Dzisiaj zajmiemy się poszukiwaniem nowej muzyki. Uwielbiam poznawać nową muzykę, poszukiwać nowych smaków i cieszyć się nowymi odkryciami. Co prawda od kilku lat coraz trudniej znaleźć coś interesującego i innego. Albo są to popłuczyny po Kornie, albo jakaś kolejna wersja wczesnego Coldplay (który z każdą nową płytą jest coraz dalej od mojego gustu).
Do poszukiwań wykorzystamy to co już znamy i lubimy. Bo najbardziej podobają mi się piosenki, które już raz słyszałem. W określeniu tego co znamy i lubimy pomoże LastFM. Serwis o którym pisałem przy okazji analizy nastrojów muzycznych zbiera nasze scrobble (przesłuchane utwory), ale posiadając tak dużo danych potrafi “polecić” coś od siebie. Algorytm polecający LastFM w dużym stopniu polega na porównywaniu gustów poszczególnych użytkowników, szukaniu podobieństw i wskazywaniu wykonawców pasujących do już znanych. Albo do innych wykonawców, mniej więcej na zasadzie: skoro dużo osób słucha Nirvany i Pearl Jam to te kapele są do siebie podobne. Oczywiście to nie jedyne cechy podobieństwa – są też tagi, lata działalności itp.
Nie będę wchodził w algorytm LastFM, a wykorzystam dane jakie można z LastFM uzyskać. A z pomocą pakietu RLastFM w łatwy sposób uzyskamy dostęp do API serwisu.
Przygotowanie R do pracy to ewentualne zainstalowanie wspomnianego pakietu, uzyskanie klucza API z LastFM oraz załadowanie potrzebnych bibliotek (tutaj: dplyr, ggplot2, reshape2). Wszystko to opisałem w poście “Jesienna deprecha”.
Konfiguracja skryptu to 4 zmienne:
- lastkey – klucz API z serisu Last.fm
- user_name – dla kogo szukamy rekomendacji?
- ile_polecanych – ilu polecanych artystów pokazać?
- ile_scrobli – jak dużo ostatnio scroblowanych utworów brać pod uwagę?
|
1 2 3 4 |
lastkey <- "xxxxxxxxxxxxxxxxxxxxxxxxxx" user_name <- "LeMUr1978KCrq" ile_polecanych <- 10 ile_scrobli <- 1000 # max 1000 |
Po załadowaniu potrzebnych bibliotek pobieramy najnowsze dane z LastFM:
|
1 2 |
recent <- as.data.frame(user.getRecentTracks(user_name, limit = ile_scrobli)) lastfm <- select(recent, Artist=artist, Album=album, Song=track, DateOrg=date) |
i po małym uporządkowaniu danych dostajemy tabelkę z historią naszej muzycznej podróży.
