W poprzednim poście zrobiłem analizę postów publikowanych przez polskie redakcje informacyjne na Facebooku. Zabrakło tam redakcji z grupy Ringier Axel Springer Polska.
W związku z licznymi prośbami – dzisiaj pogłębiona analiza postów Onetu.
Zajmiemy się fanpage’em “głównym” i ostatnimi dwoma tysiącami postów.
|
1 |
fb_page_posts <- get_fanpage_posts("Onet", 2000, token) |
Skorzystałem z funkcji get_fanpage_posts() napisanej w poprzednim poście, więc zainteresowanych tam odsyłam po szczegóły techniczne.
Zobaczmy jakiego typu posty publikuje Onet:
|
1 2 3 4 5 6 7 8 9 10 11 |
fb_page_posts %>% count(type) %>% mutate(p=100*n/sum(n)) %>% ungroup() %>% arrange(n) %>% mutate(type = factor(type, levels=type)) %>% ggplot() + geom_bar(aes(1, p, fill=type), stat="identity") + labs(fill="Typ postu") + theme_void() + coord_polar(theta="y") |
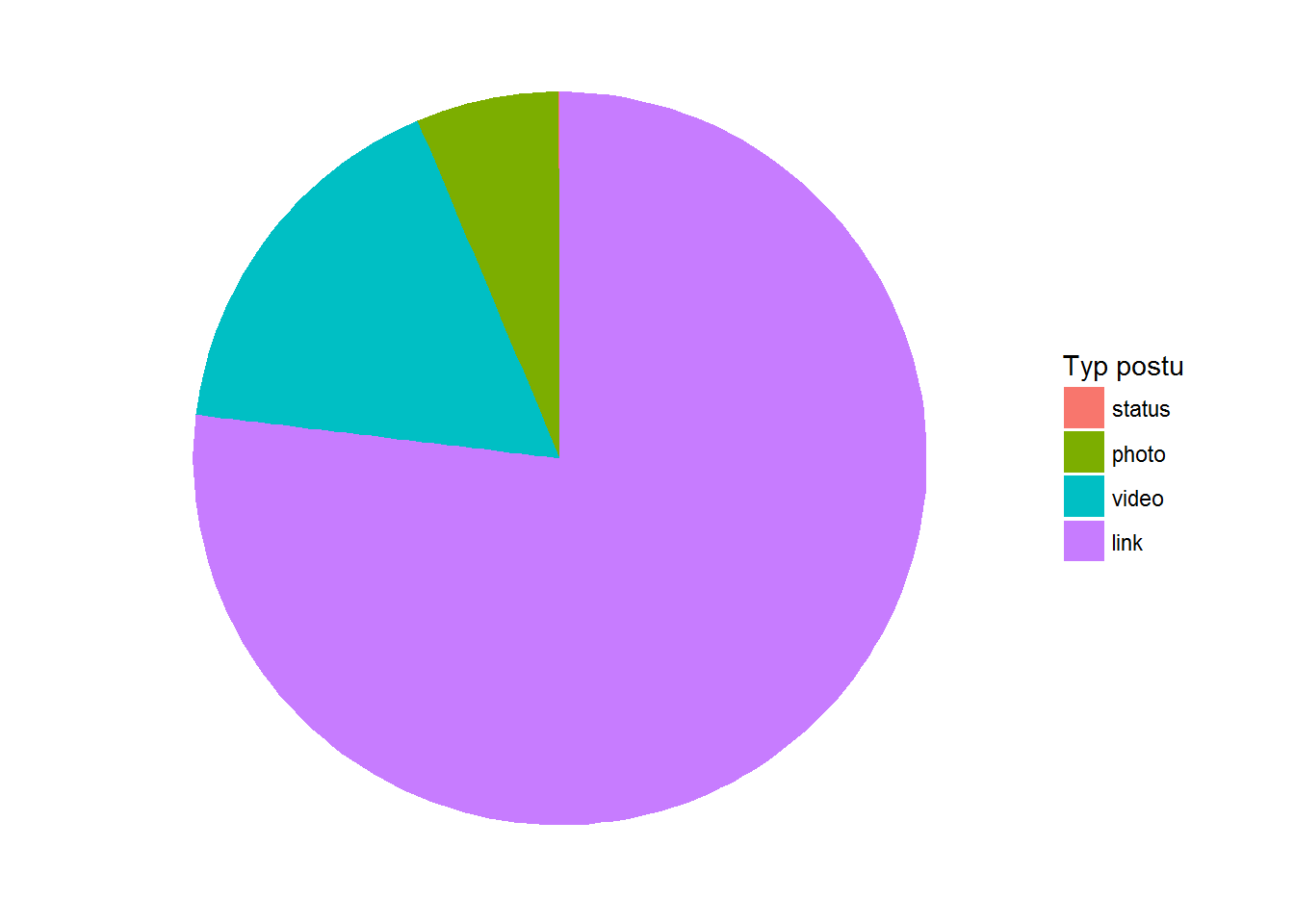
Prawie 77% – linki, 16.75% wideo, 6% zdjęcia.
