Czy da się wytypować zdobywcę Oscara za pomocą matematyki?
Spróbujmy odpowiedzieć na tak postawione pytanie. I sprawdźmy, czy model oparty na dostępnych danych wskaże faworyta “La la land” jako zwycięzcę w kategorii “Najlepszy film”.
 Na początek rozważmy czego możemy się dowiedzieć z ogólnodostępnych źródeł? Weźmy na przykład bazę filmów z serwisu IMDb.com. Mamy tam takie informacje:
Na początek rozważmy czego możemy się dowiedzieć z ogólnodostępnych źródeł? Weźmy na przykład bazę filmów z serwisu IMDb.com. Mamy tam takie informacje:
- średnia głosów społeczności
- ilość oddanych głosów
- mamy ocenę krytyków (wskaźnik MetaScore)
- informacje o obsadzie, reżyserze, gatunku
- informacje o czasie trwania
- koszt (budżet) filmu
- mamy przychód z kin – w weekend otwarcia oraz całkowity
- wreszcie – wiemy czy film zdobył Oscara wcześniej czy nie (w odpowiednim roku)
Spróbujmy zatem na początek pobrać potrzebne informacje wprost z IMDb.com.
Te biblioteki nam się przydadzą:
|
1 2 3 4 |
library(ggplot2) library(dplyr) library(rvest) library(randomForest) |
Żeby coś widzieć w danych, najpierw te dane trzeba zgromadzić.
Poniższa funkcja pobierze informacje o nominacjach oraz wygranych w kategorii “Best Picutre” wprost ze stron IMDb.com. Na początek wystarczą nam linki do stron poszczególnych filmów:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
GetBestMoviesList <- function(rok) { # czytamy odpowiednią stronę - kolejną edycję Oscarów page <- read_html(paste0("http://www.imdb.com/event/ev0000003/", rok)) # proszę zajrzeć w kod HTML strony - potrzebujemy tylko fragmentów best_picture <- page %>% html_nodes("div.award") %>% html_node("blockquote") %>% html_node("blockquote") # "Best Picture" jest w pierwszym bloku best_picture <- best_picture[1] # pobieramy wszystkie linki z wybranego bloku best_picture <- best_picture %>% html_nodes("div") %>% html_nodes("a") %>% html_attr("href") %>% unique() # wykluczenie zbędnych linków # interesują nas tylko filmy, a nie link do osoby lub wytwórnia # usuwamy to co zbędne best_picture <- best_picture[substr(best_picture, 1, 9)!="/company/"] best_picture <- best_picture[substr(best_picture, 1, 8)!="/name/nm"] # wszystkie linki włóżmy w jedną ramkę df <- data.frame(Year=rok, MovieLink=best_picture, Won=FALSE) # pierwszy film na liście wygrywał - oznaczmy to df[1,3] <- TRUE return(df) } |
Skoro mamy gotową funkcję – możemy pobrać z jej pomocą informacje z kolejnych edycji Oscarów. W przykładzie ograniczamy się do lat 2000-2016.
Dlaczego tylko tyle? Kino w XXI wieku jest nieco inne niż na przykład w latach siedemdziesiątych XX wieku. Osobiście uważam, że filmy oskarowe z lat ’70 (pierwsza i druga część “Ojca chrzestnego”, “Żądło”, “Lot nad kukułczym gniazdem”, “Annie Hall” czy “Łowca jeleni”) czy też ’80 (“Amadeusz”, “Gandhi”, “Pluton”, “Ostatni cesarz”) są zdecydowanie inne, żeby nie powiedzieć “ambitniejsze” od tych z ostatnich kilkunastu lat (lata ’90: “Angielski pacjent”, “Zakochany Szekspir”; XXI wiek: “Argo” wygrywające z “Miłością” Hanekego, “Jak zostać królem” rzekomo lepsze od “Czarnego łabędzia” czy “Prawdziwego męstwa”).
Kino jest coraz bardziej rozrywką (Oscar dla “Władcy pierścieni”), a Hollywood daje temu wyraz. To nagrody europejskie (Cannes, Berlin, Wenecja) doceniają artyzm, co świetnie spuentował Woody Allen w zakończeniu “Koniec z Hollywood”: “The French saw your movie in Paris. They say it’s the greatest American film in 50 years!” (a jeśli znacie film, który powstał w filmie Allena to łapiecie dowcip).
OK, ale koniec dygresji – do pobierania!
|
1 2 3 4 |
movies_list <- data.frame() for(y in 2000:2016) { movies_list <- rbind(movies_list, GetBestMoviesList(y)) } |
Uwaga – jeśli chcemy pobrać lata wcześniejsze (np. wszystkie edycje nagrody – od 1929 roku) trzeba uważać na niespodzianki. Są dwie:
- w 1930 były dwie edycje rozdania nagród, informacje są na stronach z końcówką “/1930-1” i “/1930-2” zamiast (jak w innych przypadkach) “/1930”
- w 1933 roku nie było Oscarów – ten rok trzeba pominąć
Z takimi wyjątkami powyższy fragment kodu będzie bardziej rozbudowany:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
for(y in 1929:2016) { # w 1930 było 2 razy w roku if(y==1930) { movies_list <- rbind(movies_list, GetBestMoviesList("1930-1")) movies_list <- rbind(movies_list, GetBestMoviesList("1930-2")) next } # w 1933 nie było nagród if(y==1933) next movies_list <- rbind(movies_list, GetBestMoviesList(y)) } # poprawka dla podwójnych rozdań z 1930 roku movies_list[movies_list[,1]=="1930-1", 1] <- 1930 movies_list[movies_list[,1]=="1930-2", 1] <- 1930 |
Warto pobrać te dane i przeanalizować w podobny (jak poniżej) sposób. Wychodzą ciekawostki.
