W dzisiejszym wpisie nieco bardziej techniczne sprawy, ale bardzo cenne dla osób, które przy pomocy R chcą pobierać dane ze stron WWW.
Przedstawię trzy narzędzia, które w tym pomogą. Dwa pomogą na pewno, trzecie to bardziej ciekawostka do robienia screen shotów.
Jak dobrać się do tabelki na stronie?
Często jakieś dane, które nas interesują są opublikowane na stronach WWW. Można je przepisać ręcznie, można je wciągnąć do Excela (jest odpowiedni, w miarę intuicyjny importer tabelek dostępny pod guzikiem Z sieci Web w menu Dane). Ale nas interesuje oczywiście w R (i Python, ale to nie w tym odcinku).
W dzisiejszych zajęciach przydadzą nam się biblioteki:
|
1 2 3 4 5 6 7 |
library(tidyverse) library(rvest) library(glue) library(stringr) library(lubridate) library(knitr) library(kableExtra) |
Za przykład niech posłuży nam strona o polskich województwach z Wikipedii. Przerwij na chwilę czytanie tego tekstu i przejdź na tę stronę (kliknij środkowym klawiszem myszki czy tam rolką w link). Na stronie mamy kilka tabelek, pobierzemy sobie jedną (pierwszą).
|
1 2 3 4 5 |
# jaką stronę wczytujemy? base_url <- "https://pl.wikipedia.org/wiki/Wojew%C3%B3dztwo" # no to wczytujemy! page <- read_html(base_url) |
Teraz potrzebujemy się dobrać do tabelek. W tym miejscu przyda się wiedza na temat struktury dokumentu HTML (kilka podstawowych tagów, drzewo tagów i zagnieżdżenia jednych tagów w drugich) oraz CSS (klasy, i identyfikatory elementów, czyli class i id). Taką wiedzę można znaleźć w innych miejscach – poszukajcie.
Korzystając z pakietu rvest mamy dwa sposoby wyboru elementów. Jeden to ścieżka do elementu w postaci XPath drugi to wędrówka po drzewie HTML z podaniem odpowiednich klas.
Zacznijmy od tego pierwszego.
Tabele znajdują się na stronie w ścieżce:
- div o id bodyContent
- w którym jest div o id mw-content-text
- wewnątrz którego mamy div o klasie mw-parser-output
- i tutaj już są tabele o klasach wikitable
Zapisując to w XPath mamy:
|
1 2 |
tabele1 <- page %>% html_nodes(xpath = "//div[@id='bodyContent']/div[@id='mw-content-text']/div[@class='mw-parser-output']/table[contains(@class, 'wikitable')]") |
Co w wyniku daje nam node’y:
|
1 2 3 4 5 6 7 8 |
tabele1 ## {xml_nodeset (5)} ## [1] <table class="wikitable sortable" style="text-align:left;">\n<tr>\n< ... ## [2] <table class="wikitable" width="100%">\n<tr>\n<th>Prowincja</th>\n<t ... ## [3] <table class="wikitable" width="500px">\n<tr>\n<th colspan="5">Podzi ... ## [4] <table class="wikitable" width="600px">\n<tr>\n<th colspan="5">Podzi ... ## [5] <table class="wikitable sortable" width="500px">\n<tr>\n<th colspan= ... |
Tak samo możemy dotrzeć korzystając z HTMLa i CSSów:
|
1 2 3 4 5 |
tabele2 <- page %>% html_nodes(css = "div#bodyContent") %>% html_nodes(css = "div#mw-content-text") %>% html_nodes("div.mw-parser-output") %>% # css jest domyślnym parametrem, więc go nie podaję html_nodes("table.wikitable") |
Wynik jest identyczny:
|
1 2 3 4 5 6 7 8 |
tabele2 ## {xml_nodeset (5)} ## [1] <table class="wikitable sortable" style="text-align:left;">\n<tr>\n< ... ## [2] <table class="wikitable" width="100%">\n<tr>\n<th>Prowincja</th>\n<t ... ## [3] <table class="wikitable" width="500px">\n<tr>\n<th colspan="5">Podzi ... ## [4] <table class="wikitable" width="600px">\n<tr>\n<th colspan="5">Podzi ... ## [5] <table class="wikitable sortable" width="500px">\n<tr>\n<th colspan= ... |
Weźmy teraz pierwszą tabelę (jej zawartość):
