Uwielbiam muzykę, lubię radio (chociaż słucham go właściwie tylko w samochodzie), kiedyś przez chwilę uczyłem się w krakowskich stacjach radiowych realizacji dźwięku. Po Więcej czadu miałem wieloletnią fazę, żeby zostać radiowcem.
Radiowcem nie zostałem, ale nad stacjami radiowymi można się trochę poznęcać.
Według badania Radio Track Millward Brown (ostatnie zestawienia można znaleźć na Wirtualnych Mediach) najpopularniejsze (top 5) w Polsce stacje radiowe to: RMF FM, Radio ZET, Jedynka, ESKA i Trójka. A że istnieje sobie taki serwis jak Radiospis.pl zawierający listę piosenek granych na antenie z ostatnich siedmiu dni to sobie porównamy kto co gra.
Na początek przygotujemy funkcję, która zbierze nam dane ze strony:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 |
library(tidyverse) library(forcats) library(stringr) library(lubridate) library(rvest) # lista stacji playlists_urls <- list( stacja = c("RMF FM", "Zet", "Jedynka", "ESKA", "Trójka"), url = c("https://radiospis.pl/stacja/rmf-fm", "https://radiospis.pl/stacja/zet", "https://radiospis.pl/stacja/jedynka", "https://radiospis.pl/stacja/eska", "https://radiospis.pl/stacja/trojka")) %>% transpose() # funkcja pobierająca playlisty getPlaylistTable <- function(verbose = TRUE) { playlist_tab <- tibble() # dla każdej stacji for(i in seq_len(length(playlists_urls))) { # bierzemy podstawowy url i nazwę stacji page_base_url <- playlists_urls[[i]]$url stacja <- playlists_urls[[i]]$stacja end <- FALSE page_no <- 1 # dopóki jest link do następnej strony - przetwarzamy kolejne strony while(!end) { # progress bas :) if(verbose) cat(sprintf("%s - %02d\n", stacja, page_no)) # wczytujemy stronę page_html <- read_html(sprintf("%s/page/%d", page_base_url, page_no)) # data i godzina emisji utworu datetime <- page_html %>% html_nodes("div.hentry") %>% html_node("p") %>% html_text() %>% dmy_hm() # wykonawca i tytuł utwory song <- page_html %>% html_nodes("div.hentry") %>% html_node("h2") %>% html_text() # budujemy tymczasową tabele z wynikow temp_tab <- tibble(datetime, song, stacja) %>% # rozdzielamy piosenkę na tytul i wykonawce rowwise() %>% mutate(artist = str_split(song, " - ")[[1]][1], title = str_split(song, " - ")[[1]][2]) %>% ungroup() # dołączamy tymczasowa tabele do pelnych wynikow playlist_tab <- bind_rows(playlist_tab, temp_tab) # czy to koniec? nie ma przycisku "Wcześniej" na stronie end <- page_html %>% html_nodes("div.morebtnall") %>% .[[2]] %>% html_text() %>% nchar() == 0 # chwilę ajemy odsapnąć serwerom Sys.sleep(0.5) page_no <- page_no + 1 } } return(playlist_tab) } |
Teraz wywołamy sobie tę funkcję i zapiszemy dane na później:
|
1 2 |
playlist_tab <- getPlaylistTable() saveRDS(playlist_tab, file = "grabbed_data.RDS") |
Mając te podstawowe dane możemy zacząć ich przegląd.
Najpopularniejsi wykonawcy według stacji radiowej
|
1 2 3 4 5 6 7 8 9 10 |
playlist_tab %>% count(artist, stacja) %>% ungroup() %>% group_by(stacja) %>% top_n(10, n) %>% ungroup() %>% ggplot() + geom_tile(aes(stacja, artist, fill = n), color = "gray10") + scale_fill_distiller(palette = "YlOrRd") + theme(legend.position = "bottom") |
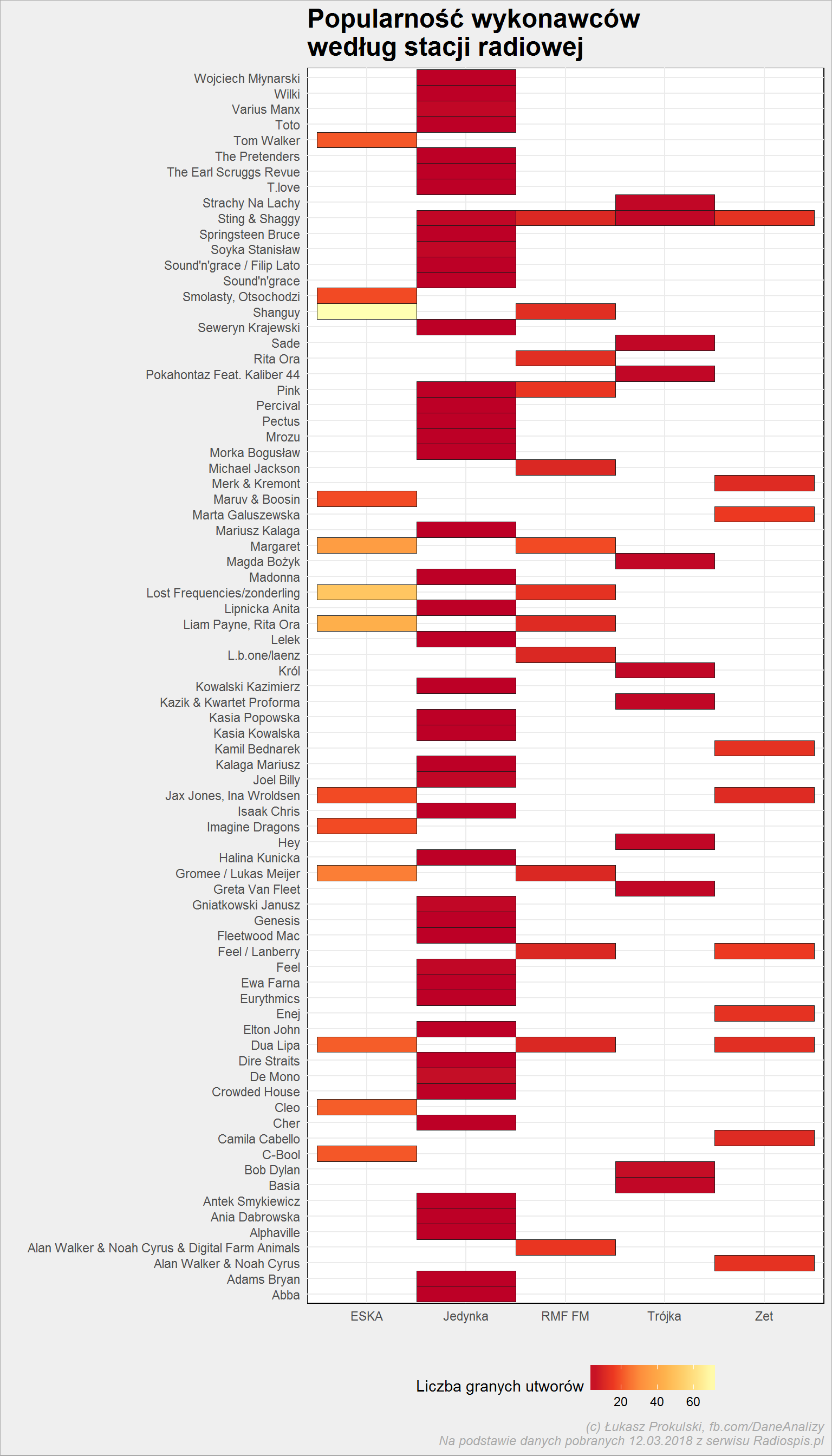
Widzimy tutaj dwie ciekawostki:
- już na pierwszy rzut oka widać, że liczba prostokątów (czyli wystąpienia danego wykonawcy na antenie) jest różna w zależności od stacji. Mówi nam to o zróżnicowaniu w doborze playlisty. ESKA gra kilku wykonawców, Jedynka całe spektrum
- to co jest grane w Jedynce prawie wcale nie jest grane w innych stacjach. Zaś to co jest grane w Esce jest często grane w RMF FM i Zetce. Trójka podobnie jak Jedynka – jest odrębna.
W sumie to dobrze z punktu widzenia słuchacza, stacje są wyraziste muzycznie. Jeśli podoba mi się muzyka w Jedynce to przy niej zostanę, bo inne stacje grają coś innego. Podobnie z Trójką. Ale większej różnicy między Eską, RMF i Zetką nie ma. Przynajmniej na poziomie doboru najpopularniejszych wykonawców.
