Jak znaleźć posłów do przejęcia z jednego klubu do drugiego?
Czy posłowie głosują zgodnie z głosem lidera?
Sprawdzimy dzisiaj jak wygląda rozkład sił w polskim Sejmie. Jak bardzo partie różnią się od siebie, komu z kim po drodze i czy są posłowie, którzy głosują inaczej niż lider?
Wszystkie te informacje wydobędziemy moim ulubionym sposobem, czyli bez czytania. A tak na prawdę to bez wnikania w politykę, bez oglądania wiadomości. Jedynie na podstawie tego jak poszczególne osoby głosują w kolejnych głosowaniach.
Jeśli nie interesują Cię technikalia – przejdź od razu do wyników:
- podobieństwo partii między sobą
- bliscy i dalecy szefa partii
- podobieństwo między liderami
- układ posłów w zależności od głosowań – to najciekawsze i najfajniejsza zabawa!
- symulacje sceny politycznej
- przejście posła z Kukiz’15 do Nowoczesnej – filmik z układem posłów głosowanie po głosowaniu
- statystyki VIII kadencji – kto jest najczęściej za, a kto przeciw? Kto nie ma zdania (wstrzymuje się), a kto nie przychodzi wcale?
Jeśli jednak wolisz technikalia w R to zapraszam do dalszej lektury :)
Dane o przebiegu głosowań znajdują się na stronach Sejmu. Wynik każdego głosowania dostępny jest w dwóch formatach – jako podsumowanie według klubów sejmowych (w HTMLu, można pokusić się o pobranie wyników bezpośrednio ze strony jakimś automatem) oraz w postaci plików PDF gdzie znajdziemy dane “atomowe” – per osoba.
Z ekstrakcją danych z PDFów też można sobie poradzić, ale żmudna to praca. Na szczęście istnieje pakiet sejmRP dzięki któremu interesujące nas dane można pobrać z bazy danych. Po szczegóły odsyłam do GitHuba.
Pobranie danych
Ja pobrałem dane wcześniej i zapisałem je sobie lokalnie. Jest ich całkiem sporo i są sensownie rozdzielone. My będziemy potrzebować:
- danych o posłach – do zdobycia funkcją get_deputies_table()
- danych o poszczególnych głosowaniach – get_votings_table()
- i przede wszystkim (na tym oprzemy analizę) – danych o oddanych głosach – get_votes_table()
|
1 2 3 4 5 6 |
library(dplyr) library(reshape2) library(ggplot2) # wczytujemy dane zapisane lokalnie load("dane.RData") |
Filtrowanie
Pobrane dane ograniczymy do obecnej kadencji (to VIII kadencja Sejmu):
|
1 2 3 4 |
deputies <- filter(deputies, nr_term_of_office == 8) deputies$id_deputy_num <- as.numeric(deputies$id_deputy) # przyda się przy łączeniu tabel później votings <- filter(votings, nr_term_of_office == 8) votes <- filter(votes, nr_term_of_office == 8) |
Poprawna numeracja głosowań
Niestety numeracja głosowań jest jakoś skopana (nie wnikałem w szczegóły, zauważyłem że tak jest). Dla ogółu danych (jakieś 3/4 tego postu) nie ma to znaczenia. Ale będziemy robić animację pokazującą zmiany z każdym kolejnym głosowaniem. W związku z tym na początek uporządkujmy numerację nadając własne numery kolejnym głosowaniom.
Wystarczy posortowanie po numerze posiedzenia spotkań i w ramach tego – po numerze głosowania. A później, od góry do dołu nadajemy nowe numerki:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
votings <- votings %>% arrange(nr_meeting, nr_voting) %>% mutate(new_id_voting = row_number()) # słownik stary numer -> nowy numer votings_dict <- select(votings, id_voting, new_id_voting) # podmiana kolumny votings <- votings %>% select(-id_voting) %>% mutate(id_voting = new_id_voting) %>% select(-new_id_voting) # porawka w wynikach głosowania, z podmianą kolumny votes <- left_join(votes, votings_dict, by="id_voting") %>% select(-id_voting) %>% mutate(id_voting = new_id_voting) %>% select(-new_id_voting) |
Przypisanie posłów do partii
Posłowie zmieniają kluby, a w danych z poszczególnych głosowań przypisani są do klubu, w którym byli w momencie głosowania. Ma to sens, ale nam wystarczy aktualny (stan na 10 lutego 2017 – do tego momentu pobrałem dane; zresztą wszystkie jakie były ostatnio dostępne). Dodajmy przynależność klubową od razu, bo później będzie potrzebna w kilku miejscach.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
deputies_votes <- votes %>% filter(id_voting==max(id_voting)) %>% select(id_deputy, club) %>% unique() deputies <- left_join(deputies, deputies_votes, by="id_deputy") # nie będziemy brać pod uwagę osób, które nie są już posłami # (wygasłe mandaty, śmierć) deputies <- na.omit(deputies) votes <- filter(votes, id_deputy %in% deputies$id_deputy) # dodanie partii do posłów - tabela z głosowaniami votes2 <- left_join(select(votes, id_voting, id_deputy, vote), deputies_votes, by="id_deputy") |
Konwersja głosów
Oddane głosy opisane są słownie. Będziemy coś liczyć – potrzebujemy więc liczb. Zamiast opisów nadajemy punkty w zależności od oddanego głosu:
- głos Za = 5 punktów
- Przeciw = -5 punktów
- Wstrzymał się = 2 punktów
- Nieobecny = 0 punktów
|
1 2 3 |
votes2$vote <- ifelse(votes2$vote == "Za", 5, ifelse(votes2$vote == "Przeciw", -5, ifelse(votes2$vote == "Wstrzymał się", 2, 0))) |
Un-pivot
Teraz coś czego nie potrafi w prosty sposób zrobić Excel i to uważam za jego sporą wadę. Zamiana tabelki “długiej” na “szeroką”. W odwrotną stronę Excel radzi sobie bardzo dobrze – tabele przestawne (pivot) się kłaniają (ileż czasu mi zajęło zrozumienie tego mechanizmu… teraz nie wyobrażam sobie bez niego pracy).
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
# po posłach votes_deputies <- dcast(select(votes2, -club), formula = id_voting ~ id_deputy, fun.aggregate = median, value.var = "vote", fill = 0, na.rm = TRUE) # po klubach votes_clubs <- dcast(select(votes2, -id_deputy), formula = id_voting ~ club, fun.aggregate = median, value.var = "vote", fill = 0, na.rm = TRUE) |
Ważne – dane agregujemy tutaj jako medianę poszczególnych wyników (wydało mi się to sensowne). O ile w przypadku posłów nie ma to znaczenia, o tyle w przypadku klubów już ma. Można spróbować agregacji inną funkcją – średnią, sumą lub czymś bardziej wymyślnym. Sprawdźcie sami, ja szczerze mówiąc nie sprawdzałem jaki to ma wpływ na wyniki.
Macierze korelacji
Czas na określenie miary podobieństwa pomiędzy posłami (i klubami). Jeśli dwie osoby głosują identycznie to w dużym uproszczeniu są identyczne. Miar podobieństwa jest sporo, ja proponuję najprostszą czyli współczynnik korelacji. Można liczyć jakąś odległość (na przykład euklidesową). Dla ciekawskich polecam zapoznanie się z funkcjami dist() oraz cmdscale().
W prosty sposób policzymy wszystkie współczynniki korelacji “każdy z każdym”:
|
1 2 3 4 5 |
# między posłami cor_mat_deputies <- cor(select(votes_deputies, -id_voting)) # między klubami cor_mat_clubs <- cor(select(votes_clubs, -id_voting), use="complete.obs") |
Obrazki!
Zobaczmy jak to wygląda. Na początek dla posłów – jak bardzo są posobni w swoich głosach? Im większa wartość współczynnika korelacji tym większe prawdopodobieństwo. Podobieństwo samego ze sobą to 1, zupełne przeciwieństwo to -1. Uwaga, bo korelacja potrafi być myląca, na co świetnym przykładem jest kwartet Anscombe’a – ten sam współczynnik mają cztery różne rozkłady. Kliknij w link, żeby się o tym przekonać. Kwartet ten jest też świetnym przykładem na to, że warto rysować dane, a nie tylko wierzyć miarą je opisującym.
Obrazki będziemy rysować standardowo z użyciem pakietu ggplot2, a ten nie potrafi sobie poradzić z macierzami, potrzebuje “długich” tabel. Czyli potrzebny pivot (tabela przestawna) z Excela, którą idealnie zastępuje funkcja melt() z pakietu reshape2.
Przy okazji do danych o posłach dodamy ich kluby. Dwa razy, bo raz dla posła A, a później dla posła B, do którego podobieństwo określa wartość w tabeli z korelacjami.
|
1 2 3 4 5 6 7 8 9 10 11 |
# przetworzenie macierzy na ramkę danych - na potrzeby ggplot cor_df_deputies <- melt(cor_mat_deputies) cor_df_clubs <- melt(cor_mat_clubs) cor_df_deputies <- left_join(cor_df_deputies, select(deputies, id_deputy_num, club), by=c("Var1"="id_deputy_num")) cor_df_deputies <- left_join(cor_df_deputies, select(deputies, id_deputy_num, club), by=c("Var2"="id_deputy_num")) colnames(cor_df_deputies) <- c("Dep1", "Dep2", "Corr", "Club1", "Club2") |
Zobaczmy co nam powychodziło. Na początek
korelacja poseł-poseł:
|
1 2 3 4 5 6 7 |
cor_df_deputies %>% filter(Dep1>=Dep2) %>% ggplot() + geom_tile(aes(Dep1, Dep2, fill=Corr)) + scale_fill_gradient(low="red", high="green") + theme_minimal() + labs(x="ID posła", y="ID posła", fill="Podobieństwo\n(wsp.korelacji)") |
Niewiele tutaj widać. To dlatego, że posłów jest bardzo dużo (460). A w dodatku ich numery nadane są w kolejności alfabetycznej według nazwisk – nie widać więc skupisk według klubów.
