Jak wykorzystać dane o numerycznym modelu terenu (NMT)? Skąd je wziąć i jak przygotować do wygodniej pracy?
Dzisiaj wpis mocno techniczny, bez szczególnych analiz. Gratka dla osób szukających sposobów na rozdzielenie danych punktowych na gminy, powiaty i województwa oraz wskazówki jak pokazywać takie dane na mapie (i agregować je zgodnie z podziałem terytorialnym). Oprzemy się na danych o wysokości terenu, ale to tylko przykład.
Potrzebne nam będą następujące biblioteki:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
library(tidyverse) # do wszystkiego :) library(rvest) # do srappingu strony library(rgdal) # do obsługi plików SHP library(rgeos) library(raster) library(ggmap) # do wczytania mapy z Google Maps library(sf) # do wczytywania plików SHP i łatwego rysowania library(RPostgreSQL) # do zapisu i odczytu danych z bazy, w tym przypadku baza PostgreSQL |
Kolejne fragmenty kodu to kilka skryptów złączonych w jedno. Stąd mogą trafić się powtórzenia w kodzie albo te same dane pod różnymi nazwami zmiennych. Nie przejmujcie się tym – czytając kod i rozumiejąc go znajdziecie sposób na wybranie tego, co najbardziej Was interesuje.
Zaczniemy od zgromadzenia danych o wysokości terenu. Centralny Ośrodek Dokumentacji Geodezyjnej i Kartograficznej (CODGiK) udostępnia takie dane w postaci plików tekstowych (jeden plik to jedno województwo). Struktura plików jest bardzo prosta – w każdym wierszu mamy informację dla jednego punktu: współrzędne punktu i jego wysokość nad poziomem morza. Pliki na serwerze CODGiK są spakowane – pobierzmy je i rozpakujmy.
Aby nie bawić się w ręczne pobieranie każdego pliku zeskanujmy automatycznie stronę i wyciągnijmy linki do plików. Nie raz już scrappowaliśmy strony, więc pójdzie łatwo:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
base_url <- "http://www.codgik.gov.pl/index.php/darmowe-dane/nmt-100.html" # wyciągamy linki do plików data_urls <- read_html(base_url) %>% html_node("table") %>% html_nodes("a") %>% html_attr("href") # każdy link: for(i in 1:length(data_urls)) { file_url <- data_urls[[i]] # sciagamy plik download.file(file_url, paste0("dane/", basename(file_url))) # rozpakowujemy go unzip(paste0("dane/", basename(file_url)), exdir = "dane/") # chwilę czekamy Sys.sleep(1) } |
Po tej operacji mamy 16 plików tekstowych w folderze dane/. Weźmy na warsztat Małopolskę.
Pierwszym krokiem będzie wczytanie danych i przygotowanie ich w odpowiednim układzie współrzędnych (takim, jaki znamy z geografii). Niestety pliki zapisane są w układzie PUWG 1992, musimy je przemapować. Oczywiście istnieją odpowiednie do tego funkcje, które potrafią to zrobić na obiektach typu Shape:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
rm(list = ls()) # sprzątamy to co było do tej pory - tutaj zaczyna się oddzielny skrypt # przygotowanie palety paleta_rgb <- c("#41786E", "#5AA03C", "#BED200", "#FFFA78", "#FCDC00", "#F5BE00", "#F0A04B", "#E68246", "#E15F32", "#D2412D") # układy współrzędnych # dane są w układzie PUWG 1992 CRS_puwg1992 <- crs("+proj=tmerc +lat_0=0 +lon_0=19 +k=0.9993 +x_0=500000 +y_0=-5300000 +ellps=GRS80 +units=m +no_defs ") # układ WGS84 (współrzędne "normalne") CRS_wgs84 <- crs("+proj=longlat +ellps=WGS84 +datum=WGS84 +no_defs;") # wczytujemy plik dane_plik <- "dane/malopolskie.txt" dane_nmt <- read_delim(dane_plik, " ", col_names = c("x", "y", "z"), col_types = "ddd") # przeliczenie wspołrzędnych coordinates(dane_nmt) <- c("x", "y") projection(dane_nmt) <- CRS_puwg1992 dane_nmt_wgs84 <- spTransform(dane_nmt, CRS_wgs84) dane_nmt <- as.data.frame(dane_nmt_wgs84@coords) %>% mutate(z = dane_nmt_wgs84$z) # zaokrąglenie danych = zmniejszenie dokładności i jednocześnie liczby punktów do narysowania plot_data <- dane_nmt %>% mutate(x = round(x, 2), y = round(y, 2)) %>% group_by(x, y) %>% summarise(z = mean(z)) %>% ungroup() |
Dane zaokrągliliśmy, aby szybciej się rysowały. Oczywiście nie musicie tego robić. Pierwsza nasza mapka to wysokość w wybranym województwie:
|
1 2 3 4 5 6 |
# rysujemy naszą pierwszą mapę plot_data %>% ggplot(aes(x, y, color = z)) + geom_point() + coord_map() + scale_color_gradientn(colors = paleta_rgb) |
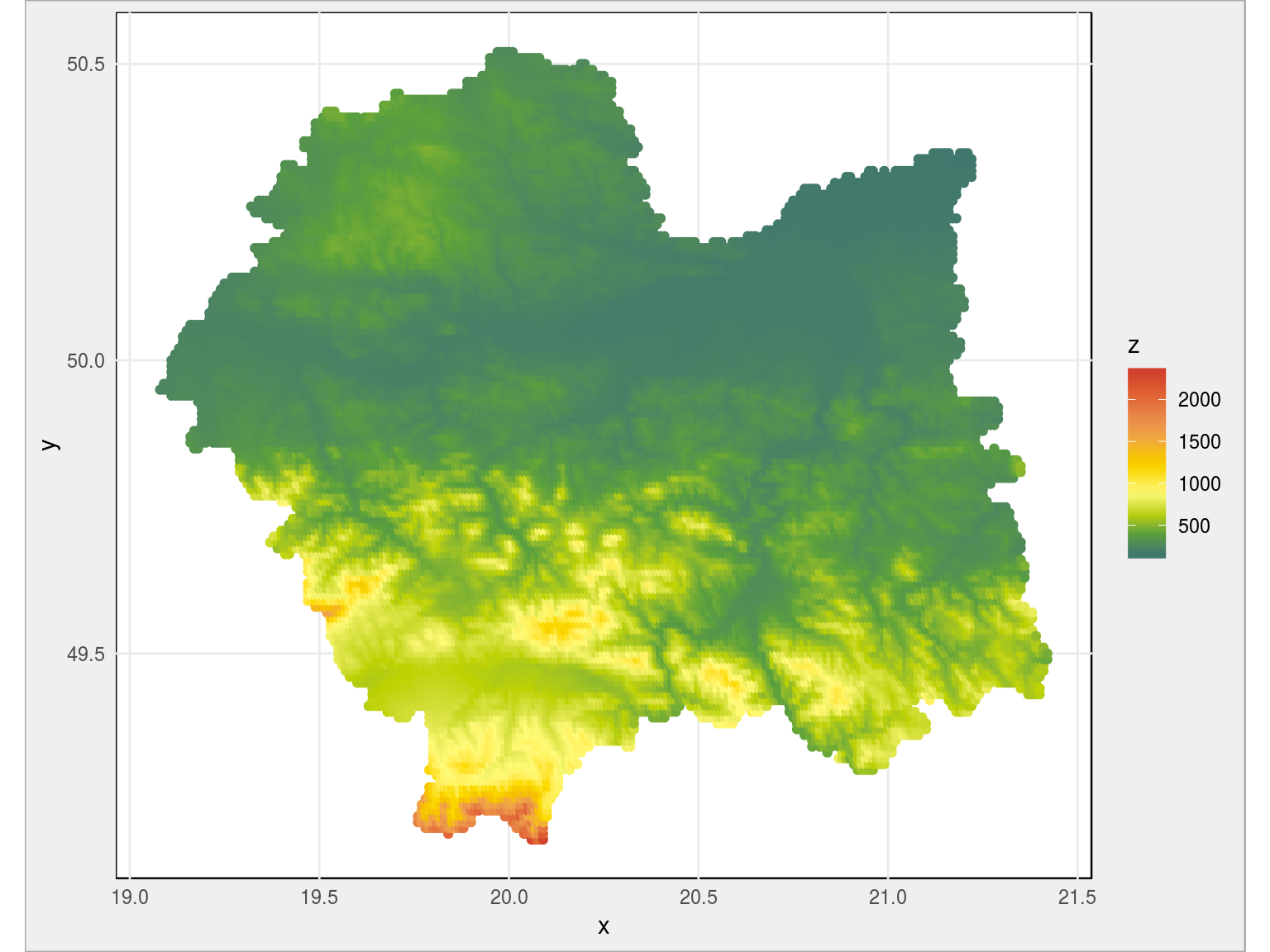
Pięknie to wygląda, prawdziwa mapa hipsometryczna. Możemy zmienić paletę z ciągłej na dyskretną – przyczyna to pokazanie niebieskim kolorem tego co jest poniżej poziomu morza.
