Jak dowiedzieć się kto wygrał Oscara? Bez czytania wiadomości. W każdej z kategorii. Korzystając tylko z Twittera, ale bez czytania poszczególnych twittów! Da się?
Oczywiście, że się da. Potrzebujemy tylko danych i odrobiny sprytu przy ich przetwarzaniu.
Najpierw dane. Napisałem skrypt, który pobierał co 5 minut wszystkie nowe twitty z hashtagu #Oscars i zapisywał je w pliku “Oscars_hash.Rds” lokalnie na dysku. Sposobów na pobranie danych z Twittera jest wiele, ja wybrałem ten – najszybciej było mi napisać odpowiedni skrypcik (w R – mniej więcej robiący tyle: wyszukaj najnowsze twitty z określonym hasłem, dodaj je do już znalezionych) i po prostu zostawić komputer na noc.
Te same dane można pobrać i wpakować do bazy danych.
Można też przygotować skrypt, który pobierze wszystko na raz.
Skrypt możecie przygotować sobie samodzielnie, zachęcam. Tak czy inaczej – w R polecam bibliotekę twitteR.
Trzeba jednak liczyć się z ograniczeniami API Twittera – określona liczba zapytań w czasie, określona (maksymalna) liczba wyników zwracanych dla jednego zapytania. Z powodu tych ograniczeń dane przygotowane przeze mnie zawierają maksymalnie 3200 Twittów pobranych raz na 5 minut. Do naszej analizy to wystarczy. Poza tym – moją ideą przy prezentowaniu kolejnych postów jest pokazanie, że bez płacenia za jakiekolwiek dane można fajnie się pobawić i czegoś nauczyć.
Dzisiaj korzystamy jak zazwyczaj z bibliotek ggplot2, dplyr, lubridate oraz tidytext do operacji na słowach. Fajna biblioteka, dużo przykładów, jeszcze się będziemy nią bawić.
