Budujemy pierwszą sieć neuronową oraz porównujemy jej wyniki z XGBoost.
W pierwszej części przygotowaliśmy dane, a i tak będziemy korzystać z gotowych z Kaggle.com.
Zanim wkroczymy w sieci neuronowe zobaczmy dla przypomnienia jaki mamy rozkład liczb (ile jest jakich)?
|
1 2 3 4 5 6 7 8 9 10 |
library(tidyverse) # wczytujemy zestaw danych data <- read_csv("data/train.csv") data %>% count(label) %>% ggplot() + geom_col(aes(as.factor(label), n, fill = as.factor(n)), color = "gray50", show.legend = FALSE) + labs(x = "Liczba", y = "Liczba obrazków") |
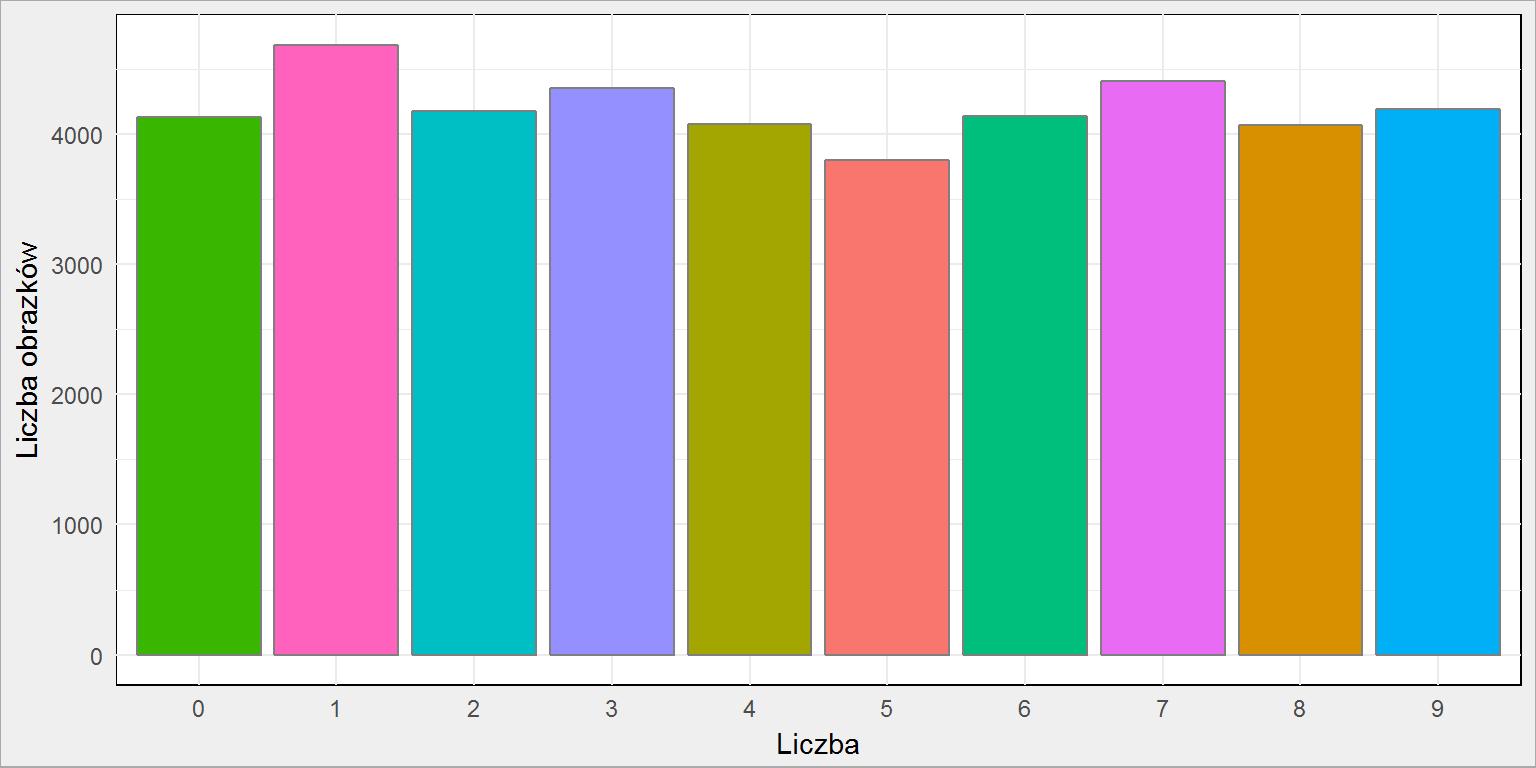
Żeby całość działa się szybciej i potrzebowała mniej pamięci wybierzemy po 250 próbek dla każdej liczby:
|
1 2 3 4 5 6 7 |
train <- data %>% group_by(label) %>% sample_n(size = 250) %>% ungroup() # liczba na obrazku to label - musi być faktorem train$label <- factor(train$label, levels = 0:9) |
W pełnym eksperymencie nie warto tego robić – najlepiej skupić się na wszystkich danych. W zasadzie tutaj obowiązuje zasada, że im więcej danych treningowych tym lepszy model.
Zaczniemy od wzmacnianych drzew, czyli XGBoost.
Już kiedyś z XGBoost korzystaliśmy – metoda ta dawała jedne z lepszych wyników, jest też bardzo popularna w konkursach Kaggle. Przygotujemy funkcję, która:
- podzieli dane na zbiór treningowy (70%) i testowy (30%)
- zbuduje najprostszy model w oparciu o dane treningowe
- na jego podstawie spróbuje określić jakie liczby mamy w zbiorze testowym
- i zwróci dokładność dopasowania (procent dobrze przypisanych klas)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 |