|
1 2 3 4 5 6 7 8 9 10 |
# dzielimy wysokość na 9 przedziałów, dziesiąty to poniżej 0 przedzialy <- c(-1000, seq(0, round(max(plot_data$z), -2), length.out=9)) # rysujemy mapę z kolorami według podziału ma przedziały plot_data %>% mutate(z_fct = cut(z, breaks = przedzialy)) %>% ggplot(aes(x, y, color = z_fct)) + geom_point() + coord_map() + scale_color_manual(values = paleta_rgb) |
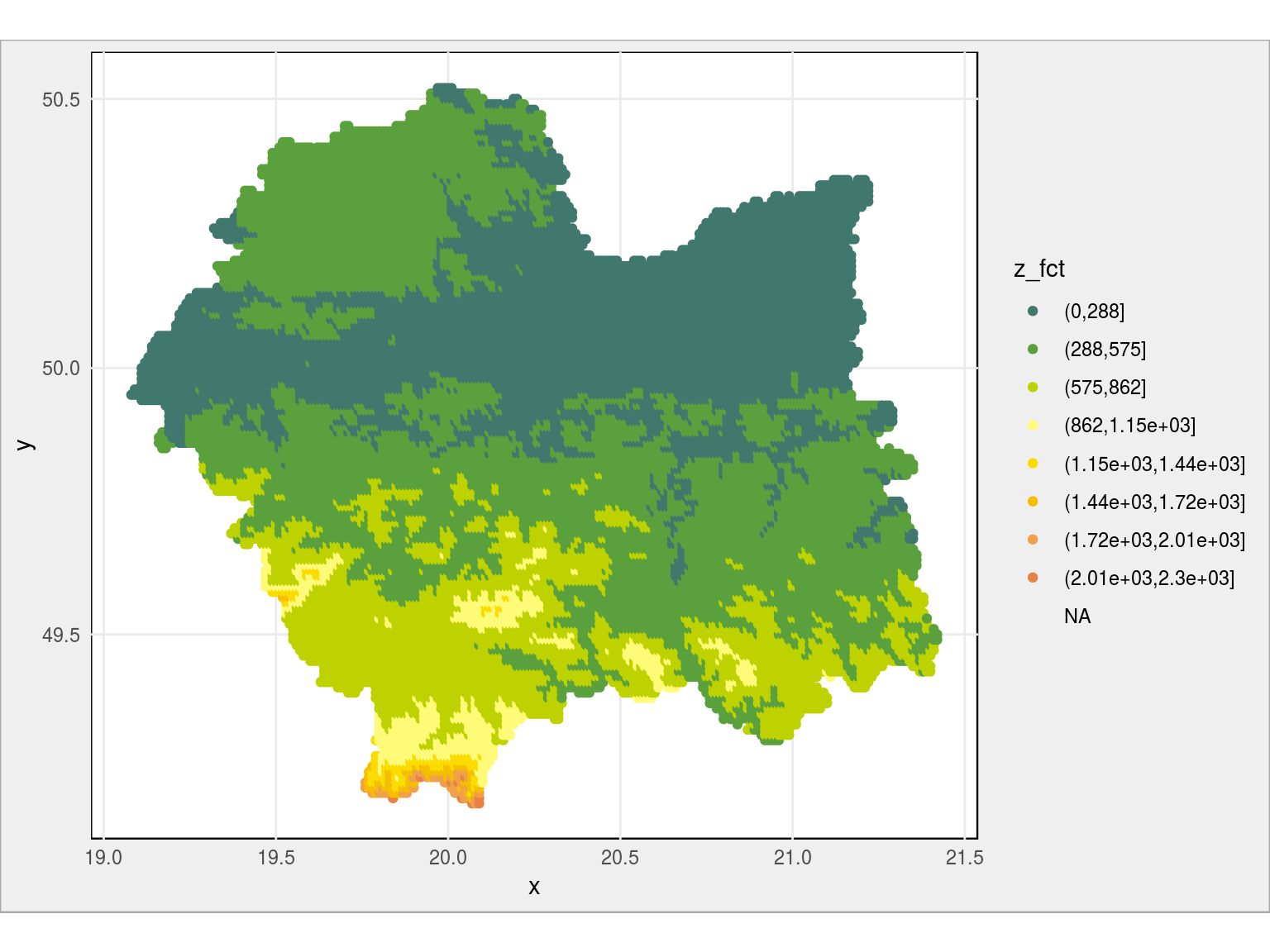
Nałóżmy nasze kolorki na rzeczywistą mapę – pobraną chociażby z Google Maps. Łatwiej będzie rozpoznać poszczególne górki i doliny. Niech będzie Kraków:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
# pobieramy współrzędne Krakowa loc <- geocode("Kraków, Poland") # ograniczamy zakres rysowanej mapy (punktów wysokości) dane_nmt_krakow <- dane_nmt %>% filter(y > as.numeric(loc[2]) - 0.25 & y < as.numeric(loc[2]) + 0.25) %>% filter(x > as.numeric(loc[1]) - 0.5 & x < as.numeric(loc[1]) + 0.5) %>% # dzielimy wysokość na przedziały mutate(z_fct = cut(z, breaks = przedzialy)) dane_nmt_krakow %>% # rysujemy mapkę ggplot(aes(x, y, color = z_fct)) + geom_point() + # zaznaczamy współrzędne Krakowa geom_point(aes(x = as.numeric(loc[1]), y = as.numeric(loc[2])), size = 5, color = "red") + coord_map() + scale_color_manual(values = paleta_rgb) |
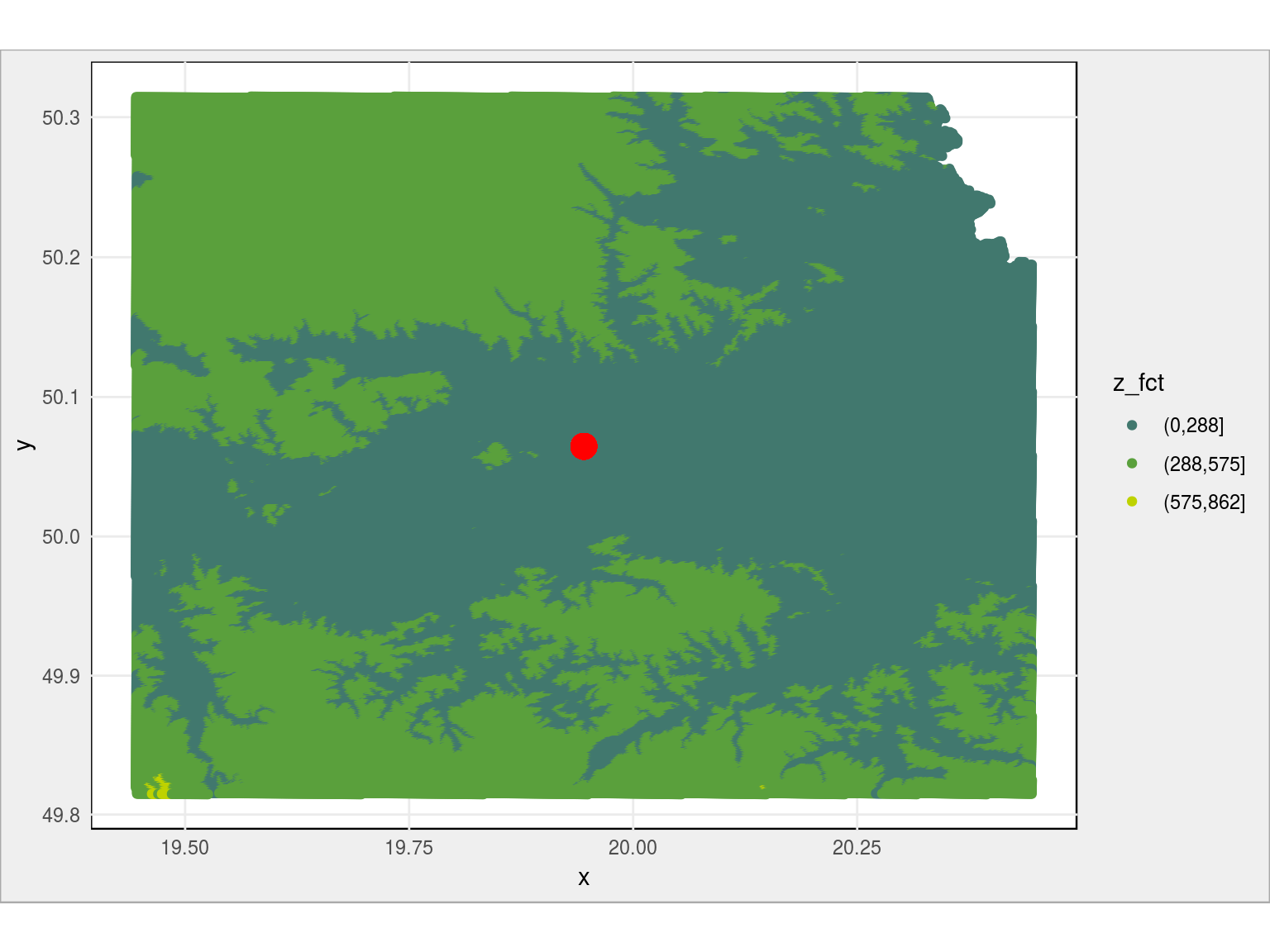
Ale to ciągle tylko dane z obszaru Krakowa. Co jest w którym miejscu?
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
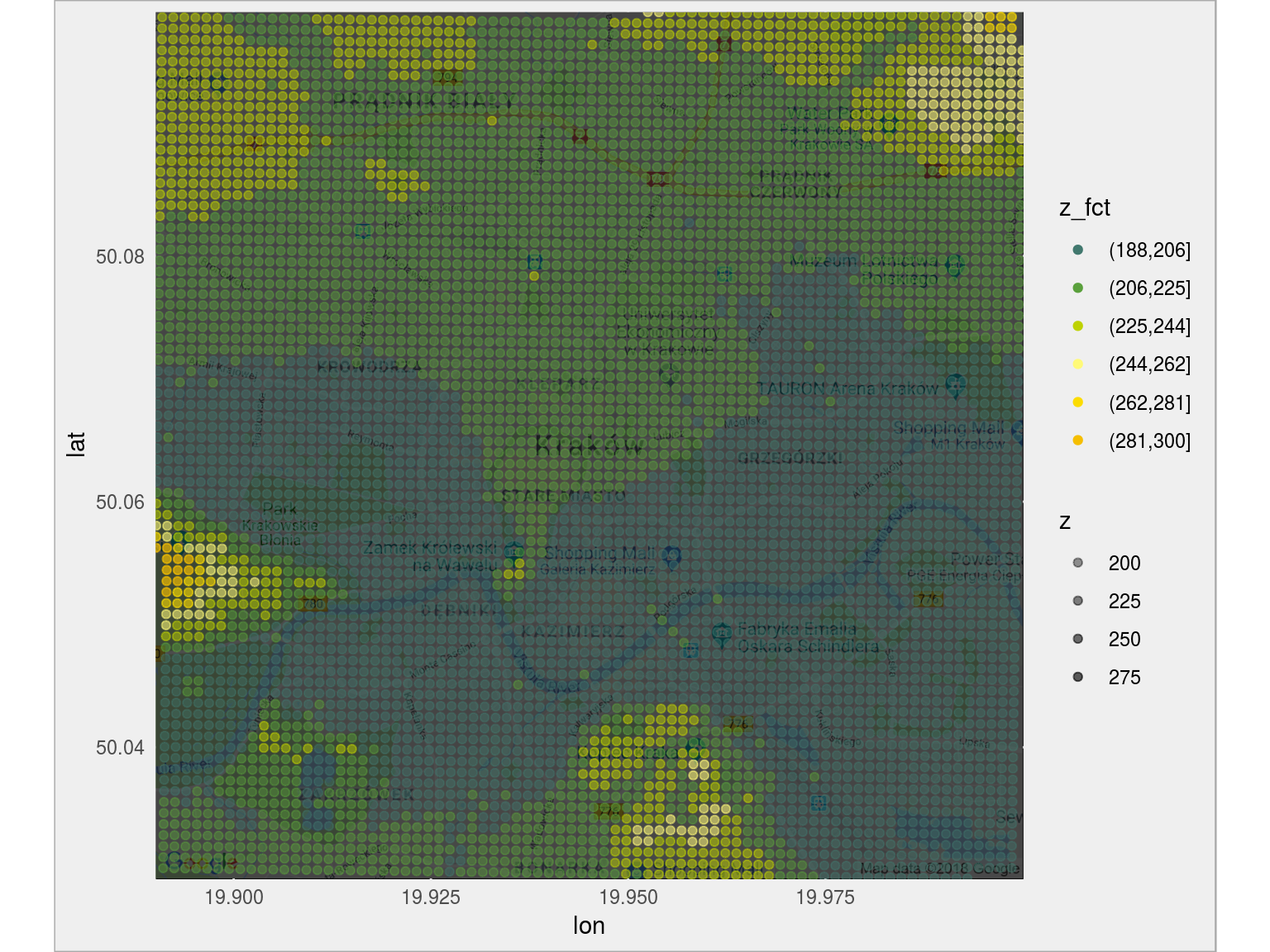
# pobieramy mapę Krakowa z Google Maps mapa_gg <- get_map(loc, source = "google", maptype = "roadmap", zoom = 13) # bierzemy wycinek odpowiadający mapie z oryginalnych danych dane_krakow <- dane_nmt %>% filter(x >= attr(mapa_gg, "bb")$ll.lon, x <= attr(mapa_gg, "bb")$ur.lon) %>% filter(y >= attr(mapa_gg, "bb")$ll.lat, y <= attr(mapa_gg, "bb")$ur.lat) # na tej mapie rysujemy wysokość ggmap(mapa_gg, darken = 0.7) + geom_point(data = dane_krakow, aes(x, y, alpha = z, color = z)) + scale_alpha_continuous(range = c(0.4, 0.7)) + scale_color_gradientn(colors = paleta_rgb) |
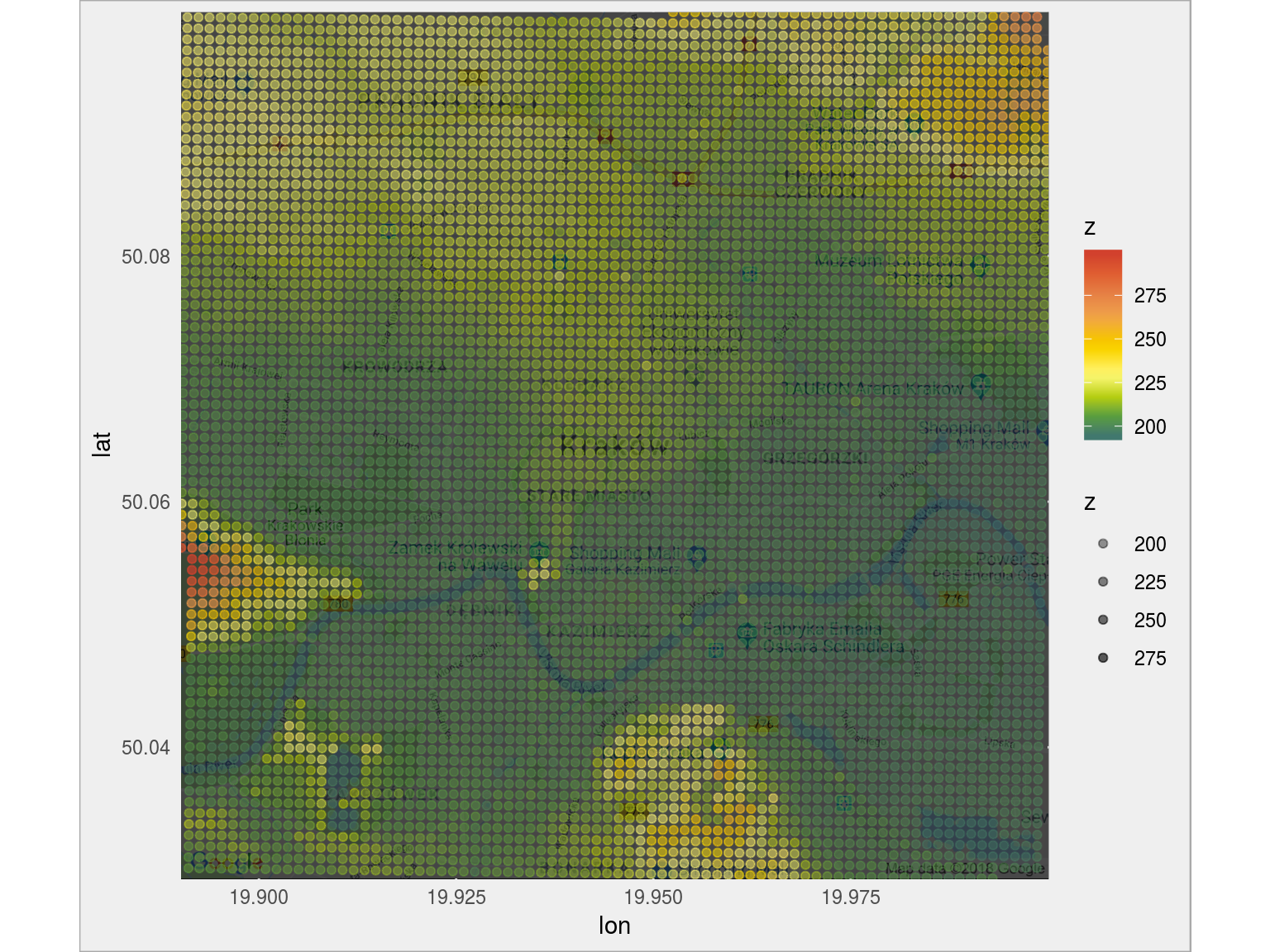
Teraz ładnie widać na przykład Wzgórze Wawelskie. Oraz przyczynę krakowskiego smogu – położenie miasta w dolinie.
