O czym w wiadomościach piszą serwisy internetowe? Czy da się jakoś pogrupować teksty? Wszystko to (i więcej) na bazie ponad roku tekstów z serwisu Wiadomości Gazeta.pl.
Zanim przejdziemy do analizy potrzebujemy danych.
Jeśli interesują Cię wyniki to przejdź od razu do części Analiza. Pierwsza część to obszerny opis tego jak uzyskać dane. Pojawiają się w komentarzach (tutaj albo na fanpage’u Dane i analizy czy też mailach do mnie) o to jak pobierać dane z WWW – poniżej znajdziecie wystarczająco szczegółowy algorytm postępowania. Wiedza na temat HTMLa i CSSa jest przydatna i do zdobycia samodzielnie.
Pobranie danych
Pobierzemy całe teksty i to co uda się z nich wyłuskać – wyłuskamy. Aby pobrać zawartość strony potrzebny jest jej adres URL. A najlepszy sposób na pobranie adresów poszczególnych artykułów to lista artykułów. Coś podobnego ćwiczyliśmy z Ugotuj.to w tekście o analizie koszykowej.
Wchodzimy zatem na stronę główną Wiadomości Gazeta.pl i patrzymy co tam mamy. Mamy listę artykułów, która kończy się guzikiem “Więcej”. Klikamy w niego i widzimy znowu listę artykułów, ale tym razem stronicowaną. Klikamy w stronę drugą, później w kolejną. Za każdym razem obserwujemy jak wygląda adres strony, którą oglądamy. Widzimy, że adres różni się tylko w jednym miejscu, a miejscem tym jest liczba określająca numer strony indeksu. Z tej listy (i jej kolejnych stron) będziemy korzystać.
Potrzebne będzie kilka pakietów, które już znamy:
|
1 2 3 4 5 6 7 8 9 10 11 |
library(tidyverse) library(rvest) library(stringr) library(lubridate) # pomiędzy pt1 a pt2 wpada numer strony indeksu base_url_pt1 <- "http://wiadomosci.gazeta.pl/wiadomosci/0,114871.html?str=" base_url_pt2 <- "_19834953" # ile stron indeksu pobieramy? n_index_pages <- 500 |
Teraz, na dowolnej stronie z listą artykułów w (na przykład) przeglądarce Chrome robimy sobie “Zbadaj” i oglądamy HTMLa strony jaką widzimy na ekranie. Szukamy interesujących nas elementów: w tym przypadku linku, do którego prowadzi tytuł artykułu na liście. Odpowiednią ścieżkę (w sensie drzewa dokumentu HTML) zapisujemy, gdzieś na boku trenujemy i w efekcie możemy przygotować funkcję do pobierania listy artykułów z jednej strony indeksu:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
get_article_list_from_page <- function(page_no) { page_url <- paste0(base_url_pt1, page_no, base_url_pt2) page <- read_html(page_url) links <- page %>% html_node("article") %>% html_nodes("li") %>% html_nodes("h2") articles_tmp <- data_frame(link = links %>% html_node("a") %>% html_attr("href"), title = links %>% html_node("a") %>% html_text()) articles_tmp <- articles_tmp %>% filter(str_sub(link, 1, 41) == "http://wiadomosci.gazeta.pl/wiadomosci/7,") return(articles_tmp) } |
W funkcji zostawiamy teksty z ciągiem /7, w urlu. Dlaczego? Bo inne to nie są artykuły (są relacjami na żywo, galeriami itp.). Ponieważ pracowałem kiedyś w Gazeta.pl to znam te mechanizmy od środka – tutaj korzystam z tej wiedzy (chociaż za moich czasów strona artykułowa to była jedynka a nie siódemka) i wiem na co patrzeć. Ale praca w serwisie internetowym nie jest wymagana :)
Dokładnie tak samo można prześledzić inne serwisy i tak samo zebrać dane. Trzeba tylko poczytać HTMLa ;)
Pobierzemy więc listę artykułów z 500 (zmienna n_index_pages) stron indeksowych po kolei:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
article_links <- data_frame() for(i in 1:n_index_pages) { article_links_tmp <- get_article_list_from_page(i) article_links <- bind_rows(article_links, article_links_tmp) # czekamy, żeby być grzecznym dla serwerów Sys.sleep(sample(seq(0.25, 1, 0.25), 1)) } rm(article_links_tmp, i) |
Po pobraniu każdej strony z listą artykułów czekamy losową wartość (maksymalnie jedną) sekund. Żeby nie zabić serwerów, żeby nie wzbudzać podejrzeń i nie dać zablokować sobie IP na jakiś czas, o ile w Agorze działają mechanizmy automatycznej blokady. Swoją drogą mogą one być oparte o machine learning według reguły: jeśli liczba zapytań z określonego IP wysłanych do serwera WWW w określonym czasie jest większa niż średnia z ostatnich na przykład 10 sekund to zablokuj IP na pół godziny.
Mając listę artykułów czas na pobranie samych artykułów. Tutaj robimy podobnie: wchodzimy na stronę dowolnego tekstu, opcją “Zbadaj” z przeglądarki szukamy miejsca w drzewie HTML dla interesujących nas elementów: tytułu, leadu, pełnej treści artykułu i czego tam jeszcze potrzebujemy. Jak znamy te selektory to budujemy kolejną funkcję:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
get_article <- function(article_url) { page <- read_html(article_url, encoding = "ISO_8859-2") # autor tekstu author <- page %>% html_node("div#gazeta_article_author") %>% html_text() %>% trimws() # data publikacji date <- page %>% html_node("div#gazeta_article_date") %>% html_text() %>% trimws() %>% str_replace_all("[\t\n ]", "") %>% dmy_hm() # tytuł tekstu title <- page %>%html_node("h1") %>% html_text() %>% trimws() # lead lead <- page %>% html_node("div#gazeta_article_lead") %>% html_text() %>% trimws() # pełna treść artykułu body <- page %>% html_node("div#gazeta_article_body") %>% html_text() %>% trimws() # wszystkie dane pakujemy razem article <- data_frame(title = title, lead = lead, body = body, author = author, date = date, url = article_url) # czekamy, żeby być grzecznym dla serwera Sys.sleep(sample(seq(0.25, 1, 0.25), 1)) return(article) } |
Dla każdego tekstu (jego adresu na liście zebranej ze stron indeksowych) pobieramy jego zawartość:
|
1 2 3 4 5 6 7 8 |
articles <- article_links %>% # działaj wierszami rowwise() %>% # dla każdego wiersza wywołaj funkcję get_article() z parametrem wziętym z kolumny "link" do(get_article(.$link)) %>% # złącz wszystkie otrzymane rezultaty bind_rows() %>% ungroup() |
Jakie zgrabne, prawda? Mogło być pętlą i pewnie byłoby bardziej czytelne, ale tak ładnie wygląda. A i nauczyć można się czegoś nowego o dplyr (bo to jego zasługa). Jeszcze tylko zapisujemy dane lokalnie, żeby za każdym razem nie czekać. A tutaj czekamy około 3 godzin! Bo na każdej stronie indeksu jest 15 artykułów, stron mamy pobranych 500, a pomiędzy zapytaniami mamy maksymalnie sekundę przerwy – to daje dwie godziny i pięć minut samego oczekiwania (w wersji maksymalnej), ale jest też potrzebny czas na same operacje.
|
1 |
saveRDS(articles, file = "articles.RDS") |
Uff. Dane pobrane, można zająć się tym co najciekawsze.
Analiza
Potrzebujemy tych samych pakietów:
|
1 2 3 4 |
library(tidyverse) library(tidytext) library(stringr) library(lubridate) |
i wczytania danych zapisanych lokalnie. Oczywiście jeśli wszystko robicie w jednej sesji R, to nie potrzeba jeszcze raz wczytywać danych i nie potrzeba jeszcze raz ładować pakietów. Jednak dobry zwyczaj to rozdzielić skrypty (u mnie jeden to pobranie danych, drugi to ich analiza) i stąd te powtórzenia (bo tekst jest sklejką dwóch skryptów).
|
1 |
articles <- readRDS("articles.RDS") |
W danych mamy kilka informacji ukrytych (ukrywa je na przykład data) – możemy je wydobyć:
|
1 2 3 4 5 6 7 8 9 10 11 |
articles <- articles %>% # oznaczenie działów na podstawie numerku w URLu mutate(dzial = str_sub(url, 42, 47)) %>% # dzien, dzien tygodnia, miesiac i godzina publikacji mutate(day = day(date), month = month(date), year = year(date), hour = hour(date), wday = factor(wday(date), levels = c(2, 3, 4, 5, 6, 7, 1), labels = c("pn", "wt", "śr", "cz", "pt", "sb", "nd"))) |
Zobaczmy teraz ile mamy tekstów z poszczególnych miesięcy:
|
1 2 3 4 5 6 |
articles %>% count(year, month) %>% ggplot() + geom_col(aes(make_date(year, month, 1), n), fill="lightgreen", color = "gray50") + scale_x_date(date_breaks = "1 months", date_labels = "%m.%Y") + theme(axis.text.x = element_text(angle = 45, hjust=1, vjust=1)) |
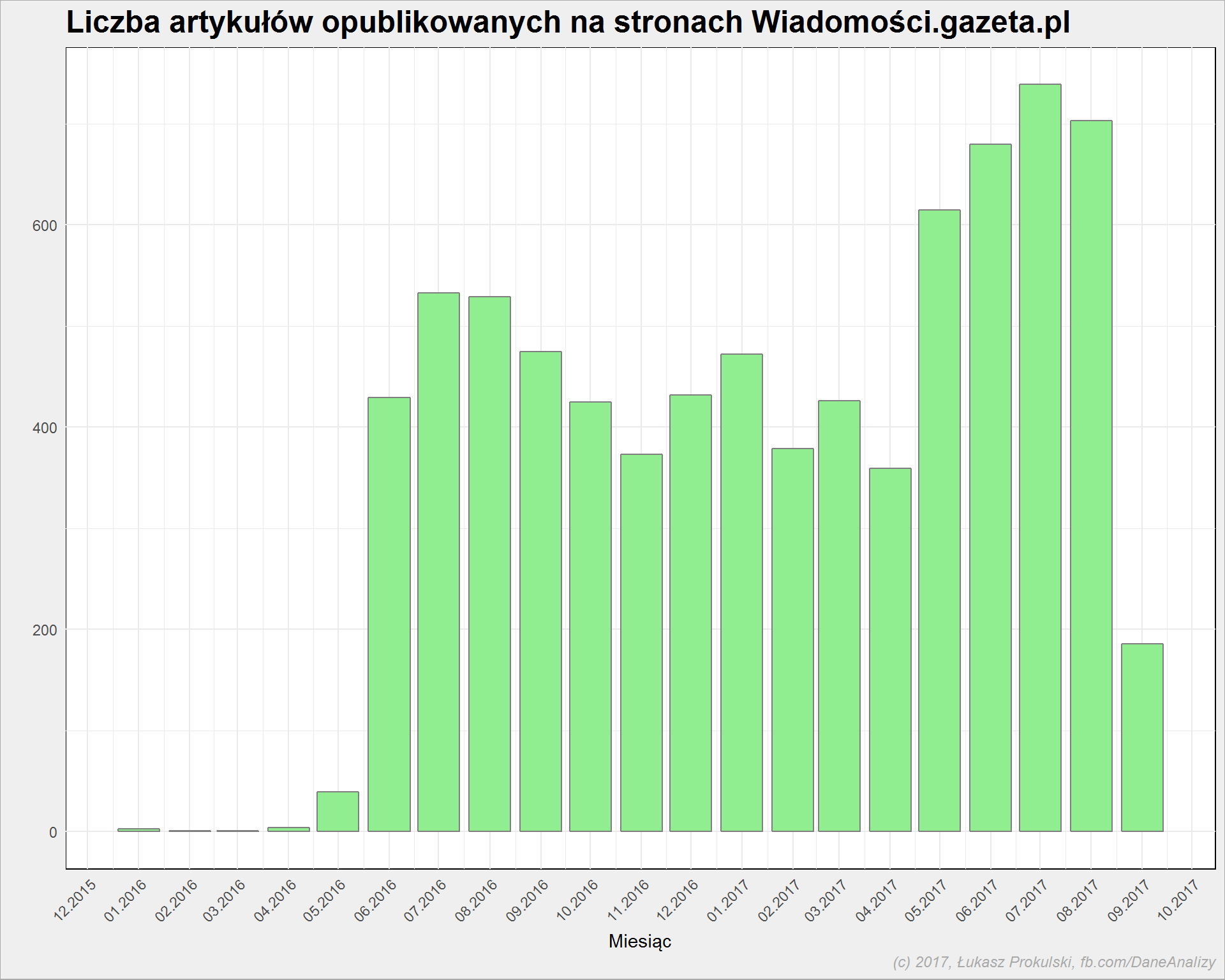
Widać, że są miesiące gdzie jest zdecydowanie mniej tekstów (co tam się działo na początku 2016? jakieś przemeblowania w serwisie zrobione pod koniec maja 2016?), a obecny wrzesień 2017 jest niepełny. Zostawmy więc tylko pełne miesiące z dużą liczbą tekstów: czerwiec 2016 do sierpnia 2017 włącznie:
|
1 |
articles <- articles %>% filter(date >= "2016-06-01", date < "2017-09-01") %>% distinct() |
Przygotowując dalszą analizę zauważyłem, że czasem po znaku przestankowym nie ma spacji. Trzeba to poprawić już na wstępie – zamieniamy takie znaki na spacje. Przy okazji zamienimy też numerki działów na ich nazwy (nazwy są na podstawie tego co znajdziecie na serwisie, zadanie już dla Was).
|
1 2 3 4 5 6 7 8 9 |
articles <- articles %>% mutate(lead = gsub("[[:punct:]]", " ", lead)) %>% mutate(body = gsub("[[:punct:]]", " ", body)) %>% # działy z numerów na nazwy mutate(dzial = case_when(.$dzial == "114871" ~ "Najnowsze", .$dzial == "114881" ~ "Świat", .$dzial == "114883" ~ "Polska", .$dzial == "114884" ~ "Polityka")) %>% mutate(dzial = factor(dzial)) |
Ostatecznie więc mamy artykuły opublikowane pomiędzy 2016-06-01 11:00:00 a 2017-08-31 20:51:00, z odpowiednim wskazaniem nazwy działu z jakiego pochodzą.
