Wydarzenia sportowe (lub inne dziejące się tu i teraz) są bardzo wdzięcznym tematem analizy tego, co dzieje się w mediach społecznościowych. Jak wyglądał Twitter podczas meczu Polska – Rumunia?
Przygotowanie tokenu
Aby zebrać dane z Twittera potrzebujemy zbudować aplikację, która wykorzysta API Twittera i jej tokenu. W samym R wykorzystamy pakiet rtweet. Koniec końców potrzebny nam jest klucz API (para Consumer Key i Consumer Sectet) – jak je zdobyć można przeczytać tutaj (z obrazkami). Odpowiednie wartości należy przypisać do zmiennych poniżej. Kod przygotuje nam token i zapisze w lokalnym pliku, dzięki temu w przyszłości będziemy mogli taki token wykorzystać:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
# devtools::install_github("mkearney/rtweet") library(rtweet) appname <- "lemurR" # nazwa aplikacji key <- "xxxx" ## Consumer Key secret <- "yyyy" ## Consumer Secret ## przygotowanie tokenu twitter_token <- create_token( app = appname, consumer_key = key, consumer_secret = secret) save(twitter_token, file="twitter_token.rdata") |
Mając zapisany token możemy zacząć
zbieranie twittów
Wykorzystamy “strumień” płynący z Twittera, który zostanie zapisany do lokalnego pliku JSON. Pakiet rtweet ma gotową funkcję, która działa tak, że od momentu jej wywołania przez podaną liczbę sekund pobiera wszystkie kolejne twitty zgodne z zadanymi kryteriami. Potrzebujemy wiedzieć jak długo ma to robić (ja skrypt uruchomiłem około dwóch godzin przed meczem i chciałem aby mniej więcej tyle samo czasu po meczu zakończyło się zbieranie danych) oraz jakie jest kryterium wyboru twittów. W naszym przypadku kryterium to twitty z hashtagiem #polrom.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
library(rtweet) # token przygotowany wcześniej load("twitter_token.rdata") # nazwa pliku na twitty twitts_filename <- "polrom_twitts_full" # do kiedy od teraz zbierać twitty? start_time <- Sys.time() # teraz end_time <- as.POSIXct("2017-06-11 00:00:00 CEST") n_secs <- as.integer(difftime(end_time, start_time, units = "secs")) # pobranie twittów - ciągły strumień stream_tweets("#polrom", timeout = n_secs, file_name = twitts_filename, parse = FALSE) |
Można było zrobić nieco inaczej – bez korzystania ze strumienia: już po meczu (na przykład dzisiaj) pobrać wszystkie twitty. Ale to jest badanie post factum. Ja w czasie meczu obserwowałem dane (i wrzucałem na TT) – potrzebowałem więc ciągłego strumienia. Jeden proces generował dane (ten kod powyżej), a drugi – robił wykresiki.
Zobaczmy co można wyłowić, a przede wszystkim – jakie są zagrożenia i jak do nich podejść.
Analiza zebranych danych
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
setwd("~/RProjects/PolRom") library(rtweet) library(tidyverse) library(lubridate) library(tidytext) library(wordcloud) theme_set(theme_minimal()) # polskie stop-words pl_stop_words <- read_lines("polish_stopwords.txt") # nazwa pliku na twitty twitts_filename <- "polrom_twitts_full" tweets <- parse_stream(paste0(twitts_filename, ".json")) |
W tabeli tweets mamy wszystkie potrzebne dane.
Na początek wybierzmy tylko to co kluczowe i uporządkujmy daty – przede wszystkim godzina jest przesunięta (inna strefa czasowa). Dodamy przy okazji oznaczenie “okresów” podczas meczu – konkretna połowa, przerwa i czas przed o po meczu (tutaj godziny się nie zgadzają znowu ze względu na przesunięcie stref czasowych – trochę eksperymentowania było potrzebne).
