Czy polskie pociągi są punktualne? To pytanie, na które poszukamy odpowiedzi, ale jest ono tylko przyczynkiem do dzisiejszego wpisu.
Chciałbym pokazać dzisiaj sposób znalezienia odpowiedzi, nawet nie samą odpowiedź. Skąd wziąć dane? Jak sobie z nimi poradzić? Czym je uzupełnić?
Pozyskanie danych
W pierwszym odruchu pomyślałem o stronach PKP i webscrappingu. Ale na Twitterze mojego bota @rstatspl obserwuje inny bot – @OpPociagow, który prezentuje ciekawe dane. Skoro prezentuje to je ma. Skoro ma, to gdzieś są. Chwila rozmowy z twórcą i uzyskujemy adres InfoPasażer Archiver – archiwum opóźnień pociągów.
Dane o rozkładach i opóźnieniach
Na stronie tej znajdziemy pliki z archiwalnymi danymi. Tego szukamy. Ściągamy więc archiwum z danymi za lata 2017/2018 i patrzymy co jest w środku (po prostu go rozpakowując i oglądając pliki).
Z poziomu systemów linuksowych wystarczy:
|
1 |
wget http://ipa.lovethosetrains.com/ipa_17_18.7z |
Plik jest archiwum 7-zip, potrzebujemy więc go czymś rozpakować. Znowu (na Ubuntu) robimy to z poziomu konsoli:
|
1 |
7zr e ipa_17_18.7z ipa_17_18/api/train/* -ojson |
co spowoduje wypakowanie plików z danymi (są w formacie JSON) do nowego folderu json. Jeśli popatrzymy na te dane to jest ich ogrom. Każdy plik zawiera informacje o poszczególnym pociągu. Przerabianie każdego po kolei będzie trwało wieki. A chcemy mieć dane globalne a nie z każdy z osobna – zresztą mając wszystkie dane możemy wyłuskać dane o pojedynczym pociągu…
Z pomocą może przyjść baza danych (w archiwum jest plik SQL wpisujący dane do bazy – jego wykorzystanie to inny sposób) albo na przykład Apache Spark. Sparka instaluje się łatwo, razem z nim przychodzi Scala. W Scali zaimportujemy pliki JSON do Sparka (do parqueta), a później z poziomu R będziemy sobie na nich operować tak jak na danych w tabeli SQLowej.
Uruchamiamy więc spark-shell i tam w konsoli uruchamiamy skrypt:
|
1 2 3 4 5 6 7 8 9 10 11 |
import org.apache.spark.sql.types._ val df1 = spark.read.json("dane/json/*") val df2 = df1.select($"train_id", $"train_name", explode($"schedules").as("schedules")) val df3 = df2.select($"train_id", $"train_name", $"schedules.schedule_id", $"schedules.schedule_date", explode($"schedules.info").as("info")) val df4 = df3.select($"train_id".cast(IntegerType), $"train_name", $"schedule_id".cast(IntegerType), $"schedule_date".cast(TimestampType), $"info.arrival_delay".cast(IntegerType), $"info.arrival_time".cast(TimestampType), $"info.departure_delay".cast(IntegerType), $"info.departure_time".cast(TimestampType), $"info.station_name") df4.write.parquet("trains_parquet") |
W kolejnych krokach skrypt robi:
- wczytuje do df1 wszystkie pliki json z podanego folderu (to jest power – jedną linią czesamy całą masę podobnych plików)
- do df2 wybiera z df1 odpowiednie pola JSONa i rozwija (explode) te, które trzeba
- do df3 z df2 rozwija kolejne zagnieżdżenie
- do df4 wybiera z df3 odpowiednie kolumny i zmienia ich typ
- na koniec df4 zapisuje do parquetu trains_parquet – to z niego będziemy korzystać w R
Teraz w R możemy połączyć się z naszym parquetem i zobaczyć co tam mamy w środku. Dzisiaj przydadzą nam się biblioteki:
|
1 2 3 4 |
library(tidyverse) library(lubridate) library(sparklyr) # konektor do Sparka library(stringdist) # podobieństwo tekstów |
|
1 2 3 4 5 6 7 8 9 |
# łączymy się ze Sparkiem sc <- spark_connect(master = "local") # wybieramy interesujący nas parquet df <- spark_read_parquet(sc, "trains", "trains_parquet", memory = FALSE) # w df mamy "link" do danych, możemy je obejrzeć, pobrać itd. # do pamięci wczytujemy je przez collect() df %>% head(10) %>% collect() |
| train_id | train_name | schedule_id | schedule_date | arrival_delay | arrival_time | departure_delay | departure_time | station_name |
|---|---|---|---|---|---|---|---|---|
| 604 | 34804/5 KAROLINKA | 53468006 | 2018-12-07 23:00:00 | NA | NA | 0 | 2018-12-08 17:04:00 | Rzeszów Główny |
| 604 | 34804/5 KAROLINKA | 53468006 | 2018-12-07 23:00:00 | 2 | 2018-12-08 17:11:00 | 2 | 2018-12-08 17:11:30 | Rudna Wielka |
| 604 | 34804/5 KAROLINKA | 53468006 | 2018-12-07 23:00:00 | 3 | 2018-12-08 17:14:00 | 3 | 2018-12-08 17:14:30 | Świlcza |
| 604 | 34804/5 KAROLINKA | 53468006 | 2018-12-07 23:00:00 | 4 | 2018-12-08 17:17:30 | 4 | 2018-12-08 17:18:00 | Trzciana |
| 604 | 34804/5 KAROLINKA | 53468006 | 2018-12-07 23:00:00 | 4 | 2018-12-08 17:21:30 | 4 | 2018-12-08 17:22:00 | Będziemyśl |
| 604 | 34804/5 KAROLINKA | 53468006 | 2018-12-07 23:00:00 | 4 | 2018-12-08 17:26:00 | 4 | 2018-12-08 17:26:30 | Sędziszów Małopolski |
| 604 | 34804/5 KAROLINKA | 53468006 | 2018-12-07 23:00:00 | 4 | 2018-12-08 17:29:36 | 4 | 2018-12-08 17:30:06 | Ropczyce Witkowice |
| 604 | 34804/5 KAROLINKA | 53468006 | 2018-12-07 23:00:00 | 4 | 2018-12-08 17:32:30 | 4 | 2018-12-08 17:33:00 | Ropczyce |
| 604 | 34804/5 KAROLINKA | 53468006 | 2018-12-07 23:00:00 | 4 | 2018-12-08 17:36:00 | 4 | 2018-12-08 17:36:30 | Lubzina |
| 604 | 34804/5 KAROLINKA | 53468006 | 2018-12-07 23:00:00 | 4 | 2018-12-08 17:40:30 | 4 | 2018-12-08 17:41:00 | Dębica Wschodnia |
Ciekawe dane, a mamy ich jakieś 16.2 mln wierszy. No to już jest big data! :)
W tym momencie możemy liczyć sobie jakieś rzeczy. Wcześniej jednak warto pooglądać dane (wybierając jeden dzień, jeden pociąg, jedną stację). Ja zrobiłem to za Was, więc wiem, że:
- opóźnienia są różne, czasem jakieś całkowicie nierealne – na przykład -520 minut (tak, minus – pociąg przyjechał za wcześnie! Kilka godzin!)
- pociąg na danej stacji może mieć opóźniony przyjazd i opóźniony odjazd, może krócej stać na stacji i niwelować opóźnienie
- jedno jest pewne – na stacji początkowej nie ma wartości dla arrival_delay, a na stacji końcowej – nie ma departure_delay.
