Bezrobocie spada, bo wszyscy wyjechali – czy to prawda?
Z miesiąca na miesiąc spada bezrobocie w Polsce. I co więcej – spada zgodnie z przewidywaniami, zgodnie z najprostszym modelem predykcji szeregów czasowych, co opisywałem pod koniec kwietnia.
Różne mogą być przyczyny spadku bezrobocia. Może to być prozaiczne jest więcej pracy (bo gospodarka przyspiesza, firmy mają pieniądze na nowych pracowników). Ale złe ludzkie języki mogą krytykować rządzących mówiąc, że wszyscy już wyjechali do Anglii czy Irlandii, więc nie ma bezrobotnych. Sprawdźmy czy to może być prawda.
W rozważaniach skorzystamy z danych publikowanych przez GUS i porównamy czy zmiana stopy bezrobocia jest równa (lub porównywalna) zmianie liczby mieszkańców. Jeśli bezrobocie spadło o na przykład 5 punktów procentowych (z 10% na 5%) to czy liczba mieszkańców też spadła o 5% (z 1000 do 950 osób)? Jeśli tak by było to oznaczałoby, że:
- przy 10% bezrobociu i 1000 mieszkańców bez pracy było 100 osób
- przy 5% bezrobociu (spadek o 5 punktów procentowych) i 950 mieszkańcach (spadek o 5%) bez pracy jest 48 osób (dokładnie 47 i pół :)
- zatem liczba bezrobotnych spadła ze 100 do 48 osób, czyli o 52%
Ze spadkiem liczby mieszkańców zdecydowanie spadła liczba bezrobotnych (o 52%). Tutaj w grę wchodzą niuanse pomiędzy spadkiem o 5 procent a spadkiem o 5 punktów procentowych.
To, że 52 osoby wyjechały (lub… umarli) to jedna z przyczyn, ale bardziej prawdopodobne jest to, że około 50 osób znalazło pracę. Ważne założenie: pod uwagę bierzemy całkowitą liczbę mieszkańców, a nie tylko osoby w tak zwanym wieku produkcyjnym (takie dane też znajdziecie w GUS). Oznacza to po prostu tyle, że liczymy zarówno noworodki jak i osoby na emeryturze czy rencie. Nie jest to praca naukowa, a prezentacja sposobu na pokazanie różnych danych, nie będziemy więc drobiazgowi.
Zaczynamy. Potrzebnych będzie kilka pakietów: tidyverse bo ggplot2 i dplyr, broom bo w nim jest funkcja tidy() która zastępuje ggplot2::fortify() oraz rgdal do wczytania mapy powiatów z plików .shp.
|
1 2 3 |
library(tidyverse) library(rgdal) library(broom) |
Zaczynamy od pobrania danych z GUSu, są na stronie Banku danych lokalnych. Niestety nie mamy aktualnej (na przykład na koniec minionego miesiąca) liczby mieszkańców, są tylko wartości na koniec roku. Zatem weźmiemy dane roczne, trudno.
Dane o bezrobociu znajdujemy w części Rynek pracy / Bezrobocie rejestrowane / Stopa bezrobocia rejestrowanego skąd pobieramy dane dla wszystkich lat i wszystkich kategorii (chociaż wystarczy tylko “Ogółem”). W kolejnym kroku wybieramy wszystkie elementy w podziale terytorialnym i otrzymane dane eksportujemy do pliku CSV (Export -> CSV – tablica relacyjna).
Dane o ludności pobieramy analogicznie, tym razem wybierając kategorię Ludność / Stan ludności / Ludność wg lokalizacji terytorialnej.
Pliki CSV zapisujemy lokalnie i wczytujemy do R (nazwy plików CSV jakie pobierzecie mogą się różnić – zaszyta w nich jest data i godzina pobierania):
|
1 2 |
ludnosc <- read_csv2("dane/LUDN_2914_CREL_20170906111443.csv") bezrobocie <- read_csv2("dane/RYNE_2392_CREL_20170906111733.csv") |
Dane są dla różnych lat, potrzebujemy części wspólnej. Przy okazji pozbędziemy się zbędnych informacji. Można to zrobić już na etapie pobierania danych (a ja wolę mieć więcej danych i najwyżej nie używać tych, które są zbędne niż pobierać je kilka razy).
|
1 2 3 4 5 6 7 8 9 10 11 12 |
ludnosc <- ludnosc %>% # zostawiamy dane z lat dla których mamy dane o bezrobociu filter(Rok >= min(bezrobocie$Rok), Rok <= max(bezrobocie$Rok)) %>% # ludność w danych rozbita jest na obszary miejskie i resztę powiatu - dla całego powiatu potrzebujemy sumy group_by(Kod, Rok) %>% summarise(Ludnosc = sum(Wartosc)) %>% ungroup() bezrobocie <- bezrobocie %>% filter(`Ogółem` == "ogółem") %>% select(Kod, Nazwa, Rok, Stopa_bezrobocia = Wartosc) |
Łączymy teraz w jedną tabelę dane o bezrobociu i liczbie mieszkańców. Dzięki temu w jednym wierszu będziemy mieć pełną informację dla konkretnego powiatu w konkretnym roku:
|
1 2 |
dane_razem <- full_join(bezrobocie, ludnosc, by = c("Kod" = "Kod", "Rok" = "Rok")) %>% filter(!is.na(Stopa_bezrobocia), !is.na(Ludnosc)) |
Do wyboru mamy lata od 2004 do 2016 – możemy porównywać ze sobą dwa dowolne (stan na koniec roku).
