Co prawda nie jest to teleturniej Wielka Gra, ale tytuł przywodzi na myśl temat “Pablo Picasso – jego życie i twórczość”. Zajmiemy się obrazami i ich analizą.
Oczywiście tytuł nie jest przypadkowy i (starszym) Czytelnikom powinien się z Wielką grą skojarzyć. Ale ilu z Was pamięta ten program? Pięcioro? Myślę nad ankietą, a teraz w planie, mamy badanie!…
Celem dzisiejszego wpisu jest sprawdzenie czy “okres czerwony” w malarstwie Picassa rzeczywiście był czerwony. Oczywiście sprawdzimy to przy pomocy R, w pewnym sensie oglądając obrazy (automatycznie). Dowiemy się też kilku rzeczy o strukturze obrazu komputerowego (totalne przedszkole).
Zaczniemy od początku, czyli krok pierwszy:
Pobranie obrazów
Na stronie Wikiart.org znajdujemy listę wszystkich obrazów – lista jest dynamiczna (kolejne obrazy są doładowywane bez przeładowania strony), ale po chwili grzebania w kodzie strony (niezawodne “Zbadaj” z Chrome) ze szczególnym uwzględnieniem zapytań sieciowych, znajdujemy link odpowiedzialny za dociągnięcie kolejnych danych. Kilka eksperymentów i widać, że pod konkretnym URLem jest JSON zwracający po 200 obrazów (przede wszystkim linki do obrazów, ich tytuły i rok powstania – to nam wystarczy). Obrazów w serwisie jest 1129, więc potrzebujemy sześciokrotnie pobrać dane (z kolejnych 6 stron JSONa).
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
library(tidyverse) library(jsonlite) ### Lista obrazów url <- "https://www.wikiart.org/en/pablo-picasso/mode/all-paintings?json=2&resultType=text&page=" paintings_list <- tibble() # 1129 obrazów, po 200 na stronie = 6 stron for(page_no in 1:6) { # zbuduj urla do JSONa page_url <- paste0(url, page_no) # pobierz JSONa json <- fromJSON(page_url) # weź tylko interesujące dane paintings_tmp <- json$Paintings # dodaj do pełnej listy paintings_list <- paintings_list %>% bind_rows(paintings_tmp) } |
Oglądamy dane (hint: glimpse(paintings_list)) i widzimy, że wszystkie kolumny są typu znakowego, a taki rok jest przecież liczbą. Zmieniamy więc rok na liczbę (a jak się nie uda to olewany konkretny obraz – w efekcie utrata 9 ze 1129 to żadna strata), jednocześnie pozostawiając tylko to co nam potrzebne:
|
1 2 3 4 |
paintings <- paintings_list %>% select(id, title, year, image) %>% mutate(year = as.numeric(year)) %>% filter(!is.na(year)) |
Tak przygotowaną listę obrazów zapisujemy sobie lokalnie (w pliku, jak ktoś chce to w bazie danych).
Kolejny krok to pobranie wszystkich plików graficznych (wpadną do folderu pics/). Zrobimy to 1120 razy przy użyciu odpowiedniej funkcji:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
download_paint <- function(paint) { # url do obrazu paint_url <- URLencode(as.character(paint$image)) # ścieżka do pliku lokalnego # () zamienione na _ dest_path <- paste0("pics/", basename(gsub("[\\(\\)]", "_", paint_url))) # pobierz plik i zapisz lokalnie download.file(paint_url, destfile = dest_path) # oddaj ścieżkę do pliku lokalnego return(dest_path) } |
którą wywołamy dla każdego z obrazów:
|
1 2 3 4 5 |
# dla każdego wiersza wywołaj funkcję i wynik jej działania umieść w kolumnie "path" paintings <- paintings %>% rowwise() %>% mutate(path = download_paint(image)) %>% ungroup() |
Cały proces trochę potrwa (w efekcie pobieramy około 350 megabajtów plików graficznych). Uzupełnioną o ścieżki do plików lokalnych listę zapisujemy lokalnie:
|
1 |
saveRDS(paintings, file = "paintings.RDS") |
Ile obrazów mamy?