Sprawdźmy czy opóźnienie przyjazdu na stację i odjazdu z niej jest mniej więcej równe (czyli czy rzeczywiście pociągi nadrabiają opóźnienia na stacjach). Przy okazji zwróćcie uwagę, że df jest tabelą w parquet Sparka, a traktujemy ją tak samo jakby była to tabela w pamięci! Niesamowicie to wygodne.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
df %>% # zliczamy ile razy wystąpiły kombinacje czasu opoznienia przyjazdu i odjazdu count(arrival_delay, departure_delay) %>% # pobieramy dane do pamięci collect() %>% # oznaczamy sobie kolumny z jednakowym opoźnieniem przyjazdu i odjazdu: # TRUE = pociąg nie nadrabia opóźnienia na stacji # FALSE = pociąg nadrabia na stacji # NA = któraś z wartości jest równa NA, czyli jest to stacja końcowa lub początkowa mutate(delta = arrival_delay == departure_delay) %>% group_by(delta) %>% summarise(n = sum(n)) %>% ungroup() %>% # przeliczamy n-ki na procenty mutate(p = 100*n/sum(n)) %>% kable() %>% kable_styling(bootstrap_options = c("striped", "hover", "condensed", "responsive")) |
| delta | n | p |
|---|---|---|
| FALSE | 1573757 | 9.736859 |
| TRUE | 12939333 | 80.055858 |
| NA | 1649791 | 10.207283 |
Widzimy, że 80% opóźnień nie jest nadrabianych na stacji. Z tego możemy wysnuć wniosek, że opóźnienie przyjazdu na stację (lub odjazdu z niej) jest poi prostu opóźnieniem pociągu na stacji. To cenna informacja, bo zamiast przerabiać dwie kolumny o opóźnieniach (arrival_delay i departure_delay) możemy skupić się na jednej – ja wybrałem arrival_delay. Dodatkowo dla uproszczenia z dalszych rozważań usuniemy stacje początkowe (czyli tam, gdzie arrival_delay jest puste). Dlaczego początkowe? Bo skupiamy się na arrival_delay.
Jak wygląda rozkład opóźnień?
|
1 2 3 4 5 6 7 8 9 10 |
df %>% filter(!is.na(arrival_delay)) %>% count(arrival_delay) %>% collect() %>% ggplot() + geom_col(aes(arrival_delay, n)) + scale_x_continuous(limits = c(-10, 30)) + labs(title = "Rozkład opóźnień pociągów w przyjazdach na stacje", subtitle = "Dane dla wszystkich pociągów", x = "Długość opóźnienia [minuty]", y = "Liczba przyjazdów") |
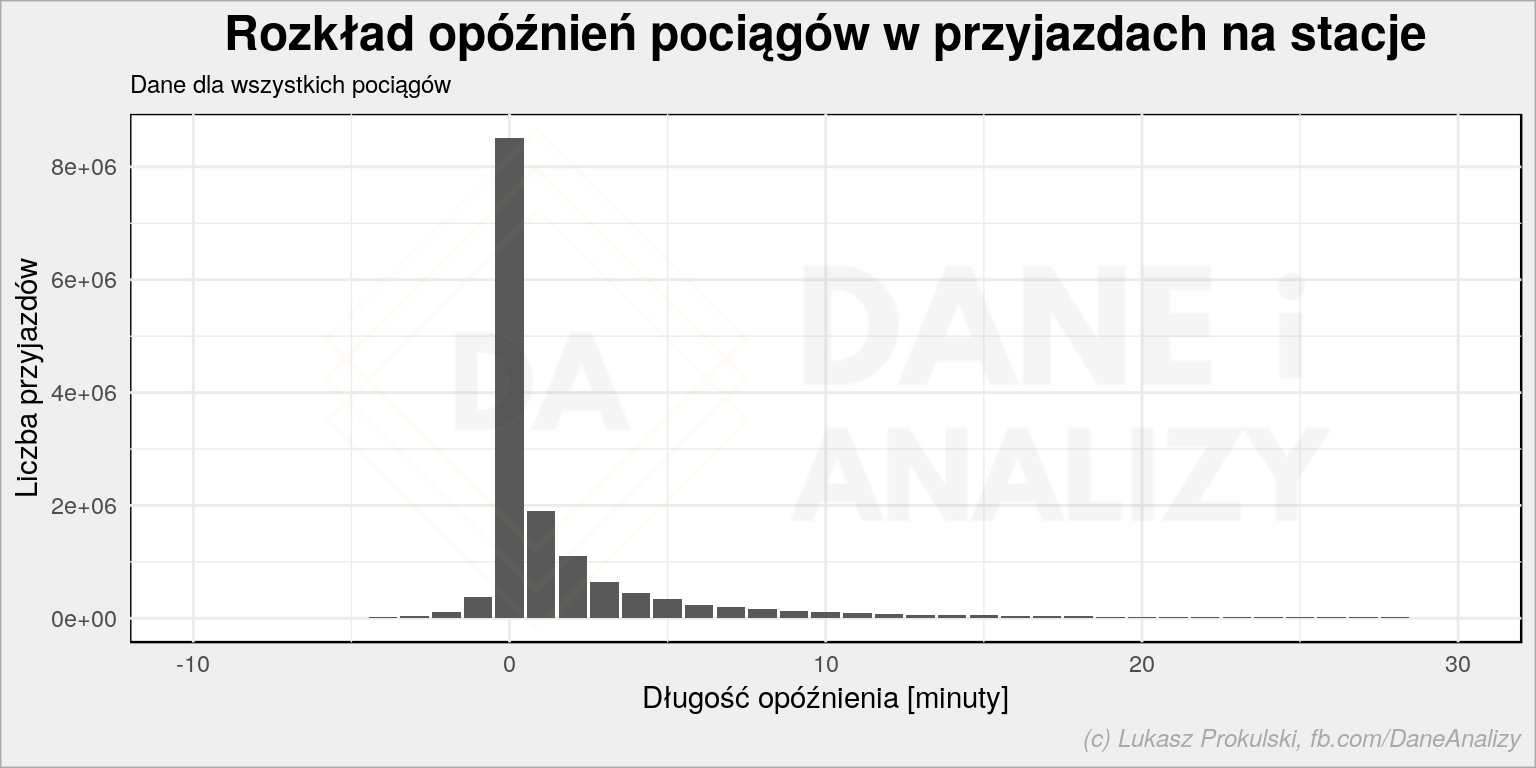
W dalszej części zastosujemy jeszcze jedno uproszczenie: wybierzemy tylko te dane, gdzie opóźnienie przyjazdu mieści się w  co oznacza wybranie 95.5% wartości leżących blisko średniej:
co oznacza wybranie 95.5% wartości leżących blisko średniej:
|
1 2 3 4 |
df_filltered <- df %>% filter(!is.na(arrival_delay)) %>% filter(arrival_delay <= mean(arrival_delay) + 2 * sd(arrival_delay)) %>% filter(arrival_delay >= mean(arrival_delay) - 2 * sd(arrival_delay)) |
Ciekawostka: zdefiniowaliśmy df_filltered i normalnie byłaby to już nowa wartość trzymana w pamięci. Jednak nie mamy wyraźnego pobrania (brak collect() na końcu) danych ze Sparka do R więc jest to tylko definicja. Wykona się dopiero wtedy kiedy wyraźnie tego zażądamy.
Opóźnienia
średnie opóźnienie według dnia
Zobaczmy teraz jak globalnie wyglądają opóźnienia pociągów (precyzyjniej: przyjazdów pociągu na stację) według dnia.
Uśredniamy dane w poszczególnych dniach dla wszystkich stacji. Powiemy tylko tyle, że w jakimś dniu roku pociągi opóźniały się bardziej lub mniej niż w innym. To nie powie nam nic o tym które to pociągi, czy zawsze tak jest itd.