Pobieramy dane zapisane przez skrypty zapisujące to, co działo się na Twitterze i rozdzielamy czas opublikowania twittu na dzień, godzinę i minutę (po tym będziemy później szukać i grupować). Przy okazji wytniemy dane tylko dla 27 lutego (ceremonia była już 27 lutego naszego czasu), żeby nie ciągnąć za dużego ogona ze sobą.
|
1 2 3 4 5 6 |
OscarTweets <- readRDS("Oscars_hash.Rds") OscarTweets <- OscarTweets %>% mutate(day = day(created), hour = hour(created), min = minute(created)) %>% filter(day==27) |
Po takim wyfiltrowaniu pozostało mi jakieś 298 tysięcy twiitów.
Jak bardzo Twitter był aktywny podczas gali?
Najpierw przygotujmy wykres słupkowy – dla każdej minuty liczymy ile wysłano twittów. Rozdzielmy to przy okazji na twitty i retwitty.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
OscarTweets %>% group_by(day, hour, min, isRetweet) %>% count() %>% ungroup() %>% ggplot() + geom_area(aes(x=make_datetime(year=2017, month=2, day=day, hour=hour, min=min), y=n, fill=isRetweet), stat="identity") + labs(x="Godzina", y="Liczba tweetów", fill="Czy RT?") + facet_grid(isRetweet~., scales="free_y") + theme_minimal() |
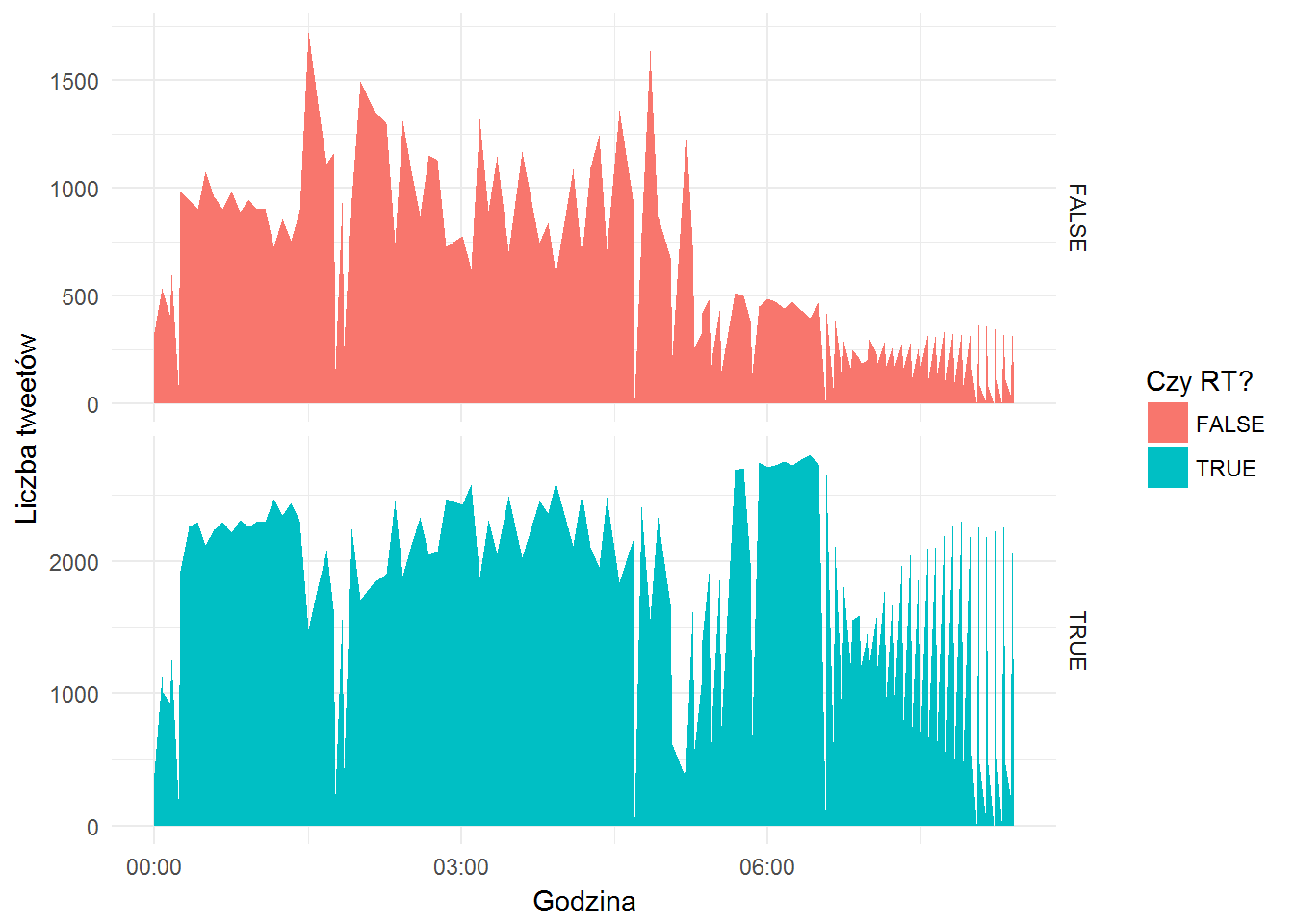
A teraz te same dane pokazane jako gęstość prawdopodobieństwa wystąpienia konkretnej godziny.
|
1 2 3 4 5 6 7 8 |
OscarTweets %>% ggplot() + geom_density(aes(created, fill=isRetweet)) + labs(x="Godzina", y="Gęstość prawdopodobieństwa", fill="Czy RT?") + facet_grid(isRetweet~., scales="free_y") + theme_minimal() |
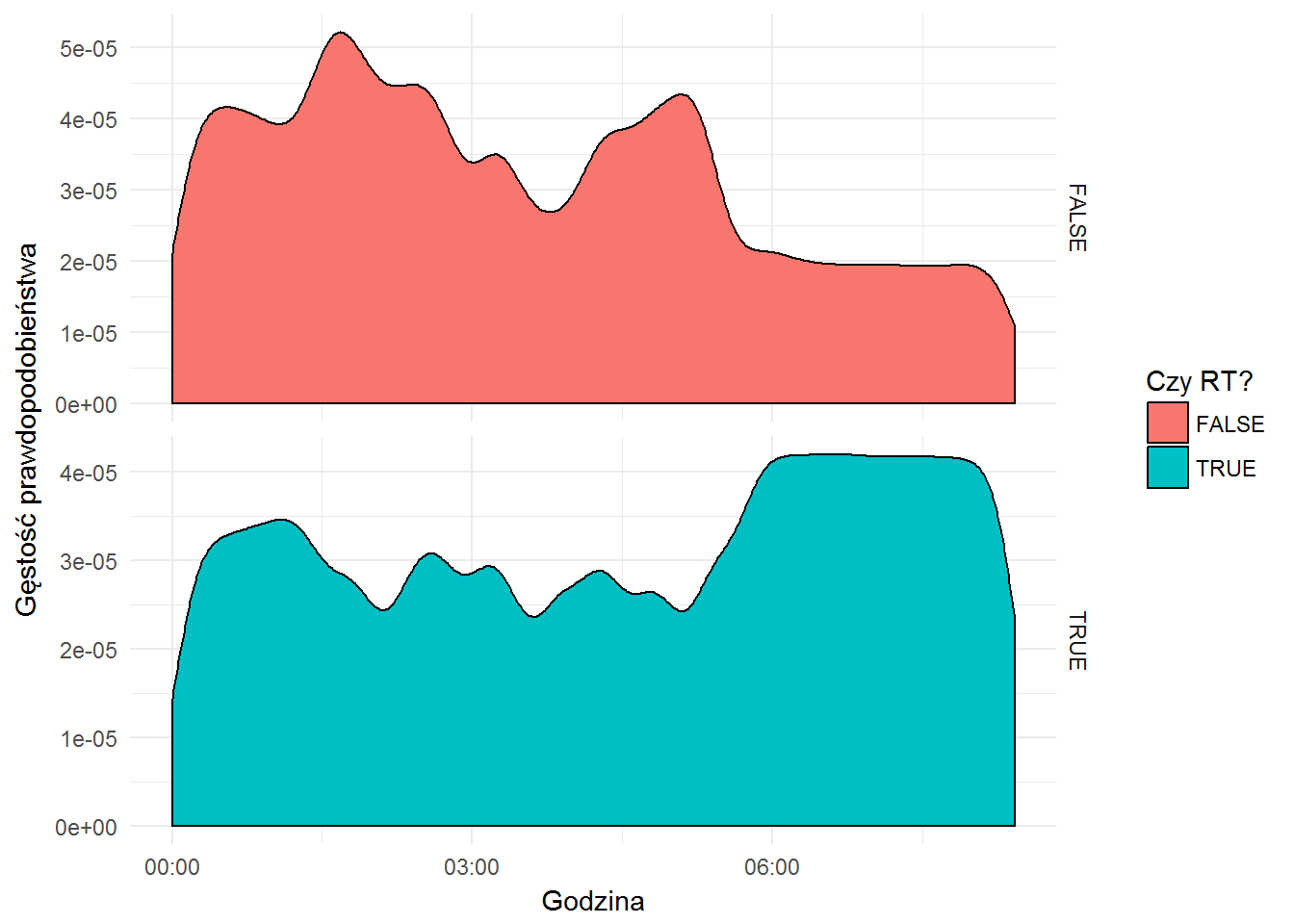
Dlaczego dwa razy pokazuję te same dane (ujęte w inny sposób)? Tylko w celach edukacyjnych – drugi wykres jest ładniejszy (bardziej wygładzony), ale na osi Y są inne wartości. Jeden (pierwszy) pokazuje “prawdę historyczną”, drugi raczej trend – górki i dołki są w tych samych miejscach (dla obu sposobów pokazania danych).
