Zainspirowany grafiką obrazującą rozkład położenia liter w słowach (angielskich) znalezioną na reddicie postanowiłem sprawdzić jak to samo wygląda w języku polskim.
Aby sprawdzić na których miejscach w słowach występują poszczególne litery alfabetu potrzebujemy przede wszystkim słów. Bo alfabet znamy. Skąd wziąć słowa? Ze słownika, ktoś powie. Oczywiście to najlepsze miejsce – w słownikach są słowa, po to właśnie są słowniki. Ale słowniki mają jedną wadę – zawierają podstawowe formy słów (rzeczowniki w mianowniku, czasowniki w bezokoliczniku), co znacząco ogranicza liczbę dostępnych słów. A język polski jest bardzo bogaty w różne formy fleksyjne. Spróbujcie wymienić wszystkie możliwe wariacje na temat jakiegoś czasownika – najwięcej zabawy i rubasznego śmiechu będzie przy wulgaryzmach. Do każdego właściwie można dodać na początek wy-, przy-, za-, pod-, s-, roz-. Można dodać też się. Można odmienić czasownik przez osoby i liczby. Podobnie z rzeczownikami, przymiotnikami i innymi częściami mowy. Wystarczy spojrzeć na pierwszy z brzegu link znaleziony w Google.
I właśnie na taki worek słów (bardzo lubię angielskie określenie bag of words) się nastawimy. Bo im więcej kombinacji tym bliższe życiu wyniki użycia literek.
Dlatego nie skorzystamy ze słownika, a z gotowych tekstów – w tym przypadku z ośmiu książek, które już analizowaliśmy w odcinku poświęconym sprawie kryminalnej poszukiwania autora. Im więcej tekstów, najlepiej różnych autorów i z różnych dziedzin, tym większy zbiór słów. W poszukiwaniu danych do dzisiejszego postu natrafiłem na stronę PWN o korpusie języka polskiego – mowa tam o stu milionach słów! Na pewno z uwzględnioną fleksją, bo słów w naszym języku jest zapewne mniej (w formach podstawowych).
Ale nie mamy tych 100 milionów słów, musimy polegać na tym co mamy.
Zaczniemy od potrzebnych pakietów:
|
1 2 3 |
library(tidyverse) # %>%, dplyr, ggplot2 library(stringr) # operacje na ciągach znaków library(tm) # usunięcie znaków przestankowych |
Następny krok to wczytanie tekstów. Jak wspomniałem – wykorzystamy książki Zygmunta Miłoszewskiego oraz Remigiusza Mroza (po cztery), skonwertowane do formatu TXT. Każdą z książek wczytujemy do tabeli:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
# lista plików z książkami pliki <- list.files("ksiazki/") books <- vector() for(i in 1:length(pliki)) { book <- read_lines(paste0("ksiazki/", pliki[i])) book <- book[nchar(book) != 0] books <- c(books, book) } rm(book, pliki, i) # tego już nie potrzebujemy |
Trochę czyścimy dane pozbywając się znaków przestankowych, cudzysłowów i sprowadzając wszystko do małych liter. Na koniec każde ze słów traktujemy specjalną funkcją, która ponumeruje nam literki w słowie:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
# bez znaków przestankowych i innych znaków books <- gsub("„", " ", books) books <- gsub("”", " ", books) books <- gsub("–", " ", books) books <- gsub("-", " ", books) books <- removePunctuation(books) # rozbicie na pojedyncze słowa slowa <- str_split(books, pattern = " ") slowa <- unlist(slowa) # usunięcie zbędnych odstępów przed i po słowie slowa <- trimws(slowa) # tylko unikalne słowa slowa <- unique(slowa) # z co najmniej 1 literą slowa <- slowa[nchar(slowa) >= 1] # funkcja rozbijająca słowo na literki # i nadająca im numerki wg kolejności w słowie znaki_df <- function(slowo) { slowo <- str_to_lower(slowo) litery <- unlist(str_split(slowo, pattern = "")) znaki <- tibble(slowo = slowo, znak = litery, pos = 1:length(litery)) return(znaki) } # dla każdego słowa: podział na literki, wszystko w jedną długą tabelę znaki <- bind_rows(lapply(slowa, znaki_df)) znaki <- distinct(znaki) |
Dane już gotowe (mamy nieco ponad 88 i pół tysiąca słów), więc możemy sobie coś pooglądać.
Ale najpierw coś dla fanów Sherlocka Holmesa i opowiadania “Tańczące sylwetki”. To moje ulubione opowiadanie z serii o Holmesie; gdzieś w młodości przeczytane u ciotki na strychu. Idealnie wpasowuje się w chęć młodzieńca lubiącego poszukiwania, rozwiązywanie zagadek, bardzo klarownie pokazuje logiczne i metodyczne podejście do rozwiązywania problemów. Tego wymaga się od analityków (rozumianych jako data scientist – Wiki twierdzi, że polski odpowiednik to mistrz danych… co za bullshit).
Dla tych, którzy nie znają opowiadania mały skrót z fabuły (tej kluczowej tutaj części). Sherlock zajmuje się sprawą tajemniczych zaszyfrowanych liścików – zamiast liter na kartkach narysowane są postacie z różnym ułożeniem rączek i nóżek. Listów jest coraz więcej (coraz więcej danych!), dzięki czemu Sherlock jest w stanie przyporządkować sylwetką odpowiednie litery alfabetu.
Wychodzi od wiedzy, że litera E jest najpopularniejsza w angielskim słowie pisanym oraz długości poszczególnych słów – bardzo łatwo rozpoznać “the”, a jak się ma “the” to ma się już trzy symbole. Z czego dwa użyte w “have”, co prowadzi do kolejnych dwóch. Które to a możemy zweryfikować po “at” (oraz samym “a” przed rzeczownikami), zaś po “to” można odszukać sylwetkę dla “o”. “O” oraz “a” pozwolą na weryfikację “n” (na podstawie “on” oraz “an”). I tak dalej, i tak dalej. A wymieniłem tylko kilka podstawowych słów: the, have, on, a, an, at, co daje już siedem liter (z 26 używanych w języku angielskim) – ponad 1/4.