Kiedy mamy już linki do wszystkich filmów z oznaczeniem czy film wygrał w kategorii “Best Picture” oraz w którym to było roku – warto uzupełnić linki do pełnego adresu URL. Na stronie linki są w postaci względnej (chociaż nie zawsze).
|
1 2 3 4 |
# zbudowanie pełnego urla movies_list$MovieLink <- ifelse(substr(movies_list$MovieLink, 1, 7) == "http://", movies_list$MovieLink, paste0("http://www.imdb.com", movies_list$MovieLink)) |
Mamy historię, ale co z nominowanymi w 2017 roku? To dodajmy ręcznie. Ręcznie wyszukałem te filmy i wpisałem je poniżej.
|
1 2 3 4 5 6 7 8 9 10 11 12 |
# filmy nominowane w 2017 movies_list <- rbind(movies_list, data.frame(Year=2017, MovieLink=c("http://www.imdb.com/title/tt2543164/", "http://www.imdb.com/title/tt3783958/", "http://www.imdb.com/title/tt2671706/", "http://www.imdb.com/title/tt3741834/", "http://www.imdb.com/title/tt2119532/", "http://www.imdb.com/title/tt4034228/", "http://www.imdb.com/title/tt4975722/", "http://www.imdb.com/title/tt2582782/", "http://www.imdb.com/title/tt4846340/"), Won=FALSE)) |
Mamy “namiary” na wszystkie interesujące nas filmy. Czas zdobyć ich “dane szczegółowe”. Posłużymy się poniższą funkcją, którą wywołamy 122 razy (tyle ile mamy filmów).
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 |
GetMovieDetalis <- function(movie_url) { # wczytajmy stronę z filmem page <- read_html(movie_url) # tytuł - interesuje nas tytuł oryginalny title <- page %>% html_node("div.title_wrapper") %>% html_node("div.originalTitle") %>% html_text() # jeśli nie ma tytułu oryginalnego w stosownym polu - weźmy tytuł "główny" # IMDb.com w tytule podaje tytuł zlokalizowany - w Polsce zobaczymy polskie tytuły # dodatkowo w nawiasach po tytule jest np. rok produkcji filmu - usuwamy to if(is.na(title)) { title <- page %>% html_node("div.title_wrapper") %>% html_node("h1") %>% html_text() sub <- page %>% html_node("div.title_wrapper") %>% html_node("h1") %>% html_node("span") %>% html_text() } else { sub <- page %>% html_node("div.title_wrapper") %>% html_node("div.originalTitle") %>% html_node("span") %>% html_text() } title <- gsub(sub, "", title, fixed = TRUE) title <- trimws(title) # ocena użytkowników rating <- page %>% html_node("div.imdbRating") %>% html_nodes("span") %>% html_text() # liczba głosóW votes <- as.integer(gsub(",", "", rating[4])) # ocena rating <- as.numeric(rating[1]) # czas trwania filmu duration <- page %>% html_node("div.title_wrapper") %>% html_node("div.subtext") %>% html_node("time") %>% html_attr("datetime") duration <- gsub("PT", "", duration) duration <- as.integer(gsub("M", "", duration)) # kategoria wiekowa pgrating <- page %>% html_node("div.title_wrapper") %>% html_node("div.subtext") %>% html_node("meta") %>% html_attr("content") # gatunki - pobieramy wszystko, na końcu wykorzystamy tylko pierwszy wskazany genres <- page %>% html_node("div.title_wrapper") %>% html_node("div.subtext") %>% html_nodes("a") %>% html_text() genres <- genres[1:(length(genres)-1)] # credits credits <- page %>% html_nodes("div.credit_summary_item") director <- credits[1] %>% html_nodes("span.itemprop") %>% html_text() writers <- credits[2] %>% html_nodes("span.itemprop") %>% html_text() stars <- credits[3] %>% html_nodes("span.itemprop") %>% html_text() # metascore metascore <- page %>% html_node("div.metacriticScore") # dla starszych filmów nie ma tej wartości # aby funkcja zadziałała dla filmów z Oscarów 1929 robimy obejście :) if(!is.na(metascore)) { metascore <- metascore %>% html_node("span") %>% html_text() %>% as.integer() } else { metascore <- NA } # budżet movie_details <- page %>% html_node("div#titleDetails") %>% html_nodes("div.txt-block") %>% html_text() movie_details <- trimws(gsub("\\n", "", movie_details)) movie_details <- gsub(" +", " ", movie_details) budget <- movie_details[substr(movie_details, 1, 8)=="Budget: "] if(length(budget)>0) { budget <- substr(budget, 9, nchar(budget)) budget <- strsplit(budget, " ")[[1]][1] budget <- gsub(",", "", budget) # niektóre wartości są w funtach # przeliczmy to na dolary według stałego kursu # 1 GBP = 1.5 USD budget <- ifelse(substr(budget, 1, 1)=="$", as.integer(substr(budget, 2, nchar(budget))), 1.5*as.integer(substr(budget, 2, nchar(budget)))) } else { # czasem nie ma informacji o budżecie - obejście budget <- NA } # przychód w weekend otwarcia # plus obejście dla brakujących danych opening <- movie_details[substr(movie_details, 1, 17)=="Opening Weekend: "] if(length(opening)>0) { opening <- substr(opening, 18, nchar(opening)) opening <- strsplit(opening, " ")[[1]][1] opening <- gsub(",", "", opening) opening <- ifelse(substr(opening, 1, 1)=="$", as.integer(substr(opening, 2, nchar(opening))), 1.5*as.integer(substr(opening, 2, nchar(opening)))) } else { opening <- NA } # całkowity przychód gross <- movie_details[substr(movie_details, 1, 7)=="Gross: "] if(length(gross)>0) { gross <- substr(gross, 8, nchar(gross)) gross <- strsplit(gross, " ")[[1]][1] gross <- gsub(",", "", gross) gross <- ifelse(substr(gross, 1, 1)=="$", as.integer(substr(gross, 2, nchar(gross))), 1.5*as.integer(substr(gross, 2, nchar(gross)))) } else { gross <- NA } # łączymy wszystkie dane w jedną ramkę, a właciwie jeden wiersz df <- data.frame(Title=title, Rating=rating, Votes=votes, Duration=duration, PG=pgrating, Genres=genres[1], Director=director[1], Writers=writers[1], StarA=stars[1], StarB=stars[2], MetaScore=metascore, Budget=budget, Openning=opening, Gross=gross) return(df) } |
Uff – mamy czym pobierać dane o filmach. Czas to zrobić, co trochę potrwa.
