W jakim województwie leży wskazany punkt?
Dzisiaj zajmiemy się obszarami, głównie w oparciu o pakiet rgeos. Wpis raczej techniczny.
Po załadowaniu poniższych pakietów:
|
1 2 3 4 |
library(rgdal) library(rgeos) library(tidyverse) library(broom) # for tidy=fortify |
przygotujemy sobie dwa testowe obszary, na których przykładzie zobaczymy jak działają wybrane funkcje z pakietu rgeos.
|
1 2 3 4 5 6 7 |
poly1 <- SpatialPolygons(list(Polygons(list(Polygon(coords=matrix(c(0, 0, 2, 2, 0, 1, 1, 0), ncol=2, byrow=FALSE))), ID=c("a")), Polygons(list(Polygon(coords=matrix(c(0, 0, 2, 2, 2, 3, 3, 2), ncol=2, byrow=FALSE))), ID=c("b")))) poly2 <- SpatialPolygons(list(Polygons(list(Polygon(coords=matrix(c(0, 0, 2, 2, 1, 1, 0.5, 3, 3, 0, 0, 2), ncol=2, byrow=FALSE))), ID=c("c")))) |
Szczerze powiedziawszy mechanika budowania polygonów jest koszmarna, ale korzystając z przykładów w sieci udało się je przygotować :) Zobaczmy jak wyglądają nasze obszary:
|
1 2 |
plot(poly1, border="orange") plot(poly2, border="blue", add=TRUE, lty=2, density=8, angle=30, col="blue") |
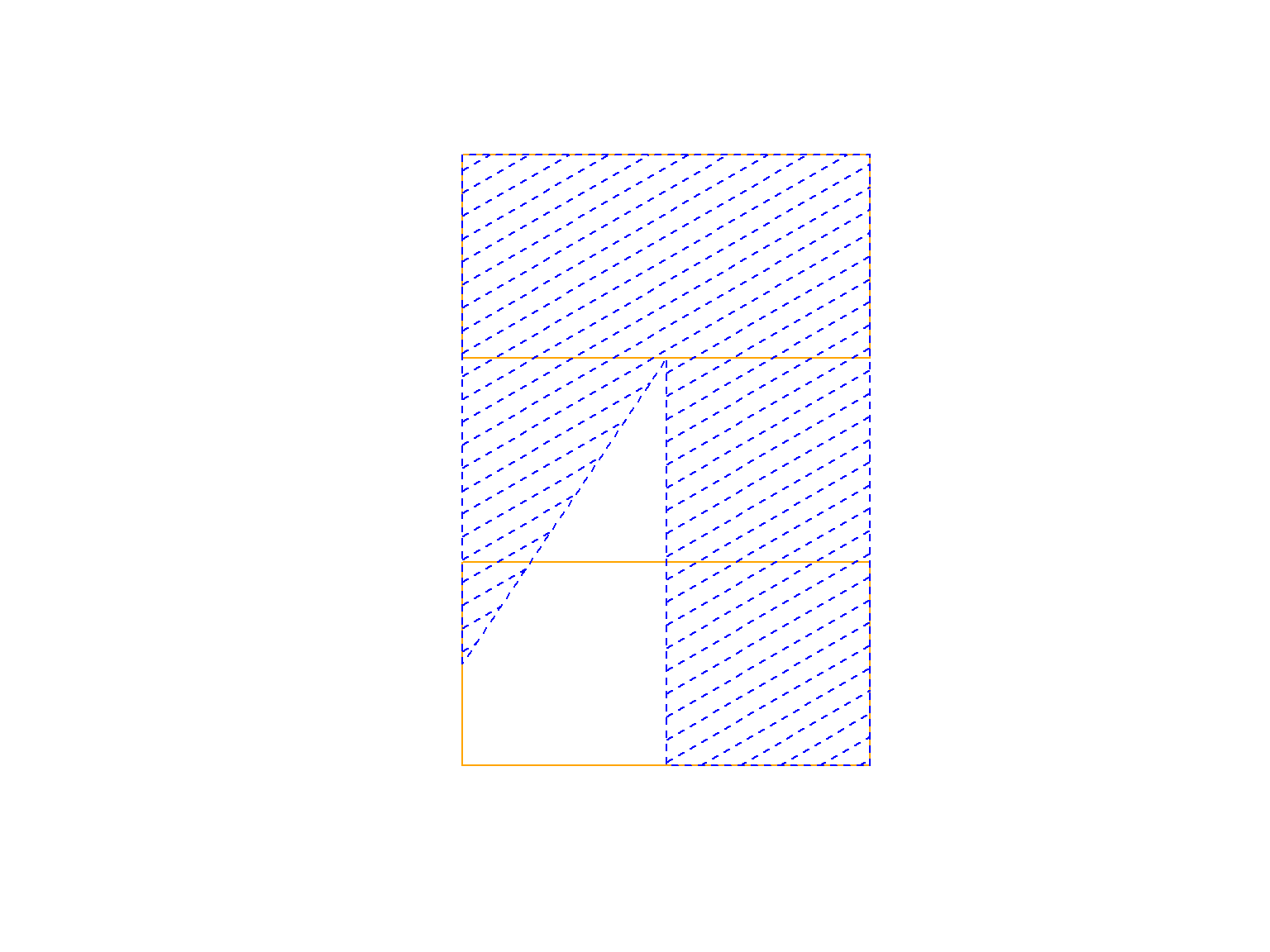
Pomarańczową obwódką zaznaczony jest obszar poly1, zakreskowany niebieski to poly2. Kształty są odpowiednio dobrane, tak aby obszary zachodziły na siebie
gIntersects
Funkcja gIntersects zwraca TRUE, jeśli podane jako parametry obszary mają co najmniej jeden punkt wspólny. Zobaczmy jak to zadziała:
|
1 2 |
gI <- gIntersection(poly1, poly2, byid=TRUE, drop_lower_td=TRUE) plot(gI, add=TRUE, border="red", lwd=3) |
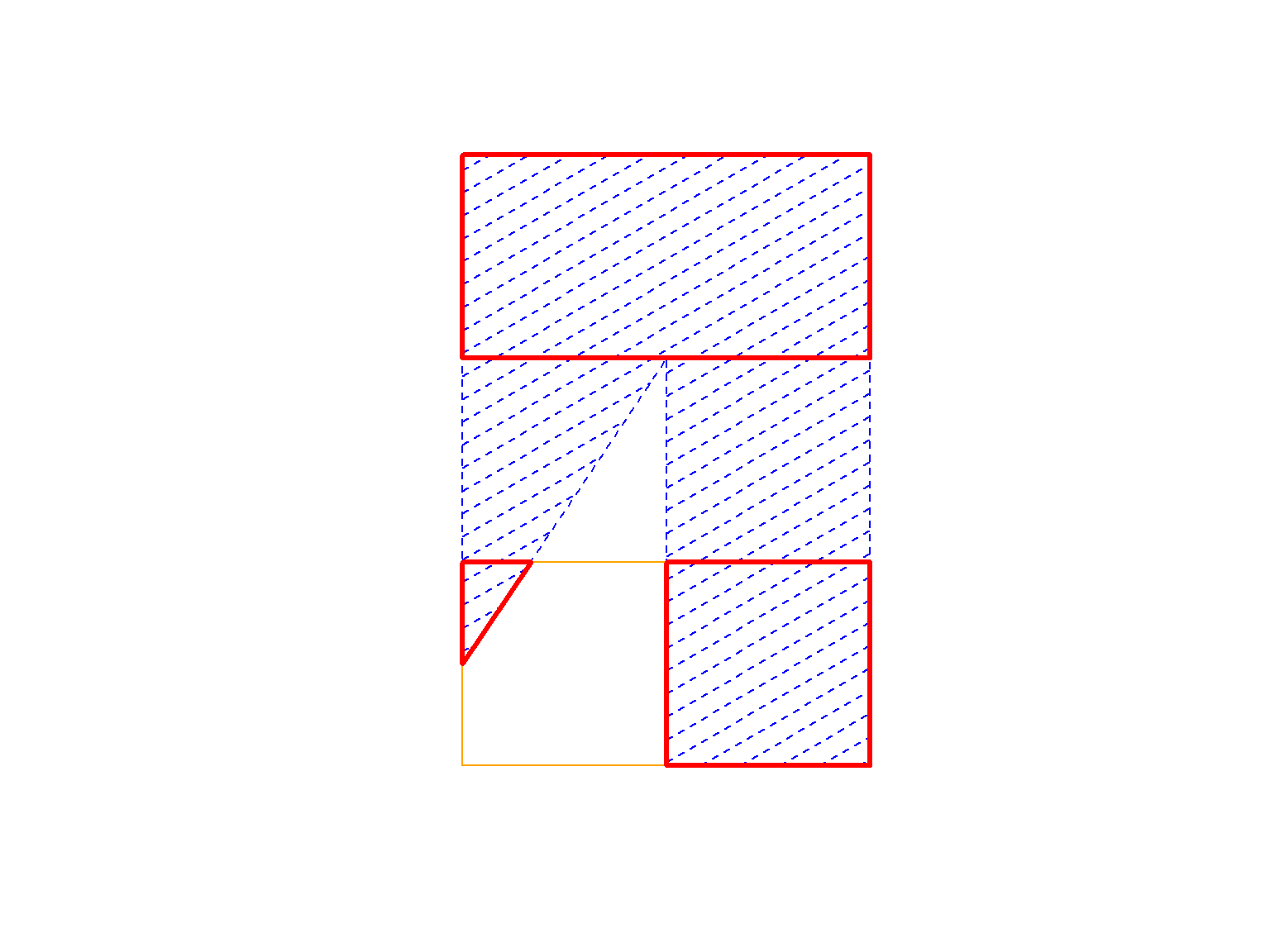
