Jak pracują redakcje serwisów informacyjnych na Facebooku?
Kiedy publikują, jakiego rodzaju treści? Czy “cała prawda całą dobę” to prawda?
Dobierzemy się do postów publikowanych przez redakcje informacyjne i zobaczymy jak wygląda obraz tych redakcji na Fejsie.
Do tego celu użyjemy biblioteki Rfacebook, której nie ma w CRANie, ale jest na GitHubie – jest sposób, aby i takie coś zainstalować w pakiecie R i korzystać tak samo jak z bibliotek z CRANa. Potrzebujemy biblioteki devtools, przy pomocy której zainstalujemy Rfacebook.
Najpierw instalujemy devtools:
|
1 |
install.packages("devtools") |
a później Rfacebook (lub cokolwiek innego z githuba):
|
1 |
devtools::install_github("pablobarbera/Rfacebook/Rfacebook") |
Tak uzbrojeni możemy załadować zwyczajowe biblioteki: ggplot2, dplyr, lubridate i reshape2 oraz oczywiście Rfacebook:
|
1 2 3 4 5 |
library(Rfacebook) library(ggplot2) library(dplyr) library(reshape2) library(lubridate) |
Aby pobrać dane z Facebooka potrzebujemy token do API – to taki długi ciąg znaków, który ważny jest dwie godziny. Ten można pobrać ze strony Facebook for Developers. Oczywiście potrzebujemy konta na Facebooku. Token przypisujemy do zmiennej token.
|
1 |
token <- "POBRANY_TOKEN" |
Teraz część najważniejsza – pobranie postów z fanpage. Po to używamy bibliotek, żeby było łatwo i przyjemnie. Łatwo i przyjemniej jest dzięki funkcji getPage() z Rfacebook, ale napiszemy sobie funkcję trochę zmieniającą na nasze potrzeby pobrane dane – głównie wartości związane z czasem publikacji postu:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
get_fanpage_posts <- function(fb_page_name, n = 100, token) { # pobierz n najnowszych postów z fanpage "fb_page_name" fb_page_posts <- getPage(fb_page_name, token=token, n=n) # poprawka i selekcja danych fb_page_posts <- fb_page_posts %>% # zmiana formatu daty mutate(created_time = ymd_hms(created_time)) %>% # rozdzielenie daty na poszczególne składowe mutate(year = year(created_time), month = month(created_time), day = day(created_time), hour = hour(created_time), minute = minute(created_time), wday = wday(created_time)) %>% # dni tygodnia w "polskiej" kolejności mutate(wday = factor(wday, levels=c(2,3,4,5,6,7,1), labels=c("pn","wt","śr","cz","pt","sb","nd"))) return(fb_page_posts) } |
Mając gotową funkcję użyjemy jej na kilkunastu stronach. Oto lista:
|
1 2 3 4 5 |
fb_page_name <- c("tvn24pl", "rmffm", "wyborcza", "radiozet", "tvp.info", "Fakty.TVN", "wiadomoscitvp", "panoramatvp", "polsatnewspl", "natematpl", "RepublikaTV", "gazetapl", "tokfm", "Bankierpl", "WirtualnaPolska", "FaktyINTERIA") |
Dla każdego z fan page pobierzemy po 2000 najnowszych postów (2000 to dość sporo, później zobaczymy ile czasu zajmuje redakcjom opublikowanie takiej ilości postów), wszystkie pobrane dane łączymy w jedną długą tabelę.
Proces zawarty w trzech poniższych linijkach może potrwać nawet do godziny. Ja pobrałem dane wcześniej i zapisałem do lokalnego pliku – przy tej ilości danych polecam to samo: najpierw pobieramy dane raz, a potem korzystamy z nich w kolejnych krokach analizy.
|
1 2 3 4 |
fb_page_posts <- data.frame() for(i in 1:length(fb_page_name)) fb_page_posts <- rbind(fb_page_posts, get_fanpage_posts(fb_page_name[i], 2000, token)) |
Skoro mamy dane to zobaczmy co w nich siedzi. Można przez standardowe str() lub glimpse() z biblioteki dplyr:
|
1 |
glimpse(fb_page_posts) |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
## Observations: 32,000 ## Variables: 13 ## $ from_id <chr> "50063176484", "50063176484", "50063176484", "5... ## $ from_name <chr> "TVN24.pl", "TVN24.pl", "TVN24.pl", "TVN24.pl",... ## $ message <chr> "To nie pierwszy tragiczny wypadek przy wycince... ## $ created_time <dttm> 2017-03-17 07:54:51, 2017-03-17 07:23:31, 2017... ## $ type <chr> "link", "video", "link", "link", "link", "link"... ## $ link <chr> "http://www.tvn24.pl/katowice,51/wypadki-przy-w... ## $ id <chr> "50063176484_10154394773921485", "50063176484_1... ## $ story <chr> NA, "TVN24.pl shared TOTERAZ's video.", NA, "TV... ## $ likes_count <dbl> 12, 404, 48, 18, 242, 26, 9, 14, 75, 66, 92, 14... ## $ comments_count <dbl> 2, 6, 91, 20, 52, 1, 4, 2, 4, 204, 345, 49, 54,... ## $ shares_count <dbl> 2, 0, 32, 0, 0, 2, 0, 0, 1, 47, 41, 21, 31, 62,... ## $ hour <int> 7, 7, 6, 6, 6, 5, 5, 4, 3, 2, 1, 0, 23, 22, 22,... ## $ wday <fctr> pt, pt, pt, pt, pt, pt, pt, pt, pt, pt, pt, pt... |
Mamy masę zmiennych, z których połowa to czas (ja przy przekształceniu odpuściłem sobie rozbicie daty utworzenia postu na rok, miesiąc, dzień, godzinę, minuty i jeszcze dzień tygodnia – zostawiłem to, bo będzie potrzebne niżej – godzinę i dzień tygodnia). Reszta to dane określające fanpage (ID, nazwa) oraz post (ID postu, jego typ, treść i ilość interakcji – like, comment i share).
