Czy da się rozpoznać kto jest autorem książki na podstawie jej treści? Są tacy badacze, którzy to robią (i na przykład podważają autorstwo niektórych dramatów Szekspira), my zrobimy to samo z kryminałami (bo jest to takie zadanie śledcze).
Na warsztat weźmiemy dwóch poczytnych polskich autorów, tak żebyście mieli szansę sprawdzić czy to co wychodzi jest zgodne z tym co znacie z książek. Oczywiście czytaliście je, prawda?
Mowa o Zygmuncie Miłoszewskim i jego trylogii o Teodorze Szackim oraz Remigiuszu Mrozie i jego trzech książkach o Joannie Chyłce. Do tego dorzucimy dwie książki – “Bezcennego” oraz “Enklawę”. Udamy, że nie wiemy kto je napisał. Żeby było trudniej – “Enklawa” podpisana jest przez Ove Løgmansbø, ale nawet sam Mróz na swojej stronie przyznaje się, że to jego pseudonim, zaś “Bezcenny” nie jest o Szackim.
Żeby było jeszcze zabawniej – ja (jeszcze, czeka właśnie w kolejce) nie czytałem żadnej książki Remigiusza Mroza, więc nie wiem o czym i o kim są (ta Chyłka to wynik tego co poniżej).
Czego potrzebujemy? Oczywiście tekstów książek. Powinny być w plikach tekstowych. Najprościej przenieść je do takiego formatu z plików .mobi przy pomocy oprogramowania Calibre – wczytujemy MOBI i konwertujemy na TXT.
Wszystkie pliki TXT nazwałem odpowiednio i umieściłem w jednym folderze. Kilka operacji i wczytujemy wszystko do jednej dużej tabeli, w której kolumny to: autor książki, jej tytuł i w kolejne wiersze tekstu.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 |