|
1 2 3 4 5 6 7 8 9 10 |
# pobranie danych do jednej ramki movies_dets <- data.frame() len <- nrow(movies_list) for(i in 1:len) { db <- data.frame(movies_list[i,]) mdet <- GetMovieDetalis(movies_list[i,2]) db <- cbind(db, mdet) movies_dets <- rbind(movies_dets, db) } |
Po wykonaniu tej pętli zgromadzimy ciekawe dane, ale tabela jest bardzo szeroka, więc jej nie pokażę :)
Co widać w tych danych? Uwaga, wreszcie jakieś obrazki!
Na początek zobaczmy jak oceniane przez społeczność IMDb.com są filmy, które zdobyły Oscara.
|
1 2 3 |
# minimalna i maksymalna ocena - do skalowania wykresów ymin <- floor(min(movies_dets$Rating)) ymax <- ceiling(max(movies_dets$Rating)) |
|
1 2 3 4 5 6 7 8 |
movies_dets %>% filter(Year != 2017) %>% ggplot() + theme_bw() + geom_point(aes(Year, Rating, col=Won), size=5) + geom_smooth(aes(Year, Rating, col=Won), se=FALSE, method = "loess") + ylim(ymin, ymax) + labs(title="Ocena IMDb.com a Oscar") |
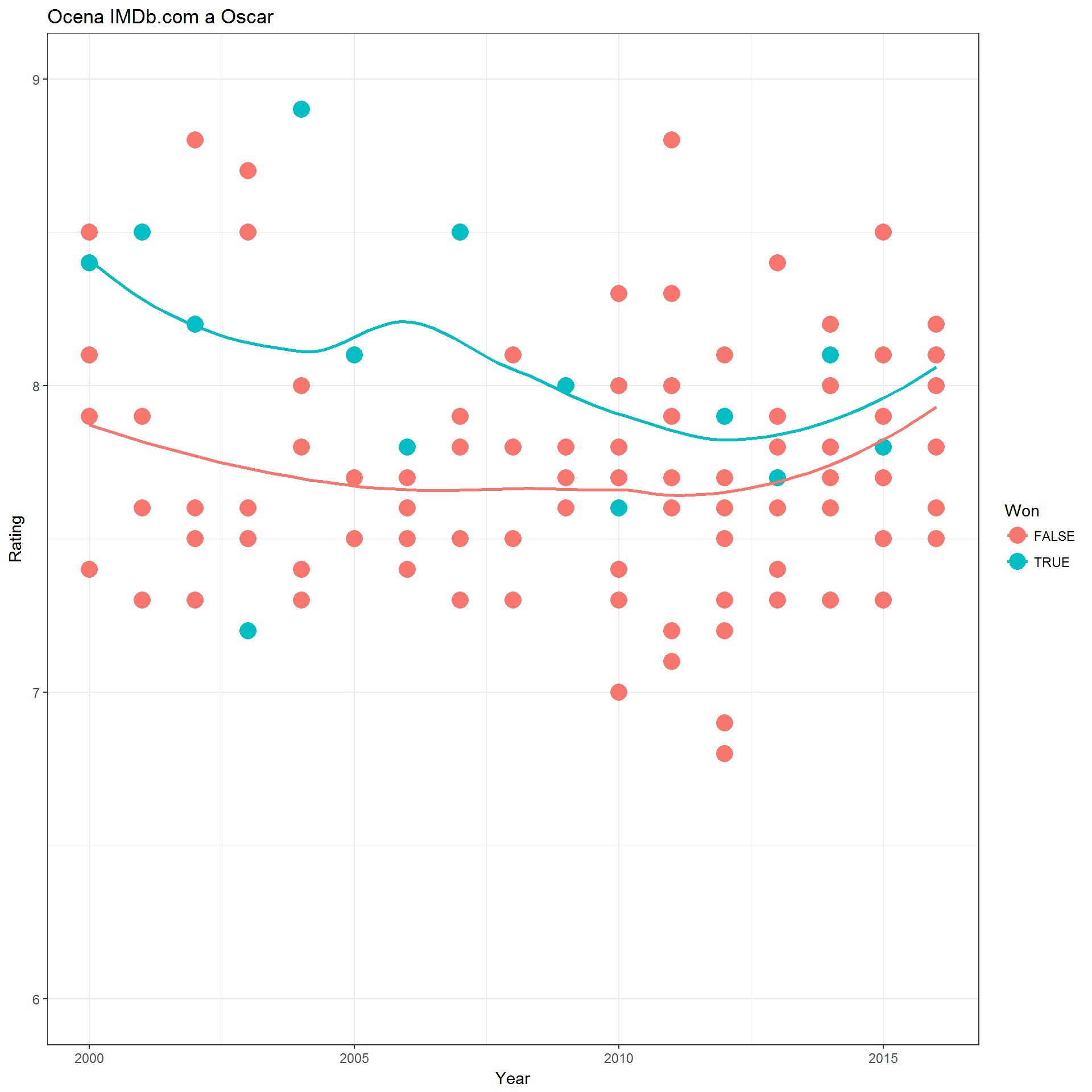
Widać, że lepiej oceniane są filmy z Oscarem. Czyli nagroda odpowiada gustom publiczności, co potwierdza tezę, że Oscar to nagroda dla kina rozrywkowego.
