Wiele razy czytałem opinie, że Python jest szybszy a R nie nadaje się na produkcję. Ale to opinie nie potwierdzone badaniami. Tutaj pierwsze badania na ten temat!
Testom podlegać będzie API zbudowane w R z użyciem frameworków Plumber i RestRserve oraz w Pythonie z użyciem Flask.
Biorąc pod uwagę analizę danych i na przykład wnioskowanie czy predykcje oparte o te dane zarówno R jak i Python dobrze się sprawdzają. Mam nadzieję, że niejednokrotnie w ramach tego bloga pokazałem, że R jest idealny do analizy danych. A o Pythonie w tym samym kontekście pisze się wszędzie (i pewnie tutaj będzie też coraz więcej). Zatem czy warto wybierać pomiędzy tymi rozwiązaniami przy wdrożeniu na produkcję?
Popularna metoda to prototyp w R żeby zobaczyć czy dostajemy jakieś wyniki i czy w ogóle jakiekolwiek przetwarzanie/modelowanie danych ma sens. Drugim krokiem po prototypie jest wdrożenie modeli napisanych w Pythonie. Często taka analiza czy szukanie odpowiedzi modelu (wcześniej wytrenowanego) sprowadza się do puszczenia strumienia danych przez jakieś coś co da odpowiedź – może to być API. I takie jakieś coś właśnie dzisiaj zrobimy i zbadamy w czym jakieś coś jest bardziej wydajne (czytaj: działa szybciej).
Weźmiemy trzy frameworki do szybkiego (to ważne – są to frameworki do szybkiego napisania API; nie wymagają dużych umiejętności programistycznych, data scientist sobie z nimi poradzi) budowania API i sprawdzimy ich wydajność. Dodatkowo w każdym zaimplementujemy takie same metody i nawet wywoływane w ten sam sposób (dlatego w jednym tego nie zrobiłem, bo nie umiałem – przyznaję się).
Metody API będą trzy:
- /alive – sprawdzamy czy API nam odpowiada. Nie podajemy parametrów, w odpowiedzi spodziewamy się ciągu znaków. To pozwoli sprawdzić jak szybko gołe API odpowiada na zapytania
- /add – proste dodawanie dwóch liczb dziesiętnych – podajemy dwie liczby i dostajemy ich sumę. Dodawanie liczb jest najprostszą operacją, zapewne oba języki mają do zaimplementowane w najszybszy możliwy sposób – zakładam, że w obu trwa to tyle samo. Liczona więc będzie tak naprawdę odpowiedź API i szybkość frameworku.
- /iris – jako parametr podajemy cztery liczby (odpowiadające kolumnom ze zbioru Iris) upakowane w JSON i w odpowiedzi oczekujemy nazwy gatunku irysa. We wszystkich przypadkach pod spodem jest wytrenowany model typu random forrest, zapisany do pliku i wczytany przy starcie serwera API a nie każdym zapytaniu. Ta metoda jest nieco bardziej wyrafinowana niż dodawanie liczb, ale może nieść narzut samego wyliczenia odpowiedzi modelu (niezwiązany z API a z implementacją modelu).