Nie znam twórczości Picassa na tyle dobrze, żeby powiedzieć czy namalował (albo narysował – wśród pobranych plików są również grafiki) 1120 obrazów czy więcej. Trzeba było doczytać. Ale to zabawa. Nauka przez zabawę
Ile obrazów powstało w kolejnych latach?
|
1 |
paintings %>% count(year) %>% ggplot() + geom_col(aes(year, n)) |
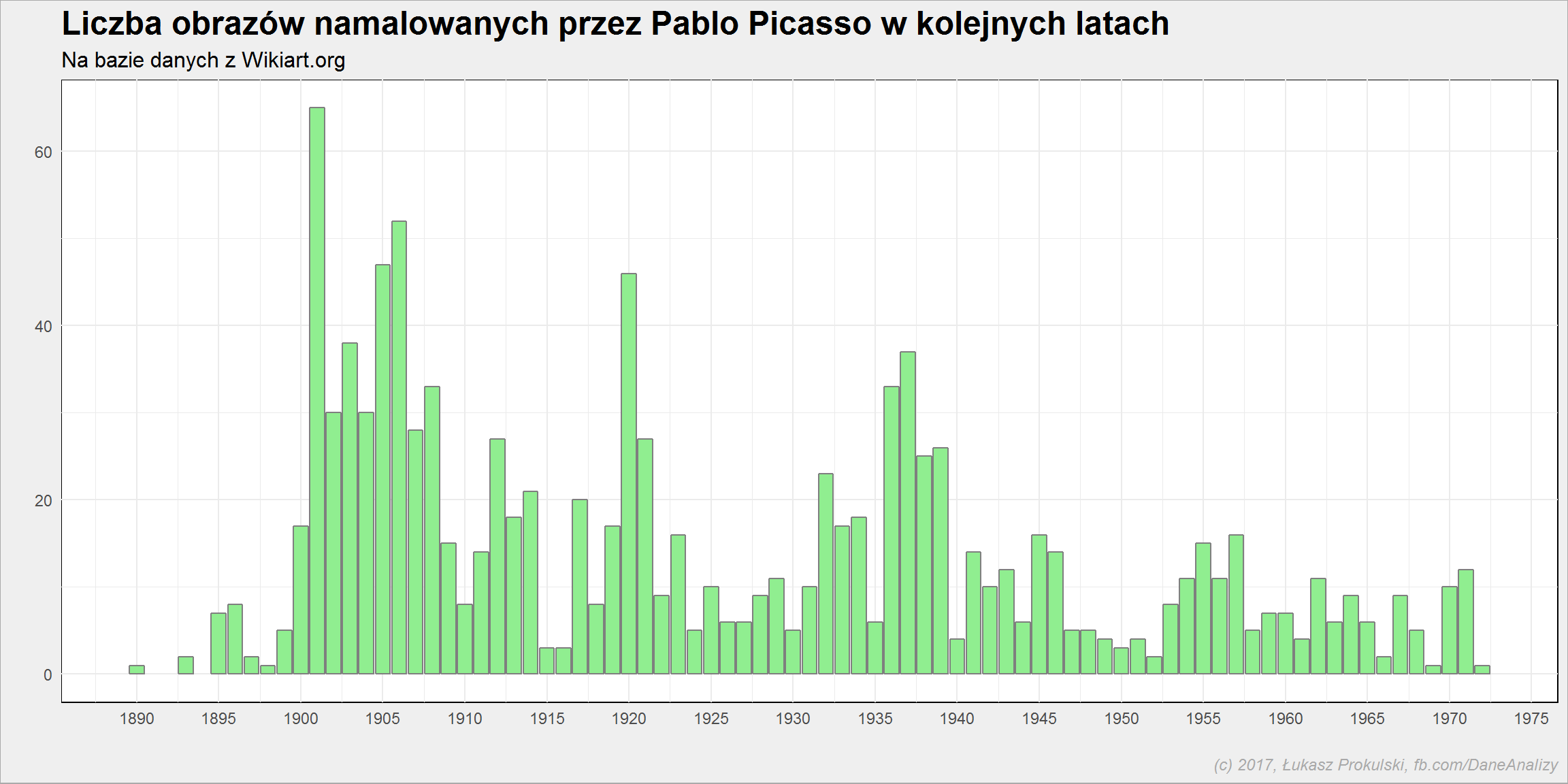
Tutaj pole do popisu dla biografów – dlaczego bywały lata kiedy malował więcej? Nowe kobiety (znając Picassa to może być przyczyna – nowa muza to większa wena). O jednym jestem przekonany: w początkowych latach twórczości artysta (każdy?) jest bardziej płodny, rozwija warsztat, szuka swojej formy wyrazu. Kiedy przychodzi sukces, a spojrzenie na sztukę jest już ugruntowane – powstają dzieła bardziej przemyślane, a ich przygotowanie zajmuje więcej czasu (albo szkoda czasu na wprawki). Tak sobie koncypuję.