Jak to wygląda ilościowo – liczba postów publikowanych w ciągu dnia w zależności od dnia tygodnia, im bardziej żółte tym więcej:
|
1 2 3 4 5 6 7 8 9 10 |
fb_page_posts %>% count(hour, wday) %>% ungroup() %>% mutate(wday = factor(wday, rev(c("pn","wt","śr","cz","pt","sb","nd")))) %>% ggplot() + geom_tile(aes(hour, wday, fill=n)) + theme_minimal() + labs(x="Godzina", y="Dzień tygodnia") + scale_fill_gradient(low="#800026", high="#ffffcc") + theme(legend.position="none") |
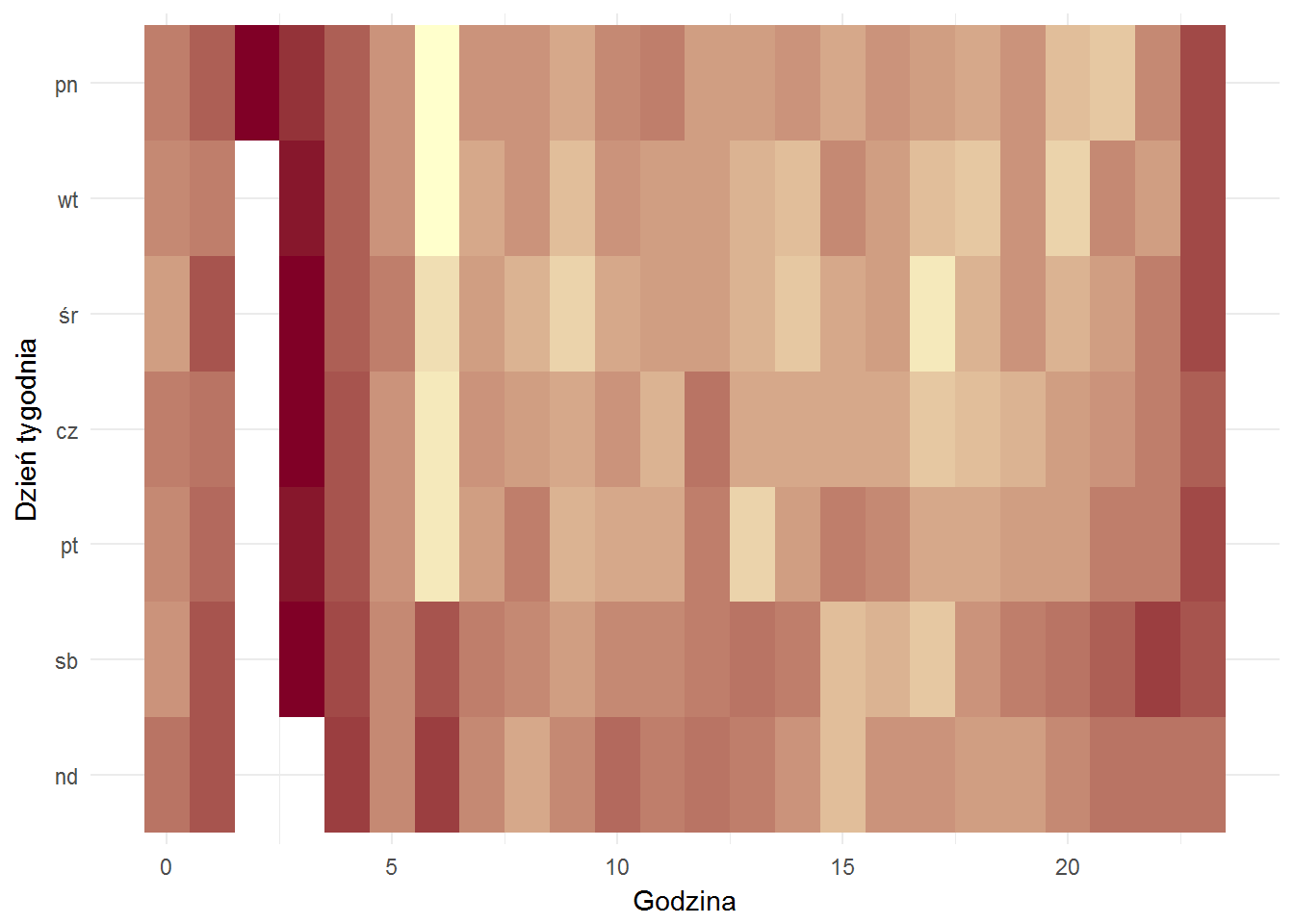
O drugiej w nocy to w Onecie się śpi. Automaty publikujące też śpią.
Jak wyglądają globalnie interakcje z postami w czasie? Zobaczmy od razu na wygładzonych krzywych:
|
1 2 3 4 5 6 7 8 9 10 |
ggplot(fb_page_posts) + geom_smooth(aes(created_time, likes_count), color="red", se = FALSE) + geom_smooth(aes(created_time, comments_count), color="green", se = FALSE) + geom_smooth(aes(created_time, shares_count), color="blue", se = FALSE) + theme_minimal() + labs(title="Liczba interakcji na post", x="Czas", y="Liczba interakcji na post") |
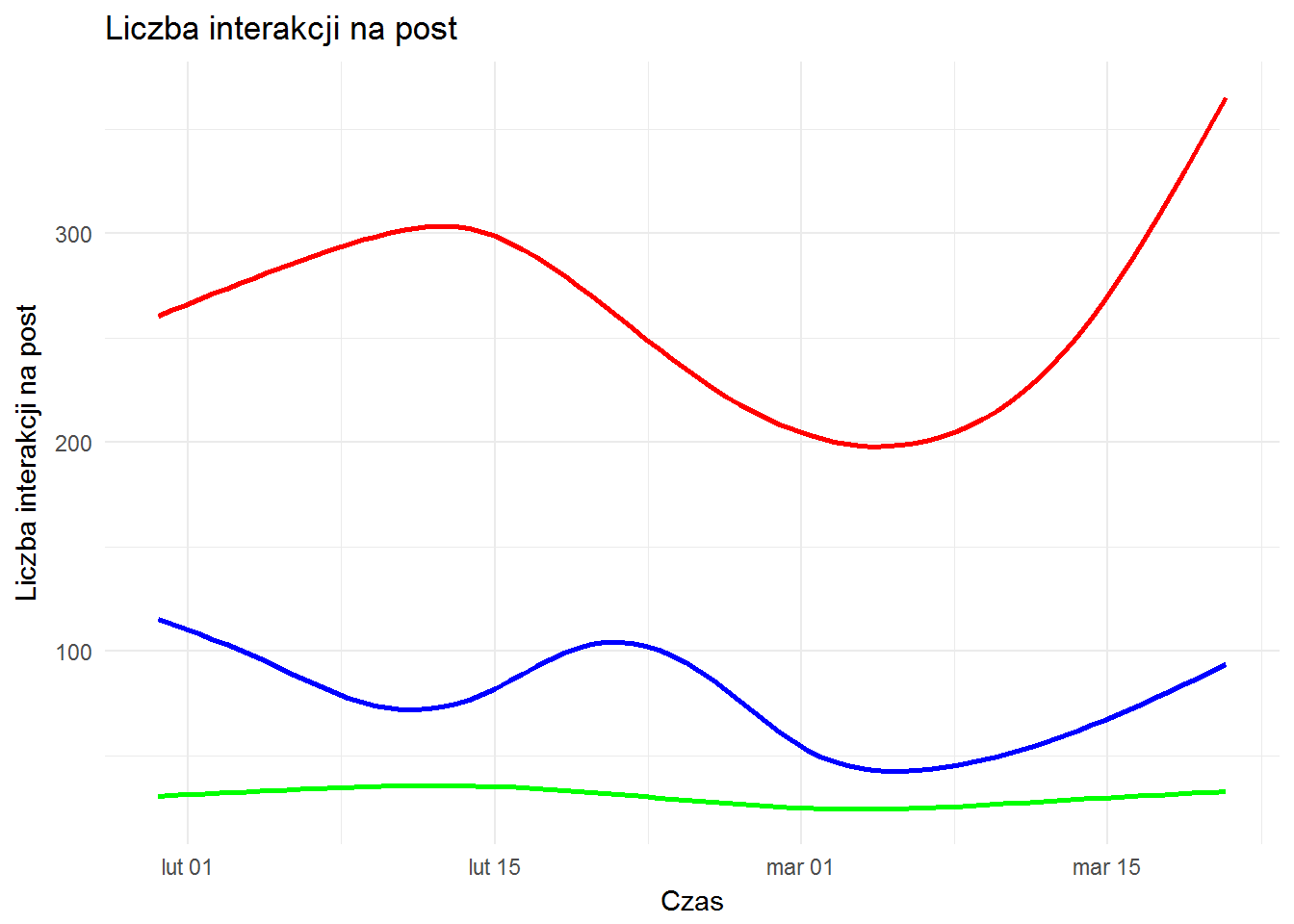
Czerwone – lajki, zielone – komentarze, a niebieskie to “szery”. Jak widać – like dominuje, co jest naturalne.
Z ciekawości sprawdźmy jeszcze rozkłady – czy na grubych wartościach przewaga lajków jest widoczne?
|
1 |
summary(fb_page_posts$likes_count) |
|
1 2 |
## Min. 1st Qu. Median Mean 3rd Qu. Max. ## 0.0 28.0 79.0 259.1 208.0 15800.0 |
|
1 |
summary(fb_page_posts$comments_count) |
|
1 2 |
## Min. 1st Qu. Median Mean 3rd Qu. Max. ## 0.00 1.00 8.00 30.44 28.00 922.00 |
|
1 |
summary(fb_page_posts$shares_count) |
|
1 2 |
## Min. 1st Qu. Median Mean 3rd Qu. Max. ## 0.0 2.0 13.0 77.2 53.0 6387.0 |
8.5 raza więcej lajków niż komentarzy (średnie 259.1 do 30.44, podobnie w medianach), dwa razy więcej “szerów” niż komentarzy. Ma to sens.