A jak mają się do nagrody informacje o pieniądzach?
Najpierw budżet:
|
1 2 3 4 5 6 7 |
movies_dets %>% filter(Year != 2017) %>% ggplot() + theme_bw() + geom_point(aes(Year, Budget, col=Won), size=5) + geom_smooth(aes(Year, Budget, col=Won), se=FALSE, method = "loess") + labs(title="Budżet a Oscar - produkcja") |
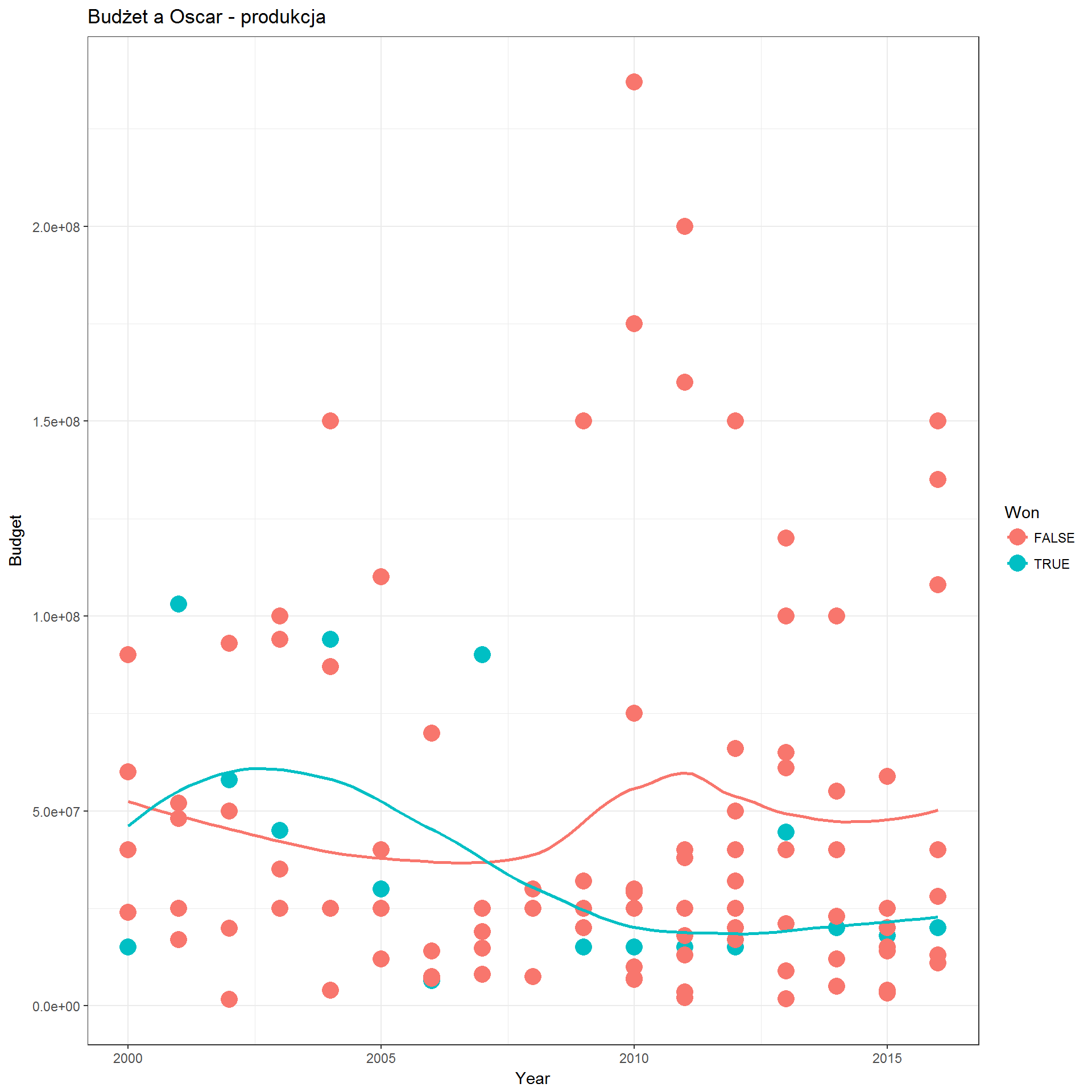
Filmy z Oscarem są ostatnio tańsze w produkcji – taka tendencja widoczna jest od 2008 roku. Czyli Akademia preferuje kino kameralne nad blockbustery? Sprawdźmy to po przychodach:
- z weekendu otwarcia:
|
1 2 3 4 5 6 7 |
movies_dets %>% filter(Year != 2017) %>% ggplot() + theme_bw() + geom_point(aes(Year, Openning, col=Won), size=5) + geom_smooth(aes(Year, Openning, col=Won), se=FALSE, method = "loess") + labs(title="Budżet a Oscar - weekend otwarcia") |
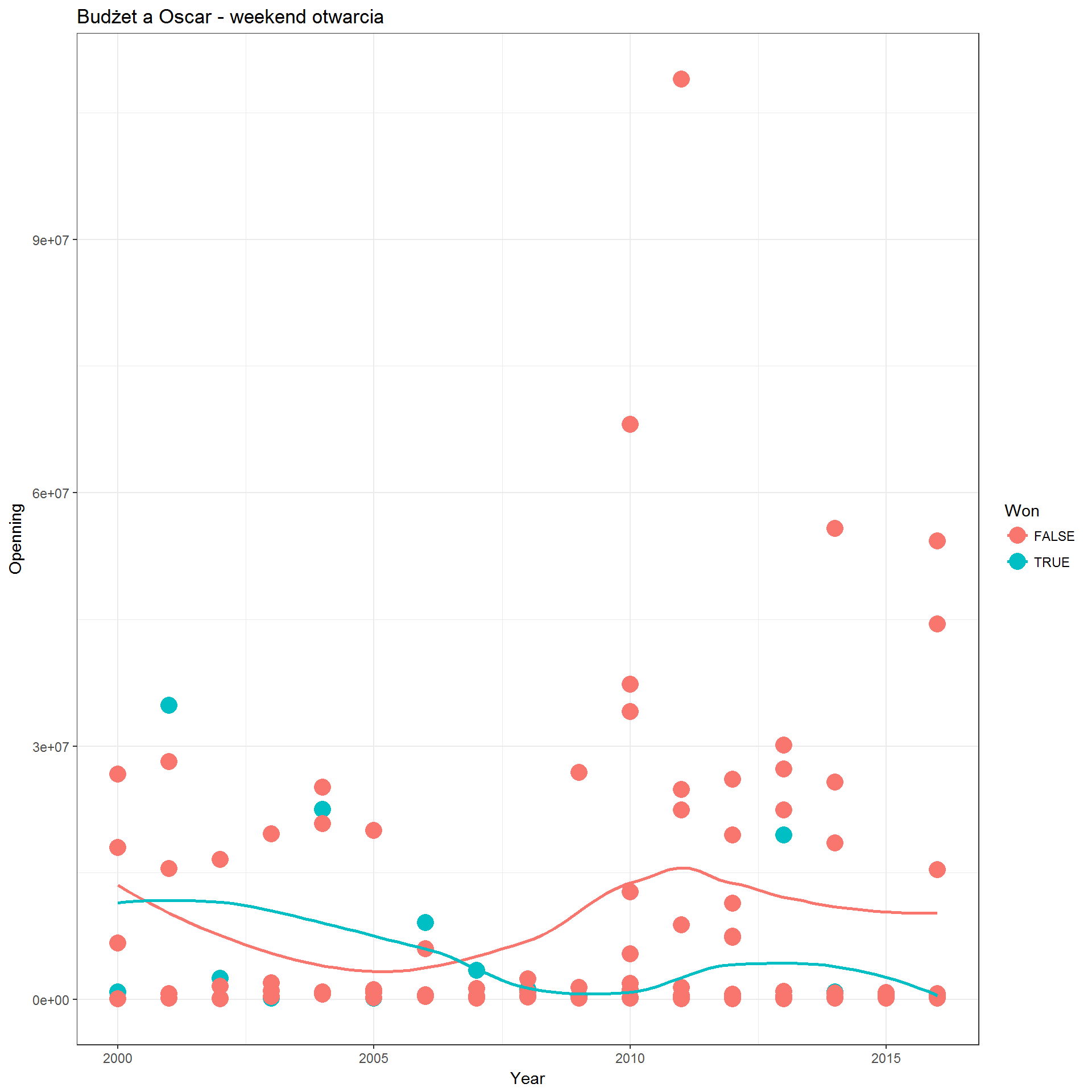
- i z całkowitego przychodu:
|
1 2 3 4 5 6 7 |
movies_dets %>% filter(Year != 2017) %>% ggplot() + theme_bw() + geom_point(aes(Year, Gross, col=Won), size=5) + geom_smooth(aes(Year, Gross, col=Won), se=FALSE, method = "loess") + labs(title="Budżet a Oscar - całkowity przychód") |
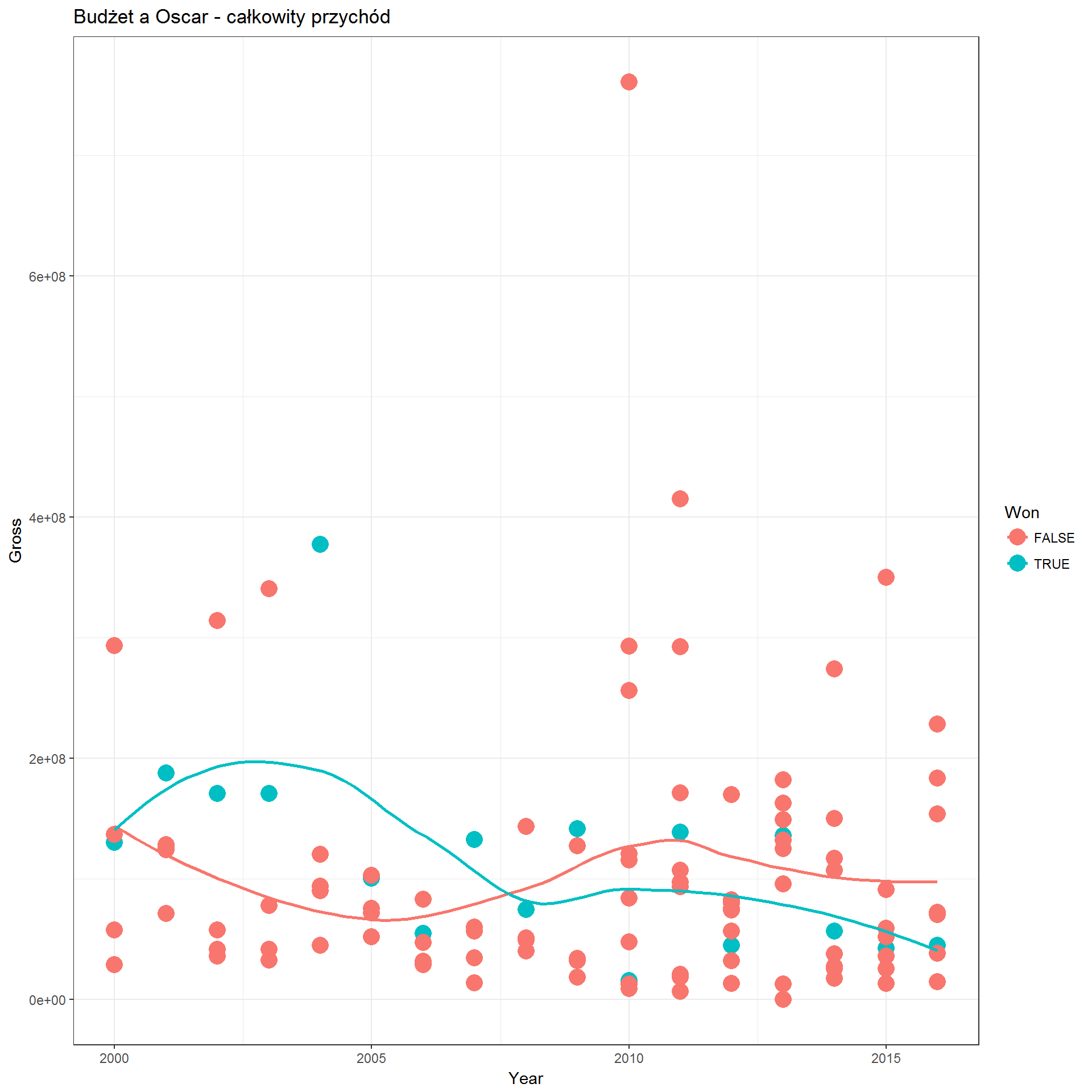
Widzieliśmy już, że publiczność wyżej ocenia filmy Oscarowe. A krytycy (oceny MetaScore)?
|
1 2 3 4 5 6 7 |
movies_dets %>% filter(Year != 2017) %>% ggplot() + theme_bw() + geom_point(aes(Year, MetaScore, col=Won), size=5) + geom_smooth(aes(Year, MetaScore, col=Won), se=FALSE, method = "loess") + labs(title="MetaScore a Oscar") |
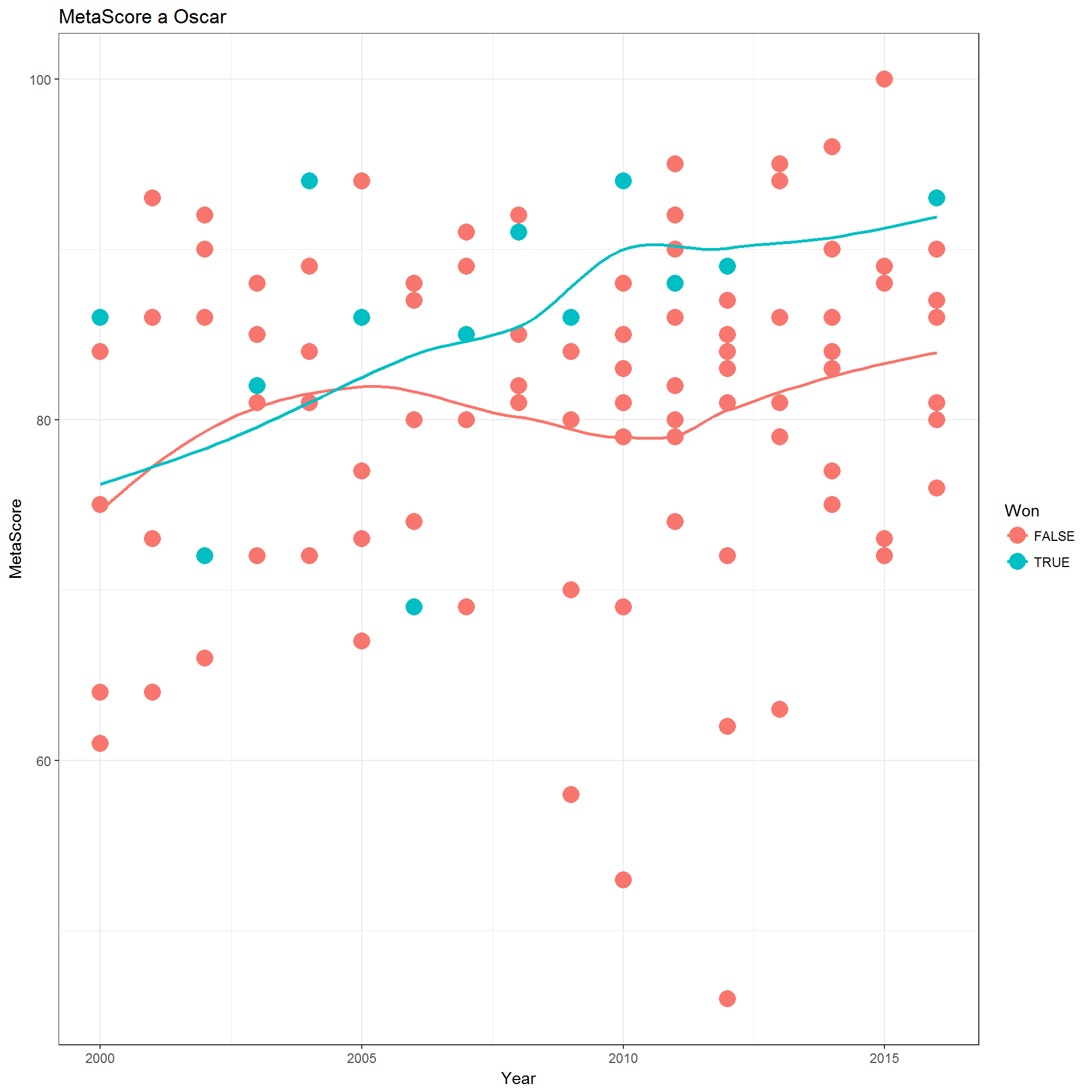
Co się stanie 26 lutego 2017?