Badanie żeby miało sens musi być na wielu próbkach. Zatem puścimy zapytania na każde z API wielokrotnie. A precyzyjniej – wiele razy po wiele powtórzeń. Po 10 razy powtarzamy pętle 10, 50, 100, 250, 500, 750, 1000, 1500, 2000, 2500, 5000, 7500 i 10000 zapytań na każdy z frameworków. Szczegółowy znajdziecie w pliku test_api.py w repozytorium. Co też ważne – wszystko dzieje w się w tamach jednej maszyny (pytamy localhost), każdy z serwerów API stoi na innym porcie i działają równolegle. Warunki badania wydają się być zatem sprawiedliwe i odporne na pojedyncze błędy pomiaru. I co też ważne: nie było żadnego czekania między zapytaniami, ot pętla for i jedziemy ile fabryka dała ;)
Jeśli chcecie powtórzyć przygotowane przez mnie badanie i porównać wyniki możecie pobrać kod z repozytorium i wykonać następujące kroki uruchamiając kolejno skrypty:
- create_model.R – wytrenowanie i zapisanie modelu predykcji irysów dla R (API w Plumber i RestRserve)
- create_model.py – wytrenowanie modelu dla Pythona (API we Flasku)
- start_api.R – uruchomienie serwera API w R/Plumber (metody zdefiniowane są w plumber.R)
- start_api_2.R – zdefiniowane metody i uruchomienie serwera w R/RestRserve
- start_api.py – uruchomienie API w Python/Flask (metody w środku)
- test_api.py – skrypt odpytujący kolejne serwery API wielokrotnie i zapisujący dane
Po uruchomieniu ostatniego skryptu spokojnie można jechać na weekend.
Aby nie narażać Was na koszty (wyjazdu na weekend) – przygotowałem to wszystko i zebrałem dane.
