W jednym z ostatnich odcinków “Ucha prezesa” było coś o tym, że teraz rząd ma mówić o tym, że jest bezpiecznie (zamiast “Przez osiem lat Polki i Polacy…”). Sprawdzimy zatem bezpieczeństwo na polskich drogach. Ale punktem wyjścia będzie specyficzny sposób pokazania danych dziennych.
Widok kalendarza
Dane dzienne (takie, które mają jedną wartość dla każdego dnia – na przykład średnia temperatura, liczba osób robiących zakupy w sklepie) można pokazać na różne sposoby. Można pokazać je jako wykres punktowy (lub liniowy, kiedy punkty są połączone) – wówczas widać na przykład “falkę” (o ile są cykliczne, na przykład w weekendy jest mniej kupujących niż w tygodniu). Można policzyć średnie (lub zastosować inne miary agregujące) dla każdego dnia tygodnia i wykorzystać najprostszy (i często najlepszy) wykres słupkowy. A można pokazać to samo w formie swego rodzaju heat-mapy rozpiętej na kalendarzu.
Wykres taki ma sens jeśli chcemy pokazać, że w danym dniu tygodnia (i być może poszczególnych tygodniach roku) coś odbiega od normy z całego tygodnia (albo innych miesięcy). Czyli przykładowe weekendy są inne niż dni od poniedziałku do piątku.
Jeśli interesują Cię tylko wyniki przeglądu statystyk policyjnych – przejdź do analizy.
Jak zbudować taki kalendarz?
Wystarczy odpowiednio (jak zawsze ;) narysować kratki dla kolejnych dni i je pokolorować w zależności od wartości. Na osi poziomej potrzebujemy tygodni, na osi pionowej – dni tygodnia. Wszystko sprowadza się do określenia tygodnia w roku do którego należy konkretny dzień (na podstawie daty). Zróbmy to zatem w R.
Na początek przygotujemy losowe dane dla sporej liczby dni:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
library(tidyverse) library(lubridate) library(forcats) # słownik nazw miesięcy i dni nazwy_miesiecy <- c("Styczeń", "Luty", "Marzec", "Kwiecień", "Maj", "Czerwiec", "Lipiec", "Sierpień", "Wrzesień", "Październik", "Listopad", "Grudzień") nazwy_dni <- c("Poniedziałek", "Wtorek", "Środa", "Czwartek", "Piątek", "Sobota", "Niedziela") # losowe dane dane <- data.frame(date = seq(as.Date("2016-06-01"), as.Date("2018-07-31"), by="1 day")) # zakres dat dane$n <- rnorm(nrow(dane), mean = 10, sd = 2) # losowe wartości dla każdego dnia |
Żeby wyróżnić weekendy zmieńmy dane dla sobót i niedziel (niech będą mniejsze) i dla czwartków (większe):
|
1 2 3 4 5 |
dane <- dane %>% # w weekendy mniejsze wartości mutate(n = ifelse(wday(date) %in% c(1, 7), n/2, n)) %>% # w czwartki - większe mutate(n = ifelse(wday(date) == 5, 1.5*n, n)) |
Funkcja wday() z pakietu lubridate działa po amerykańsku: niedziela jest pierwszym dniem tygodnia, sobota ostatnim. Stąd 1 (niedziela) i 7 (sobota) w powyższym kodzie. Później poradzimy sobie z tym zmieniając dni na normalną, prawdziwie polską, kolejność w tygodniu.
Zacznijmy od najprostszego wykresu – słupkowego. Policzymy średnie dla każdego z dni tygodnia (pierwszy dzień to nadal niedziela):
|
1 2 3 4 5 6 7 |
dane %>% mutate(Weekday = wday(date)) %>% group_by(Weekday) %>% summarise(m_n = mean(n)) %>% ungroup() %>% ggplot() + geom_col(aes(Weekday, m_n), fill = "lightgreen", color = "gray50") |
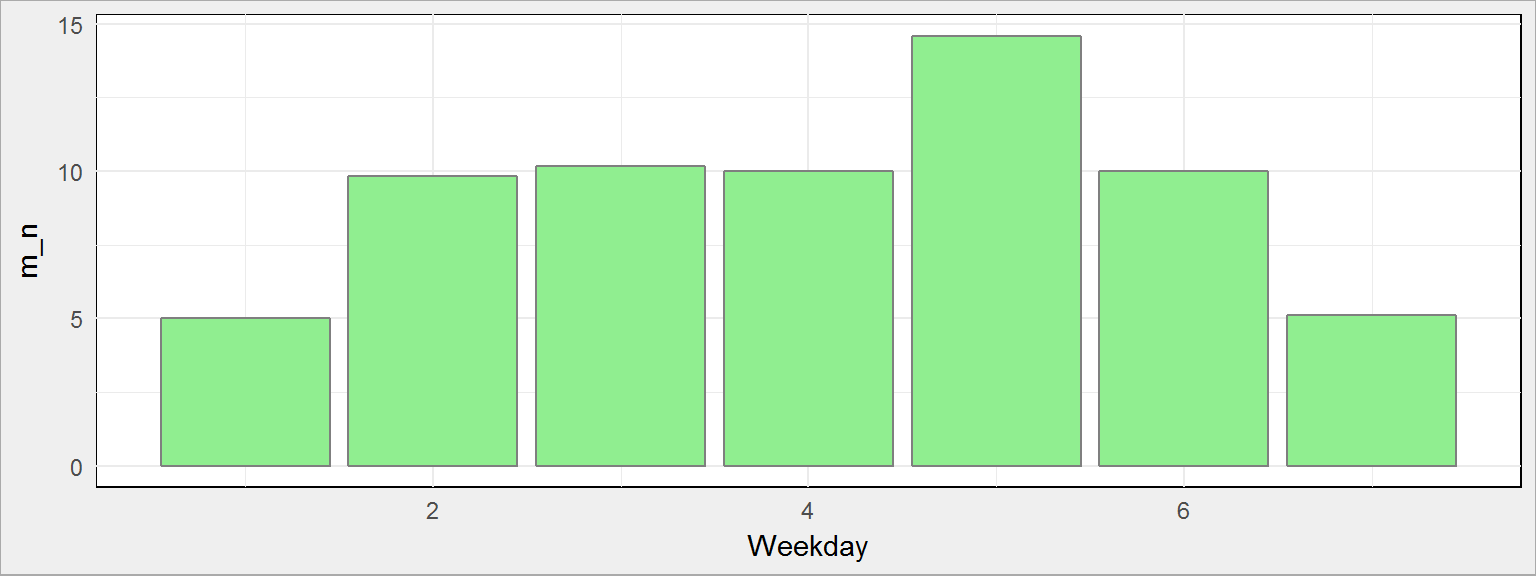
Widać, że słupki dla weekendu są niższe i dla czwartków większe – mamy to o co nam chodziło w przykładowych danych. Swoją drogą widać jak ładnie uśrednił się rozkład normalny dla poszczególnych dni.
