Gdzie mieszkasz? I gdzie pracujesz?
Daj mi dane z Google Takeout i powiem Ci wszystko!
Google nas śledzi. Wie jakie strony oglądamy, jakie filmy. Jeśli używamy Google Maps i mamy włączone śledzenie lokalizacji w telefonie – wie gdzie jesteśmy. I jeszcze do tego zarabia na tym pieniądze.
Ja mam (i wcale się tego nie boję). Dzięki temu za darmo mam dane, którymi mogę się pobawić, a co więcej – wiem dlaczego te dane są takie a nie inne, rozumiem je najlepiej jak tylko się da. Bo to moje życie.
Ale gdyby tak ktoś chciał na podstawie tylko jednej porcji danych (tych o lokalizacji) dowiedzieć się czegoś o nas… co może zobaczyć? W bardzo prosty sposób bardzo dużo. Odsłonię trochę siebie.
Na początek potrzebujemy pliku JSON z historią lokalizacji. Wchodzimy na Google Takeout i zlecamy przygotowanie danych zaznaczając Location History w formacie JSON. Po jakimś czasie (do kilkudziesięciu minut) dane trafią we wskazane w kolejnych krokach miejsce.
Teraz bierzemy je na waRsztat.
|
1 2 3 4 5 6 7 8 9 10 11 12 |
library(dplyr) library(lubridate) library(rjson) # wyjątkowo nie jsonlite, bo sobie nie umiało poradzić z plikiem :( # ścieżka do pliku z Google Takeout json_file <- "Takeout/Location History/LocationHistory.json" json <- fromJSON(file=json_file) # w odpowiedzi mamy listę, którą przekształcamy na ramkę danych locations <- as.data.frame(do.call(rbind, json$locations)) |
To potrwa jakiś czas (im więcej danych tym dłużej), a finalnie w locations dostajemy mięso, z którego najważniejsze są trzy kolumny zawierające moment rejestracji położenia określony w milisekundach oraz samą lokalizację (długość i szerokość geograficzna) – w stopniach kątowych przemnożonych (cholera wie po co – pewnie żeby trzymać w bazie inty a nie floaty) przez 10 milionów.
|
1 2 3 4 5 |
locations <- locations %>% select(timestampMs, longitudeE7, latitudeE7) %>% transmute(timestamp=as.numeric(timestampMs)/1000, long=as.numeric(longitudeE7)/10000000, lat=as.numeric(latitudeE7)/10000000) |
Trochę przekształceń daty i rozbicie jej na atomowe części:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
locations$Date <- as_datetime(locations$timestamp) locations$year <- year(locations$Date) locations$month <- month(locations$Date) locations$day <- day(locations$Date) locations$hour <- hour(locations$Date) locations$minute <- minute(locations$Date) # dni tygodnia locations$weekday <- wday(locations$Date) locations$weekday <- factor(locations$weekday, levels = c(2,3,4,5,6,7,1), labels = c("poniedziałek", "wtorek", "środa", "czwartek", "piątek", "sobota", "niedziela")) # można się już pozbyć timestamp locations$timestamp <- NULL |
i dane gotowe, w układzie zrozumiałym od razu dla przeciętnego człowieka.
Ile danych mamy dla poszczególnych dni?
|
1 2 3 4 5 6 7 8 9 |
library(ggplot2) theme_set(theme_minimal()) locations %>% count(year, month, day) %>% ggplot() + geom_line(aes(make_date(year, month, day), n), color="gray") + labs(x="", y="") |
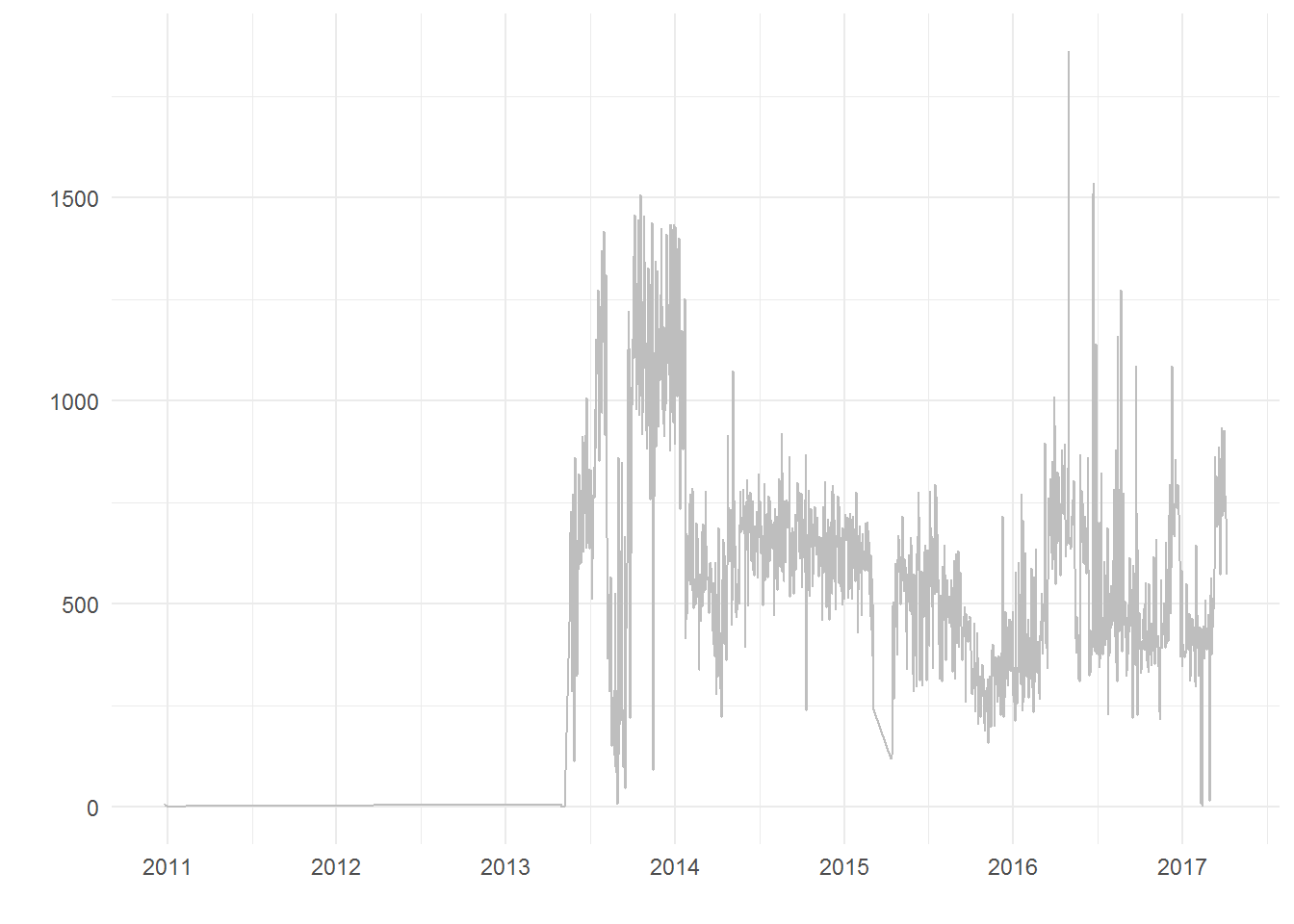
Widać, że sensowne dane (o mnie) zaczynają się gdzieś w okolicy kwietnia 2013. Usuwamy więc wcześniejsze dane.
|
1 |
locations <- filter(locations, year>=2013) |
Zobaczmy gdzie bywałem i kiedy
Najpierw jednak przygotujemy uśrednione dane godzinowe – będzie dzięki temu mniej danych, szybciej będzie się wszystko rysowało. Można oczywiście operować na wszystkich danych.