library(tidyverse) library(tidytext) library(wordcloud) theme_set(theme_minimal()) pl_stop_words <- read_lines("polish_stopwords.txt") # lista książek lista_ksiazek <- data_frame( autor = c("Miloszewski", "Miloszewski", "Miloszewski", "Miloszewski", "Mroz", "Mroz", "Mroz", "Mroz"), tytul = c("Bezcenny", "Gniew", "Uwiklanie", "Ziarno_prawdy", "Enklawa", "Kasacja", "Rewizja", "Zaginiecie") ) liczba_ksiazek <- nrow(lista_ksiazek) # nazwy plików - złożone z listy książek lista_ksiazek$plik <- paste0("ksiazki/", lista_ksiazek$autor, "-", lista_ksiazek$tytul, ".txt") # poprawiamy nazwiska i tytuły, żeby ładniej wyglądało :) lista_ksiazek$autor <- ifelse(lista_ksiazek$autor == "Mroz", "Remigiusz Mróz", "Zygmunt Miłoszewski") # dwie książki oznaczamy jako nieznani autorzy lista_ksiazek[1, "autor"] <- "Nieznany_A" lista_ksiazek[5, "autor"] <- "Nieznany_B" # polskie literki w tytułach - żeby ładniej było widać :) lista_ksiazek[3, "tytul"] <- "Uwikłanie" lista_ksiazek[4, "tytul"] <- "Ziarno prawdy" lista_ksiazek[8, "tytul"] <- "Zaginięcie" # książki do jednej tabeli ksiazki <- data_frame() for(i in 1:nrow(lista_ksiazek)) { ksiazka <- read_lines(as.character(lista_ksiazek[i, "plik"])) ksiazka <- tbl_df(ksiazka) %>% rename(text = value) %>% mutate(tytul = as.character(lista_ksiazek[i, "tytul"]), autor = as.character(lista_ksiazek[i, "autor"])) ksiazki <- rbind(ksiazki, ksiazka) } # usuwamy śmieci tymczasowe rm(ksiazka, lista_ksiazek, i) # usunięcie pustych linii ksiazki <- filter(ksiazki, nchar(text) != 0) |
Mamy więc wielką tabelę, zobaczmy co można powiedzieć o książkach.
Najpopularniejsze słowa w książkach
Autora można rozpoznać między innymi po tym jakich słów używa. Pojedynczych słów lub ich zbitek. Można też analizować na przykład długość zdań (liczbę wyrazów w zdaniu). Zajmijmy się częstością użycia słów, a żeby to policzyć potrzebujemy każdy wiersz rozbić na pojedyncze słowa:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
words <- ksiazki %>% unnest_tokens(words, text, token = "words") %>% # bez stop-words filter(!words %in% pl_stop_words) %>% # bez liczb # jeśli zamiana na liczbę da NA to znaczy że to nie liczba filter(is.na(as.numeric(words))) %>% count(autor, tytul, words) %>% ungroup() %>% group_by(tytul) %>% mutate(proc = 100*n/sum(n)) %>% ungroup() %>% # zmniejszymy tabelę usuwając słowa występujące tylko raz w książce # zostanie jakieś 37% danych filter(n > 1) |
Zobaczmy jak to wygląda – jakie słowa w poszczególnych książkach są najpopularniejsze?
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
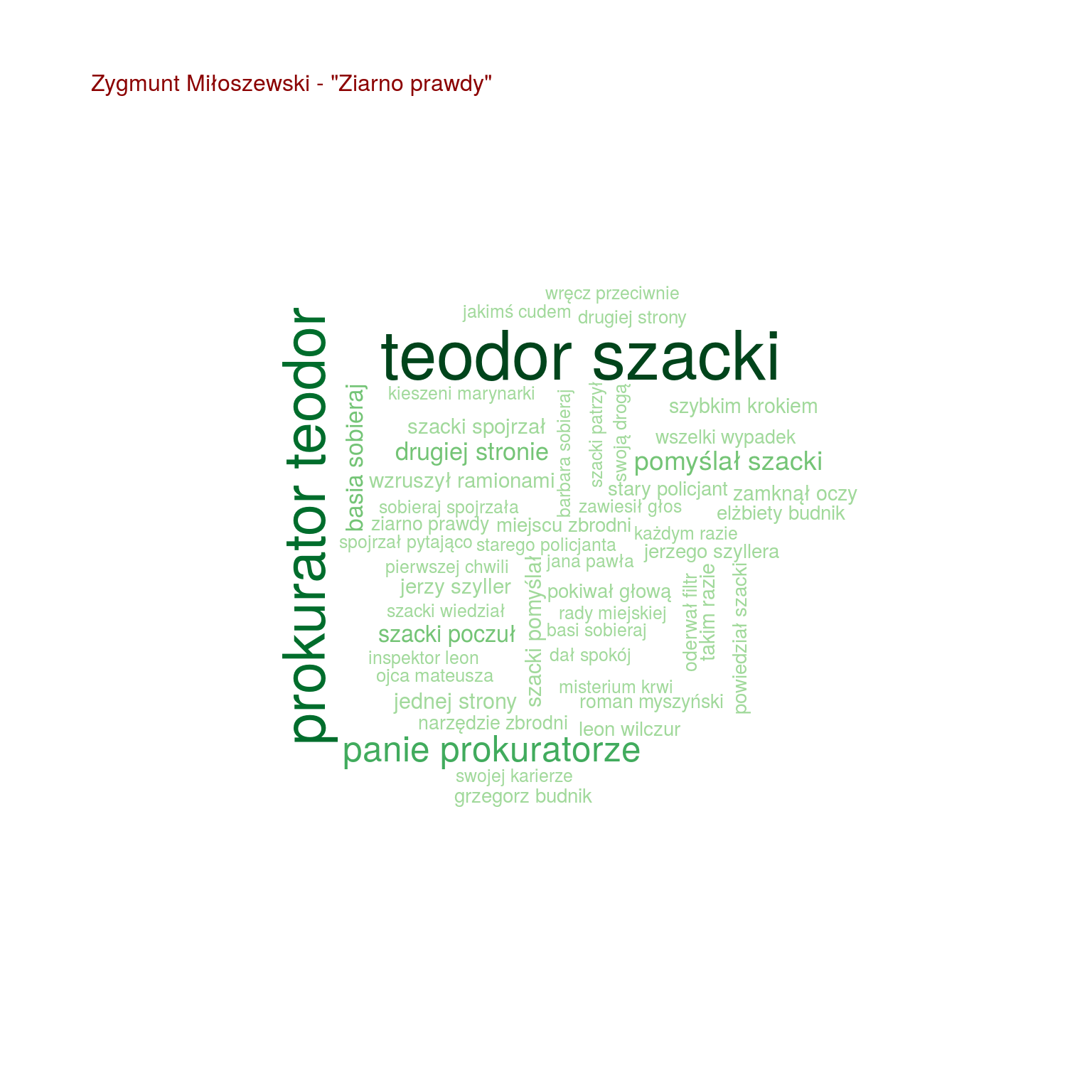