Przejdźmy jednak dalej – jak w R wyświetlić plik graficzny (w tym przypadku plik JPEG)? Sposobów jest wiele, prześledzimy jeden, który pozwoli na manipulację danymi graficznymi.
Wyświetlenie pliku JPEG
Nasze zabawy przeprowadzimy na obrazie Scéne de Corrida z 1901 roku. Nie jest to może najbardziej znany (ale taki najbardziej znany, że od razu wiadomo jak to Sylwuś mówił o Szopenie w Dniu świta) obraz, ale wybrałem go nie bez powodu.
|
1 2 3 4 5 6 7 8 9 |
library(jpeg) # dla funkcji readJPEG() # to będzie parametrem funkcji file <- "pics/bullfight-scene-1901.jpg" picture <- readJPEG(file) plot.new() rasterImage(picture, 0, 0, 1, 1) |

Rozmiary obrazka to 965, 1280, 3, gdzie kolejno mamy:
- wysokość = 965 pikseli
- szerokość = 1280 pikseli
- liczbę warstw kolorów – tutaj 3 co odpowiada składowym R, G, B
Możemy pokazać (uwaga – inna funkcja) tylko jedną składową – weźmy czerwoną (jest dość charakterystyczna na przykładowym obrazie):
|
1 |
image(picture[,,1], col = gray.colors(255)) |

Przede wszystkim obraz jest przekręcony (można temu zapobiec przekształcając macierz) – wynika to z różnicy w umieszczeniu punktu początkowego układu współrzędnych. rasterImage() rysuje punkty poczynając od lewego górnego rogu, image() tak jak ma to miejsce w kartezjańskim układzie współrzędnych – od lewego dolnego rogu.
Jeśli zaś chodzi o kolory: im bardziej biały punkt na powyższym obrazie tym silniejsza składowa czerwona (R). Zwódźcie uwagę na trybuny i czerwoną płachtę oraz na ziemię i zielone spodnie.
Przekształcenia obrazu
Kolejne manipulacje będziemy przeprowadzać na ramce danych, gdzie każdy wiersz będzie zawierał współrzędne (x, y) punktu oraz składowe jego kolorów (R, G, B). Przygotujmy zatem taką ramkę:
|
1 2 3 4 5 6 7 8 9 10 11 |
library(reshape2) # dla fukncji melt() image.R <- melt(picture[,,1]) image.G <- melt(picture[,,2]) image.B <- melt(picture[,,3]) # trzy ramki składamy w jedną image.df <- cbind(image.R, image.G[3], image.B[3]) # i poprawiamy nazwy kolumn colnames(image.df) <- c("x","y","R","G","B") |
Możemy już usunąć zbędne dane (popatrzcie na rozmiary tych tablic i rozmiar pliku JPEG – widać co oznacza porządna kompresja), aby nie zajmowały nam niepotrzebnie pamięci.
|
1 |
rm(image.R, image.G, image.B, picture) |
Dodatkowo zmniejszymy sobie nieco obrazek – na przykład zostawiając co piątą linię (i kolumnę):
|
1 2 3 4 5 6 7 8 9 10 11 12 |
# to będzie później parametrem picture_scale <- 5 image.df <- image.df %>% # przeskalowanie dla szybszych późniejszych obliczeń filter(x %% picture_scale == 0) %>% filter(y %% picture_scale == 0) %>% mutate(x = x %/% picture_scale, y = y %/% picture_scale) # rozmiary po przeskalowaniu dimx <- max(image.df$x) dimy <- max(image.df$y) |
Kolejny krok to posteryzacja (*color quantization, czyli zmniejszenie liczby kolorów. Algorytmów jest pewnie sporo (w ogóle przekształcenia obrazu to fascynująca sprawa – rozmycia, wyodrębnianie krawędzi – wszystko to są operacje na macierzach), my wykorzystamy k-means. Znajdziemy 8 centrów (punktów w przestrzeni kolorów) i wszystkie kolory przekształcimy do tych ośmiu.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
n_clusters <- 8 # k-means na przestrzeni kolorów image_df_kmeans <- kmeans(image.df[, c("R", "G", "B")], n_clusters) # tabelka z kolorami centrów image.df_centers <- image_df_kmeans$centers %>% as_data_frame() %>% mutate(cluster = as.numeric(rownames(.))) %>% rename(R_kmeans = R, G_kmeans = G, B_kmeans = B) %>% # składowe kolorów na kod HEX koloru mutate(RGB_kmeans_hex = sprintf("#%02X%02X%02X", round(255 * R_kmeans), round(255 * G_kmeans), round(255 * B_kmeans))) # łączymy oryginalny obrazek z 8 kolorami image.df_all <- image.df %>% mutate(cluster = image_df_kmeans$cluster) %>% left_join(image.df_centers, by = "cluster") # usuwamy pośrednie tabele rm(image.df, image.df_centers, image_df_kmeans) |
Teraz możemy już narysować obrazek z przekształconymi kolorami. Prawie od razu – najpierw musimy z tabeli danych przejść na macierze kolejnych składowych (czyli drogę odwrotną niż poprzednio):
|
1 2 3 4 5 6 7 |
# potrzebujemy macierzy 3-wymiarowej image.segmented <- array(dim=c(dimx, dimy, 3)) # każdy wymiar to jedna składowa koloru image.segmented[,,1] <- matrix(image.df_all$R_kmeans, nrow=dimx) # R image.segmented[,,2] <- matrix(image.df_all$G_kmeans, nrow=dimx) # G image.segmented[,,3] <- matrix(image.df_all$B_kmeans, nrow=dimx) # b |
Co wyszło?