Jak wygląda rozkład wysokości na pokazanym obszarze?
|
1 2 3 |
dane_nmt_krakow %>% ggplot() + geom_histogram(aes(z), binwidth = 1) |
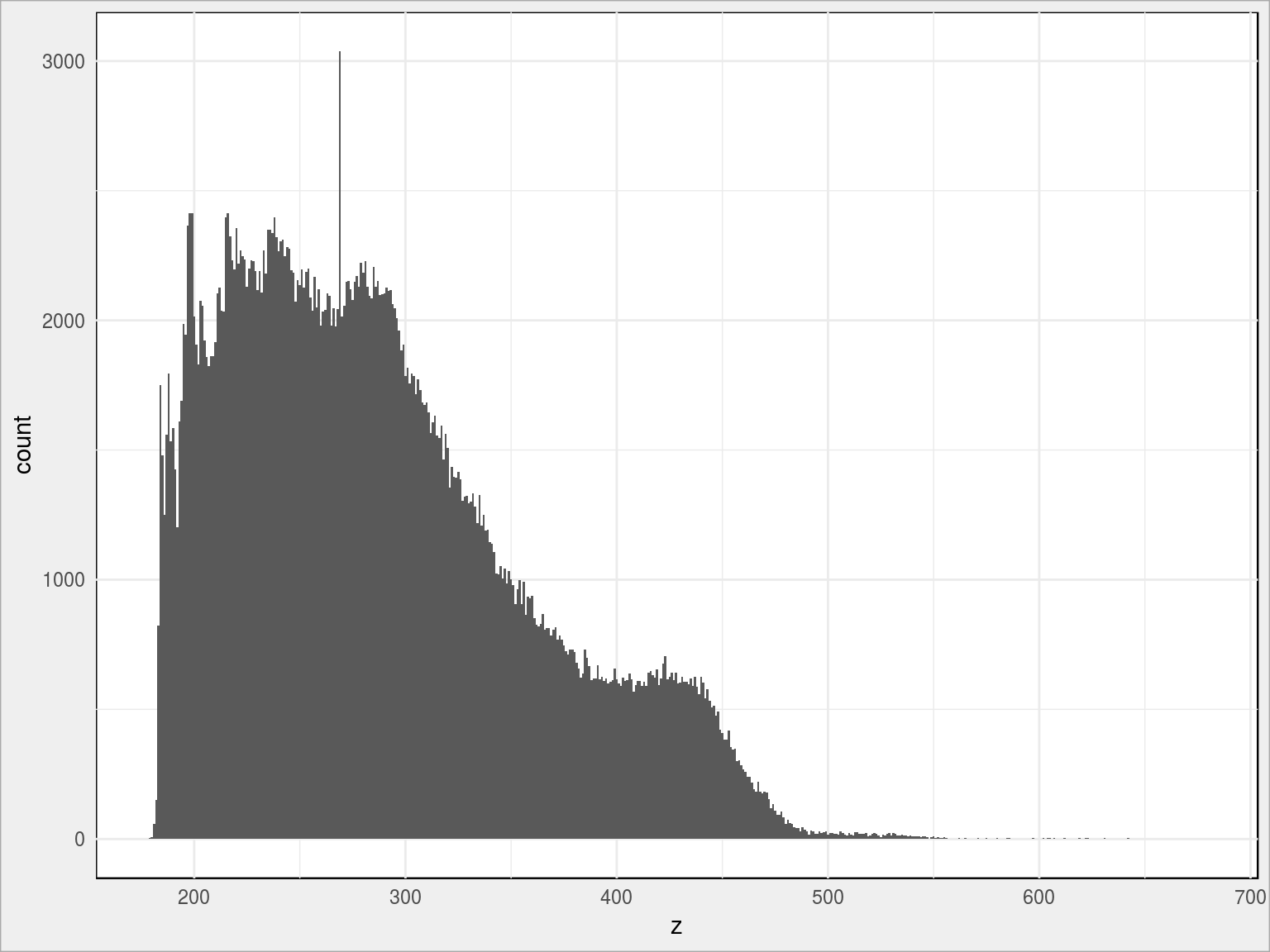
Sprawdźmy co się stanie jak podniesie się woda w Krakowie – na przykład niech poziom morza będzie teraz na wysokości 150 metrów:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
# 150 w poniższej linii to nowy poziom morza przedzialy_powodz <- c(-1000, seq(150, round(max(dane_krakow$z), -2), length.out=9)) # na nowo przydzielamy punkty do przedziałów dane_krakow <- dane_krakow %>% mutate(z_fct = cut(z, breaks = przedzialy_powodz)) # na mapie miasta rysujemy wysokość: ggmap(mapa_gg, darken = 0.7) + geom_point(data = dane_krakow, aes(x, y, alpha = z, color = z_fct)) + scale_alpha_continuous(range = c(0.4, 0.7)) + scale_color_manual(values = paleta_rgb) |
Widzimy, że całe koryto Wisły zostaje zapełnione wodą. Wawel ostaje się na lądzie. Między innymi do tego celu mogą służyć mapy z wysokością terenu.
No dobrze – wybraliśmy Kraków na postawie jakiegoś otoczenia współrzędnych jego środka. Ale na początku napisałem, że dowiemy się jak dane punktowe przypisać do gmin (i co za tym idzie powiatów i województw). Poniższy kod to właśnie robi dla jednego (małopolskiego) województwa.
Algorytm działania jest następujący (i stosunkowo prosty, chociaż obliczenia są długotrwałe):
- przygotuj punkty w takim samym układzie jak dane o granicach gmin
- dla wszystkich punktów z danymi przygotuj macierz binarną mówiącą o tym czy dany punkt należy do obszarów kolejnych gmin
- na podstawie tej macierzy przypisz do punktu kod TERYT gminy (i powiatu, i województwa – bo te są fragmentami kodu gminy)
- aby nie liczyć wszystkiego na raz dla wszystkich danych (potrzeba dużo pamięci) dzielimy punkty z danymi na mniejsze paczki
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 |
rm(list = ls()) # sprzątamy to co było do tej pory - tutaj zaczyna się oddzielny skrypt dane_plik <- "dane/malopolskie.txt" woj_TERYT <- "12" # definicja układu współrzednych CRS_puwg1992 <- crs("+proj=tmerc +lat_0=0 +lon_0=19 +k=0.9993 +x_0=500000 +y_0=-5300000 +ellps=GRS80 +units=m +no_defs ") CRS_wgs84 <- crs("+proj=longlat +ellps=WGS84 +datum=WGS84 +no_defs;") # układ WGS84 (współrzędne "normalne") # wczytujemy mapę gmin gminy_shp <- readOGR("../!mapy_shp/gminy.shp", "gminy") gminy_shp <- spTransform(gminy_shp, CRS_wgs84) # wybieramy gminy z odpowiedniego województwa wojewodztwo <- gminy_shp[substr(gminy_shp$jpt_kod_je, 1, 2) == woj_TERYT, ] # kasujemy gminy_shp dla oszczednosci pamieci rm(gminy_shp) # wyczytujemy dane o wysokoąci punków w województwie dane_nmt <- read_delim(dane_plik, " ", col_names = c("x", "y", "z"), col_types = "ddd") # funkcja sprawdza czy punkty z f_dataframe są w ramach f_shape i dodaje im kod TERYT gminy add_TERYT_code <- function(f_dataframe, f_shape) { # wyimek przerabiamy na SHP coordinates(f_dataframe) <- c("x", "y") projection(f_dataframe) <- CRS_puwg1992 f_dataframe <- spTransform(f_dataframe, CRS_wgs84) # macierz przypisania punktu do powiatu - to trochę trwa miejscowosci_mat <- gWithin(f_dataframe, f_shape, byid = TRUE) miejscowosci_mat <- t(miejscowosci_mat) # teraz numer kolumny to numer gminy, numer wiersza to numer punktu # bierzemy punkty z powrotem do tabelki punkty <- as.data.frame(f_dataframe@coords) %>% set_names(c("long", "lat")) punkty$height <- f_dataframe@data$z # szukamy kodu TERYT dla kolejnych punktów punkty$TERYT_gmn <- miejscowosci_mat %>% apply(1, function(x) min(which(x, arr.ind = TRUE), na.rm=TRUE)) %>% as.character(f_shape$jpt_kod_je)[.] # zwracamy paczkę punktów z odpowiednimi przypisaniami TERYT return(punkty) } # dla całego województwa przygotowujemy dane punkty_all <- tibble() step_i <- 100 # paczki po 2000 