Wybory parlamentarne 2019 dobiegły końca, a co za tym idzie mamy zmianę kadencji Sejmu. Podsumujmy więc mijającą, ósmą kadencję Sejmu Rzeczpospolitej Polskiej. Kiedy głosowali posłowie, o jakich porach dnia i nocy? Kto był najczęściej nieobecny?
Niniejszy wpis pokaże Wam jakieś ogólne, dość przekrojowe statystyki. Sądzę, że to dobry materiał wyjściowy dla redakcji informacyjnych. Można poszerzyć analizę o dodanie innych źródeł, szczególnie doniesień prasowych. Ale niech zajmą się tym dziennikarze, a nie analitycy. Mogę pomóc, dogadamy się (po ile teraz wierszówka? a research?).
Same wybory robi każdy, więc nie robię ich ja. Bo po co robić to samo? Świetnie robią to blogi WB data (polecam zarówno blog oraz fanpage) oraz Wybory na mapie (chociaż z minionymi nie zrobili nic), ekipa BIQData z Czerskiej też daje radę. Ja przed wyborami robiłem jakieś proste statystyki dotyczące kandydatów – przeglądając mojego Twittera możecie je znaleźć (szukaj w okolicach 10-12 września).
Kiedyś analizowałem Sejm VII kadencji korzystając ze szczątkowych danych znalezionych gdzieś w sieci, a tym razem postanowiłem dane zebrać samodzielnie.
Sam proces zbierania danych dzisiaj pominiemy (ale mam w planie coś na ten temat, o ile czas pozwoli) i zajmiemy się zgromadzonymi wynikami.
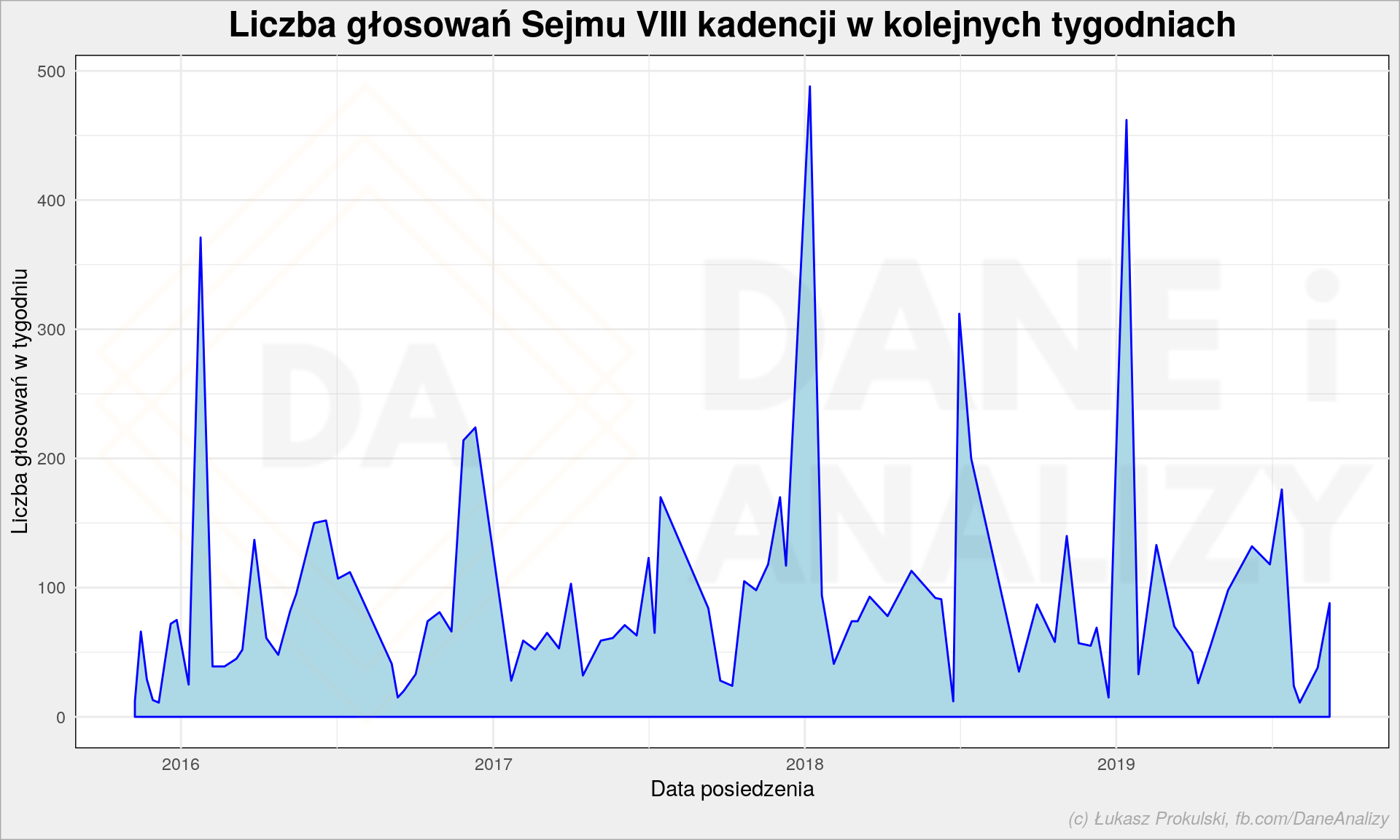
Zacznijmy od liczby głosowań. Dane szczątkowe (8114 głosowań z 8142 ~= 99.7%), które zebrałem nie są pełne, ale są na tyle duże że można pokusić się o jakieś wnioski. Zabrakło kilku głosowań – tych, które nie są typowymi głosowaniami za lub przeciw (na przykład głosowanie na szefa NIK) albo przeprowadzone zostały w nietypowych warunkach – na przykład te z 16 grudnia 2016 po godzinie 16 (polecam zapis z sali obrad, przewiń na okolice godziny 15).
Pamiętać proszę o jeszcze jednym. Głosowań jest bardzo dużo, ale samych ustaw wcale tyle nie musi być. Głosuje się za przyjęciem tej czy innej poprawki (bądź jej odrzuceniem; samych poprawek są tysiące). Głosuje się za ogłoszeniem przerwy w obradach albo za przekazaniem materiału do dalszych prac w komisjach. Wyjęcie konkretnych ustaw jest robotą właściwie ręczną. To praca dla dziennikarzy.
Tak czy inaczej – na poniższym wykresie możemy zobaczyć (zagregowaną do tygodnia) liczbę głosowań na kolejnych posiedzeniach. Widać pojedyncze piki (warto by je zestawić z tematami głosowań i doniesieniami prasowymi), ale widać też urlopy około sierpniowe:
Ciekawsze, szczególnie w tej kadencji, są jednak pory głosowań. Zobaczmy kilka przekrojów:
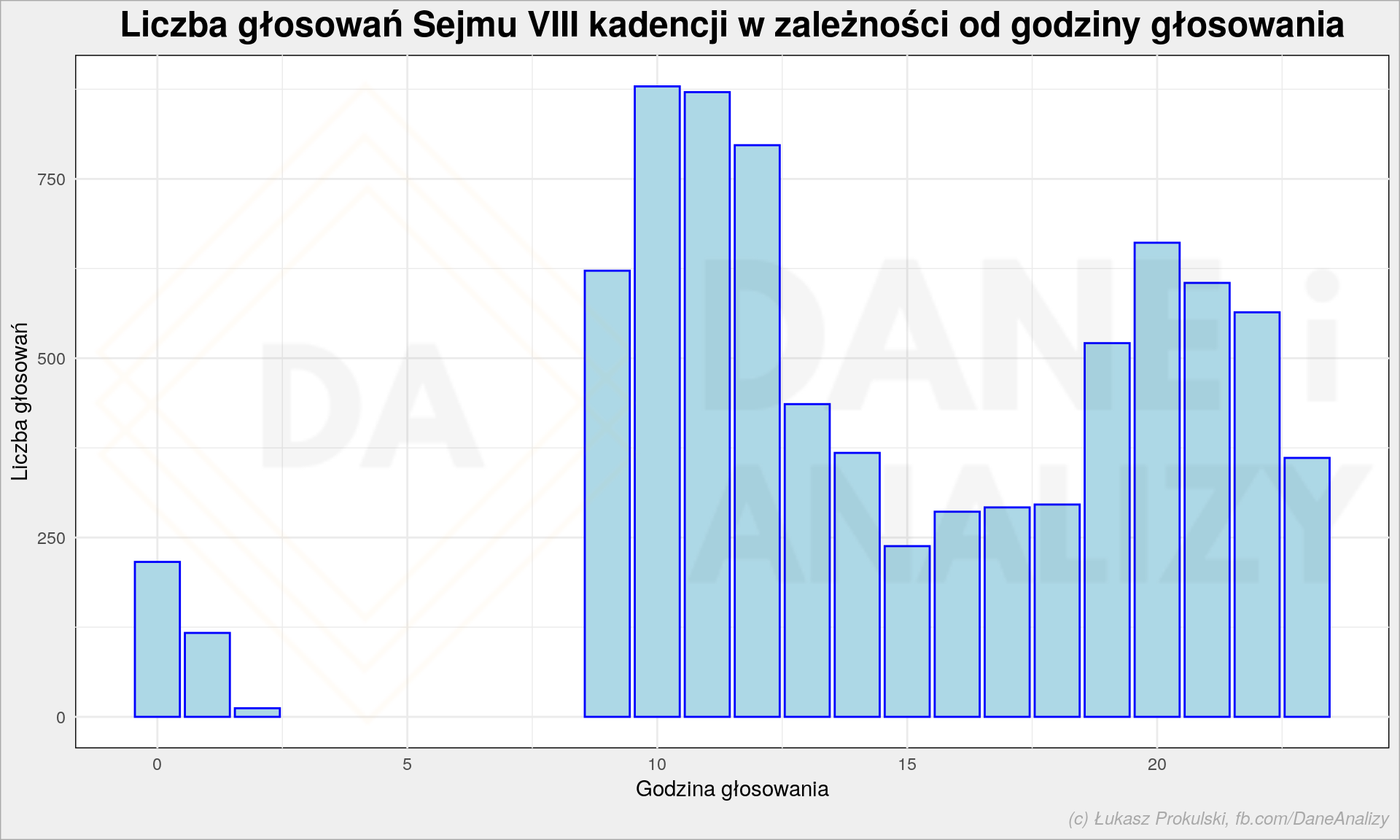
Globalnie rzecz biorąc w Sejmie głosuje się w godzinach przedpołudniowych (posiedzenia zaczynają się zwykle około 9 lub 9:30 – zapewne regulamin Sejmu coś na ten temat mówi) i wieczorem (mam na myśli okolice 19-21). Są też nocne głosowania, w czym VIII kadencja Sejmu się wyspecjalizowała…
Zobaczmy godziny głosowań nałożone na oś czasu:
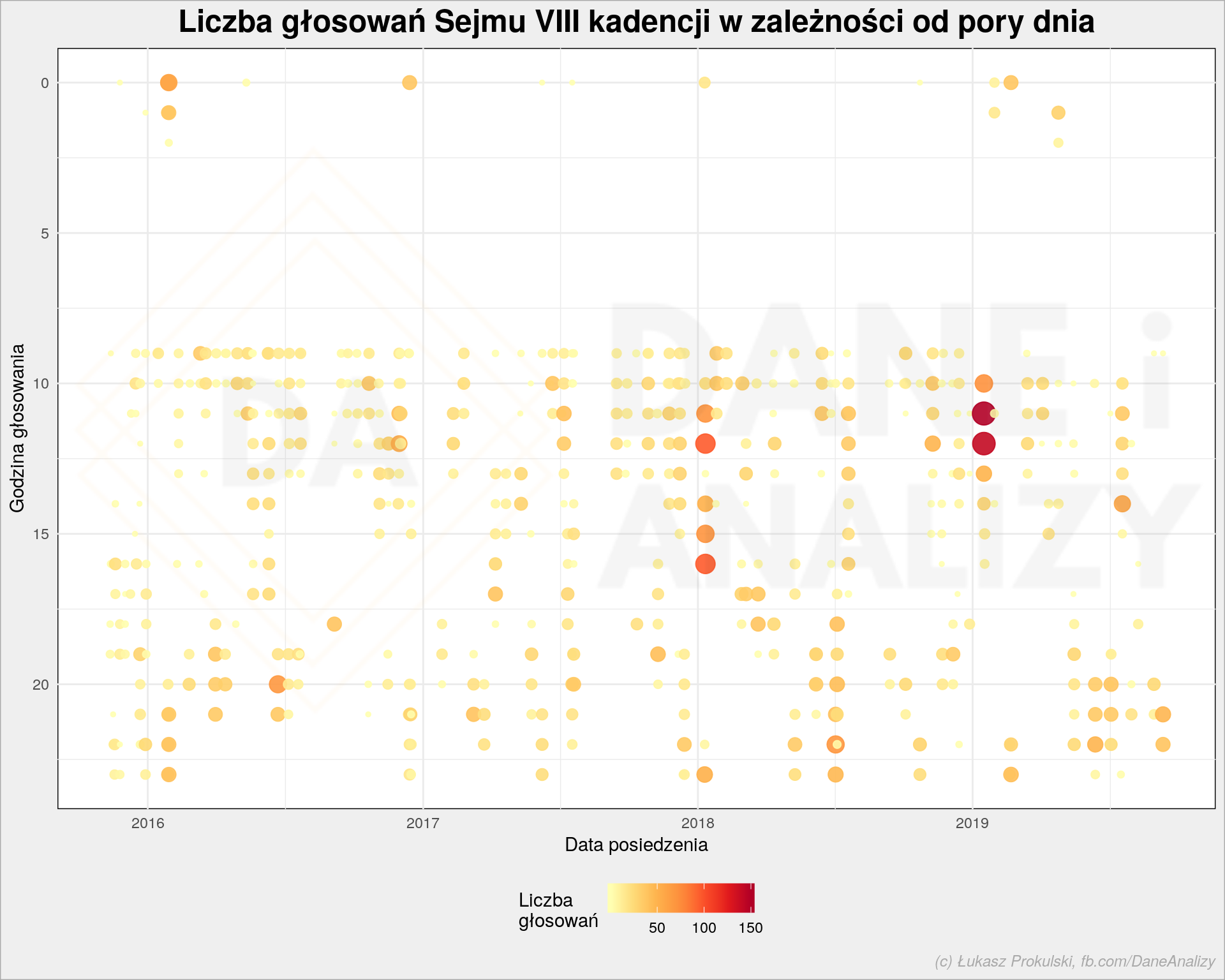
Te nocne głosowania są nieco zbieżne z okresami, kiedy było w ogóle dużo głosowań. Znowu materiał dla dziennikarzy: czy to fakt? jakie rzeczy były wówczas głosowane?
