Lista Przebojów Trójki to chyba najpopularniejsza lista przebojów w Polsce, a z pewnością najstarsza. Zobaczmy czego możemy się dowiedzieć z całej jej historii.
Potrzebne będzie kilka pakietów R (do pobrania danych dodatkowo rvest):
|
1 2 3 4 |
library(tidyverse) library(lubridate) library(ggrepel) # dla ładnego umiejscowienia labelek na wykresach |
Pobranie danych
Skorzystamy z archiwum Listy Trójki zebranym na stronie LP3.pl – klikając w kolejne numery notowań po prawej stronie widzimy, że zmienia się adres strony według schematu http://www.lp3.pl/alpt.phtml?m=1&nn=XXX gdzie XXX to kolejny numer (niekoniecznie notowania). Trzeba znaleźć największy numer (najnowsze notowanie) i przejść przez kolejne strony (kolejne XXX od jeden do tej największej liczby).
Analiza kodu HTML strony pozwala na wybranie odpowiednich jej fragmentów i tym samym zgromadzenie danych. Szczegółowym kodem nie będę zamęczał – znajduje się na GitHubie. Pojawiają się pytania od Was jak scrappować strony – być może przygotuję o tym kiedyś dedykowany wpis techniczny (choć wolę przygotowywać analizy :). Dane zapisałem w pliku lokalnym.
Swoją drogą na LP3.pl znajdziecie część z poniższych analiz.
Przygotowanie danych do dalszych analiz
Pod uwagę weźmiemy tylko piosenki z pełnego notowania (miejsca 1-30, z pominięciem poczekalnii). Aby było sprawiedliwie na przestrzeni całej historii zamiast miejsc na liście użyjemy punktacji, którą sami nadamy: 30 punktów za pierwsze miejsce, 29 za drugie itd. Tak samo nadawane są punkty podczas rocznych podsumowań Listy.
|
1 2 3 4 5 6 7 8 9 |
notowania <- readRDS("notowania_raw.RDS") # dane po zebraniu ich ze strony notowania_analiza <- notowania %>% mutate(NotowanieData = make_date(NotowanieRok, NotowanieMiesiac, NotowanieDzien)) %>% select(PozAkt, Artist, Title, NotowanieNumer, NotowanieData, NotowanieProwadzacy, Kraj) %>% filter(PozAkt <= 30) %>% # tylko pierwsza 30 piosenek mutate(Punkty = 31-PozAkt) # punktacja |
Czas zatem na…
Analizy
Mając tak przygotowane dane możemy przejść do tego, co najciekawsze.
Prowadzący notowania
Każde notowanie w serwisie LP3.pl to nie tylko informacje o pozycji konkretnych piosenek, ale też jego numer, data i osoba prowadząca. Lista Trójki kojarzy się przede wszystkim z Markiem Niedźwieckim. Zobaczmy jak dużo notowań prowadził:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
prowadzacy <- notowania_analiza %>% select(NotowanieData, NotowanieProwadzacy) %>% distinct() prowadzacy %>% group_by(NotowanieProwadzacy) %>% summarise(n=n()) %>% ungroup() %>% arrange(desc(n)) %>% mutate(Prowadzacy=factor(NotowanieProwadzacy, levels=NotowanieProwadzacy)) %>% ggplot() + geom_bar(aes(Prowadzacy, n), stat="identity", fill = "lightgreen", color = "black") + theme(axis.text.x = element_text(angle=90, hjust=1)) |
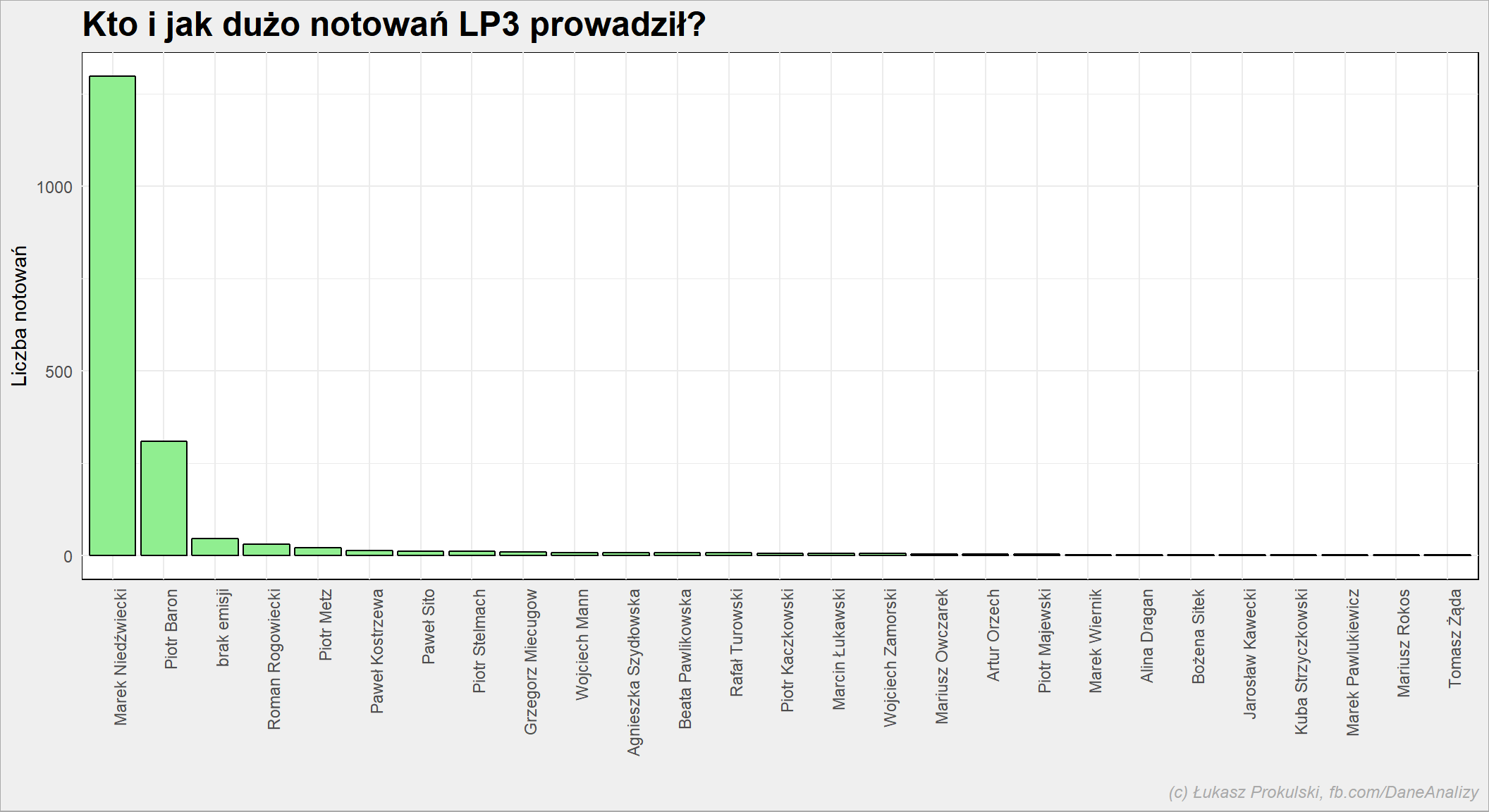
Zdecydowaną większość. A jak wyglądał podział notowań w roku pomiędzy poszczególnych prowadzących? Wybieramy tylko tych, którzy prowadzili najwięcej, resztę wrzucimy do worka “inni”:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
prowadzacy %>% mutate(Rok=year(NotowanieData), NotowanieProwadzacy = as.character(NotowanieProwadzacy)) %>% mutate(NotowanieProwadzacy = ifelse(NotowanieProwadzacy %in% c("brak emisji", "Piotr Baron", "Roman Rogowiecki", "Piotr Metz", "Piotr Stelmach", "Marek Niedźwiecki"), NotowanieProwadzacy, "inni")) %>% group_by(Rok, NotowanieProwadzacy) %>% summarise(n=n()) %>% ungroup() %>% group_by(Rok) %>% mutate(p=100*n/sum(n)) %>% ungroup() %>% mutate(NotowanieProwadzacy = factor(NotowanieProwadzacy, levels = c("brak emisji", "inni", "Piotr Stelmach", "Roman Rogowiecki", "Piotr Metz", "Piotr Baron", "Marek Niedźwiecki"))) %>% ggplot() + geom_bar(aes(Rok, p, fill=NotowanieProwadzacy), stat="identity", color = "black") + theme(legend.position = "bottom") + scale_fill_manual(values = RColorBrewer::brewer.pal(7, "Set3")) |
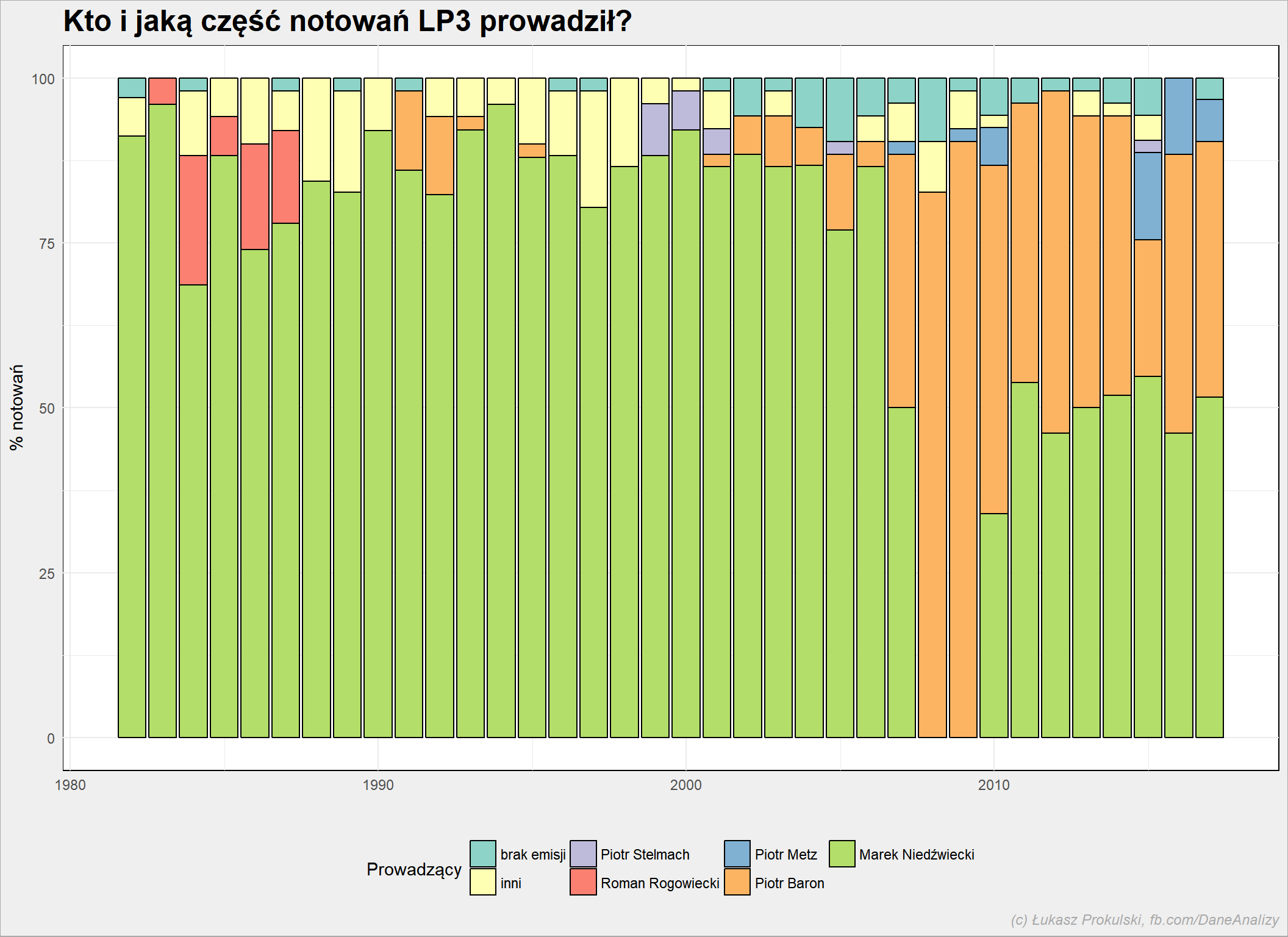
Widać, że w 2007 roku Marka zastąpił Piotr Baron. Niedźwiecki wrócił do Listy w 2010 roku i od tego czasu Listę prowadzi na zmianę z Baronem (plus sporadycznie innymi osobami, głównie Piotrem Metzem). I to się zgadza, bo przez pewien czas (od grudnia 2007 do końca marca 2010) Niedźwiecki pracował w Radiu Złote Przeboje.
Lista przebojów wykreowała osobowości radiowe, ale Lista to przede wszystkim piosenki. Przyjrzyjmy się więc im.
Piosenki
Najpoularniejsze piosenki (top wszech czasów)
Jaka piosenka była tą najlepszą w prawie 30 latach? Może ta, która najczęściej była na pierwszym miejscu? A co z tymi, które były ciągle drugie? Dlatego właśnie użyjemy punktów. Utwór mógł być na liście bardzo długo, a nigdy nie dotrzeć na szczyt – to oznacza, że był popularny i lubiany, a nie miał szczęścia.
|
1 2 3 4 5 6 7 8 9 10 11 |
notowania_analiza %>% group_by(Artist, Title) %>% summarise(Punkty = sum(Punkty)) %>% ungroup() %>% top_n(30, Punkty) %>% arrange(desc(Punkty)) %>% mutate(Song = paste(Artist, Title, sep = " - ")) %>% mutate(Song = factor(Song, levels = Song)) %>% ggplot() + geom_bar(aes(Song, Punkty), stat = "identity", fill = "lightgreen", color = "black") + theme(axis.text.x = element_text(angle=90, hjust=1)) |
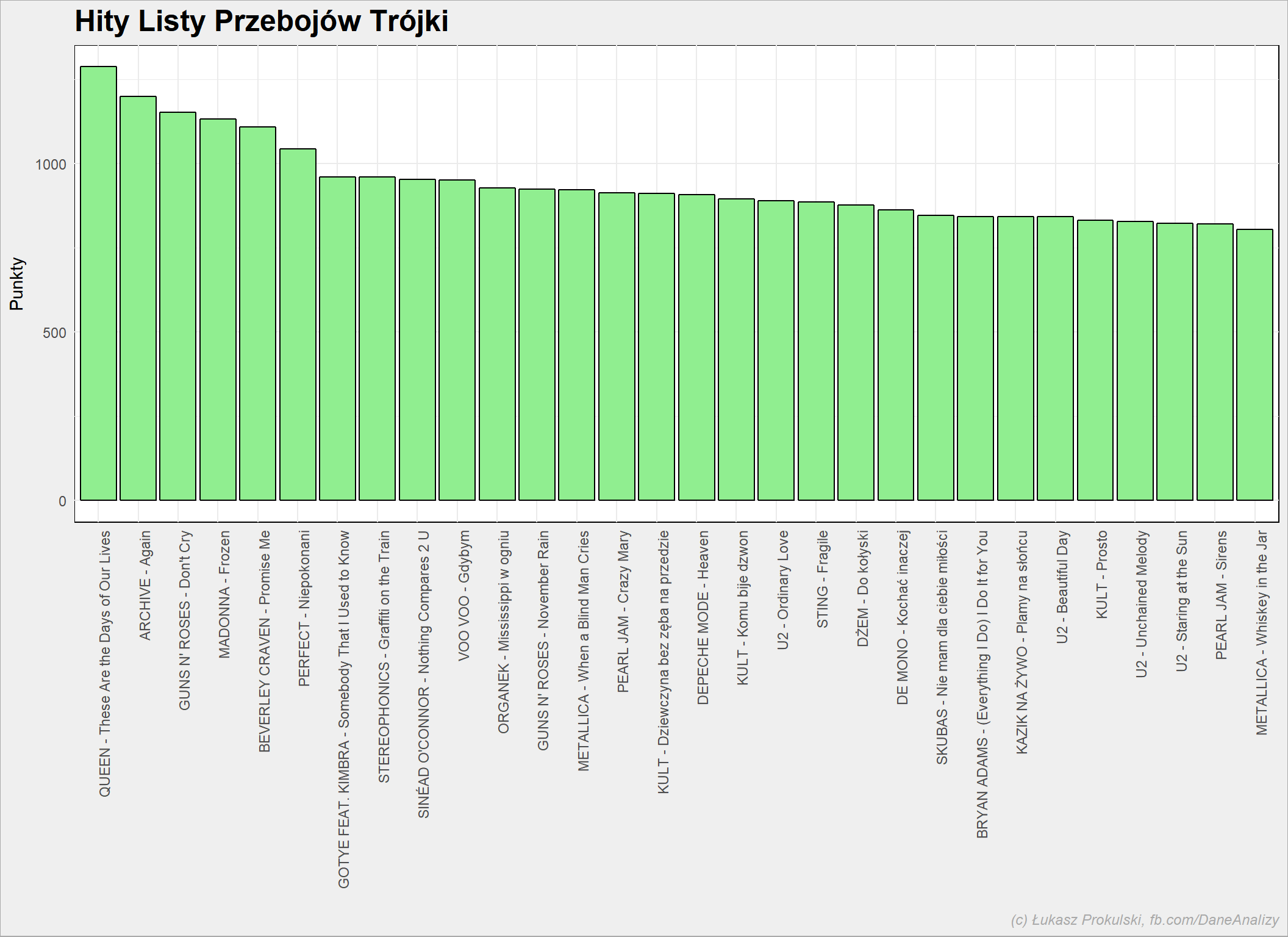
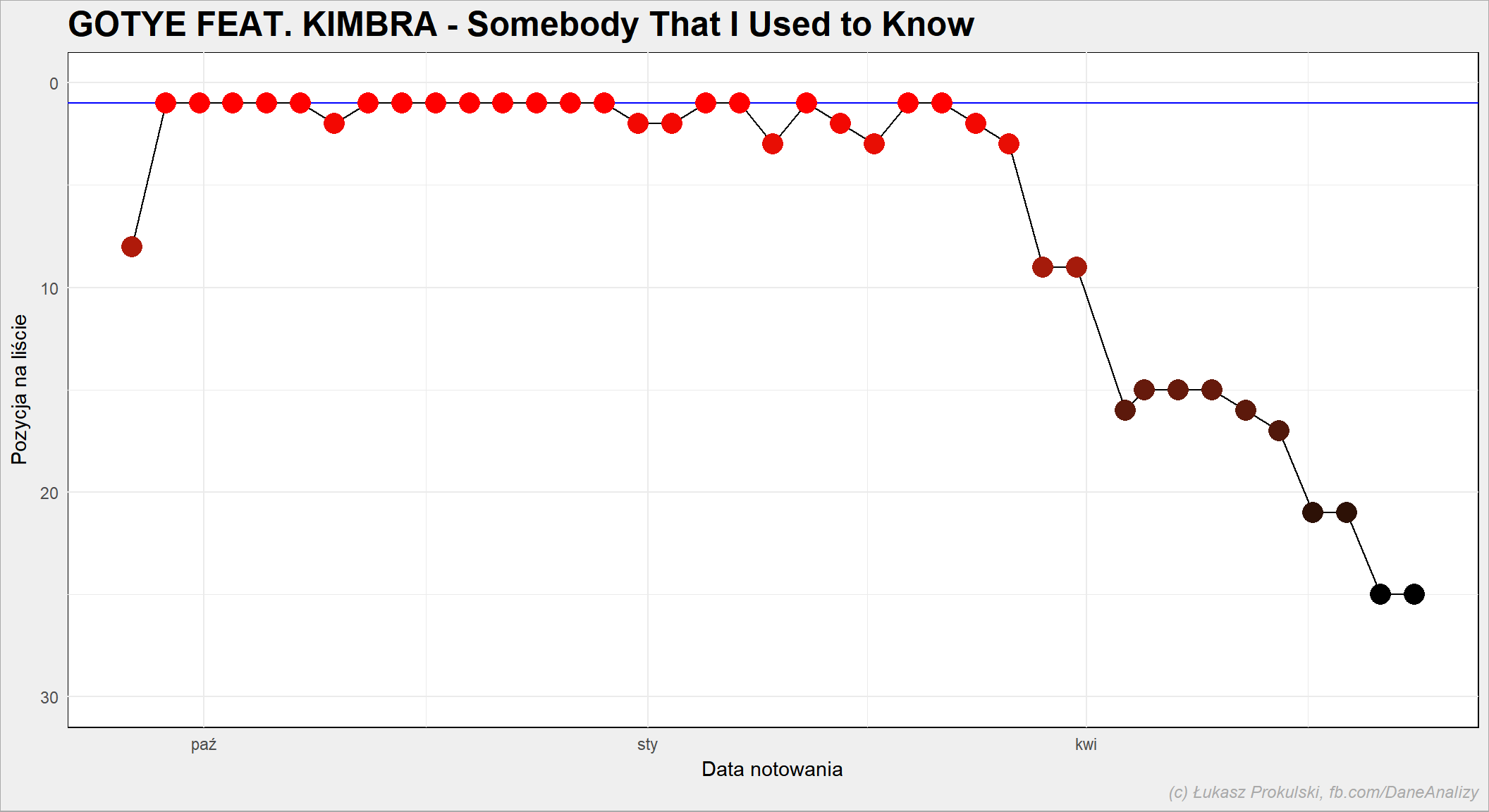
Bezapelacyjnie króluje piosenka Queenu. Zwróćcie uwagę na piosenkę Gotye – będzie o niej trochę dalej.