Czas na wykres w formie kalendarza. Kolejne kroki opisane są w komentarzach do kodu:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
dane %>% mutate(Year = year(date), Month = month(date), Day = day(date)) %>% mutate(date = make_date(Year, Month, Day)) %>% # dzień tygodnia # -1 żeby zacząć od poniedziałku mutate(Weekday = wday(date) - 1) %>% # poprawka dla niedzieli (7 zamiast 0 po odejmowaniu wyżej) mutate(Weekday = ifelse(Weekday == 0, 7, Weekday)) %>% # pierwszy dzien miesiaca - jaki to dzien tygodnia? mutate(MONTH_FIRST_WDAY = wday(make_date(Year, Month, 1))) %>% # ktory numer tygodnia? - to będą kolumny mutate(MONTHWEEK = floor((Day - Weekday + MONTH_FIRST_WDAY)/7)+1) %>% # labelki dla miesięcy mutate(Month = factor(Month, levels = c(1:12), labels = nazwy_miesiecy)) %>% # labelki dla tygodni mutate(Weekday = factor(Weekday, levels = c(1:7), labels = nazwy_dni)) %>% # żeby skala Y była po kolei trzeba odwrócić kolejność faktorów mutate(Weekday = fct_rev(Weekday)) %>% # rysujemy ggplot() + geom_tile(aes(MONTHWEEK, Weekday, fill=n), color="grey50") + scale_fill_distiller(palette="RdYlBu") + facet_grid(Year~Month) + theme_minimal() + theme(axis.text.x = element_blank()) + labs(x="", y="") |
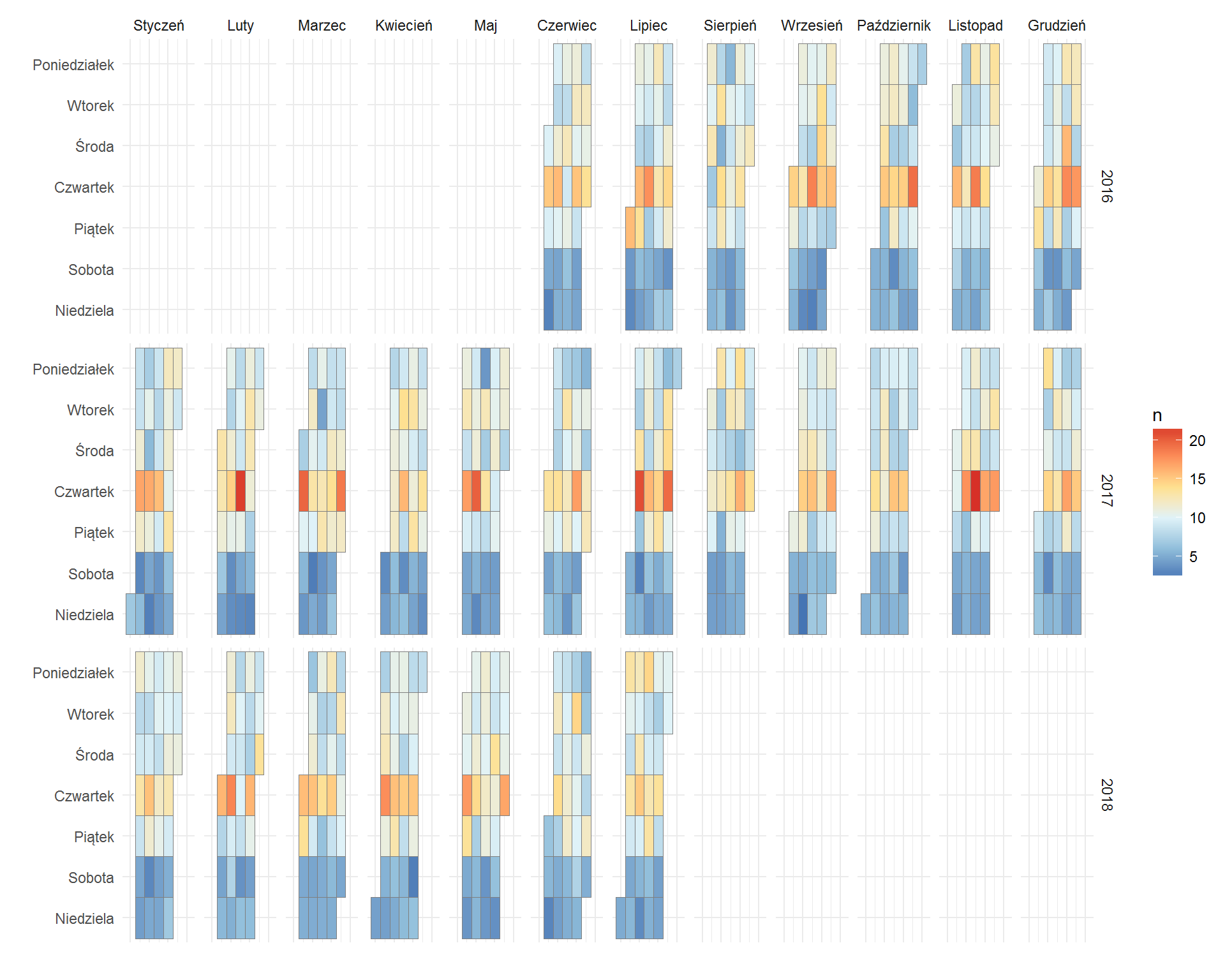
Widzimy efekt naszych prac:
- soboty i niedziele są bardziej niebieskie (według przyjętej skali kolorów mają mniejsze wartości)
- czwartki przechodzą w kierunku czerwieni (mają wartości większe)
Świetnie. Skoro wiemy jak to zrobić weźmy jakieś rzeczywiste dane i przeanalizujmy je w ujęciu czasowym. Fajne są
Statystyki policyjne
W sieci można znaleźć dane o przestępczości dla Chicago i Los Angeles. I są to świetne dane do nauki, zawierają między innymi informacje o:
- czasie (data i godzina) zajścia zdarzenia
- miejscu (współrzędne geograficzne, czasem adres)
- kategorii zajścia typu włamanie, napaść, kradzież
Na tych danych można nie tylko zrobić wykresiki gdzie i kiedy popełniane są jakieś przestępstwa, ale także próbować przewidywać wykroczenia w przyszłości i tym samym im zapobiegać. Bo skoro w nocy z piątku na sobotę w danej dzielnicy było zazwyczaj dużo pobić to warto posłać tam więcej partoli policyjnych. Zdaje się, że nawet były na te tematy konkursy na Kaggle.com.
Niestety polska rzeczywistość jest inna i dostęp do danych (bądź co bądź publicznych) nie jest taki prosty, musimy poradzić sobie inaczej. Mamy co prawda serwisy z danymi publicznymi – na przykład ogólnopolskie Dane publiczne i dane dla Warszawy, ale nie znalazłem informacji o rodzajach wykroczeń i miejscu ich popełnienia dla całego kraju (a nawet na poziomie komend wojewódzkich czy miejskich). Dla Warszawy mamy położenie komisariatów czy jednostek straży pożarnej – tylko co nam do daje? Niewiele. Może coś ciekawego jest w 19115 API?
Znalazłem za to stronę ze statystykami dziennymi (idealnie nadającymi się do widoku kalendarza, prawda? O to chodziło!), głównie dotyczącymi zatrzymań i wypadków. Skorzystamy z tych danych (jak to się mówi: z braku laku dobry kit) – znowu wykorzystując web scrapping. Poniższy kod to może być jeden oddzielny skrypt, który raz uruchomiony pobierze potrzebne nam informacje:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 |
library(tidyverse) library(rvest) library(lubridate) url <- "http://www.policja.pl/pol/form/1,Statystyki-dnia.html?page=" tabela <- tibble() # "bezpieczne" pobieranie - żeby pętla się nie zatrzymała w razie problemów safe_read_html <- purrr::safely(read_html) # pobieramy dane z kolejnych stron for(n_page in 0:214) { # czekamy, żeby oszczędzic serwer Sys.sleep(1) # pobranie zawartości strony (razem ze zbudowaniem odpowiedniego jej adresu) page <- safe_read_html(paste0(url, n_page), encoding = "UTF-8") # udało się pobrać stronę bez błędu? if(!is.null(page$result)) { # wyciagnięcie zawartości interesującej (pierwszej na stronie) tabeli tabela_tmp <- page$result %>% html_nodes("table.table-listing") %>% html_table() %>% .[[1]] # nazwy kolumn na takie bez spacji i polskich literek colnames(tabela_tmp) <- c("Data", "Zatrzymani_inflagranti", "Zatrzymani_poszukiwani", "Zatrzymani_nietrzezwi", "Wypadki_liczba", "Wypadki_zabici", "Wypadki_ranni") # datę zmieniamy na przyjazną do późniejszych przekształceń tabela_tmp$Data <- dmy(tabela_tmp$Data) # złączenie w jedną wielką tabelę danych z pojedynczych stron tabela <- tabela %>% bind_rows(tabela_tmp) } } # zapisujemy dane lokalnie saveRDS(tabela, file = "policja.RDS") |
Teraz możemy przygotować kolejny skrypt, który będzie odpowiedzialny za przygotowanie wykresów. Potrzebujemy tych samych pakietów co wcześniej (tidyverse zapewni nam załadowanie dplyr i ggplot2, dodatkowo przyda się lubridate i forcats). Dane zebrane z sieci wczytamy sobie z lokalnego pliku:
|
1 |
policja <- readRDS("policja.RDS") |
Sprawdźmy ile danych udało się pobrać:
|
1 |
max(policja$Data) - min(policja$Data) |
|
1 |
## Time difference of 3255 days |
|
1 |
nrow(policja) |
|
1 |
## [1] 3208 |
Różnica to około 50 dni (z ponad trzech tysięcy – to i tak 8 lat). Można poszukać jakich dni brakuje i je uzupełnić (na przykład wykonując web scrapping dla określonych stron raz jeszcze), można też odpuścić. Ja korzystam z tego drugiego rozwiązania, bo i tak dalej będziemy głównie uśredniać wartości (do średnich dla całego miesiąca).
Zanim coś porysujemy przygotujemy sobie dane do dalszej pracy:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
# krótsze labelki - zajmą mniej miejsca na wykresach nazwy_miesiecy <- c("Sty", "Lut", "Mar", "Kwi", "Maj", "Cze","Lip", "Sie", "Wrz", "Paź", "Lis", "Gru") nazwy_dni <- c("Pn", "Wt", "Śr", "Cz", "Pt", "Sb", "Nd") policja <- policja %>% mutate(Year = year(Data), Month = month(Data), Day = day(Data)) %>% mutate(Weekday = wday(Data) - 1) %>% mutate(Weekday = ifelse(Weekday == 0, 7, Weekday)) %>% mutate(MONTH_FIRST_WDAY = wday(make_date(Year, Month, 1))) %>% mutate(MONTHWEEK = floor((Day - Weekday + MONTH_FIRST_WDAY)/7)+1) %>% mutate(Month = factor(Month, levels = c(1:12), labels = nazwy_miesiecy)) %>% mutate(Weekday = factor(Weekday, levels = c(1:7), labels = nazwy_dni)) %>% # z 2008 roku są szczątkowe dane - usuniemy ten rok, podobnie jak dane z przyszłości (skąd ona?) filter(Year > 2008, Data < Sys.Date()) |
Poza ostatnią linią (filter()) wszystkie operacje przećwiczyliśmy z losowymi danymi dla przygotowanego widoku kalendarza.
Przejdźmy do analizy statystyk policyjnych.