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
tweets_an <- tweets %>% select(screen_name, created_at, text, is_retweet, source) %>% # twitty są przesunięte o 2 godziny względem polskiego czasu! mutate(created_at = hours(2) + created_at) %>% mutate(created_hour = hour(created_at), created_minute = minute(created_at), created_time = sprintf("%02d:%02d", created_hour, created_minute)) # okresy meczu - rozdzielenie według zegara tweets_an$period <- ifelse(tweets_an$created_at > "2017-06-11 00:37:00", "po meczu", ifelse(tweets_an$created_at > as.POSIXct("2017-06-10 23:49:00 "), "II połowa", ifelse(tweets_an$created_at > as.POSIXct("2017-06-10 23:33:00"), "przerwa", ifelse(tweets_an$created_at > as.POSIXct("2017-06-10 22:45:00"), "I połowa", "przed meczem")))) tweets_an$period <- factor(tweets_an$period, levels = c("przed meczem", "I połowa", "przerwa", "II połowa", "po meczu")) |
Zobaczmy jakie słowa są najpopularniejsze? Od razu odpuścimy sobie retweety.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
# chmurka słów words <- tweets_an %>% filter(is_retweet == FALSE) %>% # bez linków mutate(text = gsub(" ?(f|ht)tp(s?)://(.*)[.][a-z]+", "", text)) %>% unnest_tokens(words, text, token="words") %>% count(words, screen_name) %>% ungroup() %>% # bez tagów i stop-words filter(!words %in% c("polrom", "polrum", "polrou")) %>% filter(!words %in% pl_stop_words) %>% filter(!words %in% stop_words$word) wordcloud(words$words, words$n, scale = c(1.8, 0.5), max.words = 100, colors = RColorBrewer::brewer.pal(9, "YlOrRd")[4:9]) |
“Ogień i lód” nie dotyczy meczu, podobnie cała reszta tych największych w chmurce. W tym momencie warto przejrzeć ręcznie tabelę words która nam powstała, zobaczyć które słowa są najpopularniejsze i nie pasują nam do wydarzenia, a następnie wyłowić kto jest autorem twittów z tymi słowami. Wyłoniłem kilkanaście takich osób:
|
1 2 3 4 5 |
# identyfikujemy spamerów spammers <- c("99Emcia", "iPourpreCroyant", "wejdan0722", "E_mcia", "laveme224", "kiczka17", "moh_sarty", "naszewlasnenieb", "sabrina20008", "didemYahya", "yamani_alali", "mahoora1994", "Magda_Jak", "monikapolec", "Patrykkkkkkkkk1", "trendinaliaPL", "MAzN1711794") |
W dalszych analizach zostawimy sobie twitty bez re-twittów i nie pochodzące z puli nazwanej spammers. Teraz najpopularniejsze słowa wyglądają następująco:
|
1 2 |