Czas na zadawanie pytań i szukanie odpowiedzi.
Kiedy i gdzie publikuje się najwięcej?
Zobaczmy to w przekroju dział/miesiąc:
|
1 2 3 4 5 6 7 8 |
articles %>% count(dzial, year, month) %>% ungroup() %>% mutate(date = make_date(year, month, 1)) %>% ggplot() + geom_col(aes(date, n, fill = dzial), position = "dodge", color = "gray50") + scale_x_date(date_breaks = "1 months", date_labels = "%m.%Y") + theme(legend.position = "bottom") |
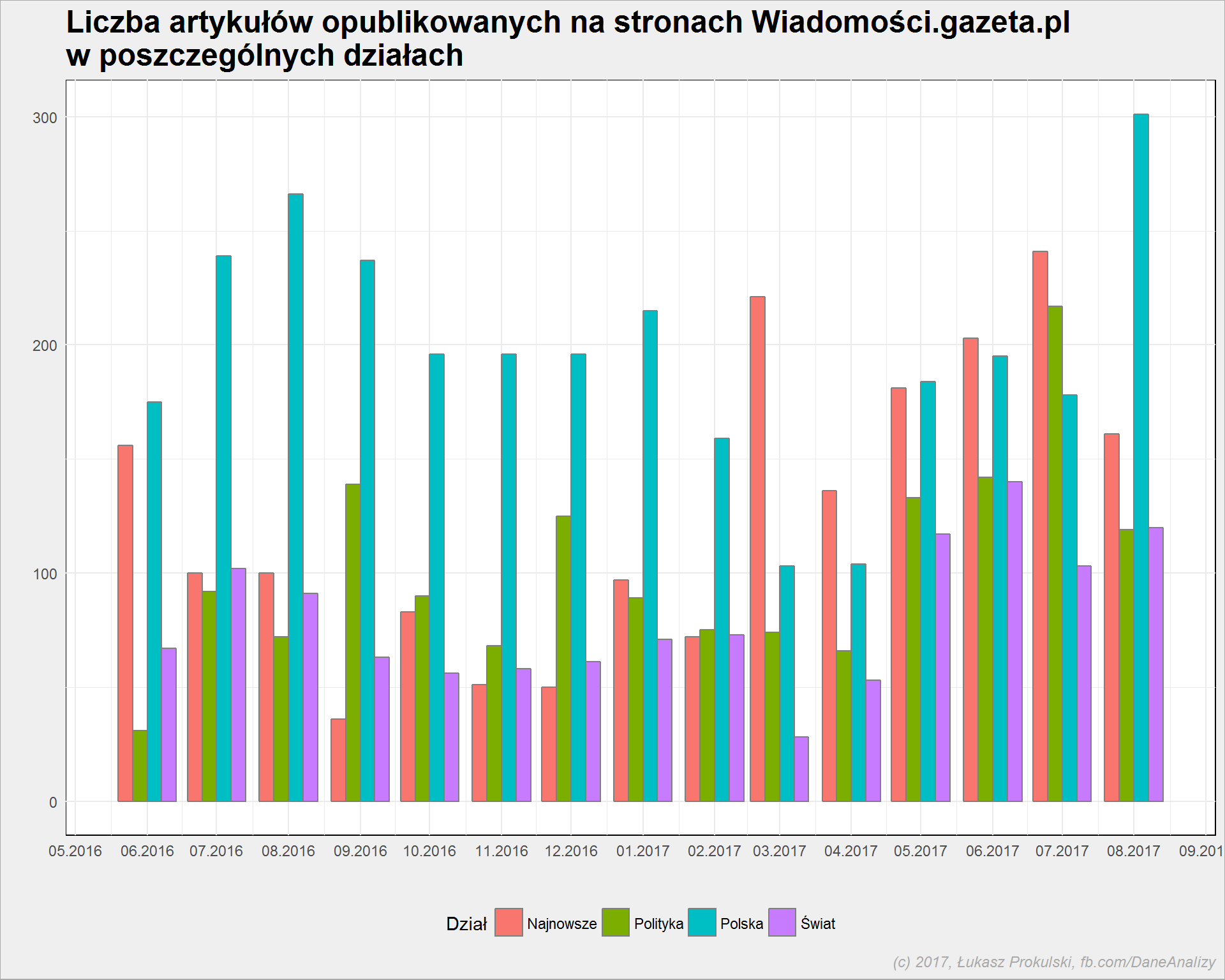
Widzimy tutaj, że z wolna liczba tekstów z działu “Polska” ustąpiła miejsca działowi “Najnowsze”, a jednocześnie wzrosła liczba tekstów z “Polityka”. Być może to jakaś strategia redakcji w dokładniejszym przydzielaniu tekstów do odpowiednich działów – coś co dotyczy polityki wewnętrznej w naszym kraju trafia teraz do “Polityka” zamiast do “Polska”?
Spróbujmy złączyć działy “Polska” oraz “Polityka” i zobaczmy udział procentowy tekstów z działów, zamiast ich bezwzględnej liczby:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
articles %>% mutate(dzial = as.character(dzial)) %>% mutate(dzial = case_when(.$dzial == "Najnowsze" ~ "Najnowsze", .$dzial == "Świat" ~ "Świat", .$dzial == "Polska" ~ "Polska + Polityka", .$dzial == "Polityka" ~ "Polska + Polityka")) %>% count(dzial, year, month) %>% ungroup() %>% group_by(year, month) %>% mutate(p = 100*n/sum(n)) %>% ungroup %>% mutate(date = make_date(year, month, 1)) %>% ggplot() + geom_line(aes(date, p, color = dzial), size = 2) + scale_x_date(date_breaks = "1 months", date_labels = "%m.%Y") + theme(legend.position = "bottom") |
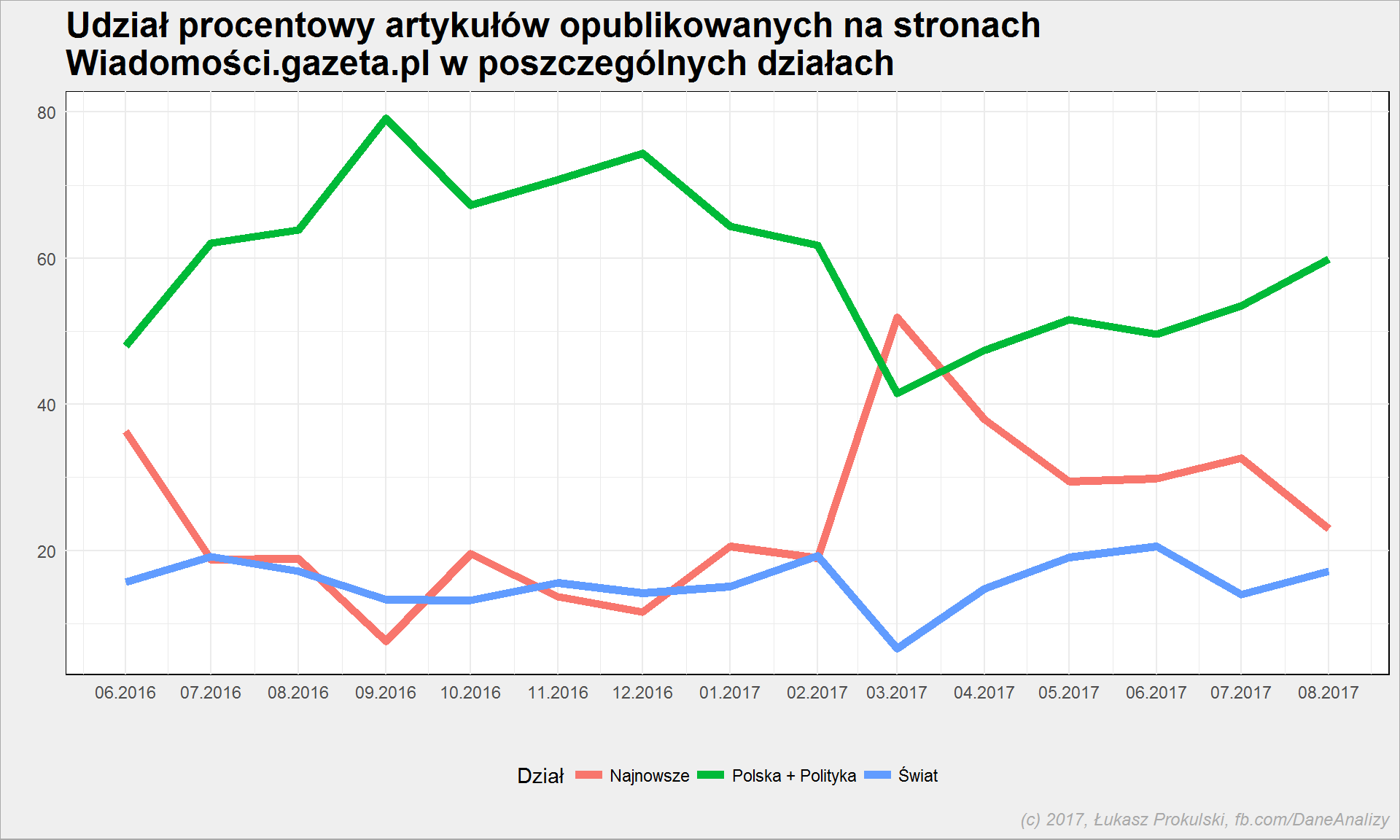
Widać, że wiadomości ze świata to niecałe 20% treści w serwisie. Mamy też potwierdzenie: nawet połączona “Polska” i “Polityka” oddała pola “Najnowszym” (ostatecznie nie dając się jednak wyeliminować z pierwszego miejsca).
Drugi przekrój to godzina/dzień tygodnia, także z rozróżnieniem działów. Wyniki porównajcie z tekstem o pracy redakcji na Facebooku.
|
1 2 3 4 5 6 7 8 |
articles %>% count(wday, hour, dzial) %>% ungroup() %>% ggplot() + geom_tile(aes(wday, hour, fill = n), color = "white") + scale_y_reverse() + scale_fill_gradient(low = "lightgreen", high = "red") + facet_wrap(~dzial) |
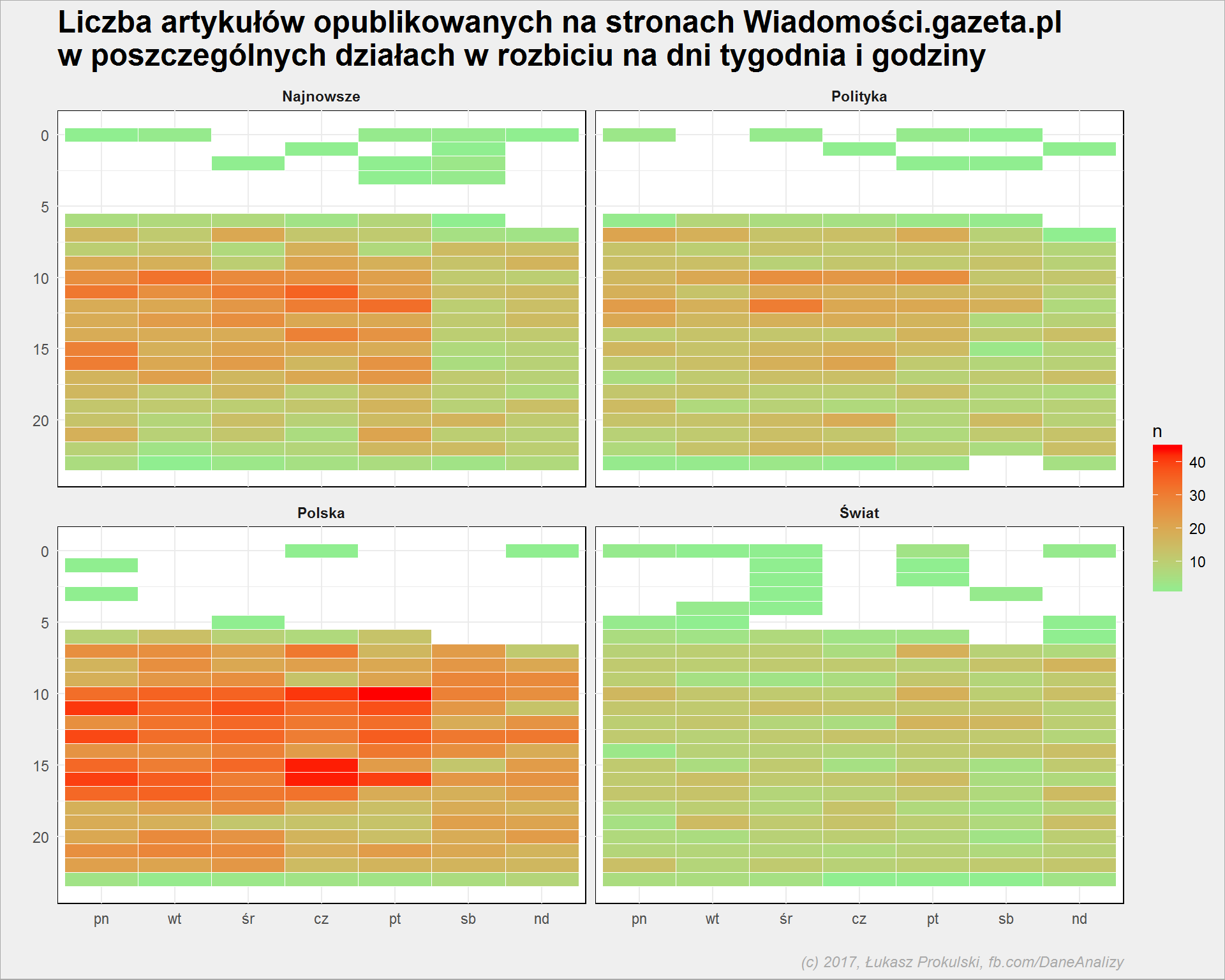
W oczy rzuca się oczywiste: w nocy się nie publikuje (ale szacun dla redakcji, że potrafi puścić tekst o 2 czy 3 w nocy – rzeczywiście trzymają oko i ucho na pulsie spraw jak to u Manna i Materny w “Za chwilę dalszy ciąg programu”” było), mniej publikuje się w weekendy. I oczywiście więcej treści jest w dziale, w którym… jest więcej treści.