Te uśrednione dane będą nam potrzebne jeszcze za chwilę – możemy pokazać je w różny sposób – więc niech Spark wyliczy, a wynik zachowamy sobie w pamięci:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
mean_arrival_delay_df <- df_filltered %>% # moment przyjazdu rozdzielamy na składowe czasu i daty mutate(ar_year = year(arrival_time), ar_month = month(arrival_time), ar_day = day(arrival_time), ar_hour = hour(arrival_time)) %>% # dla każdej z godzin liczymy średnie opóźnienia wszystkich pociągów na wszystkich stacjach group_by(ar_year, ar_month, ar_day, ar_hour) %>% summarise(mean_arrival_delay = mean(arrival_delay)) %>% ungroup() %>% # wynik wciągamy do pamięci - tego niżej nie zrobimy łatwo w Sparku collect() %>% # składamy datę w jedno mutate(ar_date = make_date(ar_year, ar_month, ar_day)) %>% # rozpoznajemy dzień tygodnia mutate(ar_wday = wday(ar_date, week_start = 1, # dzień tygodnia trzymamy jako pełną polską jego nazwę abbr = FALSE, label = TRUE, locale = "pl_PL.UTF8")) |
Policzmy teraz średnią (ze średnich godzinowych) dla każdego dnia:
|
1 2 3 4 5 6 7 8 9 10 |
mean_arrival_delay_df %>% group_by(ar_date) %>% summarise(mean_arrival_delay = mean(mean_arrival_delay)) %>% ungroup() %>% ggplot() + geom_line(aes(ar_date, mean_arrival_delay)) + geom_smooth(aes(ar_date, mean_arrival_delay)) + labs(title = "Średnie opóźnienie przyjazdu pociągu na stację", subtitle = "Dane dla wszystkich pociągów", x = "Data", y = "Średnie opóźnienie [minuty]") |
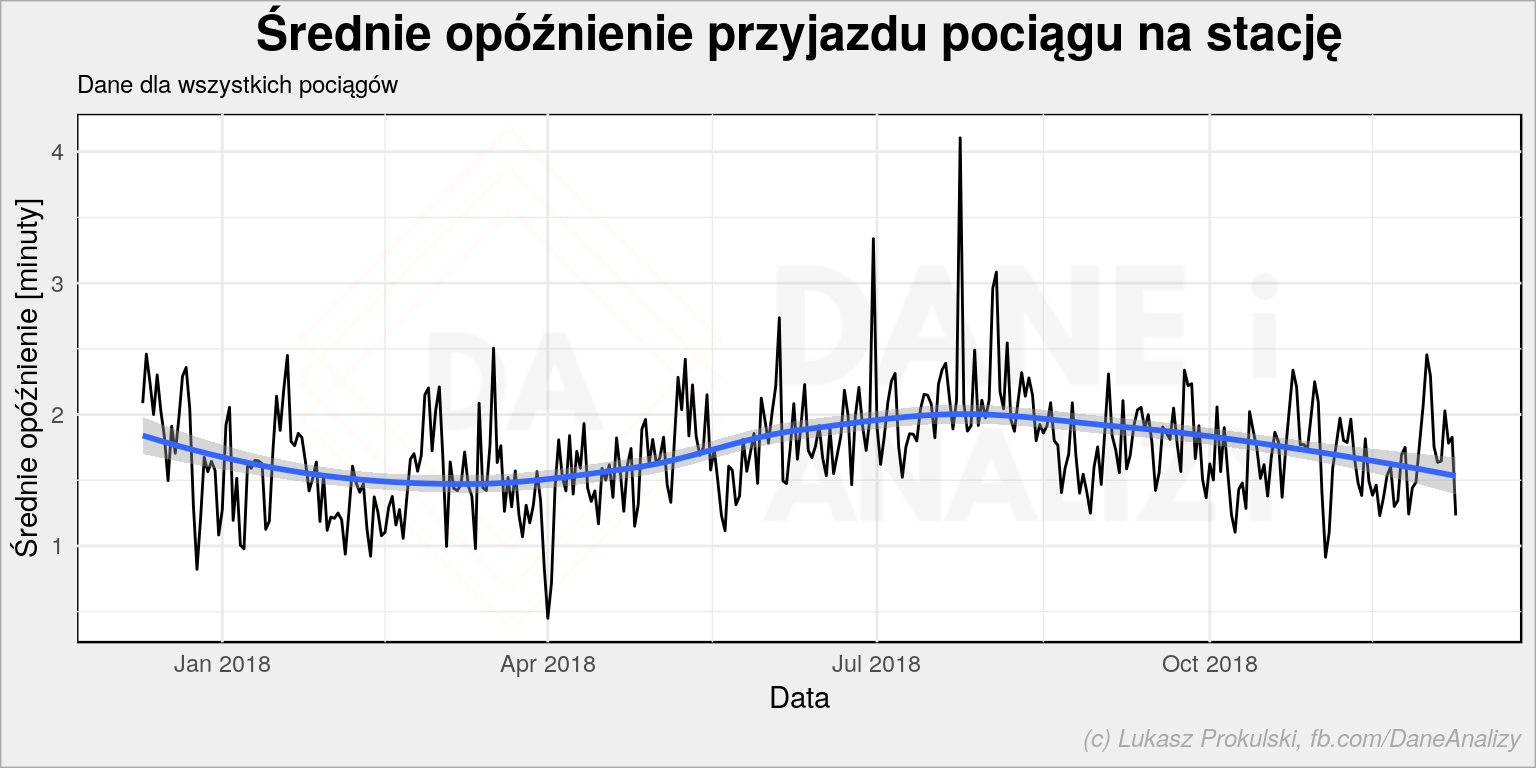
Nie jest źle – pociągi średnio spóźniają się niecałe dwie minuty. Wiosną trochę mniej niż latem i zimą. Czy to jest prawdziwe? Wkraczamy na pole statystyki i wnioski wysnute na wszystkich danych mogą być mylące. Bo w naszych danych mamy jakiś zbiór pociągów – być może wszystkie. Analizując listę stacji widać że są to często pociągi podmiejskie, SKM-ki i podobne. Te może się nie spóźniają bardzo, jeździ ich dużo co robi masę dla średnich.