punktów na raz wydaja sie byc optymalne n_steps <- ceiling(nrow(dane_nmt)/step_i) # dla każdej paczki punktów: for(i in 1:n_steps) { # bierzemy jedna paczkę punktów dane_nmt_small <- dane_nmt[ ((i-1)*step_i+1):(i*step_i), ] %>% na.omit() # dopisujemy kody TERYT gminy do punktów punkty <- add_TERYT_code(dane_nmt_small, wojewodztwo) # z TERYT gminy robimy TERYT województwa (pierwsze 2 znaki) i TERYT powiatu (pierwsze 4 znaki) punkty <- punkty %>% mutate(TERYT_woj = substr(TERYT_gmn, 1, 2), TERYT_pow = substr(TERYT_gmn, 1, 4)) # łaczymy razem z już przerobionymi punktami punkty_all <- bind_rows(punkty_all, punkty) } # zapisujemy wynikowe dane saveRDS(punkty_all, "dane/malopolskie.rds") |
Dla jednego województwa proces trwał u mnie kilkanaście minut. Ale dzięki temu możemy w łatwy sposób wybierać dane o wysokości dla konkretnej gminy. Zobaczmy gminę w której leżą Rysy. Ale na początek – całe województwo małopolskie, na które nałożymy granice gmin:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
rm(list = ls()) # sprzątamy to co było do tej pory - tutaj zaczyna się oddzielny skrypt # wczytujemy zapisane dane punkty_all <- readRDS("dane/malopolskie.rds") # przygotoiwanie palety paleta_rgb <- c("#41786E", "#5AA03C", "#BED200", "#FFFA78", "#FCDC00", "#F5BE00", "#F0A04B", "#E68246", "#E15F32", "#D2412D") # definicja układu współrzednych CRS_wgs84 <- crs("+proj=longlat +ellps=WGS84 +datum=WGS84 +no_defs;") # układ WGS84 (współrzędne "normalne") # wczytujemy mapę gmin gminy_shp <- readOGR("../!mapy_shp/gminy.shp", "gminy") |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
gminy_shp <- spTransform(gminy_shp, CRS_wgs84) # wybieramy powiaty z odpowiedniego województwa wojewodztwo <- gminy_shp[substr(gminy_shp$jpt_kod_je, 1, 2) == "12", ] # kasujemy gminy_shp dla oszczednosci pamieci rm(gminy_shp) # całe województwo ggplot() + geom_point(data = punkty_all, aes(long, lat, color = height)) + # granice gmin geom_polygon(data = wojewodztwo, aes(long, lat, group=group), color = "gray50", fill = NA) + scale_color_gradientn(colors = paleta_rgb) + coord_map() |
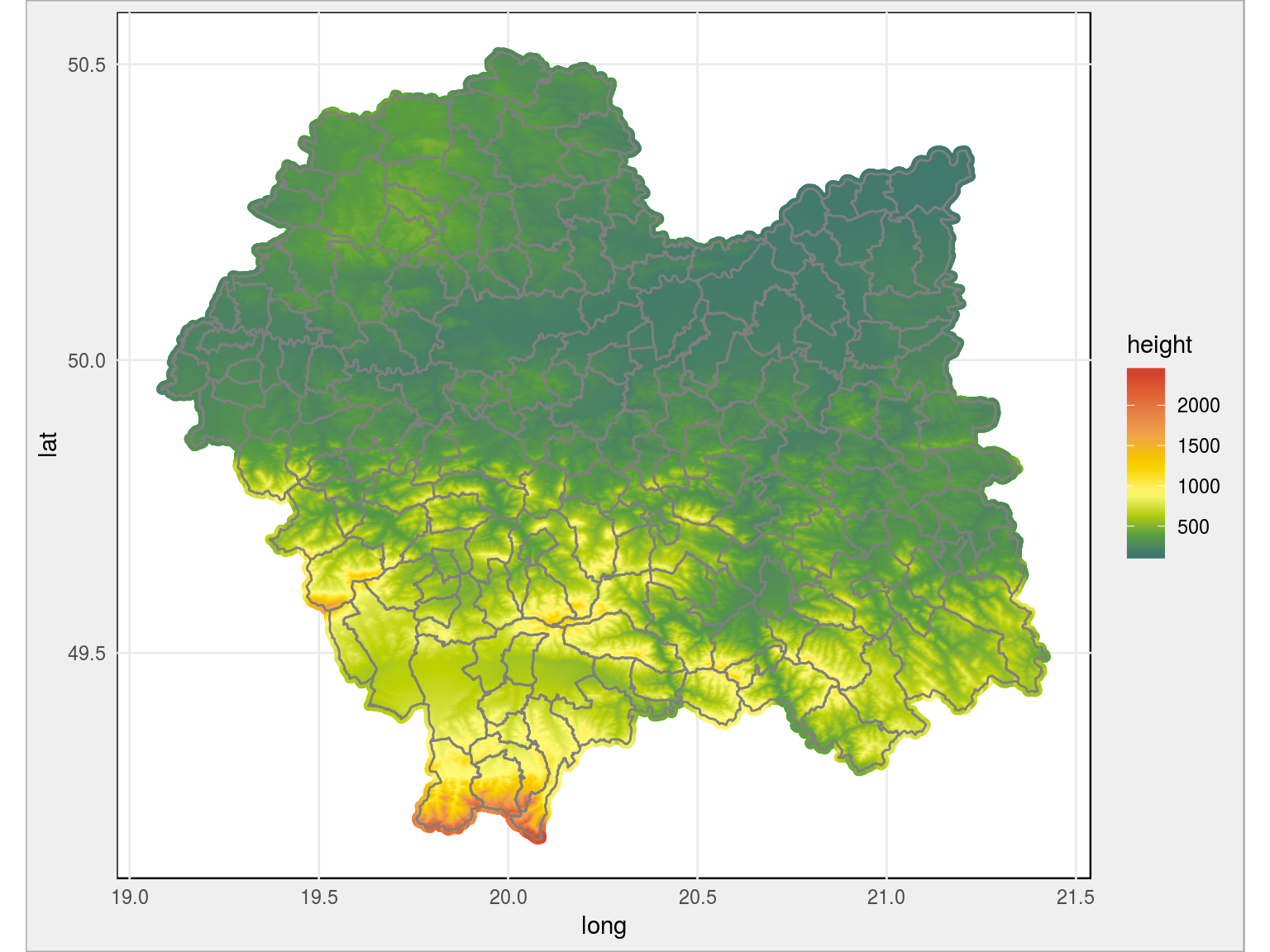
Teraz wybierzmy jedną gminę – po jej kodzie TERYT. Do tego wybierzmy granice powiatu w którym leży gmina. I narysujmy taką mapkę:
|
1 2 3 4 5 6 7 8 9 10 11 |
# wybierzmy jedną gminę i pokażmy powiat w którym leży dane_gmina <- punkty_all %>% filter(TERYT_gmn == "1217032") ggplot() + # punkty w wybranej gminie geom_point(data = dane_gmina, aes(long, lat, color = height)) + # granice powiatu geom_polygon(data = wojewodztwo[substr(wojewodztwo$jpt_kod_je, 1, 4) == "1217", ], aes(long, lat, group=group), color = "gray50", fill = NA) + scale_color_gradientn(colors = paleta_rgb) + coord_map() |
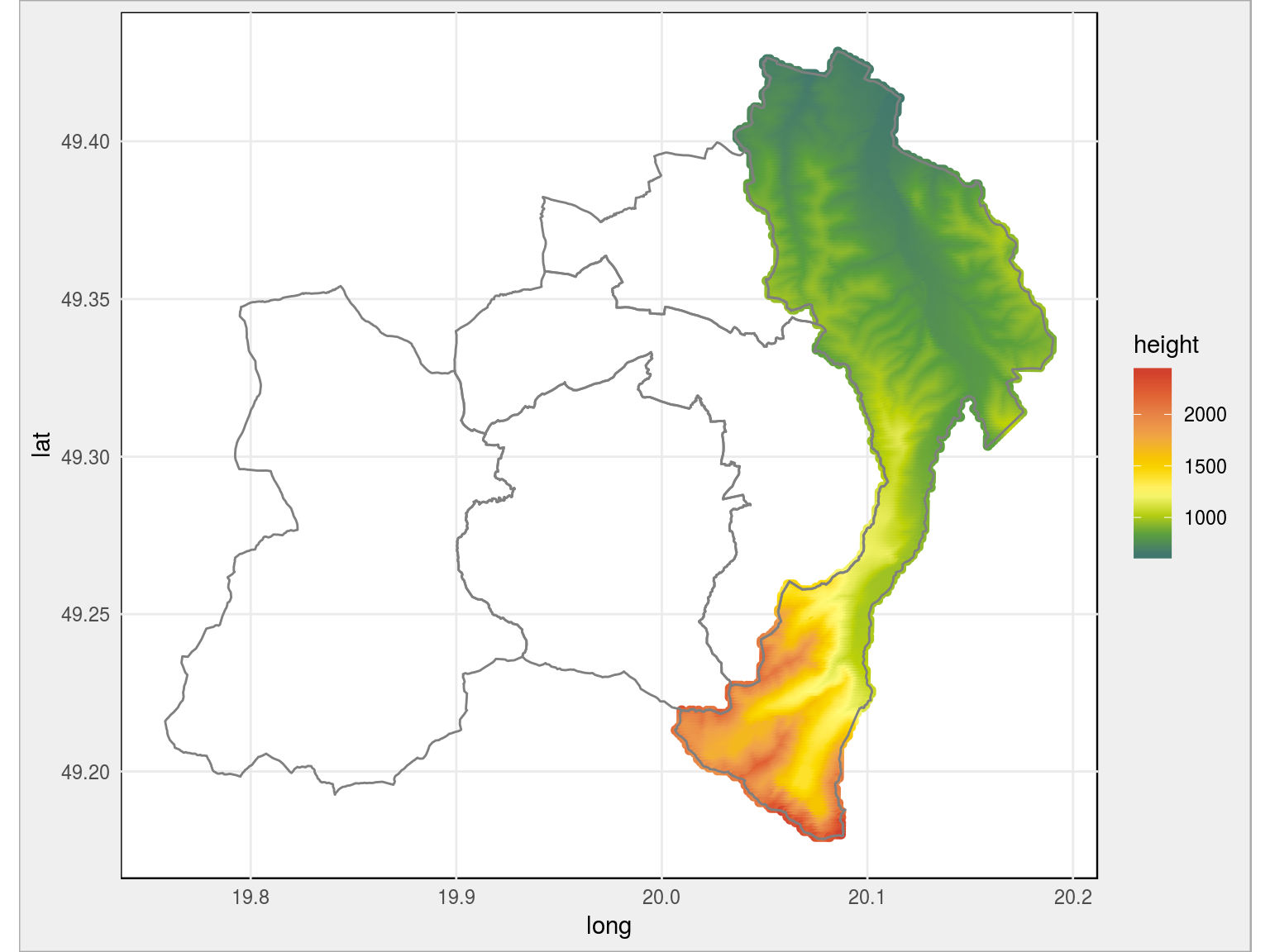
Teraz podobnie jak wcześniej z Krakowem – dla łatwiejszej orientacji w położeniu naszych kolorowych punktów – nałóżmy je na mapę z Google Maps:
|
1 2 3 4 5 6 7 8 |
# pobieramy mapę gminy (precyzyjniej: okolic jej środka) mapa_gg <- get_map(c(mean(dane_gmina$long), mean(dane_gmina$lat)), source = "google", maptype = "roadmap", zoom = 11) # narysyjmy punkty na tej mapie ggmap(mapa_gg) + # punkty w wybranej gminie geom_point(data = dane_gmina, aes(long, lat, color = height), alpha = 0.1) + scale_color_gradientn(colors = paleta_rgb) |
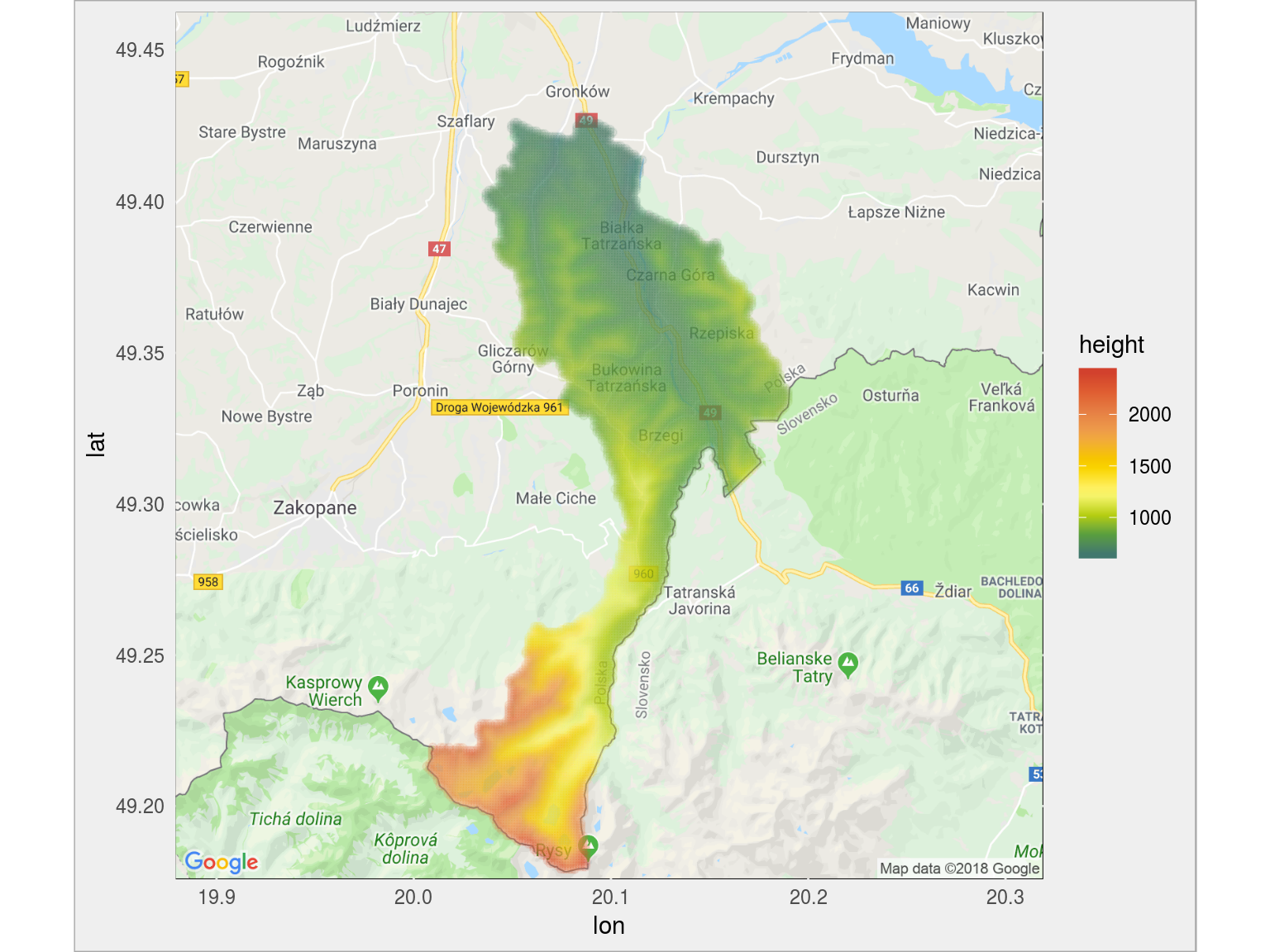
Fajnie jest mieć dane podzielone po kodach TERYT, prawda? Mamy ogrom danych – zamiast trzymać je w plikach wrzućmy je do bazy. Idea jest podobna jak poprzednio dla województwa, z tą różnicą że tutaj musimy wykonać to samo dla wszystkich 16 plików. I zamiast zapisywać plik lokalnie – dodajemy kolejne wiersze do stosownej tabeli. W dużej części jest to powtórzenie powyższego kodu (ale dla ułatwienia daję całość).
