Jak z poziomu Pythona dostać się do zawartości Outlooka (poczta, kalendarz)?
W niedawnym tekście opisałem drogę do aktualnego miejsca i zajęcia w pracy. Pisałem (chyba tak, sprawdź!), że sporo czasu zajmują mi spotkania? Sprawdźmy!

Photo by Estée Janssens on Unsplash
Poprzednio nie było też kodu, a przecież kod jest najciekawszy.
Gdzieś po drodze miałem styczność z VBA, a niedawno odkryłem, że w sumie z narzędziami MS Office można postępować dość podobnie z poziomu Pythona jak z poziomu VBA. Dzisiaj więc trochę o narzędziach MS Office dotykanych Pythonem.
Excela lepiej zastąpić Pandasem, więc się nim nie zajmiemy :P Ale może istnieć potrzeba sięgnięcia do Outlooka – albo do poczty albo do kalendarza. Tutaj będzie o odczytywaniu danych, ale zapis teź jest możliwy – poczytajcie dokumentację, o CreateItem() głownie chodzi).
Zaczniemy od początku – ogółu. Oczywiście całość przewidziana jest do działania w środowisku Windows (jest Office na Linuxy? Na MacOS nie miałem okazji sprawdzić jak i czy to zadziała). Użyjemy pythonowej biblioteki win32com, która jest swego rodzaju wrotami do systemowych DLLi dla Office, w tym przypadku podepniemy się do Outlooka.
|
1 2 3 4 |
from win32com.client import Dispatch outlook = Dispatch("Outlook.Application") ns = outlook.GetNamespace("MAPI") |
Po tych trzech linijkach w obiekcie ns mamy czubek naszego API outlookowego. Korzystając z metody GetDefaultFolder() możemy dostać się do odpowiedniego elementu (poczty, kalendarza, listy zadań) podając jako parametr odpowiedni numerek. Jaki? A sprawdźmy za co odpowiadają kolejne numeru uruchamiając kolejny fragment kodu:
|
1 2 3 4 5 6 7 |
for i in range(255): try: box = ns.GetDefaultFolder(i) name = box.Name print(i, name) except: pass |
Najbardziej interesujące nas elementy to skrzynki emailowe:
- 3 Elementy usunięte
- 5 Elementy wysłane
- 6 Skrzynka odbiorcza
oraz dodatkowo:
- 9 Kalendarz
- 10 Kontakty
- 13 Zadania
Wiadomości email
Żeby dostać się do elementów danego boxa wykorzystamy parametr Items, czyli – żeby dostać wszystkie maile ze skrzynki odbiorczej użyjemy:
|
1 |
emails = ns.GetDefaultFolder(6).Items |
a później w pętli jedziemy po elementach listy emails. Każdy z nich posiada odpowiednie właściwości (lista i opis w dokumentacji, które sobie będziemy czytać i coś z nimi robić (w tym przypadku tylko zapiszemy listę maili do pliku CSV). Każda z list (wiadomości, spotkań w kalendarzu, zadań) posiada różne elementy, a te elementy mogą mieć różny typ (być obiektem różnej klasy) – lista jest oczywiście w dokumentacji (co by nie mówić o Microsoft to dokumentację online mają spoko). Krótko mówiąc: wiadomościami jest to, co ma IPM.Note na początku. Wyjęcie interesujących elementów dla każdej z wiadomości to po prostu odczytanie jej właściwości:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
import pandas as pd email_formats = ['Unspecified', 'Plain text', 'HTML', 'RTF'] # 6 = Skrzynka odbiorcza emails = ns.GetDefaultFolder(6).Items # lista na wszystkie emaile all_rows = [] for el in emails: row = {} if el.MessageClass[:8] == 'IPM.Note': row['MessageClass'] = el.MessageClass # klasa obiektu row['UnRead'] = el.UnRead # czy wiadomość przeczytana? row['ReceivedTime'] = str(el.ReceivedTime.Format('%d/%m/%Y %H:%M')) # data otrzymania wiadomości jako string row['Size'] = el.Size # rozmiar wiadomości row['Importance'] = el.Importance # priorytet row['ConversationID'] = el.ConversationID # ID wątku wiadomości row['EntryID'] = el.EntryID # ID wiadomości row['Subject'] = el.Subject # temat maila row['BodyFormat'] = email_formats[el.BodyFormat] # format maila row['SenderName'] = el.SenderName # nadawca row['To'] = el.To # adresaci row['CC'] = el.CC # odbiorcy w CC row['Attachments'] = len(el.Attachments) # liczba załączników row['Body'] = el.Body # treść row['HTMLBody'] = el.HTMLBody # treść w HTMLu all_rows.append(row) all_table = pd.DataFrame(all_rows) |
W efekcie w all_table mamy dataframe’a z zawartością naszej skrzynki odbiorczej. Co z tym zrobimy to już nasza sprawa :)
Dodatkowo jeśli chcemy dostać się do załączników do wiadomości możemy to zrobić przez (dla każdej wiadomości, więc gdzieś tam w tej pętli):
|
1 2 |
for a in el.Attachments: print(a.DisplayName, a.FileName, a.Size) |
zaś sam załącznik można zapisać korzystając z a.SaveAsFile(ścieżka_pliku_docelowego). Oczywiście printowanie nie ma większego sensu, lepiej byłoby zapisać listę załączników do nowego elementu słownika row.
Kalendarz
Podobnie możemy potraktować kalendarz, wyjmując poszczególnie spotkania i zapisując je w CSV. Będzie to wyglądało tak:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
import datetime # 9 = Kalendarz appointments = ns.GetDefaultFolder(9).Items appointments.IncludeRecurrences = "True" appointments.Sort("[Start]") # ograniczamy zakres pobieranych wydarzeń - od początku świata do dnia "za 30 dni od dzisiaj" # begin = datetime.date.today() end = begin + datetime.timedelta(days=30) # tak możemy ograniczyć początek: restriction = "[Start] >= '" + begin.strftime("%d/%m/%Y %H:%M") + "' " restriction = "[End] <= '" + end.strftime("%d/%m/%Y %H:%M") + "'" restrictedItems = appointments.Restrict(restriction) # lista wszystkich spotkań all_rows = [] # przebiegamy przez całą listę i zapisujemy interesujące nas elementy per spotkanie for appointmentItem in restrictedItems: row = {} row['Title'] = appointmentItem.Subject row['Organizer'] = appointmentItem.Organizer row['Start'] = appointmentItem.Start.Format("%d/%m/%Y %H:%M") row['End'] = appointmentItem.End.Format("%d/%m/%Y %H:%M") row['Duration'] = appointmentItem.Duration all_rows.append(row) # budujemy tabelę pandasową i zapisujemy do CSV all_table = pd.DataFrame(all_rows) all_table.to_csv("calendar.csv", index=False) |
Właściwości wydarzeń znajdziecie oczywiście w dokumentacji.
Jak widzicie mechanika jest ta sama: z folderu pobrać listę elementów, a potem dla każdego z elementów jego metadane.