Które stacje są muzyczne? W jakich godzinach jest najwięcej muzyki?
|
1 2 3 4 5 6 7 8 9 10 |
playlist_tab %>% mutate(hour = hour(datetime), day = wday(datetime)) %>% count(stacja, day, hour) %>% ungroup() %>% group_by(stacja, hour) %>% summarise(mean_n = mean(n)) %>% ungroup() %>% ggplot() + geom_col(aes(hour, mean_n, fill = stacja), show.legend = FALSE) + facet_wrap(~stacja, ncol = 5) |
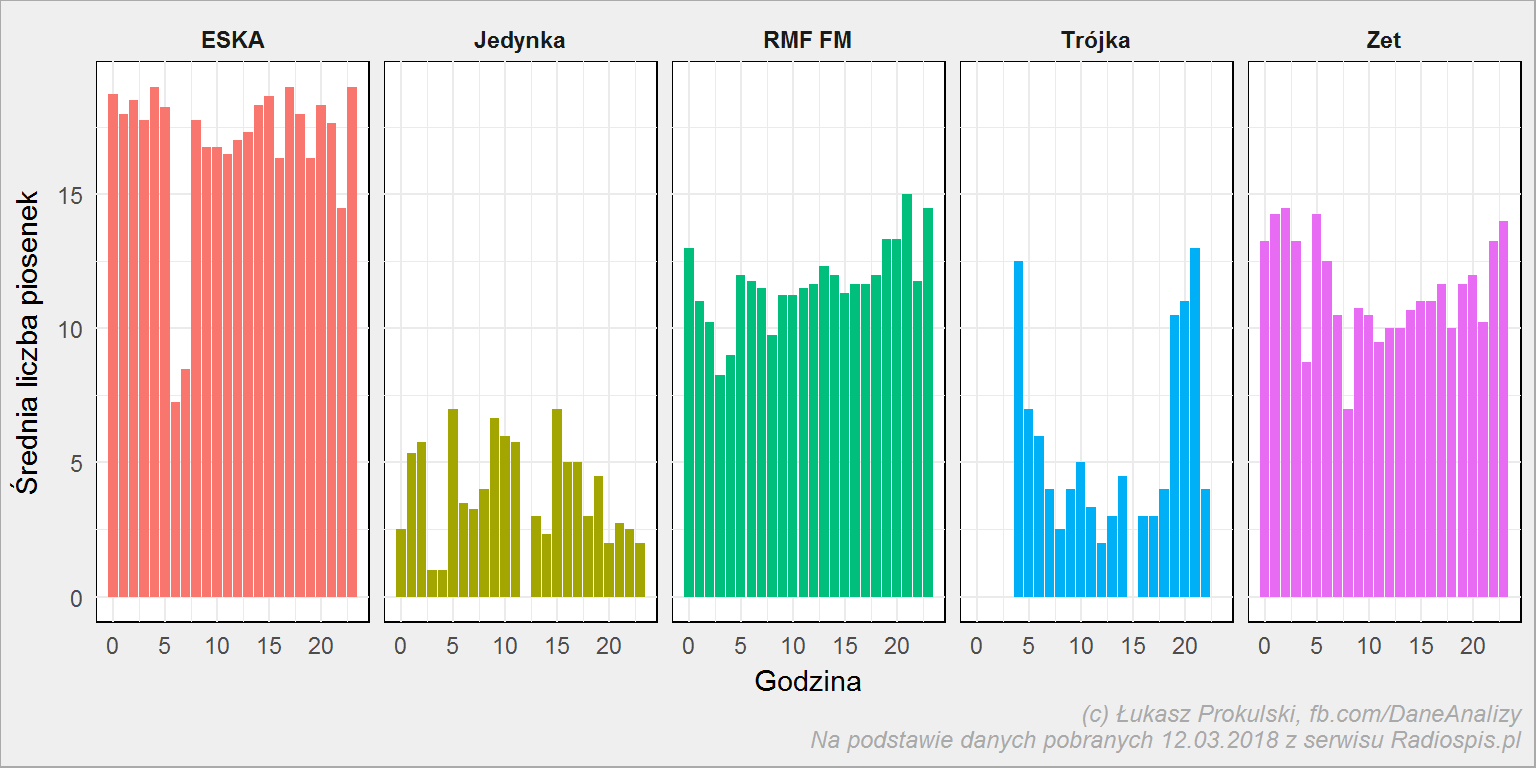
Za najbardziej muzyczną stację możemy traktować Eskę – tutaj mamy najwięcej odtworzonych piosenek na godzinę. Czy to jest prawda czy też mamy jakiś błąd w danych (około 18 piosenek na godzinę oznacza piosenki trwające średnio po 3 minuty i 20 sekund – typowo radiowe utwory, ale jest to podejrzane – gdzie czas na serwis i głupie gadki prowadzących?) to jeszcze będziemy rozstrzygać (ale nie poprawiać). W każdym razie w jakimś przybliżeniu nasz wykres ma sens – w Jedynce i Trójce więcej jest audycji gadanych (Jedynki nie słucham, Trójkę znam – w środku dnia na pewno więcej gadają niż w paśmie wieczornym koło 19-22; swoją drogą polecam te wieczorne audycje).
Liczba piosenek w sumie
Ile w badanym czasie zagrano piosenek?
|
1 2 3 4 5 6 7 |
playlist_tab %>% count(stacja) %>% ungroup() %>% mutate(n = color_tile("white", "orange")(n)) %>% kable(escape = FALSE) %>% kable_styling(bootstrap_options = c("striped", "hover", "condensed", "responsive"), full_width = FALSE) |
| Stacja | Liczba |
|---|---|
| ESKA | 1440 |
| Jedynka | 320 |
| RMF FM | 1000 |
| Trójka | 200 |
| Zet | 1000 |
Potwierdzają się nasze obserwacje: w Esce jest najwięcej muzyki, w Trójce najmniej. RMF i Zetka od zawsze były wzajemną konkurencją, a tutaj nawet identyczne liczby wyszły…
Zobaczmy jak z unikalnością piosenek – czyli ile zagrano piosenek, ale już różnych, jak duża jest biblioteka?
|
1 2 3 4 5 6 7 8 |
playlist_tab %>% distinct(stacja, title, artist) %>% count(stacja) %>% ungroup() %>% mutate(n = color_tile("white", "orange")(n)) %>% kable(escape = FALSE) %>% kable_styling(bootstrap_options = c("striped", "hover", "condensed", "responsive"), full_width = FALSE) |
| Stacja | Liczba |
|---|---|
| ESKA | 541 |
| Jedynka | 307 |
| RMF FM | 608 |
| Trójka | 165 |
| Zet | 665 |
Dla łatwiejszego porównania złóżmy to razem i sprawdźmy jak muzycznie stacje są zróżnicowane (iloraz unikalne/wszystkie):
|
1 2 3 4 5 6 7 8 9 10 |