by(words, words$tytul, function(x) { wordcloud(x$words, x$n, max.words = 100, scale = c(2.0, 0.4), colors = RColorBrewer::brewer.pal(9, "Greens")[4:9]) text(0.05, 0.95, paste0(unique(x$autor), " - \"", unique(x$tytul), "\""), col="darkred", cex=1, adj=c(0,0)) cat("\n") } ) |
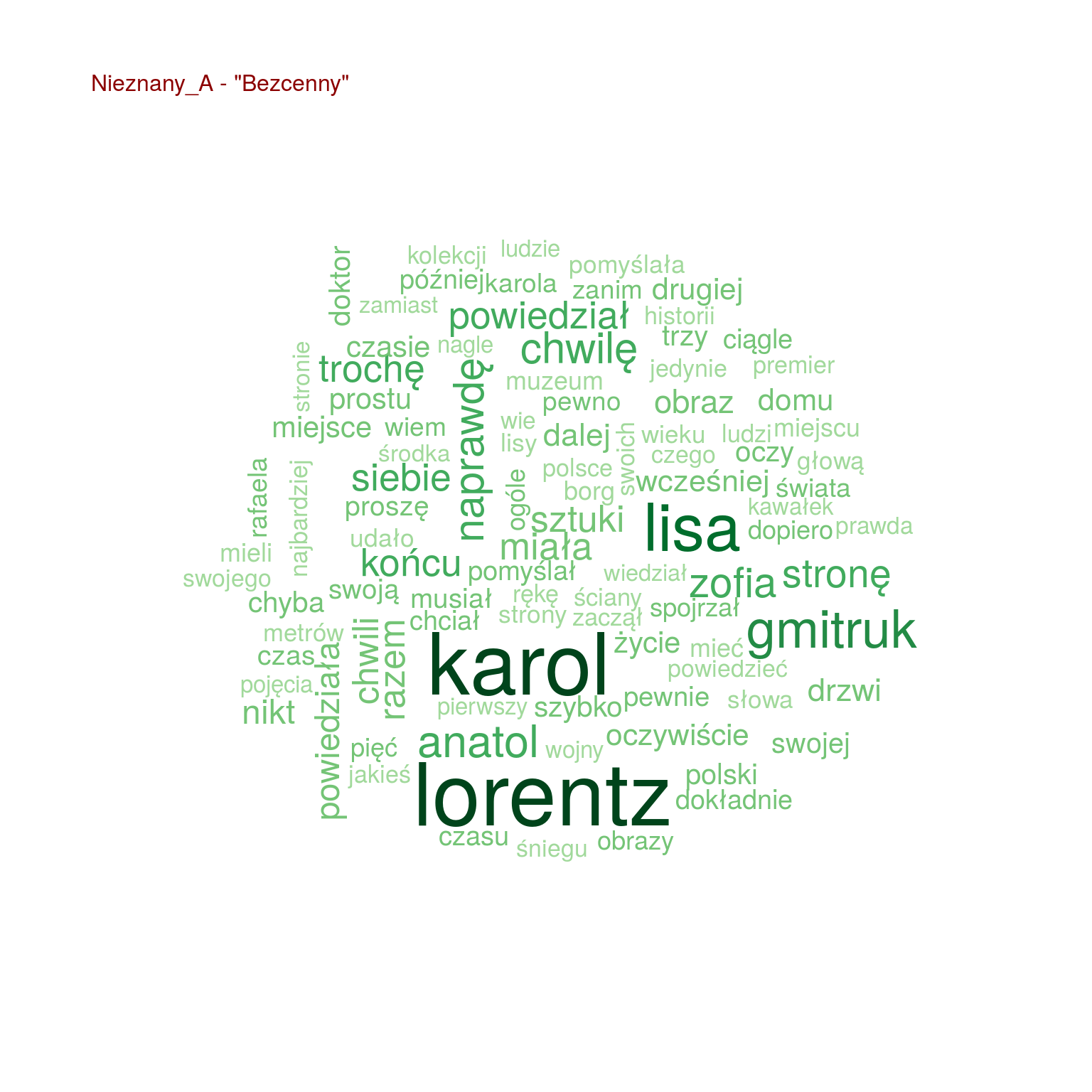
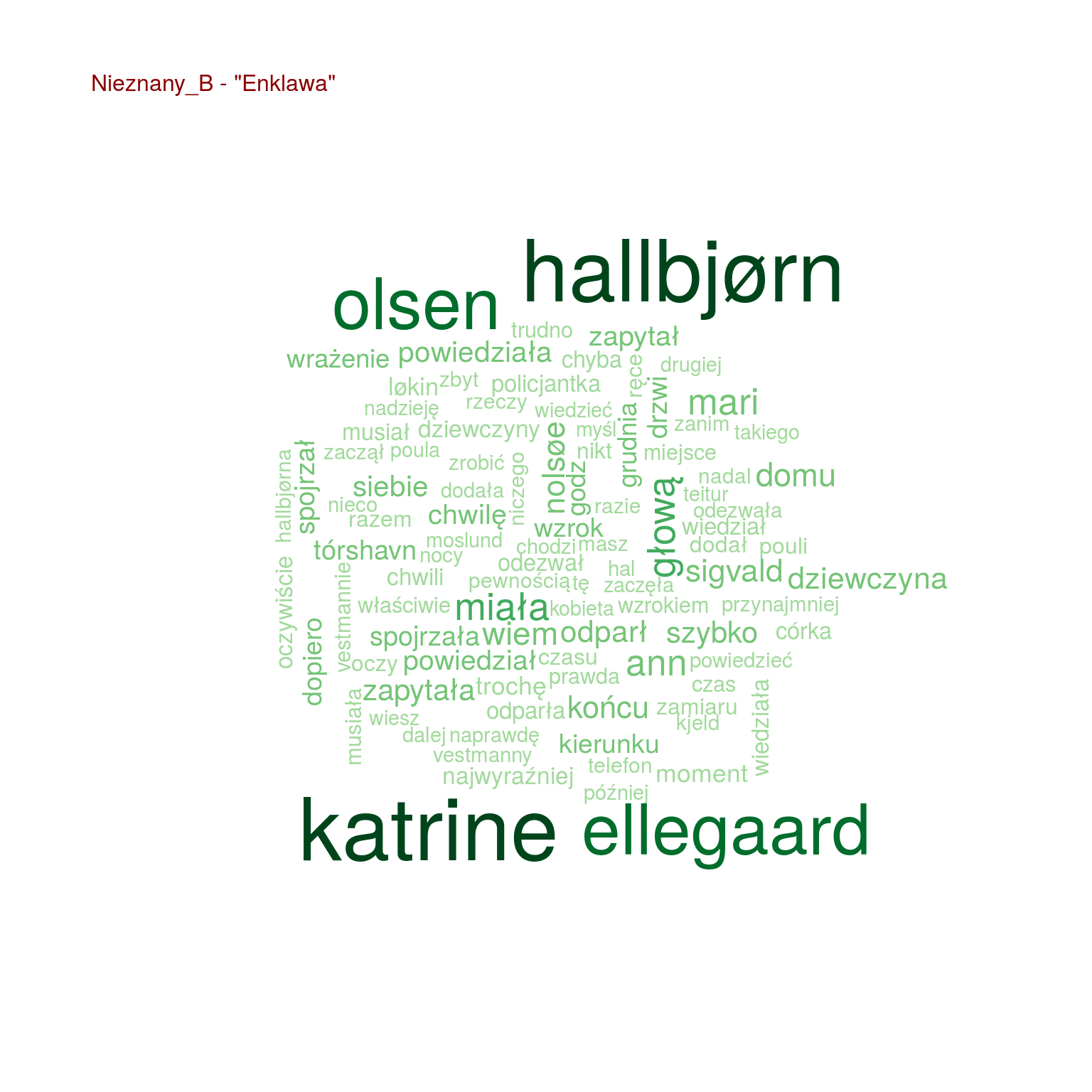
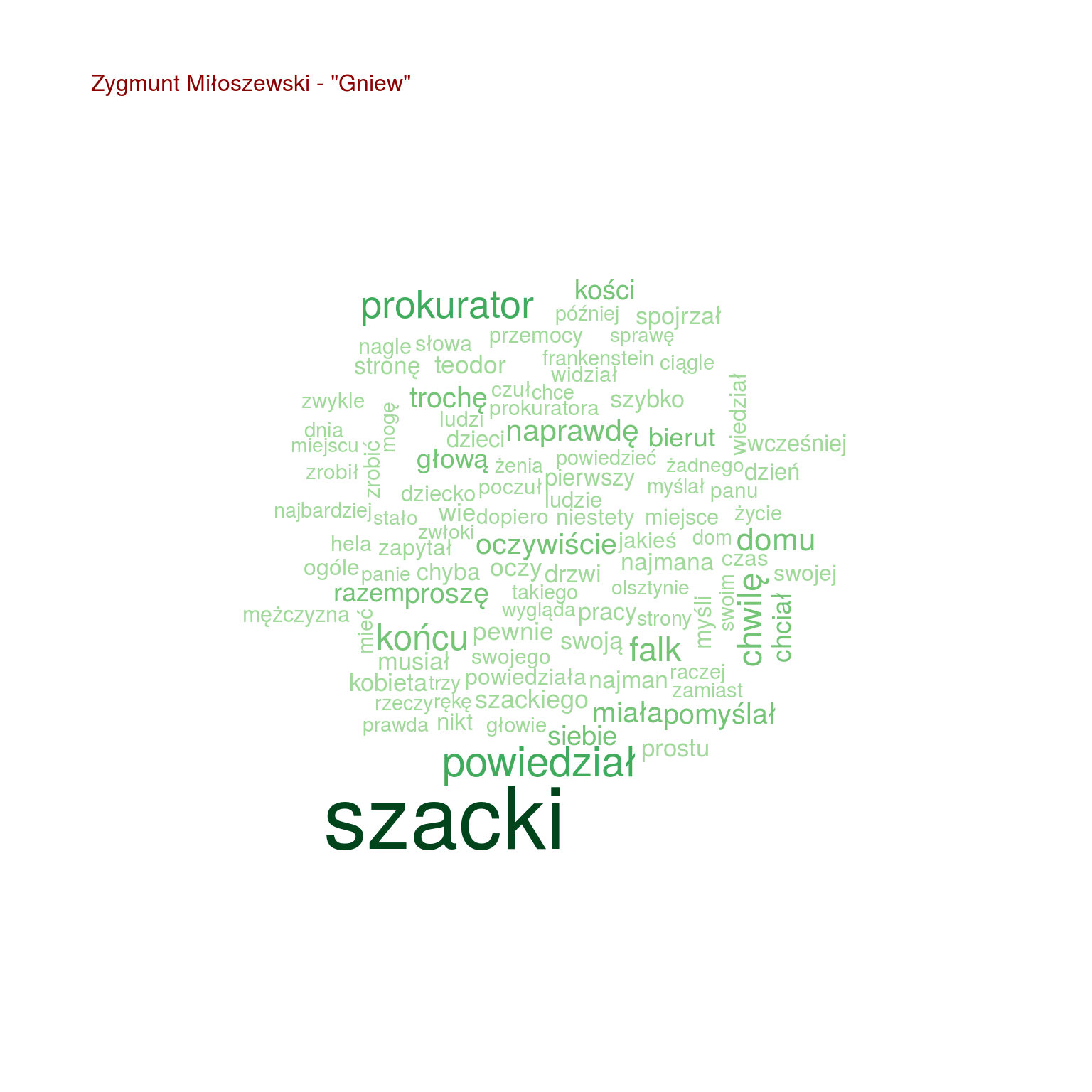
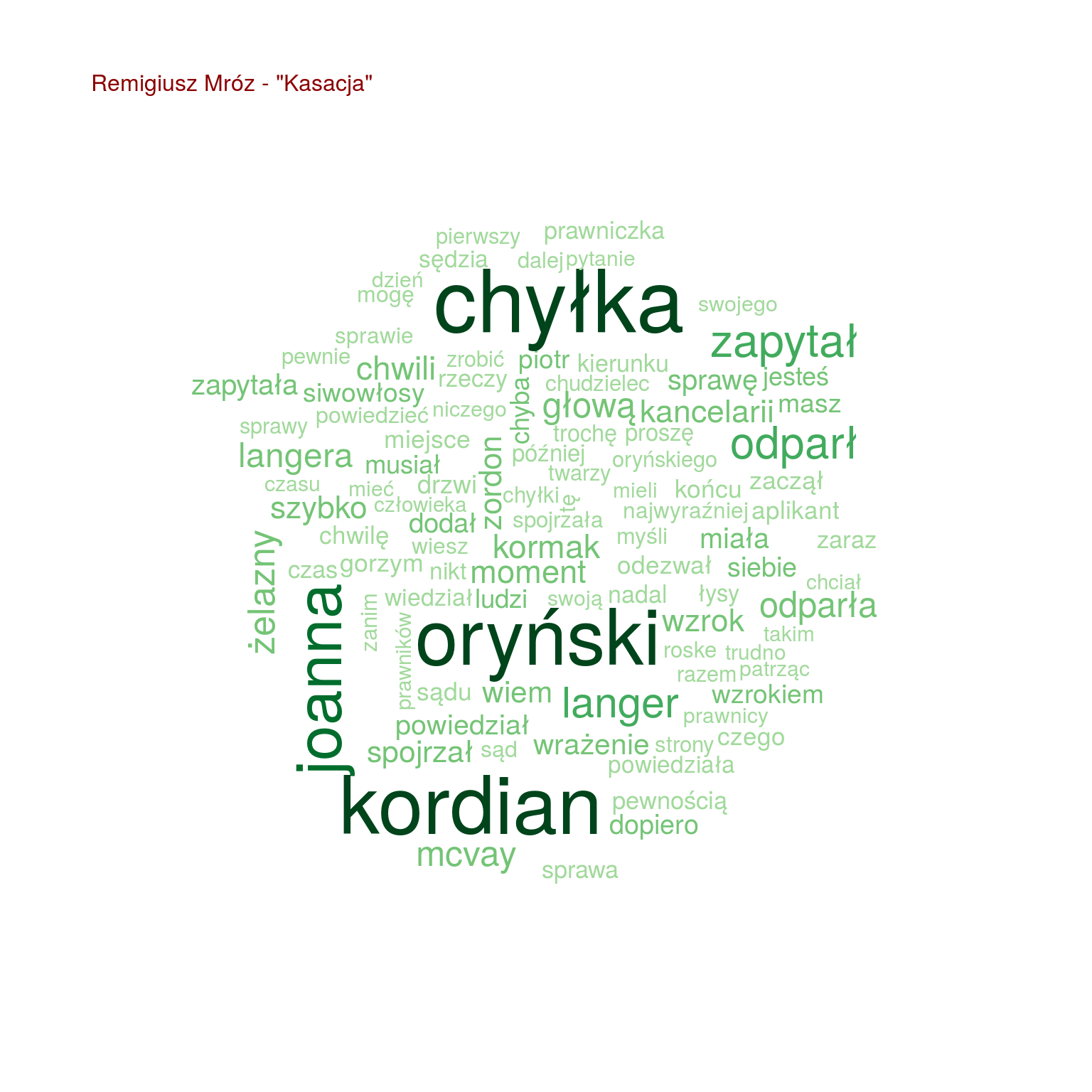
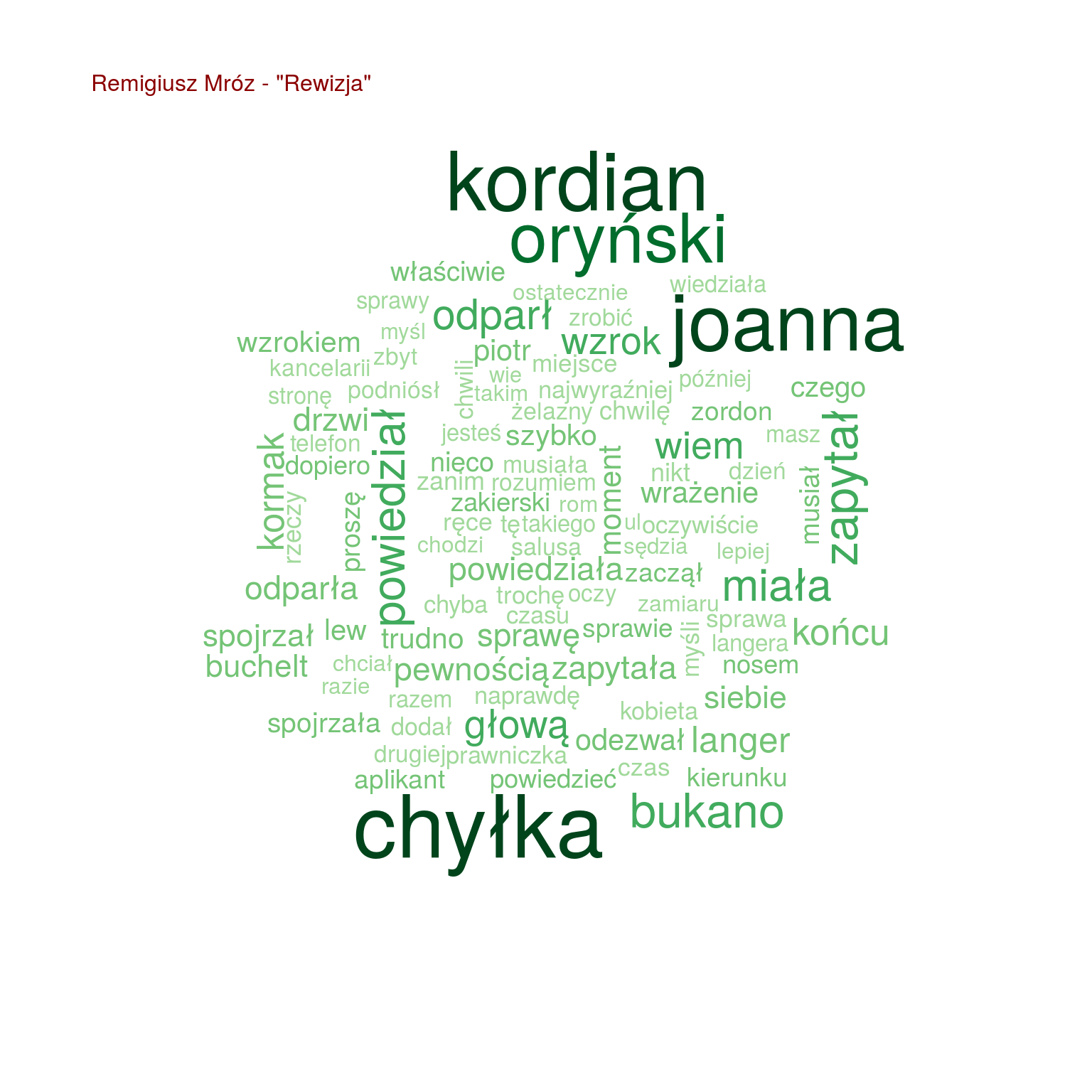
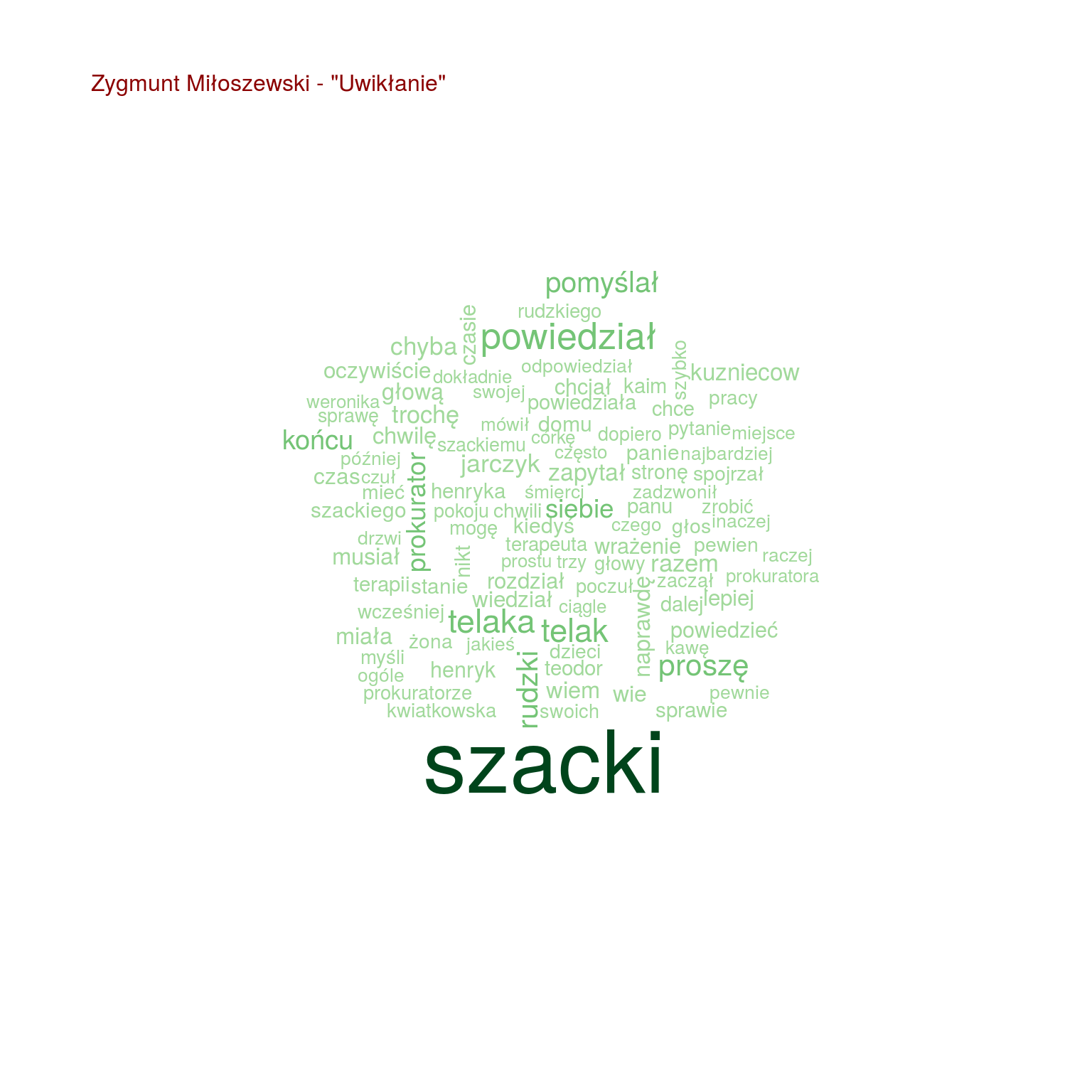
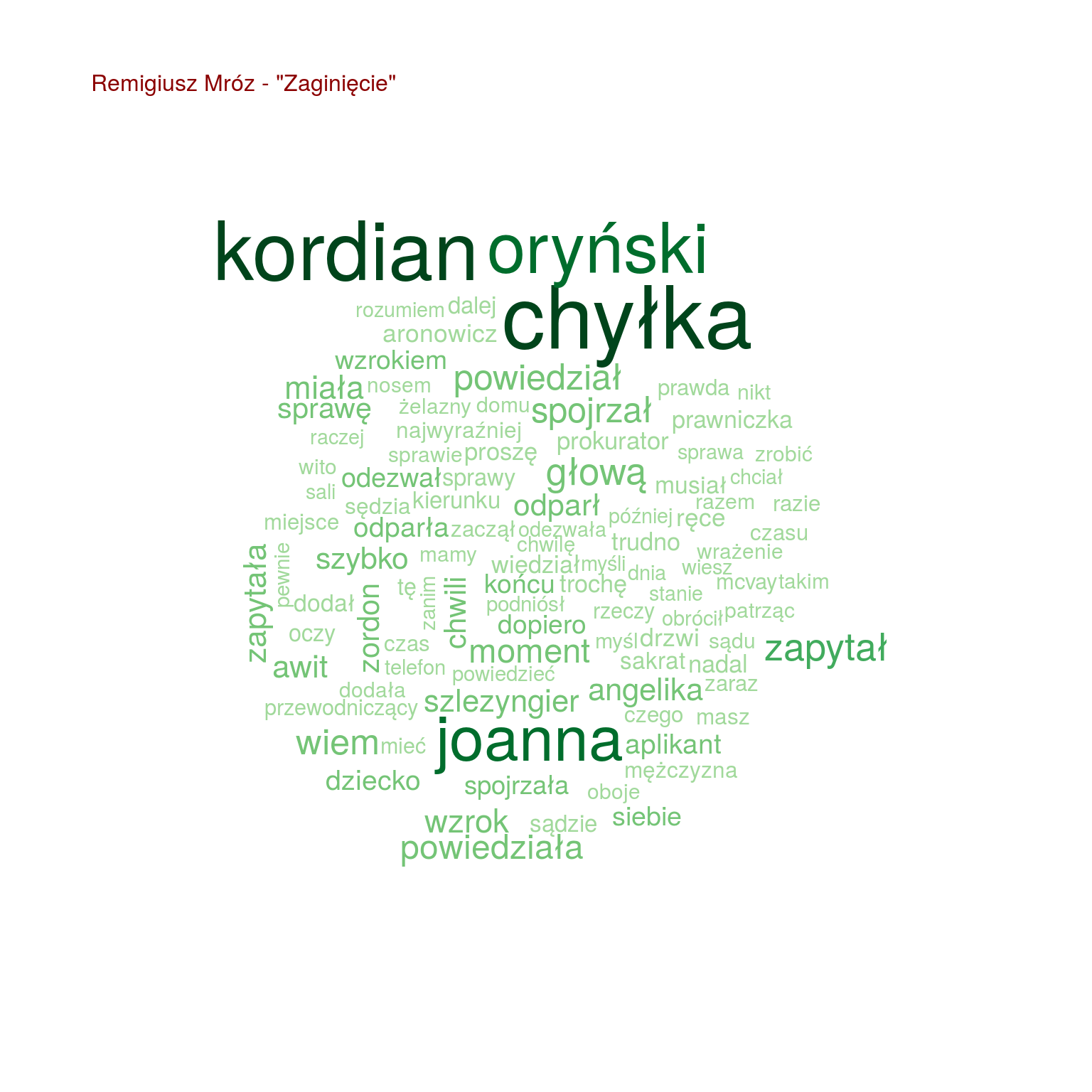
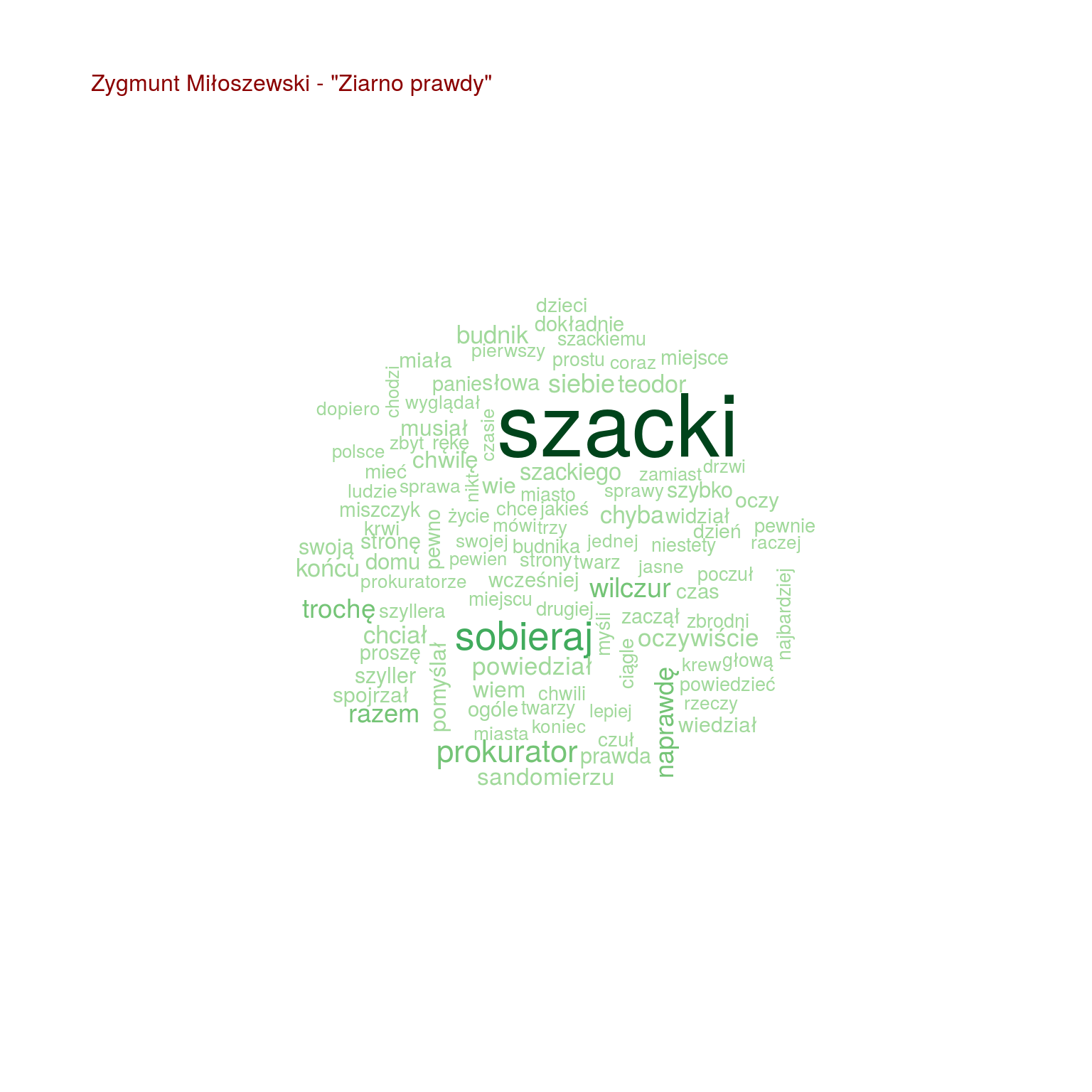
Chmurki są fajne, ale nie da się łatwo porównać popularności poszczególnych słów. Zestawmy po 20 najpopularniejszych słów z każdej z książek ze sobą, na jednym wykresie:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
words %>% group_by(tytul) %>% top_n(20, wt = proc) %>% ungroup() %>% # zabieg, żeby słowa były w porządku alfabetycznym od góry mutate(words = factor(words, levels = rev(sort(unique(words))))) %>% ggplot() + geom_bar(aes(words, proc, fill=tytul), stat="identity") + facet_wrap(~tytul, nrow = 1) + coord_flip() + theme(legend.position = "none") + labs(x="Słowo", y="Udział procentowy w tekście") |
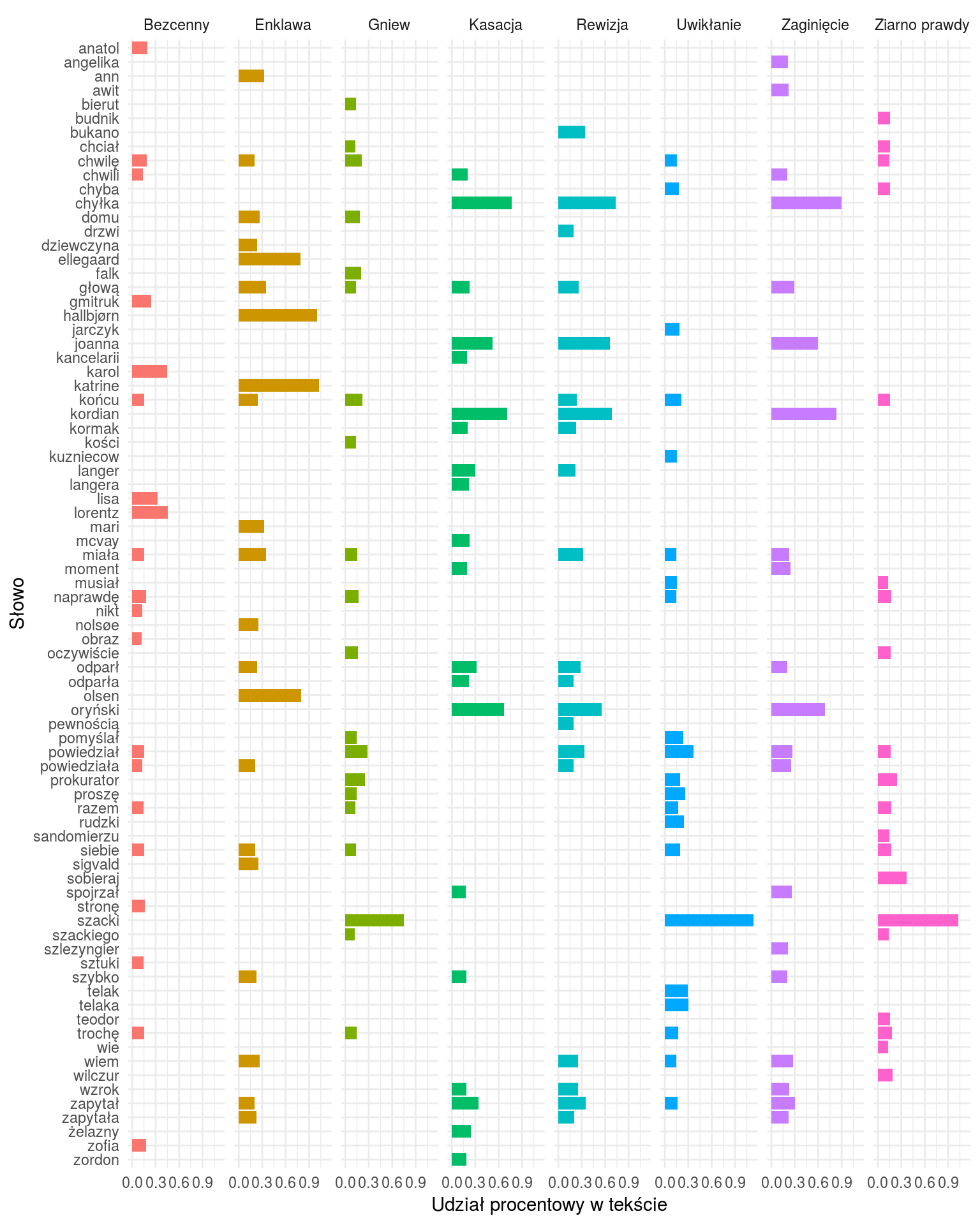
Teraz widać już o wiele więcej. Na przykład widać, że:
- Szacki występuje tylko trzech w książkach (Uwikłanie, Gniew oraz Ziarno prawdy – wiemy, że to książki Miłoszewskiego). Tak samo jest z imieniem Teodor, więc Szacki to może właśnie Teodor?