Najważniejsze liczby to czas odpowiedzi na jedno zapytanie. W tabeli poniżej mamy wartości uśrednione ze wszystkich pomiarów oraz stosunek tych uśrednionych wartości do siebie – czyli na przykład ile razy Flask jest szybszy od Plumbera (w kolumnie Flask/Plumber):
| method | Flask [ms] | Plumber [ms] | RestRserve [ms] | Flask / Plumber | Flask / RestRserve | RestRserve / Plumber |
|---|---|---|---|---|---|---|
| add | 17.7 | 23.5 | b.d. | 1.33 | b.d. | b.d. |
| alive | 17.5 | 23.6 | 373.3 | 1.35 | 21.33 | 15.81 |
| iris | 48.8 | 40.0 | 415.2 | 0.82 | 8.51 | 10.37 |
Dlaczego brakuje wartości dla metody /add w RestRserve? Ano dlatego, że RestRserve nie potrafi w prosty sposób pobrać parametrów z zapytania w postaci /metoda/param1/param2. Nie chciałem zaś zakłamywać wyników (znając już częściowe wiedziałem też że to nie będzie potrzebne) dokładając dla RestRserve warstwę na przykład na serwerze Apache czy Nginx typu mod_rewrite. Widać jednak, że w obu pozostałych przypadkach różnica między /alive i /add jest znikoma zatem pewnie i dla RestRserve byłaby znikoma.
Zobaczmy te wartości na wykresie:
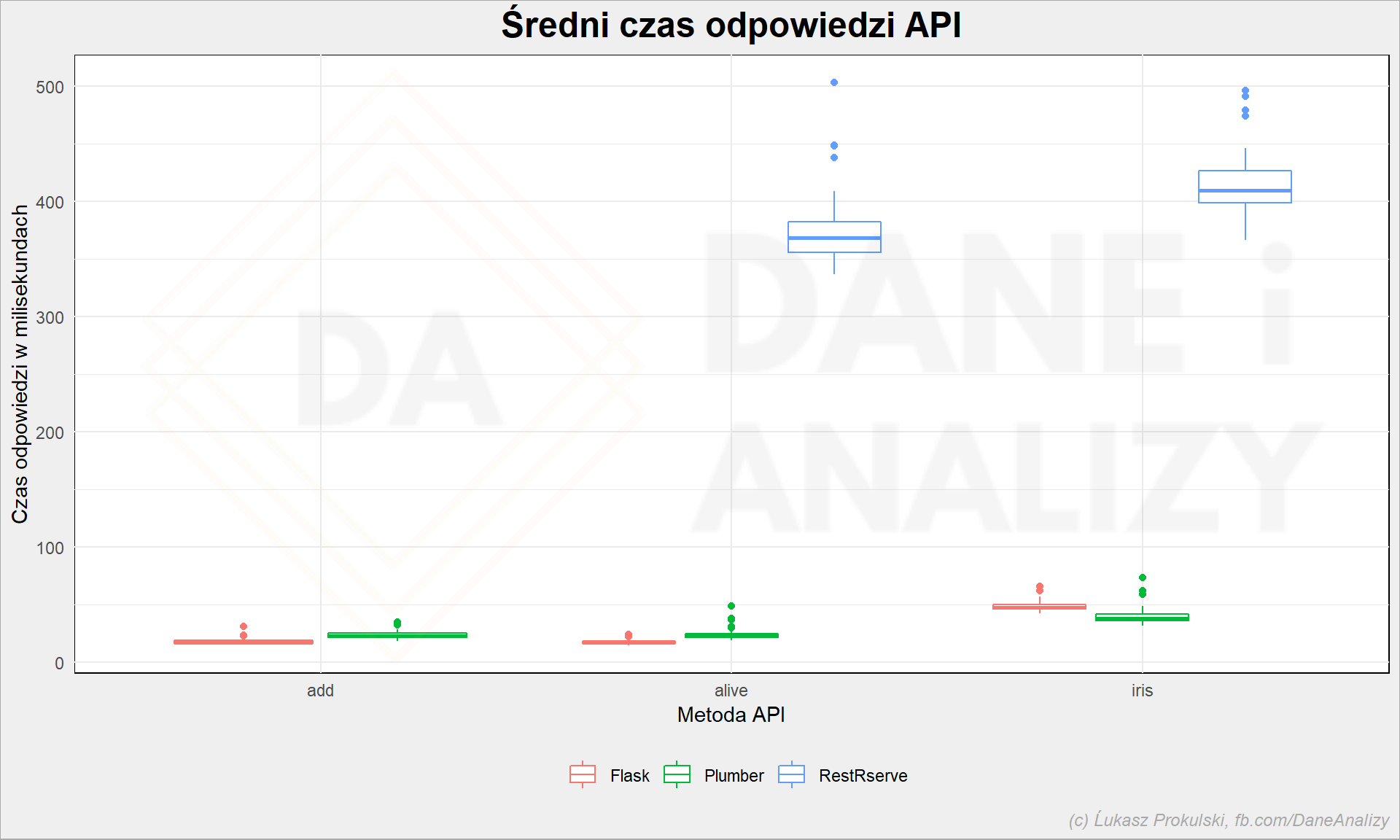
Przede wszystkim RestRserve odstaje od reszty na tyle znacząco, że chyba nie warto się nim zajmować. No, ale szczerze mówiąc wziąłem tutorial i na jego podstawie napisałem to API – być może są jakieś sztuczki, które poprawiają wydajność? Napisz w komentarzu jeśli tak jest!
