Wyniki ankiety to jedno, a drugie to narzędzie do ich uzyskania i przedstawienia. Łączymy przyjemne z pożytecznym.
Ankietę przygotowałem korzystając z Google Forms – to jedna z najwygodniejszych opcji (systemów do ankiet jest wiele), szczególnie jeśli chcemy mieć od razu dane (odpowiedzi) w postaci tabeli (w tym przypadku arkusza Google Sheets). Kiedy ankieta jeszcze trwała przygotowałem poniższe skrypty i na bieżąco mogłem śledzić zarówno liczbę oddanych głosów jak i rozkład poszczególnych odpowiedzi. To bardzo przydatne jeśli z jakiegoś powodu chcielibyście wiedzieć jak wpływają różne akcje zarówno na wypełnienie (liczbę odpowiedzi) jak i same odpowiedzi.
Jeśli interesują Cię tylko wyniki ankiety, a nie sposób ich wyciągnięcia i pokazania – przejdź do odpowiedniej sekcji.
Jak pobrać dane z Google Sheets?
Do uzyskania surowych danych z arkusza Google wykorzystamy pakiet googlesheets (jeśli go nie masz – zainstaluj przez install.packages("googlesheets").
|
1 2 3 |
library(tidyverse) library(forcats) # porządkowanie faktorów library(googlesheets) |
Jak używać tego pakietu można przeczytać w przykładach (vignettes), a te kilka linijek kodu poniżej powinno wystarczyć na początek.
Na początek pobierzemy listę dostępnych na naszym koncie skoroszytów:
|
1 |
my_sheets <- gs_ls() |
Przy pierwszym wykonaniu gs_ls() zostaniemy przekierowani do przeglądarki i poproszeni o zalogowanie się do konta Google. W końcu musimy wiedzieć z którego konta arkusze przeglądamy. Odpowiednie uprawnienia zostają zapisane na przyszłość w pliku .httr-oauth i na przyszłość nie będziemy proszeni o logowanie. Pamiętajcie, że ten plik jest bardzo cenny i w żadnym przypadku nie wrzucajcie go do sieci – na przykład na GitHuba (na szczęście RStudio automatycznie doda go do .gitignore).
Tabela my_sheets zawiera kilka informacji:
- tytuł skoroszytu
- autora
- uprawnienia (zapis/odczyt)
- wersję
- czas ostatniej zmiany
- linki do skoroszytu w kilku formach
My potrzebujemy tylko nazwy – wybieramy więc konkretny arkusz:
|
1 |
gsheet <- gs_title("Dane i Analizy (Responses)") |
Obiekt gsheet zawiera jeszcze więcej danych – poza już wymienionymi między innymi liczbę arkuszy n_ws. Interesuje nas pobranie danych z konkretnego arkusza:
|
1 |
dane <- gs_read(gsheet) |
W danych z formularza mamy tylko jeden arkusz, więc domyślne ws = 1 nam wystarczy. Gdyby dane były rozsiane po kilku arkuszach parametrem ws możemy wskazać odpowiedni. Poeksperymentujcie.
Mamy dane, robimy z nimi co chcemy :)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
# nazwanie kolumn w wygodniejszy na później sposób colnames(dane) <- c("timestamp", "Wiek", "Plec", "Wojewodztwo", "Zajecie", "FP_skad_wiesz", "FP_jak_czesto_zagladasz", "FP_Zainteresowania", "FP_jak_czesto_posty", "FP_komentowanie", "B_Zainteresowania", "Python_R", "B_zagadnienia", "B_najlepszy_wpis", "B_niepodoba") # data do przyjaznej postaci library(lubridate) dane$timestamp <- mdy_hms(dane$timestamp) # faktoryzacja kolumn dane$Wiek <- factor(dane$Wiek, levels = c("poniżej 18 lat", "18-25 lat", "25-35 lat", "35-50 lat", "ponad 50 lat")) dane$Wiek <- fct_explicit_na(dane$Wiek, na_level = "(brak)") dane$Plec <- as.factor(dane$Plec) dane$Wojewodztwo <- as.factor(dane$Wojewodztwo) |
Zanim przystąpimy do omówienia wyników kilka funkcji pomocniczych. Omówienie (poniżej) będzie polegało na przedstawieniu albo wykresów albo tabelek. Albo dla jednego wymiaru (na przykład z pytania o płeć), albo jako przecięcie dwóch (na przykład płeć versus wiek). Dzięki tym funkcją narysowanie wykresu sprowadzi się do jednej linijki kodu zamiast powielania tego samego co chwilę.
Funkcje wykorzystują elementu z pakietu dplyr dostępne od wersji 0.7 – to ważne. W starszych wersjach nie zadziałają. Funkcje te to enquo() i !! przydatne do przekazywania parametrów będącymi nazwami kolumn.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 |
# funkcja zwraca procenty dla par kolumn GetPairs <- function(data, var1, var2) { var1 <- enquo(var1) var2 <- enquo(var2) data %>% rename(label1 = !!var1, label2 = !!var2) %>% group_by(label1, label2) %>% summarise(n = n()) %>% ungroup() %>% mutate(p = 100 * n/sum(n)) %>% arrange(desc(p)) } # funkcja zwraca wykres ggplot z heatmapą dla podanych kolumn PlotPairs <- function(data, var1, var2) { var1 <- enquo(var1) var2 <- enquo(var2) GetPairs(dane, !!var1, !!var2) %>% ggplot() + geom_tile(aes(label1, label2, fill = p), color = "gray50") + geom_text(aes(label1, label2, label = sprintf("%.1f%%", p))) } # funkcja zwraca uporządkowaną listę GetBars <- function(data, var1) { var1 <- enquo(var1) data %>% rename(label = !!var1) %>% mutate(label = as.character(label)) %>% count(label) %>% ungroup() %>% mutate(p = 100 * n/sum(n)) %>% arrange(p) %>% mutate(label = fct_inorder(label)) } # funkcja zwraca wykres kolumnowy ggplot dla podanej kolumny PlotBars <- function(data, var1) { var1 <- enquo(var1) GetBars(dane, !!var1) %>% ggplot() + geom_col(aes(label, p), fill = "lightgreen", color = "gray50") + coord_flip() } |
Mamy wszystko gotowe, zatem do dzieła!
Ankieta – wyniki
Udało się zebrać 117 odpowiedzi – to dość dużo. W obecnej chwili jest około 560 fanów fanpage’a Dane i Analizy gdzie głównie promowałem ankietę.
Dla porównania w ankiecie organizowanej przez Krzysztofa Sopylę wzięło udział 115 osób, a mam wrażenie że zasięg był zdecydowanie większy (posty sponsorowane na FB, linki na grupie Data Science PL – ponad 2.6 tys. członków grupy, czy też w podcaście Data Science po polsku – około 515 fanów). Jej wyniki znajdziecie tutaj. Swoją drogą – Krzysztof udostępnił link do żywych danych, możecie na nich przećwiczyć szukanie przekrojów.
Wyniki zbierałem przez około dwa tygodnie – od 2017-10-03 do 2017-10-17. Dłużej nie było sensu, bo…
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
dane %>% mutate(day = date(timestamp)) %>% count(day) %>% ungroup() %>% arrange(day) %>% mutate(procent = 100 * n/sum(n)) %>% mutate(cum_procent = cumsum(procent)) %>% ggplot() + geom_col(aes(day, procent), fill = "lightgreen", color = "gray50") + geom_label(aes(day, procent, label = sprintf("%.1f%%", procent))) + geom_line(aes(day, cum_procent), color = "red") + geom_point(aes(day, cum_procent), size = 2, color = "red") + geom_text(aes(day, cum_procent, label = sprintf("%.1f%%", cum_procent)), vjust = -1) + scale_x_date(date_breaks = "1 day", date_labels = "%d.%m") + labs(title = "Udział odpowiedzi na ankietę w kolejnych dniach", x = "") |
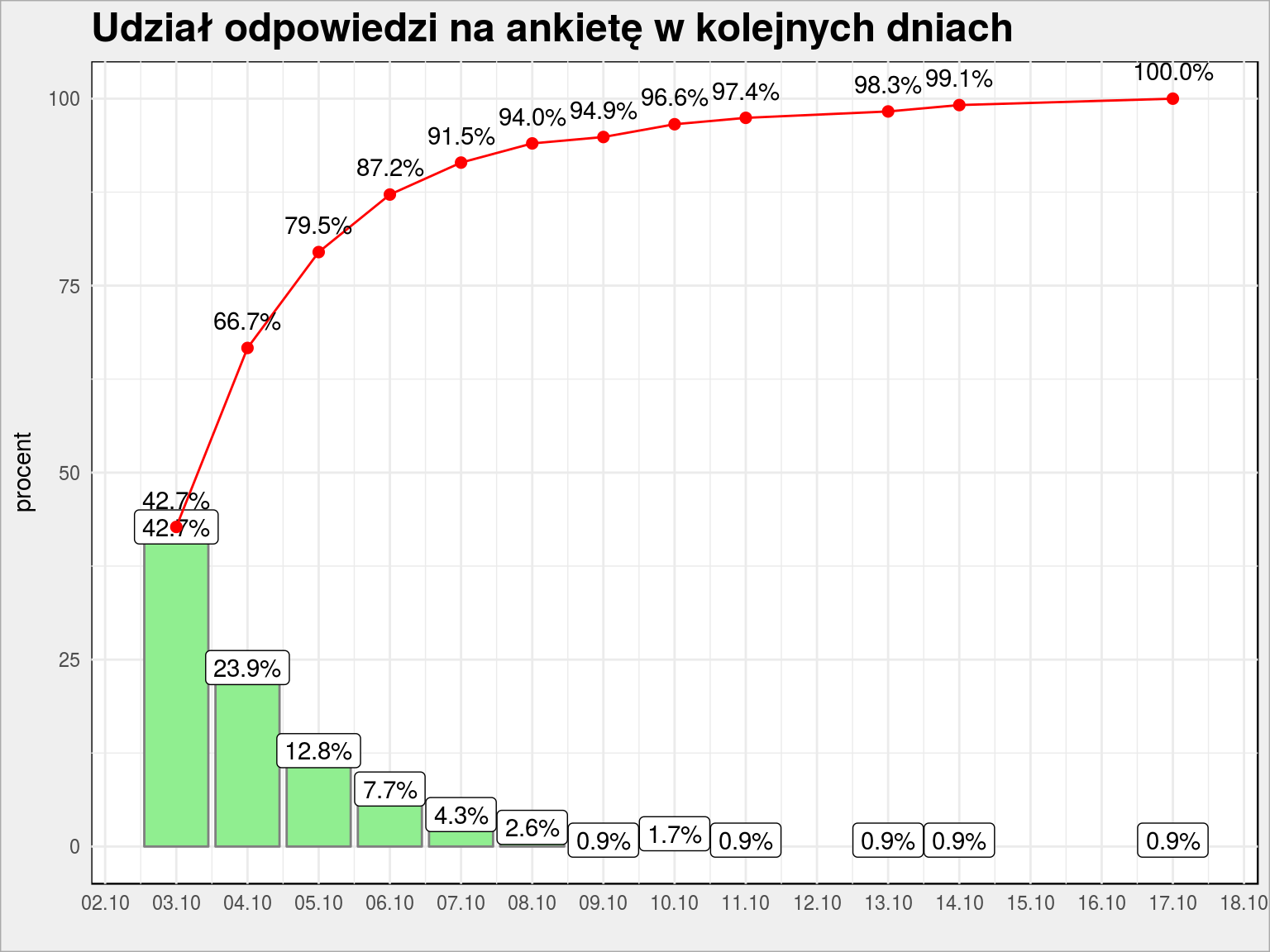
…w sumie po tygodniu było prawie 96% zgromadzonych odpowiedzi (ta czerwona linia).
Z ciekawości zobaczmy jeszcze w jakich godzinach udzielaliście odpowiedzi:
|
1 2 3 4 5 6 7 8 9 |
dane %>% mutate(hour = hour(timestamp)) %>% count(hour) %>% ungroup() %>% mutate(n = 100 * n/sum(n)) %>% ggplot() + geom_col(aes(hour, n), fill = "lightgreen", color = "gray50") + scale_x_continuous(breaks = 1:24) + labs(title = "Godziny, w których udzielano odpowiedzi", x = "", y = "Procent odpowiedzi") |
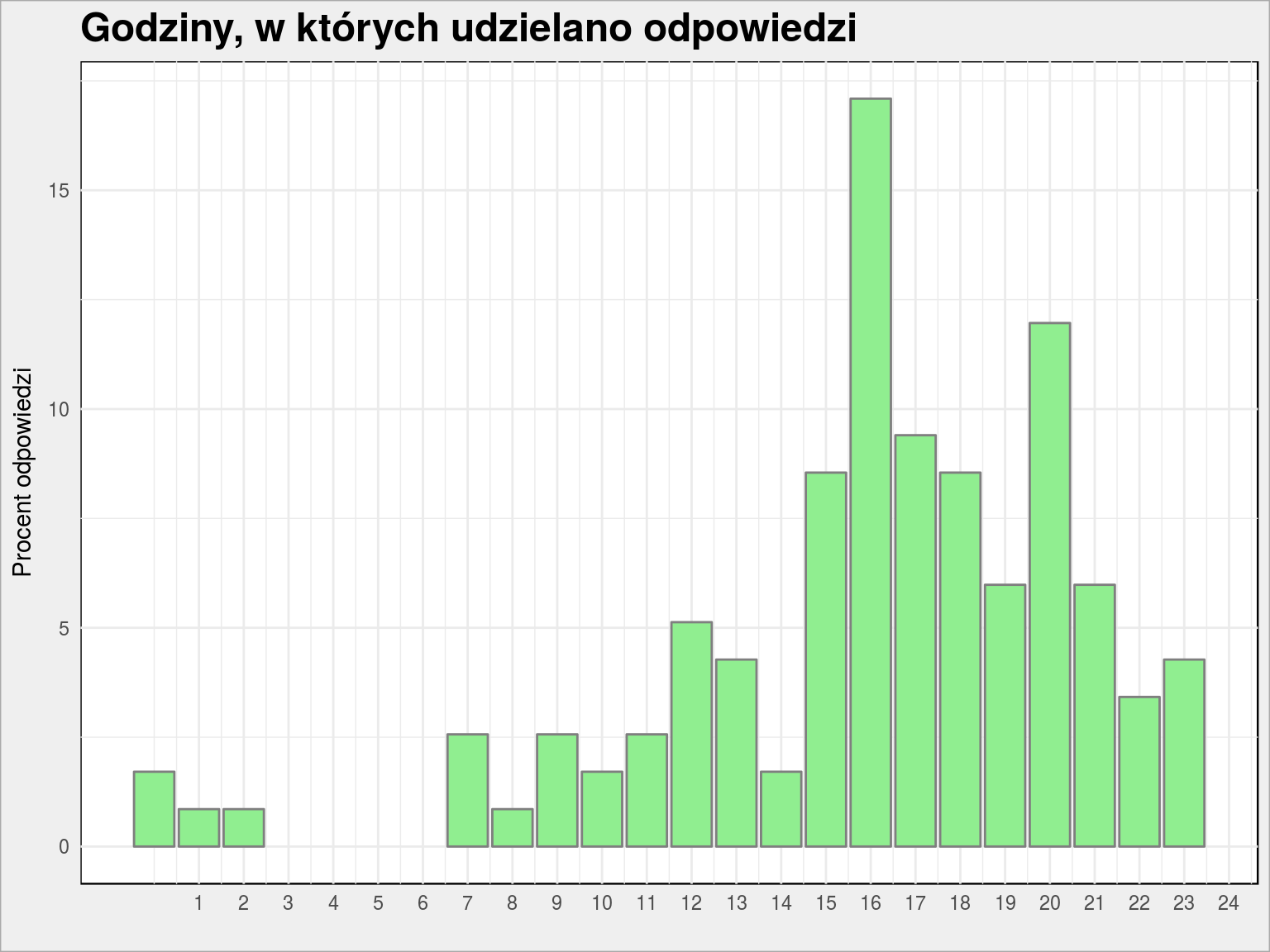
Dwa piki o 16 i 20 to wynik dwóch postów na Dane i Analizy nawołujących do wypełnienia ankietki. W sumie reagujecie dość szybko na posty. Kiedyś to zbadamy.