Zobaczmy którym klubom najbliżej do siebie? a którym najdalej? Czyli
korelacja klub-klub
|
1 2 3 4 5 6 |
ggplot(cor_df_clubs) + geom_tile(aes(Var1, Var2, fill=value), color="black") + geom_text(aes(Var1, Var2, label=round(value,2))) + scale_fill_gradient(low="red", high="green") + theme_minimal() + labs(x="", y="", fill="Podobieństwo\n(wsp.korelacji)") |
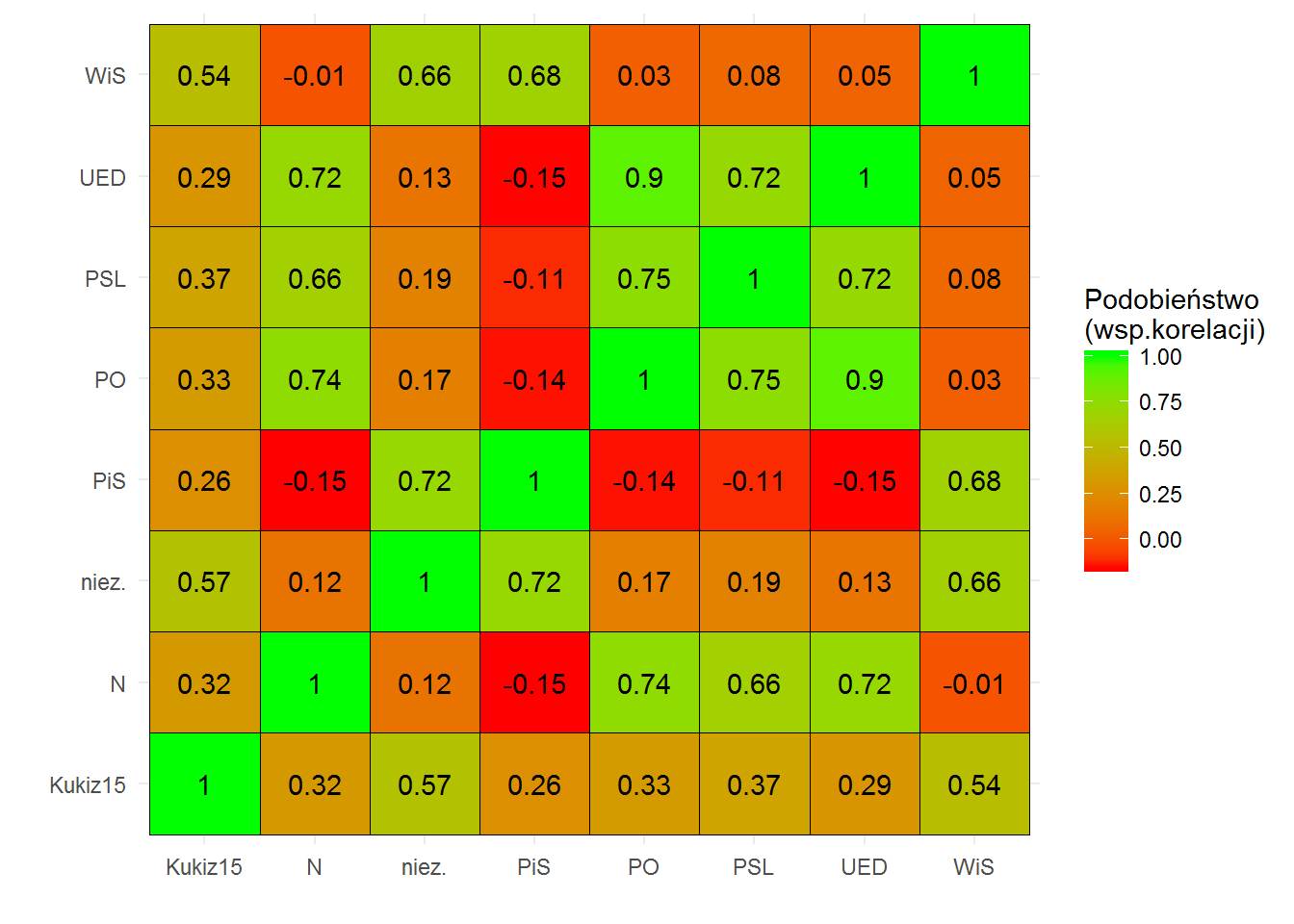
Zamiast “pivotować” dane możemy skorzystać z dedykowanych pakietów do obrazowania korelacji – corrplot lub corrgram, którym wystarczy macierz korelacji (a czasem nawet same dane). Zobaczmy jak kluby mają się ze sobą:
|
1 2 3 4 5 6 |
# install.packages("corrgram") library(corrgram) corrgram(cor_mat_clubs, order = TRUE, lower.panel= panel.shade, upper.panel = panel.cor, col.regions = colorRampPalette(c("red", "green"))) |
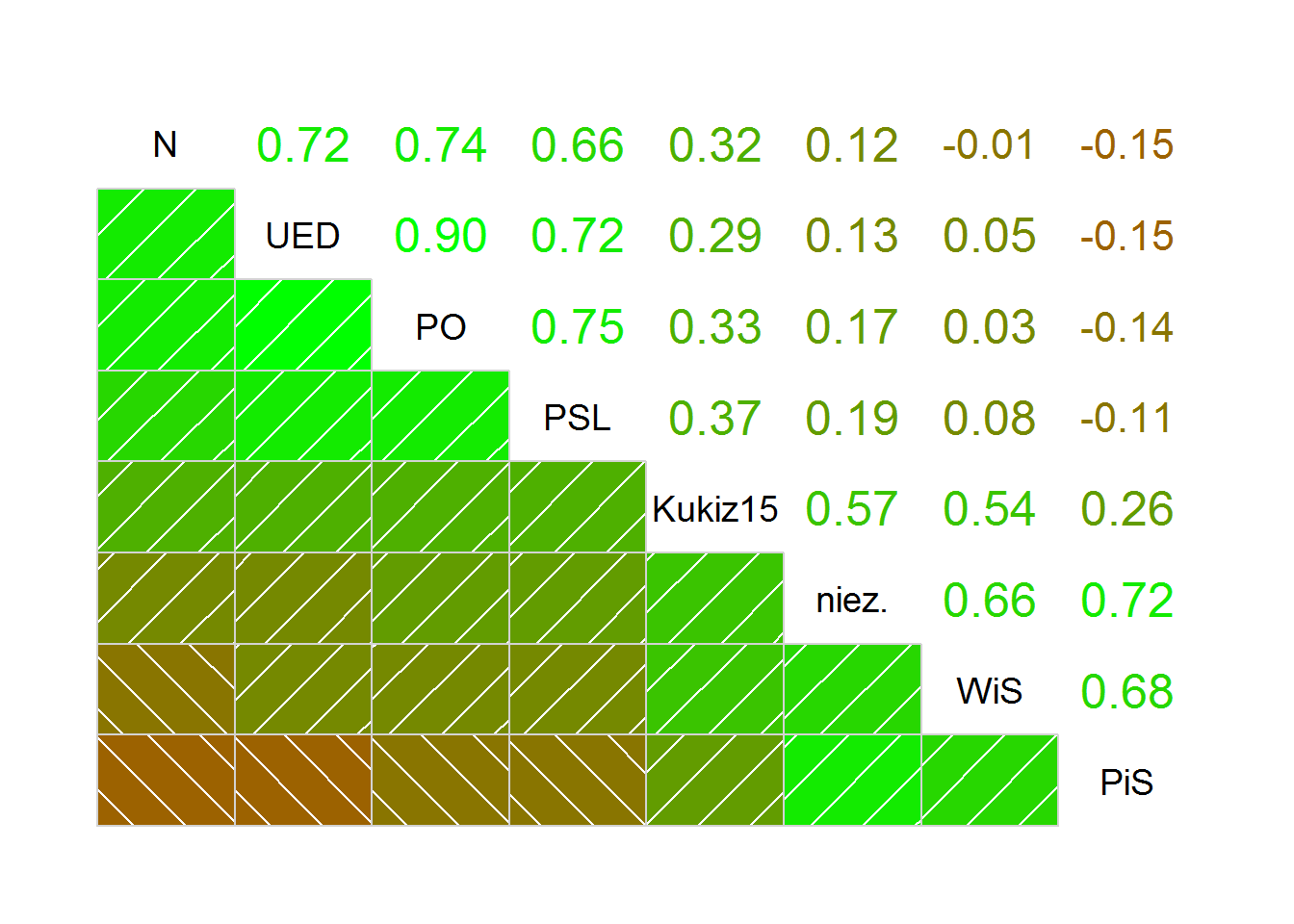
Za silną korelację dodatnią uznaje się wartości współczynnika korelacji pomiędzy 0.5 a 1.0 (odpowiednio -1.0 do -0.5 dla korelacji ujemnej, czyli w naszym przypadku przeciwieństwo). Wartości z zakresu 0.0 – 0.5 (i tak samo dla wartości ujemnych) to korelacja słaba. Interpretacja taka jest jednak arbitralna i nie możemy jej traktować zbyt ściśle (ekonomiści 0.9 uznają za silną, fizycy przy bardzo dokładnych badaniach – za słabą).