Ciekawe są te gorące godziny: czwartki o 15/16, piątki rano oraz poniedziałki o 11, 13 i 16. Jakiś wyjadacz i znawca mediów może widzi w tym zależności. Obstawiałbym wydarzenia związane z posiedzeniami Sejmu? Kto powie?
Wróćmy do tej drugiej i trzeciej w nocy. Pięć (no, piętnaście) sekund na zastanowienie: jakie wydarzenia miały miejsce nocą pomiędzy majem 2016 a końcem sierpnia 2017? Fani fanpage Dane i analizy rozwiązali zagadkę w komentarzach pod jednym z postów na FB. Spójrzmy na tytuły i daty tekstów:
| Data i godzina publikacji | Tytuł artykułu |
|---|---|
| 2016-07-15 02:36 | Zamach w Nicei. W dniu ataku we Francji prezydent zdecydował o zniesieniu stanu wyjatkowego |
| 2016-07-16 03:21 | Zamach stanu w Turcji. Dlaczego wojskowi próbowali obalić rządy Erdogana? |
| 2016-07-16 03:40 | Tak wyglądały ulice Ankary nocą. Czołgi miażdżyły zaparkowane auta [WIDEO] |
| 2016-10-10 03:05 | Tę chwilę zapamiętamy: Andrzej Wajda odbiera Oscara i zaczyna mówić po angielsku, ale zaraz… |
| 2016-11-09 02:23 | Wybory w USA. Wielkie emocje na Florydzie. Jednak wygrał Trump |
| 2016-11-09 03:26 | Paul Krugman: “Przerażająca noc. Gniew wśród białej, wiejskiej Ameryki jest większy niż myślałem” |
| 2016-12-17 02:08 | Poseł Pięta już wie, co robią wzburzeni obywatele pod Sejmem. “To jest łamanie prawa” |
| 2016-12-17 02:52 | Straż Marszałkowska próbowała usunąć dziennikarzy z Sejmu. Wyłączono światła nawet na… choince |
| 2016-12-17 03:25 | Maja Ostaszewska i Maciej Stuhr na proteście przed Sejmem. “Wolność kocham i rozumiem” |
| 2016-12-17 03:52 | Policja użyła siły. “Przywracali porządek i umożliwiali wyjazd kolumnie” z politykami PiS |
| 2017-07-15 02:33 | “Wschodni model, sądy podporządkowane woli politycznej”. Senat za zmianami w sądownictwie |
| 2017-07-19 02:16 | Kaczyńskiemu puściły nerwy. Potem wybuchła awantura. Obrady przerwano [PODSUMOWANIE] |
| 2017-07-21 02:03 | Protestujący przed Senatem śpiewali hymn. Przyłączyli się senatorowie. Oprócz jednego, z PiS |
| 2017-07-21 02:34 | Ustawa PiS o Sądzie Najwyższym przechodzi dalej. Mimo ogromnych protestów [PODSUMOWANIE] |
| 2017-07-21 03:22 | Protestujący zablokowali kontenerem ulicę przed Sejmem. Policja odpowiedziała siłą |
| 2017-07-22 02:02 | Senat przyjął ustawę o Sądzie Najwyższym bez poprawek. Został już tylko podpis prezydenta |
Zamach w Nicei (lipiec 2016), zamieszki w Ankarze (też lipiec 2016), wybory w USA (listopad 2016), “pucz” grudniowy w Sejmie (grudzień 2016) i nocne głosowania nad ustawą o Sądzie Najwyższym oraz związane z nimi protesty na ulicach Warszawy (lipiec 2017).
Popularność słów w tekstach
W tym miejscu pokazałbym chmurkę słów użytych w artykułach. I do tego dojdziemy, ale dzisiaj nieco dłuższą drogą.
Co to i po co to? Kliknijcie w linki, dowiecie się co to :) Po co? żeby sprowadzić słowa do ich formy podstawowej. Język polski to odmiana przez przypadki, osoby i liczby, a chcemy mieć formy podstawowe (idealnie gdyby to były bezokoliczniki i mianowniki).
Z githubowego repozytorium potrzebujemy wielkiego pliku dicts/polimorfologik-2.1.zip, a z tego archiwum pliku największego (jakieś 300MB) – polimorfologik-2.1.txt. Plik ten zawiera ponad 4.8 miliona słów i pozwoli nam na znalezienie form podstawowych wyrazów (lemma).
Przyda się również plik polish_stopwords.txt z tego samego miejsca.
Oba pliki trzymam w oddzielnym folderze (podobnie mam z mapami: wspólne pliki dla różnych projektów trzymam w jednym, dedykowanym miejscu; dzięki temu nie powielam tych samych danych), stąd pełniejsze ścieżki w kodzie:
|
1 2 3 4 5 6 7 8 9 |
pl_stop_words <- read_lines("../!polimorfologik/polish_stopwords.txt") stem_dictionary <- read_csv2("../!polimorfologik/polimorfologik-2.1.txt", col_names = c("stem", "word")) # słowa w słowniku na małe literki i bez duplikatów stem_dictionary <- stem_dictionary %>% mutate(stem = str_to_lower(stem), word = str_to_lower(word)) %>% distinct() |
Efekt działania stemmingu zobaczymy na przykładzie, przy użyciu odpowiedniej funkcji:
|
1 2 3 |
stem_word <- function(word_to_stem) { stem_dictionary %>% filter(word == word_to_stem) %>% .$stem %>% .[1] } |
Wywołując funkcję stem_word() z odpowiednim słowem jako parametr dostaniemy:
- dla słowa zobaczymy otrzymujemy zobaczyć
- dla zobaczył – zobaczyć
- zobaczylibyśmy – zobaczyć
Dokładnie o to nam chodziło. Jednak nie skorzystamy z funkcji, a z prostego połączenia tabel (będzie bardziej wydajnie).
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
# rozbijamy leady na pojedyncze słowa lead_words <- articles %>% unnest_tokens(word, lead, token = "words") %>% filter(!word %in% pl_stop_words) %>% # usuwamy stop words filter(nchar(word) >= 3) # zostawiamy tylko słowa 3- i więcej literowe # stemming lead_words_stem <- lead_words %>% select(-body, -url) %>% left_join(stem_dictionary, by = c("word" = "word")) %>% rename(word_stem = stem) %>% mutate(word_stem = ifelse(word == "petru", "petru", word_stem)) %>% mutate(word_stem = ifelse(word == "nowoczesna", "nowoczesna", word_stem)) %>% mutate(word_stem = ifelse(word == "nowoczesnej", "nowoczesna", word_stem)) %>% mutate(word_stem = ifelse(word == "psl", "psl", word_stem)) %>% filter(word_stem != "pisa") %>% filter(!is.na(word_stem)) |
Wyrzucamy słowo “pisa”, bo wychodzi w wyniku stemmowania słowa “pis”. Sprawdzamy w słowniku języka polskiego i dostajemy:
- Pisa – miasto we Włoszech
- Pisa lub Pissa – rzeka, prawy dopływ Narwi, płynie na Pojezierzu Mazurskim i Nizinie Północnomazowieckiej, w województwie warmińsko-mazurskim i podlaskim
Zapewne chodzi o to słowo.
Podobnie robimy z Petru (za chwilę będzie nam potrzebny) – przy stemowaniu nie dostajemy wartości, więc sztucznie ją tworzymy. Zaś “Nowoczesna” przekształcana jest na “Nowoczesny” – to zaburza nam informację o wspomnianej partii. Podobnie poprawiamy PSL.
Jakie są więc najpopularniejsze słowa w leadach?
|
1 2 3 4 5 6 7 8 9 |
lead_words_stem %>% count(word_stem) %>% ungroup() %>% arrange(n) %>% mutate(word = factor(word_stem, levels=word_stem)) %>% top_n(30, n) %>% ggplot() + geom_bar(aes(word, n), stat = "identity", fill = "lightgreen", color = "gray50") + coord_flip() |
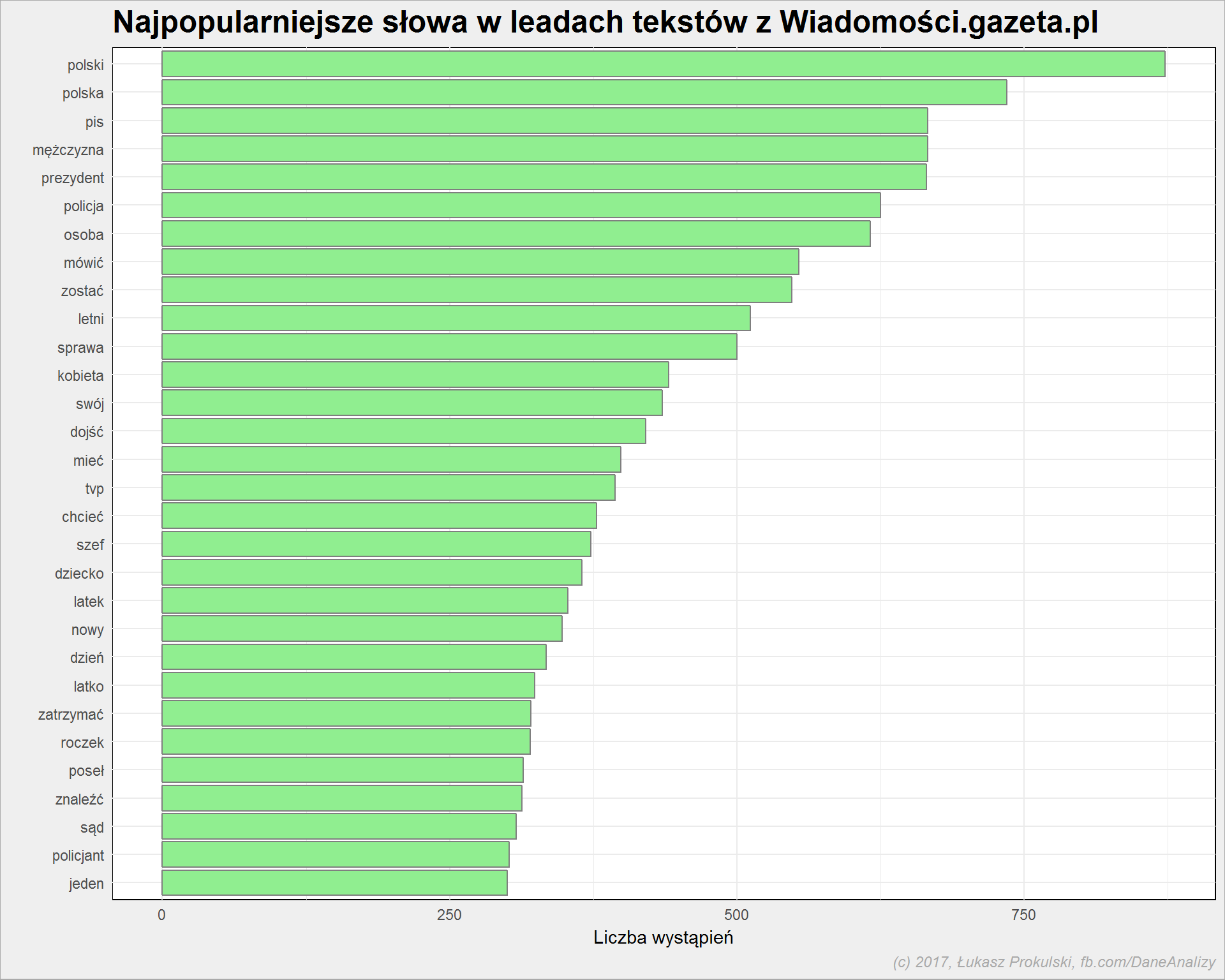
Jak widać mamy niedoskonałości – polski i polska. Właściwie powinno być samo polska (“Polski” jako odpowiedź na pytanie kogo? czego?), ale może przecież być też język polski (jako lemma od polskiego). Podobnie jest z -letni i -latek. W każdym razie jest lepiej niż na samych wydzielonych słowach.