Przejdźmy do ciekawszych wyników: chłopcy czy dziewczynki?
|
1 2 3 |
PlotBars(dane, Plec) + geom_label(aes(label, p, label = sprintf("%.1f%%", p))) + labs(title = "Płeć", x = "", y = "% wypełnionych ankiet") |
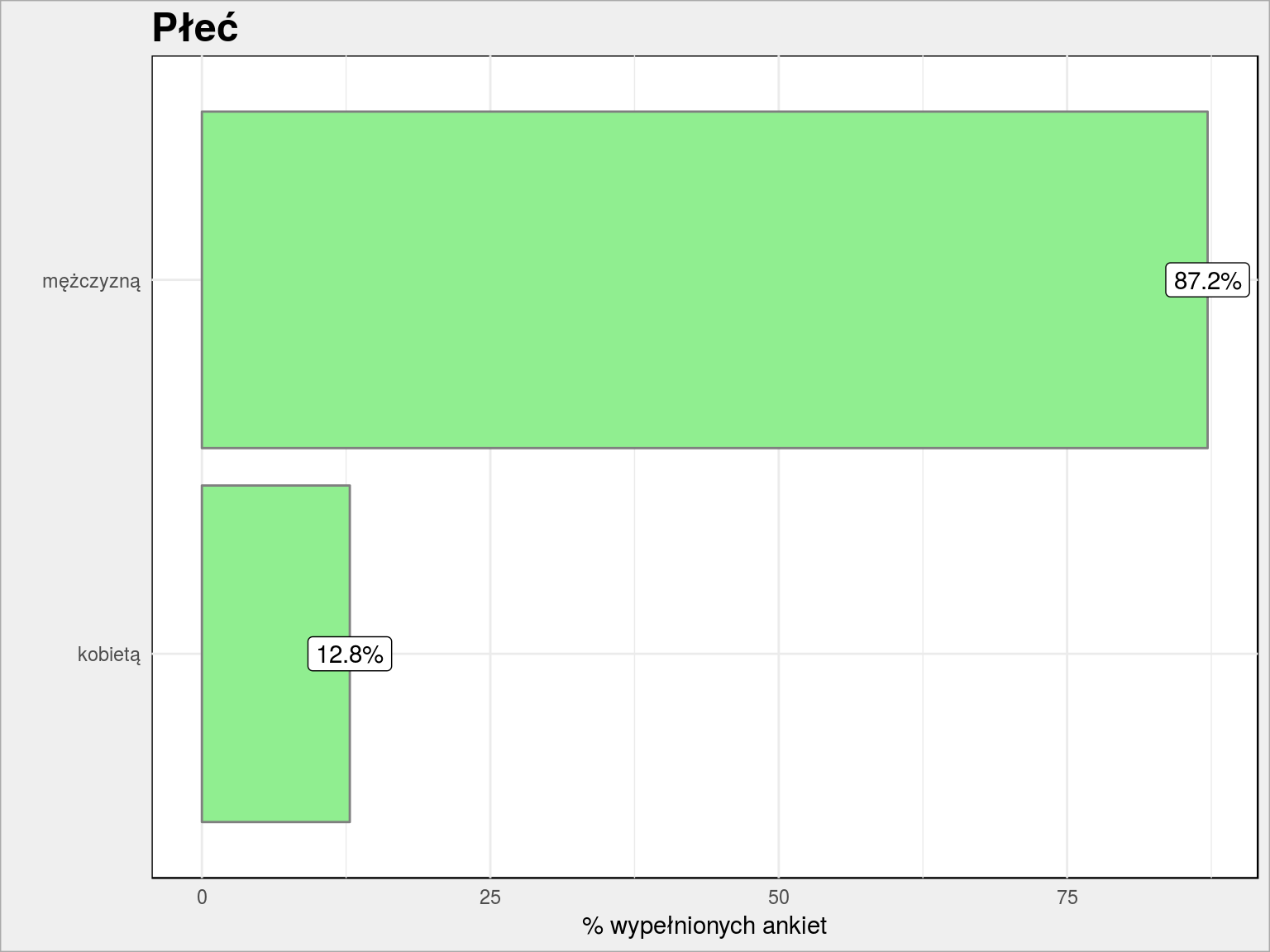
87% z Was to panowie. Jest to wynik, którego się spodziewałem.
w jakim wieku jesteście?
|
1 2 3 |
PlotBars(dane, Wiek) + geom_label(aes(label, p, label = sprintf("%.1f%%", p))) + labs(title = "Wiek", x = "", y = "% wypełnionych ankiet") |
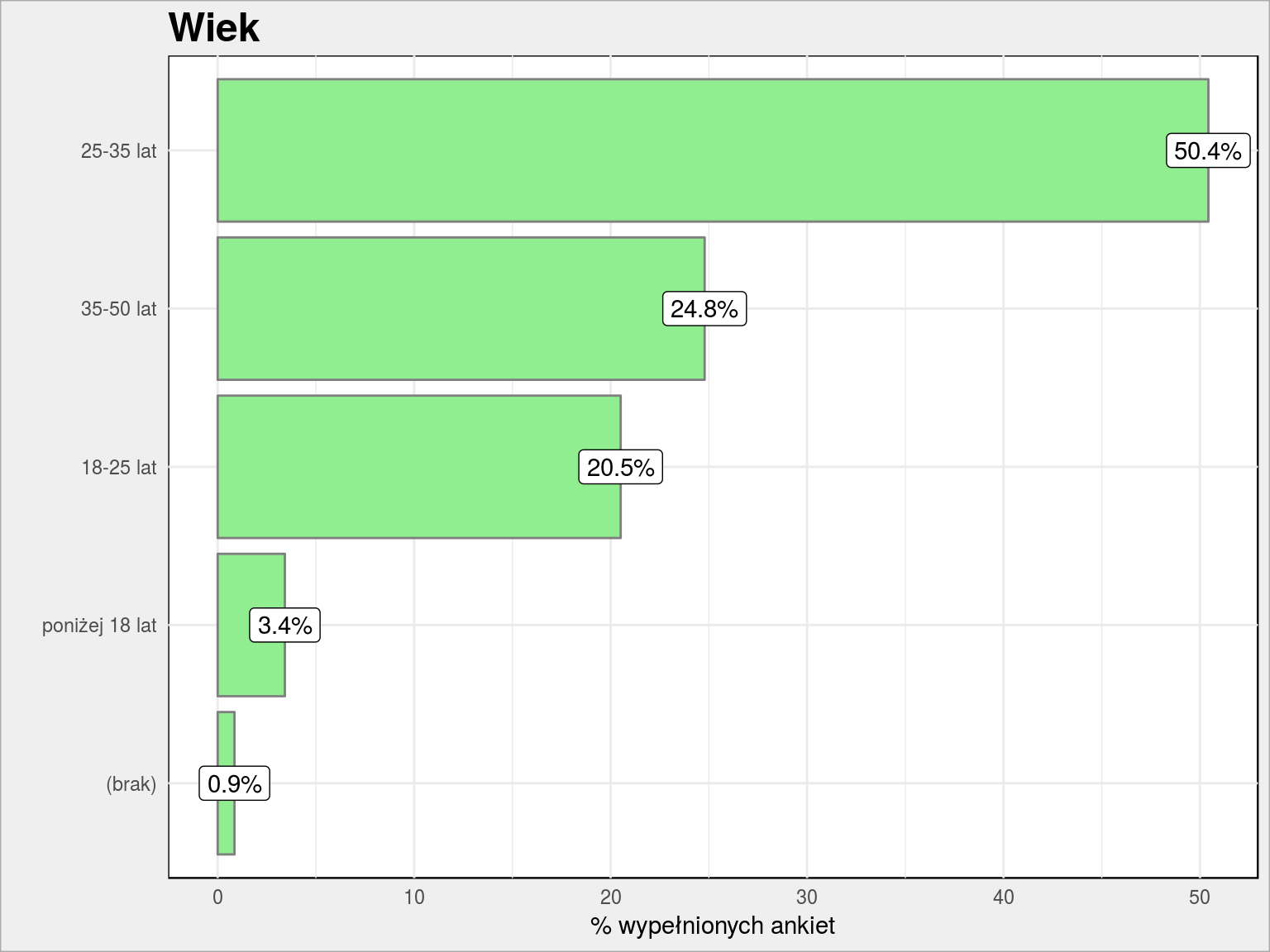
Połowa to osoby w wieku 25-35 lat. Przedziały odpowiedzi dobrałem specjalnie. Chodziło mi o znalezienie osób przed studiami, w ich trakcie i po studiach (25-35 lat – tych jak widać jest najwięcej) a także starszych, głównie albo doświadczonych badaczy danych albo managerów. Cieszy mnie, że jest wśród Was w sumie 3/4 osób w wieku wskazującym na ukończone studia. No i prawie 100% pełnoletnich – mogę więc przeklinać w postach i pisać o seksie albo alkoholu.
Płeć versus wiek
To pytanie miało na celu weryfikację czy rozkład wieku pań i panów jest podobny. Jest podobny:
|
1 2 3 4 |
PlotPairs(dane, Plec, Wiek)+ labs(x = "Płeć", y = "Wiek") + scale_fill_gradient(low = "orange", high = "yellow") + theme(legend.position = "none") |
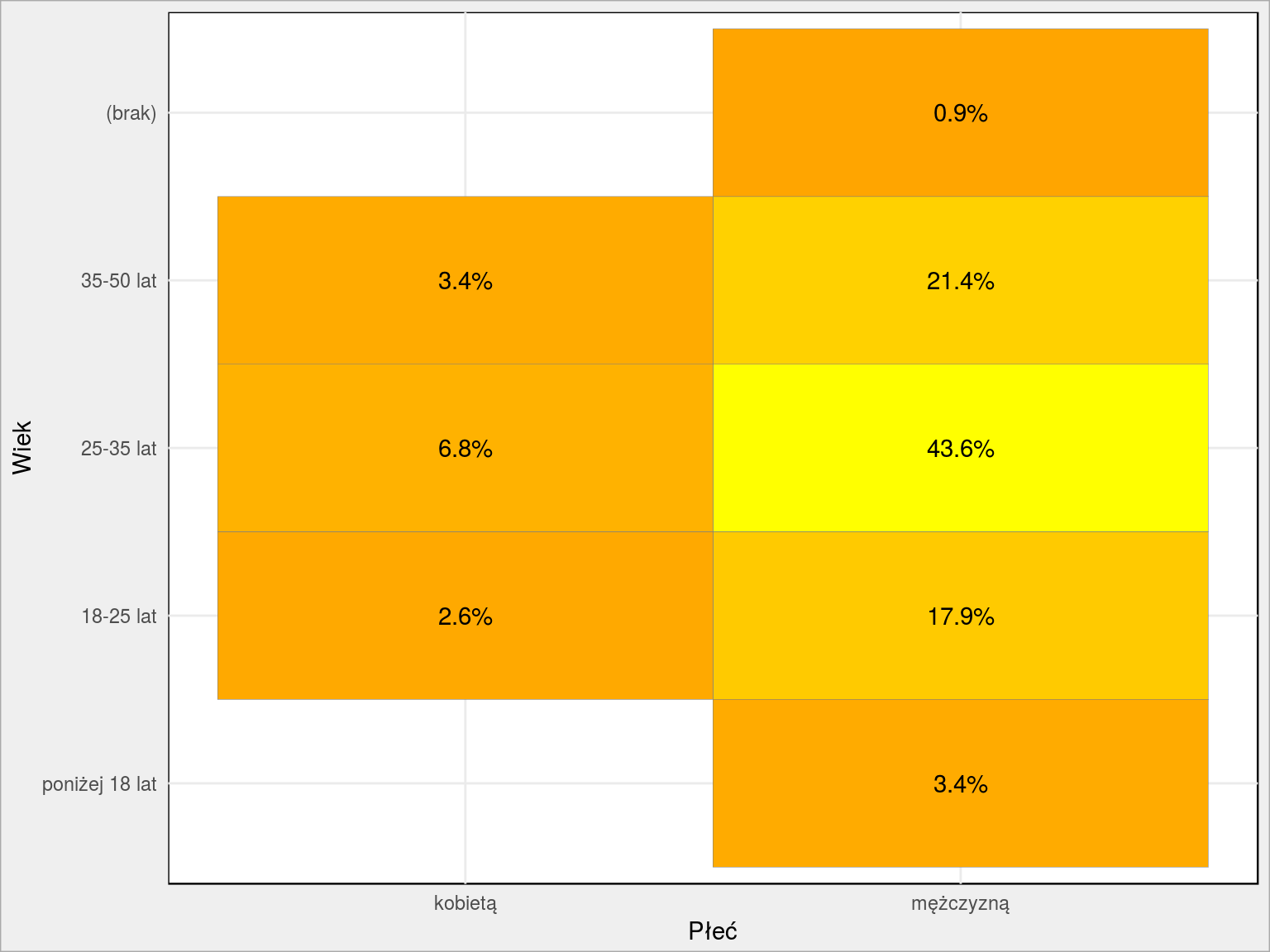
Skąd pochodzicie?
