Przełom lipca i sierpnia 2019 roku w polskiej polityce zdominowany był przez informacje o lotach – najpierw marszałka Sejmu, później kolejnych premierów. KPRM opublikował listę lotów kolejnych premierów z ostatnich kilku lat – zobaczmy czego nie zrobiły z nią media?
Listy te (na dzień 18 sierpnia 2019 roku) dostępne były pod linkami:
Nie znalazłem w żadnych mediach sensownego porównania pomiędzy premierami, więc porównam sobie sam. Przy okazji pokazując jak można w kilkadziesiąt minut przygotować rzetelny materiał.
Jeśli chcesz zobaczyć wynik analizy – przejdź niżej.
Przygotowanie danych
W pierwszej kolejności pobieramy pliki PDF (z powyżej podanych adresów). Drugi element to przepisanie danych do analizowanej postaci. Do wczytania PDFów w R można wykorzystać pakiet pdftools.
Pakiet ten wskazany plik czyta i zwraca jako listę z zawartością poszczególnych stron. Każdy z elementów tej listy to zwykły ciąg znaków. Na szczęście w tych dokumentach mamy do czynienia z jednakowymi tabelkami – możemy więc każdy z plików potraktować jednakowo. Poniższy kod zrobi za nas część pracy:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 |
library(tidyverse) library(pdftools) # lista plików PDF file_names <- c("dane/pbs.pdf", "dane/pdt.pdf", "dane/pek.pdf", "dane/pmm.pdf") # tutaj będziemy trzymać pełne dane complete = c() # dla każdego kolejnego pliku: for(file_name in file_names) { # wczytujemy PDFa pdf <- pdf_text(file_name) # miejsce na linie z aktualnie przerabianego pliku full <- c() # dla każdej ze stron w pliku for(i in 1:length(pdf)) { # dzielimy stronę na linie temp <- str_split(pdf[i], "\n")[[1]] # dodajemy linie z bierzącej strony do linii z całego pliku full <- c(full, temp) } # usuwamy puste linie full <- full[nchar(full) != 0] # więcej niż jedna spacja zostaje zamieniona na ; full <- gsub(pattern = " +", ";", full) # dodajemy kolumnę z nazwą pliku full <- paste0(full, ";", file_name) # dodajemy linie pliku do pełnych danych complete <- c(complete, full) } # zapisujemy pełne dane do pliku CSV write_lines(complete, "dane/zapis.csv") |
Teraz trochę ręcznej gimnastyki. Otwieramy zapisany plik CSV w Excelu i oglądamy każdy z wierszy. Docelowo chcemy uzyskać postać tabeli, gdzie każdy wiersz będzie zwierał trzy kolumny:
- kolumna data – data w formacie dzień.miesiąc.rok (tak jak to zapisane w dokumentach)
- kolumna trasa – trasę jaką przebył samolot w formacie lotnisko A-lotnisko B-lotnisko C; ważne żeby kolejne lotniska rozdzielone były myślnikami
- kolumna kto – nazwę pliku z jakiego pochodzi informacja – to opisuje nam z którym premierem mamy do czynienia
Wierszy było około tysiąca, ich poprawa zajęła może z 30 minut polegających głównie na złączeniu tekstów z dwóch (czasem więcej) kolumn do jednej komórki i ewentualnym przesunięciu wiersza w prawo. Niektóre wiersze trzeba było też usunąć (nagłówki tabel). Zapewne udałoby się to zrobić z poziomu R (i odpowiednich wyrażeń regularnych – tutaj sprawdzą się znakomicie), ale ręczny przegląd danych czasem też się przydaje.
Kolejny krok to oczyszczenie danych. Lotniska nazwane są kodami, ale czasem to samo lotnisko występuje pod dwoma różnymi kodami. Maszyna tego nie zrozumie, trzeba jej pomóc.
Przydatne będą dane o lokalizacji lotnisk – znajdziemy je na stronie ourairports.com. Pobieramy plik CSV z listą lotnisk (np. dla całej Europy).
Teraz czas na poprawę i oczyszczenie danych. Najpierw zobaczymy czego nam brakuje i co trzeba poprawić. Wczytujemy plik z listą lotów i rozbijamy kolumnę z trasą samolotu z danego dnia na poszczególne lotniska:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
library(tidyverse) # poprawnione ręcznie dane df <- read_csv2("dane/zapis.csv") # położenie lotnisk z http://ourairports.com/ lotniska <- read_csv("dane/airports.csv") # przygotowanie danych loty <- df %>% # rozdzielenie tracy na kolejne lotniska mutate(trasa = str_split(trasa, "-")) %>% unnest(trasa) |
w tabeli loty mamy teraz kolumnę trasa, która zwiera wszystkie kody lotnisk. Jeśli zrobimy
|
1 |
count(loty, trasa, sort = TRUE) |
dostaniemy listę ułożoną wg popularności. Na początku będzie zapewne Warszawa, Gdańsk, Kraków. Warszawa może być jako EPWA lub WAW. W pliku z ourairports.com mamy tylko EPWA – stąd potrzebne korekty (najlepiej od razu na pliku zapis.csv). Jak znaleźć wszystkie lotniska, które trzeba poprawić? Ano próbujemy złączyć tabelkę o lotach z tabelką o lotniskach – to co nie uda się połączyć trzeba poprawić. Łączymy na przykład tak:
|
1 2 3 4 |
loty %>% distinct(trasa) %>% left_join(lotniska %>% select(ident, name), by = c("trasa" = "ident")) |
To co w kolumnie name będzie mieć NA to braki. Dla tych wierszy szukamy kodu lotniska (jaki mamy) na stronie ourairports.com i przez search & replace zmieniamy w pliku zapis.csv jeden kod na taki, który podaje ourairports.com. W większości przypadków powinno się udać.
Po zmianach oczywiście zapisujemy zapis.csv.