To trochę jak rozpoznawanie kotów na obrazach, czyż nie? Koty Sieci neuronowe trzeba nakarmić (nauczyć) dużą ilością danych – mamy dużo liścików, dużo sylwetek. Później już “tylko” pozostaje odnalezienie odpowiednich patternów.
Sprawdźmy zatem czy wiedza Sherlocka Holmesa o najpopularniejszej literze E ma zastosowanie w języku polskim:
|
1 2 3 4 5 6 7 8 9 10 |
znaki %>% filter(znak %in% pl_znaki) %>% count(znak) %>% ungroup() %>% mutate(p = 100*n/sum(n)) %>% ggplot() + geom_bar(aes(znak, p, fill=p), stat="identity", show.legend = FALSE) + geom_text(aes(znak, p, label=sprintf("%.2f%%", p)), angle=90, hjust=-0.2) + expand_limits(y = c(0, 11)) + scale_y_continuous(breaks = 1:10) |
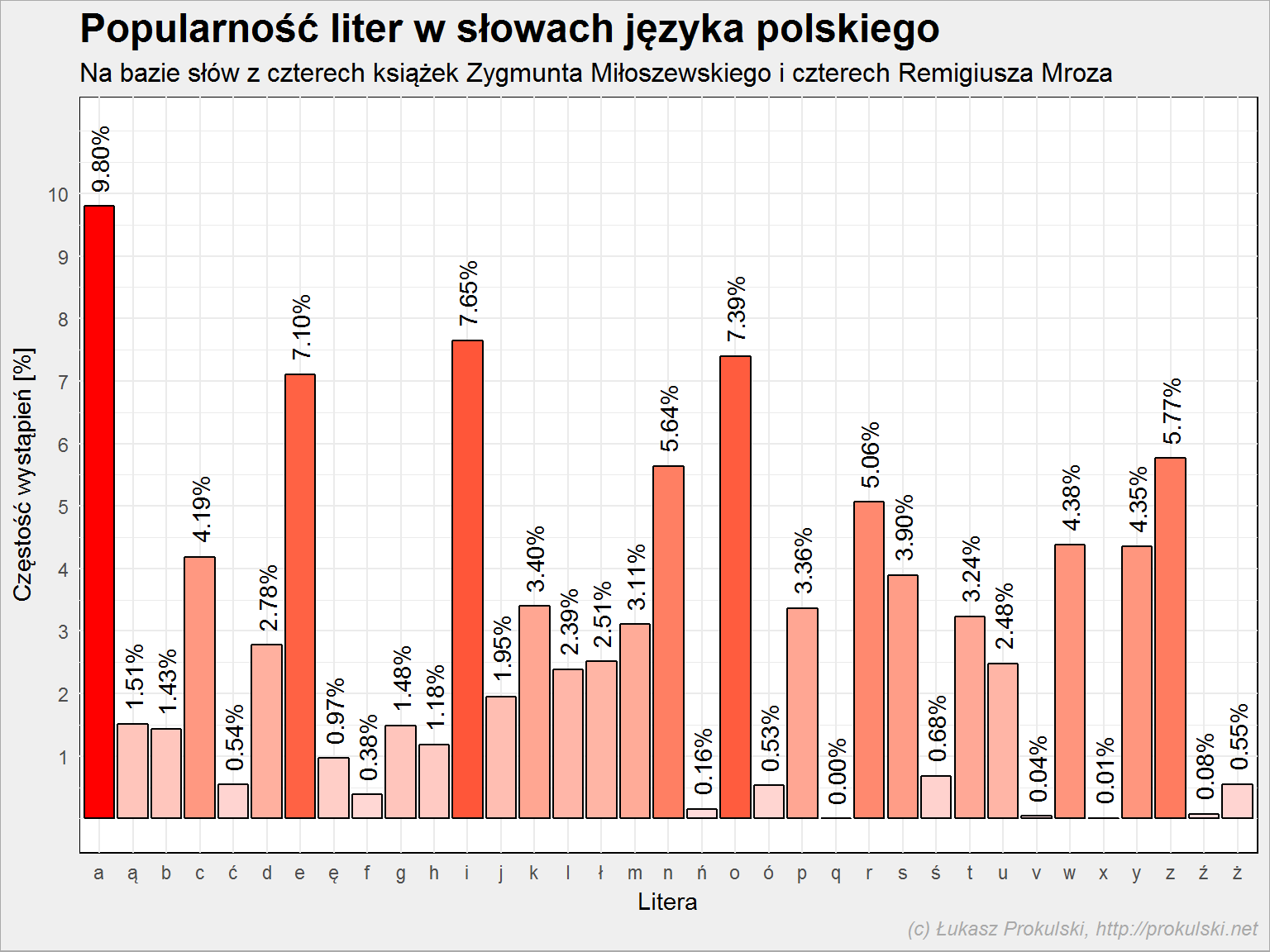
I Sherlock by się pomylił. Najpopularniejsze jest A, E zaś jest dopiero czwarte.
Widać też coś, czego zapewne sobie nie uświadamiamy: najpopularniejsze są samogłoski (kolejno: a, i, o, e). Co więcej, około 42% wykorzystywanych liter to samogłoski (rozumiane jako jedna z a, ą, e, ę, i, o, ó, u, y). Reszta to oczywiście spółgłoski.
Sherlockowi pomogło the – słowo trzyliterowe. A jak wygląda rozkład długości polskich słów?