left_join( playlist_tab %>% count(stacja, sort = T) %>% ungroup() %>% rename(total=n), playlist_tab %>% distinct(stacja, title, artist) %>% count(stacja, sort = T) %>% ungroup() %>% rename(uniq = n), by = "stacja") %>% mutate(p = round(100*uniq/total, 1)) %>% arrange(desc(p)) %>% mutate(p = color_tile("white", "orange")(p)) %>% kable(escape = FALSE) %>% kable_styling(bootstrap_options = c("striped", "hover", "condensed", "responsive"), full_width = FALSE) |
| Stacja | Piosenek łącznie | Piosenek unikalnych | Unikalność |
|---|---|---|---|
| Jedynka | 320 | 307 | 95.9 |
| Trójka | 200 | 165 | 82.5 |
| Zet | 1000 | 665 | 66.5 |
| RMF FM | 1000 | 608 | 60.8 |
| ESKA | 1440 | 541 | 37.6 |
Jedynka gra najbardziej zróżnicowanie (i jeśli komuś odpowiada dobór wykonawców to powinien być zadowolony). Trójka jest na drugim miejscu, ale Trójka zawsze była swego rodzaju popularyzatorem muzyki; to z Trójki w latach ’70 i ’80 ludzie dowiadywali się o nowych płytach, a Lista Przebojów była obrazem popularności. Teraz każda stacja ma swoją listę i jej zawartość jest odbiciem gustu słuchaczy. Według mnie nie ma jednego miejsca które powie jasno, że najbardziej popularną piosenką w Polsce jest Sławomir i “Miłość w Zakopanem” albo cokolwiek innego. Lista Trójki to jedno, lista RMF to drugie, Sylwester w TVP to trzecie, a Spotify to czwarte. Może jakby to wszystko poważyć liczbą słuchaczy/użytkowników to by coś dało…
Wróćmy do tego co mamy i zerknijmy na
najpopularniejsze piosenki
według liczby odtworzeń:
|
1 2 3 4 5 6 7 8 9 10 11 |
most_popular_songs <- playlist_tab %>% count(song, sort = T) %>% ungroup() %>% .$song %>% .[1:9] playlist_tab %>% filter(song %in% most_popular_songs) %>% ggplot() + geom_point(aes(datetime, stacja, color = stacja), size = 2, show.legend = FALSE) + facet_wrap(~song, ncol = 3) |
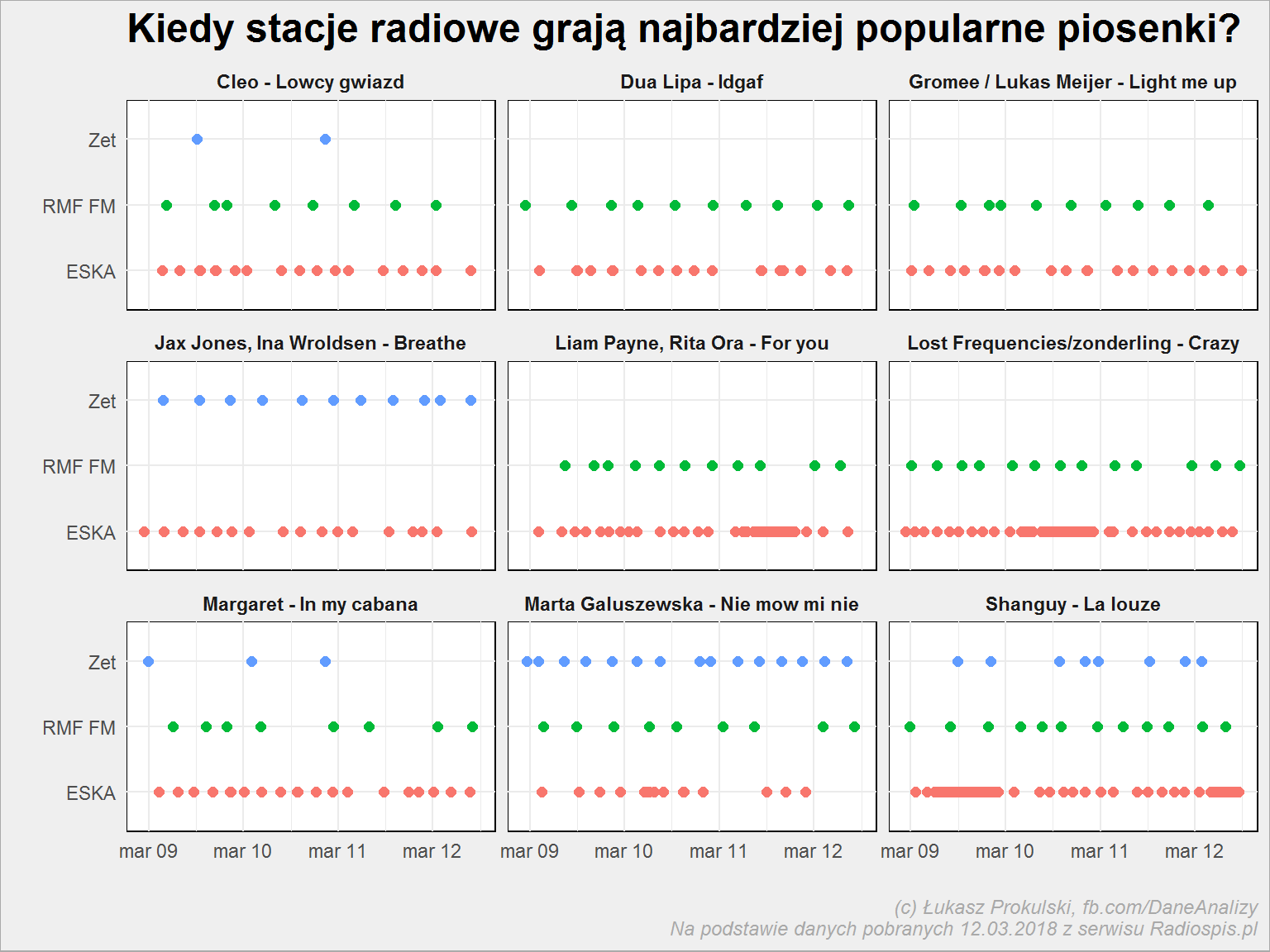
Wzięliśmy 9 najpopularniejszych utworów i jak widać wszystkie 9 swój wynik uzyskały w stacjach grających to samo: Esce, Zetce i RMFie. Zobaczmy jednak najpopularniejsze piosenki według stacji:
|
1 2 3 4 5 6 7 8 9 |
playlist_tab %>% count(song, stacja, sort = T) %>% ungroup() %>% group_by(stacja) %>% top_n(5, n) %>% left_join(playlist_tab, by = c("song" = "song", "stacja" = "stacja")) %>% ggplot() + geom_point(aes(datetime, song, color = stacja), show.legend = FALSE) + facet_wrap(~stacja, scales = "free_y", ncol=1) |
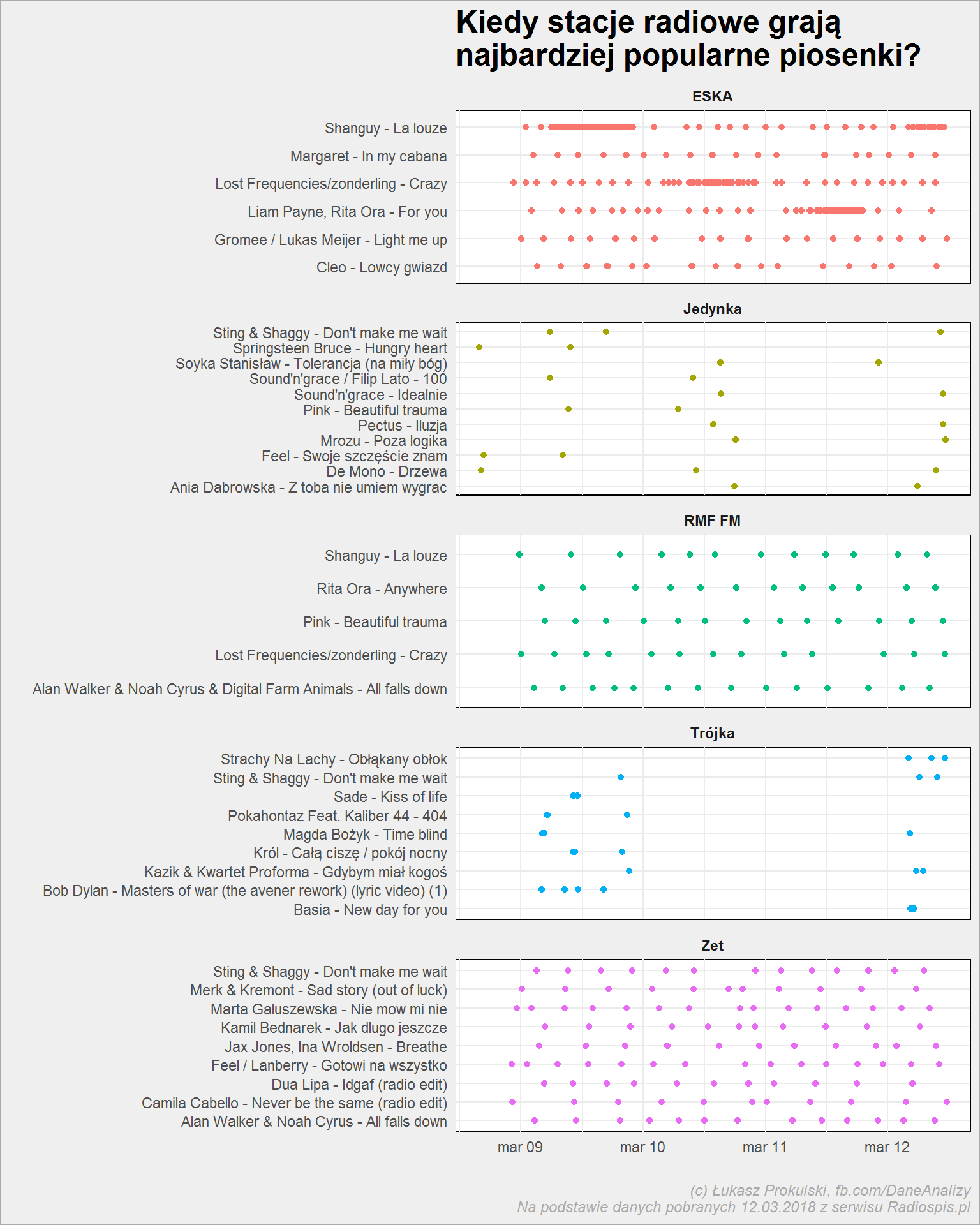
Tytuły z Trójki i Jedynki powtarzają się w jednym czy dwóch przypadkach. Listy Eski, RMFu i Zetki są mocno wspólne.