Mamy zgrubny obraz działań redakcyjnych, ale są jeszcze użytkownicy, którzy wchodzą w interakcje z postami. Kim są? Co robią? Kiedy to robią?
Potrzebujemy danych szczegółowych każdego postu. Przygotujemy odpowiednią funkcję i pobierzemy szczegóły (komentarze i lajki):
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 |
get_comments <- function(post_id, token, n_comments=500, n_likes = 500) { # zabezpieczenie dla pętli wywołującej funkcję # poprawnie te warunki powinny być poza funkcją! if(n_comments == 0) n_comments <- 500 if(n_likes == 0) n_likes <- 500 coms <- getPost(post_id, token=token, n.comments = n_comments, n.likes = n_likes, n = n_comments + n_likes) return(coms) } # pobierz komentarze i lajki do wszystkich postów fb_comments <- data.frame() fb_likes <- data.frame() for(i in 266:nrow(fb_page_posts)) { post_data <- get_comments(fb_page_posts[i, "id"], token, fb_page_posts[i, "comments_count"], fb_page_posts[i, "likes_count"]) fb_comments_tmp <- post_data$comments # czy są jakieś komentarze? # jeśli tak - dodaj do listy wszystkich if(!is.null(fb_comments_tmp)) if(nrow(fb_comments_tmp) > 0) { fb_comments_tmp$post_id <- fb_page_posts[i, "id"] fb_comments <- rbind(fb_comments, fb_comments_tmp) } fb_likes_tmp <- post_data$likes # czy są jakieś likes? # jeśli tak - dodaj do listy wszystkich if(!is.null(fb_likes_tmp)) if(nrow(fb_likes_tmp) > 0) { fb_likes_tmp$post_id <- fb_page_posts[i, "id"] fb_likes <- rbind(fb_likes, fb_likes_tmp) } } # data w przyjaznym formacie fb_comments$created_time = ymd_hms(fb_comments$created_time) |
Kod komentuje się sam i specjalnie jest napisany w tak oczywisty sposób ;)
Zresztą moje założenie jest takie, że jeśli czytasz tego bloga bo chcesz się nauczyć R to musisz trochę już znać język. A jeśli interesują Cię wyniki analiz – kod nie jest Ci potrzebny.