- i w dodatku w tych trzech książkach występuje jakiś prokurator – czyżby Teodor Szacki był prokuratorem?
- Chyłka występuje u trzech książkach (Rewizja, Zaginięcie, Kasacja – książki Mroza), podobnie Joanna (bo może to Joanna Chyłka?), Kordian i Oryński – czyżby to imiona bohaterów (książki jeszcze nie czytałem, przypominam)
- Olsen występuje w “Enklawie” – pasuje to do autora książki Ove Løgmansbø, podobnie jak Hallbjorn, Ellegaard czy Sigvald. Pewnie znowu bohaterowie
- obraz jest tylko w “Bezcennym” – czyżby o jakimś obrazie była ta książka? Słowo sztuki też naprowadza na taki trop
Ale są ciekawostki, które naprowadzają na autorstwo:
- zapytał oraz zapytała są o wiele częściej w książkach Mroza i “Enklawie” niż u Miłoszewskiego
- podobnie jest z głową
- pomyślał załapało się tylko u Miłoszewskiego – w Gniewie i w Uwikłaniu
Można tak dalej, słowo po słowie. Zobaczmy to samo nieco inaczej zaprezentowane:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
words %>% group_by(tytul) %>% top_n(20, wt = proc) %>% ungroup() %>% group_by(words) %>% mutate(p = mean(proc)) %>% ungroup() %>% arrange(p) %>% mutate(words = factor(words, levels=unique(words))) %>% ggplot() + geom_point(aes(words, proc, color=tytul)) + coord_flip() + facet_wrap(~autor, ncol = 2, scales = "free_x") + labs(x="Słowo", y="Udział procentowy w tekście", color="Tyutł książki") |
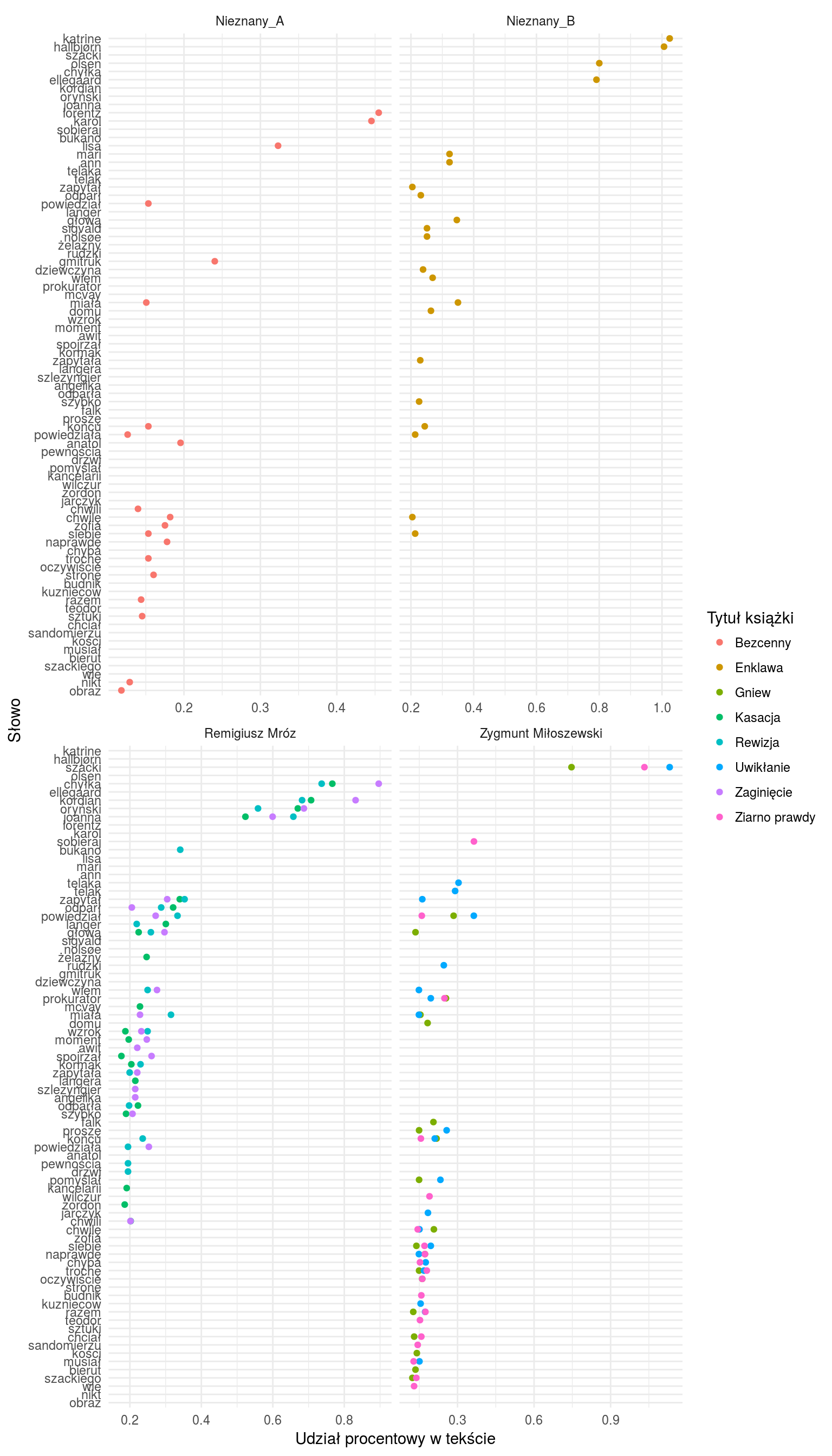
Bez wnikania w szczegóły (poszczególne słowa) widać od razu, że wykresy Nieznany_A oraz Zygmunt Miłoszewski mają zagęszczenie punktów w swojej dolnej części, a w tych samych miejscach Nieznany_B oraz Remigiusz Mróz mają raczej pusto. Analogicznie (ale odwrotnie – Nieznany_A i Miłoszewski mają mniej, Mróz i Nieznany_B mają więcej) jest w środkowej części wykresów.
Weźmy teraz
słowa, które występują we wszystkich książkach
i skupmy się na nich.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
common_words <- words %>% group_by(words) %>% mutate(n_ksiazek = n()) %>% ungroup() %>% filter(n_ksiazek == liczba_ksiazek) %>% # średni udział słów na autora group_by(autor, words) %>% summarise(proc = mean(proc)) %>% ungroup() # zmiana nazwisk, żeby kolumny się przyjemniej nazywało w kodzie common_words$autor <- ifelse(common_words$autor == "Remigiusz Mróz", "Mroz", common_words$autor) common_words$autor <- ifelse(common_words$autor == "Zygmunt Miłoszewski", "Miloszewski", common_words$autor) # pivot common_words <- spread(common_words, autor, proc) |
Mając tak przygotowane dane może wreszcie odpowiemy na pytanie
Kto napisał tę książkę?
Trochę już co prawda wywnioskowaliśmy (pamiętacie – NieznanyA to pewnie Miłoszewski, zaś NieznanyB to Mróz), ale sprawdźmy to jakimiś twardymi liczbami.