|
1 2 3 4 5 6 7 |
znaki %>% filter(znak %in% pl_znaki) %>% group_by(slowo) %>% filter(pos == max(pos)) %>% ungroup() %>% ggplot() + geom_histogram(aes(pos), binwidth = 1) |
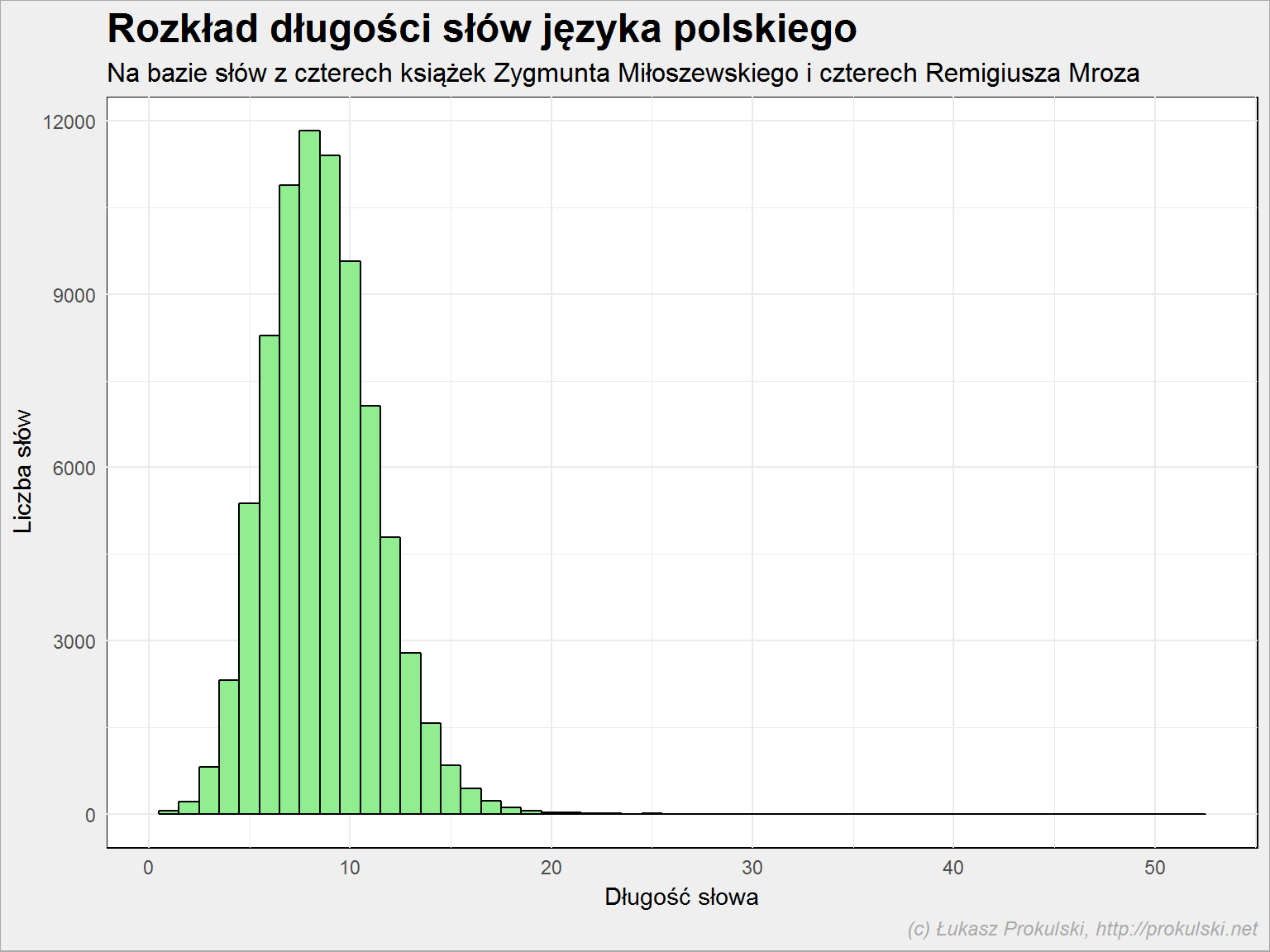
Wybierając informacje z powyższego histogramu bez ogona można zgodnie z testem Shapiro-Wilka stwierdzić, że to rozkład bliski rozkładowi normalnemu. Pojawia się ów ogon – najdłuższe słowo użyte w 8 badanych tekstach ma 52 znaki (jest to MuszeToKomusWyznacKochamKsiedzaMarkaNieMogeZycPomocy, które jako treść SMSa pada w Uwikłaniu Miłoszewskiego). Cała reszta słów jest krótsza niż 25 znaków (wszystkie dłuższe słowa to: siedemdziesięcioprocentowy, trzydziestosiedmiocalowego, osiemdziesięciosześcioletnia, trzydziestodziewięciostopniową, dziewięćdziesięcioprocentowego oraz wspomniany SMS), zatem dalsze rozważania ograniczymy do słów do 25 znaków włącznie.
Dochodzimy do zamierzonego celu, czyli odpowiedzi na pytanie na jakiej pozycji w słowie występują poszczególne litery?. Zobaczmy to dla każdej z liter z osobna:
|
1 2 3 4 5 6 |
znaki %>% filter(pos <= 25) %>% filter(znak %in% pl_znaki) %>% ggplot() + geom_histogram(aes(pos), binwidth = 1) + facet_wrap(~znak, ncol = 5, scales="free_y") |
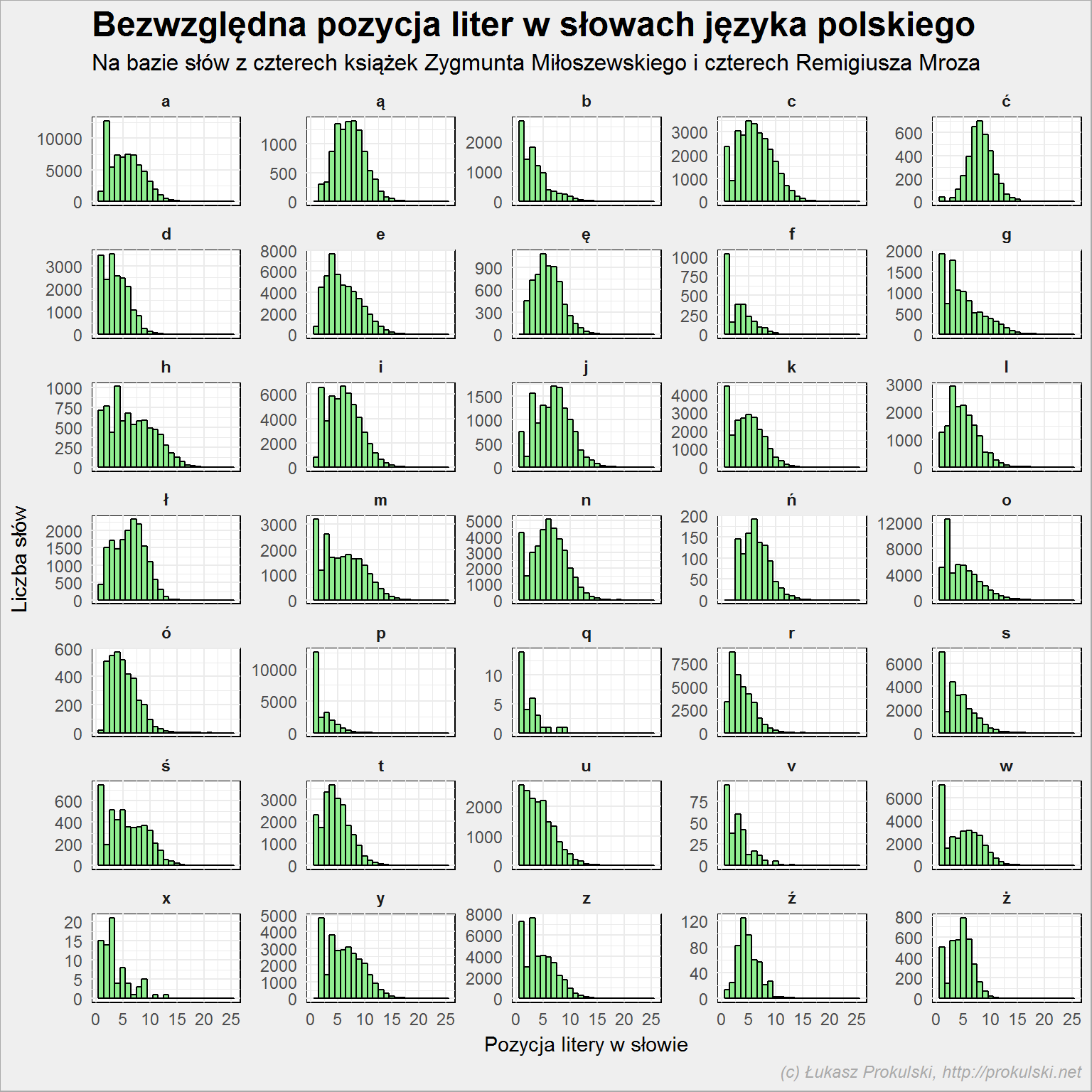
Co tutaj widać? Przede wszystkim różną skalę dla każdego z wykresów, na to należy zwrócić uwagę.