Aby nie szukać wszystkich rekomendowanych artystów ograniczymy się do pewnej próbki – tej najbardziej znaczącej. Policzmy ile piosenek danego wykonawcy słuchaliśmy:
|
1 2 3 4 |
top_artists <- lastfm %>% count(Artist) %>% ungroup() %>% arrange(desc(n)) |
A następnie wyfiltrujmy tych, których słuchamy najwięcej. Tylko jak? Sprawdźmy jak wygląda rozkład popularności:
|
1 2 3 |
ggplot(top_artists) + geom_density(aes(n), fill="red") + theme_minimal() |
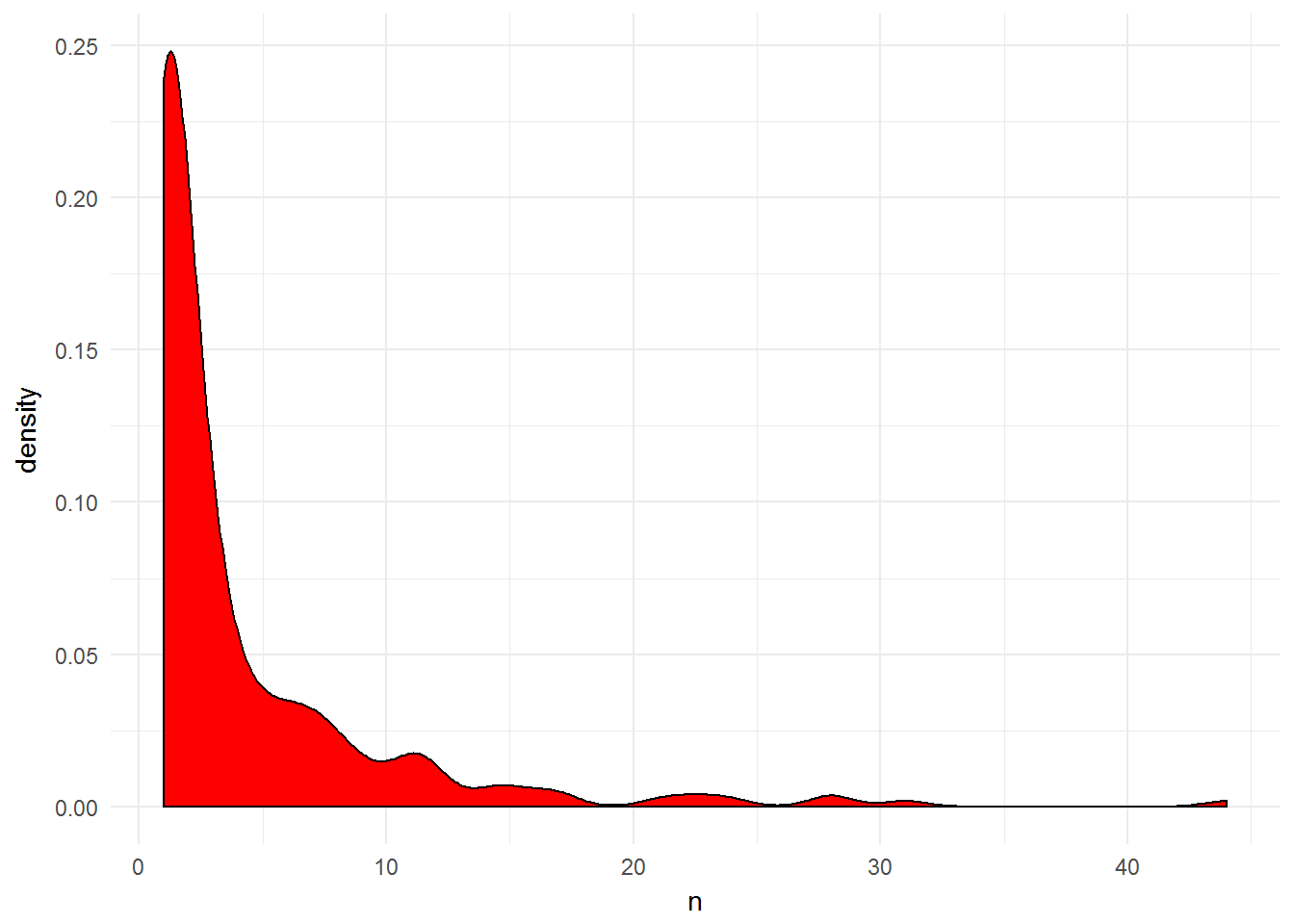
Widać, że dużo jest wykonawców, których słyszałem mniej niż 5 utworów. Ogon jest zaś długi i dobrze będzie go wykorzystać – im większa wartość n tym częściej goszczący w moich słuchawkach artysta, a co za tym idzie – z dużym prawdopodobieństwem – bardziej lubiany.