Porównamy dwa ostatnie lata – czyli zmianę z 2015 do 2016:
|
1 2 3 4 5 6 7 8 9 10 |
rok_po <- 2016 rok_przed <- 2015 # dane dla jednego roku (wcześniejszego) dane_razem_przed <- filter(dane_razem, Rok == rok_przed) %>% select(Kod, Nazwa, Stopa_bezrobocia_przed = Stopa_bezrobocia, Ludnosc_przed = Ludnosc) # dane dla drugiego roku (późniejszego) dane_razem_po <- filter(dane_razem, Rok == rok_po) %>% select(Kod, Nazwa, Stopa_bezrobocia_po = Stopa_bezrobocia, Ludnosc_po = Ludnosc) |
W danych mamy kod TEYRT (dla ciekawskich: pełne tabele, w tym nazwy ulic, znaleźć można na stosownej stronie GUS, brakuje tam tylko współrzędnych GPS, co przy odrobinie pracy można uzyskać z Google Maps API), a nie mamy nazwy województwa przy każdym powiecie. Wyłuskajmy je sobie!
|
1 2 3 4 5 |
woj <- dane_razem_po %>% filter(substr(Kod, 3, 7) == "00000") %>% # tylko województwa mutate(woj = substr(Kod, 1, 2)) %>% # pierwsze dwie liczby kodu TERYT określają województwo select(woj, Wojewodztwo = Nazwa) %>% distinct() |
Teraz możemy dodać nazwy województw do powiatów.
Od razu policzymy potrzebne nam wartości:
- liczbę bezrobotnych w obu (przed i po) latach – bazując na stopie bezrobocia i liczbie mieszkańców
- zmianę bezwzględną tej liczby
- zmianę bezwzględną liczby mieszkańców
- zmiany procentowe liczby bezrobotnych i mieszkańców
|
1 2 3 4 5 6 7 8 9 10 |
roznica <- left_join(dane_razem_przed, dane_razem_po, by = c("Kod"="Kod", "Nazwa"="Nazwa")) %>% mutate(l_bezrobotnych_przed = Ludnosc_przed*Stopa_bezrobocia_przed/100, l_bezrobotnych_po = Ludnosc_po*Stopa_bezrobocia_po/100, delta_l_bezrobotnych = l_bezrobotnych_po - l_bezrobotnych_przed, delta_Stopa_bezrobocia = 100*delta_l_bezrobotnych/l_bezrobotnych_przed) %>% mutate(delta_ludnosc = Ludnosc_po - Ludnosc_przed, delta_Ludnosc_proc = 100*delta_ludnosc/Ludnosc_przed) %>% mutate(woj = substr(Kod, 1, 2)) %>% left_join(woj, by = "woj") %>% # dodajemy jeszcze nazwy wojewodztw filter(Nazwa != "POLSKA") |
W ten sposób przygotowane dane są kompletne i gotowe do analizy. Zacznijmy od narysowania mapek.
Pliki z mapą pobieramy z Centralnego Ośrodka Dokumentacji Geodezyjnej i Kartograficznej (Dane bez opłat / PRG – jednostki administracyjne).
|
1 2 3 |
powiaty <- readOGR("mapy/powiaty.shp", "powiaty") powiaty <- spTransform(powiaty, CRS("+init=epsg:4326")) powiaty_df <- tidy(powiaty, region = "jpt_kod_je") # w przykładach znajdziecie fortify() zamiast tidy() - funkcje robią to samo |
Potrzebujemy ID po którym złączymy dane z GUSu z mapą – najlepszy jest kod TERYT każdego z powiatów:
|
1 |
roznica$TERYT <- substr(roznica$Kod, 1, 4) |
Łączymy dane z tabelą opisującą mapę:
|
1 2 3 |
powiaty_mapa <- left_join(powiaty_df, select(roznica, TERYT, delta_Stopa_bezrobocia, delta_Ludnosc_proc), by = c("id" = "TERYT")) |
i już możemy rysować.