Sprawdźmy co widać w pobranych danych – na przykład kto lajkuje najwięcej?
|
1 2 3 4 5 6 7 8 9 10 11 |
n_posts <- nrow(fb_page_posts) fb_likes %>% group_by(from_id) %>% mutate(n=n()) %>% ungroup() %>% select(from_id, n) %>% unique() %>% mutate(p = 100*n/n_posts) %>% arrange(desc(n)) %>% head(10) |
| from_id | n | p |
|---|---|---|
| 765792643488287 | 962 | 48.10 |
| 117369568765683 | 708 | 35.40 |
| 1626762774218087 | 603 | 30.15 |
| 1509454992712237 | 579 | 28.95 |
| 134406080245666 | 516 | 25.80 |
| 1497820407125220 | 511 | 25.55 |
| 694381153959631 | 505 | 25.25 |
| 1592056757683674 | 461 | 23.05 |
| 274458252970959 | 461 | 23.05 |
| 1397678880555423 | 393 | 19.65 |
W tabeli powyżej mogłyby pojawić się nazwiska (wystarczy zamienić from_id na from_name), ale nie chcę tego robić (chociaż jak widać te informacje są publiczne). Lider(ka) dał(a) lajka prawie połowie postów (48%)! No to musi być miłość…
Kto napisał najwięcej komentarzy? Znowu – tylko IDki użytkowników, nie nazwiska:
|
1 2 3 4 5 6 7 8 9 |
fb_comments %>% group_by(from_id) %>% mutate(n=n()) %>% ungroup() %>% select(from_id, n) %>% unique() %>% mutate(p = 100*n/n_posts) %>% arrange(desc(n)) %>% head(10) |
| from_id | n | p |
|---|---|---|
| 1466984766960019 | 314 | 15.70 |
| 507983079343646 | 109 | 5.45 |
| 543957139059303 | 96 | 4.80 |
| 122810131418675 | 87 | 4.35 |
| 1464805913849186 | 84 | 4.20 |
| 1030590347068474 | 72 | 3.60 |
| 115975748747575 | 66 | 3.30 |
| 769660986403035 | 65 | 3.25 |
| 528748793932975 | 64 | 3.20 |
| 219332305072990 | 62 | 3.10 |
Weźmy tego pierwszego (skomentował prawie co szóstego posta!) – czy to komentarze do różnych postów czy do jednego (jakaś dyskusja)?
|
1 2 3 4 5 |
fb_comments %>% filter(from_id =="1466984766960019") %>% count(post_id) %>% ungroup() %>% summary(n) |
|
1 2 3 4 5 6 7 |
## post_id n ## Length:313 Min. :1.000 ## Class :character 1st Qu.:1.000 ## Mode :character Median :1.000 ## Mean :1.003 ## 3rd Qu.:1.000 ## Max. :2.000 |
Przy takim rozkładzie (średnia nieco ponad 1, trzeci kwartyl równy jeden, maksimum równe dwa) można być praktycznie pewnym, że tylko kilka komentarzy dotyczy tego samego postu. Proszę sprawdzić samodzielnie.
A kto udzielał się w dyskusji (czyli napisał dużo komentarzy pod jednym postem)? Jeśli ktoś taki jest to pod jakim postem?
|
1 2 3 |
fb_comments %>% count(from_id, post_id) %>% arrange(desc(n)) |
| from_id | post_id | n |
|---|---|---|
| 1409834469287770 | 185265414715_10154394754944716 | 21 |
| 720664394689826 | 185265414715_10154468251179716 | 21 |
| 144237015938786 | 185265414715_10154501451039716 | 20 |
| 845900115496276 | 185265414715_10154501451039716 | 16 |
| 1525684074381514 | 185265414715_10154487441754716 | 15 |
| 1659327344324010 | 185265414715_10154475004724716 | 14 |
| 843981655682542 | 185265414715_10154501451039716 | 12 |
| 422307901239180 | 185265414715_10154472572149716 | 10 |
| 627261217384010 | 185265414715_10154432344394716 | 10 |
| 630185733702545 | 185265414715_10154394754944716 | 10 |
Mamy post o ID 185265414715_10154394754944716 i komentującego o ID 1409834469287770 – co to?
|
1 2 3 4 5 |
fb_comments %>% filter(post_id=="185265414715_10154394754944716", from_id=="1409834469287770") %>% select(created_time, message) %>% arrange(created_time) |
| created_time | message |
|---|---|
| 2017-02-01 12:54:44 | |
| 2017-02-01 12:58:16 | |
| 2017-02-01 12:58:28 | |
| 2017-02-01 13:07:53 | |
| 2017-02-01 13:08:03 | |
| 2017-02-01 13:08:12 | |
| 2017-02-01 13:08:18 | |
| 2017-02-01 13:08:25 | |
| 2017-02-01 13:08:31 | |
| 2017-02-01 13:08:37 | |
| 2017-02-01 13:08:43 | |
| 2017-02-01 13:08:49 | |
| 2017-02-01 13:08:56 | |
| 2017-02-01 13:09:02 | |
| 2017-02-01 13:09:10 | |
| 2017-02-01 13:09:16 | |
| 2017-02-01 13:09:22 | |
| 2017-02-01 13:09:28 | |
| 2017-02-01 13:09:34 | |
| 2017-02-01 13:09:42 | |
| 2017-02-01 13:09:48 |
Komentarze co 8 sekund, bez żadnej treści słownej – proszę zobaczyć na post i komentarze do niego, wszystko się wyjaśni. W danych można sprawdzić kim jest ten użytkownik (albo po jego ID wklejonym w URLa do Facebooka).