Widać też, że Eska ma system grania jednej piosenki w kółko przez jeden dzień; taka piosenka dnia to na przykład:
Przeanalizujmy to nieco dokładniej:
|
1 2 3 4 5 6 7 8 9 10 11 |
playlist_tab %>% filter(stacja == "ESKA") %>% mutate(day = wday(datetime)) %>% count(song, day) %>% ungroup() %>% top_n(10, n) %>% arrange(desc(n)) %>% mutate(n = color_tile("white", "orange")(n)) %>% kable(escape = FALSE) %>% kable_styling(bootstrap_options = c("striped", "hover", "condensed", "responsive"), full_width = FALSE) |
| Piosenka | Dzień tygodnia | Liczba |
|---|---|---|
| Shanguy – La louze | 6 | 43 |
| Lost Frequencies/zonderling – Crazy | 7 | 30 |
| Liam Payne‚ Rita Ora – For you | 1 | 27 |
| Shanguy – La louze | 2 | 16 |
| Marta Galuszewska – Nie mow mi nie | 7 | 9 |
| Cleo – Lowcy gwiazd | 6 | 8 |
| Lost Frequencies/zonderling – Crazy | 1 | 8 |
| Lost Frequencies/zonderling – Crazy | 6 | 8 |
| C-Bool – Wonderland | 1 | 7 |
| Cleo – Lowcy gwiazd | 7 | 7 |
| Gromee / Lukas Meijer – Light me up | 6 | 7 |
| Liam Payne‚ Rita Ora – For you | 6 | 7 |
| Liam Payne‚ Rita Ora – For you | 7 | 7 |
| Margaret – In my cabana | 7 | 7 |
| Shanguy – La louze | 1 | 7 |
Pierwsza na liście La louze grana w 6 dzień (czyli w piątek, bo liczymy od niedzieli) tygodnia 43 razy. Druga – Crazy grana w sobotę:
Niedzielę zdominowała For you:
Te piosenki powtarzają się też w inne dni, ale już nie kilkadziesiąt razy a kilka.
Ile razy na godzinę (w piątek) Eska potrafiła zagrać La louze?
|
1 2 3 4 5 6 7 |
playlist_tab %>% filter(stacja == "ESKA", song == "Shanguy - La louze") %>% mutate(day = wday(datetime), hour = hour(datetime)) %>% filter(day == 6) %>% count(hour) %>% ggplot() + geom_col(aes(hour, n), fill = "lightgreen", color = "darkgreen") |
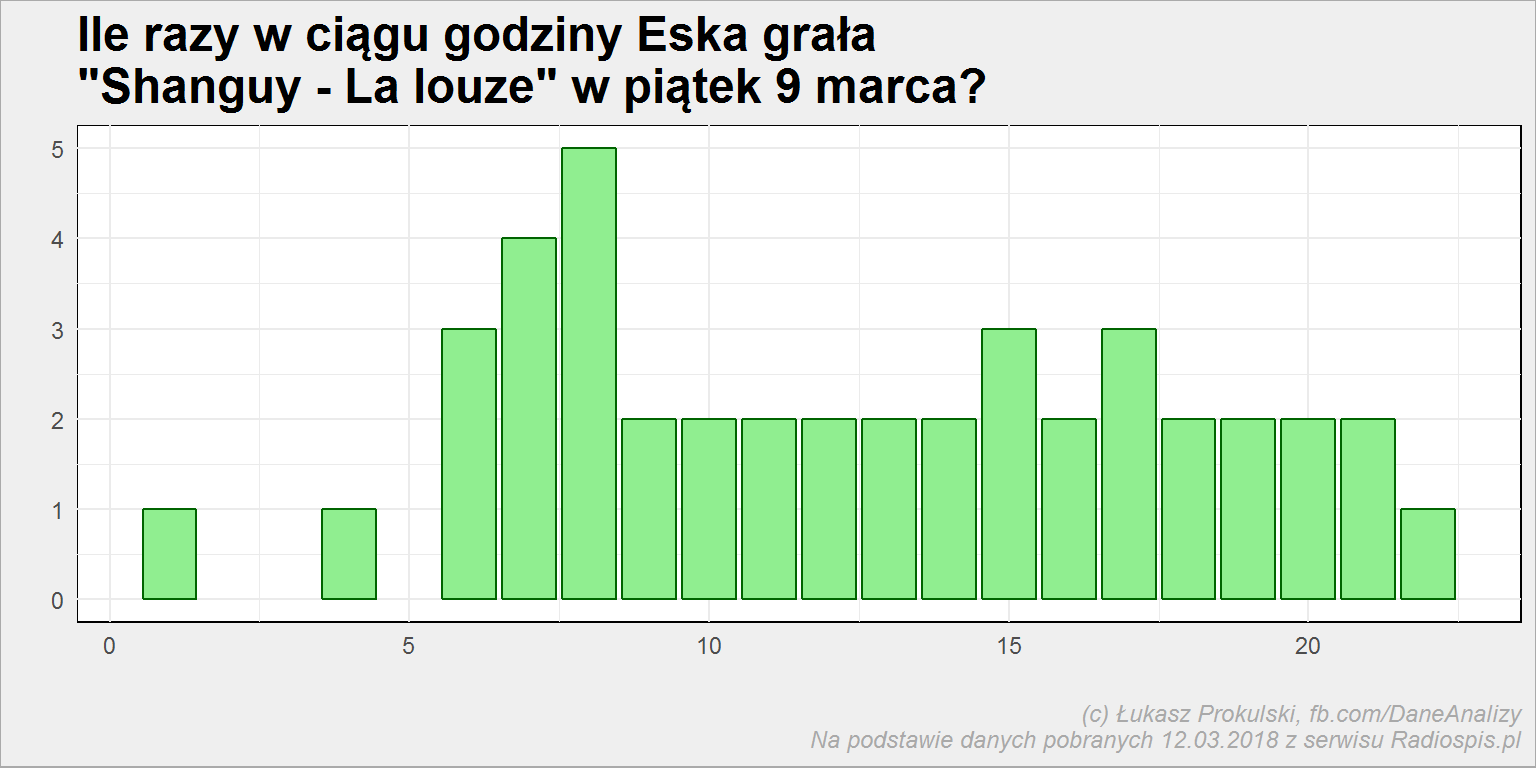
Zakładając, że nie ma błędów w danych mamy nawet pięć razy pomiędzy 9:00 a 10:00. O, dokładnie tak wyglądała poranna (6-10) playlista piątku:
|
1 2 3 4 5 6 7 |
playlist_tab %>% mutate(day = wday(datetime), hour = hour(datetime)) %>% filter(day == 6, stacja == "ESKA", hour %in% c(6, 7, 8)) %>% arrange(desc(datetime)) %>% mutate(song = fct_inorder(song)) %>% ggplot() + geom_point(aes(datetime, song)) |
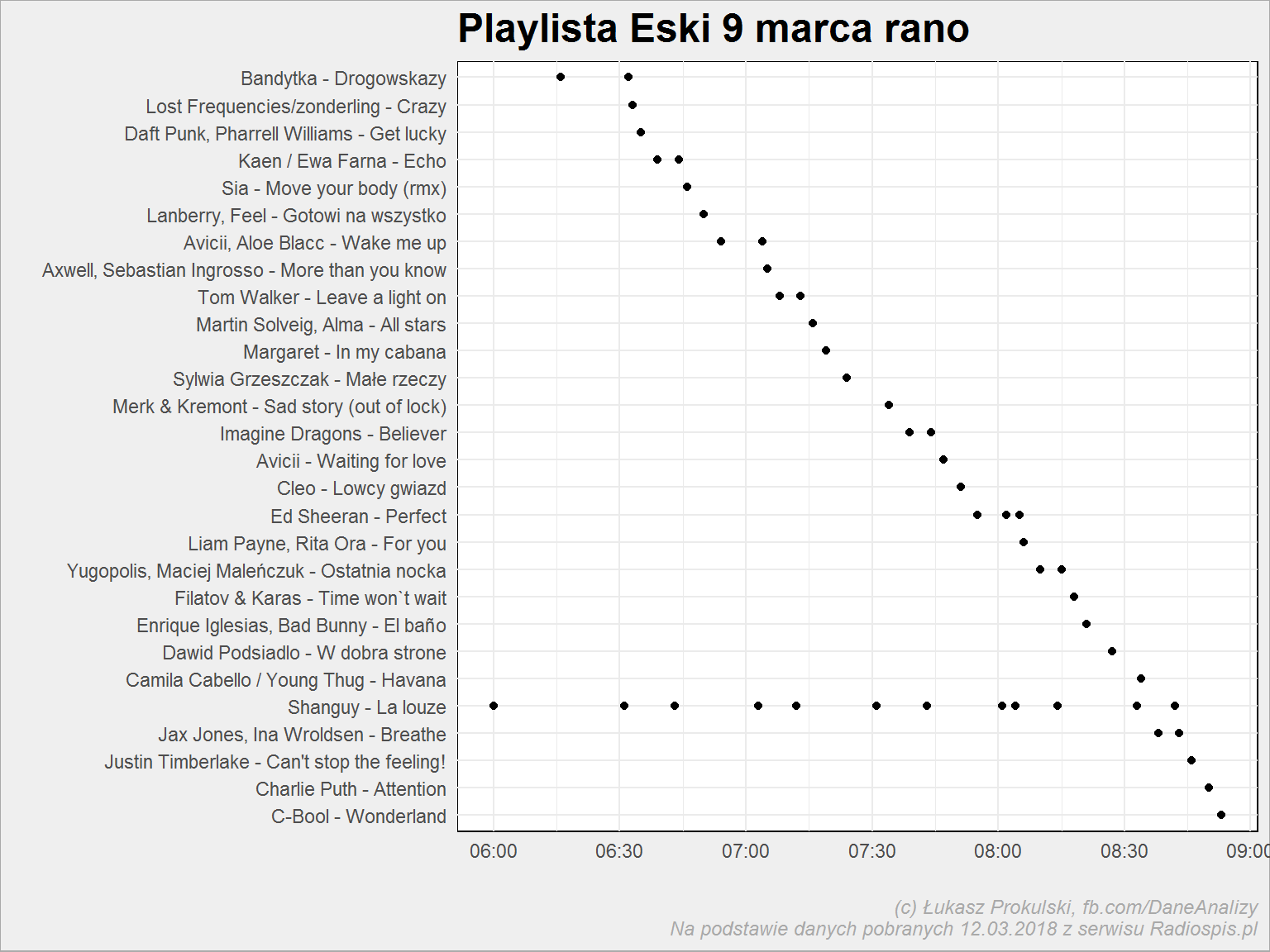
Zobaczmy to chronologicznie w tabeli:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
playlist_tab %>% mutate(day = wday(datetime), hour = hour(datetime)) %>% filter(day == 6, stacja == "ESKA", hour %in% c(6, 7, 8)) %>% arrange(datetime) %>% select(datetime, artist, title) %>% mutate(artist = ifelse(artist == "Shanguy", cell_spec(artist, "html", color = "red", bold = T), cell_spec(artist, "html", color = "black")), title = ifelse(title == "La louze", cell_spec(title, "html", color = "red", italic = T), cell_spec(title, "html", color = "black"))) %>% kable(escape = FALSE) %>% kable_styling(bootstrap_options = c("striped", "hover")) |
| Dzień i godzina emisji | Wykonawca | Tytuł |
|---|---|---|
| 2018-03-09 06:00:00 | Shanguy | La louze |
| 2018-03-09 06:16:00 | Bandytka | Drogowskazy |
| 2018-03-09 06:31:00 | Shanguy | La louze |
| 2018-03-09 06:32:00 | Bandytka | Drogowskazy |