Zobaczmy jak rozkład wygląda dla górnej części, tak powyżej 50 centyla:
|
1 |
quantile(top_artists$n, c(.5, .75, .9, .95, .99)) |
| percentyl | n |
|---|---|
| 50% | 2.00 |
| 75% | 5.00 |
| 90% | 10.70 |
| 95% | 14.85 |
| 99% | 28.00 |
Widzimy, że w dolnej połowie mieszczą się wykonawcy, których słyszałem 2 utwory (co nie znaczy unikalne – mogły ta to być ta sama piosenka odtworzona dwukrotnie). To jest ten pik na wykresie powyżej i są to piosenki z automatycznych list na Spotify – wiem, bo ja nie słucham muzyki w taki sposób (losowe utwory jeden za drugim), chyba że jest to właśnie “radio” jakiegoś wykonawcy albo playlista typu “Alternative ’90”. Wolę całe płyty od początku do końca. Inna możliwość to soundtracki z filmów, ale ostatnio chyba nie było nic takiego.
Interesuje nas jednak górna część (powyżej 50 percentyla lub ten długi ogon na wykresie). Trzeba określić dla jakiej grupy artystów będziemy szukać podobnych. Dobrą wartością byłoby top 10% (czyli odciąć od 90 percentyla w górę), ale ja sprawdziłem wynik i o ile jest zadowalający, o tyle nie ma walorów edukacyjnych. Można oczywiście dla wszystkich. Umiejętność analizy i modelowania danych polega w dużym stopniu na znalezieniu punktu, w którym zbędne dane można odrzucić widząc, że ich brak nie zmienia znacząco końcowego wyniku.
Ja wybrałem tych wykonawców, których słyszałem co najmniej 4 razy (nawet jeśli to była tylko jedna piosenka na loopie). Totalnie niezgodnie z percentylami i wykresem ale dobrze wyglądają wyniki na kolejnych obrazkach :).
|
1 |
top_artists <- filter(top_artists, n>=4) |
Sprawdźmy kto został wybrany? Ale tylko początek tabelki:
| Artist | n |
|---|---|
| Leonard Cohen | 44 |
| Pink Floyd | 31 |
| Depeche Mode | 28 |
| Pearl Jam | 28 |
| Deep Purple | 24 |
| Led Zeppelin | 23 |
| The Smashing Pumpkins | 22 |
| Kult | 21 |
| Myslovitz | 17 |
| Peter Gabriel | 17 |
| Kombajn Do Zbierania Kur Po Wioskach | 16 |
| Portishead | 15 |
| Queen | 15 |
| Metallica | 14 |
| Wojtek Mazolewski | 14 |
| Brodka | 12 |
| Dawid Podsiadło | 12 |
| Marek Grechuta | 12 |
| Pablopavo i Ludziki | 12 |
| Dio | 11 |
No tak – zgodnie z wspominanym wcześniejszym postem Cohen, do tego jeszcze doszli Pink Floyd, Portishead, Myslovitz oraz The Maccabees (to ostatnie kilka dni). Wszystko się zgadza. Swoją drogą The Maccabees to jedno z odkryć ostatniego roku-dwóch, o które mi tak trudno ostatnio.