|
1 2 |
plot.new() rasterImage(image.segmented, 0, 0, 1, 1) |

Zwróćcie uwagę na szczegóły. Są dużo mniejsze – wynika to ze zmniejszenia rozdzielczości obrazu ale też zmniejszenia rozdzielczości kolorów (zmniejszenia ich liczby). Zgubiliśmy chociażby niebieskie spodnie torreadora (tego najbardziej z lewej), zniknęły też odcienie zielonego (torreador po prawej) i czerwonego (mamy wielkie czerwone plamy).
Zobaczmy ile punktów obrazu jest danego koloru (ze zmniejszonej palety):
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
# policzmy sobie kolorki :) popular_colors_kmeans <- image.df_all %>% count(RGB_kmeans_hex) %>% ungroup() %>% arrange(desc(n)) %>% # przyda się do kolejności słupków na wykresie mutate(RGB_kmeans_hex = factor(RGB_kmeans_hex, levels = RGB_kmeans_hex)) # użyjemy nazwy kolorów (kod HEX) do pokolorowania słupków popular_colors_kmeans_palete <- as.character(popular_colors_kmeans$RGB_kmeans_hex) names(popular_colors_kmeans_palete) <- as.character(popular_colors_kmeans$RGB_kmeans_hex) # narysujmy