|
1 |
tabelka <- tabele2[[1]] %>% html_table() |
i zobaczmy zawartość jej kilku kolumn (1, 2, 3 i 9):
|
1 |
tabelka[c(1:3, 9)] |
| TERYT | województwo | miasto wojewódzkie | tablica rejestracyjna |
|---|---|---|---|
| 2 | dolnośląskie | Wrocław | D |
| 4 | kujawsko-pomorskie | Bydgoszcz ¹Toruń ² | C |
| 6 | lubelskie | Lublin | L |
| 8 | lubuskie | Gorzów Wielkopolski ¹Zielona Góra ² | F |
| 10 | łódzkie | Łódź | E |
| 12 | małopolskie | Kraków | K |
| 14 | mazowieckie | Warszawa | W |
| 16 | opolskie | Opole | O |
| 18 | podkarpackie | Rzeszów | R |
| 20 | podlaskie | Białystok | B |
| 22 | pomorskie | Gdańsk | G |
| 24 | śląskie | Katowice | S |
| 26 | świętokrzyskie | Kielce | T |
| 28 | warmińsko-mazurskie | Olsztyn | N |
| 30 | wielkopolskie | Poznań | P |
| 32 | zachodniopomorskie | Szczecin | Z |
Prawda, że proste?
Strony i treść podstron
Zajmijmy się zatem czymś trudniejszym. Wyobraźmy sobie, że mamy stronę z listą linków do innych podstron. Ta lista jest stronicowana, a nas interesują informacje zawarte na tych właściwych stronach. Czyli: mamy stronicowaną listę artykułów, a interesuje nas jakaś zawartość artykułu. Zamiast artykułów może być na przykład lista ogłoszeń, a interesować mogą nas jakieś parametry ogłoszenia.
Pozostańmy przy przykładzie z artykułami, na warsztat weźmiemy te z Wiadomości portalu Gazeta.pl. Wchodzimy zatem na stronę główną Wiadomości i jedziemy na sam dół, a następnie klikamy w którąś kolejną stronę. W efekcie widzimy, że link dla strony drugiej wygląda tak: http://wiadomosci.gazeta.pl/wiadomosci/0,114871.html?str=2_19834953, a dla trzeciej http://wiadomosci.gazeta.pl/wiadomosci/0,114871.html?str=3_19834953.
Parametr str odpowiada za numer strony. Sprawdzamy jeszcze co się stanie dla str=1. Dzieje się to co powinno – mamy pierwszą stronę. Wykorzystamy to i pobierzemy linki do artykułów z pierwszych 5 stron.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
# potrzebujemy miejsca, gdzie zgromadzimy linki linki <- vector() # dla pierwszych pięciu stron powtarzamy to samo: for(str in 1:5) { # budujemy urla kolejnej podstrony page_url <- glue("http://wiadomosci.gazeta.pl/wiadomosci/0,114871.html?str={str}_19834953") # pobieramy tą podstronę page <- read_html(page_url) # szukamy wszystkich linków do artykułów linki_tmp <- page %>% # layout strony: html_node("div#columns_wrap") %>% html_node("div#col_left") %>% html_node("div#row_1") %>% html_node("div#holder_201") %>% # właściwy indeks artykułów: html_node("article") %>% html_node("section.body") %>% # lista artykułów: html_node("ul") %>% # pojedynczy artykuł html_nodes("li") %>% # linki do artykułów html_node("a") %>% # wartość parametru href w znaczniku a html_attr("href") # dodajemy zgromadzone linki z jednej strony do wszystkich zebranych wcześniej linków linki <- c(linki, linki_tmp) } |
W efekcie zebraliśmy 115 linków. Ale uwaga – nie wszystkie linki prowadzą do artykułów (artykuły to strony typ numer 7, czyli urle zaczynające się od http://wiadomosci.gazeta.pl/wiadomosci/7,) Zostawmy więc tylko te urle, które prowadzą do artykułów:
|
1 |
linki <- linki[grepl("http://wiadomosci.gazeta.pl/wiadomosci/7,", linki)] |
Zostało 111 sztuk. Dlaczego zrobiliśmy takie przesianie? Ano dlatego, że szablon strony innej niż siódemka wymagałby innej obsługi zbierania danych ze strony z treścią. Aby nie komplikować procesu po prostu się ograniczymy.