Kalendarz analityka
Obiecałem, że powiem ile czasu zajmują mi spotkania. No to zobaczmy co wyjęliśmy z kalendarza – na podstawie zgromadzonych w CSV metadanych. Trochę więc przeanalizujemy, już w R (a co, ładniejsze są obrazki).
|
1 2 3 4 5 |
library(tidyverse) library(tidytext) # reorder_within() & scale_y_reordered() library(lubridate) cal_df <- read_csv("calendar.csv") |
Mając wczytane dane możemy przejść do ich czyszczenia – wyrzucimy jakieś stałe zdania statusowe, bloki na obiad (tak, planuję sobie obiady w kalendarzu – głównie po to, żeby była szansa, że nikt tego czasu nie zabierze) i podobne:
|
1 2 3 4 |
# powtarzalne i prywatne zadania cal_df <- cal_df %>% filter(!str_detect(Title, "obiad|Obiad")) %>% filter(!Title %in% c("Spotkanie statusowe", "Poranny standup", "Status BigData")) |
Po odrzuceniu zaśmiecających wydarzeń odrobina obróbki, głównie elementów związanych z czasem (datą początku i końca, długością trwania) spotkań:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
cal_df <- cal_df %>% mutate(Duration = Duration / 60) %>% # max 12h spotkania - żeby nie było urlopów, świąt itd filter(between(Duration, 0, 12)) %>% mutate( Start = dmy_hm(Start), End = dmy_hm(End) ) %>% arrange(Start) %>% mutate( wday = wday(Start, week_start = 1), date = date(Start), date_week = round_date(Start, unit = "week", week_start = 1), date_month = month(date), date_year = year(date), start_h = hour(Start) + minute(Start) / 60, end_h = hour(End) + minute(End) / 60 ) %>% # bez jakichś ekstremów typu wyjście na piwo do północy czy weekendowe wdrożenia ;) filter(between(end_h, 8, 18) & between(start_h, 6, 18) & (wday <= 5)) %>% mutate(Title = str_remove(Title, "PD: ")) %>% mutate(Title = str_remove(Title, "FW: ")) %>% mutate(wday = factor(x = wday, labels = c("pn", "wt", "śr", "cz", "pt"), levels = 1:5)) |
Zobaczmy jak wyglądają wszystkie moje spotkania wrzucone na jeden wykres:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
# wszystkie spotkania na linii czasu cal_df %>% ggplot() + geom_segment(aes( x = date, xend = date, y = start_h, yend = end_h ), alpha = 0.5) + scale_y_continuous(trans = "reverse", breaks = 6:18) + labs( title = "Wszystkie spotkania od początku zatrudnienia", x = "", y = "Czas spotkania" ) |
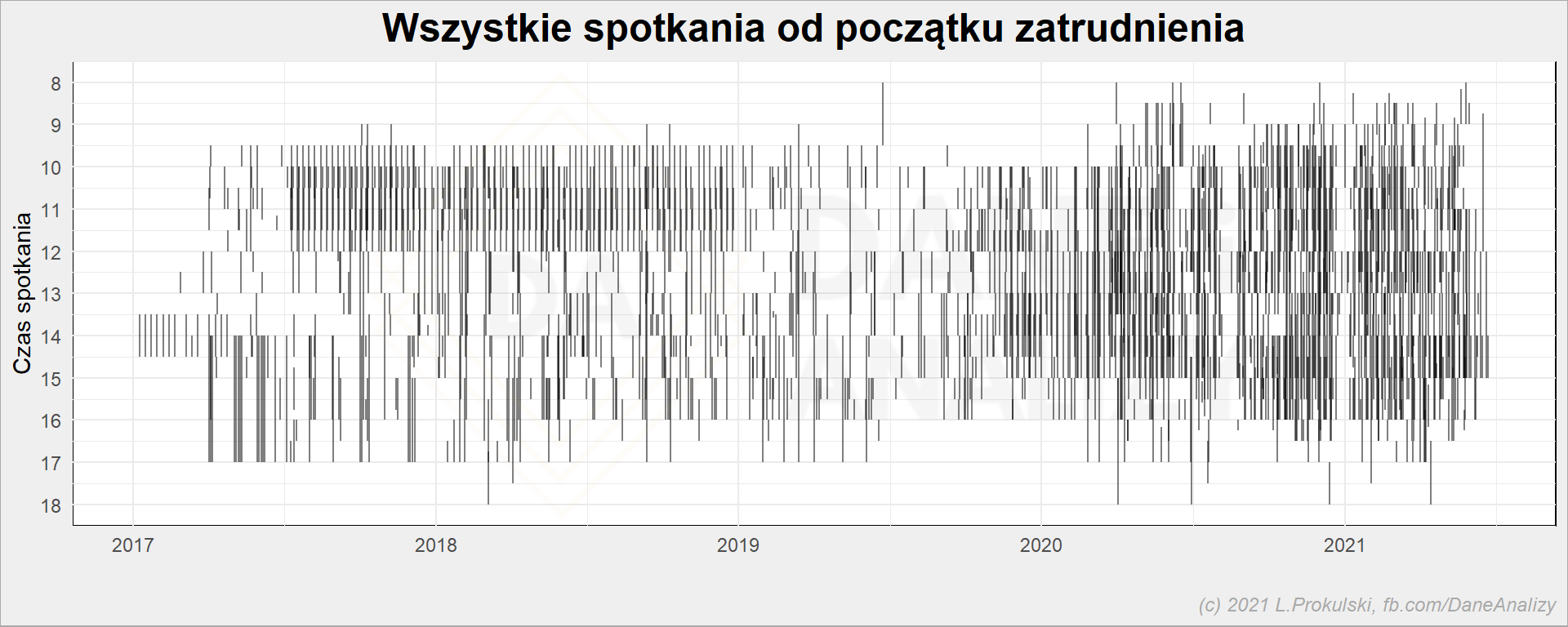
W drugiej części 2020 roku przybyło, prawda? Ile spotkań tygodniowo miałem na przestrzeni ostatnich lat?