# twitty do analizy tweets_an <- tweets_an %>% filter(!screen_name %in% spammers) %>% filter(!is_retweet) |
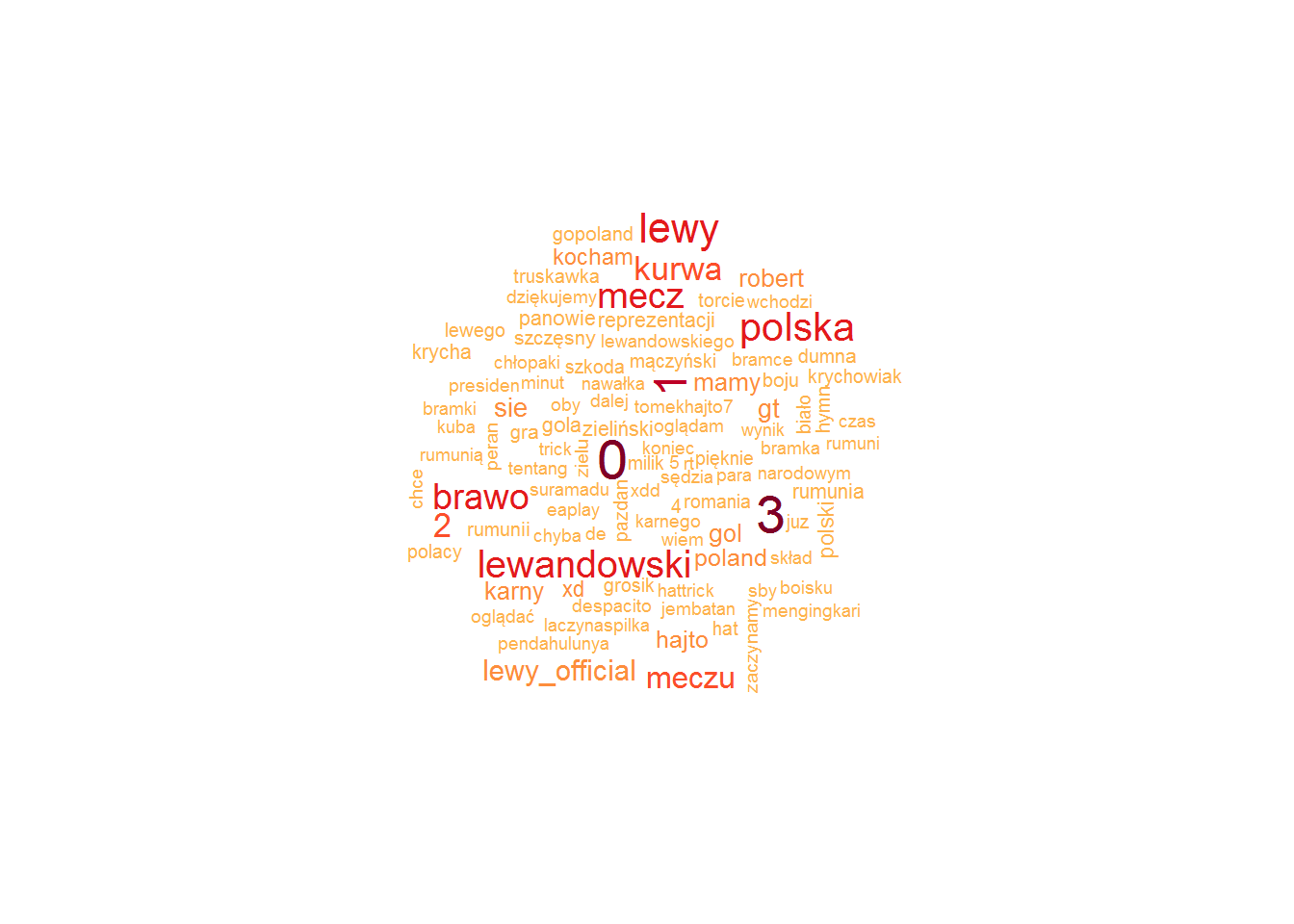
Wygląda bardziej prawdopodobnie, prawda?
Zobaczmy jak wyglądała aktywność podczas meczu (liczba twittów w poszczególnych minutach):
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
tweets_an %>% mutate(created_time = make_datetime(2017, 6, day(created_at), hour(created_at), minute(created_at))) %>% count(created_time, period) %>% ungroup() %>% ggplot() + geom_bar(aes(created_time, n, fill=period), stat="identity") + theme_minimal() + labs(x="Godzina", y="Liczba tweetów", title = "Liczba tweetów z hashtagiem #POLROM", fill = "okres") + scale_x_datetime(date_breaks = "hours", date_labels = "%H:%M") |
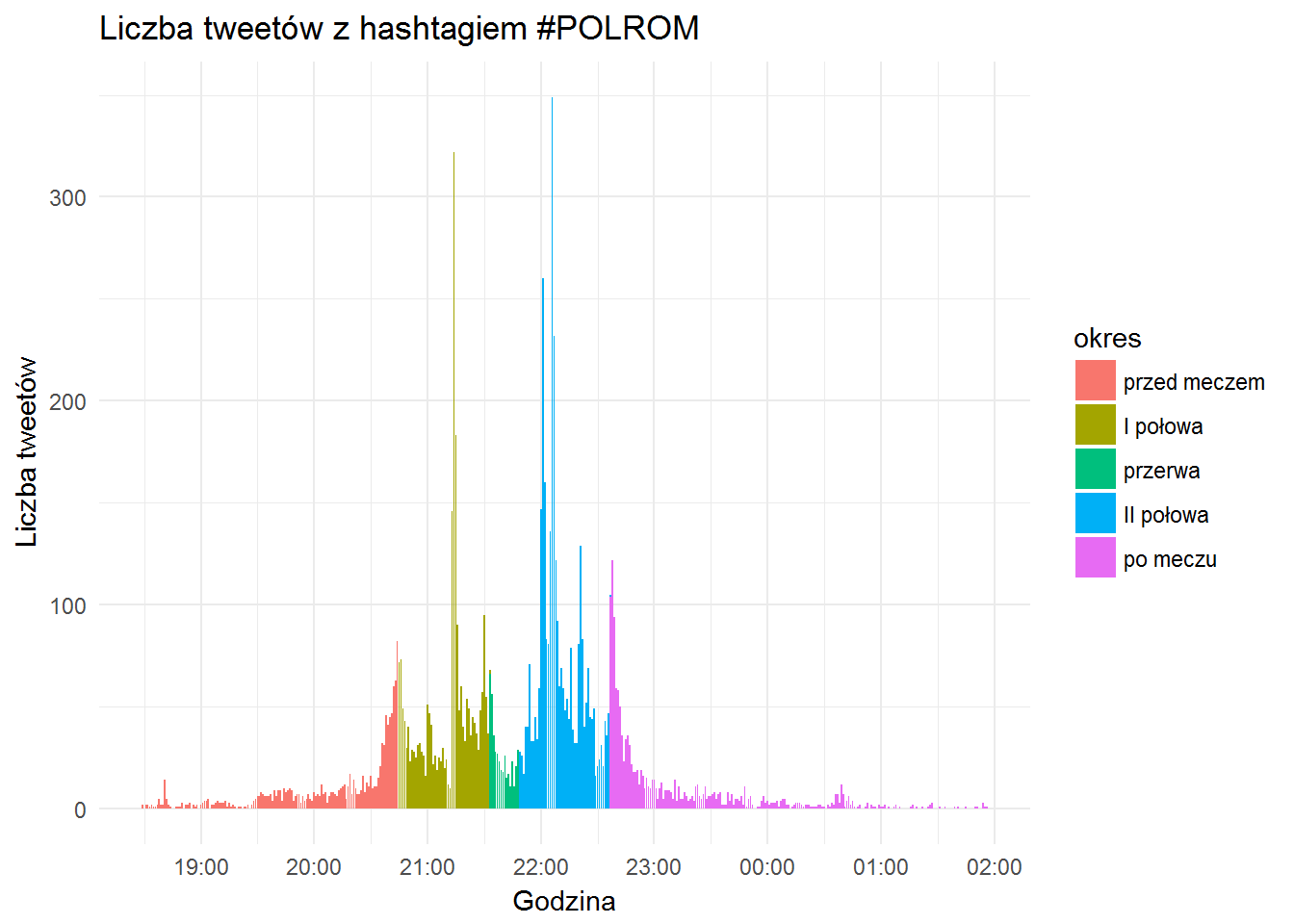
Piki w momentach kiedy padały bramki, spore górki po zakończeniu meczu i tuż przed jego rozpoczęciem. Aktywność zaczyna się godzinę przed i kończy godzinę po. Tego typu wydarzenia są dynamiczne , a dynamika na boisku przekłada się na aktywność w social media. Wniosek dość oczywisty, udowodniony liczbowo :)
Teraz jeszcze raz zerknijmy na chmurkę najpopularniejszych słów (po 200), tym razem w rozbiciu na poszczególne okresy meczu:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