Najbliżej do siebie jest PO i UED – co nie dziwi, jeśli zobaczymy skąd wywodzą się posłowie UED. Platforma Obywatelska ma nieco bliżej do PSLu niż do Nowoczesnej. Widzimy więc wyraźnie podobieństwo w ramach opozycji i to w dodatku jest to silne podobieństwo.
Z drugiej strony mamy PiS i oponentów: największy to Nowoczesna i UED, nieco mniejszy to PO. Ale co ciekawe – jest to korelacja (ujemna oczywiście) słaba.
Kukiz’15 jest pośrodku – tak samo blisko ma do PiSu jak i do opozycji (nieco bardziej do PSL niż do PO czy .N). A wydawałoby się, że głosuje jak PiS, prawda? Taki przynajmniej obraz rysują niektóre media.
Obserwacja tych trzech par (PO/.N/PSL – PiS, PO/.N/PSL – Kukiz’15 oraz PiS – Kukiz’15) pokazuje polaryzację naszej sceny politycznej na trzy obozy. Wykorzystamy tę obserwację później.
Kluby i ich szefowie
Zobaczmy czy członkowie poszczególnych klubów głosują tak jak ich szefowie (lub liderzy partii – różne z tym szefowaniem bywa; jest jeden poseł, który rządzi całym krajem a nie ma żadnego stanowiska poza przewodzeniem partii).
Najpierw musimy znać ID konkretnych osób, znajdujemy je w tabeli deputies (ręcznie):
|
1 2 3 4 5 |
szef_PO <- 337 # Schetyna Grzegorz szef_PiS <- 146 # Kaczyński Jarosław szef_N <- 296 # Petru Ryszard szef_Kukiz15 <- 200 # Kukiz Paweł szef_PSL <- 174 # Władysław Kosiniak-Kamysz |
Teraz przygotujemy sobie funkcję, która znajdzie dziesiątkę osób najbardziej i najmniej podobnych (w sensie głosowania) do szefa danej partii. A właściwie jest to na tyle uniwersalna funkcja, że wystarczy podać ID dowolnego posła.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
similar_deputies <- function(szef_id, sim=TRUE) { # który wiersz (i kolumna) w macierzy korelacji odpowiada danej osobie? szef_colname <- which(rownames(cor_mat_deputies)==szef_id) if(sim) { # podobni: # kto ma najmniejszą różnicę w głosach, # czyli największy współczynnik korelacji? szef_tab <- as.data.frame(head(sort(cor_mat_deputies[szef_colname, -szef_colname], decreasing= TRUE), 10)) } else { # różni: # kto ma największą różnicę w głosach, # czyli najmniejszy współczynnik korelacji szef_tab <- as.data.frame(head(sort(cor_mat_deputies[szef_colname, -szef_colname]), 10)) } colnames(szef_tab) <- "corr" szef_tab$id_deputy <- rownames(szef_tab) szef_tab <- left_join(szef_tab, select(deputies, id_deputy, surname_name, club), by="id_deputy") %>% arrange(desc(corr)) %>% select(ID=id_deputy, Name=surname_name, Club=club, Cor=corr) return(szef_tab) } |
Wyciągamy po prostu jeden “plasterek” (w tym przypadku wiersz, ale macierz korelacji jest kwadratowa i symetryczna, więc może to być równie dobrze kolumna) z całej wielkiej macierzy i sortujemy po jego wartościach. Bierzemy 10 największych (albo najmniejszych), a na koniec dodajemy do tego nazwiska i przynależność klubową. Oczywiście w największych nie liczymy szefa partii – on sam ze sobą jest w 100% zgodny.
Bliscy i dalecy szefa partii
Zobaczmy co otrzymamy dla poszczególnych partii:
|
1 2 |
similar_deputies(szef_PiS, sim=TRUE) # najbardziej podobni do szefa PiS similar_deputies(szef_PiS, sim=FALSE) # najmniej podobni do szefa PiS |
Tymi dwoma linikjami sprawdzamy po kolei wszystkie kluby:
PiS
najbardziej podobni do Kaczyńskiego
| ID | Name | Club | Cor |
|---|---|---|---|
| 197 | Kubów Krzysztof | PiS | 0.9428574 |
| 446 | Zbonikowski Łukasz | PiS | 0.9348380 |
| 318 | Rafalska Elżbieta | PiS | 0.9313664 |
| 368 | Suski Marek | PiS | 0.9279761 |
| 069 | Dolata Zbigniew | PiS | 0.9275911 |
| 248 | Michałkiewicz Krzysztof | PiS | 0.9274861 |
| 408 | Tułajew Sylwester | PiS | 0.9273423 |
| 415 | Warwas Robert | PiS | 0.9271060 |
| 363 | Starzycki Dariusz | PiS | 0.9269618 |
| 118 | Gwiazdowski Kazimierz | PiS | 0.9269194 |
najmniej podobni do Kaczyńskiego
| ID | Name | Club | Cor |
|---|---|---|---|
| 194 | Krząkała Marek | PO | -0.1676900 |
| 097 | Gelert Elżbieta | PO | -0.1680332 |
| 303 | Piotrowska Teresa | PO | -0.1691447 |
| 451 | Ziemniak Wojciech | PO | -0.1697906 |
| 003 | Ajchler Zbigniew | PO | -0.1706161 |
| 434 | Wójcik Marek | PO | -0.1723959 |
| 249 | Mieszkowski Krzysztof | N | -0.1728793 |
| 423 | Wilczyński Ryszard | PO | -0.1763121 |
| 422 | Wielichowska Monika | PO | -0.1772095 |
| 151 | Karpiński Włodzimierz | PO | -0.1838258 |
PO
najbardziej podobni do Schetyny
| ID | Name | Club | Cor |
|---|---|---|---|
| 270 | Neumann Sławomir | PO | 0.9629412 |
| 168 | Konwiński Zbigniew | PO | 0.9375520 |
| 262 | Mrzygłocka Izabela Katarzyna | PO | 0.9332847 |
| 349 | Skowrońska Krystyna | PO | 0.9326643 |
| 121 | Hanajczyk Agnieszka | PO | 0.9326574 |
| 013 | Augustyn Urszula | PO | 0.9317469 |
| 113 | Grabarczyk Cezary | PO | 0.9311138 |
| 304 | Plocke Kazimierz | PO | 0.9296447 |
| 347 | Siemoniak Tomasz | PO | 0.9295094 |
| 091 | Gapińska Elżbieta | PO | 0.9275951 |
najmniej podobni do Schetyny
| ID | Name | Club | Cor |
|---|---|---|---|
| 229 | Malik Ewa | PiS | -0.1759870 |
| 078 | Dziedziczak Jan | PiS | -0.1762862 |
| 286 | Osuch Jacek | PiS | -0.1763118 |
| 135 | Janik Grzegorz | PiS | -0.1788154 |
| 264 | Mularczyk Arkadiusz | PiS | -0.1790858 |
| 376 | Szewczak Jan | PiS | -0.1798131 |
| 102 | Głębocki Konrad | PiS | -0.1816140 |
| 009 | Arent Iwona | PiS | -0.1829280 |