Przeanalizowaliśmy dość szczegółowo jeden post. Wróćmy do globalnego przeglądu – ile czasu mija od publikacji postu do komentarza?
|
1 2 3 4 5 6 7 8 9 10 11 |
# same komentarze i daty com_times <- fb_comments %>% transmute(post_id=post_id, created_time_com=created_time) post_times <- fb_page_posts %>% transmute(post_id=id, created_time_post=created_time) # złączmy to po ID postu times <- left_join(com_times, post_times, by="post_id") %>% mutate(diff = floor(as.numeric(created_time_com - created_time_post) / 60)) %>% filter(diff >= 0) |
Prosta różnica czasów daje wynik w sekundach – dlatego dzielimy przez 60 (do minut) i zaokrąglamy w dół do najbliższej całkowitej (floor()).
Pierwsza doba wygląda tak (czerwone kreski to kolejne godziny):
|
1 2 3 4 5 6 |
times %>% filter(diff <= 24*60) %>% ggplot() + geom_histogram(aes(diff), bins = 24*60) + geom_vline(xintercept = 60*(1:24), color="red") + theme_minimal() |
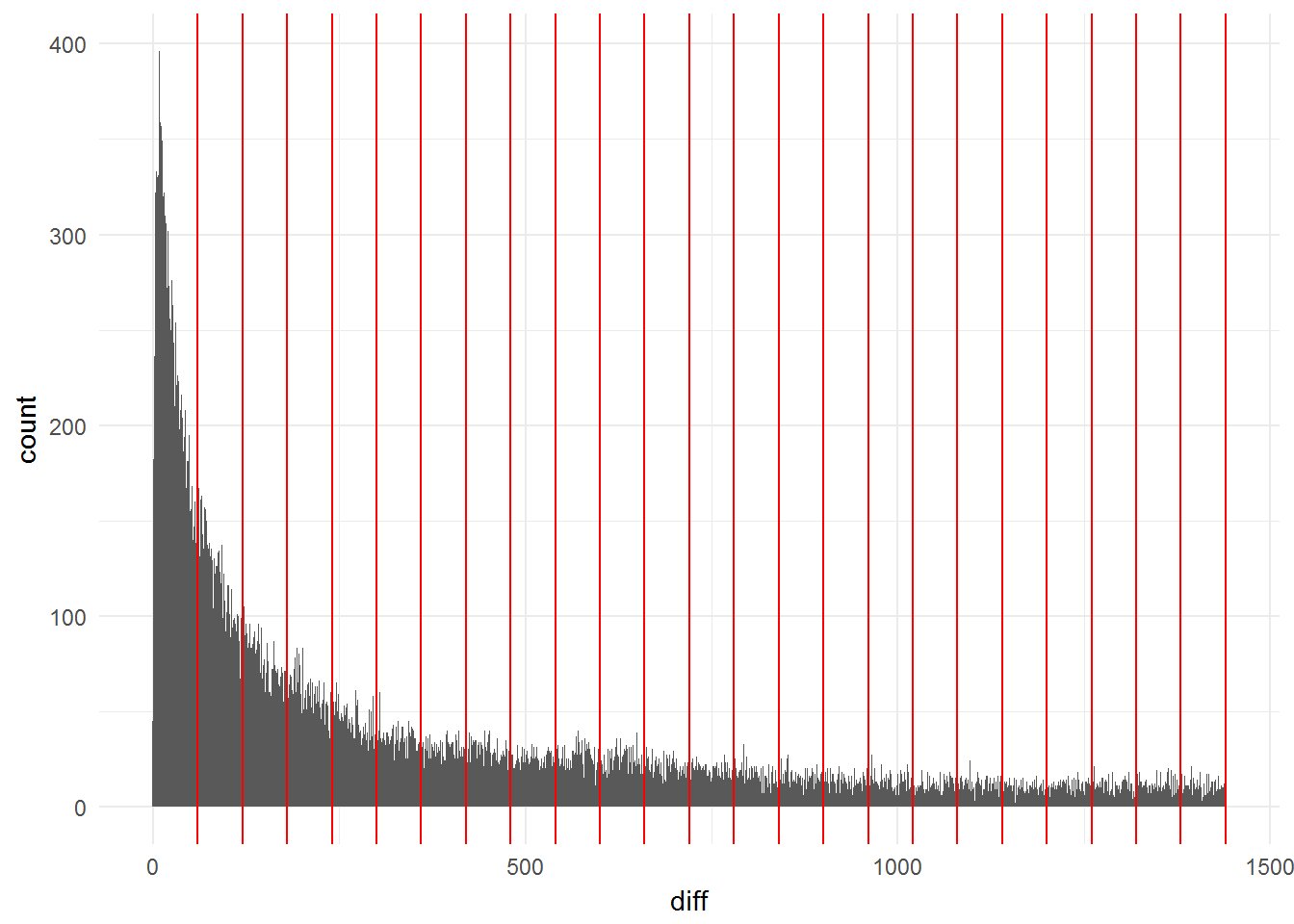
Dużo na początku, im później tym mniej.
Centyle po godzinach:
|
1 |
quantile(floor(times$diff/60), seq(0, 1, 0.1)) |
|
1 2 |
## 0% 10% 20% 30% 40% 50% 60% 70% 80% 90% 100% ## 0 0 0 1 2 3 6 9 14 22 795 |
Widać, że połowa komentarzy pojawia się do maksymalnie czterech godzin po publikacji, a w pierwszej dobie mamy ponad 90% komentarzy. W pierwszej godzinie mieści się 30% komentarzy.