Spróbujmy teraz przewidzieć który film wygra w kategorii “Best Picture”. Zbudujemy model typu random forest zasilony danymi z lat 2000-2016.
Najpierw (jak to w modelach) jednak trzeba podzielić dane na część uczącą i testową – próbką treningową będą poprzednie lata, zaś predykcję będziemy robić na roku 2017. Podział trochę szalony – 94% to dane treningowe, tylko 6% to dane testowe. Zazwyczaj jest to 80:20 albo 70:30 – może to prowadzić do nadmiernego dopasowania modelu. Nie wykorzystamy jednak wszystkich zgromadzonych danych (typu obsada czy reżyser lub scenarzysta). Porządny model powinien brać pod uwagę kilka innych czynników (na końcu znajdziecie linki do innych opracowań na ten sam temat, biorących pod uwagę inne dane), ale jak zobaczymy – to się sprawdza całkiem nieźle (random forest zazwyczaj sprawdza się nieźle – o tym będzie innym razem).
|
1 2 3 4 5 6 7 8 9 10 11 12 |
# wybieramy tylko potrzebne kolumny movies_train <- movies_dets[, c(1,3,4,5,6,7,8,9, 14,15,16,17)] # test - 2017 rok movies_test <- movies_train[movies_train$Year == 2017, -2] # trening - wszystko pozostałe movies_train <- movies_train[movies_train$Year != 2017, -3] movies_train$Won <- ifelse(movies_train$Won, 1, 0) # dane treningowe to tylko filmy, które mają wszystkie informacje movies_train <- na.omit(movies_train) |
Zbudujemy model. Banalnie – wywołując po prostu jedną fukncję. Będziemy przewidywać wartość “Won” na podstawie pozostałych danych.
|
1 2 |
# randomForest model_rf <- randomForest(Won ~ ., movies_train, importance=TRUE) |
Przy okazji, sprawdźmy jakie znaczenie w modelu mają poszczególne dane opisujące film:
|
1 |
varImpPlot(model_rf) |

Jak widać ważne są przede wszystkim:
- liczba głosów na IMDb.com – czyli popularność filmu
- średnia ocena użytkownikóW IMDb.com
- przychód – zarówno całkowity jak i z weekendu otwarcia
Utwierdza (mnie) to w przekonaniu o charakterze tej nagrody…
Przewidujemy. Znowu – jedną linijką kodu! Za to właśnie lubię R.
|
1 2 3 4 5 6 7 8 9 10 11 |
pred_rf <- predict(model_rf, newdata = movies_test[,-2]) # złączenie przewidywań z danymi movies_test_rf <- cbind(movies_test, pred_rf) # posortujmy od razu tabelę po predykcji # jednocześnie przeliczając wartości otrzymane z modelu na procenty movies_rf_list <- movies_test_rf %>% mutate(Probability=round(100*pred_rf/sum(pred_rf), 1)) %>% arrange(desc(pred_rf)) %>% select(Title, Rating, Votes, Genres, MetaScore, Probability) |
“And the winner is!…”
|
1 |
print(movies_rf_list) |
| Title | Rating | Votes | Genres | MetaScore | Probability |
|---|---|---|---|---|---|
| La La Land | 8.5 | 176689 | Comedy | 93 | 33.6% |
| Manchester by the Sea | 8.1 | 73738 | Drama | 96 | 25.5% |
| Moonlight | 7.9 | 54827 | Drama | 99 | 9.8% |
| Hidden Figures | 7.9 | 42283 | Biography | 74 | 6.5% |
| Arrival | 8.1 | 244387 | Drama | 81 | 6.2% |
| Hacksaw Ridge | 8.3 | 131307 | Drama | 71 | 6.1% |
| Lion | 8.0 | 43208 | Drama | 69 | 5.4% |
| Fences | 7.4 | 22132 | Drama | 79 | 4.0% |
| Hell or High Water | 7.7 | 88963 | Action | 88 | 2.9% |
Na pierwszym miejscu fawort.
Krytycy różnią się w opiniach.
Wspomniałem, że można też estymować inaczej, z innych danych. Bardzo ciekawe opracowana można znaleźć tutaj:
- podsumowanie FiveThrityEight.com plus znacznie więcej z tego samego serwisu
- polskie BiqData od Agory – pierwsze podejście oraz drugie
Czy model jest skuteczny?