|
1 2 |
PlotBars(dane, Wojewodztwo) + labs(x = "", y = "% wypełnionych ankiet") |
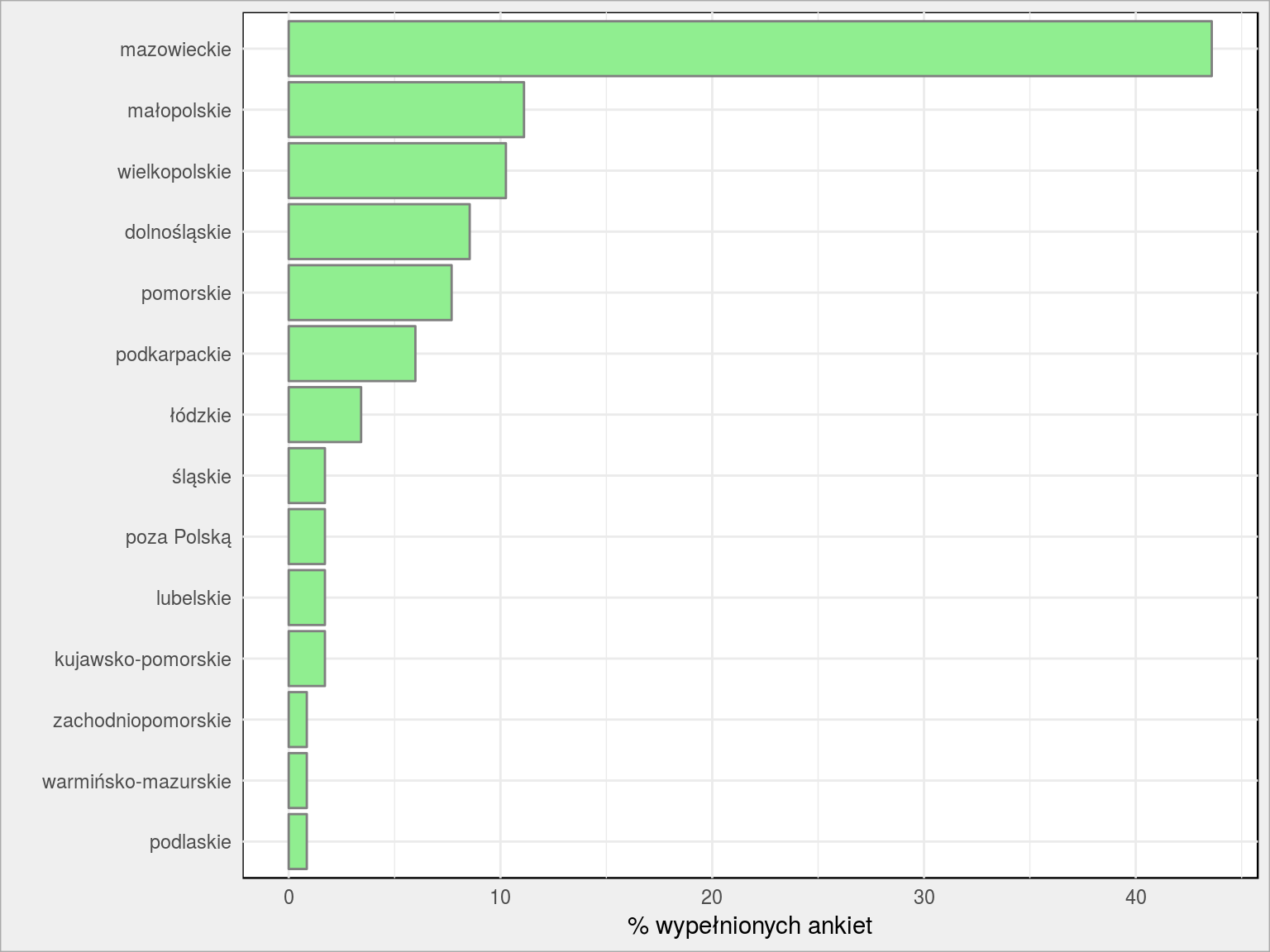
Prawie połowa to województwo mazowieckie (zapewne Warszawa). To pytanie miało ukryty sens. Ponieważ sam mieszkam w Warszawie dane, które sobie oglądam głównie pochodzą z Warszawy. Chciałem sprawdzić czy to może być dla Was ciekawe. Ma to znaczenie szczególnie w przypadku map – wiem co jest w których częściach miasta i czego można się tam spodziewać (korki, ruch rowerów, ceny mieszkań). Gdybym miał analizować dane dla Szczecina byłoby już trudniej (nie wiem gdzie w Szczecinie przebiegają główne ciągi komunikacyjne). A z drugiej strony w mediach widać tendencję Warszawo-centralistyczną – wszystko odnoszone jest do stolicy. Metro zatrzymane to już alarm w TV. A co obchodzi kogoś w Lublinie warszawskie metro czy zalana jakaś ulica? Staram się rozumieć mieszkańców innych miejscowości. Stąd to pytanie.
Po Waszych odpowiedziach widzę, że nie muszę martwić się tym, że dane warszawskie mogą być mało interesujące (i potem czytać zrób to samo dla Gdańska!). Ale obiecuję, że nie będę ograniczał się tylko do stolicy.
Czym się zajmujesz?
To bardzo ważne pytanie. I odpowiedzi jakie uzyskałem utwierdzają mnie w pewnym przekonaniu (za chwilę sami się dowiecie):
|
1 |
PlotBars(dane, Zajecie) + labs(x = "", y = "% odpowiedzi") |
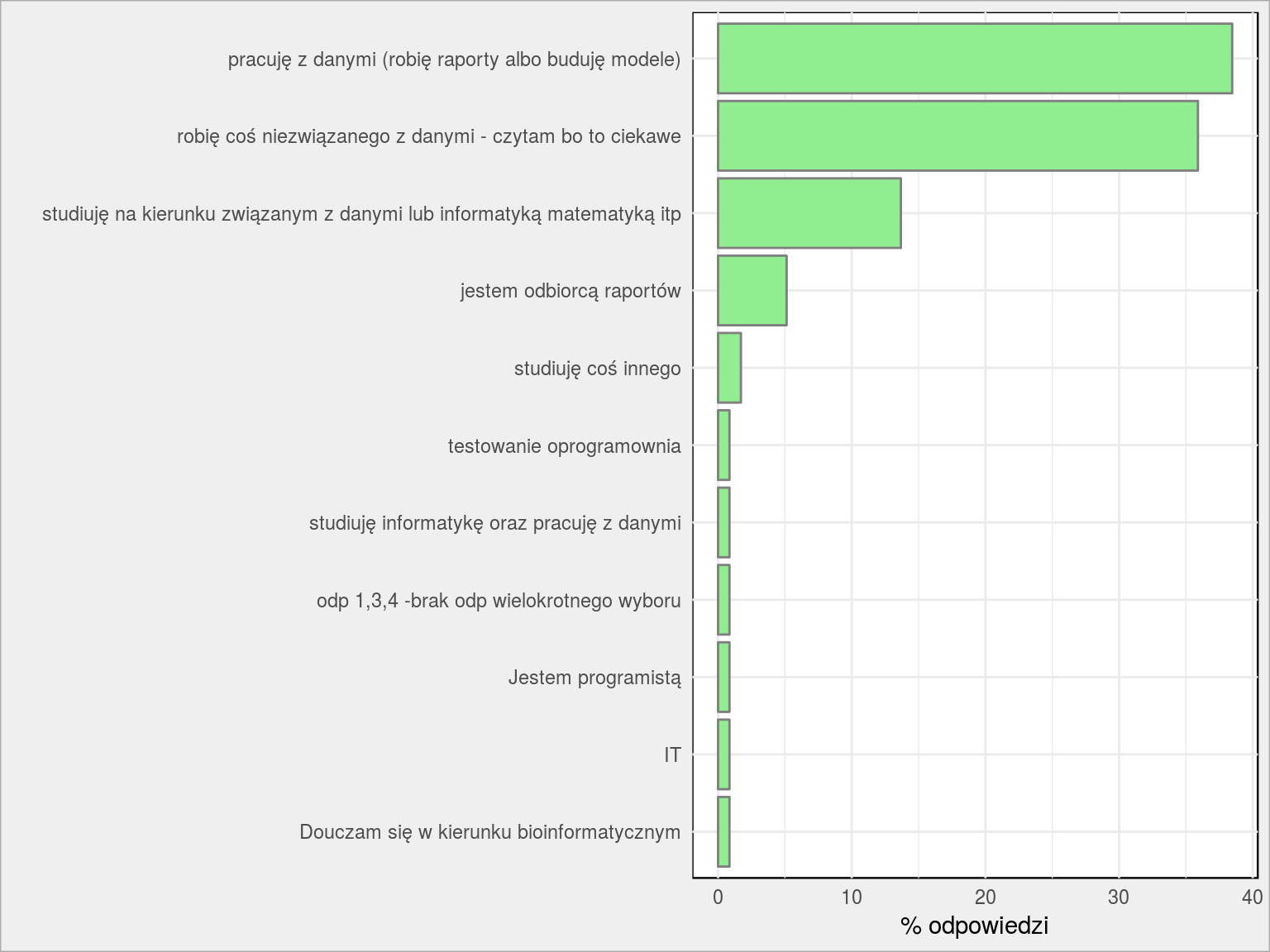
Mniej więcej po równo jest czytelników robiących to co ja (analiza danych, raporty) i takich, którzy zapewne czytają bloga jak dobrą książkę (mam nadzieję, że dobrą) – chcą się dowiedzieć czegoś o świecie, czegoś co wypływa z otaczających nas danych. Jakaś 1/8 to studenci – Wy wpadniecie za chwilę (zapewne) w tę pierwszą grupę (robiącą analizy) i szukacie czegoś co Wam pomoże w nauce (znowu: to moja projekcja, moje marzenia że tak właśnie jest). Super, dokładnie o to chodzi.
Czwarta grupa to odbiorcy raportów. Szczerze mówiąc na takich liczę najbardziej. To potencjalni pracodawcy ;-), a przede wszystkim – osoby, które mogą ocenić czy sposób przedstawienia informacji jest przyswajalny. Liczę na Wasz odzew!