| 2018-03-09 06:33:00 | Lost Frequencies/zonderling | Crazy |
| 2018-03-09 06:35:00 | Daft Punk‚ Pharrell Williams | Get lucky |
| 2018-03-09 06:39:00 | Kaen / Ewa Farna | Echo |
| 2018-03-09 06:43:00 | Shanguy | La louze |
| 2018-03-09 06:44:00 | Kaen / Ewa Farna | Echo |
| 2018-03-09 06:46:00 | Sia | Move your body (rmx) |
| 2018-03-09 06:50:00 | Lanberry‚ Feel | Gotowi na wszystko |
| 2018-03-09 06:54:00 | Avicii‚ Aloe Blacc | Wake me up |
| 2018-03-09 07:03:00 | Shanguy | La louze |
| 2018-03-09 07:04:00 | Avicii‚ Aloe Blacc | Wake me up |
| 2018-03-09 07:05:00 | Axwell‚ Sebastian Ingrosso | More than you know |
| 2018-03-09 07:08:00 | Tom Walker | Leave a light on |
| 2018-03-09 07:12:00 | Shanguy | La louze |
| 2018-03-09 07:13:00 | Tom Walker | Leave a light on |
| 2018-03-09 07:16:00 | Martin Solveig‚ Alma | All stars |
| 2018-03-09 07:19:00 | Margaret | In my cabana |
| 2018-03-09 07:24:00 | Sylwia Grzeszczak | Małe rzeczy |
| 2018-03-09 07:31:00 | Shanguy | La louze |
| 2018-03-09 07:34:00 | Merk & Kremont | Sad story (out of lock) |
| 2018-03-09 07:39:00 | Imagine Dragons | Believer |
| 2018-03-09 07:43:00 | Shanguy | La louze |
| 2018-03-09 07:44:00 | Imagine Dragons | Believer |
| 2018-03-09 07:47:00 | Avicii | Waiting for love |
| 2018-03-09 07:51:00 | Cleo | Lowcy gwiazd |
| 2018-03-09 07:55:00 | Ed Sheeran | Perfect |
| 2018-03-09 08:01:00 | Shanguy | La louze |
| 2018-03-09 08:02:00 | Ed Sheeran | Perfect |
| 2018-03-09 08:04:00 | Shanguy | La louze |
| 2018-03-09 08:05:00 | Ed Sheeran | Perfect |
| 2018-03-09 08:06:00 | Liam Payne‚ Rita Ora | For you |
| 2018-03-09 08:10:00 | Yugopolis‚ Maciej Maleńczuk | Ostatnia nocka |
| 2018-03-09 08:14:00 | Shanguy | La louze |
| 2018-03-09 08:15:00 | Yugopolis‚ Maciej Maleńczuk | Ostatnia nocka |
| 2018-03-09 08:18:00 | Filatov & Karas | Time won`t wait |
| 2018-03-09 08:21:00 | Enrique Iglesias‚ Bad Bunny | El bano |
| 2018-03-09 08:27:00 | Dawid Podsiadlo | W dobra strone |
| 2018-03-09 08:33:00 | Shanguy | La louze |
| 2018-03-09 08:34:00 | Camila Cabello / Young Thug | Havana |
| 2018-03-09 08:38:00 | Jax Jones‚ Ina Wroldsen | Breathe |
| 2018-03-09 08:42:00 | Shanguy | La louze |
| 2018-03-09 08:43:00 | Jax Jones‚ Ina Wroldsen | Breathe |
| 2018-03-09 08:46:00 | Justin Timberlake | Can’t stop the feeling! |
| 2018-03-09 08:50:00 | Charlie Puth | Attention |
| 2018-03-09 08:53:00 | C-Bool | Wonderland |
Szczerze? Albo kogoś popierdoliło albo rzeczywiście w danych jest bałagan. Nie można (tzn. można, ale jaki to ma sens?) grać jednej piosenki na przemian z jakąś inną. Jedna to nasz hicior dnia (którego nie słyszałem), a druga – Ed Sheeran i Perfet (którego też nie słyszałem) zagrany w okolicach 8 rano. Macie tego Eda, może posłuchacie:
To że są embedy niczego nie oznacza ;)
Zapewne należałoby posprzątać dane według jakiegoś klucza. Chociażby takiego, że po jednym utworze musi być 10 innych, aby zagrać go ponownie. Kiedyś pracowałem przez chwilę w pewnym lokalnym krakowskim radiu i tam zasada była prosta: piosenka nie może się powtórzyć w ciągu trzech godzin.
