Auta na sprzedaż – czego można dowiedzieć się z ogłoszeń? Jak ustrzelić okazję?
Tak się zdarzyło, że rozglądam się za samochodem. Ale też na bazie sukcesu analizy ogłoszeń mieszkań na wynajem z poprzedniego roku postanowiłem przygotować podobny materiał, tym razem o samochodach.
Przez ponad dobę maszyna zbierała informacje z ogłoszeń z serwisu Otomoto.pl. Po kolei, ogłoszenie po ogłoszeniu, skrypt zapisywał dane do lokalnego pliku. Teraz użyjemy tych danych.
|
1 2 3 4 5 6 7 8 9 10 |
library(tidyverse) library(lubridate) library(stringr) library(forcats) library(ggrepel) # wczytujemy nasze zgromadzone dane auta_otomoto <- readRDS("auta_otomoto.RDS") n_offers <- auta_otomoto %>% count(OfferID) %>% ungroup() %>% nrow() |
Udało się zebrać 40747 ogłoszeń. Niektóre są już nieaktualne (bardzo szybko auta znikają), niektóre z różnych powodów nie nadają się do analizy. Jak wyglądają zgromadzone dane?
|
1 2 3 4 5 6 7 |
# losowe ogłoszenie sample_offerID <- sample(auta_otomoto$OfferID, 1) auta_otomoto %>% filter(OfferID == sample_offerID) %>% mutate(LP = row_number()) %>% select(LP, labels, values, OfferID) |
| LP | labels | values | OfferID |
|---|---|---|---|
| 1 | Oferta od | Osoby prywatnej | 6020985570 |
| 2 | Kategoria | Osobowe | 6020985570 |
| 3 | Marka | Audi | 6020985570 |
| 4 | Model | A6 | 6020985570 |
| 5 | Wersja | C7 (2011-) | 6020985570 |
| 6 | Rok produkcji | 2012 | 6020985570 |
| 7 | Przebieg | 132 000 km | 6020985570 |
| 8 | Pojemność skokowa | 2 979 cm3 | 6020985570 |
| 9 | Moc | 245 KM | 6020985570 |
| 10 | Rodzaj paliwa | Diesel | 6020985570 |
| 11 | Skrzynia biegów | Automatyczna dwusprzęgłowa (DCT, DSG) | 6020985570 |
| 12 | Napęd | 4×4 (stały) | 6020985570 |
| 13 | Filtr cząstek stałych | Tak | 6020985570 |
| 14 | Typ | Kombi | 6020985570 |
| 15 | Liczba drzwi | 4 | 6020985570 |
| 16 | Liczba miejsc | 5 | 6020985570 |
| 17 | Kolor | Czarny | 6020985570 |
| 18 | Faktura VAT | Tak | 6020985570 |
| 19 | Kraj pochodzenia | Niemcy | 6020985570 |
| 20 | Pierwsza rejestracja | 4 sierpień 2012 | 6020985570 |
| 21 | Zarejestrowany w Polsce | Tak | 6020985570 |
| 22 | Serwisowany w ASO | Tak | 6020985570 |
| 23 | Stan | Używane | 6020985570 |
| 24 | Cena | 123000 | 6020985570 |
| 25 | Cena info | Cena Brutto, Faktura VAT | 6020985570 |
| 26 | Godzina dodania | 09:44 | 6020985570 |
| 27 | Data dodania | 10 stycznia 2018 | 6020985570 |
| 28 | Zdjęcie | zdjecie.jpg | 6020985570 |
| 29 | OfferURL | ID6ztrou | 6020985570 |
| 30 | Kierownica po prawej (Anglik) | Nie | 6020985570 |
{kind=link}
Każda cecha zawarta jest w oddzielnym wierszu, a w jedno ogłoszenie spaja je kolumna OfferID. Dlaczego tak? Bo tak było łatwiej napisać skrypt scrapujący dane. Na stronie ogłoszenia cechy występują w postaci listy, ale kiedy zrobimy przegląd kilkunastu ogłoszeń widać, że nie wszystkie elementy listy (cechy) są obecne. Zatem zbieramy całą listę, dodajemy kilka stale obecnych pól (w wierszach od Cena do końca powyższej tabeli oraz numer ogłoszenia w kolumnie OfferID), a później będziemy sobie z nią radzić – w skrócie robiąc pivota do szerokiej tabeli, gdzie każde ogłoszenie będzie w tylko jednym wierszu.
Co można tutaj zauważyć? Ano przede wszystkim to, że labelki z nazwami cech są z polskimi znakami oraz mają spacje. To jest strasznie upierdliwe w późniejszym podawaniu nazw kolumn – zatem zmieńmy je (te labelki) na takie bez polskich znaków, spacji i tym podobnych:
|
1 2 3 4 |
auta_otomoto <- auta_otomoto %>% mutate(labels = str_replace_all(labels, "[^A-Za-z0-9]", " ") %>% trimws() %>% str_replace_all("[ ]+", "_")) |
Wszystko co nie jest literą alfabetu łacińskiego lub liczbą najpierw zamieniamy na spacje, a później – spacje na podkreślniki. Przy czym kilka sąsiadujących spacji zamieniamy na jeden podkreślnik.
Teraz możemy już zobaczyć z jakimi cechami globalnie (we wszystkich ogłoszeniach) mamy do czynienia. Przy okazji zobaczmy czy są cechy, które są w każdym ogłoszeniu (100%):
|
1 2 3 4 5 |
auta_otomoto %>% count(labels) %>% ungroup() %>% mutate(p = round(100*n/n_offers, 1)) %>% arrange(desc(p)) |
| labels | n | % |
|---|---|---|
| Cena | 40747 | 100.0 |
| Cena_info | 40747 | 100.0 |
| Data dodania | 40747 | 100.0 |
| Godzina_dodania | 40747 | 100.0 |
| Kategoria | 40747 | 100.0 |
| Kierownica_po_prawej_Anglik | 40747 | 100.0 |
| Kolor | 40734 | 100.0 |
| Marka | 40734 | 100.0 |
| Model | 40747 | 100.0 |
| Oferta_od | 40747 | 100.0 |
| OfferURL | 40747 | 100.0 |
| Rodzaj_paliwa | 40734 | 100.0 |
| Rok_produkcji | 40734 | 100.0 |
| Stan | 40747 | 100.0 |
| Typ | 40734 | 100.0 |
| Zdj_cie | 40747 | 100.0 |
| Przebieg | 40625 | 99.7 |
| Pojemno_skokowa | 39115 | 96.0 |
| Skrzynia_bieg_w | 38740 | 95.1 |
| Moc | 37770 | 92.7 |
| Liczba_drzwi | 37419 | 91.8 |
| Liczba_miejsc | 36347 | 89.2 |
| Nap_d | 35090 | 86.1 |
| Wersja | 31654 | 77.7 |
| Metalik | 27920 | 68.5 |
| Kraj_pochodzenia | 27775 | 68.2 |
| Bezwypadkowy | 26860 | 65.9 |
| Serwisowany_w_ASO | 20941 | 51.4 |
| Zarejestrowany_w_Polsce | 19641 | 48.2 |
| Pierwszy_w_a_ciciel | 18791 | 46.1 |
| Mo_liwo_finansowania | 15744 | 38.6 |
| Pierwsza_rejestracja | 15355 | 37.7 |
| VAT_mar_a | 13238 | 32.5 |
| Faktura_VAT | 11909 | 29.2 |
| VIN | 9695 | 23.8 |
| Leasing | 5887 | 14.4 |
| Kod_Silnika | 4413 | 10.8 |
| Per_owy | 4159 | 10.2 |
| Filtr_cz_stek_sta_ych | 2516 | 6.2 |
| Akryl_niemetalizowany | 1647 | 4.0 |
| Uszkodzony | 1290 | 3.2 |
| Emisja_CO2 | 765 | 1.9 |
| Homologacja_ci_arowa | 289 | 0.7 |
| Miesi_czna_rata | 226 | 0.6 |
| Tuning | 222 | 0.5 |
| Liczba_pozosta_ych_rat | 133 | 0.3 |
| Matowy | 132 | 0.3 |
| Op_ata_pocz_tkowa | 131 | 0.3 |
| Warto_wykupu | 129 | 0.3 |
| Zarejestrowany_jako_zabytek | 23 | 0.1 |
| Acrylic | 1 | 0.0 |
| Body_type | 13 | 0.0 |
| Color | 13 | 0.0 |
| Country_of_origin | 11 | 0.0 |
| Door_count | 13 | 0.0 |
| Engine_capacity | 13 | 0.0 |
| Engine_Code | 1 | 0.0 |
| Engine_power | 13 | 0.0 |
| Financing_option | 9 | 0.0 |
| First_registration | 8 | 0.0 |
| Fuel_type | 13 | 0.0 |
| Gearbox | 13 | 0.0 |
| Leasing_concession | 5 | 0.0 |
| Make | 13 | 0.0 |
| Metallic | 11 | 0.0 |
| Mileage | 13 | 0.0 |
| No_accident | 10 | 0.0 |
| Nr_of_seats | 13 | 0.0 |
| Original_owner | 4 | 0.0 |
| Pearl | 1 | 0.0 |
| Registered_in_Poland | 7 | 0.0 |
| Service_record | 7 | 0.0 |
| Transmission | 13 | 0.0 |
| VAT_discount | 2 | 0.0 |
| VAT_free | 8 | 0.0 |
| Version | 9 | 0.0 |
| Year | 13 | 0.0 |
Sporo jest cech obecnych wszędzie, ale na przykład interesujące nas informacje o przebiegu nie są dostępne wszędzie (przebieg jest w 99,7% ogłoszeń). Na przykład numer VIN podany jest w niecałej 1/4 ogłoszeń.
W dolnej części powyższej tabeli widać odpowiedniki angielskie polskich nazw cech. To niespodziewane, nie wiem z czego wynika. Warto więc przygotować odpowiedni słownik. Tutaj ten krok pominiemy – utracimy najwyżej kilka ogłoszeń.
Wybieramy teraz interesujące nas kolumny, wcześniej robiąc wspomnianego pivota (zamianę tabeli długiej na szeroką – dokładnie tak samo jak w Excelu działa tabela przestawna znana po angielsku jako pivot właśnie).
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
auta_wide <- auta_otomoto %>% distinct() %>% spread(key = "labels", val = "values") %>% select(OfferID, Marka, Model, Wersja, Rok_produkcji, Przebieg, Cena, Cena_info, Pojemnosc=Pojemno_skokowa, Moc, Rodzaj_paliwa, Skrzynia_biegow=Skrzynia_bieg_w, Stan, Bezwypadkowy, Uszkodzony, Anglik=Kierownica_po_prawej_Anglik, Kolor, Metalik, Typ, Liczba_drzwi, Liczba_miejsc, Kraj_pochodzenia, Zarejestrowany_w_Polsce, Pierwszy_wlasciciel=Pierwszy_w_a_ciciel, Serwisowany_w_ASO, Zdjecie=Zdj_cie, Data_dodania, Godzina_dodania, Oferta_od, OfferURL) %>% # wiersze bez podanej Marki usuwamy filter(!is.na(Marka)) # zmiana typów auta_wide$Liczba_drzwi <- as.numeric(auta_wide$Liczba_drzwi) auta_wide$Liczba_miejsc <- as.numeric(auta_wide$Liczba_miejsc) auta_wide$Cena <- as.numeric(auta_wide$Cena) auta_wide$Rok_produkcji <- as.numeric(auta_wide$Rok_produkcji) auta_wide$Przebieg <- auta_wide$Przebieg %>% str_replace("km", "") %>% str_replace_all(" ", "") %>% as.numeric() auta_wide$Pojemnosc <- auta_wide$Pojemnosc %>% str_replace("cm3", "") %>% str_replace_all(" ", "") %>% as.numeric() auta_wide$Moc <- auta_wide$Moc %>% str_replace("KM", "") %>% str_replace_all(" ", "") %>% as.numeric() |
Przy okazji przekształciliśmy dane opisane liczbami z tekstu na wartości (trochę gimnastyki z usuwaniem km czy cm3). Możemy więc przejść do
analizy
Na początek kilka prostych zestawień – jakich aut jest najwięcej?
|
1 2 3 4 5 6 7 8 9 10 |
auta_wide %>% count(Marka) %>% ungroup() %>% arrange(n) %>% mutate(Marka = fct_inorder(Marka)) %>% ggplot() + geom_col(aes(Marka, n), color = "gray50", fill = "lightgreen") + coord_flip() + labs(title = "Liczba oferowanych samochodów według marki", y = "Liczba ofert", x = "") |
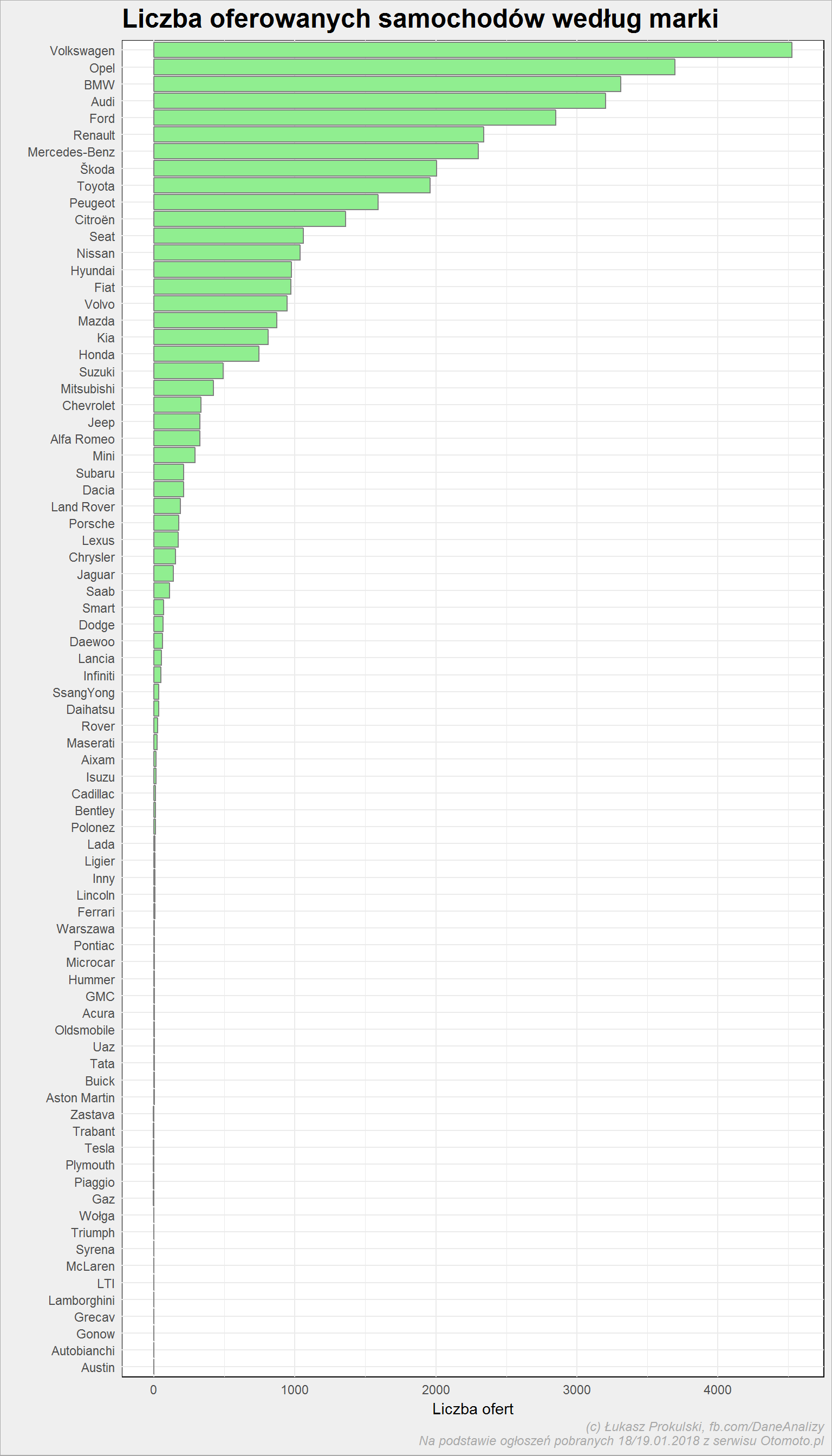
Warto ten wykres zestawić z informacjami o najchętniej kupowanych nowych autach (takie dane publikuje na przykład Instytut Badań Rynku Motoryzacyjnego Samar), z których wynika, że prowadzi Skoda (Fabia i Octavia), Opel Astra, VW Golf i Toyota Yaris. A w ogłoszeniach Otomoto Skoda jest dopiero na ósmym miejscu.
