Wczoraj wieczorem zmarł Wojciech Młynarski.
Zobaczmy czy był popularny – korzystając z Wikipedii.
Za miarę popularności uznamy liczbę wyświetleń hasła poświęconemu Panu Wojciechowi w polskiej Wikipedii. Im bardziej osoba popularna, tym częściej poszukuje się o niej informacji. Założenie dość dobre, prawda? Chyba, że… tak – w przypadku ogólnego medialnego szumu wokół osoby (na przykład z powodu śmierci) ta miara zostaje zaburzona. Co też za chwilę zobaczycie.
Potrzebne będzie kilka bibliotek – do obróbki danych dplyr oraz reshape2, do wykresów ggplot2; stringr przyda się do jednego przekształcenia ciągu znaków. Dane pobierzemy przez API w formacie JSON z serwisu Wikimedia.org przy pomocy httr i przekształcimy do formatu data.frame przez fromJSON() z biblioteki jsonlite.
|
1 2 3 4 5 6 |
library(httr) library(jsonlite) library(stringr) library(dplyr) library(reshape2) library(ggplot2) |
Na początek przygotujemy funkcję, która pobierze interesujące nas dane. Parametrami wywołania funkcji będzie zakres dat (dni od-do) oraz hasło z Wikipedii.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
get_wikipedia_views <- function(date_start, date_end, haslo) { # zbuduj URL url <- paste0("https://wikimedia.org/api/rest_v1/metrics/pageviews/per-article/pl.wikipedia/all-access/all-agents/", haslo, "/daily") url <- paste(url, date_start, date_end, sep="/") # pobierz JSON wiki <- GET(url) %>% content("text") %>% fromJSON() # JSON -> data.frame wiki <- wiki$items %>% mutate(day=str_sub(timestamp, start = 1, end = 8)) %>% mutate(day=as.POSIXct(day, format="%Y%m%d", tz="UTC")) %>% mutate(views_cum = cumsum(views)) %>% select(day, article, views, views_cum) return(wiki) } |
Funkcja buduje URL zapytania do API Wikimedia składając w odpowiedniej kolejności hasło i zakres dat. Następnie pobiera dane w formie JSON, który przekształca na ramkę danych. W samej ramce przekształcamy daty na bardziej przyjazny format rok-miesiąc-dzień oraz liczymy skumulowaną liczbę wyświetleń hasła dzień po dniu (bo tak mamy ochotę :).
Zobaczmy co to daje. Ustalimy zakres dat, dla których będziemy pobierać dane dla wszystkich haseł – niech będą to ostatnie 2 lata (od dzisiaj 730 dni wstecz):
|
1 2 3 4 5 6 7 8 9 |
# dzisiaj end_date <- Sys.time() %>% str_replace_all("[[:punct:]]", "") %>% substr(1,8) # dwa lata temu start_date <- (Sys.Date()-2*365) %>% str_replace_all("[[:punct:]]", "") %>% substr(1,8) |
Wybierzmy hasło – na początek informacje o Wojciechu Młynarskim:
|
1 |
haslo <- "Wojciech Młynarski" |
Pobieramy dane za pomocą przygotowanej funkcji
|
1 |
wikistats <- get_wikipedia_views(start_date, end_date, haslo) |
i otrzymujemy coś takiego (końcówka tabeli):
