Niedawno Ministerstwo Cyfryzacji opublikowało listę najpopularniejszych imion nadawanych dzieciom w 2018 roku. Wykorzystamy to do połączenia Pythona z R (albo R z Pythonem).
Lista opublikowana została w postaci serii tekstów na stronach Ministerstwa, w formie całkowicie niezjadliwej. Co więcej – prasa podała informacje dalej, bez żadnego obrobienia tych danych. Zróbmy to więc jak należy przy okazji łącząc R i Pythona.
Aby móc w RStudio używać Pythona oraz mieć dostęp do obiektów Pythona w sesji R potrzebujemy biblioteki reticulate – polecam się z nią zapoznać. Daje ciekawe możliwości, które właśnie za chwilę zobaczymy na konkretnym przykładzie.
|
1 |
library(reticulate) |
Cały poniższy kod (i tekst) przygotowane są w ramach dokumentu RMarkdown, dzięki czemu w odpowiednich blokach łączymy dwa języki. Magia.
Do prostych operacji, przygotowania tabel i wykresów wykorzystamy po stronie R:
|
1 2 3 |
library(tidyverse) library(knitr) library(kableExtra) |
Z poziomu Pythona potrzebne będą:
|
1 2 3 4 5 6 7 8 9 |
# wyrażenia regularne import re # webscrapping import requests from bs4 import BeautifulSoup as bs # do manipulacji danymi w ramach DataFrame import pandas as pd |
Pierwsza rzecz to zebranie danych z przykładowego tekstu, a ponieważ tekstów mamy więcej niż jeden (dokładnie 32 – każde województwo osobno, w dodatku w rozbiciu na chłopców i dziewczynki) przygotujemy odpowiednią funkcję, którą później wywołamy wielokrotnie. Tę cześć zrobimy w Pythonie:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 |
# funkcja wyciaga ze strony tabele z lista najpopularniejszych imion def get_names_list(url): # wczytaj i parsuj stronę page = requests.get(url) psoup = bs(page.content, 'html.parser') # poszukujemy konktetnego fragmentu strony - treści "artykułu" paraghaph = psoup.select('div.paragraph.article_section_content')[0] # pozbywamy się znaczników HTML, które nam nie będą potrzebne paraghaph = re.sub('<div class="paragraph article_section_content"><p>|</p></div>|</br>', '', str(paraghaph)) # <br> zmieniamy na entery paraghaph = re.sub('<.{0,1}br.{0,1}> ', '\n', paraghaph) # rozdzielamy linie do listy paraghaph = paraghaph.split('\n') # z listy tekstowej budujemy dataframe; "kolumny" są rozdzielone " - " data = pd.DataFrame([x.split(' - ') for x in paraghaph]) # nazywamy kolumny data.columns = ['imie', 'liczba'] # wartosci liczbowe zapisane jako string zamieniamy na liczby całkowite data['liczba'] = data['liczba'].astype(int) # dodajemy kolumnę z informacją o płci i wojewodztwie - na podstawie fragmentu urla # wydobywamy z urla odpowiednie ciągi url_match = re.match('.*/najpopularniejsze-imiona-dla-(.*)-2018-woj-(.*)', url) # dodajemy kolumny data['plec'] = url_match.group(1) data['wojewodztwo'] = url_match.group(2) # funkcja zwraca dataframe return(data) |
Umiejąc wydobyć tekst dla jednego województwa i jednej płci potrzebujemy znać linki do wszystkich stron z danymi. Ich lista na szczęście jest na stronie, więc trzeba ją pobrać (to już poza funkcją).
|
1 2 3 4 5 6 7 8 9 10 11 12 |
# pobieramy zawartośc strony głównej links_page = requests.get("https://www.gov.pl/web/cyfryzacja/imiona") # pobieramy jej tresc content = links_page.content # parsujemy HTMLa soups = bs(content, 'html.parser') # znajdujemy wszystkie linki o odpowiedniej klasie # interesuje nas wartosc href text_hrefs = soups.find_all("a", class_="lfr-nav-item", href=True) |
Te cztery linijki kodu spowodują, że w tabeli text_hrefs znajdziemy wszystkie potrzebne nam linki. A nawet nieco więcej.