Ale nas interesuje każdy z tych wykresów z osobna, a tutaj widzimy, że S występuje najczęściej na początku słowa jako jedna z pierwszych liter (pierwsza prawdę powiedziawszy), podobnie W, P, F czy M. Samogłoski są na kolejnych pozycjach. Tyle tylko, że są to wartości bezwzględne, a słowa jak widzieliśmy mają różną długość – raz pozycja numer trzy to środek słowa, a raz jego koniec.
Musimy zatem przejść na wartości bezwzględne – na przykład na procent długości słowa:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
znaki %>% # dla każdego słowa policz w którym procencie jego długości jest literka group_by(slowo) %>% mutate(l = max(pos)) %>% ungroup() %>% mutate(proc = 100*pos/l) %>% # podział na bloki co 5% mutate(proc = cut(proc, breaks = seq(0, 100, 5))) %>% # przygotuj histogram dla słów krótszych niż 25 znaków filter(pos <= 25) %>% filter(znak %in% pl_znaki) %>% count(znak, proc) %>% ggplot() + geom_bar(aes(proc, n), stat="identity") + facet_wrap(~znak, ncol = 5, scales="free_y") |
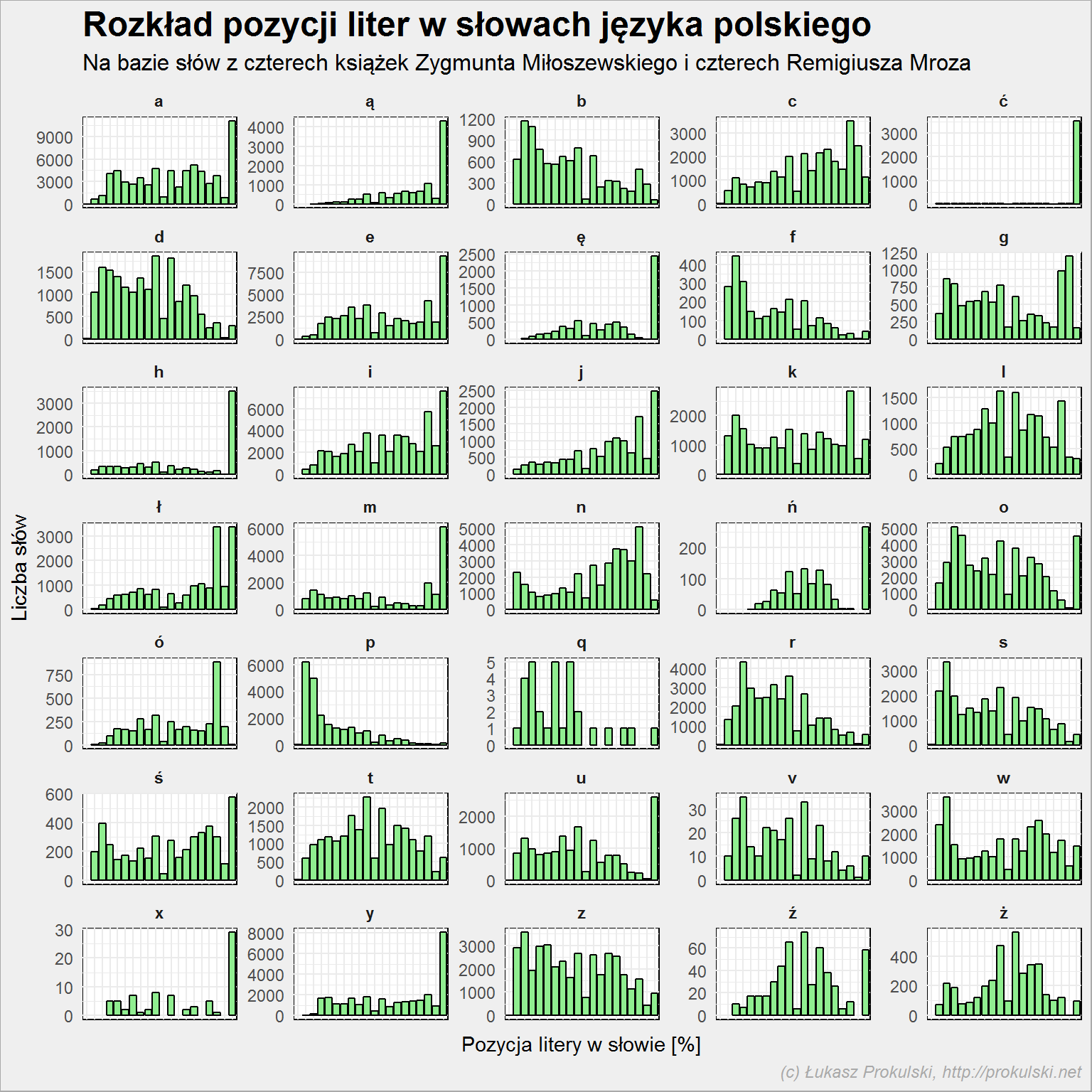
Z przeliczeniem na procenty jest pewien kłopot – dla słowa trzyliterowego każda z liter to już krok o 33%. Ale abstrahując od tego problemu widzimy, że:
- to co poprzednio: F, P, S, W oraz Z rozpoczynają słowa
- A, Ą, E, Ę, I, J, M, U kończą słowa
- Ć jest tutaj niesamowite – właściwie tylko jako ostatni znak. W połączeniu z Ś (też dominacja na końcu) mamy końcówkę -ść
- podobnie jest z Ń i Y – najczęściej są ostatnimi literami
- H podobnie – końcówka -ch
- ciekawostką jest X – pojawia się rzadko, zapewne w nazwach leków, marek lub firm (niepokonany schemat nazewnictwa firm z lat ’90 XX wieku – Pol-Ex). Ale występuje też w numerach rozdziałów (teksty nie były czyszczone z tego typu elementów)