Sprawdźmy ile czasu każdej z redakcji zajęło opublikowanie dwóh tysięcy postów:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
fb_page_posts %>% group_by(from_name) %>% summarise(od=min(created_time), do=max(created_time)) %>% ungroup() %>% select(from_name, od, do) %>% unique() %>% ggplot() + geom_segment(aes(x=od, xend=do, y=from_name, yend=from_name, color=from_name), size=3, show.legend = FALSE) + theme_minimal() + labs(title="Okres publikacji ostatnich 2000 postów", x="Data", y="Fan page") |
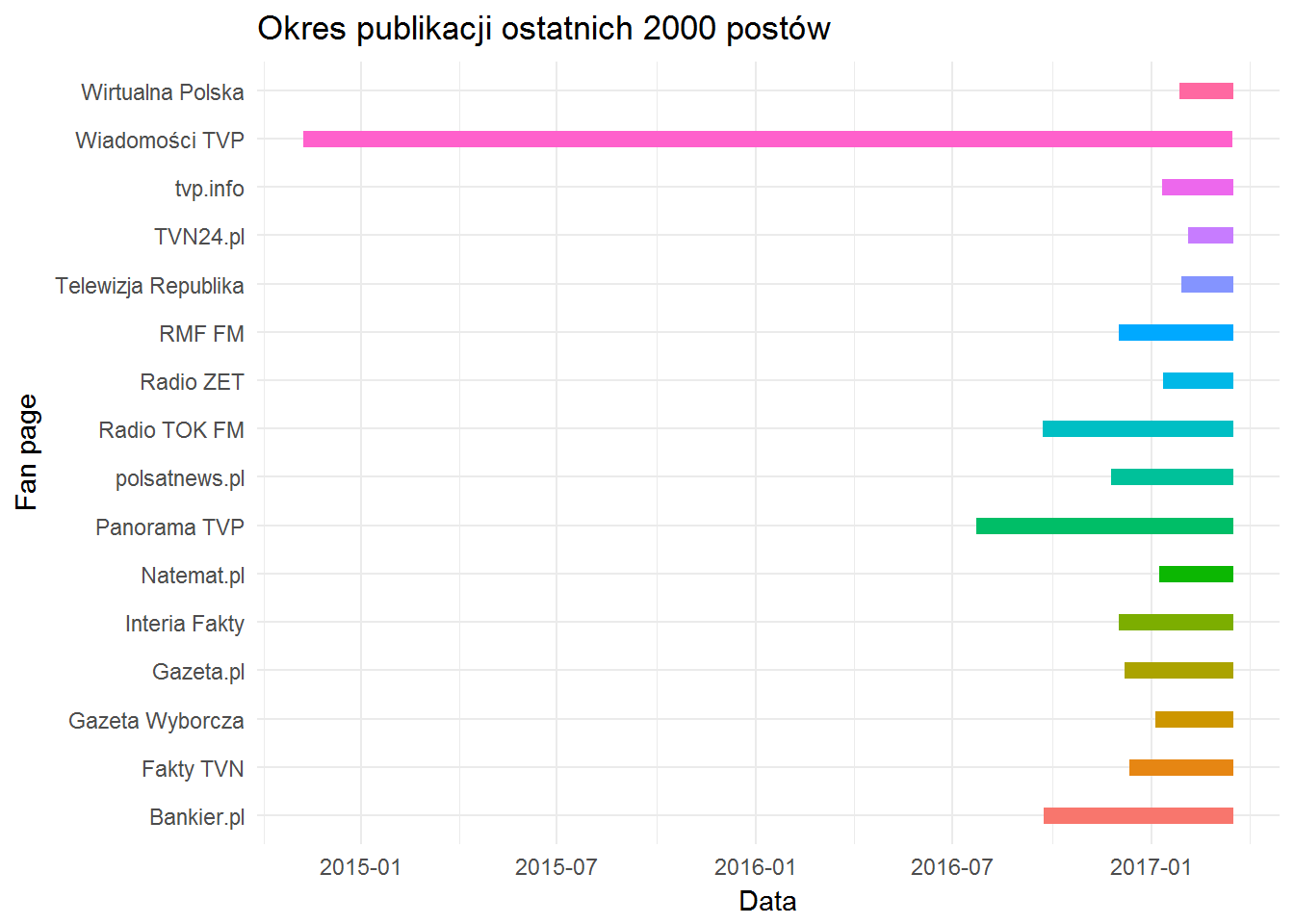
Widać od razu, że właściwie wszyscy publikują tak samo często – Wiadomości TVP wypadają tutaj najsłabiej.