Zaczniemy od mapy zmiany stopy bezrobocia:
|
1 2 3 4 5 6 |
powiaty_mapa %>% ggplot() + geom_polygon(aes(long, lat, group=group, fill=delta_Stopa_bezrobocia), color="gray") + scale_fill_gradient2(low = "green", mid = "white", high = "red", midpoint = 0) + coord_map() + theme(legend.position = "bottom", axis.text.x = element_blank(), axis.text.y = element_blank()) |
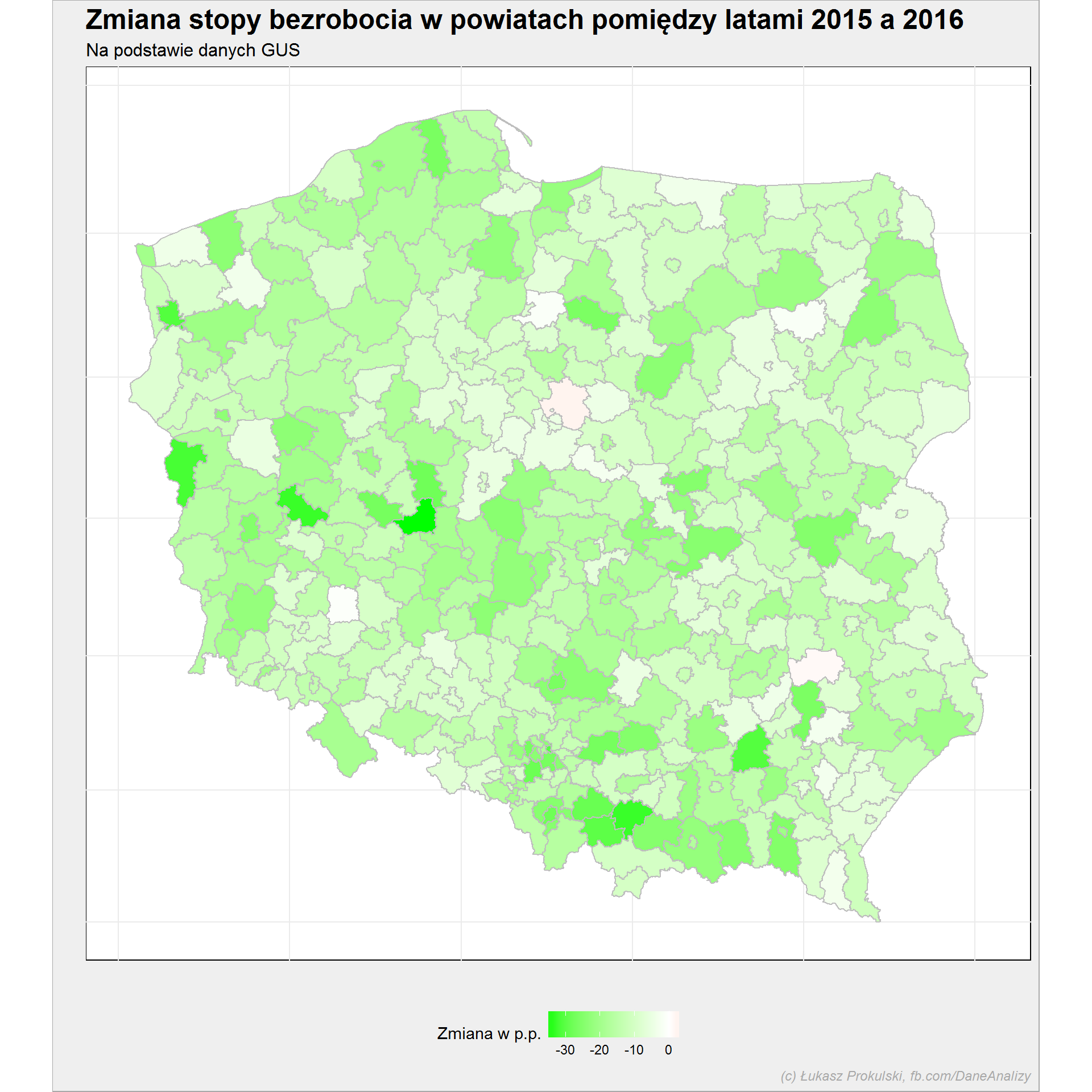
Kolory są odwrócone w stosunku do standardowej skali (standardowej, czyli czerwony = gorzej, zielony = lepiej), a to dlatego, że jeśli bezrobocie spadło to sytuacja w powiecie się poprawiła. Zatem im bardziej zielone na powyższej mapce tym w powiecie lepiej :) Widać, że prawie wszędzie jest owo lepiej (to nie jest dziwne – w skali kraju bezrobocie spadło pomiędzy 2015 a 2016) poza dwoma powiatami:
|
1 2 3 |