Na początek najprostsza rzecz, czyli
metoda korelacji
|
1 2 |
library(corrgram) corrgram(common_words, lower.panel = panel.shade, upper.panel = panel.cor) |
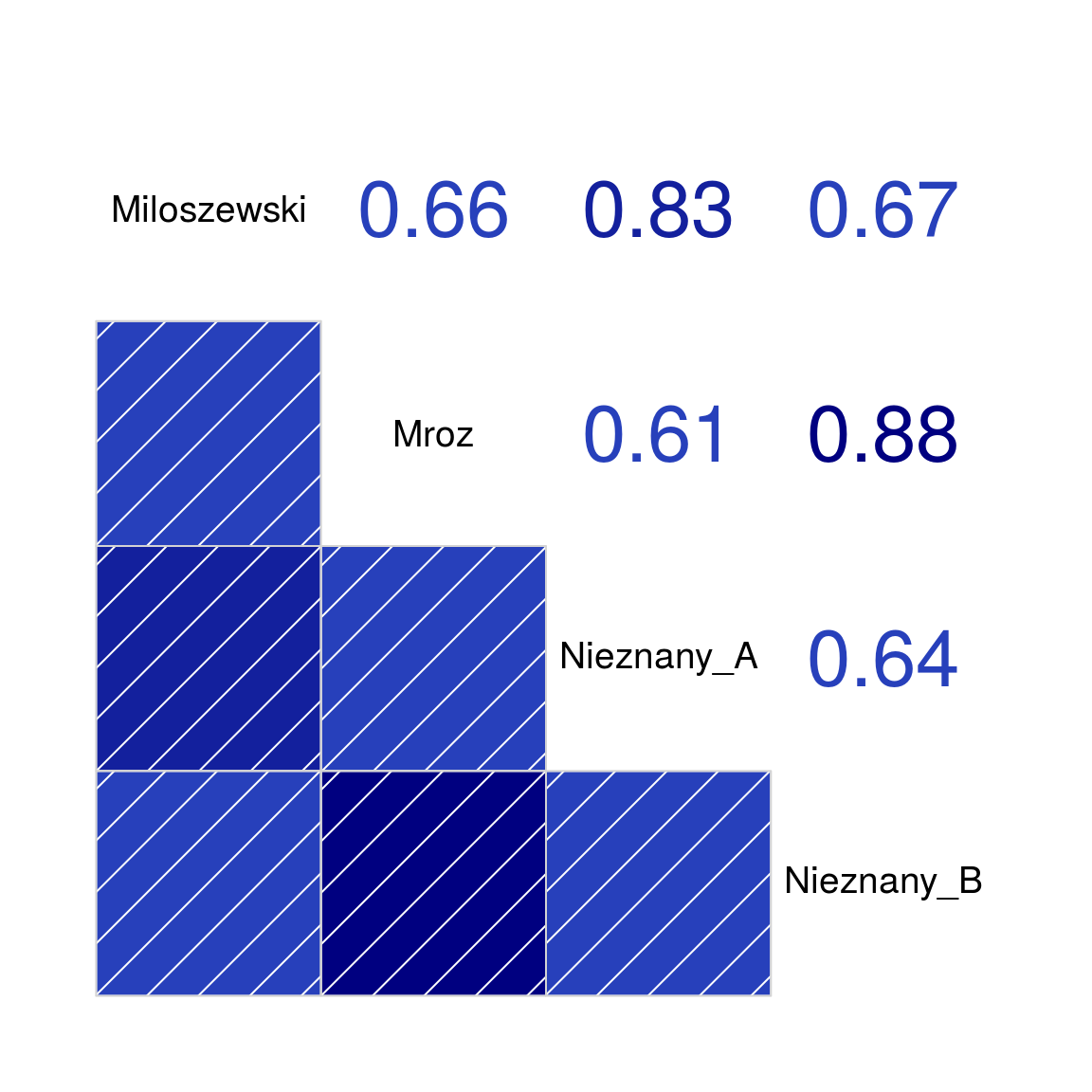
Z macierzy korelacji widać, że największe współczynniki mają pary Nieznany_A – Miłoszewski oraz Nieznany_B – Mróz. Dodatkowo są to korelacje bardzo silne.
Książka napisana przez Nieznany_A to Bezcenny zaś Nieznany_B jest autorem Enklawa. Zgada się, prawda?
Teraz spróbujmy inaczej.
Statystyka
Proponuję metodę, gdzie oprzemy się na najmniejszej odległości (różnicy) między częstością słów w tekście (ich procentowym udziałem). A takie odległości potraktujemy statystycznymi miarami – średnią, medianą i odchyleniem standardowym i porównamy te współczynniki. Tak sobie wymyśliłem, nie wiem czy się sprawdzi.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
common_words %>% # liczymy odległości pomiędzy udziałem słów # w poszczególnych parach autorów - nieznani ze znanymi mutate(NA_Miloszewski = abs(Nieznany_A - Miloszewski), NB_Miloszewski = abs(Nieznany_B - Miloszewski), NA_Mroz = abs(Nieznany_A - Mroz), NB_Mroz = abs(Nieznany_B - Mroz)) %>% select(NA_Miloszewski, NA_Mroz, NB_Miloszewski, NB_Mroz) %>% # dla każdej z odległości liczymy podstawowe współczynniki statystyczne: # średnią, medianę i odchylenie standardowe map_df(.f = function(x) { data_frame(srednia = mean(x), mediana = median(x), odchylenie_std = sd(x)) }, .id = "para") %>% # unpivot tabeli na potrzeby wykresu gather(key="key", value="val", srednia, mediana, odchylenie_std) %>% # liczby są małe to je skalujemy, żeby było czytelniej mutate(val = 1000 * val) %>% # wykres ggplot() + geom_bar(aes(para, val), stat="identity", fill="lightgreen", color="darkgreen") + # dodajmy liczby, żeby było łatwiej porównać wielkość słupków geom_text(aes(para, val, label=round(val, 2)), hjust = 1.2) + facet_wrap(~key, ncol=3) + coord_flip() + labs(x="Para autorów", y="") |
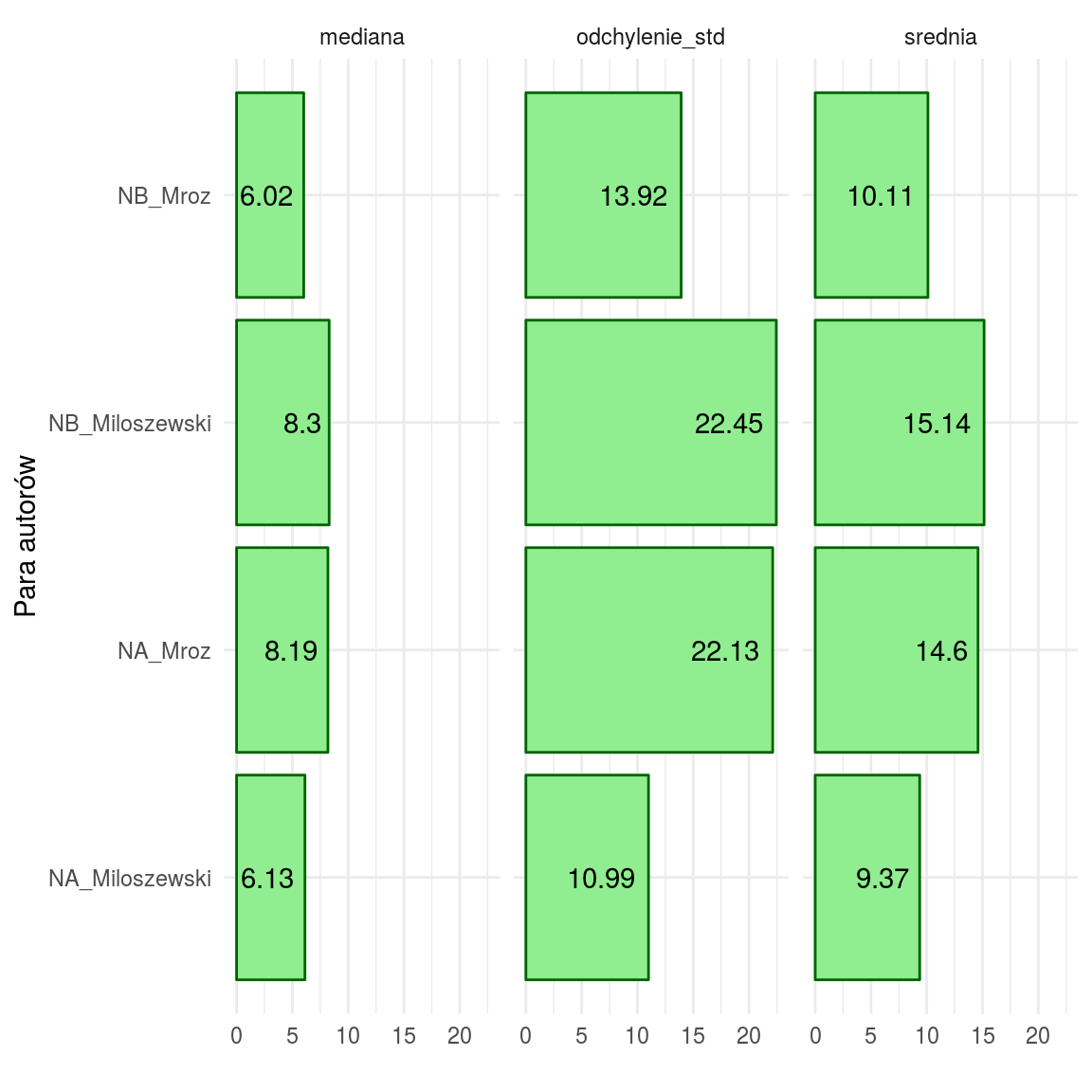
Interesują nas najmniejsze wartości, bo one oznaczają najmniejszą różnicę. Z wykresu widać, że najmniejsze wartości dla każdego z czynników mają pary NA_Miłoszewski oraz NB_Mróz.
Czyli dokładnie tak samo jak wcześniej! Znowu się udało! To już kolejny raz, zagadka chyba rozwiązana?