Poszukajmy części wspólnej dla wszystkich (na przestrzeni miesięcy od stycznia 2015 w Wiadomościach TVP trochę się mogło pozmieniać…) redakcji – najkrótszego czasu na opublikowanie 2000 postów potrzebuje TVN24.pl. Mają najkrótszy pasek powyżej, a data od jest najpóźniejsza i jest to 3 lutego 2017, 16:05. Przymnijmy więc, że będziemy analizować dane od 4 lutego 2017 włącznie.
Zobaczmy jak dużo postów zostaje:
| from_name | n |
|---|---|
| TVN24.pl | 1982 |
| Telewizja Republika | 1732 |
| Wirtualna Polska | 1698 |
| Radio ZET | 1335 |
| tvp.info | 1217 |
| Natemat.pl | 1186 |
| Gazeta Wyborcza | 1100 |
| Fakty TVN | 878 |
| Gazeta.pl | 841 |
| Interia Fakty | 776 |
| polsatnews.pl | 764 |
| RMF FM | 755 |
| Bankier.pl | 522 |
| Radio TOK FM | 440 |
| Panorama TVP | 295 |
| Wiadomości TVP | 68 |
Zobaczmy jakiego typu (link, zdjęcie, wideo, wydarzenie) publikują redakcje , a precyzyjniej – jak rozkłada się to procentowo w redakcji (bo że TVN24.pl publikuje w zadanym okresie więcej od Wiadomości TVP to już wiemy z odcięcia).
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
fb_page_posts %>% filter(created_time >= "2017-02-04") %>% count(from_name, type) %>% ungroup() %>% group_by(from_name) %>% mutate(p=100*n/sum(n)) %>% ungroup() %>% ggplot() + geom_bar(aes(from_name, p, fill=type), stat="identity")+ labs(title="Typy postów publikowanych przez redakcje", x="Fan page", y="% postów", fill="Typ postu") + theme_minimal() + theme(axis.text.x = element_text(angle=90)) |
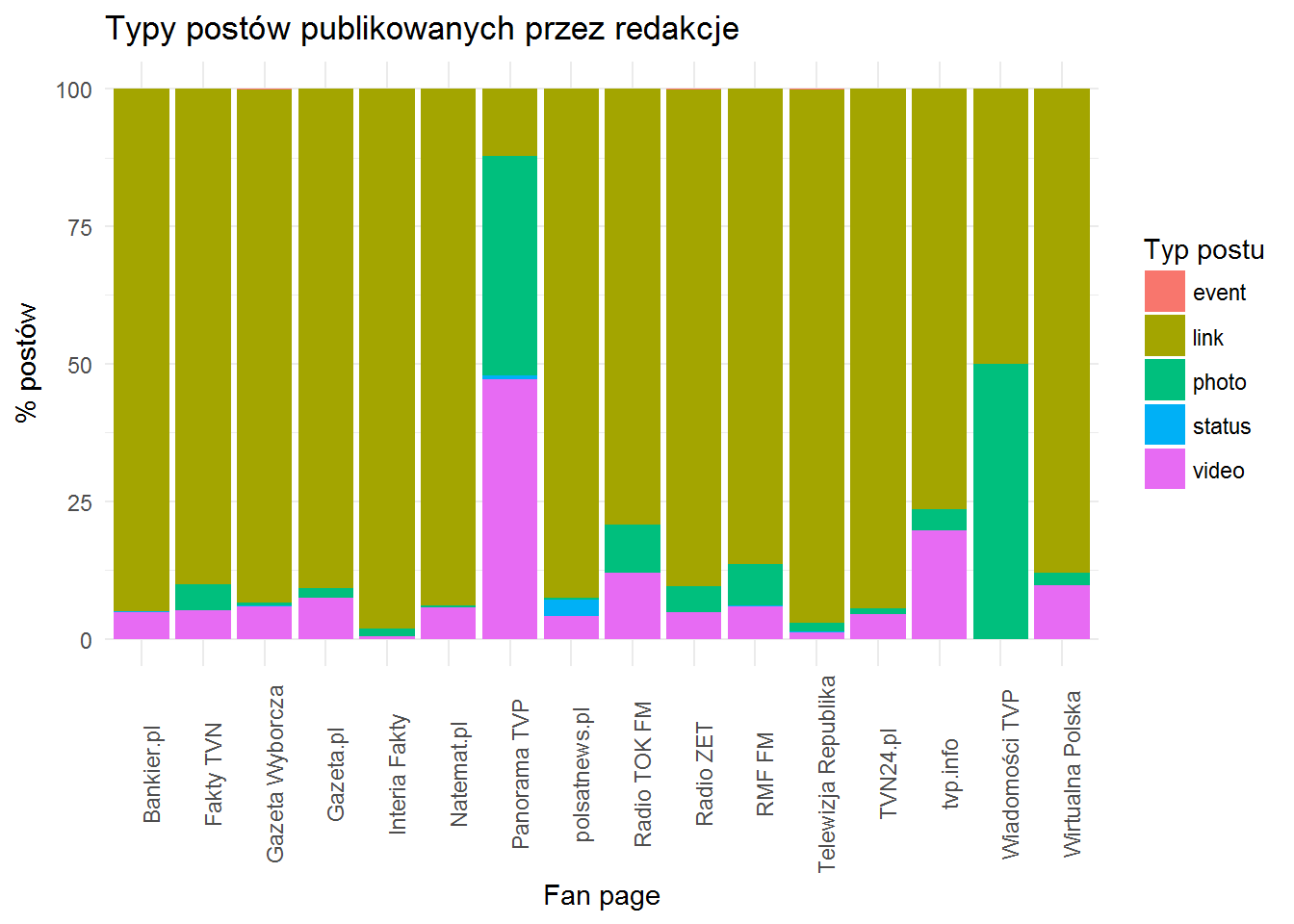
Największa różnorodność panuje w redakcjach TVP – Panorama i Wiadomości. Około połowa ich postów to zdjęcia, w Panoramie też wideo. Cała reszta w dużym uproszczeniu odsyła do swoich serwisów poprzez linki.