Należy jednak pamiętać o jednej, bardzo ważnej sprawie – to co tutaj prezentuję to tylko próbka, 40747 ogłoszeń (przeważnie jeszcze aktywnych), z czego 89% dodanych jest w ciągu 3 ostatnich dni:
|
1 2 3 4 5 6 7 |
auta_wide %>% count(Data_dodania) %>% mutate(procent = 100*n/sum(n)) %>% arrange(desc(n)) %>% mutate(procent_skumulowany = cumsum(procent)) %>% mutate(procent_skumulowany = round(procent_skumulowany, 1), procent = round(procent, 1)) |
| Data_dodania | n | % | % skumulowany |
|---|---|---|---|
| 18 stycznia 2018 | 17971 | 44.1 | 44.1 |
| 17 stycznia 2018 | 16907 | 41.5 | 85.6 |
| 16 stycznia 2018 | 1466 | 3.6 | 89.2 |
| 15 stycznia 2018 | 1365 | 3.4 | 92.6 |
| 14 stycznia 2018 | 1047 | 2.6 | 95.1 |
| 13 stycznia 2018 | 782 | 1.9 | 97.1 |
| 12 stycznia 2018 | 546 | 1.3 | 98.4 |
| 9 stycznia 2018 | 184 | 0.5 | 98.9 |
| 11 stycznia 2018 | 168 | 0.4 | 99.3 |
| 10 stycznia 2018 | 162 | 0.4 | 99.7 |
| 8 stycznia 2018 | 64 | 0.2 | 99.8 |
| 5 stycznia 2018 | 27 | 0.1 | 99.9 |
| 4 stycznia 2018 | 17 | 0.0 | 99.9 |
| 7 stycznia 2018 | 12 | 0.0 | 100.0 |
| 6 stycznia 2018 | 9 | 0.0 | 100.0 |
| 2 stycznia 2018 | 2 | 0.0 | 100.0 |
| 3 stycznia 2018 | 2 | 0.0 | 100.0 |
| 24 grudnia 2017 | 1 | 0.0 | 100.0 |
| 28 grudnia 2017 | 1 | 0.0 | 100.0 |
| 30 grudnia 2017 | 1 | 0.0 | 100.0 |
Wykresy słupkowe są fajne, ale trochę mało widać na tym powyżej… Jak wygląda procentowy udział poszczególnych marek w ogłoszeniach? Już w tabeli, dla 10 najpopularniejszych:
|
1 2 3 4 5 6 |
auta_wide %>% count(Marka, sort = TRUE) %>% ungroup() %>% mutate(procent = round(100*n/sum(n), 1)) %>% top_n(10, n) %>% select(Marka, procent) |
| Marka | % |
|---|---|
| Volkswagen | 11.1 |
| Opel | 9.1 |
| BMW | 8.1 |
| Audi | 7.9 |
| Ford | 7.0 |
| Renault | 5.7 |
| Mercedes-Benz | 5.6 |
| Škoda | 4.9 |
| Toyota | 4.8 |
| Peugeot | 3.9 |
Wiemy już coś o podziale rynku, przejdźmy dalej. Kolejny krok to oczyszczenie danych z wartości odstających, nienaturalnych i błędnych. Policzmy percentyle kilku wybranych cech, żeby określić co odsiać:
|
1 2 3 4 |
auta_wide %>% select(Cena, Przebieg, Rok_produkcji, Pojemnosc, Moc) %>% sapply(quantile, probs = c(0, 0.01, 0.05, 0.1, 0.15, 0.20, 0.8, 0.9, 0.95, 0.99, 1), na.rm = TRUE) %>% round(.) |
| Percentyl | Cena | Przebieg | Rok produkcji | Pojemność | Moc |
|---|---|---|---|---|---|
| 0% | 400 | 1 | 1900 | 1 | 1 |
| 1% | 2500 | 1 | 1993 | 973 | 60 |
| 5% | 5900 | 2 | 2000 | 1150 | 71 |
| 10% | 8000 | 10 | 2002 | 1242 | 82 |
| 15% | 10500 | 9436 | 2004 | 1390 | 90 |
| 20% | 12900 | 24441 | 2005 | 1400 | 100 |
| 80% | 74294 | 211000 | 2016 | 2000 | 177 |
| 90% | 125900 | 246000 | 2017 | 2700 | 224 |
| 95% | 186205 | 277040 | 2017 | 3000 | 272 |
| 99% | 378967 | 347467 | 2017 | 4969 | 426 |
| 100% | 6500000 | 5000000 | 2018 | 319800 | 204000 |
Wybieramy które przedziały zostawimy i odsiewamy resztę:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
# tutaj odsiewamy "wydumane" oferty Cena_quant_down <- 0.01 Cena_quant_up <- 0.99 Przebieg_quant_down <- 0.1 Przebieg_quant_up <- 0.95 # tutaj odsiewamy błędy przy wpisywaniu - silnik 320 tys cm3?! Pojemnosc_quant_down <- 0.01 Pojemnosc_quant_up <- 0.99 Moc_quant_down <- 0.01 Moc_quant_up <- 0.99 auta_wide <- auta_wide %>% filter(Przebieg >= quantile(Przebieg, Przebieg_quant_down, na.rm = TRUE), Przebieg <= quantile(Przebieg, Przebieg_quant_up, na.rm = TRUE), Cena >= quantile(Cena, Cena_quant_down, na.rm = TRUE), Cena <= quantile(Cena, Cena_quant_up, na.rm = TRUE), Pojemnosc >= quantile(Pojemnosc, Pojemnosc_quant_down, na.rm = TRUE), Pojemnosc <= quantile(Pojemnosc, Pojemnosc_quant_up, na.rm = TRUE), Moc >= quantile(Moc, Moc_quant_down, na.rm = TRUE), Moc <= quantile(Moc, Moc_quant_up, na.rm = TRUE), # zostawiamy tylko auta max 25 letnie Rok_produkcji >= 1993, # i bezwypadkowe Bezwypadkowy == "Tak") |
Zostało nam 20087 ogłoszeń. Dość dużo odpadło, ale próbka i tak jest całkiem słuszna.
W dalszej części skupimy się na 25 najpopularniejszych markach. Jednak nie usuwamy pozostałych danych – może się przydadzą. Zatem wybieramy top 25 marek:
|
1 2 3 4 5 |
top_marki <- auta_wide %>% count(Marka, sort = TRUE) %>% ungroup() %>% top_n(25, n) %>% .$Marka |
Jak to wygląda teraz, jakich aut i z jakiego rocznika jest najwięcej? Dodatkowo zobaczmy czy sprzedający to firmy czy osoby prywatne:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
auta_wide %>% filter(Marka %in% top_marki) %>% count(Marka, Rok_produkcji, Oferta_od) %>% ungroup() %>% arrange(desc(Marka)) %>% mutate(Marka = fct_inorder(Marka)) %>% ggplot() + geom_tile(aes(Rok_produkcji, Marka, fill = n), color = "gray50") + scale_fill_distiller(palette = "YlOrRd") + scale_x_continuous(breaks = seq(1990, 2020, 5)) + facet_wrap(~Oferta_od, ncol = 5) + theme(legend.position = "bottom") + labs(title = "Liczba dostępnych aut według marki,\nrocznika oraz oferenta", x = "Rok produkcji", y ="") |
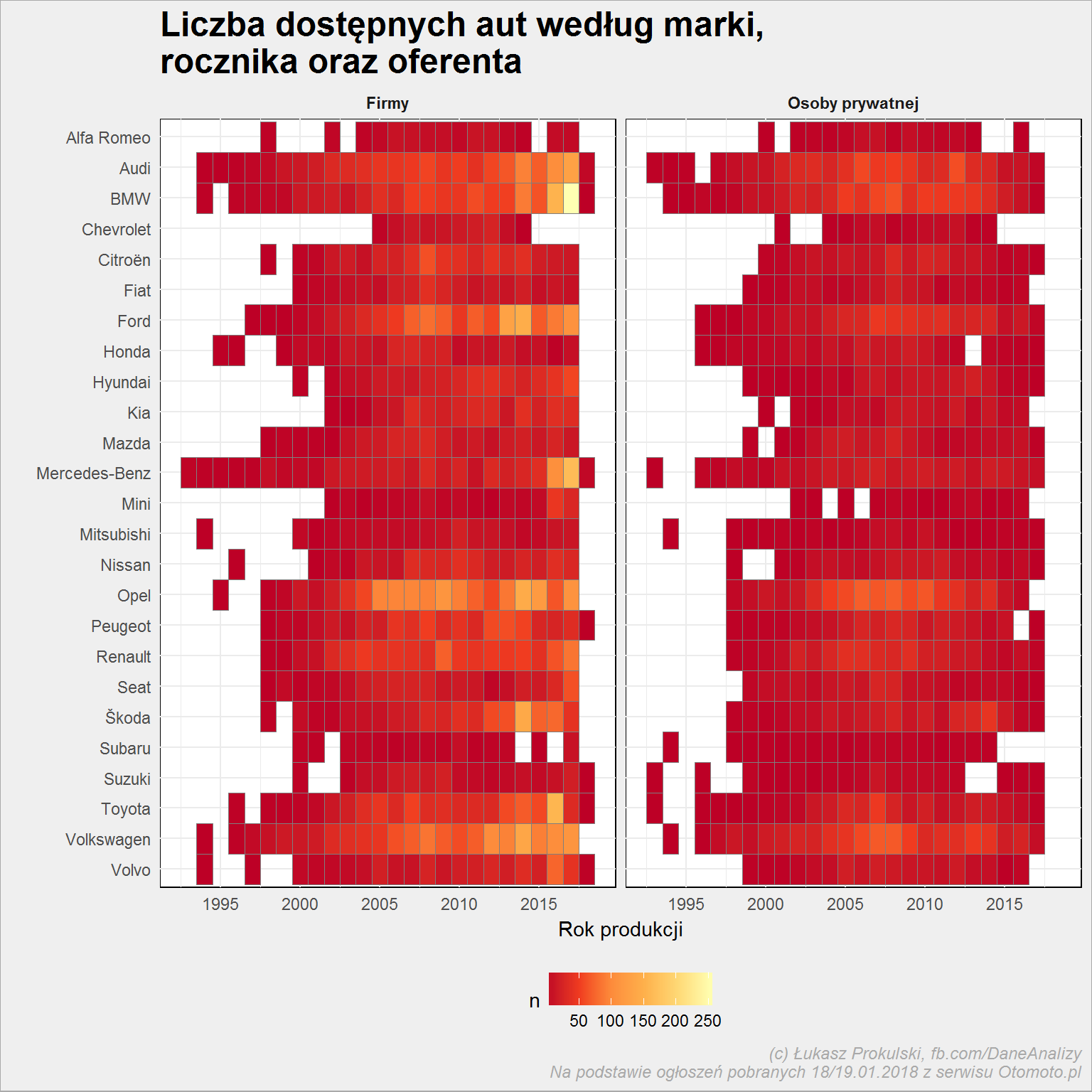
Widać, że bardziej żółto jest po lewej stronie należącej do salonów i handlarzy. Nie ma w tym nic dziwnego – biznes jest biznes. Auta sprowadzane i skupowane sprzedawane ponownie.
Ale widzimy kilka ciekawostek:
- najwięcej jest w miarę nowych (1-2 letnich) BMW
- podobnie jest z Mercedesami – też raczej sprzedawane są nowe
- Ford czy Volkswagen to już raczej auta 5-7 letnie, podobnie jak Skody
- ciekawie sprawa wygląda z Oplem: sporo jest tych starszych, prawie 10-letnich (4-5 letnich też jest trochę)
Dla mnie, jako lajkonika jeśli chodzi o samochody przy zakupie liczą się dwie informacje: cena i przebieg. Mniejszy przebieg w moim odczuciu oznacza, że auto dłużej mi posłuży i raczej mniej się będzie psuć – gdybym miał wybierać spośród samochodów tej samej marki (i modelu) o podobnej cenie i stanie wybrałbym ten z mniejszym przebiegiem.
Zobaczmy zatem jaki przebieg mają sprzedawane na Otomoto auta:
|
1 2 3 4 5 6 7 8 9 10 |
auta_wide %>% filter(Marka %in% top_marki) %>% mutate(Przebieg = round(Przebieg/1000)) %>% ggplot() + geom_histogram(aes(Przebieg), binwidth = 10, fill = "lightgreen", color = "gray50") + geom_vline(aes(xintercept = mean(Przebieg)), color = "red", size = 1) + geom_vline(aes(xintercept = median(Przebieg)), color = "blue", size = 1) + scale_x_continuous(breaks = seq(0, 350, 50)) + labs(title = "Rozkład przebiegu wszystkich oferowanych aut", x = "Przebieg w tys. km", y = "Liczba samochodów") |
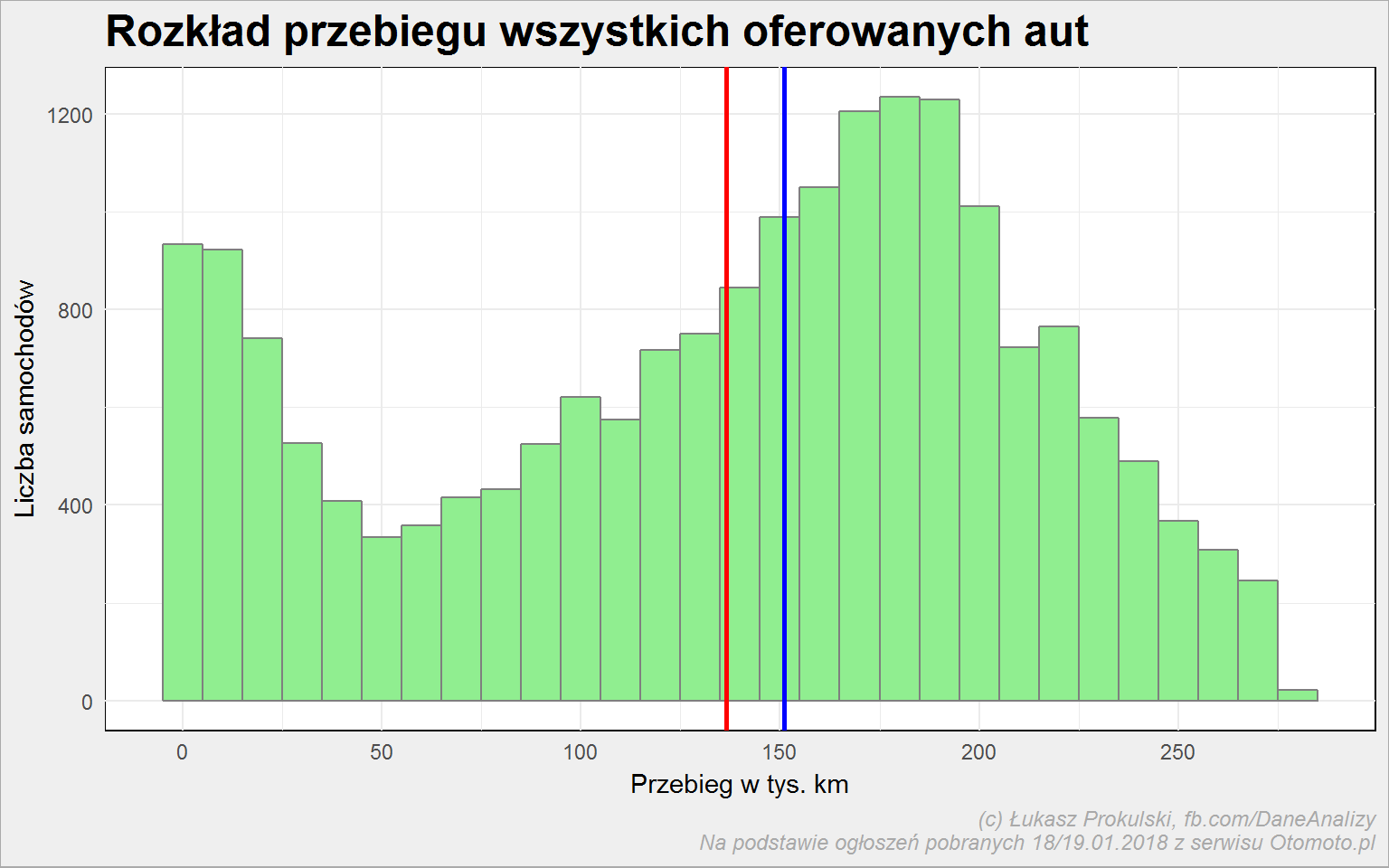
Niebieska linia to mediana, czerwona – średnia. Połowa samochodów ma przebieg większy niż około 150 tysięcy kilometrów. To całkiem sporo. Pamiętajmy, że na samym początku usunęliśmy dane o przebiegu mniejszym niż 10 km (wartość dziesiątego percentyla), czyli właściwie o samochodach nowych, co na pewno ma wpływ na kształt powyższego wykresu.
Średni przebieg to około 140 tys. km.