Najpopularniejsze polskie piosenki
Powyżej pojawiło się kilka polskich utoworów, ale zobaczmy pełne polskie top 30:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
notowania_analiza %>% filter(Kraj == "PL") %>% group_by(Artist, Title) %>% summarise(Punkty = sum(Punkty)) %>% ungroup() %>% top_n(30, Punkty) %>% arrange(desc(Punkty)) %>% mutate(Song = paste(Artist, Title, sep = " - ")) %>% mutate(Song = factor(Song, levels = Song)) %>% ggplot() + geom_bar(aes(Song, Punkty), stat="identity", fill = "lightgreen", color = "black") + theme(axis.text.x = element_text(angle=90, hjust=1)) |
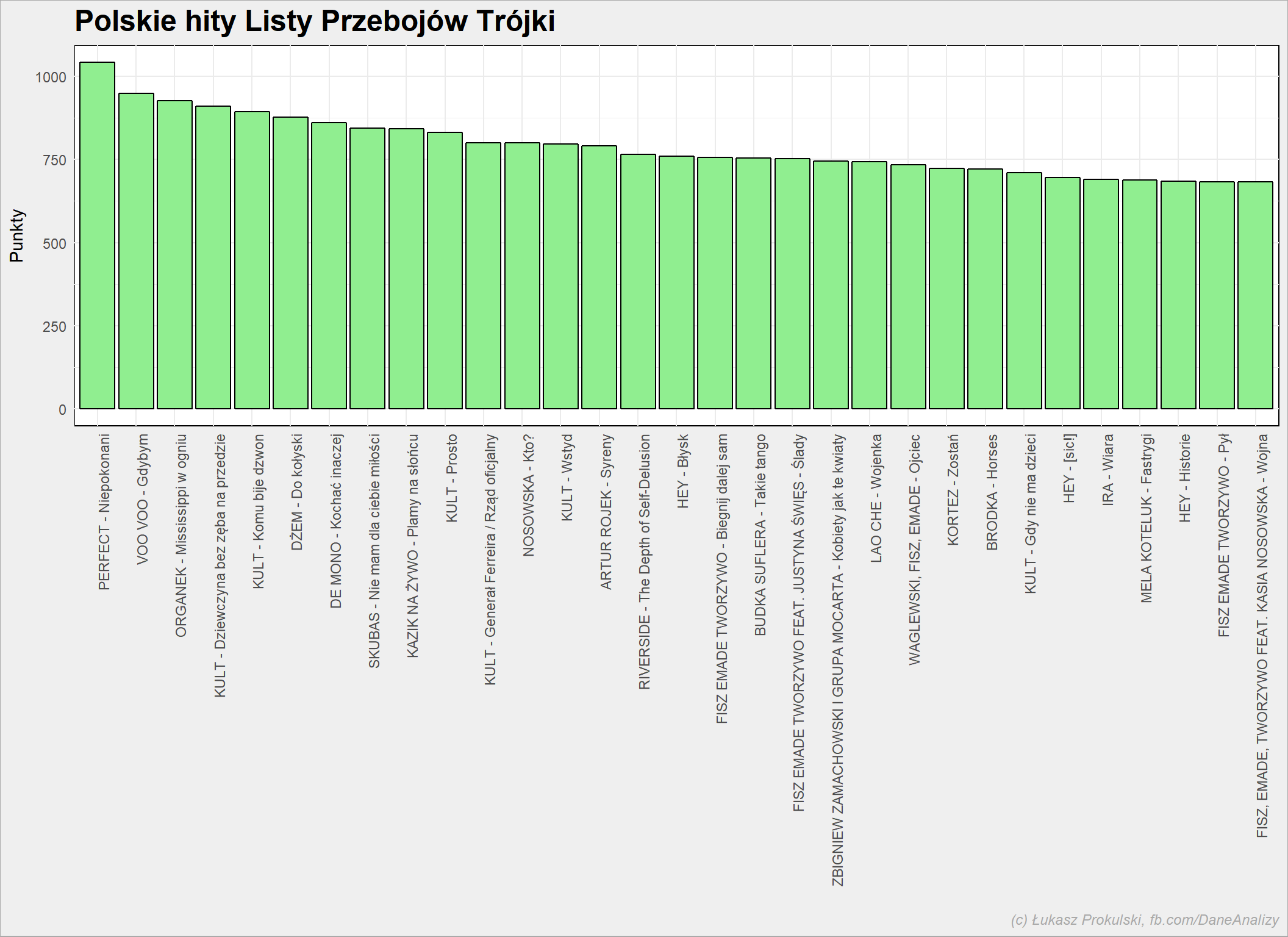
Niesamowite jest to, że piosenka stosunkowo “młoda” (jak na historię listy) znalazła się na trzecim miejscu. I jakże inna jest to piosenka w porównaniu z Perfectem – to już inne pokolenie słuchaczy. Warto zwrócić również uwagę na “Wojenkę” Lao Che.
Najpopularniejsze piosenki roku
Sprawdźmy teraz jakie były hity rok po roku:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
notowania_analiza %>% mutate(Rok=year(NotowanieData)) %>% group_by(Rok, Artist, Title) %>% summarise(Punkty=sum(Punkty)) %>% ungroup() %>% group_by(Rok) %>% arrange(desc(Punkty)) %>% mutate(PozRok = row_number()) %>% ungroup() %>% filter(PozRok == 1) %>% ggplot() + geom_bar(aes(Rok, Punkty), stat="identity", fill = "lightgreen", color = "black") + geom_text(aes(Rok, Punkty, label=paste(Artist, Title, sep=" - ")), angle=90, hjust = -0.1, vjust = 0.1) + expand_limits(y = c(0, 4000)) |
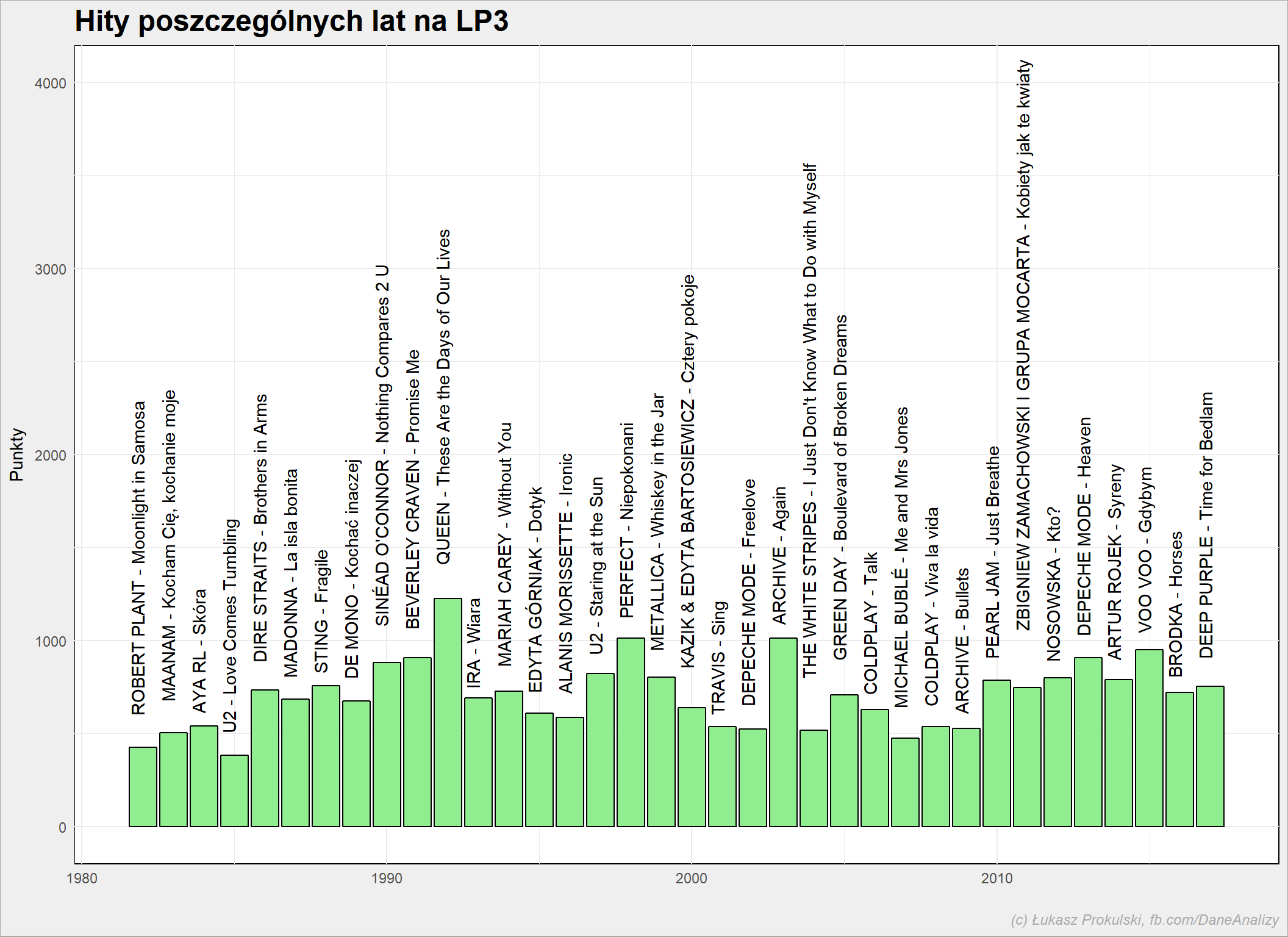
Najpopularniejsze polskie piosenki roku
I jeszcze to samo dla samych polskich utworów:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
notowania_analiza %>% filter(Kraj=="PL") %>% mutate(Rok=year(NotowanieData)) %>% group_by(Rok, Artist, Title) %>% summarise(Punkty=sum(Punkty)) %>% ungroup() %>% group_by(Rok) %>% arrange(desc(Punkty)) %>% mutate(PozRok = row_number()) %>% ungroup() %>% filter(PozRok==1) %>% ggplot() + geom_bar(aes(Rok, Punkty), stat="identity", color = "black", fill = "lightgreen") + geom_text(aes(Rok, Punkty, label=paste(Artist, Title, sep=" - ")), angle=90, hjust=-0.1, vjust=0.1) + expand_limits(y = c(0, 3500)) |
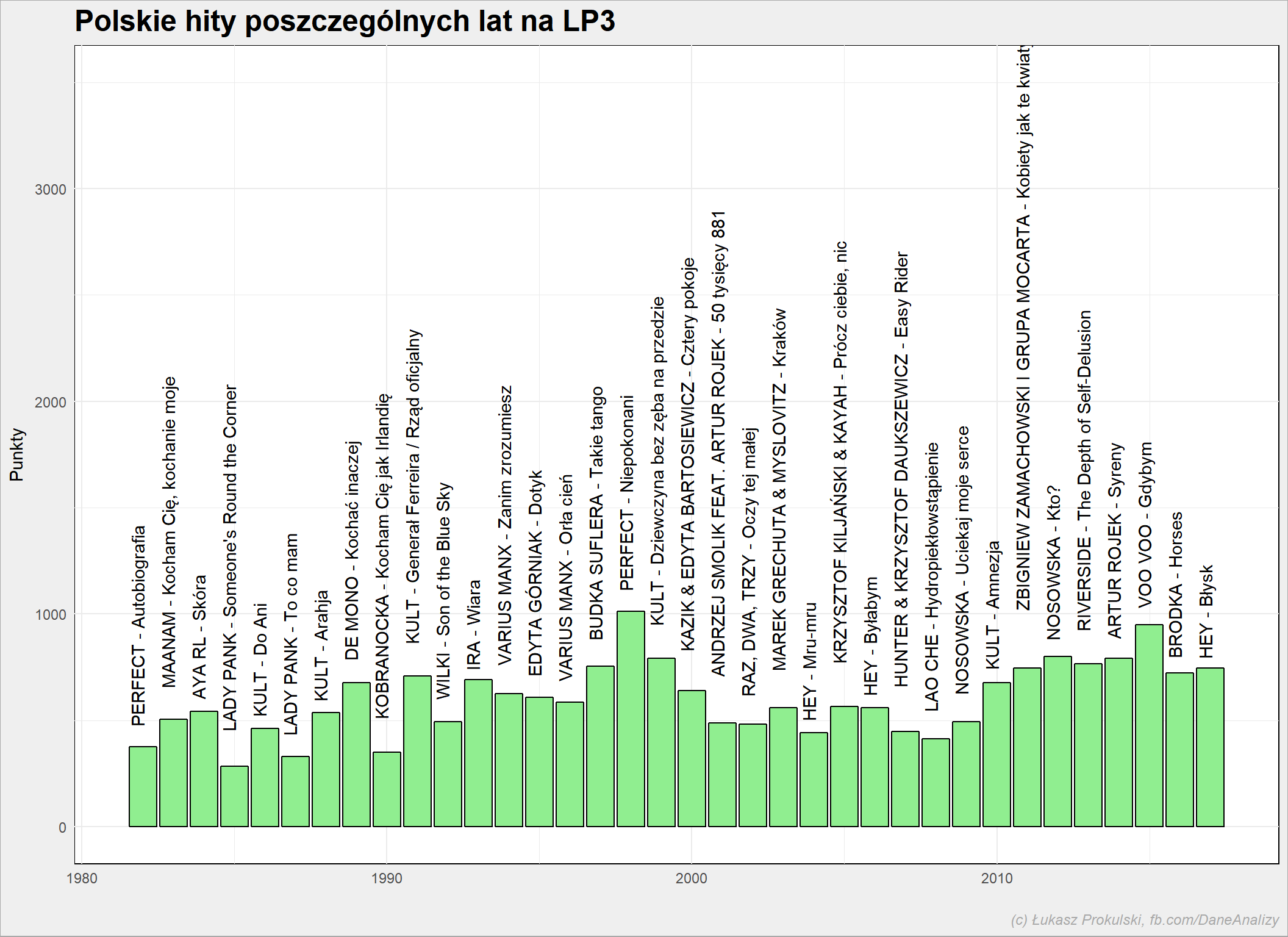
Przejdźmy do wykonawców.
Wykonawcy
Może być tak, że ktoś nagra hit, który zdobędzie popularność w krótkim czasie, a później nikt o nim nie pamięta. Gotye to idealny przykład (chociaż wolę podawać za przykład Macarenę, która swego czasu pobiła rekord ilości notowań na szcycie Billboardu).