Czym się zajmujesz a wiek
Ten przekrój to tylko weryfikacja tezy, że przedział 18-25 lat to studenci. Oczywiście zgadza się:
|
1 2 3 |
PlotPairs(dane, Wiek, Zajecie) + labs(y = "Czym sie zajmujesz", x = "Wiek") + scale_fill_gradient(low = "orange", high = "yellow") |
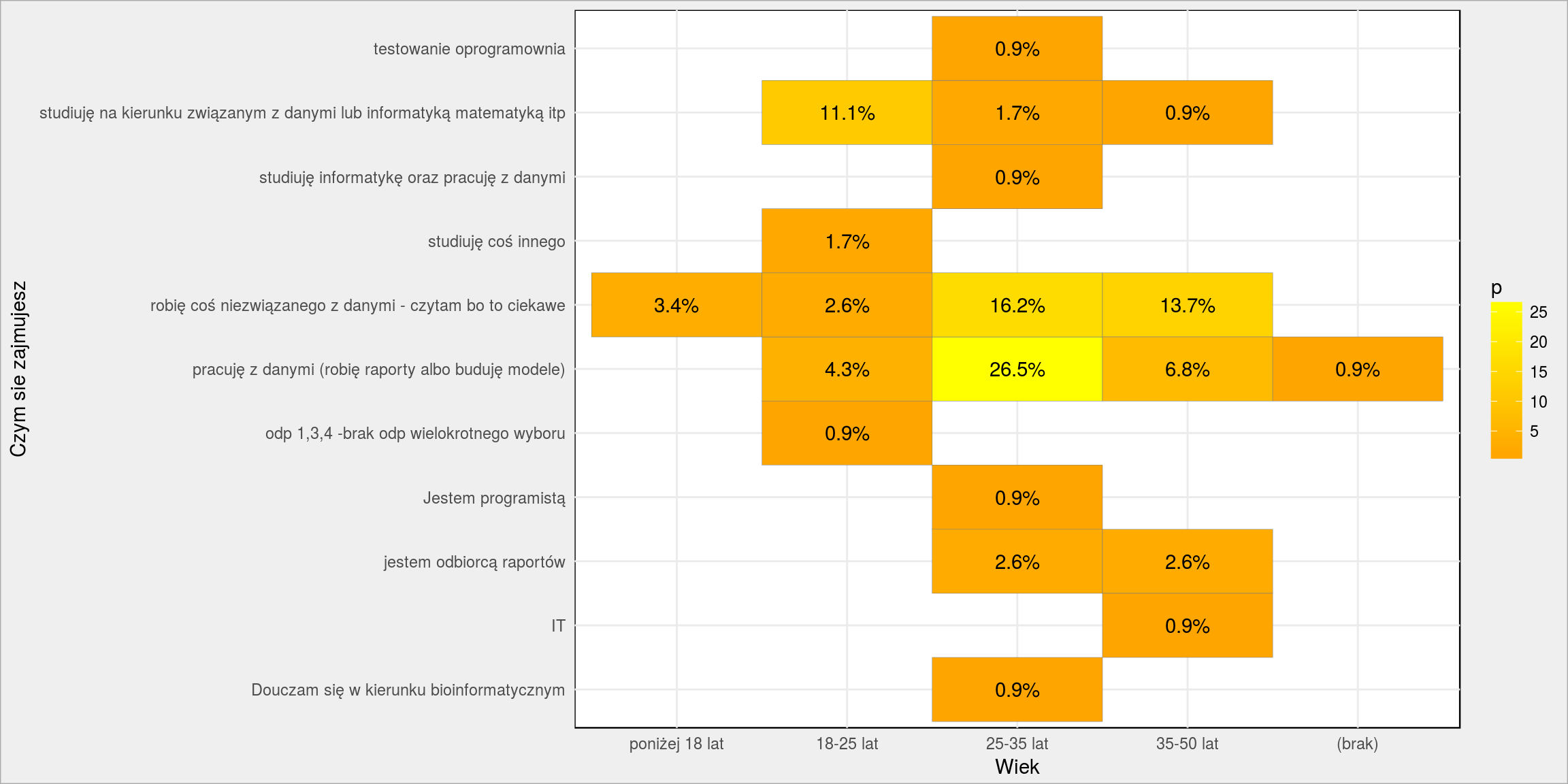
Najwięcej studiujących jest właśnie w wieku 18-25 lat. Po studiach przez pierwsze 10 lat robimy raporty i analizki (albo coś innego). Później przy tym zostajemy. Managerów mamy już przed trzydziestką ;)
Czym się zajmujesz versus płeć
|
1 2 3 |
PlotPairs(dane, Plec, Zajecie) + labs(y = "Czym sie zajmujesz", x = "Płec") + scale_fill_gradient(low = "orange", high = "yellow") |
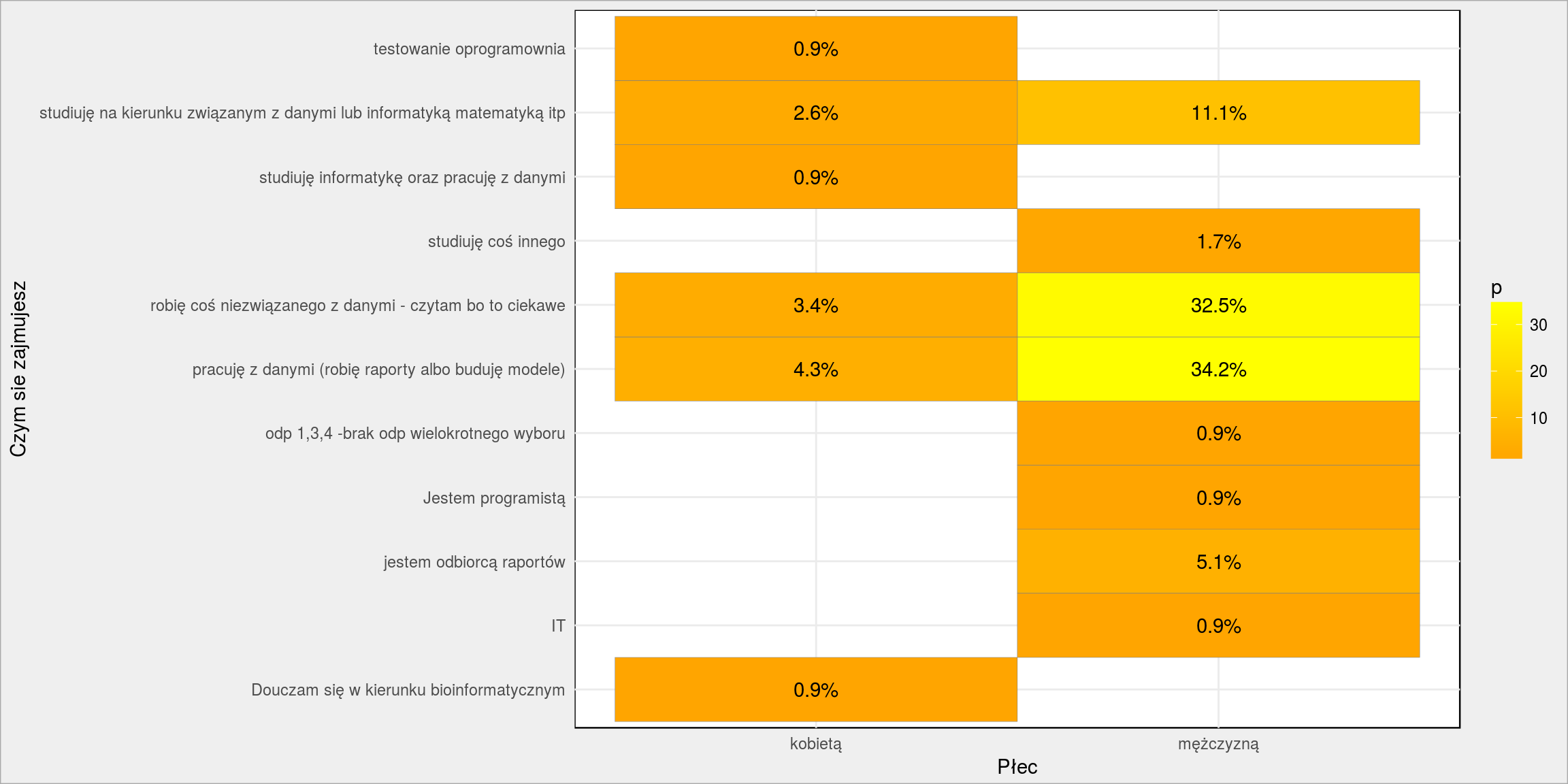
Tutaj przede wszystkim znajdujemy potwierdzenie, że nasi odbiorcy raportów są w mężczyznami mieszkającymi…
Czym się zajmujesz versus województwo w którym mieszkasz
|
1 2 3 4 |
PlotPairs(dane, Wojewodztwo, Zajecie) + labs(x = "Wojewodztwo", y = "Zajecie") + scale_fill_gradient(low = "orange", high = "yellow") + theme(axis.text.x = element_text(angle = 90, vjust = 0, hjust = 1)) |
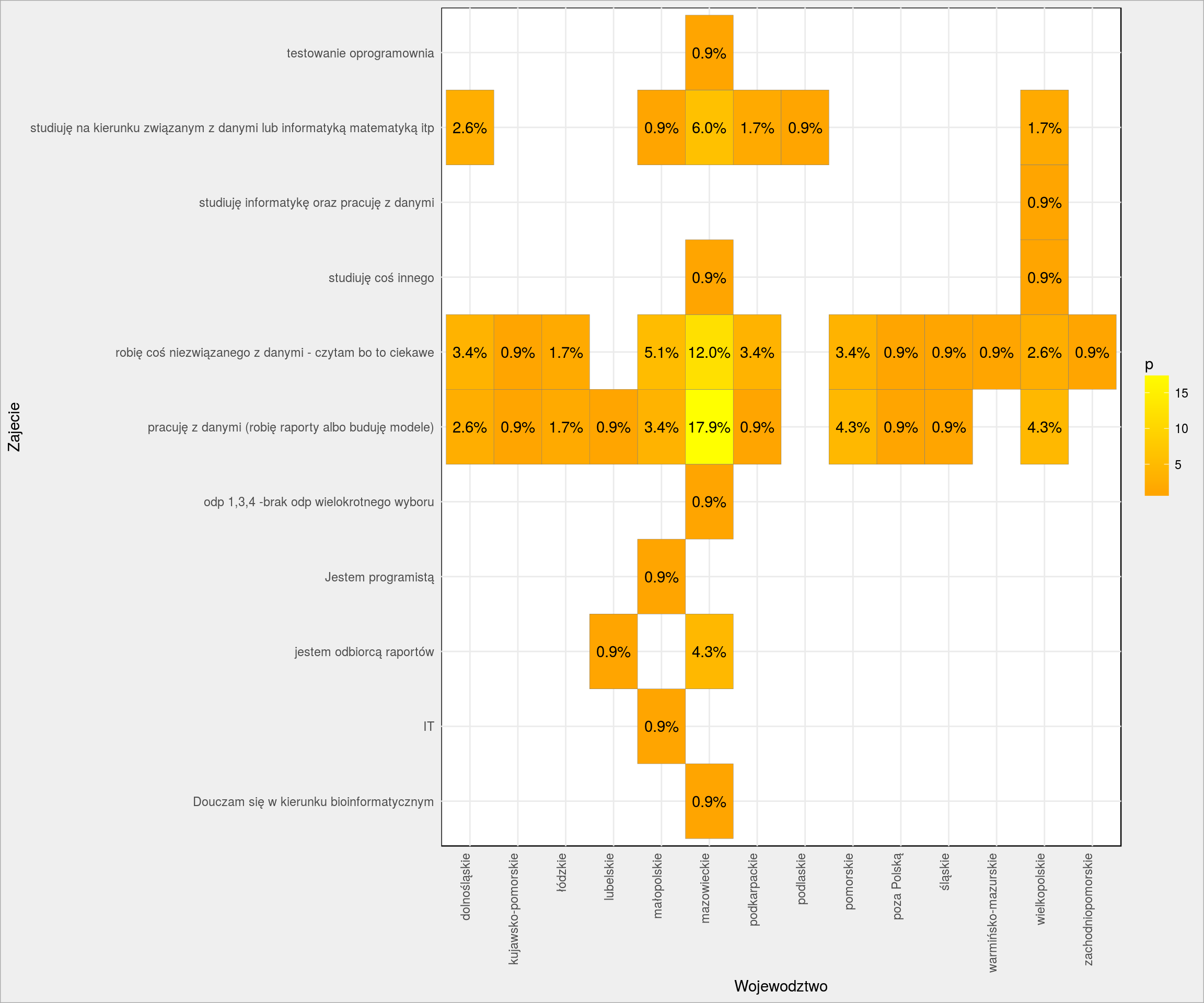
…zapewne w Warszawie (5 osób) lub Lublinie (1 osoba).
Teraz coś o skuteczności działań marketingowych.
Skąd wiesz o fan page?
Szczerze powiedziawszy zapomniałem o podcaście Niebezpiecznik.pl (polecam szczególnie trzeci odcinek – tam Piotek zrobił mi niezłe promo), a jak się o czymś zapomina to później trzeba łatać. Przy okazji łatamy i inne źródła:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
# zgrupowanie odpowiedzi wpisywanych ręcznie # podcast Niebezpiecznik.pl dane$FP_skad_wiesz <- ifelse(grepl("niebezpiecznik", tolower(dane$FP_skad_wiesz)), "Niebezpiecznik", dane$FP_skad_wiesz) dane$FP_skad_wiesz <- ifelse(grepl("podcast", tolower(dane$FP_skad_wiesz)), "Niebezpiecznik", dane$FP_skad_wiesz) dane$FP_skad_wiesz <- ifelse(grepl("na podsłuchu", tolower(dane$FP_skad_wiesz)), "Niebezpiecznik", dane$FP_skad_wiesz) # Wykop.pl dane$FP_skad_wiesz <- ifelse(grepl("wykop", tolower(dane$FP_skad_wiesz)), "Wykop", dane$FP_skad_wiesz) # Grupy na FB dane$FP_skad_wiesz <- ifelse(grepl("grupa", tolower(dane$FP_skad_wiesz)), "Grupa FB", dane$FP_skad_wiesz) # Google dane$FP_skad_wiesz <- ifelse(grepl("google", tolower(dane$FP_skad_wiesz)), "Google", dane$FP_skad_wiesz) PlotBars(dane, FP_skad_wiesz) + labs(x = "", y = "% odpowiedzi") |
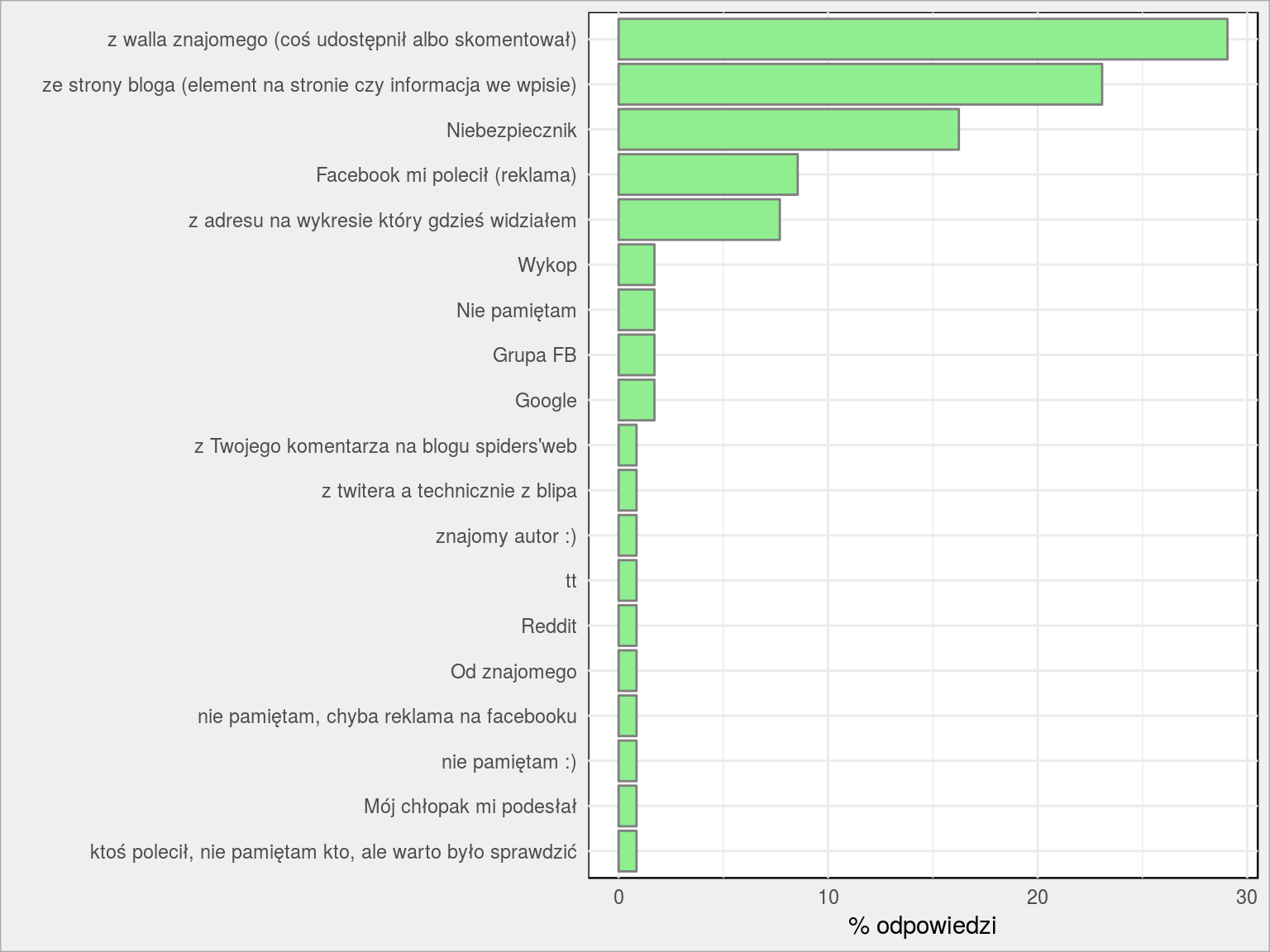
Mamy więc mniej lub bardziej prawdopodobne źródła pozyskiwania fanów stron na Facebooku:
- linki, komentarze i udostępnienia przez fanów – im ciekawsza treść tym lepiej się rozchodzi i tym więcej fanów przynosi
- wklejka na stronie bloga też swoje zrobiła
- polecenia w mniej lub bardziej podobnych mediach działa wyśmienicie (dzięki Piotr!)