Wypadki drogowe
Zaczniemy od widoku kalendarza:
|
1 2 3 4 5 6 7 8 9 10 |
policja %>% # żeby skala Y była po kolei trzeba odwrócić kolejność factora mutate(Weekday = fct_rev(Weekday)) %>% # rysujemy ggplot() + geom_tile(aes(MONTHWEEK, Weekday, fill = Wypadki_liczba), color = "grey80") + scale_fill_distiller(palette = "RdYlBu", direction = -1) + facet_grid(Year~Month) + theme(axis.text.x = element_blank()) + labs(x="", y="", title = "Liczba wypadków drogowych", fill = "Liczba\nwypadków") |

Widać bardzo delikatnie jaśniejszy niebieski dla letnich miesięcy (czerwiec – wrzesień), szczególnie do 2014 roku. Pojedyncze dni są mocno czerwone (ostatnia niedziela sierpnia 2009, początkowe poniedziałki w październiku tego samego roku) – mam wrażenie, że to jakieś błędy w danych. Można się ich pozbyć na przykład wartości odstające (np. określone jako średnia + trzy odchylenia standardowe; poniżej powinno być 99.7% danych) sprowadzając do wartości maksymalnej (czyli mean() + 3*sd()). Wartości można też zlogarytmować. Zobaczmy zatem:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
policja %>% mutate(Weekday = fct_rev(Weekday)) %>% # sprowadzenie wartości odstających w dół: mutate(Wypadki_liczba = ifelse(Wypadki_liczba > mean(Wypadki_liczba) + 3 * sd(Wypadki_liczba), mean(Wypadki_liczba) + 3 * sd(Wypadki_liczba), Wypadki_liczba)) %>% # rysujemy ggplot() + geom_tile(aes(MONTHWEEK, Weekday, fill = Wypadki_liczba), color = "grey80") + scale_fill_distiller(palette = "RdYlBu", direction = -1) + facet_grid(Year~Month) + theme(axis.text.x = element_blank()) + labs(x="", y="", title = "Liczba wypadków drogowych", fill = "Liczba\nwypadków") |
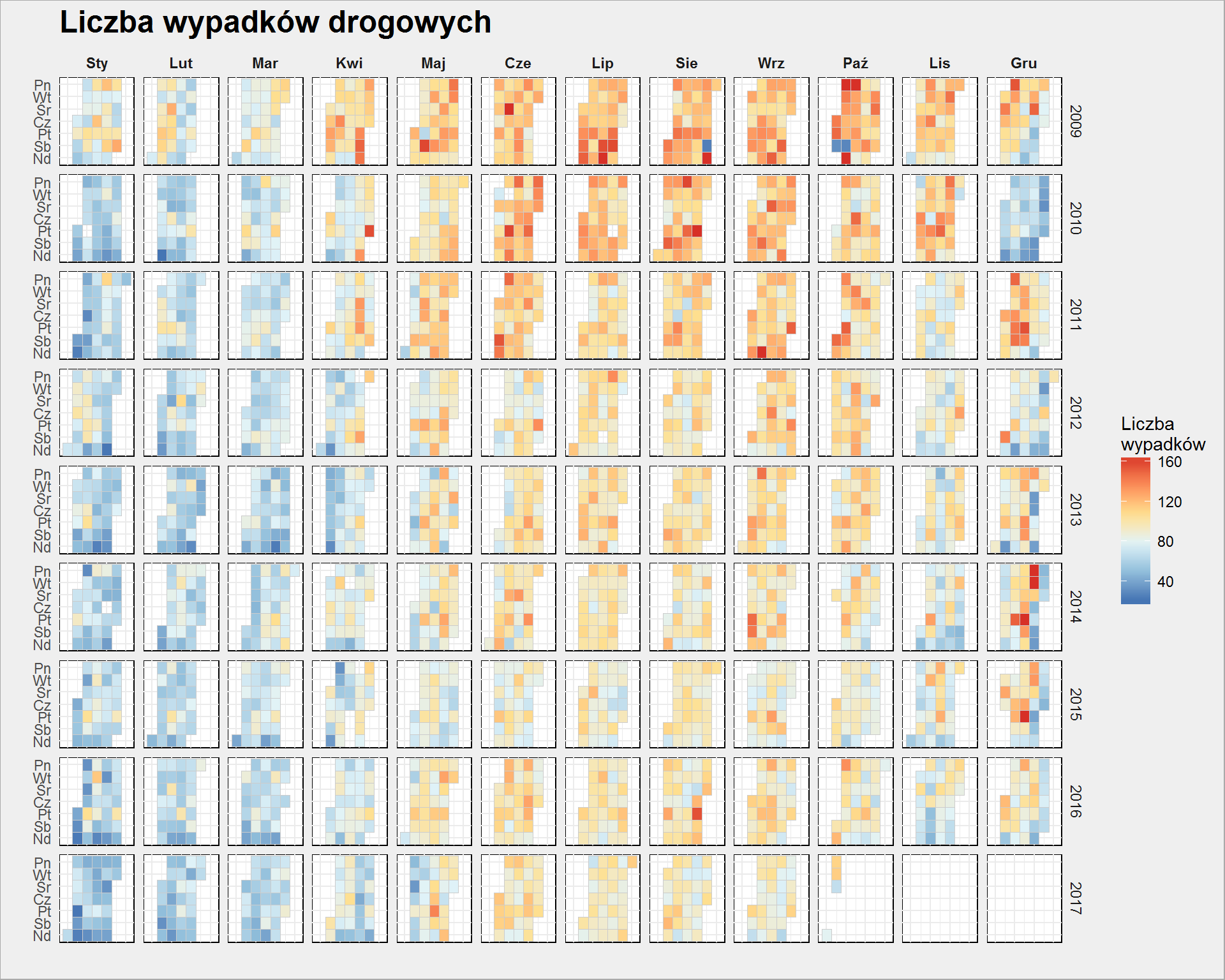
Dynamika kolorów od razu lepsza! Okolice Bożego Narodzenia (szczególnie w 2014) już wyglądają dość prawdopodobnie – większy ruch na drogach to i więcej wypadków. Podobnie widać Boże Ciało (zwróćcie uwagę na czwartki w maju i czerwcu kolejnych lat) czy Wielkanoc (weekendy w końcówkach marca i w kwietniu).
Zobaczmy (uśredniając wartości miesięcznie) czy jest jakaś sezonowość w ciągu roku. Trochę to widać już na powyższym wykresie, ale warto sprawdzić w innej formie:
|
1 2 3 4 5 6 7 8 9 |
policja %>% select(Year, Month, Wypadki_liczba) %>% group_by(Year, Month) %>% summarise_all(mean) %>% ggplot() + geom_line(aes(Month, Wypadki_liczba, group = Year, color = as.factor(Year))) + labs(title = "Liczba wypadków drogowych - średnie miesięczne", x = "", y = "", color = "Rok") + theme(axis.text.x = element_text(angle = 45, hjust = 0.5, vjust = 0.5)) |
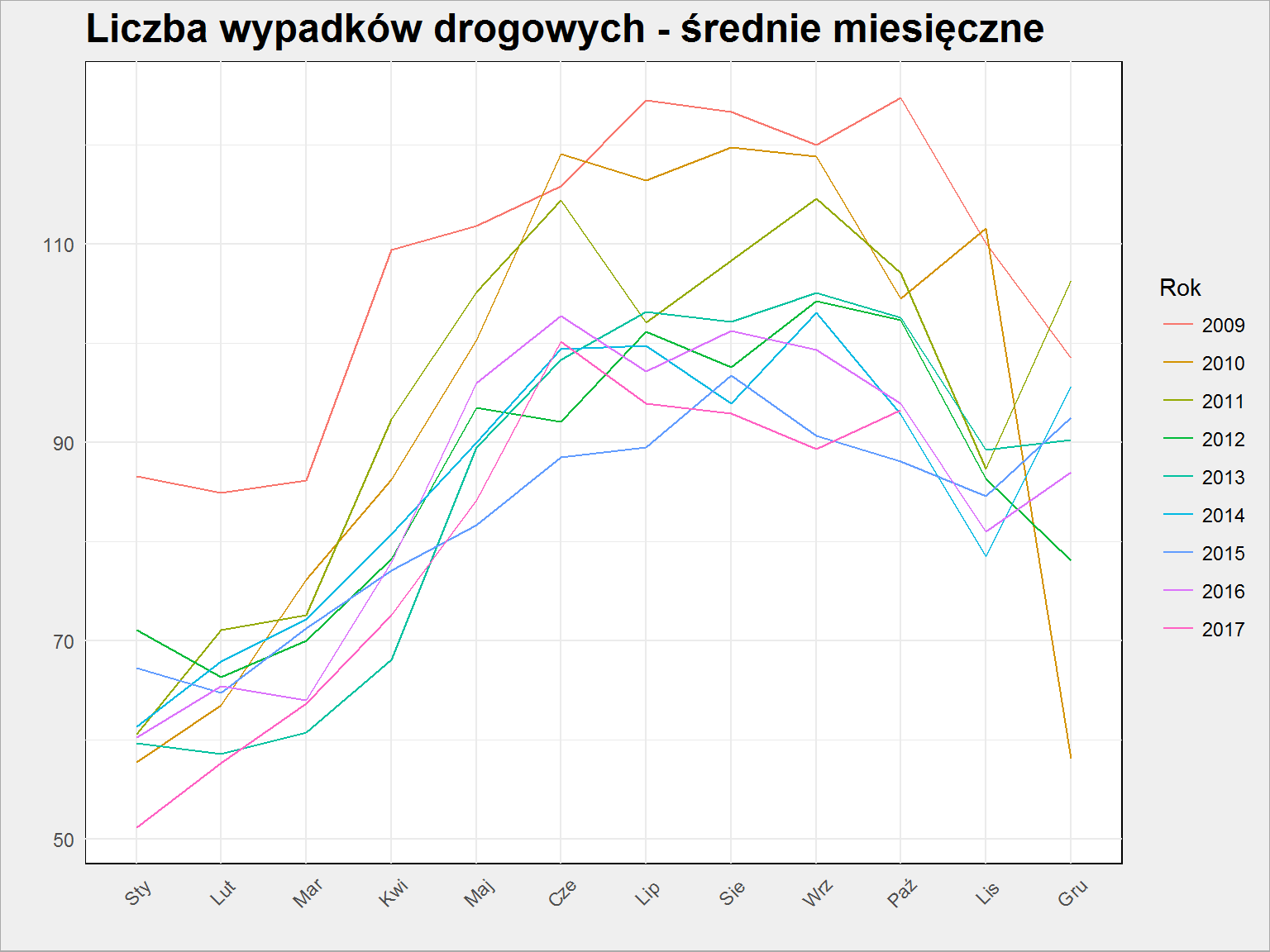
Mamy potwierdzenie wcześniejszej obserwacji: w cieplejszych miesiącach jest więcej wypadków. Widać też zmianę z roku na rok – linie nie są nałożone na siebie, rozpiętość dla lipca to różnica prawie 20 (średnio) wypadków dziennie!
