, ax = plt.subplots(figsize=(15, 6)) sns.barplot(data=wydatki_wday, x='data_operacji_wday', y='kwota_pln_float', ax=ax) plt.title("Średnie wydatki w zależności od dnia tygodnia") plt.xlabel("Dzień tygodnia") plt.ylabel("Średnia suma wydatków na dzień") plt.show() |
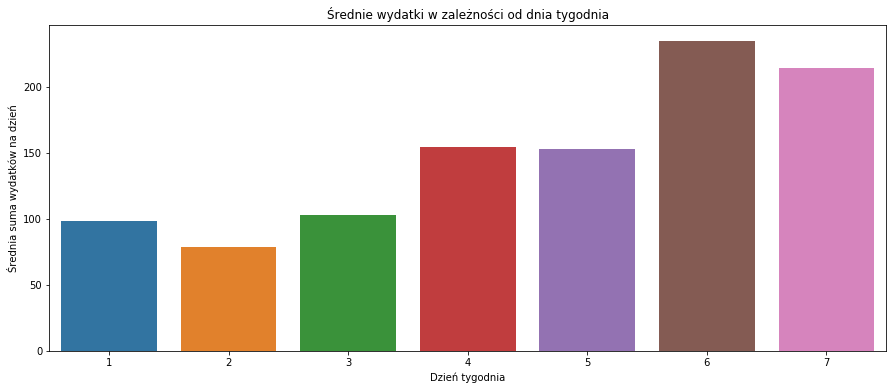
Dziwnym może być, że w sobotę wydaję najwięcej. Ale po chwili zastanowienia nie jest to wcale takie dziwne – w soboty głównie robię zakupy na cały (albo pół) kolejny tydzień. Takie z serii trzy wypchane po brzegi siaty (ja nie dam rady wszystkiego na raz z samochodu przynieść?)
|
1 2 3 4 5 6 7 8 9 |
# średnie wydatki w ciągu miesiąca wydatki_month = wyciag_day[['data_operacji_month', 'kwota_pln_float']].groupby('data_operacji_month').mean().reset_index() f, ax = plt.subplots(figsize=(15, 6)) sns.barplot(data=wydatki_month, x='data_operacji_month', y='kwota_pln_float', ax=ax) plt.title("Średnie wydatki miesięczne") plt.xlabel("Miesiąc") plt.ylabel("Średnia wydana kwota w ciągu dnia") plt.show() |
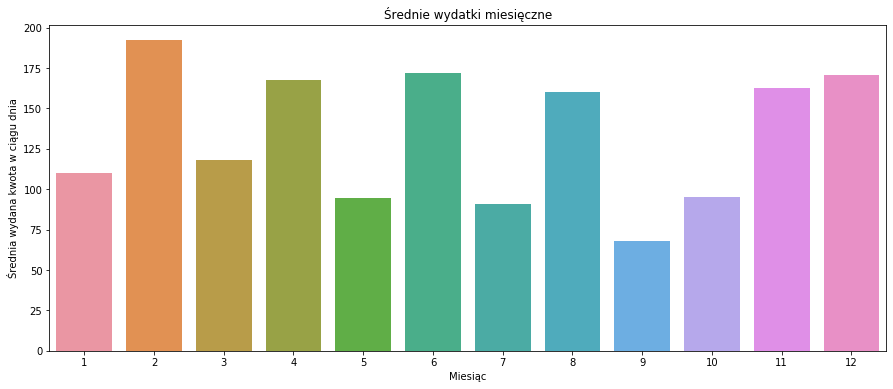
Ma to jakiś sens (znając moje wydatki), ale nie do końca jest poprawne. Dlaczego? W jednym roku na przykład w czerwcu planowałem wakacje, bukowałem hotele itd. I czerwiec jest wyższy. Ale w pozostałych latach tak wcale nie musiało być i wydatki były normalne. Czy uśrednienie wydatków dziennych po miesiącach pokaże nam, że w czerwcu zazwyczaj wydaję więcej? Trochę tak, ale trochę nie.