| 396 | Tarczyński Dominik | PiS | -0.1835764 |
| 026 | Bernacki Włodzimierz | PiS | -0.1840187 |
Nowoczesna
najbardziej podobni do Petru
| ID | Name | Club | Cor |
|---|---|---|---|
| 339 | Schmidt Joanna | N | 0.8942575 |
| 092 | Gasiuk-Pihowicz Kamila | N | 0.8890991 |
| 058 | Cyrański Adam | N | 0.8864424 |
| 322 | Rosa Monika | N | 0.8848543 |
| 364 | Stasiński Michał | N | 0.8773172 |
| 221 | Lubnauer Katarzyna | N | 0.8761827 |
| 367 | Suchoń Mirosław | N | 0.8736255 |
| 123 | Hennig-Kloska Paulina | N | 0.8728146 |
| 338 | Scheuring-Wielgus Joanna | N | 0.8725611 |
| 215 | Lieder Ewa | N | 0.8721504 |
najmniej podobni do Petru
| ID | Name | Club | Cor |
|---|---|---|---|
| 251 | Milewski Daniel | PiS | -0.1570430 |
| 376 | Szewczak Jan | PiS | -0.1658185 |
| 286 | Osuch Jacek | PiS | -0.1669345 |
| 101 | Gliński Piotr | PiS | -0.1669455 |
| 135 | Janik Grzegorz | PiS | -0.1695280 |
| 102 | Głębocki Konrad | PiS | -0.1703993 |
| 009 | Arent Iwona | PiS | -0.1704593 |
| 264 | Mularczyk Arkadiusz | PiS | -0.1723275 |
| 026 | Bernacki Włodzimierz | PiS | -0.1745658 |
| 396 | Tarczyński Dominik | PiS | -0.1812594 |
Kukiz ’15
najbardziej podobni do Kukiza
| ID | Name | Club | Cor |
|---|---|---|---|
| 409 | Tyszka Stanisław | Kukiz15 | 0.9103188 |
| 133 | Jakubiak Marek | Kukiz15 | 0.8502356 |
| 380 | Szramka Paweł | Kukiz15 | 0.8384416 |
| 182 | Kozłowski Jerzy | Kukiz15 | 0.8377922 |
| 321 | Romecki Stefan | Kukiz15 | 0.8329690 |
| 391 | Ścigaj Agnieszka | Kukiz15 | 0.8296809 |
| 162 | Kobylarz Andrzej | Kukiz15 | 0.8248375 |
| 019 | Bakun Wojciech | Kukiz15 | 0.8226198 |
| 050 | Chrobak Barbara | Kukiz15 | 0.8204780 |
| 332 | Rzymkowski Tomasz | Kukiz15 | 0.8183320 |
najmniej podobni do Kukiza
| ID | Name | Club | Cor |
|---|---|---|---|
| 009 | Arent Iwona | PiS | 0.2065164 |
| 385 | Szydło Beata | PiS | 0.1998967 |
| 078 | Dziedziczak Jan | PiS | 0.1982557 |
| 026 | Bernacki Włodzimierz | PiS | 0.1979541 |
| 376 | Szewczak Jan | PiS | 0.1976740 |
| 396 | Tarczyński Dominik | PiS | 0.1916691 |
| 101 | Gliński Piotr | PiS | 0.1883889 |
| 229 | Malik Ewa | PiS | 0.1850462 |
| 470 | Piechowiak Grzegorz | PiS | 0.1561276 |
| 471 | Janowska Małgorzata | niez. | 0.0419889 |
PSL
najbardziej podobni do Kosiniak-Kamysza
| ID | Name | Club | Cor |
|---|---|---|---|
| 023 | Baszko Mieczysław Kazimierz | PSL | 0.9126710 |
| 401 | Tokarska Genowefa | PSL | 0.9107465 |
| 025 | Bejda Paweł | PSL | 0.9056333 |
| 138 | Jarubas Krystian | PSL | 0.8997414 |
| 152 | Kasprzak Mieczysław | PSL | 0.8886886 |
| 336 | Sawicki Marek | PSL | 0.8873879 |
| 259 | Możdżanowska Andżelika | PSL | 0.8869884 |
| 224 | Łopata Jan | PSL | 0.8789245 |
| 292 | Paszyk Krzysztof | PSL | 0.8677609 |
| 358 | Sosnowski Zbigniew | PSL | 0.8667707 |
najmniej podobni do Kosiniak-Kamysza
| ID | Name | Club | Cor |
|---|---|---|---|
| 101 | Gliński Piotr | PiS | -0.1386568 |
| 286 | Osuch Jacek | PiS | -0.1389670 |
| 385 | Szydło Beata | PiS | -0.1390943 |
| 153 | Kempa Beata | PiS | -0.1404989 |
| 026 | Bernacki Włodzimierz | PiS | -0.1407964 |
| 264 | Mularczyk Arkadiusz | PiS | -0.1411777 |
| 135 | Janik Grzegorz | PiS | -0.1425853 |
| 009 | Arent Iwona | PiS | -0.1428893 |
| 396 | Tarczyński Dominik | PiS | -0.1436058 |
| 102 | Głębocki Konrad | PiS | -0.1486935 |
Jak widać najbardziej podobni są po prostu członkowie danego klubu. Przeciwnicy są… z najbardziej przeciwnych klubów (w dużym uproszczeniu – proszę przeanalizować macierz korelacji pomiędzy klubami w zestawieniu z najmniej podobnymi posłami dla poszczególnych liderów). Co ciekawe – najmniej podobni do Kukiza są ludzie z PiS, ale ciągle jest to korelacja dodatnia (czyli bardziej podobni niż różni).
Jeśli w funkcji similar_deputies() dodalibyśmy warunek filtrujący wyniki tylko do podanej partii moglibyśmy sprawdzić który z posłów danego klubu głosuje odmiennie od lidera.
Podobieństwo między liderami
Sprawdźmy jeszcze który lider ma do którego najbliżej:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
cor_df_deputies %>% filter(Dep1 %in% c(szef_PO, szef_PiS, szef_N, szef_Kukiz15, szef_PSL), Dep2 %in% c(szef_PO, szef_PiS, szef_N, szef_Kukiz15, szef_PSL)) %>% filter(Dep1 != Dep2) %>% mutate(D1 = ifelse(Dep1 > Dep2, Dep1, Dep2), D2 = ifelse(Dep1 < Dep2, Dep1, Dep2)) %>% select(D1, D2, Corr) %>% unique() %>% left_join(select(deputies, id_deputy_num, surname_name), by=c("D1"="id_deputy_num")) %>% left_join(select(deputies, id_deputy_num, surname_name), by=c("D2"="id_deputy_num")) %>% select(-D1, -D2) %>% arrange(desc(Corr)) %>% ggplot() + geom_tile(aes(surname_name.x, surname_name.y, fill=Corr), color="black") + geom_text(aes(surname_name.x, surname_name.y, label=round(Corr, 2))) + scale_fill_gradient(low="red", high="green") + theme_minimal() + theme(legend.position = "none") + labs(x="", y="") |
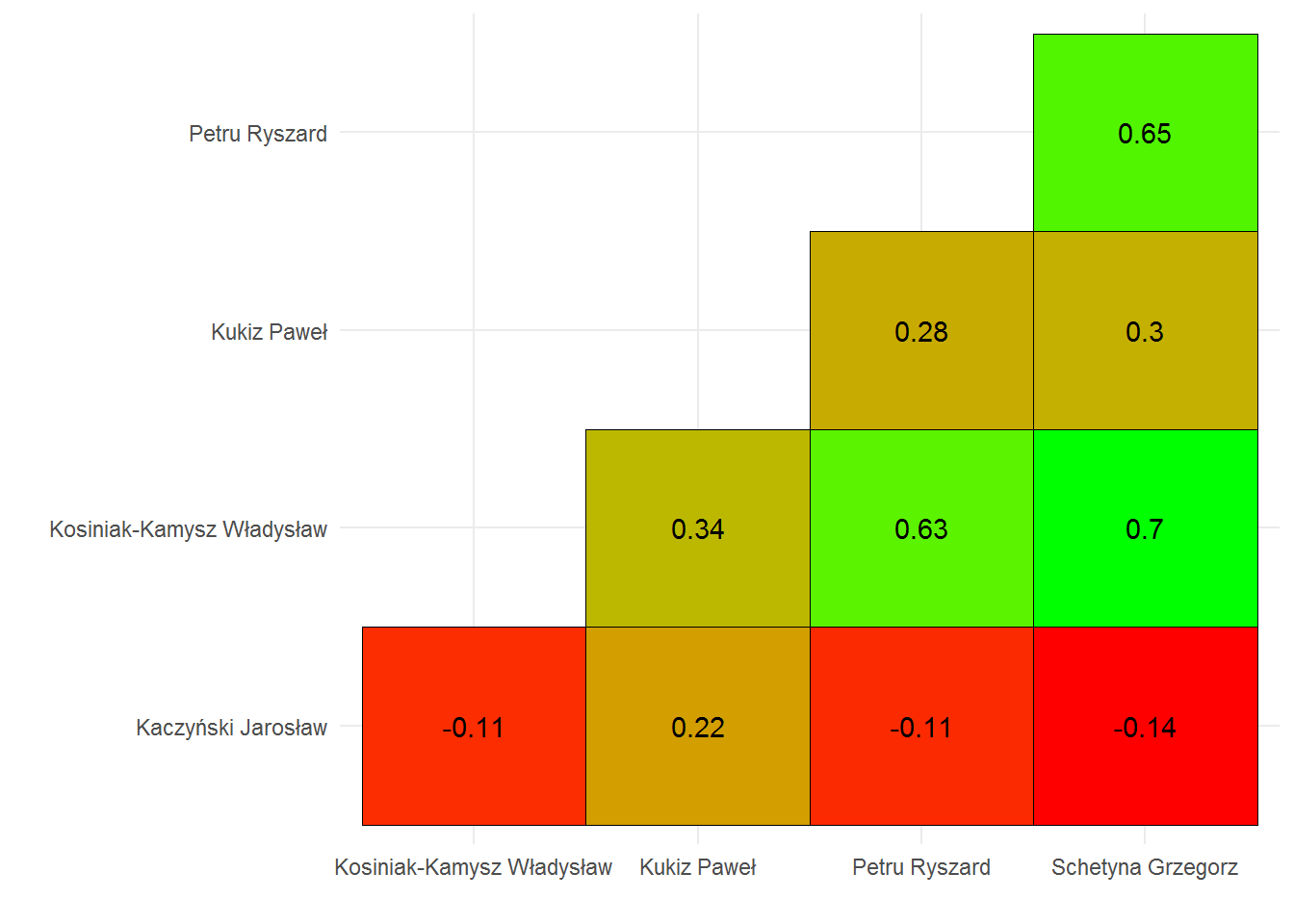
Wyniki są bardzo podobne do korelacji pomiędzy klubami. Schetyna ma najbardziej po drodze z Kosiniak-Kamyszem, nieco mniej z Petru. Chociaż korelacje są nieco mniejsze niż na poziomie klubów – na poziomie poszczególnych głosowań można zweryfikować skąd wynikają różnice. Wszyscy najdalej mają do Kaczyńskiego. Wszyscy, poza Pawłem Kukizem, który jest “umiarkowanie blisko” wszystkich.