Najpopularniejszy artysta listy
|
1 2 3 4 5 6 7 8 9 10 |
notowania_analiza %>% group_by(Artist) %>% summarise(Punkty = sum(Punkty)) %>% ungroup() %>% arrange(desc(Punkty), Artist) %>% top_n(30, Punkty) %>% mutate(Artist = factor(Artist, levels = Artist)) %>% ggplot() + geom_bar(aes(Artist, Punkty), stat="identity", fill = "lightgreen", color = "black") + theme(axis.text.x = element_text(angle=90, hjust=1)) |
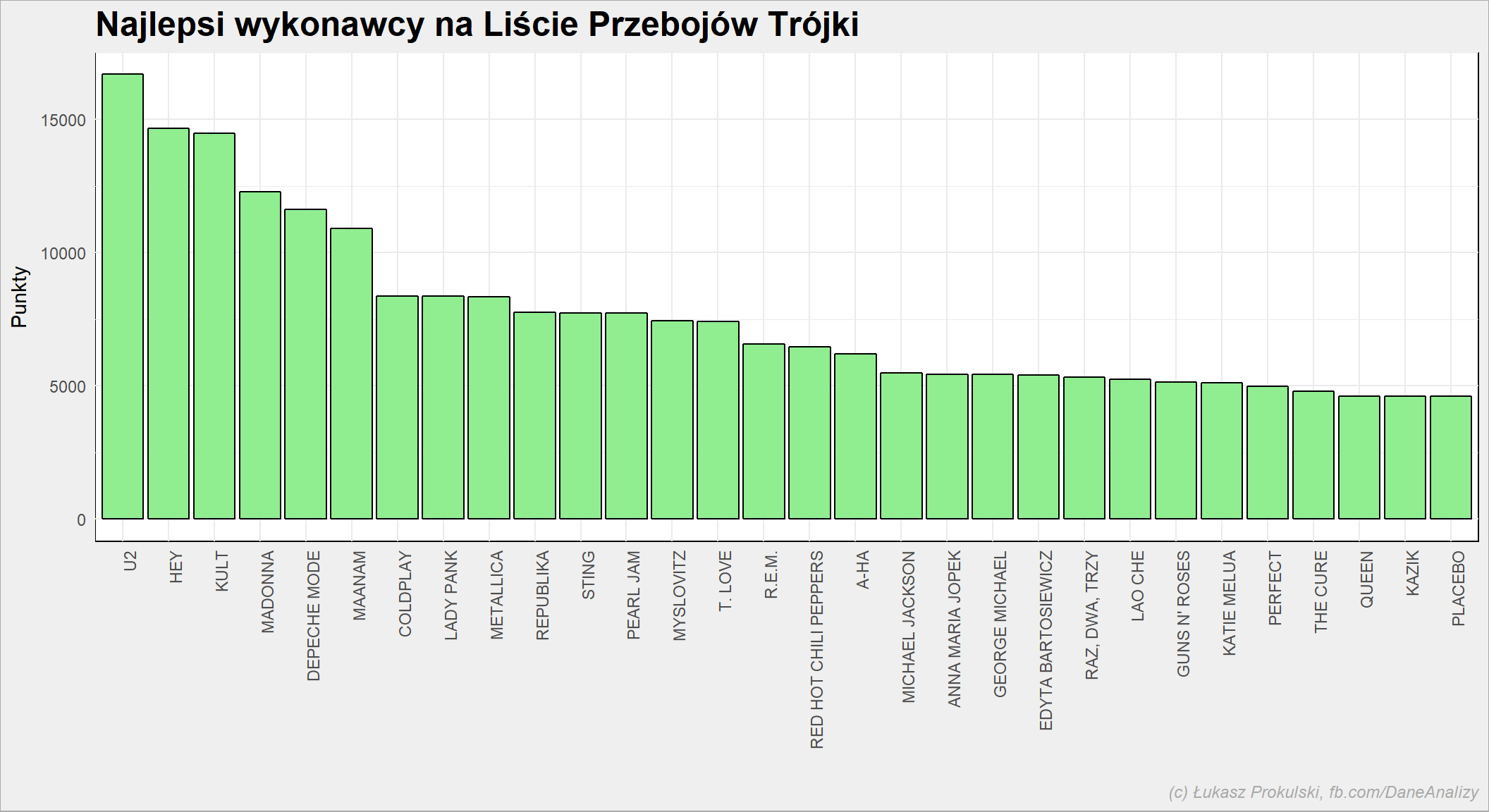
Tutaj widać gust muzyczny słuchaczy Trójki. I jakże on się różni od najpopularniejszych piosenek! Queen jest dopiero 28, chociaż wygrał w kategorii najlepszy utwór. Widać więc, że liczy się nie tyle jedna piosenka co cały ich zestaw, najlepiej przez wiele lat. Queen nie miał tego szczęścia – Freddie zmarł w 1991 roku i od tego czasu Queenu właściwie nie ma. Kolejne piosenki zapewne poprawiłyby wynik zespołu. Podobnie jest z polską Republiką – również ustąpiła miejsca innym po śmierci Ciechowskiego. Ehh… o każdym z tych wykonawców mógłbym długo i namiętnie. Cóż, kocham muzykę i jest chyba najważniejszą dziedziną sztuki dla mnie.
Najpopularniejszy polski artysta całej listy
Tradycyjnie sprawdźmy najlepszych polskich wykonawców:
|
1 2 3 4 5 6 7 8 9 10 11 |
notowania_analiza %>% filter(Kraj=="PL") %>% group_by(Artist) %>% summarise(Punkty=sum(Punkty)) %>% ungroup() %>% arrange(desc(Punkty), Artist) %>% top_n(30, Punkty) %>% mutate(Artist=factor(Artist, levels = Artist)) %>% ggplot() + geom_bar(aes(Artist, Punkty), stat="identity", fill = "lightgreen", color = "black") + theme(axis.text.x = element_text(angle=90, hjust=1)) |
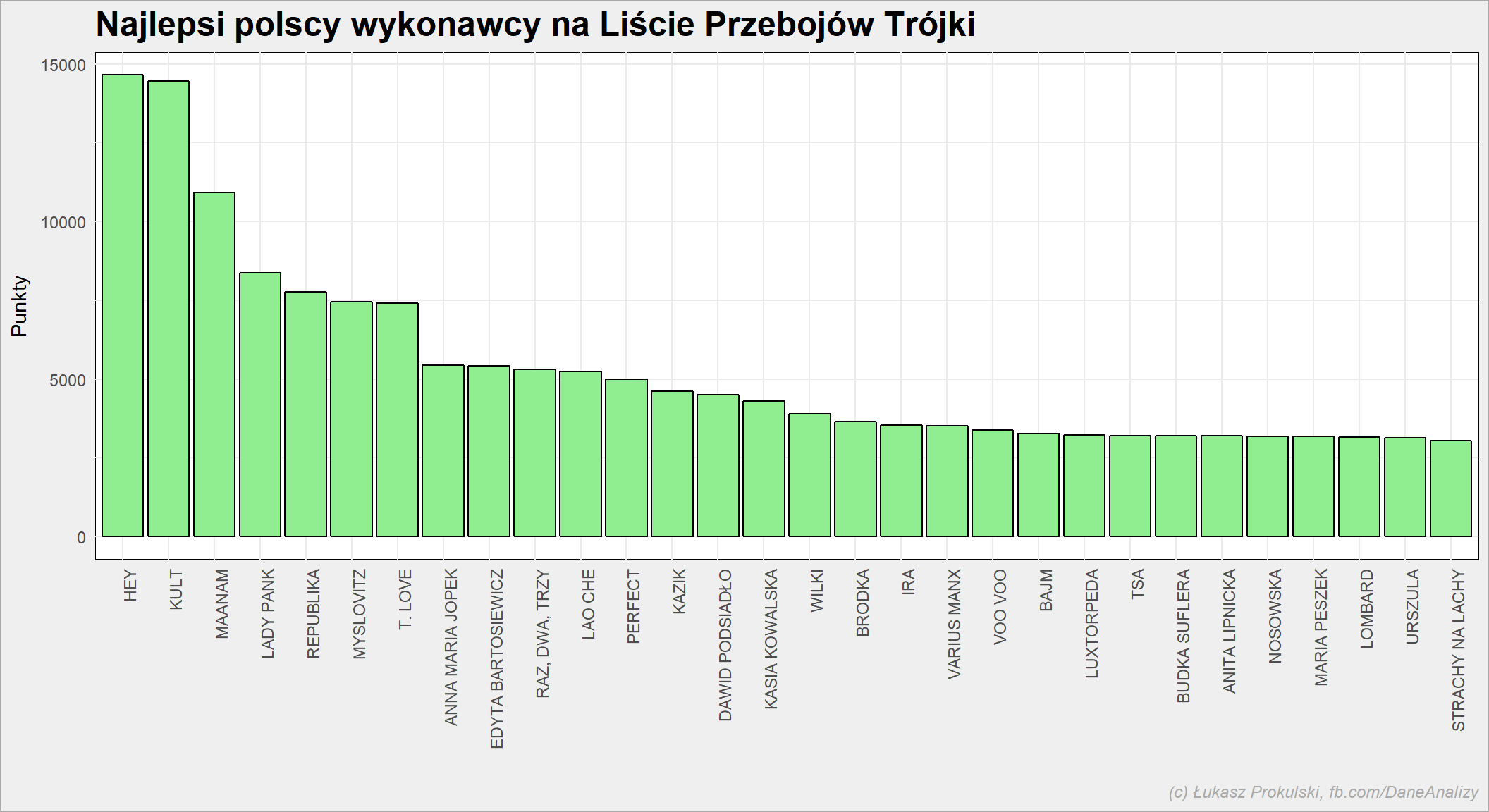
Przygotujmy sobie listę najlepszych artystów, z której będziemy korzystać później. Nie jesst to pełne Top 30 – kolejne wykresy będą mniejsze i bardziej czytelne.
|
1 |
top_artists <- c("U2", "HEY", "KULT", "MADONNA", "DEPECHE MODE", "MAANAM", "COLDPLAY", "LADY PANK", "METALLICA", "REPUBLIKA", "STING", "PEARL JAM") |
Forma artystów na przestrzeni lat
Teraz wybierzemy artystów, których piosenki były na liście przez co najmniej 15 lat i sprawdzimy ile punktów zdobyli (wszystkie ich piosenki) w poszczególnych latach. Da to jakiś obraz tego jak przebiegała historia popularności wykonawcy.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
notowania_analiza %>% # liczba punktów artysty per rok mutate(Rok = year(NotowanieData)) %>% group_by(Rok, Artist) %>% summarise(Punkty=sum(Punkty)) %>% ungroup() %>% # liczba lat, w których artysta był notowany group_by(Artist) %>% mutate(n_years = n()) %>% ungroup() %>% # tylko ci, którzy są na liście co najmniej w 15 latach filter(n_years >= 15) %>% # kolejność artystów wg punktów dla każdego roku group_by(Rok) %>% arrange(desc(Punkty)) %>% mutate(npos = row_number()) %>% ungroup() %>% ggplot() + geom_point(aes(Rok, npos, color=Artist), size = 2, show.legend = FALSE) + geom_smooth(aes(Rok, npos, color=Artist), method = "loess", show.legend = FALSE, se = FALSE, size=1, alpha = 0.4) + facet_wrap(~Artist, ncol = 3) + scale_y_reverse() |
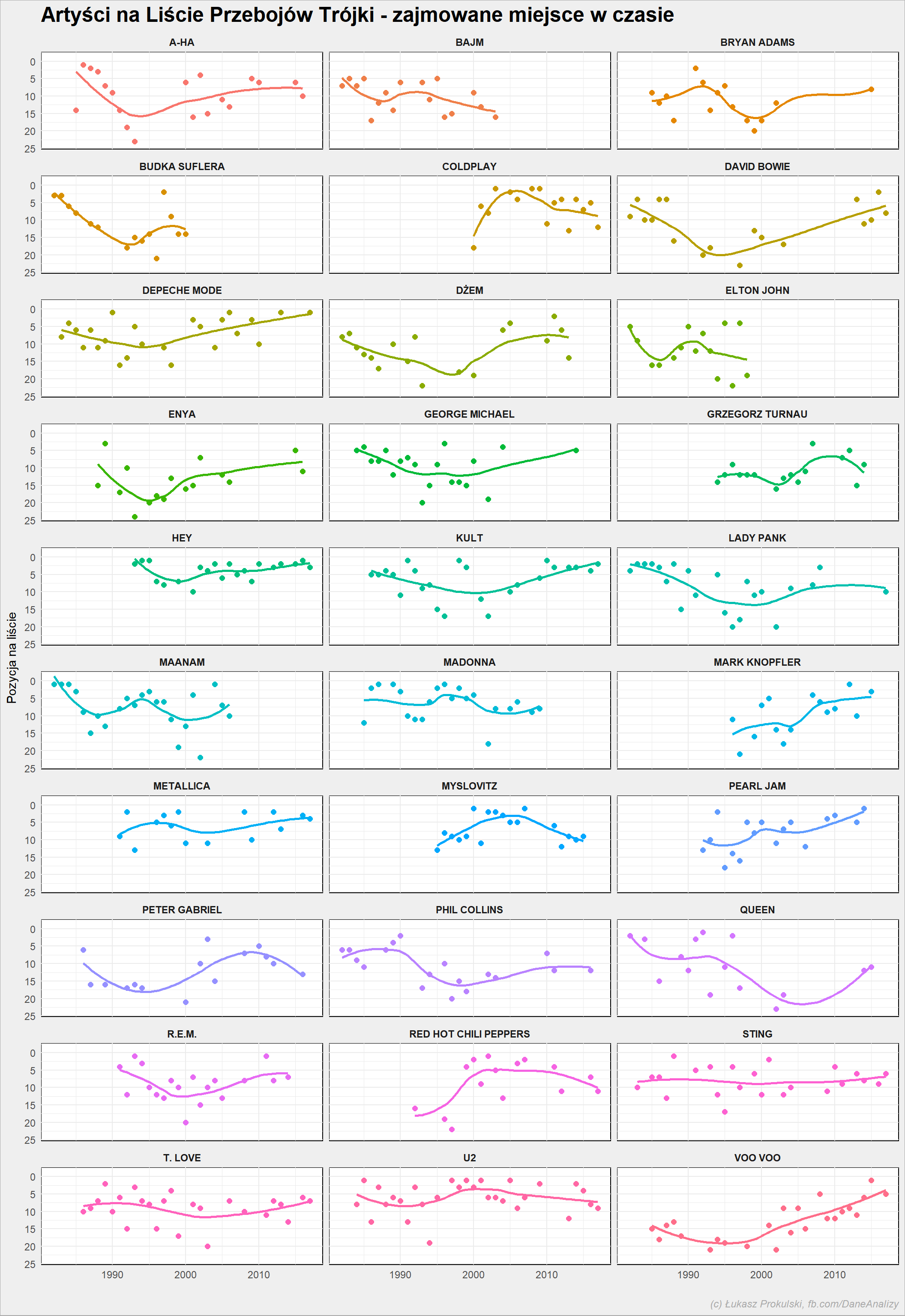
Tym razem z punktów przeszliśmy na miejsce na liście (same punkty dałyby straszliwie rozstrzeloną skalę osi Y). Widzimy oczywiście, że niektórzy przestali pojawiać się na liście, a inni pokazali się dopiero w pewnym momencie (Coldplay, Hey, Myslovitz).
Wynik artysty dla kolejnych notowań
Teraz coś podobnego (dla wybranej dwunastki najlepszych) – suma punktów zdobytych w kolejnych notowaniach:
|
1 2 3 4 5 6 7 8 9 10 11 |
notowania_analiza %>% filter(Artist %in% top_artists) %>% group_by(NotowanieData) %>% mutate(Punkty = sum(Punkty)) %>% ungroup() %>% ggplot() + geom_point(aes(NotowanieData, Punkty), color = "gray", alpha = 0.4, show.legend = FALSE) + geom_smooth(aes(NotowanieData, Punkty), method = "loess", show.legend = FALSE, se = FALSE, size = 1.4, color = "orange") + facet_wrap(~Artist) |
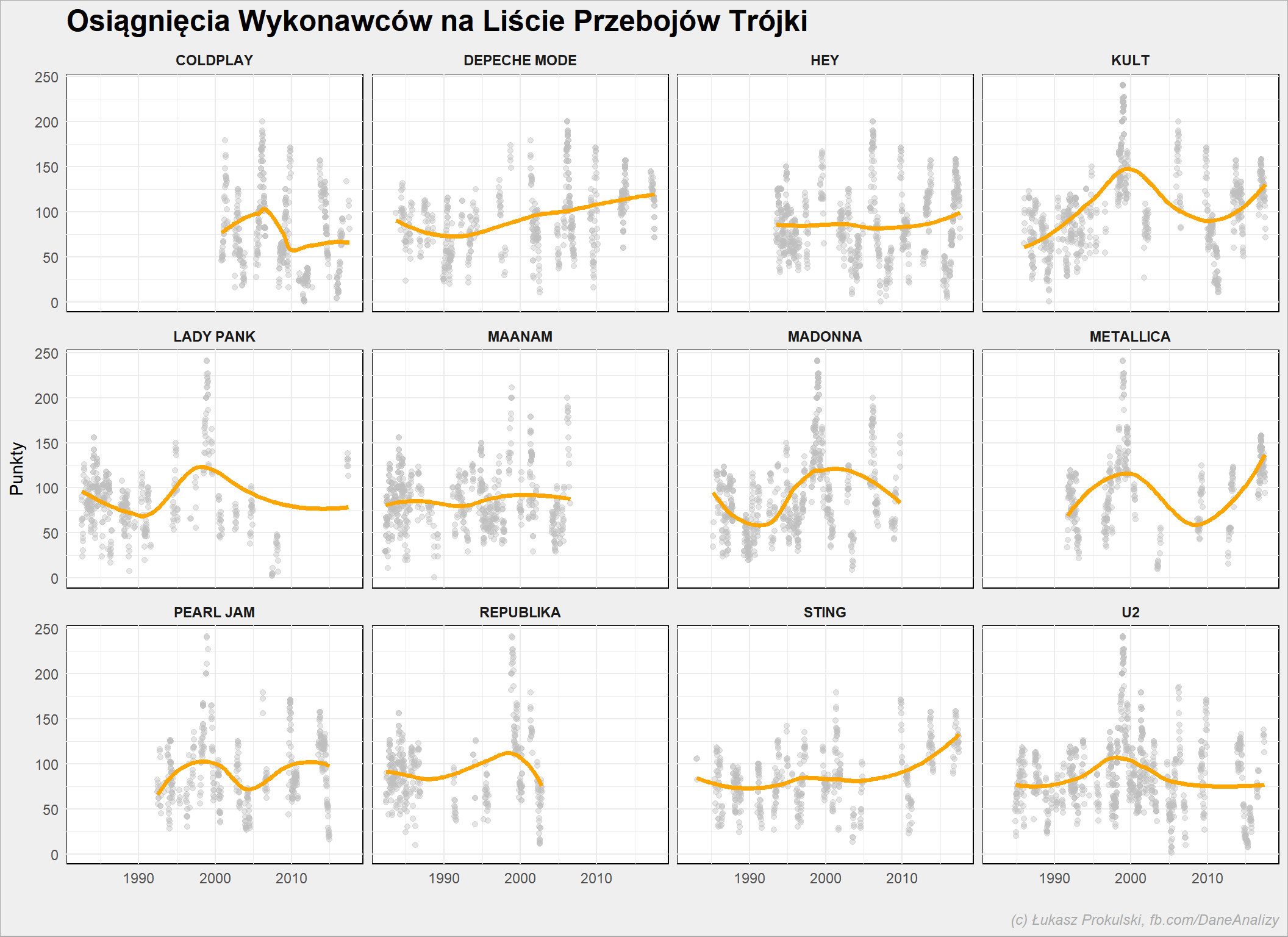
Wykresy są bardziej “dynamiczne” w pionie – przeliczenie punktów na kolejność na liście spłaszczyło wykresy.