Dodatkowe parametry pozwoliły na uzyskanie kształtu z częścią wspólną (zaznaczony na czerwono). Jak widać wyszło znakomicie!
gDisjoint
Kolejna funkcja – gDisjoint zwraca TRUE, jeśli obszary nie mają punktów wspólnych:
|
1 2 3 |
gDisjoint(poly1, poly2) ## [1] FALSE |
Oczywiście w naszym przypadku jest to fałsz.
gContains
gContains zwraca TRUE, jeśli żaden z elementów poly1 nie znajduje się poza poly2, a co najmniej jeden punkt poly2 mieści się w poly1.
|
1 2 3 |
gContains(poly1, poly2) ## [1] FALSE |
Też fałsz.
gContainsProperly
gContainsProperly zwraca TRUE w tych samych warunkach co gContains z dodatkowym wymogiem, że poly2 nie przecina się z granicą poly1.
|
1 2 3 |
gContainsProperly(poly1, poly2) ## [1] FALSE |
gCovers
gCovers zwraca TRUE, jeśli żaden punkt poly2 nie jest wewnątrz poly1. To trochę różni się od gContains, ponieważ nie wymaga punktu w poly1, co może stanowić problem, ponieważ granice nie są uważane za leżące “wewnątrz” obszaru.
|
1 2 3 |
gCovers(poly1, poly2) ## [1] FALSE |
gCoveredBy
gCoveredBy jest przeciwieństwem gCovers i jest równoważne zamianie kolejności parametrów poly1 i poly2.
|
1 2 3 |
gCoveredBy(poly1, poly2) ## [1] FALSE |
gWithin
gWithin jest przeciwieństwem gContains i jest równoważne zamianie poly1 i poly2.
|
1 2 3 |
gWithin(poly1, poly2) ## [1] FALSE |
Ta funkcja przyda nam się najbardziej.
Na początek potrzebujemy plików z mapami – są ogólnodostępne i za darmo na stronie Centralnego Ośrodka Dokumentacji Geodezyjnej i Kartograficznej. Pobieramy paczkę PRG – jednostki administracyjne.