Dla przykładu weźmy pierwszy z kraju pociąg pospieszny jadący z Przemyśla do Szczecina 38174/5 PRZEMYŚLANIN:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
df %>% filter(!is.na(arrival_delay)) %>% filter(train_name == "38174/5 PRZEMYŚLANIN") %>% group_by(schedule_date) %>% summarise(mean_arrival_delay = mean(arrival_delay)) %>% ungroup() %>% collect() %>% ggplot() + geom_point(aes(schedule_date, mean_arrival_delay)) + geom_smooth(aes(schedule_date, mean_arrival_delay), alpha = 0.6) + labs(title = "Średnie opóźnienie przyjazdu pociągu na stację", subtitle = "Dane dla pociągu 38174/5 PRZEMYŚLANIN", x = "Data", y = "Średnie opóźnienie [minuty]") |
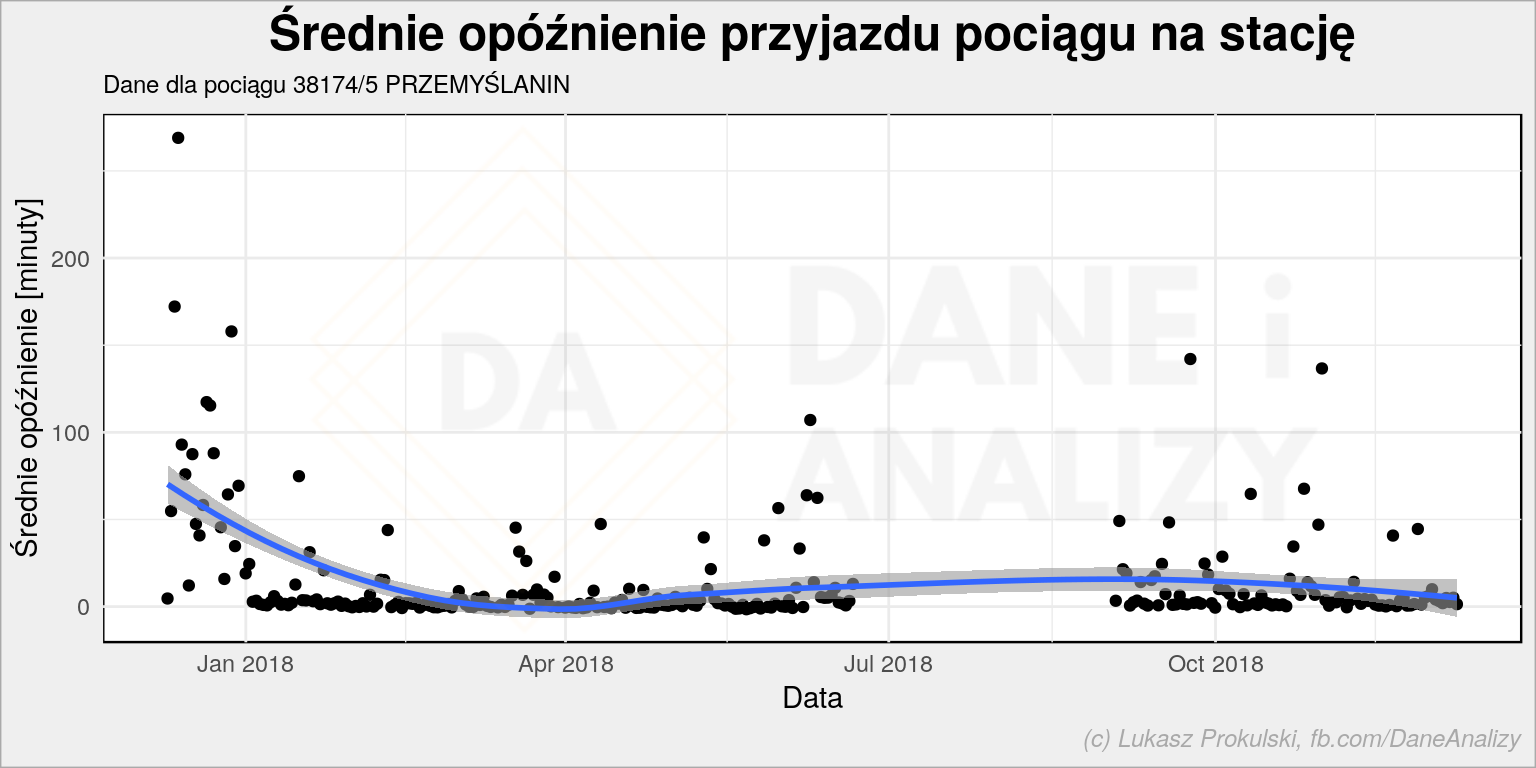
I tutaj sytuacja nie wygląda już tak różowo. Możemy jeszcze rozłożyć te dane na poszczególne stacje:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
df %>% filter(!is.na(arrival_delay)) %>% filter(train_name == "38174/5 PRZEMYŚLANIN") %>% group_by(schedule_date, station_name) %>% summarise(mean_arrival_delay = mean(arrival_delay)) %>% ungroup() %>% collect() %>% ggplot() + geom_tile(aes(schedule_date, station_name, fill = mean_arrival_delay)) + scale_fill_gradient(low = "white", high = "red") + theme(legend.position = "bottom") + labs(title = "Średnie opóźnienie przyjazdu pociągu na stację", subtitle = "Dane dla pociągu 38174/5 PRZEMYŚLANIN", x = "Data", y = "Stacja", fill = "Średnie opóźnienie [minuty]") |
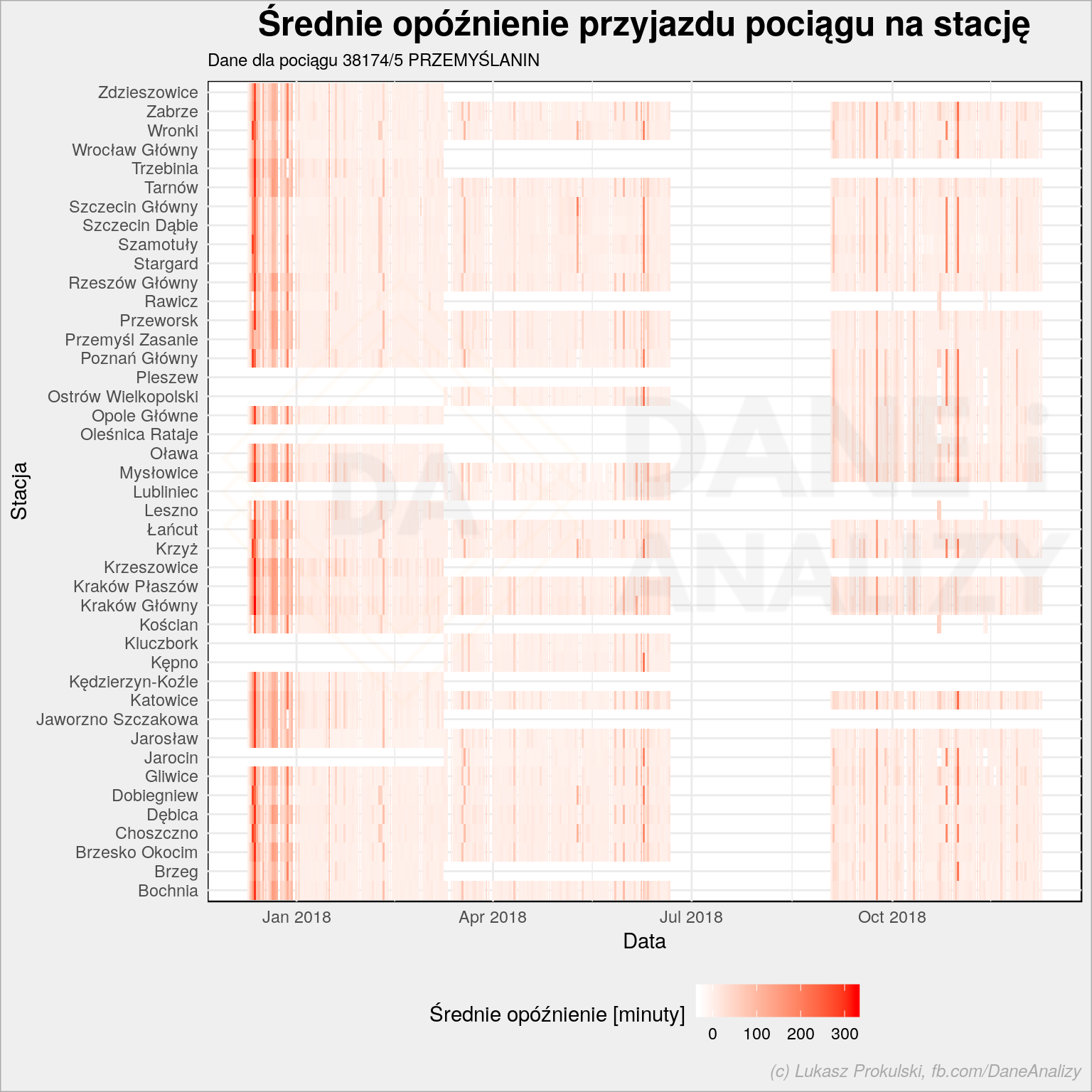
Od razu rzuca się w oczy, że pociąg jeździ różną trasą w różnych okresach roku (raz przez Wrocław, raz przez Ostrów Wielkopolski), w wakacje ten konkretny nie jeździ (ale są inne “Przemyślaniny” z innymi numerami). Gdyby poukładać stacje zgodnie z trasą być może udałoby się zobaczyć, że na pewnych odcinkach opóźnienie rośnie.