Kult swój szczyt miał w okolicy 1998-2000 roku, ostatnio jest znowu bardziej lubiany. Maanam się skończył, podobnie jak Republika (tutaj akurat nie jest to dziwne). Śmiem twierdzić, że Metallica zyskuje głównie przez sentyment i wiek głosujących – ci, którzy byli w liceum w czasie “Master of Puppets” albo czarnej płyty głosują teraz na nowe utwory (które na ostatniej płycie są całkiem całkiem).
Analiza poszczególnych artystów
Przyjrzyjmy się historii wybranego artysty na przestrzeni lat. Wybrałem Maanam ze względu na liczbę piosenek notowanych na liście.
Najpopularniejsze piosenki w danym roku
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
artysta <- "MAANAM" notowania_analiza %>% filter(Artist==artysta) %>% mutate(Rok=year(NotowanieData)) %>% group_by(Rok, Title) %>% summarise(Punkty=sum(Punkty)) %>% ungroup() %>% group_by(Rok) %>% arrange(desc(Punkty)) %>% mutate(RokPoz=row_number()) %>% ungroup() %>% arrange(Rok, desc(Punkty), Title) %>% filter(RokPoz==1) %>% ggplot() + geom_bar(aes(Rok, Punkty), stat="identity", color = "black", fill = "lightgreen") + geom_text(aes(Rok, Punkty, label=Title), angle=90, hjust=-0.1, vjust=0.1) + expand_limits(y = c(0, 900)) |
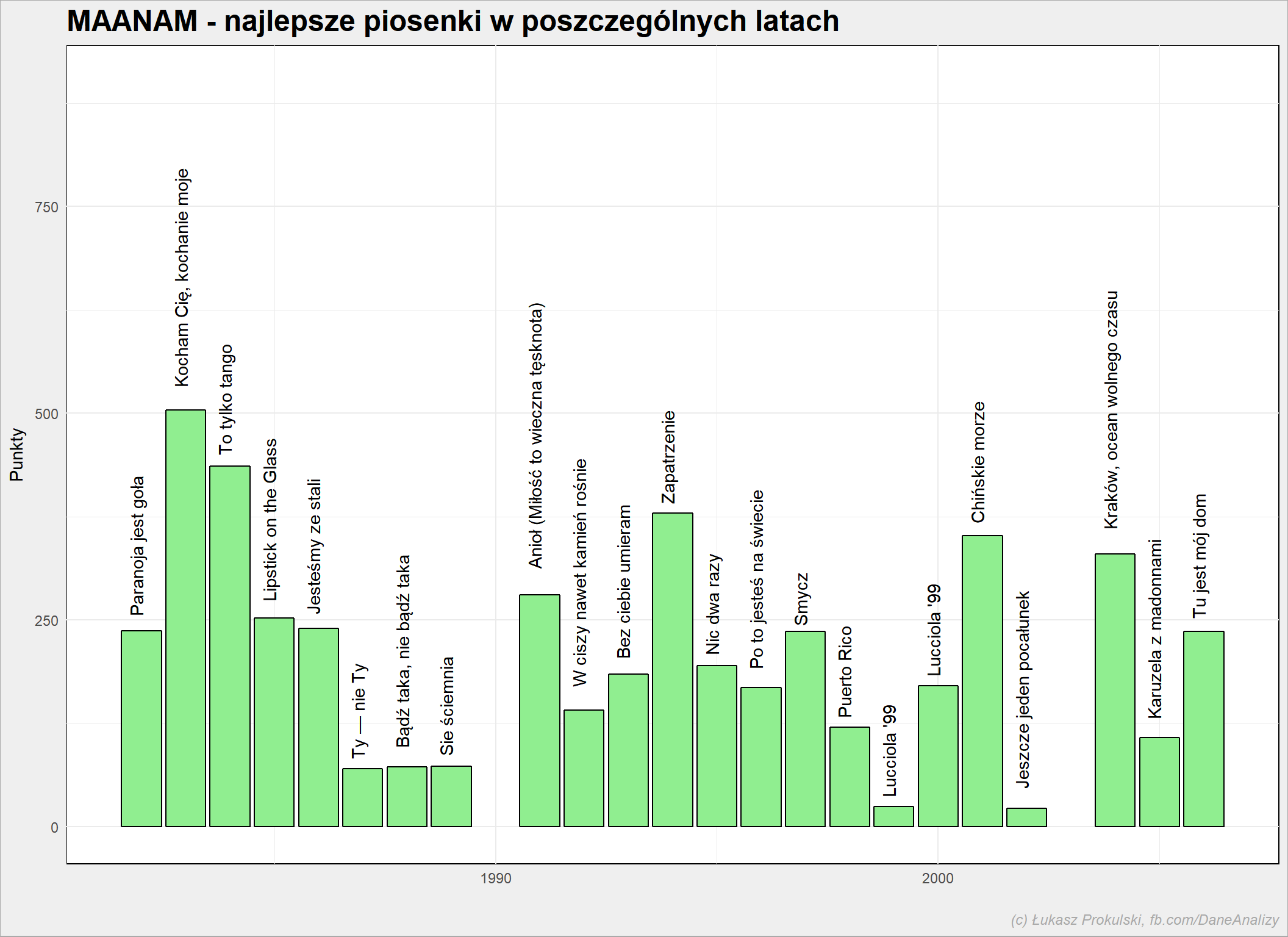
Dlaczego “Luciola ’99” występuje w 1999 i 2000 roku? Pewnie weszła do notowania pod koniec 1999 i jednocześnie była jedyną (albo najlepszą) piosenką Maanamu w tym roku – zerknięcie w dane pokazuje, że zadebiutowała 3 grudnia 1999 (załapała się na 4 notowania w 1999), z listy wypadła w marcu 2000. W 2000 była na liście dłużej (niż w 1999) i wyżej (najwyżej na 8 miejscy w styczniu 2000).
Sprawdźmy jak poszczególni wykonawcy zdobywali popularność (albo raczej punkty na liście):
Skumulowana liczba punktów per wykonawca
|
1 2 3 4 5 6 7 |
notowania_analiza %>% filter(Artist %in% top_artists) %>% group_by(Artist) %>% mutate(Punkty = cumsum(Punkty)) %>% ungroup() %>% ggplot() + geom_line(aes(NotowanieData, Punkty, color=Artist)) |
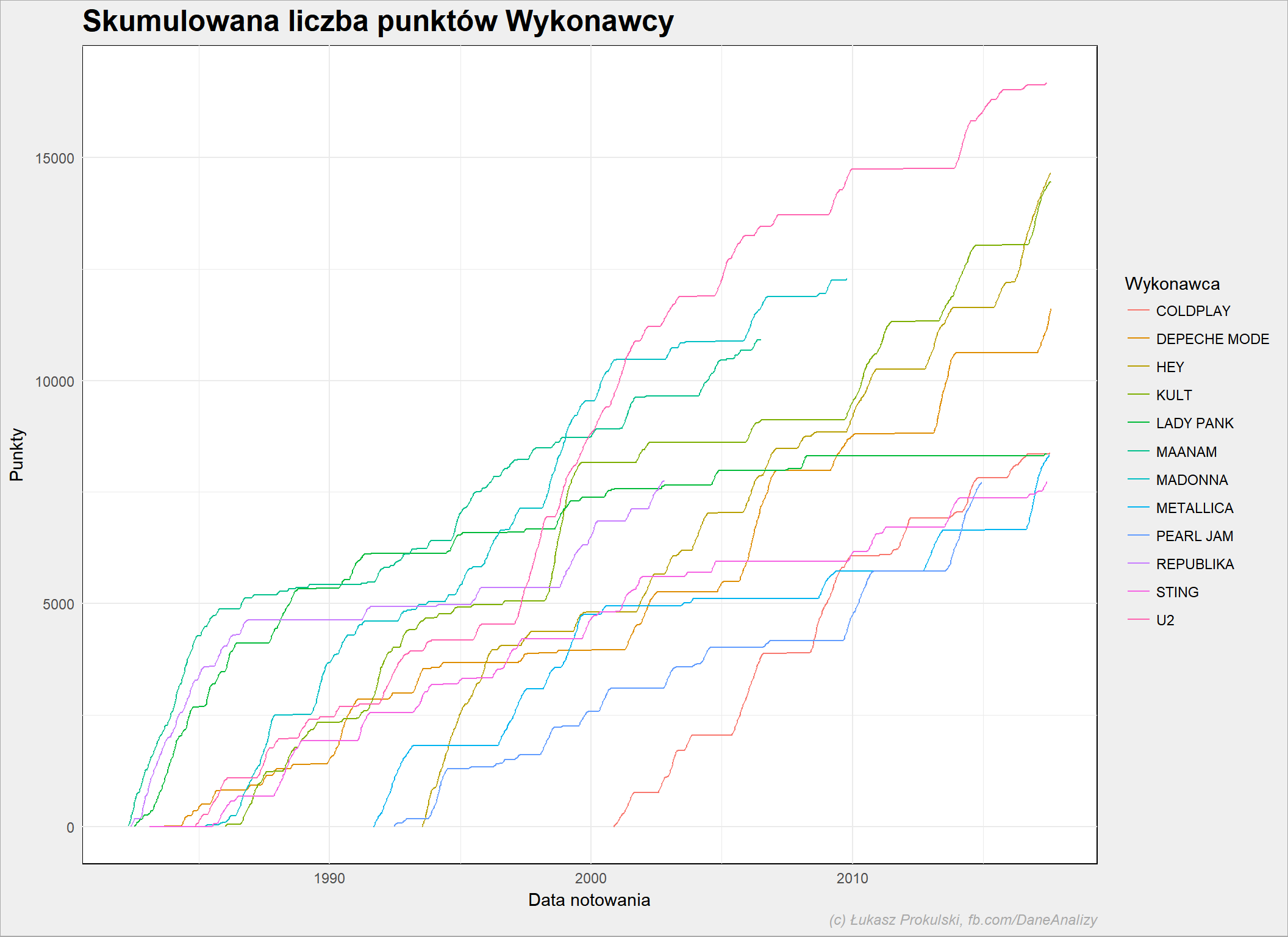
Najwyżej jak do tej pory jest U2. Hey i Kult w ostatnich kilku latach idą łeb w łeb mijając się na drugim i trzecim miejscu. Ale ten wykres jest nieco mylący: nie widać tempa zmian, bo poszczególne linie zaczynają się w różnych momentach. Zróbmy tak, żeby wszystkie linie zaczynały się w tym samym miejscu:
|
1 2 3 4 5 6 7 8 |
notowania_analiza %>% filter(Artist %in% top_artists) %>% group_by(Artist) %>% mutate(Punkty = cumsum(Punkty)) %>% mutate(NotowanieData_p = NotowanieData-min(NotowanieData)) %>% ungroup() %>% ggplot() + geom_line(aes(NotowanieData_p, Punkty, color=Artist)) |
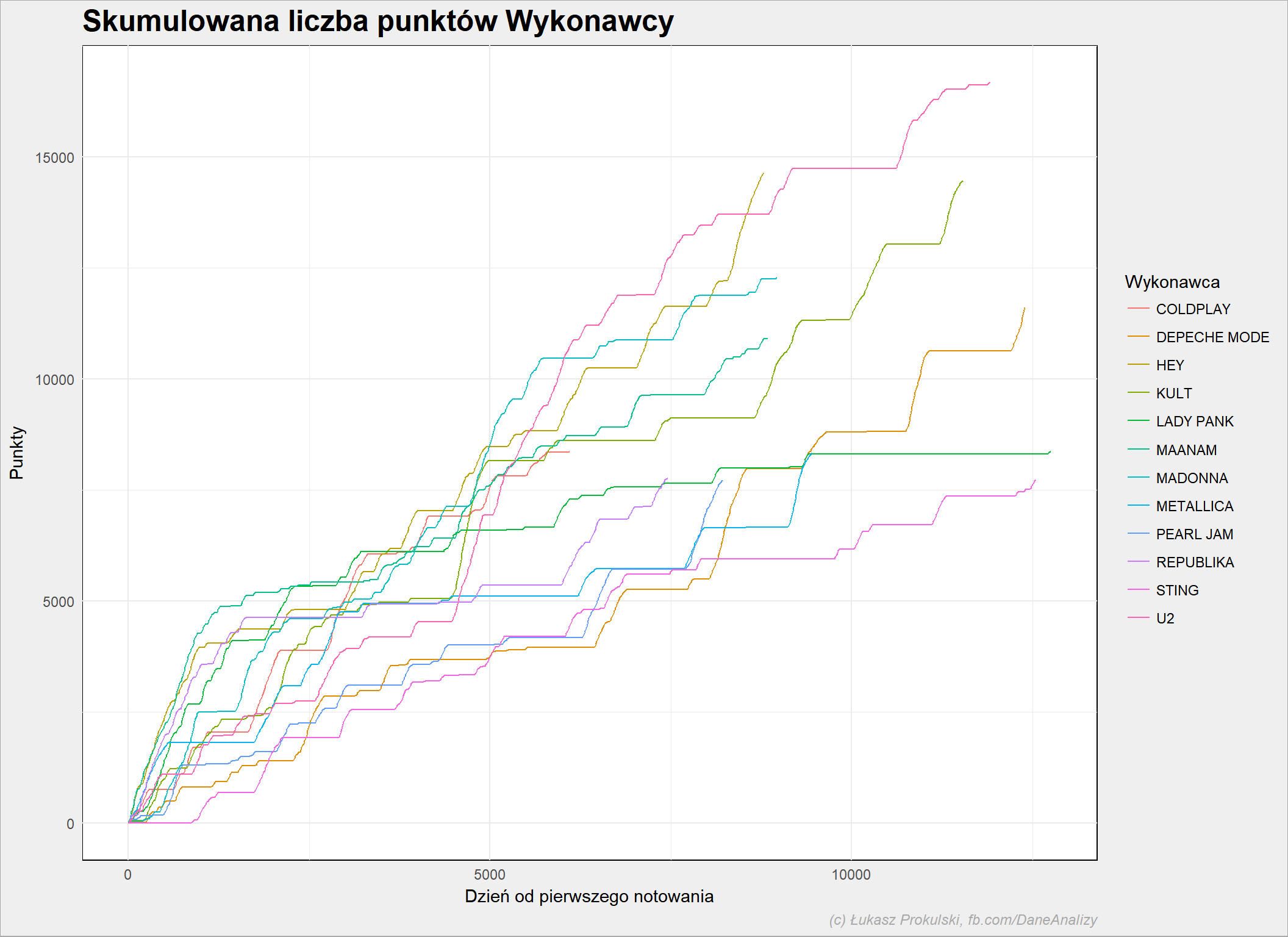
I tutaj widać ciekawostkę: Hey potrzebował mniej więcej rok mniej niż Kult aby dojść do tego samego poziomu. I jeśli Hey będzie podążał tą samą drogą to za rok, może dwa przebije U2 (o ile U2 nie zrobi kilku hiciorów, a nowa płyta ponoć 1 grudnia tego roku, pierwszy singiel już za kilkanaście dni).