wykres ggplot(popular_colors_kmeans) + geom_col(aes(RGB_kmeans_hex, n, fill = RGB_kmeans_hex)) + scale_fill_manual(values = popular_colors_kmeans_palete) |
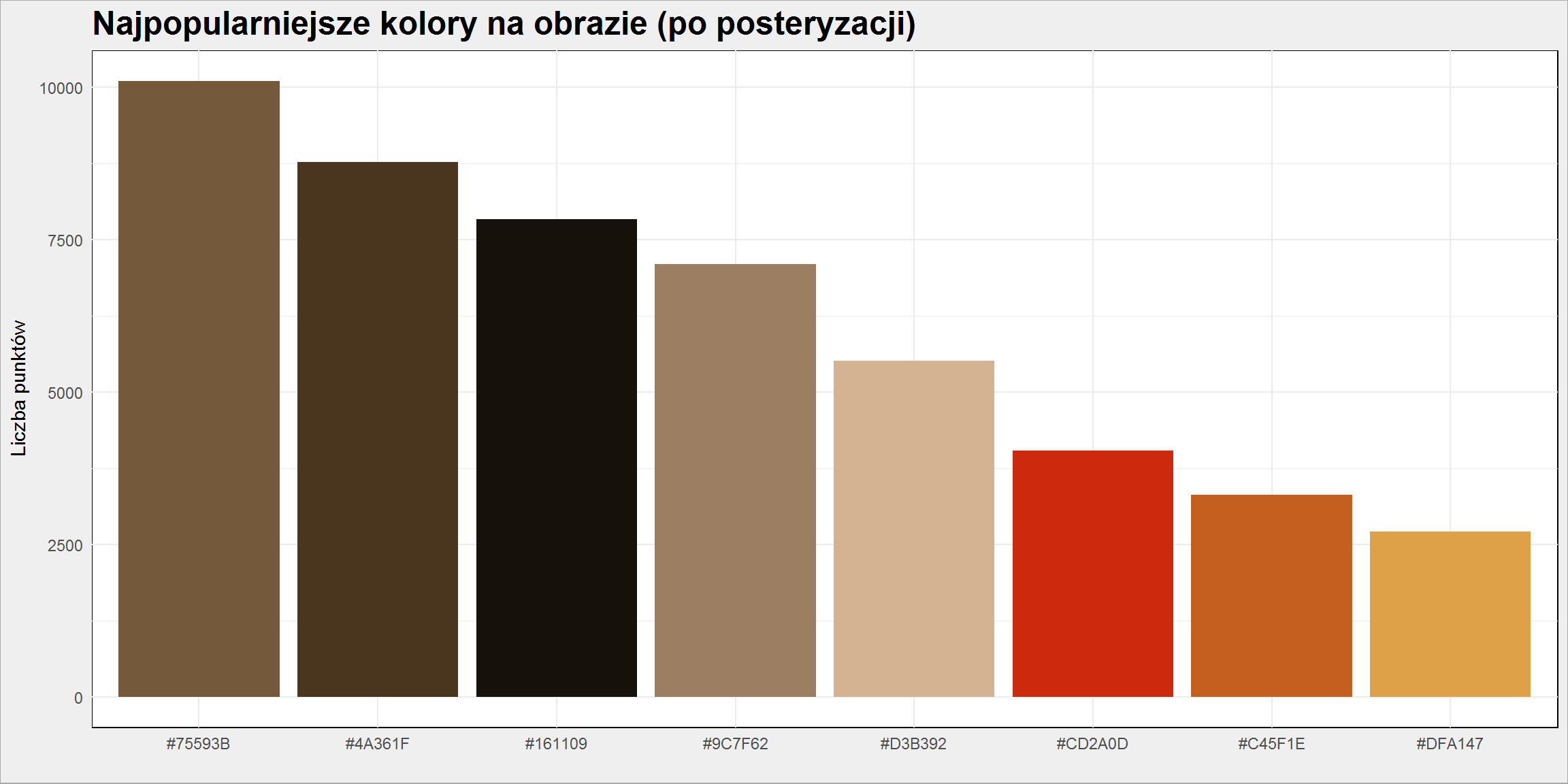
Tych kolorów i informacji o liczbie punktów użyjemy do zobaczymy jak zmieniała się paleta używana przez Picassa na przestrzeni jego życia.
Korzystając z okazji zabawmy się w principal components analysis na przestrzeni oryginalnych kolorów – czy da się wyłowić ze samych składowych (bez informacji o położeniu punktów danego koloru) wyłowić jakieś informacje? Przeprowadźmy analizę PCA i narysujmy jej wynik:
|
1 2 3 4 5 6 7 |
pca <- princomp(image.df_all[, 3:5]) pca$scores %>% as_data_frame() %>% ggplot() + geom_point(aes(Comp.1, Comp.2, color = Comp.3), alpha = 0.1) + scale_color_gradient2(low = "red", mid = "blue", high = "green", midpoint = 0) |
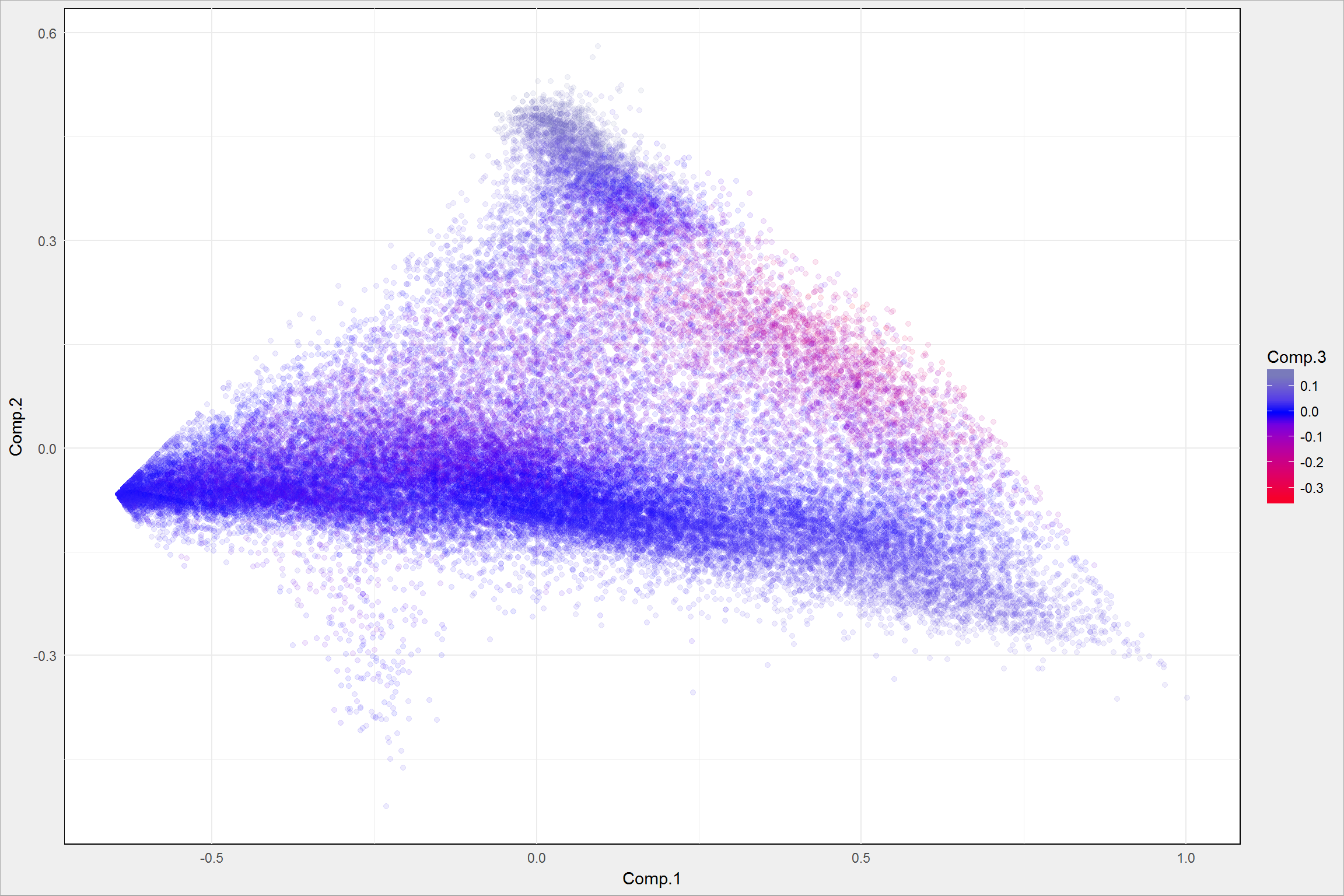