|
1 2 3 4 |
locations_hour <- locations %>% group_by(year, month, day, weekday, hour) %>% summarise(long=mean(long), lat=mean(lat)) %>% ungroup() |
Wiem, że w ostatnich 4 latach nie ruszyłem się poza Europę (Chiny były dawno temu… niestety), więc mapa starego kontynentu wystarczy. Pobieramy
|
1 2 |
library(ggmap) map_eu <- get_map(location = c(lon=10, lat=52), zoom = 4) |
i rysujemy mapę, a nawet kilka – każdy rok osobno:
|
1 2 3 4 5 6 7 |
ggmap(map_eu, darken = 0.3) + geom_count(data=locations_hour, aes(long, lat, alpha=..prop..), size=1, color="red") + scale_alpha(range = c(0.2, 0.8)) + facet_wrap(~year) + theme_void() + theme(legend.position = "none") |
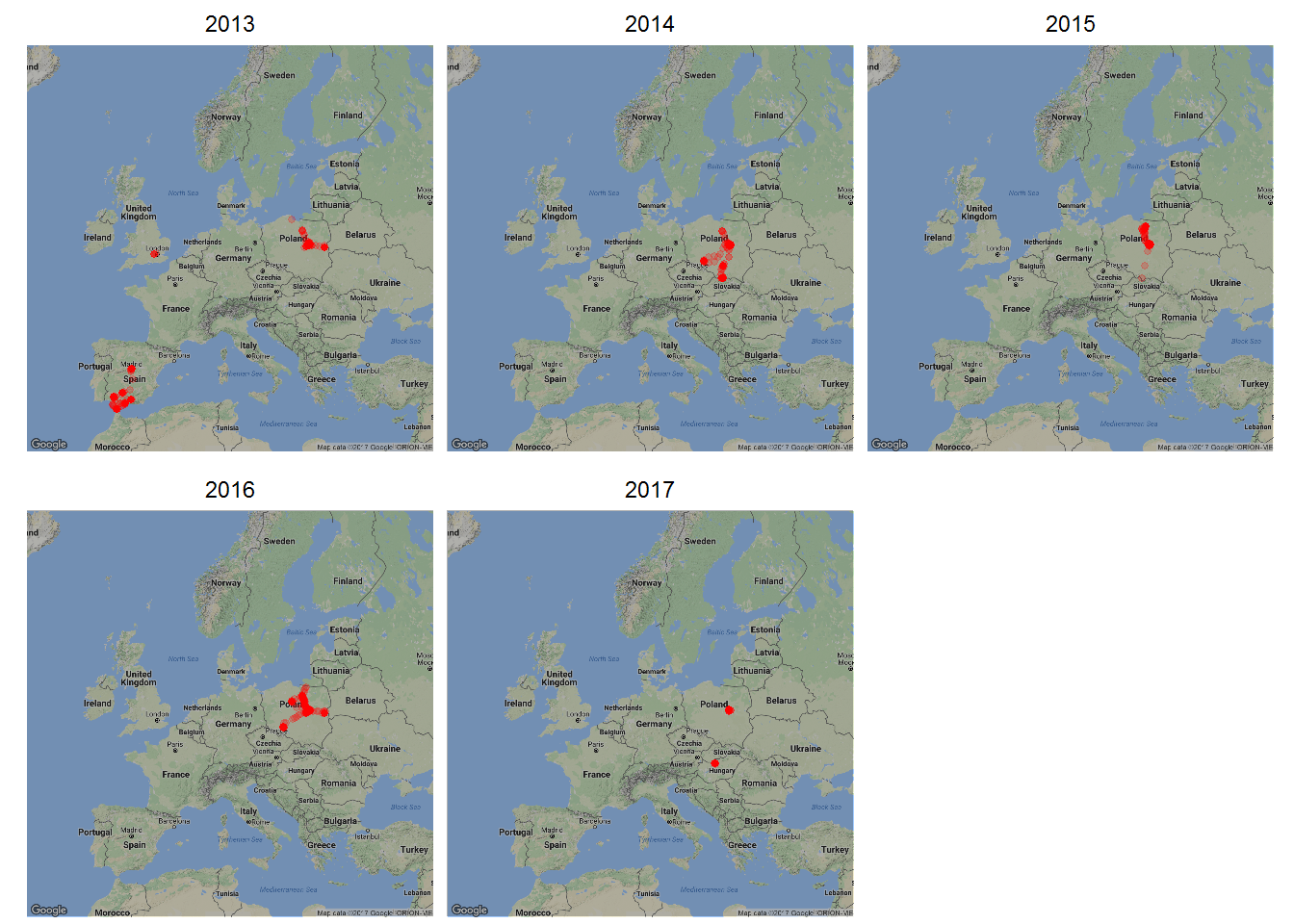
wszystko się zgadza (o ile pamiętam miejsca, bo z datami już gorzej):
- mieszkam gdzieś w środku Polski
- w 2013 zrobiliśmy objazd Andaluzji, z lotem do i z Madrytu przez Londyn
- w 2017 zdążyłem odwiedzić Budapeszt
Przybliżmy Polskę:
|
1 2 3 4 5 6 7 8 9 |
map_pl <- get_map(location = c(lon=19, lat=52), zoom = 6) ggmap(map_pl, darken = 0.3) + geom_count(data=locations_hour, aes(long, lat, alpha=..prop..), size=1, color="red") + scale_alpha(range = c(0.3, 0.8)) + facet_wrap(~year) + theme_void() + theme(legend.position = "none") |
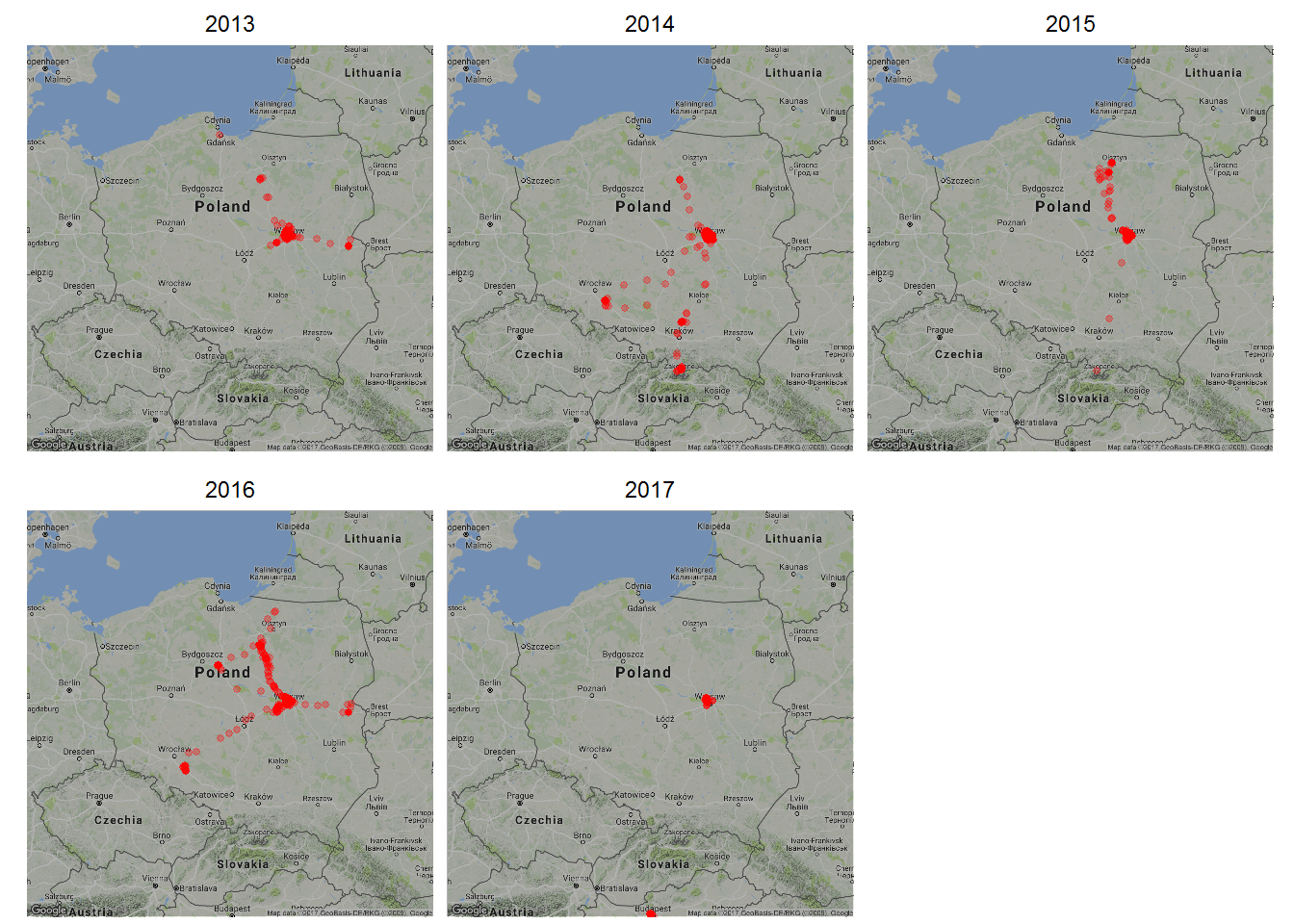
Teraz wiemy trochę więcej, na przykład, że
mieszkam w Warszawie
bo tutaj tych punkcików najwięcej, ale też:
- w 2013 byłem w Gdańsku (może słabo to widać) i na Podlasiu
- w 2014 byłem na Opolszczyźnie (dwoma trasami), w Tatrach, na Warmii
- w 2015 – już tylko na Warmii, zahaczając o Olsztyn. Pojawiają się też punkty w stronę Tatr – być może miałem wyłączoną lokalizację przez większość czasu w telefonie i dlatego jest to takie niepewne?