Szukamy podobnych artystów (według LastFM)
Wykorzystamy API LastFM, które na pytanie o podobnych artystów zwraca listę pięciu najbardziej podobnych. Gdyby użyć funkcji artist.getSimilar() zamiast artist.getInfo() dostajemy do stu podobnych artystów wraz z miarą jak bardzo są podobni do poszukiwanego. Na przykład pierwsza dziesiątka podobnych do Led Zeppelin to:
|
1 2 3 |
led <- artist.getSimilar("Led Zeppelin") led_df <- data.frame(name=led$name, match=led$match) head(led_df, 10) |
| name | match |
|---|---|
| Deep Purple | 1.000000 |
| Pink Floyd | 0.976878 |
| The Who | 0.952403 |
| The Doors | 0.935807 |
| The Rolling Stones | 0.917782 |
| Page & Plant | 0.852395 |
| The Jimi Hendrix Experience | 0.826372 |
| Robert Plant | 0.824445 |
| Black Sabbath | 0.747600 |
| Jimi Hendrix | 0.729817 |
W naszym prostym podeściu wystarczy pięciu najbardziej podobnych. Dla każdego z kolejnych “topowych artystów” z tabelki top_artists pobierzemy ich poniższą funkcją. W pętli (zapewne można też inaczej – np. przez funkcje z rodziny apply()):
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
GetSimilar <- function(x) { # poszukaj podobnych artystów sims <- artist.getInfo(x)$similar if(length(sims) != 5) # jeśli nie ma podobnych wg LastFM zwróć puste sims <- rep(NA, 5) return(data.frame(Artist=rep(x, 5), sims=sims, stringsAsFactors = FALSE)) } sim_df <- data.frame(stringsAsFactors = FALSE) for(i in 1:nrow(top_artists)) { sim_df <- rbind(sim_df, GetSimilar(as.character(top_artists[i, "Artist"]))) } t <- melt(sim_df, id.vars = "Artist") %>% filter(!is.na(value)) |
Na koniec w tabeli t mamy listę par: znany artysta i artysta polecany.
Ale czy ma sens polecać tego, którego już słuchałem? Chyba nie. Oznaczmy więc odpowiednio znanych w tabeli t:
|
1 |
t$znany <- t$value %in% top_artists$Artist |
Ci, którzy będą mieć wartość znany równą TRUE nas nie interesują – tych już znamy.
Uwaga – tutaj porównuję z listą top_artists, która jest już wyfiltrowana do najbardziej popularnych artystów. Można sprawdzać czy dany artysta był grany chociaż raz. Wówczas przydatna będzie kolumna lastfm$Artist (najlepiej jej unikalne wartości).