|
1 2 3 4 5 6 7 8 9 10 |
# liczba spotkań per tydzień cal_df %>% count(date_week) %>% ggplot() + geom_smooth(aes(date_week, n)) + geom_point(aes(date_week, n)) + labs( title = "Tygodniowa liczba spotkań", x = "", y = "Liczba spotkań w tygodniu" ) |
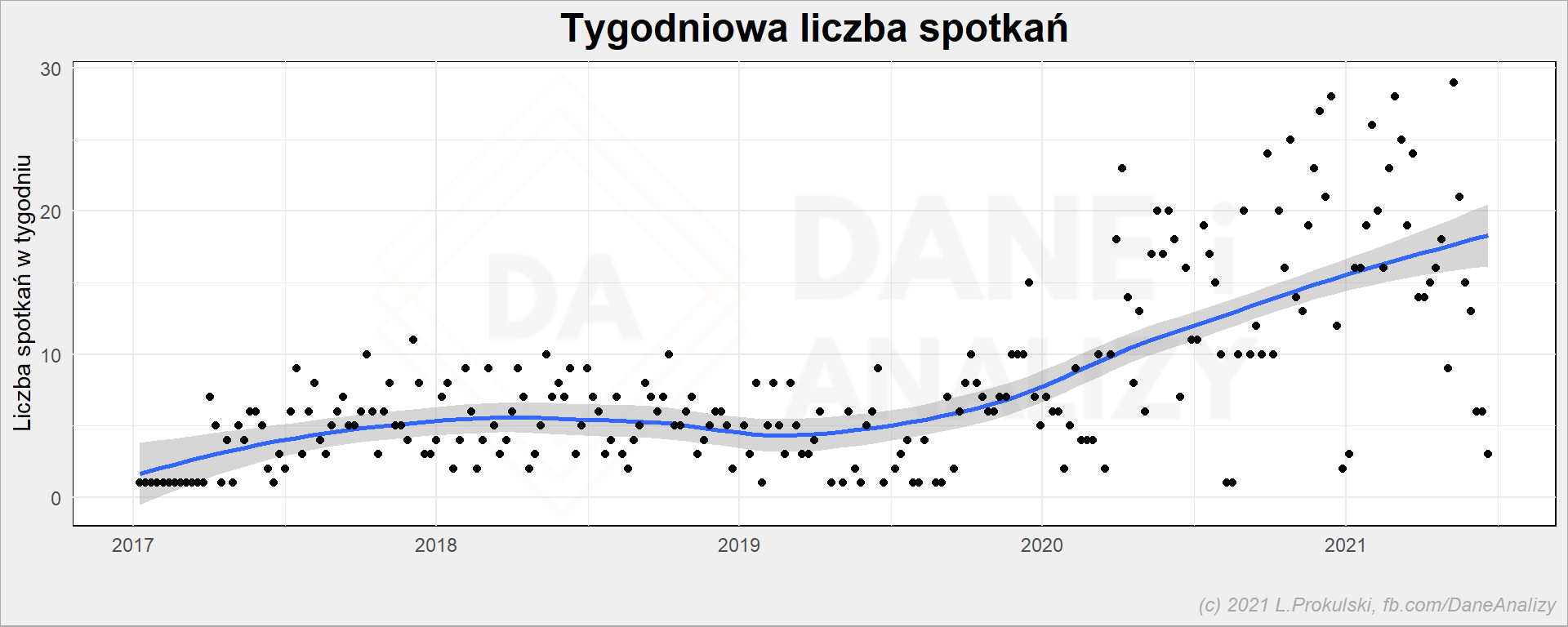
Jak widać nie ma lekko – mniej więcej jesienią 2019 roku zamieniłem zespół i trochę też zajęcie (więcej spotkań, mniej pracy samodzielnej) ale również inaczej zacząłem zarządzać kalendarzem – zacząłem bukować sobie w kalendarzu czas na robienie tych samodzielnych rzeczy, chociażby po to żeby nie być od nich odrywany.
Jeśli nie wiesz jak zarządzać swoim czasem – obejrzyj HRejterów (wiem, że to robisz) i ich szkolenie.
Widać też początek pandemii i przejście na pracę zdalną. To sprawiło znaczny wzrost spotkań (nie potrzeba salek, wystarczy Skype/Teams). U mnie skorelowało się to z pracami nad kilkoma sporymi projektami, więc trudno na moim przykładzie pokazać czysty wpływ lockdownu na liczbę spotkań.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
# czas zajęty przez spotkania per tydzień cal_df %>% group_by(date_week) %>% summarise(Duration = sum(Duration)) %>% ungroup() %>% ggplot() + geom_smooth(aes(date_week, Duration)) + geom_point(aes(date_week, Duration)) + geom_hline(yintercept = c(10, 20, 30, 40), color = "red") + labs( title = "Łączny czas spotkań w tygodniu", x = "Data", y = "Łączny czas spotkań [h]" ) |
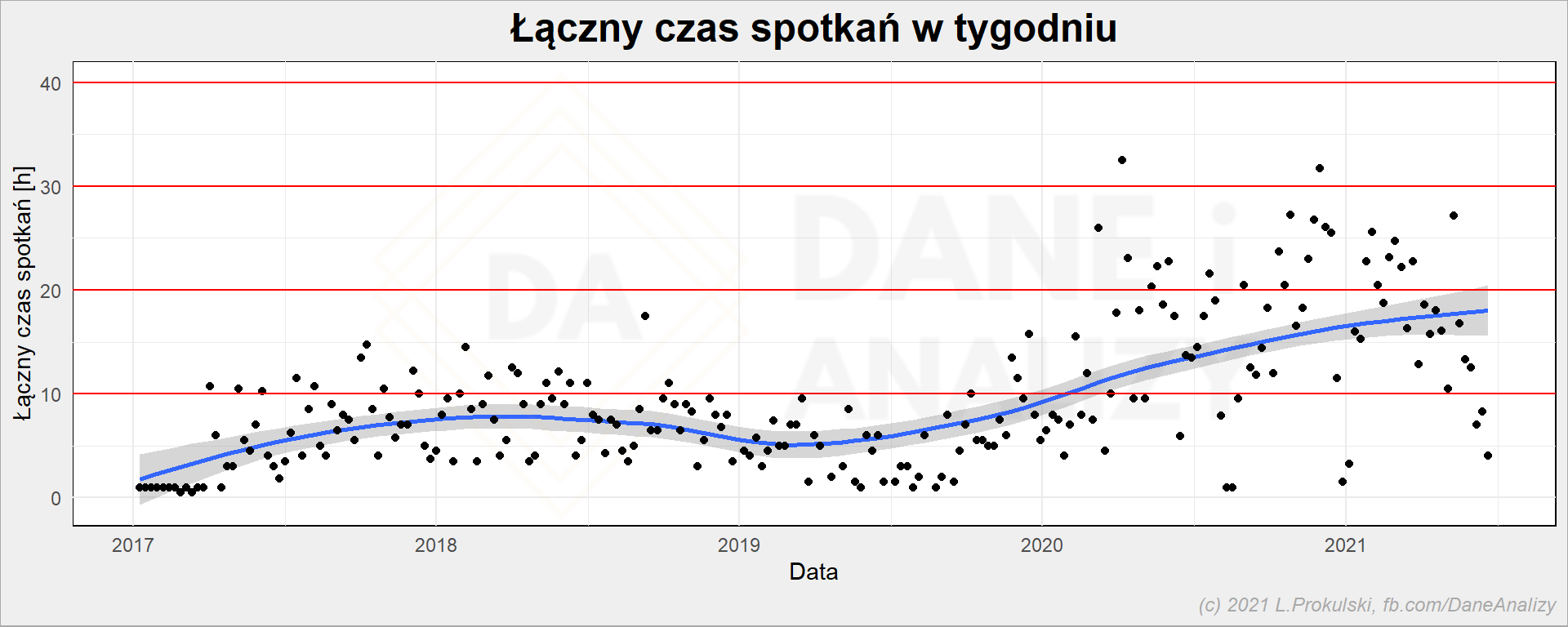
Oczywiście im więcej spotkań tym więcej czasu zajmują. Ale 5 spotkań po 30 minut to nie to samo co trzy godzinne spotkania. Powyższy wykres obrazuje zajętość czasu, a precyzyjniej jaki procent tygodnia zajmują spotkania. Bywało, że 3/4… ale czasem jest tak, że jest się na 2 spotkaniach równolegle. Na prawdę jest się na jednym z nich, ale w kalendarzu zostają oba. Pamiętacie też, że wypadły z listy obiady i poranne daily.