Za chwilę zbierzemy treści artykułów, ale a co jeśli się nie uda pobrać strony? Skrypt nam się wywali. Aby do tego nie dopuścić skorzystamy ze świetnej funkcji safely() z pakietu purrr mapując funkcję read_html(). Pozwoli nam to sprawdzić czy pobranie strony się udało czy nie (bo na Czerskiej założyli nam bana, albo po prostu padła sieć ;)
|
1 |
safe_read_html <- safely(read_html) |
Teraz dla każdego z artykułów pobierzemy autora, datę publikacji i lead. Ponieważ jest to czynność mocno powtarzalna – zrobimy do tego stosowną funkcję.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 |
get_article_details <- function(art_url) { # próbujemy pobrać stronę page <- safe_read_html(art_url, encoding = "iso-8859-2") # jeśli się nie udało - wychodzimy z pustą tabelką if(is.null(page$result)) { return(tibble()) } # udało się - wynik mamy w $result page <- page$result # tytuł - to H1 na stronie tytul <- page %>% html_node(xpath = "//h1") %>% html_text() %>% trimws() # autor autor <- page %>% html_node(xpath = "//div[@id='gazeta_article_author']/span") %>% html_text() %>% trimws() # data publikacji data <- page %>% html_node(xpath = "//div[@id='gazeta_article_date']/time") %>% html_attr("datetime") %>% ymd_hm() # lead lead <- page %>% html_node(xpath = "//div[@id='gazeta_article_lead']") %>% html_text() %>% trimws() # pakujemy to w 1-wierszowa tabele article <- tibble(url = art_url, title = tytul, author = autor, date = data, lead = lead) return(article) } |