checkXGB <- function(depth, rounds) { library(xgboost) # podział na dane treningowe i testowe ids <- sample(1:nrow(train), 0.7 * nrow(train)) train_data <- train[ids,] test_data <- train[-ids,] # labelki na potrzeby XGBoost labels <- train_data$label # przygotowanie danych w formie zjadliwej dla XGBoost :) dtrain <- xgb.DMatrix(train_data %>% select(-label) %>% mutate_all(as.numeric) %>% data.matrix(), label = labels) # zbudowanie najprostrzego modelu XGBoost # tutaj jest największe pole do popisu jeśli chodzi o dobór parametrów xgb <- xgboost(data = dtrain, labels = labels, eta = 0.1, max_depth = depth, # to parametr naszej funkcji nround = rounds, # to parametr naszej funkcji subsample = 0.7, # tym teź można sterować colsample_bytree = 0.7, # i tym eval_metric = "merror", objective = "multi:softprob", num_class = 1+length(unique(labels)) ) # przygotowanie danych zbioru testowego labels_test <- test_data$label dtest <- xgb.DMatrix(test_data %>% select(-label) %>% mutate_all(as.numeric) %>% data.matrix(), label = labels_test) # predykcja pred <- predict(xgb, dtest) pred_mat <- matrix(pred, ncol = 11, byrow = T) colnames(pred_mat) <- c("dummy", as.character(0:9)) # z prawdopodobieństwa każdej klasy przechodzimy na klasę (o największym prawdopodobieństwie) pred_mat <- as.data.frame(pred_mat) pred_mat$pred <- apply(pred_mat[, 1:(ncol(pred_mat)-1)], 1, function(x) colnames(pred_mat)[which(x == max(x))]) pred_mat$oryg <- as.character(labels_test) # dokładność przypisania klas sum(diag(table(pred_mat$pred, pred_mat$oryg)))/sum(table(pred_mat$pred, pred_mat$oryg)) } |
Tak przygotowaną funkcję możemy wywołać z różnymi parametrami, na przykład:
|
1 |
checkXGB(15, 25) |
Zestawienie wyników dla XGBoost znajdziecie na końcu tekstu. Funkcję wywoływałem z różnymi wartościami max_depth (im więcej tym lepsze wyniki) oraz nrounds (tutaj granica jest w okolicach 50-75 rund, później wynik już się nie poprawia).