- reklama na FB zrobiła początkową masę, później z niej zrezygnowałem i dzieje się samo
- zdziwiło mnie, że tak dobrze działa fb.com/DaneAnalizy umieszczone na wykresach które publikuję – mi osobiście nie chce się przepisywać takich adresów
Jak często zaglądasz na fan page?
Tutaj chciałem sprawdzić przyzwyczajenia i sposób przeglądania Facebooka. Zapewne są setki opracowań na ten temat, ale nie ma jak własne dane :)
|
1 |
PlotBars(dane, FP_jak_czesto_zagladasz) + labs(x = "", y = "% odpowiedzi") |
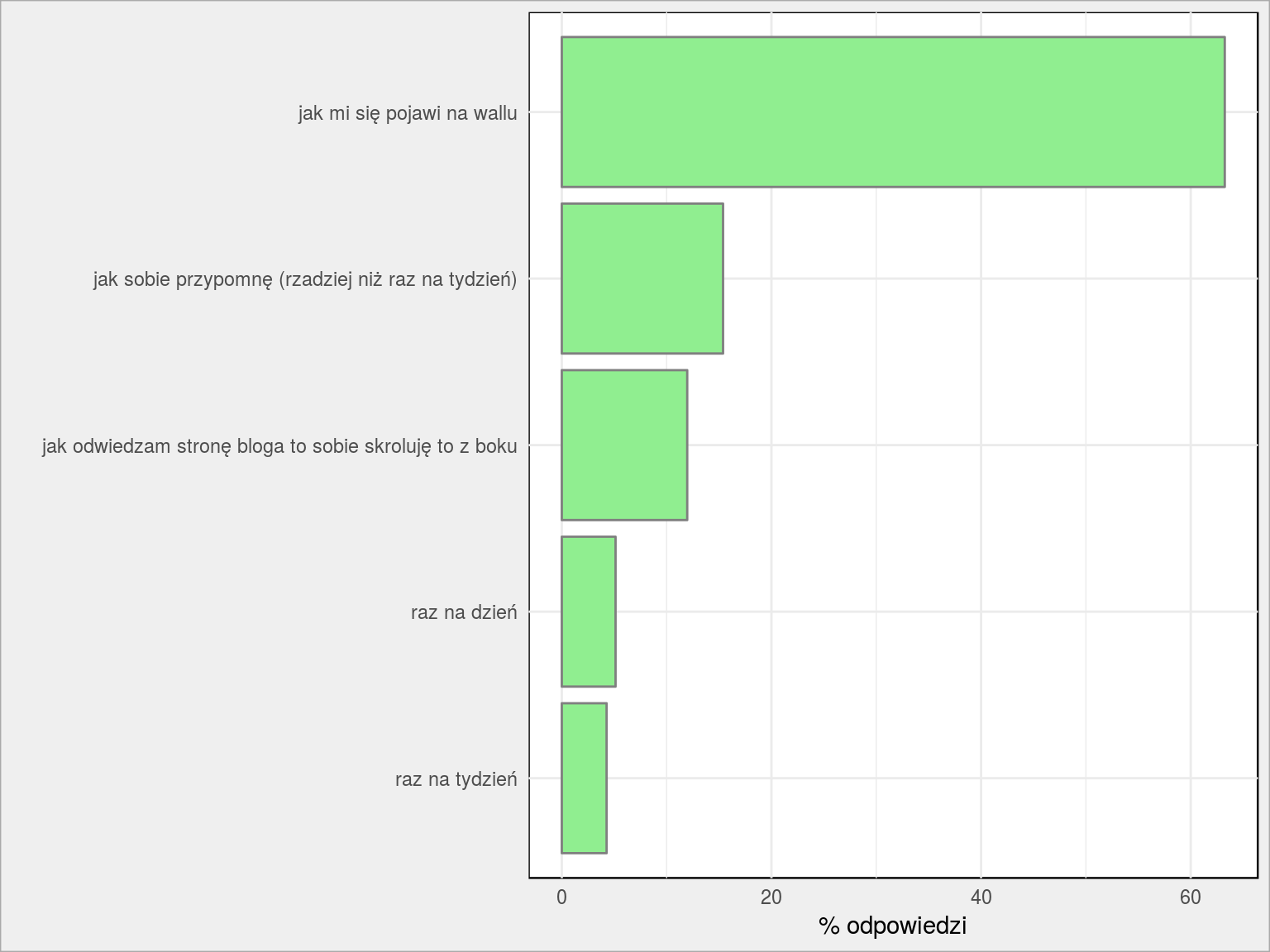
Zasięg, zasięg i jeszcze raz zasięg. Jeśli Facebook nie pokaże sam z siebie czegoś na czyimś wallu to nikt nie wchodzi specjalnie na fan page’a. Nie wchodzi, bo ma tych fanpage’ów zalajkowanych dziesiątki. A FB pokaże jak uzna, że jest warto pokazać jak inni uznają, że jest ciekawe (komentując czy lajkując). Na tym to polega. Zatem lajkujcie i komentujcie to co znajdziecie na fanpage’u!
Jak często powinny być posty na fan page?
|
1 |
PlotBars(dane, FP_jak_czesto_posty) + labs(x = "", y = "% odpowiedzi") |
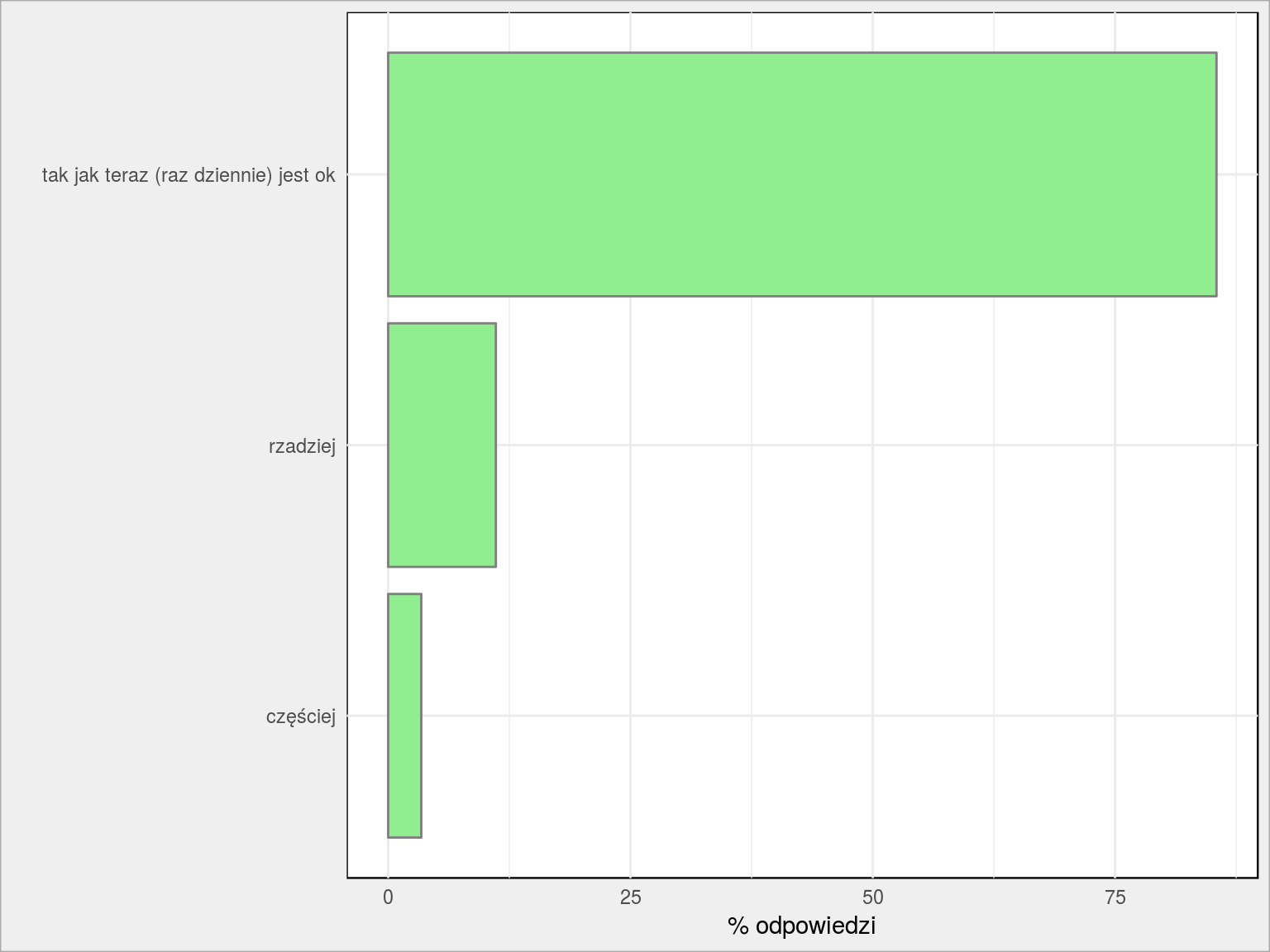
Tego się bałem najbardziej. Wcale nie jest łatwo wyszukać coś ciekawego. Raz na dzień wystarczy. Uff…
A może chcecie newsletter?
Dlaczego nie komentujesz postów?
I nie robisz mi zasięgów?
|
1 |
GetBars(dane, FP_komentowanie) %>% arrange(desc(p)) %>% select(-n) |
| label | % |
|---|---|
| bo nie mam nic do powiedzenia | 58.9 |
| bo mi się nie chce :P | 25.6 |
| przecież komentuję! | 6.8 |
| bo ciężko mi pisać po polsku, ale nie chcę obrazić kogoś, używając angielskich komentarzy | 0.8 |
| Bo nie od razu uwaznie czytam, a pozniej jak juz czytam/przestudiuje to nie wracam do postu, w ktorym to bylo.. | 0.8 |
| Brak konta | 0.8 |
| Brak potrzeby | 0.8 |
| Narazie obserwuje | 0.8 |
| nic, używam RSSa | 0.8 |
| nie wiem jak | 0.8 |
| Nie zawsze mam coś ciekawego do powiedzenia. Zwykle w ciszy czytam sobie to co zostanie opublikowane. Częściej komentuję pod samym wpisem z bloga niż na facebooku. | 0.8 |
| Unikam komentowania w internecie | 0.8 |
| zacznę ;) | 0.8 |
Powody czysto ludzkie, nic zaskakującego. Nie jestem social media ninja i nie potrafię prowokować komentarzy. A żebrolajki (czyli akcje “jeśli lubisz to lajk, a jeśli nie to komć”) chyba już nie działają.
Co Was interesuje?
To najważniejsza dla mnie sekcja – od tych odpowiedzi zależy przyszłość tematów.
Czego oczekuję od fanpage?
Odpowiedzi z Google Forms dla pytań wielokrotnego wyboru umieszczone są jako jeden ciąg rozdzielony przecinkami (to słabe rozwiązanie, powinno się dać zdefiniować na poziomie formularza znak rozdzielający). W związku z tym musimy podejść nieco inaczej do tej kolumny:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
lapply(dane$FP_Zainteresowania, strsplit, split = ", ") %>% unlist() %>% as_data_frame() %>% count(value) %>% ungroup() %>% mutate(p = 100*n/nrow(dane)) %>% arrange(p) %>% mutate(value = fct_inorder(value)) %>% ggplot() + geom_col(aes(value, p), fill = "lightgreen", color = "gray50") + coord_flip() + labs(x = "", y = "% odpowiedzi") |
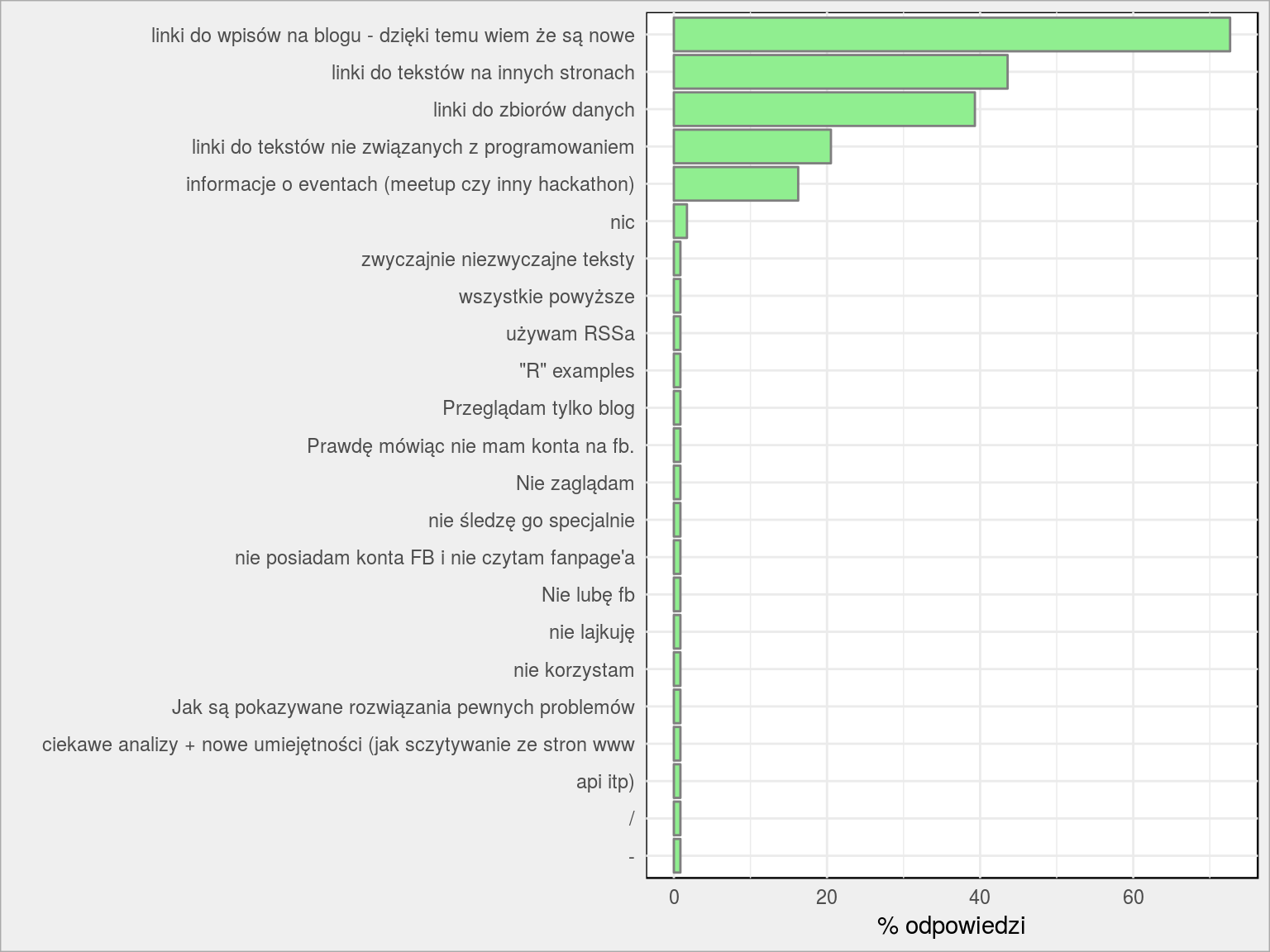
Procenty nie sumują się do 100% (pytanie wielokrotnego wyboru).