- analogicznie jest z Q – występuje jeszcze rzadziej (słowa: tequila, squash i aquapark)
- Ó występuje najczęściej pod koniec – to wszystkie końcówki -ów
- B, D, K, L, O, R, T, Z, Ź i Ż dominują w środkach wyrazów
Zestawiając oba wykresy (bezwzględną pozycję w słowie i “pozycję” procentową) widzimy, że:
- Ą jest najczęściej 5-8 literą, a jednocześnie raczej ostatnią – to słowa 5-8 literowe, takich słów mamy ponad 2200
- podobnie jest z Ę
- O występuje najczęściej w okolicach 15-20% długości wyrazu jednocześnie będąc najczęściej drugim znakiem. Skoro 2 znaki to 15% (lub 20%) to całość to słowo ma 13 lub 14 znaków (dla 20% – 10 znaków). Znacie takie słowa? Chwila na zastanowienie się… Znowu mamy ich około 2300, a przykładowe to postanowił oraz powinienem albo monopolowy
- Ł występuje w 85-90% oraz 95-100% długości słowa jednocześnie będąc gdzieś 5-8 literką. Jakieś 8 tysięcy słów, od urodziłam do zdechł
Bardzo przyjemna rozrywka intelektualna: szukanie słów przy znajomości położenia danej litery i długości słowa. Przypomina scrabble albo krzyżówkę, prawda?
Wróćmy do rozkładu literek po pozycji w wyrazie i zobaczmy te same dane nieco inaczej – w postaci heatmapy:
|
1 2 3 4 5 6 |
znaki %>% filter(znak %in% pl_znaki) %>% group_by(znak, pos) %>% summarise(n=n()) %>% ggplot() + geom_tile(aes(znak, pos, fill=n)) |
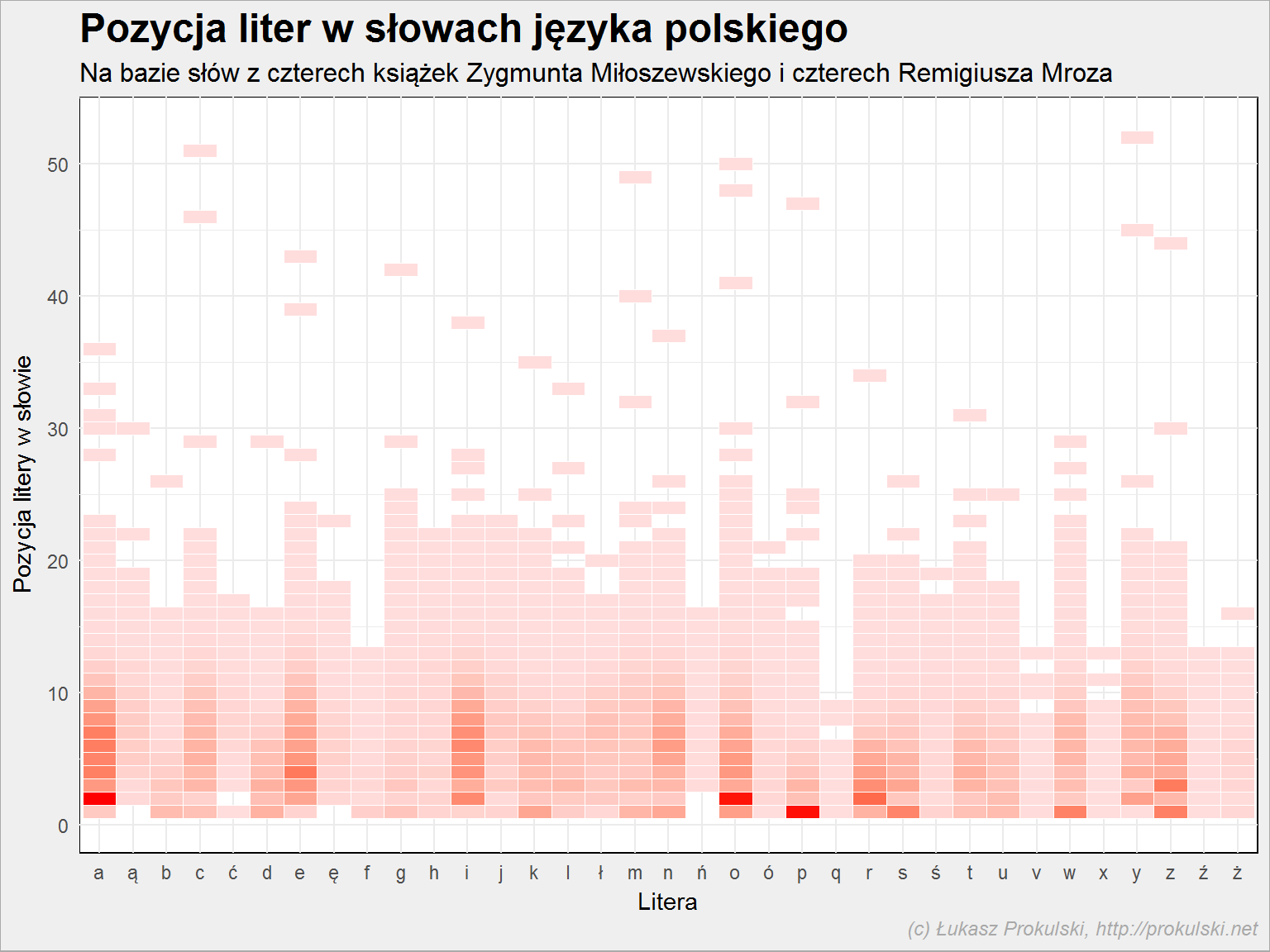
Widzimy, że żadne słowa nie zaczynają się na Ą, Ę czy Ń. To dość oczywiste.