Kto zatem jest najczęściej polecany? Liczymy i rysujemy wykres.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
polecani <- t %>% filter(znany==FALSE) %>% mutate(n=1) %>% group_by(value) %>% mutate(n=sum(n)) %>% ungroup() %>% arrange(desc(n)) %>% select(Artist, Polecany=value, n) polecani_plot <- polecani %>% select(Polecany, n) %>% unique() %>% top_n(ile_polecanych, n) %>% arrange(n) %>% mutate(Polecany=factor(Polecany, level=Polecany)) %>% ggplot() + geom_bar(aes(Polecany, n, fill=Polecany), stat="identity") + theme_minimal() + theme(legend.position = "none") + coord_flip() polecani_plot |
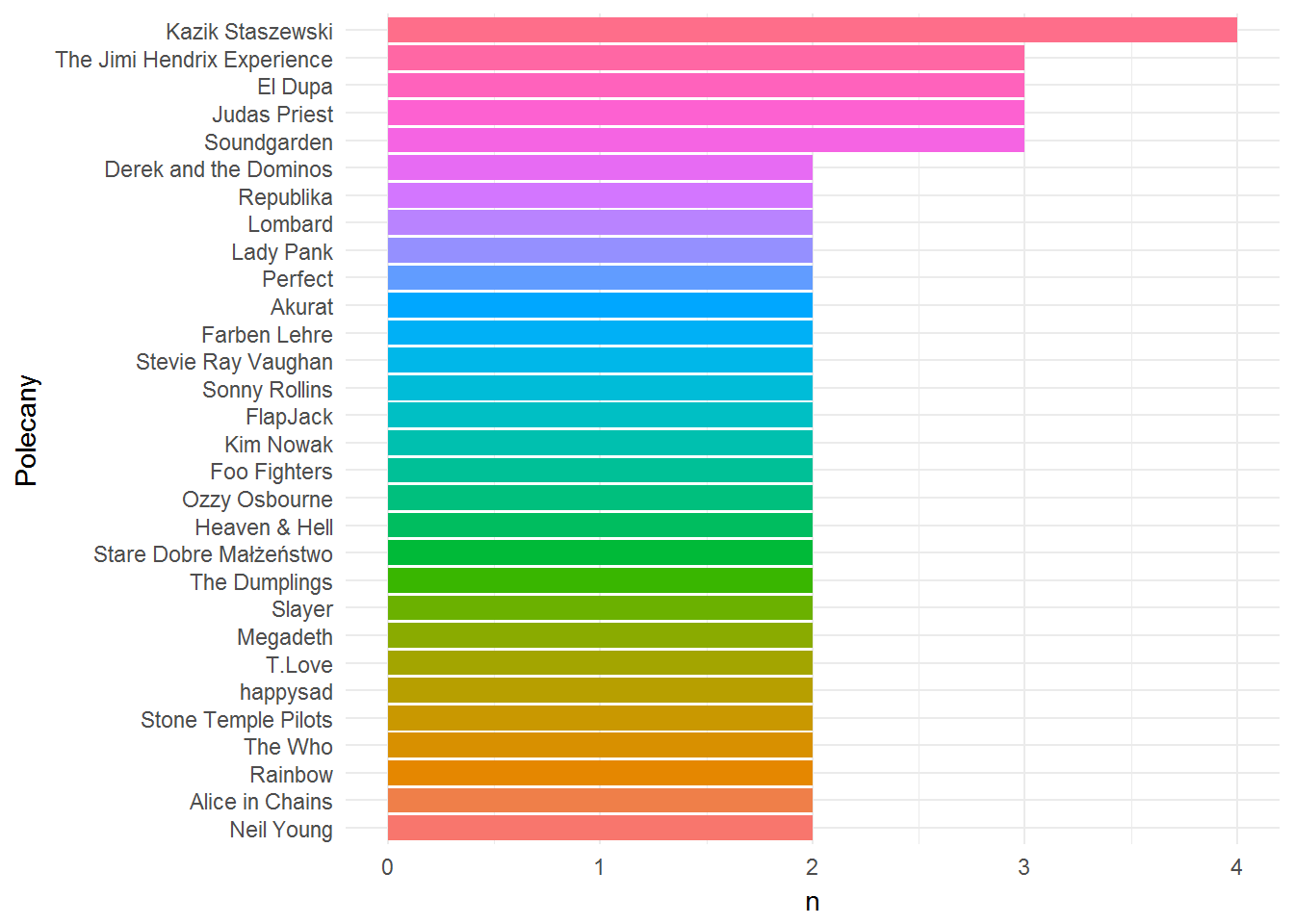
Wartość n na wykresie to liczba poleceń danego artysty – im więcej, tym bardziej prawdopodobne, że nam się spodoba. Właśnie dla tego wykresu (i zróżnicowania na nim długości pasków) odpowiednio dobierałem punkt odcięcia (filtrowanie po n >= 4).
A teraz to samo w tabeli – kto jest polecany i na podstawie jakich przesłuchanych artystów?
| Sluchany | Polecany | n |
|---|---|---|
| Buldog | Kazik Staszewski | 4 |
| Kazik | Kazik Staszewski | 4 |
| Kazik na Żywo | Kazik Staszewski | 4 |
| Kult | Kazik Staszewski | 4 |
| Buldog | El Dupa | 3 |
| Kazik | El Dupa | 3 |
| Kazik na Żywo | El Dupa | 3 |
| Black Sabbath | Judas Priest | 3 |
| Dio | Judas Priest | 3 |
| Iron Maiden | Judas Priest | 3 |
| Nirvana | Soundgarden | 3 |
| Pearl Jam | Soundgarden | 3 |
| The Smashing Pumpkins | Soundgarden | 3 |
| Cream | The Jimi Hendrix Experience | 3 |
| Jimi Hendrix | The Jimi Hendrix Experience | 3 |
| The Doors | The Jimi Hendrix Experience | 3 |
Co tutaj widać? Staszewski we wszystkich odmianach. Głównie dlatego, że Staszewski nagrywa w tych wszystkich odmianach. Skoro słuchałem dużo Kultu to spodoba mi się zapewne Kazik na Żywo. Kazik udzielał się też na pierwszych płytach El Dupy i Buldoga. Wszystko się zazębia. Jak ktoś lubi Kult i Kazika to łyka wszystko. U mnie jest tak samo, a Dupa z Buldogiem nie złapali się na listę ostatnio słuchanych, dlatego nie wypadli z polecanych.