Trudno chyba cokolwiek powiedzieć… ale widać pewne obszary. Można by spróbować zrobić PCA (to już mamy), a później k-means na wyniku PCA i na tej podstawie przypisać kategorie do poszczególnych punktów obrazka. Niewiele się zmieni – przekształcenia (PCA, k-means) robimy na samej przestrzeni barw.
Spróbujmy dodać do tego współrzędne poszczególnych punktów (normalizując je automatycznie – skorzystamy z prcomp() zamiast z princomp())
|
1 2 3 4 5 6 7 8 9 10 11 |
pca_all <- prcomp(image.df_all[, 1:5], scale. = TRUE) pca_kmeans <- kmeans(pca_all$x, 8) image.df_all$pca_cluster <- pca_kmeans$cluster ggplot(image.df_all) + geom_point(aes(y, x, color = as.factor(pca_cluster))) + scale_color_brewer(palette = "YlOrRd") + scale_y_reverse() + labs(color = "PCA cluster", x = "", y = "") |

Nadal widać zarysy. Niewiele w sumie się zmieniło. Widać przejście tonalne po przekątnej co jest ciekawostką i wynikiem dodania składowych X i Y do analizy PCA.
Tyle znęcania się nad jednym obrazem – weźmy na warsztat wszystkie.