Przy okazji widać ciekawostkę – retwittów jest mniej więcej trzy razy więcej. To pewnie przez lenistwo – wystarczy kliknąć jedną ikonkę, zamiast wymyślać tekst i go w dodatku pisać. Zapewne są badania dotyczące ilości akcji nie wymagających pisania w zestawieniu do np. komentarzy czy odpowiedzi. Kiedyś możemy zająć się tym tematem – na przykład przy okazji oglądania danych z Facebooka.
Jaka dokładnie jest ta różnica, dla tych konkretnych danych?
|
1 2 3 4 5 |
OscarTweets %>% filter(day>=27) %>% group_by(isRetweet) %>% count() %>% ungroup() |
| isRetweet | n |
|---|---|
| FALSE | 75895 |
| TRUE | 222433 |
Trzeba podzielić oczywiście wartość dla TRUE przez wartość dla FALSE, co daje w przybliżeniu 2.931 ;-)
Teraz przygotujemy kilka funkcji, które ułatwią później zadanie. Będziemy je wywoływać kilkukrotnie, a programowanie oparte o użycie funkcji jest ładniejsze niż wpychanie wszystkiego w jedną wielką pętlę.
Analizować będziemy każdą z kategorii z osobna. Dlatego potrzebujemy danych podzielonych na kategorie. Można to zrobić na wiele sposobów (jak wszystko właściwie), na przykład dodając kolumnę mówiącą do jakiego kategorii odnosi się dany twitt. Albo wybierając twitty pasujące do kategorii nagród i później zajmować się już tylko nimi.
Jak stwierdzić do której kategorii Oscarów nawiązuje twitt? Proponuję po zawartości (można jeszcze dodać czas twittnięcia – jeśli mamy szukać wyników to później niż chwila ogłoszenia zwycięzcy), najprościej sprawdzając czy w twicie występuje określony ciąg znaków, który opisuje kategorię.