Przeanalizujmy więc dokładniej Plumbera i Flaska:
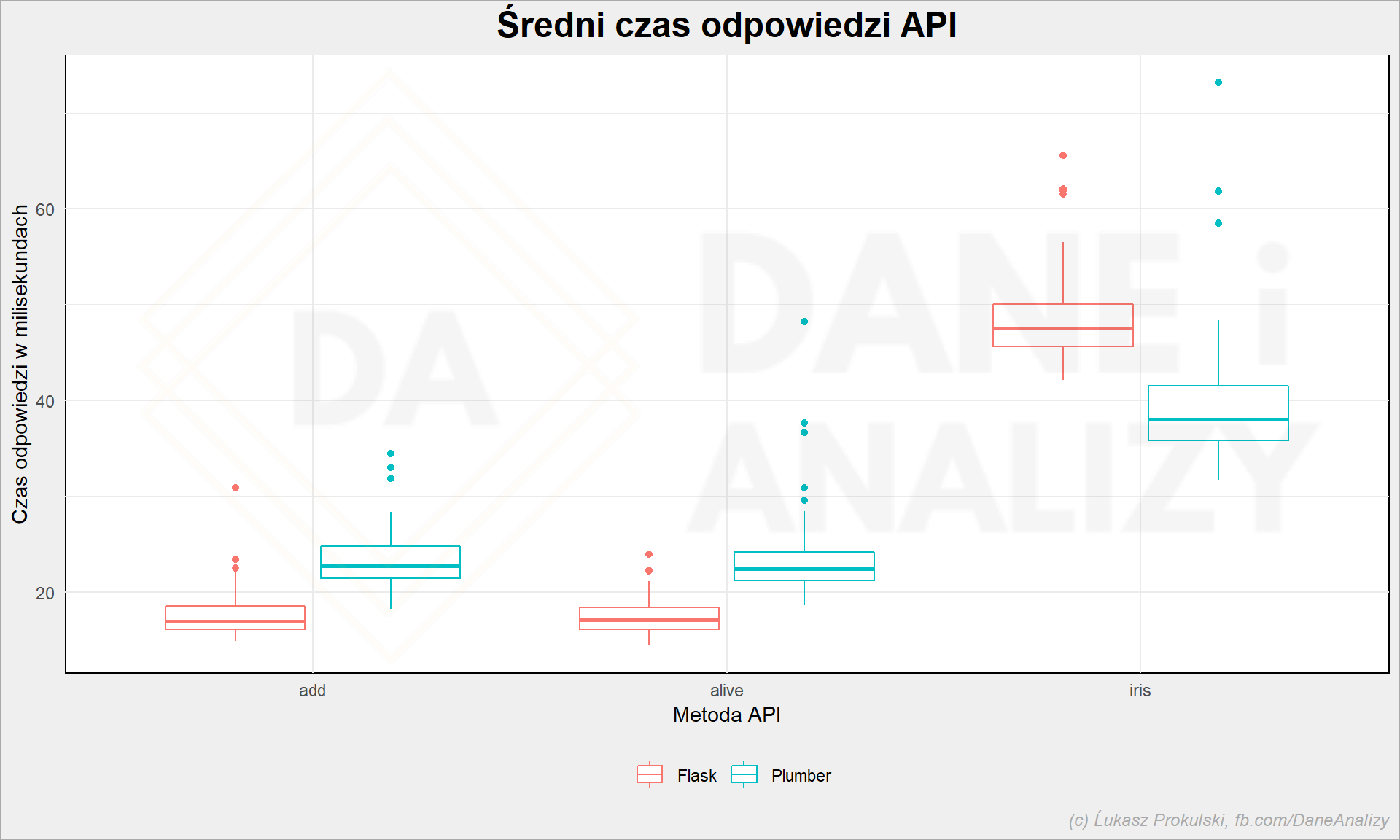
Flask w prostych operacjach jest szybszy niż Plumber. Różnica to około 30% na korzyść Flaska (patrząc na początkową tabelkę). Zatem wydaje się, że wdrożenie produkcyjnie w Pythonie powinno być wydajniejsze.
Ale to dla prostych operacji. Bo już w odpowiedzi właściwie banalnego modelu wypada lepiej R z Plumberem – jakieś 20% różnicy. Ciekawy wynik. Tylko czy winne jest API czy też biblioteka odpowiadająca za predykcję? Aby się upewnić należałoby przygotować kilka modeli, w różnych implementacjach (pakietach, bibliotekach) i zmierzyć każdy z osobna.
Ale czy wyniki są stabilne? Czy średnia nie zgubi nam jakichś wartości odstających? Czy z liczbą powtórzeń ciągle mamy taki sam czas odpowiedzi? A może serwer jakoś magicznie sobie zakolejkuje zapytania i odpowie zbiorowo wszystkim? Gdyby tak było to dla bardziej obciążonych API może warto wybrać inny język?