Zobaczmy co zawiera mapa z województwami. Wczytujemy ją do R i zmieniamy układ współrzędnych na taki znany z geografii (są zapisane w innym układzie):
|
1 2 3 |
wojewodztwa <- readOGR("../!mapy_shp/wojewodztwa.shp", "wojewodztwa") wojewodztwa <- spTransform(wojewodztwa, CRS("+init=epsg:4326")) |
Po tym przekształceniu możemy je narysować. ggplot2 poradzi sobie z danymi typu SpatialPolygons:
|
1 2 3 4 |
ggplot(wojewodztwa) + geom_polygon(aes(long, lat, group=group, fill=group), color="gray", show.legend = FALSE) + coord_map() + theme_void() |
ale możemy z nich wyciągnąć interesujące nas informacje – współrzędne opisujące granice obszarów i nazwy obszarów (lub ich kody TERYT – przykład łączenia danych z mapą pokazywałem już dawniej – kod TERYT jest świetnym kluczem łączącym) i upakować je w ramkę danych.
|
1 2 3 |
wojewodztwa_nazwy <- wojewodztwa@data %>% select(jpt_kod_je, jpt_nazwa_) wojewodztwa_df <- tidy(wojewodztwa, region = "jpt_kod_je") wojewodztwa_df <- left_join(wojewodztwa_df, wojewodztwa_nazwy, by=c("id"="jpt_kod_je")) |
Z taką ramką ggplot też sobie poradzi:
|
1 2 3 4 |
ggplot(wojewodztwa_df) + geom_polygon(aes(long, lat, group=group, fill=jpt_nazwa_), color="gray") + coord_map() + theme_void() |
Wyznaczmy teraz środki obszarów (województw) – z pomocą przychodzi funkcja coordinates z pakietu sp (rgdal go ładuje, nie trzeba tego robić bezpośrednio).
|
1 2 3 4 5 6 |
srodki <- coordinates(wojewodztwa) %>% as_tibble() %>% set_names(c("long", "lat")) %>% mutate(nazwa = wojewodztwa@data$jpt_nazwa_, powierzchnia = wojewodztwa@data$jpt_powier) %>% select(nazwa, long, lat, powierzchnia) |
Przy okazji wyciągnąłem inną informację zawartą w plikach shp – powierzchnię województwa (to jakaś dziwna jednostka; mazowieckie ma 35559.20km2, tutaj wartość ta jest przemnożona przez 100). Bo pliki shp to nie tylko obszary, ale też dane. Zobaczmy co uzyskaliśmy:
| Województwo | Długość geograficzna | Szerokość geograficzna | Powierzchnia |
|---|---|---|---|
| opolskie | 17.89988 | 50.64711 | 941272 |
| świętokrzyskie | 20.76909 | 50.76339 | 1171136 |
| kujawsko-pomorskie | 18.48822 | 53.07270 | 1797058 |
| mazowieckie | 21.09645 | 52.34576 | 3555920 |
| pomorskie | 17.98619 | 54.15424 | 1831001 |
| śląskie | 18.99410 | 50.33108 | 1233406 |
| warmińsko-mazurskie | 20.82493 | 53.85721 | 2417419 |
| zachodniopomorskie | 15.54329 | 53.58476 | 2289315 |
| dolnośląskie | 16.41069 | 51.08950 | 1994777 |
| wielkopolskie | 17.24310 | 52.33078 | 2982774 |
| łódzkie | 19.41760 | 51.60487 | 1821720 |
| podlaskie | 22.92931 | 53.26452 | 2018598 |
| małopolskie | 20.26933 | 49.85895 | 1518007 |
| lubuskie | 15.34275 | 52.19617 | 1398751 |
| podkarpackie | 22.16912 | 49.95367 | 1784523 |
| lubelskie | 22.90027 | 51.22072 | 2512291 |
Przygotujmy więc mapę województw z zaznaczonymi ich środkami, nazwami i informacją o powierzchni (wielkość i jasność kropki):
|
1 2 3 4 5 6 7 8 9 10 11 |
ggplot() + geom_polygon(data = wojewodztwa_df, aes(long, lat, group=group), fill = "gray80", color="gray30", show.legend = FALSE) + geom_point(data = srodki, aes(long, lat, size = powierzchnia, color = powierzchnia), show.legend = FALSE) + geom_text(data = srodki, aes(long, lat, label = nazwa), vjust = 1.7, size = 2.8) + coord_map() + theme_void() + scale_color_gradient(low = "red", high = "yellow") + scale_size(range=c(2,6)) |
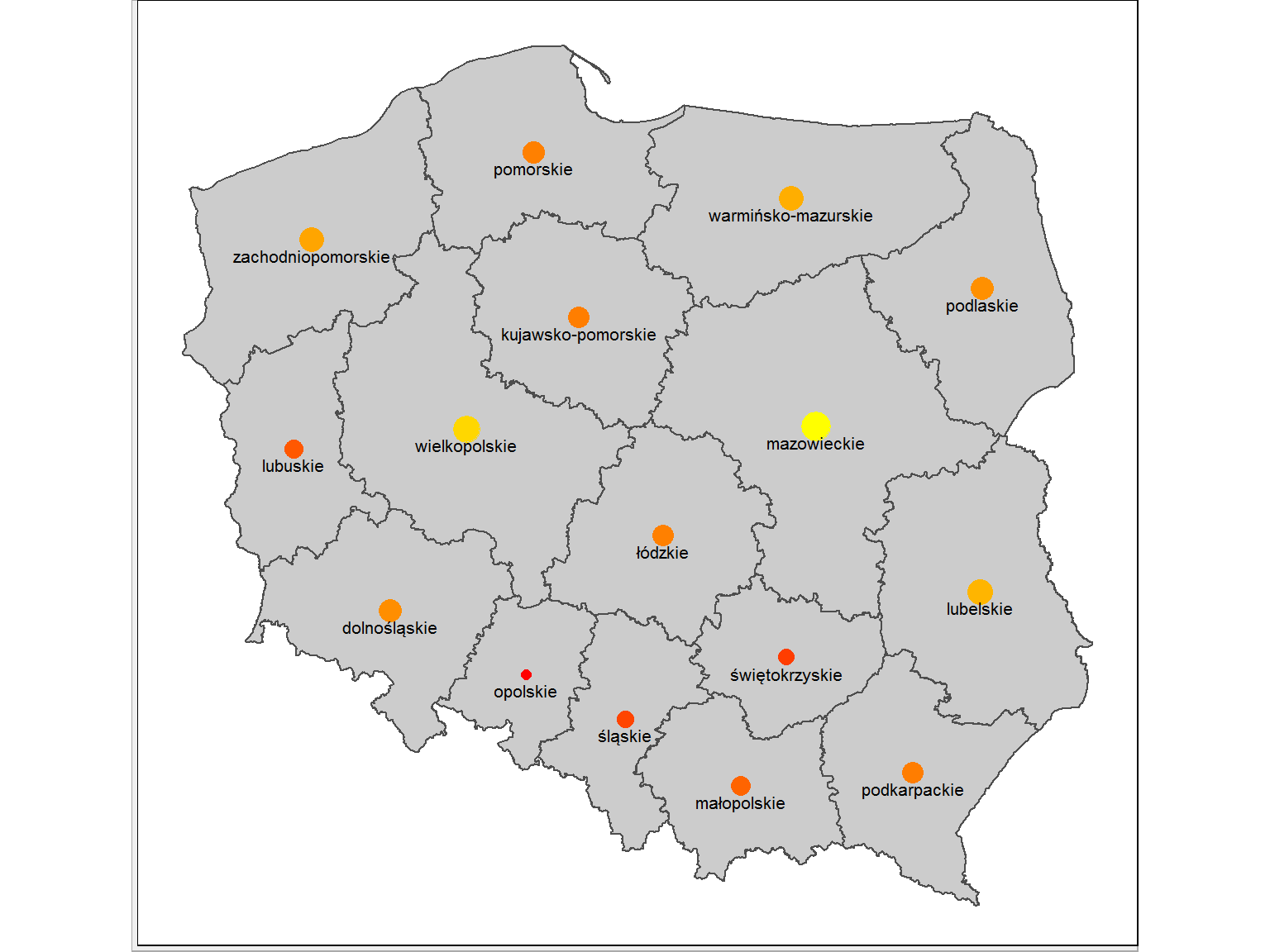
Przechodząc do postawionego na początku pytania (w jakim województwie leży dany punkt) weźmy środek lubelskiego:
|
1 |
punkt <- SpatialPoints(matrix(c(22.90027, 51.22072), ncol=2), CRS("+init=epsg:4326")) |
i tylko jedno województwo:
|
1 |
mazowsze <- wojewodztwa[wojewodztwa@data$jpt_nazwa_ == "mazowieckie", ] |
Czy środek lubelskiego wypada w mazowieckim?