Chmurka słów użytych w leadach – a jakże, na to pewnie czekacie?
|
1 2 3 4 5 6 7 8 9 |
library(wordcloud) lead_word_cloud <- lead_words_stem %>% count(word_stem) %>% ungroup() wordcloud(lead_word_cloud$word_stem, lead_word_cloud$n, max.words = 200, scale = c(2.4, 0.6), colors = RColorBrewer::brewer.pal(9, "Reds")[3:9]) |

Pojawia się “Jarosław” oraz “Jarosława” w rozumieniu przypadku imienia męskiego… ale przecież jest też takie imię żeńskie. No to są niedoskonałości stemmingu i lematyzacji a jednocześnie barwność polskiego języka.
Czy najpopularniejsze słowa użyte w leadzie zmieniają się z miesiąca na miesiąc? Oprócz odpowiedzi na to pytanie – w gratisie – ciekawa forma obrazowania danych o słowach:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
lead_words_stem %>% count(word_stem, year, month) %>% ungroup() %>% group_by(year, month) %>% arrange(desc(n)) %>% mutate(rank = 1:n()) %>% filter(rank <= 10) %>% ungroup() %>% mutate(date = make_date(year, month, 1)) %>% ggplot() + geom_text(aes(date, rank, label = word_stem, size = (11-rank), color = as.factor(month)), show.legend = FALSE) + scale_y_reverse() + theme(line = element_blank(), axis.text.y = element_blank()) |
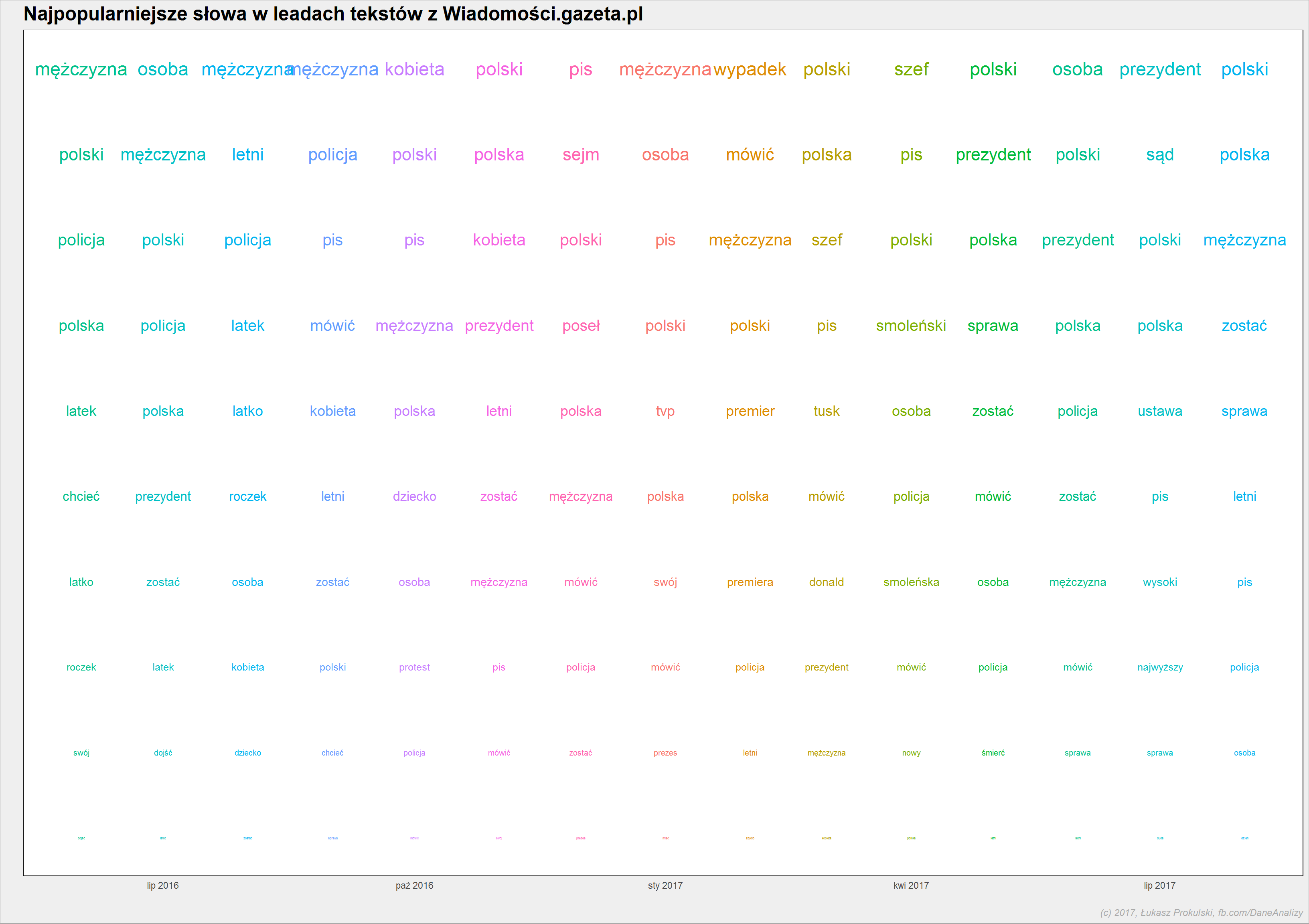
Zwróćcie uwagę na pierwsze miejsce słowa “wypadek” w lutym 2017 roku. I zapamiętajcie.
Możemy sprawdzić również poszczególne słowa i liczbę ich wystąpień w leadach na przestrzeni czasu. Na przykład nazwy partii (po to był manewr z Nowoczesną):
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
articles_per_month <- articles %>% count(year, month) %>% ungroup() %>% rename(n_arts = n) lead_words_stem %>% filter(word_stem %in% c("pis", "platforma", "nowoczesna", "kukiz", "psl")) %>% count(year, month, word_stem) %>% ungroup() %>% rename(n_words = n) %>% left_join(articles_per_month, by = c("year" = "year", "month" = "month")) %>% # przeskalowanie danych o liczbie słów mutate(n_words_plot = n_words * max(n_arts)/max(n_words), scala = max(n_arts)/max(n_words)) %>% mutate(date = make_date(year, month, 1)) %>% ggplot() + # bar = liczba tesktów geom_bar(data = articles_per_month, aes(make_date(year, month, 1), n_arts), stat="identity", fill = "gray80") + # line = liczba słów geom_line(aes(date, n_words_plot, color = word_stem), size = 2) + # ze sprawdzenia wiemy, że dane są przeskalowane o 7.083 scale_y_continuous("Liczba tekstów w miesiącu", sec.axis = sec_axis(~./7.038, "Liczba wystąpień słowa w leadzie w miesiącu")) + theme(legend.position = "bottom") |
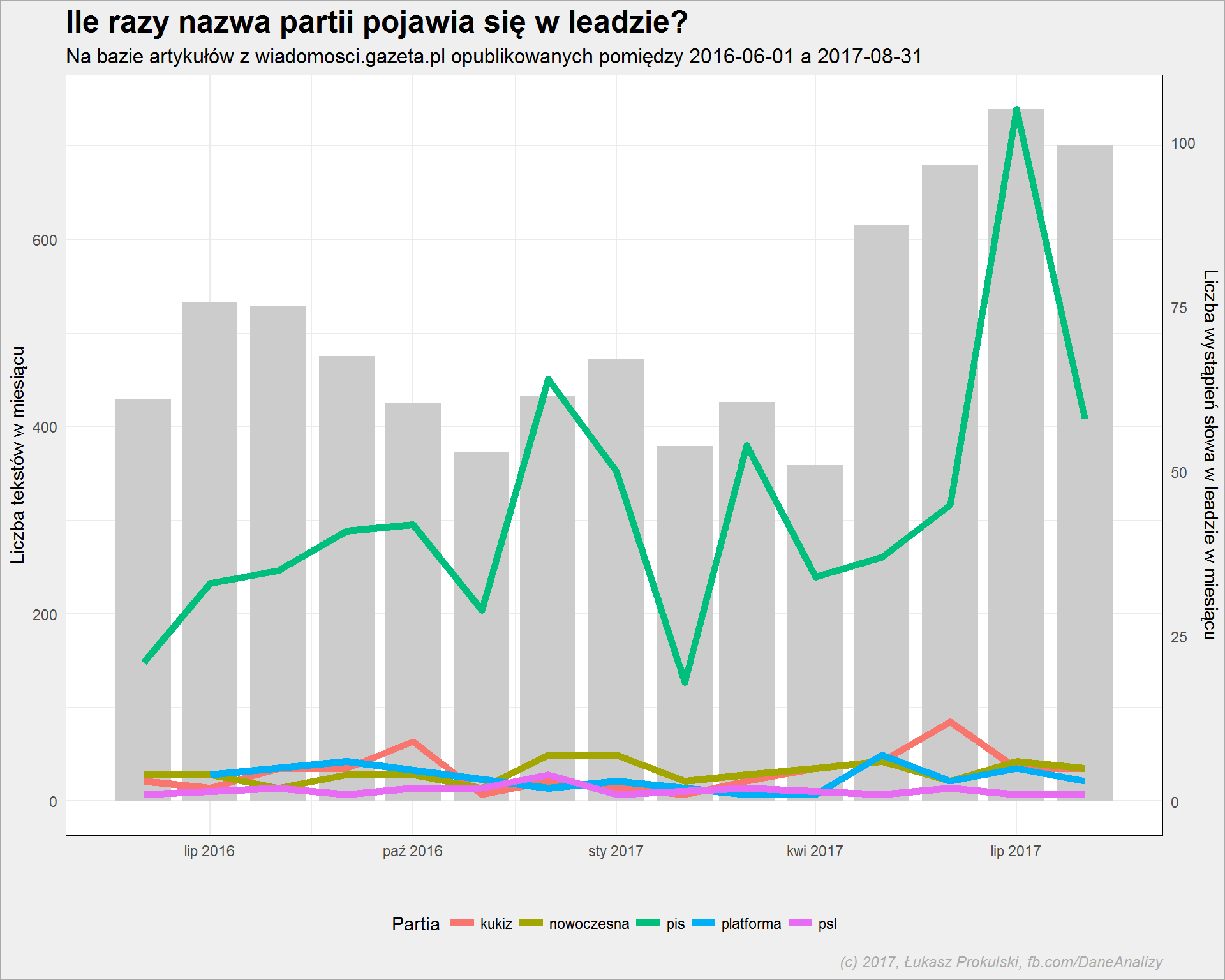
Słupki to liczba tekstów opublikowanych w danym miesiącu (oś lewa), linie zaś – liczba wystąpień nazwy partii w leadzie (w miesiącu, oś prawa). Stosunek wysokości słupka do pozycji linii nie ma żadnego znaczenia, nie przywiązujcie się do tego.
Gazeta.pl pisze głównie o PiSie (kilkadziesiąt tekstów miesięcznie). Cała reszta partii pokryta jest mniej więcej jednakowo (po kilka tekstów na miesiąc), PO mija się z Nowoczesną.