W rozkładzie godzin w poszczególnych dniach tygodnia:
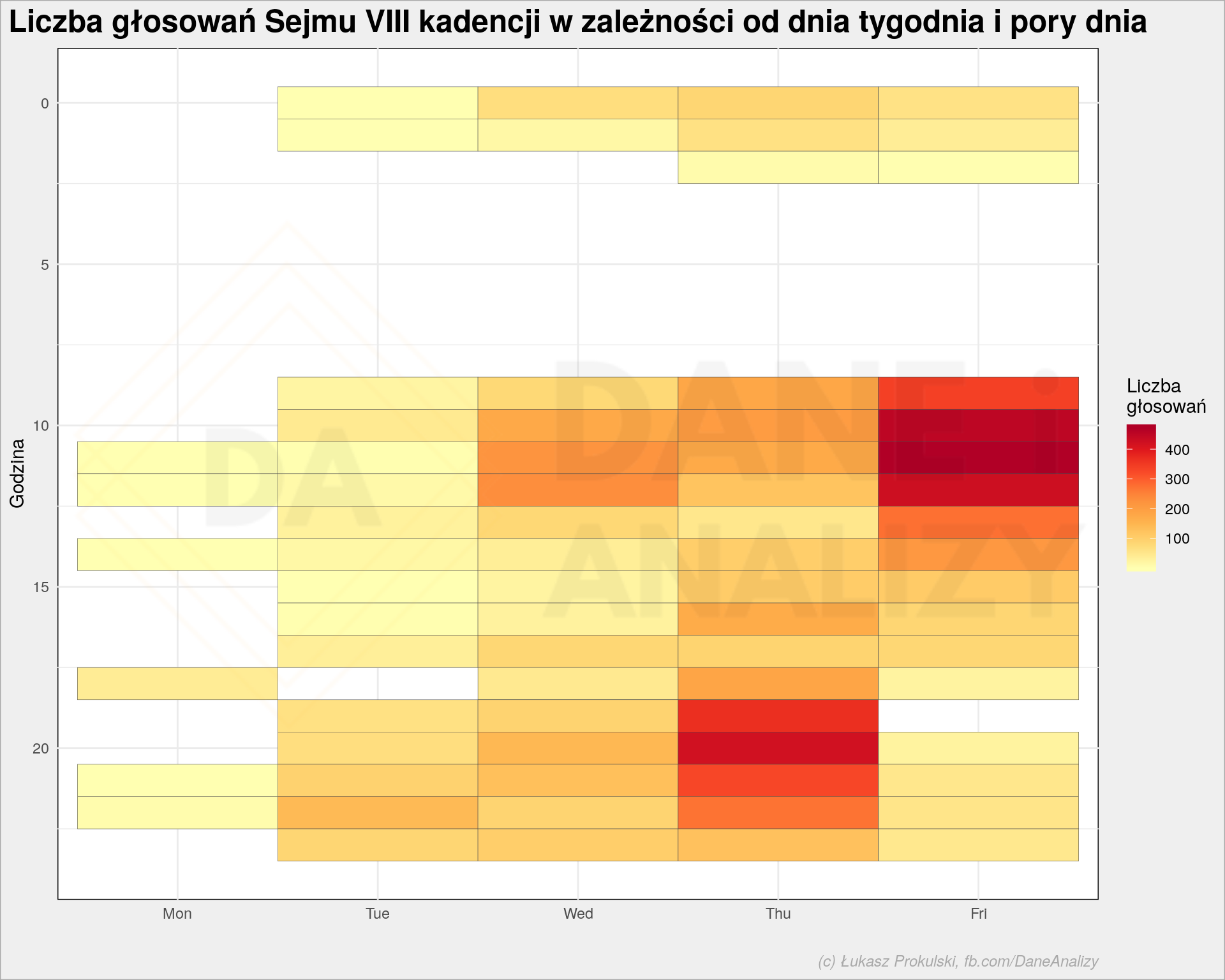
widać standard pracy – posiedzenia najczęściej zaczynają się w środy lub czwartki i trwają dwa lub trzy dni. Wyobrażam sobie, że w normalnych warunkach, rzetelnej pracy nad prawem proces wygląda następująco:
- poniedziałek i wtorek to praca w komisjach nad projektami ustaw
- środa i kawałek czwartku to debata wszystkich posłanek i posłów, zgłoszenie ewentualnych poprawek i tym podobne działania
- na koniec czwartku, już po debacie, następuje głosowanie – zapewne nad poprawkami
- w piątek powinno nastąpić czytanie finalnego projektu ustawy i głosowanie nad całością
Jak to wygląda w praktyce mamy na co dzień okazję oglądać w wiadomościach… Mimo to powyższy obraz pokazuje, że w teorii ten proces tak właśnie wygląda: mało głosowań na początku tygodnia, czerwono pod koniec. No i nocne głosowania głównie w czwartki.
Kolejny element to przepływ posłów z klubu do klubu. Łączenie się klubów, zmiany nazw i tym podobne roszady. Proszę bardzo:
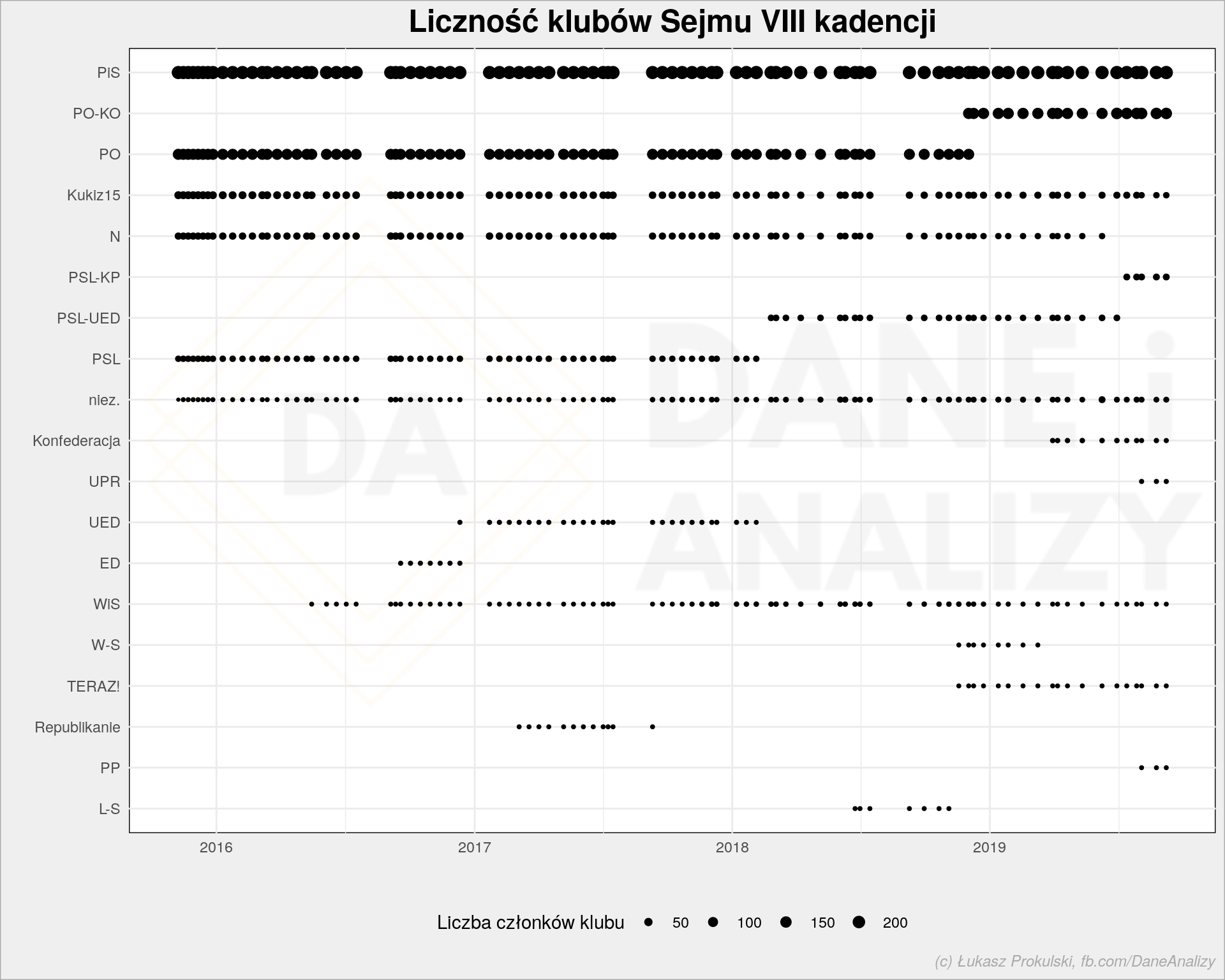
Wykres strumienowy (z angielska Senkey diagram) byłby tutaj pewnie lepszy.