|
1 2 3 |
gWithin(punkt, mazowsze) ## [1] FALSE |
Nie leży. W zasadzie nie powinien ;-)
A teraz zrobimy to dla całej listy środków województw:
|
1 2 3 4 5 6 7 8 |
# bierzemy wszystkie punkty punkty <- SpatialPoints(srodki[,c(2:3)], CRS("+init=epsg:4326")) # czy leżą w mazowieckim? srodki$czy_mazowsze <- gWithin(punkty, mazowsze, byid = TRUE) %>% as.logical() # wynik: srodki %>% select(nazwa, czy_mazowsze) |
| Województwo (środek) | Czy w mazowieckim? |
|---|---|
| opolskie | FALSE |
| świętokrzyskie | FALSE |
| kujawsko-pomorskie | FALSE |
| mazowieckie | TRUE |
| pomorskie | FALSE |
| śląskie | FALSE |
| warmińsko-mazurskie | FALSE |
| zachodniopomorskie | FALSE |
| dolnośląskie | FALSE |
| wielkopolskie | FALSE |
| łódzkie | FALSE |
| podlaskie | FALSE |
| małopolskie | FALSE |
| lubuskie | FALSE |
| podkarpackie | FALSE |
| lubelskie | FALSE |
Tylko jeden punkt powinien leżeć w mazowieckim i tak właśnie jest. Oczywiście jest to punkt środkowy tego województwa.
Możemy też sprawdzić hurtowo wszystkie punkty:
|
1 |
gWithin(punkty, wojewodztwa, byid = TRUE) |
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | T | f | f | f | f | f | f | f | f | f | f | f | f | f | f | f |
| 1 | f | T | f | f | f | f | f | f | f | f | f | f | f | f | f | f |
| 2 | f | f | T | f | f | f | f | f | f | f | f | f | f | f | f | f |
| 3 | f | f | f | T | f | f | f | f | f | f | f | f | f | f | f | f |
| 4 | f | f | f | f | T | f | f | f | f | f | f | f | f | f | f | f |
| 5 | f | f | f | f | f | T | f | f | f | f | f | f | f | f | f | f |
| 6 | f | f | f | f | f | f | T | f | f | f | f | f | f | f | f | f |
| 7 | f | f | f | f | f | f | f | T | f | f | f | f | f | f | f | f |
| 8 | f | f | f | f | f | f | f | f | T | f | f | f | f | f | f | f |
| 9 | f | f | f | f | f | f | f | f | f | T | f | f | f | f | f | f |
| 10 | f | f | f | f | f | f | f | f | f | f | T | f | f | f | f | f |
| 11 | f | f | f | f | f | f | f | f | f | f | f | T | f | f | f | f |
| 12 | f | f | f | f | f | f | f | f | f | f | f | f | T | f | f | f |
| 13 | f | f | f | f | f | f | f | f | f | f | f | f | f | T | f | f |
| 14 | f | f | f | f | f | f | f | f | f | f | f | f | f | f | T | f |
| 15 | f | f | f | f | f | f | f | f | f | f | f | f | f | f | f | T |
Oczywiście po przekątnej mamy TRUE, bo środki województw ułożone są w tej samej kolejności co województwa.
Tyle o punktach, przejdźmy do obszarów. Na przykład poszukując województwa, w którym leży powiat. Potrzebujemy mapy (precyzyjniej: regionów) z powiatami. Jest w paczce ściągniętej z CODiG. Wczytujemy dane, dostosowujemy układ współrzędnych, tworzymy tabelkę z nazwami i dodajemy do niej informację czy powiat leży w województwie mazowieckim:
|
1 2 3 4 5 6 7 |
powiaty <- readOGR("../!mapy_shp/powiaty.shp", "powiaty") powiaty <- spTransform(powiaty, CRS("+init=epsg:4326")) powiaty_df <- tibble(powiat = powiaty@data$jpt_nazwa_) powiaty_df$czy_mazowsze <- gWithin(powiaty, mazowsze, byid = TRUE) %>% as.logical() |
Ile powiatów mamy? Google mówi:
Województwo mazowieckie składa się z 37 powiatów i 5 miast na prawach powiatu. Powiaty dzielą się na 314 gmin – 35 miejskich, 50 miejsko-wiejskich i 229 wiejskich
Powiatów łącznie zatem jest 37+5=42, tak?
|
1 |
powiaty_df %>% count(czy_mazowsze) |
| czy_mazowsze | n |
|---|---|
| FALSE | 338 |
| TRUE | 42 |
Tak! Które to powiaty?