Teraz będzie ciekawie – kiedy pojawiają się posty? W jakich godzinach redakcje pracują? Cała prawda całą dobę?
|
1 2 3 4 5 6 7 8 9 10 11 12 |
fb_page_posts %>% filter(created_time >= "2017-02-04") %>% count(from_name, hour) %>% ungroup() %>% ggplot() + geom_bar(aes(hour, n, fill=from_name), stat="identity", show.legend = FALSE) + theme_minimal() + labs(x="Godzina", y="Łączna liczba postów") + scale_x_continuous(breaks=1:23, limits=c(0,23)) + scale_y_continuous(breaks=seq(0,100,25)) + facet_grid(from_name ~., scales = "free_y") + theme(strip.text.y= element_text(angle=0), legend.position="none") |
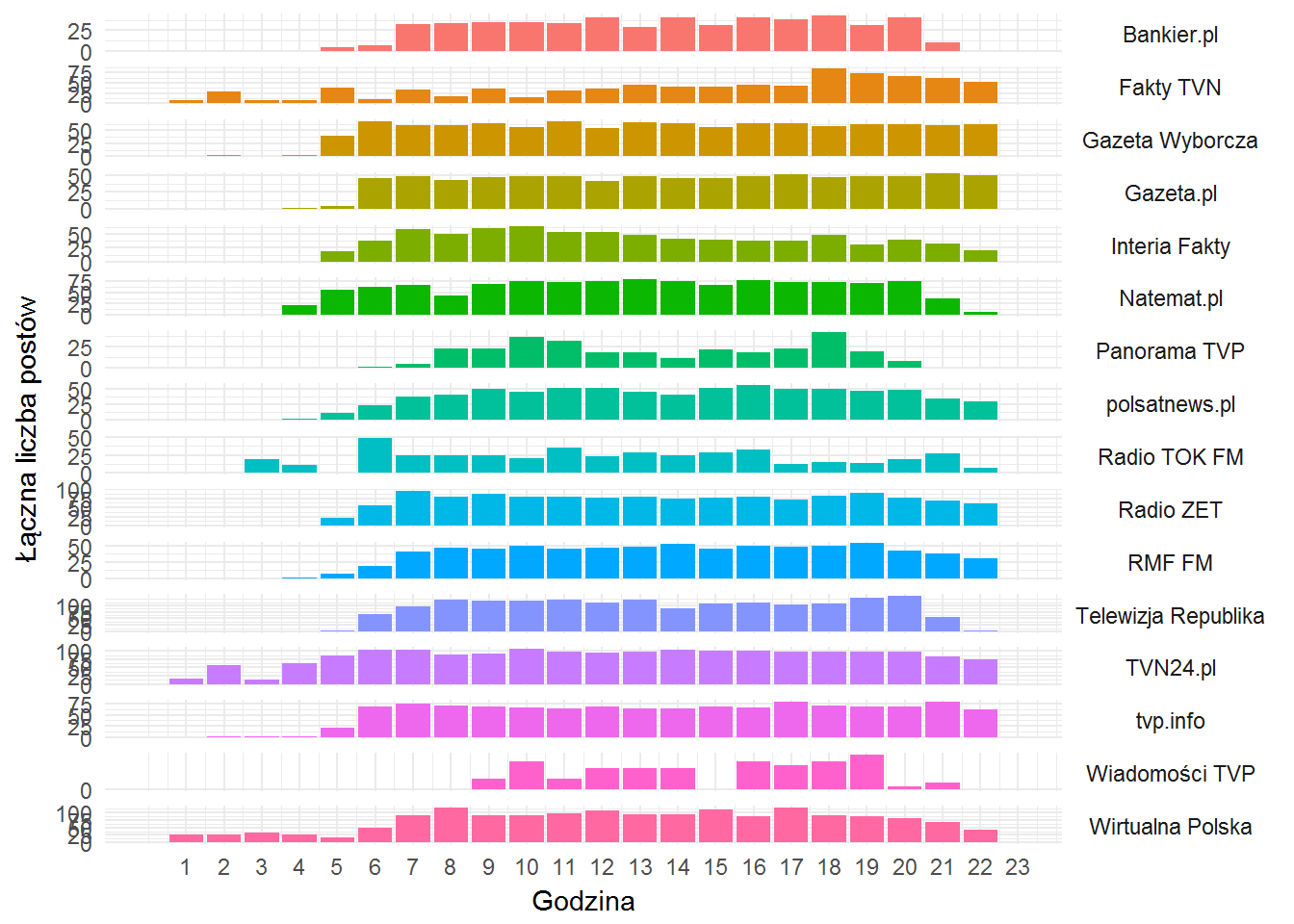
Przede wszystkim – wysokość słupka nie ma znaczenia (chyba, że popatrzycie na wartość na osi Y dla tego słupka).