- w 2016 – Warmia (z Toruniem po drodze), Opolszczyzna i Podlasie
Mieszkam w Warszawie, ale jak się po niej poruszam? Bez rozdzielenia na lata, za to z nieco zmienionym nasyceniem czerwonego (żeby wydobyć to co trzeba):
|
1 2 3 4 5 6 7 8 |
map_waw <- get_map(location = c(lon=21, lat=52.25), zoom = 11) ggmap(map_waw, darken = 0.3) + geom_count(data=locations_hour, aes(long, lat, alpha=..prop..), size=1, color="red") + scale_alpha(range = c(0.05, 0.7)) + theme_void() + theme(legend.position = "none") |
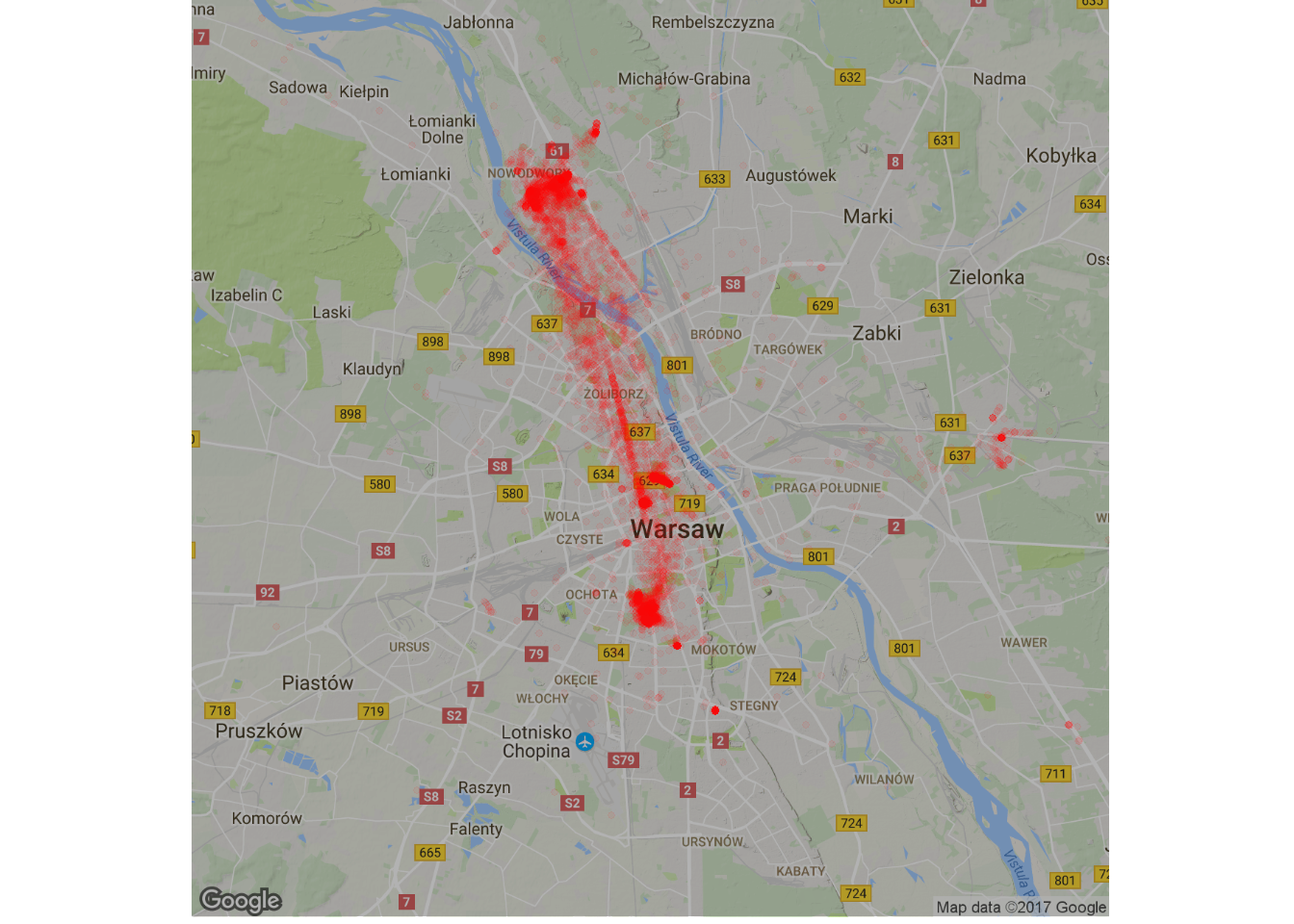
Warszawa to dla mnie oś północ – południe, gdzieś pomiędzy Tarchominem, Mokotowem i Śródmieściem. Widać nagromadzenie punktów w sumie w 4 miejscach i smugę (to w dużym uproszczeniu metro i tramwaje pomiędzy Świętokrzyską a Placem Wilsona).
Czy coś tutaj zależy od dnia tygodnia?
|
1 2 3 4 5 6 7 |
ggmap(map_waw, darken = 0.3) + geom_count(data=locations_hour, aes(long, lat, alpha=..prop..), size=1, color="red") + scale_alpha(range = c(0.05, 0.7)) + facet_wrap(~weekday) + theme_void() + theme(legend.position = "none") |

Wiecie już gdzie mieszkam? Tam gdzie najczęściej jestem w weekend… albo pomiędzy 19 a 6 rano – bo i tak można do tego podejść:
|
1 2 3 4 5 6 7 |
ggmap(map_waw, darken = 0.3) + geom_count(data=filter(locations_hour, hour>19 | hour<6), aes(long, lat, alpha=..prop..), size=1, color="red") + scale_alpha(range = c(0.05, 0.7)) + theme_void() + theme(legend.position = "none") |
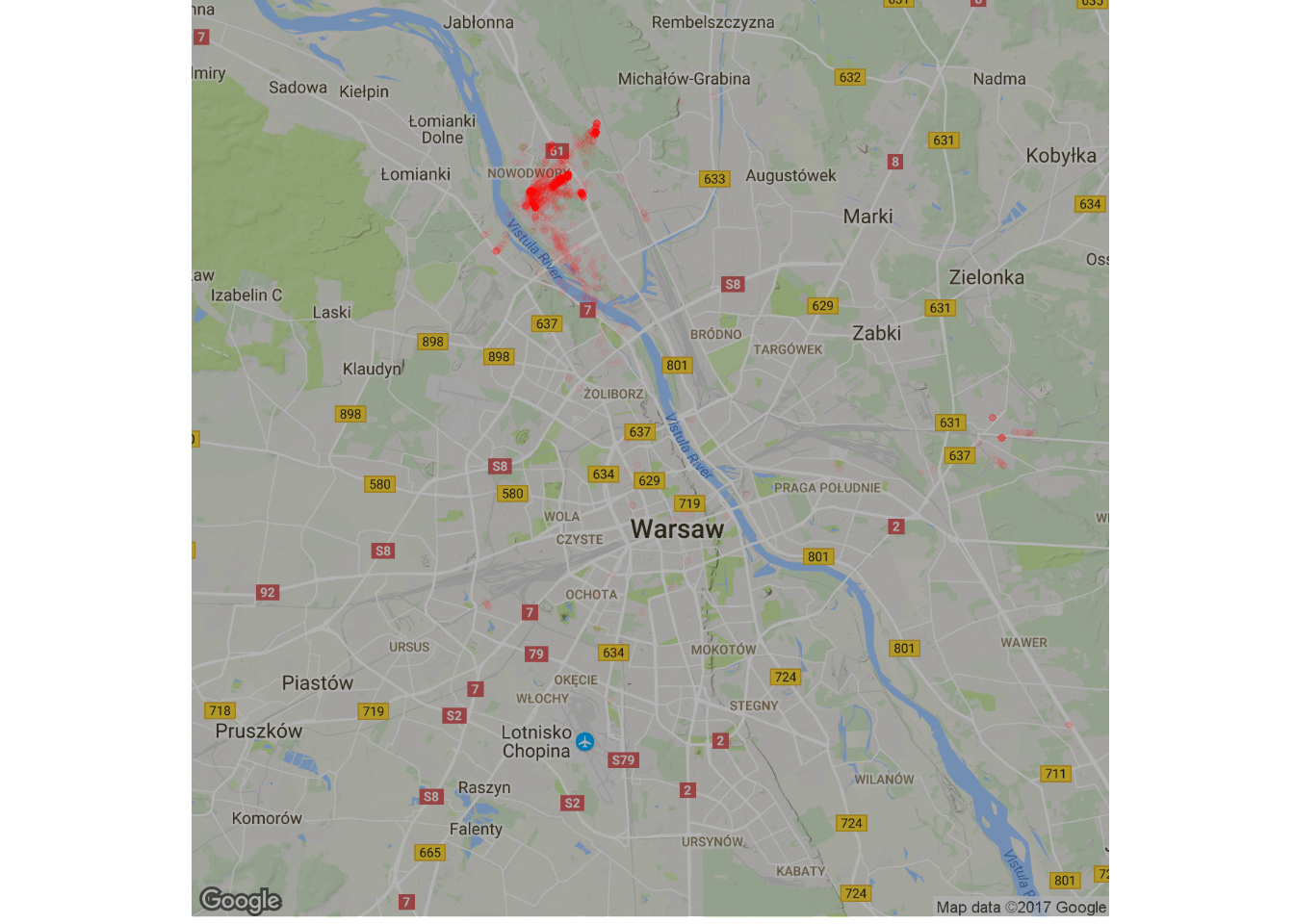
Przy odpowiednim przybliżeniu mapy (tego Wam nie pokażę, nie przesadzajmy – odrobina prywatności być musi, a nie tak adres na tacy) widać dwa punkty. Gdyby rozdzielić dodatkowo dane na poszczególne lata to widać byłoby przeprowadzkę w ramach dzielnicy w 2014 roku. Wszystko się zgadza.
Współrzędne domu
znajdziemy dla każdego miesiąca. Szukać będziemy tylko w “kwadracie” Warszawy, tylko nocami, tylko w weekendy. Normalnie jak jacyś bywalcy nocnych lokali. Użyjemy w agregacji nie średniej, a mediany, która daje lepsze efekty w tym przypadku (po bożemu powinna być wartość najczęściej występująca).
|
1 2 3 4 5 6 7 8 |
mieszkanie <- locations_hour %>% filter(long > 20.8 | long < 21.2, lat > 52.1 | lat < 52.5, hour > 19 | hour < 6, weekday %in% c("sobota", "niedziela")) %>% group_by(year, month) %>% summarise(mlong=median(long), mlat=median(lat)) %>% ungroup() |
Wiadomo gdzie mieszkam (i wyjaśnia się dlaczego chciałem wiedzieć ile kosztuje wynajęcie mieszkania na Białołęce, prawda?), a w takim razie co z tym Mokotowem i Śródmieściem?
Gdzie pracuję?