Pokażmy to samo jeszcze inaczej, wykorzystując wykres słupkowy, gdzie każdy słupek to rok, a wszystko podzielone na kolejne miesiące:
|
1 2 3 4 5 6 7 8 9 |
policja %>% select(Year, Month, Wypadki_liczba) %>% group_by(Year, Month) %>% summarise_all(mean) %>% ggplot() + geom_col(aes(as.factor(Year), Wypadki_liczba), fill="#1a9850", color = "#4d4d4d") + facet_wrap(~Month) + labs(title = "Liczba wypadków drogowych - średnie miesięczne", x = "", y = "") + theme(axis.text.x = element_text(angle = 45, hjust = 0.5, vjust = 0.5)) |
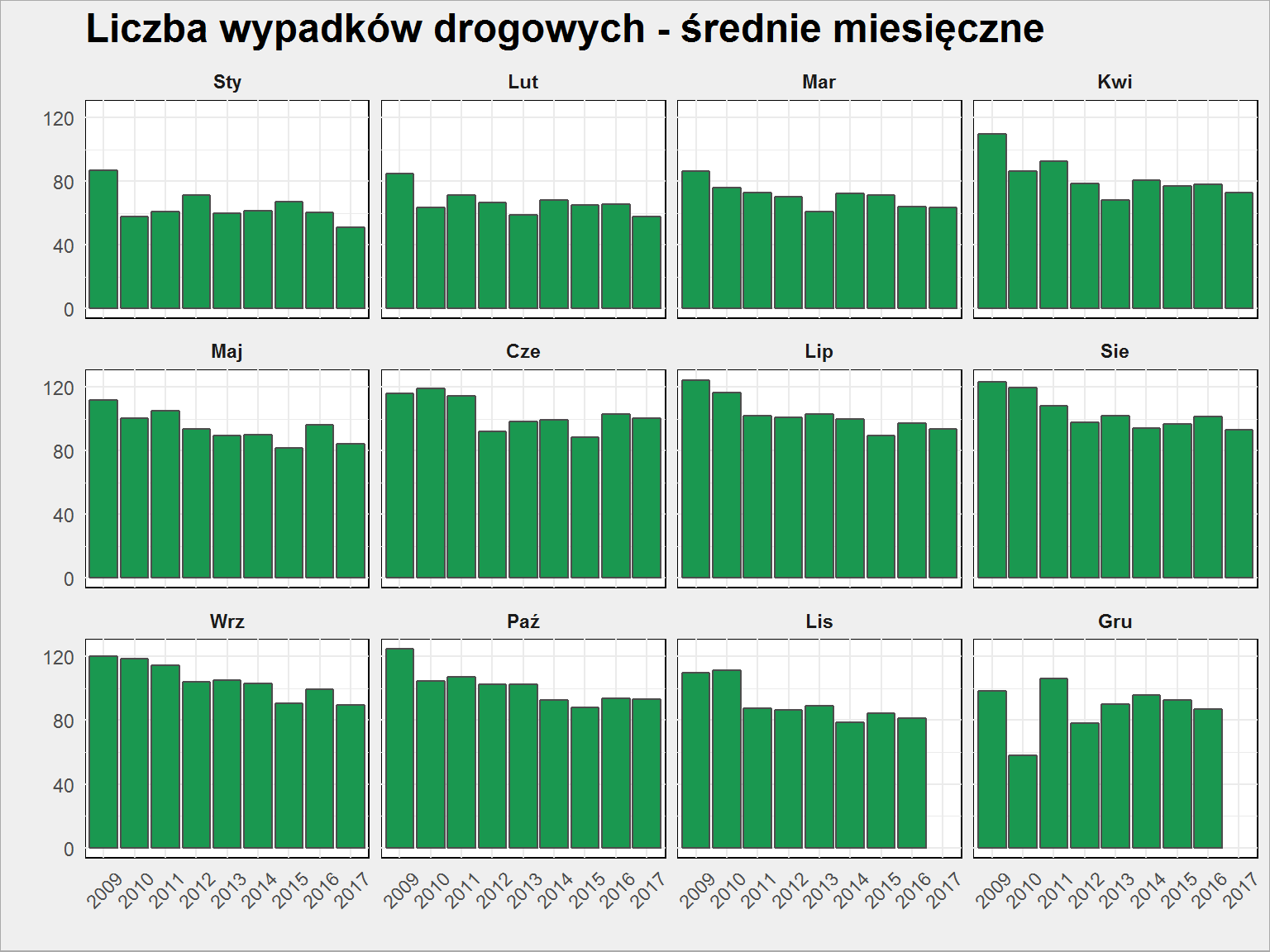
Dla większości miesięcy widać spadek z kolejnymi latami. Tam gdzie jest mniej wypadków (styczeń – marzec) różnica nie jest tak drastyczna, ale w okresach lipiec – listopad już widać wyraźną poprawę bezpieczeństwa na drogach.
Wypadki wypadkami, ale co z ofiarami wypadków? Ograniczymy się do wykresu słupkowego i linii trendu:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
# dwie tabelki - na potrzeby słupków i linii wypadki_zabici <- policja %>% mutate(Zabici = Wypadki_zabici/Wypadki_liczba) # słupki = dane zagregowane wypadki_zabici_miesiace <- wypadki_zabici %>% group_by(Year) %>% summarise(mZabici = mean(Zabici)) %>% ungroup() # wykres łączący obie tabele ggplot() + # pierwsza tabela - słupki geom_col(data = wypadki_zabici_miesiace, aes(make_date(Year, 1, 1), mZabici), fill="#1a9850", color = "#4d4d4d", alpha = 0.7) + geom_text(data = wypadki_zabici_miesiace, aes(make_date(Year, 1,1), 0.9*mZabici, label = sprintf("%.1f", 1/mZabici)), color = "black") + # druga tabela - punkty (wygładzone) geom_smooth(data = wypadki_zabici, aes(Data, Zabici), color = "blue", size = 2) + scale_x_date(date_breaks = "1 year", date_labels = "%Y") + labs(x= "Rok", y = "", title = "Wypadki drogowe z ofiarami śmiertelnymi", subtitle = "Liczba na słupku: na ile wypadków przypada jedna ofiara śmiertelna?") |
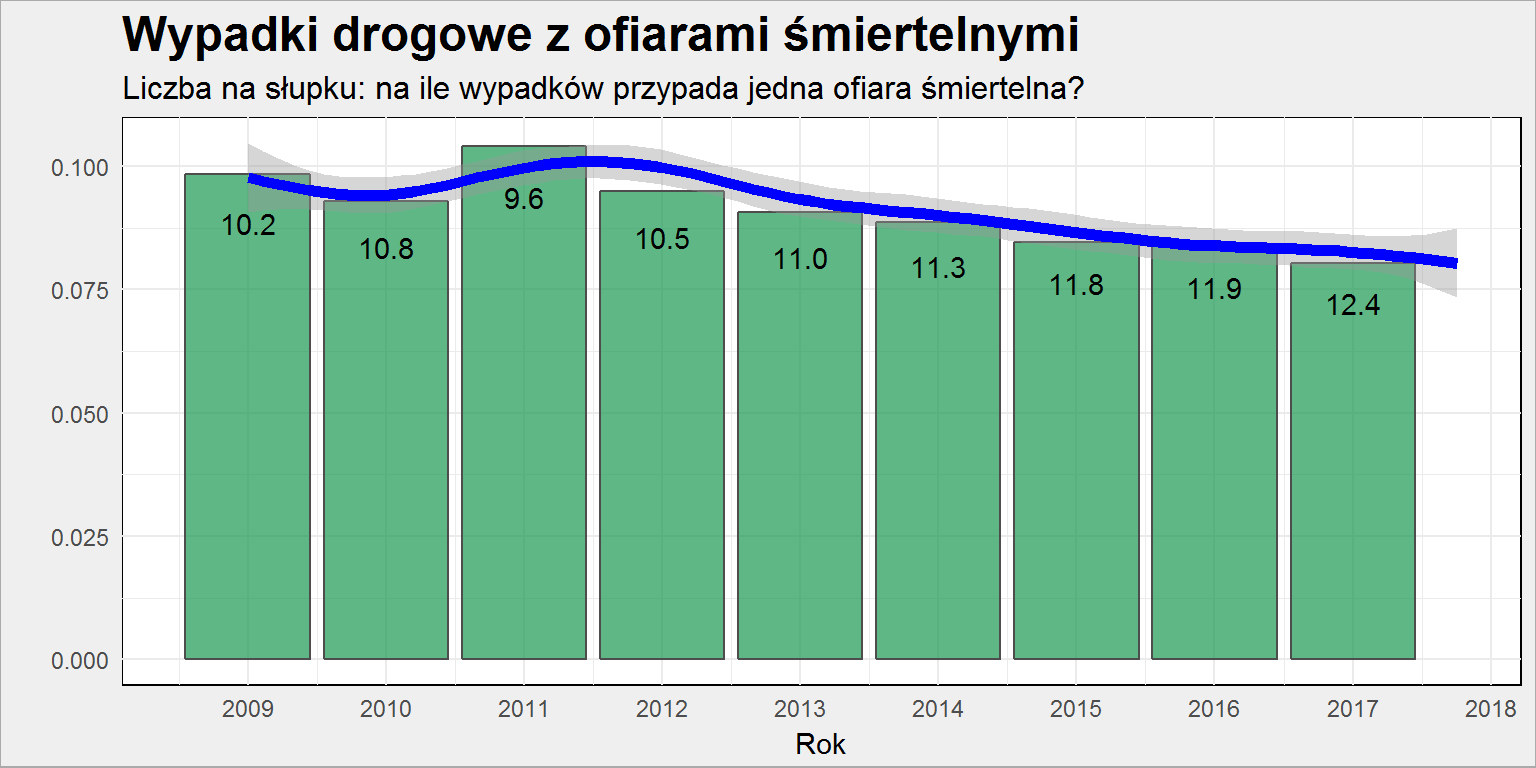
Wysokość słupka to średnia (ze wszystkich dni w roku) dla danego roku dla stosunku liczby zabitych do liczby wypadków, linia niebieska to trend dzień po dniu. Liczby na słupkach oznaczają co który wypadek mamy do czynienia z ofiarą śmiertelną (czyli jest odwrotnością wysokości słupka).