Przygotujmy więc funkcję, która wybierze podzbiór twittów zawierających określony ciąg znaków. I nic więcej. Jeśli jest ciąg “jakaś kategoria” to twit należy do tej kategorii.
|
1 2 3 4 5 |
sliceTweets <- function(string) { OscarTweets %>% filter(day>=27) %>% filter(grepl(string, text, fixed = TRUE)) } |
Napisałem wyżej, że dodatkowym ograniczeniem może być moment ogłoszenia zwycięzcy w danej kategorii. Ale nie znamy scenariusza, nie oglądaliśmy transmisji (bo spaliśmy – o wynikach dowiemy się za chwilę z danych; szkoda snu, kiedy są dane!), nie czytamy danych. Czytać, albo chociaż oglądać na wykresach dane trzeba zawsze, szczególnie te nieznane. Żeby analizować dane trzeba je zrozumieć.
Jesteśmy jednak leniwi, czas mija, minęła już prawie doba, wszyscy wiedzą kto zgarnął Oscary, a my jeszcze nie.
Założenie znowu jest proste – ludzie (i boty, głównie boty i redakcje) reagują natychmiast po wydarzeniu transmitowanym w TV. To wiadomo, wystarczy w czasie meczu otworzyć okno i czekać na bramkę; szczególnie w ciepły dzień, na dużym osiedlu… Tak się dzieje też na Twitterze, w związku z tym dużo reakcji powinno być tuż po słowach “And the winner is…”.
Najpierw przygotujmy narzędzie – funkcję która zwróci nam czas, kiedy było najwięcej twittów oraz stosowny wykres z liczbą tych twittów oraz zaznaczonym czasem maksimum.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
plotTimeline <- function(string) { # najpierw wycinamy sobie grupę tweetów z ciągiem tab <- sliceTweets(string) %>% group_by(day, hour, min) %>% count() %>% ungroup() # określamy czas największej ilości tweetów z wygranej puli time_tab <- tab %>% filter(n==max(n)) time_lab <- paste0(time_tab$hour, ":", sprintf("%02d", time_tab$min)) time <- make_datetime(year=2017, month=2, day=time_tab$day, hour=time_tab$hour, min=time_tab$min) # przygotowujemy wykres plot <- tab %>% ggplot() + geom_point(aes(make_datetime(year=2017, month=2, day=day, hour=hour, min=min), n)) + geom_vline(xintercept = as.numeric(time), color="red") + geom_text(x=as.numeric(time)+1100, # +1100, żeby nie nałaziło na kreskę y=max(tab$n), label=time_lab, color="red") + labs(x="Godzina", y="Liczba tweetów") + theme_minimal() # zwracamy paczkę danych return(list(time=time, plot=plot)) } |