Zrobimy podobnie – w swoich pracach ludzie są od 9 do 17 (jak na biurowe standardy w Warszawie przystało). Dla bezpieczeństwa zawęzimy to jeszcze o godzinę (spóźnienia, wcześniejsze wyjścia) i wybierzmy tylko poniedziałki do piątków.
|
1 2 3 4 5 6 7 8 |
ggmap(map_waw, darken = 0.3) + geom_count(data=filter(locations_hour, hour>10, hour<16, weekday %in% c("poniedziałek", "wtorek", "środa", "czwartek", "piątek")), aes(long, lat, alpha=..prop..), size=1, color="red") + scale_alpha(range = c(0.05, 0.7)) + theme_void() + theme(legend.position = "none") |
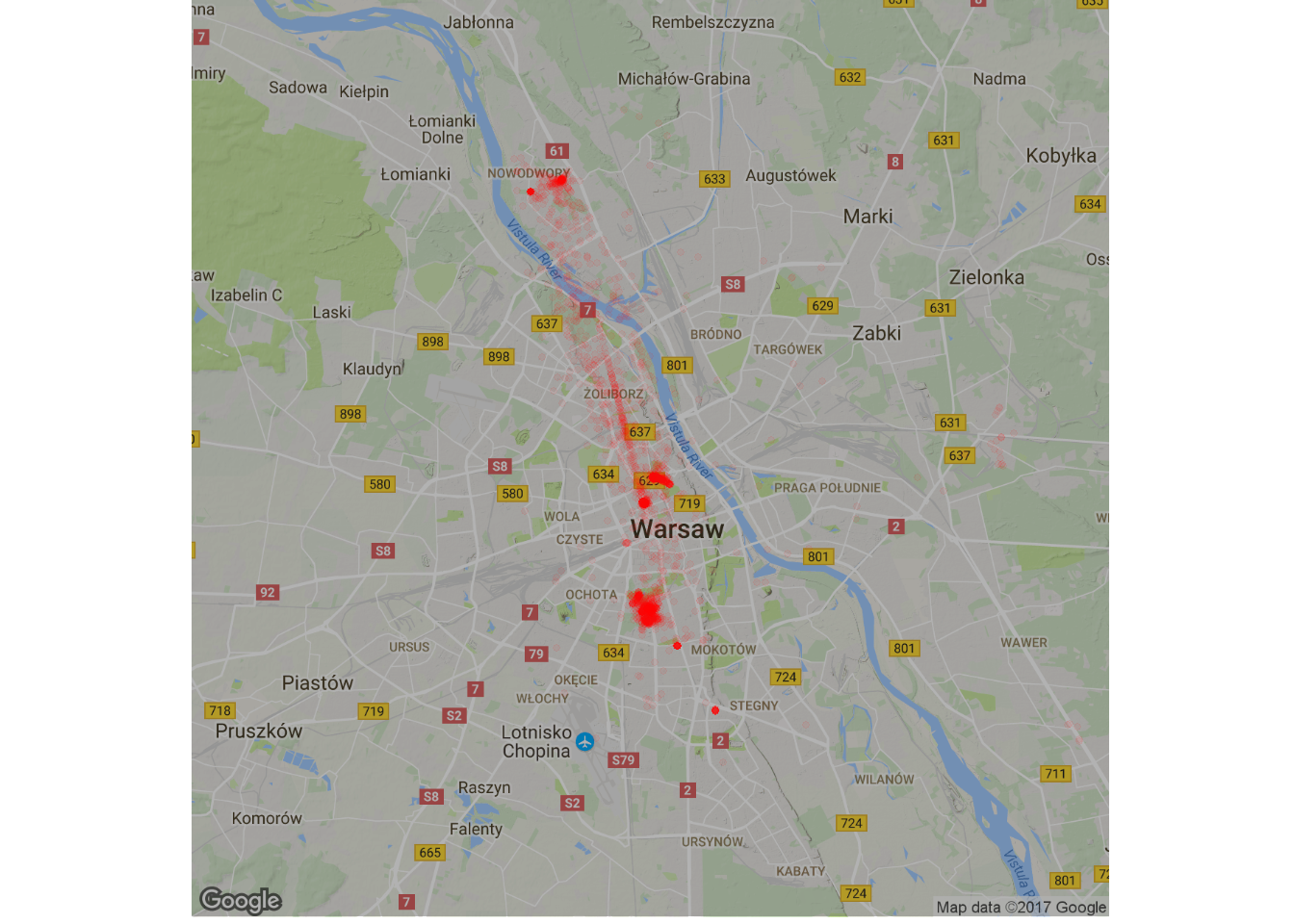
- widać Tarchomin – pewnie święta przypadające w tygodniu, ale był też pewien czas freelancerki i bezrobocia
- widać wyraźnie Mokotów – pracowałem tam przez jakieś dwa lata z badanego okresu (w dodatku w dwóch miejscach)
- w Śródmieściu pracuję w drugim już miejscu – oba widać na mapie
A teraz dodajmy lokalizacje mieszkania (obu) do oryginalnych danych i zobaczmy
jak daleko się wypuszczam
Dane o położeniu mieszkania mamy zagregowane do miesięcy, więc połączenie rok-miesiąc będzie dobrym kluczem łączącym dwie tabele. W obu przygotujemy klucz i połączymy:
|
1 2 3 4 5 6 |
mieszkanie$id <- paste0(mieszkanie$year, mieszkanie$month) locations_hour$id <- paste0(locations_hour$year, locations_hour$month) locations_hour <- left_join(locations_hour, mieszkanie[,c("id", "mlong", "mlat")], by="id") |
Możemy policzyć odległość pomiędzy mieszkaniem a punktem (średnim) w jakim przebywałem w danej godzinie. Weźmiemy najprostszą odległość – w stopniach, w mierze euklidesowej (pierwiastek z sumy kwadratów różnicy współrzędnych)
![\[odleglosc = \sqrt{(x_0-x_1)^2+(y_0-y_1)^2}\]](https://quicklatex.com/cache3/1d/ql_047b054531f72f76d2f1261029cff11d_l3.png "Rendered by QuickLaTeX.com")
|
1 2 |
locations_hour$dist <- sqrt((locations_hour$mlong - locations_hour$long)^2 + (locations_hour$mlat - locations_hour$lat)^2) |
i zobaczmy jak odległość od domu wyglądała w czasie:
|
1 2 3 |
ggplot(locations_hour) + geom_line(aes(make_date(year, month, day), dist)) + labs(x="", y="Odległość od domu (w stopniach)") |
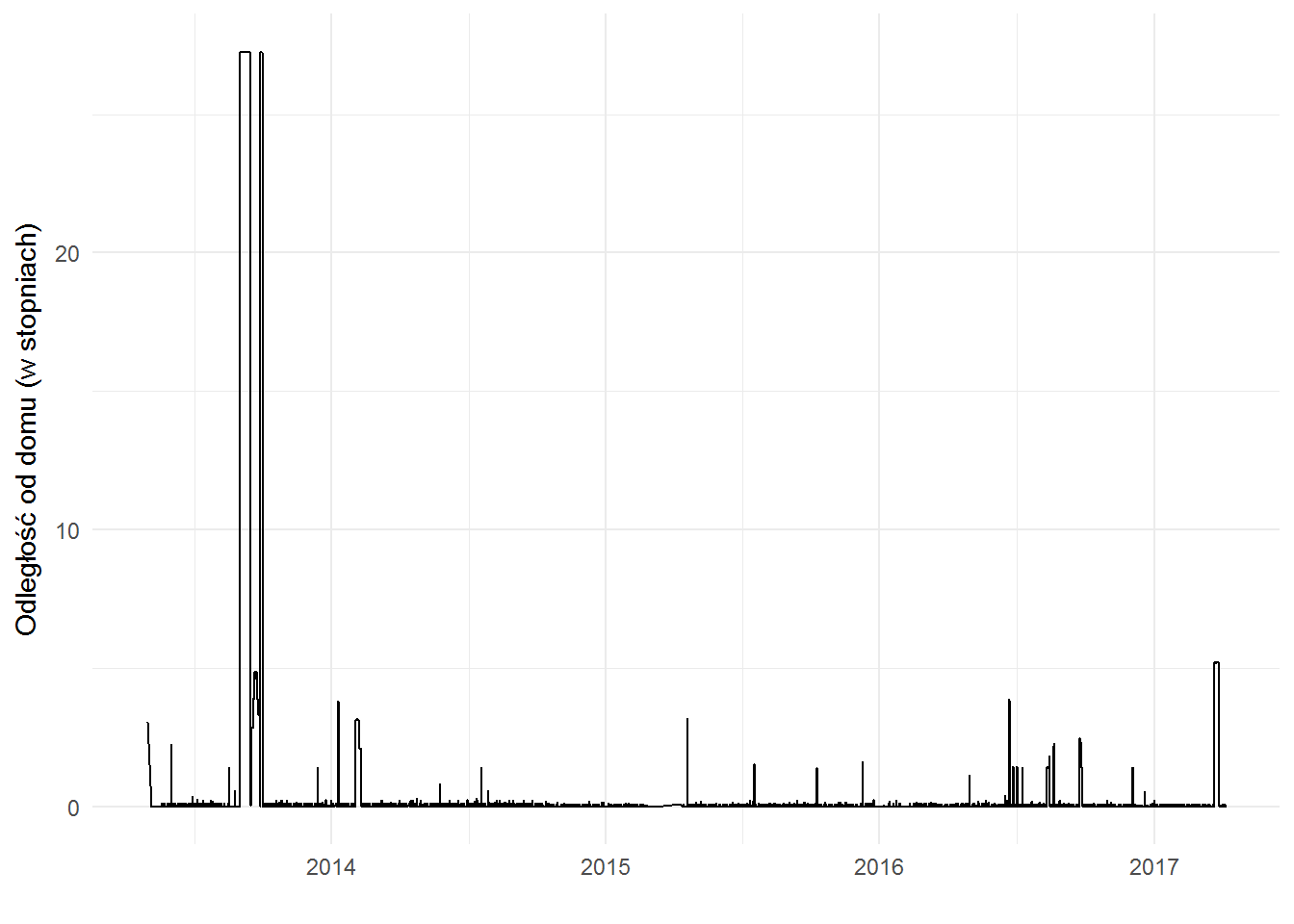
Najdalej od domu byłem w 2013 – pamiętacie? To Andaluzja.