Koniec końców: jakaś 1/3 tygodnia to spotkania.
Ile trwają spotkania?
|
1 2 3 4 5 6 7 8 9 10 11 |
# rozkład długości spotkań cal_df %>% ggplot() + geom_histogram(aes(Duration), binwidth = 0.25, fill = "lightgreen", color = "black" ) + labs( title = "Rozkład długości spotkań", x = "Czas trwania spotkania [h]", y = "Liczba spotkań" ) |
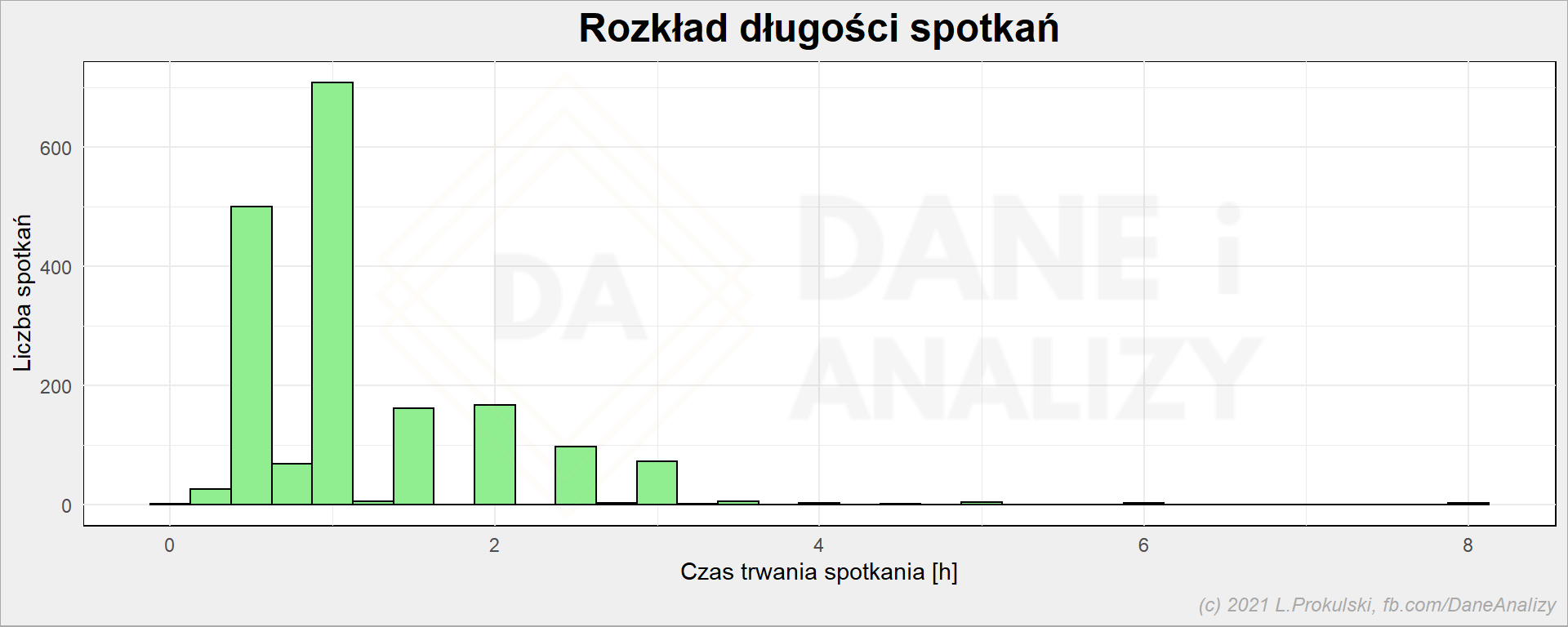
Standardowo godzinę, a ewentualne dogrywki 30 minut. Ta reguła nie wynika wprost z powyższego wykresu, ale z wykresu popartego doświadczeniem. A bierze się to pewnie ze standardowego ustawienia Outlooka, gdzie szybko da się ustawić spotkania dla których kwant czasu to 30 minut. Idę o zakład, że gdyby każdy miał domyślnie siatkę 15 minutową to byłoby więcej spotkań 45 minutowych i zaczynałyby się one o pełnej godzinie. Tak działa nasz mózg.
Szkoda, że nie zebrałem liczby osób zaproszonych na spotkania. To też byłaby ciekawa statystyka.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
# liczba spotkań per miesiąc cal_df %>% count(date_year, date_month) %>% mutate(date_month = factor(date_month, levels = 1:12, labels = month.abb )) %>% ggplot() + geom_col(aes(date_month, n), fill = "lightgreen", color = "black" ) + facet_wrap(~date_year, ncol = 1) + labs( title = "W których miesiącach odbywa się najwięcej spotkań?", x = "Miesiąc", y = "Liczba spotkań" ) |
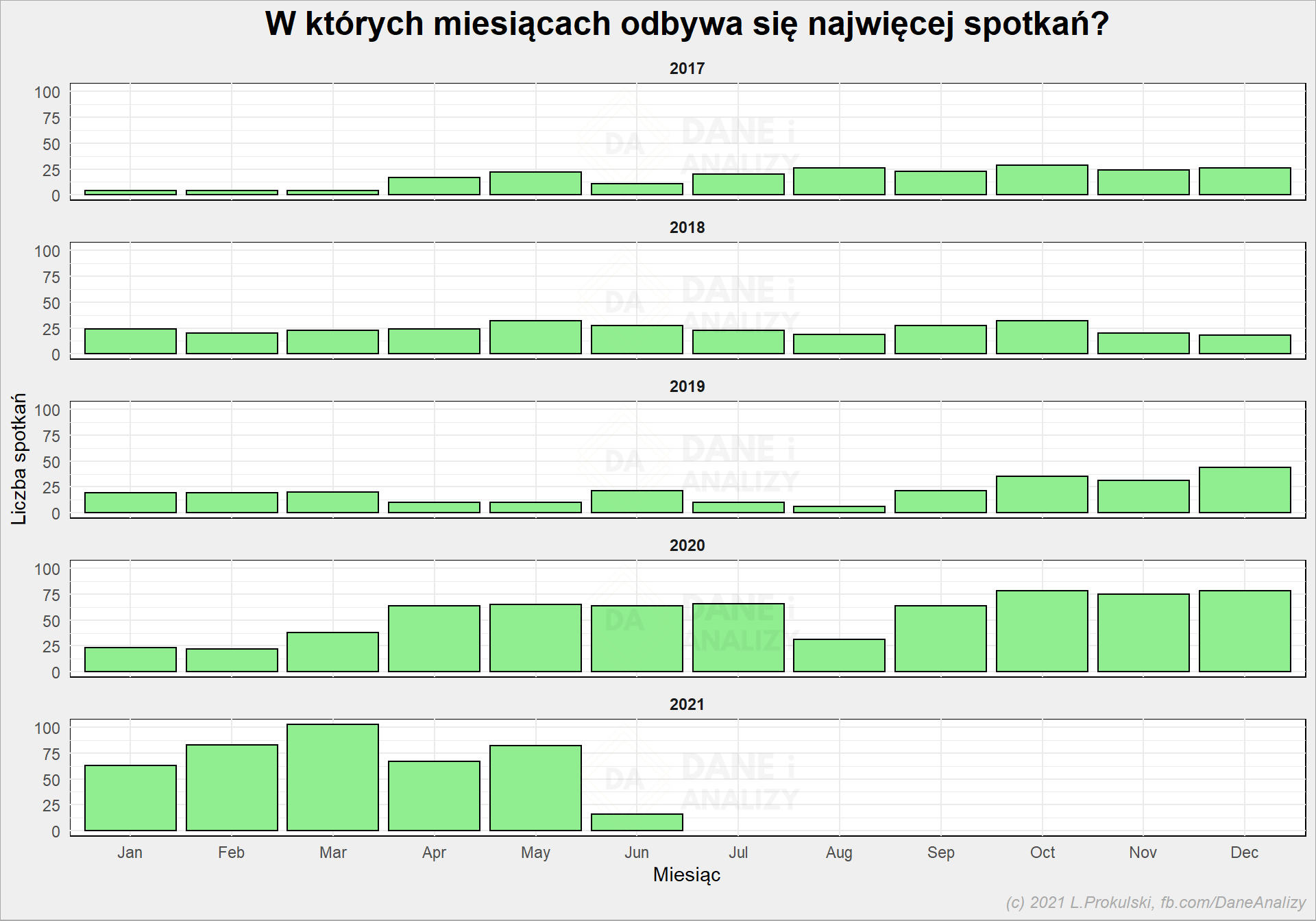
Tutaj może lepiej widać początek pandemii niż na którymś z wykresów wcześniej. Marzec 2020 to ten przełomowy moment i jak widać słupki z późniejszych miesięcy są wyższe. Bardzo jestem ciekaw jak to się zmieni po powrocie do biura… Dobrze widać też sierpniowe wakacje w 2020.