Zobaczmy jak to wygląda w podziale na marki:
|
1 2 3 4 5 6 7 8 9 |
auta_wide %>% filter(Marka %in% top_marki) %>% mutate(Przebieg = round(Przebieg/1000)) %>% ggplot() + geom_histogram(aes(Przebieg, fill=Marka), binwidth = 10, color = "gray50", show.legend = FALSE) + scale_x_continuous(breaks = seq(0, 400, 50)) + facet_wrap(~Marka, scales = "free_y")+ labs(title = "Rozkład przebiegu oferowanych aut, w podziale na marki", x = "Przebieg w tys. km", y = "Liczba samochodów") |
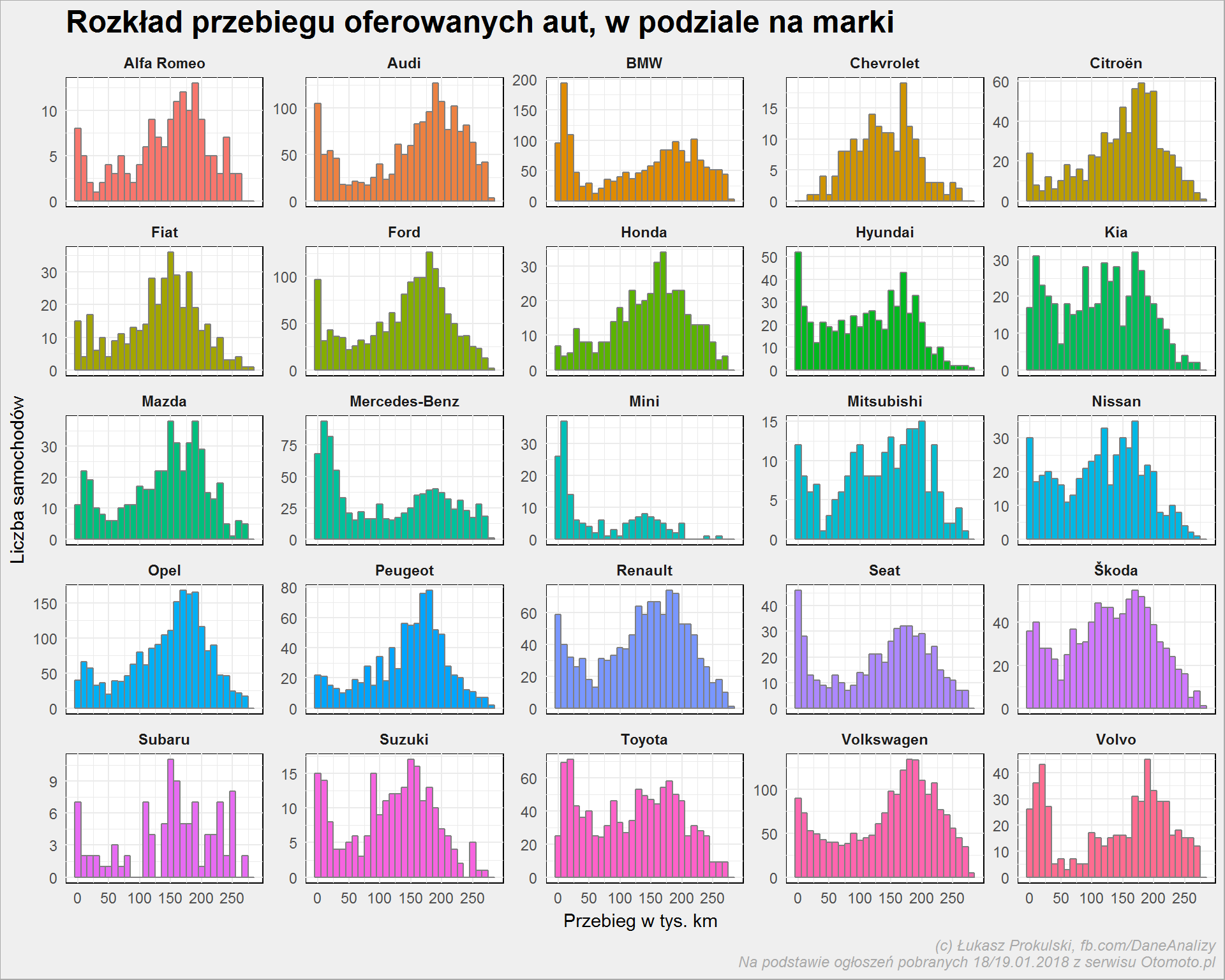
To jest ciekawe i chyba trochę mówi o samochodach a także o tym jak są używane. Otóż:
- Audi górkę zalicza przy około 180-200 tysiącach km – można wnioskować, że to auto wytrzymałe i takie z 120 tys. na liczniku jeszcze posłuży
- podobnie jest z większością popularnych marek (Ford, Skoda, Renault, Peugeot, Opel czy VW)
- ale w przypadku Fiatów górka jest już bliżej – przy 150 tysiącach. Czy to jest tak, że w tym momencie auto zaczyna się częściej psuć i trzeba się go pozbyć?
- ciekawe są tutaj Mercedesy, BMW, Volvo i Mini – czyli auta raczej drogie, więcej jest tych z mniejszym przebiegiem. Zgaduję, że są to samochody sprowadzone z zagranicy, gdzie średni wiek samochodu jest zdecydowanie mniejszy niż w Polsce, a i społeczeństwo częściej (a tym samym szybciej patrząc na przebieg) pozbywa się samochodów
- Toyota to podobne zagadnienie, ale być może znaczenie ma popularność tej marki w ostatnich latach. Wcześniej kupowało się prawie wyłącznie Opla, VW, Forda, teraz w grę wchodzą też japończyki czy koreańce
Mam rację czy się mylę? Nie znam się na samochodach – podpowiedzcie!
Spójrzmy na podobne zestawienie, ale dla cen, czyli – jak wygląda rozkład cen sprzedawanych samochodów?
|
1 2 3 4 5 6 7 8 |
auta_wide %>% filter(Marka %in% top_marki) %>% mutate(Cena = round(Cena/1000)) %>% ggplot() + geom_histogram(aes(Cena, fill=Marka), binwidth = 5, color = "gray50", show.legend = FALSE) + facet_wrap(~Marka, scales = "free_y")+ labs(title = "Rozkład cen oferowanych aut, w podziale na marki", x = "Cena w tys. PLN", y = "Liczba samochodów") |
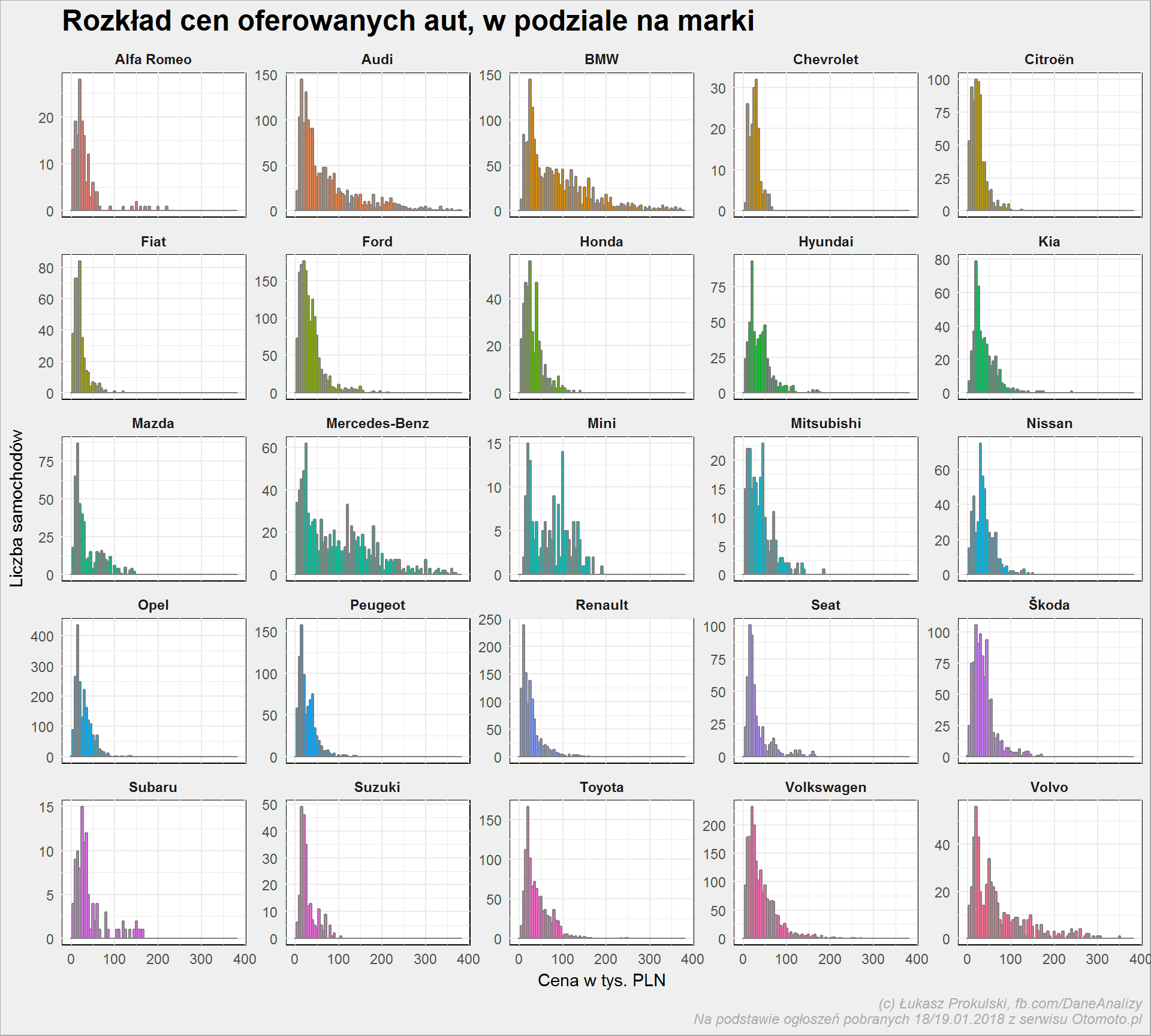
Oczywiście są auta droższe i tańsze. Wyraźnie widać, które są jakie :) Poza Mercedesem, BMW i Volvo większość mieści się w cenie do 100 tysięcy złotych. Pamiętajmy, że są to tylko najpopularniejsze marki, bez podziału na modele – inaczej kosztuje Skoda Fabia, inaczej Octavia, a jeszcze inaczej Superb:
|
1 2 3 4 5 6 7 8 |
auta_wide %>% filter(Marka == "Škoda", Model %in% c("Fabia", "Octavia", "Superb")) %>% mutate(Cena = round(Cena/1000)) %>% ggplot() + geom_histogram(aes(Cena, fill=Model), binwidth = 5, color = "gray50", show.legend = FALSE) + facet_wrap(~Model, scales = "free_y", ncol=3)+ labs(title = "Rozkład cen oferowanych aut wśród najpopularniejszych\nmodeli Škody", x = "Cena w tys. PLN", y = "Liczba samochodów") |
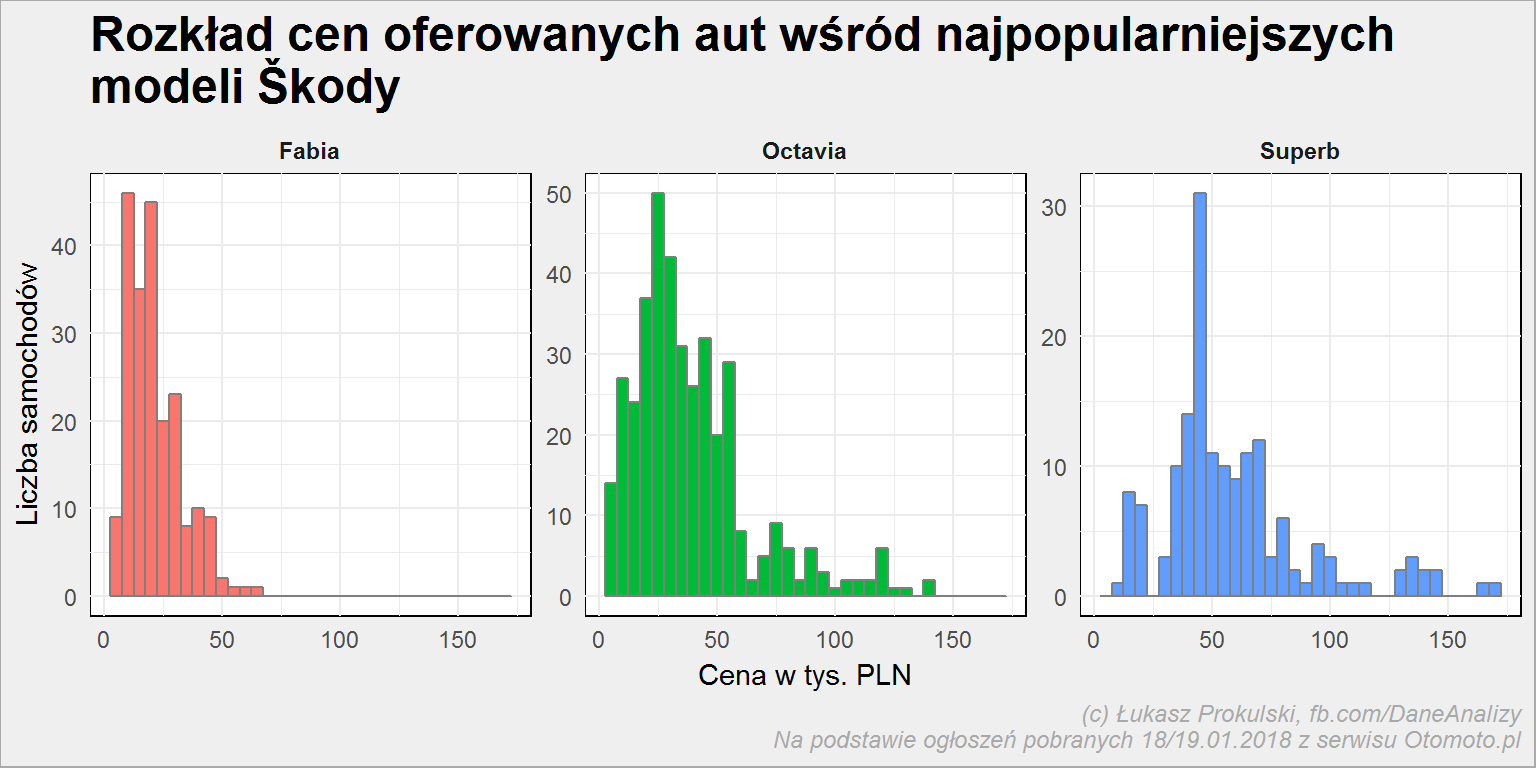
Czy cena jakoś zależy od przebiegu?
|
1 2 3 4 5 6 7 8 9 10 |
auta_wide %>% filter(Marka %in% top_marki) %>% mutate(Przebieg = round(Przebieg/1000), Cena = round(Cena/1000)) %>% ggplot() + geom_point(aes(Przebieg, Cena, color = Marka), show.legend = FALSE, alpha = 0.1, size = 0.5) + geom_smooth(aes(Przebieg, Cena, color = Marka), show.legend = FALSE) + facet_wrap(~Marka, scales = "free_y") + labs(title = "Cena w zależności od przebiegu auta, w podziale na marki", x = "Przebieg w tys. km", y = "Cena w tys. PLN") |
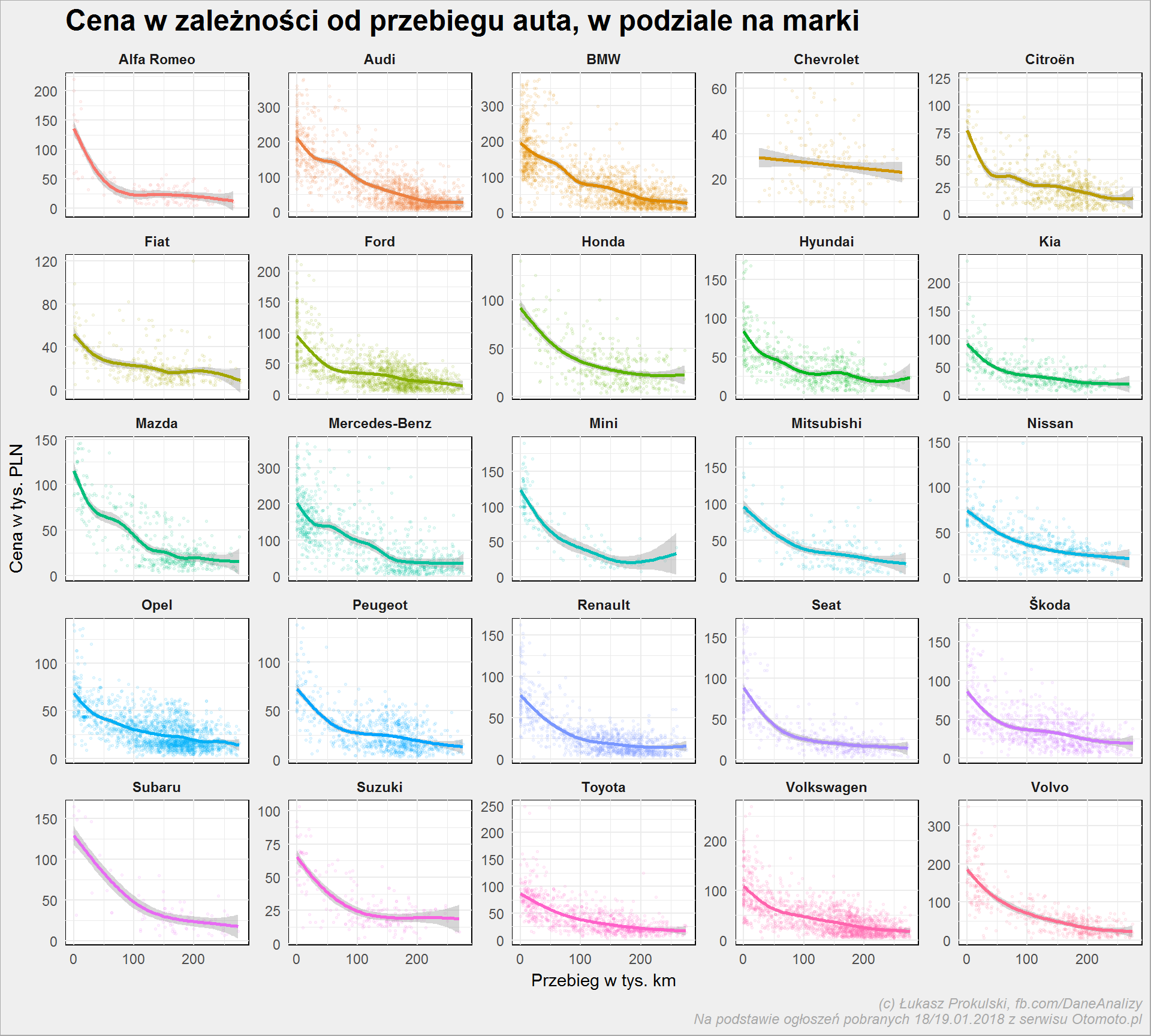
Oczywiście, że zależy. Powyższe wykresy są nieco mylące – oś Y jest indywidualna dla każdego z wykresów, zatem nie należy porównywać kształtu krzywych. Ale do tego jeszcze dojdziemy.