# pojedyncze słowa words <- tweets_an %>% mutate(text = gsub(" ?(f|ht)tp(s?)://(.*)[.][a-z]+", "", text)) %>% unnest_tokens(words, text, token="words") %>% count(words, period) %>% ungroup() %>% filter(!words %in% c("polrom", "polrum", "polrou")) %>% filter(!words %in% pl_stop_words) %>% filter(!words %in% stop_words$word) by(words, words$period, function(x) { wordcloud(x$words, x$n, scale = c(1.8, 0.5), max.words = 200, colors = RColorBrewer::brewer.pal(9, "YlOrRd")[4:9]) text(0.05, 0.95, unique(x$period), col="darkred", cex=1.3, adj=c(0,0)) } ) |

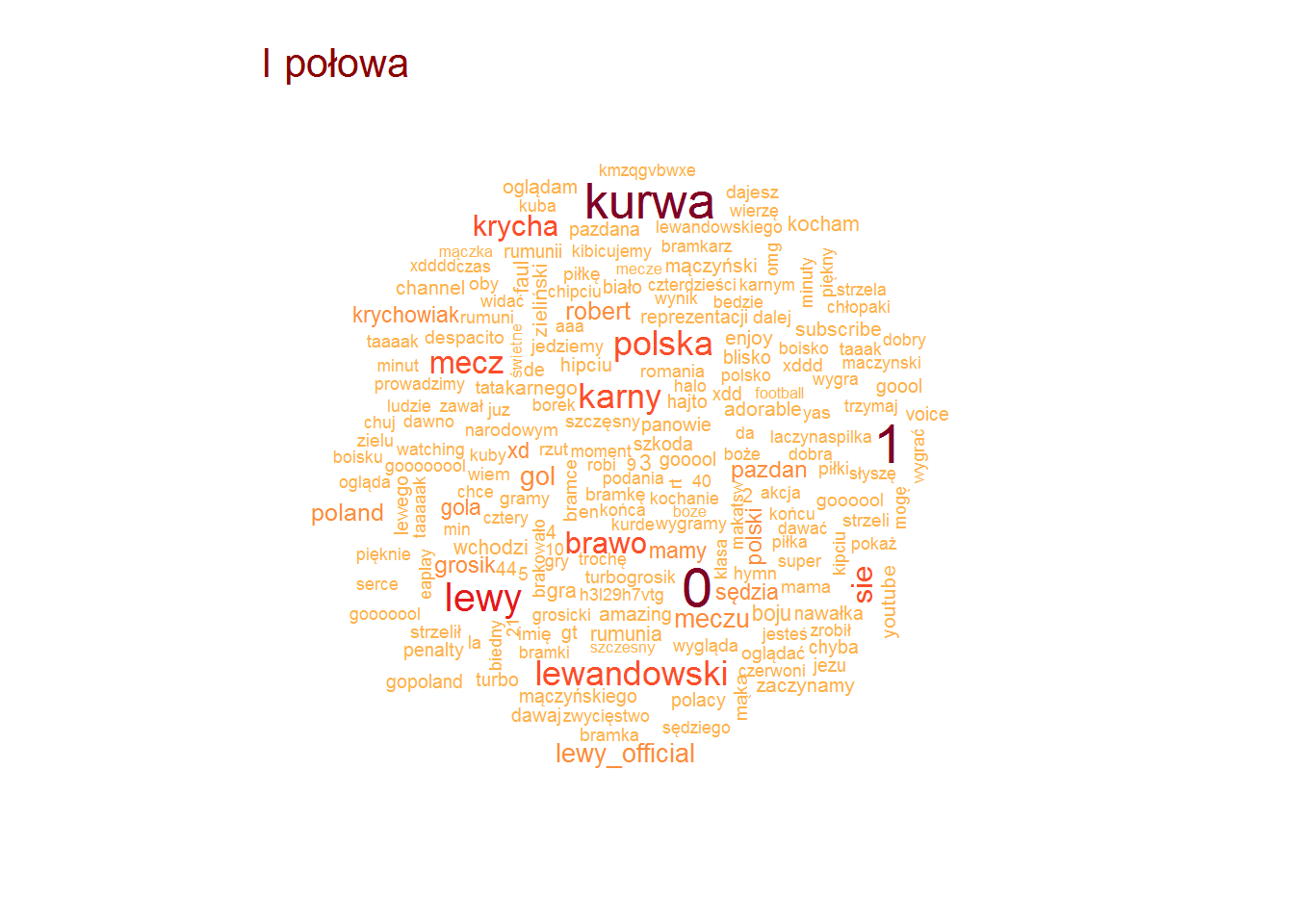



Po meczu – radość (brawo panowie, mamy mundial). W drugiej połowie – wyniki (3:0, wcześniej 2:0, później dochodzi jedynka do 3:1) i strzelec dwóch bramek. Pierwsza połowa to nieodzowne “kurwa” (dziwne że tak mało – jakbyśmy przegrywali to byłoby pewnie więcej), “Lewy” i pierwsza bramka – karny. Przed meczem standardowe “gopoland, do boju, Szczęsny w bramce, hymn, ciary” ;)
Na koniec zobaczmy jak często wymieniany był bohater w trakcie trwania meczu:
Lewandowski w czasie meczu