Spotify
Wykorzystamy sobie teraz Spotify do przeanalizowania stacji pod kątem parametrów muzycznych (ot, takie hasło uknułem z braku lepszego pomysłu). Na początek potrzebujemy danych identyfikujących naszą aplikację (dostęp do API) na Spotify – trzeba ją założyć na stronie dla developerów, a potem uzyskać tymczasowy token:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
library(httr) library(jsonlite) library(RCurl) load("spotify_cred.rda") # zmienne client_id i client_secret - do uzyskania na https://developer.spotify.com/ # funkcja zwraca token getSpotifyToken <- function() { res <- POST("https://accounts.spotify.com/api/token", body = list(grant_type = "client_credentials"), config = add_headers("Authorization" = paste0("Basic ", base64(paste(client_id,client_secret,sep=':'))[[1]])), encode = "form") if(res$status_code == 200) { return(content(res)$access_token) } else { return(NA) } } |
W danych mamy tylko tytuł i wykonawcę utworu, zaś wszystkie informacje o konkretnej piosence (to samo dotyczy wykonawcy czy albumu) pobieramy z API korzystając z ID utworu (analogicznie dla wykonawcy i albumu). Przygotujmy odpowiednią funkcję, która owo ID nam wyszuka (mniej lub bardziej dokładnie):
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 |
# funkcja szuka ID utworu na postawie wykonawcy i tytuły getSpotifyTrackID <- function(track_artist, track_title) { # na potrzeby zapytania podmieniamy znaki typu spacja track_title <- gsub("[^a-zA-Z0-9]", "+", as.character(track_title)) track_artist <- gsub("[^a-zA-Z0-9]", "+", as.character(track_artist)) # wywołujemy API - wyszukiwanie utworu response <- GET(paste0("https://api.spotify.com/v1/search?q=", track_title, "+", track_artist, "&type=track"), add_headers("Authorization:" = paste("Bearer", spotify_token), "Content-Type:" = "application/json", "Accept:" = "application/json")) # jeśli API coś zwróciło... if(response$status_code == 200) { # parsujemy JSONa z odpowiedzią response_json <- rawToChar(response$content) query_results <- fromJSON(response_json, flatten = TRUE) # jeśli w odpowiedzi jest więcej niż jeden utwór - bierzemy ten najbardziej popularny if(query_results$tracks$total != 0) { track_id <- query_results$tracks$items %>% filter(popularity == max(popularity)) %>% .$id %>% .[[1]] } else { track_id <- NA } return(track_id) } else { return(NA) } } |
Mając ID utworu możemy zapytać o jego cechy audio:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 |
# Funkcja pobiera cechy audio utworu track_id getSporifyTrackFeatures <- function(track_id) { # zapytanie o cechy response <- GET(paste0("https://api.spotify.com/v1/audio-features/", as.character(track_id)), add_headers("Authorization:" = paste("Bearer", spotify_token), "Content-Type:" = "application/json", "Accept:" = "application/json")) # udało się? if(response$status_code == 200) { # parsujemy JSONa, odpowiednio zmieniając kodowanie liter # (bez tego całość lubi się wywalić w np. polskim Windowsie) response_json <- rawToChar(response$content) %>% iconv(from = "UTF-8", to = Sys.getenv("CHARSET")) query_results <- fromJSON(response_json, flatten = TRUE) # budujemy ramkę (dokładniej - wiersz) danych z cechami track_features <- tibble( id = query_results$id, danceability = query_results$danceability, energy = query_results$energy, loudness = query_results$loudness, mode = query_results$mode, speechiness = query_results$speechiness, acousticness = query_results$acousticness, instrumentalness = query_results$instrumentalness, liveness = query_results$liveness, valence = query_results$valence, tempo = query_results$tempo, time_signature = query_results$time_signature) } else { return(tibble()) } return(track_features) } |
W powyższej funkcji możemy wykorzystać inną metodę API i zapytać od razu o maksymalnie 100 utworów. Dla czystości kodu zostawiłem jednak pytanie o każdy utwór z osobna.
Dla przypomnienia (w ślad za dokumentacją Spotify oraz moim starym wpisem) poszczególne cechy to:
- acousticness – czy utwór jest akustyczny? 1.0 to z bardzo dużym prawdopodobieństwem utwory instrumentalne
- danceability – czy utwór “nadaje się” do tańca; wskaźnik opiera się na połączeniu różnych miar w tym tempa i rytmu. Im wyżej, tym bardziej taneczny kawałek. Na dancingi bierzcie te numery, które są z lat ’70-80 i mają wysokie danceability – powinno się sprawdzić, szczególnie jak doda się do tego filtr na wysoką popularność.
- energy – zazwyczaj utwory energiczne są szybkie i głośne. Na przykład death metal ma wysoką energię, podczas gdy Bach raczej niską
- instrumentalness – wskaźnik określający czy utwór zawiera wokale. Wszelakie “oooo” i “aaaaa” są traktowane jako części instrumentalne. Rap lub melodeklamacje są wyraźnie “wokalne”. Im wartość instrumentalness jest bliżej jedynki, tym większe prawdopodobieństwo, że utwór nie zawiera wokali. Wartości powyżej 0.5 mają reprezentować utwory instrumentalne, ale pewność jest większa gdy wartość ta osiąga 1.
- liveness – wykrywa obecność publiczności w nagraniu. Wyższe wartości liveness reprezentują zwiększone prawdopodobieństwo, że utwór był wykonywany na żywo, przy wartości powyżej 0.8 mamy już nieomal pewność nagrania koncertowego
- loudness – ogólna głośność utworu w decybelach (dB), wartości przyjmują wartości od -60 od 0 decybeli. Wartość jest uśredniona dla całego utworu, jest silnie skorelowana z amplitudą dźwięku
- mode to określenie skali w jakiej jest melodia (minor lub major, po polsku odpowiednio molowa i durowa); gdzie skala molowa (minor) to 0, a durowa (major) to 1. Melodie odbierane jako wesołe są zazwyczaj w skali durowej, a smutne – w molowej. Chyba, że coś pokręciłem ;-) (w oryginale oczywiście tak – dzięki za zwrócenie uwagi w komentarzach!)
- speechiness – obecność wypowiadanych słów w utworze – im więcej słów (na przykład nagrania audiobooków czy poezja śpiewana) tym bliżej do jedynki. Wartości powyżej 0.66 opisują utwory, które prawdopodobnie są wykonane w całości z wypowiadanych słów. Wartości pomiędzy 0.33 i 0.66 opisują utwory, które mogą zawierać zarówno muzykę jak i słowa – na przykład rap. Wartości poniżej 0.33 to najprawdopodobniej utwory instrumentalne
- tempo – szacunkowe tempo wyrażone w BPM (beats per minute)
- valence – miara opisująca nastrój; utwory o wysokiej wartości współczynnika brzmią bardziej pozytywne
Mając gotowe funkcje możemy przetworzyć całą bazę zgromadzonych playlist:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 |
# token Spotify spotify_token <- getSpotifyToken() # bierzemy unikalne piosenki, żeby nie przetwarzać kilkukrotnie tych samych danych unique_tracks <- playlist_tab %>% distinct(title, artist) n_unique_tracks <- nrow(unique_tracks) # szukamy dla nich ID w Sporify # na pewno da się to zrobić w purrr-way :) for(i in 1:n_unique_tracks) { cat(sprintf("\r%04d / %d", i, n_unique_tracks)) unique_tracks[i, "trackID"] <- getSpotifyTrackID(unique_tracks[i, "artist"], unique_tracks[i, "title"]) } # dla tych, które w Spotify się znalazły szukamy cech unique_tracks <- filter(unique_tracks, !is.na(trackID)) nrow(unique_tracks) # purrr way: # unique_tracks_features <- unique_tracks$trackID %>% map_df(getSporifyTrackFeatures) # odswiezamy token, gdyby wszystko za długo trwało spotify_token <- getSpotifyToken() # szukamy dla unkialnych piosenek ich cech w Spotify tracks_features <- tibble() n_unique_tracks <- nrow(unique_tracks) for(i in 1:n_unique_tracks) { cat(sprintf("\r%04d / %d", i, n_unique_tracks)) tmp_tracks_features <- getSporifyTrackFeatures(unique_tracks[i, "trackID"]) tracks_features <- bind_rows(tracks_features, tmp_tracks_features) } # łączymy listę piosenek z cechami unique_tracks_features <- left_join(unique_tracks, tracks_features, by = c("trackID" = "id")) %>% filter(!is.na(energy)) %>% distinct() # łączymy playlistę z cechami playlist_tab_features <- left_join(playlist_tab, unique_tracks_features, by = c("title" = "title", "artist" = "artist")) %>% filter(!is.na(energy)) # zapisujemy sobie na później saveRDS(playlist_tab_features, "playlist_tab_features.RDS") |
Mając te wszystkie dane możemy zobaczyć
która stacja jest jaka?