No dobrze, ale to nie ma nic wspólnego z sieciami neuronowymi. Daje nam za to jakiś punkt odniesienia dla wyników sieci. Ten punkt odniesienia można też określić korzystając z innych algorytmów klasyfikacji – kilka z nich opisałem we wspomnianym już tekście o kółkach w zbożu. Problemem jest liczba cech (tutaj mamy ich tyle ile pikseli na obrazku 28 * 28 = 784) i co za tym idzie pamięciożerność algorytmów. Można próbować metod zmniejszenia liczby cech – na przykład PCA i później użyć na przykład SVM do klasyfikacji. Daje to niezłe efekty – poszukajcie kerneli we wspomnianym konkursie Kaggle.
Pierwszą naszą siecią będzie najprostsza jednowarstwowa sieć neuronowa (FF – feed-forward-neuralnet). O tym jak to wszystko działa i jaka matematyka za sieciami stoi możecie poczytać w wielu opracowaniach – polecam chociażby artykuł z Delty. Najprościej rzecz ujmując:
- algorytm szuka wag dla poszczególnych neuronów
- wagi te są czymś w rodzaju współczynników z regresji liniowej
- dla każdego neuronu (i tym samym wagi) mamy równanie regresji złożone z wszystkich danych wejściowych (784 zmienne w naszym przypadku) i jednej danej wyjściowej (konkretna liczba, która jest na obrazku)
Po obliczeniu wszystkich wag we wszystkich iteracjach, dla wszystkich danych treningowych otrzymujemy macierz, która po przemnożeniu przez wektor opisujący obrazek testowy da nam wektor 10-elementowy (tyle ile mamy liczb) z prawdopodobieństwem przypisania obrazka do konkretnej liczby. Brzmi zagmatwanie, ale w gruncie rzeczy to dość prosta operacja, oparta na prostej algebrze liniowej.
W sieci FF możemy sterować tylko liczbą neuronów w warstwie ukrytej i to będzie parametrem naszej funkcji:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
checkNet <- function(n_neurons) { require(nnet) # podział na dane treningowe i testowe ids <- sample(1:nrow(train), 0.7 * nrow(train)) train_data <- train[ids,] test_data <- train[-ids,] # model net_model <- nnet(label ~ ., data = train_data, size = n_neurons, rang = 0.5, maxit = 100, MaxNWts = 100000, verbose = FALSE) # przewidywania test_data$digits_pred <- predict(net_model, newdata = test_data, type = "class") # accuracy sum(diag(table(test_data$label, test_data$digits_pred)))/sum(table(test_data$label, test_data$digits_pred)) } |