Pierwsza piątka odpowiedzi idealnie trafia w to co sam planuję (i staram się realizować). Zdaję sobie sprawę, że mało jest linków do zbiorów danych. Ale trochę jest tak, że jak znajduję coś ciekawego to chcę to dla siebie (jako temat na kolejne wpisy). Obiecuję poprawę :)
Czego oczekujesz od bloga?
|
1 2 3 4 5 6 7 8 9 10 11 12 |
lapply(dane$B_zagadnienia, strsplit, split = ", ") %>% unlist() %>% as_data_frame() %>% count(value) %>% ungroup() %>% mutate(p = 100*n/nrow(dane)) %>% arrange(p) %>% mutate(value = fct_inorder(value)) %>% ggplot() + geom_col(aes(value, p), fill = "lightgreen", color = "gray50") + coord_flip() + labs(x = "", y = "% odpowiedzi") |
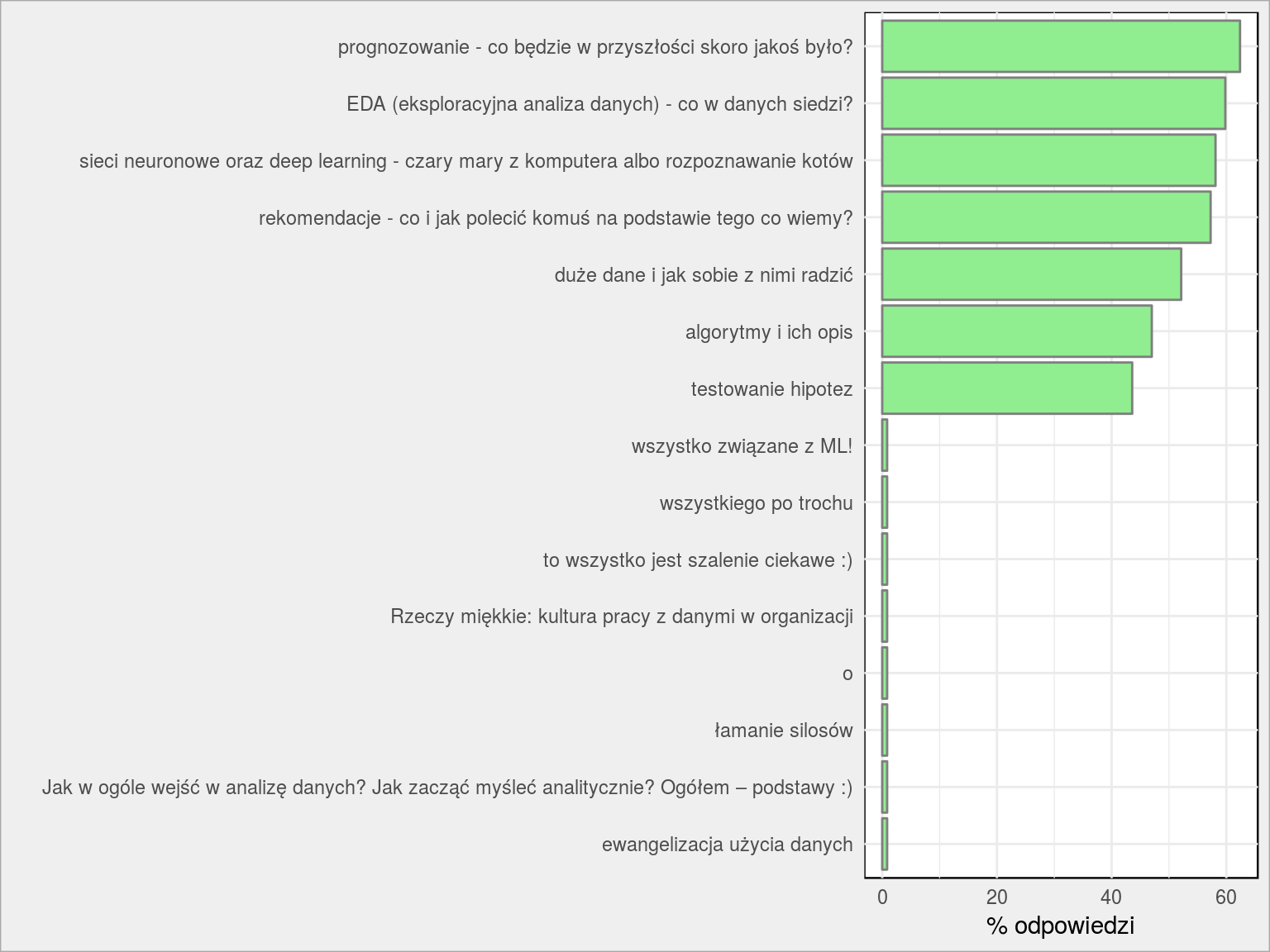
Znowu pytanie wielokrotnego wyboru. Cieszę się, że interesuje Was prognozowanie – mnie też. EDA przerabialiśmy wielokrotnie i w sumie chyba nic odkrywczego już nie zrobimy. Zazwyczaj polega to na znalezieniu danych, narysowaniu kilku wykresów w różnych przekrojach (czasem wzbogacając dane albo je agregując). Dla wyjadaczy R: dplyr i ggplot2 wystarczają :)
Sieci neuronowe to coś co sam chcę zgłębić i pewnie z czasem coraz więcej tego typu treści się pojawi. Z dużymi danymi jest trudniej – wymagają architektury (Spark, jakieś SQLowe bazy). Ale też się postaram. O rekomendacjach będzie niedługo (pewnie na podstawie filmów i Filmwebu).
Sprawdźmy jeszcze jak zbieżne są zainteresowana odnośnie postów na fan page i na blogu:
|
1 2 3 4 5 6 7 8 9 |
dane %>% mutate(label1 = substr(FP_Zainteresowania, 1, 30), label2 = substr(B_zagadnienia, 1, 30)) %>% count(label1, label2) %>% ggplot() + geom_tile(aes(label1, label2, fill = n), show.legend = FALSE, color = "grey50") + geom_text(aes(label1, label2, label = n)) + scale_fill_gradient(low = "orange", high = "yellow") + theme(axis.text.x = element_text(angle = 90)) + labs(x = "Zainteresowania fan page", y = "Zainteresowania blog") |
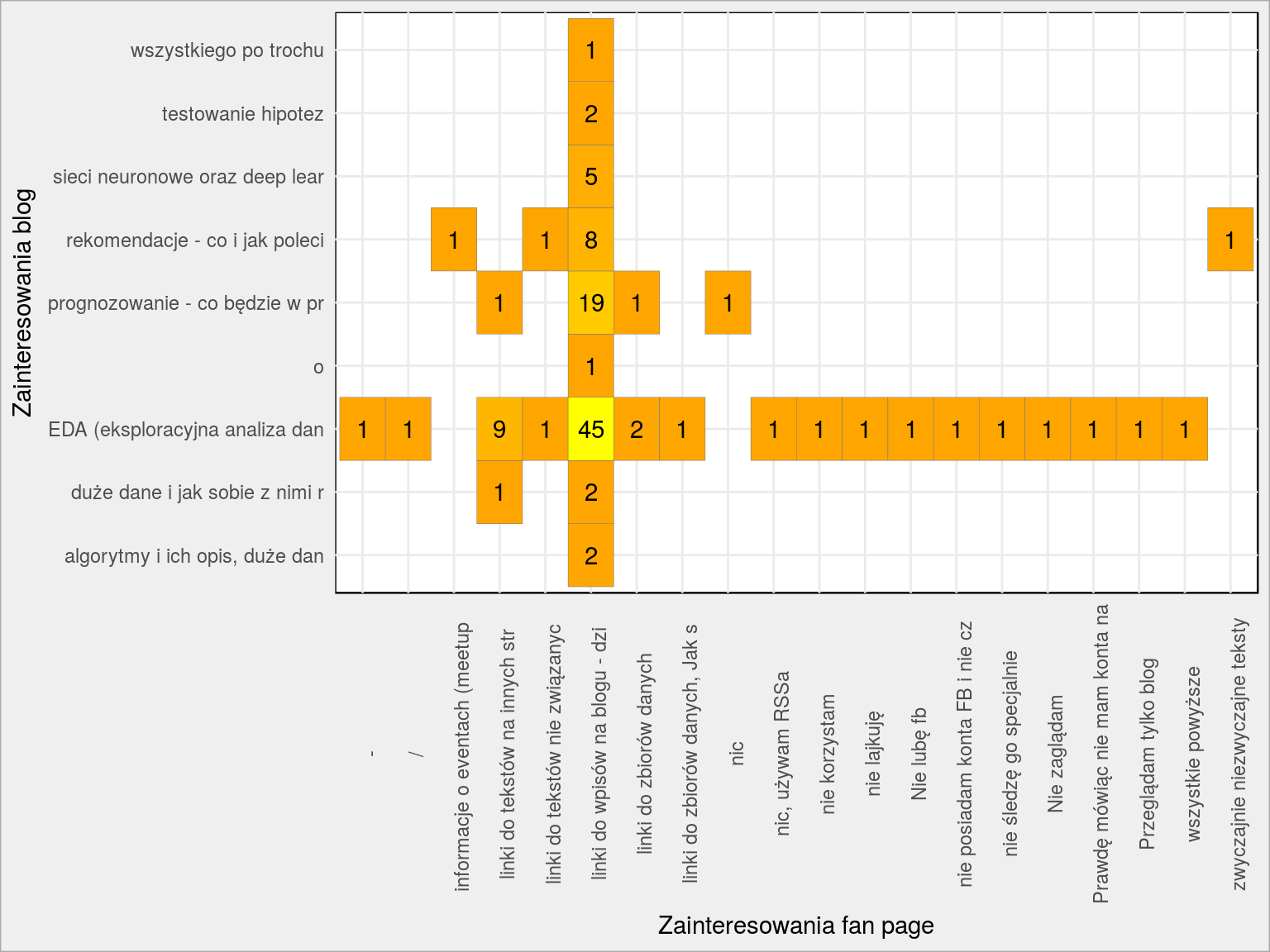
Oraz co kogo interesuje (w zależności od zajęcia):
|
1 2 3 4 |
PlotPairs(dane, Zajecie, B_Zainteresowania) + theme(axis.text.x = element_text(angle = 90, vjust = 0, hjust = 1), legend.position = "none") + scale_fill_gradient(low = "orange", high = "yellow") + labs(x = "", y = "") |
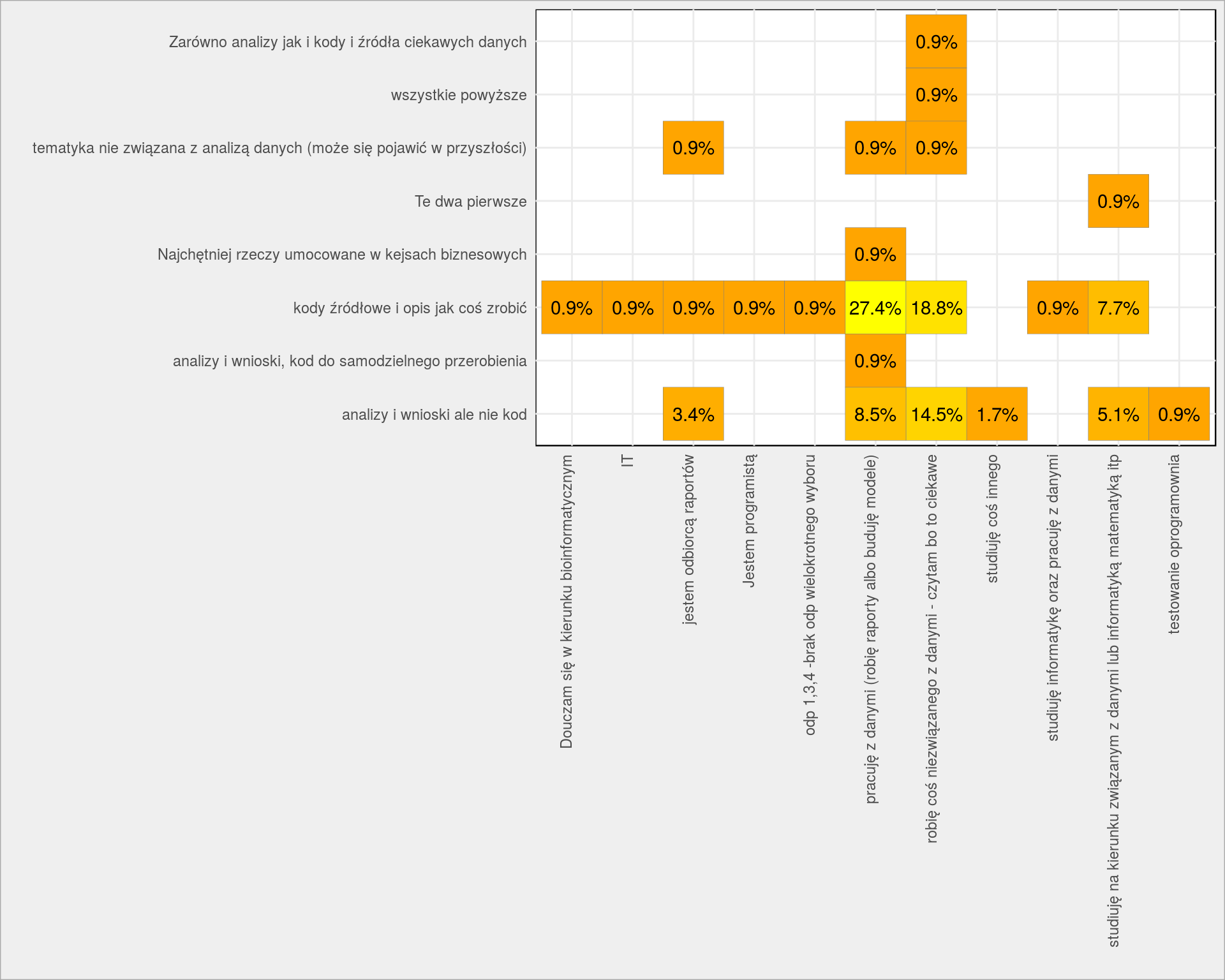
Jeśli ktoś pracuje z danymi – chciałby poznać magię i kuchnię. Nawet jeśli ktoś nie pracuje na co dzień z danymi chciały wiedzieć jak coś “wyłuskać” (podobna mi się to – kwestionowanie świata zastanego to postawa godna inteligentnych ludzi; trzeba szukać, podważać i sprawdzać samodzielnie), a jeśli nawet samodzielnie nie chce tego robić to chętnie się dowie o wynikach.