Teraz przygotujemy jedną dużą ramkę (DataFrame w Pandas) zawierającą to co zwróci nam przygotowana wcześniej funkcja get_names_list(). Po prostu dla każdego linku do strony z wynikiem dla województwa (i płci) pobierzemy dane i zapiszemy w tablicy tymczasowej. Na koniec tablicę tymczasową dołączymy do pełnych danych. I tak w kółko, dopóki są jakieś linki:
|
1 2 3 4 5 6 7 8 9 10 11 |
# pusta ramka danych names = pd.DataFrame() # dla każdego linku zebranego wcześniej for i in text_hrefs: # sprawdzamy czy w adresie wystepuje "ogolnopolski" if re.search('ogolnopolski', i['href'], flags=0) == None: # jeśli nie to pobieramy ranking w postaci dataframe tmp = get_names_list(i['href']) # i dolaczamy do pełnych danych names = names.append(tmp) |
W efekcie mamy DataFrame z 6894 wierszami, a w sumie co najmniej 397478 urodzonych dzieci. Co najmniej, bo ze względu na ochronę danych osobowych nie ma na liście imion, które pojawiły się tylko raz w danym województwie.
W tym miejscu można dane z Pythona zapisać na dysku (np. jako plik CSV), a następnie wciągnąć do R i tam poddać dalszej obróbce. Ale mieliśmy łączyć, a nie dzielić. Ideą tego postu jest też jak najwięcej zrobić w Pythonie, a w R tylko prezentację wyników.
Na początek poszukajmy najpopularniejszych imion w skali całego kraju. Zacznijmy od dziewczynek.
|
1 2 |
# najpopularniejsze imiona dziewczynek ogółem most_popular_girls = names[names['plec'] == 'dziewczynek'].groupby('imie').sum().sort_values('liczba', ascending = False).reset_index() |
Odpowiednie fragmenty powyższego wyrażenia po kolei robią:
- names[names[‘plec’] == ‘dziewczynek’] – wybieramy tylko dziewczynki z całej tabeli
- .groupby(‘imie’) – będziemy zliczać po imieniu
- .sum() – zliczanie w tym przypadku to suma
- .sort_values(‘liczba’, ascending = False) – sortujemy wynik
- .reset_index() – resetujemy indeks – interesują nas nowe kolumny, a nie indeksy tabeli
To samo robimy dla chłopców:
|
1 |
most_popular_boys = names[names['plec'] == 'chlopcow'].groupby('imie').sum().sort_values('liczba', ascending = False).reset_index()[:10] |
Zwróćcie uwagę na sam koniec: [:10] oznacza, że z powstałej tabeli bierzemy tylko 10 pierwszych wierszy.