Na niebieskiej linii widać pocieszający trend: średnio w wypadkach ginie coraz mniej osób. Chociaż jedna ofiara na 12 wypadków (w 2017) to i tak sporo…
Sprawdźmy czy możemy mówić, że jest bezpieczniej biorąc pod uwagę liczbę rannych w wypadkach:
|
1 2 3 4 5 |
policja %>% mutate(Ranni = Wypadki_ranni/Wypadki_liczba) %>% ggplot() + geom_smooth(aes(Data, Ranni), color = "green") + labs(title = "Średnia liczba osób rannych w wypadku") |
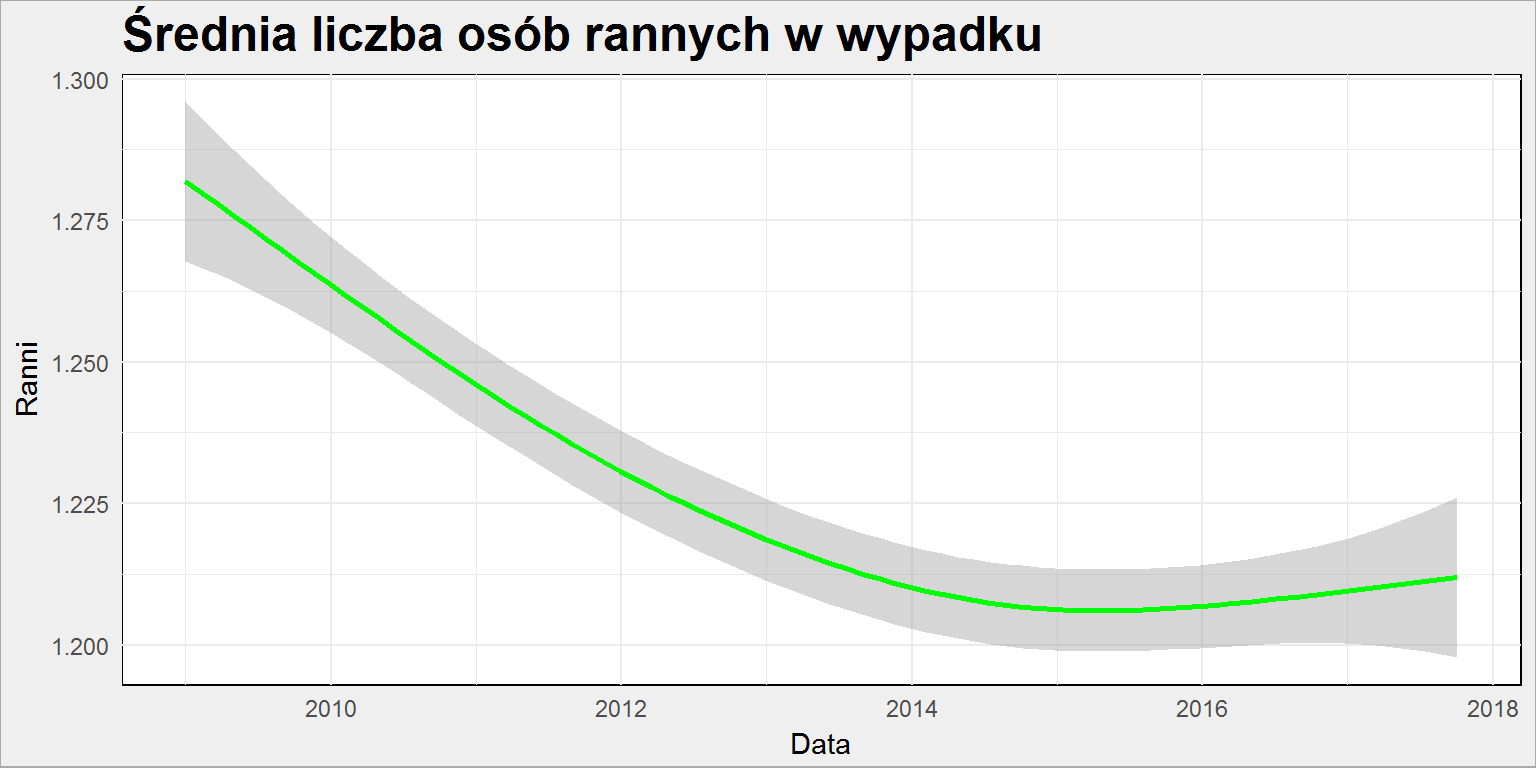
Tutaj też widać spadek (o około 4.7% pomiędzy 2009 a 2017). Zestawiając ze sobą wszystkie trzy parametry jakie przeanalizowaliśmy:
- liczbę wypadków (spada z roku na rok, szczególnie widać to w cieplejszych miesiącach)
- liczbę ofiar śmiertelnych (coraz rzadziej dochodzi do takich wypadków)
- liczbę rannych w wypadkach (spadek o wspomniane niecałe 5%)
możemy powiedzieć, że w ciągu ostatnich 8-9 lat bezpieczeństwo na drogach wzrosło.
Pytanie tylko kiedy? Kto nam to zapewnił? Patrząc na ostatni wykres widać, że krzywa wypłaszcza się po 2014 roku. Patrząc na wykresy słupkowe (Liczba wypadków w poszczególnych miesiącach ze słupkami rok po roku) wyraźny skok widać pomiędzy 2010 a 2011 rokiem (popatrzcie na lipiec albo listopad).
Komunikat dla prasy w wersji pierwszej: bezpieczeństwo znacznie poprawiło się pomiędzy 2010 a 2014 rokiem (upraszczając w stylu pasków z Wiadomości TVP: zasługa PO).
W 2016 słupki nieco podskoczyły i teraz znowu spadły. Można to również sprzedać jako sukces… Komunikat dla prasy w wersji drugiej: poprawiło się bezpieczeństwo na drogach w porównaniu do zeszłego roku (w domyśle: od kiedy rządzi PiS).
Oba prawdziwe, wszystko zależy od intencji. Idźmy jednak dalej.
Pijani na drogach
a konkretnie liczba zatrzymanych pijanych kierowców. Wróćmy na chwilę do wykresu kalendarzowego (obcinając wartości odstające, żeby nadać więcej dramatyzmu – tylko na potrzeby tego wykresu):
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
policja %>% mutate(Weekday = fct_rev(Weekday)) %>% # sprowadzenie wartości odstających w dół: mutate(Zatrzymani_nietrzezwi = ifelse(Zatrzymani_nietrzezwi > mean(Zatrzymani_nietrzezwi) + 3 * sd(Zatrzymani_nietrzezwi), mean(Zatrzymani_nietrzezwi) + 3 * sd(Zatrzymani_nietrzezwi), Zatrzymani_nietrzezwi)) %>% # rysujemy ggplot() + geom_tile(aes(MONTHWEEK, Weekday, fill = Zatrzymani_nietrzezwi), color = "grey50") + scale_fill_distiller(palette = "RdYlBu", direction = -1) + facet_grid(Year~Month) + theme(axis.text.x = element_blank()) + labs(x="", y="", title = "Liczba zatrzymanych pijanych kierowców", fill = "Liczba\nzatrzymanych") |

Czy coś Wam to przypomina? Jest podobnie jak na wykresie z liczbą wypadków: w latach przed 2014 mamy więcej czerwonego i żółtego, szczególnie w ciepłych miesiącach. Ale tutaj już wyraźniej widać weekendy, szczególnie latem (są bardziej czerwone od tygodni).