A jak często występują określone osoby w leadach? Weźmy na warsztat tych najważniejszych (po to była potrzebna korekta z Ryszardem P., gdybyśmy chcieli zobaczyć tutaj Schetynę też potrzebna byłaby korekta):
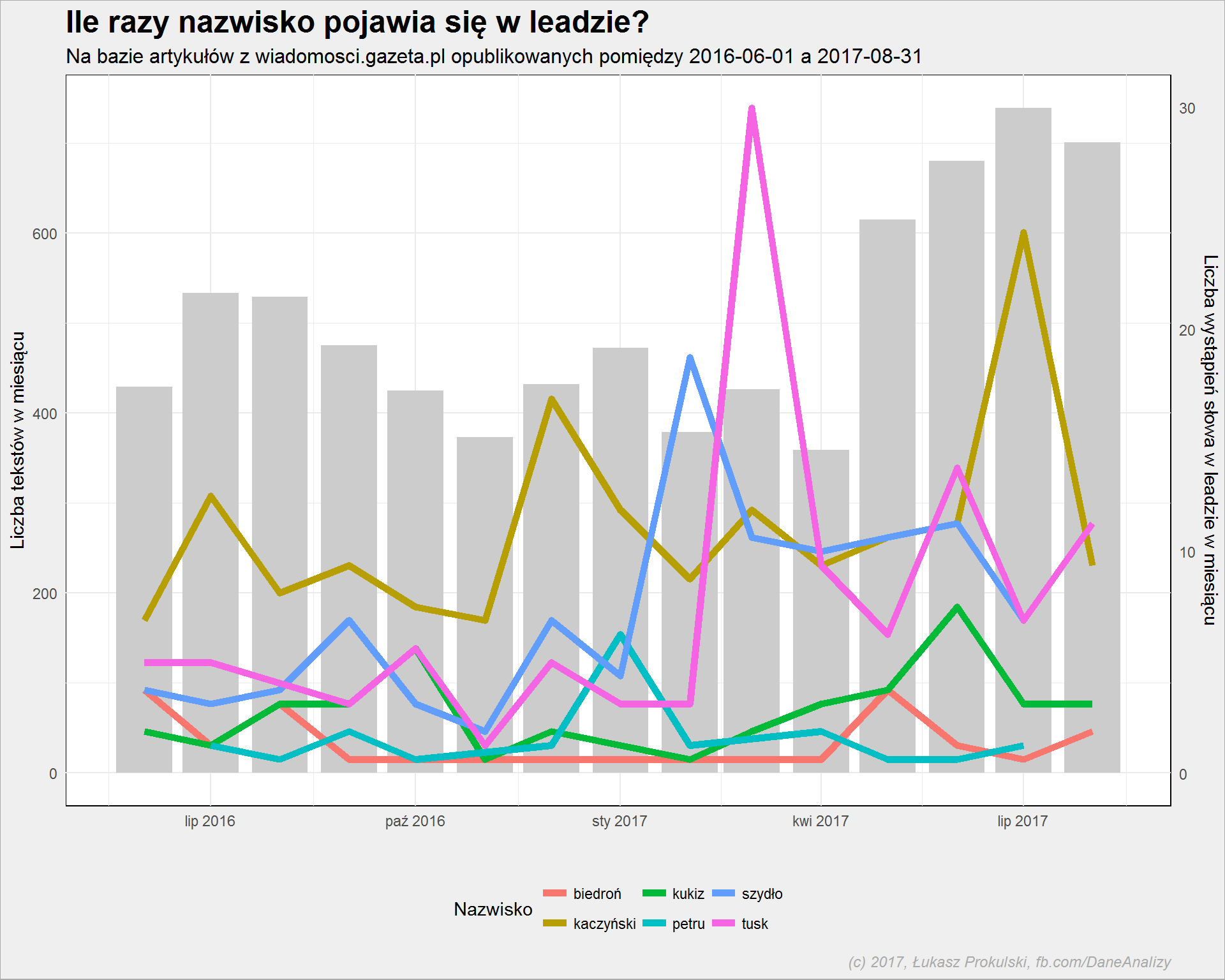
Kod generujący ten wykres jest analogiczny. Wynik już nieco mniej: dużo jest o Kaczyńskim (oczywiste, skoro dużo jest o PiSie), sporo o Tusku (co się działo z nim w marcu 2017?). Przypominamy sobie słowo wypadek, patrzymy na luty 2017 i linię przeznaczoną dla Beaty Szydło. Mamy odpowiedź.
Roberta Biedronia wybrałem nieprzypadkowo – Gazeta lubi tego polityka, czasem coś o nim napisze.
Jak wygląda parytet płci? Zobaczmy po liczbie użytych słów kobieta oraz mężczyzna (kod znowu analogiczny):
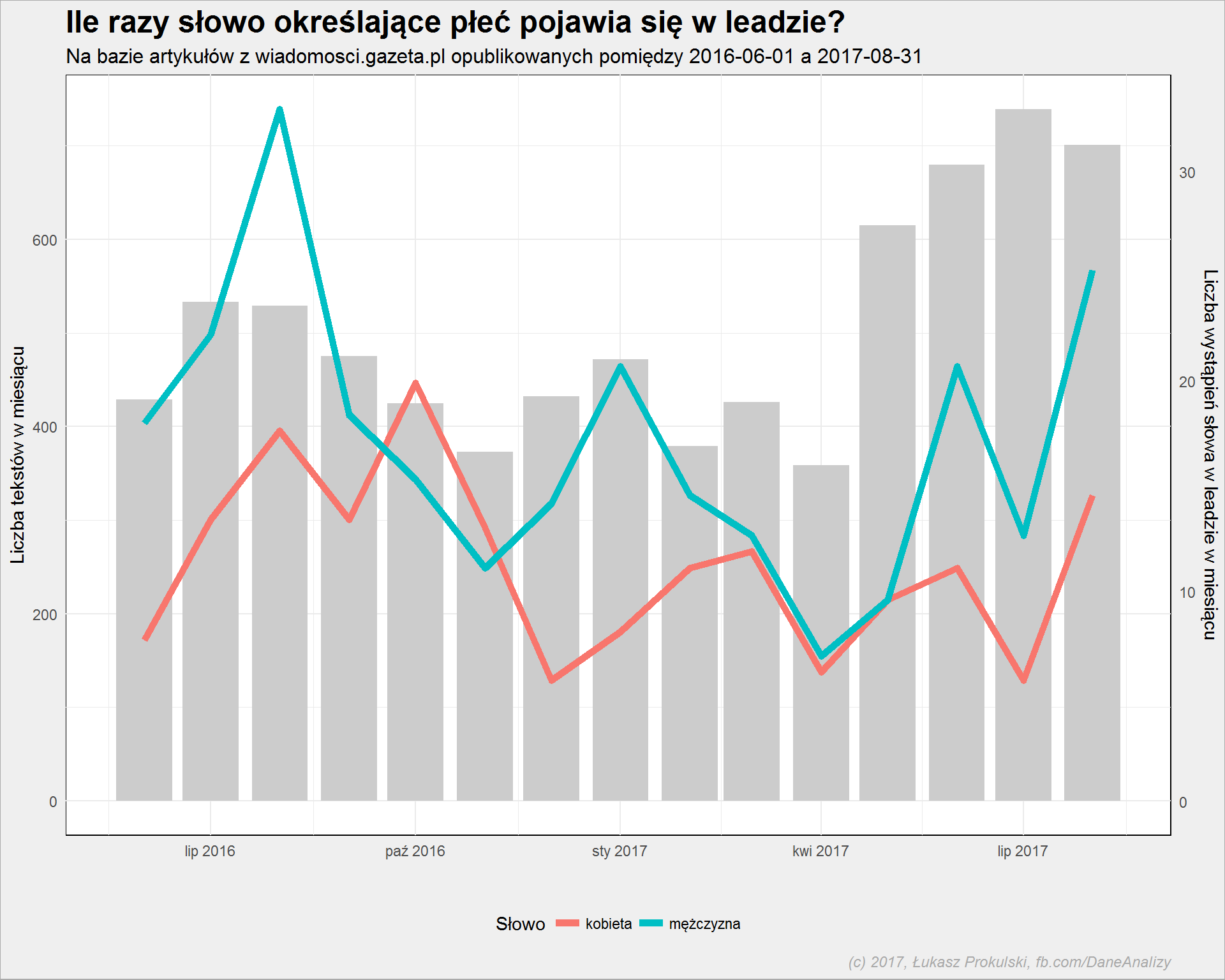
Mężczyźni generują więcej wiadomości. Bo to raczej “mężczyzna został pobity” lub “mężczyzna pobił”. Czasem “znaleziono zwłoki kobiety”.
Treść artykułów
Przygotujmy teraz dane dotyczące treści artykułów. Mechanika ta sama co wcześniej: rozbicie treści na słowa, usunięcie zbędnych słów, lematyzacja i ręczne poprawki. Kodu oszczędzam (operujemy na kolumnie body zamiast lead, całość trwa dłużej – słów jest kilkadziesiąt razy więcej).
W efekcie możemy przygotować chmurkę słów w tresci artykułów (słów zlematyzowanych):
|
1 2 3 4 5 6 7 |
body_word_cloud <- body_words_stem %>% count(word_stem) %>% ungroup() wordcloud(body_word_cloud$word_stem, body_word_cloud$n, max.words = 200, scale = c(2.4, 0.7), colors = RColorBrewer::brewer.pal(9, "Reds")[3:9]) |

Dość podobnie, przynajmniej jeśli chodzi o te najpopularniejsze słowa. Nieco inaczej rozłożone są akcenty.
W tym miejscu można teraz przygotować chmurkę bi-gramów. Ale oszczędzę Wam, bo to mało rozwojowe. Ciekawszy jest:
Topic modeling
Nie mam na to dobrego polskiego określenia, w każdym razie chodzi o statystyczne podejście do odkrywania tematów, których dotyczą badane teksty. Polecam angielski tutorial ze strony opisującej pakiet tidytext, który krok po kroku wykorzystałem tutaj.
Potrzebujemy na początek macierzy wiążącej dokumenty (po naszemu: artykuły) ze słowami, czyli macierzy DTM (Document Term Matrix). To taka wielka macierz mówiąca o tym ile razy dane słowo wystąpiło w danym dokumencie. Użyjemy do tego oczywiście lemmatów:
|
1 2 3 4 5 6 7 |
body_dtm <- body_words_stem %>% count(url, word_stem) %>% ungroup() %>% cast_dtm(url, word_stem, n) # co dostajemy? body_dtm |
|
1 2 3 4 5 |
## <<DocumentTermMatrix (documents: 7548, terms: 35477)>> ## Non-/sparse entries: 1048624/266731772 ## Sparsity : 100% ## Maximal term length: 34 ## Weighting : term frequency (tf) |
W efekcie dostaliśmy macierz 7548 dokumentów i 35477 słów. Spora macierz, bardzo rzadka (dużo zer – tylko niecałe 0.4% elementów to nie zera). Skoro rzadka, to zmniejszymy ją nieco:
|
1 2 3 |
body_dtm <- tm::removeSparseTerms(body_dtm, 0.99) body_dtm |
|
1 2 3 4 5 |
## <<DocumentTermMatrix (documents: 7548, terms: 2841)>> ## Non-/sparse entries: 770350/20673518 ## Sparsity : 96% ## Maximal term length: 17 ## Weighting : term frequency (tf) |
Ubyło słów (pozostało 2841), liczba dokumentów jest bez zmian, teraz około 3.6% elementów to nie zera (dziesięciokrotnie mniejsza rzadkość, jeśli można tak powiedzieć). Na takiej macierzy przeprowadzimy analizę LDA, (czyli Latent Dirichlet allocation) jeden z najpopularniejszych algorytmów w zadaniu wykrywania tematów (o, to może być polski odpowiednik topic modeling). W skrócie chodzi o to, że:
- każdy dokument to zbiór słów z różnych dziedzin (tematów). Na przykład dokument 1 to w 90% słowa z tematu A oraz 10% słów z tematu B. Zaś dokument 2 to 30% słów z tematu A i 70% z tematu B. Można więc wnioskować, że dokument 1 dotyczy tematu A, dokument 2 – tematu B.
- każdy temat to również zbiór słów. Niektóre słowa w danym temacie pojawiają się częściej niż w innych tematach. Dla przykładu słowa pieniądze, biznes, umowa – pojawiają się w tematach o sprawach gospodarczych; a słowa reżyser, rola, aktor, scena – w tematach związanych z filmem. Oczywiście są słowa, które mogą pojawić się w obu tematach – w naszym przykładzie może to być budżet.
- LDA to matematyczne metody połączenia jednego z drugim – dzięki temu znajdziemy słowa charakterystyczne dla tematu, jak i dokumenty pasujące do niego.
|
1 2 3 4 5 |
library(topicmodels) # k to liczba tematów do rozpoznania, tutaj k = 4, bo mamy cztery działy # seed dla powtarzalności wyników body_lda <- LDA(body_dtm, k = 4, control = list(seed = 12345)) |
Trochę to trwało (a trwałoby dłużej jeśli nie zmniejszylibyśmy macierzy DTM), na koniec dostaliśmy dwie tabelki (macierze). Jedna opisuje prawdopodobieństwo przynależności słowa do tematu (tabela beta), druga – prawdopodobieństwo przynależności dokumentu do tematu (tabela gamma).
Najpierw ta pierwsza. Przekładamy (pivotujemy) macierz z wartościami beta na długą tabelę:
|
1 |
body_topics <- tidy(body_lda, matrix = "beta") |
Dla każdego słowa (term) określone zostało prawdopodobieństwo (beta), że słowo należy do tematu (topic).