Zestawmy jeszcze mapę z odległościami:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
map_plot <- ggmap(map_eu, darken = 0.3) + geom_count(data=locations_hour, aes(long, lat, alpha=..prop..), size=1, color="red") + scale_alpha(range = c(0.2, 0.8)) + facet_wrap(~year, nrow = 1) + theme_void() + theme(legend.position = "none") dist_plot <- ggplot(locations_hour) + geom_line(aes(make_date(year, month, day), dist)) + scale_x_date(date_breaks = "3 months", date_labels="%m") + labs(x="", y="") + facet_wrap(~year, scales = "free_x", nrow=1) library(gridExtra) grid.arrange(map_plot, dist_plot, nrow = 2) |
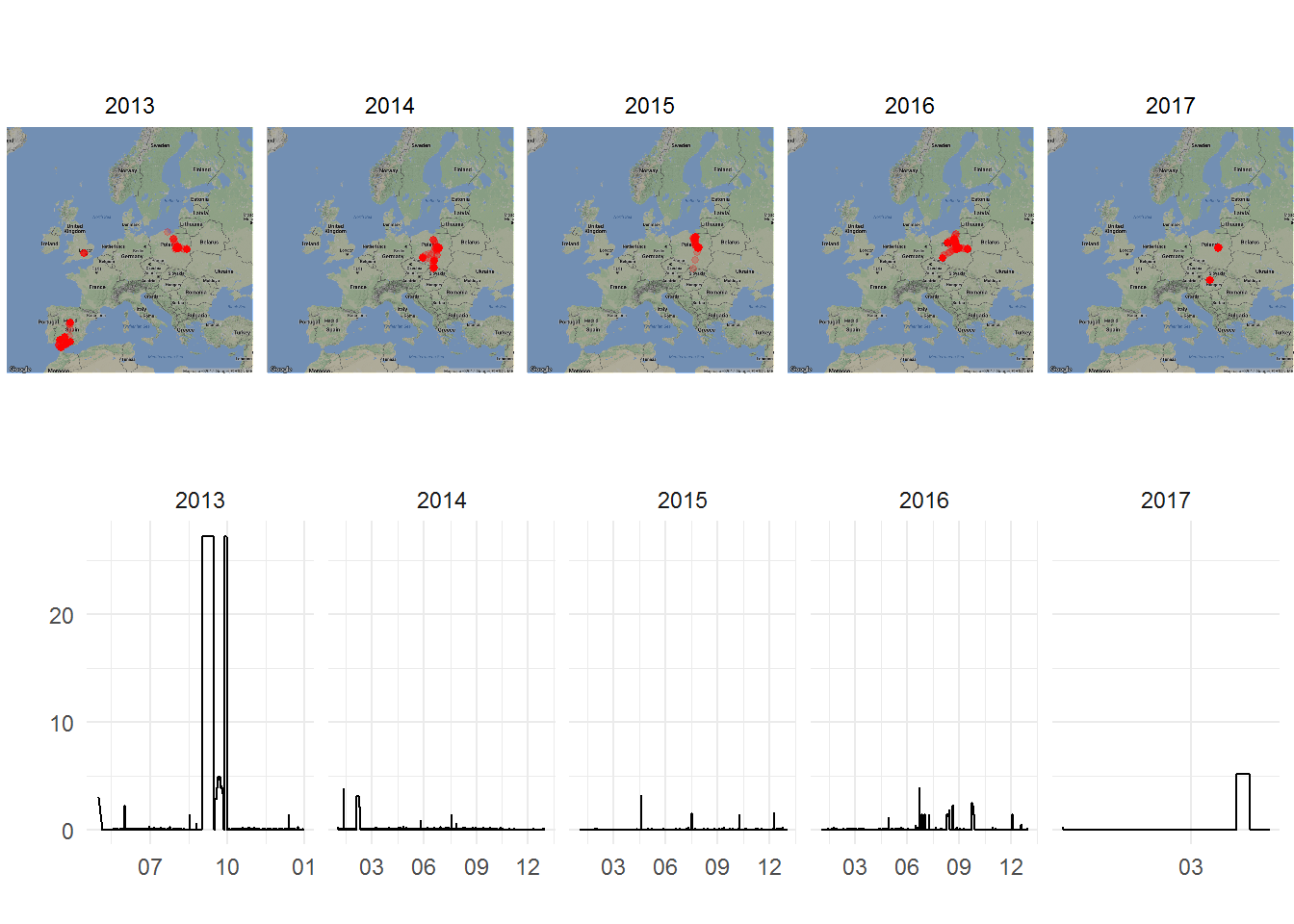
Teraz widać, że w Andaluzji byłem we wrześniu/październiku (to oczywiście można zobaczyć też inaczej – np. 2013 rok rozdzielić na mapki dla danego miesiąca, albo po prostu patrząc w dane).
W kolejnym – 2014 roku – najdalej od domu byłem w początku roku, ale to nic (kilkukrotnie mniej) w porównaniu z Hiszpanią; podobnie dla kolejnych lat. W 2017 roku poza Budapesztem nie ruszałem się (jeszcze) nigdzie poza Warszawę.
Zastanawiające jest coś innego – spadek odległości od domu w drugiej połowie września 2013 i później powrót wysokich wartości:
|
1 2 3 4 5 |
locations_hour %>% filter(year==2013, month>=8, month<=10) %>% ggplot() + geom_line(aes(make_date(year, month, day), dist)) + labs(x="", y="Odległość od domu (w stopniach)") |
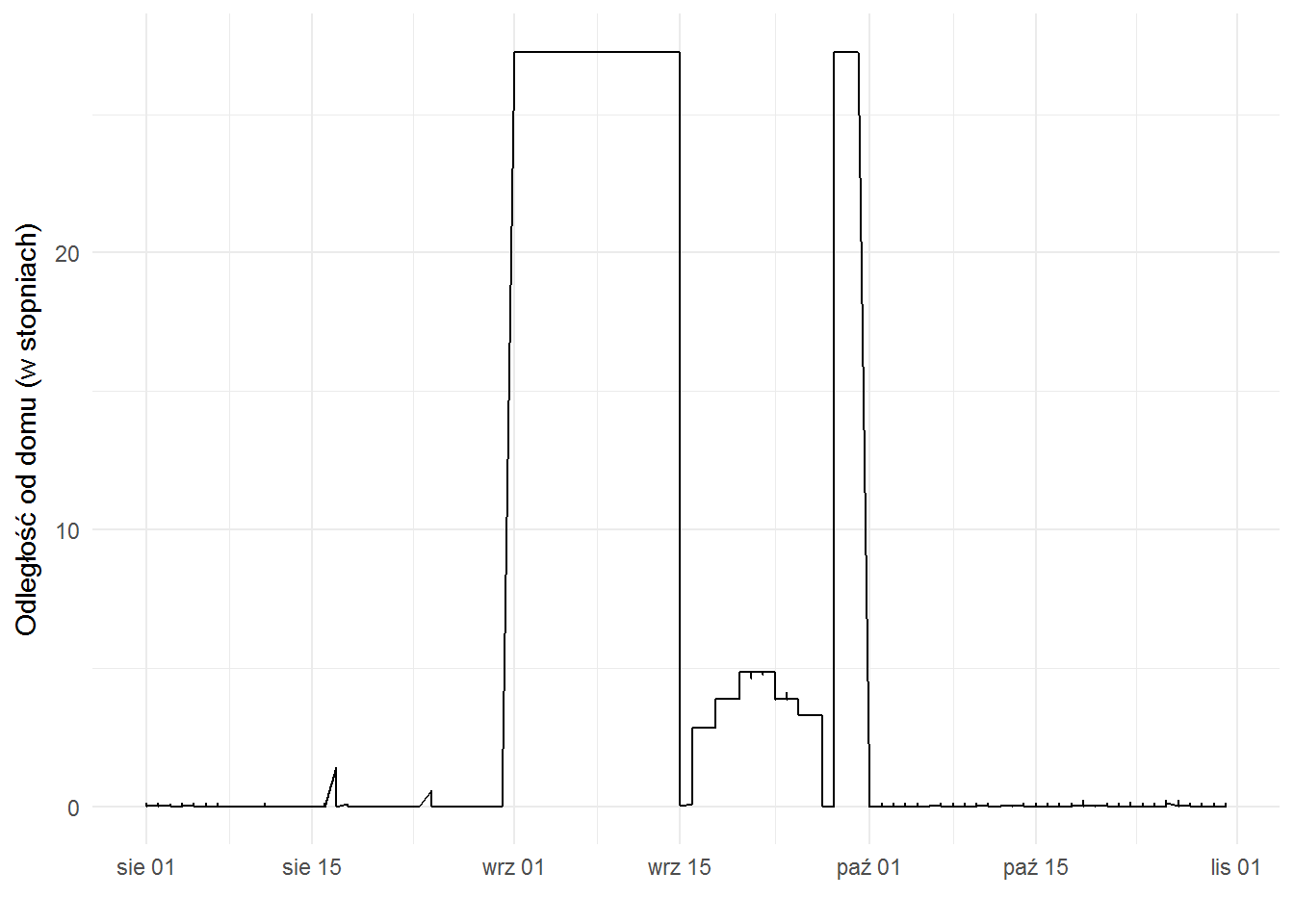
Tak naprawdę to wcale nie jest zaskakujący. Pamiętacie jak liczyliśmy miejsca, w których jest dom? Tam była mediana położenia dla sobót i niedziel w nocy.