Zobaczmy łączne wydatki rok po roku:
|
1 2 3 4 5 6 7 8 9 |
# suma wydatków rok po roku wyciag_y = wyciag_day[['data_operacji_year', 'kwota_pln_float']].groupby('data_operacji_year').sum().reset_index() f, ax = plt.subplots(figsize=(15, 6)) sns.barplot(data=wyciag_y, x='data_operacji_year', y='kwota_pln_float', ax=ax) plt.title("Łączne wydatki roczne") plt.xlabel("") plt.ylabel("Suma wydatków w roku") plt.show() |
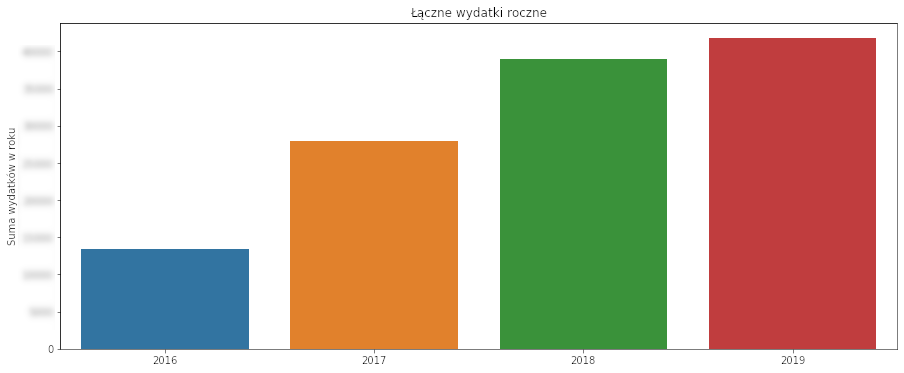
Wygląda na to że wydaję coraz więcej. Chyba czas zainteresować się jakimiś ograniczeniami ;)
Ale idąc tym samym tropem – policzmy sumę dla każdego miesiąca w kolejnych latach. Użyjemy do tego pivot_table() zamiast grupowania – wynik łatwo narysować z pomocą heatmap() z pakietu seaborn:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
# wydatki w roki i miesiącu wyciag_ym = wyciag_day.pivot_table(values='kwota_pln_float', index=['data_operacji_year'], columns=['data_operacji_month'], aggfunc=lambda x: math.sqrt(sum(x))) f, ax = plt.subplots(figsize=(15, 6)) sns.heatmap(wyciag_ym, ax=ax, linewidths=1, linecolor='white', cmap="OrRd") plt.title("Łączne wydatki miesięczne - rok po roku") plt.xlabel("Miesiąc") plt.ylabel("Rok") plt.show() |
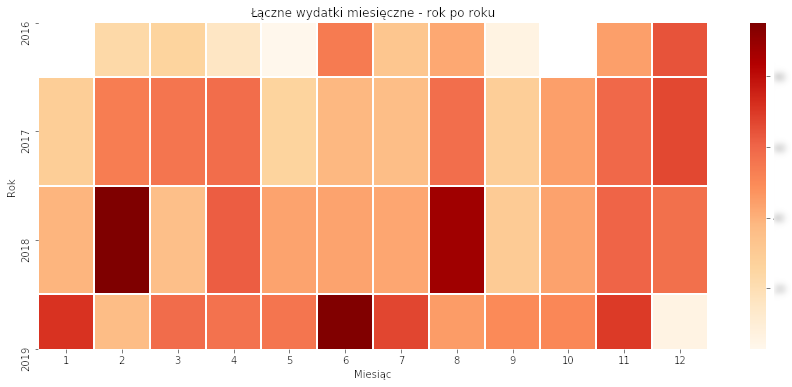
Tutaj wyraźnie widać w którym miesiącu płaciłem za wakacje. Zwróćcie uwagę (w kodzie), że nie są to sumy, a pierwiastki kwadratowe z sum. To zabieg na potrzeby zdynamizowania wykresu – aby większe (ale nawet nie jakoś bardzo) wydatki bardziej się wybijały. Sztuczka dobra, ale skala staje się przez to nieczytelna i trudniejsza w odbiorze. Lepszy na ogół jest logarytm dziesiętny – wówczas widać różnice na poziomie rzędów wielkości (10 a 100 i tak dalej), ale tutaj się nie sprawdziło. Wydatek dwa razy większy (np. 4 i 2 tysiące) po zlogarytmowaniu nie jest różnicą na poziomie 10 i 100.