| day | article | views | views_cum | |
|---|---|---|---|---|
| 619 | 2017-03-10 | Wojciech_Młynarski | 262 | 194 672 |
| 620 | 2017-03-11 | Wojciech_Młynarski | 647 | 195 319 |
| 621 | 2017-03-12 | Wojciech_Młynarski | 378 | 195 697 |
| 622 | 2017-03-13 | Wojciech_Młynarski | 281 | 195 978 |
| 623 | 2017-03-14 | Wojciech_Młynarski | 296 | 196 274 |
| 624 | 2017-03-15 | Wojciech_Młynarski | 68 902 | 265 176 |
Wygląda przyjemnie, dane są wystarczające do narysowania wykresów z popularnością hasła. Wyświetlenia hasła dzień po dniu:
|
1 2 3 4 5 6 7 |
ggplot(wikistats) + geom_line(aes(day, views)) + labs(title=paste0("Popularność hasła \"", haslo, "\" w polskiej Wikipedii"), x="Data", y="Liczba wyświetleń dziennie") + theme_light() |
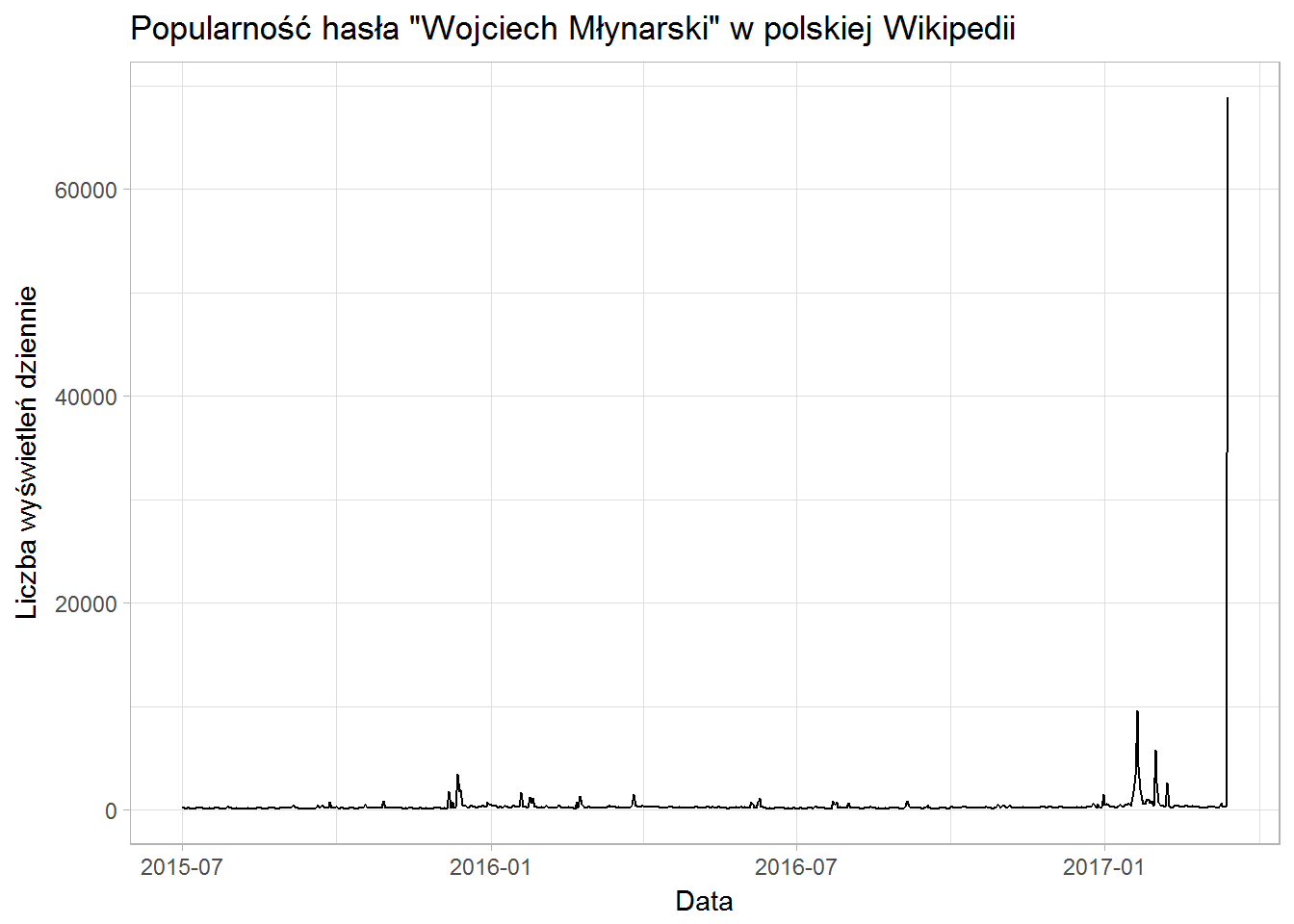
I to samo dla skumulowanej liczby wyświetleń:
|
1 2 3 4 5 6 7 |
ggplot(wikistats) + geom_line(aes(day, views_cum)) + labs(title=paste0("Popularność hasła \"", haslo, "\" w polskiej Wikipedii"), x="Data", y="Skumulowana liczba wyświetleń") + theme_light() |
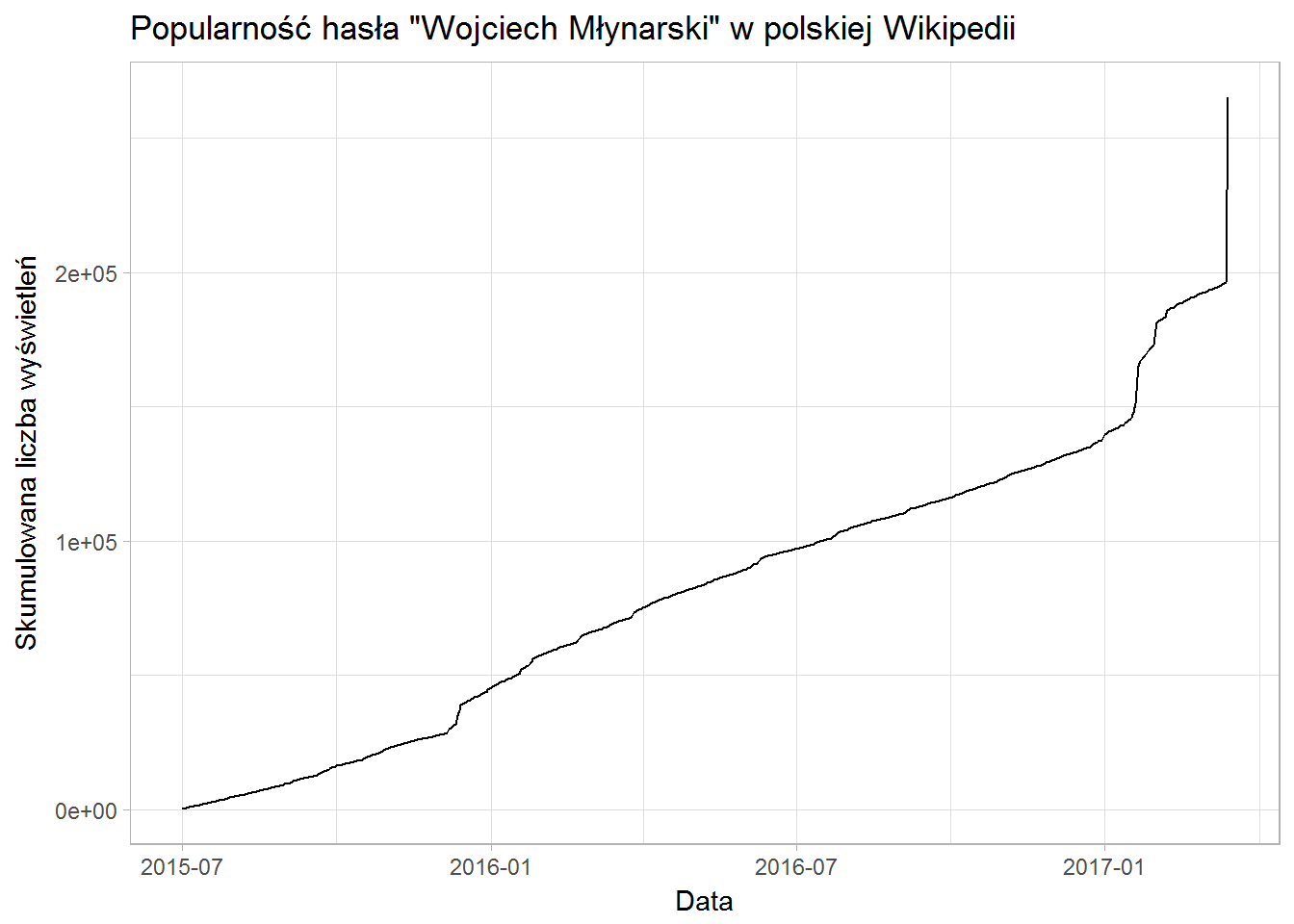
Widać ewidentnie, że zainteresowanie Młynarskim wzrosło gwałtownie w dniu jego śmierci. Średnia liczba wyświetleń to około 280 dziennie – jeśli wyjmiemy ze zbioru dni z liczbą wyświetleń mieszczącą się w zakresie  – czyli jakieś 68,2% danych.