Zobaczmy jak dokładniej wygląda ta pierwsza godzina:
|
1 2 3 4 5 |
times %>% filter(diff <= 60) %>% ggplot() + geom_histogram(aes(diff), bins = 60) + scale_x_continuous(breaks = seq(0, 60, 5)) |
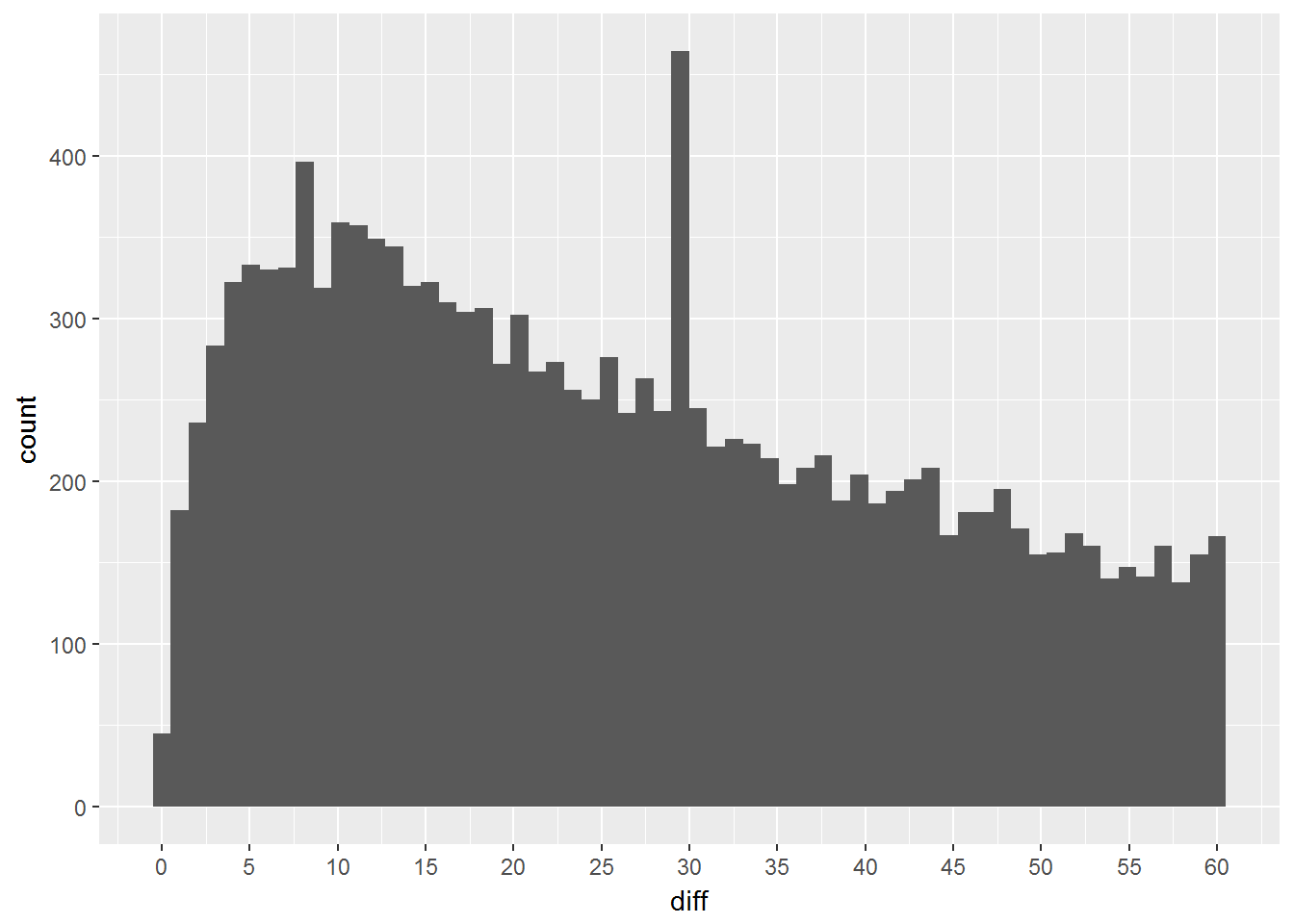
Skąd pik przy 30 minutach? Ten pik w połączeniu z 50% percentylem w okolicach 3 godziny łączyłbym z sposobem sortowania treści na wallu jaki widzimy na Facebooku. Ciekaw jestem (wie to zapewne Facebook) jaki procent ogląda swojego walla z poziomu sortowania “najnowsze najpierw”, a jaki “najpopularniejsze najpierw”. Zgadnijcie, których jest więcej…
Czy widać jakieś szczególne pory kiedy pojawiają się komentarze?