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 |
rm(list = ls()) # sprzątamy to co było do tej pory - tutaj zaczyna się oddzielny skrypt # dostęp do bazy danych dbname = "***" user = "***" password = "***" host = "***" # użyjemy bazy PostgreSQL db_connector <- dbDriver("PostgreSQL") # definicja układu współrzednych CRS_puwg1992 <- crs("+proj=tmerc +lat_0=0 +lon_0=19 +k=0.9993 +x_0=500000 +y_0=-5300000 +ellps=GRS80 +units=m +no_defs ") CRS_wgs84 <- crs("+proj=longlat +ellps=WGS84 +datum=WGS84 +no_defs;") # układ WGS84 (współrzędne "normalne") # wczytujemy mapę gmin gminy_shp <- readOGR("../!mapy_shp/gminy.shp", "gminy") gminy_shp <- spTransform(gminy_shp, CRS_wgs84) # lista plików z danymi o województwach i odpowiadające im kody TERYT województw pliczki <- tribble(~plik, ~teryt, "dolnoslaskie.txt", "02", "kujawsko_pomorskie.txt", "04", "lubelskie.txt", "06", "lubuskie.txt", "08", "lodzkie.txt", "10", "malopolskie.txt", "12", "mazowieckie.txt", "14", "opolskie.txt", "16", "podkarpackie.txt", "18", "podlaskie.txt", "20", "pomorskie.txt", "22", "slaskie.txt", "24", "swietokrzyskie.txt", "26", "warminsko_mazurskie.txt", "28", "wielkopolskie.txt", "30", "zachodniopomorskie.txt", "32") # funkcja sprawdza czy punkty z f_dataframe są w ramach f_shape i dodaje im kod TERYT gminy add_TERYT_code <- function(f_dataframe, f_shape) { # wyimek przerabiamy na SHP coordinates(f_dataframe) <- c("long", "lat") projection(f_dataframe) <- CRS_puwg1992 f_dataframe <- spTransform(f_dataframe, CRS_wgs84) # macierz przypisania punktu do powiatu - to trochę trwa miejscowosci_mat <- gWithin(f_dataframe, f_shape, byid = TRUE) %>% t() # teraz numer kolumny to numer powiatu, numer wiersza to numer punktu # bierzemy punkty z powrotem do tabelki punkty <- as.data.frame(f_dataframe@coords) # dodajemy ich wysokość punkty$height <- f_dataframe@data$height # na podstawie numeru kolumny z TRUE dla każdego wiersza wypełniamy wartość z kodem TERYT gminy punkty$TERYT_gmn <- miejscowosci_mat %>% apply(1, function(x) min(which(x, arr.ind = TRUE), na.rm=TRUE)) %>% as.character(f_shape$jpt_kod_je)[.] # zwracamy gotową paczkę danych return(punkty) } # wielkość paczki step_i <- 100 # podpinamy się do bazy danych db_con <- dbConnect(db_connector, dbname = dbname, user = user, password = password, host = host) # dla kazdego wojewodztwa for(woj_num in 1:nrow(pliczki)) { # jaki plik i jaki kod TERYT wojweództwa? dane_plik <- paste0("dane/", as.character(pliczki[woj_num, 1])) woj_TERYT <- as.character(pliczki[woj_num, 2]) # wybieramy gminy z odpowiedniego województwa - żeby nie sprawdzać dla całego kraju wojewodztwo <- gminy_shp[str_sub(gminy_shp$jpt_kod_je, 1, 2) == woj_TERYT, ] # wyczytujemy dane o wysokości punków w województwie dane_nmt <- read_delim(dane_plik, " ", col_names = c("long", "lat", "height"), col_types = "ddd") # ile paczek będzie? n_steps <- ceiling(nrow(dane_nmt)/step_i) # jedziemy plik z wysokościami, w paczkach for(i in 1:n_steps) { # bierzemy jedna paczkę punktów