Zobaczmy ile najczęściej wydaję jednorazowo, czyi jaki jest rozkład kwot poszczególnych wydatków:
|
1 2 3 4 5 |
# rozkład kwoty wydatków f, ax = plt.subplots(figsize=(7, 7)) ax.set(xscale="log") sns.distplot(wyciag.kwota_pln_float, ax=ax, hist=False, rug=False) plt.show() |
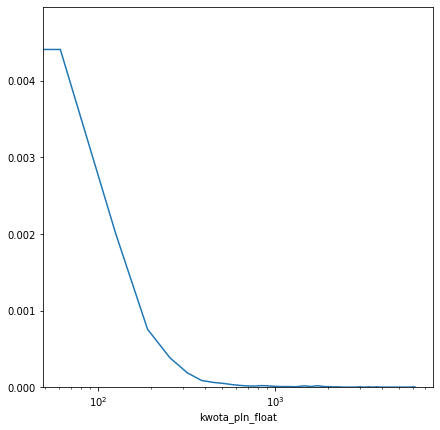
Jak można się się spodziewać najwięcej jest kwot stosunkowo małych (do 100 złotych). Tych większych jest bardzo małych (i co z tego, skoro najbardziej obciążają kieszeń?).
Ciekawszą analizą jest to u kogo zostawiamy swoje pieniądze. Policzmy więc u kogo ile w sumie, ile razy i jaka jest średnia wydatków:
|
1 2 3 4 |
# zliczamy u kogo i ile razy wydajemy wyciag['count'] = 1 wyciag_operacje = wyciag[['szczegoly_operacji', 'count', 'kwota_pln_float']].groupby(['szczegoly_operacji']).sum().sort_values('kwota_pln_float', ascending=False).reset_index() wyciag_operacje['mean_kwota'] = wyciag_operacje['kwota_pln_float'] / wyciag_operacje['count'] |
Najwięcej wydałem u… (kwoty prawdziwe, ale nazwy zmieniłem ręcznie):
|
1 |
wyciag_operacje[['szczegoly_operacji', 'kwota_pln_float']].head(20) |
| szczegoly_operacji | kwota_pln_float | |
|---|---|---|
| 0 | STACJA BENZYNOWA | 7933.02 |
| 1 | DUŻY ZAKUP | 5998.00 |
| 2 | CARREFOUR | 4814.83 |
| 3 | DUŻY ZAKUP | 4470.00 |
| 4 | DUŻY ZAKUP | 3748.00 |
| 5 | DUŻY ZAKUP | 3731.18 |
| 6 | WAKACJE | 3382.28 |
| 7 | AUCHAN | 3288.40 |
| 8 | GIOVANNI | 2720.30 |
| 9 | DUŻY ZAKUP | 2371.15 |
| 10 | BELLA PASTA | 2271.00 |
| 11 | DUŻY ZAKUP | 2183.83 |
| 12 | KOLPORTER | 2090.69 |
| 13 | DUŻY ZAKUP | 2050.00 |
| 14 | WAKACJE | 1840.38 |
| 15 | DUŻY ZAKUP | 1758.00 |
| 16 | POSMAKUJ | 1748.50 |
| 17 | DUŻY ZAKUP | 1732.00 |
| 18 | WAKACJE | 1716.05 |
| 19 | DUŻY ZAKUP | 1700.00 |
Najwięcej w sumie wydałem na benzynę. Później mamy codzienne zakupy w hipermarketach, kilka pojedynczych dużych wydatków, sporo miejsc do których chodzę na lunche. Dużą część zajmują też hotele czy inne miejsca związane z wakacjami.
Weźmy pod uwagę kilka często odwiedzanych miejsc i zobaczmy średnie wydatki w tych miejscach (tutaj odpuściłem sobie anonimizację – nie jest tajemnicą, że mieskam w Warszawie i pracuję w okolicach centrum):
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
sklepy = wyciag_operacje[wyciag_operacje.szczegoly_operacji.isin(['CARREFOUR', 'Spozywczy DZIADEK', 'POSMAKUJ', 'KAUFLAND'])] 'KOLPORTER', 'BELLA PASTA', 'GIOVANNI', 'STACJA BENZYNOWA', 'Sajgonki', 'PIEKARNIA&BISTRO', 'AUCHAN', 'ZABKA', 'STOKROTKA', 'BELLA PASTA LE DINH TUNG', sklepy[['szczegoly_operacji', 'mean_kwota']].sort_values('mean_kwota', ascending=False).head(20) |
| szczegoly_operacji | mean_kwota | |
|---|---|---|
| 0 | STAJCA BENZYNOWA | 214.405946 |
| 2 | CARREFOUR | 209.340435 |
| 7 | AUCHAN | 173.073684 |
| 62 | KAUFLAND | 89.180000 |
| 61 | STOKROTKA | 35.687000 |
| 49 | PIEKARNIA&BISTRO | 22.075000 |
| 22 | Spozywczy DZIADEK | 21.114237 |
| 10 | BELLA PASTA | 19.410256 |
| 116 | BELLA PASTA LE DINH TUNG | 19.055556 |
| 118 | ZABKA | 15.380909 |
| 12 | KOLPORTER | 15.260511 |
| 16 | POSMAKUJ | 14.570833 |
| 54 | Sajgonki | 14.310345 |
| 8 | GIOVANNI | 12.892417 |
Na paliwo wydaję średnio około 200 zł, podobnie na zakupy. Okazuje się, że Carrefour jest średnio droższy niż Auchan – na przestrzeni kilku lat aż tak bardzo mój średni koszyk zakupów się nie zmienił. Ale z drugiej strony – w Auchan kupowałem wcześniej, teraz raczej korzystam z Carrefour. Być może większa średnia ma związek z inflacją?