Znajdźmy po pięć słów z największym prawdopodobieństwem w ramach tematu – te słowa powinny być kluczowe dla kolejnych tematów:
| Temat | Słowo | beta |
|---|---|---|
| 1 | ustawa | 0.0175455 |
| 1 | sąd | 0.0164652 |
| 1 | sejm | 0.0143702 |
| 1 | poseł | 0.0138158 |
| 1 | sędzia | 0.0122840 |
| 2 | policja | 0.0135139 |
| 2 | mężczyzna | 0.0114728 |
| 2 | osoba | 0.0079594 |
| 2 | zostać | 0.0075431 |
| 2 | kobieta | 0.0062239 |
| 3 | polski | 0.0127011 |
| 3 | prezydent | 0.0123784 |
| 3 | polska | 0.0103335 |
| 3 | pis | 0.0100107 |
| 3 | minister | 0.0070602 |
| 4 | mówić | 0.0066777 |
| 4 | swój | 0.0062319 |
| 4 | człowiek | 0.0062065 |
| 4 | polski | 0.0054003 |
| 4 | mieć | 0.0052856 |
Zobaczmy to samo na wykresie, ale dla 15 słów:
|
1 2 3 4 5 6 7 8 9 10 |
body_topics %>% group_by(topic) %>% top_n(15, beta) %>% ungroup() %>% arrange(beta) %>% mutate(term = factor(term, levels = unique(term))) %>% ggplot() + geom_col(aes(term, beta, fill = factor(topic)), color = "gray50", show.legend = FALSE) + facet_wrap(~topic, scales = "free_y") + coord_flip() |
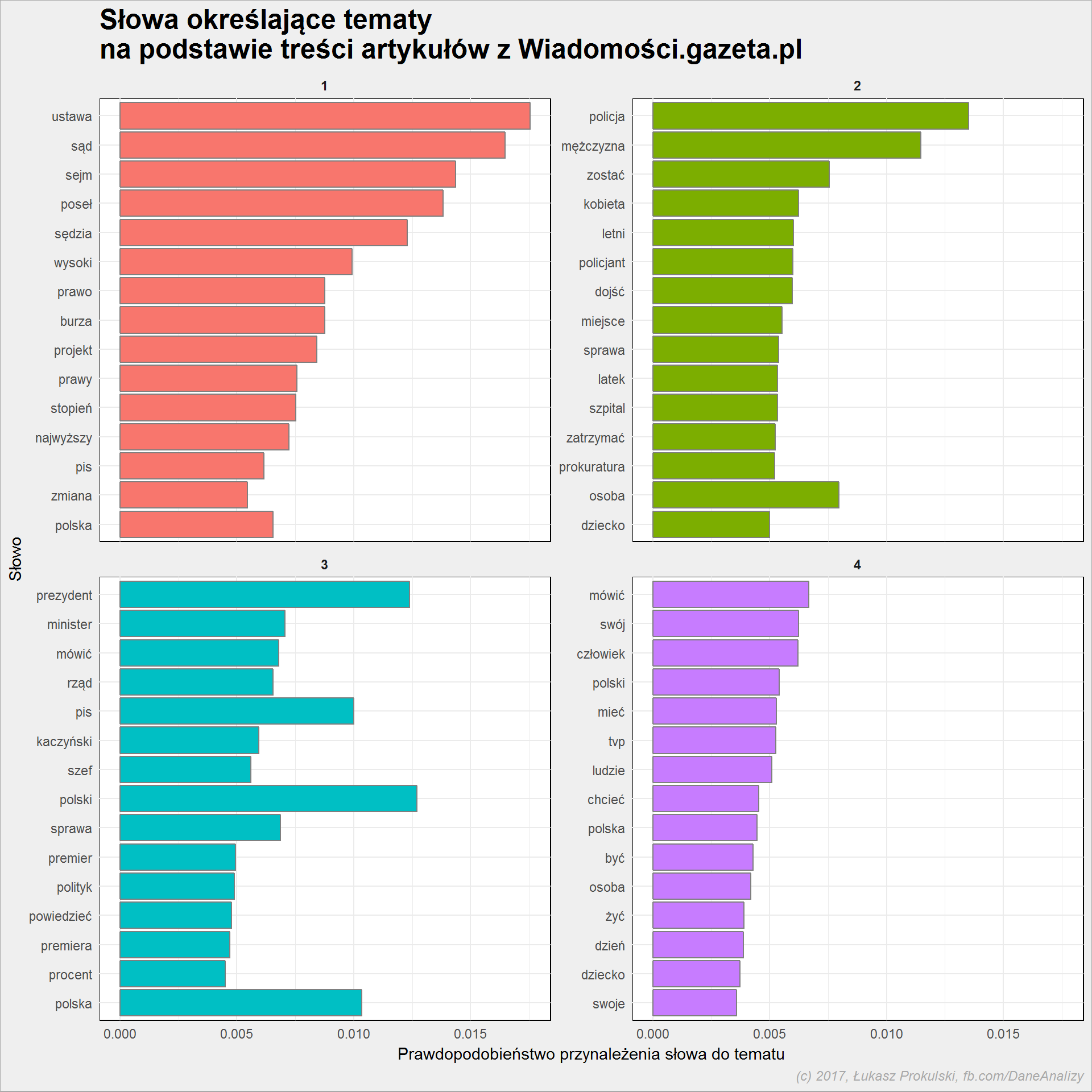
W bardzo dużym uproszczeniu możemy przyjąć, że:
- temat 1 to teksty dotyczące ustaw związanych z tzw. reformą sądownictwa w Polsce
- temat 2 – sprawy związane z policją, przestępstwami, informacjami o wypadkach
- temat 3 – polska polityka i wydarzenia na styku prezydenta, rządu, Kaczyńskiego
- ostatni, czwarty temat: relacje z tego co ktoś powiedział w telewizji (zapewne TVP Info)
Tabelę gamma wykorzystamy do przypisania tematów do tekstów:
|
1 |
articles_gamma <- tidy(body_lda, matrix = "gamma") |
i złączmy te informacje z informacjami o dziale:
|
1 2 3 |
articles_gamma <- left_join(articles_gamma, articles %>% select(url, dzial), by = c("document" = "url")) |
Zobaczmy jak wygląda uśredniona wartość gamma dla poszczególnych działów w ramach poszczególnych tematów:
|
1 2 3 4 5 |
articles_gamma %>% group_by(topic, dzial) %>% summarise(gamma = mean(gamma)) %>% ggplot() + geom_point(aes(dzial, gamma, color = factor(topic)), size = 4) |
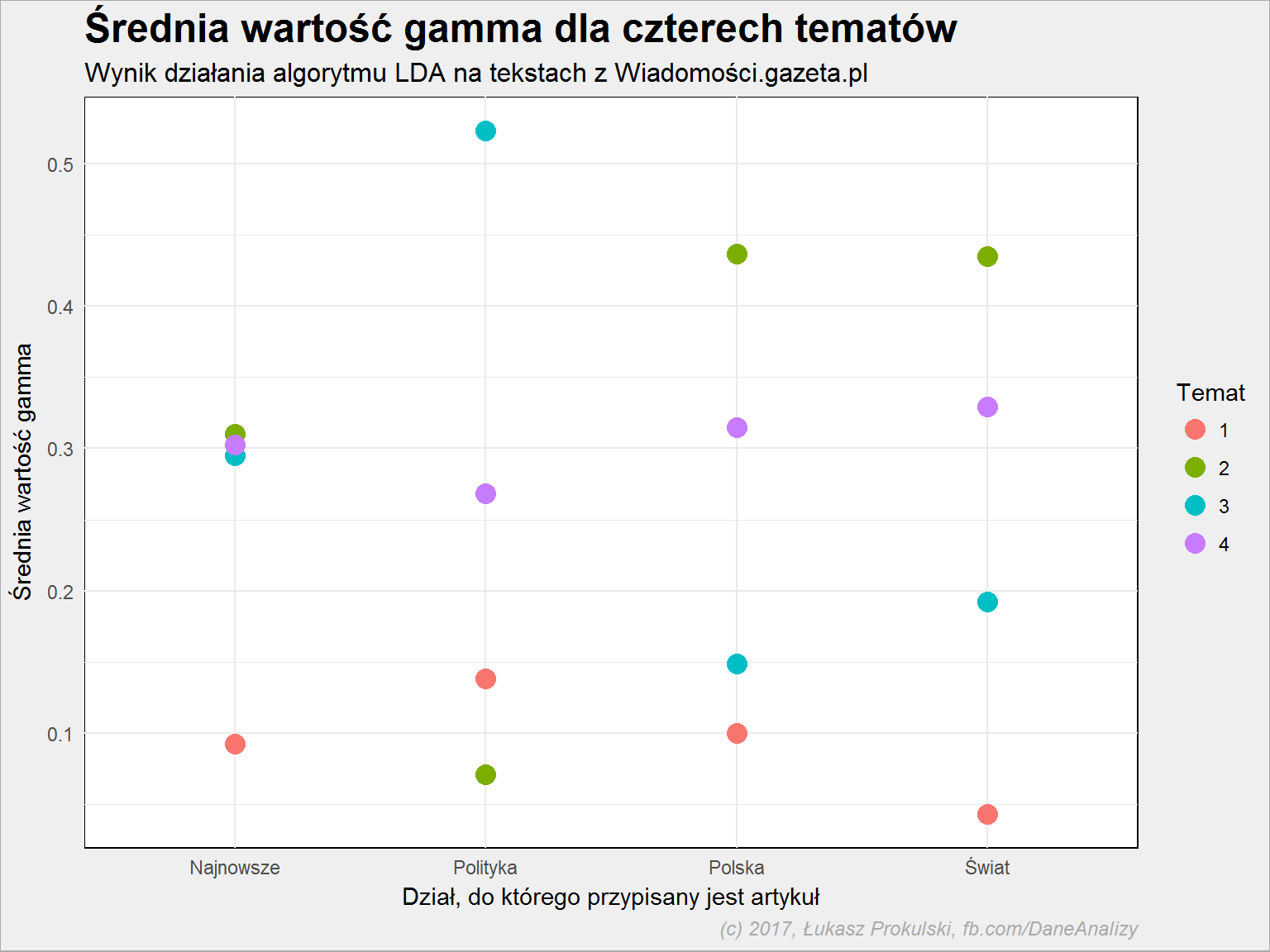
Dla działu “Najnowsze” wartości są stosunkowo bliskie – ma to sens, wpadają tutaj treści z różnych tematów. W “Polityce” wybija się temat 3 (prezydent, pis, minister, polski, rząd, kaczyński), na “Świecie” i w “Polsce” mniej więcej jednakowo – wiodący jest temat 2 (policja, mężczyzna, miejsce, sprawa). Zdecydowanie najsłabsza jest reprezentacja tematu 4 (relacje z wypowiedzi w TV) w dziale “Polityka”.
Niestety nie udało się jasno powiązać tematu z działem publikacji. Nic w tym dziwnego: wszystkie teksty są tekstami informacyjnymi, dotyczą podobnych spraw. Bo czy tekst o omawianych w Sejmie ustawach powodujących dużą liczbę wypowiedzi w telewizji zarówno strony rządowej, prezydenta jak i opozycji powinien być zakwalifikowany do “Polski” czy do “Polityki”? A jeśli są to informacje z ostatniej chwili to pewnie też do “Najnowszych”?
Gdybyśmy użyli tekstów ze zdecydowanie różnych działów (dorzucili na przykład kulturę i gospodarkę do worka) efekty byłyby bardziej widoczne. Próbujcie z innymi źródłami – chociażby danymi ukrytymi pod nazwą AssociatedPress w pakiecie topicmodels.
Do czego to można wykorzystać? Na przykład do automatycznego tagowania tekstów. Weźmy bazę tekstów, przypiszmy im tematy na podstawie treści. Znajdźmy słowa opisujące te tematy. Czyli zróbmy wszystko to, co widzieliście już wyżej. A teraz weźmy nowy tekst. Spróbujmy dla niego określić temat. I na tej podstawie przypiszmy do niego tagi (słowa), które ten temat opisują. Na przykład 10 słów opisujących temat, z których wyrzucimy te, które w tekście się nie pojawiają. Zadziała?
Sentiment czyli wydźwięk emocjonalny
W poprzednich wpisach, kiedy robiłem analizę sentymentu używałem angielskich tekstów i słownika z pakietu tidytext (funkcja get_sentiments()). Ale w jednym z postów bloga Szychta w danych znalazłem link do strony z polskim słownikiem sentymentu, z którego skorzystamy. Swoją drogą Piotr Sobczyk na swoim blogu zrobił analizę sentymentu dla Pana Tadeusza oraz Potopu – warto zerknąć.
|
1 2 3 4 5 6 7 |
pl_words_sentiment <- read_csv2("pl_words.csv") pl_words_sentiment <- pl_words_sentiment[, 2:8] body_words_sentiment <- inner_join(body_words_stem %>% select(word_stem, dzial, year, month, day, wday), pl_words_sentiment, by = c("word_stem" = "word")) |
Każde słowo w słowniku opisane jest wartością punktową dla 5 kategorii: anger, disgust, fear, happiness oraz sadness – im większa wartość tym słowo wyraża silniej emocję danej kategorii. Dodatkowo jednoznacznie określona jest kategoria słowa (wspomniane 5 kategorii plus Neutral oraz Unknown).
Policzmy ile słów (jaki procent wszystkich słów) danej kategorii występuje w danym dniu. Dzięki temu będzie można powiedzieć z pewną dokładnością czy teksty z danego dnia bardziej budziły strach czy też przyprawiały o szczęście. Dodatkowo utrudnieniem jest to, że w słowniku mamy tylko 2902 słów.