roznica %>% filter(delta_Stopa_bezrobocia > 0) %>% select(Nazwa, Wojewodztwo, delta_Stopa_bezrobocia) |
| Powiat | Województwo | zmiana liczby bezrobotnych (%) |
|---|---|---|
| Powiat lipnowski | KUJAWSKO-POMORSKIE | 2.08 |
| Powiat kraśnicki | LUBELSKIE | 1.02 |
Zobaczmy też mapę zmiany liczby ludności:
|
1 2 3 4 5 6 |
powiaty_mapa %>% ggplot() + geom_polygon(aes(long, lat, group=group, fill=delta_Ludnosc_proc), color="gray") + scale_fill_gradient2(low = "red", mid = "white", high = "green", midpoint = 0) + coord_map() + theme(legend.position = "bottom", axis.text.x = element_blank(), axis.text.y = element_blank()) |
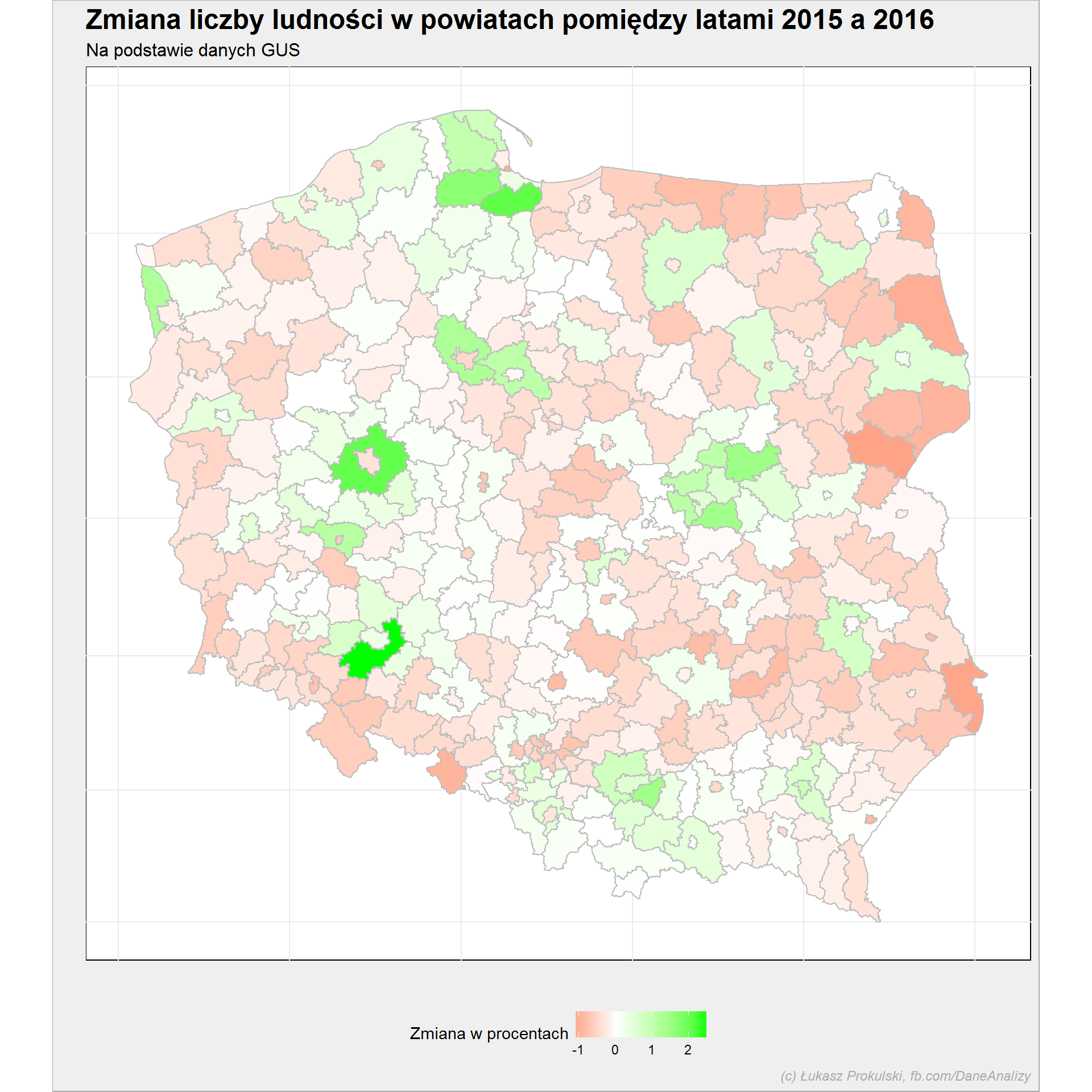
Tutaj skala kolorów jest już normalna: im bardziej czerwone tym ludzi w danym powiecie mieszka mniej, im bardziej zielone – tym ludzi mieszka więcej.