Wróćmy do globalnych rozważań: czy opóźnienia w ciągu tygodnia wyglądają jakoś charakterystycznie?
|
1 2 3 4 5 6 7 8 9 10 11 12 |
mean_arrival_delay_df %>% group_by(ar_wday, ar_hour) %>% summarise(mean_arrival_delay = mean(mean_arrival_delay)) %>% ungroup() %>% ggplot() + geom_tile(aes(ar_wday, ar_hour, fill = mean_arrival_delay), color = "gray50") + scale_y_reverse() + scale_fill_gradient2(low = "green", mid = "white", high = "red", midpoint = 0) + theme(legend.position = "bottom") + labs(title = "Średnie opóźnienie przyjazdu pociągu na stację", subtitle = "Dane dla wszystkich pociągów", x = "", y = "Godzina", fill = "Średnie opóźnienie [minuty]") |
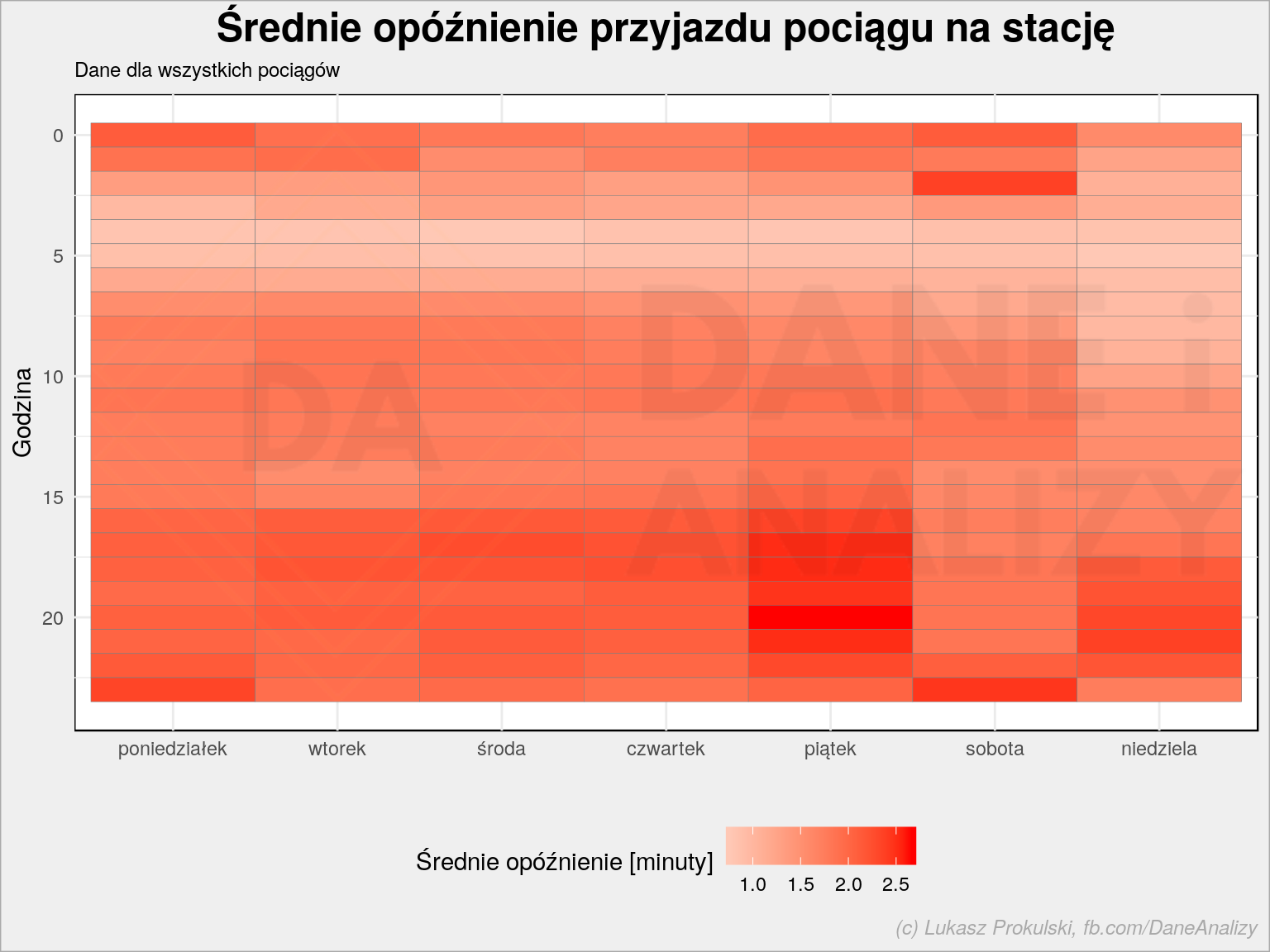
Te poranne pociągi są raczej punktualne. Popołudniowy szczyt w piątki generuje opóźnienia. Znowu – są one niewielkie, bo patrzymy na wszystkie pociągi. Być może w rozbiciu na poszczególne składy wygląda to inaczej?
średnie opóźnienie według pociągu
Czy są pociągi, które opóźniają się zazwyczaj najbardziej? Poszukajmy 10 takich, dla których średnia opóźnień na kolejnych stacjach jest największa:
|
1 2 3 4 5 6 7 8 9 |
df_filltered %>% group_by(train_id, train_name) %>% summarise(ma = mean(arrival_delay, na.rm = TRUE)) %>% ungroup() %>% collect() %>% top_n(10, ma) %>% arrange(desc(ma)) %>% kable() %>% kable_styling(bootstrap_options = c("striped", "hover", "condensed", "responsive")) |
| train_id | train_name | ma |
|---|---|---|
| 2759 | 50966 | 28.00000 |
| 2332 | 90807/6 | 27.07143 |
| 2574 | 77728 | 27.00000 |
| 3837 | 15205/4 CZERWONY | 27.00000 |
| 4446 | 84104/5 NIEKOŃCZĄCA SIĘ OPOW | 27.00000 |
| 4357 | 90529 | 26.88889 |
| 2775 | 31142/3 | 25.00000 |
| 3330 | 60708 | 24.89474 |
| 4663 | 55376 | 24.40000 |
| 2765 | 95903 | 24.17647 |
Co to za pociągi? Którędy jeżdżą? Trzeba wyszukać :P
średnie opóźnienie wg stacji
To samo możemy sprawdzić dla poszczególnych stacji – czy są stacje, na które wszystkie pociągi zazwyczaj przyjeżdżają opóźnione?
|
1 2 3 4 5 6 7 8 9 |
df %>% group_by(station_name) %>% summarise(ma = mean(arrival_delay, na.rm = TRUE)) %>% ungroup() %>% collect() %>% top_n(10, ma) %>% arrange(desc(ma)) %>% kable() %>% kable_styling(bootstrap_options = c("striped", "hover", "condensed", "responsive")) |
| station_name | ma |
|---|---|
| Stalowa Wola Rozwadów Towarowa | 329.00000 |
| Psary | 93.00000 |
| Przemyśl Bakończyce | 86.18182 |
| Grodno | 72.50000 |
| Hrubieszów Miasto | 39.43284 |
| Warszawa Grochów | 33.28571 |
| Cierpice | 30.00000 |
| Warszawa Gdańska | 29.94444 |
| Doboszowice | 27.22222 |
| Paczków | 27.11111 |
| Otmuchów Jezioro | 27.11111 |
Stalowa Wola Rozwadów Towarowa to jakiś pojedynczy przypadek, outliner (występuje chyba tylko raz w bazie).
Lokalizacja stacji
Przejdźmy jednak dalej. Spróbujmy narysować sieć połączeń.
Dane o lokalizacji stacji
Przede wszystkim potrzebujemy lokalizacji poszczególnych stacji. W danych tej informacji nie mamy, trzeba posiłkować się innym źródłem. I znowu z pomocą przychodzi internet, trochę Googla i znajdujemy stronę bazakolejnowa.pl na której mamy bogatą bazę stacji, między innymi z ich położeniem na mapie.