Zobaczmy czy liczba zatrzymanych nietrzeźwych zmieniła się w czasie:
|
1 2 3 4 |
policja %>% ggplot() + geom_smooth(aes(Data, Zatrzymani_nietrzezwi), color = "red") + labs(title = "Średnia liczba zatrzymych nietrzeźwych kierowców") |
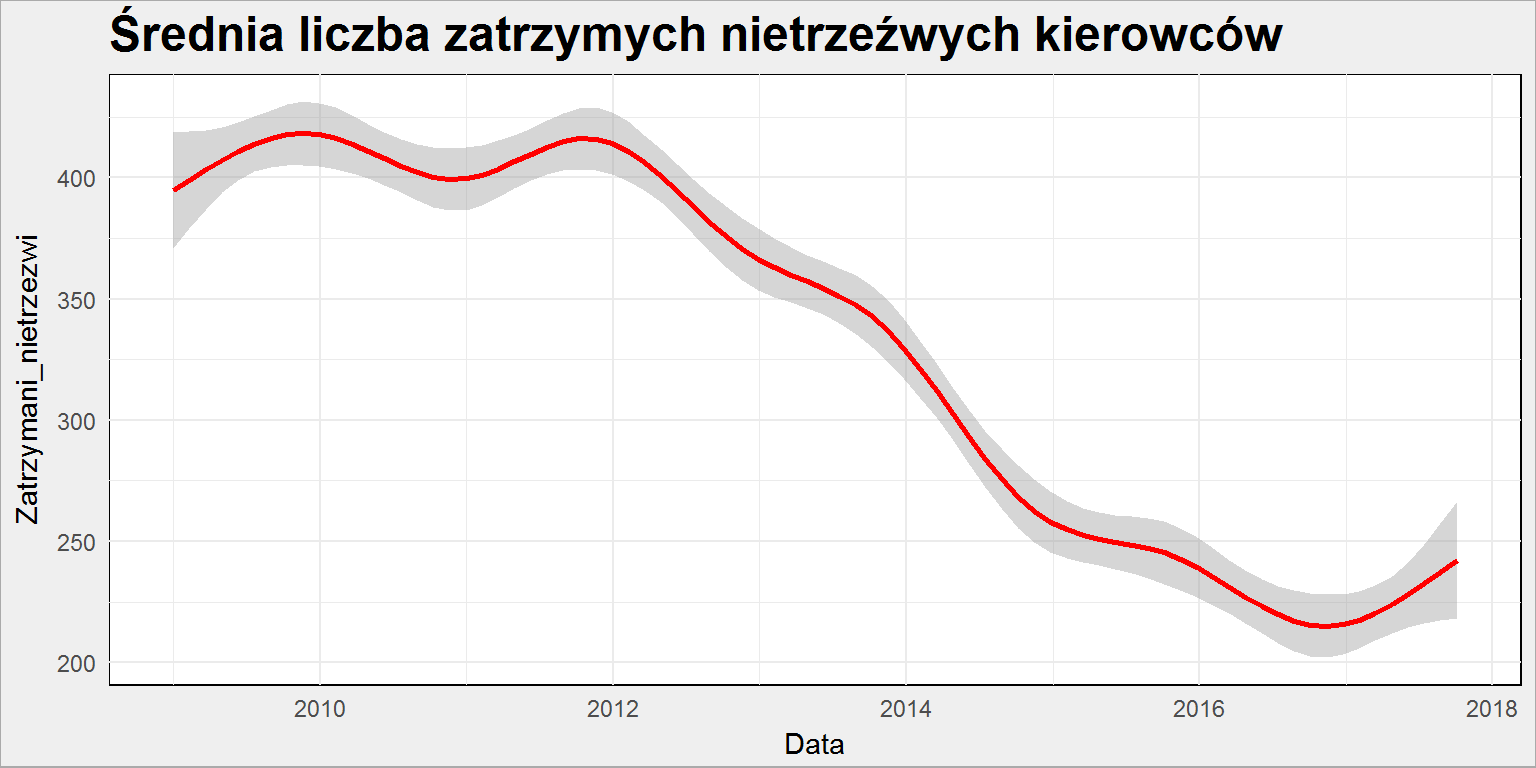
Pomiędzy 2012 a 2016 spadek o połowę! Ogromny sukces, jeździ dwa razy mniej pijanych kierowców! A może tylko dwa razy mniej jest zatrzymanych, bo patroli jest dwa razy mniej? Tego nie wiemy – nie mamy danych o liczbie kontroli… a szkoda. Spróbujmy coś wywnioskować z tego co mamy. Kiedy liczba pijanych za kółkiem zmalała? Taki wykres już widzieliśmy, dotyczył czegoś innego:
|
1 2 3 4 5 6 7 8 9 10 |
policja %>% select(Year, Month, Zatrzymani_nietrzezwi) %>% group_by(Year, Month) %>% summarise_all(mean) %>% ggplot() + geom_col(aes(as.factor(Year), Zatrzymani_nietrzezwi), fill="#1a9850", color = "#4d4d4d") + facet_wrap(~Month, ncol = 3) + theme(axis.text.x = element_text(angle = 45, hjust = 0.5, vjust = 0.5)) + labs(title = "Średnia liczba zatrzymanych nietrzeźwych kierowców\nw poszczególnych miesiącach", x = "", y = "") |
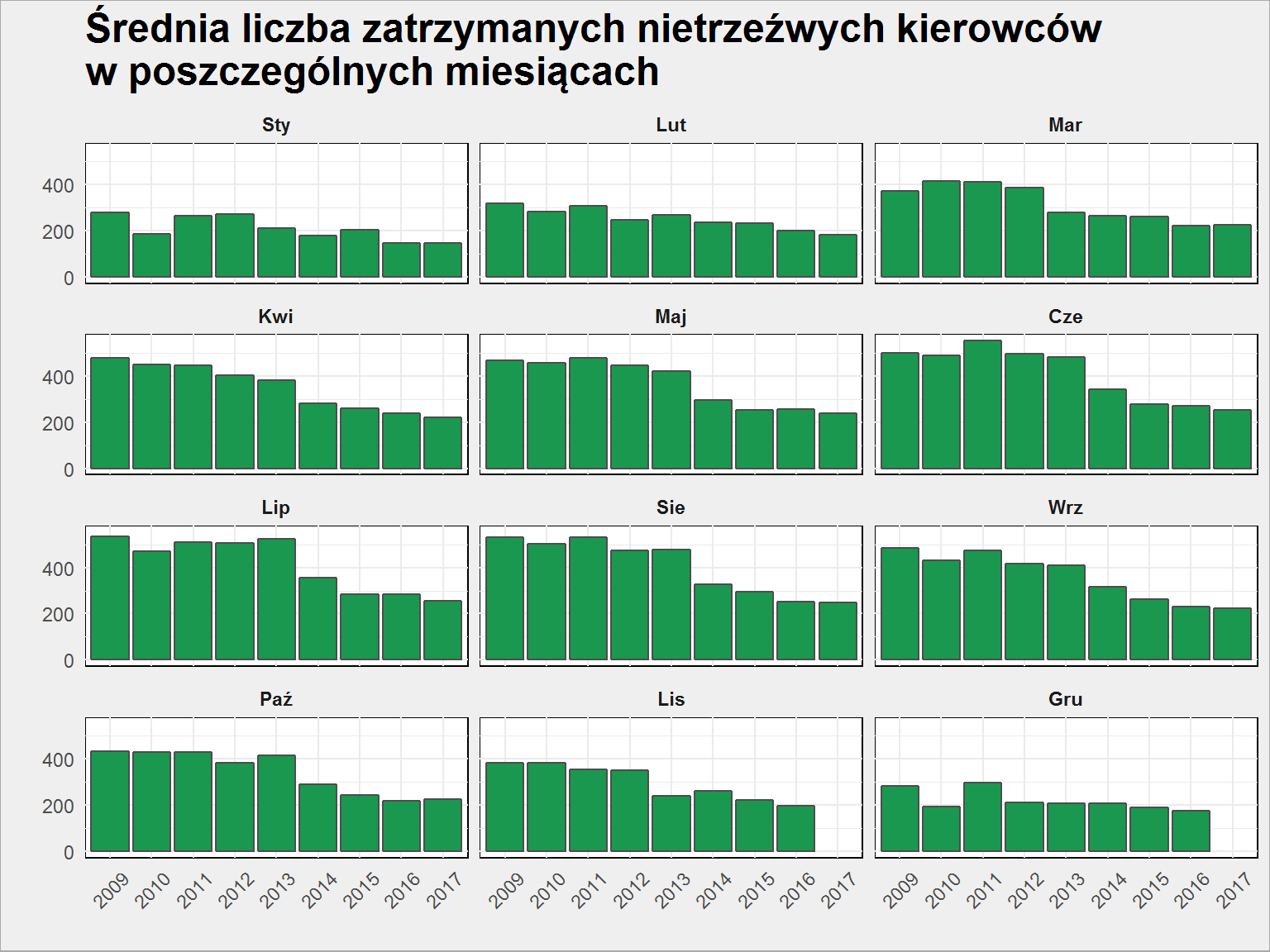
Widać spadek pomiędzy 2013 a 2014 (analogicznie do średniej liczby rannych w wypadkach) – można upatrywać tutaj jakiejś zmiany.