|
1 |
powiaty_df %>% filter(czy_mazowsze) %>% mutate(lp = row_number()) %>% select(lp, powiat) |
| lp | powiat |
|---|---|
| 1 | powiat makowski |
| 2 | powiat Radom |
| 3 | powiat łosicki |
| 4 | powiat żyrardowski |
| 5 | powiat nowodworski |
| 6 | powiat Ostrołęka |
| 7 | powiat Warszawa |
| 8 | powiat ostrołęcki |
| 9 | powiat ostrowski |
| 10 | powiat otwocki |
| 11 | powiat piaseczyński |
| 12 | powiat płocki |
| 13 | powiat płoński |
| 14 | powiat pruszkowski |
| 15 | powiat przasnyski |
| 16 | powiat przysuski |
| 17 | powiat miński |
| 18 | powiat mławski |
| 19 | powiat pułtuski |
| 20 | powiat Siedlce |
| 21 | powiat radomski |
| 22 | powiat siedlecki |
| 23 | powiat sierpecki |
| 24 | powiat sokołowski |
| 25 | powiat sochaczewski |
| 26 | powiat szydłowiecki |
| 27 | powiat warszawski zachodni |
| 28 | powiat węgrowski |
| 29 | powiat Płock |
| 30 | powiat białobrzeski |
| 31 | powiat ciechanowski |
| 32 | powiat garwoliński |
| 33 | powiat gostyniński |
| 34 | powiat grodziski |
| 35 | powiat grójecki |
| 36 | powiat kozienicki |
| 37 | powiat zwoleński |
| 38 | powiat legionowski |
| 39 | powiat lipski |
| 40 | powiat wołomiński |
| 41 | powiat wyszkowski |
| 42 | powiat żuromiński |
Do czego możemy to wykorzystać?
Kiedyś znalazłem jakąś listę polskich miejscowości z ich współrzędnymi geograficznymi. Nazwa, województwo, szerokość i długość geograficzna. Nie jestem pewien przypisania miejscowości do województwa. Na obrazku wygląda to tak:
|
1 2 3 4 5 6 7 8 9 10 11 |
library(readxl) miejscowosci <- read_excel("Wspolrzedne_miejscowosci.xlsx") %>% set_names(c("Miejscowosc", "Wojewodztwo", "Lat", "Long")) ggplot() + # najpierw punkty, a na nie granice województw geom_point(data = miejscowosci, aes(Long, Lat, color = Wojewodztwo), alpha = 0.5, show.legend = FALSE, size = 0.9) + geom_polygon(data = wojewodztwa_df, aes(long, lat, group=group), fill = NA, color = "gray30") + facet_wrap(~Wojewodztwo) + coord_map() + theme_void() |
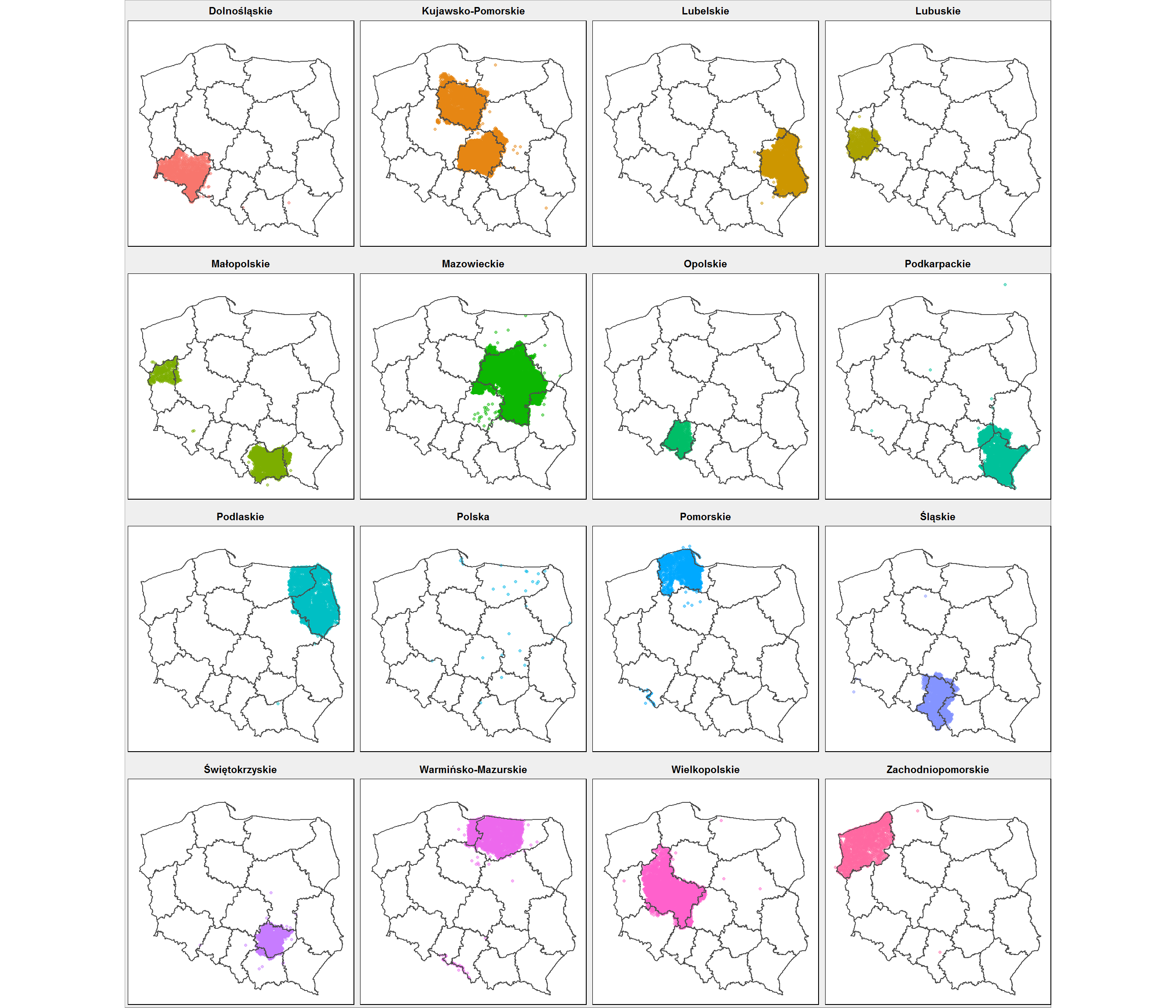
Klikając w obrazek możesz go powiększyć
Specjalnie rozdzieliłem mapę na województwa, aby było widać że przypisania są błędne. Mamy 44555 miejscowości, całkiem sporo – być może są to wszystkie. Nie pamiętam źródła tych danych, ale jak widać nie są idealne. Co się dzieje w kujawsko-pomorskim (zaanektowało łódzkie), małopolskim (połowa lubuskiego została do niego przypisana), mazowieckim (nieco się rozrosło), mamy województwo “Polska” i tak dalej. No słabo.