bi-gramy
Jak już mamy dane to zobaczmy jakie są najpopularniejsze dwuwyrazowe zbitki w poszczególnych książkach:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
biwords <- ksiazki %>% unnest_tokens(words, text, token = "ngrams", n=2) %>% separate(words, c("word1", "word2")) %>% filter(!word1 %in% pl_stop_words, is.na(as.numeric(word1))) %>% filter(!word2 %in% pl_stop_words, is.na(as.numeric(word2))) %>% unite(words, word1, word2, sep = " ") %>% count(tytul, autor, words) %>% ungroup() by(biwords, biwords$tytul, function(x) { wordcloud(x$words, x$n, max.words = 50, scale = c(1.8, 0.4), colors = RColorBrewer::brewer.pal(9, "Greens")[4:9]) text(0.05, 0.95, paste0(unique(x$autor), " - \"", unique(x$tytul), "\""), col="darkred", cex=1, adj=c(0,0)) cat("\n") } ) |
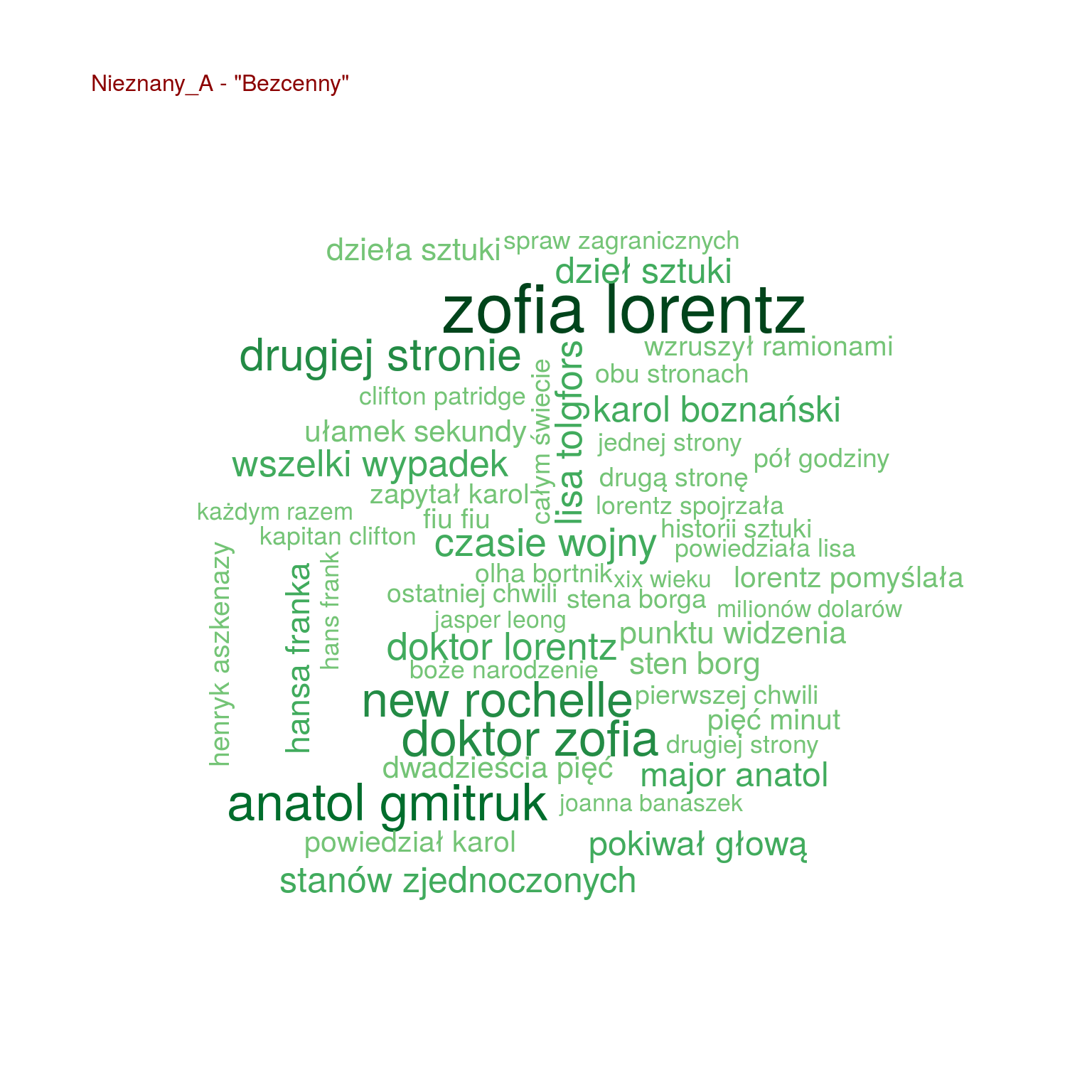
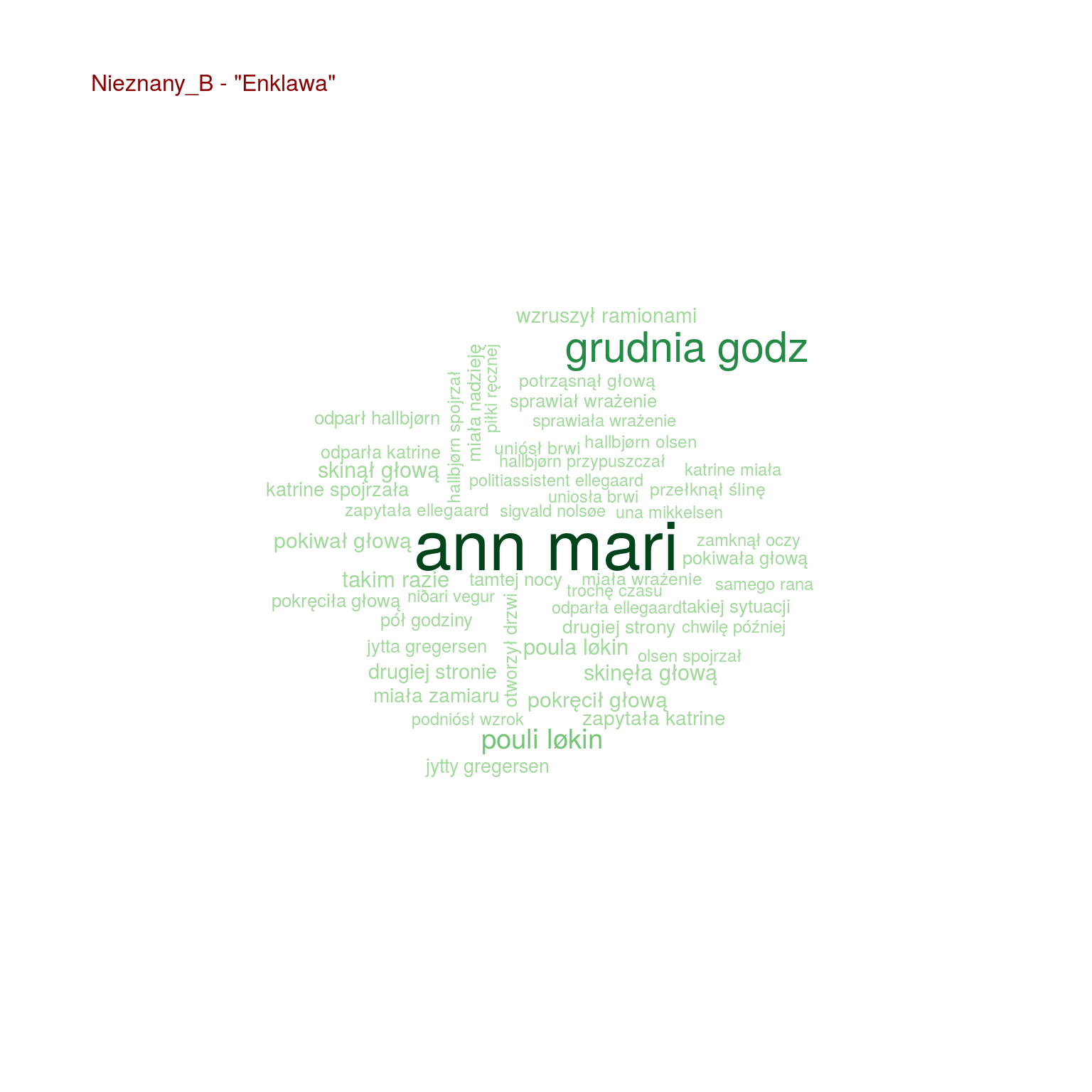
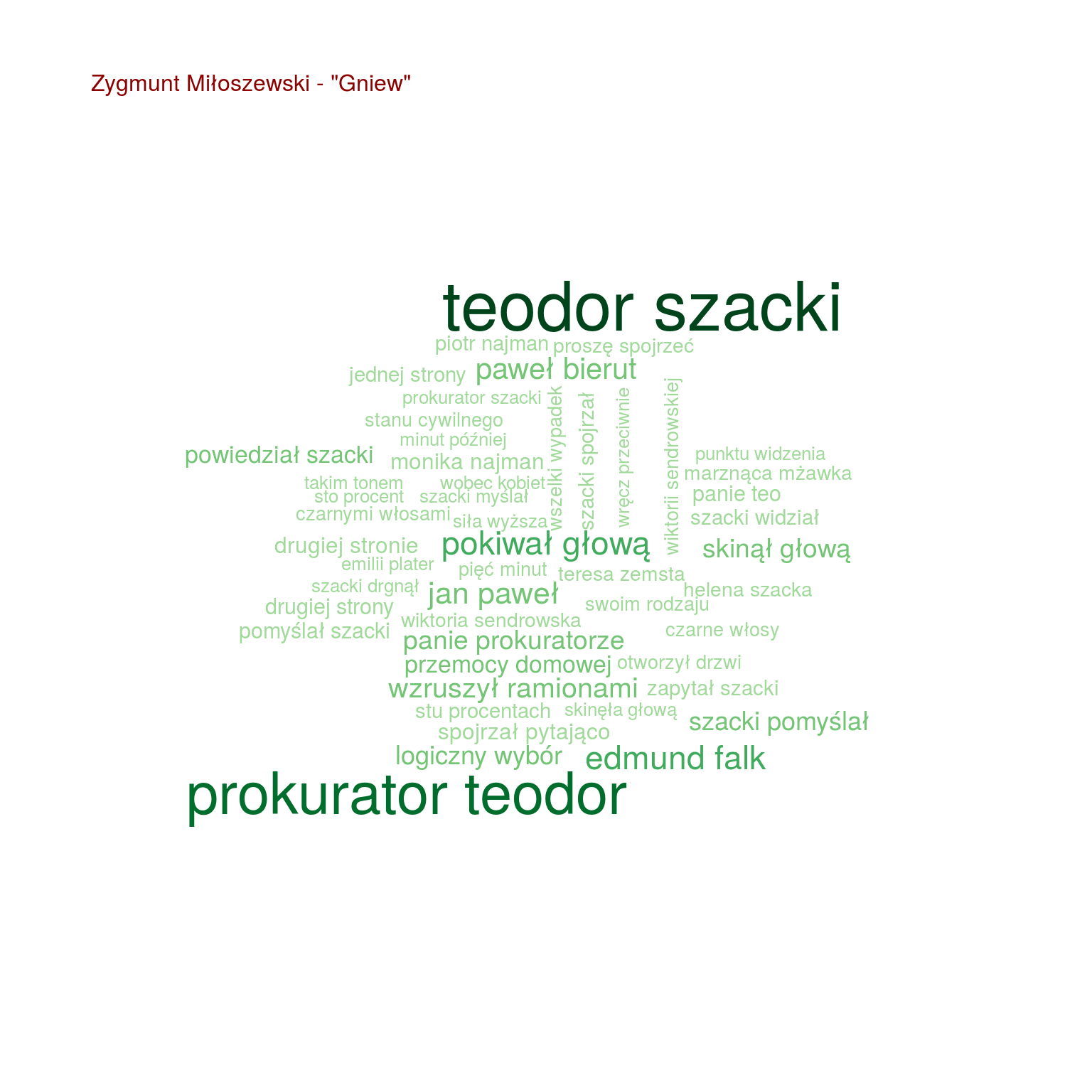


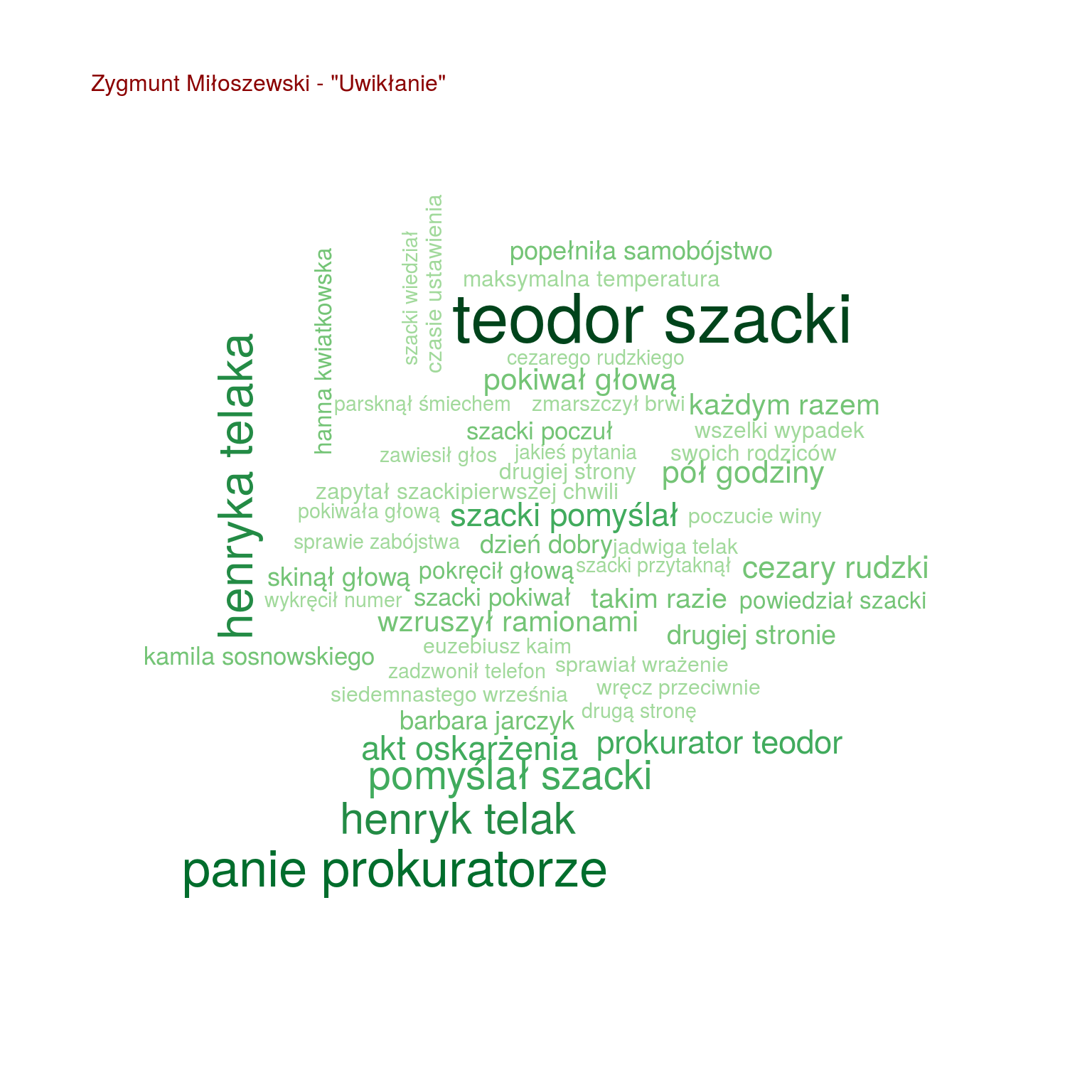

Widać na przykład, że u Mroza pokiwał głową występuje częściej niż u Miłoszewskiego. W ogóle u Mroza dużo z głową robią (kiwają, kręcą, jedna pani zaś skinęła i to wiele razy).
Tutaj można zrobić dokładnie to samo co z pojedynczymi słowami – zestawić takie same zbitki u obu (właściwie czterech – w końcu co do dwóch Nieznanych nie mamy pewności) autorów i policzyć wzajemne korelacje lub odległości. Mechanika jest dokładnie taka sama jak wyżej. Danych jest jednak mniej i w związku z tym wyniki mogą nie wyjść tak wyraźnie.
Zróbmy to samo dla trójek wyrazów, czyli
tri-gramy
|
1 2 3 4 5 6 7 8 9 |