A kiedy pijani jeżdżą (są zatrzymywani) najwięcej?
|
1 2 3 4 5 6 7 8 9 10 11 |
policja %>% select(Month, Weekday, Zatrzymani_nietrzezwi) %>% group_by(Month, Weekday) %>% summarise_all(mean) %>% ungroup() %>% mutate(Month = fct_rev(Month)) %>% ggplot() + geom_tile(aes(Weekday, Month, fill = Zatrzymani_nietrzezwi), color = "gray80") + scale_fill_distiller(palette = "RdYlBu") + labs(title = "W jakie dni tygodnia poszczególnych miesięcy kierowcy piją?", x = "", y ="") |
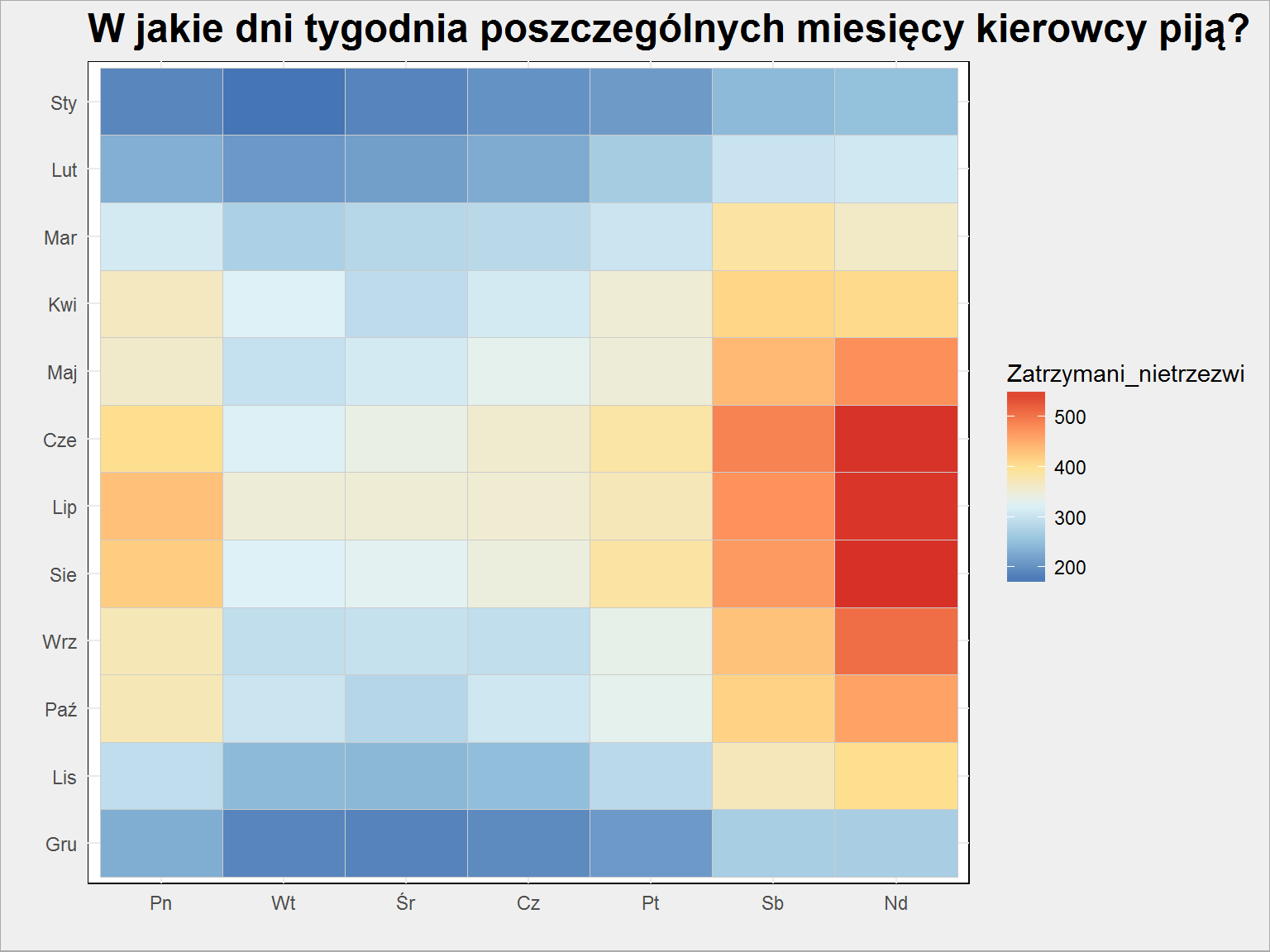
Jak jest ciepło i w weekend, do tego dochodzą soboty w marcu i poniedziałki w kwietniu (Wielkanoc?) oraz maju (majówka?). Znowu postawię pytanie: czy tak jest rzeczywiście czy wówczas jest więcej patroli i sito ma mniejsze oczka? Zapewne jedno i drugie.
Pijani a liczba wypadków
Zestawmy ze sobą dwie wartości: liczba wypadków i liczba zatrzymanych pijanych kierowców. Miesiąc po miesiącu, rok po roku:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
policja %>% select(Year, Month, Zatrzymani_nietrzezwi, Wypadki_liczba) %>% group_by(Year, Month) %>% summarise_all(mean) %>% ungroup() %>% gather(key = Kategoria, value = Wartosc, -Year, -Month) %>% ggplot() + geom_bar(aes(make_date(Year, Month, 1), Wartosc, fill = Kategoria), alpha = 0.7, stat = "identity", position = "dodge") + geom_smooth(aes(make_date(Year, Month, 1), Wartosc, color = Kategoria), se = FALSE) + scale_fill_manual(values = c("Wypadki_liczba" = "#fc8662", "Zatrzymani_nietrzezwi" = "#66c2a5")) + scale_color_manual(values = c("Wypadki_liczba" = "#e41a1c", "Zatrzymani_nietrzezwi" = "#4daf4a")) + labs(x = "", y = "", title = "Liczba wypadków a liczba zatrzymanych pijanych kierowców") |
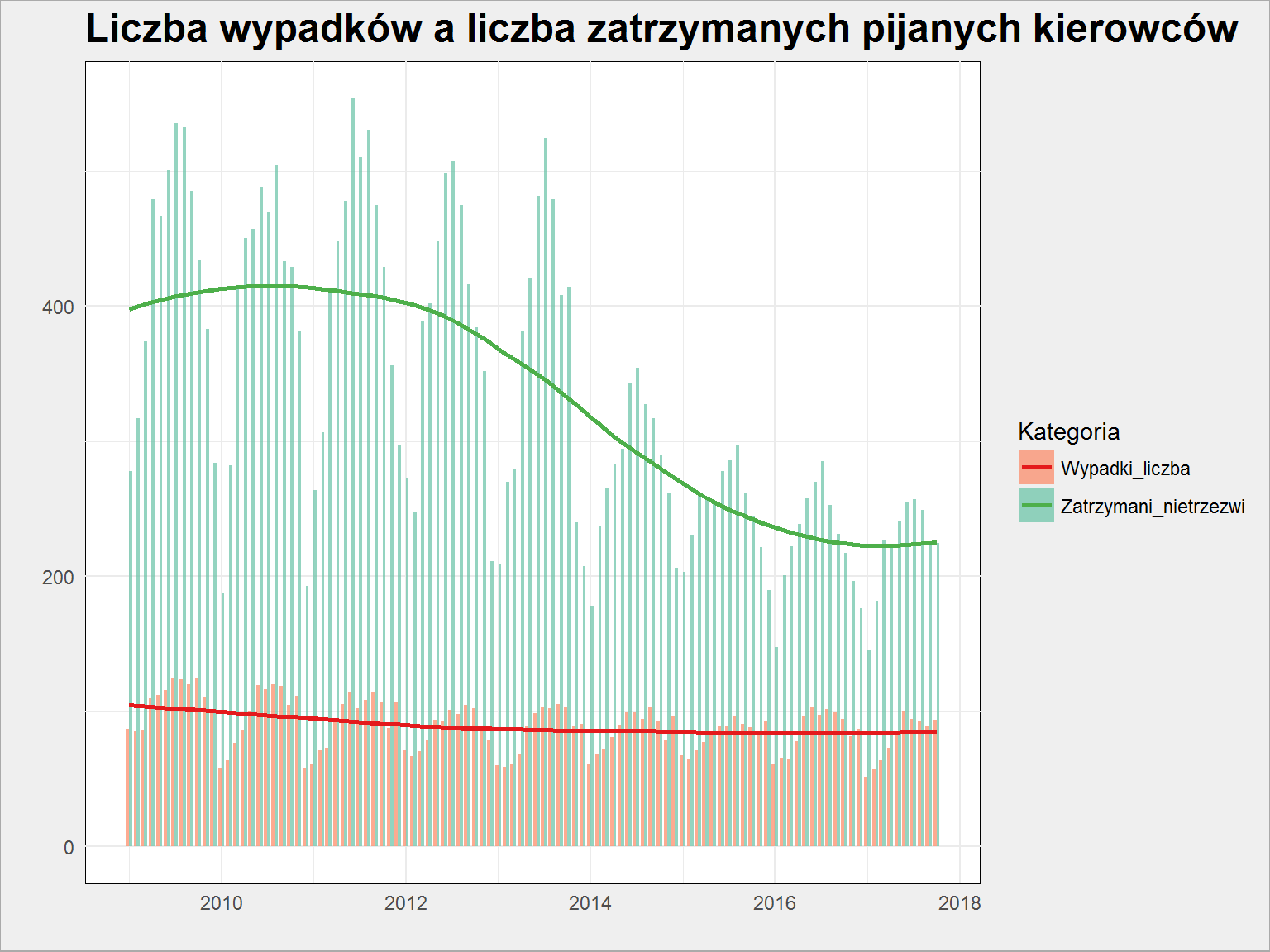
Zaskakujące prawda? Wcześniej zaobserwowaliśmy, że obie wartości spadły. Ale tutaj widzimy różnicę w tym spadku! Jak duża to różnica? Policzmy wskaźnik będący stosunkiem liczby wypadków do liczby zatrzymanych nietrzeźwych:
|
1 2 3 4 5 6 7 8 9 10 11 |