Co widzimy? Stabilność klubu PiS. Zmiany w PSL oraz .Nowoczesnej. Oraz wyraźne pojawienie się PO-KO z okazji wyborów do Europarlamentu.
Wszystko do tej pory to dość łagodne informacje. Ciekawsze jest kto nie wykonuje stosunku pracy i po prostu nie przychodzi na głosowania. Najpierw na grubo: liczymy ile jakich głosów (a do wyboru mamy cztery typy głosów: za, przeciw, wstrzymujący i nieobecny) oddał w całej swojej historii każdy z członków klubu i wybieramy z tego nieobecności:
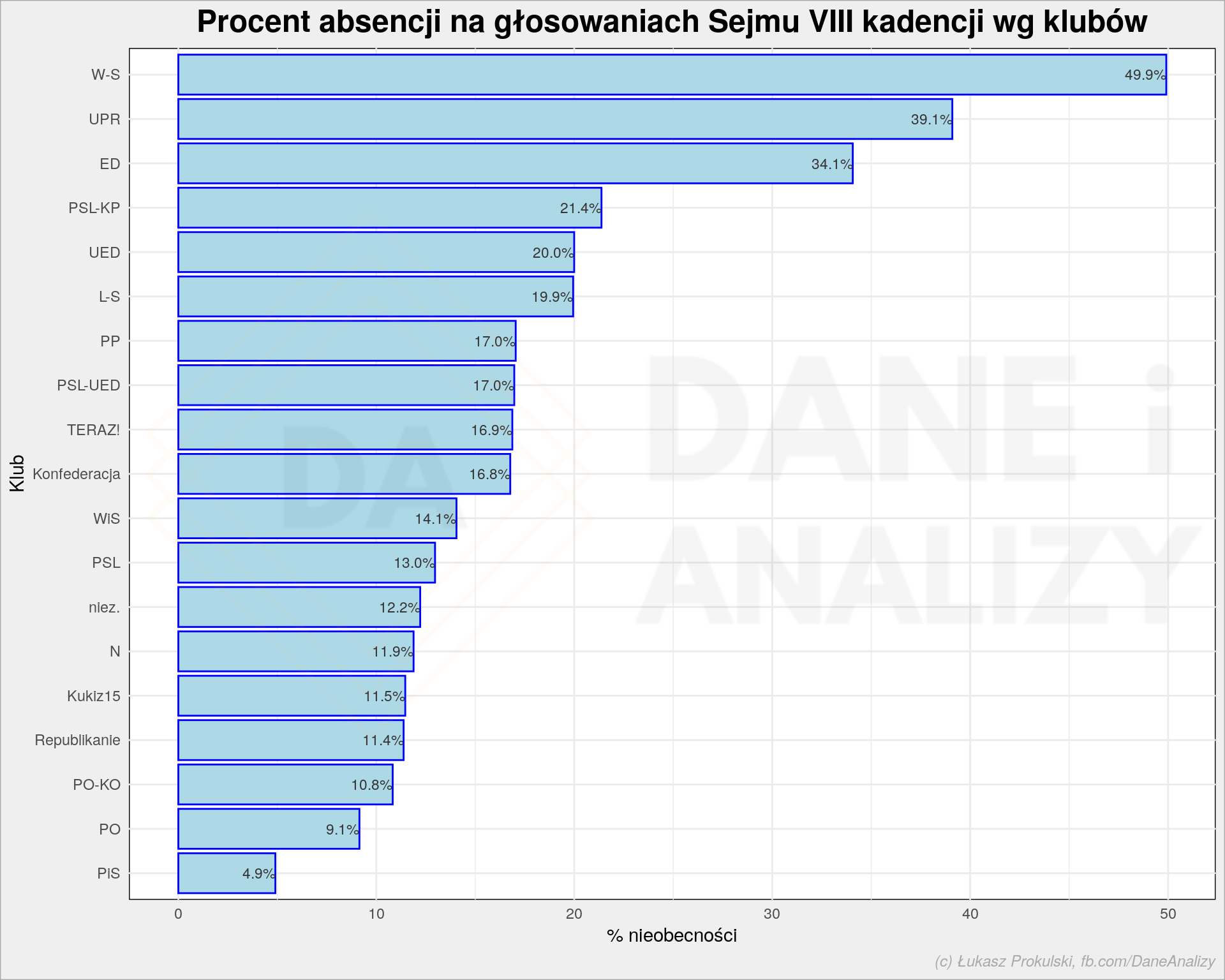
To jest trochę tricky ujęcie. Klub W-S składający się z trzech posłów (Kulesza Jakub, Liroy-Marzec Piotr, Wilk Jacek) ma łatwiej w osiągnięciu wysokiego stopnia nieobecności. Wystarczy, że jeden z posłów będzie głównie nieobecny, a już robi się jedna trzecia nieobecności całego klubu. Dodatkowo klub W-S nie był obecny przez całą kadencję (powstał gdzieś jesienią 2018 i przestał istnieć w połowie 2019 – do sprawdzenia samodzielnie dlaczego tak się działo).
Ale i duże dość stabilne kluby mają swoje za uszami. Posłowie klubu PiS powinni właściwie oddać prawie 5% (uśredniając po wszystkich) swoich zarobków za brak pracy. PO 9%, a w koalicji PO-KO nawet prawie 11%.
Jak to wygląda w przypadku poszczególnych posłów? Zobaczmy pierwszą trzydziestkę największych wagarowiczów:
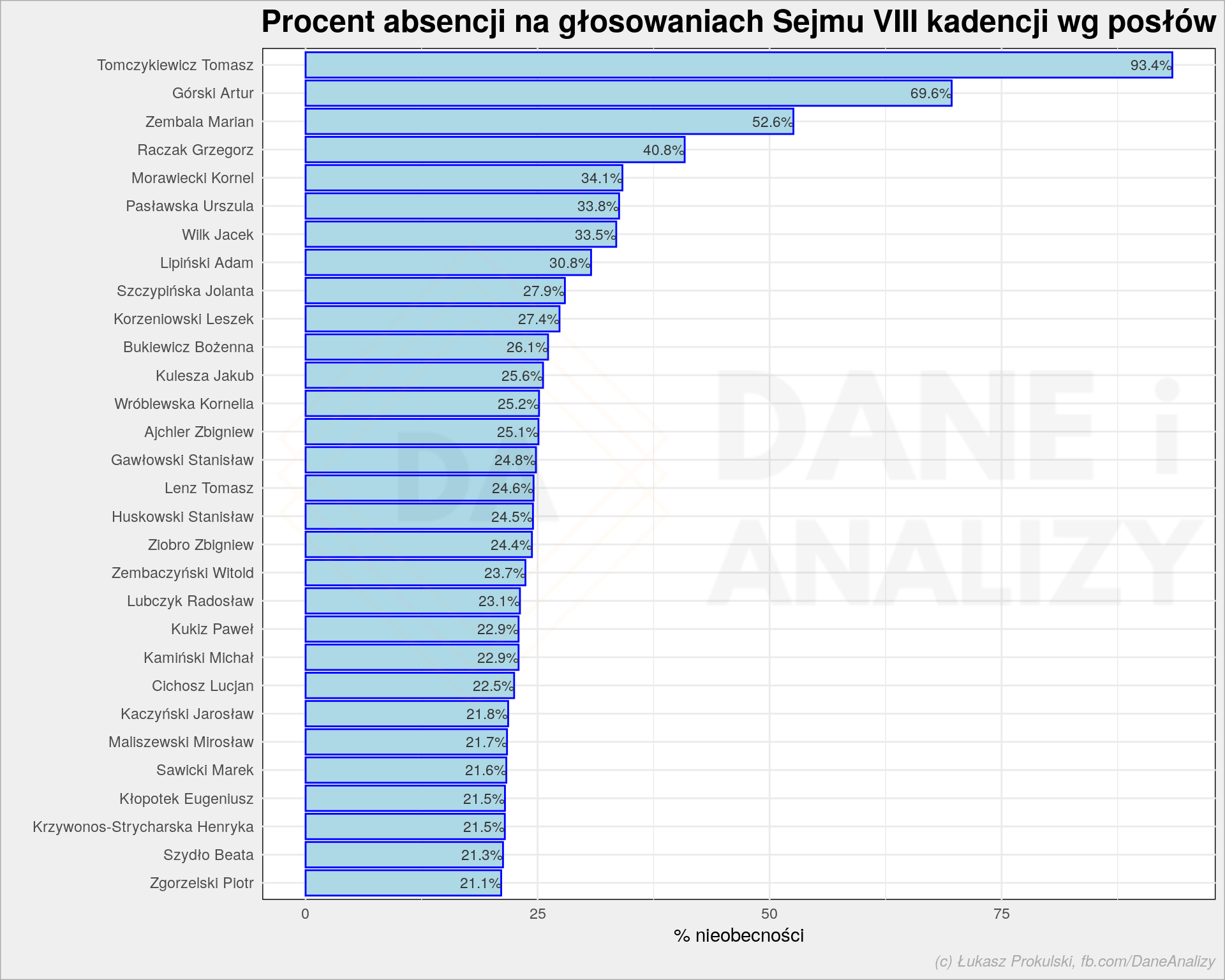
Zapewne z czegoś te nieobecności wynikają. Zapewne są usprawiedliwione… Poseł Tomasz Tomczykiewicz zmarł podczas trwania kadencji w wyniku choroby nerek. Analogicznie Artur Górski, ale Marian Zembala żyje.
Na liście mamy też wspomnianych już Jacka Wilka (33% nieobecności) oraz Jakuba Kuleszę (25%). Już wiecie skąd wyniki W-S wyżej? Statystyka…
Żeby oddać cześć przodownikom pracy zobaczmy najpilniejszych trzydziestu:
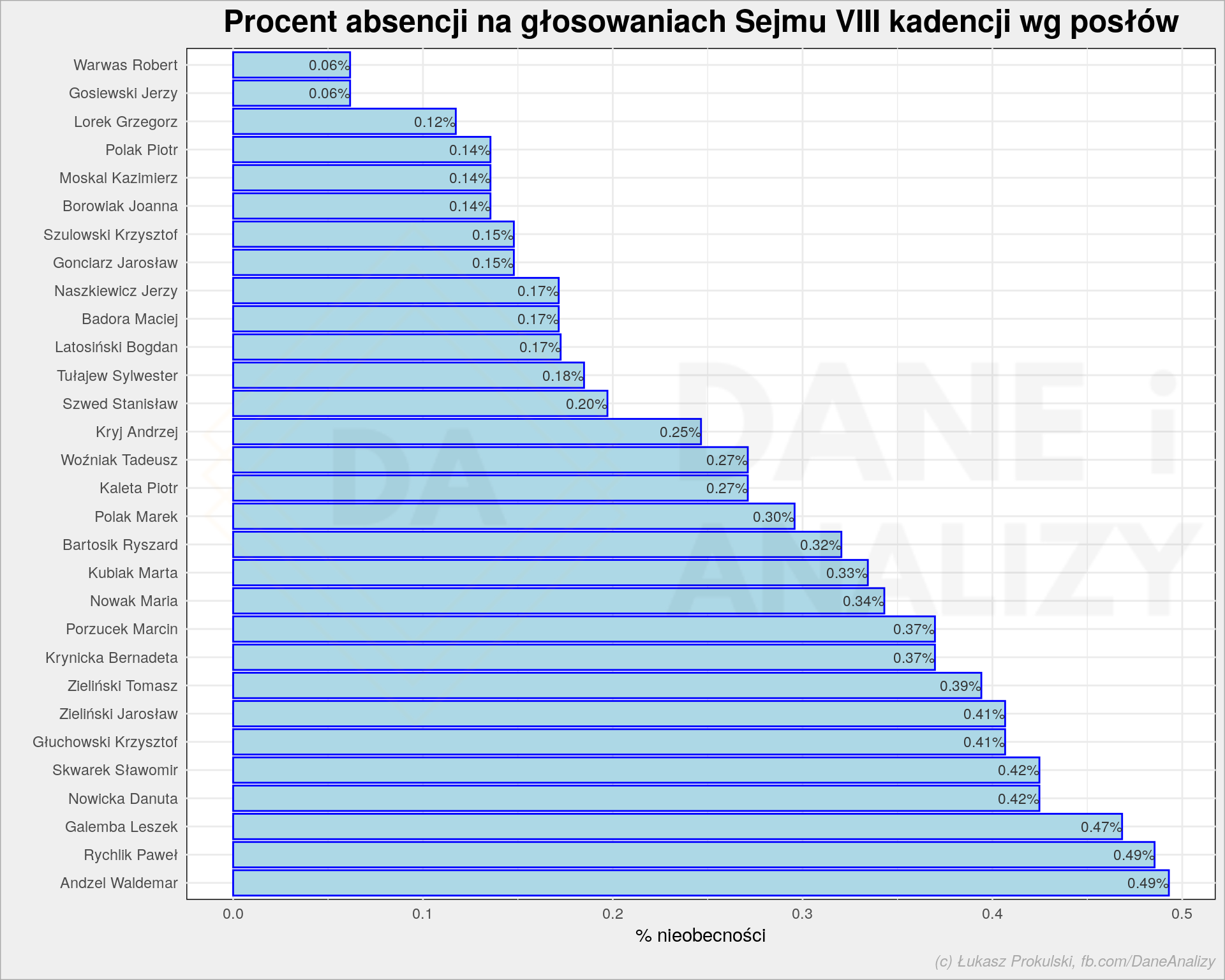
Panowie Jerzy Gosiewski i Robert Warwas – szacunek!