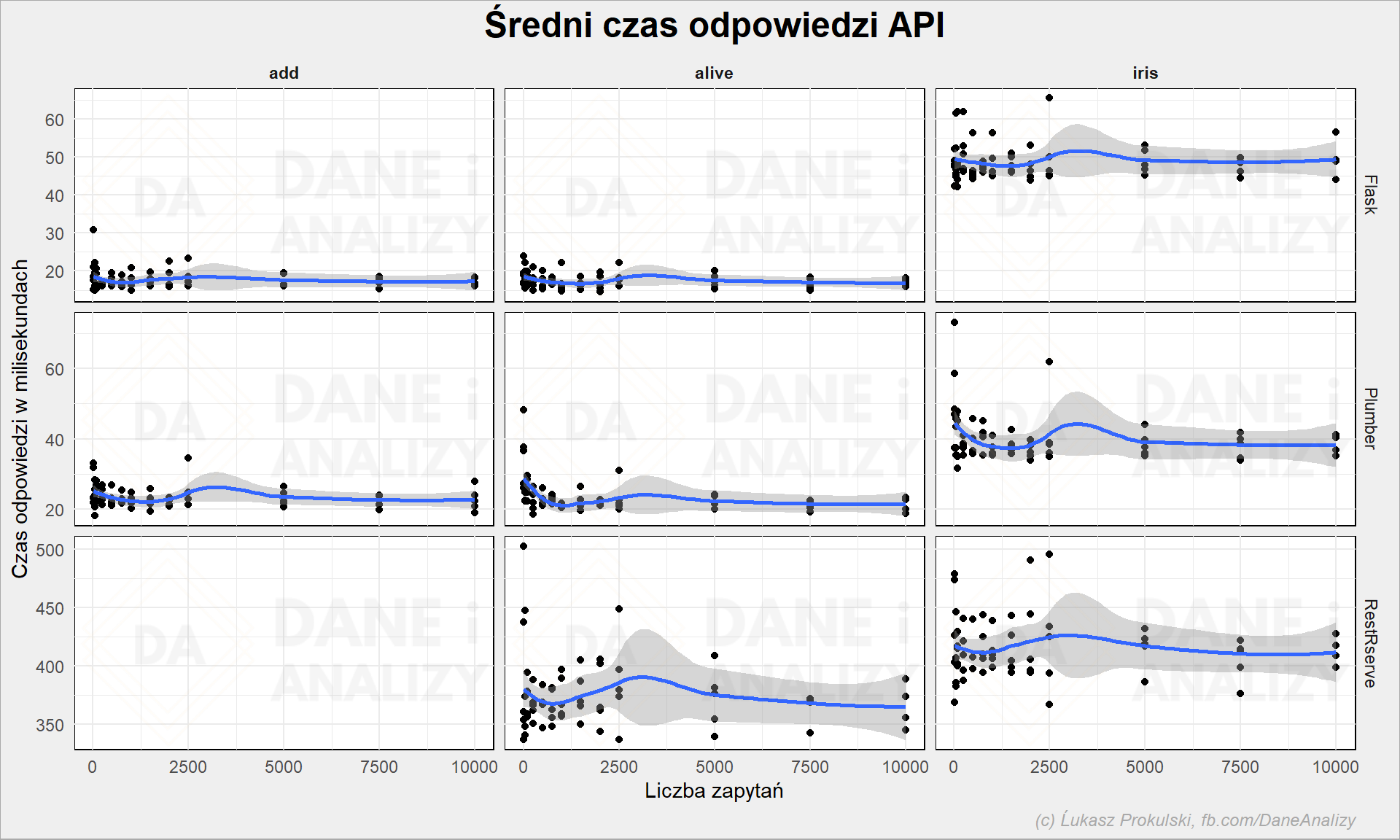
Wygląda na to, że jest stabilnie. Możemy to porównać też w inny sposób – badając średnie w ramach każdej z paczki iteracyjnej (każda z nich była liczona 10 razy; czyli