We wrześniu 2013 tak długo (bodaj trzy tygodnie) przebywałem poza Warszawą, że według tego algorytmu Hiszpania stała się moim domem. Co zabawne – w Madrycie byliśmy tylko dwie noce – pomiędzy przylotem do Hiszpanii a wyruszeniem autem w kierunku Andaluzji i tak samo w drodze powrotnej. Nie pamiętam czy były to weekendy.
Stąd właśnie spadek odległości od domu. Bo domy w 2013 roku były w następujących miejscach (wg algorytmu):
|
1 2 3 4 5 |
ggmap(map_eu) + geom_point(data=filter(mieszkanie, year==2013), aes(mlong, mlat), size=3, color="red") + theme_void() |
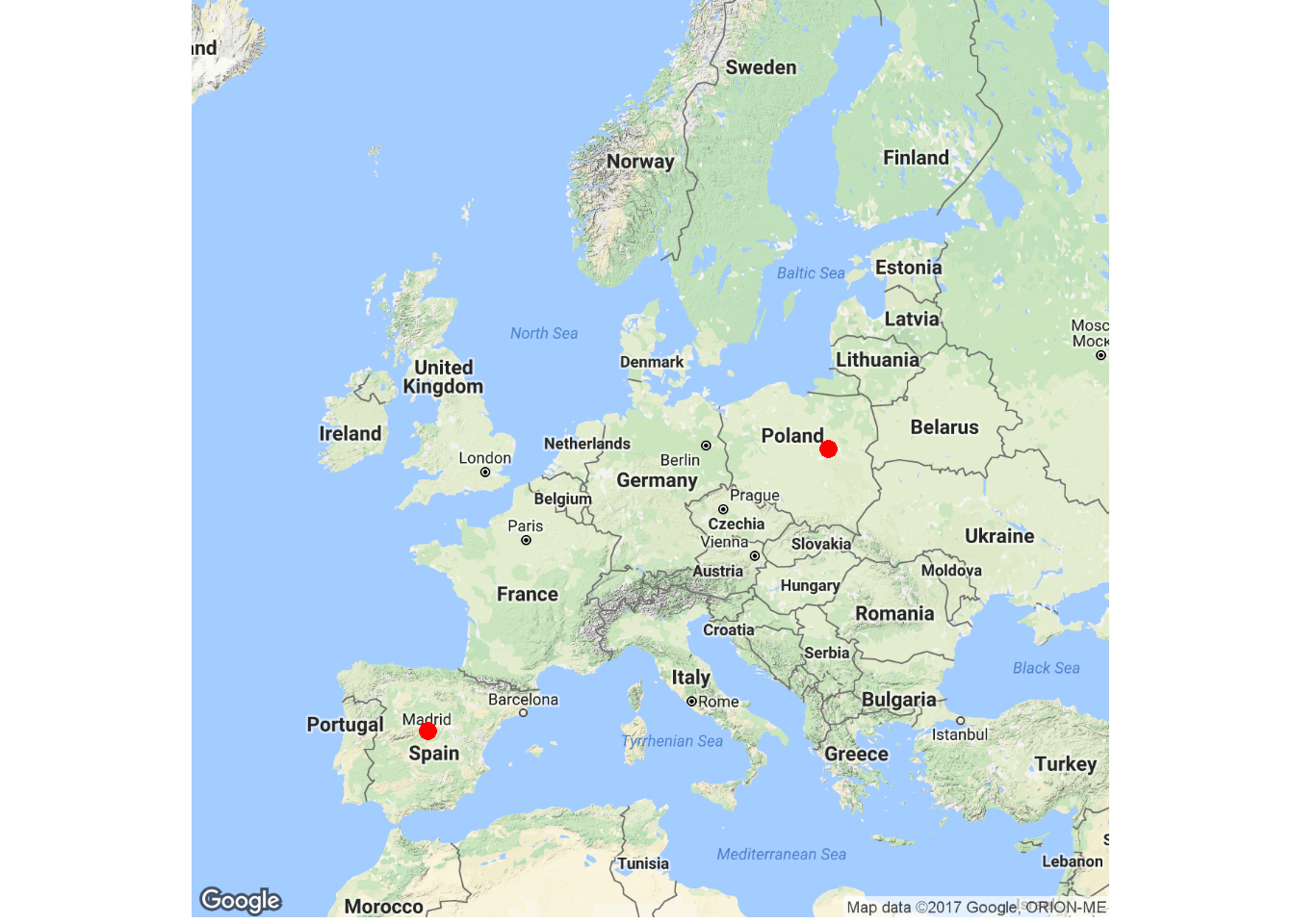
Warszawa i Madryt.
Należałoby zatem w tabeli mieszkanie odpowiednio wygładzić dane – np. dla każdego punktu (miesiąca) sprawdzić czy odstaje od dwóch sąsiednich i jeśli tak to nadać mu nowe wartości (chociażby średnią z sąsiadów)
Weźmy jeszcze 2017 bez Budapesztu (wyłączymy cały marzec), żeby sprawdzić
gdzie się bywa w Warszawie?
chociaż raczej – jak daleko od domu poruszam się po mieście?
|
1 2 3 4 5 |