Najlepsze lata wykonawców
Możemy zobaczyć jak wyglądała liczba punktów zdobytych przez artystów w poszczególnych latach – to daje obraz tego, kiedy artyści byli “na fali”.
|
1 2 3 4 5 6 7 8 9 |
notowania_analiza %>% filter(Artist %in% top_artists) %>% mutate(Rok = year(NotowanieData)) %>% group_by(Artist, Rok) %>% mutate(Punkty = sum(Punkty)) %>% ungroup() %>% ggplot() + geom_bar(aes(Rok, Punkty, fill=Artist), stat = "identity", show.legend = FALSE) + facet_wrap(~Artist) |
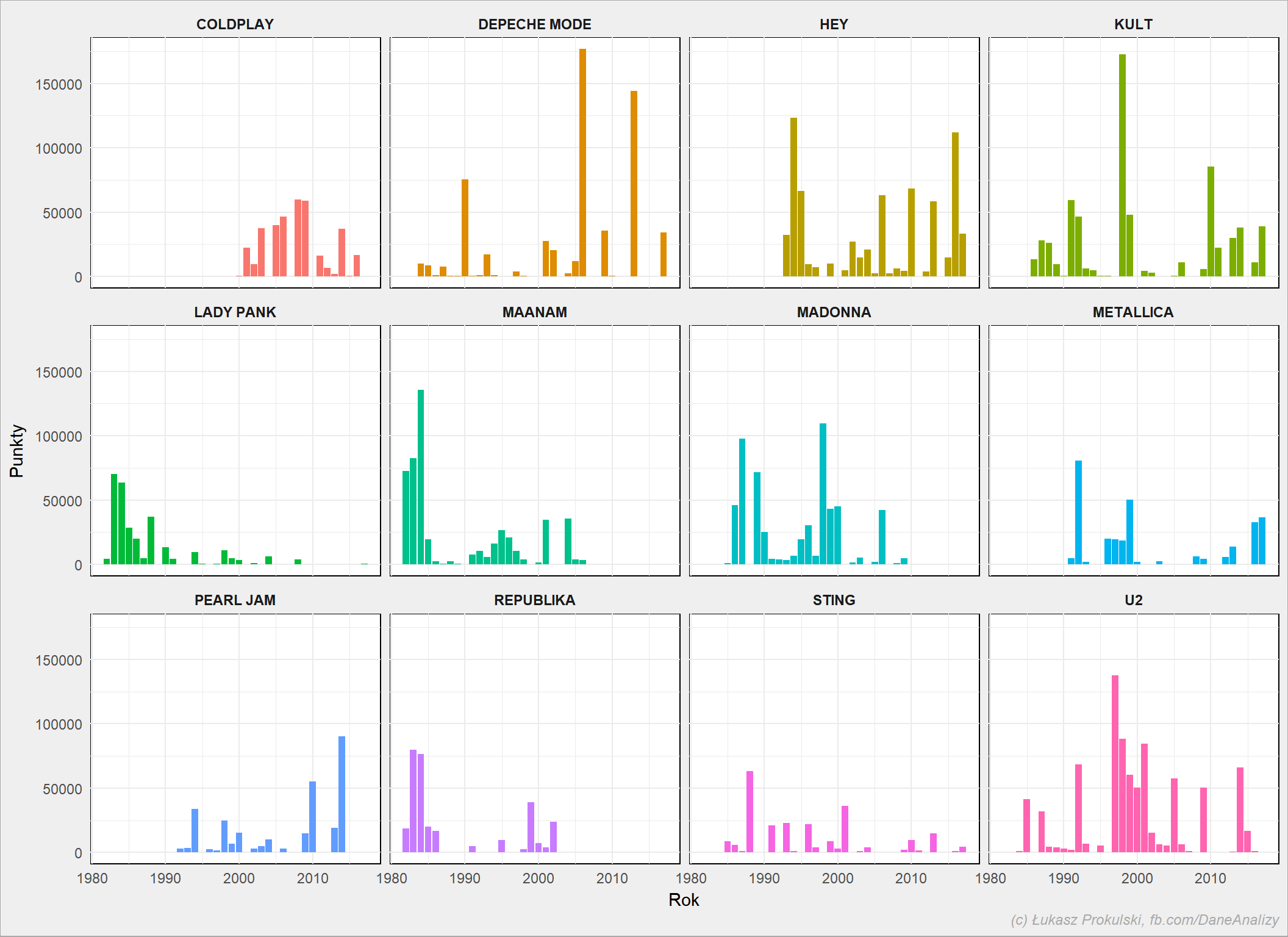
Hey świetnie zadebiutował i pociągnął passę pierwszymi płytami (było notowanie, gdzie “Dreams” i “Teksański” były w pierwszej trójce, później “Misie”, “Ja sowa” i “Ho”), teraz wracają (płytą, która do mnie nie dociera – chyba za mało słucham nowości, a ciągle wierzę w to, że najlepsze płyty najtrudniej wchodzą).
Maanam i Republika to najlepsze polskie kapele tal 80, bezapelacyjnie. Depeche Mode pozamiatało 2006 rok głównie singlem “Martyr” oraz “John the Revelator”. U2 to z kolei wielki sukces płyty “POP” (po “Achtung baby!” moja ulubiona, a słabo znana wśród znajomych) i singlem “Sweetest Thing”. Kult najwięcej zgarnął za piosenki z “Ostatecznego krachu systemu korporacji”.
Największe hity wykonawców
Zobaczmy jeszcze liczbę punktów zdobytych przez poszczególne piosenki wybranych artystów – która piosenka była największym hitem?
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
notowania_analiza %>% filter(Artist %in% top_artists) %>% group_by(Artist, Title) %>% summarise(Punkty = sum(Punkty)) %>% ungroup() %>% group_by(Artist) %>% mutate(PunktyProc = 100*Punkty/sum(Punkty)) %>% arrange(PunktyProc) %>% top_n(10, Punkty) %>% ungroup() %>% mutate(Title = factor(Title, levels = Title)) %>% ggplot() + geom_bar(aes(Title, PunktyProc, fill=Artist), color = "black", stat = "identity", show.legend = FALSE) + facet_wrap(~Artist, scales = "free_y", ncol = 1) + coord_flip() |
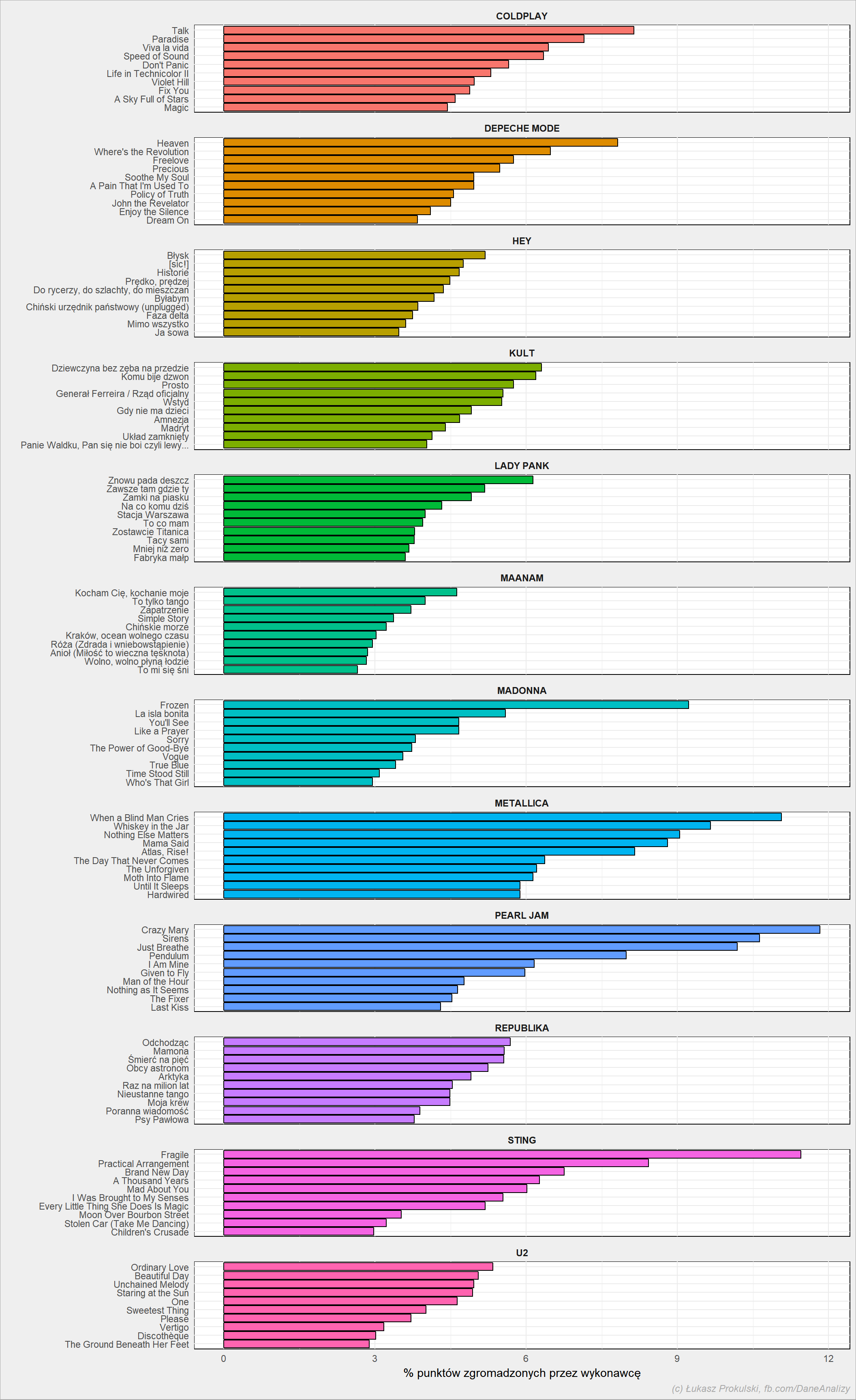
Hity
Czas na analizę hitów. Najpierw tych z pierwszego miejsca:
Najczęściej na 1 miejscu
To będzie fajne:
|
1 2 3 4 5 6 |
notowania_analiza %>% filter(PozAkt == 1) %>% count(Artist, Title) %>% ungroup() %>% top_n(20, n) %>% arrange(desc(n)) |
| Artist | Title | n |
|---|---|---|
| GOTYE FEAT. KIMBRA | Somebody That I Used to Know | 18 |
| LAO CHE | Wojenka | 14 |
| QUEEN | These Are the Days of Our Lives | 14 |
| BRYAN ADAMS | (Everything I Do) I Do It for You | 11 |
| MADONNA | Frozen | 11 |
| ARTUR ROJEK | Syreny | 10 |
| DIRE STRAITS | Brothers in Arms | 10 |
| ANITA LIPNICKA | I wszystko się może zdarzyć | 9 |
| DEPECHE MODE | Heaven | 9 |
| DEPECHE MODE | Where’s the Revolution | 9 |
| KULT | Gdy nie ma dzieci | 9 |
| LUXTORPEDA | Wilki dwa | 9 |
| MICHAEL JACKSON FEAT. SLASH | Give in to Me | 9 |
| PET SHOP BOYS | It’s a Sin | 9 |
| EDYTA BARTOSIEWICZ | Sen | 8 |
| EUROPE | The Final Countdown | 8 |
| GUNS N’ ROSES | Don’t Cry | 8 |
| JAROMÍR NOHAVICA | Minulost | 8 |
| METALLICA | Whiskey in the Jar | 8 |
| NO DOUBT | Don’t Speak | 8 |
Wygrywa Gotye. Jednorazowy hicior był najczęściej na pierwszym miejscu w całej historii Listy Trójki. Bijąc na głowę (4 notowania więcej na pierwszym miejscu) najlepszą piosenkę Listy (“These Are the Days of Our Lives”).
Ale czy pierwsze miejsce to jest jakiś wyznacznik? Wspominałem Makarenę. Może trzeba policzyć pierwszą trójkę?
Najczęściej w Top3
|
1 2 3 4 5 6 7 8 9 10 11 12 |
# najczęściej w top3: notowania_analiza %>% filter(PozAkt %in% c(1,2,3)) %>% count(Artist, Title, PozAkt) %>% ungroup() %>% group_by(Artist, Title) %>% mutate(nn = sum(n)) %>% ungroup() %>% spread(key=PozAkt, value=n) %>% top_n(20, nn) %>% arrange(desc(nn), desc(`1`), desc(`2`), desc(`3`)) %>% rename(`W top3`=nn) |
| Artist | Title | W top3 | 1 | 2 | 3 |
|---|---|---|---|---|---|
| QUEEN | These Are the Days of Our Lives | 27 | 14 | 9 | 4 |
| GOTYE FEAT. KIMBRA | Somebody That I Used to Know | 26 | 18 | 5 | 3 |
| GUNS N’ ROSES | Don’t Cry | 23 | 8 | 9 | 6 |
| ARTUR ROJEK | Syreny | 20 | 10 | 5 | 5 |
| DEPECHE MODE | Where’s the Revolution | 19 | 9 | 6 | 4 |
| ORGANEK | Mississippi w ogniu | 19 | 6 | 9 | 4 |
| LAO CHE | Wojenka | 18 | 14 | 3 | 1 |
| U2 | Ordinary Love | 18 | 4 | 10 | 4 |
| DEPECHE MODE | Heaven | 17 | 9 | 4 | 4 |
| LUXTORPEDA | Wilki dwa | 17 | 9 | 3 | 5 |
| METALLICA | Whiskey in the Jar | 17 | 8 | 7 | 2 |
| KULT | Dziewczyna bez zęba na przedzie | 17 | 5 | 5 | 7 |
| MICHAEL JACKSON FEAT. SLASH | Give in to Me | 16 | 9 | 2 | 5 |
| FISZ EMADE TWORZYWO FEAT. JUSTYNA ŚWIĘS | Ślady | 16 | 7 | 7 | 2 |
| KAZIK | 12 groszy | 16 | 6 | 7 | 3 |
| BRYAN ADAMS | (Everything I Do) I Do It for You | 15 | 11 | 3 | 1 |
| MADONNA | Frozen | 15 | 11 | 3 | 1 |
| DIRE STRAITS | Brothers in Arms | 15 | 10 | 3 | 2 |
| EUROPE | The Final Countdown | 15 | 8 | 5 | 2 |
| ARTUR ROJEK | Beksa | 15 | 7 | 6 | 2 |
| BON JOVI | Born to Be My Baby | 15 | 6 | 5 | 4 |
| KULT | Prosto | 15 | 6 | 3 | 6 |
| MYSLOVITZ | Długość dźwięku samotności | 15 | 6 | 2 | 7 |
| VOO VOO | Gdybym | 15 | 5 | 4 | 6 |
| BRODKA | Varsovie | 15 | 2 | 9 | 4 |
Tutaj sytuacja jest już bardziej wyprostowana. Zaskakują wysokie pozycje dwóch nowych piosenek Depeche Mode oraz Rojek, Lao Che i Organek. “Brothers in Arms”, która jest zazwyczaj w top 3 każdego “Topu wszech czasów” w pierwszej trójce kolejnych notowań była tylko 15 razy.
Czy są jakieś jednorazowe hity? Czyli takie piosenki, które wpadły na szczyt, ale tylko raz (na szczycie właśnie) były w pierwszej piątce?
|
1 2 3 4 5 6 7 8 9 |
notowania_analiza %>% filter(PozAkt <= 5) %>% # były w top5 count(Artist, Title, PozAkt) %>% # ile razy? ungroup() %>% group_by(Artist, Title) %>% mutate(wtop = sum(n)) %>% ungroup() %>% filter(wtop == 1, PozAkt==1) %>% # były tylko raz w top5 i to na 1 miejscu select(-PozAkt, -n, -wtop) |
| Artist | Title |
|---|---|
| CHŁOPCY Z PLACU BRONI | Kocham Cię ’93 |
| LECH JANERKA | Ramydada |
Kto był
Najdłużej na liście
Przy okazji: poniższy kod nadaje się doskonale do rysowania wykresów Gantta.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
notowania_analiza %>% group_by(Artist, Title) %>% mutate(min_Data = min(NotowanieData), max_Data = max(NotowanieData), n_notowan = n()) %>% ungroup() %>% select(Artist, Title, min_Data, max_Data, n_notowan) %>% distinct() %>% mutate(dni = as.numeric(max_Data-min_Data)) %>% top_n(20, dni) %>% arrange(dni) %>% mutate(Song = paste(Artist, Title, sep = " - ")) %>% mutate(Song = factor(Song, levels=Song)) %>% ggplot() + geom_segment(aes(x=min_Data, y=Song, xend=max_Data, yend=Song, color = Song), size = 3, show.legend = FALSE) + geom_text(aes(x=max_Data, y=Song, label=sprintf("%d dni (%d)", dni, n_notowan)), hjust = -0.1, vjust = 0.2, show.legend = FALSE) + expand_limits(x = c(make_date(1982, 1, 1), make_date(2020, 1, 1))) |
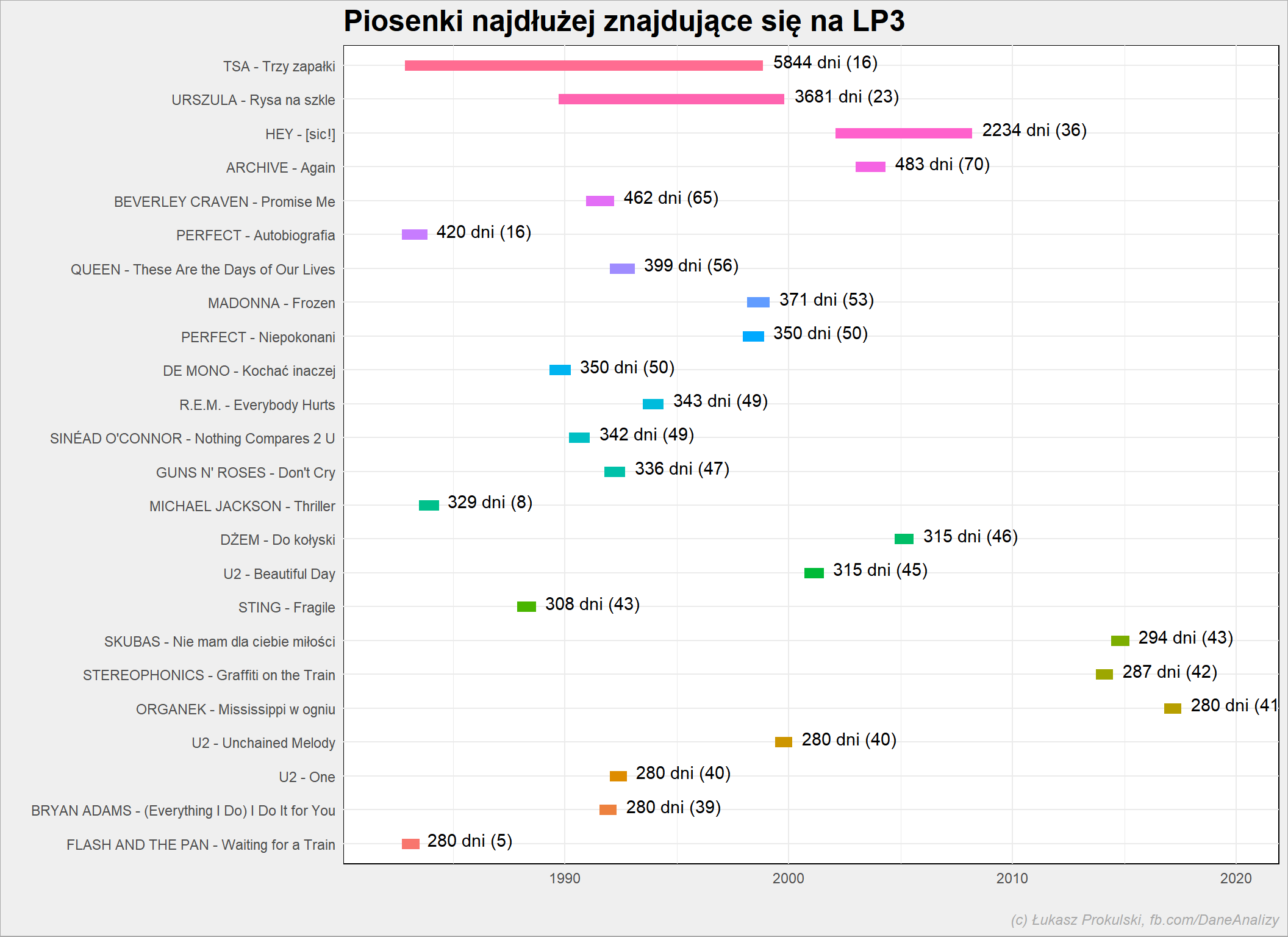
W nawiasie liczba notowań, w których dany utwór wystąpił.