– czyli jakieś 68,2% danych.
W okolicach 20 stycznia widać wzrost ponad średnią – nie jestem w 100% przekonany, ale właśnie wtedy któryś z tabloidów (obstawiam Superaka, bo to są “specjaliści” od takiego gówna) opublikował zdjęcia Młynarskiego w bardzo złym stanie (od dłuższego czasu walczył z chorobą).
Sprawdźmy teraz kilka innych osób, aby porównać popularność haseł na ich temat z Młynarskim. Dla każdej z osób wywołujemy naszą funkcję get_wikipedia_views() dla tego samego przedziału czasu, zmieniając tylko osobę (czyli wartość parametru hasło).
Wybrałem kilka osób znanych oraz (być może – ja wiem kim są, bez zaglądania do Wikipedii) nieco mniej znanych:
|
1 2 3 4 5 6 7 |
osoby <- c("Agnieszka Osiecka", "Czesław Niemen", "Andrzej Duda", "Jarosław Kaczyński", "Donald Tusk", "Andrzej Wajda", "Danuta Szaflarska") for(i in 1:length(osoby)) wikistats <- rbind(wikistats, get_wikipedia_views(start_date, end_date, osoby[i])) |
W wikistats mieliśmy już dane o Młynarskim, dodaliśmy dane o innych osobach. Jeszcze tylko przekształcenie tabelki na taką, z której w łatwy sposób narysujemy wykres z pomocą biblioteki ggplot2:
|
1 2 3 |
osoby_plotdata <- wikistats %>% select(article, day, views, views_cum) %>% melt(id.vars = 1:2) |
I zobaczmy co wychodzi:
|
1 2 3 4 5 6 7 8 9 |
osoby_plotdata %>% # tylko wyświetlenia w ciągu dnia, bez wartości skumulowanych! filter(variable=="views") %>% ggplot() + geom_line(aes(day, value, color=article)) + labs(title="Popularność hasła w polskiej Wikipedii", x="Data", y="Liczba wyświetleń", color="Osoba (hasło)") + theme_light() |
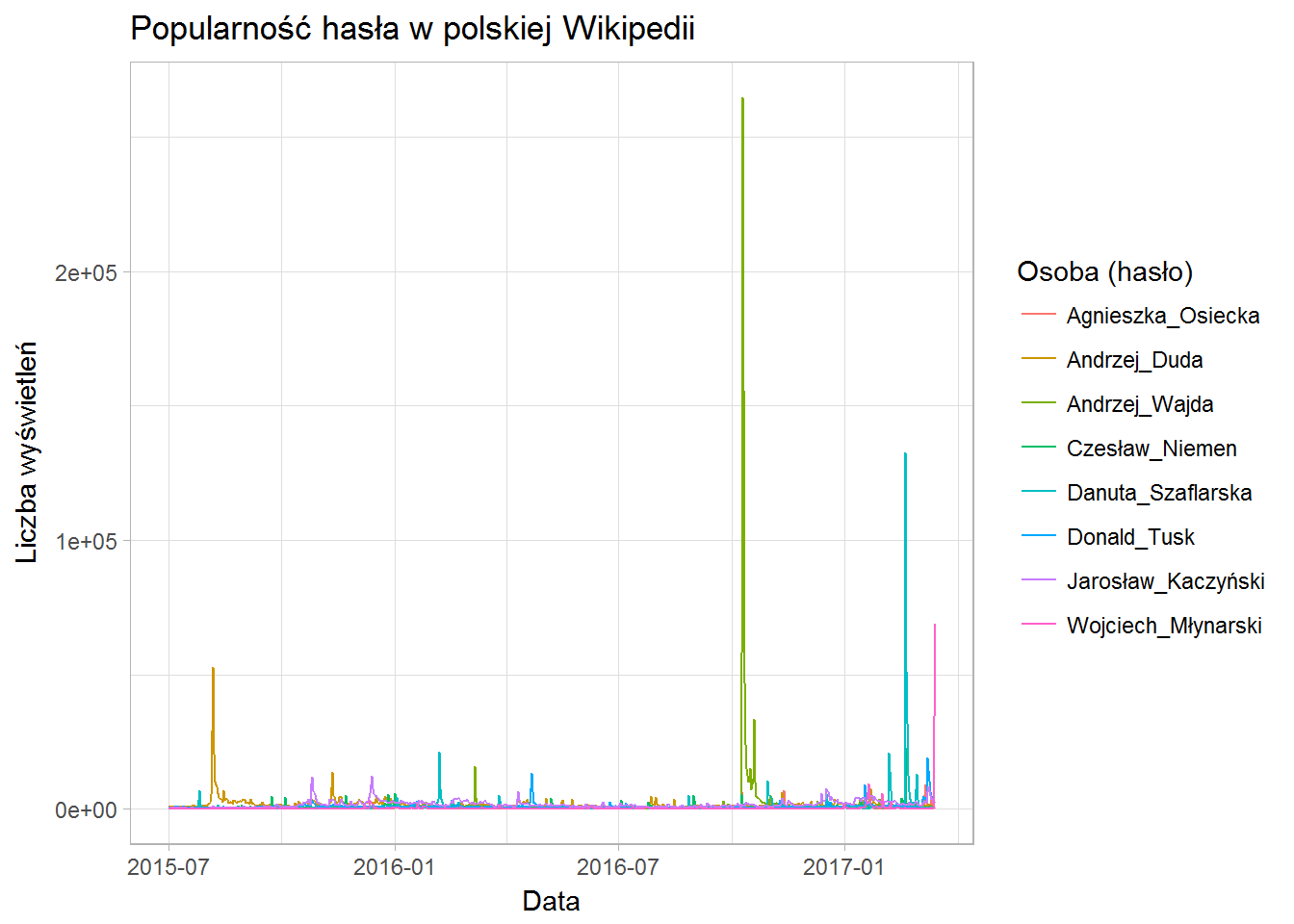
Wszyscy są prawie na jednym poziomie (specjalnie tak dobrałem nazwiska). Widać jednak piki w określonych momentach:
- wybory prezydenckie wygrane przez Andrzeja Dudę (sierpien 2016) – kolor brązowy
- śmierć Andrzeja Wajdy (październik 2016) – kolor zielony
- śmierć Danuty Szaflarskiej (luty 2017) – kolor niebieski
- śmierć Młynarskiego – kolor różowy
Spróbujmy “spłaszczyć” nieco wykres, na przykład przez zastosowanie skali logarytmicznej dla osi Y:
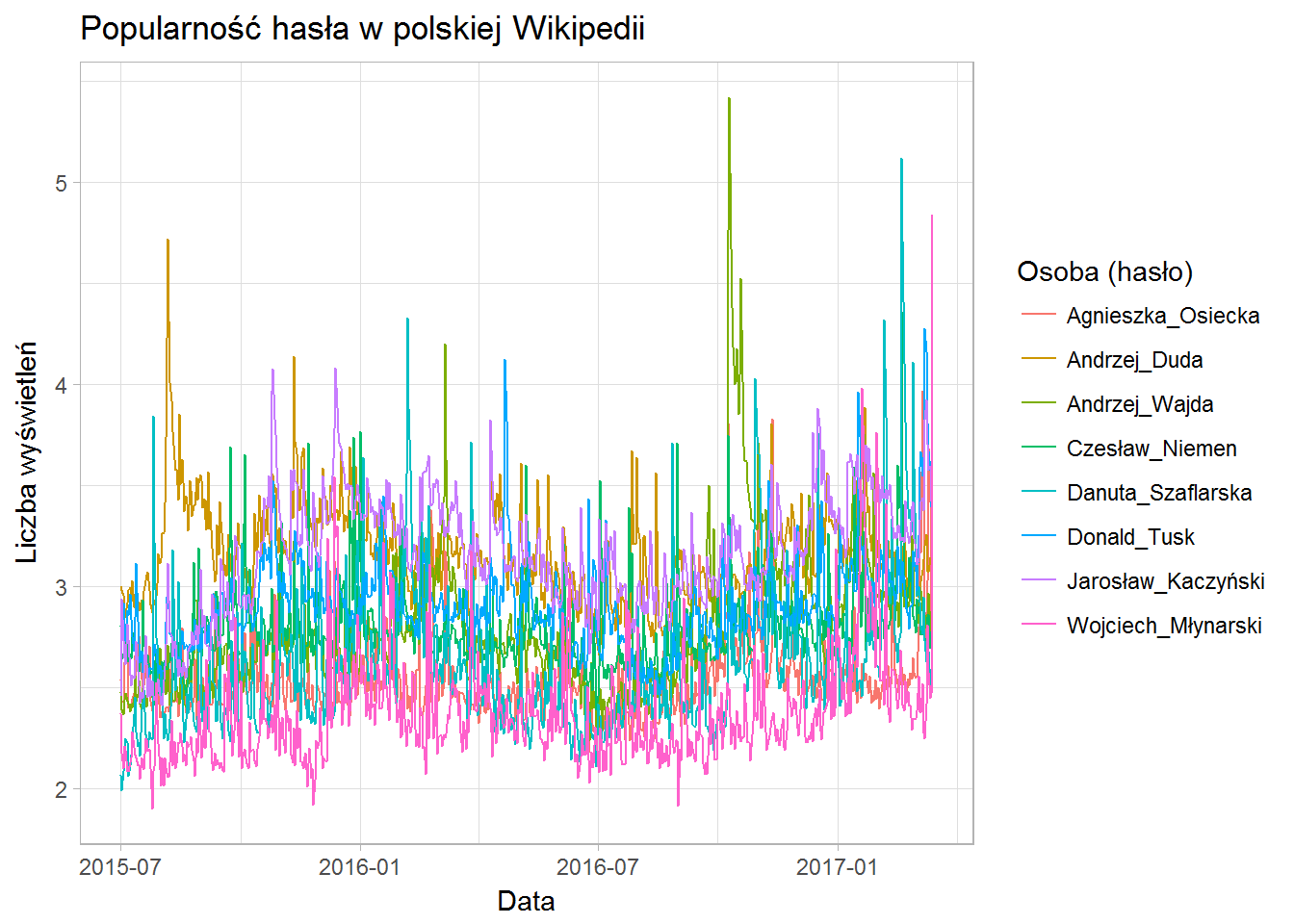
Jest lepiej, ale wcale nie bardziej czytelnie. Zamiast linii (geom_line()) narysujmy krzywe wygładzone (geom_smooth()), nadal z logarytmiczną osią Y:
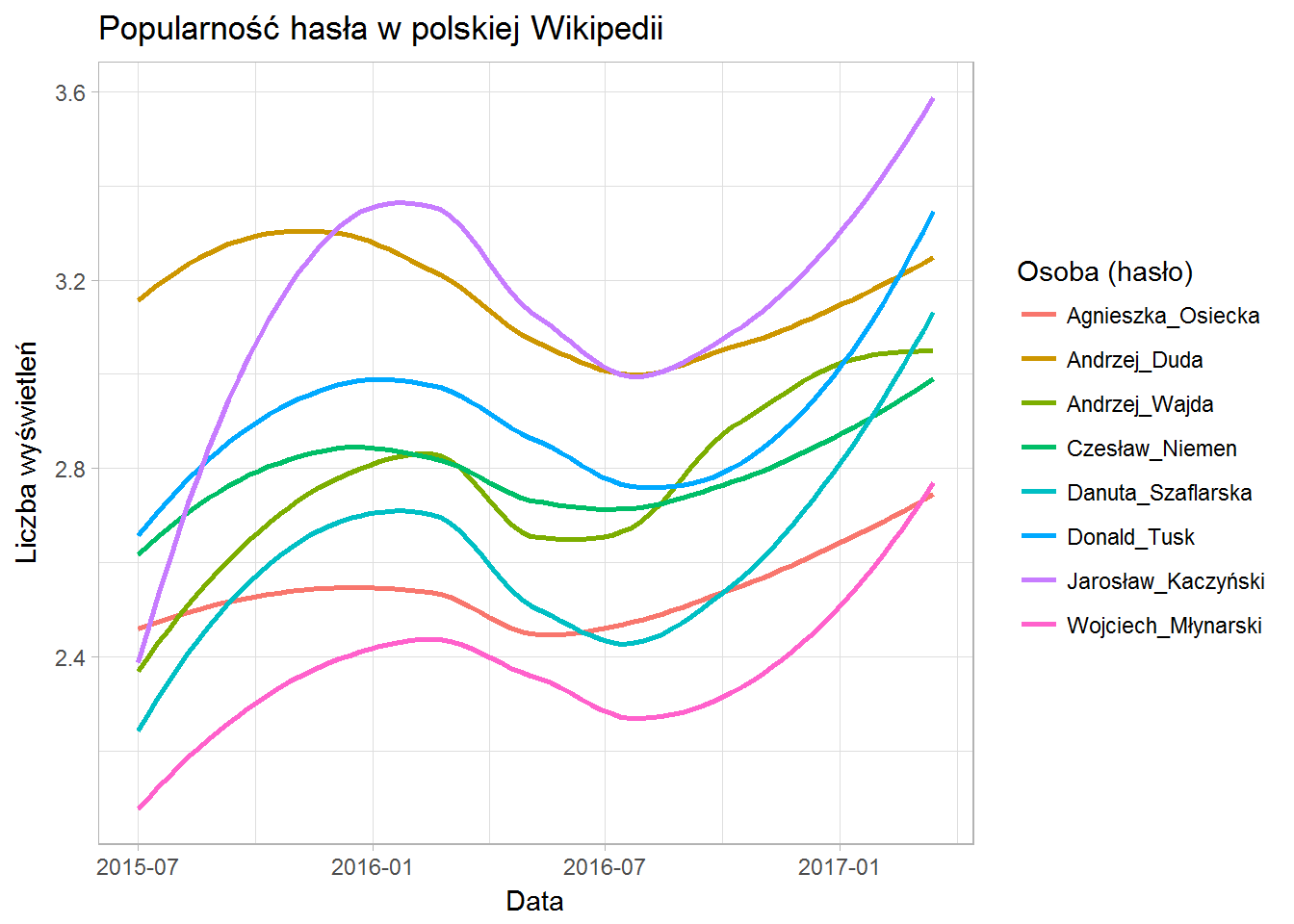
Tutaj już znacznie wyraźniej widać popularność (haseł). Na oko z wykresów możemy odczytać kolejność: najpierw żyjący politycy (o których każdego dnia jest w mediach) – Kaczyński (fiolet), Duda (brąz), Tusk (niebieski); później kolejno: Wajda, Niemen, Szaflarska, Osiecka i na koniec Młynarski. Taki jest obraz świadomości użytkowników polskiej Wikipedii.