triwords <- ksiazki %>% unnest_tokens(words, text, token = "ngrams", n=3) %>% separate(words, c("word1", "word2", "word3")) %>% filter(!word1 %in% pl_stop_words, is.na(as.numeric(word1))) %>% filter(!word2 %in% pl_stop_words, is.na(as.numeric(word2))) %>% filter(!word3 %in% pl_stop_words, is.na(as.numeric(word3))) %>% unite(words, word1, word2, word3, sep = " ") %>% count(tytul, autor, words) %>% ungroup() |
Usuwamy trójki, które występuja najczęściej w każdej z książek (wcześniej obejrzałem te same chmurki bez filtrowania) – żeby obrazki były bardziej czytelne:
|
1 2 3 4 |
triwords <- filter(triwords, !words %in% c("kancelarii żelazny mcvay", "argentyńska saska kępa", "ul argentyńska saska", "prokurator teodor szacki")) |
Pierwsza trójka usuniętych to książki Mroza (bez Enklawy), ostatnia – to oczywiście Miłoszewski (bez Bezcennego). Rysujemy takie wyczyszczone chmurki:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
by(triwords, triwords$tytul, function(x) { wordcloud(x$words, x$n, max.words = 50, scale = c(1.0, 0.4), colors = RColorBrewer::brewer.pal(9, "Greens")[4:9]) text(0.05, 0.95, paste0(unique(x$autor), " - \"", unique(x$tytul), "\""), col="darkred", cex=1, adj=c(0,0)) cat("\n") } ) |






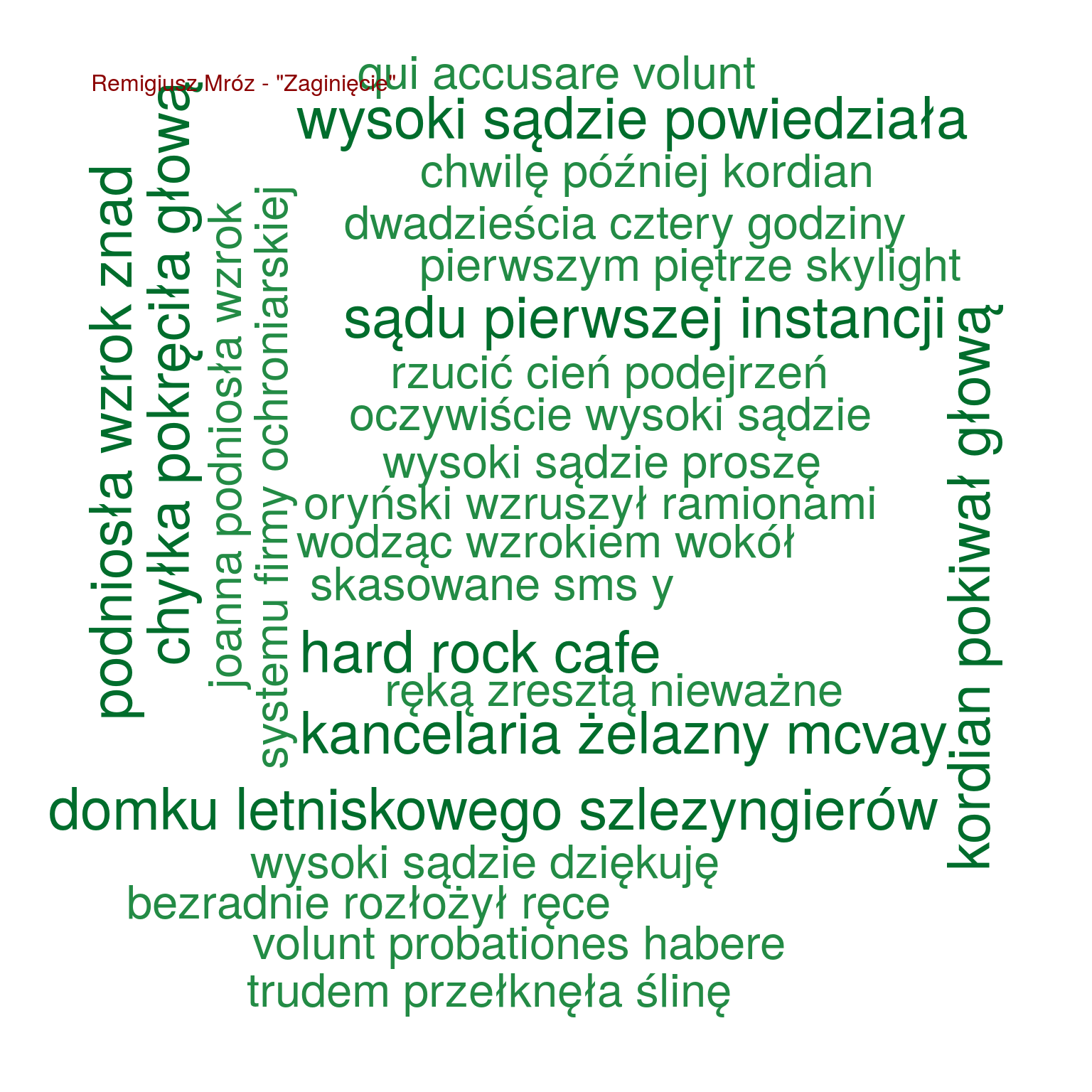

Widzę, że to co mnie czeka u Remigiusza Mroza to XXI piętro wieżowca Skylight, Hard Rock Cafe i Saska Kępa (ulica Argentyńska konkretnie). Znaczy – w Warszawie się będzie działo. Wśród prawników z kancelarii Żelazny McVay, która mieści się na Saskiej Kępie?
Dowiem się już niedługo.
Pingback: Polskie liter(a)ki | Łukasz Prokulski
Trafiłem przypadkiem na Pana bloga, poprzez dziennikarz.pl (jakiś z komentarzy Pana mnie pokierował tu) – zostanę baardzo długo. Wrócę do domu to zacznę porównywać sobie w podobny sposób prace Sienkiewicza z na przykład Arthurem Conanem Doyle :)
Proszę dać znać co wyszło!
Pingback: Newsletter Dane i Analizy, 2024-08-26 | Łukasz Prokulski