Jak to zadziała? Sprawdźmy dla kategorii “Najlepszy film zagraniczny”:
|
1 |
plotTimeline("Foreign Language Film")$plot |
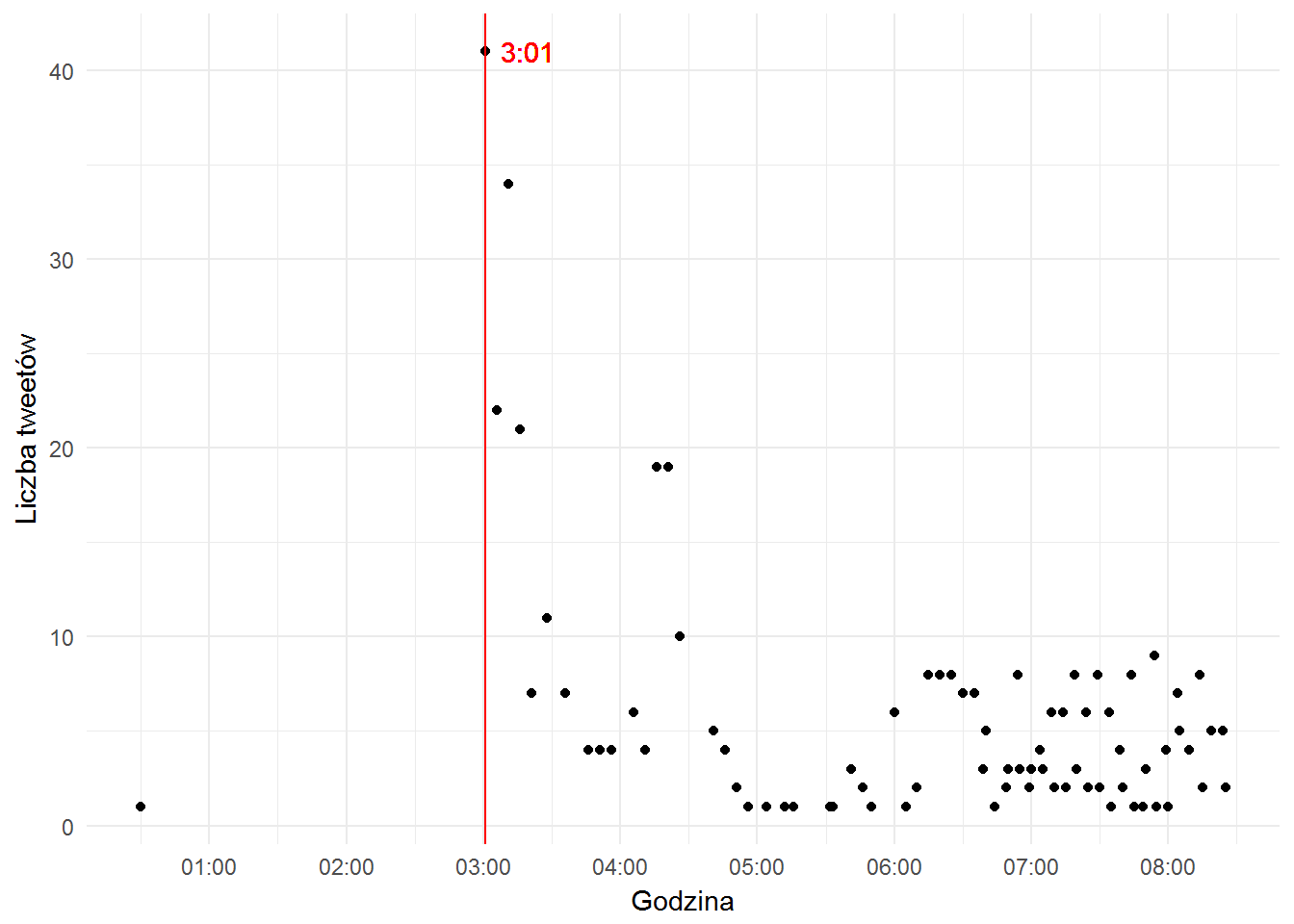
Punkty to liczba twittów, czerwona linia oznacza czas, kiedy twittów było najwięcej – 3:01. Jak widać na wykresie jest ich trochę ponad 40. Zobaczmy je…
|
1 2 3 4 5 6 7 |
OscarTweets %>% filter(day==27, # o tej konkretnej godzine hour==3, min==1, # z tej kategorii grepl("Foreign Language Film", text)) %>% select(created, screenName, text) |
…ale może tylko te nie będące retwittami:
| created | screenName | text |
|---|---|---|
| 03:01:52 | BetoRangel_17 | The Salesman wins The #Oscars for Best Foreign Language Film. |
| 03:01:52 | michaelares1 | Best Foreign Language Film goes to “The Salesman,” from Iran #Oscars. Did it win cuz it was good? Or so they could address the Trump ban? |
| 03:01:49 | EyeForFilm | Asghar Farhadi’s The Salesman has won Best Foreign Language Film #Oscars |
| 03:01:48 | GulfFilm | The award for Foreign Language Film goes to #TheSalesman! #Oscars https://t.co/TVLpRYukXM |
| 03:01:47 | JasonCKillpack | Massive congrats to #AsgharFarhadi #oscars Best Foreign Language Film! |
| 03:01:47 | ArtificialEye | Huge congratulations to #TheSalesman which has won the Best Foreign Language Film Oscar! https://t.co/fHmg9CNoD2… https://t.co/ZDnmQkCgkG |
Jak dowiedzieć się kto wygrał? Weźmy analogię do meczu piłkarskiego – jak gola strzeli Lewandowski, to Szpaku albo Gmoch w TV krzyczą “Lewandowski!!!” i to samo ludzie piszą w social mediach. Czyli jak wygrał “La La Land” to powinni pisać “Nagroda dla La La Land, super! Na to liczyłem, cieszę się bardzo!”.
Czyli, że w treści jest tytuł filmu albo nazwisko jakiejś osoby (aktora, aktorki). Nie chciało mi się szukać wszystkich nominowanych, nie chciało mi się pisać skryptu wyciągającego te dane z internetu. Postanowiłem policzyć słowa i te, które występują najczęściej powinny zawierać tytuł filmu.