W dużym uproszczeniu jest tak, że im auto więcej przejedzie tym tańsze. W imię mojego sposobu pojmowania świata samochodów: więcej przejechał, to niższa jego wartość (bo będzie się pewnie szybciej psuł).
Zobaczmy jeszcze kilka podobnych przekrojów, aby dość dalej. Cena w zależności od roku produkcji:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
auta_wide %>% filter(Marka %in% top_marki) %>% mutate(Przebieg = round(Przebieg/1000), Cena = round(Cena/1000)) %>% ggplot() + geom_point(aes(Rok_produkcji, Cena, color = Marka), show.legend = FALSE, alpha = 0.1, size = 0.5) + geom_smooth(aes(Rok_produkcji, Cena, color = Marka), show.legend = FALSE) + scale_x_continuous(breaks = seq(1990, 2018, 5)) + scale_y_continuous(breaks = seq(0, 400, 50)) + facet_wrap(~Marka) + labs(title = "Zależność ceny od roku produkcji samochodu, według marek", x = "Rok produkcji", y = "Cena w tys. PLN") |
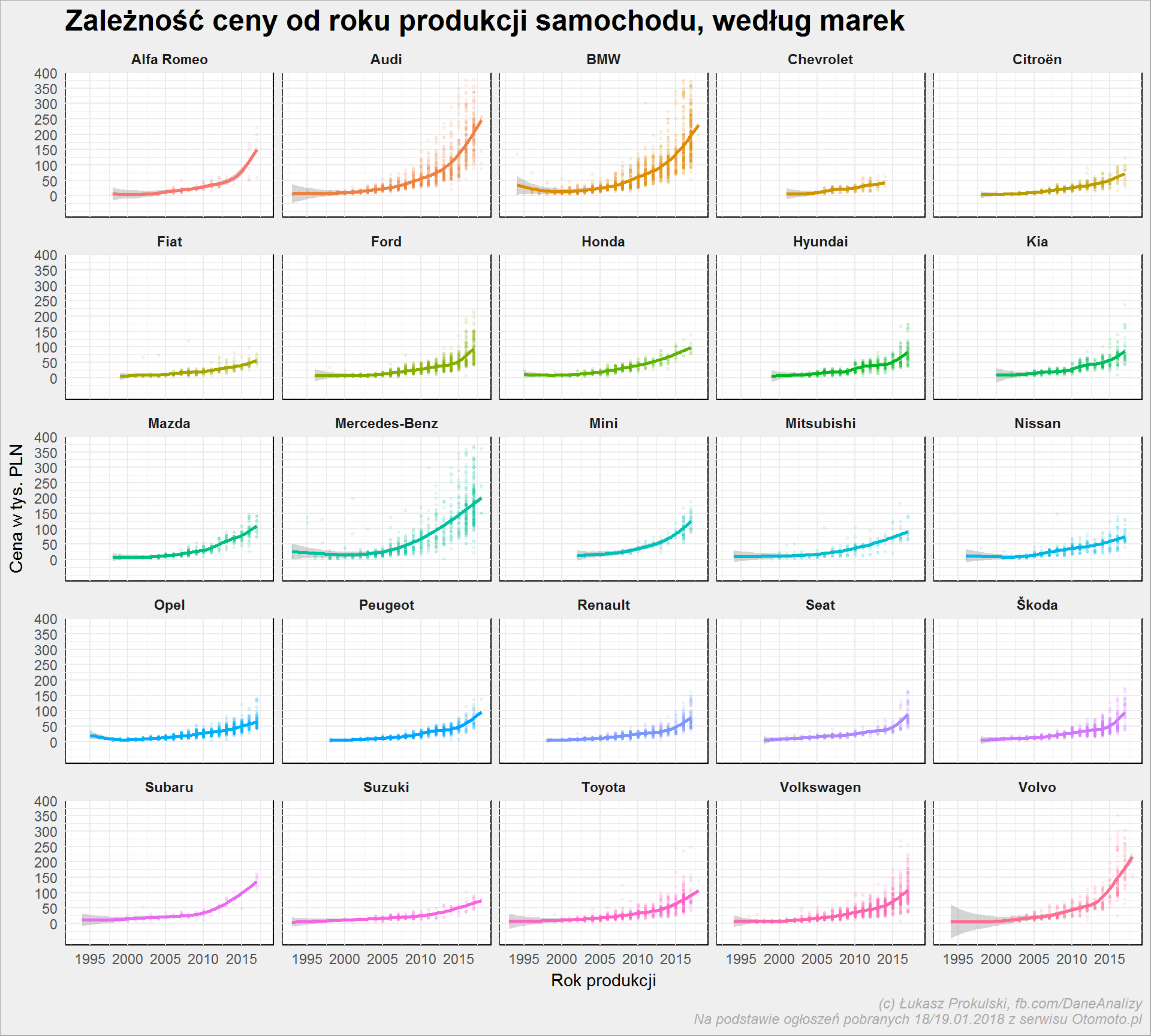
Tutaj osie X i Y trzymają skale (specjalnie), co może sprawić, że poczynicie pewne obserwacje. Już czytacie w moich myślach? Cierpliwości! :)
Przebieg w zależności od rok produkcji:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
auta_wide %>% filter(Marka %in% top_marki) %>% mutate(Przebieg = round(Przebieg/1000)) %>% ggplot() + geom_boxplot(aes(Rok_produkcji, Przebieg, group = Rok_produkcji, color = Marka), show.legend = FALSE, alpha = 0.1, size = 0.5) + geom_smooth(aes(Rok_produkcji, Przebieg, color = Marka), show.legend = FALSE) + scale_x_continuous(breaks = seq(1990, 2018, 5)) + scale_y_continuous(breaks = seq(0, 350, 50)) + facet_wrap(~Marka) + labs(title = "Zależność przebiegu od roku produkcji samochodu, według marek", x = "Rok produkcji", y = "Przebieg w tys. km") |
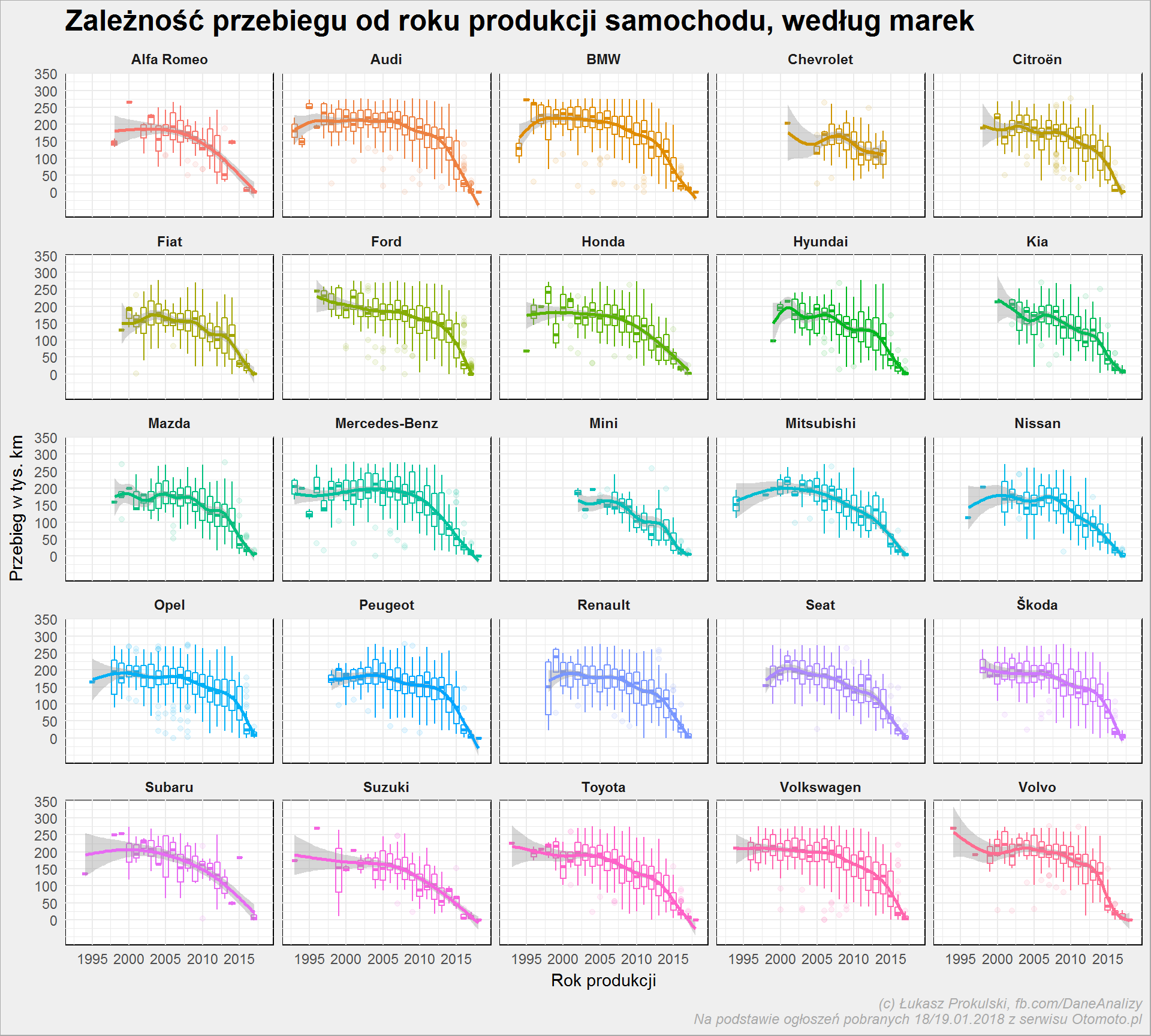
Tym razem zamiast punktów mamy wykres pudełkowy, dzięki czemu widać rozstrzał dla poszczególnych lat. Oczywiście im bliżej 2018 roku tym rozstrzał mniejszy (bez względu na markę) – tych nowych aut jest mniej.
Zobaczmy teraz bardziej dokładne rozbicie: ile jest samochodów danej marki i modelu według rocznika – biorąc pod uwagę najpopularniejsze modele danej marki:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
auta_wide %>% filter(Marka %in% top_marki) %>% count(Marka, Model, Rok_produkcji, sort = TRUE) %>% ungroup() %>% group_by(Marka, Model) %>% mutate(Marka_suma = sum(n)) %>% ungroup() %>% group_by(Marka) %>% filter(Marka_suma >= quantile(Marka_suma, 0.75)) %>% ungroup() %>% ggplot() + geom_tile(aes(Rok_produkcji, Model, fill = n), color = "gray50")+ scale_fill_distiller(palette = "YlOrRd") + scale_x_continuous(breaks = seq(1990, 2018, 10)) + facet_wrap(~Marka, scales = "free_y", ncol = 5) + labs(title = "Liczba oferowanych samochodów z poszczególnych roczników", subtitle = "Według marek, tylko najpopularniejsze modele", x = "Rok produkcji", y = "", fill = "Liczba ofert") + theme(legend.position = "bottom") |
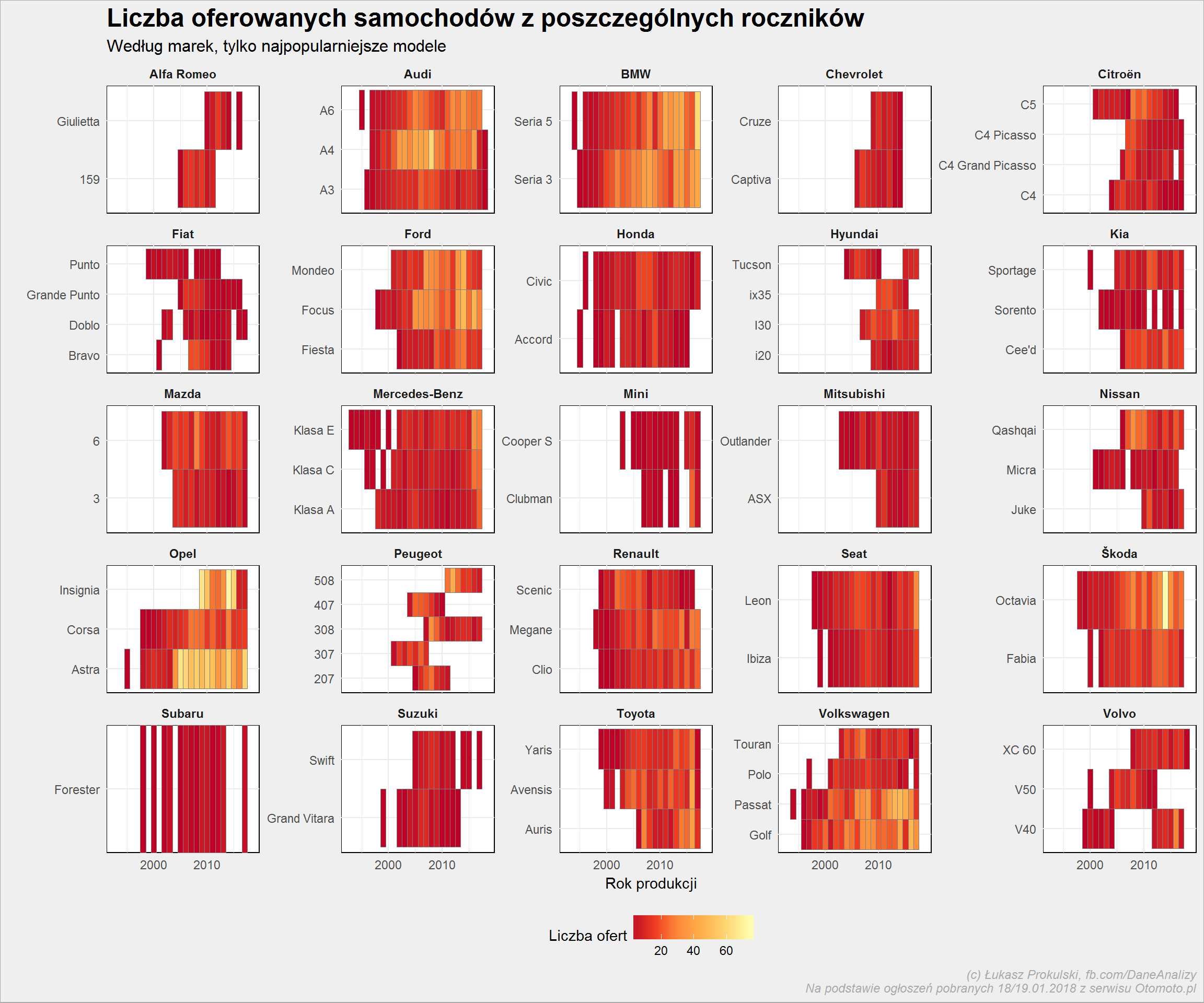
Niektóre marki dopiero zrobiły się popularne (Toyota, Mitsubishi, Hyundai) – dokładnie tak, jak napisałem wyżej.
- Astra cieszy się popularnością bez względu na rocznik (ważne, żeby nie była starsza niż jakieś 15-20 lat ;). Nowa (do 3-4 lat) Insignia zapewne świetnie się sprawdza, więc nie ma wielu sprzedających to auto – starsze już tak
- Volkswagen już lepiej (nieco) młodszy i to raczej Passat albo Golf
- Skoda Octavia jest do sprzedania po 4 latach – dlaczego?
Przed nami bardzo interesujące pytanie, które przyszło mi do głowy w związku z reklamą Toyoty: czy są marki, które z czasem bardziej tracą na cenie niż inne?