Spróbujmy przypisać punkty do poprawnych województw opisanych mapą:
|
1 2 3 4 5 6 7 8 9 10 |
# zwróć uwagę, że kolumny long i lat są odwrotnie! miejscowosci_sp <- SpatialPoints(miejscowosci[,c(4,3)], CRS("+init=epsg:4326")) # macierz przypisania punktu do województwa - to trochę trwa miejscowosci_mat <- gWithin(miejscowosci_sp, wojewodztwa, byid = TRUE) %>% matrix(ncol = 16, byrow = TRUE) # dla każdego wiersza macierzy szukamy kolumny (województwa) z TRUE i wpisujemy do tabeli miejscowosci nazwę województwa miejscowosci$wojewodztwo_mapa <- miejscowosci_mat %>% apply(1, function(x) min(which(x, arr.ind = TRUE), na.rm=TRUE)) %>% as.character(wojewodztwa@data$jpt_nazwa_)[.] |
Mając takie dane możemy sprawdzić czy udało się poprawnie przypisać województwa:
|
1 2 3 4 5 6 7 |
ggplot() + geom_point(data = miejscowosci, aes(Long, Lat, color = wojewodztwo_mapa), alpha = 0.5, show.legend = FALSE, size = 0.9) + geom_polygon(data = wojewodztwa_df, aes(long, lat, group=group), fill = NA, color = "gray30") + scale_color_manual(values = rainbow(17)) + facet_wrap(~wojewodztwo_mapa) + coord_map() + theme_void() |
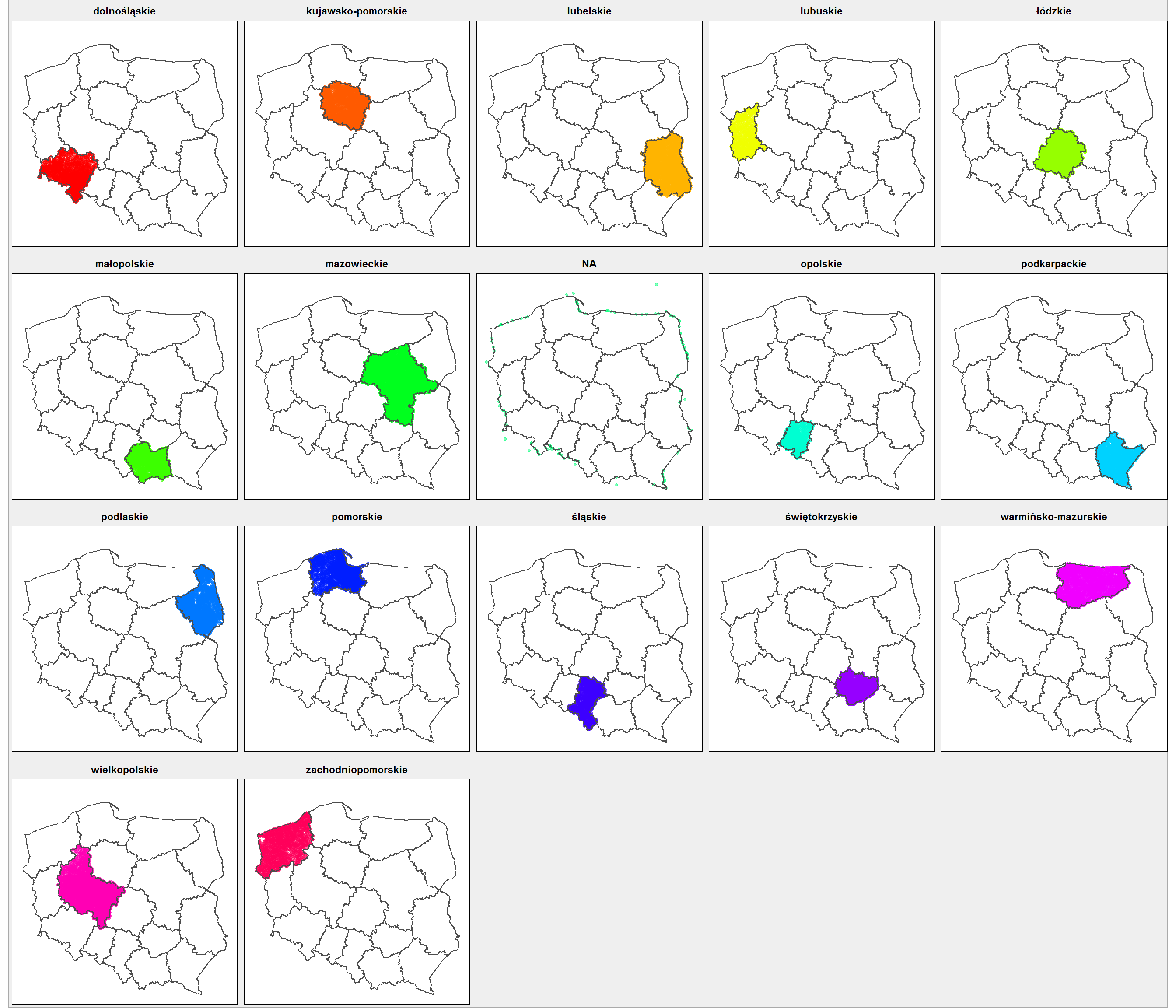
Klikając w obrazek możesz go powiększyć
Nie wszystko udało się przypisać (niektóre punkty są poza mapą Polski – widać to już było na pierwszej mapce), ale teraz wygląda to już sensowniej. Nie było też województwa łódzkiego.