Z tak poprawionym plikiem robimy porządek w danych doprowadzając je do postaci, gdzie w jednym wierszu będziemy mieć informacje o konkretnym locie, w konkretnym dniu, konkretnego premiera, z jednego do drugiego lotniska:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 |
library(tidyverse) library(lubridate) # poprawnione ręcznie dane df <- read_csv2("dane/zapis.csv") # położenie lotnisk z http://ourairports.com/ lotniska <- read_csv("dane/airports.csv") # przygotowanie danych loty <- df %>% # rozdzielenie tracy na kolejne lotniska mutate(trasa = str_split(trasa, "-")) %>% unnest(trasa) %>% select(data, kto, lotnisko_z=trasa) %>% # przesuwamy o jeden lotniska group_by(kto, data) %>% mutate(lotnisko_do = lead(lotnisko_z)) %>% filter(!is.na(lotnisko_do)) %>% filter(lotnisko_do != lotnisko_z) %>% ungroup() %>% # dodajemy położenie dla lotniska źródłowego i docelowego left_join(lotniska %>% select(ident, lat_z=latitude_deg, long_z=longitude_deg, miasto_z=municipality), by = c("lotnisko_z" = "ident")) %>% left_join(lotniska %>% select(ident, lat_do=latitude_deg, long_do=longitude_deg, miasto_do=municipality), by = c("lotnisko_do" = "ident")) %>% # wybieramy potrzebne kolumny select(kto, data, lotnisko_z, lotnisko_do, lat_z, long_z, miasto_z, lat_do, long_do, miasto_do) %>% # usuwamy niedopasowane lotniska - uwaga: tracimy część danych! na.omit() %>% # budujemy trasę przelotu mutate(lot = paste0(miasto_z, " - ", miasto_do)) %>% # poprawiamy format daty rowwise() %>% mutate(data2 = str_match(data, "(\\d{2}\\.\\d{2}\\.\\d{4})")[[1,1]] %>% dmy()) %>% ungroup() %>% mutate(kto = toupper(kto)) |
Przykładowe wiersze wyglądają następująco:
| kto | data | lotnisko_z | lotnisko_do | lat_z | long_z | miasto_z | lat_do | long_do | miasto_do | lot | data2 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| PMM | 18.03.2019 | EPKK | EPWA | 50.07770 | 19.78480 | Kraków | 52.1657 | 20.96710 | Warsaw | Kraków – Warsaw | 2019-03-18 |
| PDT | 01.12.2008 | EPPO | EPWA | 52.42100 | 16.82630 | Poznań | 52.1657 | 20.96710 | Warsaw | Poznań – Warsaw | 2008-12-01 |
| PBS | 29-30.11.2015 | EPWA | EBBR | 52.16570 | 20.96710 | Warsaw | 50.9014 | 4.48444 | Brussels | Warsaw – Brussels | 2015-11-30 |
| PMM | 16.12.2018 | EPKT | EPWA | 50.47430 | 19.08000 | Katowice | 52.1657 | 20.96710 | Warsaw | Katowice – Warsaw | 2018-12-16 |
| PDT | 27.08.2011 | EPWA | EPWR | 52.16570 | 20.96710 | Warsaw | 51.1027 | 16.88580 | Wrocław | Warsaw – Wrocław | 2011-08-27 |
| PEK | 15.10.2015 | EBBR | EPWA | 50.90140 | 4.48444 | Brussels | 52.1657 | 20.96710 | Warsaw | Brussels – Warsaw | 2015-10-15 |
| PEK | 03.09.2015 | EPWA | EPKT | 52.16570 | 20.96710 | Warsaw | 50.4743 | 19.08000 | Katowice | Warsaw – Katowice | 2015-09-03 |
| PMM | 28.04.2018 | EPZG | EPOK | 52.13850 | 15.79860 | Babimost | 54.5797 | 18.51720 | Gdynia | Babimost – Gdynia | 2018-04-28 |
| PMM | 26.04.2019 | LUZ | EPWA | 51.24028 | 22.71361 | Lublin | 52.1657 | 20.96710 | Warsaw | Lublin – Warsaw | 2019-04-26 |
| PMM | 09.02.2019 | EPRZ | EPWA | 50.11000 | 22.01900 | Rzeszów | 52.1657 | 20.96710 | Warsaw | Rzeszów – Warsaw | 2019-02-09 |
Dane są przygotowane, można przejść do opracowania materiału tak, jak nie zrobiły tego media.