Dziadek to lokalny sklep tuż obok osiedla, gdzie wpada się po coś na szybko lub w drodze z pracy. Podobnie ze Stokrotką i Kauflandem – raczej nie robię tam często zakupów, a jeśli już to jakieś mniejsze (na jedną siatę ;). Kioski czy Żabka to głównie fajki, a cała reszta to lunchownie.
Znając poszczególne punkty i wiedząc gdzie dają lunch możemy zobaczyć coś więcej na ten temat:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
# kiedy gdzie chodziłem na lunch? lunch = wyciag[wyciag.szczegoly_operacji.isin(['WARSZAWA GIOVANNI CATERING', 'WARSZAWA POSMAKUJ 01', 'WARSZAWA BELLA PASTA', 'WARSZAWA BELLA PASTA LE DINH TUNG', 'Warszawa Sajgonki Bar-Restauracj', 'WARSZAWA PIEKARNIA&BISTRO'])] f, ax = plt.subplots(figsize=(15, 6)) sns.scatterplot(data=lunch, x='data_operacji', y='szczegoly_operacji') plt.title("Ile i kiedy u kogo wydałem?") plt.xlabel("") plt.ylabel("") plt.show() |
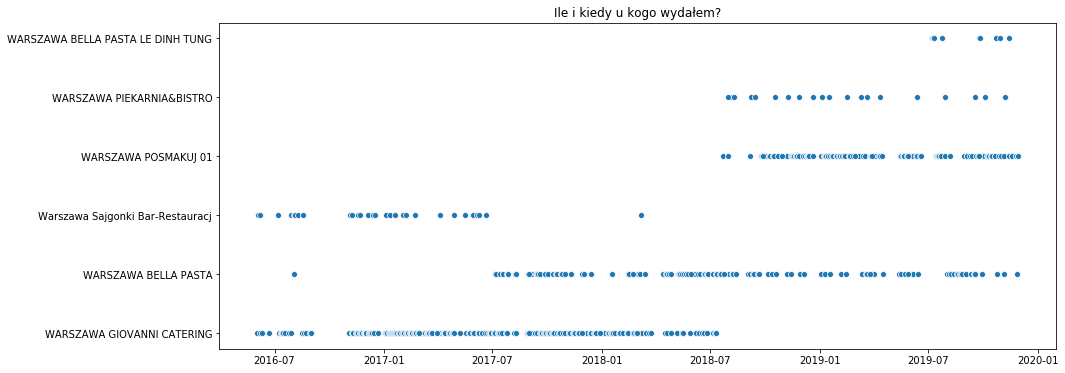
Osoby które pracują tu gdzie ja rozpoznają zmianę Giovani na Posmakuj w jednym z biurowców. Bella Pasta kiedyś była knajpą typu włoskiego i tam się nie stołowałem. Ale kiedy zaczęła być lepszym chińczykiem niż Sajgonki – przerzuciliśmy się z ekipą na to miejsce. Widać też, że Bella Pasta ma od jakiegoś czasu drugi terminal.