|
1 2 3 4 5 6 7 8 9 10 11 |
# kiedy są spotkania - pod względem sztuk cal_df %>% count(wday) %>% ggplot() + geom_col(aes(wday, n), fill = "lightgreen", color = "black" ) + labs( title = "W jakich dniach tygodnia odbywa się najwięcej spotkań?", x = "", y = "Skumulowana liczba spotkań" ) |
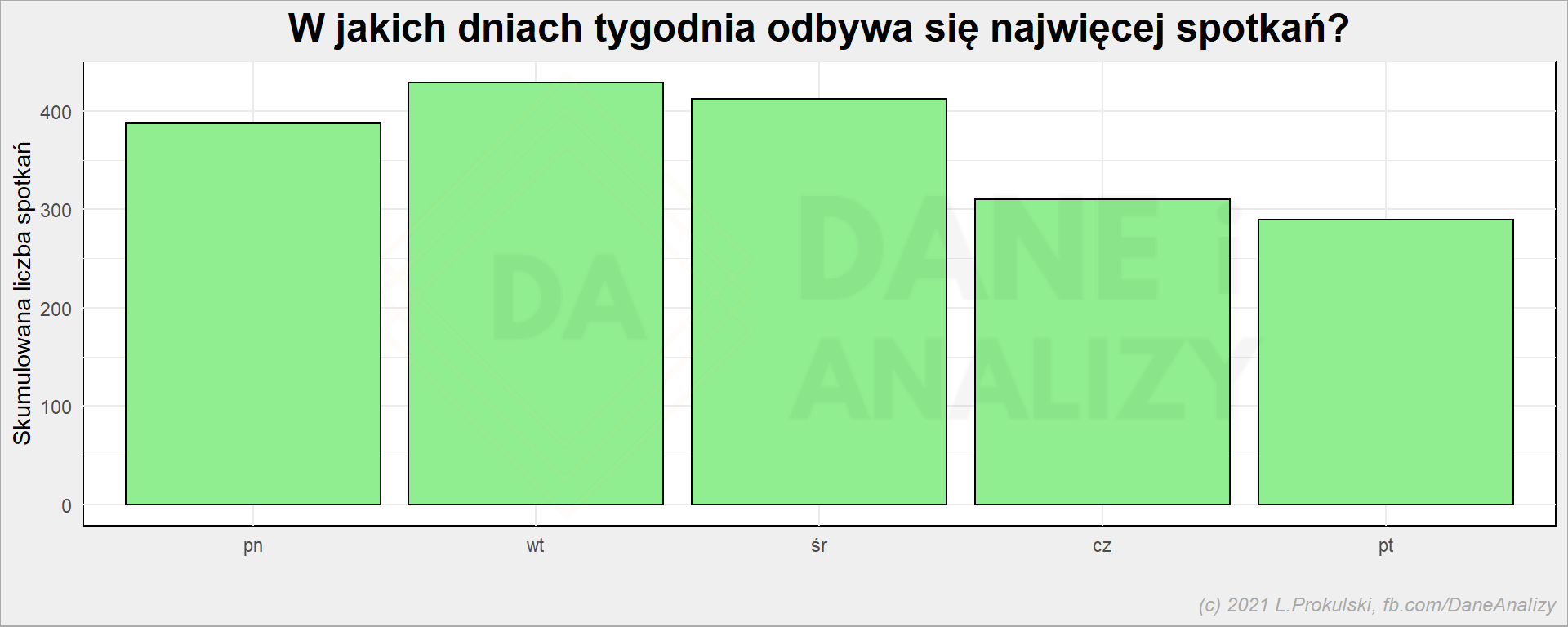
Rytm tygodnia jest taki, że w pierwszej połowie się ustala co trzeba zrobić w drugiej. I to doskonale widać na powyższym wykresie. Ale czy to jest prawda? Bo wykres pokazuje wszystkie spotkania łącznie. Jak to wygląda jeśli chodzi o czas?