Analiza
Na przykład – najpopularniejsze trasy (3/4 wszystkich dla każdego z premierów):
|
1 2 3 4 5 6 7 8 9 10 11 |
loty %>% count(kto, lot) %>% group_by(kto) %>% mutate(total = sum(n)) %>% ungroup() %>% mutate(procent_lotow = 100*n/total) %>% arrange(kto, desc(procent_lotow)) %>% group_by(kto) %>% mutate(total = cumsum(procent_lotow)) %>% filter(total <= 75) %>% ungroup() |
Premier Donald Tusk:
| Trasa lotu | Liczba lotów | % lotów premiera | % skumulowany |
|---|---|---|---|
| Warsaw – Gdańsk | 207 | 27.97 | 27.97 |
| Gdańsk – Warsaw | 165 | 22.30 | 50.27 |
| Brussels – Warsaw | 45 | 6.08 | 56.35 |
| Warsaw – Brussels | 43 | 5.81 | 62.16 |
| Warsaw – Kraków | 26 | 3.51 | 65.68 |
| Katowice – Warsaw | 20 | 2.70 | 68.38 |
| Kraków – Warsaw | 17 | 2.30 | 70.68 |
| Warsaw – Katowice | 13 | 1.76 | 72.43 |
| Warsaw – Wrocław | 13 | 1.76 | 74.19 |
Premier Ewa Kopacz:
| Trasa lotu | Liczba lotów | % lotów premiera | % skumulowany |
|---|---|---|---|
| Brussels – Warsaw | 10 | 13.33 | 13.33 |
| Warsaw – Brussels | 10 | 13.33 | 26.67 |
| Katowice – Warsaw | 7 | 9.33 | 36.00 |
| Warsaw – Katowice | 6 | 8.00 | 44.00 |
| Warsaw – Gdańsk | 4 | 5.33 | 49.33 |
| Wrocław – Warsaw | 4 | 5.33 | 54.67 |
| Gdańsk – Warsaw | 3 | 4.00 | 58.67 |
| Paris – Warsaw | 3 | 4.00 | 62.67 |
| Prague – Warsaw | 3 | 4.00 | 66.67 |
| Warsaw – Wrocław | 3 | 4.00 | 70.67 |
| Kraków – Warsaw | 2 | 2.67 | 73.33 |
Premier Beata Szydło:
| Trasa lotu | Liczba lotów | % lotów premiera | % skumulowany |
|---|---|---|---|
| Kraków – Warsaw | 54 | 27.0 | 27.0 |
| Warsaw – Kraków | 42 | 21.0 | 48.0 |
| Warsaw – Brussels | 13 | 6.5 | 54.5 |
| Warsaw – Katowice | 8 | 4.0 | 58.5 |
| Rzeszów – Warsaw | 7 | 3.5 | 62.0 |
| Brussels – Kraków | 6 | 3.0 | 65.0 |
| Brussels – Warsaw | 5 | 2.5 | 67.5 |
| Warsaw – Rzeszów | 5 | 2.5 | 70.0 |
| Budapest – Warsaw | 4 | 2.0 | 72.0 |
| Katowice – Warsaw | 4 | 2.0 | 74.0 |