Analiza wszystkich obrazów
Wszystkie potrzebne operacje już przeprowadzaliśmy, czas upakować je w funkcję, którą wywołamy dla każdego z obrazów:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 |
prepare_kmeans_palete <- function(title, year, path, picture_scale = 5, n_clusters = 8) { # wczytanie obrazka picture <- readJPEG(path) # przygotowanie data frames dla każdej ze składowych kolorów image.R <- melt(picture[,,1]) image.G <- melt(picture[,,2]) image.B <- melt(picture[,,3]) # złączenie składowych w jedną dużą tabelę image.df <- cbind(image.R, image.G[3], image.B[3]) colnames(image.df) <- c("x","y","R","G","B") # dla oszczędzenia pamięci usuwamy co zbędne rm(image.R, image.G, image.B, picture) image.df <- image.df %>% # kolory do HEX) mutate(RGB_hex = sprintf("#%02X%02X%02X", round(R * 255), round(G * 255), round(B * 255))) %>% # przeskalowanie dla szybszych późniejszych obliczeń filter(x %% picture_scale == 0) %>% filter(y %% picture_scale == 0) %>% mutate(x = x %/% picture_scale, y = y %/% picture_scale) # rozmiary przeskalowanego obrazu dimx <- max(image.df$x) dimy <- max(image.df$y) # kmeans dla składowych koloru image_df_kmeans <- kmeans(image.df[, c("R", "G", "B")], n_clusters) # centra image.df_centers <- image_df_kmeans$centers %>% as_data_frame() %>% mutate(cluster = as.numeric(rownames(.))) %>% rename(R_kmeans = R, G_kmeans = G, B_kmeans = B) %>% # kolory RGB mutate(RGB_kmeans_hex = sprintf("#%02X%02X%02X", round(255 * R_kmeans), round(255 * G_kmeans), round(255 * B_kmeans))) # łączymy dane oryginalne przeskalowanego obrazu z wynikiem kmeans image.df_all <- image.df %>% mutate(cluster = image_df_kmeans$cluster) %>% left_join(image.df_centers, by = "cluster") # znowu usuwamy śmieci z pamięci rm(image.df, image.df_centers, image_df_kmeans) # rozkład kolorów po kmeans popular_colors_kmeans <- image.df_all %>% count(RGB_kmeans_hex) %>% ungroup() %>% arrange(desc(n)) %>% mutate(color_n = row_number()) # dodajemy dane o obrazie popular_colors_kmeans$title <- title popular_colors_kmeans$year <- year popular_colors_kmeans$path <- path return(popular_colors_kmeans) } |
Nie będę wnikał w powyższy kod – przeszliśmy to krok po kroku, a i same komentarze dobrze tłumaczą co jest robione.
Potraktujemy tą funkcją wszystkie obrazy:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
kmeans_colors <- data_frame() for(i in 1:nrow(paintings)) { tmp_df <- prepare_kmeans_palete(title = as.character(paintings[i, "title"]), year = as.numeric(paintings[i, "year"]), path = as.character(paintings[i, "path"]), picture_scale = 5, n_clusters = 8) # numer obrazu, na wszelki wypadek :) tmp_df$i <- i kmeans_colors <- kmeans_colors %>% bind_rows(tmp_df) } |