uśredniając wartości cech dla poszczególnych stacji:
|
1 2 3 4 5 6 7 8 9 |
playlist_tab_features %>% group_by(stacja) %>% summarise_at(.cols = vars(danceability:tempo), .funs = mean) %>% ungroup() %>% gather("feature", "value", -stacja) %>% ggplot() + geom_col(aes(stacja, value, fill = stacja), show.legend = FALSE) + coord_flip() + facet_wrap(~feature, scales = "free_x", ncol = 5) |
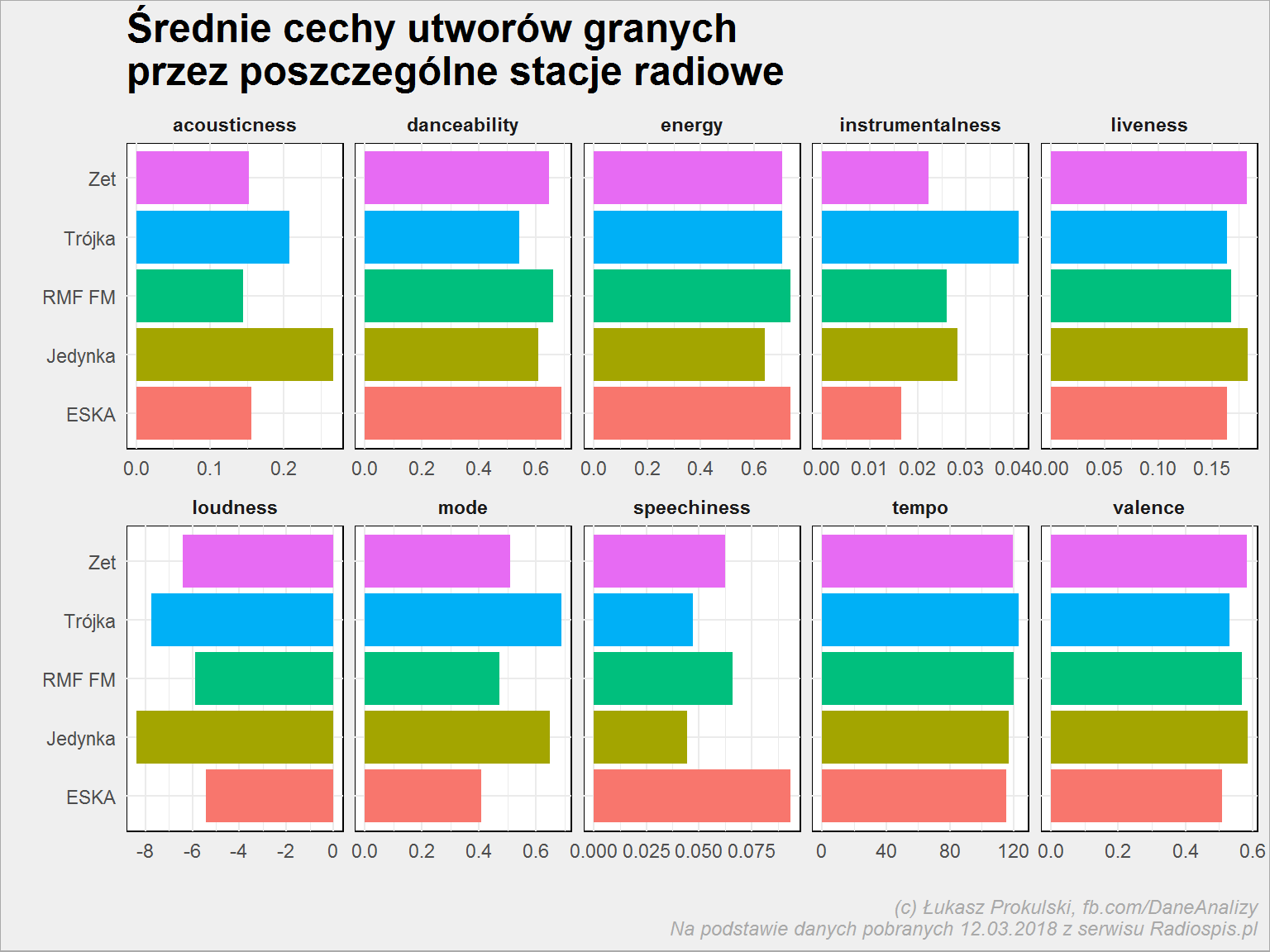
Podsumujmy to co widzimy, razem ze wskazaniem piosenek i stacji które je grają:
- Jedynka jest najbardziej akustyczna, RMF najmniej
|
1 2 3 4 5 6 7 |
playlist_tab_features %>% filter(acousticness == min(acousticness) | acousticness == max(acousticness)) %>% count(song, stacja, acousticness) %>% ungroup() %>% mutate(acousticness = color_tile("white", "orange")(acousticness)) %>% kable(escape = FALSE) %>% kable_styling(bootstrap_options = c("striped", "hover")) |
| Piosenka | Stacja | acousticness | n |
|---|---|---|---|
| Avicii‚ Aloe Blacc – Wake me up | ESKA | 9.95e-01 | 2 |
| Illusion – Kto jest winien | Trójka | 2.61e-05 | 2 |
- Eska, Zetka i RMF – najbardziej (i mniej więcej równo) taneczne
|
1 2 3 4 5 6 7 |
playlist_tab_features %>% filter(danceability == min(danceability) | danceability == max(danceability)) %>% count(song, stacja, danceability) %>% ungroup() %>% mutate(danceability = color_tile("white", "orange")(danceability)) %>% kable(escape = FALSE) %>% kable_styling(bootstrap_options = c("striped", "hover")) |
| Piosenka | Stacja | danceability | n |
|---|---|---|---|
| Kardinal Offishall Feat. Akon – Dangerous | Zet | 0.972 | 2 |
| The Cranberries – The glory | Trójka | 0.161 | 1 |
- najniższą energię gra Jedynka, zaś największą – Eska
|
1 2 3 4 5 6 7 |
playlist_tab_features %>% filter(energy == min(energy) | energy == max(energy)) %>% count(song, stacja, energy) %>% ungroup() %>% mutate(energy = color_tile("white", "orange")(energy)) %>% kable(escape = FALSE) %>% kable_styling(bootstrap_options = c("striped", "hover")) |
| Piosenka | Stacja | energy | n |
|---|---|---|---|
| Jennifer Lopez – Let’s get loud | RMF FM | 0.129 | 1 |
| Kombii – Awinion | RMF FM | 0.986 | 1 |
- Trójka jest najbardziej instrumentalna, ale nie jest to tak że mamy do czynienia z utworami instrumentalnymi (średnio 0.04 to niewiele)
- Jedynka i Trójka grają utwory cichsze i jednocześnie bardziej durowe (wartość mode bliższa jedynki)
- wygląda też na to, że w Esce jest najwięcej przegadanych piosenek
Zobaczmy na koniec jak wygląda rozkład energii (według cech ze Spotify) poszczególnych stacji w ciągu dnia:
|
1 2 3 4 5 6 7 8 9 |
playlist_tab_features %>% mutate(hour = hour(datetime)) %>% group_by(stacja, hour) %>% summarise(m_energy = mean(energy)) %>% ungroup() %>% ggplot() + geom_area(aes(hour, m_energy, fill = stacja), alpha = 0.6, show.legend = FALSE) + geom_line(aes(hour, m_energy, color = stacja), size = 2, show.legend = FALSE) + facet_wrap(~stacja, ncol = 5) |
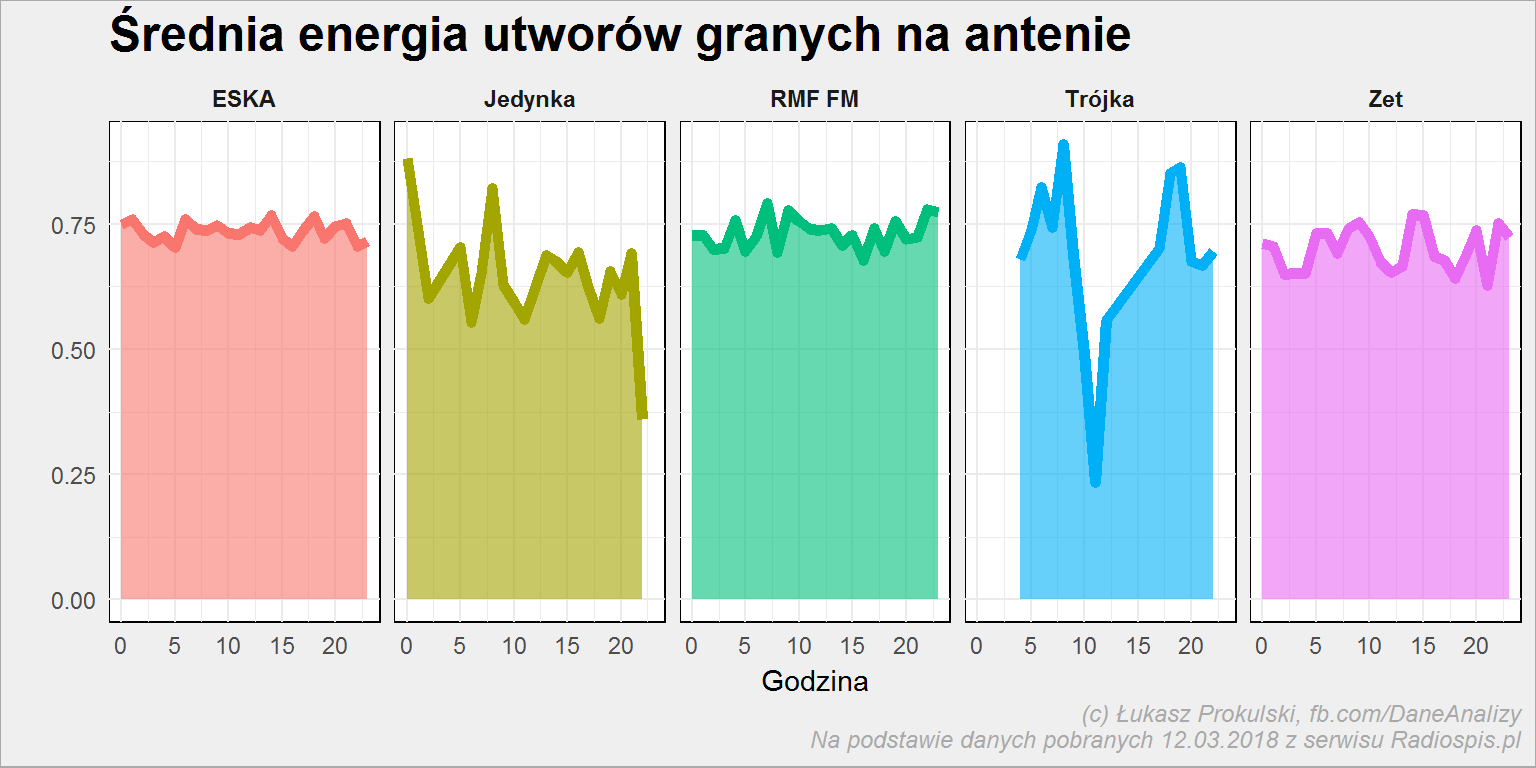
Ten dołek w środku dnia w Trójce i mocne spadki w okolicach północy w Jedynce to wynik małej ilości danych. Widać jednak (jak się dobrze przyjrzeć), że rano (od 5 do 10) energia lekko rośnie w większości stacji. Radio stara budzić się ludzi do pracy?
