Jakiś czas temu pokazywałem jak w prosty sposób narysować mapę w R. Dzisiaj powtórzymy zadanie dla Pythona.
Skorzystamy z danych GUS na temat bezrobocia oraz liczby ludności (pomijając dokładność złożenia danych – interesuje nas rysowanie map, a nie analiza bezrobocia) oraz map z Głównego Urzędu Geodezji i Kartografii.
Jeśli potrzebujesz podobnych informacji jak zrobić to wszysto w R sprawdź na początek wszystko co jest w ramach tagu mapa
Skąd pobrać dane?
- Dane o liczbie ludności: Ludność / Stan ludności / Ludność wg grup wieku i płci w tzw. BDLu (czyli Banku Danych Lokalnych GUS) – bierzemy dane z 2018 roku (najnowsze pełne jakie są); Wiek = ogółem, Płeć = ogółem; wszystkie jednostki terytorialne. W wyniku klikania dostaniemy się do tabeli, którą ściągamy lokalnie poprzez Export / CSV – tablica wielowymiarowa.
- Dokładnie tak samo pozyskujemy dane o liczbie bezrobotnych: Rynek pracy / Bezrobocie rejestrowane / Bezrobotni zarejestrowani wg płci w gminach (znowu: ogółem, 2019 rok, wszystkie jednostki; pobieramy plik CSV dokładnie tak samo jak wyżej).
- Dane mapowe bierzemy z GUGiK – interesuje nas archiwum PRG – jednostki administracyjne (uwaga – to ma 375 MB!). To archiwum rozpakowujemy i (coś co ja robię, żeby później nie było problemów) zmieniamy nazwy plików tak, aby pozbyć się polskich znaków i wszystkie litery w nazwie były małe.
Przygotowanie danych z GUS
Ale zanim – potrzebne nam będzie kilka pakietów Pythona do dalszej pracy:`
|
1 2 3 4 |
import pandas as pd import matplotlib.pyplot as plt import geopandas as gpd import folium |
Mapy w Shapefile
Pobrane z BDLa pliki mają swoje nazwy, które są zależne od daty wygenerowania danych. Zapiszmy więc je w zmiennych, aby ewentualnie zmieniać je tylko w jednym miejscu:
|
1 2 |
dane_gus_ludnosc_file = 'LUDN_2137_CTAB_20200228102408.csv' dane_gus_bezrobocie_file = 'RYNE_1944_CTAB_20200228102648.csv' |
Teraz możemy wczytać i przejrzeć z grubsza te dane. Zaczniemy od ludności:
|
1 2 |
ludnosc_gus = pd.read_csv(dane_gus_ludnosc_file, delimiter=';') ludnosc_gus.head() |
|
1 2 3 4 5 6 |
## Kod Nazwa ogółem;ogółem;2018;[osoba] Unnamed: 3 ## 0 0 POLSKA 38411148 NaN ## 1 200000 DOLNOŚLĄSKIE 2901225 NaN ## 2 201000 Powiat bolesławiecki 90200 NaN ## 3 201011 Bolesławiec (1) 38935 NaN ## 4 201022 Bolesławiec (2) 14626 NaN |
Jest tutaj lekki bałagan. Ale co jest czym?