Po drodze coś nam się wykopyrtnie, coś się zawiesi, a to obrazek się ściągnął z błędem, a to zabraknie pamięci albo prądu. Teoretycznie kod jest poprawny, ale warto czuwać nad całym procesem.
Mając zebrane po 8 najpopularniejszych kolorów (przypominam – po posteryzacji) dla każdego obrazu i wiedząc kiedy obraz został namalowany możemy pokusić się o narysowanie na osi czasu popularności kolorów. Wybierzemy tylko ten najpopularniejszy kolor na danym obrazie i policzymy jaki procent punktów ma ten kolor:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
plot_data <- kmeans_colors %>% filter(color_n == 1) %>% group_by(year) %>% mutate(p = n/sum(n)) %>% ungroup() palete_vec <- as.character(unique(plot_data$RGB_kmeans_hex)) palete <- palete_vec names(palete) <- palete_vec plot_data %>% ggplot() + geom_vline(xintercept = c(1901, 1904, 1907, 1909, 1912, 1919, 1930, 1939, 1949), color = "red") + geom_bar(aes(year, p, fill = RGB_kmeans_hex), stat = "identity", show.legend = FALSE) + scale_fill_manual(values = palete) + scale_x_continuous(breaks = seq(1880, 1990, 5)) + annotate("text", label = "Blue\nPeriod", x = 1901, y = 1.1, hjust = 0) + annotate("text", label = "Rose\nPeriod", x = 1904, y = -0.1, hjust = 0) + annotate("text", label = "African art\nand primitivism", x = 1907, y = 1.2, hjust = 0) + annotate("text", label = "Analytic\ncubism", x = 1909, y = -0.1, hjust = 0) + annotate("text", label = "Synthetic\ncubism", x = 1912, y = 1.1, hjust = 0) + annotate("text", label = "Neoclassicism\nand surrealism", x = 1919, y = -0.1, hjust = 0) + annotate("text", label = "The Great Depression\nto MoMA exhibition", x = 1930, y = 1.1, hjust = 0) + annotate("text", label = "World War II\nand late 1940s", x = 1939, y = -0.1, hjust = 0) + annotate("text", label = "Later works\nto final years", x = 1949, y = 1.1, hjust = 0) |
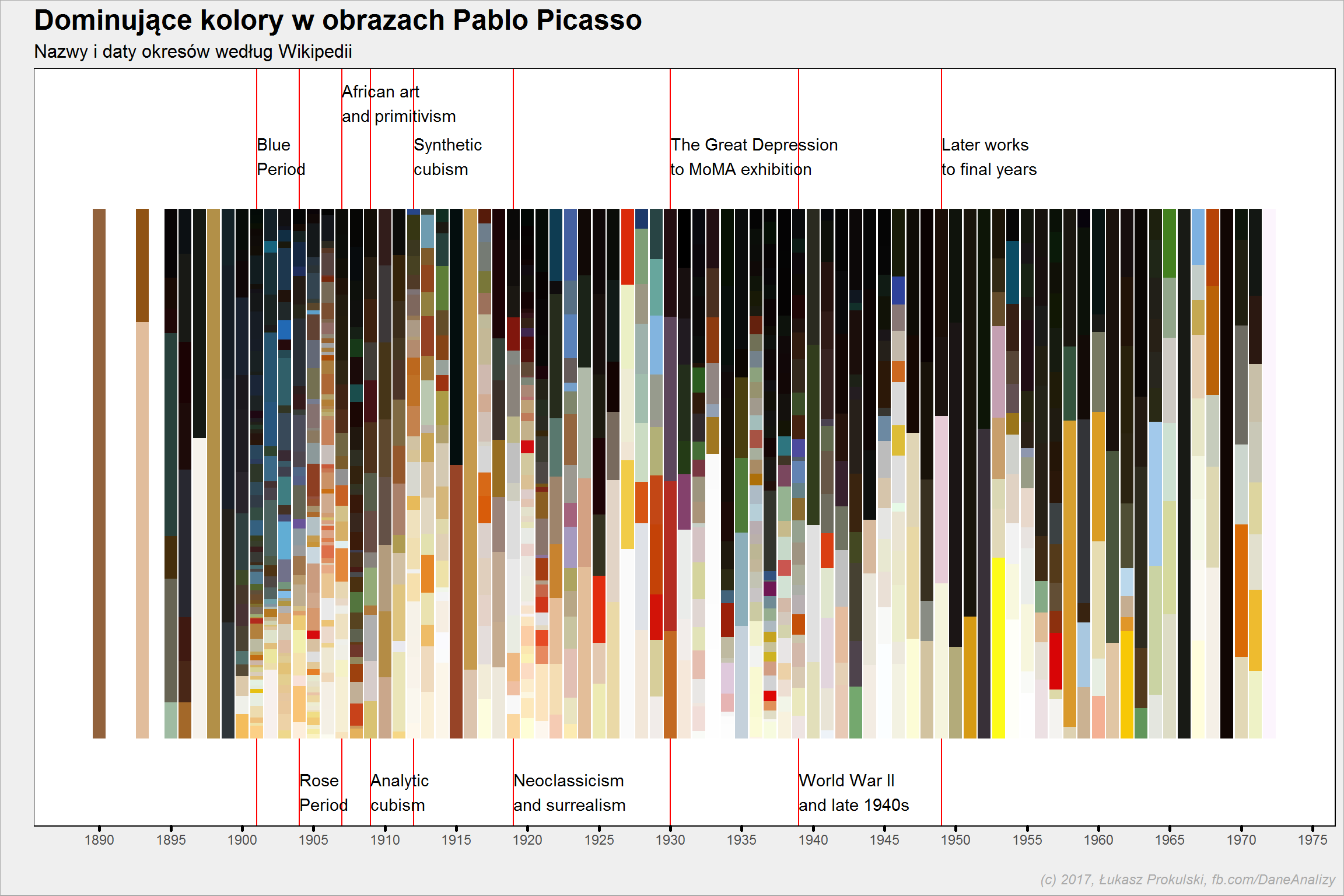
Przy okazji dodałem do wykresów informacje o okresach w twórczości Picassa zaczerpnięte z Wikipedii:
- Before 1900
- Blue Period: 1901–1904
- Rose Period: 1904–1906
- African art and primitivism: 1907–1909
- Analytic cubism: 1909–1912
- Synthetic cubism: 1912–1919
- Neoclassicism and surrealism: 1919–1929
- The Great Depression to MoMA exhibition: 1930–1939
- World War II and late 1940s: 1939–1949
- Later works to final years: 1949–1973
Czy okres niebieski był rzeczywiście niebieski? A w czerwonym dominowała czerwień? W niebieskim rzeczywiście widać sporo odcieni niebieskiego, ale w czerwonym to chyba raczej czerwone akcenty. Widać zaś coś interesującego – w okresie neoklasycyzmu i surrealizmu obrazy Picassa były jaśniejsze, z barwami o mocnym nasyceniu. Podczas II wojny światowej widać dużo ciemnych barw – czy to wyniki życia prywatnego czy odczuć związanych z trwającą wojną?
Czy jest na sali znawca twórczości (i życia) Pabla Picassa? Proszę o komentarze!