było 10 podejść do 2500 iteracji zapytań do API):
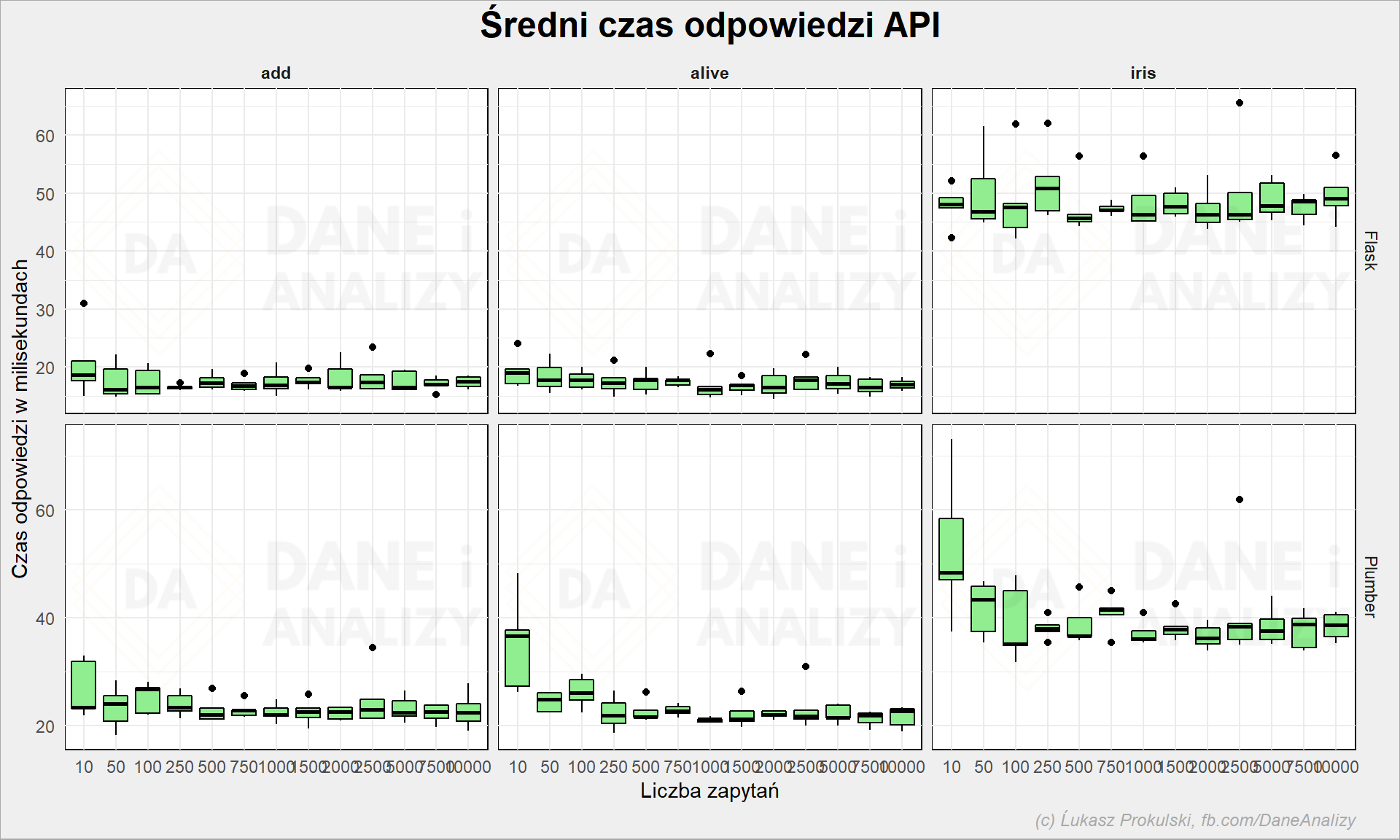
Plumber wygląda na takiego, co by potrzebował się rozpędzić i dopiero po jakiejś chwili zaczyna nabierać mocy.