Dla pięciu neuronów wywołanie funkcji będzie następujące:
|
1 |
checkNet(5) |
Tę funkcję wywołujemy dla różnej liczby neuronów (mój komputer klęknął przy 50). Wyniki działania obu funkcji (opartej o XGBoost i NNet) zgromadziłem w tabeli:
| Wielkość próby | Metoda | Parametry | Wynik |
|---|---|---|---|
| 250 | nnet, 100 iteracji | 5 | 0.377 |
| 250 | nnet, 100 iteracji | 10 | 0.509 |
| 250 | nnet, 100 iteracji | 20 | 0.623 |
| 500 | nnet, 100 iteracji | 5 | 0.371 |
| 500 | nnet, 100 iteracji | 10 | 0.547 |
| 500 | nnet, 100 iteracji | 20 | 0.717 |
| pełne | nnet, 100 iteracji | 5 | 0.634 |
| 250 | nnet, 1000 iteracji | 5 | 0.157 |
| 250 | nnet, 1000 iteracji | 10 | 0.623 |
| 250 | nnet, 1000 iteracji | 20 | 0.712 |
| 250 | xgboost | 15/25 | 0.787 |
| 250 | xgboost | 25/25 | 0.803 |
| 250 | xgboost | 25/50 | 0.815 |
| 250 | xgboost | 50/100 | 0.820 |
| 250 | xgboost | 100/200 | 0.814 |
| 250 | xgboost | 250/500 | 0.841 |
| 250 | xgboost | 500/50 | 0.829 |
| 250 | xgboost | 750/50 | 0.812 |
| 500 | xgboost | 250/50 | 0.843 |
| 500 | xgboost | 750/50 | 0.824 |
| pełne | xgboost | 250/50 | 0.871 |
Widać, że:
- sieć feedforward radzi sobie coraz lepiej im więcej neuronów ma do dyspozycji. Mamy 784 punkty wejściowe i to jest sensowna graniczna liczba neuronów. Potrzeba do tego jednak bardzo dużo pamięci
- budowę modelu kończymy po 100 iteracjach – to może być mało, warto zmienić parametr maxit dla funkcji
nnet()– tabelka wyżej uwzględnia już te zmiany - im więcej mamy danych tym lepsze wyniki – dla sieci jest to poprawka o prawie 10 punktów procentowych przy dwukrotnie większych danych treningowych
Dla pełnych danych, wykorzystując funkcję checkXGB(250, 50) wynik to 0.871, co jeszcze można poprawić szukając odpowiednich parametrów eta czy subsample lub gamma). To już zadanie dla Was.