Co widać na szybko:
- całą dobę pracuje (taki jest obraz ostatniego miesiąca – to ważne) TVN – zarówno Fakty TVN jak i TVN24.pl, do tego dochodzi też Wirtualna Polska
- większość zaczyna około 6 rano i kończy przed północą.
- Panorama publikuje w okolicach 18 – czyli w pobliżu emisji programu w TV. Podobnie Wiadomości (po zakończeniu Dziennika seria postów z likami do materiałów online) oraz Fakty TVN
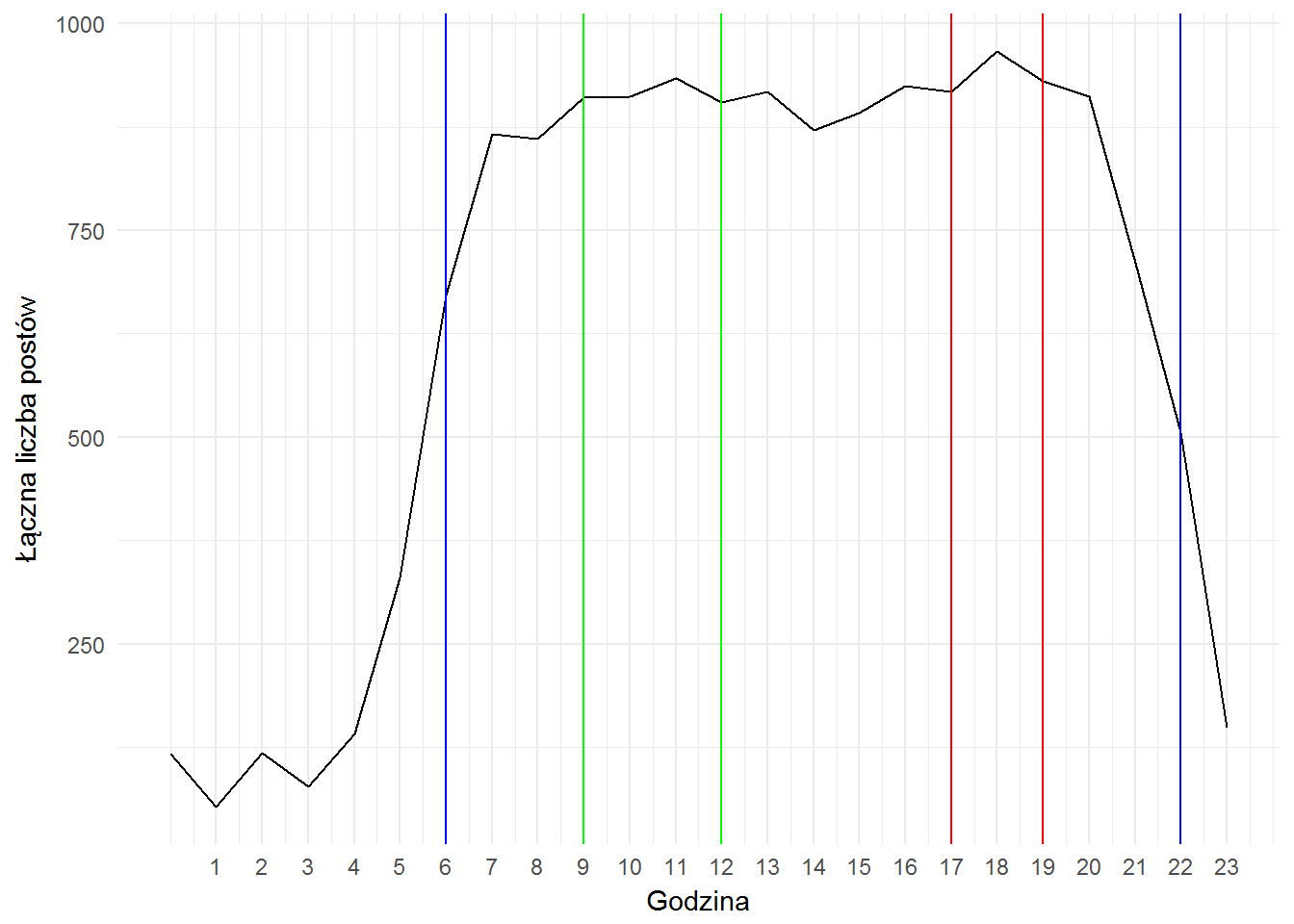
Jeśli zbijemy dane niezależnie od redakcji zobaczymy, że najwięcej treści informacyjnych pojawia się w okolicach 9-12 (internet do porannej kawy – linie zielone poniżej) i później około 16-19 (internet podczas powrotu z pracy i wieczorem plus materiały online przy głównych wydaniach serwisów w TV – linie czerwone). Wygląda to mniej więcej tak samo jak ruch w polskim internecie – znakomita większość ruchu pomiędzy 6 a 22 (linie niebieskie).