Odrzućmy pierwsze trzy (były na liście przez kilka tygodni, wypadały i wracały na listę po kilku latach – stąd takie wyniki) i przyjrzyjmy się kolejnym pozycjom dla czwartej piosenki:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
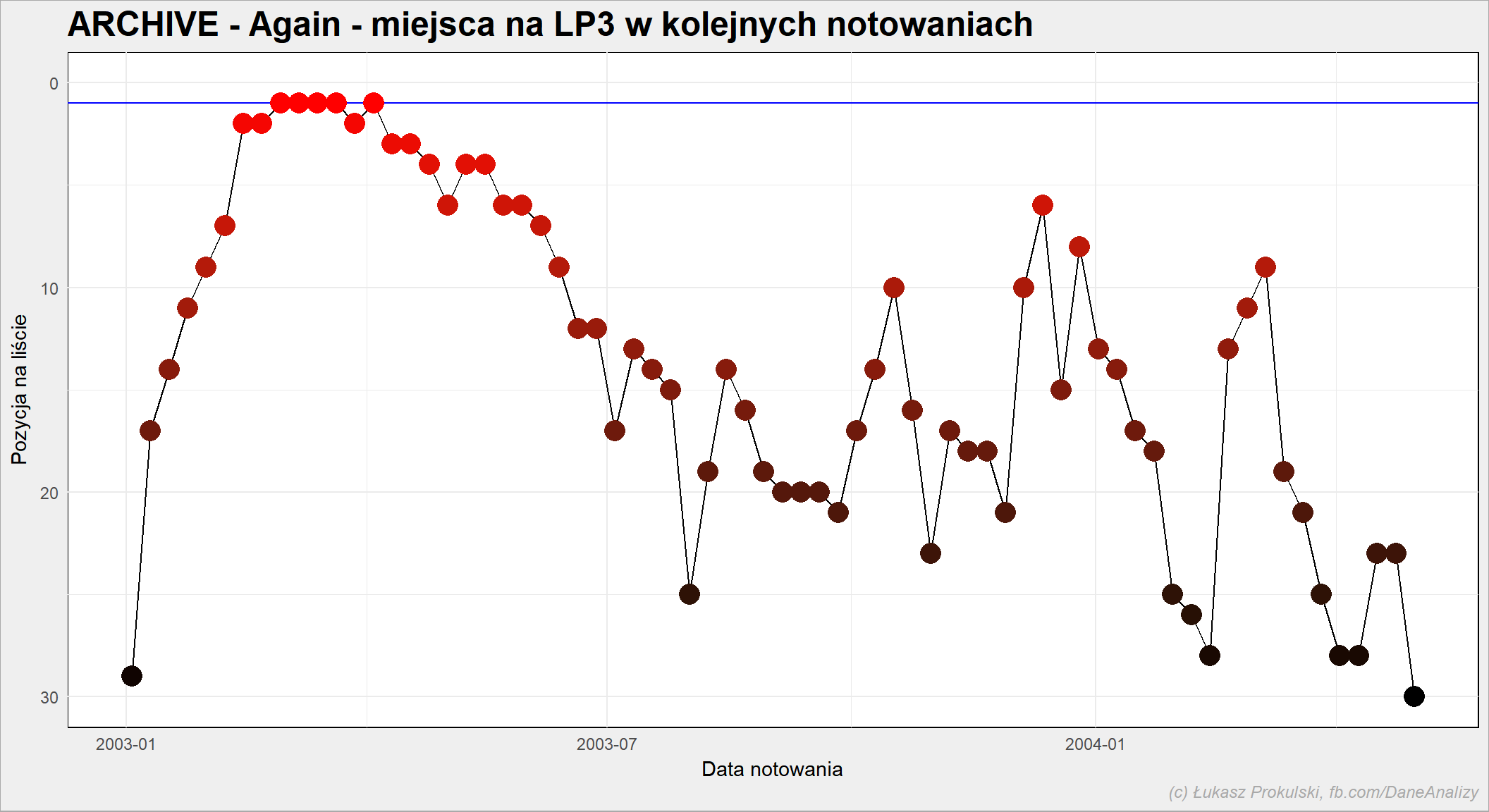
artysta <- "ARCHIVE" piosenka <- "Again" notowania_analiza %>% filter(Artist==artysta, Title==piosenka) %>% ggplot() + geom_hline(yintercept = 1, color = "blue") + geom_line(aes(NotowanieData, PozAkt)) + geom_point(aes(NotowanieData, PozAkt, col=PozAkt), size=5) + scale_color_gradient(low="red", high="black") + ylim(30,0) + theme(legend.position = "none") |
To samo dla Gotye:
Spróbujmy czegoś więcej: przygotujmy jakieś wskaźniki. Na przykład jak wygląda (i czy jest) wpływ liczby piosenek na liście z osiągniętą średnią liczbą punktów.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
# liczba piosenek artysty n_songs <- notowania_analiza %>% select(Artist, Title) %>% distinct() %>% count(Artist, sort = TRUE) %>% ungroup() # średnia liczba punktów artysty m_punkty <- notowania_analiza %>% group_by(Artist) %>% summarise(m_Punkty = mean(Punkty)) %>% ungroup() # średnia punktów vs liczba piosenek na liście - per artysta left_join(n_songs, m_punkty, by = "Artist") %>% top_n(20, n) %>% ggplot() + geom_hline(aes(yintercept = mean(m_Punkty)), color = "red") + geom_vline(aes(xintercept = mean(n)), color = "red") + geom_text_repel(aes(n, m_Punkty, label = Artist, color=Artist), show.legend = FALSE) + geom_point(aes(n, m_Punkty, color=Artist), show.legend = FALSE) |
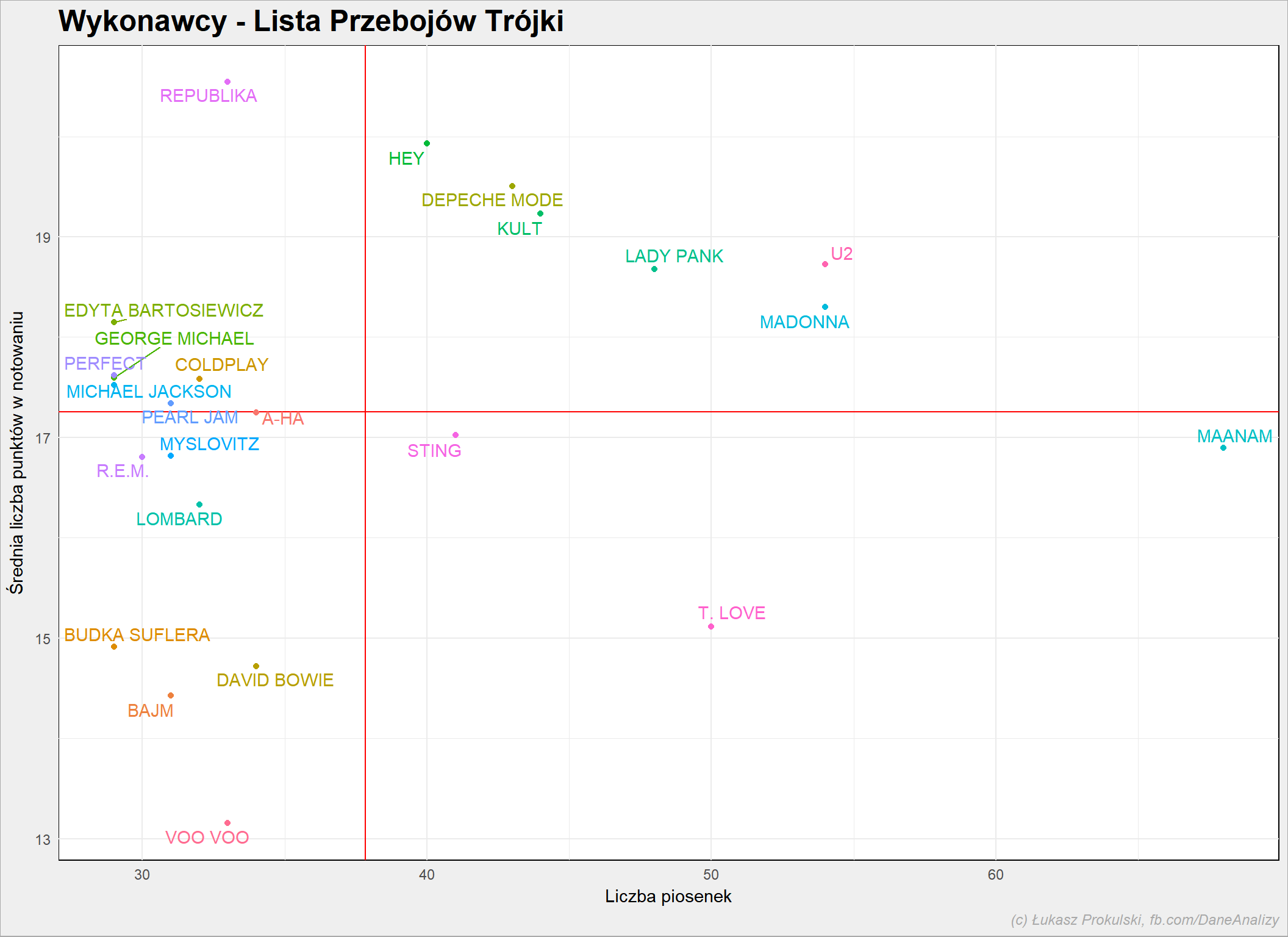
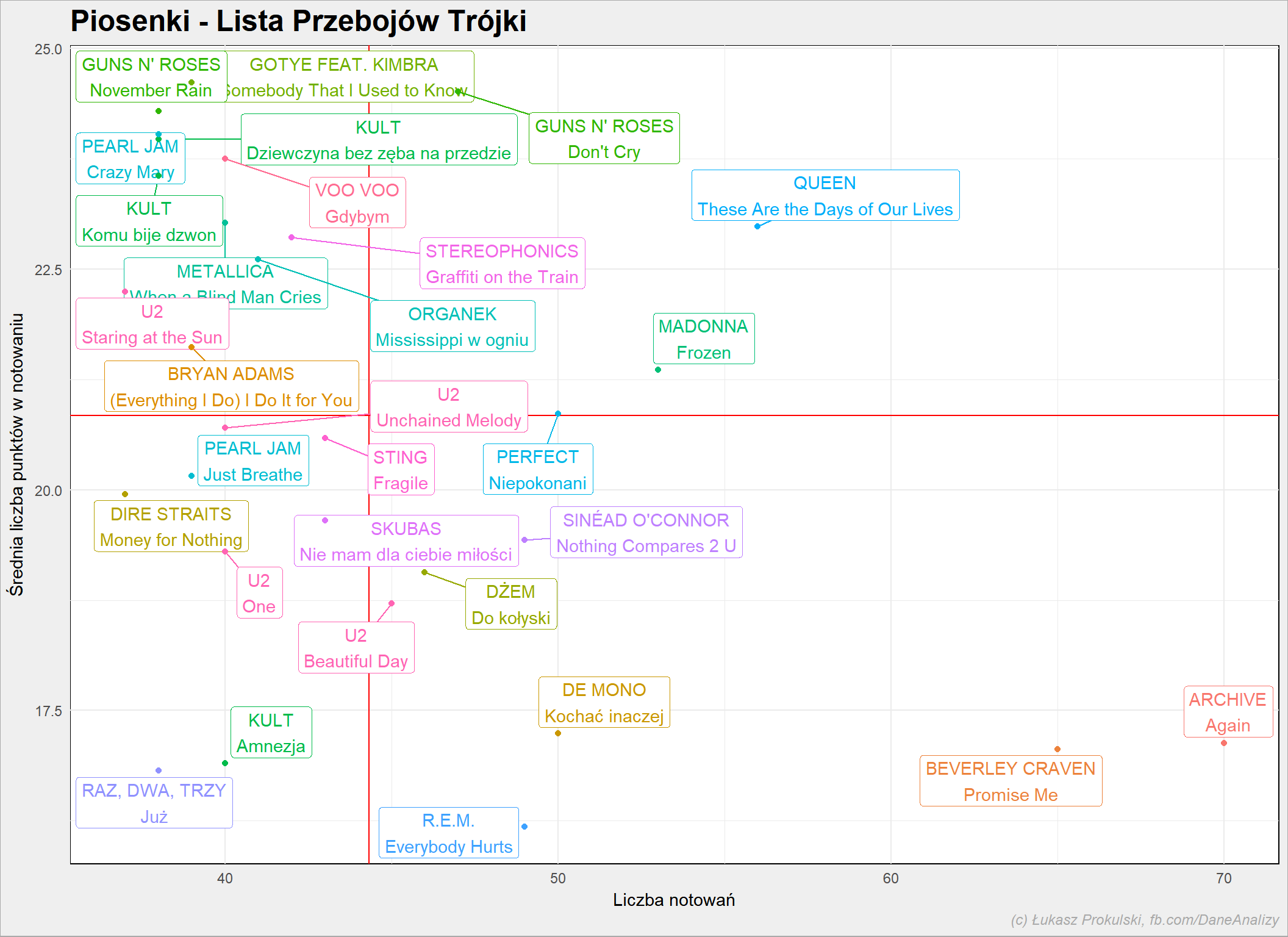
Górna lewa ćwiartka to w pewnym sensie fenomenalni artyści: prawie każda ich piosenka okazywała się hitem (było ich mniej, ale były wyżej). Górna prawa część to wyjadacze, sprawdzone maszyny – dużo numerów, dobrze odbieranych przez słuchaczy.
Sprawdźmy coś podobnego dla konkretnych utworów:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
# ile raz piosenka była na liście n_times_song <- notowania_analiza %>% count(Artist, Title) %>% ungroup() # średnia liczba punktów piosenki m_punkty_song <- notowania_analiza %>% group_by(Artist, Title) %>% summarise(m_Punkty = mean(Punkty)) %>% ungroup() # średnia ocena vs liczba notowań na liście - per piosenka left_join(n_times_song, m_punkty_song, by = c("Artist"="Artist", "Title"="Title")) %>% top_n(30, n) %>% ggplot() + geom_hline(aes(yintercept = mean(m_Punkty)), color = "red") + geom_vline(aes(xintercept = mean(n)), color = "red") + geom_label_repel(aes(n, m_Punkty, label = sprintf("%s\n%s", Artist, Title), color=Artist), show.legend = FALSE) + geom_point(aes(n, m_Punkty, color=Artist), show.legend = FALSE) |
Liczba notowań a liczba na pierwszym miejscu
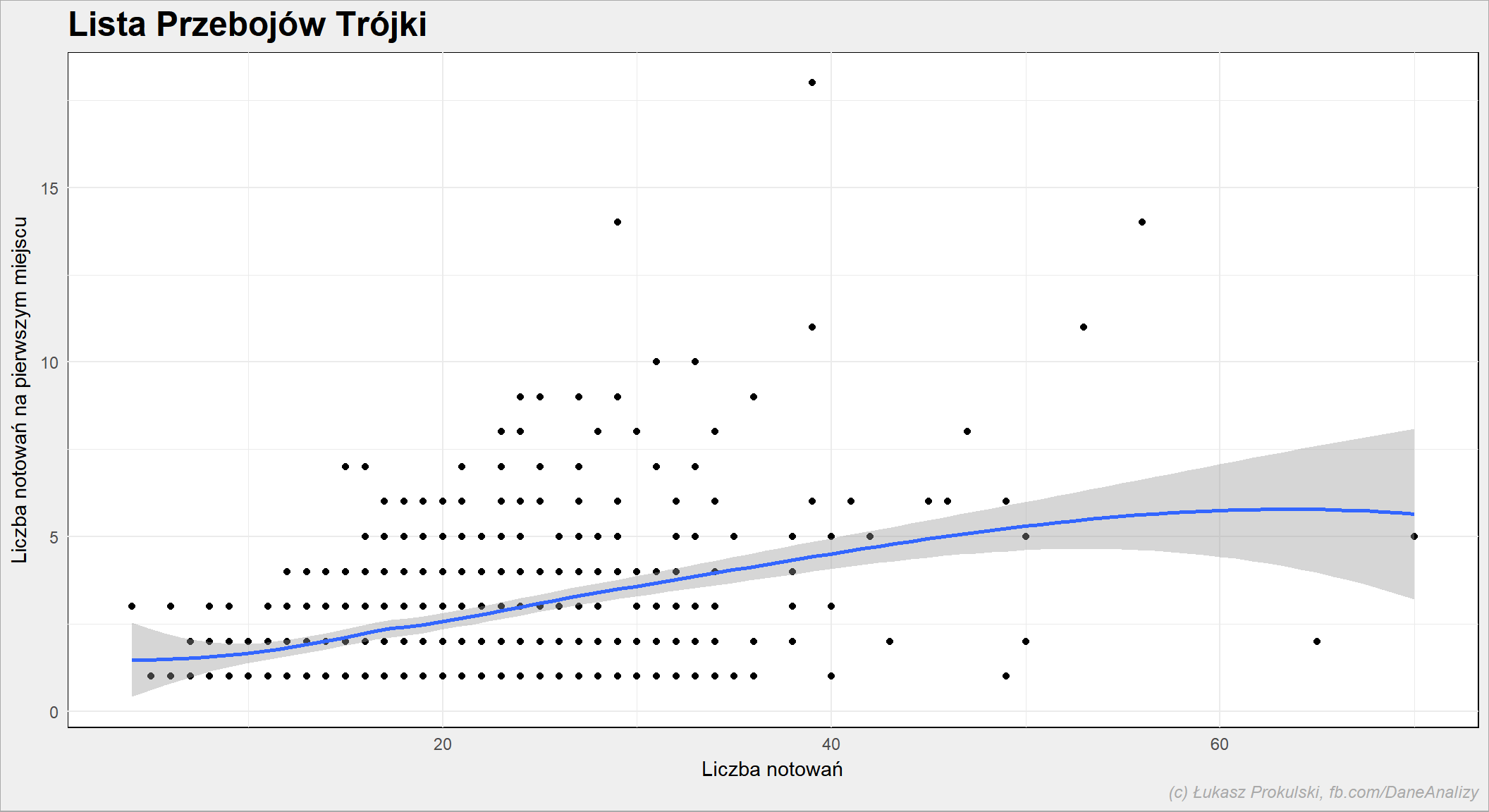
Czy im dłużej piosenka jest na liście tym większe ma szanse na pierwsze miejsce?