Ważna sprawa, która jest delikatnie mówiąc upierdliwa jeśli chodzi o mapy powiatów. W lipcu 2012 roku przywrócono miastu Wałbrzych status miasta na prawach powiatu oraz ustalono na nowo granice powiatu wałbrzyskiego (uwzględniając miasto – wydzielono je z powiatu wałbrzyskiego). Dlatego w danych sprzed 2012 roku mamy powiat wałbrzyski zawierający miasto, a po 2012 – mamy to rozdzielone na dwa powiaty. Biorąc to pod uwagę rozmyślnie wybrałem do porównania 2016 (najnowsze dane) z 2015.
Na powyższej mapie można zaobserwować ciekawostkę, którą być może znacie z innych opracowań (na BIQData o tym było): migrację z miast na przedmieścia. Szczególnie widać to w Poznaniu (ludzie z Poznania (powiat m.Poznań) wyprowadzają się do miejscowości pod Poznaniem w powiecie poznańskim) i we Wrocławiu. Zobaczmy gdzie najbardziej wzrosła liczba ludności:
|
1 2 3 4 |
roznica %>% top_n(10, delta_Ludnosc_proc) %>% select(Nazwa, Wojewodztwo, delta_Ludnosc_proc) %>% arrange(desc(delta_Ludnosc_proc)) |
| Powiat | Województwo | zmiana liczby mieszkańców (%) |
|---|---|---|
| Powiat wrocławski | DOLNOŚLĄSKIE | 2.44 |
| Powiat gdański | POMORSKIE | 2.09 |
| Powiat poznański | WIELKOPOLSKIE | 2.06 |
| Powiat kartuski | POMORSKIE | 1.66 |
| Powiat wołomiński | MAZOWIECKIE | 1.46 |
| Powiat wielicki | MAŁOPOLSKIE | 1.41 |
| Powiat piaseczyński | MAZOWIECKIE | 1.41 |
| Powiat bydgoski | KUJAWSKO-POMORSKIE | 1.26 |
| Powiat policki | ZACHODNIOPOMORSKIE | 1.25 |
| Powiat leszczyński | WIELKOPOLSKIE | 1.14 |
i gdzie najbardziej zmalała:
|
1 2 3 4 |
roznica %>% top_n(-10, delta_Ludnosc_proc) %>% select(Nazwa, Wojewodztwo, delta_Ludnosc_proc) %>% arrange(delta_Ludnosc_proc) |