Jak bardzo można mu wierzyć? Warto to sprawdzić (zanim pójdziemy do bukmachera postawić grube miliony na “La la land”). Na przykład próbując wytypować to, co już wiemy. Sprawdźmy więc, czy z tych samych danych, tym samym modelem możemy wytypować laureatów z lat poprzednich. Wszystkich (pomiędzy 2000 a 2016) lat.
Odpowiednio wybierając za dane testowe określony rok, a resztę jako dane treningowe i wrzucając wszystko w pętlę możemy porównać dane estymowane z rzeczywistością.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
# z danych zgromadzonych na początek wycinamy to co nam potrzebne # i usuwamy 2017 rok movies_train <- movies_dets[, c(1,3,4,5,6,7,8,9, 14,15,16,17)] movies_train <- movies_train[movies_train$Year != 2017, ] movies_train <- na.omit(movies_train) # tutaj zbierzemy sobie wyniki z kolejnych lat wyniki_rf <- data.frame() # teraz typujemy zwycięzcę dla kolejnych lat for(rok in 2000:2016) { # próbka testowa na określonym roku movies_test_year <- movies_train[movies_train$Year == rok, ] # próbka treningowa na latach pozostałych movies_train_year <- movies_train[movies_train$Year != rok, -3] movies_train_year$Won <- ifelse(movies_train_year$Won, 1, 0) # model randomForest i predykcja model_rf <- randomForest(Won ~ ., movies_train_year) pred_rf <- predict(model_rf, newdata = movies_test_year) movies_test_year_rf <- cbind(movies_test_year, pred_rf) # interesuje nas tylko pierwsze miejsce według predykcji wyniki_rf <- rbind(wyniki_rf, movies_test_year_rf[order(-movies_test_year_rf$pred_rf)[1], c(1,3,2)]) } |
Co trafiliśmy? A raczej z jaką skutecznością?
|
1 2 |
wynik <- table(wyniki_rf$Won) wynik["TRUE"]/sum(wynik) |
|
1 2 |
## TRUE ## 0.3529412 |
Może więc warto zaczekać z tym bukmacherem ;)
Wiemy, że skuteczność jest taka sobie, ale kto powinien wygrać według modelu – to jest ciekawe!
|
1 |
print(wyniki_rf) |
| Year | Title | Won |
|---|---|---|
| 2000 | The Green Mile | FALSE |
| 2001 | Wo hu cang long | FALSE |
| 2002 | The Lord of the Rings: The Fellowship of the Ring | FALSE |
| 2003 | The Pianist | FALSE |
| 2004 | Mystic River | FALSE |
| 2005 | Sideways | FALSE |
| 2006 | Crash | TRUE |
| 2007 | Little Miss Sunshine | FALSE |
| 2008 | No Country for Old Men | TRUE |
| 2009 | Slumdog Millionaire | TRUE |
| 2010 | Inglourious Basterds | FALSE |
| 2011 | The King’s Speech | TRUE |
| 2012 | The Artist | TRUE |
| 2013 | Silver Linings Playbook | FALSE |
| 2014 | 12 Years a Slave | TRUE |
| 2015 | The Imitation Game | FALSE |
| 2016 | Mad Max: Fury Road | FALSE |
Widzicie to? “Zielona mila”, “Pianista”, “Rzeka tajemnic”, Tarantino, czy “Tajemnica Brokeback Mountain” – same dobre filmy!
Sprawdźmy jeszcze kto wygrywał, bo że się mylimy to już wiadomo…
|
1 2 3 |
movies_train %>% filter(Won) %>% select(Year, Title) |
| Year | Title |
|---|---|
| 2000 | American Beauty |
| 2001 | Gladiator |
| 2002 | A Beautiful Mind |
| 2003 | Chicago |
| 2004 | The Lord of the Rings: The Return of the King |
| 2005 | Million Dollar Baby |
| 2006 | Crash |
| 2007 | The Departed |
| 2008 | No Country for Old Men |
| 2009 | Slumdog Millionaire |
| 2010 | The Hurt Locker |
| 2011 | The King’s Speech |
| 2012 | The Artist |
| 2013 | Argo |
| 2014 | 12 Years a Slave |
| 2015 | Birdman or (The Unexpected Virtue of Ignorance) |
| 2016 | Spotlight |
Różnice – jako zapalony kinoman – mogę skomentować tak:
- “American Beauty” uważam za lepszy film, jest też bardziej hollywoodzki
- “Pianista” – Polański nie mógł dostać Oscara z oczywistych względów…
- widowiskowy “Władca pierścieni” wygrywa ze znakomitym, ciężkim i mrocznym thrillerem – kolejne potwierdzenie, że Oscar to nagroda dla rozrywki
- Tarantino przegrał z wojną na Bliskim Wschodzie – w Ameryce nic dziwnego, szczególnie po 9/11
- “Spotlight” się należało, to jakiś wyjątek w nagrodach dla kina rozrywkowego
Dużo było dzisiaj. Mam nadzieję, że ciekawie. I mam nadzieję, że Akademia poprawi skuteczność tego prostego modelu dając już za kilkadziesiąt godzin nagrodę dla „La la land”. Chociaż film uważam za taki właśnie „oskarowy” – ładny, kolorowy, z prostą fabułą. Sobotni wieczór, kiedy dzieci już śpią, butla Prosecco i można oglądać. Uleci z głowy tak samo jak „Artysta” z 2012 roku.
Pingback: Kto wygrał Oscary 2017. Bez czytania! | Łukasz Prokulski