Czego zabrakło? Nie zmierzyłem wykorzystania pamięci i procesora, a to byłaby cenna informacja dla kogoś kto projektuje infrastrukturę. Na tej samej maszynie pracowałem podczas testu nad innymi tematami (raczej mało obciążającymi), blog który czytasz nie dostał czkawki – W każdym razie serwer przeżył i chyba nie było z nim żadnych problemów.
Rekomendacja? Trudno żeby nie wpisała się w wyczytaną w wielu miejscach opinię (ale nie potwierdzoną badaniami – to pierwsze badania na ten temat jakie znalazłem): prototypuj w R, wdrażaj w Pythonie. Pewnie Java jeszcze bardziej wydajna…
Repozytorium z kodem znajdziecie na GitHubie
Cześć, fajny post. Jakby co to spór mnie nie dotyczy :) pierwsze słyszę o nim. Dziwi mnie jednak to, że do czasu wliczasz przygotowanie parametrów. W pierwszej kolejności usunąłbym to z pętli.
Druga sprawa dotyczy tego, że teraz mierzysz czas obioru wszystkich danych oraz sparsowania odpowiedzi po twojej stronie a można zmierzyć to bez tej operacji (po prostu dostać czas odbioru „pierwszych bajtów”)
https://requests.readthedocs.io/en/master/api/#requests.Response.elapsed .
Ze swojego doświadczenia mogę powiedzieć, że RestRserve jest około dwukrotnie szybszy niż Plumber, więc coś nie do końca jest OK z samym kodem. Wydaje mi się, że w teście żądania powinny być wysłane równolegle, a nie sekwencyjnie – w przypadku RestRserve zrobi to ogromną różnicę.
Otworzyłem issue i pojawiła się odpowiedź Dmitriy’a Selivanov’a (twórcy RestRserve): https://github.com/rexyai/RestRserve/issues/146 Zwraca uwagę m. in. na parametr 'keep-alive’, który zapobiega nawiązywaniu nowych połączeń TCP za każdym razem, co tworzy nowy proces potomny.
Jeszcze dorzucę od siebie do mojej poprzedniej wiadomości. Osobiście nigdy nie byłem przekonany do wykonywania testów pomiaru czasu w pythonie. Jest to język interpretowany i nie wiadomo jaki to generuje narzut. Poza tym, tak jak pisałem requests mierzy czas do każdego zapytania, więc w zasadzie w twoim kodzie pomiar jest robiony dwa razy. Sam pomiar czasu w zależności od metody i systemu może wymagać syscalla i też będzie to generować jakiś narzut (na linuksie akurat nie powinno być syscalla, patrz vdso).
W python3 preferowaną metodą pomiaru czasu jest perf_counter, bo time nie jest monotoniczny, ale jak spojrzymy w kod requests to na linuksie też używają time…
Błąd przypadkowy jesteśmy w stanie zniwelować średnią, ale systematyczny już nie.
Oczywiście nie potrzebujemy w tym przypadków tak bardzo dokładnych wyników, bo interesują nas względne wartości w ramach pojedynczej metody, ale może warto jednak zrobić pomiary JMeterem i nie zastanawiać się nad tym.
Szybkość szybkością. Ale czy plumber oferuje w ogóle tak podstawową funkcję jak autoryzacja? Na stronie nie znalazłem na szybko. Wydaje mi się że główne argumenty przeciwko R na produkcji to nie tyle szybkość, co właśnie bezpieczeństwo i słaba integracja z innymi komponentami architektury. Poza tym w większych organizacjach często developujemy api i później przekazujemy do utrzymania na produkcji przez „ludzi z IT”. A tam dużo prędzej spotkamy pythonowca niż człowieka od R.
Fajny artykuł, jak zwykle dobrze się czyta :)