| Powiat | Województwo | zmiana liczby mieszkańców (%) |
|---|---|---|
| Powiat siemiatycki | PODLASKIE | -1.16 |
| Powiat hrubieszowski | LUBELSKIE | -1.13 |
| Powiat m.Sopot | POMORSKIE | -1.03 |
| Powiat sokólski | PODLASKIE | -1.02 |
| Powiat głubczycki | OPOLSKIE | -0.95 |
| Powiat hajnowski | PODLASKIE | -0.94 |
| Powiat sejneński | PODLASKIE | -0.92 |
| Powiat m.Przemyśl | PODKARPACKIE | -0.90 |
| Powiat bielski | PODLASKIE | -0.86 |
| Powiat m.Częstochowa | ŚLĄSKIE | -0.86 |
Nie widać tutaj Poznania i Wrocławia, bo zmiana była zbyt mała (nie załapały się w bottom 10) – to duże miasta, przybywają do nich ludzie z wielu okolicznych powiatów oraz rodzi się dużo dzieci. Ten przyrost jest skompensowany przez odpływ na przedmieścia, ale nie w całości.
A gdyby zestawić obie mapki na jednym wykresie?
Nie jest to proste zadanie, aby przygotować mapę ale można przygotować wykres punktowy (scatter plot). Na jednej osi pokażemy zmianę liczby ludności, na drugiej – liczby bezrobotnych. Dodatkowo rozdzielimy to na poszczególne województwa i dodamy linie dla wartości zerowych zmian:
|
1 2 3 4 5 6 |
roznica %>% ggplot() + geom_hline(yintercept = 0, color = "red") + geom_vline(xintercept = 0, color = "red") + geom_point(aes(delta_Stopa_bezrobocia, delta_Ludnosc_proc, color = Wojewodztwo), show.legend = FALSE) + facet_wrap(~Wojewodztwo) |
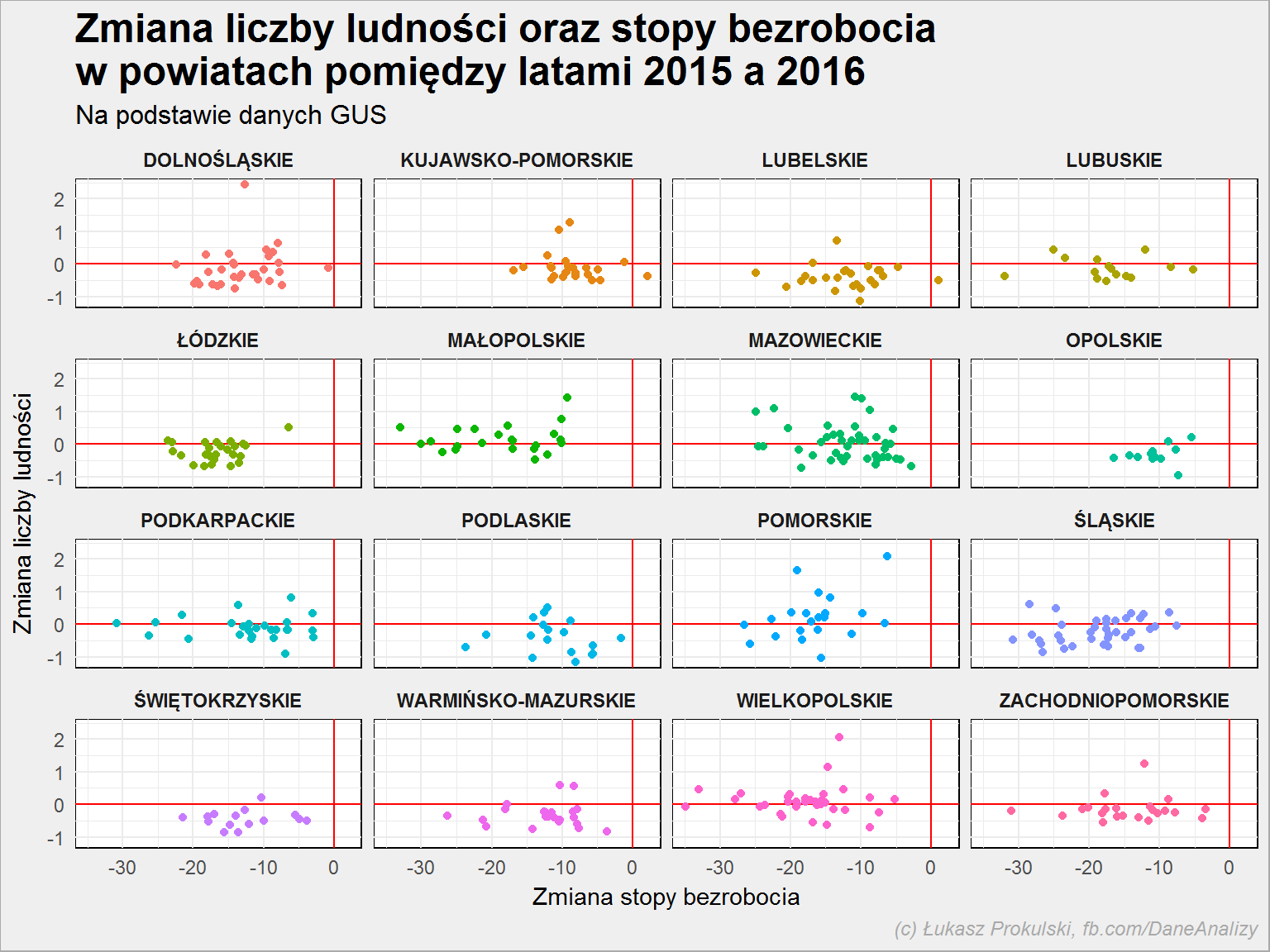
W lewej górnej ćwiartce mamy powiaty, w których przybyło ludzi, a ubyło bezrobotnych. W dolnej lewej: spadek liczby bezrobotnych i spadek liczby mieszkańców.
Ciekawe są powiaty po prawej stronie (szczególnie w dolnej części): w nich liczba mieszkańców zmalała, a bezrobocie wzrosło. Gdzie tak jest?