(nieco) Mniej oczywiste jest to, że Ć nie występuje na drugiej pozycji (ale może być pierwsze – chwila na zastanowienie się – ćpać i okolice oraz ćwiczenia i pochodne). Z Ń jest tak samo, jest dopiero na trzecim miejscu. Wiecie w jakim słowie? W wielu:
|
1 2 3 4 5 6 |
znaki %>% filter(znak == "ń") %>% filter(pos == min(pos)) %>% # w tym przypadku może być również pos = 3 select(slowo) %>% distinct() %>% arrange(slowo) |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 |
## [1] "bańki" "bińczyk" "bińczyka" "bońka" ## [5] "buńczucznym" "dań" "duńczycy" "duńczyk" ## [9] "duńczyka" "duńczykami" "duńczykom" "duńczyków" ## [13] "duńska" "duńską" "duński" "duńskich" ## [17] "duńskie" "duńskiego" "duńskiej" "duńskim" ## [21] "duńsku" "fiński" "fińskich" "goń" ## [25] "gończe" "gończy" "gończym" "hańbić" ## [29] "hańbił" "jońskiej" "koń" "końca" ## [33] "końcach" "końce" "końcem" "końcowa" ## [37] "końcową" "końcowe" "końcowej" "końcowy" ## [41] "końcowych" "końców" "końcówce" "końcówka" ## [45] "końcówkami" "końcówkę" "końcówki" "końcu" ## [49] "końcu…" "kończą" "kończąc" "kończącą" ## [53] "kończące" "kończącego" "kończący" "kończę" ## [57] "kończmy" "kończy" "kończyć" "kończyli" ## [61] "kończył" "kończyła" "kończyłby" "kończyło" ## [65] "kończyłoby" "kończyły" "kończymy" "kończyn" ## [69] "kończyna" "kończynach" "kończynami" "kończynę" ## [73] "kończyny" "kończysz" "końmi" "koński" ## [77] "końskim" "łańcuch" "łańcucha" "łańcuchach" ## [81] "łańcuchami" "łańcuchem" "łańcuchowym" "łańcuchów" ## [85] "łańcuchu" "łańcuchy" "mońkach" "nań" ## [89] "pań" "pańscy" "pańska" "pańską" ## [93] "pański" "pańskich" "pańskie" "pańskiego" ## [97] "pańskiej" "pańskim" "państewku" "państw" ## [101] "państwa" "państwach" "państwem" "państwie" ## [105] "państwo" "państwo…" "państwowa" "państwową" ## [109] "państwowe" "państwowego" "państwowej" "państwowy" ## [113] "państwowych" "państwowym" "państwowymi" "państwu" ## [117] "pańszczyzna" "pańszczyźniani" "pończoch" "pończochach" ## [121] "pończochy" "sińców" "tańca" "tańce" ## [125] "tańcu" "tańczą" "tańczące" "tańczącego" ## [129] "tańczący" "tańczącym" "tańczenie" "tańczy" ## [133] "tańczyć" "tańczyli" "tańczył" "tańczymy" ## [137] "tańsze" "tańszych" "tańszymi" "wańkowicza" ## [141] "wiń" "woń" "żeńską" "żeńskiego" ## [145] "żeńskim" |
Należy pamiętać, że baza słów pochodzi z kilku książek, a nie ze wszystkich słów w języku polskim. Jest to fajna próba, ale raczej nie 100% reprezentatywna.
Zobaczmy jeszcze które litery występują po sobie?
Aby to uzyskać grupujemy dane według słów i przesuwamy (w dodatkowej kolumnie) o jeden każdą literkę. Dzięki temu w wierszu otrzymamy literkę oraz jej następnika – tak słowo po słowie. Następnie zliczamy pary literek.
|
1 2 3 4 5 6 7 8 9 10 11 |
znaki_pary <- znaki %>% group_by(slowo) %>% mutate(znak_next = lead(znak)) %>% ungroup() %>% select(znak, znak_next) %>% filter(znak %in% pl_znaki) %>% filter(znak_next %in% pl_znaki) %>% count(znak, znak_next) %>% ungroup() %>% mutate(p = 100 * n/sum(n)) %>% mutate(proc = cut(p, 10)) |
Mając przygotowane dane możemy pokazać heatmapkę z kolejnością liter – która po której i jak często?