locations_hour %>% filter(year==2017, month < 3) %>% ggplot() + geom_point(aes(make_date(year, month, day), dist)) + labs(x="", y="Odległość od domu (w stopniach)") |
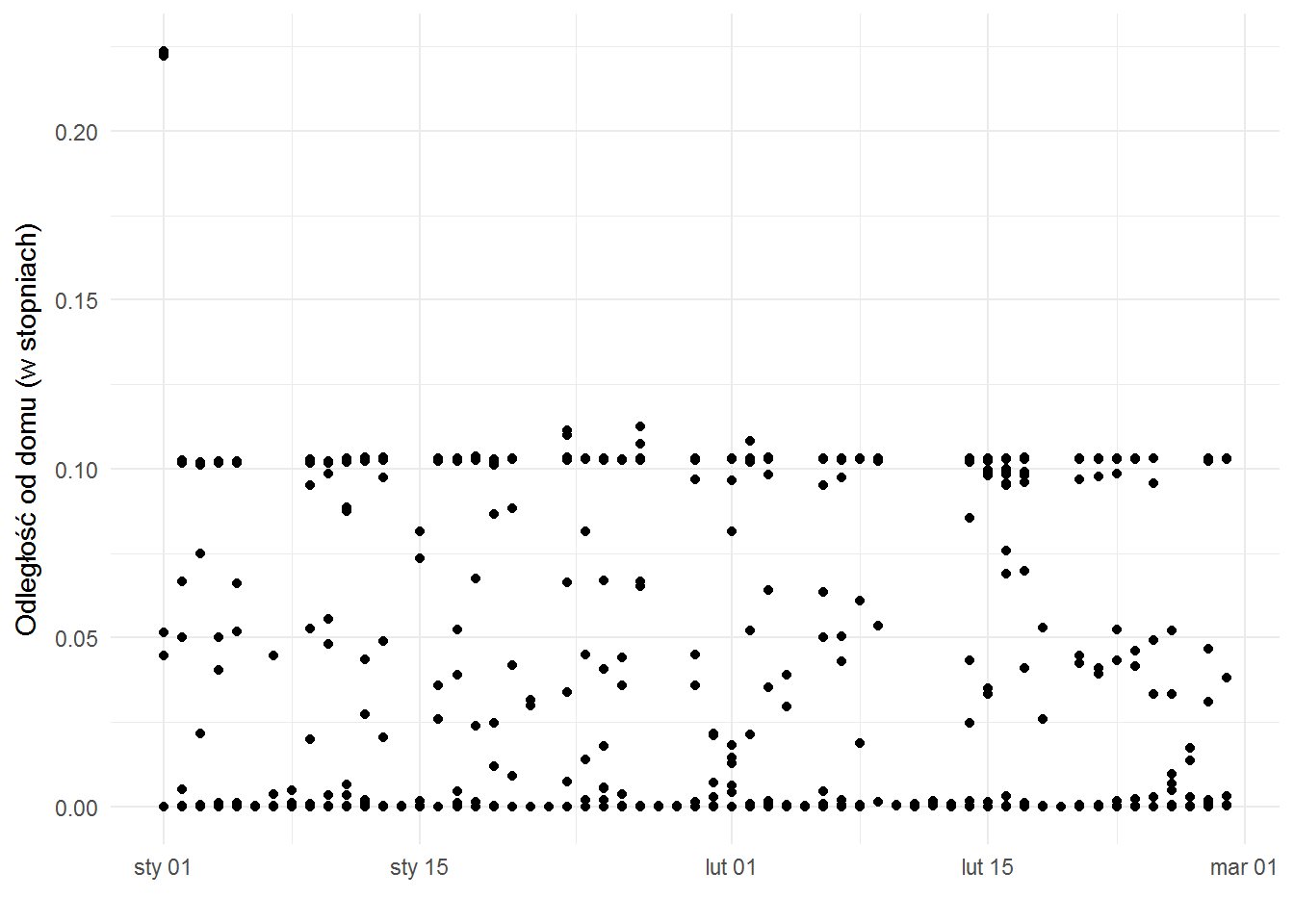
widać tutaj periodyczność (i pierwszą kropkę związaną z powrotem spoza Warszawy po Nowym Roku) – kilka kropek na górze, przerwa i znowu kilka na górze. Kilka to zazwyczaj pięć. To może prowadzić do wniosku, że coś dzieje się w tygodniu. Wiadomo co, ale zobaczmy:
|
1 2 3 4 5 |
locations_hour %>% filter(year==2017, month < 3) %>% ggplot() + geom_boxplot(aes(weekday, dist), fill="lightgreen") + labs(x="", y="Odległość od domu (w stopniach)") |
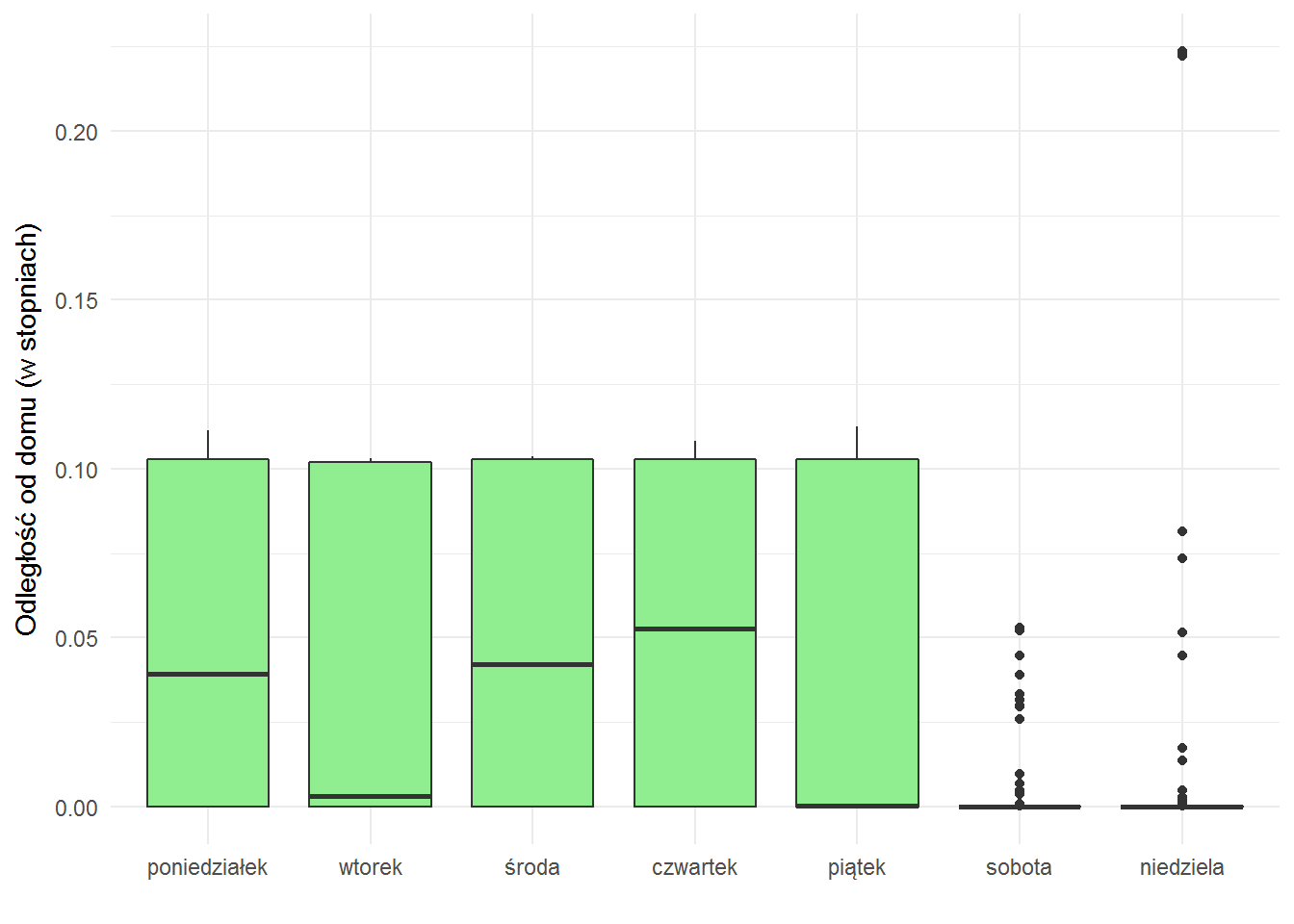
W weekendu stycznia i lutego 2017 siedziałem w pobliżu domu, ot co.
|
1 2 3 4 5 6 7 8 |
locations_hour %>% group_by(weekday) %>% summarise(mist=median(dist, na.rm = TRUE)) %>% ungroup() %>% ggplot() + geom_bar(aes(weekday, mist), stat="identity", fill="lightgreen", color="darkgreen") + labs(x="", y="Średnia odległość od domu (w stopniach)") |
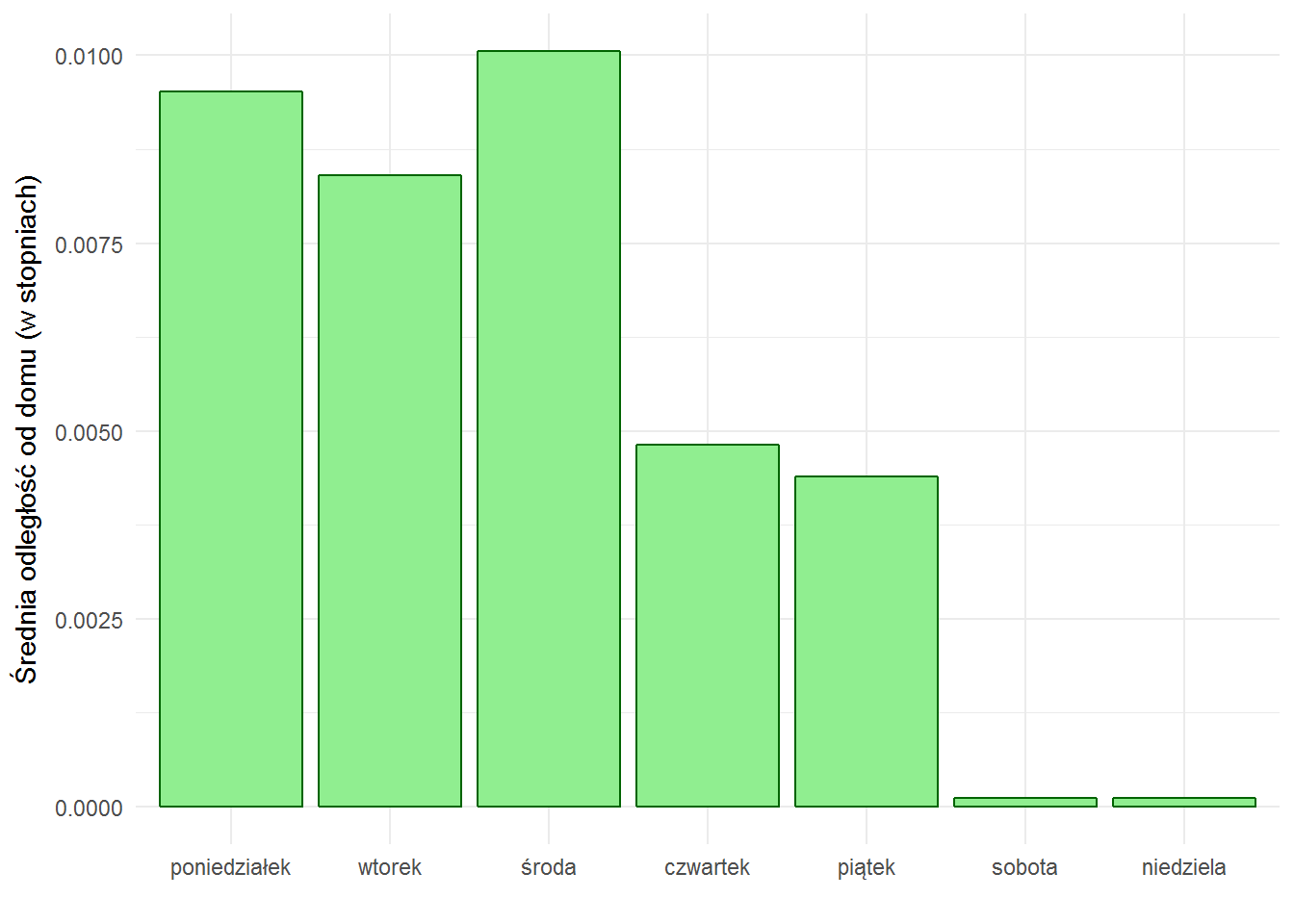
Średnio (mediana) w innych latach też :) Domator znaczy.