|
1 2 3 4 5 6 7 8 |
fb_comments %>% mutate(hour = hour(created_time)) %>% count(hour) %>% ungroup() %>% ggplot() + geom_bar(aes(hour, n), stat="identity") + theme_minimal() + labs(x="Godzina", y="Łączna liczba komentarzy") |
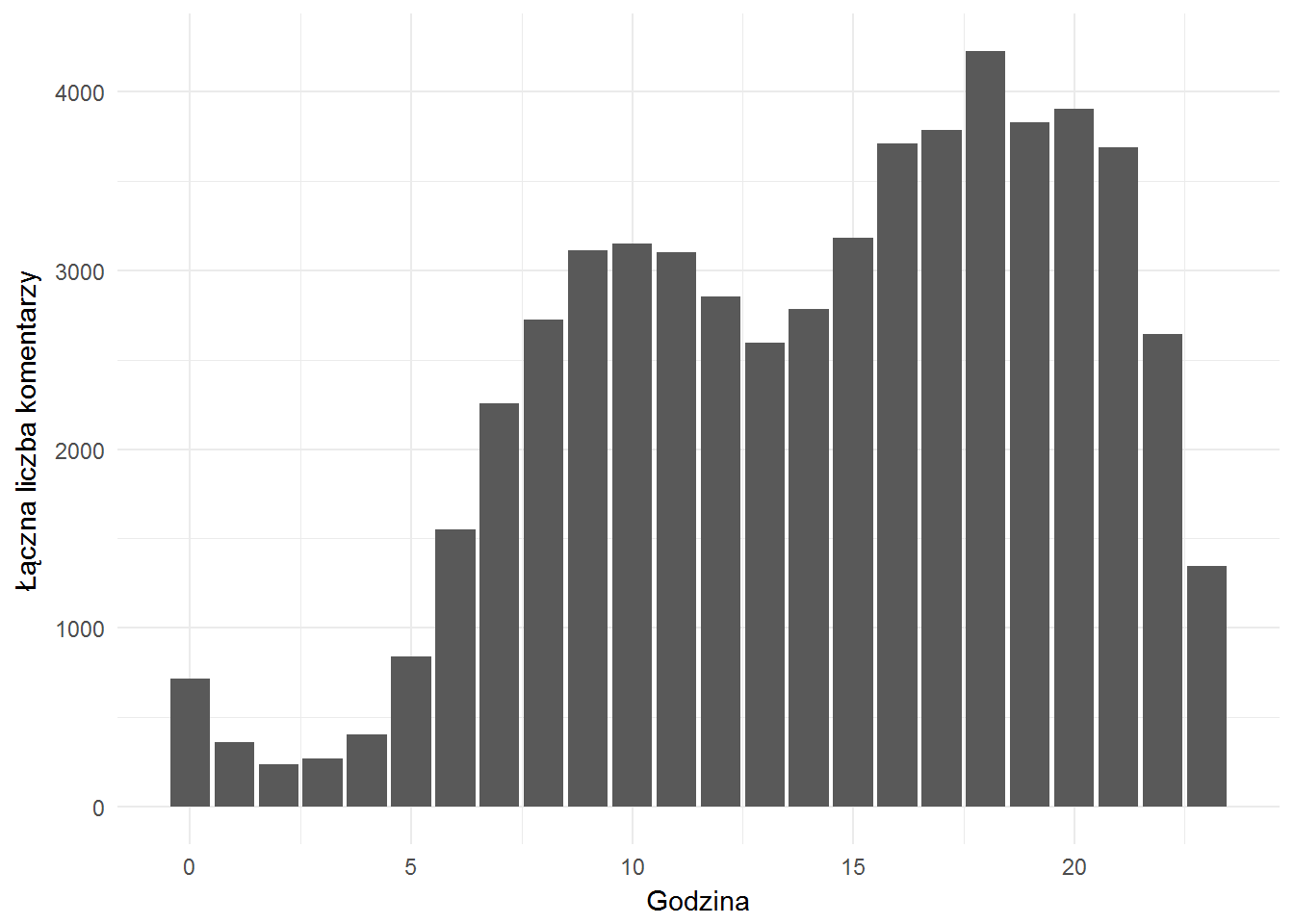
To jest na sumach a nie średnich per post czy cokolwiek… Metodologicznie nie za dobrze, ale ważny jest charakter rozkładu (uśredniony będzie podobny – sprawdźcie).
Znowu widać rozkład “konsumpcji” internetu w Polsce – do porannej kawy i po południu albo wieczorem. O tym było też poprzednio.
Sprawdźmy jeszcze to samo jako mapa cieplna w tygodniu (żółty = bardziej):
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
fb_comments %>% mutate(hour = hour(created_time), wday = wday(created_time)) %>% mutate(wday = factor(wday, levels=c(2,3,4,5,6,7,1), labels=c("pn","wt","śr","cz","pt","sb","nd"))) %>% count(wday, hour) %>% ungroup() %>% ggplot() + geom_tile(aes(hour, wday, fill=n)) + theme_minimal() + labs(x="Godzina", y="Dzień tygodnia") + scale_fill_gradient(low="#800026", high="#ffffcc") + theme(legend.position="none") |
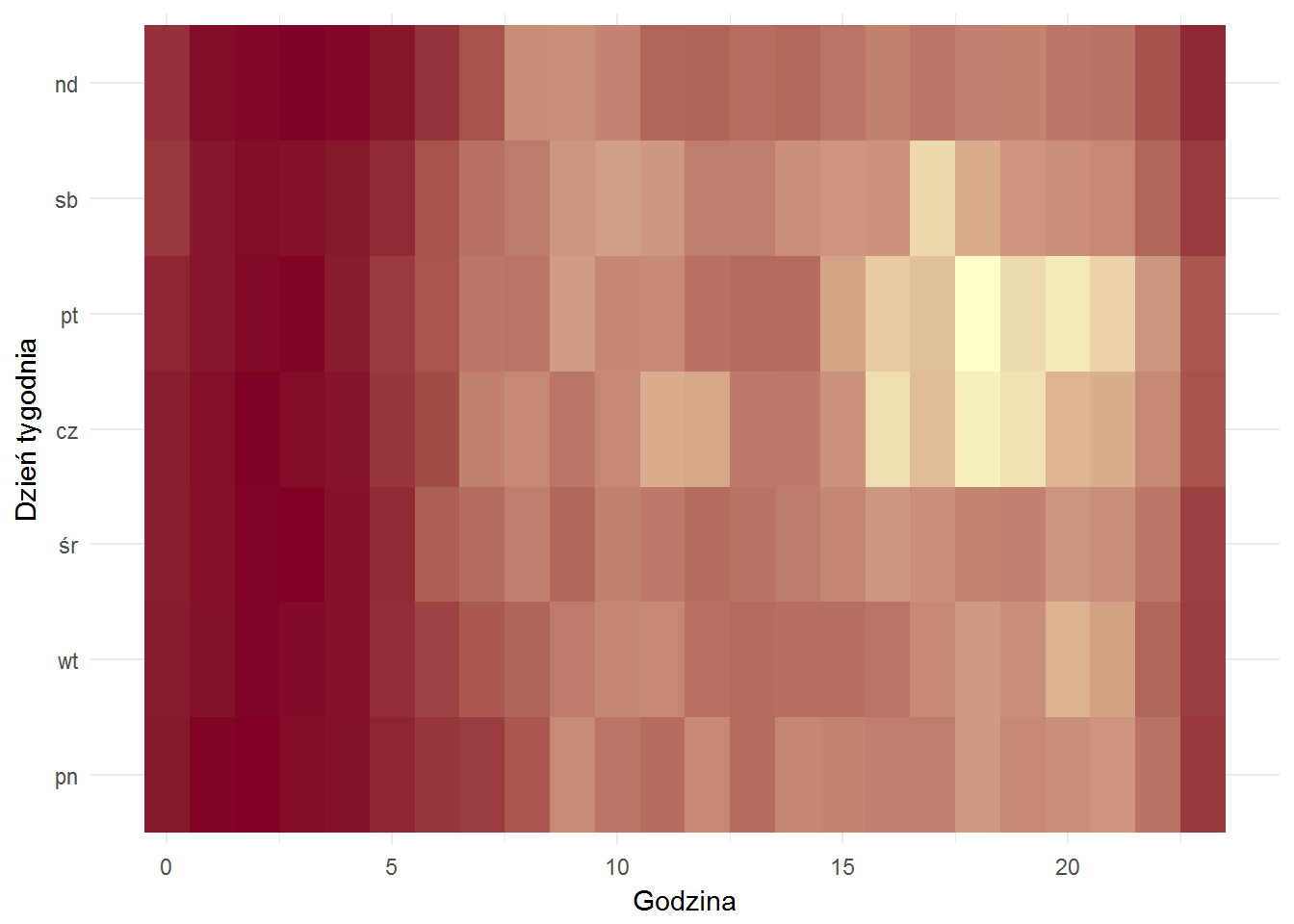
Weźmy ten najbardziej żółty moment – to jest godzina 18 w piątek. Co to?