Programowanie funkcyjne, więc funkcją.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
whoWon <- function(category) { # słowa z nazwy kategorii będziemy usuwać category_stop <- unlist(strsplit(category, " ")) # wybieramy pulę tweetów tab <- sliceTweets(category) # szukamy najpopularniejszych słów tab_tokens <- unnest_tokens(tbl = tab, input = text, output = tokens) %>% count(tokens) %>% # pozbywamy się angielskich "stop words" # (słów nie znaczących w treści) filter(!tokens %in% stop_words$word) %>% # pozbywamy się słów, które zaciemniają obraz: # tweeterowe skróty linków # hasła związane z samymi nagrodami filter(!tokens %in% c("https", "t.co", "http", "rt", "oscar", "oscars", "wins", "film", "award", "beasts", "oscar2017", "bestpicture")) %>% # pozbywamy się słów z nazwy kategorii filter(!tokens %in% tolower(category_stop)) %>% # słowa dłuższe niż 30 znaków są podejżane ;) filter(nchar(tokens) <= 30) %>% arrange(desc(n)) # zwracamy tabelkę najpopularniejszych słów return(tab_tokens) } |
Zwróćcie uwagę na to co jest w komentarzach kodu powyżej – kilka(naście) słów jest wyciętych z wyników wyszukiwania. Jak ktoś krzyczy “Gol!!! Lewandowski, gol!” to interesuje nas, że Lewandowski a nie, że gol (to też) – dlatego “gola” nie trzeba nam liczyć. Na tej zasadzie wycinamy kilka słów – np. “Oscar”, bo przecież wiadomo o jaką nagrodę chodzi…
Jeszcze tylko przygotujemy sobie dane słownikowe, które po prostu definiują kategorię, w jakich przyznano nagrody.
|
1 2 3 4 5 6 7 8 9 10 |
OscarCategories <- c("Best Original Screenplay", "Best Adapted Screenplay", "Best Achievement in Directing", "Actor in a Leading Role", "Actress in a Leading Role", "Best Picture", "Original Song", "Original Score", "Cinematography", "Action Short", "Documentary Short", "Film Editing", "Visual Effects", "Production Design", "Animated Feature Film", "Animated Short", "Foreign Language Film", "Actress in a Supporting Role", "Actor in a Supporting Role", "Sound Mixing", "Sound Editing", "Documentary Feature", "Costume Design", "Makeup and Hairstyling") |
Cała zabawa zaczyna się tutaj.
Dla wszystkich kategorii pobieramy czas, kiedy twitty związane z kategorią były najpopularniejsze.
|
1 2 3 4 5 |
df <- data.frame() for(i in 1:length(OscarCategories)) { df <- rbind(df, data.frame(cat = OscarCategories[i], time = plotTimeline(OscarCategories[i])$time)) } |
Możemy zobaczyć przebieg gali i to bez jej oglądania czy czytania scenariusza! O której godzinie jakie nagrody wręczano?
|
1 2 3 4 |
df %>% arrange(time) %>% mutate(time=paste0(sprintf("%02d", hour(time)), ":", sprintf("%02d", minute(time)))) %>% select(time, cat) |
| time | cat |
|---|---|
| 01:50 | Actor in a Supporting Role |
| 02:01 | Costume Design |
| 02:01 | Makeup and Hairstyling |
| 02:16 | Documentary Feature |
| 02:31 | Sound Mixing |
| 02:31 | Sound Editing |
| 02:46 | Actress in a Supporting Role |
| 03:01 | Foreign Language Film |
| 03:11 | Animated Short |
| 03:16 | Production Design |
| 03:16 | Animated Feature Film |
| 03:36 | Film Editing |
| 03:36 | Visual Effects |
| 03:46 | Documentary Short |
| 03:51 | Action Short |
| 04:06 | Cinematography |
| 04:16 | Original Score |
| 04:21 | Original Song |
| 04:33 | Best Original Screenplay |
| 04:41 | Best Adapted Screenplay |
| 04:46 | Best Achievement in Directing |
| 04:51 | Actor in a Leading Role |
| 05:03 | Actress in a Leading Role |
| 06:15 | Best Picture |
Ma to ręce i nogi – zazwyczaj zaczyna się od roli drugoplanowej, kwestii technicznych, żeby przejść do części “artystycznej” filmu – zdjęć, muzyki. Potem “szkielet” czyli scenariusz i reżyseria. Na koniec pozostają główni aktorzy i na deser – najlepszy film.
Widać też, że każda statuetka to jakieś 5-10 minut trwania imprezy. Cykl jest powtarzalny, schematyczny dla większości tego typu imprez:
- wyczytanie nominowanych (30 sekund),
- chwila napięcia,
- odczytanie zwycięzcy (30 sekund),
- brawa,
- speech (chyba mają minutę),
- żart prowadzącego (30 sekund),
- następni wręczający nagrody (wejście, uśmiechy, żart – 30 sekund),
- kolejne nominacje…
Po drodze przerwa na reklamy albo jakąś piosenkę. Spina się? Widać w danych ;-)
A kto wygrał? Bo przecież po to to wszystko robimy… i ciągle niczego nie czytaliśmy!