Teraz weźmy obie tabelki do R i przygotujmy zgrabne tabelki (z pomocą pakietu kableExtra). Dostęp do obiektów Pythona w R zapewnia pakiet reticulate, a dostępne one (te obiekty) są w ramach R-owego obiektu py:
|
1 2 3 4 5 6 7 8 |
# zmienna Pythona most_popular_girls dostępna w R py$most_popular_girls %>% # tutaj wybieramy 10 pierwszych wierszy z poziomu R top_n(10, liczba) %>% # nadajemy ładne nazwy kolumnom set_names(c("Imię", "Liczba")) %>% kable(escape = FALSE) %>% kable_styling(bootstrap_options = c("striped", "hover", "condensed", "responsive")) |
| Imię | Liczba |
|---|---|
| ZUZANNA | 8862 |
| JULIA | 8463 |
| MAJA | 8027 |
| ZOFIA | 7928 |
| HANNA | 7718 |
| LENA | 7647 |
| ALICJA | 5757 |
| MARIA | 5440 |
| AMELIA | 5309 |
| OLIWIA | 5057 |
I to samo dla chłopców:
|
1 2 3 4 |
py$most_popular_boys %>% set_names(c("Imię", "Liczba")) %>% kable(escape = FALSE) %>% kable_styling(bootstrap_options = c("striped", "hover", "condensed", "responsive")) |
| Imię | Liczba |
|---|---|
| ANTONI | 9325 |
| JAKUB | 8905 |
| JAN | 8455 |
| SZYMON | 8234 |
| ALEKSANDER | 7323 |
| FRANCISZEK | 7093 |
| FILIP | 6406 |
| MIKOŁAJ | 6008 |
| WOJCIECH | 5860 |
| KACPER | 5433 |
Widzicie różnicę w obu kodach R? W pierwszym mówiliśmy wprost weź 10 wierszy z największą wartością kolumny liczba, w drugim pokazujemy całą tabelę. Ale wracając do przygotowania danych w Pythonie – w pierwszym przypadku dostaliśmy wszystkie imiona, a drugim końcowe [:10] ograniczyło ich liczbę do 10 elementów.
No dobrze, ale bezwzględne liczby nie mówią do końca prawdy. Jak w dwóch województwach mamy po 1000 nowych Jasiów i Antków to jeszcze popularność imienia zależy od udziału Antków i Jasiów w całej grupie chłopców. Zatem policzmy ile chłopców i dziewczynek urodziło się w każdym z województw:
|
1 2 |
# liczba dzieci w wojweodztwach children_by_woj = names.groupby(['plec', 'wojewodztwo']).sum().reset_index() |
.reset_index() już znamy, samo grupowanie też. Do tabel z poszczególnymi imionami dołączmy informacje o liczbie urodzonych chłopców i dziewczynek (taki zwykły LEFT JOIN):
|
1 2 3 4 5 |
# laczenie tabel names_woj = pd.merge(names, children_by_woj, on = ['wojewodztwo', 'plec']) # procent danego imienia w wojewodztwie names_woj['percent'] = 100 * names_woj['liczba_x'] / names_woj['liczba_y'] |
Teraz w tabeli names_woj mamy również informację względną (procent dzieci danej płci o danym imieniu w danym województwie). Wybierzmy te najpopularniejsze imiona (w podziale na płeć) dla każdego z województw:
|
1 2 |
# ktore imiona sa najpopularniejsze w danym wojewodztwie? most_popular_woj = names_woj.loc[names_woj.groupby(['plec', 'wojewodztwo'])['percent'].idxmax(), [ 'wojewodztwo', 'plec', 'imie', 'percent']] |
Tym razem mamy do czynienia z nieco inaczej zagmatwanym kodem. Można go podzielić na części:
- names_woj.groupby([‘plec’, ‘wojewodztwo’]) powoduje zgrupowanie
names_wojpo kolumnachpleciwojewodztwo - [‘percent’] powoduje wybranie tylko tej jednej kolumny