Zobaczmy macierz różnic (w formie graficznej):
|
1 2 3 4 5 6 7 8 |
miejscowosci %>% count(Wojewodztwo, wojewodztwo_mapa) %>% ungroup() %>% ggplot() + geom_tile(aes(Wojewodztwo, wojewodztwo_mapa, fill = n), color = "gray80", show.legend = FALSE) + scale_fill_distiller(palette = "YlGnBu") + labs(x = "Województwo w danych", y = "Województwo odczytane ze współrzędnych") + theme(axis.text.x = element_text(angle=90, hjust=1, vjust=0)) |
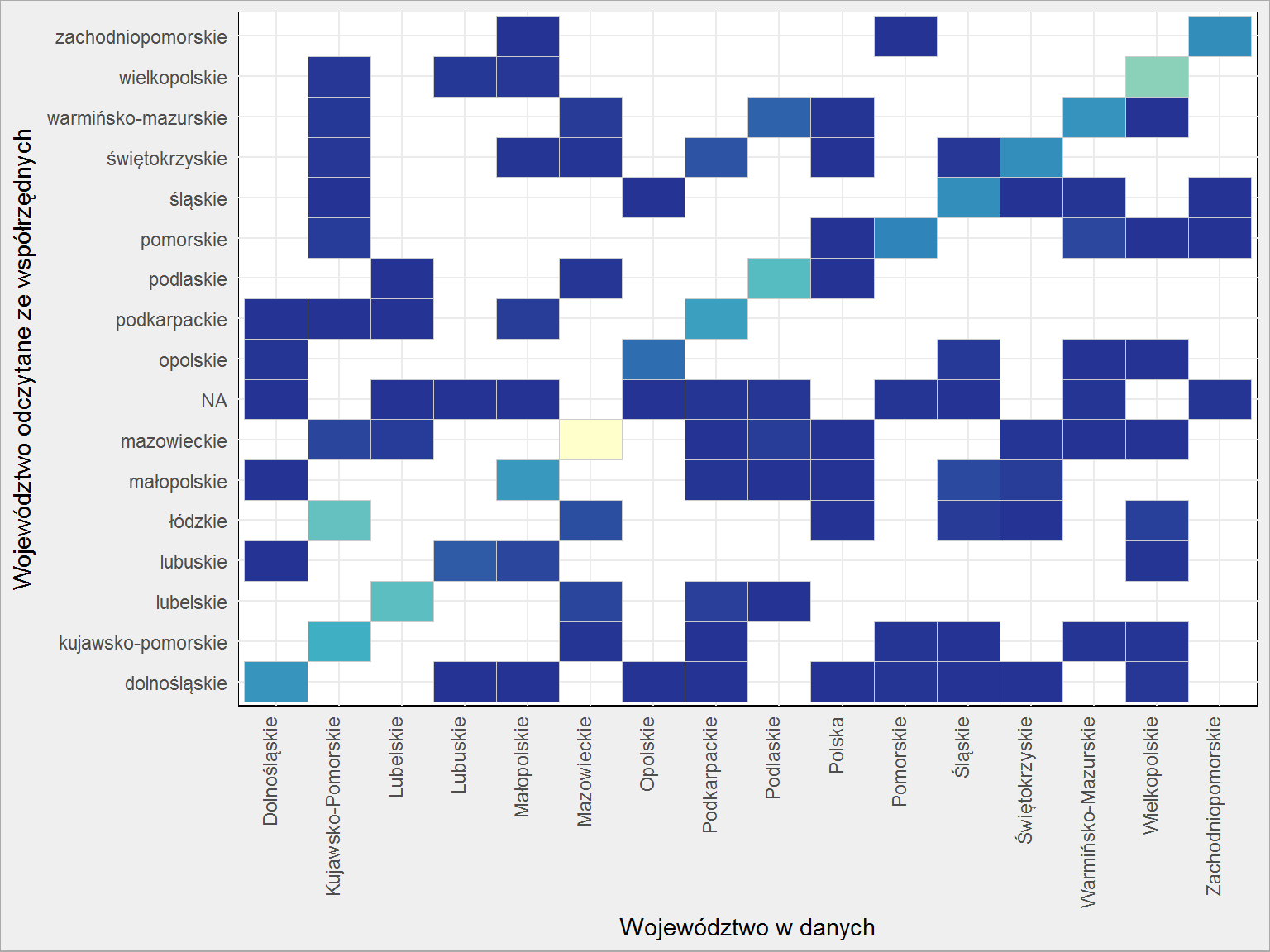
Gdyby wszystko było od razu poprawnie przypisane mielibyśmy znaczniki tylko na przekątnej i tylko żółte. Już z mapy widzieliśmy, że tak nie było.
Mam też drugą listę – z kodami pocztowymi (ulica, miejscowość, gmina, kod pocztowy). Tylko co z tym zrobić? Zwykły join dwóch tabel nie pomoże. Pierwszy z brzegu (pierwsza z alfabetu) Adamów występuje na liście miejscowości 27 razy (rekord do Nowa Wieś – 116 razy) i bądź tu mądry który jest gdzie. A dodatkowo z powyższych mapek widać, że przypisania do województwa są niepoprawne.
Przy małych miejscowościach nie ma nazwy ulicy, więc przypisanie kodu pocztowego musi nastąpić na podstawie na przykład gminy (bo nazwy miejscowości nie są unikalne).
Bierzemy zatem listę miejscowości, mapę gmin (ta sama paczka z mapami), przypisujemy (analogicznie do przypisania miejscowości do województw wyżej) miejscowości do gmin i już mamy bardziej kompletne dane. Na koniec wystarczy złączyć odpowiednio dane z tabel miejscowość-gmina oraz gmina-kod pocztowy i otrzymamy pełny wykaz kodów pocztowych poszczególnych miejsc. Powinno pasować, nie sprawdzałem.
Pytanie początkującego:
Jakie znaczenie ma symbol %>% który używasz w kodzie?
Nie ma chyba takiej definicji w R.
To jest definicja z jakiegoś pakietu?
To tzw pipe. Pochodzi z pakietu tidyverse, w uproszczeniu przekazuje wynik funkcji która jest przed nim do kolejnej, jako jej pierwszy parametr.
Super opis!
R Studio to dla mnie nowość, ale sporo się z tego nauczyłem. :)
Mam takie pytanie uzupełniające.
Czy można w jakiś sposób grupować gminy inaczej niż w powiaty albo powiaty inaczej niż w województwa?
To znaczy chcę osiągnąć efekt jakby nowego powiatu czy też województwa stworzonego przez siebie z wybranych gmin.
A co za tym idzie sprawdzać potem czy dany punkt (o określonych współrzędnych) znajduje się w takim nowym powiecie/województwie.
Z góry dziękuję za wskazówki.
Zrób sobie słownik gmina – nowa grupa. Potem połącz dane geograficzne z poziomu gmin z tym słownikiem (np inner join tych tabel). A potem zgrupuj wynik połączenia wg kolumny „nowa grupa” i dalej już jak z województwami.
Dziękuję za szybką odpowiedź, do tej pory pisałem tylko makra w Excelu a tu takie możliwości.