|
1 2 3 4 5 |
roznica %>% filter(substr(Kod, 3, 7) != "00000") %>% # tylko powiaty - wykluczenie województw filter(delta_Stopa_bezrobocia > delta_Ludnosc_proc) %>% select(Nazwa, Wojewodztwo, delta_Stopa_bezrobocia, delta_Ludnosc_proc) %>% arrange(delta_Ludnosc_proc, delta_Stopa_bezrobocia) |
| Powiat | Województwo | zmiana liczby bezrobotnych (%) | zmiana liczby mieszkańców (%) |
|---|---|---|---|
| Powiat kraśnicki | LUBELSKIE | 1.0 | -0.51 |
| Powiat lipnowski | KUJAWSKO-POMORSKIE | 2.1 | -0.37 |
Czy wartości zmian wykazują jakąś korelację? Na pierwszy rzut oka widać, że nie bardzo (punkty ułożone są raczej poziomo, przy korelacji mamy punkty ułożone po skosie). Współczynnik korelacji (dla całego kraju, biorąc dane na poziomie powiatów) pomiędzy zmianą stopy bezrobocia a zmianą liczby ludności to:
|
1 2 3 4 5 6 7 8 9 |
korelacja_kraj <- roznica %>% filter(substr(Kod, 3, 7) != "00000") %>% # tylko powiaty - wykluczenie województw mutate(korelacja = cor(delta_Stopa_bezrobocia, delta_Ludnosc_proc)) %>% arrange(korelacja) %>% select(korelacja) %>% distinct() %>% .[1,1] %>% as.numeric() %>% round(3) |
-0.041 to nie jest korelacja silna. Zobaczmy jak to wygląda dla poszczególnych województw (licząc współczynnik korelacji dla każdego z województw z osobna):
|
1 2 3 4 5 6 |
roznica %>% filter(substr(Kod, 3, 7) != "00000") %>% # tylko powiaty - wykluczenie województw group_by(Wojewodztwo) %>% summarise(korelacja = cor(delta_Stopa_bezrobocia, delta_Ludnosc_proc)) %>% ungroup() %>% arrange(korelacja) |
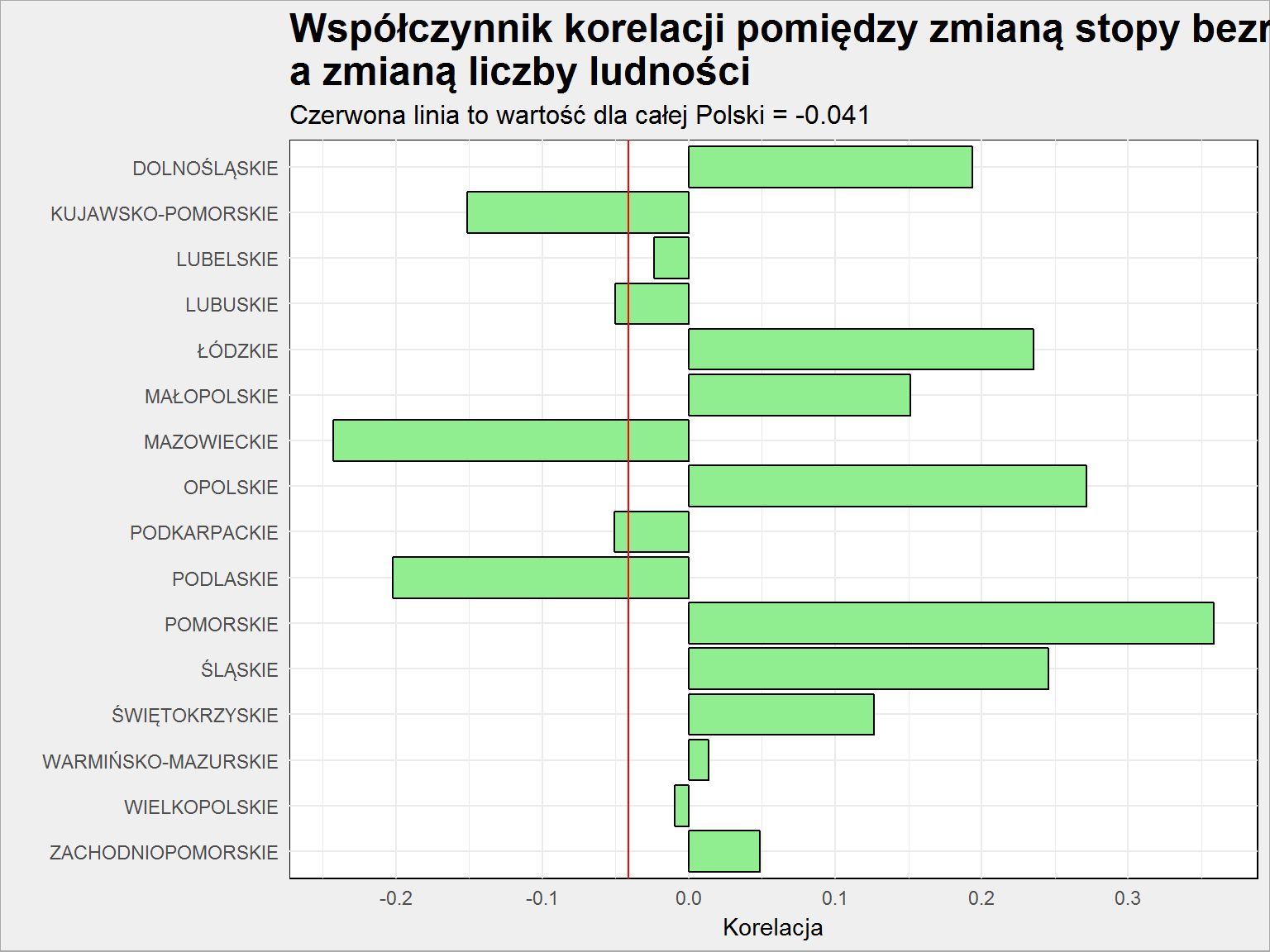
Widać, że w 9 województwach spadek stopy bezrobocia związany jest ze spadkiem liczby osób mieszkających w województwie (korelacja dodatnia). Można więc przyjąć tezę, że bezrobocie spadło, bo jest mniej ludzi za prawdopodobną. Odwrotnie jest w 7 województwach. Przy czym województwa lubelskie, warmińsko-mazurskie i wielkopolskie mają korelację bliską zeru, co oznacza że właściwie nie ma żadnej korelacji :) Czy można zatem powiedzieć że bezrobocie spadło, bo jest mniej ludzi? I tak, i nie. Czyli nie da się tego określić. Ja nie dałbym głowy broniąc tej tezy.