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
# kiedy są spotkania - pod względem czasu cal_df %>% group_by(wday) %>% summarise( Duration = sum(Duration), n = n() ) %>% ungroup() %>% mutate(p = Duration / (8 * n)) %>% ggplot() + geom_col(aes(wday, p), fill = "lightgreen", color = "black" ) + scale_y_continuous(labels = scales::percent) + labs( title = "W jakich dniach tygodnia spotkania zjadają najwięcej czasu?", x = "", y = "Średnia część dnia na spotkaniach" ) |
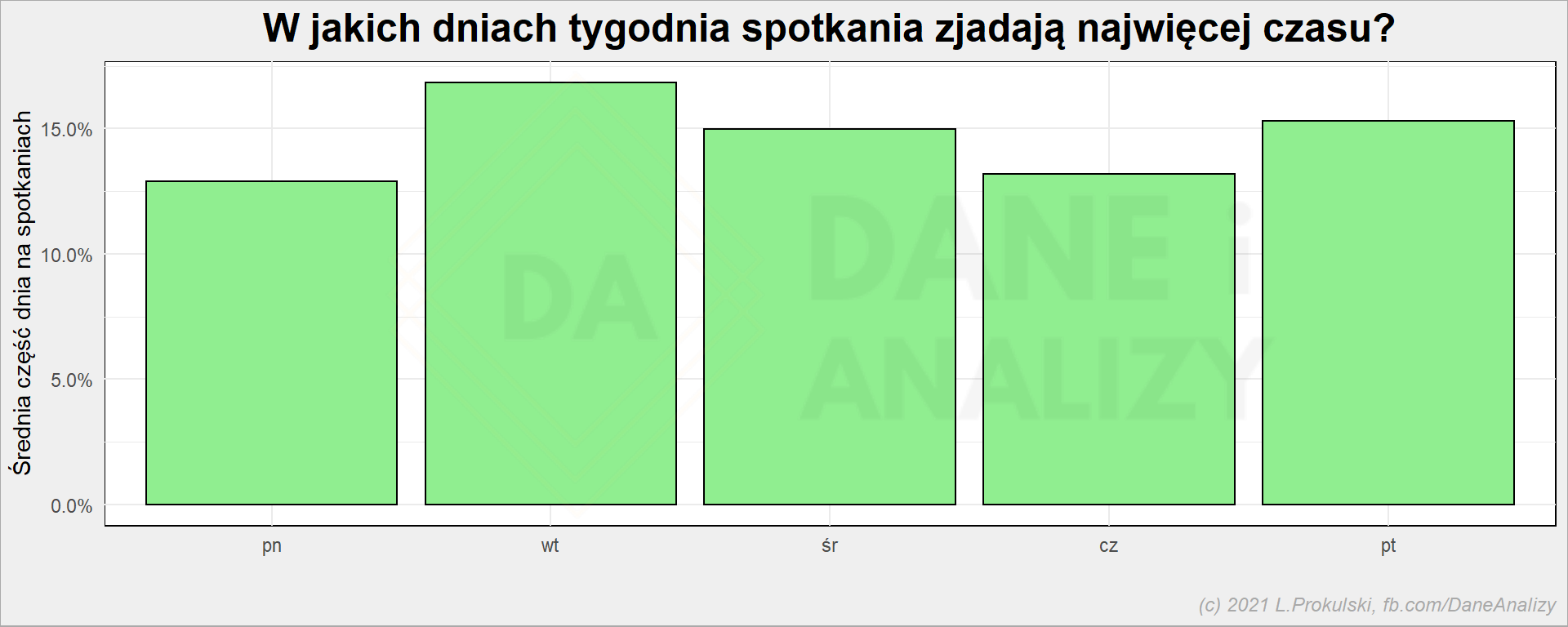
Tutaj mamy inny obrazek. Nadal najwięcej czasu zajmują spotkania wtorkowe, ale piątki wcale nie są najlżejsze. W piątki jest mniej ale dłużej. Bo piątki do dobry czas na rzeczy typu szkolenia wewnętrzne (bach, dwie godzinki), demo rzeczy powstałych w zakończonym sprincie (bach, 3 godziny), albo bloki praca własna (czytaj: nie wsadzajcie mi tu już niczego, bo może urwę się wcześniej z pracy na weekend ;-).
|
1 2 3 4 5 6 7 8 9 10 11 |
# rozkład czasu wg dni tygodnia cal_df %>% ggplot() + geom_violin(aes(wday, Duration), fill = "lightgreen", color = "black" ) + scale_y_continuous(breaks = seq(0, 8, 0.5)) + labs( title = "Rozkład długości spotkań w zależności od dnia tygodnia", x = "", y = "Czas trwania spotkań [h]" ) |
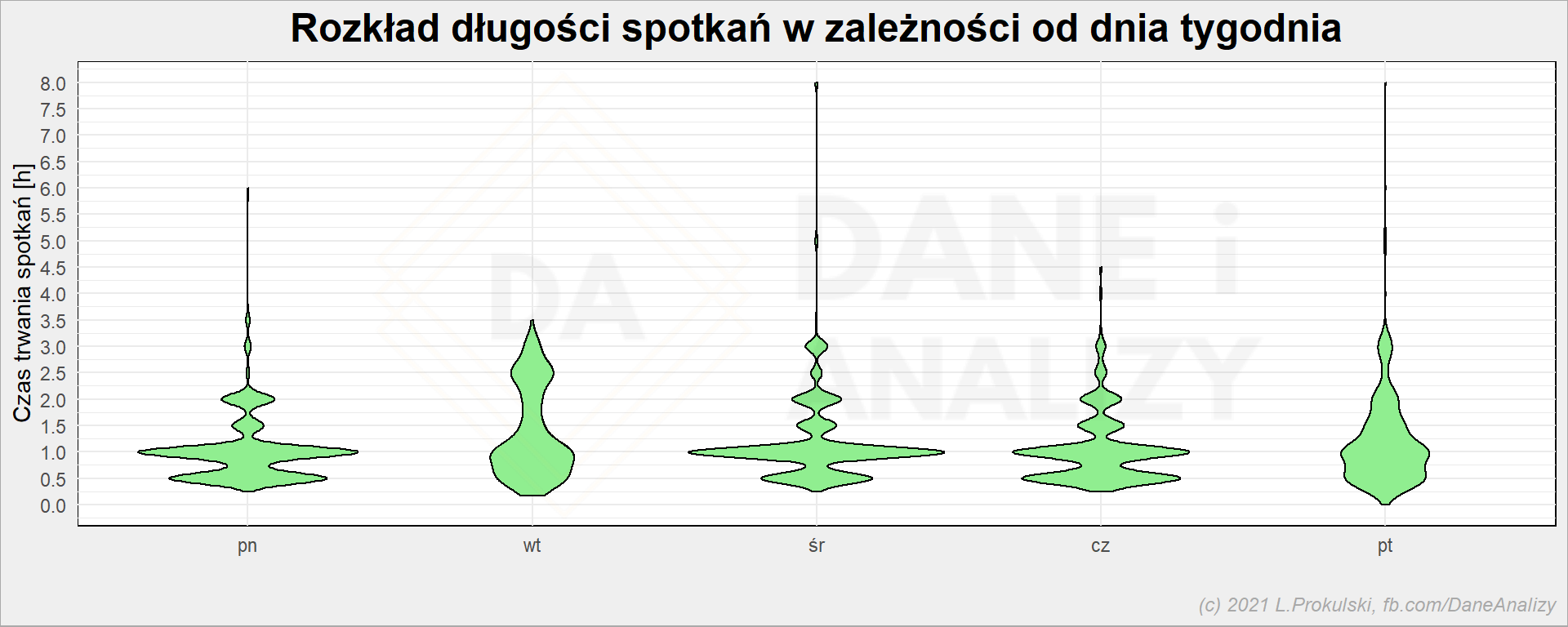
Teorię o dłuższych piątkowych spotkaniach potwierdza powyższy wykres. Krótkich spotkań (30 minutowych) najwięcej jest w poniedziałki (statusy projektów, których nie usunąłem w przeciwieństwie do statusów zespołów) i w czwartki (przygotowanie do sprint demo). I te krótkie przebiegi są prawdę mówiąc gorsze (więcej przełączania się między tematami).