Premier Mateusz Morawiecki:
| Trasa lotu | Liczba lotów | % lotów premiera | % skumulowany |
|---|---|---|---|
| Kraków – Warsaw | 29 | 8.95 | 8.95 |
| Warsaw – Kraków | 21 | 6.48 | 15.43 |
| Wrocław – Warsaw | 19 | 5.86 | 21.30 |
| Warsaw – Katowice | 17 | 5.25 | 26.54 |
| Katowice – Warsaw | 16 | 4.94 | 31.48 |
| Warsaw – Brussels | 15 | 4.63 | 36.11 |
| Warsaw – Wrocław | 15 | 4.63 | 40.74 |
| Brussels – Warsaw | 13 | 4.01 | 44.75 |
| Rzeszów – Warsaw | 12 | 3.70 | 48.46 |
| Warsaw – Gdańsk | 11 | 3.40 | 51.85 |
| Warsaw – Rzeszów | 11 | 3.40 | 55.25 |
| Gdańsk – Warsaw | 9 | 2.78 | 58.02 |
| Gdynia – Warsaw | 9 | 2.78 | 60.80 |
| Warsaw – Gdynia | 8 | 2.47 | 63.27 |
| Warsaw – Goleniow | 8 | 2.47 | 65.74 |
| Warsaw – Poznań | 8 | 2.47 | 68.21 |
| Goleniow – Warsaw | 7 | 2.16 | 70.37 |
| Lublin – Warsaw | 6 | 1.85 | 72.22 |
| Warsaw – Lublin | 6 | 1.85 | 74.07 |
Albo – co ciekawsze – narysujmy mapkę z najczęściej pokonywanymi połączeniami przez każdego z premierów w Polsce:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 |
# lista polskich lotnisk lotniska_pl <- lotniska %>% filter(iso_country == "PL") %>% pull(ident) loty %>% # tylko polskie lotniska filter(lotnisko_z %in% lotniska_pl & lotnisko_do %in% lotniska_pl) %>% # ile razy premier pokonywał daną trasę? count(kto, lat_z, long_z, miasto_z, lat_do, long_do, miasto_do) %>% # jaka to część jej/jego lotów group_by(kto) %>% mutate(n = n/sum(n)) %>% ungroup() %>% # rysujemy: ggplot() + # kontury Polski geom_polygon(data = map_data("world") %>% filter(region == "Poland"), aes(long, lat, group=group), color = "gray30", fill = "gray90") + # połączenia lotnicze geom_segment(aes(x = long_z, xend = long_do, y = lat_z, yend = lat_do, size = n), alpha = 0.25, color = "red", show.legend = FALSE) + # punkty pokazujące położenie lotnisk geom_point(data = lotniska %>% filter(iso_country == "PL") %>% filter(ident %in% loty$lotnisko_z | ident %in% loty$lotnisko_do), aes(longitude_deg, latitude_deg), size = 1) + # nazwy miast, w których są lotniska geom_text(data = lotniska %>% filter(iso_country == "PL") %>% filter(ident %in% loty$lotnisko_z | ident %in% loty$lotnisko_do), aes(longitude_deg, latitude_deg, label = municipality), size = 2, hjust = -0.1, vjust = 0) + # ograniczamy zakres wykresu xlim(13, 25) + ylim(49, 55) + coord_map() + scale_size_continuous(range=c(0.5, 3)) + # każdy premier na swojej mapce facet_wrap(~kto) + # kosmetyka theme_minimal() + theme(axis.text = element_blank(), panel.grid = element_blank()) + labs(x = "", y = "") |
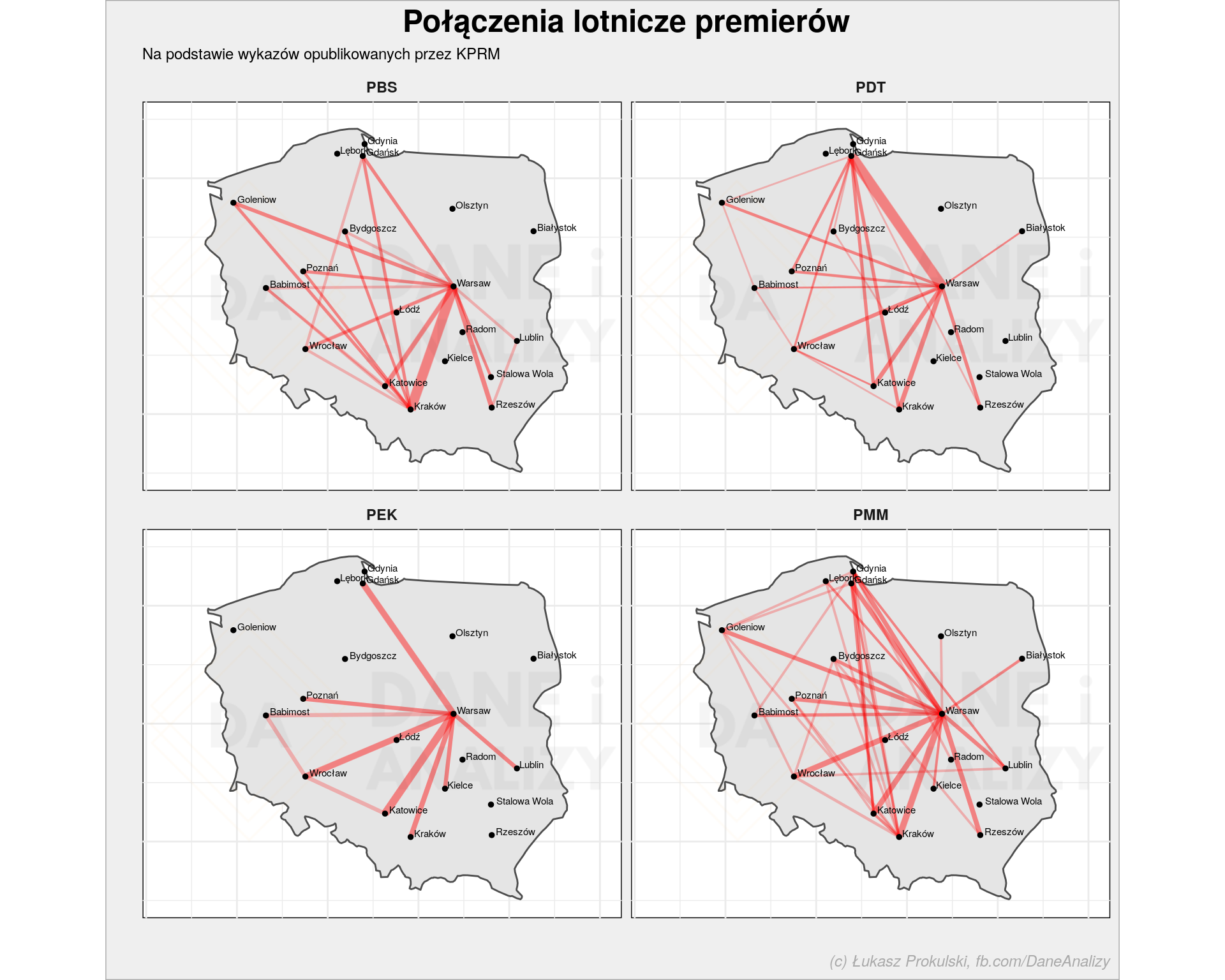
Możemy też sprawdzić jak latali po Europie:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
# gdzie latają po Europie? loty %>% count(kto, lat_z, long_z, miasto_z, lat_do, long_do, miasto_do) %>% mutate(kto = toupper(kto)) %>% group_by(kto) %>% mutate(n = n/sum(n)) %>% ungroup() %>% ggplot() + borders("world", xlim = c(-10, 25), ylim = c(39, 70), fill = "gray90") + geom_segment(aes(x = long_z, xend = long_do, y = lat_z, yend = lat_do, size = n), alpha = 0.25, color = "red", show.legend = FALSE) + coord_map() + scale_size_continuous(range=c(0.5, 3)) + facet_wrap(~kto) + theme_minimal() + theme(axis.text = element_blank(), panel.grid = element_blank()) + labs(x = "", y = "") |
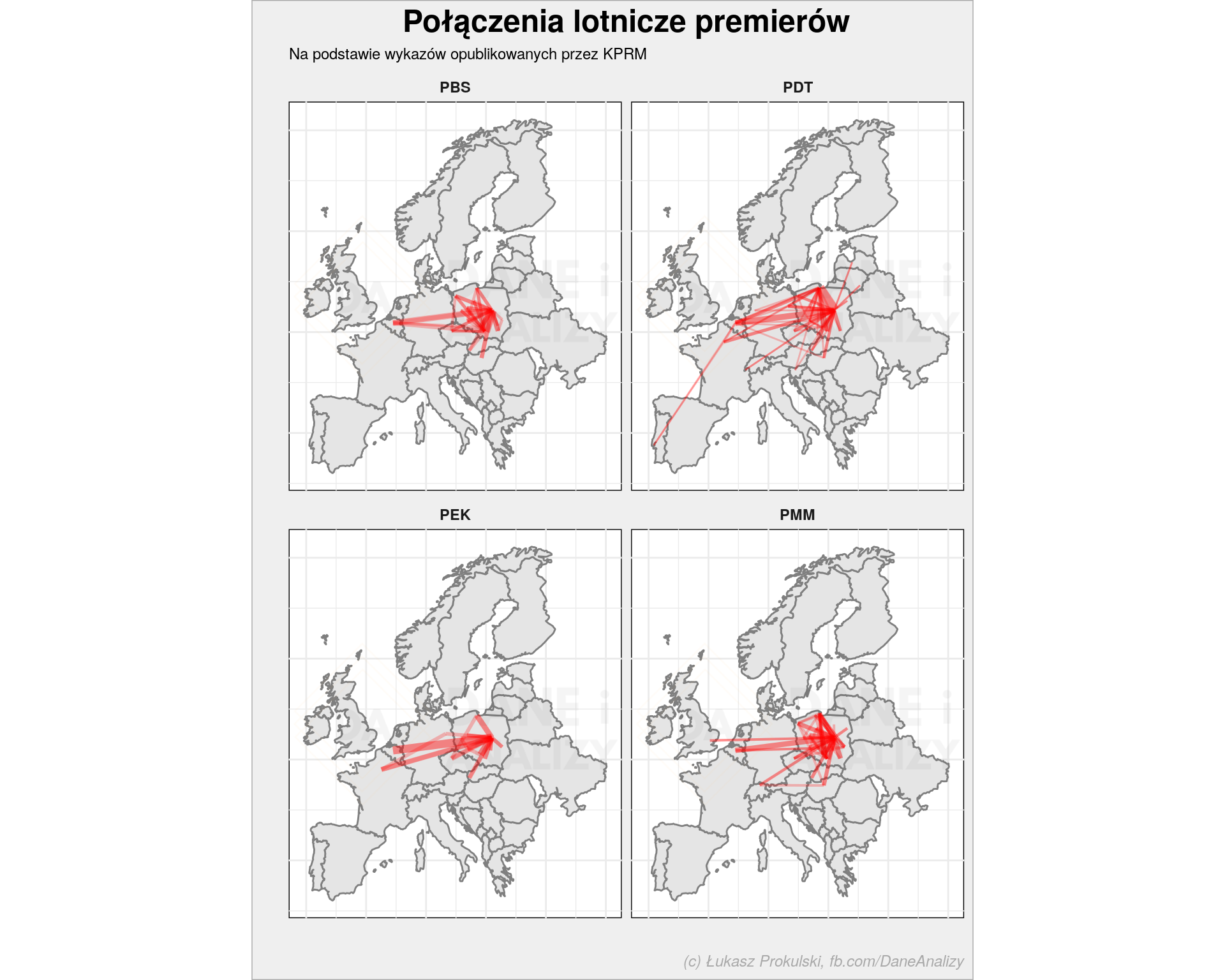
oraz liczbę lotów w kolejnych miesiącach:
|
1 2 3 4 5 6 7 8 9 10 |
loty %>% mutate(data2 = floor_date(data2, "month")) %>% count(kto, data2) %>% ggplot() + geom_col(aes(data2, n, fill = kto), show.legend = FALSE) + geom_smooth(aes(data2, n, color = kto), show.legend = FALSE) + facet_wrap(~kto, scales = "free_x") + scale_x_date(date_labels = "%m/%Y") + theme_minimal() + labs(x = "", y = "Liczba lotów w miesiącu") |
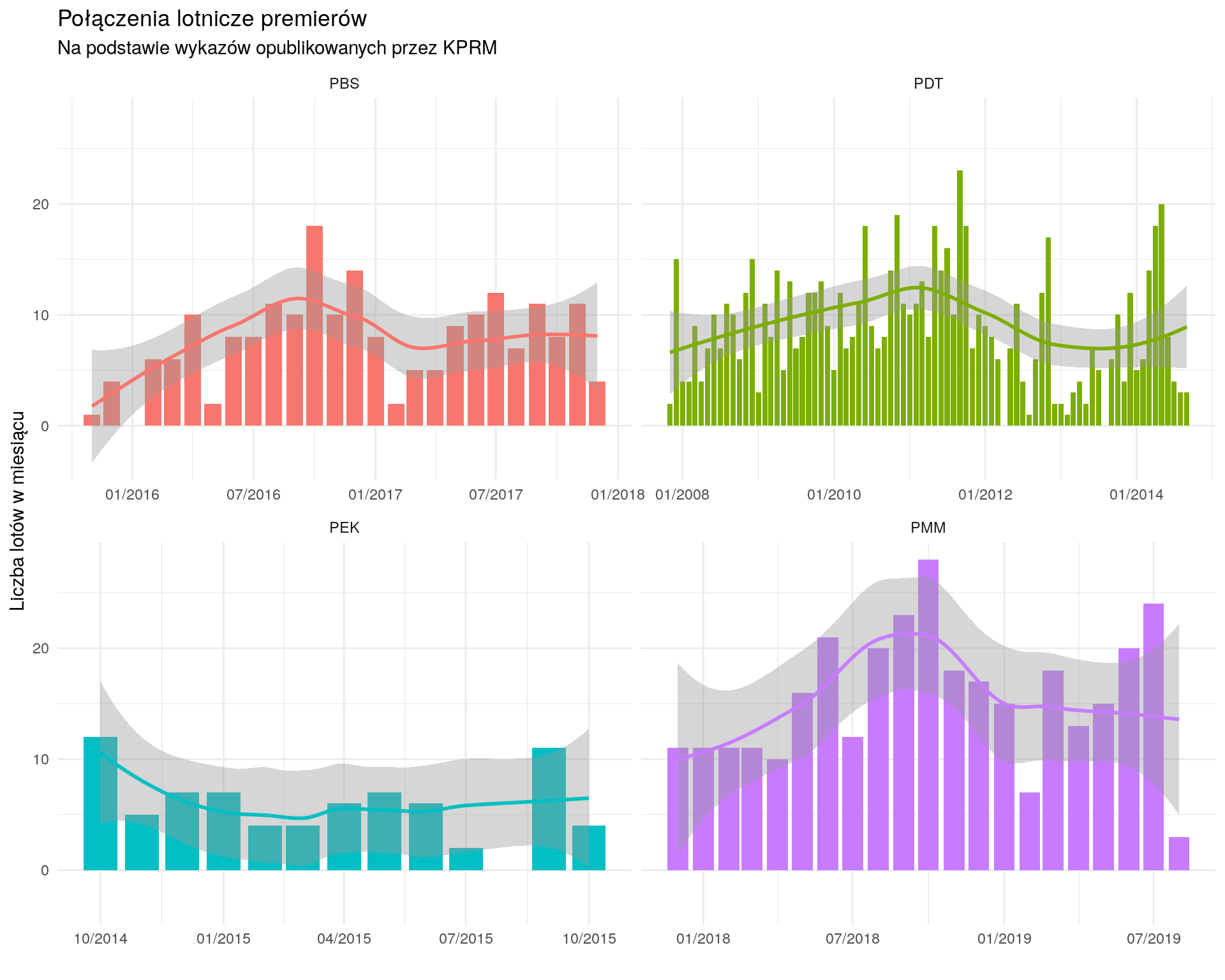
Kto lata najczęściej?