Principal Component Analysis
…czyli po polsku analiza głównych składowych to metoda takiego przekształcenia układu współrzędnych, aby z pozornie jednorodnych danych wyłuskać jakieś cechy dominujące. Podlinkowany artykuł z Wikipedii dobrze objaśnia ideę PCA. W bardzo dużym uproszczeniu wiele cech (zmiennych opisujących jakiś element) sprowadzamy do innej przestrzeni i wybieramy te, które najbardziej się wybijają. Dzięki temu mamy mniejszą ilość cech, które możemy chociażby narysować na płaszczyźnie. W Wikipedii podany jest ciekawy przykład: 5 cech opisujących daną osobę (wzrost, waga, dochód, wielkość mieszkania oraz wiek) wybieramy trzy czynniki, z których dwa są złożone z silnie ze sobą skorelowanych par cech (wzrost i waga jako jedna para, dochód i wielkość mieszkania jako druga). Dzięki temu mamy finalnie trzy czynniki: wielkość (wzrost i waga), majątek (dochód i wielkość mieszkania) oraz wiek. Jak u kogoś czynnik “wielkość” jest duży to ta osoba najprawdopodobniej jest wysoka i cięższa, analogicznie dla pozostałych czynników.
PCA używa się w wielu analizach, chociażby na rynku kapitałowym (analiza portfela, analiza ryzyka). Istnieje kilka odmian i rozwinięć tej metody. PCA jest przekształceniem liniowym, co przy niektórych zestawach danych wcale nie ułatwia zadania – wtedy rozwiązaniem może być t-SNE. W analizie głosowań posłów t-SNE się jednak nie sprawdziło.
W R do dyspozycji mamy dwie funkcje – princomp() oraz prcomp(). Po szczegóły zapraszam do dokumentacji. Poniżej wykorzystamy tą drugą, analizę przeprowadzimy na głosowaniach posłów.
|
1 2 3 |
votes_deputies_pca <- t(select(votes_deputies, - id_voting)) pca_deputies <- prcomp(votes_deputies_pca, scale. = TRUE) |
W obiekcie pca_deputies mamy bardzo dużo ciekawych danych – między innymi wartości poszczególnych czynników. Możemy pokusić się o wybranie tych, którymi będziemy się zajmować w dalszej kolejności (wybierzemy dwa, żeby narysować je na płaszczyźnie).
Które czynniki mają znaczenie? Najprościej odczytać to z wykresu:
|
1 |
plot(pca_deputies, type = "lines") |
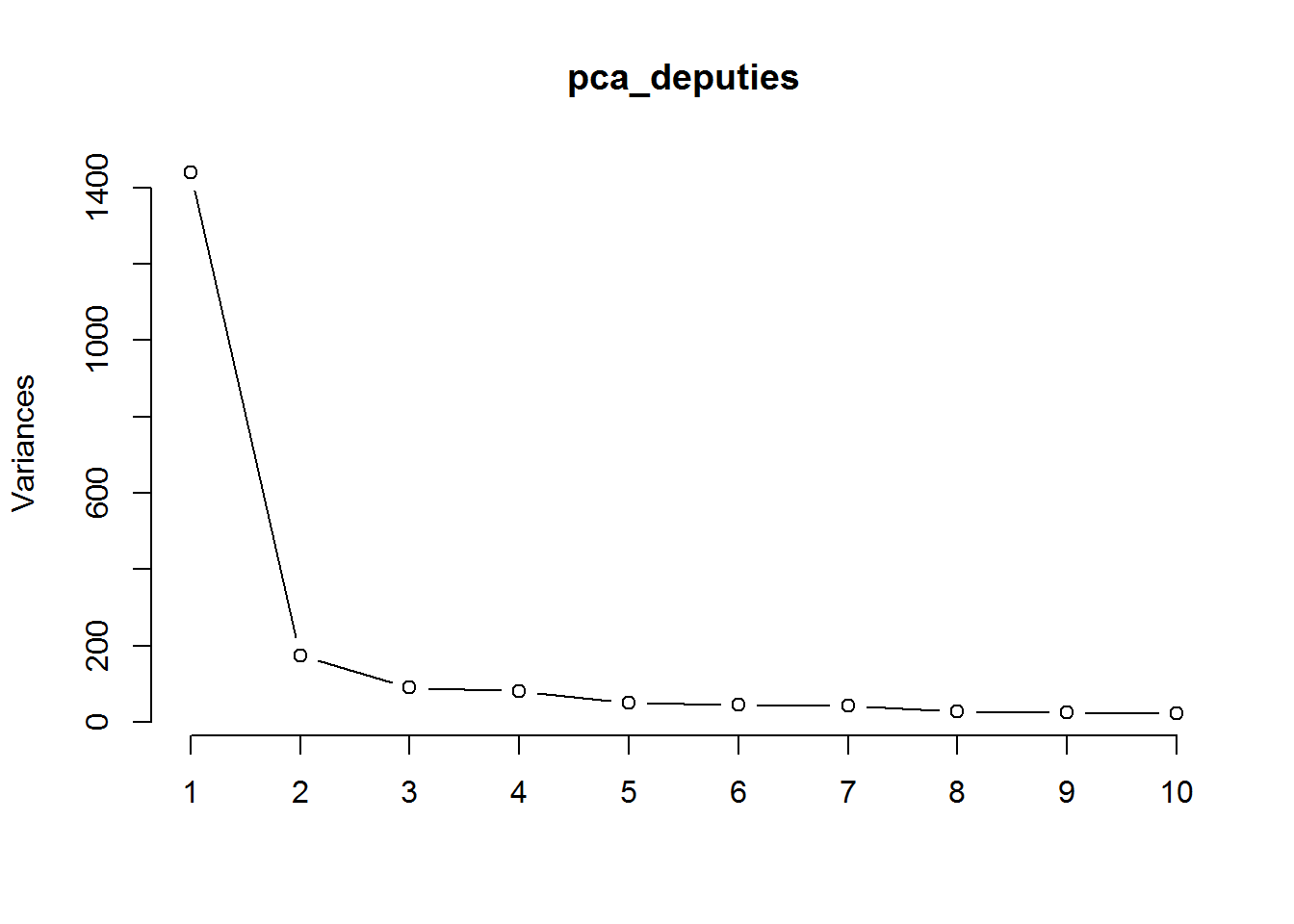
Czynniki zawsze ułożone są od najbardziej znaczących. Wykres ten posłużyć może do decyzji ile czynników wybrać – my potrzebujemy dwóch, weźmiemy pierwsze dwa, ale sprawdźmy jednocześnie jak wyglądałby wybór wszystkich par z pierwszej piątki czynników (w sumie 10 par):
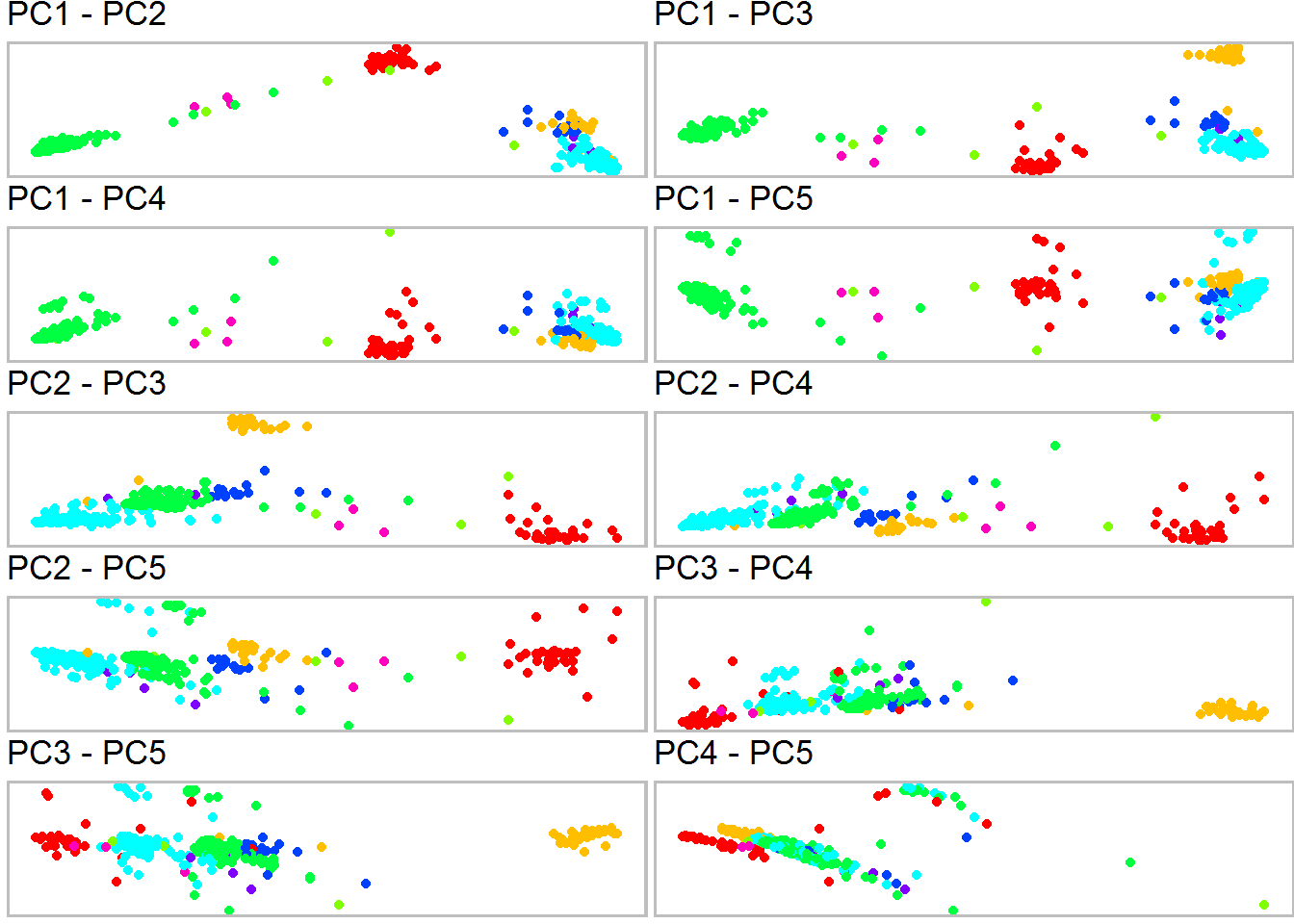
Każdy kolor to klub parlamentarny. Od razu widać, że po przekształceniu PCA wyodrębniły się skupiska posłów w ramach jednego koloru. Tego nie da się narysować inaczej – macierz korelacji czy też same głosowania mają za dużo danych, trzeba znaleźć metodę na redukcję wymiarów. PCA jest właśnie tą metodą.