Nie jest jednak tak wesoło, bo położenie jest pokazane na mapie a nie zapisane gdzieś na stronie. Rzut oka w kod strony prezentującej mapę dla losowej stacji i widzimy, że mapa generowana jest jedną funkcją w JavaScript, w której zaszyte są współrzędne geograficzne stacji. Trzeba więc pobrać stronę, wyłuskać z niej kod JS i z tego kodu współrzędne. Pełny skrypt poniżej:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 |
library(tidyverse) library(rvest) library(glue) # jesli trzeba tworzymy folder na logi if(!dir.exists("logs")) dir.create("logs") # czy sa zapisane jakies dane? if(file.exists("lokalizacje_stacji.rds")) { # tak - wczytujemy i jedziemy dalej stacje <- readRDS("lokalizacje_stacji.rds") m_id <- max(stacje$id)+1 } else { # nie - zaczynamy od zera stacje <- tibble() m_id <- 1 } # zeby sie nie wywaliło przy timeoucie safe_read_html <- safely(read_html) # jedziemy po kolei wszystkie stacje (do id 40000) for(id in m_id:40000) { cat(paste0("\rID = ", id)) base_url <- glue("https://www.bazakolejowa.pl/index.php?dzial=stacje&id={id}&ed=0&okno=polozenie") # proba wczytania strony page <- safe_read_html(base_url) # czy udalo sie? if(!is_null(page$result)) { script_js <- page$result %>% html_nodes("script") %>% html_text() %>% .[str_detect(., "mapInit")] if(length(script_js) != 0) { df <- str_match_all(script_js, "([\\d.]+), ([\\d.]+),.*'(.*)', ") %>% unlist() %>% .[2:4] df <- tibble(id = id, station_name = df[[3]], long = as.numeric(df[[1]]), lat = as.numeric(df[[2]])) stacje <- bind_rows(stacje, df) } } else { cat(paste0("\nID = ", id, ": ", page$error, "\n")) # chyba zabijam serwer, z obserwacji wynika, że po około 15 minutach się podnosi - czekajmy więc 20 minut Sys.sleep(20*60) # i jedziemy dalej } # chwilę czekamy - nie zabijajmy serwera od razu ;) Sys.sleep(sample(seq(0.5, 1.5, 0.25), 1)) # co 10 requestów zapisujemy plik - żeby nie pobierać wszystkiego od początku if(id %% 10 == 0) saveRDS(stacje, "lokalizacje_stacji.rds") } # pełne dane zapisujemy na koniec saveRDS(stacje, "lokalizacje_stacji.rds") |
W wyniku (po dobie, może dwóch) dostajemy plik lokalizacje_stacji.rds z informacjami o lokalizacjach stacji. Możemy sobie narysować mapkę stacji – to niezła ciekawostka typu #widaćzabory:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
stacje <- readRDS("lokalizacje_stacji.rds") %>% filter(!is.na(station_name)) ggplot() + # konruty Polski geom_polygon(data = map_data("world", region = "Poland"), aes(long, lat, group=group), color = "red", fill = "white") + # położenie stacji geom_point(data = stacje, aes(long, lat), size = 0.1) + coord_quickmap() + theme_minimal() + labs(title = "Polskie stacje kolejowe", subtitle = "według danych www.bazakolejowa.pl", x = "", y = "") |
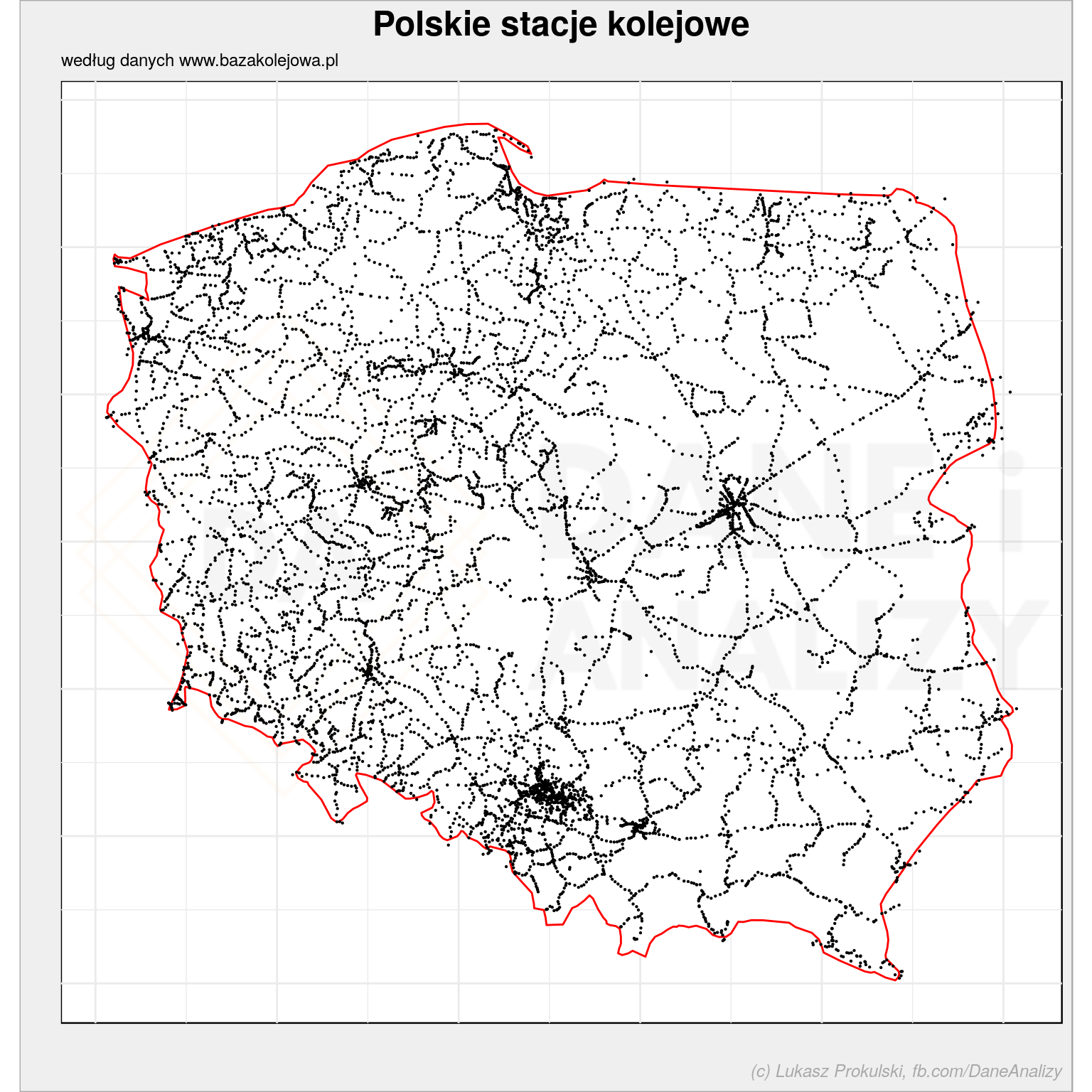
Obserwujący Dane i Analizy na Facebooku już widzieli powyższą mapkę. Dlatego warto zostać fanem :)
Najpopularniejsze połączenia
Problem z narysowaniem mapy jest jeden, ale istotny – nazwy stacji w rozkładzie (w tabeli z opóźnieniami) różnią się czasem od nazw zebranych razem z ich lokalizacjami. Trzeba to jakoś ujednolicić. Można ręcznie (hehehe, oszalał!), a można sposobem.