Na szczęście szablony stron Gazeta.pl są bardzo czytelnie przygotowane, każdy właściwie element ma swoją klasę i wystarczyło skorzystać z odpowiednich selektorów. Wykorzystałem XPath, ale równie dobrze działa wybieranie elementów po CSSie. Zanim napisałem powyższy kod otworzyłem stronę artykułu w Chrome, kliknąłem w “Zbadaj” i wio, element po elemencie, sprawdzałem jaką ma klasę, w jakim znaczniku HTML jest zapisany. I czy jest tekstem wewnątrz znacznika, czy też jego atrybutem. Tego inaczej nie da się zrobić – potrzebna jest praca z przeglądarką.
Mając gotowe narzędzie dla wszystkich zgromadzonych urli wywołujemy funkcję i zbijamy dane w jedną długą tabelę (co trochę trwa):
|
1 2 |
articles <- linki %>% map_df(get_article_details) |
Zebraliśmy 107 wierszy w tabeli. Czyli nie udało się dla wszystkich zgromadzonych z indeksu linków. Ale to nic… jak mawia moje młodsze dziecko – nie o to w tym chodzi.
Co z tymi danymi można zrobić? A na przykład sprawdzić jaki autor publikuje najczęściej:
|
1 |
articles %>% count(author) %>% arrange(n) %>% mutate(author = fct_inorder(author)) %>% ggplot(aes(author, n)) + geom_col() + coord_flip() |
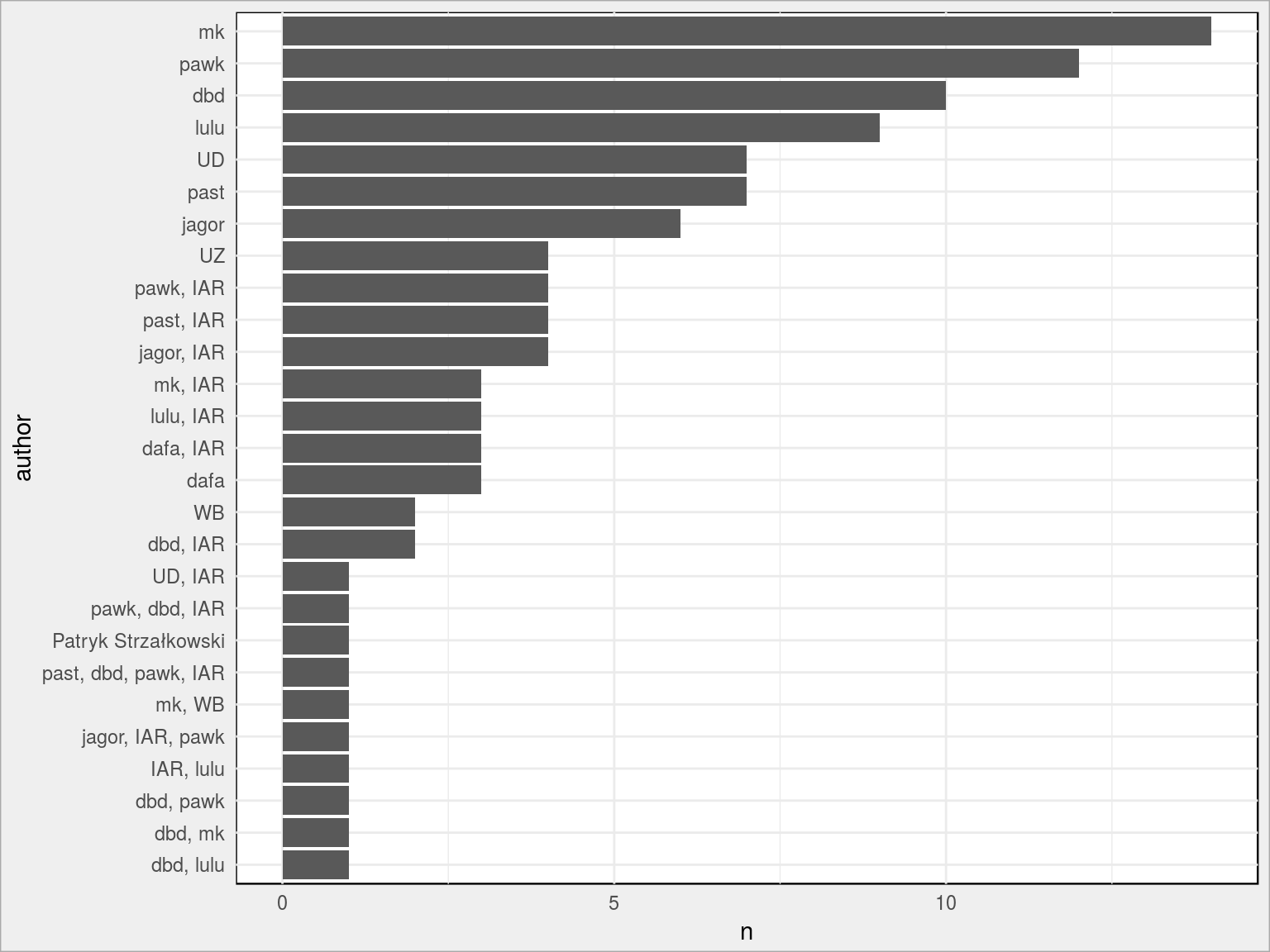
Albo coś więcej, ale o tym już pisałem ponad pół roku temu! Tam też znajdziecie (w pierwszej części tekstu) informacje jak artykuły zostały pobrane.
Strony dynamiczne i formularze
Wszystko ładnie pięknie działa w przypadku stron statycznych, które nie doczytują sobie żadnych danych w trakcie. A co jeśli te mechanizmy nie zadziałają? Pozostaje nam udawanie klikania po stronie, tak jakbyśmy to sami robili. Z pomocą przychodzi Selenium którego warto się nauczyć. W R mamy bibliotekę
|
1 |
library(RSelenium) |
Idea Selenium to uruchomienie rzeczywistej przeglądarki na jakiejś wirtualnej maszynie i udawanie prawdziwego zachowania użytkownika. Wirtualną maszynę zapewni nam Docker. Kiedyś może więcej o tym napiszę, na dzisiaj wystarczy instalacja (tutaj opisano jak to zrobi na Ubuntu).