Kod– kolumna odpowiadająca za kod TERYT gminy, a tak na prawdę jest to TERC. Jeśli chociaż raz analizowałeś (lub -aś) dane geograficzne dotyczące Polski to na pewno to znasz. Będzie to klucz łączący dane z obszarami na mapie.Nazwa– nazwa regionu. W zależności od regionu będzie to nazwa gminy, powiatu albo województwa. Lub też POLSKA dla całego kraju. Do niczego nam to w sumie tutaj nie jest potrzebne.ogółem;ogółem;2018;[osoba]– to jest interesująca nas liczba, ale nazwa kolumny jest jakimś babolem. Tak to przychodzi z GUSu :(- ostatnia kolumna to śmieć (bo linie kończą się średnikiem nie wiedzieć czemu)
Zostawimy więc interesujące nas kolumny i zmienimy ich nazwy:
|
1 2 3 |
ludnosc_gus = ludnosc_gus.iloc[:, 0:3] ludnosc_gus.columns = ['TERYT', 'Nazwa', 'Ludnosc'] ludnosc_gus.head() |
|
1 2 3 4 5 6 |
## TERYT Nazwa Ludnosc ## 0 0 POLSKA 38411148 ## 1 200000 DOLNOŚLĄSKIE 2901225 ## 2 201000 Powiat bolesławiecki 90200 ## 3 201011 Bolesławiec (1) 38935 ## 4 201022 Bolesławiec (2) 14626 |
Mamy to czego chcieliśmy. Teraz ta sama operacja dla danych o bezrobociu:
|
1 2 |
bezrobocie_gus = pd.read_csv(dane_gus_bezrobocie_file, delimiter=';') bezrobocie_gus.head() |
|
1 2 3 4 5 6 |
## Kod Nazwa ogółem;2019;[osoba] Unnamed: 3 ## 0 0 POLSKA 866374 NaN ## 1 200000 DOLNOŚLĄSKIE 56022 NaN ## 2 201000 Powiat bolesławiecki 1293 NaN ## 3 201011 Bolesławiec (1) 516 NaN ## 4 201022 Bolesławiec (2) 198 NaN |
Pierwsze dwie kolumny znaczą to samo co w poprzednim zbiorze, trzecia to liczba zarejestrowanych bezrobotnych. Tym razem pozbędziemy się od razu kolumny z nazwą – nie będzie nam do niczego potrzebna, a sam TERYT wystarczy jako klucz łączący.
|
1 2 3 |
bezrobocie_gus = bezrobocie_gus.iloc[:, [0, 2]] bezrobocie_gus.columns = ['TERYT', 'Bezrobotni'] bezrobocie_gus.head() |
|
1 2 3 4 5 6 |
## TERYT Bezrobotni ## 0 0 866374 ## 1 200000 56022 ## 2 201000 1293 ## 3 201011 516 ## 4 201022 198 |
Kolejny krok to złączenie danych – w jednej tabeli będziemy trzymać informacje o ludności i liczbie bezrobotnych i na tej podstawie łatwo policzymy stopę bezrobocia.
Tutaj uwaga – wynik nie będzie poprawny metodologicznie. Dane o ludności mamy z połowy 2019 roku, a o bezrobociu – z końca lutego 2020. Liczba ludności mogła się zmienić przez te półtora roku. Druga rzecz – w liczbę ludności wchodzą też osoby, które nie są w wieku produkcyjnym, więc nie powinny być liczone. Ale ten drobny niuans pomijamy, bo naszym celem jest nauczyć się rysować mapę, a nie liczyć stopę bezrobocia. Oczywiście można w GUSie znaleźć dane o liczbie osób w wieku produkcyjnym – niestety nie będą one tak samo aktualne jak te związane z liczbą bezrobotnych. Ale przed nami narodowy spis powszechny, więc niedługo nowe dane o Polakach.
|
1 2 3 4 5 6 7 8 |
# łączymy dane ze sobą - tylko te kody TERYT, które istnieją w obu tabelach dane_gus = pd.merge(ludnosc_gus, bezrobocie_gus, how='inner', on='TERYT') # liczymy stopę bezrobocia w każdym z TERYTów: dane_gus['Stopa_bezrobocia'] = 100* dane_gus['Bezrobotni'] / dane_gus['Ludnosc'] # 10 przykładowych wierszy: dane_gus.sample(10) |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
## TERYT Nazwa ... Bezrobotni Stopa_bezrobocia ## 885 804043 Kożuchów (3) ... 396 2.466368 ## 307 262000 Powiat m.Legnica ... 1908 1.912744 ## 1673 1410032 Olszanka (2) ... 45 1.519757 ## 361 405011 Golub-Dobrzyń (1) ... 627 4.964371 ## 943 808064 Zbąszynek - miasto (4) ... 47 0.936069 ## 1807 1419155 Wyszogród - obszar wiejski (5) ... 63 2.107728 ## 3809 3027042 Kawęczyn (2) ... 70 1.344602 ## 976 810073 Szprotawa (3) ... 593 2.851647 ## 3804 3027011 Turek (1) ... 493 1.818584 ## 968 810032 Brzeźnica (2) ... 79 2.099389 ## ## [10 rows x 5 columns] |
Wydawać się może, że to wszystko. Ale… poczekajmy ;)