dane_nmt_small <- dane_nmt[ ((i-1)*step_i+1):(i*step_i), ] %>% na.omit() # dopisujemy kody TERYT gminy do punktów punkty <- add_TERYT_code(dane_nmt_small, wojewodztwo) # z TERYT gminy robimy TERYT województwa (pierwsze 2 znaki) i TERYT powiatu (pierwsze 4 znaki) punkty <- punkty %>% mutate(TERYT_woj = str_sub(TERYT_gmn, 1, 2), TERYT_pow = str_sub(TERYT_gmn, 1, 4)) # dopisujemy wynik do pełnej listy w bazie dbWriteTable(db_con, "nmt_polska", punkty, append = TRUE, row.names = FALSE) } } # odłączamy się od bazy danych dbDisconnect(db_con) |
Gotowe! Tylko kilkadziesiąt godzin i sprawa załatwiona. Ale za to jak uprości to dalszą pracę! Zobaczmy sami.
Najpierw parametry dostępu do bazy danych:
|
1 2 3 4 5 6 |
rm(list = ls()) # sprzątamy to co było do tej pory - tutaj zaczyna się oddzielny skrypt dbname = "***" user = "***" password = "***" host = "***" |
A teraz się z nią łączymy i zapytaniami w SQL wyciągamy średnią wysokość na poziomie gminy, powiatu i województwa:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
sterownik <- dbDriver("PostgreSQL") polaczenie <- dbConnect(sterownik, dbname = dbname, user = user, password = password, host = host) # pobieramy zagregowane dane na 3 poziomach # srednia wysokość w wojewodztwie sr_h_woj <- dbGetQuery(polaczenie,' SELECT "TERYT_woj", AVG(height) AS height FROM nmt_polska GROUP BY "TERYT_woj";') # srednia wysokość w powiecie sr_h_pow <- dbGetQuery(polaczenie,' SELECT "TERYT_pow", AVG(height) AS height FROM nmt_polska GROUP BY "TERYT_pow";') # srednia wysokość w gminie sr_h_gmn <- dbGetQuery(polaczenie,' SELECT "TERYT_gmn", AVG(height) AS height FROM nmt_polska GROUP BY "TERYT_gmn";') dbDisconnect(polaczenie) |
Możemy już zamknąć połączenie z bazą danych. Jeśli spojrzycie w wielkość danych jakie zajmują w pamięci będziecie zachwyceni ;) Całą matematykę (grupowanie i liczenie średnich) wykonał serwer bazodanowy – my mamy gotowy wynik.
Zobaczmy jak wyglądają średnie wysokości dla każdego z województw. Uwaga – poniżej do wczytania mapy (plików shp) i połączenia jej z danymi wykorzystuję pakiet sf – o wiele bardziej przyjemny w użyciu niż cała reszta readOGR() i tak dalej:
|
1 2 3 4 5 6 |
wojewodztwa_sf <- read_sf("~/RProjects/!mapy_shp/wojewodztwa.shp") wojewodztwa_sf <- left_join(wojewodztwa_sf, sr_h_woj, by = c("jpt_kod_je" = "TERYT_woj")) ggplot(wojewodztwa_sf) + geom_sf(aes(fill = height), color = "white", size = 0.1) + scale_fill_distiller(palette = "RdYlGn") |
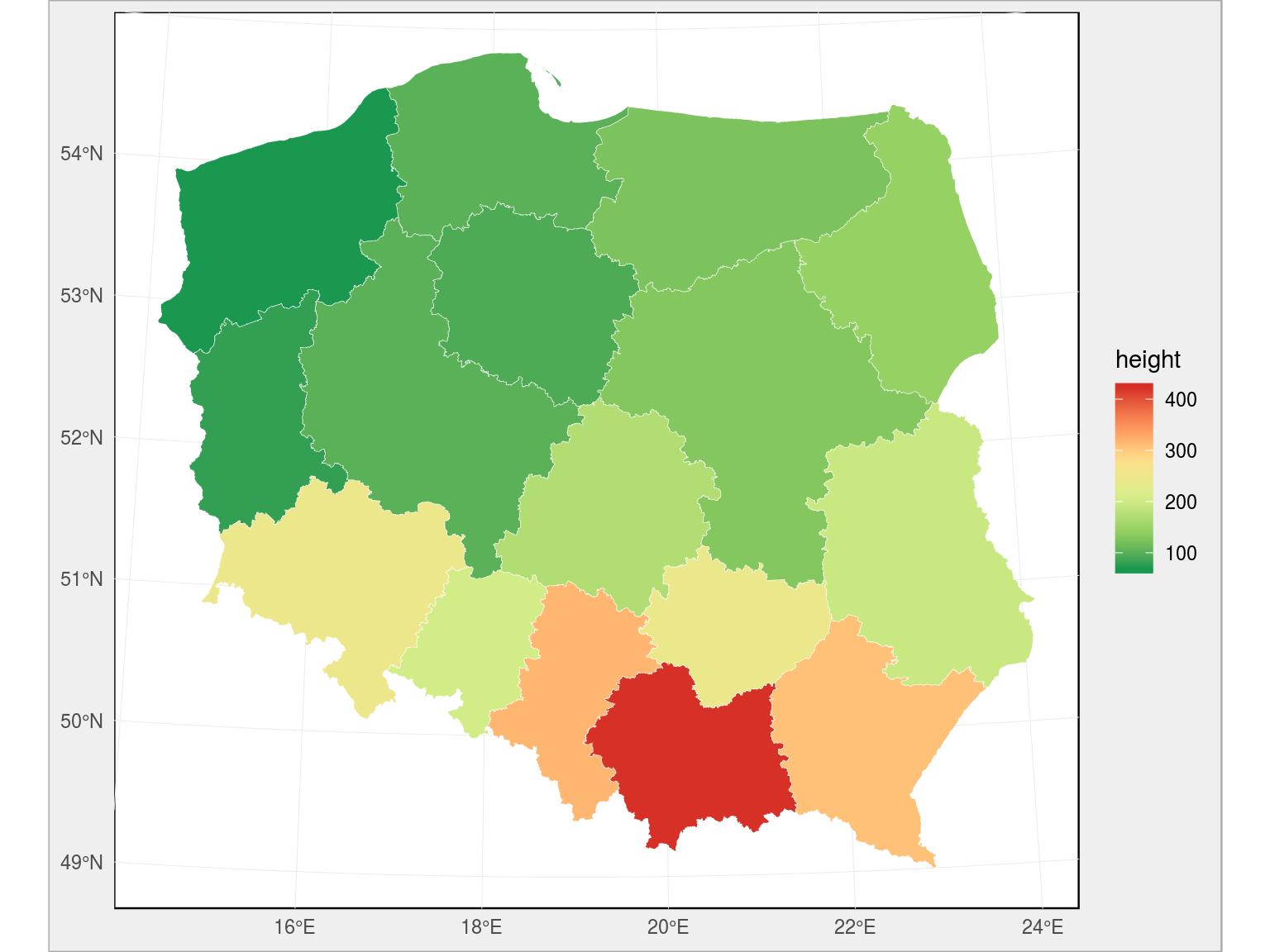
To samo możemy zrobić na poziomie powiatów:
|
1 2 3 4 5 6 7 |
# mapa na poziomie powiatów powiaty_sf <- read_sf("~/RProjects/!mapy_shp/powiaty.shp") powiaty_sf <- left_join(powiaty_sf, sr_h_pow, by = c("jpt_kod_je" = "TERYT_pow")) ggplot(powiaty_sf) + geom_sf(aes(fill = height), color = "white", size = 0.1) + scale_fill_distiller(palette = "RdYlGn") |
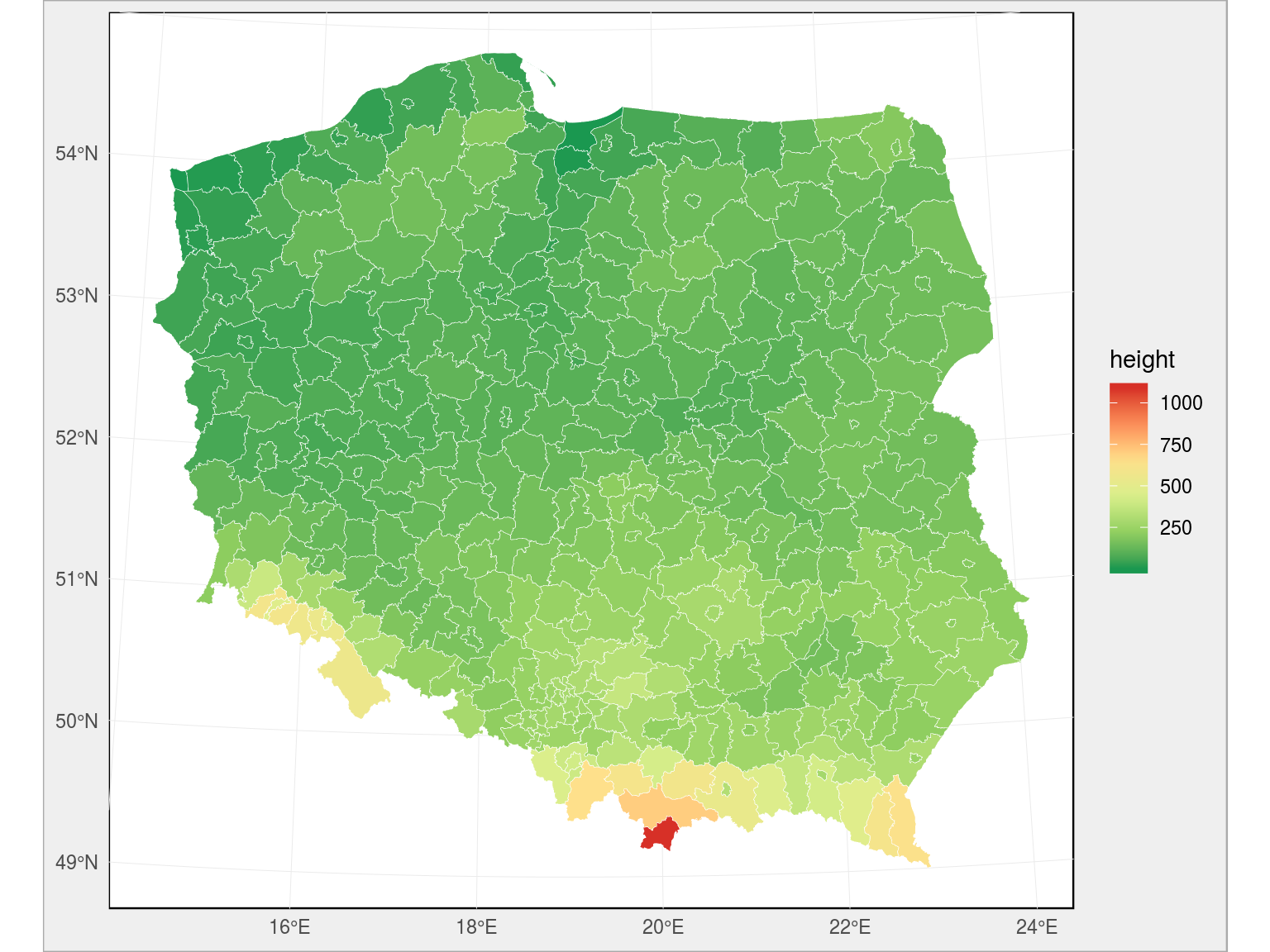
oraz gmin:
|
1 2 3 4 5 6 7 |