Druga pozycja jest ciekawsza – Judas Priest bardzo dobrze pasuje do Black Sabbath i Iron Maiden. O ile ostatnie dwie kapele lubię, o tyle Judas jakoś mi do gustu nie przypadł (a nie wyleciał z poleceń, bo nie było go w scrobble’ach). Ciekawostką jest Dio. Około dwa miesiące temu po raz pierwszy robiłem to, co właśnie przeczytaliście i wówczas Dio było kapelą polecaną, o której wcześniej nawet nie słyszałem. Posłuchałem więc. I jednak nie, chociaż to już kwestia niuansów.
Soundgarden znam dobrze, ale widocznie dawno nie słuchałem. A Chris Connel z kumplami świetnie uzupełniają to co zrobiła Nirvana i Pearl Jam – w trójkę te kapele stworzyły najbardziej znane utwory grandżowe. Do tego Smashing Pumpkins, które Soundgardenów tylko podbiły.
Na koniec Jimi Hendrix pasujący latami do Creamu i Doorsów, oraz do samego siebie (jego Experience do niego samego). Trochę tutaj widać też to co przy Kaziku – ta sama osoba występująca pod różnymi nazwami (w dużym uproszczeniu).
Co jeszcze można zrobić?
Można wizualizować zależności – na przykład na grafach. Wtedy rezygnujemy z wyboru artystów już słuchanych i w oparciu o pary z tabeli t możemy narysować graf nieskierowany.
|
1 2 3 4 5 6 7 |
library(igraph) g <- graph_from_data_frame(t[,c(1,3)], directed = FALSE) V(g)$membership <- cluster_edge_betweenness(g)$membership plot(g, vertex.size=6, vertex.label.cex=0.1, vertex.color=V(g)$membership, layout=layout_with_fr) |