Po zerknięciu w dane (już rozdzielone na słowa i z policzoną częstotliwością ich występowania) możemy wybrać kilka wyrazów, które określają Roberta Lewandowskiego. Oczywiście nazwisko razem z odmianą przez przypadki, ale też nick w social mediach, oraz “Lewy” jako skrót nazwiska.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
tweets_an %>% mutate(created_time = make_datetime(2017, 6, day(created_at), hour(created_at), minute(created_at))) %>% filter(created_time > "2017-06-10 22:45", created_time < "2017-06-11 00:37:00") %>% mutate(text = gsub(" ?(f|ht)tp(s?)://(.*)[.][a-z]+", "", text)) %>% unnest_tokens(words, text, token="words") %>% count(words, created_time) %>% ungroup() %>% filter(tolower(words) %in% c("lewy", "lewandowski", "lewy_official", "lewandowskiego")) %>% group_by(created_time) %>% summarise(n = sum(n)) %>% ungroup() %>% ggplot() + geom_area(aes(created_time, n), color="darkgreen", fill="lightgreen") + scale_x_datetime(date_labels = "%H:%M") |
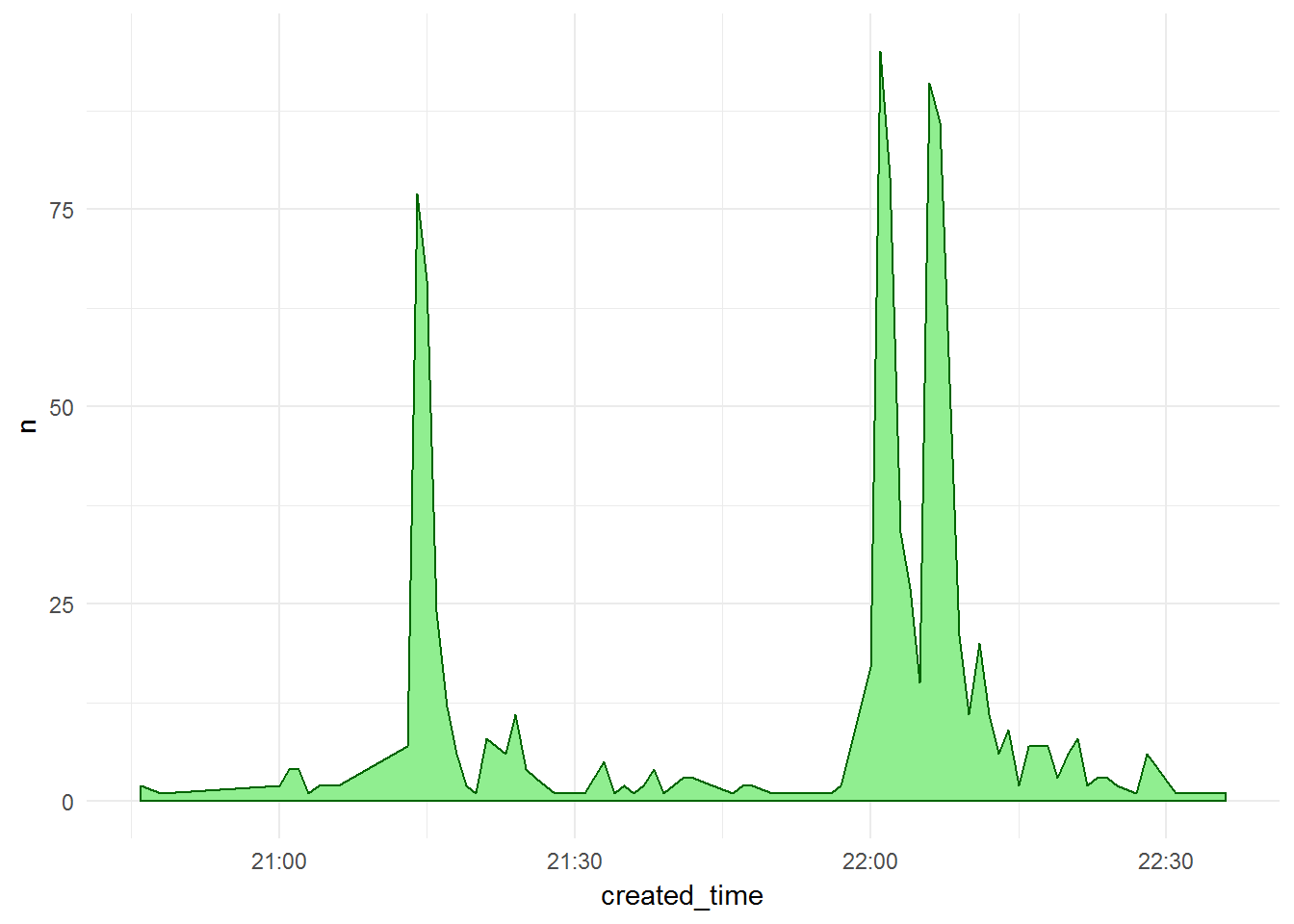
Nie ma nic dziwnego: Lewandowski wymieniany był najczęściej wtedy, kiedy strzelał bramki. Jeśli zrobimy to samo dla słowa “kurwa” otrzymamy podobny układ pików. Jakże to słowo jest uniwersalne…