Zbudujmy prosty model, który rozjaśni sposób myślenia. Sprawdzimy do na bazie BMW:
|
1 2 3 4 5 6 |
auta_lin_reg <- auta_wide %>% filter(Marka == "BMW") %>% select(Rok_produkcji, Cena, Przebieg) lin_reg_cena <- lm(Cena ~ Rok_produkcji, data = auta_lin_reg) summary(lin_reg_cena) |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
## Call: ## lm(formula = Cena ~ Rok_produkcji, data = auta_lin_reg) ## ## Residuals: ## Min 1Q Median 3Q Max ## -104875 -31308 -8994 16942 227688 ## ## Coefficients: ## Estimate Std. Error t value Pr(>|t|) ## (Intercept) -2.199e+07 4.515e+05 -48.70 <2e-16 *** ## Rok_produkcji 1.098e+04 2.246e+02 48.89 <2e-16 *** ## --- ## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 ## ## Residual standard error: 48640 on 1725 degrees of freedom ## Multiple R-squared: 0.5809, Adjusted R-squared: 0.5806 ## F-statistic: 2391 on 1 and 1725 DF, p-value: < 2.2e-16 |
Powyżej zamodelowaliśmy metodą regresji liniowej cenę na podstawie roku produkcji. To najprostsza metoda, wynik dopasowania jest taki sobie (R2 = 0.58 co nie powala):
|
1 2 3 4 5 6 7 8 |
ggplot(auta_lin_reg) + geom_jitter(aes(Rok_produkcji, Cena), width = 0.45, alpha = 0.6) + geom_abline(intercept = coef(lin_reg_cena)[1], slope = coef(lin_reg_cena)[2], size = 2, color = "red") + scale_x_continuous(breaks = seq(1990, 2020, 5), labels = scales::dollar_format(prefix = "", suffix = "", big.mark = " ", decimal.mark = ",")) + scale_y_continuous(labels = scales::dollar_format(prefix = "", suffix = " zł", big.mark = " ", decimal.mark = ",")) + labs(title = "Cena a rok produkcji dla BMW", subtitle = "Dodana linia na podstawie regresji liniowej", x = "Rok produkcji", y = "Cena") |
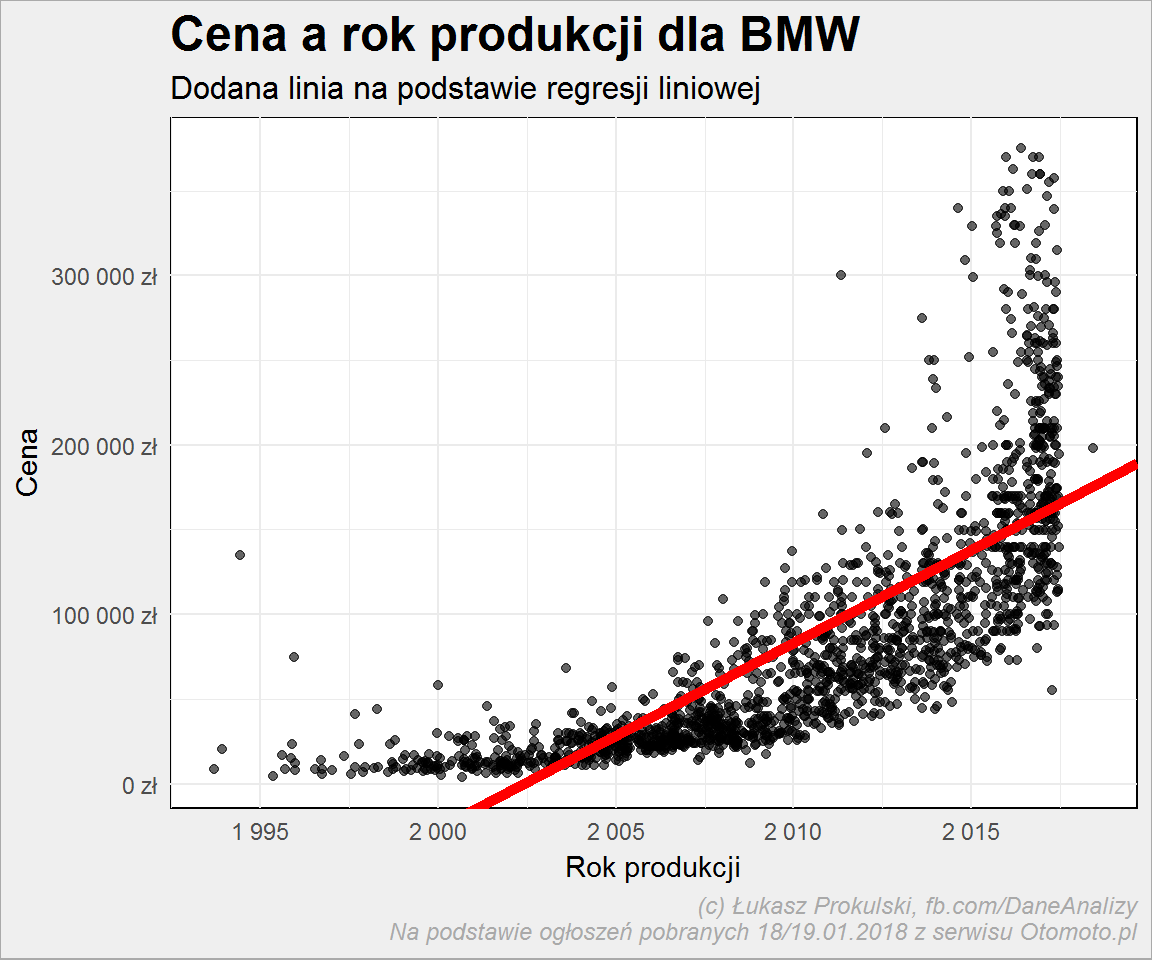
Ale coś już to mówi. Interesuje nas nachylenie prostej regresji – im większe to nachylenie tym większa strata na cenie z roku na rok. Policzmy więc ten współczynnik dla wszystkich marek i zobaczmy na wykresie wynik:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
reg_cena <- auta_wide %>% filter(Marka %in% top_marki) %>% select(Marka, Rok_produkcji, Cena) %>% split(.$Marka) %>% map(~ lm(Cena ~ Rok_produkcji, data = .x)) %>% map(~ t(coef(.)[2])) %>% unlist() %>% data.frame(Slope_cena = .) %>% rownames_to_column("Marka") reg_cena %>% arrange(Slope_cena) %>% mutate(Marka = fct_inorder(Marka)) %>% ggplot() + geom_point(aes(Marka, Slope_cena), color = "red", size = 5) + coord_flip() + labs(title = "Współczynnik utraty wartości samochodu z wiekiem", subtitle = "Mniejsza wartość = auta mniej tracące na wartości", y = "Współczynnik", x = "") |
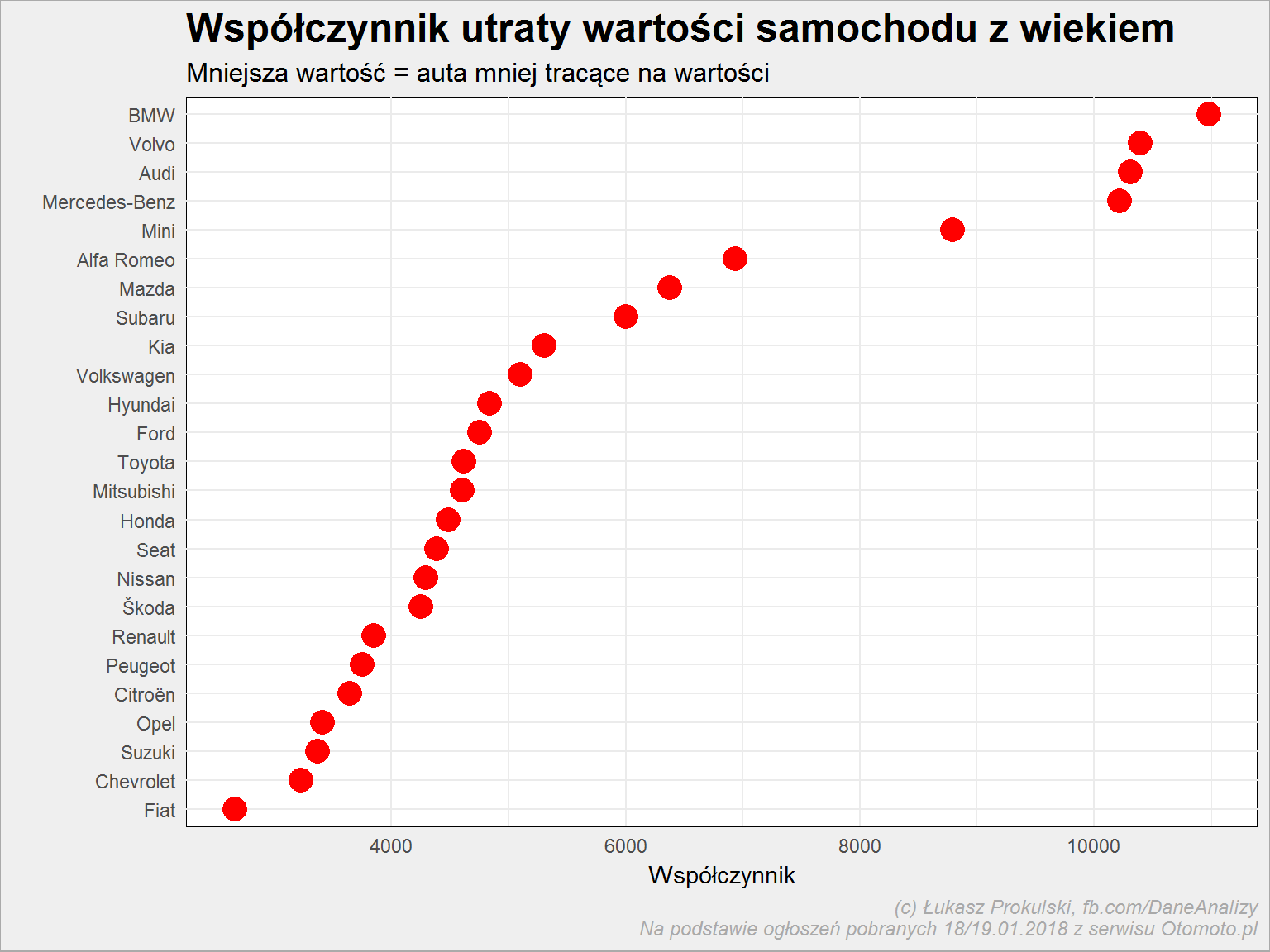
Różnice są jak widać duże. W sumie wychodzi na to, że drogie auta tracą na wartości najszybciej. Wspomniana Toyota z reklamy traci mniej więcej tak samo jak Ford. Obie marki są w Polsce popularne, a jeszcze bardziej popularna jest Skoda, która traci mniej niż Toyota. Czy więc reklama Toyoty wprowadza w błąd? Natomiast Fiat kosztuje już na początku na tyle mało, że nie bardzo z czego ma tracić…
Sprawdźmy na wybranych markach jak to wygląda na pełnych danych, nie tylko na współczynnikach regresji:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
auta_wide %>% select(Marka, Rok_produkcji, Cena) %>% filter(Marka %in% c("BMW", "Ford", "Fiat")) %>% mutate(Cena = round(Cena/1000)) %>% ggplot() + geom_jitter(aes(Rok_produkcji, Cena, color = Marka), width = 0.4, show.legend = FALSE, alpha = 0.3, size = 0.5) + geom_smooth(aes(Rok_produkcji, Cena, color = Marka)) + scale_x_continuous(breaks = seq(1990, 2018, 5), trans = "reverse") + scale_y_continuous(breaks = seq(0, 400, 50)) + theme(legend.position = "bottom") + labs(title = "Porównanie utraty wartości samochodu z wiekiem\ndla wybranych marek", y = "Cena w tys. PLN", x = "Rok produkcji") |
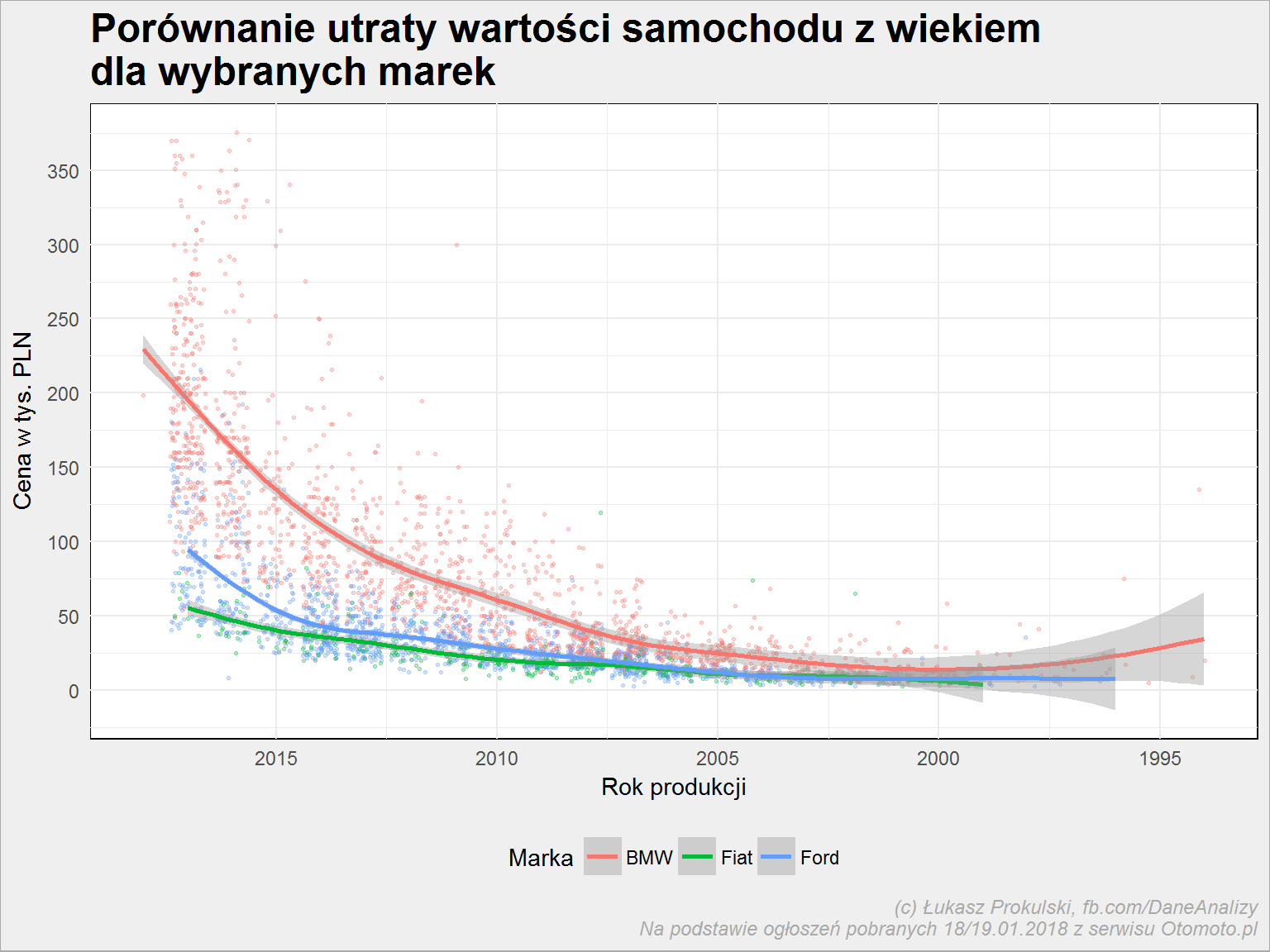
Oś z rokiem produkcji jest w kolejności odwrotnej, aby lepiej zobrazować spadek krzywej. I rzeczywiście: największy spadek na przestrzeni czasu zalicza BMW (czerwone), a Fiat (zielone) trzyma się najbardziej płasko, o ile można tak powiedzieć.