Przeanalizujmy teraz obecność jednego posła. Konkretnego, wybranego losowo, Jarosława Kaczyńskiego (mając zgromadzone dane może to być każdy).
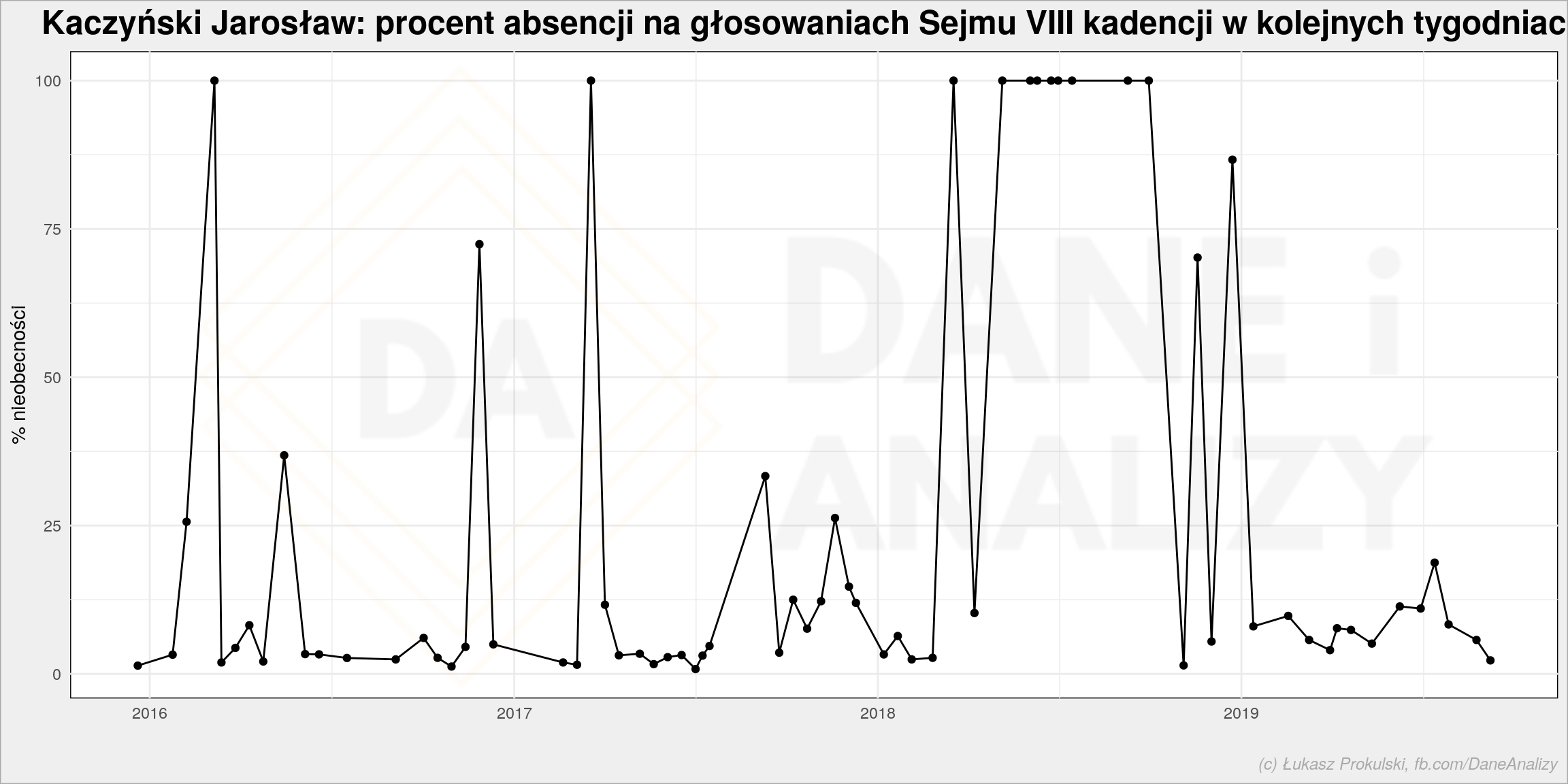
Tutaj zliczamy nieobecność w tygodniowych okresach. Prezes najliczniej reprezentowanej w Sejmie partii zwykle jest w pracy (opuszcza na oko 10% głosowań), ale miał prawie pół roku (pomiędzy kwietniem a sierpniem 2018 roku) przerwy. Było to najprawdopodobniej (o ile pamiętam) spowodowane operacją i późniejszą rehabilitacją (dziennikarze: sprawdzić).
Sprawdźmy jeszcze czy godzina głosowania przekłada się ogólnie (u wszystkich) na nieobecność?
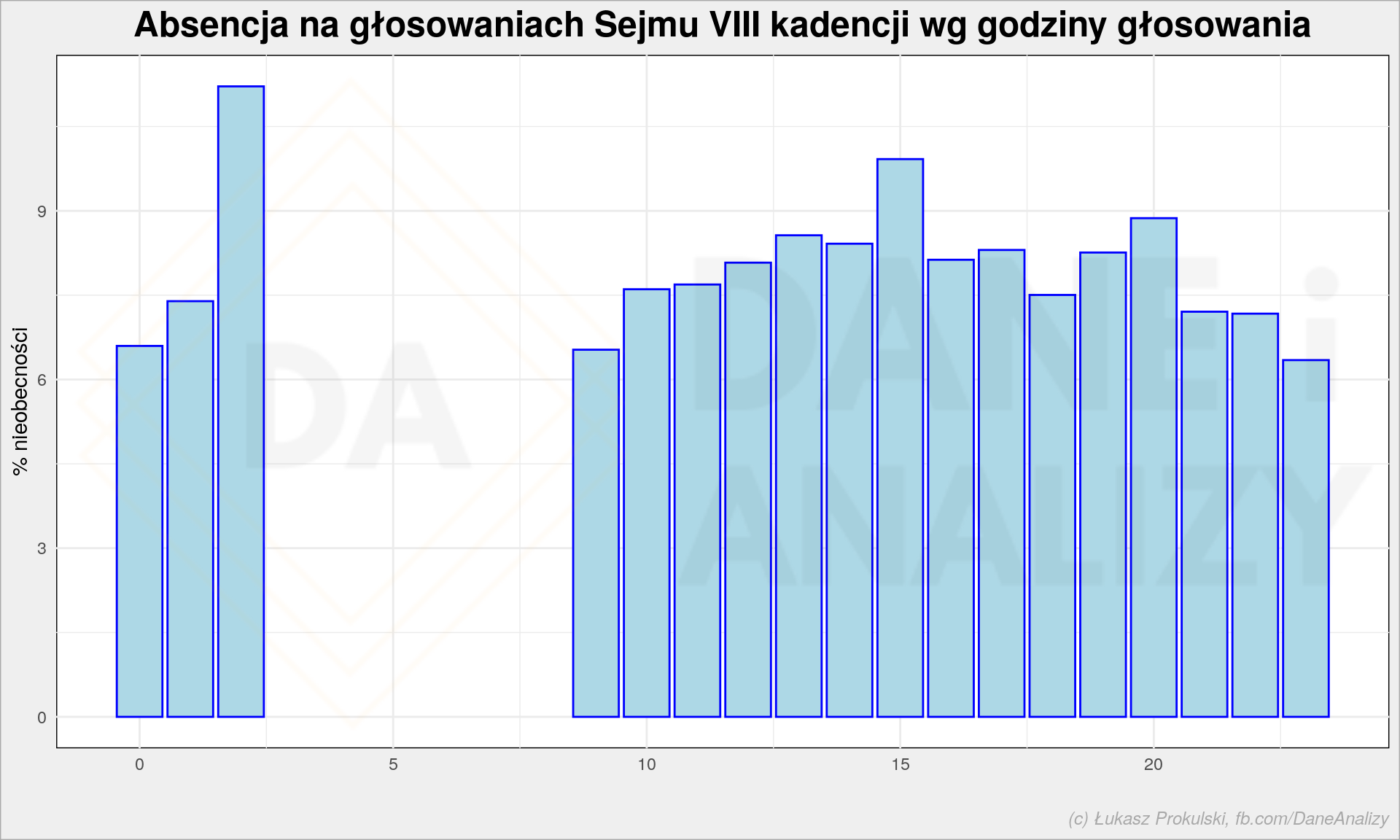
Przekłada się, oczywiście. Nie każdy ma ochotę głosować po nocy. Dokładniej rzecz biorąc 11.2% głosów oddanych pomiędzy 2:00 a 2:59 w nocy to nieobecność. Obiady jada się w Sejmie o 15, a kolacje – o 20. Przynajmniej tak można wnioskować po nieobecności na głosowaniach w tych godzinach.
Czy nasz losowo wybrany poseł Kaczyński wpisuje się w ten trend?