Po zainstalowaniu Dockera instalujemy obraz z przeglądarką – w tym przypadku z Chrome. W konsoli wpisujemy po prostu:
|
1 |
docker pull selenium/standalone-chrome |
Następnie uruchamiamy maszynę z przeglądarką, możemy to zrobić z poziomu R:
|
1 2 3 4 5 |
docker_pid <- system("docker run -d -p 4445:4444 --shm-size=2g selenium/standalone-chrome", intern = TRUE) print(docker_pid) ## [1] "b72061c2aca73208aa5a0212c961d95a370a26492e16fa5569db79623f5dc461" |
Zapisujemy sobie tutaj process id uruchomionej maszyny – po zakończeniu zabawy maszynę wyłączymy. Cyferki 4445 i 4444 mogą się różnic w Twojej konfiguracji, to kwestia otwartych portów na konkretnej maszynie, w konkretnej sieci.
W kolejnym kroku przygotowujemy driver do przeglądarki, czyli odpalamy maszynę Dockera:
|
1 |
remDr <- remoteDriver(remoteServerAddr = "localhost", port = 4445L, browserName = "chrome") |
chwilę czekamy, żeby Docker wystartował, na przykład:
|
1 |
Sys.sleep(5) # 5 sekund |
i uruchamiamy przeglądarkę:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 |
remDr$open() ## [1] "Connecting to remote server" ## $applicationCacheEnabled ## [1] FALSE ## ## $rotatable ## [1] FALSE ## ## $mobileEmulationEnabled ## [1] FALSE ## ## $networkConnectionEnabled ## [1] FALSE ## ## $chrome ## $chrome$chromedriverVersion ## [1] "2.38.552522 (437e6fbedfa8762dec75e2c5b3ddb86763dc9dcb)" ## ## $chrome$userDataDir ## [1] "/tmp/.org.chromium.Chromium.KQD4Wk" ## ## ## $takesHeapSnapshot ## [1] TRUE ## ## $pageLoadStrategy ## [1] "normal" ## ## $databaseEnabled ## [1] FALSE ## ## $handlesAlerts ## [1] TRUE ## ## $hasTouchScreen ## [1] FALSE ## ## $version ## [1] "66.0.3359.117" ## ## $platform ## [1] "Linux" ## ## $browserConnectionEnabled ## [1] FALSE ## ## $nativeEvents ## [1] TRUE ## ## $acceptSslCerts ## [1] FALSE ## ## $acceptInsecureCerts ## [1] FALSE ## ## $locationContextEnabled ## [1] TRUE ## ## $webStorageEnabled ## [1] TRUE ## ## $browserName ## [1] "chrome" ## ## $takesScreenshot ## [1] TRUE ## ## $javascriptEnabled ## [1] TRUE ## ## $cssSelectorsEnabled ## [1] TRUE ## ## $setWindowRect ## [1] TRUE ## ## $unexpectedAlertBehaviour ## [1] "" ## ## $webdriver.remote.sessionid ## [1] "f565ce429ae569f878ee61c6b8b2f0fa" ## ## $id ## [1] "f565ce429ae569f878ee61c6b8b2f0fa" |
Powyżej widzimy informacje o przeglądarce. Ale interesuje nas jednak wejście na konkretną stronę – na przykład Google:
|
1 |
remDr$navigate("http://www.google.com/ncr") |
Zobaczmy cośmy narobili:
|
1 2 3 4 5 6 7 8 9 |
remDr$getTitle() # tytul strony ## [[1]] ## [1] "Google" remDr$getCurrentUrl() # url ## [[1]] ## [1] "https://www.google.com/?gws_rd=ssl" |
Mamy określony tytuł strony, mamy jej adres.
Teraz wyszukajmy coś w tym otwartym Google wypełniając pole formularza. Poszukamy ciągu R Cran:
|
1 2 3 4 5 |
# szukamy elementu o okreslonej nazwie (atrybut name) webElem <- remDr$findElement(using = 'name', value = "q") # wysylamy do niego ciag znakow i na koniec Enter webElem$sendKeysToElement(list("R Cran", key = "enter")) |
Co się wydarzyło, czy zadziałało i gdzieś przeszliśmy?
|
1 2 3 4 5 6 7 8 9 |
remDr$getTitle() ## [[1]] ## [1] "R Cran - Google Search" remDr$getCurrentUrl() ## [[1]] ## [1] "https://www.google.com/search?source=hp&ei=lJgWW4TnLMvm0gKatJOIDQ&q=R+Cran&oq=R+Cran&gs_l=psy-ab.3...691.730.0.734.6.1.0.0.0.0.0.0..0.0....0...1c.1.64.psy-ab..6.0.0....0.66eOJiJvxr8" |
Jak widać tytuł i adres strony się zmieniły! Świetnie.