Czy są marki, które są bardziej eksploatowane? Pytanie podobne do wartości, metoda dokładnie ta sama – tym razem jednak zamiast ceny weźmiemy przebieg:
|
1 2 |
lin_reg_przebieg <- lm(Przebieg ~ Rok_produkcji, data = auta_lin_reg) summary(lin_reg_przebieg) |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
## Call: ## lm(formula = Przebieg ~ Rok_produkcji, data = auta_lin_reg) ## ## Residuals: ## Min 1Q Median 3Q Max ## -292742 -38831 -7250 40169 150130 ## ## Coefficients: ## Estimate Std. Error t value Pr(>|t|) ## (Intercept) 26511585.9 500890.7 52.93 <2e-16 *** ## Rok_produkcji -13120.1 249.1 -52.66 <2e-16 *** ## --- ## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 ## ## Residual standard error: 53960 on 1725 degrees of freedom ## Multiple R-squared: 0.6165, Adjusted R-squared: 0.6163 ## F-statistic: 2773 on 1 and 1725 DF, p-value: < 2.2e-16 |
Dopasowanie dla testowego BMW wydaje się odrobinę lepsze (R2 = 0.61). Tutaj współczynnik nachylenia należy traktować dokładnie tak samo (im bliżej zera tym lepiej), chociaż prosta skierowana jest odwrotnie, co widać na wykresie:
|
1 2 3 4 5 6 7 8 |
ggplot(auta_lin_reg) + geom_jitter(aes(Rok_produkcji, Przebieg), width = 0.45, alpha = 0.6) + geom_abline(intercept = coef(lin_reg_przebieg)[1], slope = coef(lin_reg_przebieg)[2], size = 2, color = "red") + scale_x_continuous(breaks = seq(1990, 2020, 5), labels = scales::dollar_format(prefix = "", suffix = "", big.mark = " ", decimal.mark = ",")) + scale_y_continuous(labels = scales::dollar_format(prefix = "", suffix = " km", big.mark = " ", decimal.mark = ",")) + labs(title = "Przebieg a rok produkcji dla BMW", subtitle = "Dodana linia na podstawie regresji liniowej", x = "Rok produkcji", y = "Przebieg") |
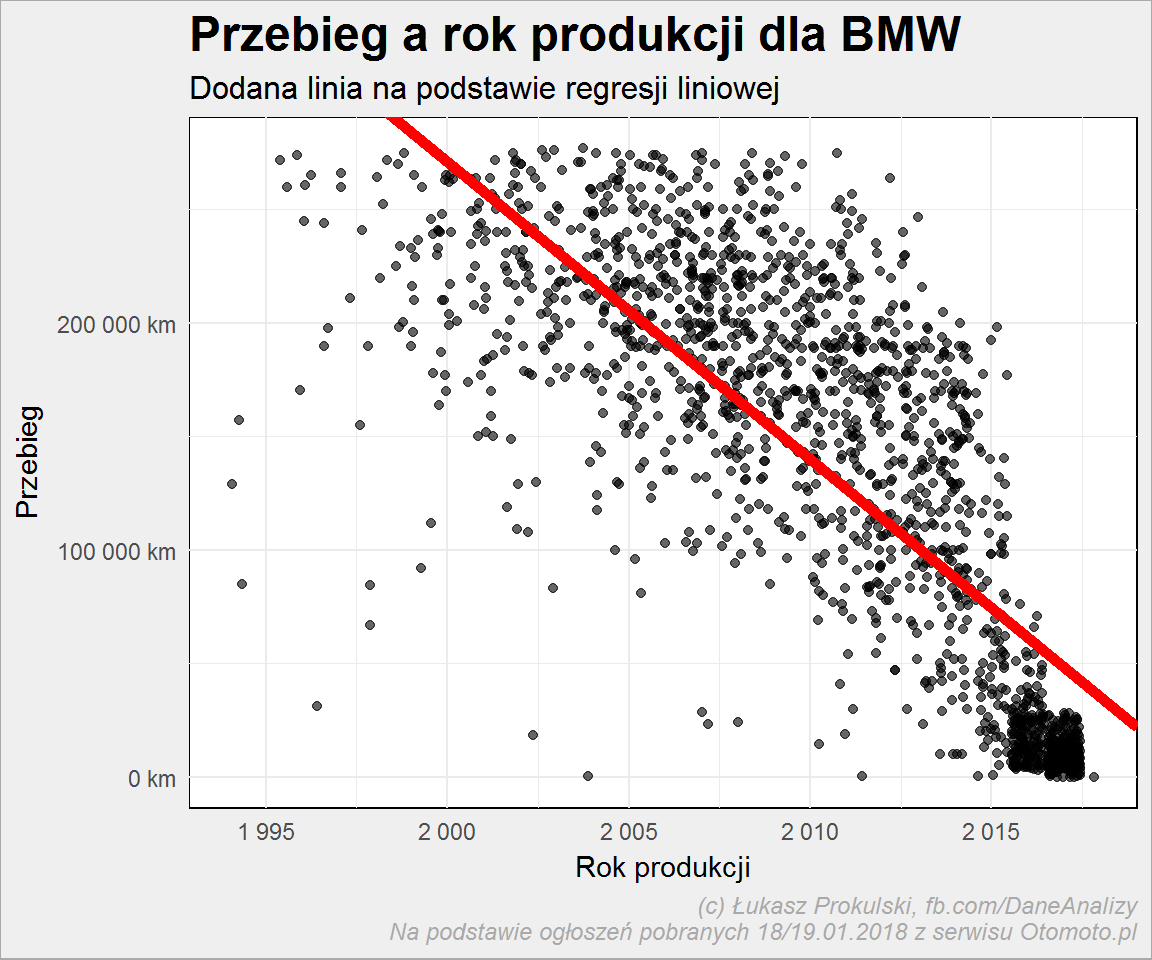
Zobaczmy podsumowanie dla wszystkich marek:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
reg_przebieg <- auta_wide %>% filter(Marka %in% top_marki) %>% select(Marka, Rok_produkcji, Przebieg) %>% split(.$Marka) %>% map(~ lm(Przebieg ~ Rok_produkcji, data = .x)) %>% map(~ t(coef(.)[2])) %>% unlist() %>% data.frame(Slope_przebieg = .) %>% rownames_to_column("Marka") reg_przebieg %>% arrange(Slope_przebieg) %>% mutate(Marka = fct_inorder(Marka)) %>% ggplot() + geom_point(aes(Marka, Slope_przebieg), color = "red", size = 5) + coord_flip() + labs(title = "Współczynnik eksploataci samochodu z wiekiem\nokreślony na podstawie przebiegu", subtitle = "Mniejsza (bardziej ujemna) wartość = auta bardziej eksploatowane", y = "Współczynnik", x = "") |
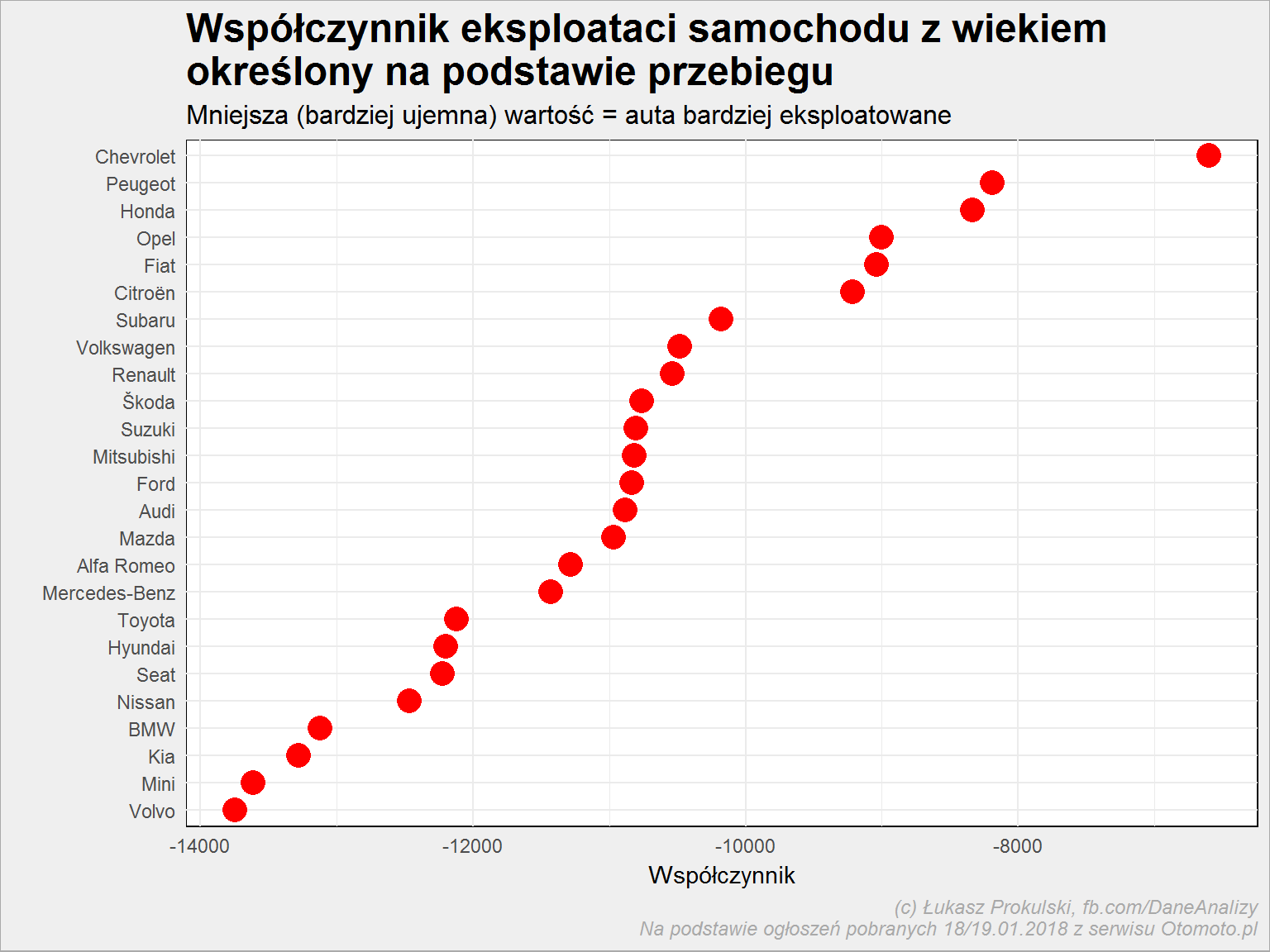
Można jeszcze zestawić współczynniki z obu regresji:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
# łączymy tabele współczynników reg_both <- left_join(reg_przebieg, reg_cena, by = "Marka") # wyznaczamy jedną z 4 klas dla marki na podstawie współczynników reg_both$klasa <- kmeans(select(reg_both, Slope_przebieg, Slope_cena), 4)$cluster ggplot(reg_both) + geom_point(aes(Slope_cena, Slope_przebieg, color = as.factor(klasa)), show.legend = FALSE) + # otaczamy elipsą każdą z klas stat_ellipse(aes(Slope_cena, Slope_przebieg, color = as.factor(klasa)), show.legend = FALSE) + # dodajemy labelki do punktów geom_text_repel(aes(Slope_cena, Slope_przebieg, label = Marka, color = as.factor(klasa)), show.legend = FALSE) + labs(title = "Współczynnik eksploatacji vs współczynnik utraty wartości", x = "Współczynnik utraty wartości\ndalej od zera = gorzej", y = "Współczynnik eksploatacji\ndalej od zera = gorzej") |
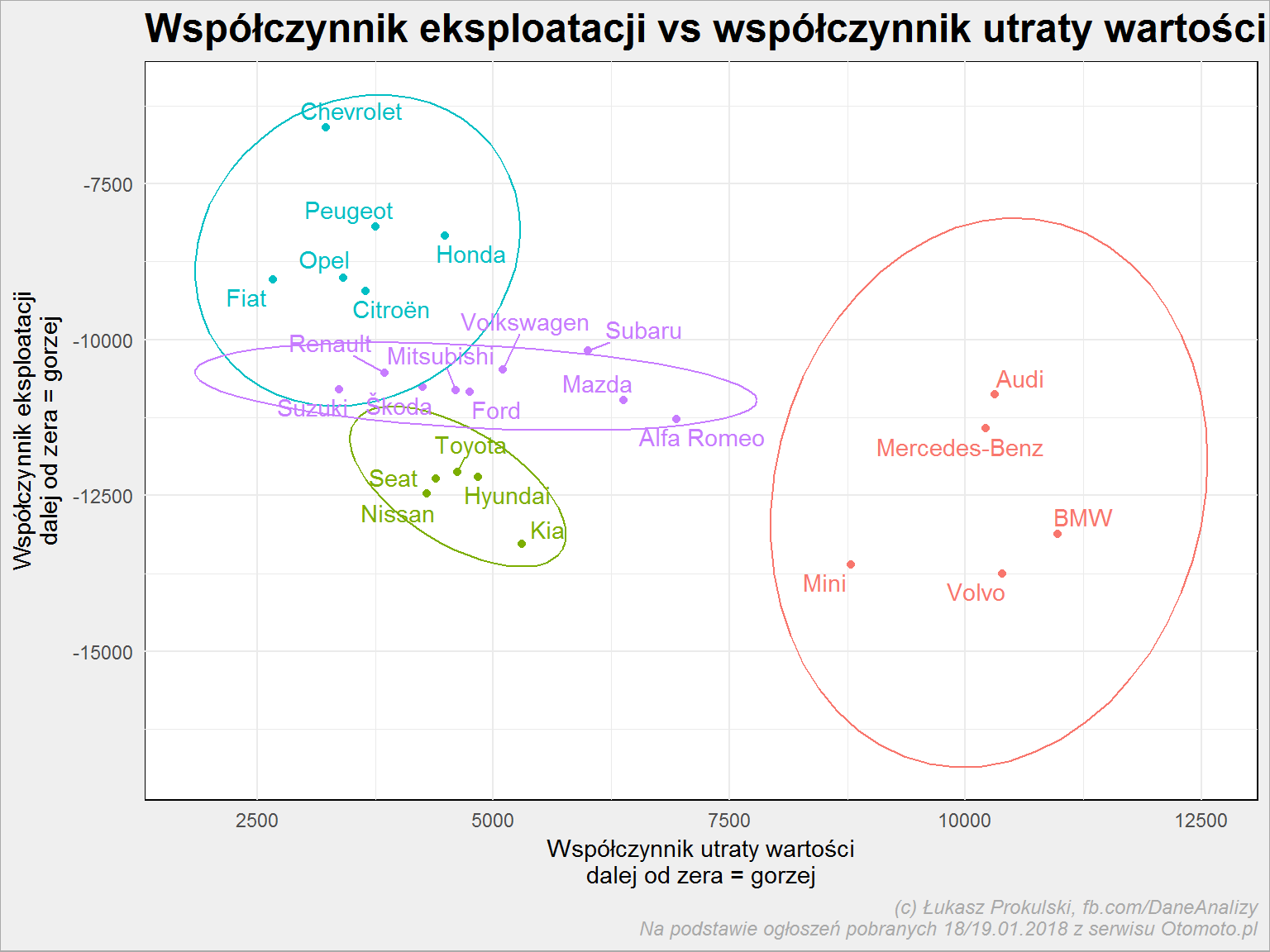
Najbardziej opłacalne (tracące mało na wartości oraz najmniej zajeżdżone) są auta najbliższe na powyższym wykresie górnego lewego rogu – co jest dla mnie zaskoczeniem są to Chevrolet i Peugeot (razem w grupie z Oplem, Hondą, Citroenem i Fiatem). Z tego zestawienia wynika, że nie opłaca się kupować BMW czy Volvo.
Nawet dla takiego laika jak ja widać, że auta podobnej klasy są zgrupowane:
- Audi blisko Mercedesa, w grupie razem z Mini, BMW i Volvo – to samochody drogie
- do tej samej grupy co Ford i Volkswagen zalicza się Skoda – to dość ciekawe (ale przecież właścicielem Skody jest Volkswagen)
- japońsko-koreańskie (Toyota, Hyundai, Nissan, Kia) trzymają się razem, dochodzi do nich Seat (czy ze względu na właścicielstwo nie powinien trafić do grupy z VW?)
Uwaga – algorytm kmeans() jest dość losowy, w domu mogą Wam wyjść inne przypisania do klas.
Przed nami ostatni element, najbardziej pasjonujący:
Szukanie okazji
Jak znaleźć auto, które jest bardziej atrakcyjne od innych? Jako miarę atrakcyjności uznajmy jego cenę oraz przebieg na tle takich samych samochodów. Takich samych, czyli tej samej marki, modelu i rocznika. Przy dużym zbiorze można dorzucić jeszcze wersję, o ile modele różnią się od siebie – taki VW Passat ma na przykład sześć wersji jak wynika z zebranych danych, z popularnością taką, o:
|
1 2 3 4 |
auta_wide %>% filter(Marka == "Volkswagen", Model == "Passat") %>% select(Marka, Model, Wersja) %>% count(Wersja, sort = T) |
| Wersja | n |
|---|---|
| B7 (2010-2014) | 166 |
| B6 (2005-2010) | 138 |
| B8 (2014-) | 85 |
| B5 FL (2000-2005) | 77 |
| B5 (1996-2000) | 20 |
| B4 (1993-1997) | 3 |
Na początek wybierzmy nasze auta z top marek do oddzielnej tabelki i policzmy średnie dla przebiegu i ceny dla każdego modelu (oraz oczywiście marki) i rocznika – wersję sobie odpuszczamy:
|
1 2 3 4 5 6 7 8 9 10 |
# wybrane auta auta <- filter(auta_wide, Marka %in% top_marki) # liczymy średnie auta_srednie <- auta %>% group_by(Marka, Model, Rok_produkcji) %>% summarise(Przebieg_srednia = round(mean(Przebieg), -2), Cena_srednia = round(mean(Cena), -2), n = n()) %>% ungroup() |
Teraz już dość prosto możemy zestawić ceny poszczególnych aut z średnimi i poszukać samochodów według interesujących nas kryteriów, na przykład dość ekstremalnie:
- cena co najmniej 50% niższa niż średnia dla modelu
- przebieg co najmniej 50% niższy niż średnia
|
1 2 3 4 5 6 7 8 9 |
auta %>% left_join(auta_srednie, by = c("Marka" = "Marka", "Model" = "Model", "Rok_produkcji" = "Rok_produkcji")) %>% select(Marka, Model, Rok_produkcji, Cena, Cena_srednia, Przebieg, Przebieg_srednia, OfferURL) %>% mutate(cena_procent = round(100*(Cena/Cena_srednia - 1), 1)) %>% mutate(przebieg_procent = round(100*(Przebieg/Przebieg_srednia - 1), 1)) %>% filter(cena_procent < -50, przebieg_procent < -50) %>% arrange(Marka, Model, desc(cena_procent), desc(przebieg_procent)) %>% select(Marka, Model, Rok_produkcji, Cena, Cena_srednia, cena_procent, Przebieg, Przebieg_srednia, przebieg_procent, OfferURL) |
| Marka | Model | Rok produkcji | Cena | Średnia cena | % ceny średniej | Przebieg | Średni przebieg | % średniego przebiegu | OfferURL |
|---|---|---|---|---|---|---|---|---|---|
| BMW | Seria 7 | 2012 | 54000 | 122000 | -55.7 | 54300 | 125200 | -56.6 | ID6zsWYl |
| Ford | Mondeo | 2004 | 4198 | 9100 | -53.9 | 34239 | 184400 | -81.4 | ID6zuFiM |
| Mazda | 6 | 2006 | 5000 | 14100 | -64.5 | 70000 | 174400 | -59.9 | ID6zw3T3 |
| Mercedes-Benz | Klasa E | 2017 | 38900 | 214500 | -81.9 | 3000 | 11500 | -73.9 | ID6zsKa0 |
| Peugeot | 508 | 2015 | 6150 | 57400 | -89.3 | 24800 | 113900 | -78.2 | ID6zt7rI |
Co mamy (trzeba kliknąć w każde ogłoszenie, wcześniej z kolumny OfferURL budując odpowiedni link):
- BMW Seria 7 – z treści ogłoszenia: Samochód po zalaniu do wysokości foteli, nie odpala. Aha.