- .idxmax() zwróci nam indeksy wierszy o największej wartości w ramach grupy
Do tego miejsca mamy indeksy (numery wierszy) z całej tabelki. Teraz poprzez
- names_woj.loc[…, [ ‘wojewodztwo’, ‘plec’, ‘imie’, ‘percent’]] – wybieramy wiersze wg indeksów (wcześniejsze instrukcje wpadną w miejsce …) i wskazane wprost kolumny
To samo w R (wspomaganym dplyr) można osiągnąć w bardziej czytelny i zrozumiały (wg mnie) sposób:
|
1 2 3 4 5 |
py$names_woj %>% group_by(plec, wojewodztwo) %>% # grupowanie po płci i województwie top_n(1, percent) %>% # wiersz z największą wartością percent ungroup() %>% select(wojwodztwo, plec, imie, percent) |
lub bardziej wprost zapisując filtrowanie po największej wartości w grupie:
|
1 2 3 4 5 |
py$names_woj %>% group_by(plec, wojewodztwo) %>% # grupowanie po płci i województwie filter(percent == max(percent)) %>% # wiersz z największą wartością percent ungroup() %>% select(wojwodztwo, plec, imie, percent) |
Mając przygotowane tabelki w Pythonie możemy je pokazać w ładnie sformatowanej tabeli przygotowanej w R:
|
1 2 3 4 5 6 7 8 |
py$most_popular_woj %>% mutate(imie = sprintf("<strong>%s</strong> <em>(%.2f%%)</em>", imie, percent)) %>% select(-percent) %>% spread(plec, imie) %>% # nadajemy ładne nazwy kolumnom set_names(c("Województwo", "Najpopularniejsze imię chłopca<br/>(procent chłopców urodzonych w województwie)", "Najpopularniejsze imię dziewczynki<br/>(procent dziewczynek urodzonych w województwie)")) %>% kable(escape = FALSE) %>% kable_styling(bootstrap_options = c("striped", "hover", "condensed", "responsive")) |
| Województwo |
Najpopularniejsze imię chłopca (procent chłopców urodzonych w województwie) |
Najpopularniejsze imię dziewczynki (procent dziewczynek urodzonych w województwie) |
|---|---|---|
| dolnoslaskie | JAKUB (4.29%) | HANNA (4.77%) |
| kujawsko-pomorskie | ANTONI (4.81%) | ZUZANNA (4.79%) |
| lodzkie | ANTONI (4.92%) | ZUZANNA (4.86%) |
| lubelskie | SZYMON (5.33%) | ZUZANNA (5.02%) |
| lubuskie | ANTONI (5.79%) | HANNA (5.20%) |
| malopolskie | JAKUB (4.87%) | JULIA (4.87%) |
| mazowieckie | JAN (5.18%) | ZUZANNA (4.57%) |
| opolskie | JAKUB (4.70%) | HANNA (5.71%) |
| podkarpackie | SZYMON (5.59%) | ZUZANNA (5.35%) |
| podlaskie | JAKUB (4.47%) | ZUZANNA (4.62%) |
| pomorskie | JAKUB (4.18%) | ZUZANNA (4.37%) |
| slaskie | JAKUB (4.77%) | ZUZANNA (4.64%) |
| swietokrzyskie | ANTONI (5.57%) | MAJA (4.96%) |
| warminsko-mazurskie | ANTONI (4.61%) | ZUZANNA (5.00%) |
| wielkopolskie | ANTONI (4.69%) | ZOFIA (4.60%) |
| zachodniopomorskie | ANTONI (4.49%) | HANNA (5.31%) |
Robimy małą sztuczkę zlepiając dwie kolumny w jedną (i odpowiednio formatując jej zawartość w HTMLu – boldem piszemy imię, a w nawiasie kursywą procent dzieci o danym imieniu w ramach województwa i płci). Następnie rozsmarowujemy tabelkę długą nieco na szerokość, tak aby został jeden wiersz dla województwa i w osobnych kolumnach imiona chłopców i dziewczynek (już sformatowane z procentami).