Jak to, co robicie przekłada się na to o czym chcecie przecytać?
|
1 2 3 4 5 6 7 8 9 |
dane %>% mutate(label1 = substr(Zajecie, 1, 40), label2 = substr(B_zagadnienia, 1, 50)) %>% count(label1, label2) %>% ggplot() + geom_tile(aes(label1, label2, fill = n), color = "grey50") + geom_text(aes(label1, label2, label = n)) + theme(axis.text.x = element_text(angle = 90, vjust = 0, hjust = 1), legend.position = "none") + scale_fill_gradient(low = "orange", high = "yellow") + labs(x = "", y = "") |

Na prawdę interesuje Was tylko co można wydobyć z danych? W machine learningu ciekawsze jest co można zrobić dzięki danym – co przewidzieć, co podpowiedzieć, jakie problemy rozwiązać. A nie tylko wykresiki… Oczywiście eksploracja danych jest ciekawa, szczególnie kiedy złączymy dane z wielu źródeł. I jeśli będzie coś na ten temat to zapewne w tym kierunku (ale nie tylko mapka i dane ;).
Za najlepszy wpis na blogu uważacie…
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
lapply(dane$B_najlepszy_wpis, strsplit, split = ", ") %>% unlist() %>% as_data_frame() %>% count(value) %>% ungroup() %>% mutate(p = 100*n/nrow(dane)) %>% filter(p != min(p)) %>% arrange(p) %>% mutate(value = fct_inorder(substr(as.character(value), 1, 75))) %>% ggplot() + geom_col(aes(value, p), fill = "lightgreen", color = "gray50") + coord_flip() + labs(x = "", y = "% odpowiedzi") |
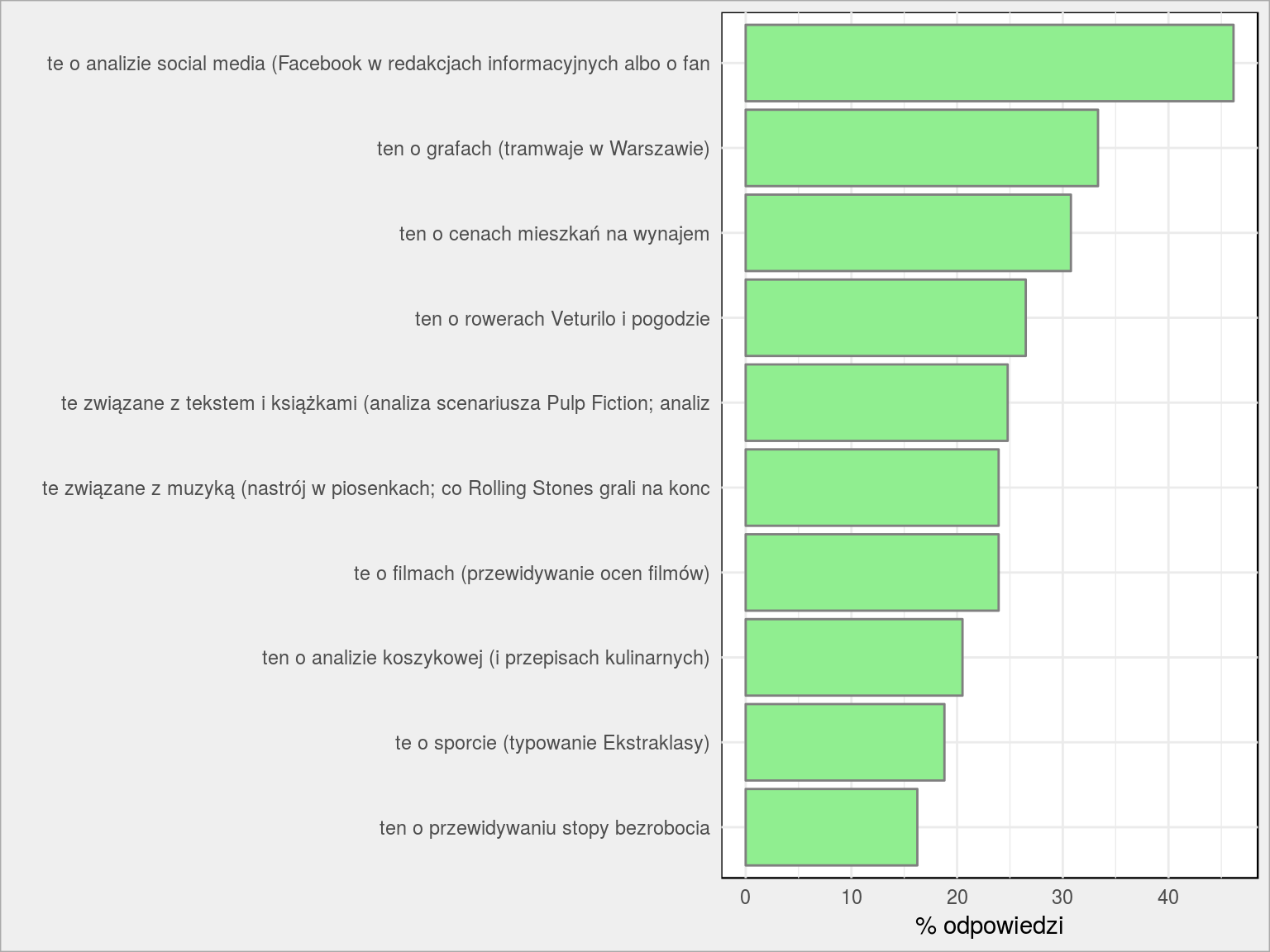
Social media interesują większość. Bo to ciekawe jak z niczego (ot, jakieś komcie na fejsie) wyciągnąć target swoich działań. Jakim językiem ma mówić partia polityczna do swoich zwolenników (szczególnie przyszłych)? Ano takim, jakich ma fanów (a skoro wiemy, że noszą okulary, mają około 35-45 lat i lubią piłkę nożną to… sami pomyślcie).
Grafy sam lubię – tam była teoria na przykładzie prawdziwego życia. Ceny mieszkań to hit Wykopu i zarazem kompleksowy przykład rozwiązania konkretnego problemu (znalezienie danych, ich przygotowanie i obserwacja z wyciągnięciem wniosków; powinienem za to brać grubą kasę).
Najlepszy wpis a zajęcie odpowiadającego
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
# reczna korekta odpowiedzi dane$B_najlepszy_wpis <- ifelse(grepl("Picasso|Picassa", dane$B_najlepszy_wpis), "Obrazy Picasso", dane$B_najlepszy_wpis) dane$B_najlepszy_wpis <- ifelse(grepl("Migracje|Migracja", dane$B_najlepszy_wpis), "Migracje Polaków", dane$B_najlepszy_wpis) dane %>% mutate(label1 = substr(Zajecie, 1, 30), label2 = substr(B_najlepszy_wpis, 1, 30)) %>% count(label1, label2) %>% ungroup() %>% top_n(20, wt = n) %>% ggplot() + geom_tile(aes(label1, label2, fill = n), color = "grey50") + geom_text(aes(label1, label2, label = n)) + theme(axis.text.x = element_text(angle = 90, vjust = 0, hjust = 1), legend.position = "none") + scale_fill_gradient(low = "orange", high = "yellow") + labs(x = "", y = "") |
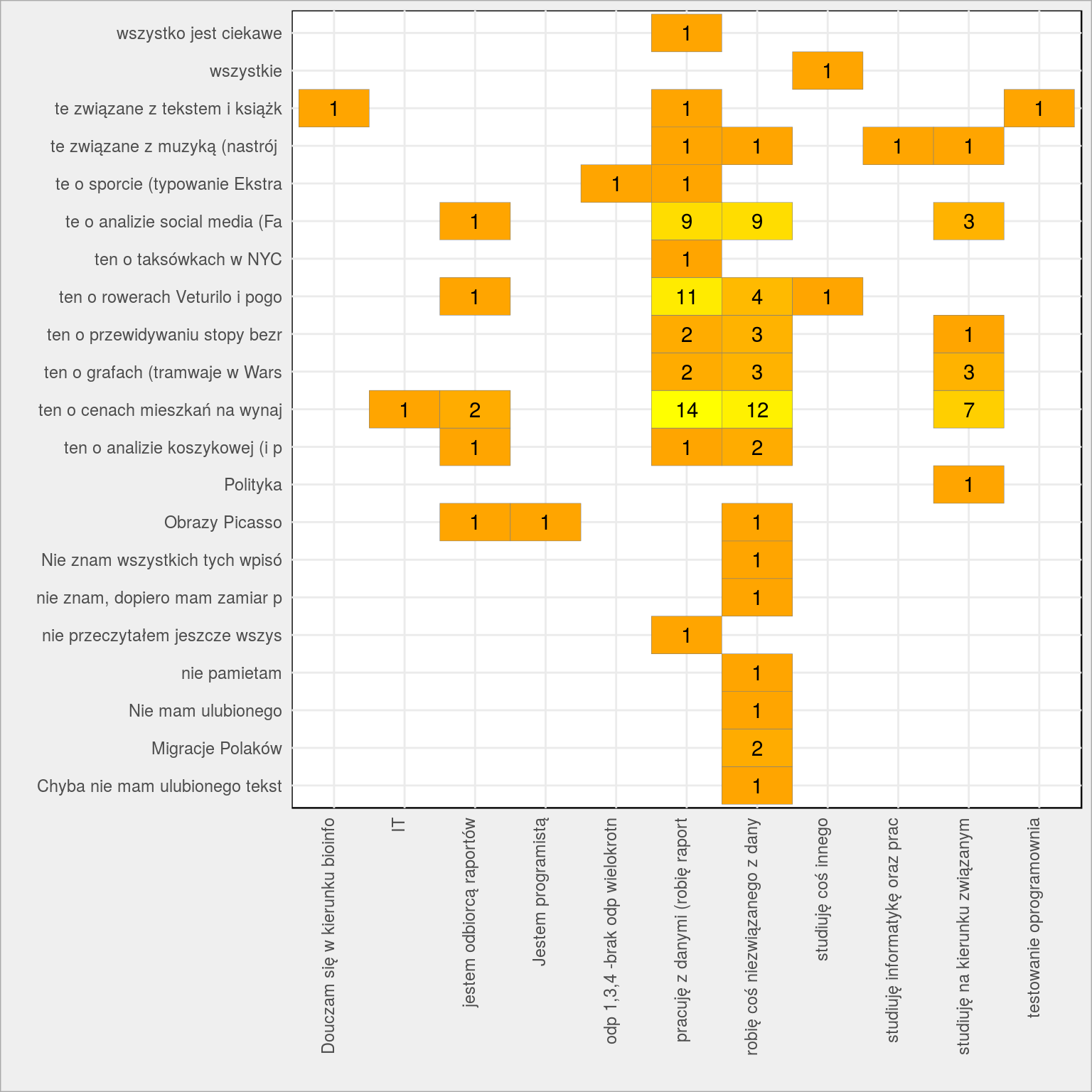
Tutaj mam kolejne potwierdzenie swoich przewidywań: kopiesz w danych to chcesz wiedzieć jak to robić (kompleksowo – ceny mieszkań, Veturilo, social media). Nie kopiesz – interesują Cię uniwersalne analizy (i dobrze opisane, nie tylko jeśli chodzi o kod).
Co Ci się nie podoba?