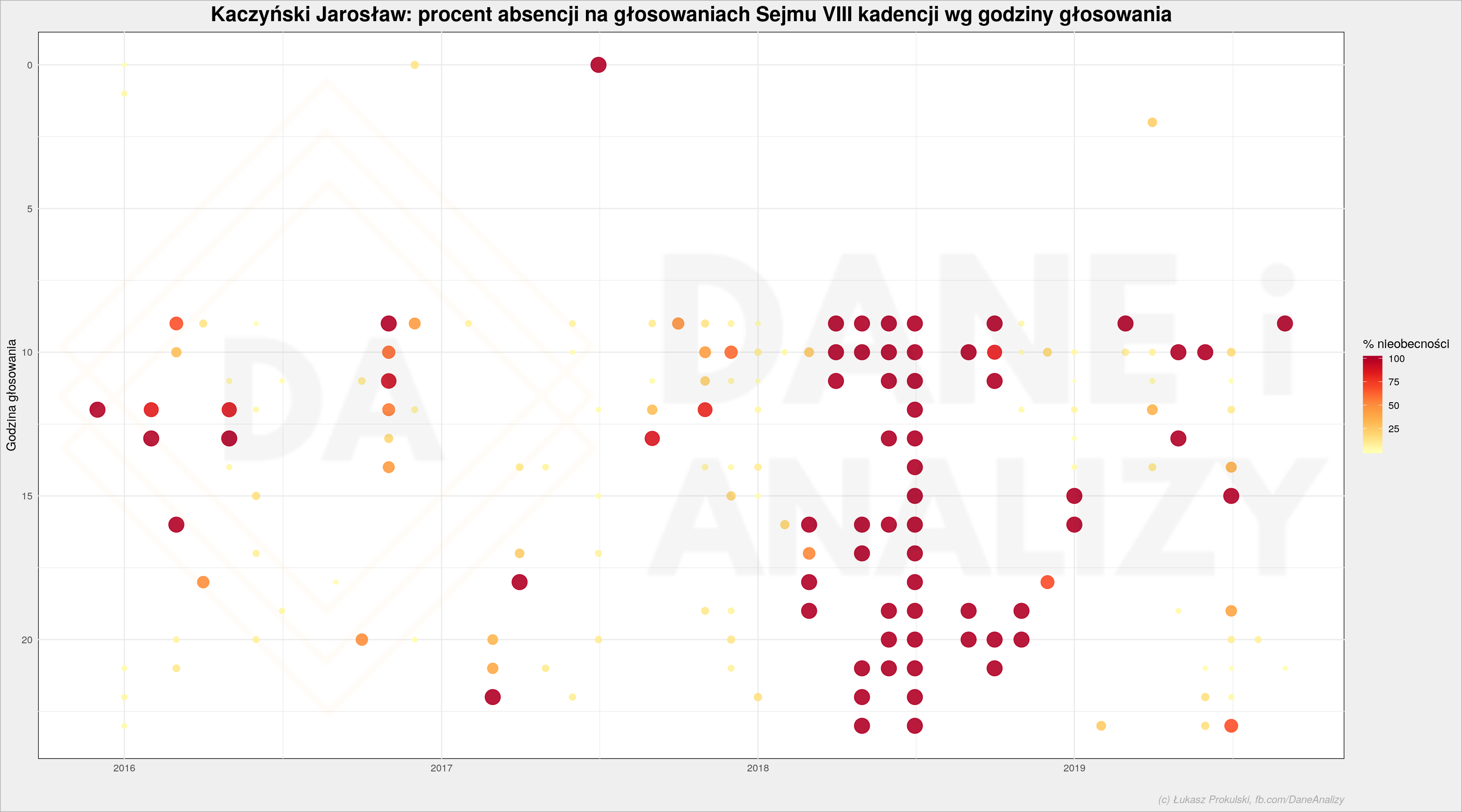
Poseł Kaczyński jest raczej sumiennym posłem, nawet w nocy.
A teraz zobaczmy czy są posłowie wyłamujący się z głosu klubu. Policzmy dla każdego głosowania jak głosowała większość klubu (nie licząc nieobecności) i znajdźmy takich, którzy głosowali inaczej. A potem policzmy w ilu głosowaniach głosowali inaczej.
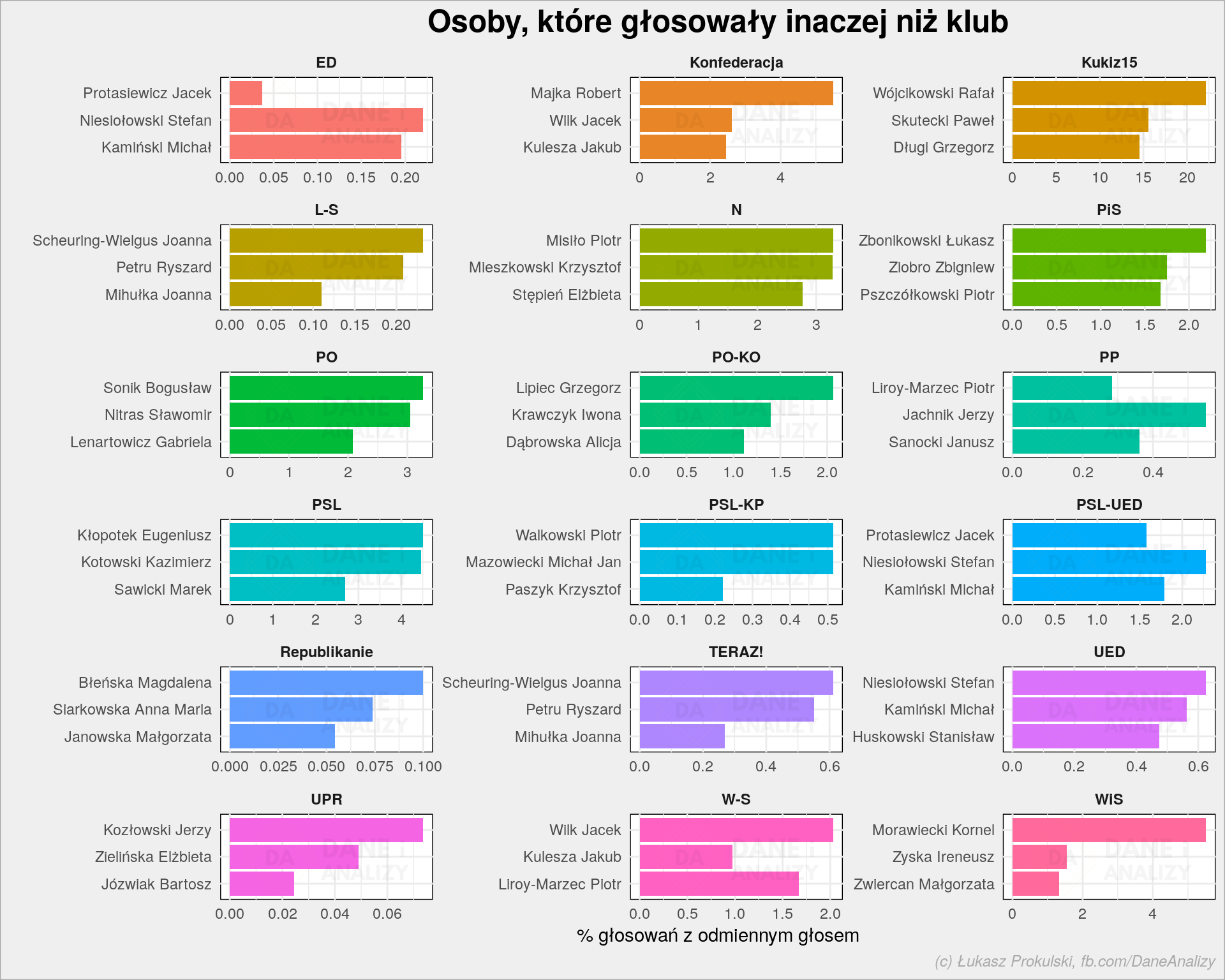
Oś X dla każdego z małych wykresików jest różna (aby było widać różnice), więc należy czytać także ją. Najbardziej niezgodny z klubem macierzystym był Rafał Wójcikowski – w 1/5 głosowań głosował inaczej niż większość klubu Kukiz’15. W pozostałych dużych klubach mamy:
- PO – Bogusław Sonik (3,27% różnic)
- PiS – Łukasz Zbonikowski (2,19%)
- .Nowoczesna – Piotr Misiło (3,29%)
- PSL (ten podstawowy) – Eugeniusz Kłopotek (4,51%)
Wróćmy do naszego losowego posła (można to zrobić dla każdego, pamiętajcie) – jak głosował Kaczyński a jak jego klub?
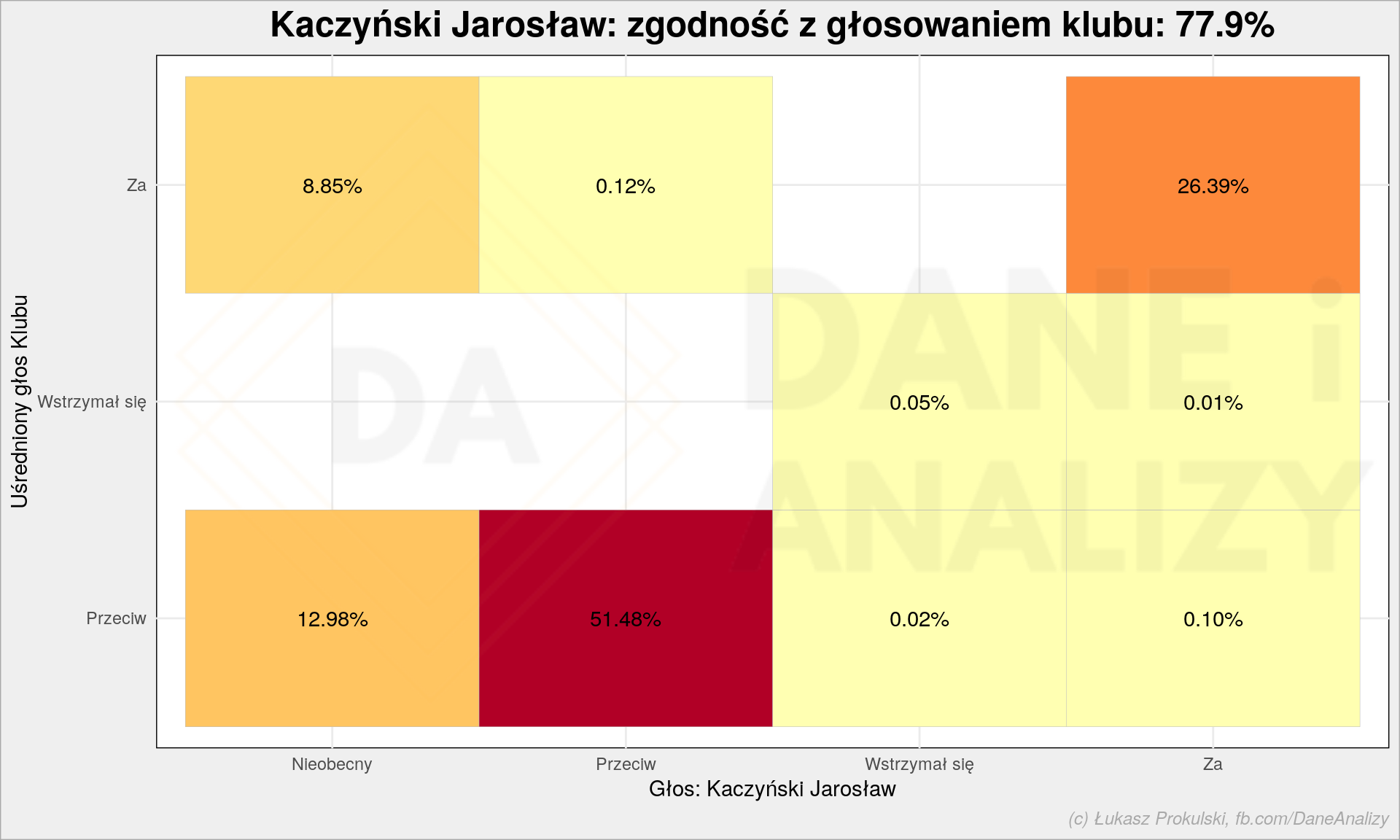
W 77,9% swoich głosowań oddał dokładnie taki sam głos jak klub (albo klub tak jak on… bo to działa w obie strony). Gdyby odjąć nieobecności (zachowane tutaj umyślnie) wynik ten były zapewne jeszcze wyższy.