- Mazda 6 – w tym momencie ogłoszenie jest już nieaktualne – pewnie oznacza to, że była to niezła okazja i ktoś ją kupił/zarezerwował. Nasz algorytm działa!
- Mercedes Klasa E – cena jest w euro, warto dodać do scrappera zaciąganie waluty w jakiej podawana jest cena – ciekawe, że dopiero tutaj to wyszło
- Peugeot 508 – cena dotyczy przeniesienia umowy leasingowej, co napisane jest w pełnej treści ogłoszenia
Ford Mondeo wygląda na sensowne ogłoszenie (coś tam obtarte czy lekko wgniecione), trochę dziwi mnie przebieg, zobaczmy jak wygląda ten konkretny samochód w porównaniu ze średnimi dla tego modelu.
Pod względem przebiegu:
|
1 2 3 4 5 6 7 8 9 10 |
auta_srednie %>% filter(Marka == "Ford", Model == "Mondeo") %>% ggplot() + geom_col(aes(Rok_produkcji, Przebieg_srednia, fill = ifelse(Rok_produkcji == 2004, "lightgreen", "lightblue")), color = "gray50", show.legend = FALSE) + geom_hline(aes(yintercept = 34239), color = "red", size = 2) + scale_fill_manual(values = c("lightgreen" = "lightgreen", "lightblue" = "lightblue")) + scale_y_continuous(labels = scales::dollar_format(prefix = "", suffix = " km", big.mark = " ", decimal.mark = ",")) + labs(x = "Rok produkcji", y = "Średni przebieg") |
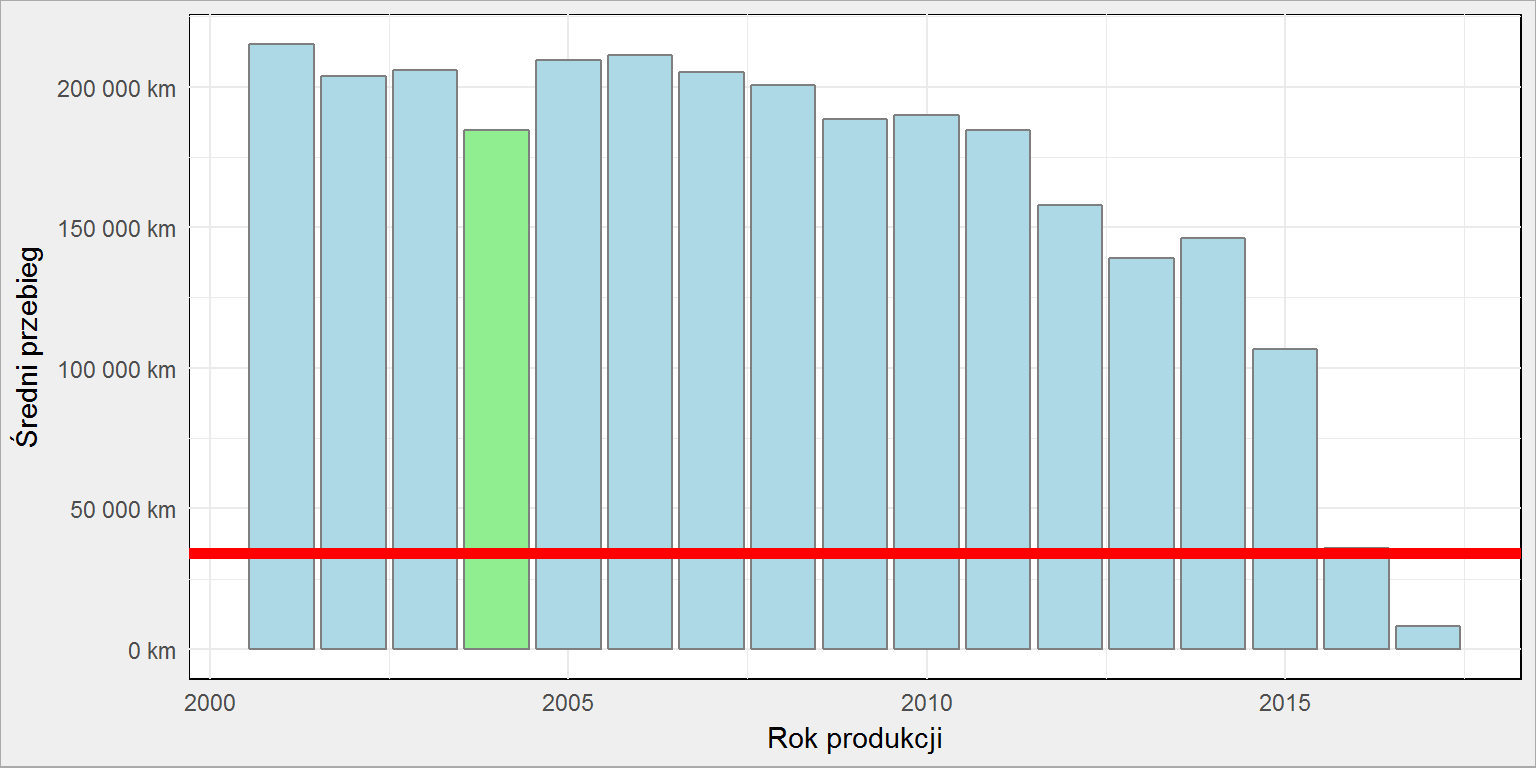
Przebieg jak na średnie Mondeo z 2016 roku… a auto jest o 12 lat starsze. Podejrzane?
A pod względem ceny?
|
1 2 3 4 5 6 7 8 9 10 |
auta_srednie %>% filter(Marka == "Ford", Model == "Mondeo") %>% ggplot() + geom_col(aes(Rok_produkcji, Cena_srednia, fill = ifelse(Rok_produkcji == 2004, "lightgreen", "lightblue")), color = "gray50", show.legend = FALSE) + geom_hline(aes(yintercept = 4198), color = "red", size = 2) + scale_fill_manual(values = c("lightgreen" = "lightgreen", "lightblue" = "lightblue")) + scale_y_continuous(labels = scales::dollar_format(prefix = "", suffix = " zł", big.mark = " ", decimal.mark = ",")) + labs(x = "Rok produkcji", y = "Średnia cena") |
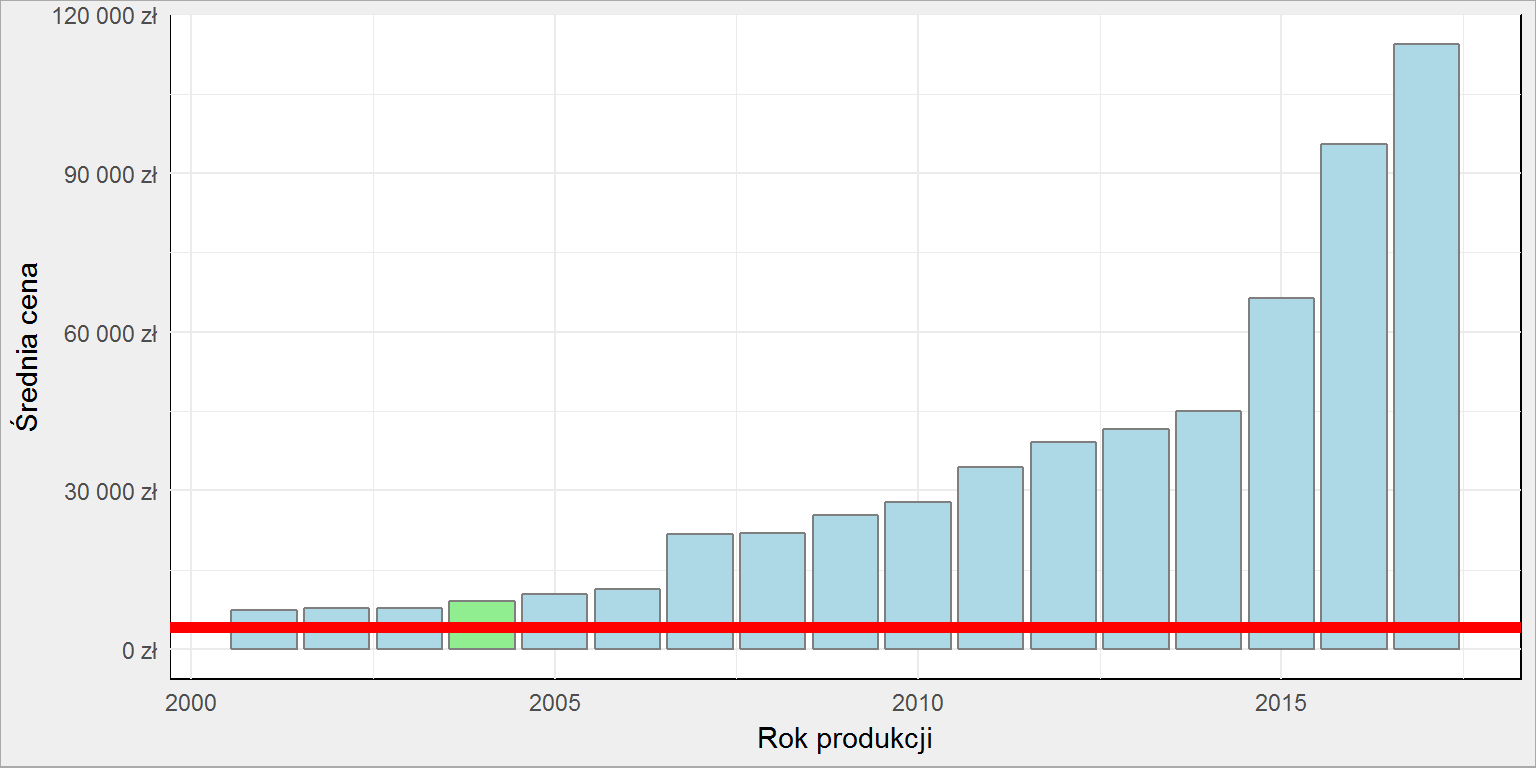
No tańsze od najtańszych (i starszych). WTF?
Zamiast tych dwóch powyższych wykresów można zestawić wszystkie trzy cechy (cena, przebieg i rok produkcji) na jednym obrazie dla wszystkich Fordów Mondeo:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
auta_wide %>% filter(Marka == "Ford", Model == "Mondeo", Bezwypadkowy == "Tak") %>% ggplot() + geom_point(aes(Przebieg, Cena, color = as.factor(Rok_produkcji)), size = 2) + stat_ellipse(aes(Przebieg, Cena, color = as.factor(Rok_produkcji), alpha = ifelse(Rok_produkcji == 2004, 1, 0.1)), show.legend = FALSE) + geom_point(aes(x = 34239, y = 4198), color = "red", size = 5, show.legend = FALSE) + scale_x_continuous(labels = scales::dollar_format(prefix = "", suffix = " km", big.mark = " ", decimal.mark = ",")) + scale_y_continuous(labels = scales::dollar_format(prefix = "", suffix = " zł", big.mark = " ", decimal.mark = ",")) + labs(title = "Ford Mondedo: przebieg vs cena", subtitle = "Porównanie konkretnej oferty ze wszystkimi Fordami Mondeo", x = "Przebieg", y = "Cena", color = "Rok produkcji") + theme(legend.position = "bottom") + guides(col = guide_legend(nrow = 2, byrow = TRUE)) |
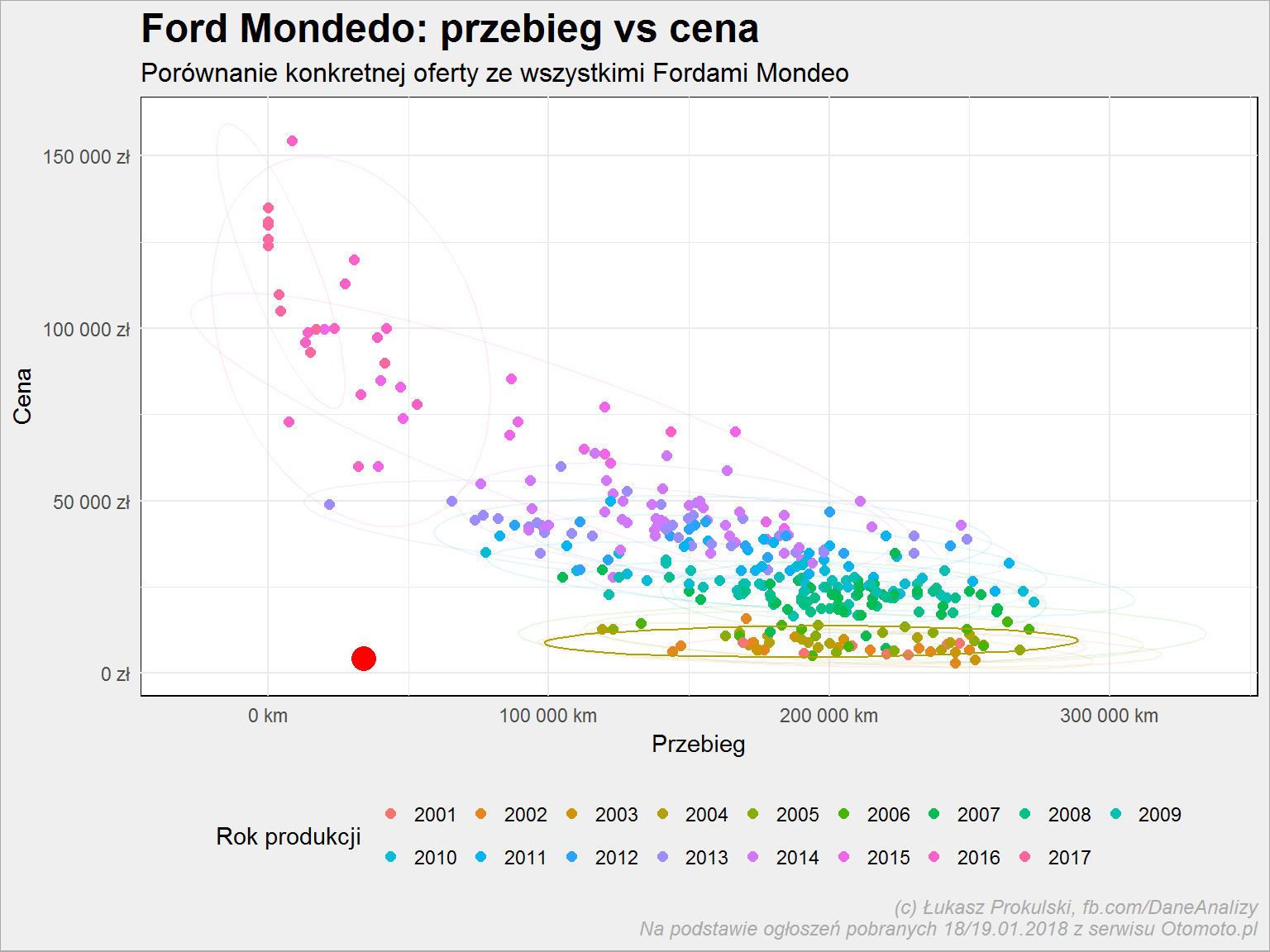
Czerwony punkt to nasze wyszukane ogłoszenie, elipsy otaczają ogłoszenia dotyczące tego samego rocznika, ta najlepiej widoczna to rocznik 2004. Czy to okazja czy jakiś kant? Nie mnie oceniać, nie znam się na samochodach…
Aha – w nawiązaniu do tytułu postu: sprzedam, ale nie Opla, a Forda. Bitego.
Na dzisiaj to wszystko. Jeśli podobało Ci się, udostępnij proszę ten post, wrzuć na jakiś Wykop czy reddita. No i zostań fanem strony Dane i analizy na Facebooku – tam nie tylko takie rzeczy.
FAjna analiza :) pierwsze co mi przyszli do głowy jak zobaczyłem tytuł to: ciekawe ile z tych aut ma „kręcone liczniki”? :D
Jak patrzę na rozkład przebiegu aut, to jest on troszkę podejrzany. Auta z 200k km są rzadko spotykane.
Idę o zakład, że gdyby zrobić porównanie histogramów dwóch grup aut: sprowadzanych i krajowych, o tych samych rocznikach to wyjdzie nam, że te sprowadzane mają raczej mniejsze przebiegi. Szczególnie fajnie mogłoby to wyglądać na nieco starszych BMW sprowadzanych z Niemiec.