Wczytanie mapy
Czas na wczytanie naszych danych geograficznych. Użyjemy dwóch map: podziału na gminy i podziału na województwa. Bo też narysujemy dwie mapki – dwoma sposobami! Ha, jaka niespodzianka :)
Zaczynamy od wczytania danych z Shapefile (taki format danych – to pobraliśmy z GUGiK):
|
1 2 3 |
# mapa z województwami: mapa_woj = gpd.read_file('../map_data/wojewodztwa.shp') mapa_woj.dtypes |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
## JPT_SJR_KO object ## JPT_KOD_JE object ## JPT_NAZWA_ object ## JPT_ORGAN_ object ## JPT_JOR_ID int64 ## WERSJA_OD object ## WERSJA_DO object ## WAZNY_OD object ## WAZNY_DO object ## JPT_KOD__1 object ## JPT_NAZWA1 object ## JPT_ORGAN1 object ## JPT_WAZNA_ object ## ID_BUFORA_ float64 ## ID_BUFORA1 float64 ## ID_TECHNIC int64 ## IIP_PRZEST object ## IIP_IDENTY object ## IIP_WERSJA object ## JPT_KJ_IIP object ## JPT_KJ_I_1 object ## JPT_KJ_I_2 object ## JPT_OPIS object ## JPT_SPS_KO object ## ID_BUFOR_1 int64 ## JPT_ID int64 ## JPT_KJ_I_3 object ## Shape_Leng float64 ## Shape_Area float64 ## geometry geometry ## dtype: object |
|
1 2 3 |
# mapa z gminami: mapa_gmn = gpd.read_file('../map_data/gminy.shp') mapa_gmn.dtypes |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
## JPT_SJR_KO object ## JPT_KOD_JE object ## JPT_NAZWA_ object ## JPT_ORGAN_ object ## JPT_JOR_ID int64 ## WERSJA_OD object ## WERSJA_DO object ## WAZNY_OD object ## WAZNY_DO object ## JPT_KOD__1 object ## JPT_NAZWA1 object ## JPT_ORGAN1 object ## JPT_WAZNA_ object ## ID_BUFORA_ float64 ## ID_BUFORA1 float64 ## ID_TECHNIC int64 ## IIP_PRZEST object ## IIP_IDENTY object ## IIP_WERSJA object ## JPT_KJ_IIP object ## JPT_KJ_I_1 object ## JPT_KJ_I_2 object ## JPT_OPIS object ## JPT_SPS_KO object ## ID_BUFOR_1 int64 ## JPT_ID int64 ## JPT_KJ_I_3 object ## Shape_Leng float64 ## Shape_Area float64 ## geometry geometry ## dtype: object |
Co my tutaj mamy? Dużo różnych kolumn, ale interesują nas tak naprawdę tylko dwie: JPT_KOD_JE oraz geometry. Pierwsza to po prostu kod TERYT, a druga opisuje kształt obszaru. Zostawmy więc sobie tylko te dwie kolumny i zobaczmy jak wyglądają dane:
|
1 2 3 4 |
mapa_woj = mapa_woj[['JPT_KOD_JE', "geometry"]] mapa_gmn = mapa_gmn[['JPT_KOD_JE', "geometry"]] mapa_gmn.head() |
|
1 2 3 4 5 6 |
## JPT_KOD_JE geometry ## 0 1203022 POLYGON ((19.43443 50.02313, 19.43409 50.02316... ## 1 1204042 POLYGON ((20.92531 50.24308, 20.92531 50.24308... ## 2 2010082 POLYGON ((22.60796 52.51705, 22.60798 52.51711... ## 3 0222033 POLYGON ((16.49835 51.22612, 16.49692 51.22615... ## 4 0223022 POLYGON ((17.24961 51.10001, 17.24918 51.10003... |
Proszę zwrócić uwagę, że kody TERYT (dla gmin) mają wiodące zero i zawsze jest to 7 cyfr. W danych z GUS pandas potraktował tę kolumnę jako liczbę i obciął nam wiodące zera. Można o to zadbać na poziomie wczytywania danych (odpowiednia wartość parametru dtype dla pd.read_csv()) ale trzeba znać listę kolumn.