Najpierw dodajmy kolumnę na informacje o zwycięzcy.
|
1 |
df$won <- NA |
A teraz dla wszystkich kategorii – szukamy zwycięzcy (trzy najpopularniejsze słowa).
|
1 2 3 4 |
for(i in 1:length(OscarCategories)) { temp_df <- whoWon(OscarCategories[i]) df[i, "won"] <- paste(temp_df[1,1], temp_df[2,1], temp_df[3,1]) } |
Zobaczmy podsumowanie naszych poszukiwań:
|
1 2 3 4 5 |
df %>% arrange(time) %>% mutate(time=paste0(sprintf("%02d", hour(time)), ":", sprintf("%02d", minute(time)))) %>% select(time, cat, won) |
| time | cat | won |
|---|---|---|
| 01:50 | Actor in a Supporting Role | ali mahershala moonlight |
| 02:01 | Costume Design | fantastic fantasticbeasts ew |
| 02:01 | Makeup and Hairstyling | suicide squad suicidesquad |
| 02:16 | Documentary Feature | america o.j ojmadeinamerica |
| 02:31 | Sound Mixing | hacksaw hacksawridge ridge |
| 02:31 | Sound Editing | arrival arrivalmovie f1 |
| 02:46 | Actress in a Supporting Role | davis viola fences |
| 03:01 | Foreign Language Film | asghar farhadi salesman |
| 03:11 | Animated Short | piper disneypixar congrats |
| 03:16 | Production Design | la lalaland wasco |
| 03:16 | Animated Feature Film | vote zootopia livetheoscars |
| 03:36 | Film Editing | hacksaw ridge hacksawridge |
| 03:36 | Visual Effects | jungle book thejunglebook |
| 03:46 | Documentary Short | white helmets thewhitehelmets |
| 03:51 | Action Short | live sing winners |
| 04:06 | Cinematography | la lalaland cast |
| 04:16 | Original Score | la lalaland land |
| 04:21 | Original Song | la land deserves |
| 04:33 | Best Original Screenplay | manchester sea lonergan |
| 04:41 | Best Adapted Screenplay | moonlight barry jenkins |
| 04:46 | Best Achievement in Directing | la chazelle damien |
| 04:51 | Actor in a Leading Role | casey affleck manchester |
| 05:03 | Actress in a Leading Role | la blame reallavender |
| 06:15 | Best Picture | moonlight la land |
Jeśli znamy listę nominacji (mniej więcej), to z powyższej tabeli wywnioskujemy kto wygrał. Nie widać tego super dokładnie jak na jakiejś zredagowanej stronie internetowej, chociażby tutaj, na oficjalnej stronie, ale trzeba przyznać, że efekt jest zadowalający, prawda?
I to wszystko bez czytania ani jednego Twitta i śledzenia relacji!
Tylko ten kicks z “Best Picture” dla “La La Land” (zgodnie z moimi przewidywaniami, a co!) trochę popsuł końcówkę. W ostatnim wierszu tabeli widać dwa tytuły (“Moonlight” oraz “La La Land”) – trzeba by więc dokładniej przekopać się przez dane.
Można ten wydzielony pod kategorię zbiór twittów rozdzielić na “Moonlight” i “La La Land” – sprawdzić czego więcej (podpowiem: “Moonlight”, co wynika z kodu i tabelki – pierwsze słowo w tabeli występuje częściej niż drugie).