Żeby ładnie wyglądało trzeba się tym pobawić. To już zostawiam Wam.
Z takiego dużego grafu można wydzielić mniejsze grupy, zobaczmy skład i powiązania dla najliczniejszej:
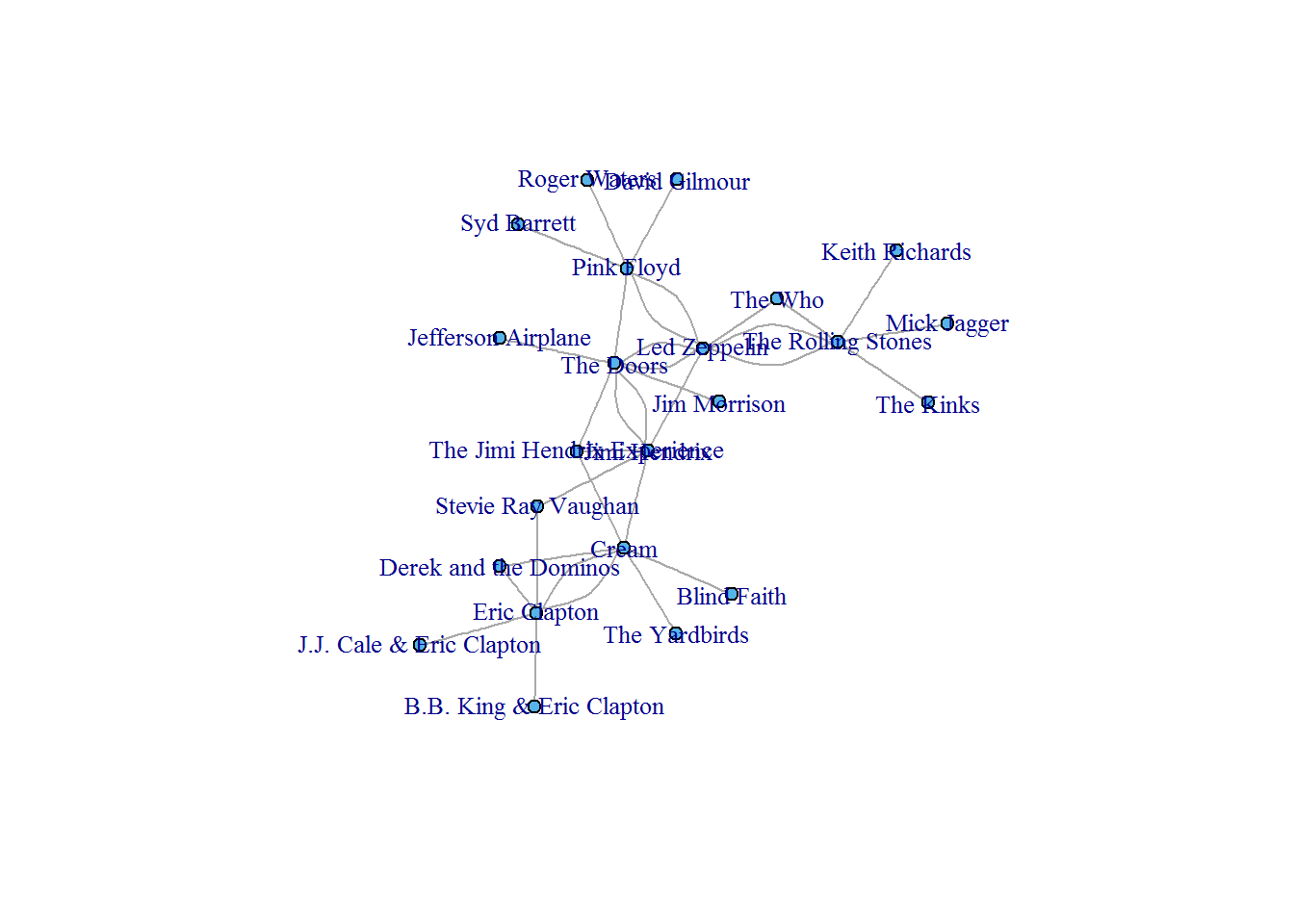
Widać tutaj powiązania:
- Pink Floyd łączą się z Watersem, Gilmourem i Barrettem (ciekawe dlaczego?) oraz Led Zeppelin i The Doors
- Led Zeppelin – z The Who, Hendrixem, Stonesami
- Eric Clapton łączy się z Cream
Polecam analizę poszczególnych grup samodzielnie. Gdyby do tych powiązań dodać daty wydania poszczególnych płyt można dojść do informacji kto kogo inspirował (najprawdopodobniej).
Ale co można zrobić z samą metodą rekomendacji? Zakładając, że podobnych artystów bierzemy z LastFM a nie z innego miejsca (API Spotify też to umożliwia) czy tym bardziej nie próbujemy wskazać samodzielnie?
Możemy nadać wagi poszczególnym rekomendacją z LastFM – na przykład może to być liczba słuchanych piosenek danego artysty, ta sama liczba ale dla unikalnych piosenek (czyli bez duplikatów). Możemy skorzystać z wskaźnika dopasowania (funkcja artist.getSimilar() zamiast artist.getInfo()). Możemy kombinować z liczbą słuchanych albumów artysty. API LastFM pozwala również szukać piosenek podobnych do wskazanej, a nie tylko podobnych artystów. I tagów, bo każdy (prawie) utwór i artysta jest otagowany. Do wyboru, do koloru – wszystko jest kwestią inwencji twórczej :)
Poklepcie trochę kodu, powodzenia!
Pingback: Przez losowy las Spotify | Łukasz Prokulski