Sprawdźmy to samo jeszcze na łącznej liczbie wyświetleń hasła przez ostatnie dwa lata:
|
1 2 3 4 5 6 |
osoby_plotdata %>% filter(variable=="views") %>% group_by(article) %>% summarise(n=sum(value)) %>% ungroup() %>% arrange(desc(n)) |
| article | n |
|---|---|
| Jarosław_Kaczyński | 1 117 240 |
| Andrzej_Duda | 1 113 470 |
| Andrzej_Wajda | 956 694 |
| Danuta_Szaflarska | 616 339 |
| Donald_Tusk | 614 966 |
| Czesław_Niemen | 477 325 |
| Agnieszka_Osiecka | 265 662 |
| Wojciech_Młynarski | 265 176 |
oraz na wykresie wartości skumulowanych:
|
1 2 3 4 5 6 7 8 9 |
osoby_plotdata %>% # tutaj z kolei tylko wartości skumulowane filter(variable=="views_cum") %>% ggplot() + geom_line(aes(day, value, color=article)) + labs(title="Popularność hasła w polskiej Wikipedii", x="Data", y="Skumulowana liczba wyświetleń", color="Osoba (hasło)") + theme_light() |
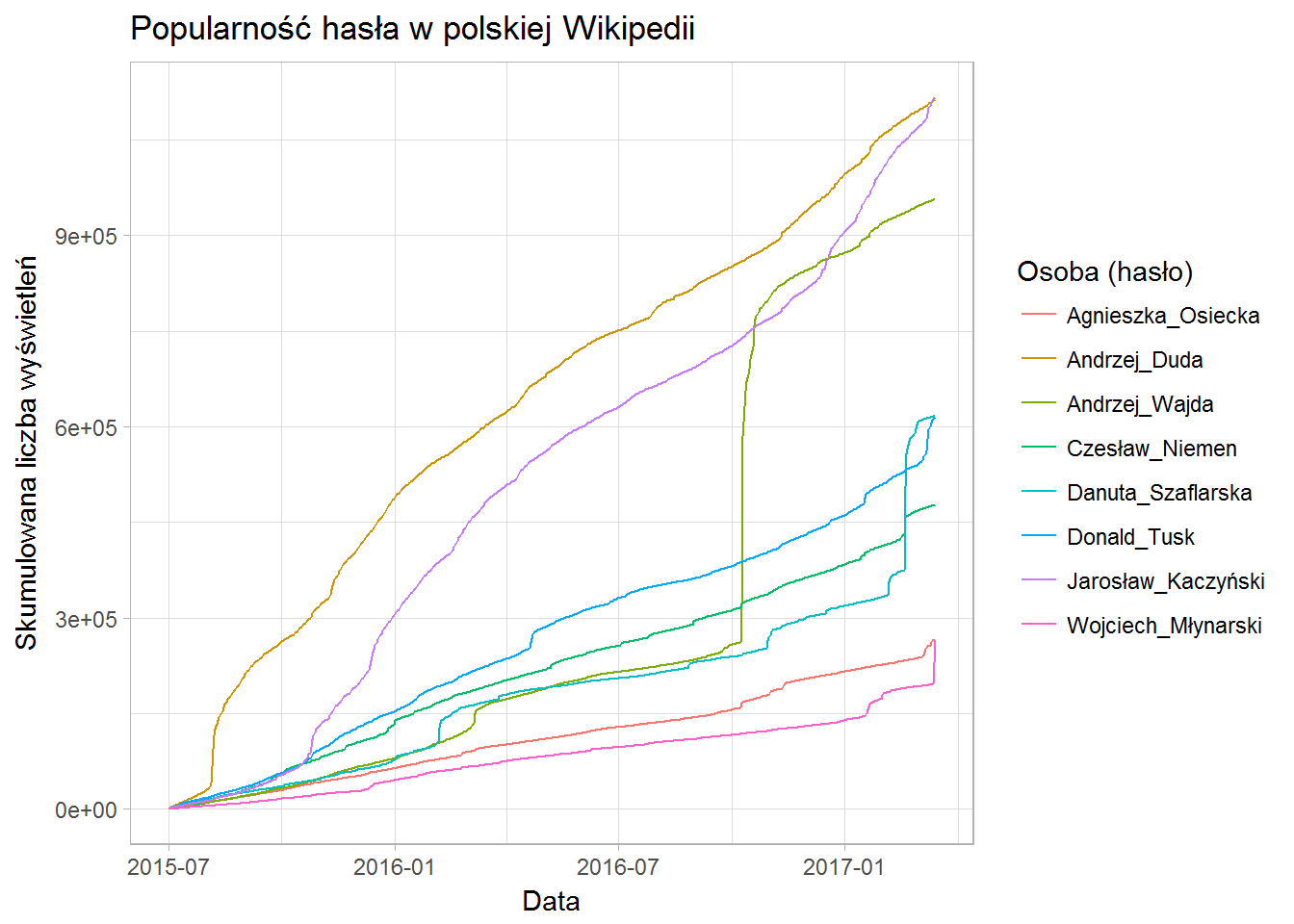
Tutaj nagły wzrost zainteresowania widać najlepiej! W miarę stabilny wzrost, nagły skok, a później znowu w miarę stabilnie w górę. Świetnie to widać na linii dla Danuty Szaflarskiej – skok w początku 2016 roku (kolejne setne urodziny) i oczywisty nagły przyrost w 2017.
Tylko jakie to ma znaczenie? Szaflarska wyprzedziła Tuska głównie ze względu na swoją śmierć. Młynarski zapewne za chwilę (dwa dni max) wyprzedzi Osiecką dokładnie z tego samego powodu.
Czy użytkownicy Wikipedii znają dokonania tych osób?
Czy bez zaglądania do Wiki wiedzieliby kim był Młynarski czy kim była Szaflarska, o których właśnie usłyszeli że nie żyją?
Odpowiedź na te pytania pozostawiam Wam. Róbmy swoje, Panie Wojciechu, róbmy swoje.
Bardzo fajny wpis :-) lubię takie analizy powiązane z bieżącymi wydarzeniami.