Dodałem do pliku TERC_Urzedowy przy każdej gminie kolumnę „nowa grupa”, wychodząc z założenia, że jest to dość stały plik, dane w nim prawie wcale się nie zmieniają.
Ale za Chiny ludowe nie mogę tego zgrupować dla potrzeb stworzenia takiego sztucznego obszaru na mapie Polski :)
Pokaż kod jakim usiłujesz to osiągnąć.
gminy %
filter(!is.na(GMI)) %>%
dplyr::select(WOJ, POW, GMI, RODZ, Gmina = NAZWA, NAZWA_DOD, nowe_wojewodztwo) %>%
mutate(NAZWA_DOD = ifelse(NAZWA_DOD == „dzielnica”, „dzielnica Warszawy”, NAZWA_DOD)) %>%
mutate(TERYT = paste0(WOJ, POW, GMI, RODZ), Nazwa_gminy = paste0(Gmina, ” („, NAZWA_DOD, „)”)) %>%
left_join(powiaty, by = c(„WOJ” = „WOJ”, „POW” = „POW”)) %>%
left_join(wojewodztwa, by = c(„WOJ” = „WOJ”)) %>%
dplyr::select(TERYT, Nazwa_gminy, Powiat, Wojewodztwo, nowe_wojewodztwo)
gminy %>%
group_by(nowe_wojewodztwo) %>%
summarise(nowe.granice = ???)
I tu na końcu jak żółtodziób poległem, zakładam że muszę mieć tu jakąś sumę logiczną z TERYT, by traktować w tym wypadku wybrane gminy jako jeden spójny obszar.
Klucz to odpowiednia funkcja agregująca. Coś w ten sposób będzie ok:
gminy %>%
group_by(nowe_wojewodztwo) %>%
summarise(geometry = sf::st_union(geometry)) %>%
ungroup()
Ważne – żeby cokolwiek później zrobić z danymi przestrzennymi potrzebujesz kolumny „geometry” bo w niej zapisane jest położenie i kształt obszaru.
Chyba źle szukam, bo nie mogę namierzyć w plikach źródłowych kolumny „geometry”.
ShapeFile bez geometry to się na nic nie przyda…
Zrobiłem tak:
gminy %>%
group_by(nowe_wojewodztwo) %>%
summarise(Polygons = sf::st_union(Polygons)
ungroup()
Ale dostaję taki błąd:
BŁĄD: nieoczekiwany symbol in:
” summarise(Polygons = sf::st_union(Polygons)
ungroup”
Bo nawiasy trzeba domykać…
Błąd w poleceniu 'UseMethod(„group_by”)’:
niestosowalna metoda dla 'group_by’ zastosowana do obiektu klasy „c(’SpatialPolygonsDataFrame’, 'SpatialPolygons’, 'Spatial’, 'SpatialPolygonsNULL’, 'SpatialVector’)”
Czy to brak jakiejś biblioteki? Strasznie topornie mi to idzie :)
Googlaj błędy. Googlaj „how to join spatial regions in R” i inne takie.
Nic nie uczy tak dobrze jak zwalczanie własnych błędów.
Powodzenia!
Gotowy kod:
Dziękuję bardzo za dotychczasową pomoc.
Zrobiłem coś takiego:
mapa_wykres %
dplyr::select(JPT_NAZWA_, grupa, geometry)
ale krzyczy mi to:
BŁĄD: Can’t subset columns that don’t exist.
x Column
grupadoesn’t exist.A tak na marginesie, to przy odczytywaniu shf poprzez read_sf widzi mi polskie znaki, przy readOGR kodowanie się nie zgadzało.
OK, gdzieś przy kopiowaniu zabrakło joina:
Uwaga: mam na różnych komputerach różne wersje (z różnych dat i może różnych źródeł) pliku wojewodztwa.shp. Sprawdź jak nazywa się kolumna jpt_kod_je – może mieć duże albo małe litery.
Na obu komputerach (po ewentualnej zmianie ścieżki i tej nazwy kolumny) to działa, więc kod jest poprawny.
Działa bezbłędnie, jesteś wielki i super, że dzielisz się tą wiedzą z innymi.
Tak na marginesie, to te wizualizacje są mega, stwarzają dużo możliwości a przede mną jeszcze dużo nauki.
Zastanawiam się jeszcze nad dwiema rzeczami.
To znaczy mam jakiś punkt centralny województwa (środek) oraz listę miejscowości wraz z ich współrzędnymi. Czy da się sprawdzić która z nich jest najbliżej centrum wykorzystując polygony? Czy raczej trzeba bazować na samej matematyce i zwykłych różnicach we współrzędnych?
A drugie to w przykładzie filtrowałeś po mazowieckim a czy da się pójść jakby w drugą stronę, to znaczy sprawdzając współrzędne miejscowości z listy przypisać do nich nazwy województw?
Mam nadzieję, że nie przesadzam z pytaniami i nie wykraczają one poza przykład.
Pozdrawiam i dziękuję za cenne rady. :)
Trzeba liczyć odległość „każdy z każdym”. Nie potrzeba do tego jakiejś specjalnej matematyki – jest gotowa funkcja:
Co do określenia np. powiatu na bazie współrzędnych – trzeba przygotować funkcję, która przejdzie przez wszystkie powiaty i sprawdzi wynik gWithin dla danego punktu. Powiaty się nie nakładają, więc powinien być tylko jeden w którym jest punkt. We wpisie Mapy hipsometryczne jest funkcja add_TERYT_code() – robi co trzeba.
Czy żeby wykorzystać funkcję add_TERYT_code() do nowych utworzonych obszarów (geometry_new), konieczne jest stworzenie nowego pliku shp, jak ewentualnie zapisać taki plik?
Pytam dlatego, ponieważ otwierając oryginalny plik Gminy.shp poprzez read_sf nie widać długości i szerokości geograficznej (a może źle szukam), które są wprost widoczne z poziomu metody readOGR.
Na ostatnie pytanie sam znalazłem odpowiedź, źle mi się tworzyły kody TERYT, nie uwzględniałem zera przy oznaczeniu jednocyfrowym (np. dla województwa). :)
Pytanie uzupełniające, dla kodu:
mapa %
ggplot() +
geom_sf(aes(geometry = geometry), color = „black”)
pojawiają się tylko pojedyncze gminy.
Z czego to może wynikać?
mapa %
ggplot() +
geom_sf(aes(geometry = geometry), color = „black”)
Coś ucina mi tekst przy wstawianiu, chodzi o read_sf.