Pamiętajcie jednak, że korelacja to nie przyczyna, polecam poszukać obrazów dla tego hasła (w angielskiej wersji correlation isn’t causation) – znaleźć można na przykład wykres liczby utonięć w basenach zestawionych z liczbą filmów z Nicolasem Cage’em. Cała strona o tym jest :)
Na bazie tak przygotowanych danych (i całego powyższego kodu źródłowego) możecie sprawdzić, czy przez osiem lat rządów PO i PSL Polki i Polacy… I to na poziomie powiatów. Odpowiedź: pomiędzy 2007 a 2015 w 94 powiatach (około 25% wszystkich, w tym wspomniany Wałbrzych) zmiana liczby bezrobotnych była większa niż zmiana liczby mieszkańców (czyli albo wzrosło bardziej albo spadło mniej). Na przykład w Warszawie przybyło około 8 tys. bezrobotnych (z 49.5 tys. do 57.5 tys. – wzrost o około 16%) i jednocześnie przybyło prawie 38 tys. mieszkańców (wzrost o 2.2%). Ale czy można porównać takie różnice? Zastanówcie się.
Kiedy GUS opublikuje dane za 2017 rok (pewnie w okolicach wiosny 2018) będzie można sprawdzić jak wygląda #dobrazmiana.
Ten wpis jest prowokacyjny i to z premedytacją. Użyta metoda porównania nie jest najlepsza! Zastanówcie się i napiszcie dlaczego. Macie pomysł jak taką analizę uatrakcyjnić i przygotować poprawnie? Może przygotować jeden wskaźnik opisujący relację zmiany liczby mieszkańców i liczby bezrobotnych tak, aby można ją pokazać na mapie? Przygotujcie swoje opracowania i podajcie linki do nich w komentarzach!
Choć jestem w temacie raczej la(jkon)ikiem, to mam takie jedno pytanie:
Czy ujemny współczynnik korelacji nie sugeruje że zależność (mimo że oczywiście bardzo nikła) jest raczej odwrotna? Stopa bezrobocia tym mocniej spada im więcej przybywa mieszkańców? Co raczej obala tezę z tytułu…
Można by to może wyjaśnić migracją zarobkową Polaków bez (rzeczywistej, bądź formalnej) zmiany miejsca zamieszkania. Widać to szczególnie dobrze w mazowieckim, gdzie w Warszawie koszt mieszkania dla osoby przyjezdnej jest bardzo wysoki. Za to w moim pomorskim wygląda na to że taka korelacja jest całkiem silna. Gdybyś pominął Warszawę korelacja powinna być dodatnia i wyraźniejsza.
Trzeba by może jeszcze uwzględnić inne parametry np. napływ imigrantów zarobkowych ze wschodu. Nie wspominając o wpływie pracy na czarno i zmian jej powszechności.
W ogóle mam wrażenie że próbujesz wychodząc z niejednoznacznego parametru jakim jest stopa bezrobocia (bądź jej zmiana), przy pomocy innych parametrów, dojść do parametru który mamy jak na dłoni – ilość osób aktywnych zawodowo. Może jeszcze najlepiej byłoby wziąć pod uwagę tylko sektor prywatny.
Ale być może tu właśnie wyłazi moje lajkonictwo.
Po krótkich przemyśleniach doszedłem do wniosku, że zmiana liczby ludności nie powinna mieć wpływu na stopę bezrobocia – co zresztą pokazują Twoje analizy. Przecież nie ma prostej zależności, że gdy ktoś wyjeżdża lub umiera, to ktoś wchodzi na jego miejsce. Gdy zmniejsza się populacja zmniejsza się również popyt na usługi, łatwość zdobywania i utrzymywania kontrachentów, więc de facto zmniejszy się też zatrudnienie. To takie spostrzeżenie w duchu „austriackiej szkoły ekonomii”.
Tak więc spadek stopy bezrobocia, jednoznacznie wskazuje na poprawę warunków. Nie ma sensu rozpatrywać tego w kontekście #dobrazmiana, bo bezrobocie spada już od wielu lat mniej więcej w tym samym tempie (choć powinno się już nasycać, bo poniżej zera to raczej spaść nie powinno ;) ).
Myślę, że chodzi tutaj o „correlation isn’t causation”
Oh, właśnie doczytałem do końca – wspomniał pan o tym w swoim artykule.