|
1 2 3 4 5 6 7 8 9 |
n_first <- notowania_analiza %>% filter(PozAkt == 1) %>% count(Artist, Title) %>% ungroup() left_join(n_times_song, n_first %>% rename(n_first=n), by = c("Artist"="Artist", "Title"="Title")) %>% filter(n_first >= 1) %>% ggplot() + geom_point(aes(n, n_first )) + geom_smooth(aes(n, n_first), show.legend = FALSE) |
Dla tych co były najczęściej na pierwszym miejscu:
|
1 2 3 4 5 6 7 8 9 10 11 |
left_join(n_times_song, n_first %>% rename(n_first=n), by = c("Artist"="Artist", "Title"="Title")) %>% top_n(10, n_first) %>% ggplot() + geom_label_repel(aes(n, n_first, label = sprintf("%s\n%s", Artist, Title), color = Title), max.iter = 50000, show.legend = FALSE) + geom_point(aes(n, n_first, color = Title), size=4, show.legend = FALSE) + expand_limits(y = c(0, 20)) |
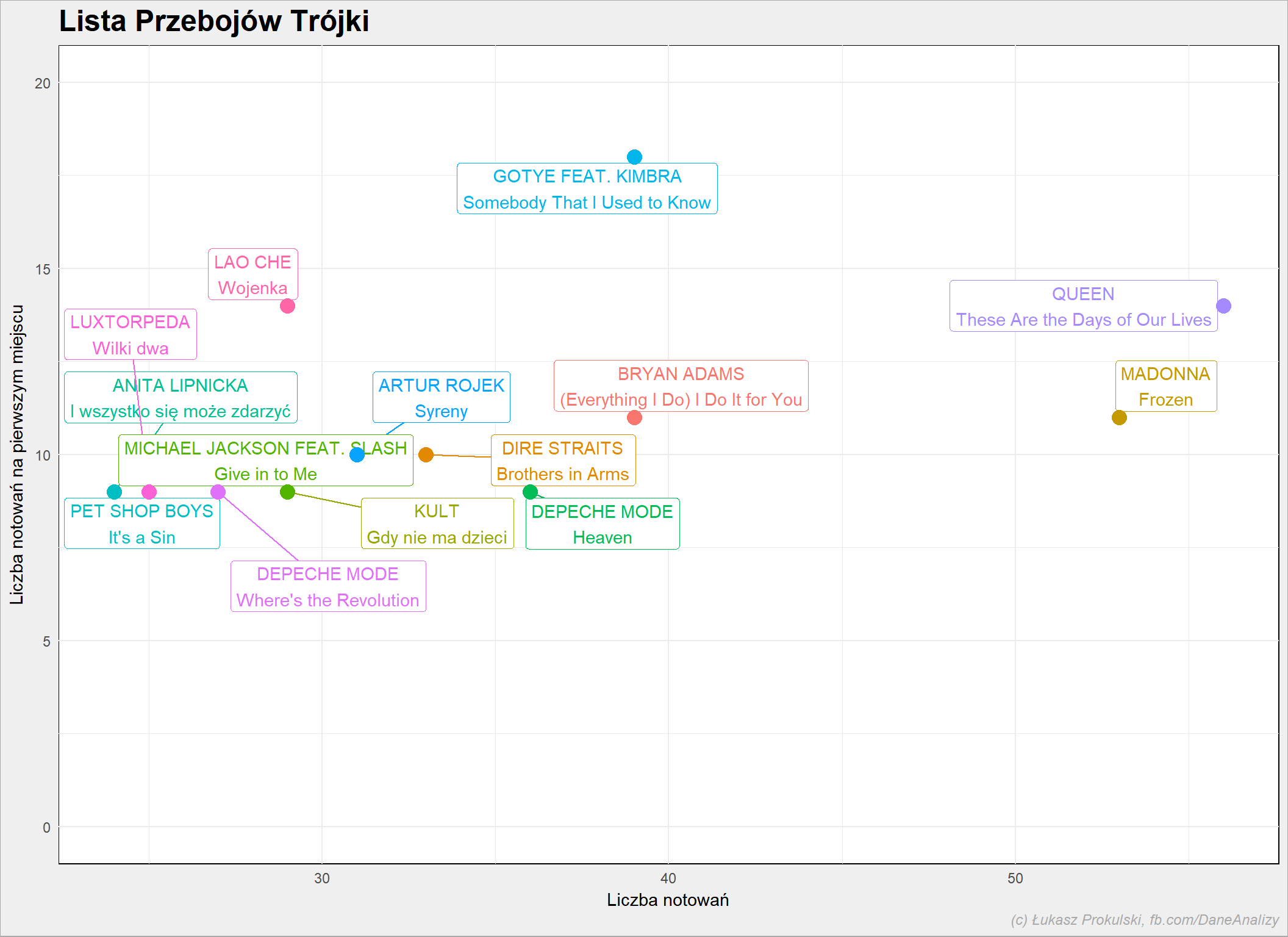
Nie powiedziałbym, że istnieje taka zależność. Można być na Liście długo i nie trafić na pierwsze miejsce.
Te same dane można przedstawić niego inaczej, czyli
Jaki procent notowań dana piosenka była na pierwszym miejscu?
|
1 2 3 4 5 6 7 8 9 10 11 12 |
left_join(n_times_song, n_first %>% rename(n_first=n), by = c("Artist"="Artist", "Title"="Title")) %>% top_n(20, n_first) %>% mutate(p = 100*n_first/n) %>% arrange(p) %>% mutate(Song = sprintf("%s - %s", Artist, Title)) %>% mutate(Song = factor(Song, levels = Song)) %>% ggplot() + geom_bar(aes(Song, p), stat="identity", fill = "lightgreen", color = "black") + geom_hline(yintercept = c(0, 25, 50), color = "red") + coord_flip() |
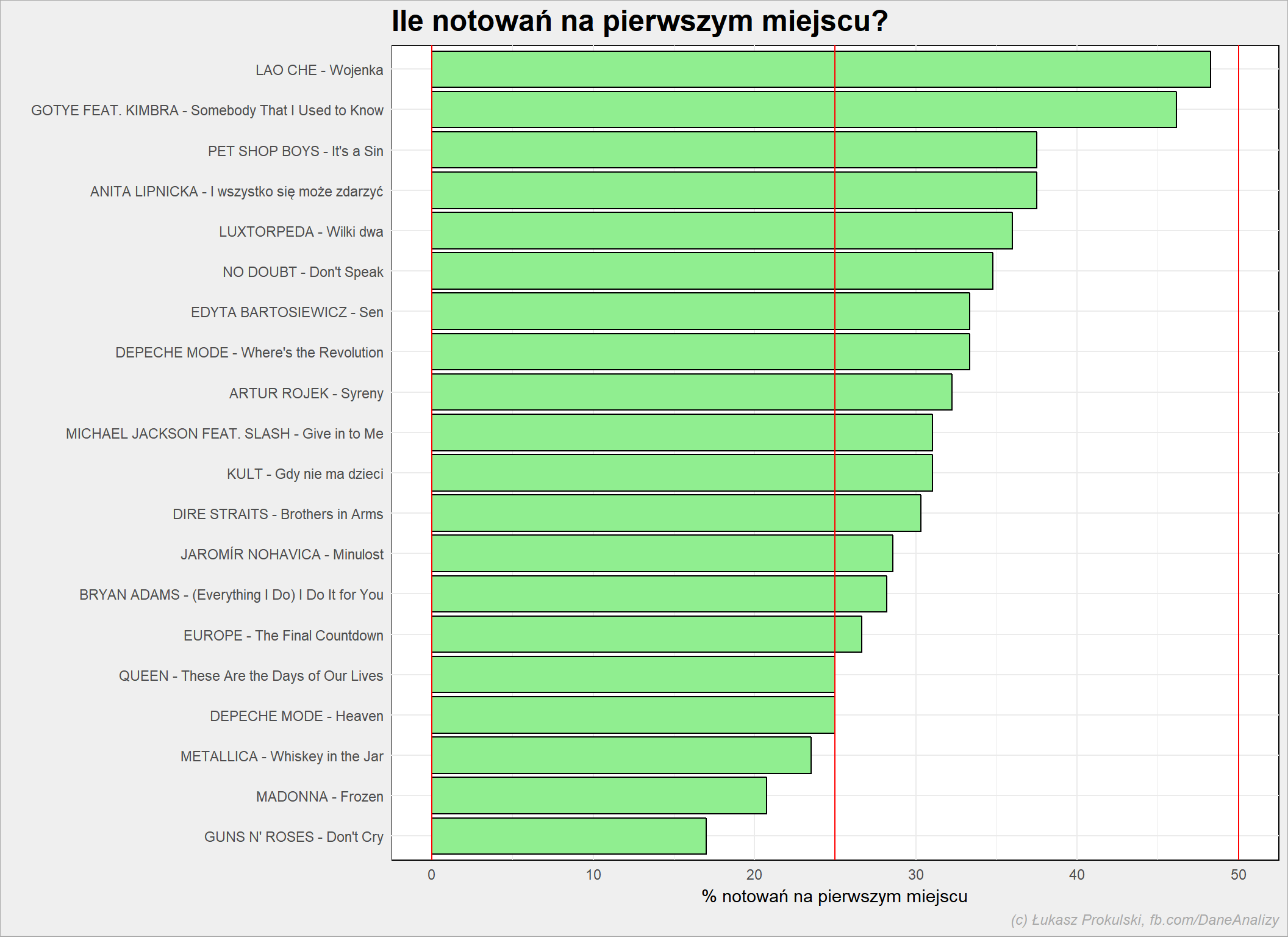
Tutaj Lao Che (ze świetną piosenką) pobiło Gotye. Najlepszy utwór (piosenka Queenu) tylko przez 1/4 notowań była na pierwszym miejscu – sprawdza się więc teza, że punkty mają sens.
Jak długo piosenki są na liście?
|
1 2 |
ggplot(n_times_song) + geom_histogram(aes(n), binwidth = 1, fill="lightgreen", color = "black") |
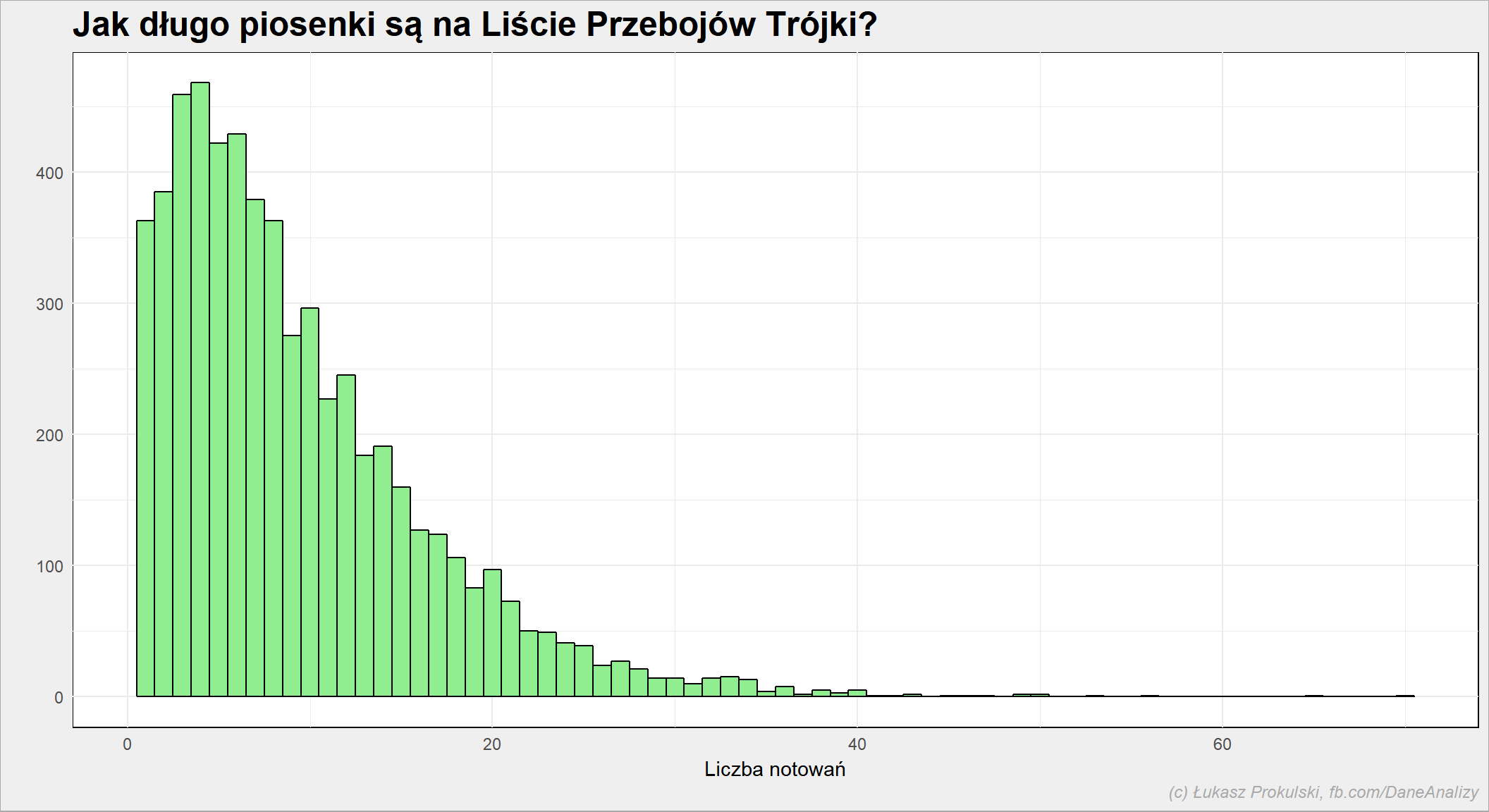
Średnio piosenka jest na liście przez 9.3 notowań, przy medianie 8. Najdłużej (w sensie liczby notowań) było ARCHIVE z “Again” (70 razy).
Ile czasu zajmuje dotarcie do pierwszego miejsca?