Warto też sprawdzić co się działo w ciągu 15-20 minut po 5:03 (czas wręczenia nagrody za najlepszą pierwszoplanową rolę kobiecą) – zauważcie, że “Best Picture” widnieje przy 6:15, czyli za późno. Do analizy jest okres pomiędzy zieloną a czerwoną kreską na wykresie:
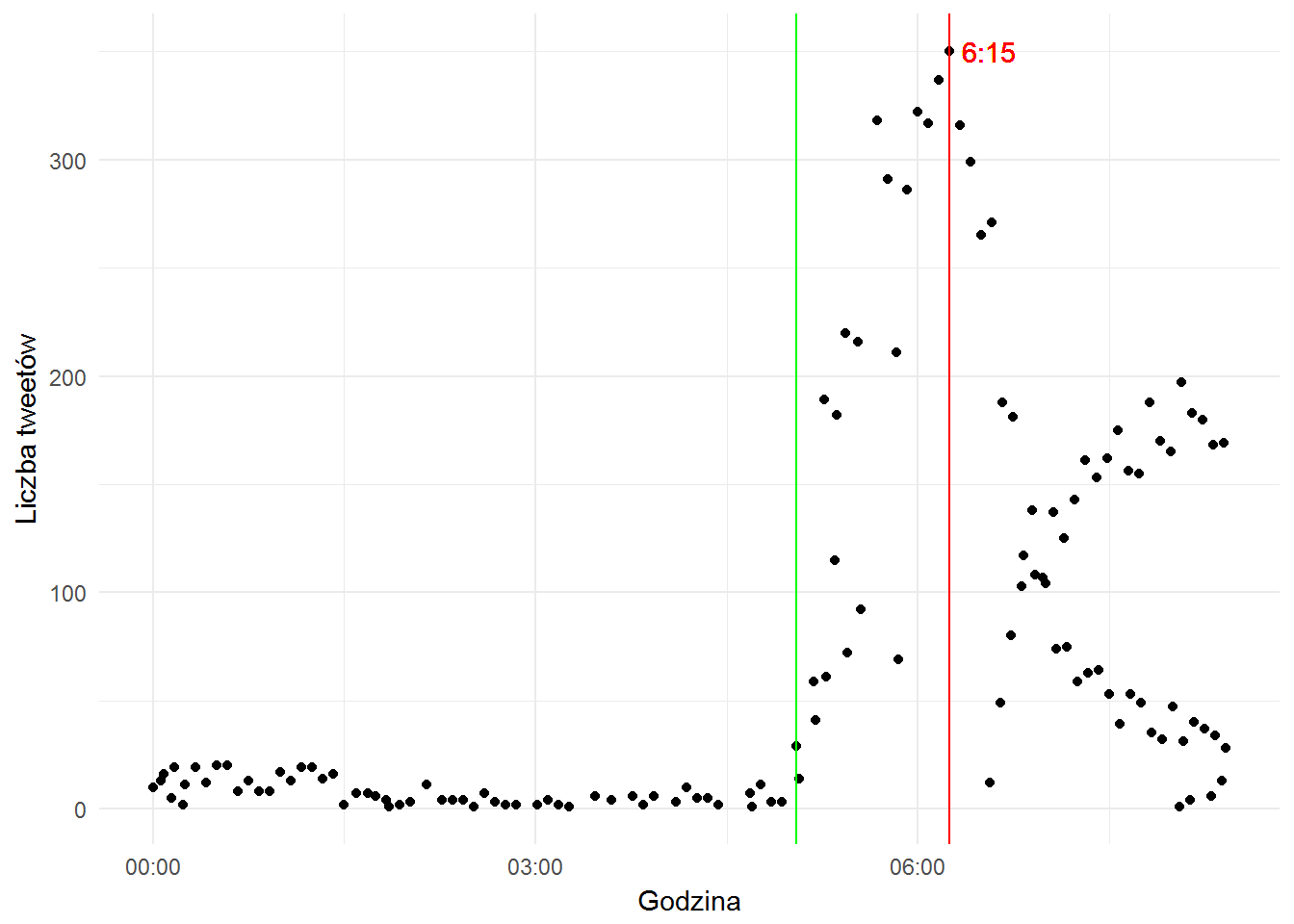
Liczba twittów z kategorii “best picture” rośnie tutaj mocno, widać, że coś się dzieje.
Pobienie jest z “Actress in a Leading Role”. Zobaczmy jak wyglądają dane dla tej kategorii zwrócone przez naszą funkcję filtrująco-zliczającą whoWon, pierwsze 20 słów:
|
1 |
whoWon("Actress in a Leading Role") %>% head(20) |
| tokens | n |
|---|---|
| la | 246 |
| blame | 245 |
| reallavender | 245 |
| warrenbeatty | 245 |
| hpvadk1n9n | 244 |
| emma | 159 |
| stone | 159 |
| land | 123 |
| abc | 56 |
| yoz5x2ihdg | 56 |
| p0dili | 45 |
| cnn | 30 |
| n0v3jbsbg2 | 28 |
| qa7pkhxvsv | 28 |
| beatty | 26 |
| congratulations | 25 |
| warren | 24 |
| decía | 20 |
| el | 20 |
| en | 20 |
Wyboldowane pozycje w tabeli powyżej są ciekawe i prowadzą do wnoisku “La Land Emma Stone”. Warren Beatty najprawdopodobniej nie startował w konkurencji “najlepsza aktorka”, więc pewnie też nie wygrał…
Może czas przeczytać dane? ;) Neee… przecież wszytko już wiemy!
Pingback: Pulp Fiction - analiza filmu | Łukasz Prokulski
Pingback: Maszynka do czytania Twittera | Łukasz Prokulski