policja %>% select(Year, Month, Zatrzymani_nietrzezwi, Wypadki_liczba) %>% group_by(Year, Month) %>% summarise_all(mean) %>% ungroup() %>% mutate(w = Zatrzymani_nietrzezwi/Wypadki_liczba) %>% ggplot() + geom_col(aes(make_date(Year, Month, 1), w), color = "#4daf4a", fill = "#66c2a5", alpha = 0.7) + geom_smooth(aes(make_date(Year, Month, 1), w), color = "#e41a1c", se = FALSE) + labs(x = "", y = "Stosunek liczby zatrzymanych nietrzeźwych kierowców do liczby wypadków", title = "Czy liczba zatrzymanych nietrzeźwych\nma wpływ na liczbę wypadków?") |
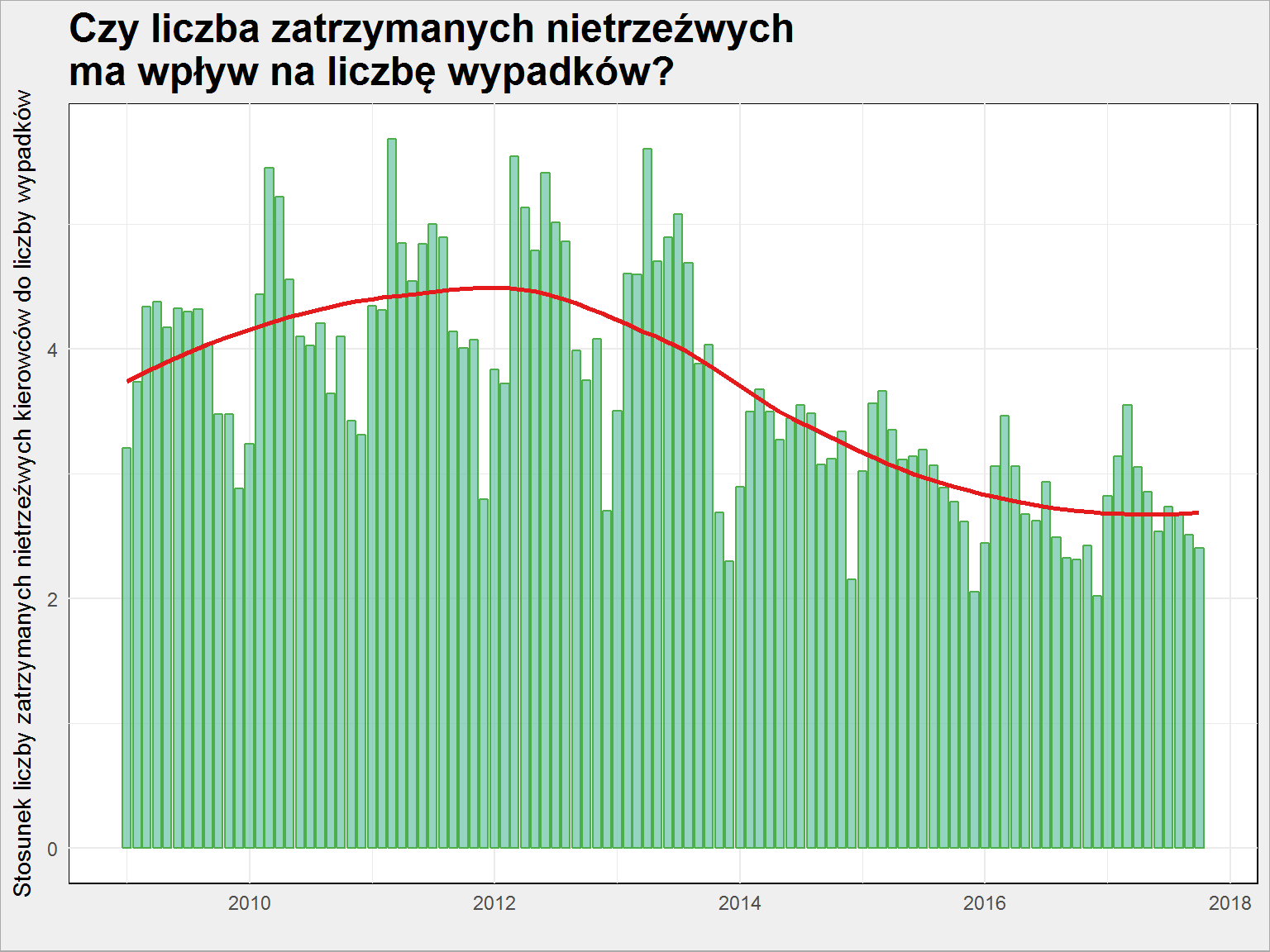
Wskaźnik ten spada. Pamiętamy, że liczba wypadków oraz liczba zatrzymanych pijanych spadały – tutaj mamy dowód na to, że spadek nie był jednakowy. Jeździmy nieco bezpieczniej (wolny spadek liczby wypadków) i jednocześnie coraz bardziej unikamy jazdy na podwójnym gazie (szybszy spadek zatrzymanych pijanych)? Albo znowu patroli mniej – bez jednej liczby nie jesteśmy w stanie powiedzieć czy jeździ coraz mniej pijanych czy też zatrzymywanych jest coraz mniej pijanych. Delikatna, a znacząca różnica.
Zostawmy drogi i z innej strony sprawdźmy czy jest w Polsce coraz bardziej bezpiecznie.
Zatrzymani na gorącym uczynku
W statystykach policyjnych mamy też takie dane. Z tego co myślę powinny mówić o skuteczności działań Policji. Zobaczmy je w takim układzie:
|
1 2 3 4 5 6 7 8 9 10 |
policja %>% group_by(Year, Month) %>% summarise(Zatrzymani = mean(Zatrzymani_inflagranti)) %>% ungroup() %>% mutate(Month = fct_rev(Month)) %>% ggplot() + geom_tile(aes(as.factor(Year), Month, fill = Zatrzymani), color = "gray80") + scale_fill_distiller(palette = "RdYlBu") + labs(title = "Liczba osób zatrzymanych na gorącym uczynku", x = "", y ="", fill = "Liczba\nzatrzymanych") |
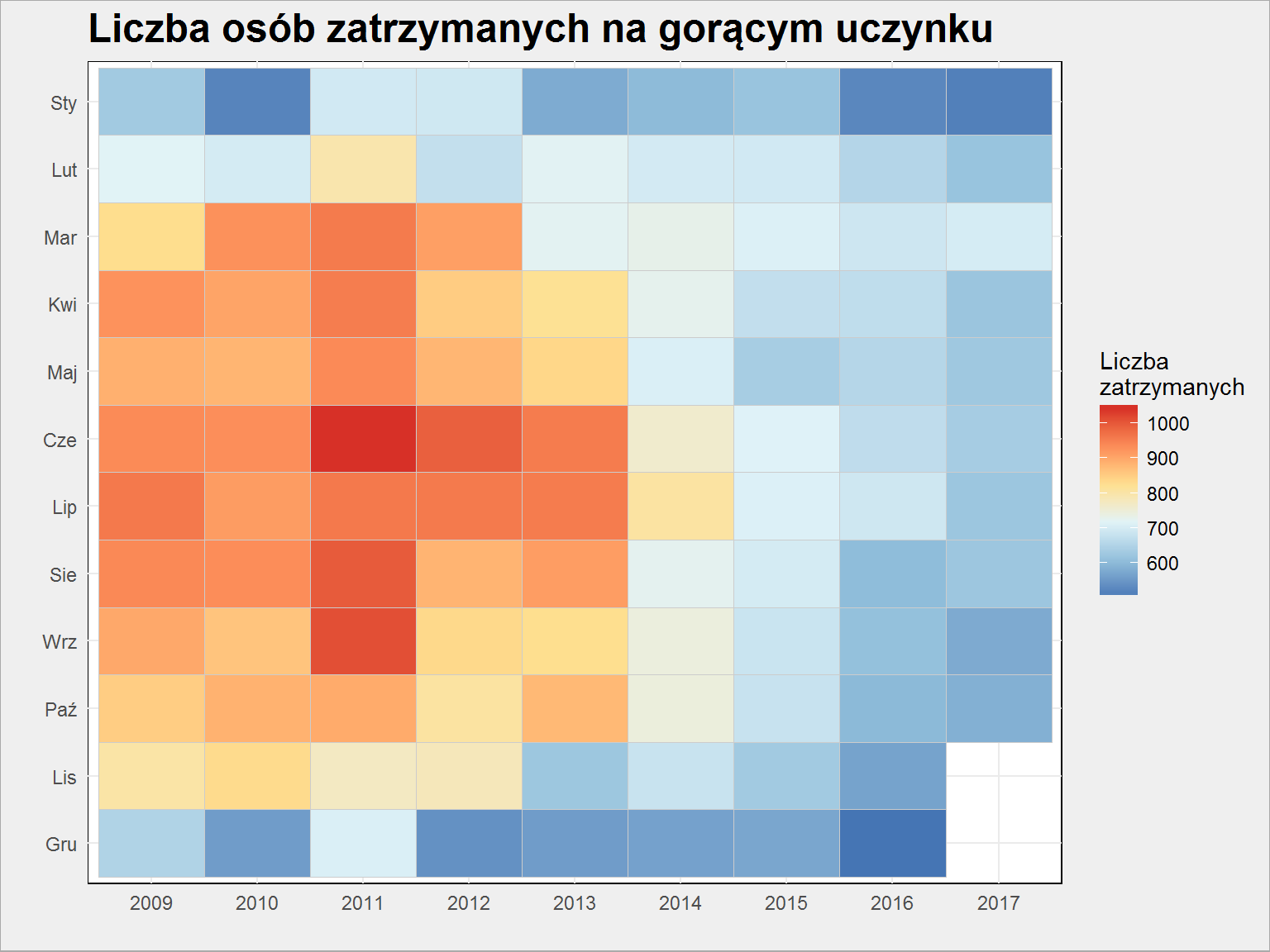
Znowu widzimy spadek po 2014 roku. I co to oznacza? Coraz mniejsza przestępczość czy coraz mniejsza skuteczność (bo mniej łapią)? Pozostawię Was z tym pytaniem. Może znajdziecie inne dane, które w połączeniu z przedstawionymi wyżej dadzą pełniejszy obraz?