Kliknijmy teraz w jakiś link w wynikach wyszukiwania:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
# szukamy elementów o określonym CSSie webElems <- remDr$findElements(using = 'css selector', "h3.r") # bierzemy teksty tych elementow resHeaders <- unlist(lapply(webElems, function(x){x$getElementText()})) resHeaders ## [1] "The Comprehensive R Archive Network" ## [2] "Cran" ## [3] "CRAN Packages By Name" ## [4] "Windows" ## [5] "CRAN - Mirrors" ## [6] "Contributed Packages" ## [7] "(Mac) OS X" ## [8] "The R Project for Statistical Computing" ## [9] "Cran - Wikipedia" ## [10] "CRAN - Package RUnit" ## [11] "CRAN - Package gjam" ## [12] "CRAN - Package matrixStats" ## [13] "CRAN - Package pbapply" # potrzebujemy elementu z tekstem "CRAN Packages By Name" webElem <- webElems[[which(resHeaders == "CRAN Packages By Name")]] # klikamy w niego webElem$clickElement() |
powinniśmy przejść na inna stronę – sprawdzamy tak samo jak poprzednio gdzie jesteśmy:
|
1 2 3 4 5 6 7 8 |
remDr$getCurrentUrl() ## [[1]] ## [1] "https://cran.r-project.org/web/packages/available_packages_by_name.html" remDr$getTitle() ## [[1]] ## [1] "CRAN Packages By Name" |
Zobaczmy co widać w naszej wirtualnej przeglądarce:
|
1 2 3 4 5 |
# rozmiar okna przeglądarki remDr$setWindowSize(1920, 1080, "current") # screen shot zapisany do pliku remDr$screenshot(display = FALSE, file = "webscrap_screen_shot.png") |
Oto co mamy:

A może potrzebne źródło strony? Proszę bardzo:
|
1 2 3 4 |
html_source <- remDr$getPageSource() # z tego można już korzystać w rvest html_page <- read_html(html_source[[1]]) |
Formularze możemy również wypełniać z poziomu pakietu rvest:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 |
# tworzymy sesję, w ramach której wypełnimy formularz: google_url <- "http://google.com" www_sess <- html_session(google_url) # szukamy wszystkich formularzy form <- html_form(www_sess) # kopiujemy pierwszy (tutaj akurat jest jedyny) filled_form <- form[[1]] # jak on wygląda, jakie ma pola? filled_form ## <form> 'f' (GET /search) ## <input hidden> 'ie': ISO-8859-1 ## <input hidden> 'hl': en ## <input hidden> 'source': hp ## <input hidden> 'biw': ## <input hidden> 'bih': ## <input text> 'q': ## <input submit> 'btnG': Google Search ## <input submit> 'btnI': I'm Feeling Lucky ## <input hidden> 'gbv': 1 # wypełniamy pola formularza (w kopii) filled_form <- set_values(filled_form, q = "R CRAN") # wysyłamy formularz w ramach sesji form_response <- submit_form(www_sess, filled_form, submit = "btnG") # odpowiedź jest taka sama jak z read_html(), zatem możemy znaleźć np tytuły znalezionych linków: form_response %>% html_nodes("h3.r") %>% html_node("a") %>% html_text() ## [1] "The Comprehensive R Archive Network" ## [2] "Cran" ## [3] "CRAN Packages By Name" ## [4] "Windows" ## [5] "CRAN - Mirrors" ## [6] "Contributed Packages" ## [7] "(Mac) OS X" ## [8] "The R Project for Statistical Computing" ## [9] "Cran - Wikipedia" ## [10] "CRAN - Package RUnit" ## [11] "CRAN - Package gjam" ## [12] "CRAN - Package matrixStats" ## [13] "CRAN - Package pbapply" |
Logowanie do Facebooka
A jak zalogować się na jakaś stronę? Też najwygodniej Selenium i Dockerem. Zaloguję się do Facebooka:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
fb_login_str <- "xxxx" # login do Facebooka fb_pass_str <- "yyyy" # hasło do Facebooka # otwieramy strone remDr$navigate("https://www.facebook.com") # co nam sie otwarlo? remDr$getTitle() # tutul strony remDr$getCurrentUrl() # url # co widac w przegladarce? remDr$screenshot(display = FALSE, file = "webscrap_facebook_1.png") |

|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
# login # szukamy elementu o okreslonej nazwie (atrybut name) webElem <- remDr$findElement(using = 'name', value = "email") # wysylamy do niego ciag znakow i na koniec Enter webElem$sendKeysToElement(list(fb_login_str)) # hasło # szukamy elementu o okreslonej nazwie (atrybut name) webElem <- remDr$findElement(using = 'name', value = "pass") # wysylamy do niego ciag znakow i na koniec Enter, który od razu wyśle nam formularz webElem$sendKeysToElement(list(fb_pass_str, key = "enter")) # co widac w przegladarce? remDr$screenshot(display = FALSE, file = "webscrap_facebook_2.png") |

To zaciemnienie wynika z samego Facebooka – loguję się na konto z innego niż zazwyczaj adresu, gdzieś tam w rogu na dole pokazuje się komunikat o tym informujący.