Widać także, że dość trudno wskazać wersję z wyraźnie rozdzielonymi niebieskimi kropkami (tym jasnym i ciemnym – to PO i PSL). Układ PC1-PC3 wydaje się być całkiem dobry. Im dalsze czynniki zestawiamy ze sobą tym mniej rozdzielone są poszczególne grupy (kluby), na przykład zestawienie PC4-PC5 już nie obrazuje “wysp”. Widać to również na wykresie pca_deputies wyżej – czynniki 5-6 i dalej są na właściwie jednym poziomie wariancji, a więc nie różnią się od siebie znacznie.
Do dalszej analizy zdecydowałem się jednak na parę PC1-PC2, bo te dwa czynniki mają największe wariancje. Zbudujmy więc tabelę z wartościami współczynników PCA (1 i 2) oraz przypisanymi nazwiskami posłów oraz ich ugrupowań:
|
1 2 3 4 5 6 |
pca_deputies_df <- as.data.frame(pca_deputies$x[,c("PC1", "PC2")]) pca_deputies_df$id_deputy <- rownames(pca_deputies_df) pca_plot_df <- left_join(pca_deputies_df, select(deputies, surname_name, club, id_deputy), by="id_deputy") |
Teraz możemy to narysować. Jeszcze drobna uwaga: dodałem “minus” przy PC1 żeby odwrócić oś X – tak, aby PiS wypadł po prawej stronie, PO, .N i PSL po lewej.
|
1 2 3 |
ggplot(pca_plot_df) + geom_point(aes(-PC1, PC2, color=club, text=surname_name)) + theme_void() |
Zamiast statycznego obrazka przygotowałem wersję interaktywną (z użyciem plotly):
Partie i posłowie
Podzielmy jeszcze dla czytelności powyższy wykres na pojedyncze kluby:
|
1 2 3 4 5 6 |
ggplot(pca_plot_df) + geom_point(aes(-PC1, PC2, color=club, text=surname_name)) + facet_wrap(~club) + theme_void() + theme(legend.position = "none", panel.border = element_rect(colour = "gray", fill=NA, size=1)) |
Teraz świetnie widać kogo można “chapnąć” do swojego klubu. Marek Sowa i Michał Jaros z Nowoczesnej bardziej pasują do PO. Widać, że klub UED wydzielił się z PO. Trójce z WiS bliżej do PiSu niż poprzedniego ich klubu – Kukiz’15. Niezrzeszeni Janusz Sanocki pasuje do PiSu, zaś Małgorzata Janowska – do Kukiz’15.
Bardzo dobrze (szczególnie na wykresie z rozdzielonymi klubami) widać “zwarcie” szeregów w poszczególnych partiach. Czy jest to wynik dyscypliny na głosowaniach czy własnych poglądów – nie mnie o tym rozsądzać. Ciekawe są cztery osoby idące w kierunku centrum (centrum wykresu, nie koniecznie poglądów) w PiSie.
Ciekawe jest też to, czego nie było widać w korelacjach. Otóż po analizie PCA posłowie Nowoczesnej są bliżej z PSLem niż z Platformą. W ujęciu współczynników korelacji wyglądało to odwrotnie (dla przypomnienia korelacja N-PSL to 0.66, PO-N – 0.74, zaś PO-PSL – 0.75). Być może znaczenie ma sposób agregacji przy przygotowaniu macierzy korelacji partia-partia (pamiętacie – mediana).
Symulacje sceny politycznej
Możemy pokusić się o symulację – co by było gdyby miały być tylko trzy partie: lewica, prawica i środek? Spróbujmy najprościej – metodą k-means przypiszmy do trzech grup dane jakie mamy. Zwróćcie uwagę, że klasyfikujemy dane z PCA a nie dane oryginalne!
|
1 2 3 4 5 6 7 |
pca_plot_df$kmeans <- kmeans(pca_plot_df[, 1:2], centers = 3)$cluster ggplot(pca_plot_df) + geom_point(aes(-PC1, PC2, color=club)) + facet_grid(club~kmeans) + theme_void() + theme(legend.position = "none", panel.border = element_rect(colour = "gray", fill=NA, size=1)) |

Sprawdźmy ilu posłów z której partii trafiłoby do odpowiednich grup?
|
1 |
table(pca_plot_df$club, pca_plot_df$kmeans) |
| 1 | 2 | 3 | |
|---|---|---|---|
| Kukiz15 | 0 | 35 | 0 |
| N | 0 | 0 | 31 |
| niez. | 2 | 2 | 1 |
| PiS | 232 | 2 | 0 |
| PO | 0 | 0 | 132 |
| PSL | 0 | 0 | 16 |
| UED | 0 | 0 | 4 |
| WiS | 1 | 2 | 0 |
Scena jest spolaryzowana – jedna strona to PiS, druga to Nowoczesna, PO i PSL. W środku Kukiz’15. Widać także, że w PiSie są osoby pasujące do “środka” – kim one są?
|
1 |
filter(pca_plot_df, club=="PiS", kmeans==2) %>% select(surname_name) |
|
1 2 3 |
## surname_name ## 1 Raczak Grzegorz ## 2 Piechowiak Grzegorz |
Wiecie co to za nazwiska? To te dwie najbardziej wysunięte na środek i w górę zielone kropki. To potencjalni kandydaci do przejścia tam, gdzie jest najwięcej “środkowych” – czyli do Kukiza. Na naszej scenie taki transfer jest mało prawdopodobny. Z przyczyn innych niż same dane…
A gdyby miały być tylko dwie partie?
|
1 2 3 4 5 6 7 |
pca_plot_df$kmeans <- kmeans(pca_plot_df[, 1:2], centers = 2)$cluster ggplot(pca_plot_df) + geom_point(aes(-PC1, PC2, color=club)) + facet_grid(club~kmeans) + theme_void() + theme(legend.position = "none", panel.border = element_rect(colour = "gray", fill=NA, size=1)) |
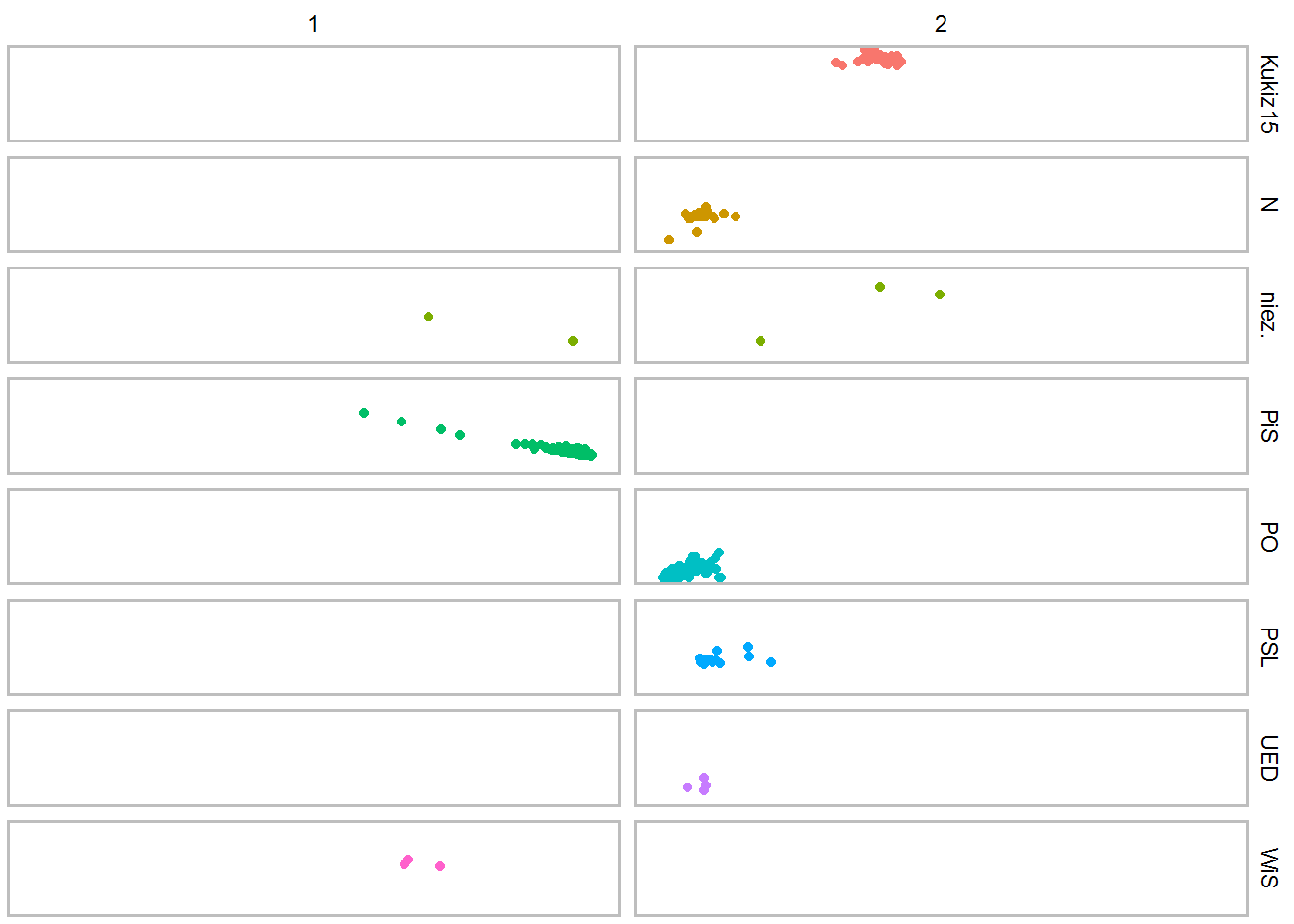
Ilu posłów z poszczególnych partii trafiłoby do odpowiednich grup?