Spróbujmy poczynić tak:
- porównajmy listę stacji z rozkładu z listą z lokalizacjami
- to co się zgadza łatwo dopasujemy (join na tabelach doda nam współrzędne)
- to co się nie zgadza dopasujemy przez podobieństwo nazw jakimś algorytmem
- każdą niepasującą nazwę z lokalizacji porównamy ze wszystkimi nazwami z rozkładu
- za właściwą uznamy tę, która będzie najbardziej podobna i z niej weźmiemy współrzędne
Zatem do dzieła! Poniżej więcej treści w komentarzach w kodzie
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
# bierzemy listę wszystkich stacji występujących w rozkładzie stacje_df <- df %>% distinct(station_name) %>% collect() # po próbach wiem, że te stacje są mylnie rozpoznawane (niepoprawne ciągi są bardziej podobne) # zatem zmieniam je ręcznie stacje_df <- stacje_df %>% mutate(station_name = case_when( station_name == "Warszawa Zoo" ~ "Warszawa ZOO", station_name == "Warszawa Wschodnia" ~ "Warszawa Wschodnia Osobowa", station_name == "Kraków Główny" ~ "Kraków Główny Osobowy", station_name == "Tułowice Niemodlińskie" ~ "Tułowice", station_name == "Małaszewicze Przystanek" ~ "Małaszewicze", station_name == "Wolin Pomorski" ~ "Wolin", station_name == "Przylep" ~ "Zielona Góra Przylep", station_name == "Brest Centralny" ~ "Brest", station_name == "Forst Lausitz" ~ "Forst (Baršć)", TRUE ~ station_name)) # tutaj mamy zgromdzone nazwy i współrzędne z bazy kolejowej stacje <- readRDS("lokalizacje_stacji.rds") %>% drop_na() # łączymy na początek wszystko razem razem <- left_join(stacje_df, stacje, by = "station_name") |
Teraz szukamy stacji, których nie udało się połączyć.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 |
# szukamy najbardziej podobnych nazw stacji dla tych, których nie udało się złączyć joinem automatycznie # to będzie nasz słownik pośredni str_mat <- razem %>% filter(is.na(id)) %>% pull(station_name) %>% # liczymy podobieństwo ciągów stringdistmatrix(stacje$station_name, method= "cosine") # macierz potrzebuje nazw kolumn i wierszy rownames(str_mat) <- razem %>% filter(is.na(id)) %>% pull(station_name) colnames(str_mat) <- stacje$station_name # z macierzy budujemy data.frame str_mat_d <- str_mat %>% as.data.frame() %>% rownames_to_column("station_1") %>% # szeroką tabelę zamieniamy w długą gather(key = "station_2", value = "simmilarity", -station_1) %>% filter(!is.nan(simmilarity)) %>% # znajdujemy najbardziej podobne (najmniejsza odległość kosinusowa) stacje group_by(station_1) %>% filter(simmilarity == min(simmilarity)) %>% ungroup() # łączymy ze słownikiem pośrednim polozenie_stacji <- left_join(razem, str_mat_d %>% select(-simmilarity), by = c("station_name" = "station_1")) %>% # jeśli nie ma nazwy stacji w słowniku pośrednim to bierzemy oryginalną (znalazła się w tabeli ze współrzędnymi) # w przeciwnym przypadku - nazwę ze słownika mutate(station_name = if_else(is.na(station_2), station_name, station_2)) %>% # potrzebujemy tylko unikalne nazwy select(station_name) %>% distinct() %>% # dodajemy info o wspołrzędnych left_join(stacje, by = "station_name") %>% # jeśli nazwa się powtarza (ale stacja ma inne id) to uśredniamy położenie group_by(station_name) %>% summarise(long = mean(long, na.rm = TRUE), lat = mean(lat, na.rm = TRUE)) %>% ungroup() %>% drop_na() # uzupełniamy słownik dla brakujących stacji polozenie_stacji <- left_join(polozenie_stacji, str_mat_d %>% select(-simmilarity), by = c("station_name" = "station_2")) %>% mutate(station_1 = if_else(is.na(station_1), station_name, station_1)) |
Teraz wygenerujemy sobie trasy pociągów. Dany pociąg jedzie przez poszczególne stacje zgodnie z czasem (nie może być na stacji numer 3 wcześniej niż na stacji numer 2).
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
# kolejnosc stacji dla kazdego z pociagow: trasy <- df %>% # jesli nie ma czasu przyjazdu to jest taki sam jak odjazdu - to dzieje sie na stacji poczatkowej mutate(arrival_time = if_else(is.na(arrival_time), departure_time, arrival_time)) %>% # dla kazdego pociagu w kazdym dniu group_by(train_name, schedule_date) %>% # ustawiamy kolejnosc wg czasu przyjazdu (wiec w efekcie wg kolejnosci stacji) arrange(train_name, arrival_time) %>% # nadajemy numerki kolejno mutate(n = row_number()) %>% ungroup() %>% # wybieramy unikalne wiersze z nazwa pociagu, kolejnym numerem i nazwa stacji distinct(train_name, n, station_name) %>% # sortujemy wg numerow (w ramach nazwy pociagu) arrange(train_name, n) %>% collect() |
Relacja pociągu to pierwsza i ostatnia stacja. Na podstawie numerów możemy to oszacować (z jakimś błędem):
|
1 2 3 4 5 6 7 8 9 10 11 12 |
# relacje pociagow: relacje <- trasy %>% # dla każdego pociągu szukamy stacji o największym i najmniejszym numerze na trasie group_by(train_name) %>% filter(n == max(n) | n == min(n)) %>% # która stacja jest "z" a który "do"? mutate(direction = if_else(n == min(n), "from", "to")) %>% ungroup() %>% select(-n) %>% distinct(train_name, direction, .keep_all = TRUE) %>% # robimy tabelkę z dwoma kolumnami "z" i "do" spread(direction, station_name) |
Policzmy jak dużo pociągów jeździ na danych relacjach:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