# mapa na poziomie gmin gminy_sf <- read_sf("~/RProjects/!mapy_shp/gminy.shp") gminy_sf <- left_join(gminy_sf, sr_h_gmn, by = c("jpt_kod_je" = "TERYT_gmn")) ggplot(gminy_sf) + geom_sf(aes(fill = height), color = "white", size = 0.1) + scale_fill_distiller(palette = "RdYlGn") |
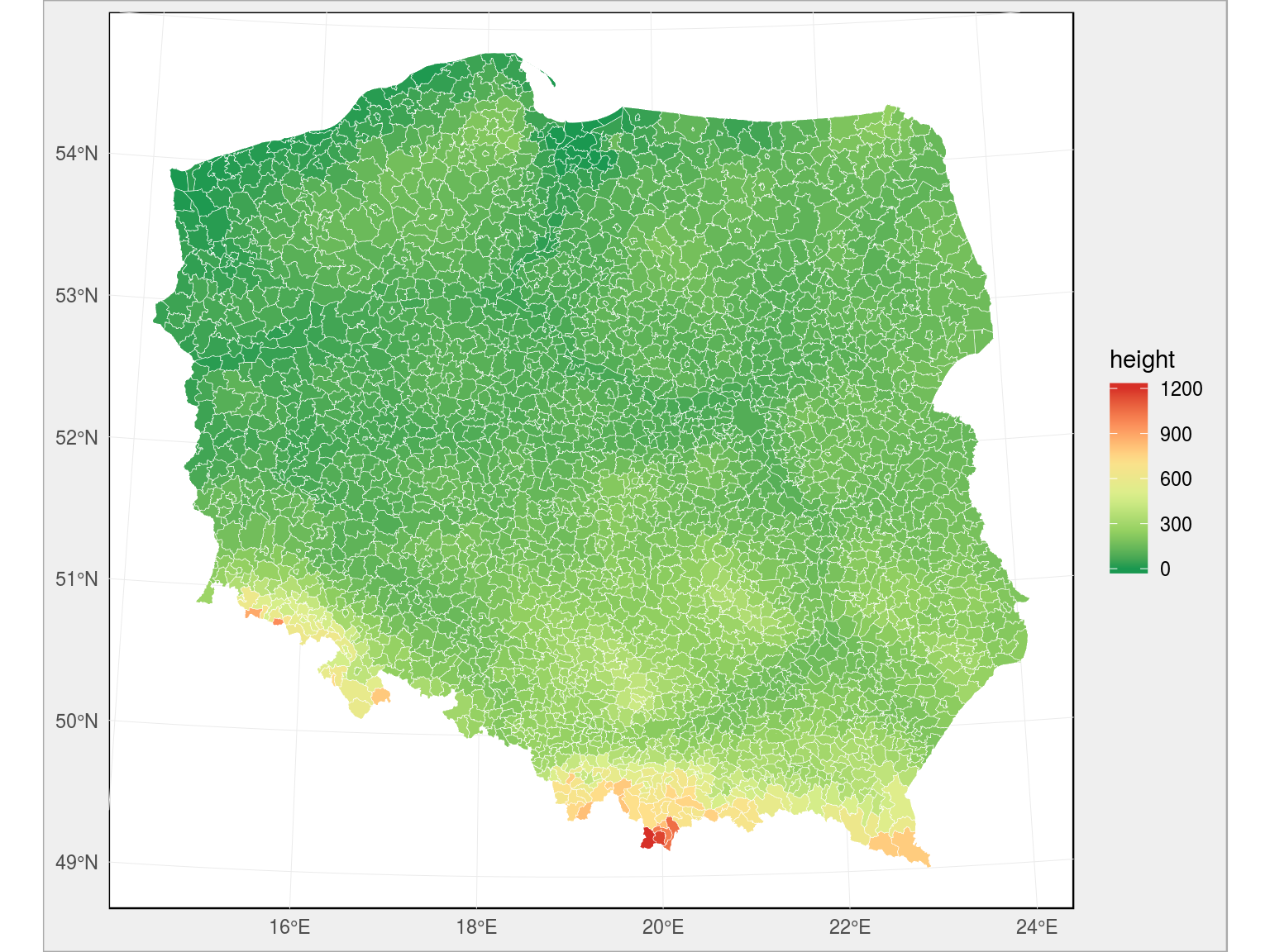
W samych mapach oczywiście nie ma zaskoczenia – na południu mamy góry, a reszta to mniej więcej równina na jakiejś średniej wysokości… Właśnie – jakiej? Skorzystajmy z danych uśrednionych na poziom gmin:
|
1 |
summary(gminy_sf$height) |
|
1 2 |
## Min. 1st Qu. Median Mean 3rd Qu. Max. ## -0.1786 105.3366 155.2762 185.6863 226.9315 1204.1620 |
|
1 2 |
ggplot(gminy_sf) + geom_histogram(aes(height), bins = 380) |
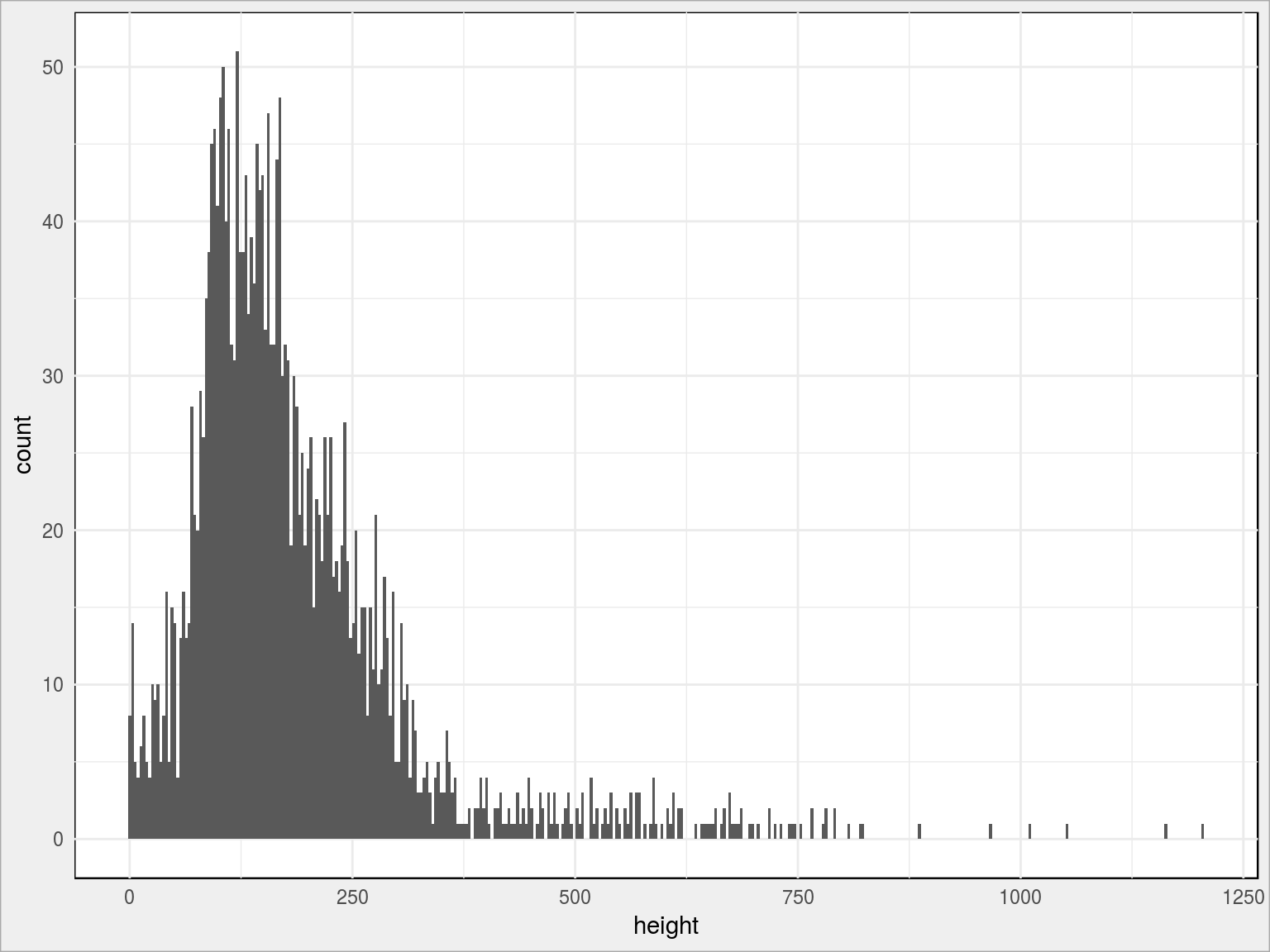
Z rozkładu widzimy, że 3/4 kraju jest na wysokości nie większej niż około 225 metrów. Gdyby poziom wód podniósł się o te 225 metrów byłby prawdziwy potop…
Na koniec możemy przygotować dwie funkcje, które na mapie z Google Maps narysują nam wysokość terenu – na podstawie kodu TERYT gminy lub powiatu (korzystając z danych zapisanych w bazie):
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 |
library(tidyverse) library(ggmap) library(RPostgreSQL) dbname = "***" user = "***" password = "***" host = "***" sterownik <- dbDriver("PostgreSQL") wysokosc_gmina <- function(TERYT_gmn) { polaczenie <- dbConnect(sterownik, dbname = dbname, user = user, password = password, host = host) dane_gmina <- dbGetQuery(polaczenie, paste0('SELECT long, lat, height FROM nmt_polska WHERE "TERYT_gmn" = \'', TERYT_gmn ,'\';')) dbDisconnect(polaczenie) mapa_gg <- get_map(c(mean(dane_gmina$long), mean(dane_gmina$lat)), source = "google", maptype = "roadmap", zoom = 11) ggmap(mapa_gg) + geom_point(data = dane_gmina, aes(long, lat, color = height), alpha = 0.15) + scale_color_distiller(palette = "RdYlGn") + labs(x = "", y = "", color = "Wysokość n.p.m.") + theme(legend.position = "bottom") } wysokosc_powiat <- function(TERYT_pow) { polaczenie <- dbConnect(sterownik, dbname = dbname, user = user, password = password, host = host) dane_gmina <- dbGetQuery(polaczenie, paste0('SELECT long, lat, height FROM nmt_polska WHERE "TERYT_pow" = \'', TERYT_pow ,'\';')) dbDisconnect(polaczenie) mapa_gg <- get_map(c(mean(dane_gmina$long), mean(dane_gmina$lat)), source = "google", maptype = "roadmap", zoom = 10) ggmap(mapa_gg) + geom_point(data = dane_gmina, aes(long, lat, color = height), alpha = 0.05) + scale_color_distiller(palette = "RdYlGn") + labs(x = "", y = "", color = "Wysokość n.p.m.") + theme(legend.position = "bottom") } |
Zobaczmy kilka przykładów:
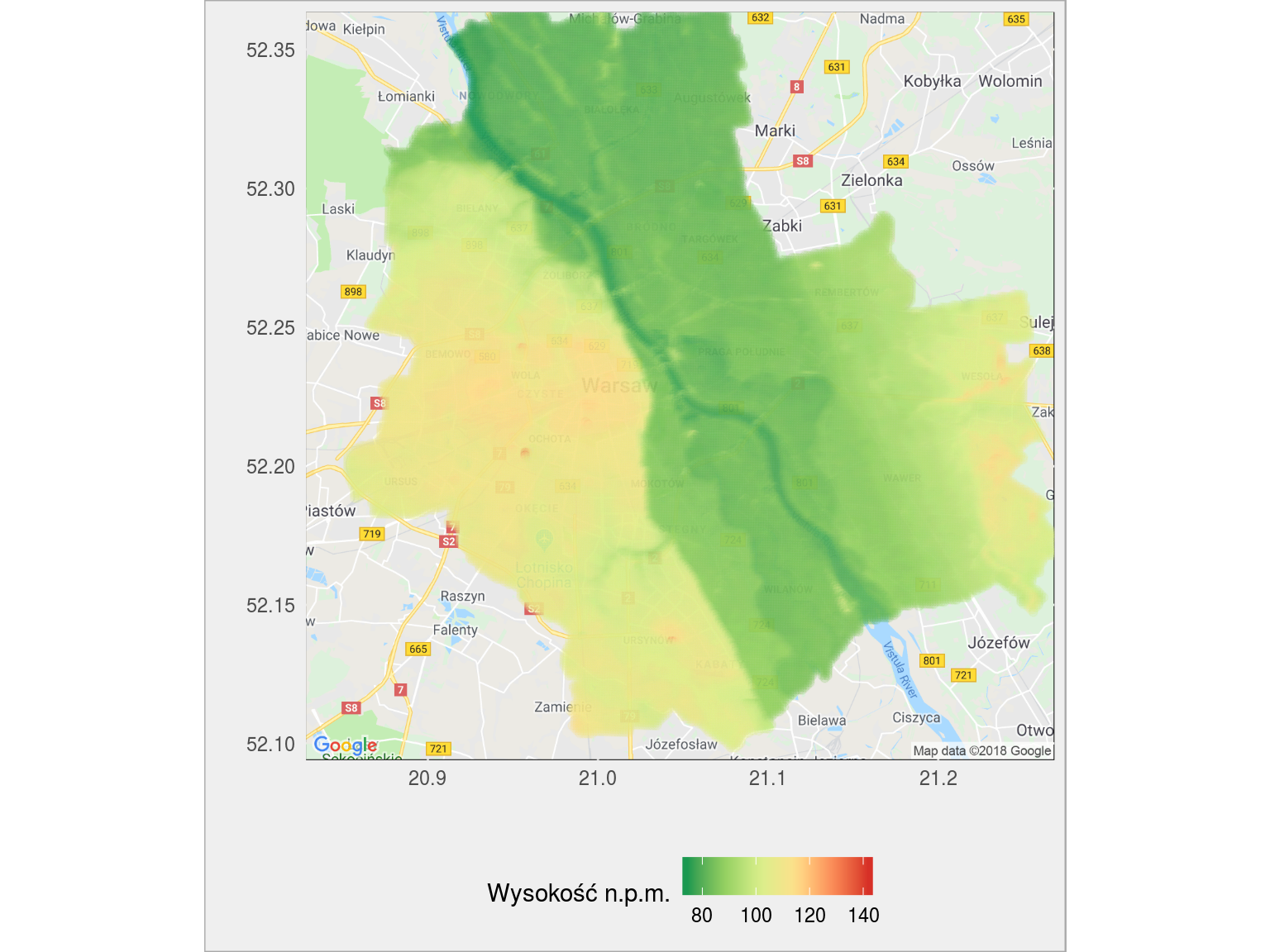
Warszawa:
|
1 |
wysokosc_gmina("1465011") |
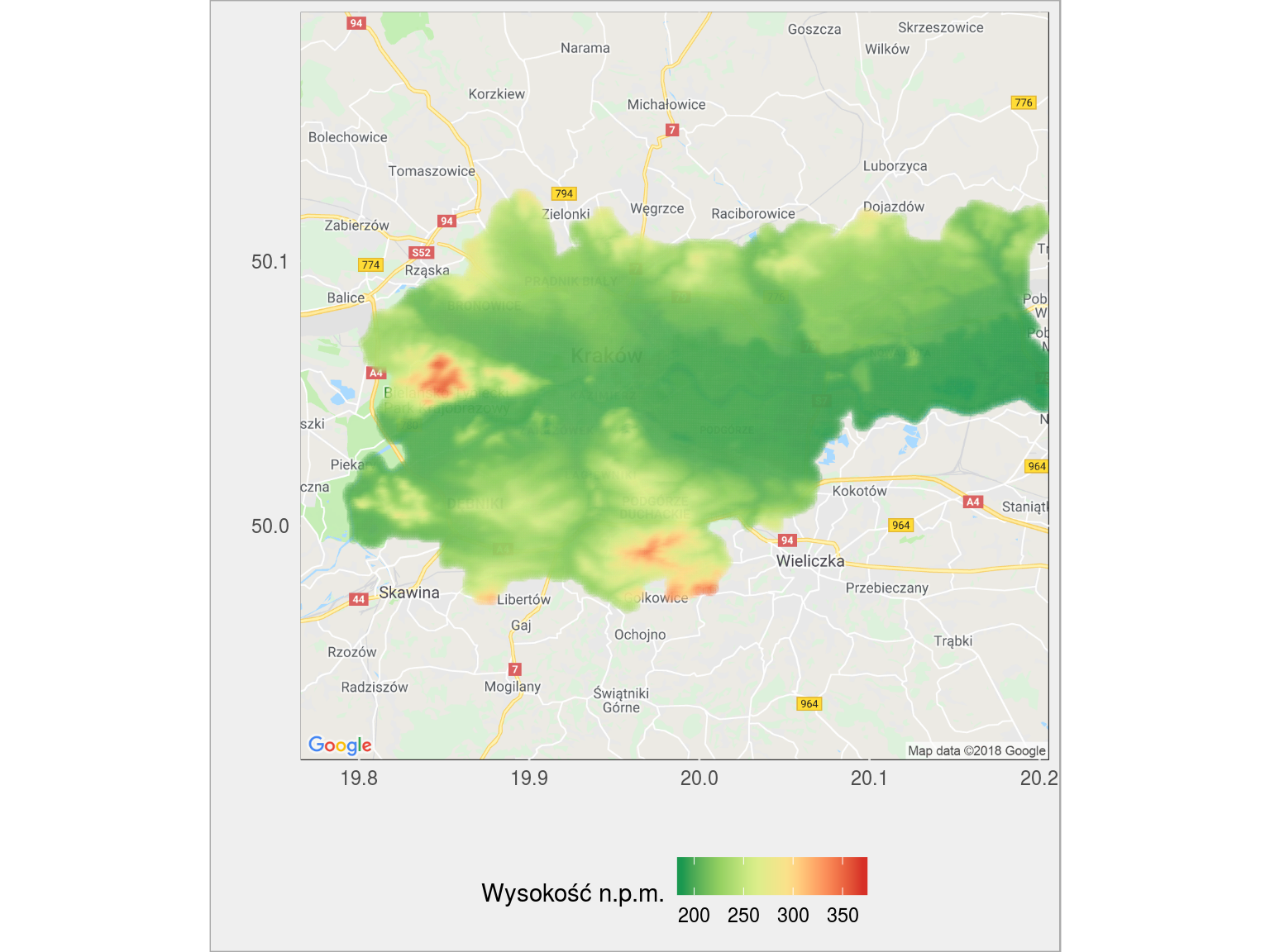
Kraków:
to czerwone po lewej to miejsce gdzie znajduje się klasztor w Tyńcu (Bielańsko-Tyniecki Park Krajobrazowy)
|
1 |
wysokosc_gmina("1261011") |
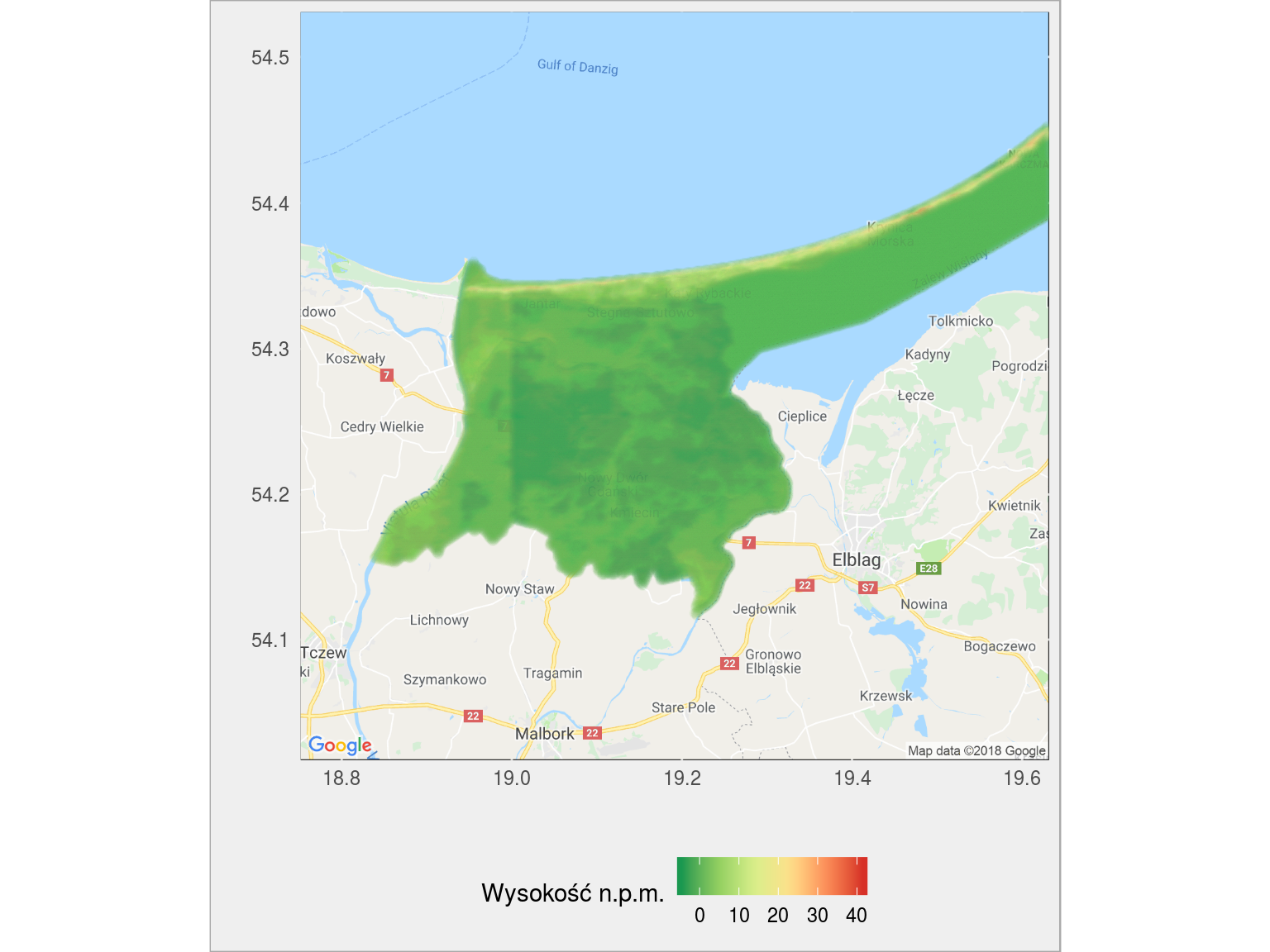
powiat Nowy Dwór Gdański
czyli Żuławy Wiślane (ich fragment) – zwróćcie uwagę, że to co jest mocno zielone jest poniżej poziomu morza.