Po zakończonej pracy zamykamy przeglądarkę:
|
1 |
remDr$close() |
i zatrzymujemy Dockera:
|
1 2 3 4 |
system(paste0("docker stop ", str_sub(docker_pid, 1, 12))) # zostaly jakies odpalone Dockery? to będzie widac w konsoli system("docker ps") |
Screen shot ze strony
Wyżej pobraliśmy screen shot z odwiedzanej w Selenium strony. To samo możemy zrobić prościej, bez Dockera. Posłuży do tego pakiet webshot:
|
1 |
library(webshot) |
Zanim jednak z niego zaczniemy korzystać musimy zainstalować wirtualną przeglądarkę (ale to nie to samo co Selenium):
|
1 |
webshot::install_phantomjs() |
Teraz możemy pobrać po prostu screen całej strony (całej, czyli do jej końca a nie tylko tego co widać na ekranie):
|
1 |
webshot(url = "http://blog.prokulski.science", file = "webscrap_prokulski_net.png") |
Albo tylko jakiś fragment określony CSSem:
|
1 |
webshot(url = "http://gazeta.pl", file = "webscrap_gazeta_pl.png", selector = "ul#live-feed") |

Gdzieś widziałem kod funkcji robiącej screen shota z podanego tweetu (wg jego ID) – to bardzo fajna sprawa. I na przykład jak @dziennikarz publikuje najbardziej popularne tweety dziennikarzy to warto je mieć czasem w formie obrazka… Śpieszmy się zapisywać tweety, tak szybko są czasem kasowane ;)
Pamiętaj, żeby wpaść na fanpage’a Dane i Analizy, zalajkować go i udzielać się w komentarzach ;) A jak chcesz – rzuć piątaka na serwer, korzystając z linku obok.
Jak zwykle przystępny artykuł. To kiedy ten Python?
Do „wybierania” elementów ze strony polecam dodatek do Chrome’a „SelectorGadget” — można sprawdzić klasę/id elementu i od razu przerobić dane informacje na xpatha. Z takich ciekawostek warto jeszcze się zapoznać z httrem, połączenie rvest + httr sporo czasu mi oszczędziło w pracy już na porównywaniu danych z różnych zabezpieczonych projektów i jakoś wolę to od RSelenium. Mniej setupu :)
Tak, httr też przydatny szczególnie w „rozmowach” z api.
A Python może w następnym odcinku? Bo pomysł na wpis jest dość banalny, więc można przy okazji nauczyć się Pythona (to o mnie).
Banalne wpisy też się przydają. Jakoś próbuję się przekonać do Pandasów i Seaborna, ale w porównaniu do R jakieś to wszystkie takie toporne. Kwestia przyzwyczajenia zapewne.
Świetny artykuł. Dziękuję.
Pozwolę sobie polecać wszystkim zainteresowanym R lekturę. Bo jest to chyba jeden z wiodących blogów R „data journalism” w PL
A że robię prasówkę z konkretnego działu Rynek Zdrowia, zaraz wykorzystam. btw też marzy mi się nauka Pythona, ale najpierw chciałbym poznać dobrze R… i chyba poczekam aż będzie można używać Pythona zamiennie w R notebooks w RStudio.