relacje_n <- relacje %>% count(from, to) %>% # trick z podmianą nazw, z którymi był problem # najpierw kolumna "z" mutate(from = case_when( from == "Warszawa Zoo" ~ "Warszawa ZOO", from == "Warszawa Wschodnia" ~ "Warszawa Wschodnia Osobowa", from == "Kraków Główny" ~ "Kraków Główny Osobowy", from == "Tułowice Niemodlińskie" ~ "Tułowice", from == "Małaszewicze Przystanek" ~ "Małaszewicze", from == "Wolin Pomorski" ~ "Wolin", from == "Przylep" ~ "Zielona Góra Przylep", from == "Brest Centralny" ~ "Brest", from == "Forst Lausitz" ~ "Forst (Baršć)", TRUE ~ from), # teraz kolumna "do" to = case_when( to == "Warszawa Zoo" ~ "Warszawa ZOO", to == "Warszawa Wschodnia" ~ "Warszawa Wschodnia Osobowa", to == "Kraków Główny" ~ "Kraków Główny Osobowy", to == "Tułowice Niemodlińskie" ~ "Tułowice", to == "Małaszewicze Przystanek" ~ "Małaszewicze", to == "Wolin Pomorski" ~ "Wolin", to == "Przylep" ~ "Zielona Góra Przylep", to == "Brest Centralny" ~ "Brest", to == "Forst Lausitz" ~ "Forst (Baršć)", TRUE ~ to)) |
Dodajmy do tego współrzędne stacji:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
relacje_n_plot <- relacje_n %>% # stacje w kolejności alfabetyczniej - to wiele ułatwia mutate(stationA = if_else(from < to, from, to), stationB = if_else(from < to, to, from)) %>% select(from = stationA, to = stationB, n) %>% # sumujemy raz jeszcze, w poprawionej kolejności group_by(from, to) %>% summarise(n = sum(n)) %>% ungroup() %>% # dodajemy współrzędne dla stacji "z" left_join(polozenie_stacji, by = c("from" = "station_1")) %>% select(-from) %>% rename(from = station_name, from_lon = long, from_lat = lat) %>% # dodajemy współrzędne dla stacji "do" left_join(polozenie_stacji, by = c("to" = "station_1")) %>% select(-to) %>% rename(to = station_name, to_lon = long, to_lat = lat) %>% # usuwamy śmieci drop_na() %>% filter(from_lon != to_lon) %>% filter(from_lat != to_lat) |
Na mapce pokażemy nazwy najbardziej popularnych początków i końców tras – wybierzmy więc miasta najczęściej będące początkiem/końcem trasy:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
top_cities <- bind_rows( # najczęściej występujące stacje "z" relacje_n_plot %>% group_by(from, from_lon, from_lat) %>% summarise(n = sum(n)) %>% ungroup() %>% set_names(c("city", "long", "lat", "n")), relacje_n_plot %>% # najczęściej występujące stacje "do" group_by(to, to_lon, to_lat) %>% summarise(n = sum(n)) %>% ungroup() %>% set_names(c("city", "long", "lat", "n")) ) %>% # 100 najczęściej występujących wystaczy top_n(100, n) %>% select(-n) %>% # tylko unikaty, których będzie mniej niż 100 distinct() |
I na koniec mamy gotową mapę z siecią połączeń:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
relacje_n_plot %>% ggplot() + # kontury Polski geom_polygon(data = map_data("world", region = "Poland"), aes(long, lat, group=group), color = "red", fill = "white") + # krzywe łączące stacje geom_curve(aes(x = from_lon, y = from_lat, xend = to_lon, yend = to_lat, # grubość i natężenie koloru w zależności od liczby połączeń na danej trasie alpha = n, size = n), show.legend = FALSE) + # punkty z lokalizacjami najpopularniejszych stacji geom_point(data = top_cities, aes(long, lat)) + # nazwy tych stacji ggrepel::geom_text_repel(data = top_cities, aes(long, lat, label = city ), size = 2) + scale_alpha_continuous(range = c(0.1, 0.6)) + scale_size_continuous(range = c(0.1, 0.6)) + coord_quickmap() + theme_void() + labs(title = "Najpopularniejsze połączenia kolejowe", x = "", y = "") |
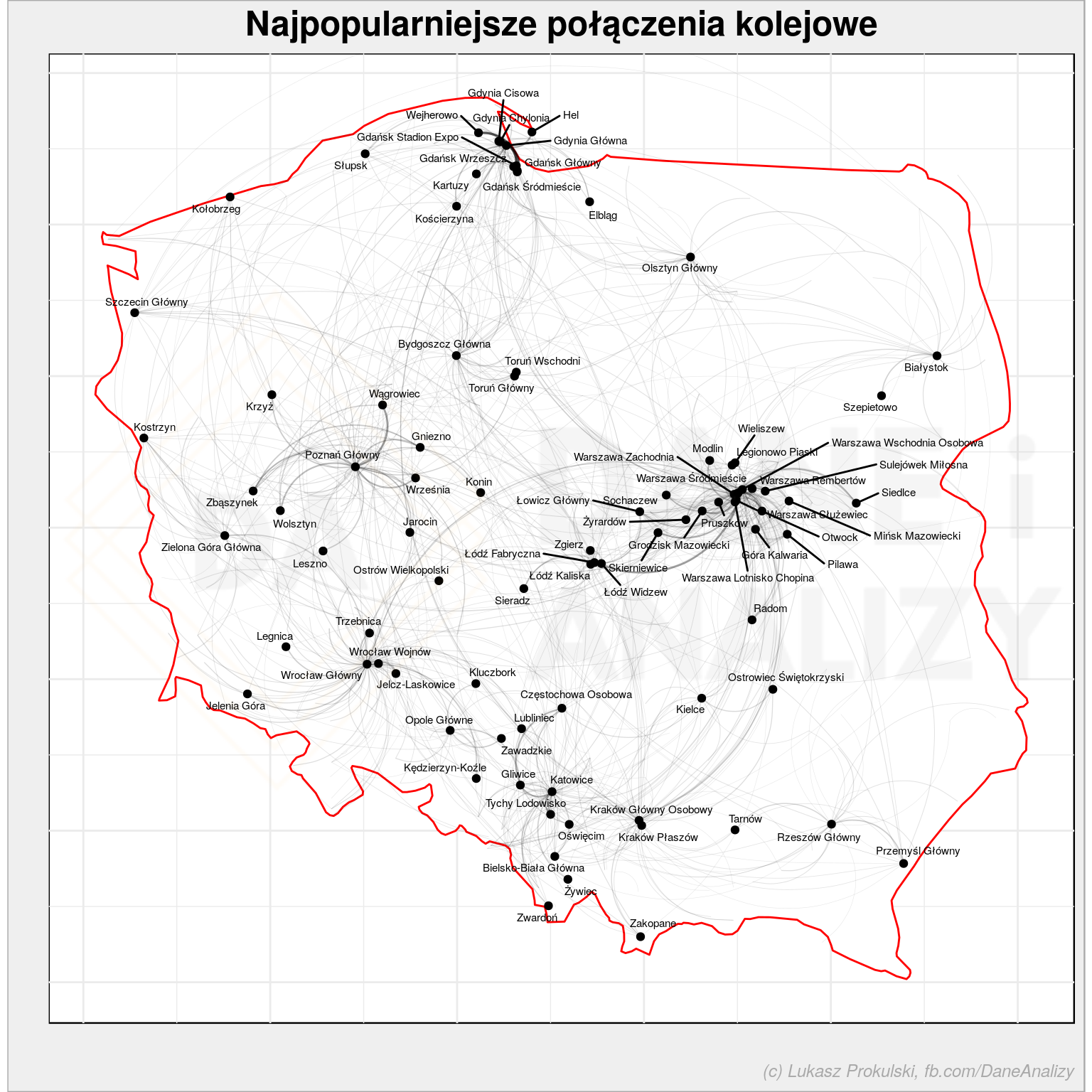
Co z tym jeszcze można zrobić? Na pewno jest kilka rzeczy:
- można poszukać wszystkich odcinków pomiędzy stacjami i policzyć średni czas przejazdu na tych odcinkach
- dla wszystkich pociągów
- dla wybranej relacji
- porównując taki czas z czasem w poszczególnych dniach znajdziemy momenty w roku, kiedy pociągi na danym odcinku mają największe opóźnienia
- mając sieć połączeń pomiędzy dwoma stacjami jesteśmy w stanie zbudować graf takich połączeń
- a mając taki graf możemy zrobić wyszukiwarkę najbardziej optymalnych połączeń (ale trzeba pamiętać, że nie każdy pociąg zatrzymuje się na każdej stacji)
Jeśli ktoś interesuje się koleją o wiele bardziej niż ja (czytaj: posiada wiedzę dziedzinową) na pewno wpadnie na kilka innych pomysłów. Będzie też potrafił rozróżnić pociągi po ich numerach (bo coś te numery znaczą – typ pociągu (osobowy, pospieszny, ekspres), być może przewoźnika albo relację), a na tej podstawie przygotować odpowiednie zestawienia.
Celem dzisiejszego wpisu było przede wszystkim pokazanie Wam jak posłużyć się Sparkiem z poziomu R (wcześniej importując do Sparka potężne ilości danych z plików – w tym wypadku – JSON) oraz jak wyciągnąć ze strony kawałek kodu JavaScript i informacje w nim zawarte. Dodatkowo (mam nadzieję) dowiedzieliście się jak połączyć dane z różnych źródeł, nawet jeśli klucze nie są identyczne (mam na myśli szukanie podobieństwa tekstów w nazwach stacji). Sama informacja o tym czy pociągi się spóźniają czy nie była drugorzędna.
Pingback: Złapane w sieci #2 - Marcin Gierbisz
Pingback: Data Hackathons – #TRACKathon19 – Pawel Cislo