Są to oczywiście bardzo delikatne kwestie i bez czytania samych tekstów nie można jednoznacznie wyrokować o trafności obliczeń. Nasz język nie jest językiem prostym, metody obliczeniowe jakie stosujemy w rozważaniach są bardzo uproszczone. Ale zabawa fajna :)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
body_words_sentiment %>% count(year, month, day, category) %>% ungroup() %>% group_by(year, month, day) %>% mutate(p = 100*n/sum(n)) %>% ungroup() %>% filter(!category %in% c("N", "U")) %>% mutate(category = case_when(.$category == "A" ~ "Anger", .$category == "H" ~ "Happiness", .$category == "S" ~ "Sadness", .$category == "D" ~ "Disgust", .$category == "F" ~ "Fear")) %>% ggplot() + geom_col(aes(make_date(year, month, day), p, fill=category), show.legend = FALSE) + facet_wrap(~category, ncol=1) |
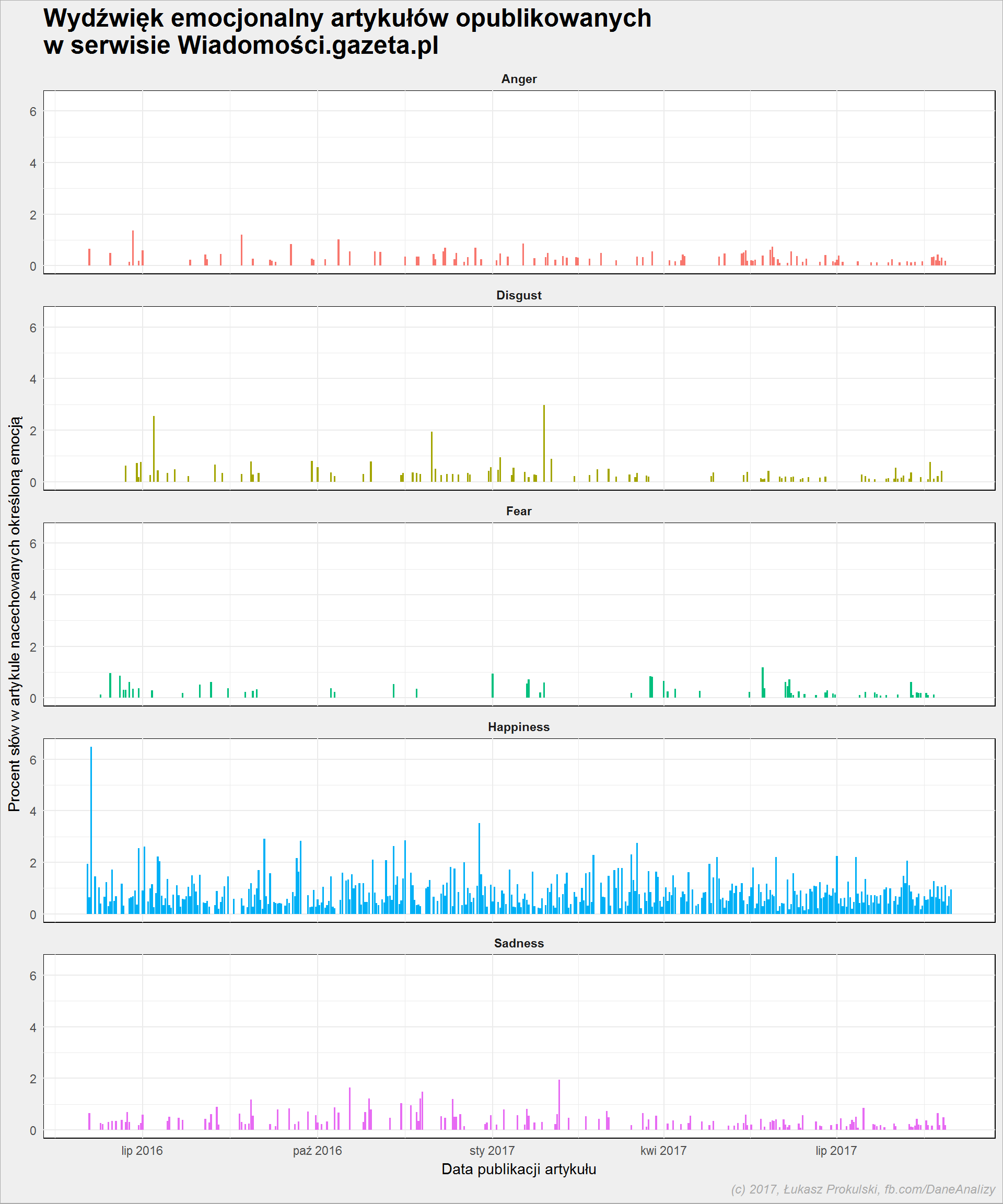
Z powyższego wykresu usunięte zostały kategorie słów “Neutral” i “Unknown”, których jest łącznie około 90% – oznacza to tyle, że słowa używane w tekstach nie budzą większych emocji.
To informacje o słowach (ich liczbie i udziale w treści), a jak wygląda wartość wydźwięku w czasie? Czyli czy teksty zawierały słowa mniej czy bardziej nasycone emocjami? Jest różnica w natężeniu emocji pomiędzy “kochać” i “lubić” – na poniższym wykresie linia dla “kochać” będzie wyżej, a na wykresie wyżej – sztuka to sztuka (jak powiedział Boguś Linda w Krollu).
|
1 2 3 4 5 6 7 8 |
body_words_sentiment %>% select(-word_stem, -category, -dzial, -wday) %>% gather(key = sent_category, value = score, mean.Happiness, mean.Anger, mean.Sadness, mean.Fear, mean.Disgust) %>% ggplot() + geom_smooth(aes(make_date(year, month, day), score, color = sent_category), show.legend = FALSE) + facet_wrap(~sent_category, scale = "free_y", ncol=1) |
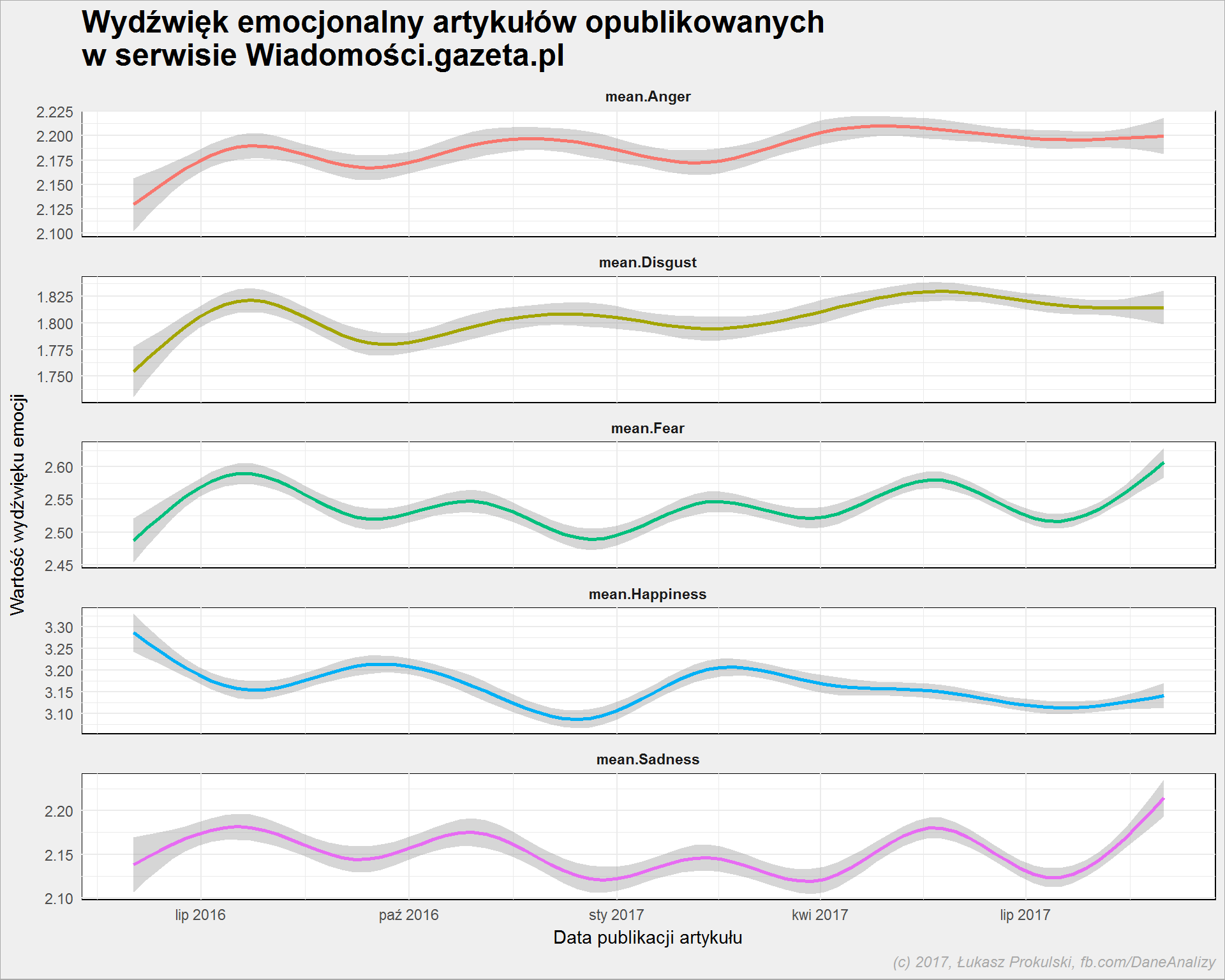
Wahania są bardzo niskie (zwróćcie uwagę na skale osi Y na każdym z wykresów). Z grubych obserwacji można powiedzieć tylko tyle, że od kwietnia 2017 mamy coraz mniej szczęśliwe słowa a coraz więcej smutku i strachu.
Policzmy teraz procent słów danej kategorii emocjonalnej w poszczególnych działach. To trochę takie badanie jak z rozpoznawaniem tematów – nie ma większego sensu, w końcu teksty są podobnej treści, ale może jest ciekawe? Kod w każdym razie jest do zastosowania dla innych tekstach.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
body_words_sentiment %>% count(dzial, category) %>% ungroup() %>% group_by(dzial) %>% mutate(p = 100*n/sum(n)) %>% ungroup() %>% filter(!category %in% c("N", "U")) %>% mutate(category = case_when(.$category == "A" ~ "Anger", .$category == "H" ~ "Happiness", .$category == "S" ~ "Sadness", .$category == "D" ~ "Disgust", .$category == "F" ~ "Fear")) %>% ggplot() + geom_tile(aes(dzial, category, fill=p), color = "black") + geom_text(aes(dzial, category, label=sprintf("%.2f", p)), color = "black") + scale_fill_gradient(low="lightgreen", high="red") + theme(legend.position = "bottom") |
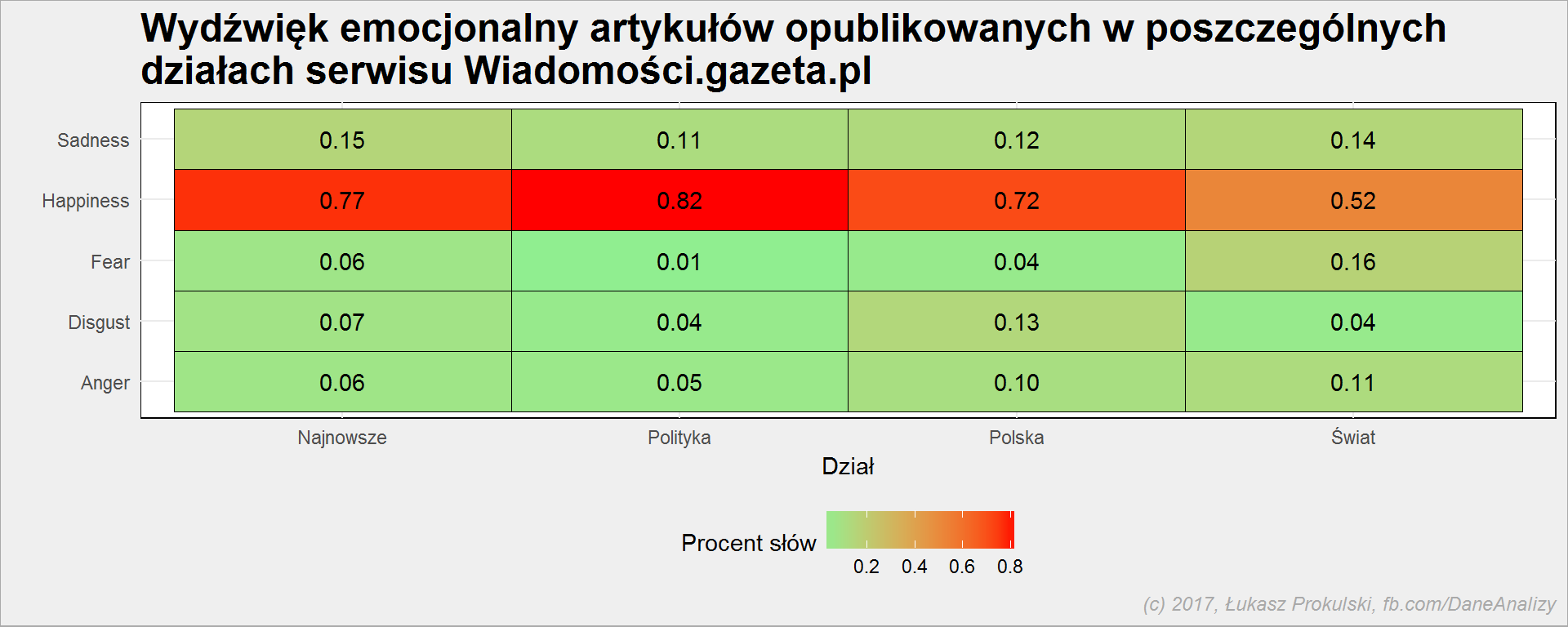
Już wcześniej wyszło nam, że najwięcej słów (po odrzuceniu Neutral i Unknown) należy do kategorii Happiness. Tutaj widzimy, że treści z działu “Polityka” są nieco bardziej nasycone szczęściem niż z działu “Świat”, a dokładnie odwrotnie jest jeśli chodzi o Fear. Bo doniesienia ze świata to informacje o zamachach, których nie ma w polskiej polityce? Być może. Za to z działu “Polska” pochodzi więcej treści ze słowami przypisanymi do kategorii obrzydzenie.