Podobne zestawienie można zrobić po dniach tygodnia. Albo złączyć godziny i dni tygodnia. Wówczas zobaczymy to (po wyjęciu Panoramy i Wiadomości – mała liczba postów niewiele wnosi do analizy):
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
fb_page_posts %>% filter(created_time >= "2017-02-25") %>% filter(!from_name %in% c("Wiadomości TVP", "Panorama TVP")) %>% count(from_name, hour, wday) %>% ungroup() %>% ggplot() + geom_jitter(aes(hour, wday, size=n, color=from_name), width = 0.1, height = 0.1) + theme_minimal() + labs(x="Godzina", y="Dzień tygodnia") + scale_x_continuous(breaks=1:23, limits=c(0,23)) + facet_grid(from_name ~.) + theme(strip.text.y= element_text(angle=0), legend.position="none") |
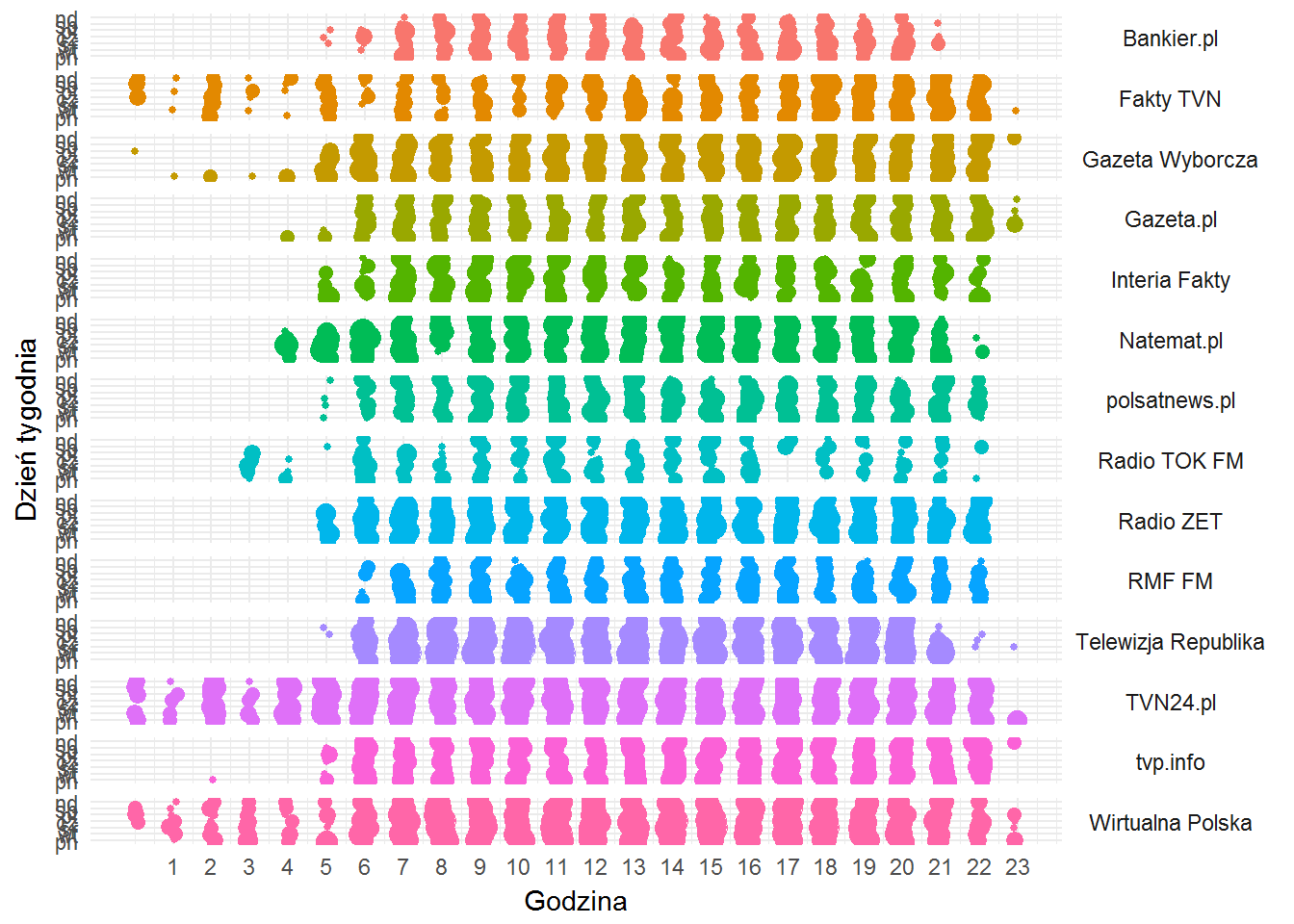
- Natemat.pl w weekend pracuje krócej (7-21, w porównaniu do 5-22 w tygodniu)
- Bankier zaczyna o 7, kończy o 20, w weekend też śpi o godzinę dłużej
- TV Republika po 21 już właściwie nie istnieje
- około 3:55 (spójrzcie dokładnie w dane) TOK FM zaprasza na “Pierwsze Śniadanie w TOKu”
- o 2 w nocy jest najprawdopodobniej powtórka Faktów po Południu (zgaduję – nie sprawdzam w programie!) – tak wynika z postów Fakty TVN
Zobaczmy jak użytkownicy Facebooka reagują na poszczególne posty redakcji – u kogo najwięcej (średnio na post) się lajkuje i komentuje?