Teraz ciekawski bardziej analityczne. Które kluby są do siebie podobne? Bierzemy pod uwagę tylko głosy obecnych osób, liczymy ile w poszczególnych głosowaniach głosów na tak (oraz nie i wstrzymujących) oddał każdy z klubów. A potem liczymy współczynniki korelacji pomiędzy poszczególnymi klubami. Może to uproszczenie, ale wynik jest ciekawy:
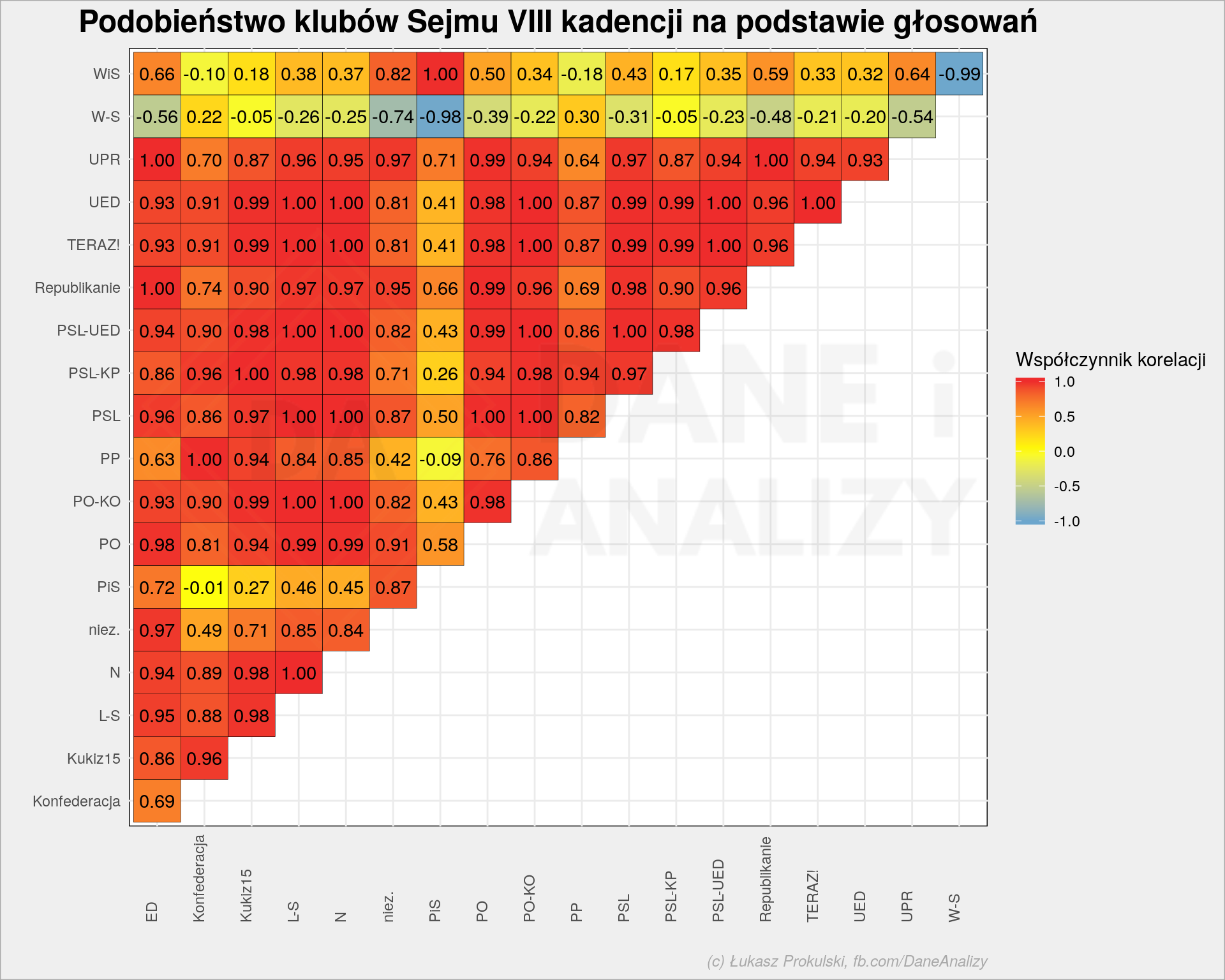
Mamy właściwie trzy obozy: PiS, W-S (tych trzech posłów) i dość spójną resztę.
A jak to wygląda między posłami? Kto głosował najbardziej podobnie do Kaczyńskiego?
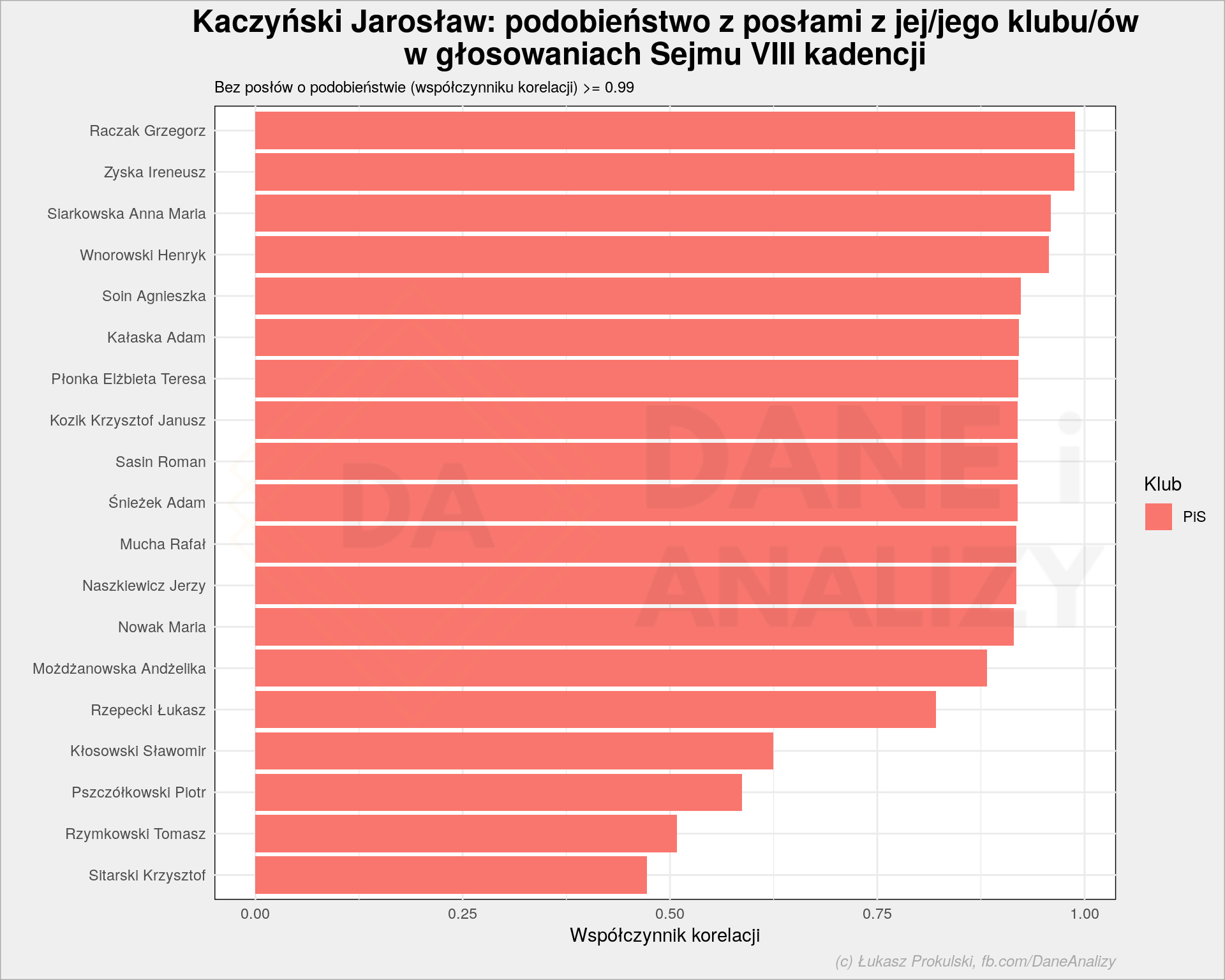
Na powyższym wykresie zastosowałem pewną manipulację – nie pokazałem osób, które głosują dokładnie jak Kaczyński (współczynnik korelacji równy 1), a tylko te prawie dokładne.
Podobnie jak w każdym innym przypadku – można wybrać innego posła i poszukać jemu (bądź jej) podobnych w ramach jej klubu (lub klubów, jeśli wybraniec przewinął się przez kilka).
A gdyby tak każdego posła umiejscowić na jakiejś płaszczyźnie i sprawdzić czy tworzą się jakieś wzory związane z przynależnością do klubu? Jak to zrobić?
Policzmy ile razy każda z osób zagłosowała w określony sposób – to da nam dużą tablicę o wymiarach liczba posłów x 4 (bo mamy 4 warianty głosowania: tak, nie, wstrzymał się i nieobecny). Ale czterech wymiarów nie da się łatwo narysować, więc skorzystamy z metody t-SNE która zredukuje nam wynik do dwóch wymiarów. Dzięki czemu każdy będzie kropką. I ta kropka ma osobny kolor na obrazku poniżej:
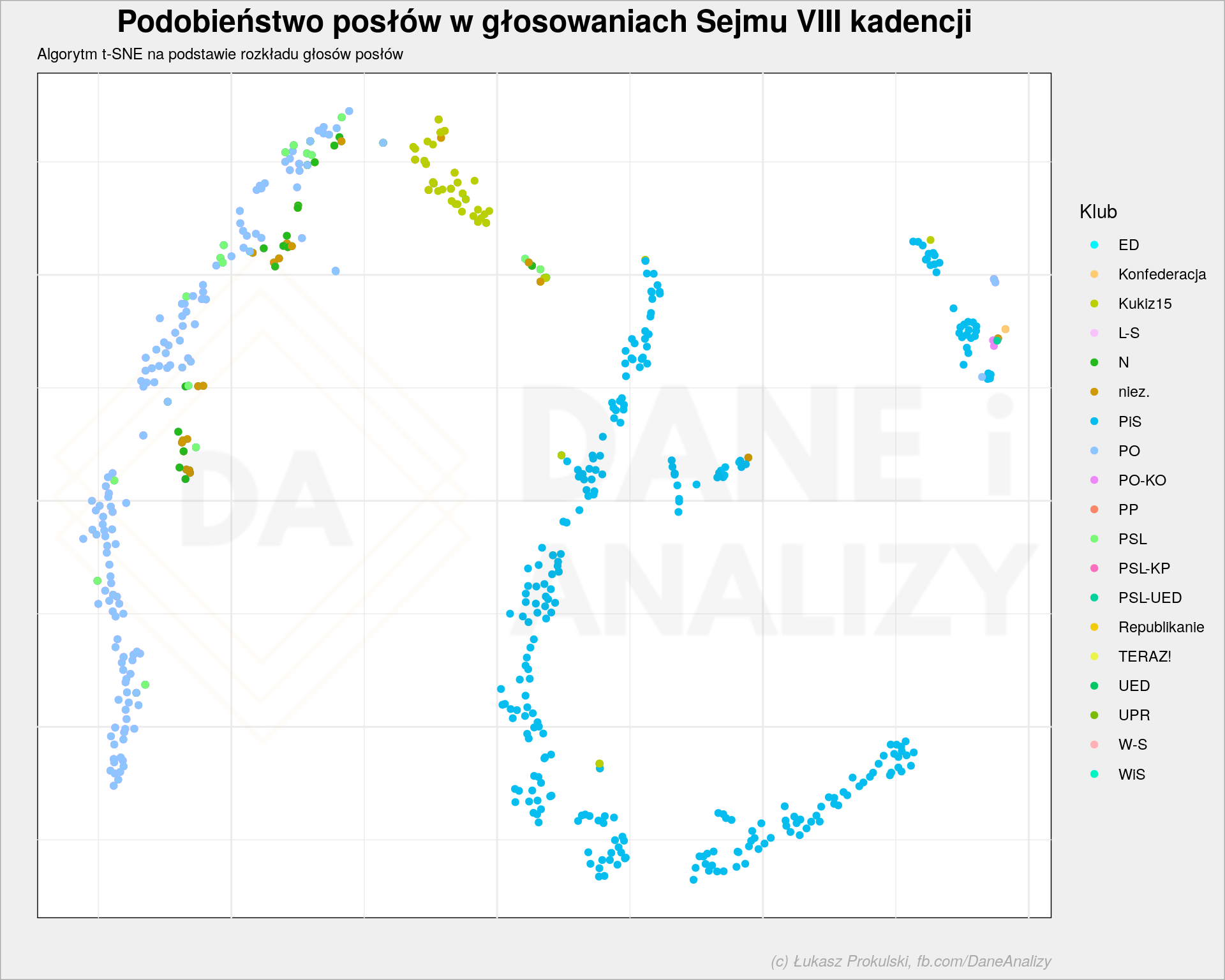
Kolory dobierają się losowo. Ale widać że są zebrane w jakieś grupy. Mamy z lewej węża PO z przyległościami typu .Nowoczesna. Na dole mamy węża w kształcie U z posłankami i posłami PiSu. Ale są oni też na wyspie po prawej stronie. Pomiędzy nimi mamy posłów z Kukiz’15.