Na koniec zobaczmy jaki jest wydźwięk tekstów w zależności od słów użytych w leadzie. Jakie są emocje kiedy w leadzie pojawia się PiS ja jakie kiedy jest tam inna partia?
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
# lista artykułów z wybranymi słowami w lidzie art_list <- lead_words %>% filter(word %in% c("pis", "platforma", "nowoczesna", "kaczyński", "tusk", "duda", "szydło")) %>% select(url, word) %>% distinct() # sentyment dla słow z treści # poprzenio nie było kolumny url - stąd jeszcze raz łączymy słowa ze słownikiem sentymentu body_sentiment <- inner_join(body_words_stem %>% select(word_stem, year, month, day, url), pl_words_sentiment, by = c("word_stem" = "word")) %>% # łączymy dane o sentymencie z listą artykułów i słowami z leadu left_join(art_list, by = c("url" = "url")) %>% filter(!is.na(word)) %>% # pivot tabelki gather(key = sent_category, value = score, mean.Happiness, mean.Anger, mean.Sadness, mean.Fear, mean.Disgust) |
wykres:
|
1 2 3 4 |
body_sentiment %>% ggplot() + geom_boxplot(aes(sent_category, score, color = word)) + theme(legend.position = "bottom") |
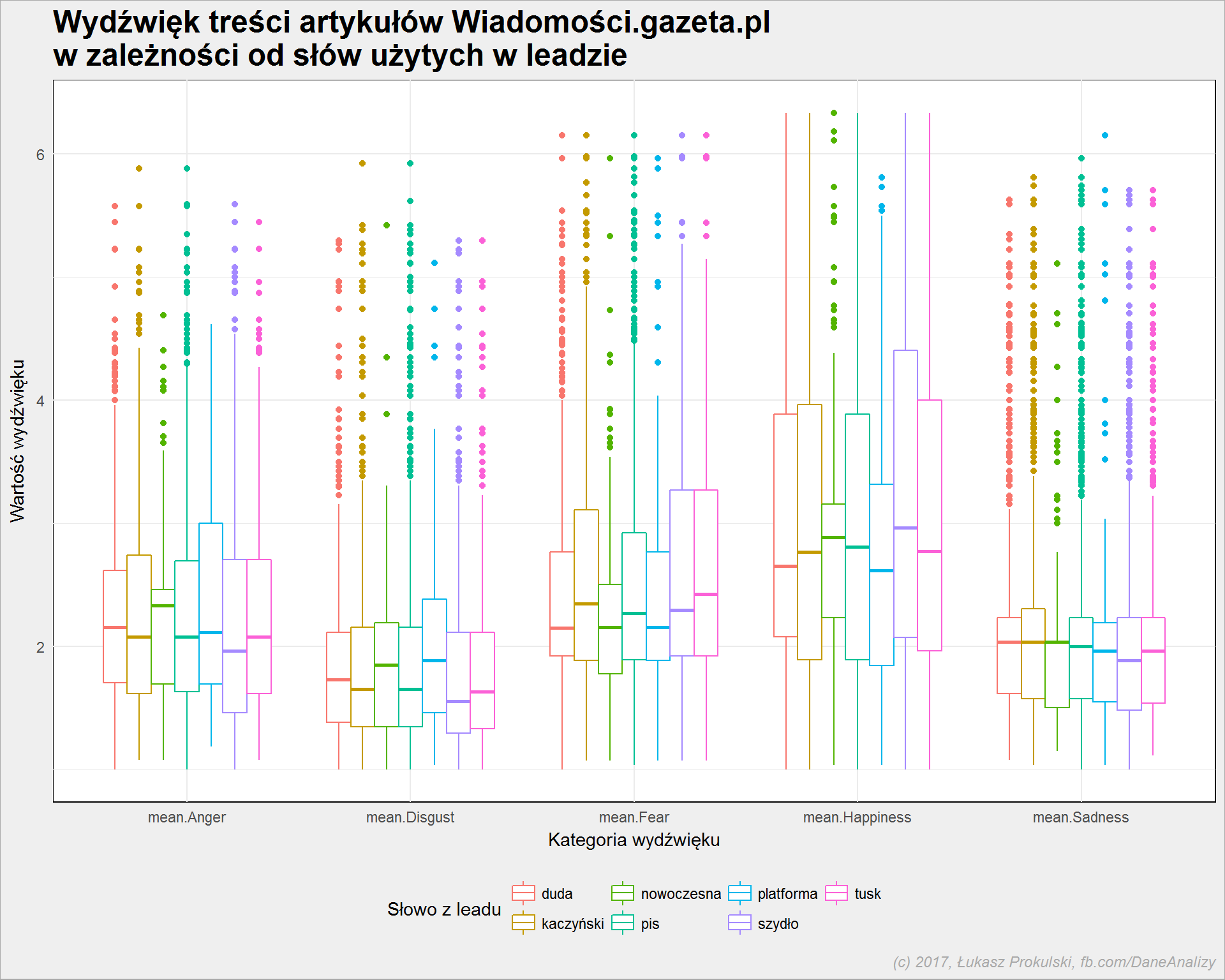
Widać, że w kategorii “Anger” największą medianę (kreska w środku boksu) mają teksty z Nowoczesną wymienioną w leadzie, najmniejszą – z Beatą Szydło. I teraz co to oznacza? Albo to, że o Nowoczesnej Gazeta.pl pisze używając słów wzbudzających złość albo Nowoczesna jest przyczynkiem do napisania np. o PiSie w słowach wzbudzających takie a nie inne emocje. Bez czytania i rozumienia tekstu nie da się tego określić.
Słowa uważane za powodujące obrzydzenie częściej występują w tekstach, gdzie w leadzie wymieniona jest Nowoczesna i Platforma. Powód ten sam co wyżej? Nie wiadomo i proszę nie upraszczać ewentualnie powołując się na mój tekst. To wcale nie znaczy, że Gazeta.pl z obrzydzeniem pisze o PO i .N! Może tak być ale nie musi, co więcej – może być wręcz odwrotnie. Wystarczy znak zapytania na końcu zdania zamiast kropki.
Albo taki przykład: weźmy kategorię Fear i Donalda Tuska. Napisanie, że PiS chce, aby Donald Tusk trafił do więzienia w treści artykułu opatrzonego leadem Tusk wezwany do prokuratury oznacza, że:
- tekst trafi do worka tekstów powiązanych (leadem) z Tuskiem
- wydźwięk tekstu będzie wzbudzał strach poprzez słowo więzienie
Ale czy to oznacza, że Tusk wzbudza strach? Zastanówcie się sami. To takie ćwiczenie z czytania ze zrozumieniem, na poziomie pierwszych klas podstawówki.
Czy dla tych wybranych słów z leadu zmienił się wydźwięk tekstów w czasie?
|
1 2 3 4 5 6 7 |
body_sentiment %>% filter(word != "platforma") %>% # za mało jest tekstów, wychodzi pusty wykres ggplot() + geom_smooth(aes(make_date(year, month, day), score, color = sent_category), se = FALSE) + facet_wrap(~word, ncol = 3) + theme(legend.position = "bottom") |
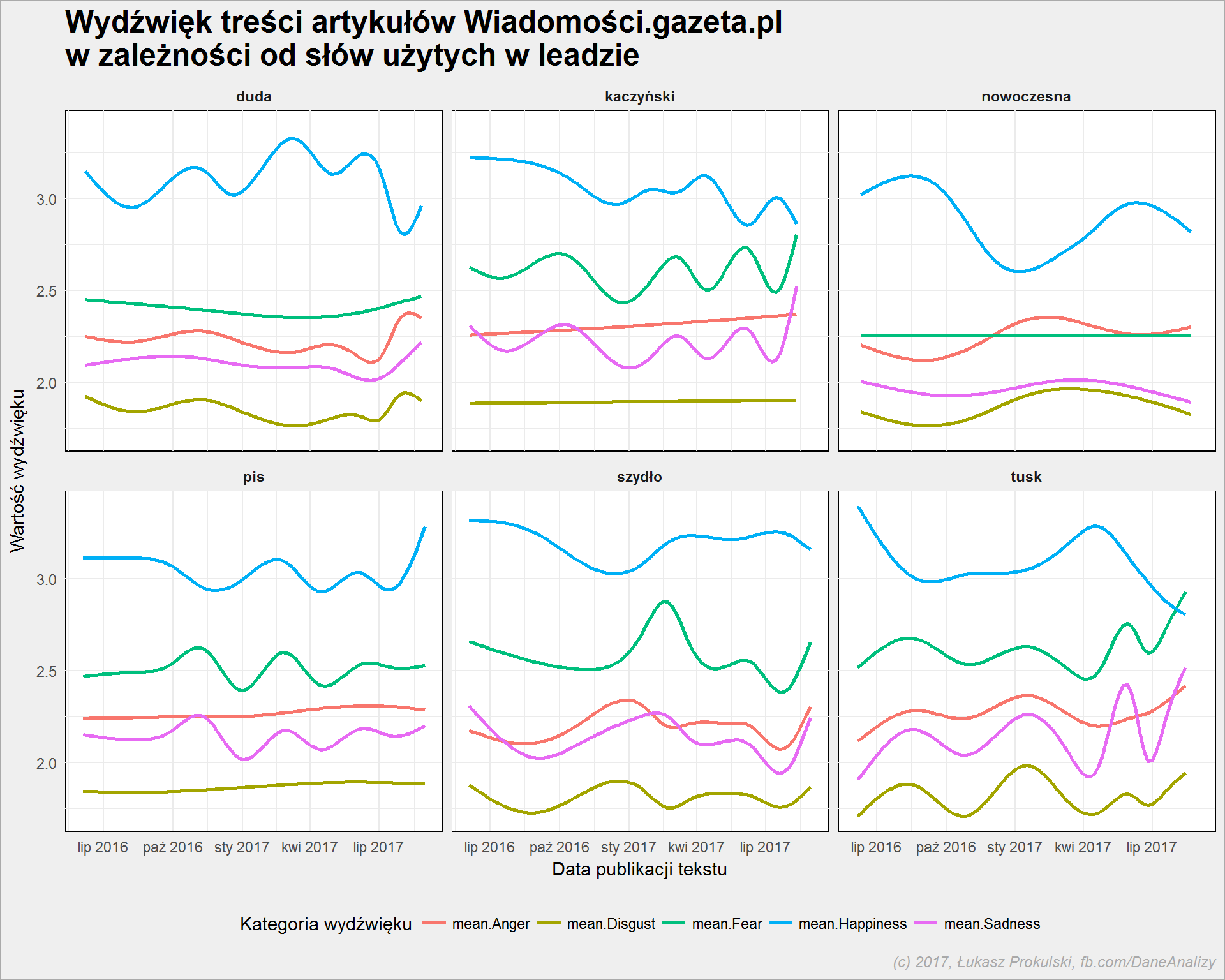
Przykład Tuska może znaleźć tutaj potwierdzenie: spada wartość wydźwięku w kategorii szczęście, wzrasta w kategorii strach. Jestem mocno przekonany (obserwując polskie media i ich sympatie polityczne), że właśnie sprawy kolejnych przesłuchań i wezwań do prokuratury są przyczyną takich zmian.
Ciekawy jest wzrost wartości Fear dla Beaty Szydło w początku 2017 roku – pamiętacie wypadek w lutym? Czy jakoś to się ze sobą klei?
Podobną analizę można przeprowadzić dla innych serwisów. Ciekawe będzie zestawienie informacji z prawej strony (na przykład Niezależna lub TV Republika) z lewą stroną (bardziej Gazeta Wyborcza niż Gazeta.pl), w szczególności w analizie wydźwięku dla poszczególnych słów. Gdyby jeszcze udało się dopasować teksty mówiące o tym samym wydarzeniu w rożnych mediach i to porównać… Powodzenia!
Super wpis, jak zawsze. Fajnie, że dałeś link do polskiego słownika sentiment analysis. Mam nadzieję, że kiedyś się przyda :)
Za słownik trzeba podziękować Piotrowi z Szychta w danych.pl – tam to wypatrzyłem.
Fantastyczny wpis do nauki.
Brakuje chyba kawałka kodu.
Chciałem go przejść i brakuje sekcji, która tworzy „body_words_stem”. Czy mógłbym prosić o ten kawałek? Z góry dzięki.
Brakuje, bo to do nauki i samodzielnego szukania rozwiązań. A kod jest analogiczny do tego samego dla leadów – połączenie tabeli pojedynczych słów ze słownikiem stemowania.
Taki problem zaistniał.
> articles %
+
+ rowwise() %>%
+
+ do(get_article(.$link)) %>%
+
+ bind_rows() %>%
+ ungroup()
|============ | 21% ~8 m remaining
Show Traceback
Rerun with Debug
Error in open.connection(x, „rb”) : HTTP error 500.
Jak widać z komunikatu – błąd 500 przy pobieraniu danych ze strony. Rzuć okiem na wpis – tam jest obejście przez funkcję safety(). Należy odpowiednio zmodyfikować kod w get_article().
Dziękuję za odpowiedź, idę zatem zmagać się dalej z kodem! Swoją drogą świetny blog :)
Wlasnie szukam linku do polimorfologika w pliku. Trafilem na ten wpis a tu link do mojego repo : ) Dzieki Lukasz za wpis