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
fb_page_posts %>% filter(created_time >= "2017-02-25") %>% group_by(from_name) %>% summarise(n=n(), likes=mean(likes_count)/n, comments=mean(comments_count)/n, shares=mean(shares_count)/n) %>% ungroup() %>% melt() %>% filter(variable!="n", from_name!="Teleexpress TVP") %>% ggplot() + geom_bar(aes(variable, value, fill=from_name), stat="identity", position = "dodge") + theme_minimal() + labs(title="Liczba interakcji na post", x="Rodzaj interakcji", y="Średnia liczba interakcji na post", fill="Fan page") |
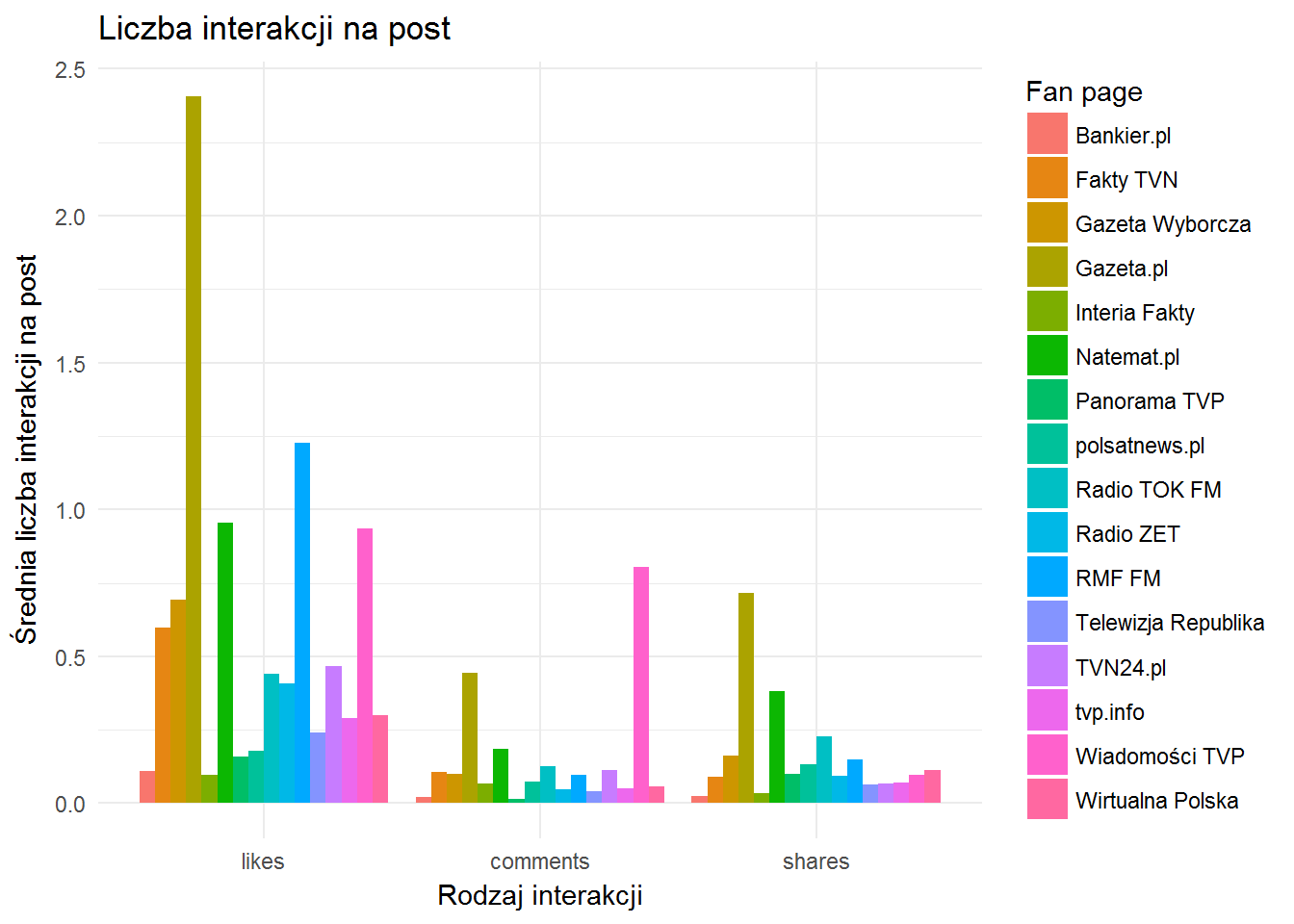
- oczywiście lajków jest najwięcej – to jedno kliknięcie. Przoduje tutaj Gazeta.pl, RMF FM i Natemat.pl
- Gazeta.pl i Natemat.pl (znowu – różnica dwukrotna) dominują w kategorii “shares”, trzeci jest TOK FM
- w ilości komentarzy na post przodują Wiadomości (ale należy pamiętać o małej próbce postów, dużo komentarzy dostały Wiadomości z brakiem wiadomości o Wielkiej Orkiestrze Świątecznej Pomocy), pozostałe dwa miejsca na podium to Gazeta.pl i dużo dalej (ponad 2 razy mniej komciów na post) Natemat.pl
Sprawdźmy te Wiadomości… 10 najbardziej komentowanych postów Wiadomości TVP (już bez ograniczenia do ostatniego miesiąca) to:
|
1 2 3 4 5 |
fb_page_posts %>% filter(from_name=="Wiadomości TVP") %>% select(created_time, id, comments_count) %>% arrange(desc(comments_count)) %>% head(10) |
| created_time | id | comments_count |
|---|---|---|
| 2017-01-15 16:52:41 | 219693331462091_1131554380275977 | 313 |
| 2017-01-15 19:16:09 | 219693331462091_1131666090264806 | 294 |
| 2017-03-09 17:54:08 | 219693331462091_1177884552309626 | 181 |
| 2017-03-08 18:03:11 | 219693331462091_1176918335739581 | 152 |
| 2017-03-07 18:10:17 | 219693331462091_1176000019164746 | 128 |
| 2016-12-16 12:38:57 | 219693331462091_1107924555972293 | 113 |
| 2016-01-08 10:12:45 | 219693331462091_868016269963124 | 112 |
| 2017-01-14 16:52:10 | 219693331462091_1130768990354516 | 109 |
| 2017-01-14 13:37:04 | 219693331462091_1130641170367298 | 109 |
| 2016-01-14 18:09:36 | 219693331462091_871256156305802 | 109 |