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
to_the_top <- notowania_analiza %>% select(Artist, Title, PozAkt, NotowanieData) %>% group_by(Artist, Title) %>% arrange(NotowanieData) %>% mutate(NotowanieN = row_number()) %>% ungroup() %>% select(-NotowanieData) %>% filter(PozAkt == 1) %>% group_by(Artist, Title) %>% filter(NotowanieN == min(NotowanieN)) %>% ungroup() to_the_top %>% ggplot() + geom_histogram(aes(NotowanieN), binwidth = 1, fill="lightgreen", color = "black") |
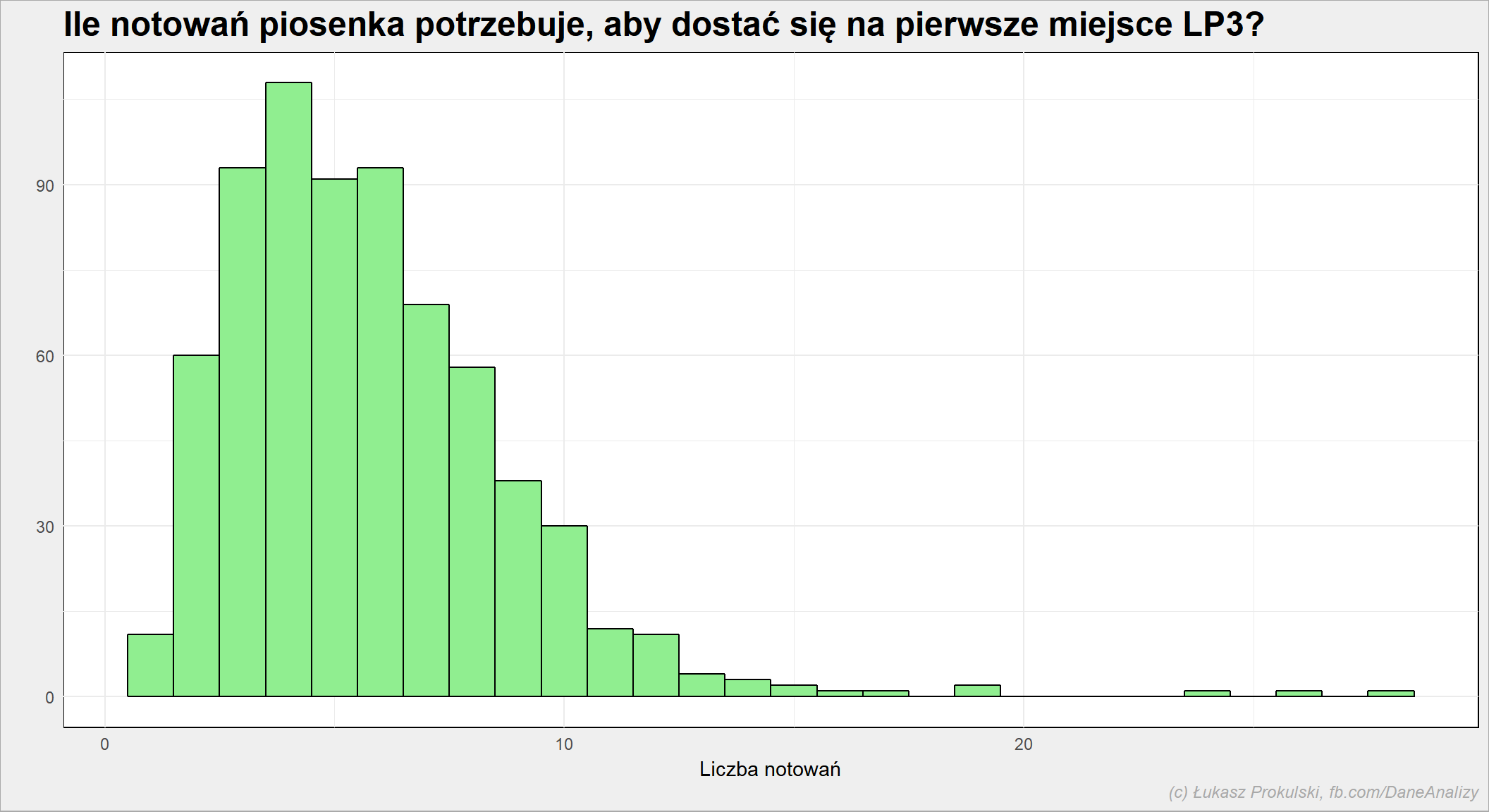
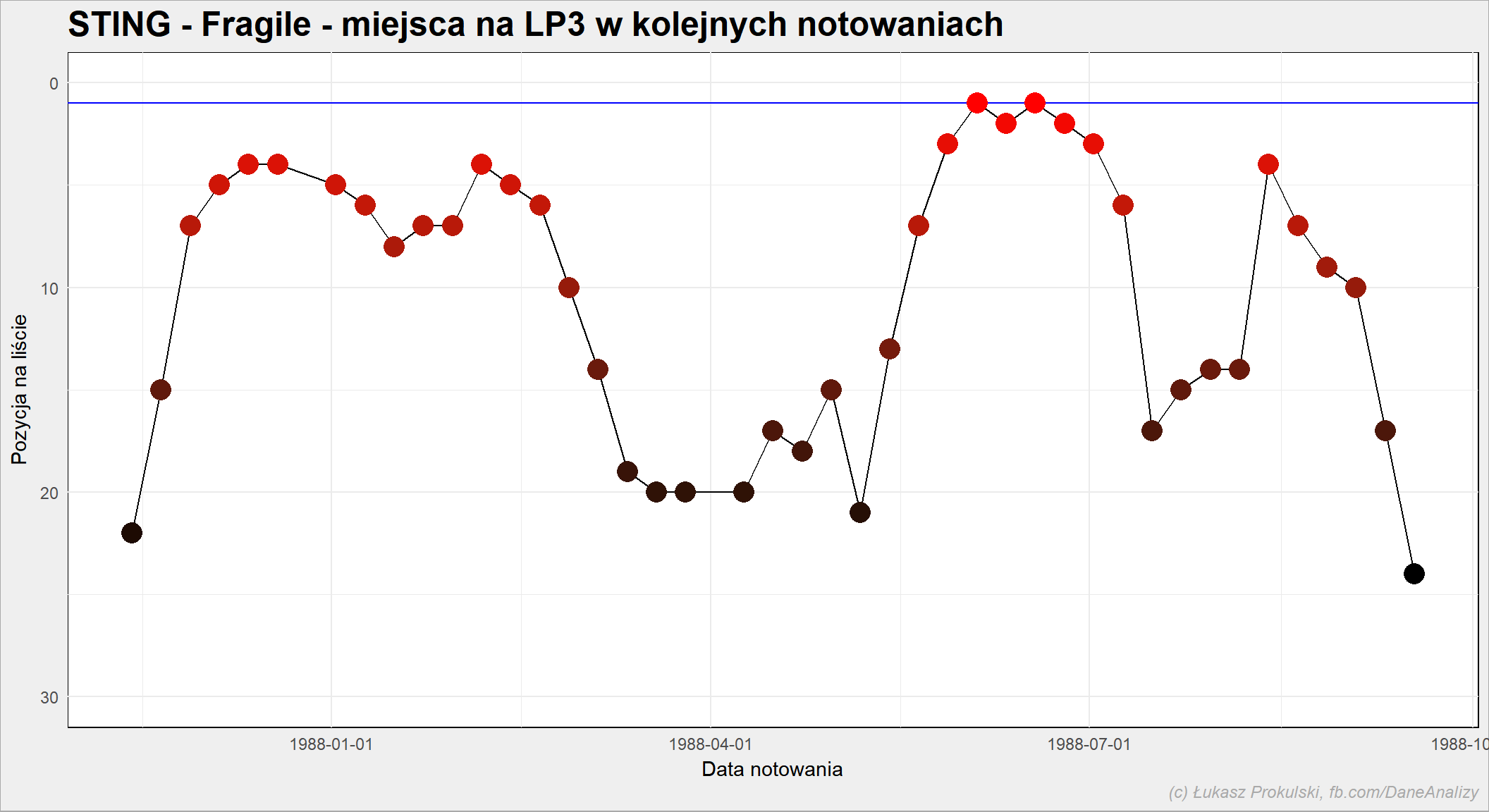
Średnio piosenka dociera do pierwszego miejsca po 5.8 notowaniach przy medianie 5. 3/4 piosenek robi to w 7 notowań, zaś najdłużej zajęło to (28 notowań) STING – Fragile.
Zobaczmy historię tego Stinga:
Na pierwszym miejscu debiutowały:
|
1 2 3 |
to_the_top %>% filter(NotowanieN == min(NotowanieN)) %>% select(Artist, Title) |
| Artist | Title |
|---|---|
| JON & VANGELIS | I’ll Find My Way Home |
| REPUBLIKA | Tak długo czekam (Ciało) |
| EDYTA GÓRNIAK | To nie ja |
| PRZYJACIELE KARPIA IV | Karp IV — Restauracja |
| ARTUR ANDRUS | Ballada o Baronie, Niedźwiedziu i Czarnej Helenie |
| ADELE | Skyfall |
| KULT | Prosto |
| ARTUR ROJEK | Beksa |
| ARTUR ROJEK | Syreny |
| LAO CHE | Wojenka |
| ADELE | Hello |
Przy czym zaznaczyć trzeba, że Jon & Vangelis to pierwsze miejsce z pierwszego notowania.
Tagi
Możemy zabawić się w złączenie danych z innym źródłem. Na przykład z informacjami o piosenkach z LastFM.
Dodanie tagów z LastFM
O LastFM pisałem kilka miesięcy temu, poszukajcie stosownych wpisów. Dla każdej z piosenek pobierzemy tagi jakimi została opisana w serwisie LastFM.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
library(RLastFM) lastkey <- "xxxx" # potrzebujesz własnego klucza # unikalna lista piosenek - tego szukamy w LastFM piosenki <- notowania_analiza %>% select(Artist, Title) %>% distinct() # miejsce na tag piosenki$Tag <- NA # dla wszystkich utowrów - przypisz znaleziony tag (tylko pierwszy z listy wszystkich) len <- nrow(piosenki) for(i in 1:len) { cat(paste0("\r", i, "/", len)) # nie wszystkie piosenki są w bazie LastFM - stąd z obsługą błędów (niedoskonałą) # lepiej użyć purrr::safely() tag <- withCallingHandlers( tryCatch( track.getTopTags(track = piosenki[i, "Title"], artist = piosenki[i, "Artist"])$tag, error=function(e) e) ) if(length(tag) != 0) { piosenki[i, "Tag"] <- tag[1] } else { piosenki[i, "Tag"] <- "notag" } } piosenki$Tag <- tolower(piosenki$Tag) notowania_analiza <- left_join(notowania_analiza, piosenki, by = c("Artist"="Artist", "Title"="Title")) |
Mając otagowane kolejne piosenki możemy zobaczyć jaki był
najpopularniejszy tag
|
1 2 3 4 5 6 7 8 9 10 |
notowania_analiza %>% group_by(Tag) %>% summarise(Punkty=sum(Punkty)) %>% ungroup() %>% arrange(desc(Punkty), Tag) %>% top_n(30, Punkty) %>% mutate(Tag=factor(Tag, levels = Tag)) %>% ggplot() + geom_bar(aes(Tag, Punkty), stat="identity", fill = "lightgreen", color = "black") + theme(axis.text.x = element_text(angle=90, hjust=1)) |
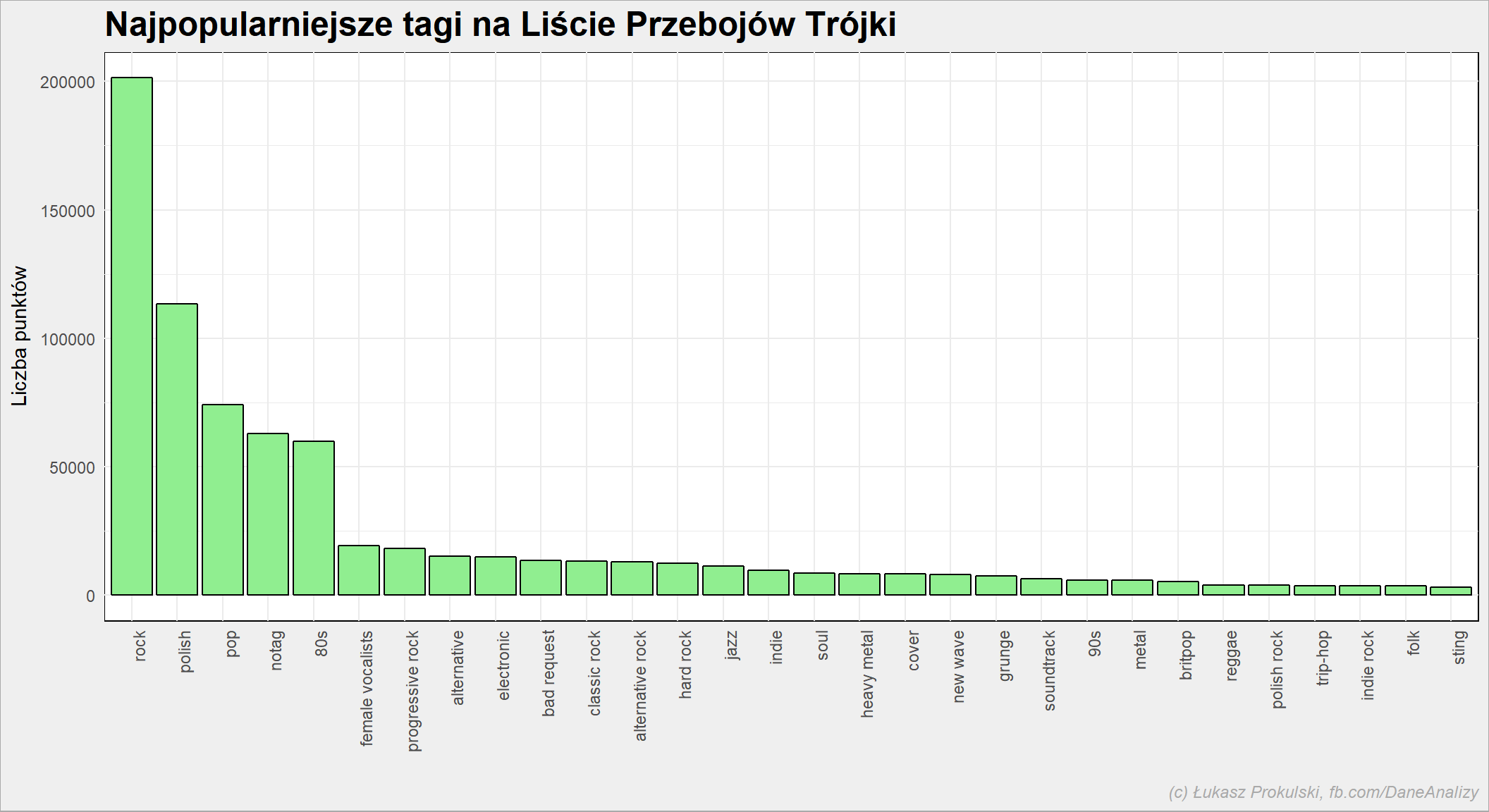
oraz
najpopularniejszy tag w poszczególnych latach
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
notowania_analiza %>% mutate(Rok=year(NotowanieData)) %>% group_by(Rok, Tag) %>% summarise(Punkty=sum(Punkty)) %>% ungroup() %>% group_by(Rok) %>% arrange(desc(Punkty)) %>% mutate(PozRok = row_number()) %>% ungroup() %>% arrange(Rok, PozRok, desc(Punkty), Tag) %>% filter(PozRok==1) %>% ggplot() + geom_bar(aes(Rok, Punkty, fill=Tag), stat="identity", show.legend = FALSE) + geom_text(aes(Rok, Punkty, label=Tag), angle=90, hjust=-0.1) + expand_limits(y = c(0, 11000)) |
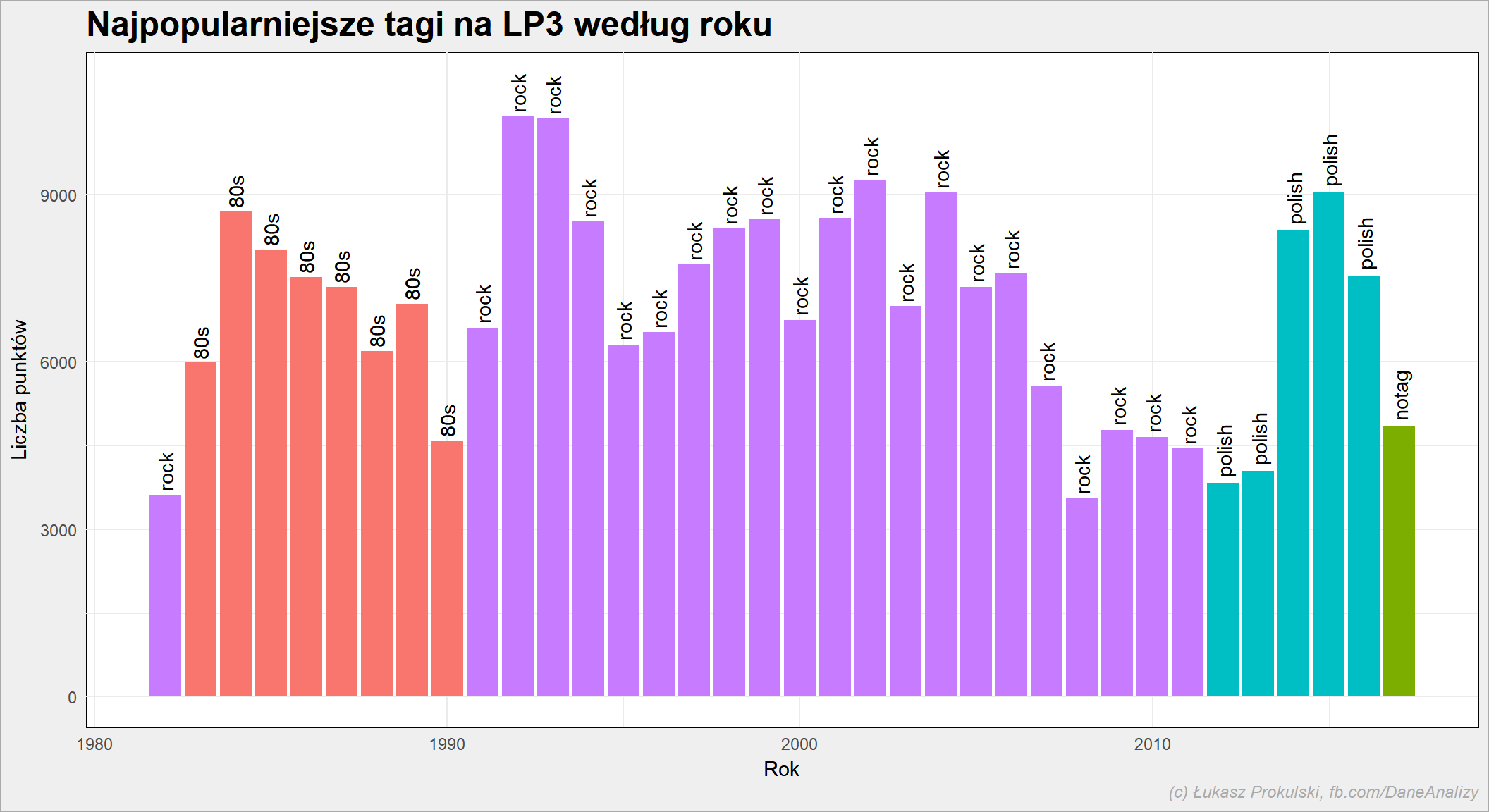
To “80s” to trochę nieszczęśliwy tag (może należało brać drugi tag w kolejności, a nie tylko pierwszy?). Warto też skorzystać z innego źródła, na przykład ze Spotify. Sporify da nam też informacje o kilku parametrach piosenek, co również może być ciekawe (czy tempo, energia i inne numeryczne wartości mają wpływ na wynik na liście? Czy jest jakaś zależność?). Ale to pozostawiam już Wam. Warto zerknąć na jeden z wcześniejszych wpisów.
Dla zainteresowanych: kod źródłowy w R na GitHubie, razem z danymi.
Przyjżyjmy -> przyjrzyjmy (to samo dla pozostałych wystąpień, zauważyłem 2).
Poprawione. Pisanie nocą bez słownika nie pomaga :/
Wow, zawsze chciałem to zrobić :)