Poniżej wersja interaktywna – możesz najechać na dany punkt i zobaczyć kto się pod nim kryje. I jakich ma sąsiadów.
Teraz, na tak zredukowanych wymiarach, spróbujmy poklastrować punkty. Nie jest to za mądre podejście (bo są tylko cztery wyjściowe wymiary), ale często się tak robi szukając ukrytych grup (szczególnie jak wymiarów wejściowych jest dużo albo bardzo dużo).
Na początek użyjemy algorytmu k-means i założenia, że mamy 8 grup. Teraz kolor to taka grupa znaleziona przez k-means:
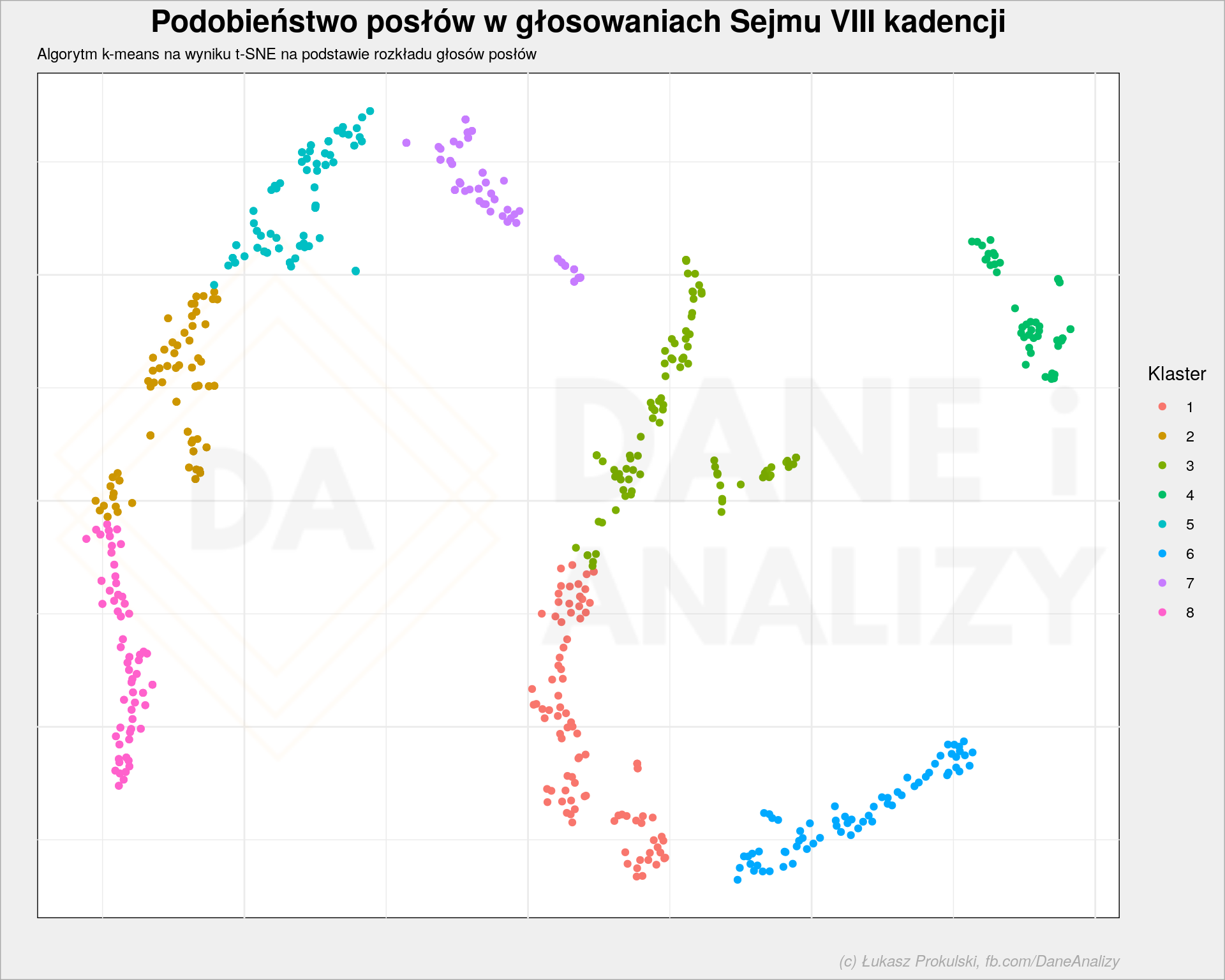
Widzimy, że nasze węże porozbijały się na kolory. Gdyby teraz użyć tych kolorów do policzenia do której grupy (koloru) powinien należeć dany klub dostaniemy coś takiego:
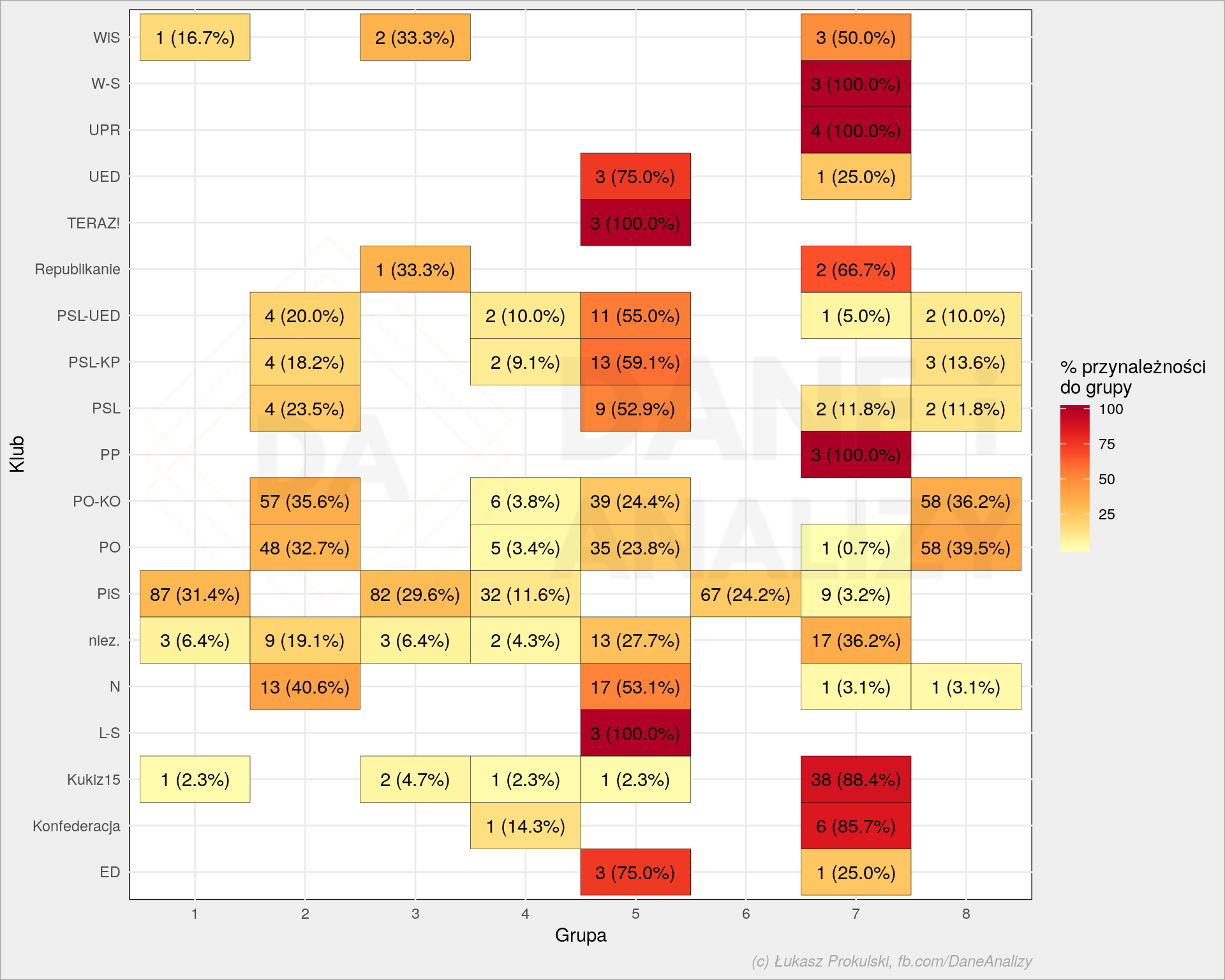
Z tego możemy wywnioskować, że w jednej grupie mamy posłów z PSL (czystego oraz po transformacjach – PSL-UED i PSL-KP), część .Nowoczesnej oraz po 1/4 PO/PO-KO. Jedna trzecia posłów PO/PO-KO oraz 40% .Nowoczesnej to kolejna spora grupa. PiS dzieli się na trzy grupy, ale właściwie do wszystkich trzech należą prawie wyłącznie posłowie PiS. Ostatnią sporą grupą są posłowie PO/PO-KO.
Możemy zastosować inny algorytm do grupowania wyników działania algorytmu t-SNE – oparty na skupieniach DBScan. Dobry tekst o DBScan znajdziecie na blogu Mateusza Grzyba.