Sami zobaczcie:
Czy można zobaczyć komentarze dla tego pierwszego postu?
|
1 2 |
post <- getPost("219693331462091_1131554380275977", token = token, n = 500) |
Co mamy w odpowiedzi (data frames w liście post)?
- informacje o samym poście (post)
- komentarze (comments) – kto i co napisał w komentarzu, o której godzinie i ile komentarz dostał lajków
- lajki (likes) – kto zalajkował
Sprawdźmy komentarze do tego postu pod kątem WOŚP – w ilu komentarzach występuje WOŚP (poprawnie, w wersji z małymi literami i w wersji bez polskich liter)?
|
1 2 3 4 5 |
coms <- post$comments %>% select(message) %>% mutate(WOSP = grepl("wosp|wośp|WOŚP|WOSP", message)) table(coms$WOSP) |
|
1 2 |
## FALSE TRUE ## 95 188 |
66.4 procent komentarzy odwołujących się do Wielkiej Orkiestry Świątecznej Pomocy. O czymś to świadczy, prawda? @MarzenaPaczuska ma na to zapewne odpowiedź.
Mając w ręku narzędzie (getPage() oraz getPost()) możecie z nim zrobić co tylko zechcecie. Z publicznymi postami. Z danymi prywatnymi już nie jest tak łatwo.
W liczbie interakcji na post mamy błąd – policzona jest jakaś abstrakcyjna wartość – średnia liczba lajków przez ilość postów. Taka średnia ze średniej.
Zamiast:
summarise(n=n(),
likes=mean(likes_count)/n,
comments=mean(comments_count)/n,
shares=mean(shares_count)/n) %>%
powinno być
summarise(n=n(),
likes=sum(likes_count)/n,
comments=sum(comments_count)/n,
shares=sum(shares_count)/n) %>%
Fajny artykuł. Jestem pod wrażeniem.
Pingback: Jak Onet pracuje na FB? | Łukasz Prokulski
Pingback: Analiza redakcji informacyjnych na FB / Analysis of news agencies on FB | Blog | tabodesign.com | fotograf fotografia photographer warszawa gdańsk londyn
Pingback: Partie polityczne i sport | Łukasz Prokulski
Pingback: Jak zrobić animowany wykres kołowy? | Łukasz Prokulski
Jakim skryptem łatwo zapisać te pobrane posty (tabela) do xlsx? Pobierało się ponad godzinę i szkoda pracy :) btw super blog, nauczyłem się sporo.
U mnie sprawdza się pakiet writexls. Ale po co zapisywać dane do Excela jeśli robi się coś w R? CSV jeszcze rozumiem…