|
1 2 3 4 5 6 7 8 9 10 |
fb_comments %>% mutate(hour = hour(created_time), wday = wday(created_time)) %>% mutate(wday = factor(wday, levels=c(2,3,4,5,6,7,1), labels=c("pn","wt","śr","cz","pt","sb","nd"))) %>% filter(wday=="pt", hour==18) %>% count(post_id) %>% ungroup() %>% arrange(desc(n)) |
| post_id | n |
|---|---|
| 185265414715_10154420101434716 | 155 |
| 185265414715_10154498692109716 | 88 |
| 185265414715_10154440933599716 | 54 |
| 185265414715_10154401824069716 | 47 |
| 185265414715_10154475866729716 | 46 |
| 185265414715_10154439805594716 | 41 |
| 185265414715_10154419804359716 | 30 |
| 185265414715_10154398679889716 | 26 |
| 185265414715_10154498303154716 | 24 |
| 185265414715_1800396303617326 | 23 |
Widzimy, że maksymalna liczba komentarzy pojawiła się pod poste numer 185265414715_10154420101434716 – co to było? Ta dam!
|
1 |
fb_page_posts[fb_page_posts$id=="185265414715_10154420101434716", "message"] |
|
1 |
## [1] "Premier trafiła do szpitala" |
Na koniec jeszcze zobaczmy na treść postów. Z grubsza, “bez czytania” (uwielbiam to podejście – zobaczcie wyniki Oskarów o ile nie znacie). Zobaczymy jakie słowa są najbardziej popularne w postach jak i w komentarzach. Pojedyncze słowa – zmniejszamy litery, rozdzielamy, liczymy, zostawiamy te co mają co najmniej 3 znaki.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
library(tidytext) words_comments <- fb_comments %>% transmute(message = tolower(iconv(message, "UTF-8", "LATIN2"))) %>% unnest_tokens(words, message) %>% count(words) %>% ungroup() %>% filter(nchar(words) > 2) words_posts <- fb_page_posts %>% transmute(message = tolower(iconv(message, "UTF-8", "LATIN2"))) %>% unnest_tokens(words, message) %>% count(words) %>% ungroup() %>% filter(nchar(words) > 2) |
W tym momencie warto zerknąć w powstałe tabelki words_posts oraz words_comments. Można pozwolić sobie na jeszcze nieco filtrowania, na pewno polskie stop-words (słownik znalazłem w Google):
|
1 2 3 |
pl_stop_words <- readLines("../textmining/polish_stopwords.txt", encoding = "UTF-8") words_comments <- filter(words_comments, !words %in% pl_stop_words) words_posts <- filter(words_posts, !words %in% pl_stop_words) |
To samo powtarzamy dla tych samych słów pozbawionych polskich literek – słownik jest ten sam, ręcznie edytowany przez “znajdź i zamień” znaki z ogonkami na takie bez ogonków. Bo ludziom się nie chce czasem wcisnąć ALT.
Później zaglądamy w dane, szczególnie do words_posts i znajdujemy tam dużą liczbę przy słowie “wiem” – to reklamowy hash tag Onetu, widać go często, także na Twitterze. Usuwamy.
Teraz możemy narysować chmurki najpopularniejszych słów. Najpierw potrzebne biblioteki i paleta kolorów, a już za moment wyniki.
|
1 2 3 |
library(wordcloud) library(RColorBrewer) pal <- brewer.pal(12, "Paired") |
Najpopularniejesze słowa w postach:
|
1 2 3 |
wordcloud(words_posts$words, words_posts$n, scale=c(1.9,.9), colors = pal, max.words = 100) |
Najpopularniejsze słowa w komentarzach:
|
1 2 3 |
wordcloud(words_comments$words, words_comments$n, scale=c(1.9,.9), colors = pal, max.words = 100) |
Co jeszcze można zrobić? Można spróbować na podstawie częstości występowania słów w postach określić “charakteru” postu (sport, polityka – tego trzeba maszynę nauczyć). Później z takim “charakterem” też można się pobawić – kiedy więcej polityki, a kiedy informacje bardziej rozrywkowe? Co przynosi więcej lajków, a co więcej komentarzy? Jakie są to komentarze?