| 1 | 2 | |
|---|---|---|
| Kukiz15 | 0 | 35 |
| N | 0 | 31 |
| niez. | 2 | 3 |
| PiS | 234 | 0 |
| PO | 0 | 132 |
| PSL | 0 | 16 |
| UED | 0 | 4 |
| WiS | 3 | 0 |
Tutaj sytuacja jest czysta – nikt nigdzie nie przechodzi (poza posłami niezrzeszonymi), ponownie widać wyraźną polaryzację – tak samo jak poprzednio.
Przejście z Kukiz’15 do Nowoczesnej
Paweł Kobyliński przeszedł z klubu Kukiz’15 do Nowoczesnej (w między czasie będąc posłem niezrzeszonym). Możemy prześledzić jego drogę (jest czerwoną kropką na filmie). Przy okazji zobaczymy jak z każdym kolejnym głosowaniem zmieniało się wzajemne położenie partii oraz jak bardzo partie są zwarte i czy zawsze tak było.
Animację przygotowałem robiąc dla każdej klatki cały opisany powyżej proces: PCA na danych ze wszystkich przeszłych głosowań, czyli dla głosowania numer 152 biorę dane tylko ze 152 głosowań (a nie wszystkich 2689). I tak po kolei. Na koniec składam wszystko w VitrualDub, identycznie jak w poście o warszawskich tramwajach.
Bardzo ładnie widać pierwsze głosowania – wybór marszałka Sejmu i wicemarszałków. Im dalej w las tym bardziej widać polaryzację i wyodrębnienie się opozycji.
Elipsy otaczają 95% punktów każdej z grup – im mniejsza elipsa, tym bardziej jednorodne głosy w klubie.
Statystyki VIII kadencji
Możemy pokusić się o inne statystyki, już w mojej opinii mniej ciekawe. Chociażby kto jest bardziej za, a kto przeciw i – co ciekawsze – kogo częściej nie ma:
|
1 2 3 4 5 6 7 8 9 10 |
votes %>% count(club, vote) %>% ungroup() %>% group_by(club) %>% mutate(p=100*n/sum(n)) %>% ungroup() %>% ggplot() + geom_bar(aes(club, p, fill=vote), stat="identity") + theme_minimal() + labs(x="", y="% głosów", fill="Głos") |
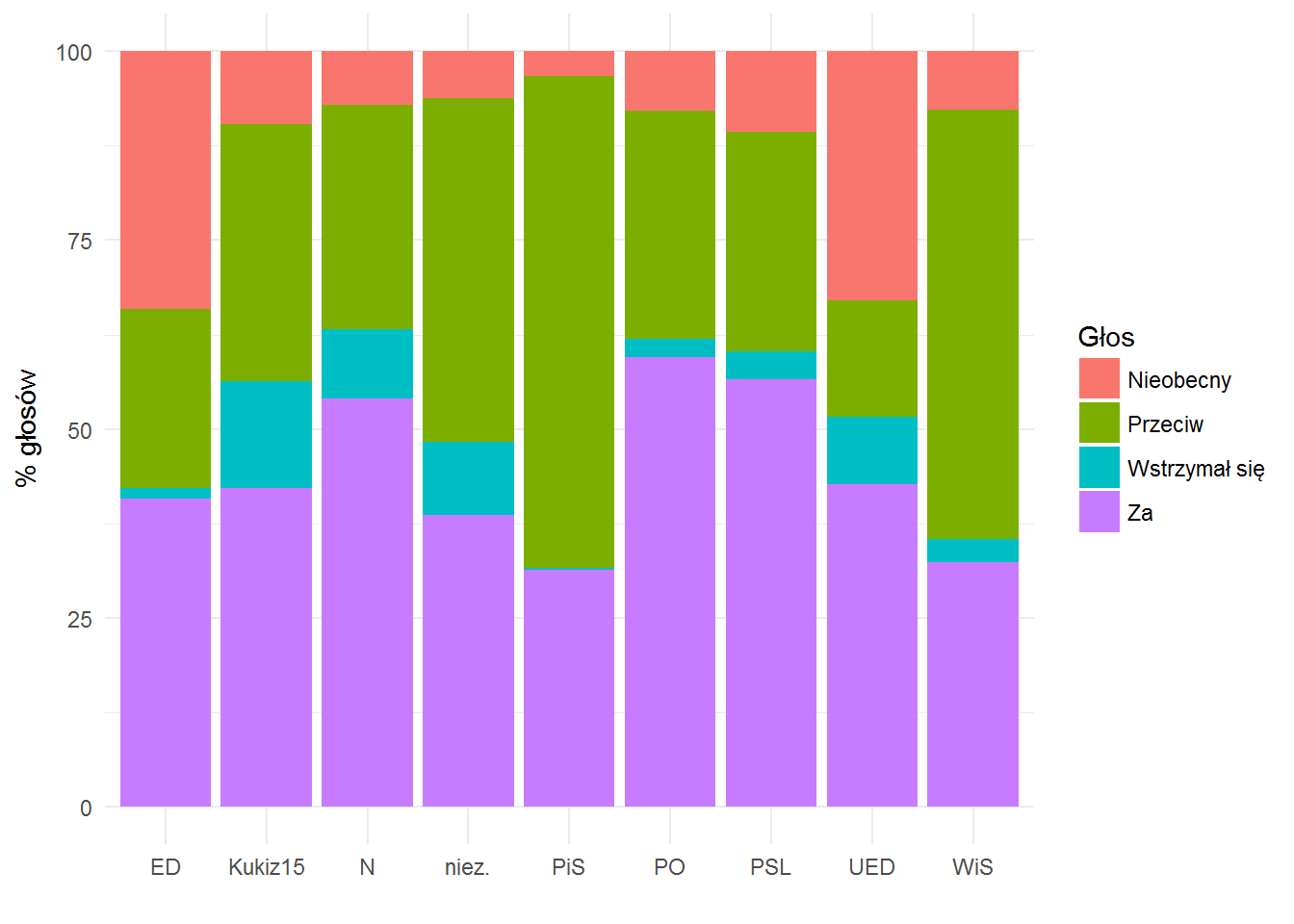
Mnie osobiście zdziwiło, że PiS jest głównie przeciw (zdziwiło, bo mają swój Sejm, rząd i prezydenta – projekty uchwał też powinny być swoje, więc raczej się głosuje Za nimi…). Owo głównie to 65% głosowań! Należałoby spojrzeć w dane – w projekty uchwał.
Dla formalności – najczęściej za są PO (59%), PSL (56%) i Nowoczesna (54%).
Najczęściej (14% głosowań) wstrzymuje się klub Kukiz’15.