|
1 2 3 4 5 6 7 8 9 10 11 12 |
loty %>% group_by(kto) %>% summarise(mind = min(data2, na.rm = T), maxd = max(data2, na.rm = T), n = n()) %>% ungroup() %>% mutate(diff_date = as.numeric(maxd - mind)) %>% mutate(day_per_flight = round(diff_date/n, 2)) %>% select(-mind, -maxd) %>% set_names(c("Premier", "Liczba lotów", "Liczba dni urzędowania", "Częstotliwość lotów")) %>% kable() %>% kable_styling(bootstrap_options = c("striped", "hover", "condensed", "responsive")) |
| Premier | Liczba lotów | Liczba dni urzędowania |
Częstość lotów (co ile dni lot) |
|---|---|---|---|
| PBS | 200 | 741 | 3.70 |
| PDT | 740 | 2471 | 3.34 |
| PEK | 75 | 382 | 5.09 |
| PMM | 324 | 598 | 1.85 |
Wnioski wyciągajcie sami (są mocno zależne od upodobań politycznych). Widać kilka rzeczy:
- Beata Szydło często latała na trasie Warszawa-Kraków oraz Warszawa-Katowice (lub odwrotnie) – to 54% jej lotów
- Donald Tusk często latał na trasie Warszawa-Gdańsk i z powrotem – to 50% jego lotów
- Ewa Kopacz latała głównie do Brukseli, latała też najrzadziej – średnio o 5 dni
- Mateusz Morawiecki lata dużo, więcej niż inni – ot średnio co niecałe dwa dni
Aktualizacja: nieco inaczej wyczyściłem dane i udało się wyłuskać jakimi samolotami latali poszczególni premierzy. Zestawienie w tabelce:
| Premier | Samolot | Liczba przelotów | % przelotów premiera |
|---|---|---|---|
| PDT | EMB | 276 | 48.68 |
| PDT | YK | 171 | 30.16 |
| PDT | TU | 58 | 10.23 |
| PDT | W3 | 39 | 6.88 |
| PDT | Bell | 13 | 2.29 |
| PDT | MI8 | 2 | 0.35 |
| PDT | YK/Bell | 2 | 0.35 |
| PDT | CASA | 1 | 0.18 |
| PDT | czarter | 1 | 0.18 |
| PDT | policja | 1 | 0.18 |
| PDT | W-3 | 1 | 0.18 |
| PDT | YK / EMB | 1 | 0.18 |
| PDT | YK/W3 | 1 | 0.18 |
| PEK | EMB | 41 | 87.23 |
| PEK | W3 | 5 | 10.64 |
| PEK | CASA | 1 | 2.13 |
| PBS | EMB | 73 | 45.34 |
| PBS | CASA | 72 | 44.72 |
| PBS | W-3 Sokół | 14 | 8.70 |
| PBS | B-737 czarter | 1 | 0.62 |
| PBS | W-3Sokół/CASA | 1 | 0.62 |
| PMM | EMB-175 | 131 | 63.59 |
| PMM | Gulfstream G-550 | 33 | 16.02 |
| PMM | CASA | 30 | 14.56 |
| PMM | Śmigłowiec W-3 | 7 | 3.40 |
| PMM | W-3 Sokół | 3 | 1.46 |
| PMM | G-550 | 1 | 0.49 |
| PMM | W3 | 1 | 0.49 |
W tabelce powyżej jeden przelot to jedna linia z pliku źródłowego, zatem na przykład lot Warszawa – Kraków – Rzeszów – Warszawa liczony jest jako jeden, chociaż wcześniej rozbity był na trzy odcinki. Trochę to miesza i może wprowadzić konfuzję jeśli chodzi o sumowanie, ale chodzi o porównanie skali a nie aptekę
Całość opracowania danych zajęła mi może z pół dnia. Dlaczego media tego nie zrobiły?
Cenisz rzetelne dziennikarstwo? To wymagaj go od mediów, za które płacisz. Albo płać tym, których cenisz :-)
Ekstra!! Świetna analiza
częstość =/= częstotliwość – chyba, że latający najwięcej Morawiecki lata jednocześnie najrzadziej
W tabeli jest podana odwrotność częstotliwości, a nie częstotliwość, co jest dość mylące.
Artykuł na pewno bardzo dobry ale TL;DR, prosto do danych i…
Ta częstotliwość bardzo myląca…
Innymi słowy wysoka wartość w kolumnie częstotliwości latania to tak na prawdę rzadkie loty, ssup wit dat ?
Poprawiłem tą częstotliwość/częstość – teraz powinno być to jasne :)
A czy z dostępnych danych można wywnioskować ile lotów odbyło się wojskową CASĄ, samolotami rządowymi i rejsowymi?
Tak, te informacje są w źródłowych pdfach – we wpisie je pominąłem po prostu
To również istotny element w całej sprawie, bo wskazywałby na ile dany Premier liczył się z kosztami. Można bowiem przyjąć, że loty rejsowe są tańsze niż loty ze statusem HEAD. Czy udałoby Ci się to zawrzeć w porównaniu?
Trzeba inaczej podejść do wyczyszczenia danych po wyjęciu ich z PDFów – ja po prostu usunąłem kolumnę mówiącą o samolocie. Nie mam też wiedzy który samolot jest HEAD, a który nie.
Zaktualizowałem wpis o dodatkową tabelę.
Doskonaly material. Pozwolilem sobie przesunac do znajomych. Zwrotki pozytywne. Gratuluje.