Bardzo ciekawy wpis! Regularnie podczytuję bloga od czasu posta o markach najczęściej sprzedawanych samochodów i mimo że strona techniczna analizy danych jest dla mnie czarną magią, to wnioski za każdym razem dobrze się czyta :) Jeśli chodzi o problem z tym, czy dana piosenka była faktycznie grana kilka razy w ciągu godziny, to może pomogłoby rozwiązać tę kwestię skorzystanie z innej bazy zbierającej informacje o utworach? Wiem na pewno, że od kilku lat istnieje odsluchane.eu, gdzie dane nie dotyczą tylko ostatniego tygodnia, czasem informacje o utworach wykorzystanych w audycji pojawiają się na stronach samych stacji radiowych.
Obstawiam, że źródłem danych dla obu stron są strony stacji radiowych. Zobacz na Eskę z analizowanego poranka 9 marca https://www.odsluchane.eu/szukaj.php?r=3&date=09-03-2018&time_from=6&time_to=8
Trafiłem tu z beznadziejnego merytorycznie Wykopu i choć nie zwykłem komentować blogów, tym wpisem jestem bardzo mile zaskoczony! Brawo!
Trafiłem tu z wysoce merytorycznego Wykopu i choć nie zwykłem komentować blogów to uważam, że wykonałeś kawał dobrej roboty. Zaraz sobie przejrzę dodatkowe artykuły. Pozdrawiam
co to za skrypt do czytania danych?
Skrypt jest w języku R.
Bardzo ciekawa analiza.
Dodam tylko, że molowa tonacja brzmi smutno, z durowa wesoło – mały błąd w opisie.
Dzięki, już poprawiam. Swoją drogą – zawsze jak jest podobna sytuacja i są dwie opcje do wyboru to najczęściej je mylę ;)
Super artykuł! Dostajesz Awans!
Trojka nie zawsze jest „przegadana” – tak mało utworów wynika również z tego, że grają dłuższe utwory, czasem bardzo długie jak na standardy radiowe bo kilkunastominutowe.
Eska nigdy nie puszcza całych piosenek, zawsze ucina w połowie albo w 2/3 utworu. Jest to strasznie denerwujące i to właśnie dlatego wychodzi tak duży wynik.
Trafiłem tu z Wykopu – ja jebie. Ale mega artykuł. Świetna robota. Pokazuje tylko że radio jak piwo, wraz z komercjalizacją staje się bardziej mdłe i puste.
Najgorsze, że na wioskach trudno wyłapać inne stacje radiowe niż RMF czy radio 3 (lub Maryja).
Nie chce spamować ale Radio Kampus ma zróżnicowaną muzykę – dlatego słucham online. Niestety studenckie radio w Polsce jest niszowe, nie wiedzieć czemu.
Bardzo dobry artykuł. Lubię słuchać muzyki (w tym z radia :-)) i największe zrobiło na mnie wrażenie Twoje podejście analityczne (a praktycznie nic nie piszesz o Twoich gustach muzycznych i bardzo dobrze!). Nie wiem na ile ten materiał jest efektem Tego czym się zajmujesz zawodowo (pomijając kwestię niewątpliwego doświadczenia informatycznego), ale wielki szacun za analityczne „wyliczenie” tego, co podskórnie się czuło. np odrębność Trojki/Jedynki od stacji komercyjnych. Ciekawe, na ile możnaby tą analizę zrobić na zasadzie online? Wtedy takie narzędzie z pewnością znalazłoby też wielu biznesowych zainteresowanych. Jeszcze raz gratulacje!
Da się online. Przy pisaniu tego tekstu kilka razy pobierałem dane (w różnych dniach) i musiałem dostosowywać kod do tego hitu dnia w Esce.
Ciekaw jestem tego zainteresowania biznesowego – ja go nie widzę. A wytwórnie upychające single w stacjach radiowych mają na pewno swoje analizy (chociażby zaiks)
Również z wykopu i uważam że jest to bardzo przydatny artukuł.
Fantastyczny materiał i kawał świetnej roboty! Mam wrażenie, że do tego artykułu będzie się wracać jeszcze przez dobrych kilka lat, by udowodnić, jakiej muzyki i w jakim stylu można usłyszeć w najpopularniejszych polskich radiach.
Mam wrazenie ze minutowe utwory na liscie to są po prostu Jingle poprzedzajace reklamy. Jest sposob to zweryfikowac?
Na 99,9% nie są to żadne jingle. Po pierwsze – przeciętny jingiel trwa od 5 do 20s maksymalnie. Po drugie – systemy emisyjne wypuszczają jingle i inne elementy oprawy jako elementy inne niż „muzyka” w związku z czym metadane dotyczące tych elementów nie trafiają na zewnątrz.
nie jingle tylko hooki, czyli zlepki kilku fragmentów po kilkanaście sekund ładnie zmiksowanych utworów w stylu: 'tylko my to gramy: i tu leci jeden takt kawałka, potem drugi, potem lektor: ale to też gramy i leca kolejne dwa. a algorytm rozpoznaje to jako 4 oddzielne utwory. taka metoda wprowadza nieco błędów ale i tak jestem pod wrażeniem. tylko tak naprawdę. a pracuje w różnych radiach od 94 roku to o tym czy muzyka jest ok nie decydują żadne analizy tylko to co ma w głowie muzyczny. matematyka nie powie, że w deszczowy poranek warto zagrać coś skocznego i powiedzieć ludziom, wstawajcie, choć jest brzydko posłuchajmy coś pozytywnego (to już dj mówi). nie da się znaleźć matematycznej formuły na antenę podobnie jak nie istnieje św. Graal muzyki. są pewne kanony, jest analityka, która pozwoli wystrzec się błędów. tylko tyle.
Jak ty mnie zaimponowałeś teraz! Czegoś takiego brakowało mi w kwestii słuchania radia :D Swoją drogą dobrze z edytowany kod może posłużyć do innych rzeczy. Pozdrawiam :)
Jak zauważył jeden z komentujących, statystyka liczby utworów dla Trójki może nie być w zupełności miarodajna. Graja sporo starych, dobrych utworów w albumowych wersjach (nieskracanych).
Kiedyś na RMF słyszałem „November Rain” Gunsów, który był skrócony do ok. 4 minut i miał zupełnie wycięte pierwsze solo :)
Jaka biblioteka potrzebna jest do korzystania z kodów:
playlist_tab %>%
count(stacja) %>%
ungroup() %>%
mutate(n = color_tile(„white”, „orange”)(n)) %>%
kable(escape = FALSE) %>%
kable_styling(bootstrap_options = c(„striped”, „hover”, „condensed”, „responsive”),
full_width = FALSE)
Zwraca mi błąd:
Error in kable_styling(., bootstrap_options = c(„striped”, „hover”, „condensed”, :
could not find function „kable_styling”
lub
Error in kable(., escape = FALSE) : could not find function „kable”
Knitr do kable() plus knitrExtra do kable_styling(). Ta ostatnia to rewelacja do formatowania tabelek.
Ok sprawdzę i dam znać czy działa, wydaje mi się że knitr mam a mimo to wywala ten błąd (drugi wymieniony).
Tyle tabelek do analizy i do tego dobry komentarz :D, aż się prosi o więcej takich analiz :D
Dobra robota.