Dla porządku: wynik dla pełnych danych dla checkNet(5) to 0.634 (dwa razy lepiej niż na próbce po 250 liczb). Dodatkowo to samo zrobiłem zwiększając limit iteracji dziesięciokrotnie (parametr maxit w wywołaniu nnet() ustawiony na 1000). Wyniki to:
- 0.157 dla 5 neuronów przy próbkach po 250 na liczbę (zmiana z 0.377 – pogorszenie dość niespodziewane)
- 0.623 przy sieci złożonej z 10 neuronów (wersja z setką iteracji dała wynik 0.509). To wynik równy sieci 20 neuronów i 100 iteracji i 5 neuronom na pełnych danych
- dla sieci 20 neuronów i max 100 iteracji – 0.712
Zobaczmy jeszcze na wykresie zestawienie wyników dla sieci neuronowej:
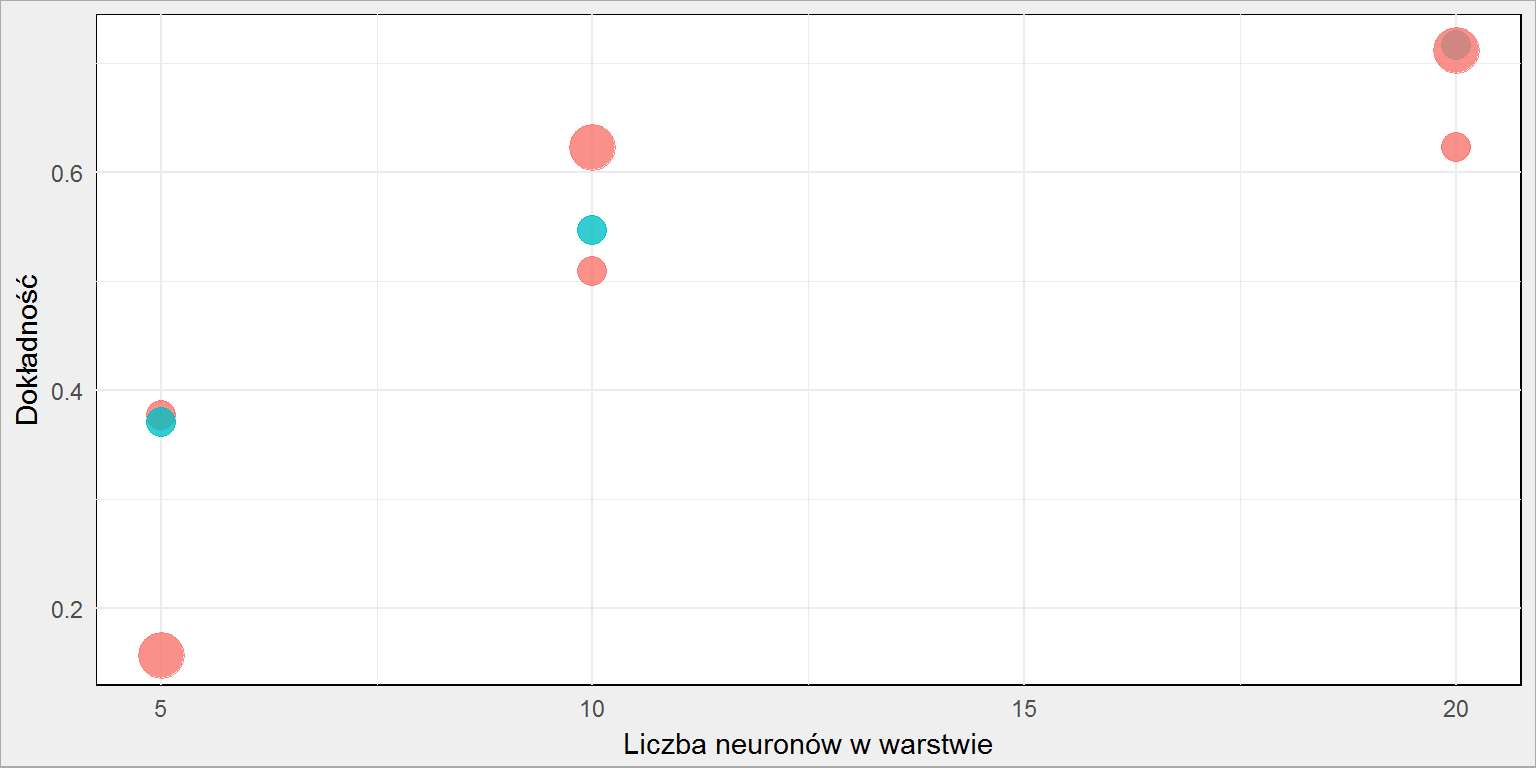
Punkty czerwone to wielkość próbki (liczba obrazów dla danej cyfry), punkty większe to sieć trenowana w maksymalnie 1000 iteracjach, mniejsze – 100. Widzimy, że zasadniczo im więcej neuronów w warstwie tym lepsze mamy efekty. Podobnie jest z liczbą iteracji i wielkością próbki (zwróćcie uwagę na wartości przy 10 neuronach).
Czas trwania trenowania sieci jednak zależy dokładnie od tych samych parametrów. Ktoś dysponuje lepszym sprzętem i puści test dla pełnych danych przy na przykład 200 neuronach i 5000 iteracji?
W kolejnej części zajmiemy się instalacją Keras oraz zbudujemy prostą sieć – już w oparciu o Keras.
Coś mnie nie działa. Błąd u mnie czy brakuje kawałka kodu powyżej?
> train %
+ group_by(label) %>%
+ sample_n(size = 250) %>%
+ ungroup()
BŁĄD:
sizemust be less or equal than 1 (size of data), setreplace= TRUE to use sampling with replacementCall
rlang::last_error()to see a backtraceBłąd dość jasno jest wytłumaczony, więc wiadomo co trzeba sprawdzić (liczbę wierszy w train) i ewentualnie zmienić…
Poradziłem sobie tak:
train % group_by(label)) %>% sample_n(size=250) %>% ungroup()
Coś wcięło:
train = as.data.frame( data %>% group_by(label)) %>% sample_n(size=250) %>% ungroup()
A jak złamać captcha? najwiekszym wyzwaniem jest odróżnienie litery od nie litery.
tu są dane https://github.com/aero2a/kape-