Dzień Dobry,
W mojej ocenie nie wziął Pan pod uwagę bardzo ważnej kwestii, czyli jak często premierzy korzystali z lotów liniami lotniczymi a jak często korzystali z lotów wojskową Casą czy ze statusu Head. Jest to kluczowe z punktu widzenia sposobu korzystania z uprawnień przez poszczególnych premierów oraz dla oceny ich podejścia do publicznych finansów. Ostatnio ujawniło się, że marszałek sejmu korzystał ze statusu Head, zarezerwowanego dla oficjalnych podróży najważniejszych osób w państwie, latając na weekend do domu, co zostało uznane za nadużywanie uprawnień i spowodowało jego dymisję. Z tego względu usunięcie rodzaju samolotu i nie wzięcie pod uwagę statusu lotu jest mylące dla opinii publicznej.
Zgaszam się z Anna – ” jak często premierzy korzystali z lotów liniami lotniczymi a jak często korzystali z lotów wojskową Casą czy ze statusu Head.”
Bez tego te wyliczenia za bardzo nie mają sensu.
Ale oboje patrzyliście w wykazy przygotowane przez KPRM, prawda? I wiecie że tych informacji tam nie ma? Oraz zdajecie sobie sprawie, że wpis ten jest o prezentacji istniejących danych?
To po co robic analize przez pol dnia, ktora odpowiada tylko na pytanie jak czesto latal premier, a nie odpowiada na pytanie ile nas to kosztowalo, bo nie ma informacji jakicjest status lotu? Rownie dobrze ten ktory latal najmniej mogl nas najbardziej obciazyc. Mnie jako podatnika interesuje ile mnie ich loty kosztowaly. A nie ile ktos przesiedzial w samolocie. Z danych ktore Pan prezentuje moge co najwyzej stwierdzic, ze wspolczuje DT, bo musial latan najwiecej, i ze EK nie wspolczuje bo lata rzadko
Proszę poprosić KPRM o więcej danych to się dowiemy.
Nie wiem czy latanie do domu (lub w jego okolice) za pieniądze podatników (nawet niewielkie) jest fair. Mi żaden pracodawca nie płacił za transport praca-dom-praca. Może Panu płaci, nie wiem.
Po co robić? Dla zabawy, dla sprawdzenia czy potrafię, dla pokazania że to jest proste. Oraz dlatego, żeby pokazać że wizualizacje ułatwiają odbiór danych. A pomimo tego że to jest proste to żadna gazeta nie pokazała mapki.
Po co robić cokolwiek co zaspokaja ciekawość czy chęć sprawdzenia siebie? Po co nam (jako ludziom) jakikolwiek rozwój?
Bardzo ładna analiza, pokazująca swobodę używania narzędzi przez autora. Mnie się podoba, ale wracając do meritum dyskusji należy to potraktować jako temat poboczny. Dlaczego?
Po pierwsze wrzutka dotycząca premierów, była zrobiona dla odwrócenia uwagi od lotów marszałków – na temat byłoby zestawienie tychże statystyk.
Po drugie idzie o loty ze statusem HEAD, a nie loty kursami pasażerskimi, bo to inna bajka.
Oczywiście tych danych celowo nie umieszczano, ale wtedy należy się zastanowić, czy nie pracujemy w grajdołku, specjalnie przygotowanym dla „jajogłowych”. W tym kontekście mam na myśli podatność na manipulację.
Pozwolę sobie zauważyć, że wprawdzie wizualizacja jest czytelna i rzeczywiście ułatwia odbiór informacji o częstotliwości lotów, to z całym szacunkiem, w mojej ocenie tak postawiony cel wizualizacji po prostu nie przybliża nas to do zrozumienia istoty problemu korzystania z połączeń samolotowych przez premierów. Wizualizacja nie ułatwia niestety odbioru danych, lecz zakłóca niestety ich sens. Stąd słusznie postawione wyżej pytanie o to po co robić taką wizualizację? Zapewne nieświadomie ale tą wizualizacją idealnie wpisał się Pan w narrację obecnej władzy. Po ujawnieniu informacji o lotach marszałka Sejmu, w wyniku których został on zdymisjonowany, przedstawiciele partii rządzącej próbowali przekonać opinię publiczną, że premier Tusk także często latał, w tym także na weekend do domu. No latał, ale rejsowym samolotem, a nie wojskową Casą, czy innymi maszynami rządowymi i bez statusu Head. Są to nieporównywalne koszty dla podatników, nie mówiąc już o naruszeniu prawa i dobrych obyczajów przez wykorzystywanie lotów ze statusem Head do wożenia rodziny i znajomych polityków. Poza oficjalnymi delegacjami oczywiści, czyli w drodze do domu na weekend.
Uważam, że premier i kilka najważniejszych osób w państwie mają prawo korzystać z darmowych lotów, w związku z pracą muszą szybko się przemieszczać i ja jako podatnik to akceptuję. Nie akceptuję jednak marnotrawstwa i wykorzystywania przywilejów do celów prywatnych.
Nie mamy statusu lotu, ale mamy informację o samolocie. Wspominana CASA:
W-3 Sokół też raczej rejsowym nie jest…
Policzmy więc ile lotów każdy z premierów odbył CASĄ z uwzględnieniem trasy. Po max trzy najliczniejsze trasy CASĄ:
Interesująco wyglądają loty Beaty Szydło w tym ujęciu, prawda? Zobaczmy więc gdzie latała CASĄ w piątek, sobotę lub niedzielę – i ile razy:
w danym dniu tygodnia
Zaznaczyłem potencjalne loty z i do okolic domu pani premier. Policzyłem ręcznie – 26 sztuk (o ile się nie pomyliłem), wszystkich jest 32.
Dodam jeszcze, że jest 18 lotów CASĄ z PBS na pokładzie w poniedziałki na trasie Kraków-Warszawa.
Rozbijając loty poszczególnych premierów na dni tygodnia (w przybliżeniu – daty czasem są okresami, a nie pojedynczymi dniami) i bez uwzględnienia jakim samolotem lot był wykonany mamy taki układ (aby zwiększyć czytelność musiały być co najmniej 3 loty na danej trasie w danym dniu tygodnia aby trasa pojawiła się na obrazku):
(klik w obrazek otwiera większą wersję)
Chciałbym zauważyć, że Łask jest lotniskiem wojskowym i przelot wojskowym samolotem na lotnisko wojskowe jest, moim zdaniem, uzasadniony.