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
lapply(dane$B_niepodoba, strsplit, split = ", ") %>% unlist() %>% as_data_frame() %>% # mutate(value = substr(value, 1, 40)) %>% # trochę ręcznych poprawek mutate(value = ifelse(grepl("wszystko mi sie podoba|wszystko mi się podoba|wszytko jest okej|wszystko ok|nic|jest ok|wszystko gra|wszystko sie podoba", tolower(value)), "Wszystko jest OK", value)) %>% count(value) %>% ungroup() %>% mutate(p = 100*n/nrow(dane)) %>% filter(p != min(p)) %>% top_n(10, p) %>% arrange(p) %>% mutate(value = fct_inorder(value)) %>% ggplot() + geom_col(aes(value, p), fill = "lightgreen", color = "gray50") + coord_flip() + labs(x = "", y = "% odpowiedzi") |
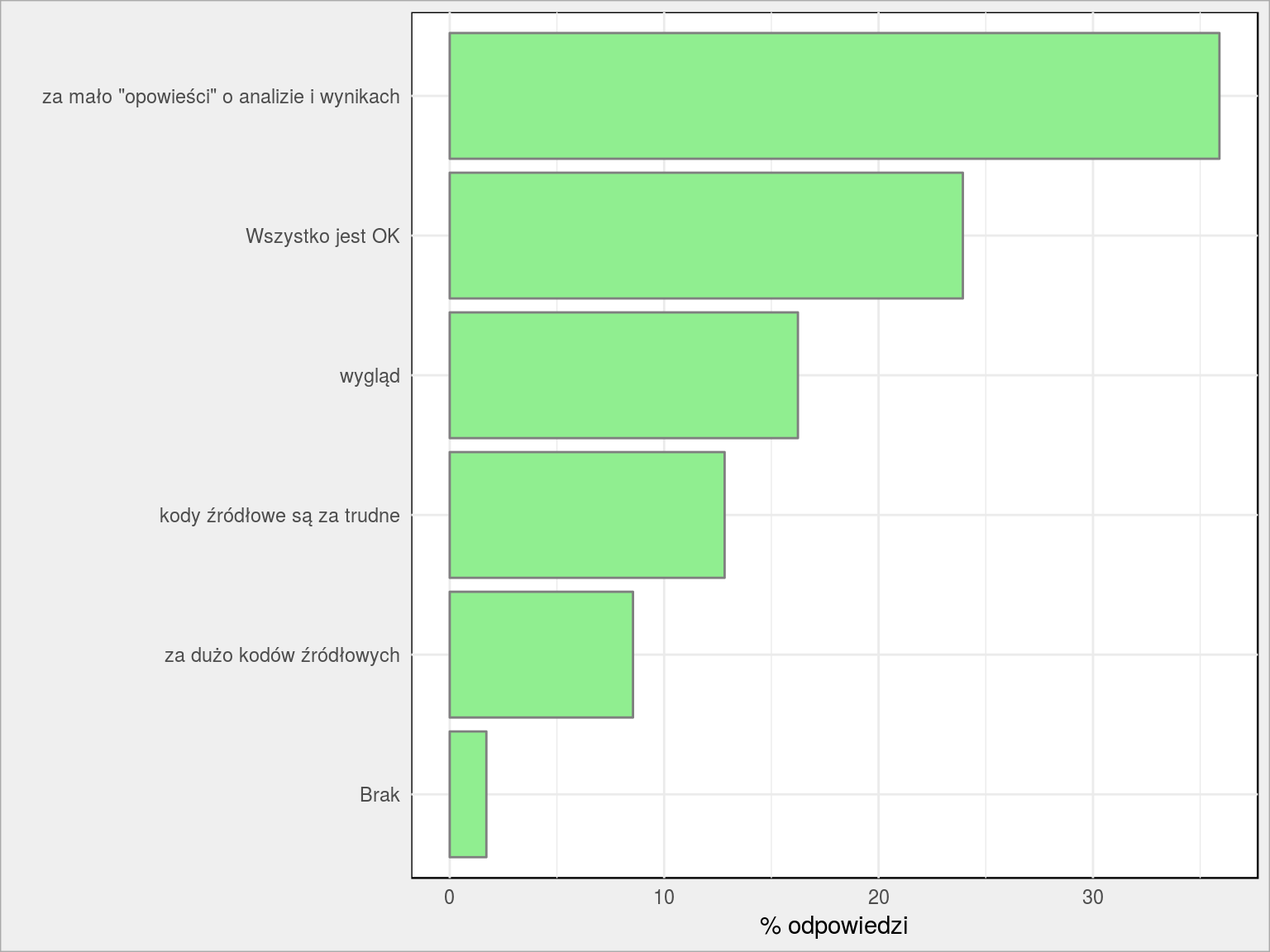
Mam nadzieję, że ostatni wpis o statystykach związanych z wypadkami drogowymi i działaniami Policji Was chociaż trochę zaspokoił? Problem polega na tym, że pisząc kolejne wpisy najbardziej interesuje mnie znalezienie rozwiązania problemu. Późniejsze opisanie problemu i wyniku poszukiwań jest już nieco nudne – ja już przecież wiem jakie są wyniki ;)
Wygląd. Tego nie zamierzam zmieniać. Szablon bloga w założeniu ma być minimalistyczny na maksa. Może dopracuję się kiedyś ładniejszych kolorków na wykresach. Jestem typem, który może powiedzieć czy ładne czy brzydkie, ale żeby samemu zrobić ładne to już gorsza sprawa…
Pytanie było otwarte, więc znalazły się wpisy z wolnej ręki, lejące miód na moje serce:
- kocham autora za jego wkład pracy
- muszę też nauczyć się myśleć analitycznie – ale Twoje teksty są tak dobre!
- pozyskujesz dane nie wiadomo skąd i robisz z tego świetne analizy
- jak znajdujesz interesujące pytania, których sam bym nie zadał – nie wpadłbym na to
- najlepszy polskojęzyczny blog o DS w R
Z tym ostatnim się nie zgadzam (ale też nie znam innego polskojęzycznego bloga o R ;).
Na koniec coś o kodach, czyli odwieczne pytanie:
Python czy R?
|
1 2 3 4 5 |
# ujednolicenie odpowiedzi dane$Python_R <- ifelse(grepl("Oba|oba|Obydwa|obydwa|razem|R i Python", dane$Python_R), "R i Python", dane$Python_R) PlotBars(dane, Python_R) + labs(x = "", y = "% odpowiedzi") |
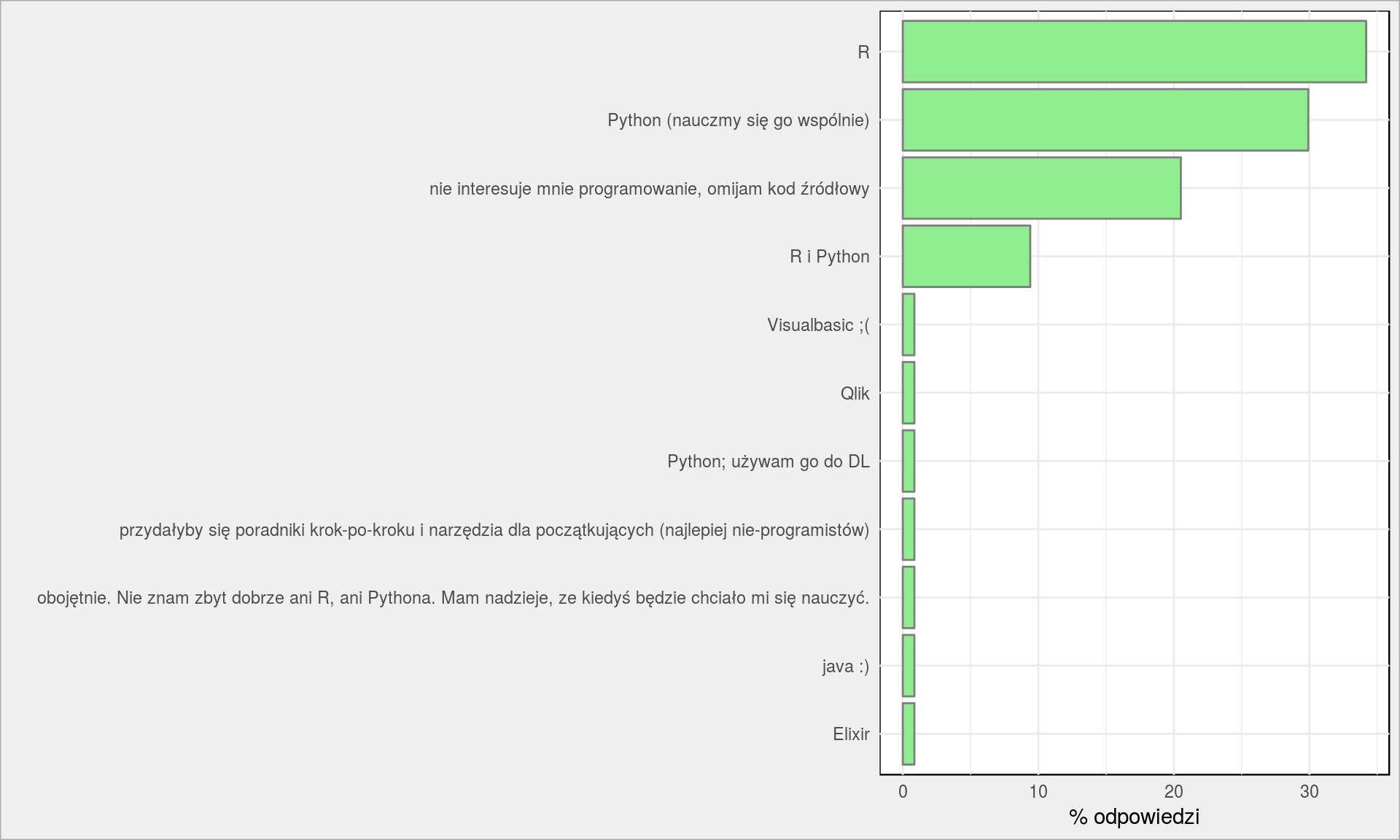
Osobiście uważam, że oba. Pythona nie znam – czytam, rozumiem, ale nie piszę. Uważam, że R jest wygodny (świetne IDE – RStudio), według mnie szybszy w pisaniu. Python z kolei jest bardziej uniwersalny, szybszy w działaniu, na linuksowych systemach nie wymaga instalacji (R jednak trzeba zainstalować). R ma Shiny i flexdashboard świetne do robienia szybko interaktywnych paneli (zobacz na post o migracjach Polaków – więcej kodu zajmuje ściąganie i przygotowanie danych niż warstwa wizualizacji). Oba narzędzia się uzupełniają. W R wygodniej pisze się bloga (Rmarkdown z kodem i komentarzem, na koniec eksport do HTMLa).
Odpowiedzi są z tym zbieżne. Blog jest o R, więc oczywiście oczekujecie R. Ale chcecie nauczyć się Pythona.
Qlika nie będzie, już prędzej byłoby Tableau albo PowerBI, ale z nimi jest problem taki że nie da się łatwo opisać tego co i jak zrobić (screenów nie będę wklejał), a i publikacja wyników jest utrudniona. Visual Basic… no używam w pracy. Głównie po to, żeby w Accessie wywołać napisane w SQLu query, przekleić dane do Excela i odświeżyć pivoty w tym ostatnim. Ewentualnie przepisać dane z jednej tabelki do drugiej (w Excelu) i odpowiednio przeformatować dane (kolorki, ułożenie w tabelki). Swoją drogą, że też Excel nie ma funkcji filtrujących dane… takiego filter() z dplyr potrzebuję…
Ciekawe jest coś innego:
Python czy R – w zależności od zajęcia
|
1 2 3 4 5 6 7 8 |
GetPairs(dane, Zajecie, Python_R) %>% mutate(label1 = substr(label1, 1, 30), label2 = substr(label2, 1, 30)) %>% ggplot() + geom_tile(aes(label1, label2, fill = n), color = "grey50") + geom_text(aes(label1, label2, label = n)) + theme(axis.text.x = element_text(angle = 90, vjust = 0, hjust = 1), legend.position = "none") + scale_fill_gradient(low = "orange", high = "yellow") + labs(x = "", y = "") |
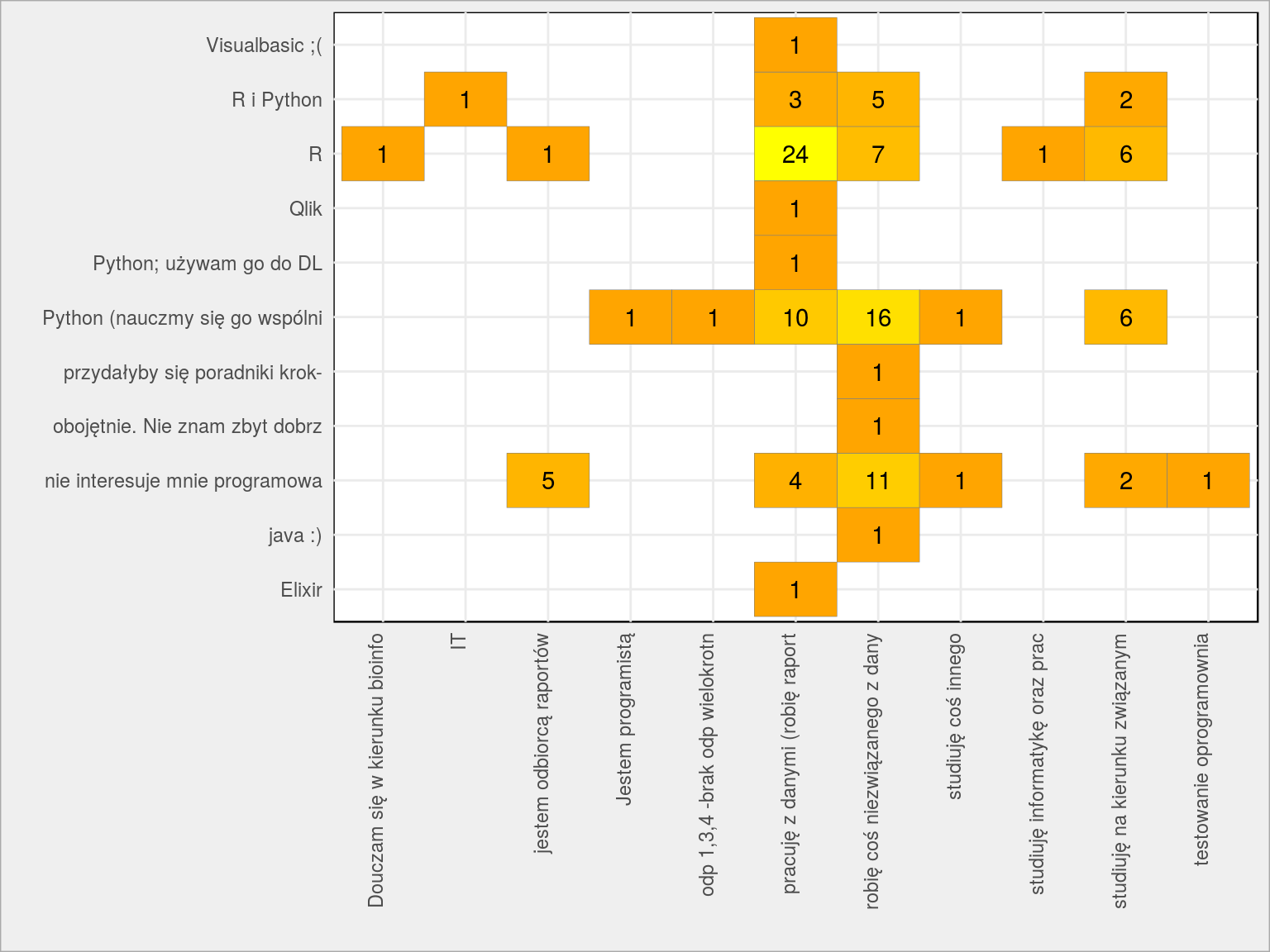
Analitycy używający R chcą R albo nauczyć się Pythona. Oczywiste. Ale 16 osób to osoby, które nie zajmują się analizą danych a chciałby nauczyć się Pythona.
I to wszystkie wyniki. Serdecznie dziękuję za Wasz poświęcony czas na odpowiedź na te kilka pytań. Mam nadzieję, że się dostosuję i będziecie zadowoleni.
„Qlika nie będzie, już prędzej byłoby Tableau albo PowerBI, ale z nimi jest problem taki że nie da się łatwo opisać tego co i jak zrobić (screenów nie będę wklejał), a i publikacja wyników jest utrudniona”
– tutaj bym się nie zgodził, z Tableau możesz wrzucić na Tableau Public i osadzić to potem we wpisie
Do ankiet polecam również pakiet „likert” http://rcompanion.org/handbook/E_03.html
Pingback: Sondaże przedwyborcze | Łukasz Prokulski
Pingback: Parsowanie XMLa w R | Łukasz Prokulski