|
1 2 3 4 5 |
znaki_pary %>% ggplot() + geom_tile(aes(znak_next, znak, fill=proc), show.legend = FALSE) + scale_fill_brewer(palette = "YlOrRd") + scale_y_discrete(limits = rev(pl_znaki)) |
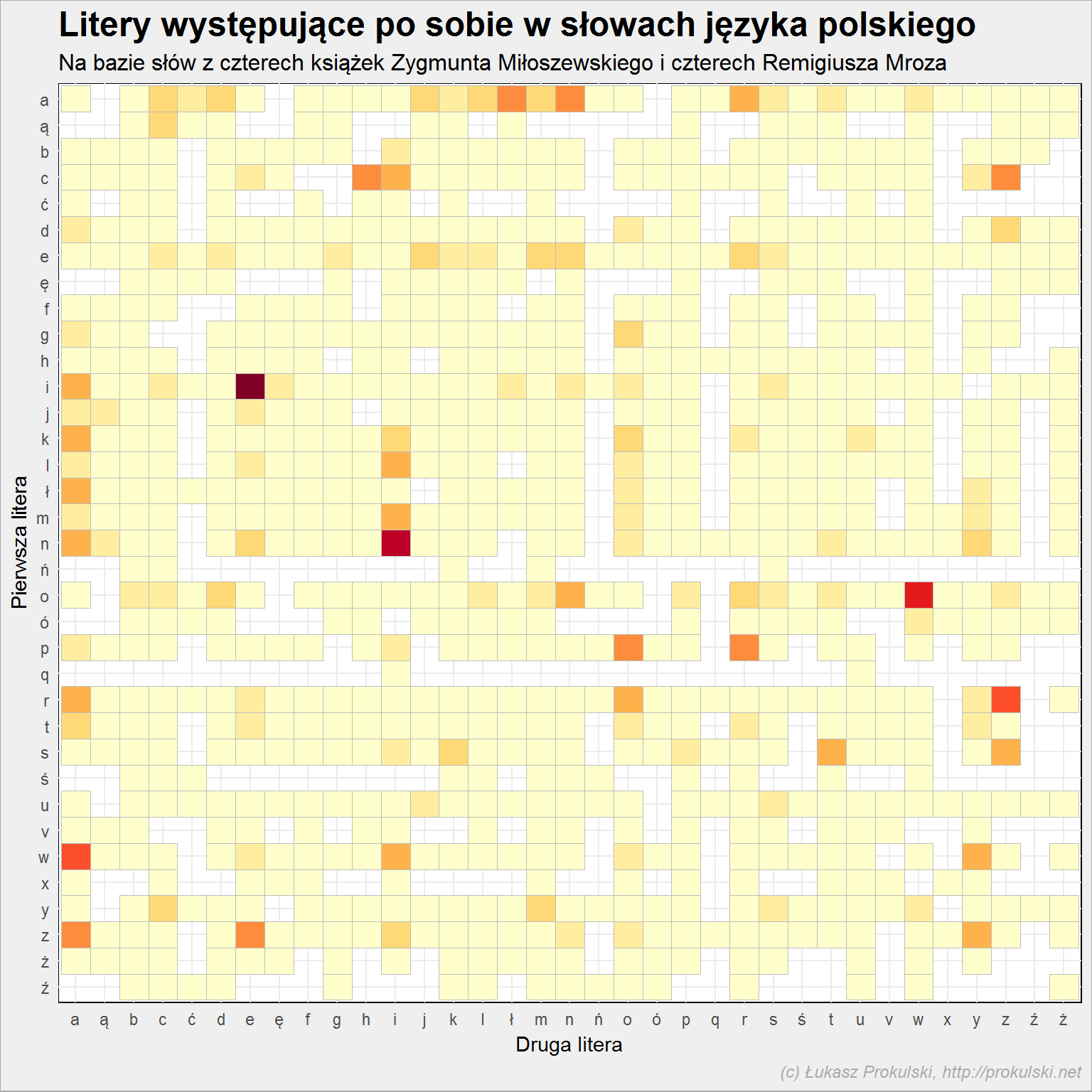
Widać wręcz kilka najmocniejszych połączeń. Najpopularniejsze zbitki to:
|
1 2 3 4 5 6 7 8 |
znaki_pary %>% mutate(para = paste0(znak, znak_next)) %>% top_n(30, wt = p) %>% arrange(p) %>% mutate(para = factor(para, levels=para)) %>% ggplot() + geom_bar(aes(para, p, fill=para), stat="identity") + coord_flip() |
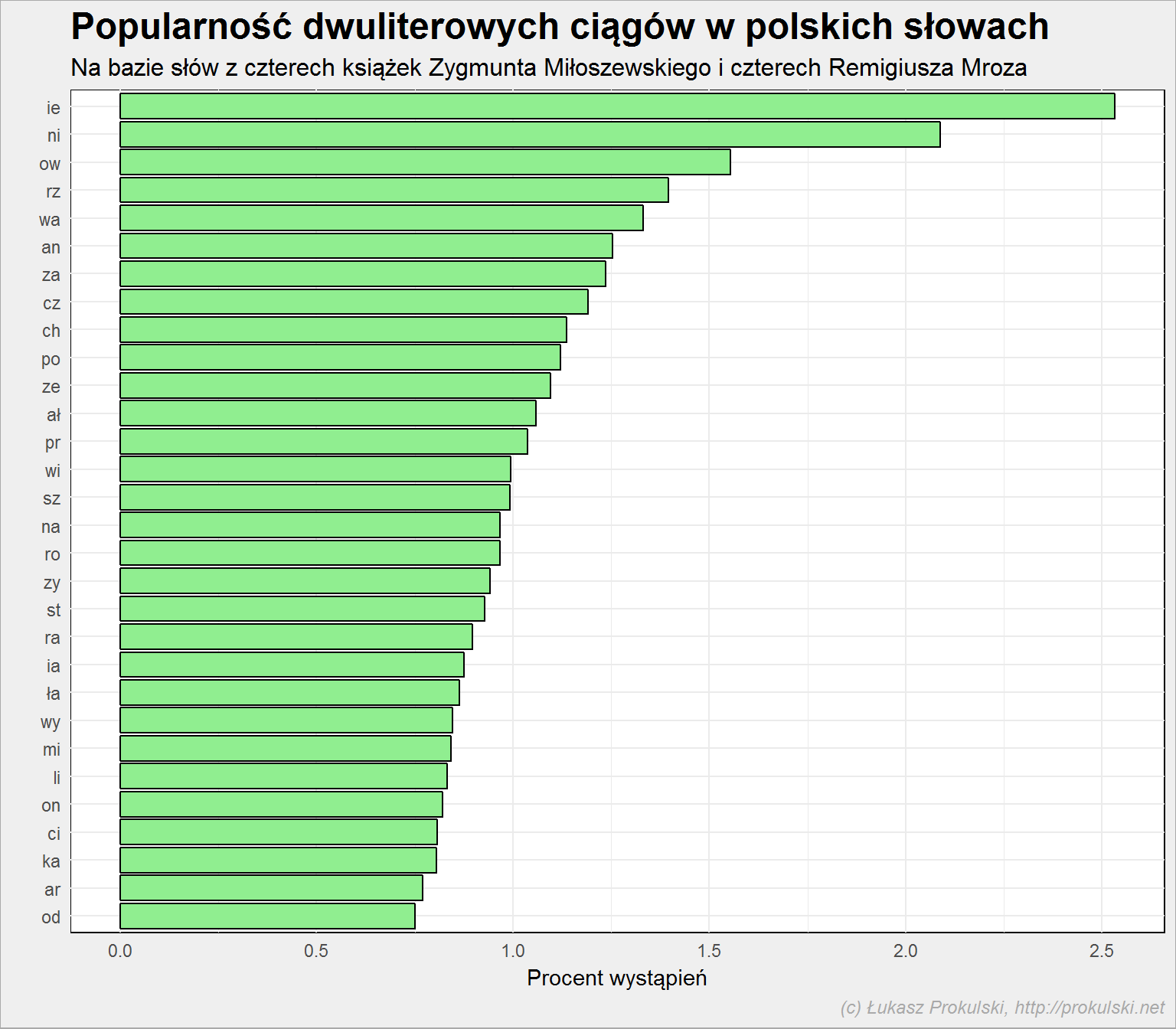
Nie. To najpopularniejsza zbitka. Do tego nasze ortograficzne problemy: rz, ch (a takie cz jest bardziej popularne niż ch). Na wykres nie załapało się ść (287 na liście popularności, dla porównania śc – 128), ąc (jest 44 na liście), ów (jest 89) a także uj (94).
Fajne? Podziel się linkiem do tekstu ze znajomymi (tam są takie ikonki na dole) albo wrzuć na Wykop. Napisz co myślisz w komentarzu. Zapraszam też na facebookowy fanpage Dane i Analizy gdzie trailery i teasery nowych wpisów, a także linki do ciekawych treści o analizie danych.
Jestes absolutnie odjechany… czytam z zapartym tchem.
Biorę się za R bo to co robisz to z jednej strony fun, z drugiej fantastyczne narzędzie poznania świata takim jakim jest. A to przydatne i prywanie i w pracy.
Brawo.
Moja znajomosc R do wczoraj byla 0. Będę wdzięczny jeżeli zrobisz kilka tekstów, które pozwolą komuś z nikłą znajomością R odtworzyć to co robisz. Nie wiem czy z tymi analizami mi się uda – dopiero będę próbował.
Pozdro,
M
Idea jest taka, żeby pokazane kody źródłowe dały się uruchomić u każdego. Najczęściej sprawdzam je na R w wersji 3.2.1 (tak, taką archaiczną mam w pracy – strasznie utrudnia to aktualizację pakietów; niestety bezpieczniki nie dopuszczają oprogramowania, którego nie znają) i 3.4.0 (na AWS) albo 3.4.1. (w domu).
Nie chcę (i szczerze mówiąc nie zamierzam) prowadzić „kursu programowania w R”. Są od tego inne miejsca i książki (zobacz ostatni wpis). Ja wolę skupić się na konkretnych zastosowaniach.
A można by powtórzyć analizę stosując dostępny słownik sjp.pl?