Dzięki, ciekawie to wygląda. Czy dałoby się np. zrobić zestawienie ile razy średnio w miesiącu kto latał? (Procentowo rodzaj samolotu już mamy) Interesujące by to było z tego względu, że każda z tych osób była premierem przez inny czas a zatem wykaz zbiorczy ilości lotów nie daje pełnego obrazu sytuacji. A zatem jak się mają loty p. Szydło (ok. 2 lat premierowania) do lotów p. Tuska (ok. 7 lat premierowania).
Ostatni wykres we wpisie pokazuje liczbę lotów na miesiąc oraz tabelka ze średnią liczbą dni między lotami. Rozdzielanie tego na rodzaj samolotu (być może) niewiele zmieni. W końcu chodzi o to, kto latał prywatnie – tutaj wystarczy procent wszystkich lotów.
Coraz ciekawiej się robi. Czyli p. Tusk latał w sumie z podobną częstotliwości jak p. Szydło, z tym że nie latał do domu Casą ani Sokołem, a to najdroższe przeloty :)
Latał Embr., czyli liniami LOT, w których o ile mi wiadomo, premier w ogóle nie płaci za przelot. Zabiera się niejako „przy okazji” lotem rejsowym co nie generuje dodatkowych kosztów dla podatników.
A najczęściej lata p. Morawiecki. Przy czym trzeba wziąć pod uwagę, że mieszka z rodziną w Warszawie i w przeciwieństwie do Tuska czy Szydło nie lata „do domu”. Czy to prowadzi do wniosku, że lata w związku z intensywną kampanią wyborczą?
Dokładnie tak rozumiem te wyniki…
Przydałoby się dołożenie do tej analizy postów z FB, twittera czy insta, komunikatów Centrum Informacyjnego Rządu oraz Polskiej Agencji Prasowej. Od razu wyszłoby czy faktycznie po przylocie na miejsce premierzy wykonywali jakieś obowiązki służbowe. Ale to już powinno być zajęcie dla porządnych dziennikarzy, których w tym kraju jestem w stanie policzyć na palcach obu rąk.
Ale to już poza czas pół dnia wykracza… A idea była taka, że niewielkim nakładem pracy można było informacje o lotach w mediach rozbudować.
Jasne. 80% efektu przy 20% nakładu. I tak bardzo dziękuję za ten wpis i poświęcenie pół dnia. Gdyby jednak jakaś redakcja (może OKO.press?) zapragnęła rozbudować swój dział analiz, to ma do dyspozycji wiele dodatkowych źródeł, nie tylko dane liczbowe. I wtedy prostackie tłumaczenie „wykonywał(a) w tym czasie obowiązki służbowe” byłoby o wiele mniej skuteczne.
Do wszystkich, którzy zaczynają się bawić w analizę analizy i dyskusję czego w niej nie ma, co być powinno oraz które wnioski są poprawne…
Czy Wy naprawdę nie widzicie, że sens całego wpisu jest zawarty w ostatnim zdaniu? Nie bawcie się do k**** nędzy w wytykanie autorowi literówek albo czego nie uwzględnił bo nie o tym jest wpis. Wpis jest o tym co dzisiaj można robić z danymi i jak je wykorzystywać w debacie publicznej. Zacznijcie wymagać od dziennikarzy takiej jakości pracy!!! Od lat 90-tych mamy problem z miałkością życia dziennikarskiego w kraju. Gdy byłem na poziomie liceum, chłonąłem ówczesnych publicystów. Ale dziś mam 40-tkę na karku i nie jestem już w liceum, a mam wrażenie, że ich poziom analiz i dyskusji jest wciąż na tym poziomie. To dziennikarze w dużym stopniu kształcą obywateli, bo to oni tłumaczą co i jak wygląda w państwie. Niestety, niewykształcone pismaki wychowały całe pokolenie niewykształconych obywateli. I teraz zbieramy tego żniwo. Dyktatury chamów i fornali są możliwe tylko tam, gdzie nie ma instytucji albo są one niedojrzałe. Bo wtedy wygrywa tupet, rympał, brak skrupułów. Dziennikarstwo jest kluczową instytucją demokracji liberalnej. Dziennikarze uwielbiają to powtarzać bo to zawsze miłe dla ego być kimś ważnym. Szkoda tylko, że z równym zapałem nie dbają o jakość swojej pracy.
Właściwie to mogę się tylko ukłonić po tym komentarzu.
Niestety będzie gorzej. Czas obejrzeć „Idiocracy” po raz kolejny…
Niestety ale zastępy niewykształconych produkuje masowo szkoła. Statystyczny Polak nie czyta już nawet 1 książki rocznie. Mamy rzesze wtórnych analfabetów, którzy nie rozumieją słowa pisanego i nie potrafią wyciągać najprostszych nawet wniosków. Można im wcisnąć każdą bzdurę. I to jest prawdziwy problem.
Bawią mnie niektóre odpowiedzi i jednocześnie ubolewam nad tym ile czasu Pan w to włożył. To roszczeniowe podejście niektórych czy narzekanie że mało danych…albo nie takie rany ja bym tak w życiu nie napisał. Opisał Pan jak zebrać raport, interesowało coś Pana i coś Pan ludziom dał, a teraz ktoś – mając pełne dane podane przez Pana – zamiast samemu siąść na czterech literach męczy Pana żeby coś tam jeszcze za darmo mu pokazać, siąść w domu po śniadaniu i mu policzyć. LUDZIE, apeluję! O pamiętajcie się. Widząc te nagatywne komentarze, kręcenie nosem na wnioski, a że czegoś brakuje (czegoś czego nie ma w danych!) aż mi niedobrze. Dokąd my zmierzamy.