Wśród liderów sprawa wygląda następująco:
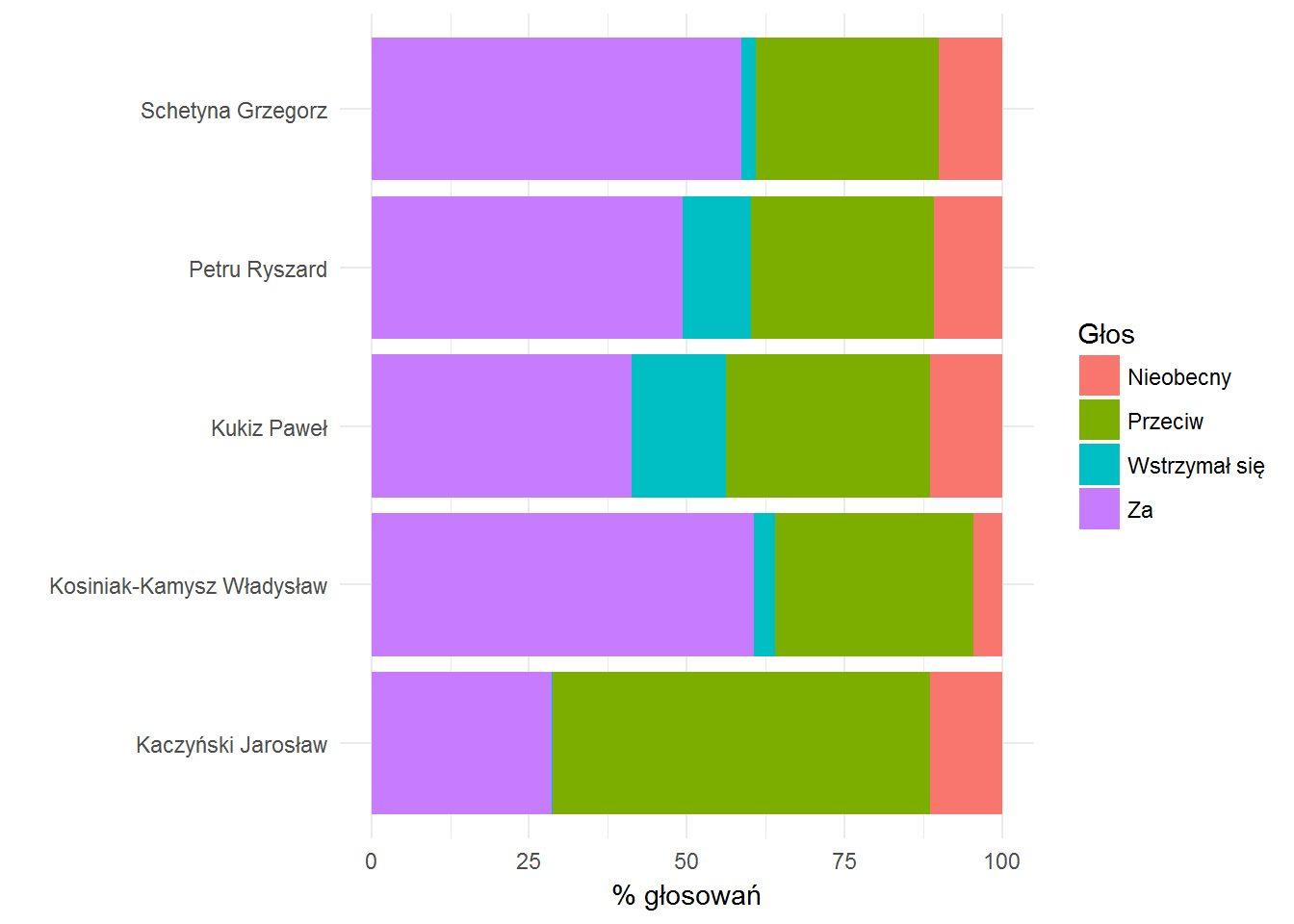
Zobaczmy jeszcze kto jest najbardziej niezdecydowany:
|
1 2 3 4 5 6 7 8 9 10 11 |
votes %>% count(id_deputy, vote) %>% ungroup() %>% group_by(id_deputy) %>% mutate(p=round(100*n/sum(n),1)) %>% ungroup() %>% filter(vote=="Wstrzymał się") %>% left_join(deputies, by="id_deputy") %>% select(surname_name, club, p) %>% top_n(10, p) %>% arrange(desc(p)) |
| Posel | Klub | Procent_glosowan |
|---|---|---|
| Jaskóła Tomasz | Kukiz15 | 20.7 |
| Chrobak Barbara | Kukiz15 | 19.0 |
| Długi Grzegorz | Kukiz15 | 18.3 |
| Brynkus Józef | Kukiz15 | 17.2 |
| Winnicki Robert | niez. | 16.8 |
| Parda Błażej | Kukiz15 | 16.0 |
| Tyszka Stanisław | Kukiz15 | 16.0 |
| Skutecki Paweł | Kukiz15 | 15.6 |
| Porwich Jarosław | Kukiz15 | 15.5 |
| Sanocki Janusz | niez. | 15.3 |
i kogo najczęściej nie ma:
| Posel | Klub | Procent_glosowan |
|---|---|---|
| Pasławska Urszula | PSL | 33.4 |
| Wilk Jacek | Kukiz15 | 31.7 |
| Mordak Robert | Kukiz15 | 31.0 |
| Bukiewicz Bożenna | PO | 29.3 |
| Krzywonos-Strycharska Henryka | PO | 29.1 |
| Zgorzelski Piotr | PSL | 29.1 |
| Cimoszewicz Tomasz | PO | 25.9 |
| Błeńska Magdalena | Kukiz15 | 25.4 |
| Osos Katarzyna | PO | 23.5 |
| Morawiecki Kornel | WiS | 23.4 |
Na koniec dwie obserwacje na podstawie liczby głosowań na poszczególnych posiedzeniach:
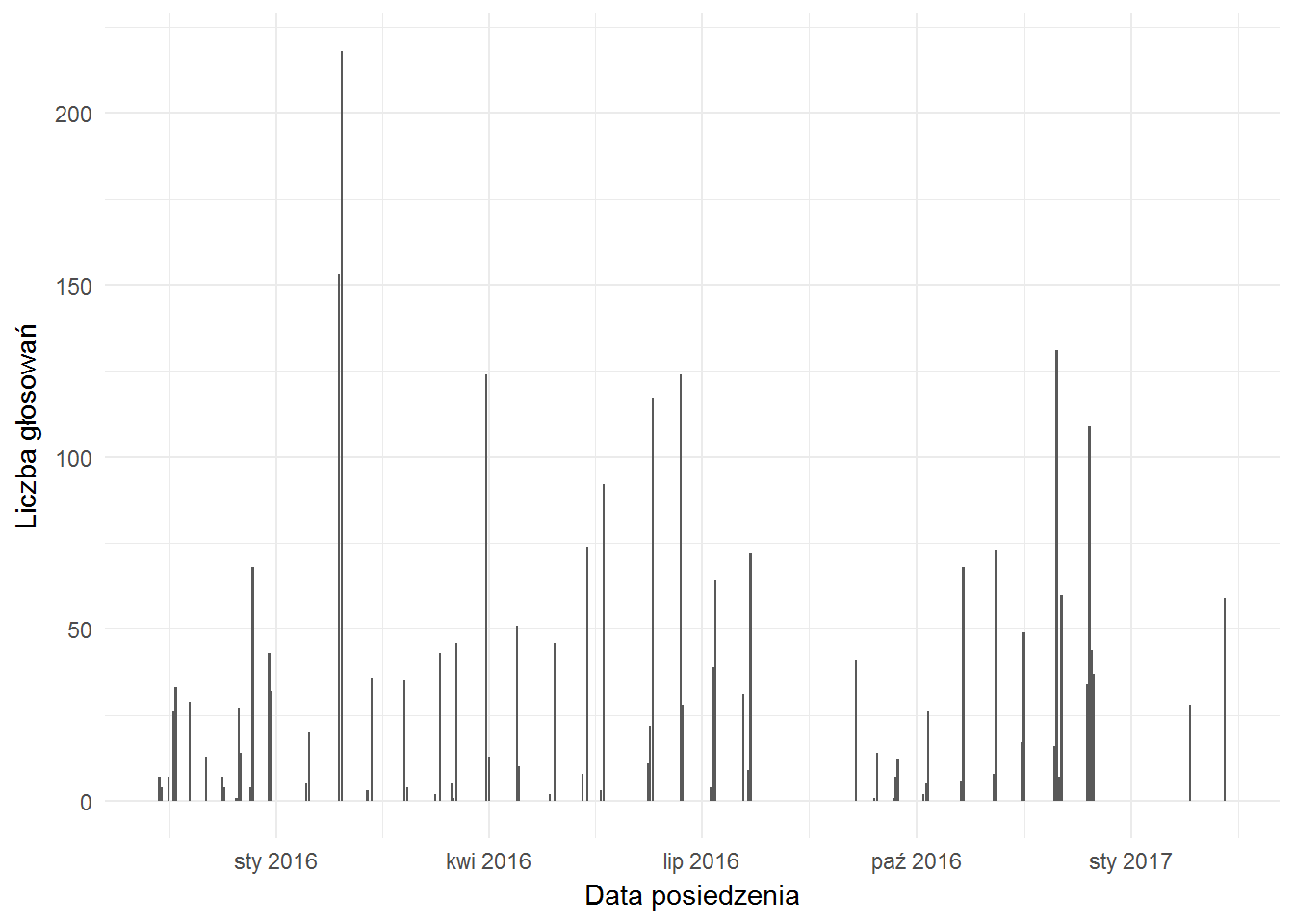
Najwięcej głosowań było pod koniec stycznia 2016 – wówczas przyjmowano ustawę budżetową na 2016 rok (cała masa poprawek). Ale widać też dwie przerwy – wakacyjną (sierpień 2016) oraz tą spowodowaną blokadą Sejmu przez opozycję – przełom 2016 i 2017.
Pingback: Jak nauczyć się R? | Łukasz Prokulski
Bardzo często głosuje się za ODRZUCENIEM ustawy w którymś tam czytaniu. Więc oczywiste jest, że wtedy głosuje się przeciw odrzuceniu swojej ustawy, więc nic dziwnego, że PiS miał najwięcej głosów na „przeciw”.