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
# kiedy najczęściej rozpoczynają się spotkania? cal_df %>% mutate(start_h = round(start_h)) %>% count(wday, start_h) %>% mutate(p = n / sum(n)) %>% ggplot() + geom_tile(aes(wday, start_h, fill = n), color = "gray50", show.legend = FALSE) + geom_text(aes(wday, start_h, label = sprintf("%0.1f%%", 100 * p))) + scale_y_continuous(breaks = 6:18, trans = "reverse") + scale_fill_distiller(palette = "OrRd", direction = 1) + theme(legend.position = "bottom") + labs( title = "W jakich godzinach rozpoczynają się spotkania?", x = "", y = "Godzina rozpoczęcia spotkania", fill = "% wszystkich spotkań" ) |
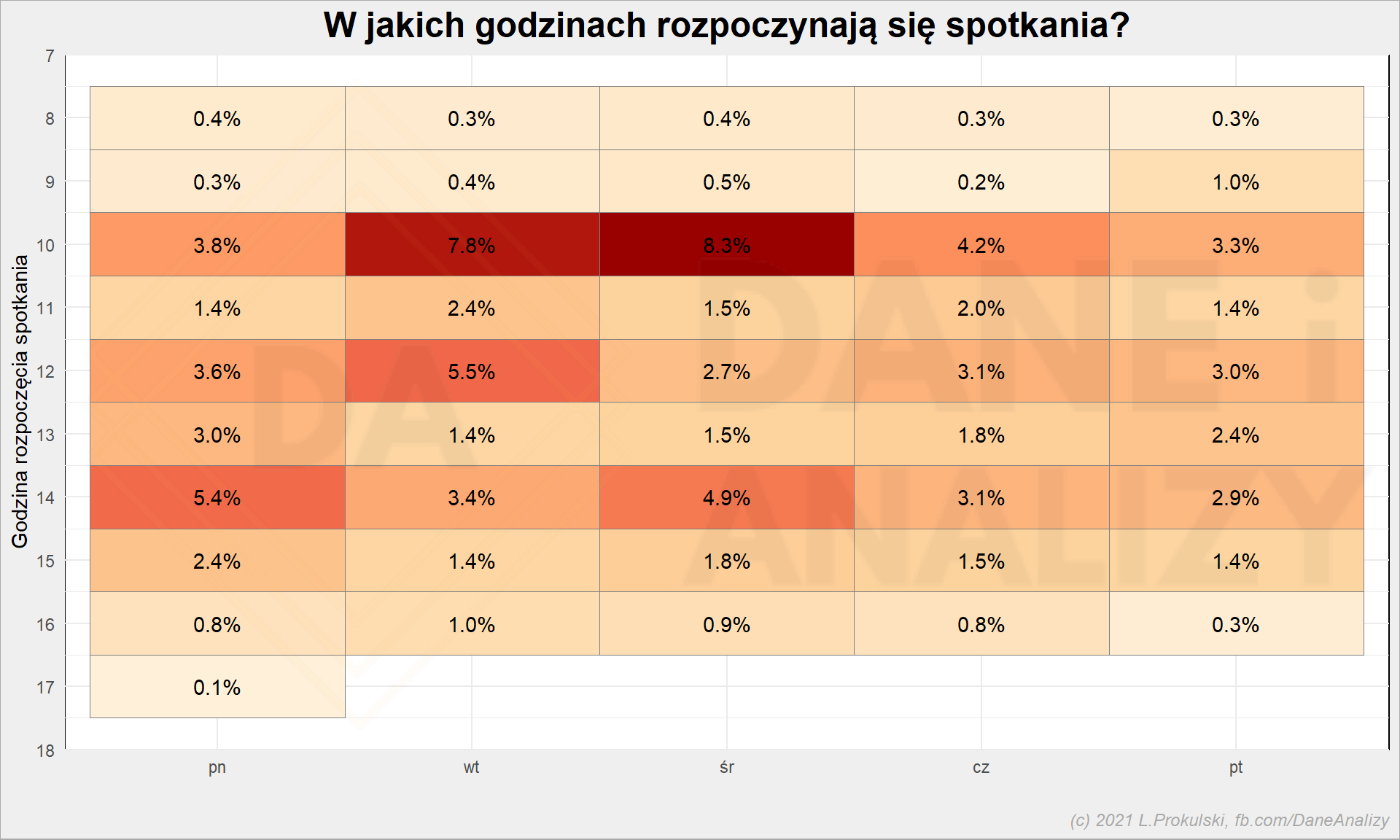
A teraz coś innego – jakie jest prawdopodobieństwo, że w danym momencie dnia mam spotkanie?
Przygotujmy siatkę wszystkich możliwych terminów (co 15 minut) i sprawdźmy ile spotkań odbywało się w każdym z nich. Poniższy sposób robi robotę, ale chyba nie jest najbardziej optymalny (przechodzimy przez kolejne terminy i zliczamy ile spotkań trwało w danej chwili), ale działa.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
# ile % czasu w danym slocie jest zajęte? min_d <- min(cal_df$Start) max_d <- max(cal_df$End) new_dates <- tibble(datetime = seq(make_datetime(year(min_d), month(min_d), 1), make_datetime(year(max_d), month(max_d) + 1, 1), by = "15 min" )) %>% mutate( datetime_h = hour(datetime), datetime_wday = wday(datetime, week_start = 1) ) %>% filter(between(datetime_h, 8, 18) & (datetime_wday <= 5)) count_occupacy <- function(dt) { return(cal_df %>% filter(Start <= dt) %>% filter(End > dt) %>% nrow()) } new_dates$n_meetings <- lapply(new_dates$datetime, count_occupacy) %>% unlist() |
Teraz pozostaje nam tylko tą całą siatkę pogrupować, posumować i narysować:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
new_dates %>% group_by(datetime_h) %>% summarise(m = mean(n_meetings)) %>% ungroup() %>% ggplot() + geom_col(aes(datetime_h, m), fill = "lightgreen", color = "black" ) + scale_x_continuous(breaks = 6:18) + labs( title = "Średnia liczba spotkań w zależności od godziny", x = "", y = "Średnia liczba spotkań\n(prawdopodobieństwo, że jestem na spotkaniu)" ) |
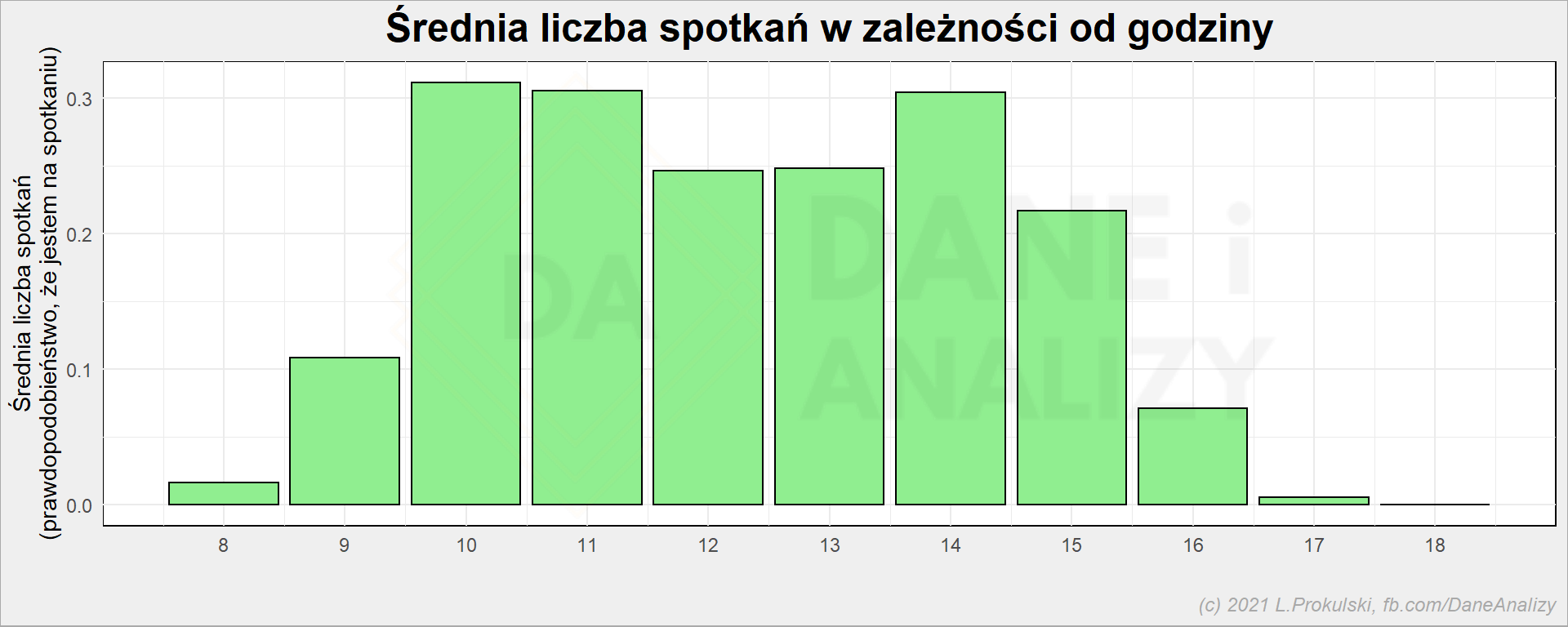
Dodajmy do tego wykresu jeszcze wymiar dnia tygodnia:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
new_dates %>% group_by(datetime_wday, datetime_h) %>% summarise(m = mean(n_meetings)) %>% ungroup() %>% ggplot() + geom_tile(aes(datetime_wday, datetime_h, fill = m), color = "gray50") + geom_text(aes(datetime_wday, datetime_h, label = sprintf("%.1f%%", 100 * m))) + scale_y_continuous(trans = "reverse", breaks = 6:18) + scale_fill_distiller(palette = "OrRd", direction = 1) + theme(legend.position = "bottom") + labs( title = "Obłożenie spotkaniami w zależności od pory tygodnia", x = "", y = "", fill = "Prawdopodobieństwo,\nże jestem na spotkaniu" ) |
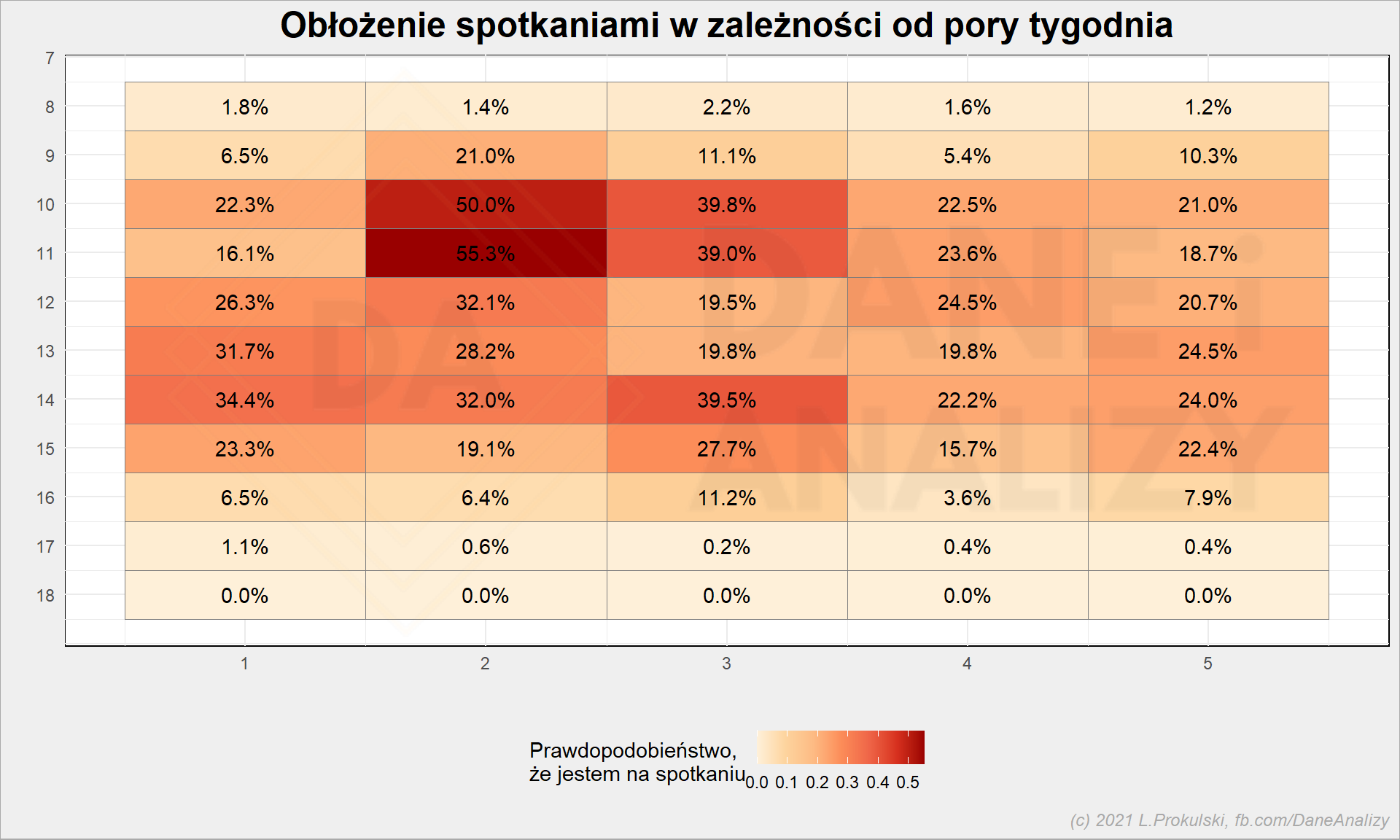
Chcesz się ze mną spotkać? Celuj w środek środy i od połowy czwartku. To, że o 8 rano jest stosunkowo wolne nie oznacza, że chętnie o tej godzinie się umawiam ;)
Bardzo ciekawy wpis