Zamiast tego zrobimy korektę w naszych danych przy okazji wyłuskując kod TERYT województwa z kodu gminy:
|
1 2 3 4 5 6 7 |
# kod ma być stringiem o stałejdługości (dodanie wiodących zer) dane_gus['TERYT_gmn'] = dane_gus.TERYT.apply(lambda x: '0'+str(x) if len(str(x)) < 7 else str(x)) # TERYT województwa dane_gus['TERYT_woj'] = dane_gus.TERYT_gmn.apply(lambda s: s[:2]) dane_gus.head() |
|
1 2 3 4 5 6 7 8 |
## TERYT Nazwa Ludnosc ... Stopa_bezrobocia TERYT_gmn TERYT_woj ## 0 0 POLSKA 38411148 ... 2.255527 00 00 ## 1 200000 DOLNOŚLĄSKIE 2901225 ... 1.930977 0200000 02 ## 2 201000 Powiat bolesławiecki 90200 ... 1.433481 0201000 02 ## 3 201011 Bolesławiec (1) 38935 ... 1.325286 0201011 02 ## 4 201022 Bolesławiec (2) 14626 ... 1.353754 0201022 02 ## ## [5 rows x 7 columns] |
Jeszcze przydałoby się usunąć agregaty do poziomu powiatów oraz informację dla całego kraju. Rozdzielimy też tabelę na dane o gminach i województwach.
Powiat charakteryzuje się tym, że ostatnie 3 cyfry w kodzie TERYT to zera, zaś w przypadku województwa – to ostatnie 5 cyfr jest zerami. Zadanie więc dość proste:
|
1 2 3 4 5 6 |
# usuwamy wiersz dla całego kraju: dane_gus = dane_gus[dane_gus['TERYT'] != '0'] # wybieramy same województwa - 00000 na końcu dane_gus_woj = dane_gus[dane_gus.TERYT_gmn.str[2:7] == '00000'] dane_gus_woj |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
## TERYT Nazwa ... TERYT_gmn TERYT_woj ## 1 200000 DOLNOŚLĄSKIE ... 0200000 02 ## 313 400000 KUJAWSKO-POMORSKIE ... 0400000 04 ## 551 600000 LUBELSKIE ... 0600000 06 ## 845 800000 LUBUSKIE ... 0800000 08 ## 1010 1000000 ŁÓDZKIE ... 1000000 10 ## 1264 1200000 MAŁOPOLSKIE ... 1200000 12 ## 1562 1400000 MAZOWIECKIE ... 1400000 14 ## 2022 1600000 OPOLSKIE ... 1600000 16 ## 2172 1800000 PODKARPACKIE ... 1800000 18 ## 2428 2000000 PODLASKIE ... 2000000 20 ## 2618 2200000 POMORSKIE ... 2200000 22 ## 2802 2400000 ŚLĄSKIE ... 2400000 24 ## 3050 2600000 ŚWIĘTOKRZYSKIE ... 2600000 26 ## 3221 2800000 WARMIŃSKO-MAZURSKIE ... 2800000 28 ## 3424 3000000 WIELKOPOLSKIE ... 3000000 30 ## 3872 3200000 ZACHODNIOPOMORSKIE ... 3200000 32 ## ## [16 rows x 7 columns] |
|
1 2 3 |
# wybieramy same gminy - 00000 na końcu dane_gus_gmn = dane_gus[dane_gus.TERYT_gmn.str[4:7] != '000'] dane_gus_gmn |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
## TERYT Nazwa ... TERYT_gmn TERYT_woj ## 0 0 POLSKA ... 00 00 ## 3 201011 Bolesławiec (1) ... 0201011 02 ## 4 201022 Bolesławiec (2) ... 0201022 02 ## 5 201032 Gromadka (2) ... 0201032 02 ## 6 201043 Nowogrodziec (3) ... 0201043 02 ## ... ... ... ... ... ... ## 4109 3218054 Węgorzyno - miasto (4) ... 3218054 32 ## 4110 3218055 Węgorzyno - obszar wiejski (5) ... 3218055 32 ## 4112 3261011 Koszalin (1) ... 3261011 32 ## 4114 3262011 Szczecin (1) ... 3262011 32 ## 4116 3263011 Świnoujście (1) ... 3263011 32 ## ## [3721 rows x 7 columns] |
Narysowanie mapy – matplotlib
To teraz najciekawsze – rysujemy wreszcie mapę.