Swoją drogą ciekawostką jest to, że zmieniła się nazwa lokalu (bo to nie jest już dawno Bella Pasta) a nie zmienił identyfikatora terminala płatniczego…
Kolejna ciekawostka to ile średnio wydaję na lunch? A może nie tyle średnio, co najczęściej?
|
1 2 3 4 5 6 7 |
f, ax = plt.subplots(figsize=(15, 6)) sns.distplot(lunch[lunch['kwota_pln_float'] <= 30][['kwota_pln_float']], bins=120) plt.title("Ile najczęściej wydaję na lunch?") plt.xlabel("Cena lunchu") plt.ylabel("") plt.xticks(ticks= np.arange(0, 31, 1)) plt.show() |
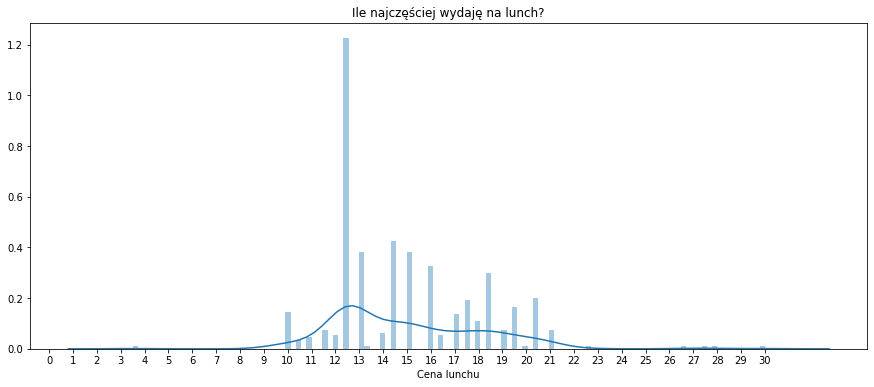
Widać ograniczenie kwoty do 30 zł już na początku. To dlatego, żeby odsiać sytuacje typu ja płacę a potem mi oddasz, które przecież się zdarzają. Widać też modę (najczęściej występującą wartość) na poziomie 12-13 złotych ale zdarzają się wyskoki za piętnastaka, 18-19 zł czy nawet ponad 20 zł. Gdzie? Dowiemy się z innego wykresu:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
# podzielenie na miejsca f, ax = plt.subplots(figsize=(15, 6)) sns.distplot(lunch[(lunch['kwota_pln_float'] <= 30) & (lunch['szczegoly_operacji'] == 'WARSZAWA GIOVANNI CATERING')][['kwota_pln_float']], hist=False, color="red", label="Giovani") sns.distplot(lunch[(lunch['kwota_pln_float'] <= 30) & (lunch['szczegoly_operacji'] == 'WARSZAWA POSMAKUJ 01')][['kwota_pln_float']], hist=False, color="green", label="Posmakuj") sns.distplot(lunch[(lunch['kwota_pln_float'] <= 30) & (lunch['szczegoly_operacji'] == 'WARSZAWA BELLA PASTA')][['kwota_pln_float']], hist=False, color="blue", label="Bella Pasta") sns.distplot(lunch[(lunch['kwota_pln_float'] <= 30) & (lunch['szczegoly_operacji'] == 'WARSZAWA BELLA PASTA LE DINH TUNG')][['kwota_pln_float']], hist=False, color="brown", label="Bella Pasta 2") sns.distplot(lunch[(lunch['kwota_pln_float'] <= 30) & (lunch['szczegoly_operacji'] == 'Warszawa Sajgonki Bar-Restauracj')][['kwota_pln_float']], hist=False, color="orange", label="Sajgonki") sns.distplot(lunch[(lunch['kwota_pln_float'] <= 30) & (lunch['szczegoly_operacji'] == 'WARSZAWA PIEKARNIA&BISTRO')][['kwota_pln_float']], hist=False, color="black", label="Pazzo") plt.title("Ile najczęściej wydaję na lunch?") plt.xlabel("Cena lunchu") plt.ylabel("") plt.xticks(ticks= np.arange(0, 31, 1)) plt.show() |
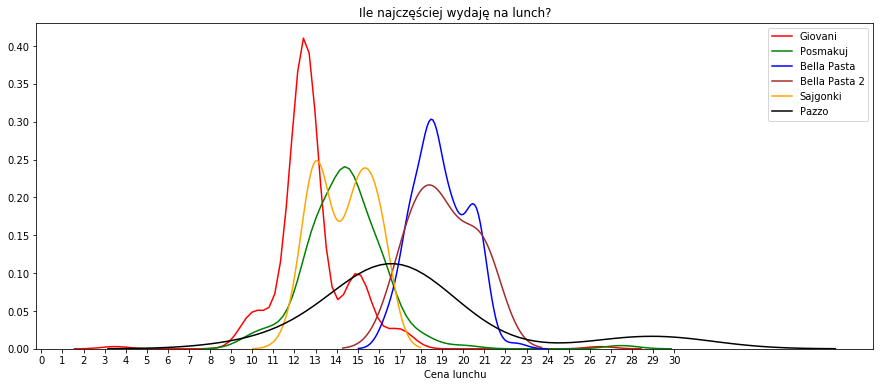
Bella Pasta i Bella Pasta 2 to ta sama knajpa, dwa różne terminale – prawie idealnie pokrywają się te krzywe. Okazuje się, że Giovani był tańszy niż Posmakuj dostępny w naszym biurowcu. Sajgonki były tańsze niż chińczyk występujący tutaj pod nazwą Bella Pasta, ale wierzcie mi – różnica w smaku warta jest tych kilku złotych.