Zdaje się, że nie ma słownika w pliku. Chyba nawet go szukałem.
Jeśli znajdziesz – spróbuj samodzielnie! :)
Otóż jest pod poniższym linkiem, od razu w gotowej formie to analizy, zawiera 2 906 483 unikalnych slow, choć o maksymalnej długości 15 znaków, z uwagi na ograniczenia planszy do gry…
https://sjp.pl/slownik/growy/
Na marginesie, jest także plik z pełnym słownikiem, choć pewnie oczyszczenie takiego pliku byłoby dosyć kłopotliwe.
W każdym razie, owszem, próbuję samodzielnie sobie powtórzyć analizę, jako że interesuję się grami słownymi i miałbym kilka wstępnych pytań:
Jeżeli już na wejściu mam prawie 3 miliony słów, tj. wierszy, to ile wierszy może liczyć output z funkcji znaki_df? Czy a) mielenie tego nie będzie trwało godzinami b) jaki jest w ogóle górny limit wierszy na jeden df?
Puściłem sobie te funkcję na bardzo okrojonym zbiorze, żeby sobie przetestować jak to wygląda, ale później natknąłem się na taki błąd „object 'pl_znaki’ not found.” Czy coś ominąłem po drodze?
pl_znakifaktycznie nie ma w kodzie pokazanym w poście (gdzieś mi musiało umknąć), ale to po prostu kolejne małe polskie litery alfabetu, razem z tymi z ogonkami – można użyć wbudowanego w R LETTERS żeby i dodać polskie literki, konkretnie:pl_znaki < - tolower(c(LETTERS, "ą", "ć", "ę", "ł", "ń", "ó", "ś", "ź", "ż"))Godzinami to chyba nie będzie trwało, chociaż kod jest dość czasochłonny (każde słowo rozbijane nie za bardzo efektywną funkcją na pojedyncze znaki - można znaleźć lepsze rozwiązanie).
Tutaj (w przypadku słownika z SJP) jeszcze jest ta szczęśliwa sytuacja, że znamy maksymalną długość słowa - z góry można założyć, że mamy 15 kolumn (maks 15 znaków) i w nich umieszczać kolejne litery. Dla przykładu słowo "kot" w kolumnie pierwszej miałoby literę "k", w drugiej - "o", w trzeciej "t". W czwartej i kolejnych NA. Później lepiej policzyć ile jakich liter jest w danej kolumnie. To da ten czerwony wykres (pozycja liter w słowach).
Limit wierszy (i kolumn) dla data frame to limit dostępnego miejsca w pamięci. Przy większych rozmiarach danych warto skorzystać z jakiejś bazy - chociażby SQLowej, a w przypadku braku serwera - SQLite.