Co więcej, 40% czasu spędzam w pobliżu domu, jakieś 8% spędziłem w odległości 0.1 stopnia od domu, 6% – w odległości 0.135 stopnia. Wiem to z tego rozkładu:
|
1 2 3 4 5 6 7 8 |
locations_hour %>% filter(dist<=0.15) %>% ggplot() + geom_density(aes(dist), fill="lightgreen", color="darkgreen") + geom_vline(xintercept = c(0.1, 0.135)) + geom_text(x=0.1, y=9, label="8%", hjust=-0.2) + geom_text(x=0.135, y=7, label="6%", hjust=-0.2) + labs(x="odległość od domu (w stopniach)", y="Gęstość prawdopodobieństwa") |
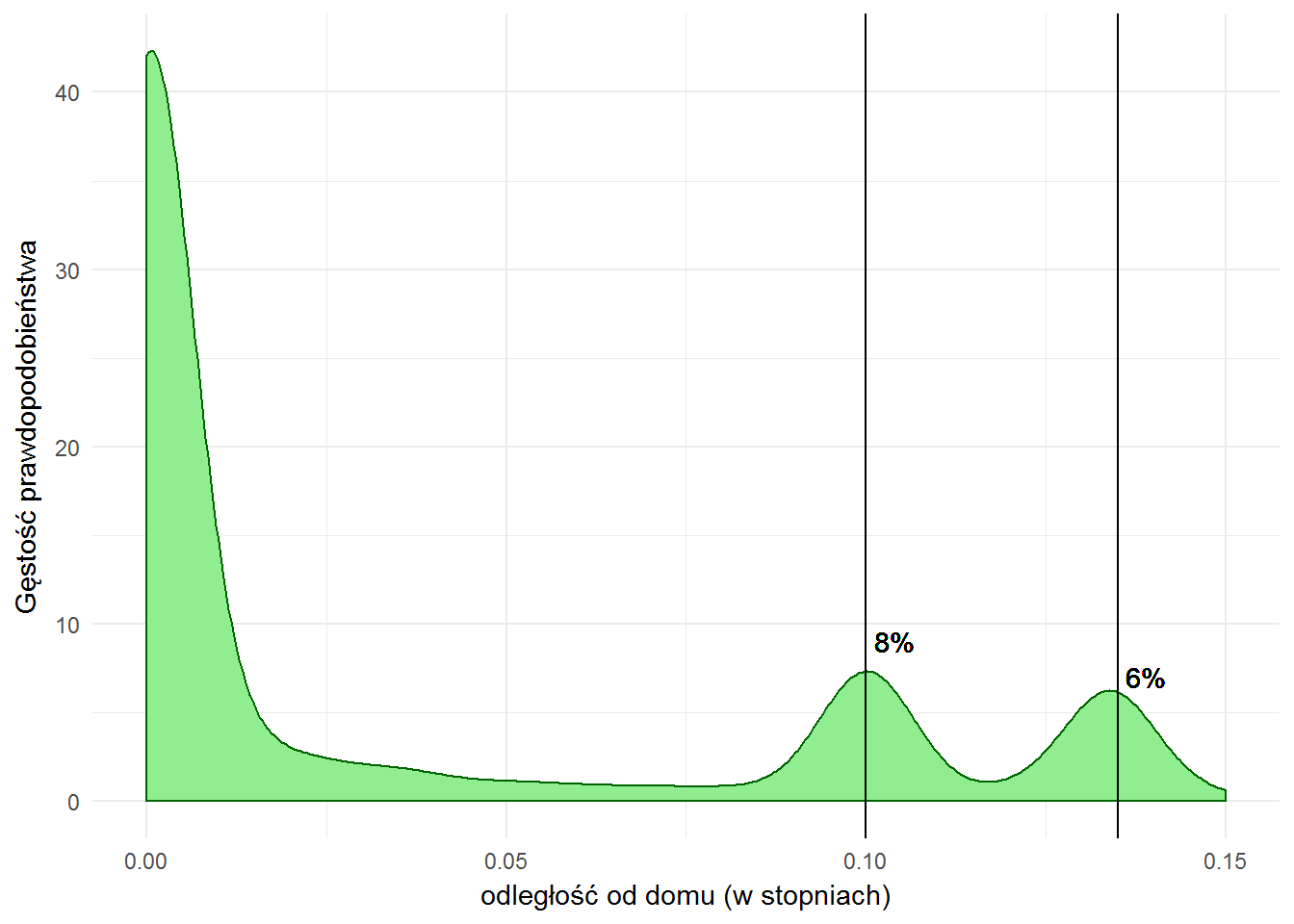
Mam wrażenie, że te procenty trochę są oszukane… bo 40 godzin pracy tygodniowo to 23.8% całego tygodnia (tak, pracujemy 1/4 swojego życia, a do tego ze dwie godziny dziennie robimy trasę dom-praca-dom), a 6 i 8 to tytlko 14… Ktoś ma pomysł?
Obstawiam urlopy, czas bez pracy, święta itp. Szczegółowo warto przyjrzeć się rozkładowi miesiąc po miesiącu. Bo taki luty 2017 to już wychodzi 1/3 w pracy, 2/3 w domu co ma zdecydowanie większy sens.
Odległość w stopniach to raczej nie jest intuicyjna miara. Na równiku według Wikipedii 1 stopień to 111 km (w przybliżeniu), na warszawskiej szerokości geograficznej jest to raczej około 70 km (jeśli ktoś nie wierzy niech poszuka stosownych wzorów).
Zatem te 0.135 stopnia to około 9.9 km, zaś 0.1 – 7 km. W linii prostej. Domyślam się jakie to są miejsca (praca oczywiście) i używając miarki na Google Maps widzę, że Google uznaje, że 1 stopień to bardziej te 111 km niż 70…
Konkurs
To kto się podzieli plikami z Google Takeout i da się przebadać? Najchętniej ktoś, kto dużo podróżuje po Polsce albo i świecie. Do wygrania darmowa inwigilacja.
A to tylko jeden element tego, co Google wie o nas…
Przerażające. I fascynujące zarazem.
Hej,
probowalem sam i wysypuje sie w tym miejscu:
> ggmap(map_eu, darken = 0.3) +
+ geom_count(data=locations_hour, aes(long, lat, alpha=..prop..),
+ size=1, color=”red”) +
+ scale_alpha(range = c(0.2, 0.8)) +
+ facet_wrap(~year) +
+ theme_void() +
+ theme(legend.position = „none”)
Warning message:
Removed 1 rows containing non-finite values (stat_sum).
Wiesz może co robię źle?
To tylko warning mówiący o tym, że jeden punkt nie został narysowany na wykresie. Jakiś wynik jest, czy jest pusta mapka?
Bez wglądu w dane trudno wyrokować.
No właśnie nic, pustka.
https://dl.dropboxusercontent.com/u/97748/map.json
ok, wykonałem drugi raz i jest mapka :)
To chyba raczej prędkość działania R/RStudio – przy tej ilości danych generowanie wykresu trochę trwa i RStudio nie wyświetla gotowego wyniku natychmiast. Bywają sytuacje (przy milionach punktów) kiedy trwa to nawet kilkanaście sekund. Pobrałem Twoje dane i rzeczywiście tak było – wykres pojawia się po kilkunastu sekundach.
Z tego powodu dane w pierwszej fazie są agregowane do średnich godzinowych – żeby z milionów punktów zrobić kilkanaście tysięcy.
Cieszę się, że czytają nas w Londynie, niedaleko Portland Palace, przy Beaconsfield Rd. Podróż po UK (11-13 sierpnia) udana? :) Oleg, skasuj ten plik JSONa z publicznego dostępu.
Usunięty :)
ale nie trafiłeś z miejscem zamieszkania, jakies 600m różnicy :)
Edynburg warty polecenia oczywiscie, zwlaszcza w sierpniu na festiwal Fringe, warto polaczyc z jakas degustacja szkockiej.
zastanawialem sie czy na podstawie tego wyciagniesz 4 ostatnie adresy zamieszkania, oraz gdzie pracowalem w Polsce i UK, ale z jakiegos powodu historia nie pokazuje danych ktore byly w Google Latitude, tylko Maps.
Ale jak sie bedziesz nudzic to mozesz poanalizowac do woli.
Ten Londyn to mediana z sierpnia tego roku. Nie analizowałem jakoś specjalnie – ot sprawdziłem czy kod działa.
Łukaszu mam jedno pytanie związane ggmap() – jeśli wykonuję polecenia linia po linii, to po wykonaniu komendy ggmap(map_pl)[…] pojawia mi się okno Quartz ze stosowną mapką.
Ale jak uruchomię R, przepiszę wszystkie komendy do pliku (łącznie z tym ggmap() na końcu) i uruchomię jako source(„nazwapliku.R”) – wszystko się przemieli, ale okno Quartz z mapą się nie pojawia :(
To dlatego, że w wersji source() dzieje się to samo co w przypadku uruchomienia z konsoli – R nie ma wyjścia graficznego. Plik graficzny można zapisać na dysku (przez ggsave()).
Co ciekawe – RStudio sobie radzi i wyświetla wykresy w oknie podglądu.
Broniłem się przes RStudio, bo jestem bardzo przywiązany do SublimeText. Ale rzeczywiście do R pewnie nie ma nic lepszego. Dzięki za odpowiedź Łukaszu!
Spróbuję czy wyśledzi moją oborę.
Co do wzorów na przelicznik „stopień – kilometr” to sprawa wcale nie jest taka skomplikowana, jak się wydaje.
Patrząc na globus: na południku (pionowej kresce rozpiętej pomiędzy biegunami) odkładasz wartości dla szerokości geograficznej. Od -90 stopi na południu, przez 0 (równik) po 90 stopni na północy. Ziemia to w przybliżeniu kulka, 40000km dzielisz przez 360stopni i masz piękne 111 kilometrów na stopień.
Inaczej ma się sprawa dla długości geograficznej, czyli „poplasterkowaniu” globusa na poziome warstwy. Dla równika długość jest największa, im dalej to się zmniejsza, aż przy biegunie wynosi 0 i równoleżnik dla szerokości 90 stopni nie jest już okręgiem, a kropką.
Odległość km dla jednego stopnia długości geograficznej trzeba przemnożyć przez cos(lat). Czyli dla Polski to będzie mniej więcej:
40000km / 360st * cos(52st) = 68,4 km/stopień
Jeżeli ma mapie Warszawy zrobisz podróż o X stopni w osi N-S , to przemnóż przez 111km.
Jeżeli jest to podróż E-W to przez 68km.
Trasy po ukosie to już większy wzorek:
https://pl.wikibooks.org/wiki/Astronomiczne_podstawy_geografii/Odleg%C5%82o%C5%9Bci