|
1 |
wysokosc_powiat("2210") |
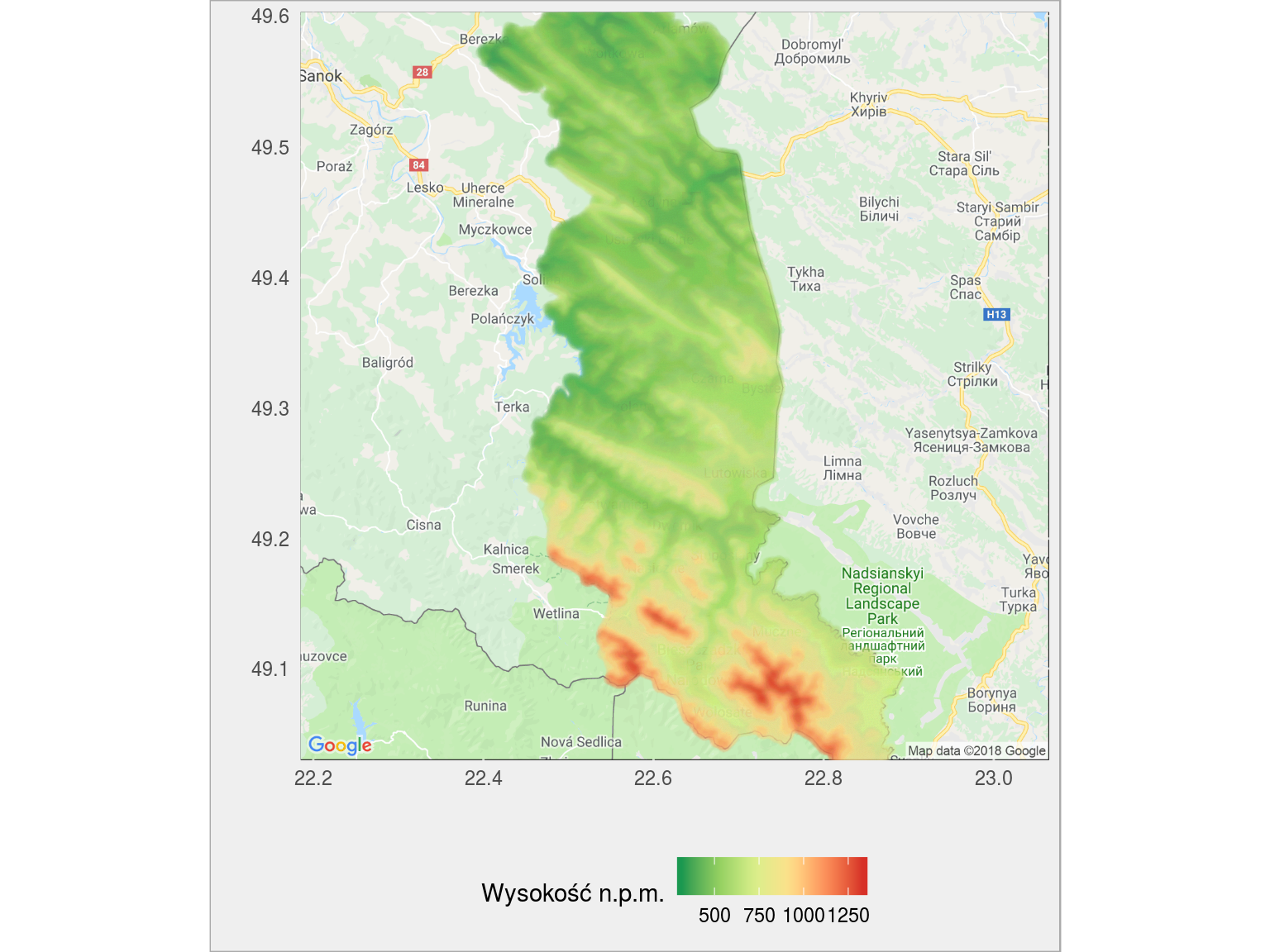
Bieszczady:
pięknie widać połoniny (dwa czerwone pasma nad Wetliną) oraz masyw z Tarnicą i Krzemieniem (ta większa czerwona plama)
|
1 |
wysokosc_powiat("1801") |
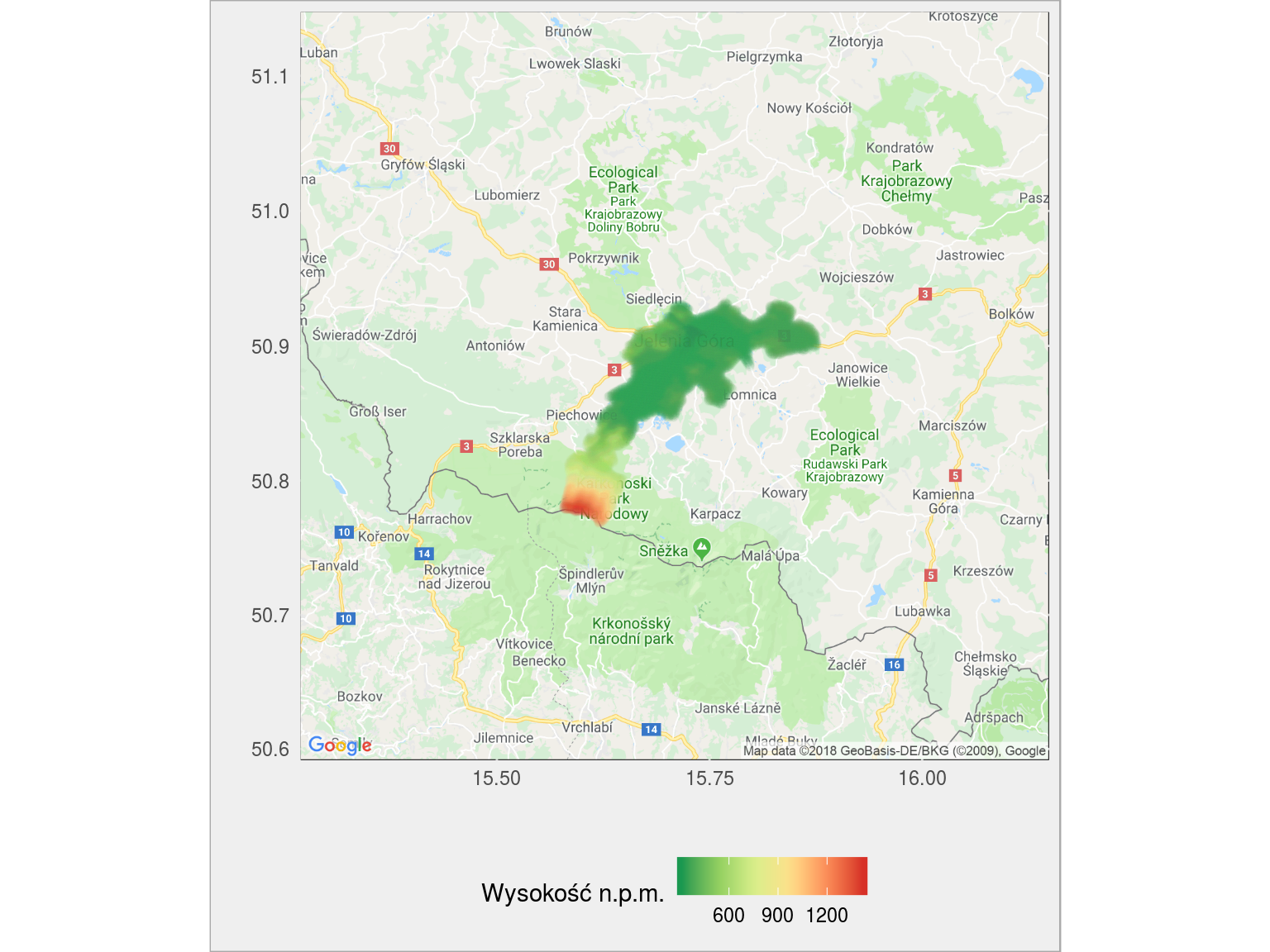
okolice Karpacza:
tam gdzie najbardziej czerwono leży Wielki Szyszak
|
1 |
wysokosc_powiat("0201") |
Z dzisiejszego postu nauczyliśmy się (mam nadzieję) przede wszystkim:
-
- jak sprawdzić czy dany punkt leży w określonym obszarze – to ćwiczyliśmy w dopisywaniu kodu TERYT do punktów
- jak połączyć dane punktowe z mapą
- że pakiet sf jest bardzo wygodny jeśli chodzi o pliki SHP
- jak dane zapisać do bazy danych oraz je z niej pobrać
Jeśli Ci się podobało – udostępniaj, ślij znajomym. I wracaj tutaj w przyszłości.
Super, zawsze wiele się uczę z tych przykładów!
Przy okazji, zainteresowałem się tematem przekształceń, odwzorowania: kod:
CRS_puwg1992 <- crs("+proj=tmerc +lat_0=0 +lon_0=19 +k=0.9993 +x_0=500000 +y_0=-5300000 +ellps=GRS80 +units=m +no_defs ")
# układ WGS84 (współrzędne "normalne")
CRS_wgs84 <- crs("+proj=longlat +ellps=WGS84 +datum=WGS84 +no_defs;")
W pakiecie simple features (SF) można posługiwać się czterocyfrowym kodem (EPSG) odwzorowań już przy ładowaniu lub przy przekształcaniu danych, np:
dane_nmt %
sample_n(size = 1000, replace=F) %>%
st_as_sf( coords = c(„x”, „y”), crs = 2180, agr = „constant”, precision = 0.1) %>%
st_transform(crs = 4326) %>%
as_Spatial(.)
korekta, ucieło pierwszą linię:
dane_nmt =
read_delim(dane_plik, ” „, col_names = c(„x”, „y”, „z”), col_types = „ddd”) %>%
sample_n(size = 1000, replace=F) %>%
st_as_sf( coords = c(„x”, „y”), crs = 2180, agr = „constant”, precision = 0.1) %>%
st_transform(crs = 4326) %>%
as_Spatial(.)