Na koniec spróbujmy z wykresem. Wybierzmy teraz jedno imię i sprawdźmy jego popularność w poszczególnych województwach. Oczywiście (zgodnie z założeniami) dane wybieramy po stronie Pythona:
|
1 |
lukasze = names_woj[names_woj.imie == 'ŁUKASZ'] |
a prezentujemy po stronie R:
|
1 2 3 4 |
py$lukasze %>% arrange(wojewodztwo) %>% kable(escape = FALSE) %>% kable_styling(bootstrap_options = c("striped", "hover", "condensed", "responsive")) |
| imie | liczba_x | plec | wojewodztwo | liczba_y | percent |
|---|---|---|---|---|---|
| ŁUKASZ | 43 | chlopcow | dolnoslaskie | 14575 | 0.2950257 |
| ŁUKASZ | 34 | chlopcow | kujawsko-pomorskie | 10761 | 0.3159558 |
| ŁUKASZ | 25 | chlopcow | lodzkie | 12013 | 0.2081079 |
| ŁUKASZ | 45 | chlopcow | lubelskie | 10072 | 0.4467832 |
| ŁUKASZ | 9 | chlopcow | lubuskie | 4920 | 0.1829268 |
| ŁUKASZ | 57 | chlopcow | malopolskie | 20467 | 0.2784971 |
| ŁUKASZ | 69 | chlopcow | mazowieckie | 32245 | 0.2139867 |
| ŁUKASZ | 26 | chlopcow | opolskie | 4557 | 0.5705508 |
| ŁUKASZ | 27 | chlopcow | podkarpackie | 11379 | 0.2372792 |
| ŁUKASZ | 40 | chlopcow | podlaskie | 6265 | 0.6384677 |
| ŁUKASZ | 48 | chlopcow | pomorskie | 13651 | 0.3516226 |
| ŁUKASZ | 89 | chlopcow | slaskie | 22714 | 0.3918288 |
| ŁUKASZ | 10 | chlopcow | swietokrzyskie | 5276 | 0.1895375 |
| ŁUKASZ | 25 | chlopcow | warminsko-mazurskie | 7324 | 0.3413435 |
| ŁUKASZ | 52 | chlopcow | wielkopolskie | 20243 | 0.2568789 |
| ŁUKASZ | 31 | chlopcow | zachodniopomorskie | 8302 | 0.3734040 |
Zamiast tabeli możemy narysować prosty wykres słupkowy. ggplot2 z R daje (znowu: wg mnie) lepsze efekty mniejszym nakładem pracy, zatem wykres przygotujemy w R:
|
1 2 3 4 5 6 7 8 9 10 11 |
plot <- py$lukasze %>% arrange(percent) %>% mutate(wojewodztwo = fct_inorder(wojewodztwo)) %>% ggplot() + geom_col(aes(wojewodztwo, percent), fill = "orange") + coord_flip() + labs(title = "Popularność imienia Łukasz wśród dzieci urodzonych w 2018 roku", subtitle = "Na bazie informacji opublikowanych przez Ministerstwo Cyfryzacji", x = "", y = "Procent urodzonych w województwie chłopców") da_plot(plot) |
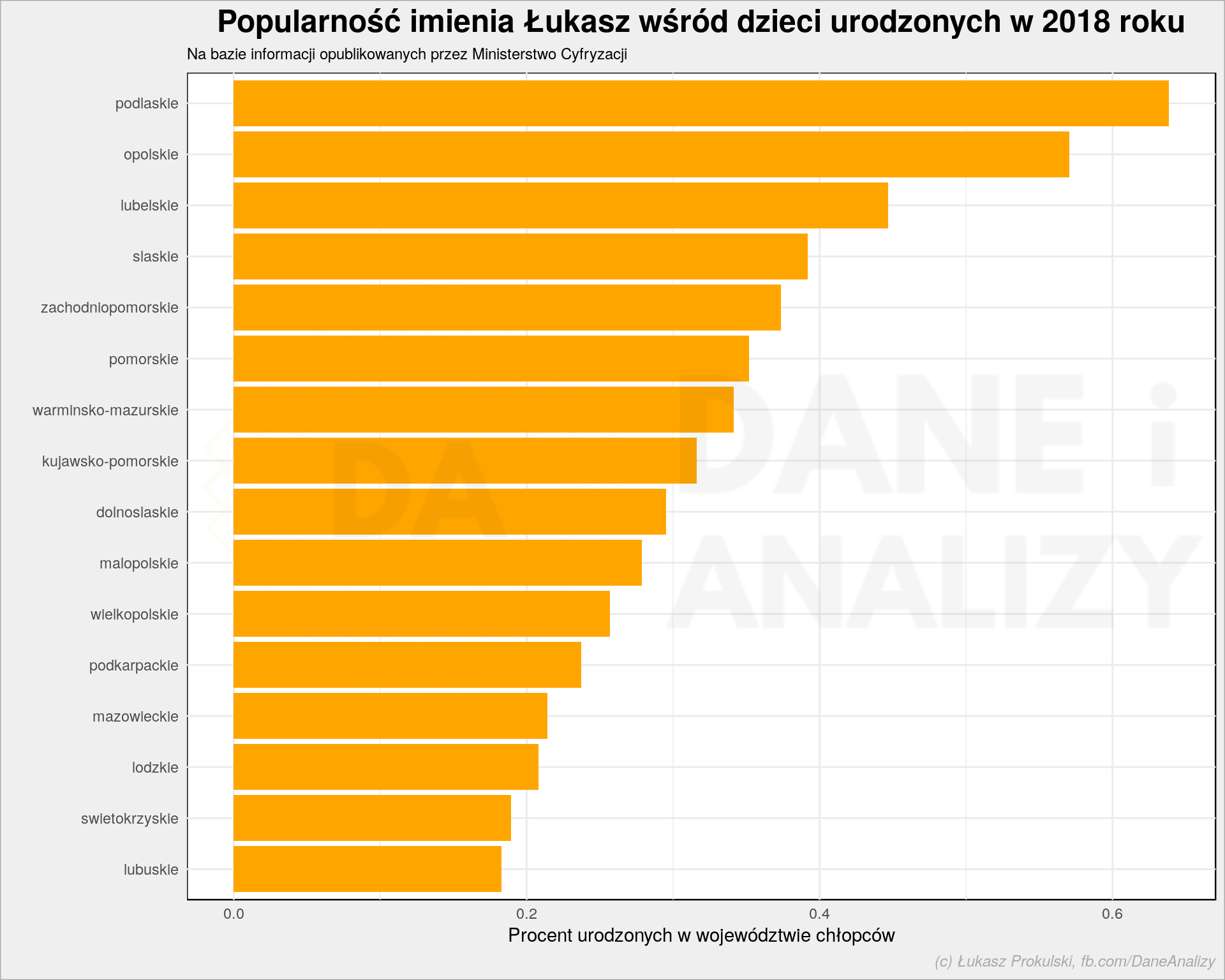
Logo Dane i Analizy oraz formatowanie wykresu dzieje się poza powyższym kodem (a mam taką funkcję, żeby wykresy wyglądały tak samo we wpisach i jeszcze żeby był na nich watermark).
To samo można zrobić w Pythonie, na przykład używając seaborn:
|
1 2 3 4 5 |
import seaborn as sns import matplotlib.pyplot as plt sns.barplot(x = 'percent', y = 'wojewodztwo', data = lukasze) plt.show() |
Problem tylko w tym taki, że nie udało mi się pokazać wykresu w RMarkdown bez zapisywania go do lokalnego pliku.
To wszystko na dzisiaj. Krótki wpis, ale mam nadzieję, że otwierający oczy na współpracę R z Pythonem. W przyszłości pewnie będzie więcej takich – swoją przygodę z Pythonem dopiero zaczynam.
Cieszę się, że na Twój blog wjechał Python :) BTW skąd czerpiesz wiedzę o Pythonie ? Czy są to głównie książki, czy może polecasz jakieś źródło wiedzy?
Głównie internet i analiza cudzych skryptów, zmienianie ich po kawałku i sprawdzanie co się stanie, jak zmienią się zmienne itp. Plus oczywiście dokumentacja pakietów.
Nie wiem czy istnieje lepszy sposób niż „learning by doing”