Pierwsze podejście to użycie standardowego matplotlib. Aby tego dokonać znowu musimy połączyć dane do jednego data frame’a. Zajmijmy się województwami.
|
1 2 3 |
# łączymy tabelę opisującą kształt województw z danymi o bezrobosiu w województwach dane_mapa_woj = pd.merge(mapa_woj, dane_gus_woj, how='left', left_on='JPT_KOD_JE', right_on='TERYT_woj') dane_mapa_woj |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
## JPT_KOD_JE ... TERYT_woj ## 0 24 ... 24 ## 1 16 ... 16 ## 2 30 ... 30 ## 3 32 ... 32 ## 4 26 ... 26 ## 5 04 ... 04 ## 6 20 ... 20 ## 7 02 ... 02 ## 8 18 ... 18 ## 9 12 ... 12 ## 10 22 ... 22 ## 11 28 ... 28 ## 12 10 ... 10 ## 13 14 ... 14 ## 14 06 ... 06 ## 15 08 ... 08 ## ## [16 rows x 9 columns] |
|
1 2 3 4 5 6 7 8 9 10 11 12 |
## rysujemy mapkę: # wielkość naszego obrazka fig, ax = plt.subplots(1, figsize = (8,8)) # rysowanie mapy dane_mapa_woj.plot(column='Stopa_bezrobocia', ax=ax, cmap='YlOrRd', linewidth=0.8, edgecolor='gray') # usuwamy osie ax.axis('off') # pokazujemy obrazek plt.show() |
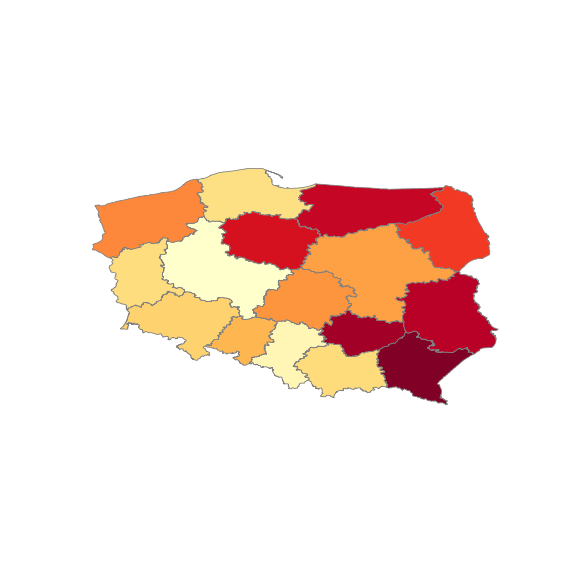
Wyszło jakoś, chociaż kształt Polski jest spłaszczony. Odpowiada za to kodowanie współrzędnych w plikach z GUGiK. Dane o współrzędnych trzeba nieco przekonwertować (było trochę googlania za wartością EPSG, macie gotowy efekt poniżej) Zróbmy to i powtórzmy operację rysowania:
|
1 2 3 4 5 6 |
dane_mapa_woj = dane_mapa_woj.to_crs(epsg=2180) fig, ax = plt.subplots(1, figsize = (8,8)) dane_mapa_woj.plot(column='Stopa_bezrobocia', ax=ax, cmap='YlOrRd', linewidth=0.8, edgecolor='gray') ax.axis('off') plt.show() |
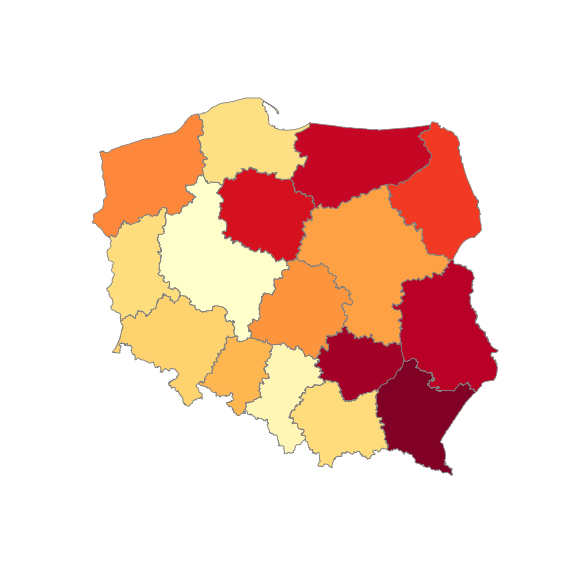
Od razu lepiej!
Narysowanie mapy – Folium
A gdyby tak zrobić mapę interaktywną? Taką, którą można przesuwać i skalować? Do tego użyjemy pakietu Folium oraz danych na poziomie gmin.