Już widzę tłumaczenia handlarzy: Niemiec tylko po autostradzie do kościoła jeździł! :D
Bardzo fajny wpis. Dzięki ;)
Według mnie skok przebiegu jest przez to, że przykładowo niemiec kupuje nowego dużego sedana na codzienne dojazdy do pracy oddalonej 50-100km od miejsca zamieszkania(jeździ dopóki ma gwarancję z salonu 5 lat więc jakby nie patrzeć nastuka w pizdu km) , a jak ma blisko to kupuje mały samochód bo nie potrzebuje mieć super wygodnej podróży która trwa 10-15 min. To praktyczni ludzie. Więc kiedy takie autko przejdzie od niemca do polak,a który kupi bwm na dojazdy do pracy do której ma 15 min drogi albo mniej przebieg przez lata maleje.
PS: nie jestem mirkiem handlarzem tak tylko czysto teoretycznie sobie to wydedukowałem bo też przymierzam się do zmiany auta :)
Super analiza!
Co do przebiegu to tutaj byłbym mocno ostrożny w wysuwaniu daleko idących wniosków. Na wykresie zależności przebiegu od roku produkcji widać nagłe „wypłaszczenie” po kilku latach eksploatacji – czy oznacza to, że ktoś nagle przestaje jeździć samochodem, bo mu go szkoda? A może chodzi raczej o „cofanie licznika”?
W przypadku 4-letniej Skody chodzi najpewniej o to, że to bardzo popularna opcja leasingowa i po prostu na rynek trafiają samochody używane przez firmy.
Dokladnie!
Super analizy ale warunek wyjsciowy ze „przebieg samochodów jest prawdziwy” jest troche niestety mylacy. Wszyscy wiedza jak wyglada przebieg aut po ok 200kkm. Plaski!
” czy oznacza to, że ktoś nagle przestaje jeździć samochodem, bo mu go szkoda? A może chodzi raczej o „cofanie licznika”?”
Odpowiedź jest banalnie prosta – w pierwszym okresie „życia” auta, użytkuje je ktoś, kto kupił nowe: najczęściej firma. Auto firmowe robi duże przebiegi.
Po pewnym czasie firma sprzedaje auto w cenie zależnej od przebiegu – im większy, tym taniej.
Najtańsze auta (te z największym przebiegiem) kupuja ci, którzy mają najmniej pieniędzy – a tacy ludzie najmniej jeżdżą – bo ich nie stać i nie mają dokąd.
Twoja propozycja brzmi bardzo prawdopodobnie :-) A wiesz może, jaki procent sprzedawanych kilkuletnich stanowią te używane wcześniej przez firmy?
Mimo wszystko dane dotyczące przebiegu są mocno zaniżone, bo powyżej 200 tys. kilometrów dzieją się dziwne rzeczy ;-)
Zacnie Milordzie,
taką analizę powinien wziąć na warsztat ekspert rynku motoryzacyjnego, by nałożyć na to wiedzę i doświadczenie, no bo:
1. Dla danego modelu auta są zawsze silniki lepsze i gorsze (np. wspominana Insignia ma szeroką paletę silników, ale tylko 2-3 są godne uwagi)
2. Diesle, preferowane w przypadku aut flotowych, które mają nabijać km, będą miały domyślnie więcej nalatane, co w granicach zdroworozsądkowej logiki nie powinno być wadą – takie auta muszą być stosownie serwisowane. To auto o innej wartości, niż sprowadzone auto ze skręconą budą, bo „Niemiec w niedzielę do kościoła jeździł”.
3. Kraj pochodzenia ma znaczenie – najniżej IMHO leżą Niemcy, wysoko jest np. Szwajcaria, bo tam mają rygorystyczne normy odnośnie dopuszczaniem aut do ruchu
4. Mirki nadal preferują Passerati w TeDeI, by móc na powiecie błysnąć.
Co do samego wyboru – IMHO odcinać najtańsze egzemplarze danego modelu, bo z jakiegoś powodu kosztują jak kosztują i zaczynać analizę od najdroższych.
Problem ze Szwajcarią jest tak, że sprowadzając stamtąd samochód trzeba zapłacić VAT (bo ten kraj nie należy do UE), więc dla mnie podejrzane są ceny samochodów ze Szwajcarii na tym samym poziomie co samochodów z Niemiec.
Fajna analiza, tyle że wkład pracy nieadekwatny do efektów. Przy Twoich umiejętnościach pewnie mógłbyś kupić sobie nowe auto z wyższej półki (na raty albo w leasingu) i spokojnie na nie zarobić nie przejmując się utratą wartości. :)
Potęga matematyki! Piękny wpis. Gdyby tylko te dane skonsultować ze znawcą rynku motoryzacji i spiąć to w aplikacje mobilną…
Pozdrawiam, życzę sukcesów i dobrze dobranego auta.
Rewelacyjna analiza!
Super robota i fajna lektura.
Nie wiem czy skorzystasz ale tak czy inaczej zasugeruję powtórzenie snapshota po 6, 12, 18 itd… miesiącach. Pozwoliłoby to zaobserwować realną zmianę cen dla tych samych modeli i tych samych roczników wraz z upływem czasu. Tak samo przebieg. Utratę wartości wyliczasz dla wszystkich aut od nowości, interesujący byłby współczynnik utraty wartości dla aut 5+ (statystyczne auto Kowalskiego). Najlepiej dla 20 najpopularniejszych w Polsce modeli, nie marek.
Powodzenia w kolejnych analizach!
Wykonałeś dobrą robotę z analizą danych. Natomiast wnioski są do d….
Po części dlatego, że się pewnie nie znasz na rynku samochodowym, a po części dlatego, że dane z ogłoszeń w Polsce są delikatnie mówiąc sfałszowane.
Korzystam z danych takich jakie są. Faktycznie nie znam się na samochodach ani rynku motoryzacyjnym. Ale chętnie poznam wnioski jakie można z tych informacji wyciągnąć – śmiało!
Świetna analiza, która pokazuje jak działa rynek motoryzacyjny w PL. Okazji nie ma :)
Cześć Łukasz,
Bardzo podoba mi się to, że z własnej inicjatywy wykonałeś taki kawał solidnej pracy, wliczając w to scraping. Well done!
Gdybyś chciał się zagłębić w temat, to zostawię tutaj dwa (być może przydatne) linki:
Poznań: https://www.joinolx.com/careers/job/855462
Berlin: https://www.joinolx.com/careers/job/838405
Pozdrawiam serdecznie!
Widać sporo pracy i czasu włożonego w analizę. Brawo, czytało się z przyjemnością. Sam kupiłem kiedyś passata b5 z 2001 roku i na liczniku ile? … tak 180 tys, jednak wtedy byłem młody. Na dodatek jak go sprzedłem to się okazało że na dodatek anglik;( Jak się nie mylę to od przyszłego roku mają być kary za „kotektorów liczników”. I dobrze.
Tej, to genialny pokaz edukacyjny jak używać R :-)
Chyba przeczwiczę trochę by sobie przypomnieć, dzięki!
Hej, a czy jest to dostępne w jakiejś formie githubowej?
Dane na pewno nie. Skrypt w sumie jest w treści.
A dałoby się to zestawić porównawczo z autoscout24.de?
Generalnie auta od osób prywatnych oferowane tam są trochę bardziej wiarygodne co do przebiegu (i ceny wyższe niż analogicznie u nas).
Bardzo ciekawa analiza i widać, że autor się zna na analizie danych. Gdyby do tego dodać wiedzę motoryzacyjną, to byłoby jeszcze lepiej. W każdym razie wielkie brawa!
Cześć. Fajny pomysł na analizę.
Zwróciłbym tylko uwagę na fragment, w którym mówisz, że współczynnik nachylenia prostej w regresji mówi jak szybko samochód traci na wartości. Opieranie się tutaj na wartościach bezwzględnych jest trochę bez sensu. To, że fiat wg tej analizy najlepiej trzyma cenę (tj. ma najniższy współczynnik) wynika w dużym stopniu, że jest tańszy przy zakupie i zakres zmian jest węższy niż w przypadku marek takich jak BMW. Cenę dla kolejnych roczników trzeba by tutaj było odnieść do wartości początkowej.
Pomysł ciekawy, wykonanie takie sobie, wnioski bssz sensu. Popełniłeś podstawowy grzech analityka – niezrozumienie problemu, ktòry analizujesz. Efektem tego są wnioski od czapy, zgodnie z zasadą GIGO. Owszem, można potraktować zabawę cyferkami jako sztukę dla sztuki, ale wartości poznawczej nie ma to żadnej (poza ewentualną nauką narzędzia).
Podstawowy błąd polega na zaufaniu niewiarygodnym danym (przebieg). Drugą rzecz to bardzo nieładnie czyszczenie danych (odrzucasz sobie skrajne wartości i już). W porządnym projekcie istotne jest przede wszystkim dobre wyczyszczenia i znormalizowanie danych (jak traktujesz np. ogłoszenia „wabikowe” – ogłoszenie udające jeden typ samochodu, a w opisie zupełnie coś innego?). Liczenie statystyk dla agregatów „marka” też się dość mocno mija z celem. Gdyby to jeszcze była marka, która ma tylko dwa zbliżone modele (tylko np. inaczej nazywa się sedan, a inaczej hatchback). A tak masz BMW, które ma rozrzut cenowy za nowe samochody od ok. 111tys. do okolic miliona. O tym, że część ogłoszeń to ceny netto, albo cesja leasingu, szkoda nawet wspominać.
Podsumowując – kawał ładnej, nikomu niepotrzebnej roboty.
Zapraszam zatem do opublikowania porządnie wykonanej analizy z uwzględnieniem wszystkiego o czym piszesz. Zrobionej za darmo w powiedzmy jakieś dwadzieścia godzin roboczych licząc z pobraniem danych.
Wszystko co napisałeś jest prawdziwe. Zważ jednak na to, że opracowanie jest hobbystyczne i dostępne za darmo. Za fachowe raporty trzeba płacić. Zarówno za dostęp do nich jak i ich przygotowanie.
Zgadza się. Ale „za darmo” nie jest usprawiedliwieniem dla „bez sensu” albo „na odp.*ol” (akurat tu ten drugi przypadek nie ma zastosowania, bo widać, że włożyłeś sporo pracy; szkoda tylko, że bez sensu właśnie).
Powiem więcej – można było to zrobić nawet na podstawie tych danych dużo sensowniej – właśnie zakładając ich niepewność i pokazując co można zrobić, ale zaznaczając, że nie jest to obraz odpowiadający rzeczywistości. A Ty się uparłeś zrobić coś, co udaje rzetelną analizę, ale z zastrzeżeniem, że:
1) Nie znasz się,
2) Jest za darmo, więc klękajcie narody.
Za to ktoś, komu się chce poświęcić dziesięć minut na przeczytanie i kolejne pięć na napisanie komentarza może wyrazić swoje zdanie. A na to, żeby spędzać kilkadziesiąt godzin, żeby zrobić „to samo”, tylko porządnie, mnie po prostu nie stać. Za bardzo cenię sobie swój czas. Dlatego jeśli już go poświęcam na prace pro publico bono, robię to porządnie, tak aby wynik miał sens.
„Za bardzo cenię sobie swój czas. Dlatego jeśli już go poświęcam na prace pro publico bono, robię to porządnie, tak aby wynik miał sens.” — może podasz przykład potwierdzający te słowa?
Po pierwsze: Nie przejmuj się marudami.
Po drugie (sam pomarudzę): Jak chcesz zobaczyć coś ciekawego to podziel dane w zależności od rodzaju paliwa (diesel, benzyna). Kilka lat temu ktoś zrobił podobną pracę ale skupiając siętylko na jednym najpopularniejszym modelu VW passat. Efekt był taki że przy benzynie przebiego rośnie sobie może nie liniowo ale stabilnie. Natomiast przy dieslu rośnie na początku znacznie gwałtowniej (samochody użytkowane przez firmy) by dojść do 180-190 tys i zostać w tej okolicy na kilka lat. Stara prawda mówi, że samochody z dwójką z przodu się nie sprzedają, więc się je „koryguje”.
Jestem pod wrażeniem, mega praca a od szczegółowych konkluzji to już specjalista od rynku motoryzacyjnego. Sam wchodzę w DataScience pracując wcześniej jako analityk-starteg/zawodowy pokerzysta i mimo dużego doświadczenia analityczno/strategicznego wykorzystanie sprawna obsługa narzędzi nie przychodzi mi lekko – taki mentoring techniczny byłby nieoceniony….
Hej, artykuł bardzo ciekawy i pokazuje moc narzędzia, jednym słowem świetna robota która np. mnie inspiruje do własnej analizy :) Mógłbyś wrzucić przykład tego skryptu którym zbierałeś dane?
Super wpis, super że chce ci się popularyzować R.
Co do samej analizy to bardzo bym chciał kiedyś zobaczyć porównanie naszego serwisu ogłoszeniowego z niemieckim (np. mobile.de).
Zawsze mnie zastanawiało to, że zdarza się, że samochód o tych samych parametrach (model, przebieg, rocznik, silnik) jest w mateczniku (Niemcy) droższy niż w Polsce. Przecież sprowadzenie kosztuje czas, opłaty dla państwa itp. Zescrapowanie ogłoszeń z różnych krajów pozwoliłoby wyłowić modele/producentów przy których najmniej się kombinuje przy imporcie. Super cenna wiedza dla kupującego.
Proponował bym do analizy brać modele (a nie marki) które w dzisiejszych czasach są wytworem marketingowym. Lub zamiast marek producentów. Peugeot, Citroen i Opel (od niedawna) mają jednego właściciela-producenta -grupę PSA. Tak samo VW to Seat, Skoda. Mini to BMW. Dacia to Renault.Alfa Romeo to Fiat. Właściwości użytkowe pojazdów są w moim mniemaniu bardziej zależne od producenta niż od „marki”. Widać to w serwisie – jak dzwonisz do serwisu to słyszysz „wciśnij 1 Fiat wciśnij 2 Alfa Romeo”. Tak pogrupowane dane dałyby lepszy obraz stanu rynku.
Fajna analiza. Zastanawia mnie jakby wyglądał wykres współczynnika wartości vs współczynnika przebiegu – gdyby były one wyznaczane dla grup samochodów w zakresie zakresach cenowych – bo w tej chwili współczynniki są wyznaczone dla całej populacji. Czyli opracowanie tego samego wykresu po wyfiltrowaniu subpopulacji wg ceny w zakresach co 5000 zł. Bo zakładam, że przy zakupie samochodu każdy najpierw zakłada jakiś budżet i względem niego optymalizuje jakość i możliwą utratę wartości w czasie.
Myślę, że wnioski w stosunku do cytowanej Toyoty byłyby inne. Po prostu inne – nie wiadomo czy lepsze lub gorsze :D.
W ten sposób możliwe byłoby określenie jakiego rocznika i przebiegu szukasz … jeżeli chcesz samochód sprzedać po jakimś założonym czasie i jak najmniej na tym stracić. Gdyby jeszcze wpisać zakładany przebieg roczny wówczas w ogóle masz bardzo ciekawe narzędzie co kupić – pod kątem optymalizacji spadku wartości.
Zastanawiałeś się nad tym dlaczego tyle Skod 4 letnich. Nie jestem pewien bo mam dwie, jedną 8 letnią i drugą 2 letnią, ale wydaje mi się, że to może mieć związek z ofertą leasingową i kredytową vw banku. Zarówno w przypadku kredytu i leasingu możesz zmienić samochód po 3/4 latach.
jeśli nie znasz się na rynku aut, to pewnie nawet nie zdajesz sobie sprawy jak poteżną moc ma analiza, którą zrobiłeś. Na czymś takim głownie bazuja gazety jak motor czy auto-świat.
Czy możesz udostępnić skrypt, którym zbierałeś dane z otomoto ?
Chciałbym taką anlizę powtórzyć dla siebie.
Pisałem kiedyś do Otomoto wprost o udostępnienie statystyk ogłoszeń, żeby chociaż znać medianę ceny interesujących mnie modeli, niestety bez odzewu.
Jak pisałem wcześniej w jakimś innym komentarzu – skrypt do pobierania danych jest stosunkowo prosty. Wystarczy poczytać kilka innych podobnych postów na tym blogu (np o mieszkaniach – tam zdaje się jest pełny kod scrappera) i przeanalizować html stron z otomoto.
Cześć
Moim zdaniem warto niedługo wrócić do tematu aby sprawdzić jaki wpływ na rynek będzie miało wejście w życie (25.05.2019r.) przepisów penalizujących grzebanie przy przebiegu pojazdu… :)
Super analiza, bardzo przyjemnie się czytało :)
Mamy 2021 rok, a ja ciągle podsyłam ten artykuł znajomym.
Kiedy znowu zmieniasz auto? :)
Świetna analiza! Szczególnie dla tych, którzy szukają używanego auta. Ja akurat kupowałem w salonie Peugeot, ale gdybym jeszcze raz szukał samochodu (od prywatnej osoby), to pewnie wiele z tych rad ułatwiłoby mi wybór! Będę wracać na ten blog. Dzięki!
Mamy 2025r, jest szansa na odświeżenie tego artykułu o aktualne dane?