No ładny wykres, ale ile się trzeba naklepać kodu żeby go dostać. Każda lokalizacja osobno, trzeba je znać przy pisaniu kodu. Można inaczej:
|
1 2 3 4 5 6 7 |
g = sns.FacetGrid(lunch[lunch['kwota_pln_float'] <= 30][['kwota_pln_float', 'szczegoly_operacji']], col='szczegoly_operacji', hue="szczegoly_operacji", palette="Paired", sharey=False, aspect=2, col_wrap=3) g = (g.map(sns.distplot, "kwota_pln_float", hist=True, bins=30).set_titles("{col_name}")) |
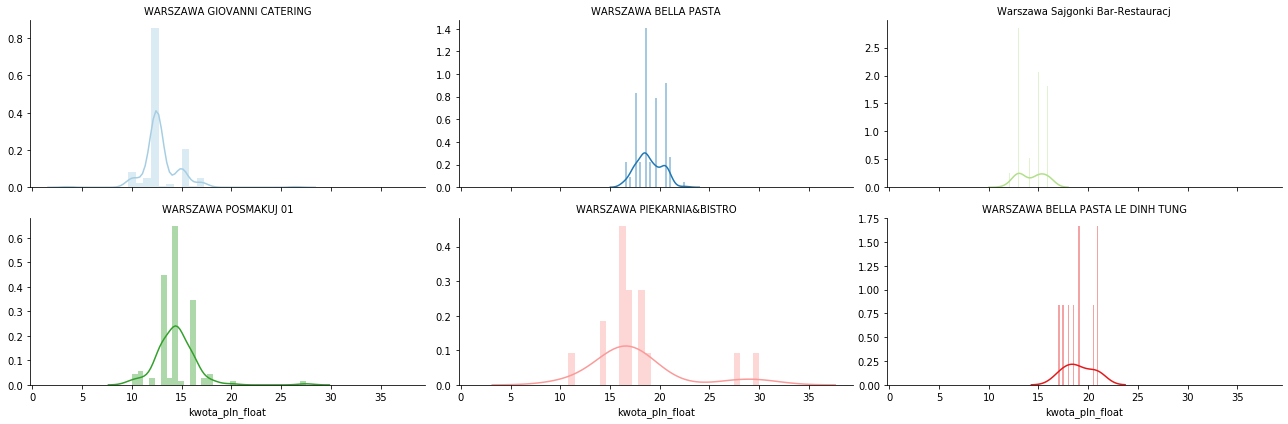
To tyle na dzisiaj. Wiecie teraz gdzie jadam i za ile. Oraz kiedy robiłem większe zakupy do domu albo jechałem na wakacje (precyzyjniej: kiedy płaciłem za nie).
Analiza własnych wydatków to bardzo dobra zabawa (może też przerazić), a na pewno dobra szkoła filtrowania, agregowania i rysowania danych. I o to właśnie w tym odcinku chodziło.
Świetny tekst , pracuję aktualnie nad zastosowaniem R w raportach dla księgowości , przykład z analizą wyciągu bardzo mi pomógł , dziękuję.
Oczywiście trzeba się było zareklamować mimo korzystania z darmowej wiedzy?
Dziękuję, że trafiłam na takie praktyczne podejście do analizy. Lubię życiowe rzeczy, które odrazu mogę wprowadzić.
Rzadko kiedy komentuje, ale trafiłeś w sedno. Zagłębie się w dalsze posty.
Sama zdobywam wiedzę na temat analizy i to mnie strasznie fascynuje.