Jednak Folium potrzebuje danych o obszarach w formacie GeoJSON, zatem musimy je odpowiednio przygotować.
Uproszczenie kształtu
W pierwszej kolejności uprościmy (zaokrąglimy) dane mapowe, aby nie zajmowały zbyt wiele miejsca. Będzie to miało wpływ na niedokładność kształtów gmin.
|
1 2 3 4 5 |
# uproszczenie geometrii mapa_gmn.geometry = mapa_gmn.geometry.simplify(0.005) # mniejsza wartosc = bardziej dokładnie # dane do GeOJSON na potrzeby Folium gmn_geoPath = mapa_gmn.to_json() |
Teraz już możemy rysować naszą mapkę:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
# 52,19 to w przybliżeniu środek mapy w postaci lat,long mapa = folium.Map([52, 19], zoom_start=6) folium.Choropleth(geo_data=gmn_geoPath, # GeJSON z danymi geograficznymi obszarów data=dane_gus_gmn, # data frame z danymi do pokazania columns=['TERYT_gmn', 'Stopa_bezrobocia'], # kolumna z kluczem, kolumna z wartościami key_on='feature.properties.JPT_KOD_JE', # gdzie jests klucz w GeoJSON? fill_color='YlOrRd', fill_opacity=0.7, line_opacity=0.2, legend_name="Stopa bezrobocia w gminie").add_to(mapa) # zapisanie utworzonej mapy do pliku HTML mapa.save(outfile = 'bezrobocie_gminy.html') # pokazujemy mapę mapa |
Przy dużym zoomie widać, że granice gmin się ze sobą nie stykają – to wynik uproszczenia geometrii. Bez tego kroku powinno wszystko do siebie pasować.
Jeśli potrzebujesz podobnych informacji jak zrobić to wszysto w R sprawdź na początek tekst Mapy, mapy raz jeszcze oraz wszystko co jest w ramach tagu mapa
Ale widać też coś innego – niektóre z gmin są szare. Dlaczego? Ponieważ brakuje dla nich danych. To z kolei wynika z rozbieżności pomiędzy kodami TERYT w danych geograficznych z GUGiK oraz danych o bezrobociu z GUS. Najczęściej chodzi o to, że w GUS są bardziej aktualne dane uwzględniające na przykład zmianę charakteru gminy (ostatnia cyfra w kodzie TERYT) z wiejskiej na miejską lub odwrotnie. Podobny problem można spotkać w przypadku Warszawy – dane mapowe traktują ją jako całość, a dane w GUS często odnoszą się do każdej z dzielnic (i tym samym gmin) oddzielnie.
Jak z tym sobie poradzić? Najprościej byłoby nie przejmować się ostatnią cyfrą w kodzie TERYT. Wówczas trzeba wykonać dwa ruchy wyprzedzające:
- obciąć kod TERYT do 6 cyfr i agregować dane do tak powstałych kodów – dla danych np. z GUS. To dość proste przekształcenie w Pandas
- zrobić dokładnie to samo dla danych mapowych – tutaj agregacja jest nieco trudniejsza (obliczeniowo), ale dokumentacja wyjaśnia co i jak
Problemem jaki się wówczas pojawi będzie brak różnicy dla obszarów, gdzie jedną z gmin jest miasto (lub większa wieś), a drugą – teren wokół niego.
Mam nadzieję, że dzisiaj zdobyta wiedza na coś Ci się przyda. Wiedza za darmo, ale zawsze możesz postawić witrualną kawę.
Jeśli prowadzisz biznes i zadajesz sobie jakieś pytania to może mogę Ci pomóc? Trochę już w swoim życiu danych przerzuciłem w różne strony, trochę pytań zadałem. I projektów zrobiłem.
Jeśli chcesz być na bieżąco z tym co dzieje się w analizie danych, machine learning i AI polub Dane i Analizy na Facebooku oraz rstatspl na Twitterze. Znajdziesz tam potężną dawkę wiedzy.
Dość prężnie działa też konto na Instagramie gdzie znajdziecie różne wykresiki :)
Bardzo ciekawe. Dzięki
Super! Wiesz jak dodać do mapy wartość dla każdego z województw? Lub chociaż legendę z heatmap i wartościami jakim poszczególne kolory odpowiadają?
Można dodać atrybut legend = True przy plotowaniu DF :)
Bardzo pomocny artykuł, dzięki !