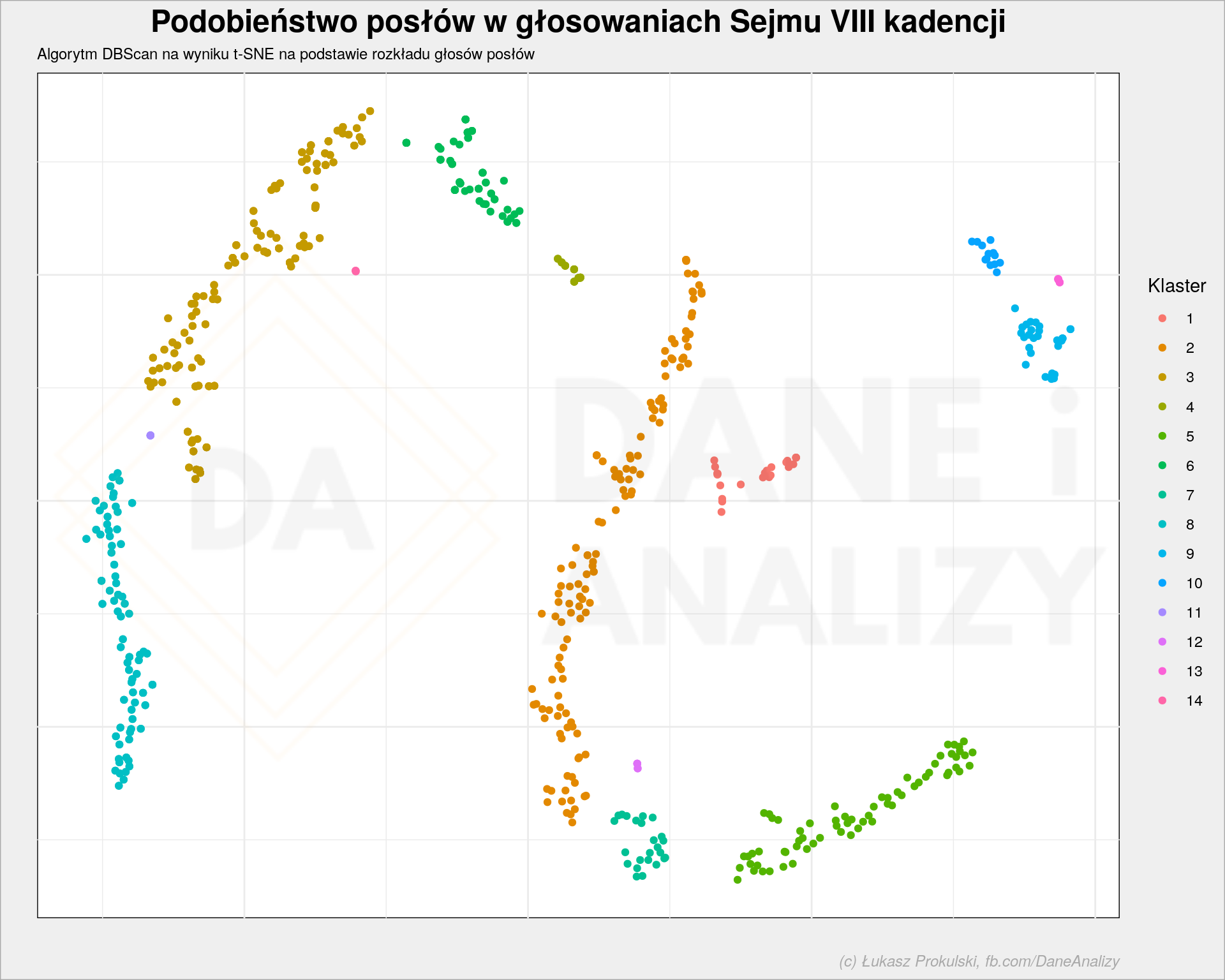
Grupy tym razem są bardziej spójne z kształtem naszych węży. Jednocześnie powstało ich więcej. Podzielmy posłów podobnie jak poprzednio:
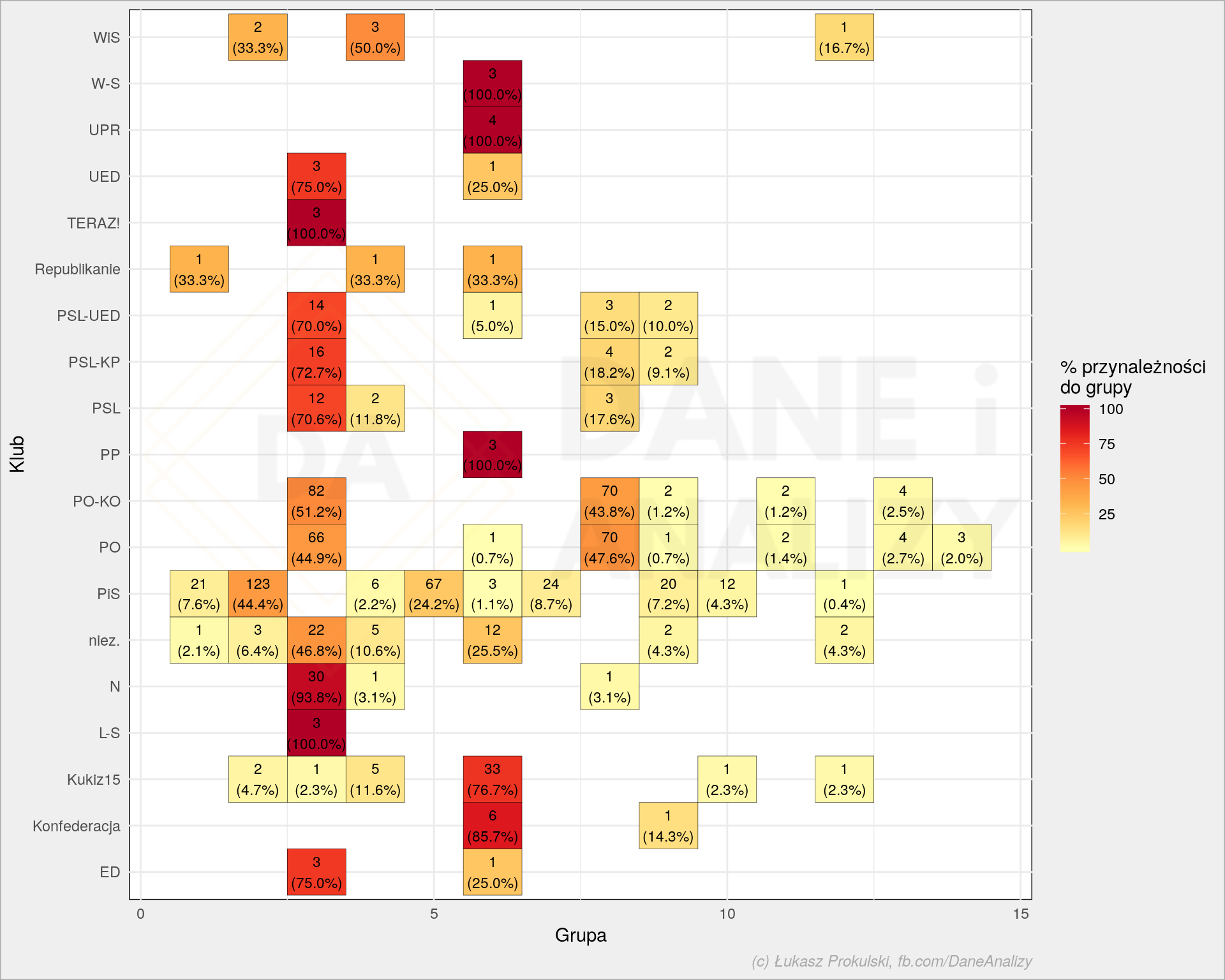
W takim ujęciu PiS podzielił się na kilka obozów, ale w dużym uproszczeniu wszystkie składają się tylko z PiSu. Duże obozy tworzą .N, PO/PO-KO, PSL (z przyległościami) – jako jeden obóz oraz połowa posłów PO/PO-KO jako drugi. Kukiz’15 tworzy obóz z Konfederacją. Jak widać matematyka potrafi odwzorować istniejące granice na polskiej scenie politycznej. Oczywiście są one widoczne bo istnieją, a nie istnieją bo tak mówi matematyka.
Ostatni element to sprawdzenie czy dwie osoby się do siebie zbliżają w głosowaniach czy oddalają. To może być dobre narzędzie do sprawdzenia czy dany poseł z czasem głosuje podobnie do na przykład lidera klubu, który chciałby go przejąć. Wybrałem dwie barwne postacie, które powinny różnić się w swoich głosach – Sławomira Nitrasa oraz Marka Suskiego.
Algorytm polega na tym, że dla każdego kolejnego głosowania bierzemy historię oddanych głosów przez te dwie osoby i na tej historii liczymy współczynnik korelacji. Dla następnego głosowania robimy to samo. I tak idziemy przez wszystkie głosowania otrzymując coś tego typu:
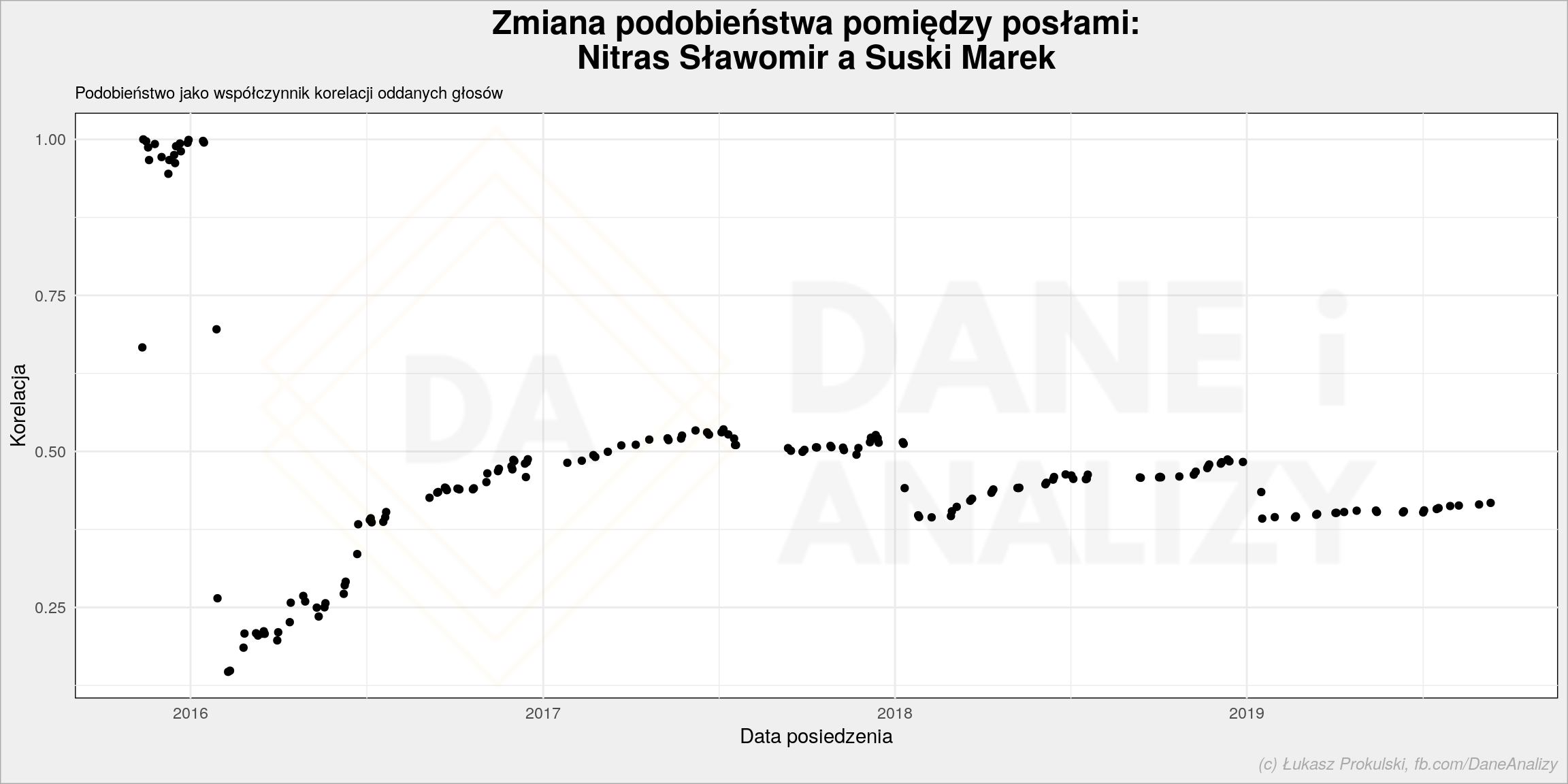
Widzimy, że w pierwszych głosowaniach panowie Suski i Nitras głosowali dość podobnie (współczynnik korelacji bliski jedynki). Później (na początku 2016 roku) poróżnili się i z czasem zaczęli się do siebie zbliżać. Na przełomie 2017 i 2018 znowu coś ich poróżniło.
Dla większości posłów (szczególnie z tego samego klubu) wykresy tego typu będą stale bliskie jedynki. Możecie samodzielnie porównać sobie dwie osoby – odpowiednie kody źródłowe (oraz dane w plikach RDS) znajdziecie na moim GitHubie.
Podobieństwo można mierzyć też na inne sposoby. Na przykład jako odległość kosinusową wektorów zbudowanych z kolejnych głosów przy przyjęciu że np. głos za to wartość 1, wstrzymujący się lub nieobecność to 0 a przeciw to -1. Daje następujące wyniki:
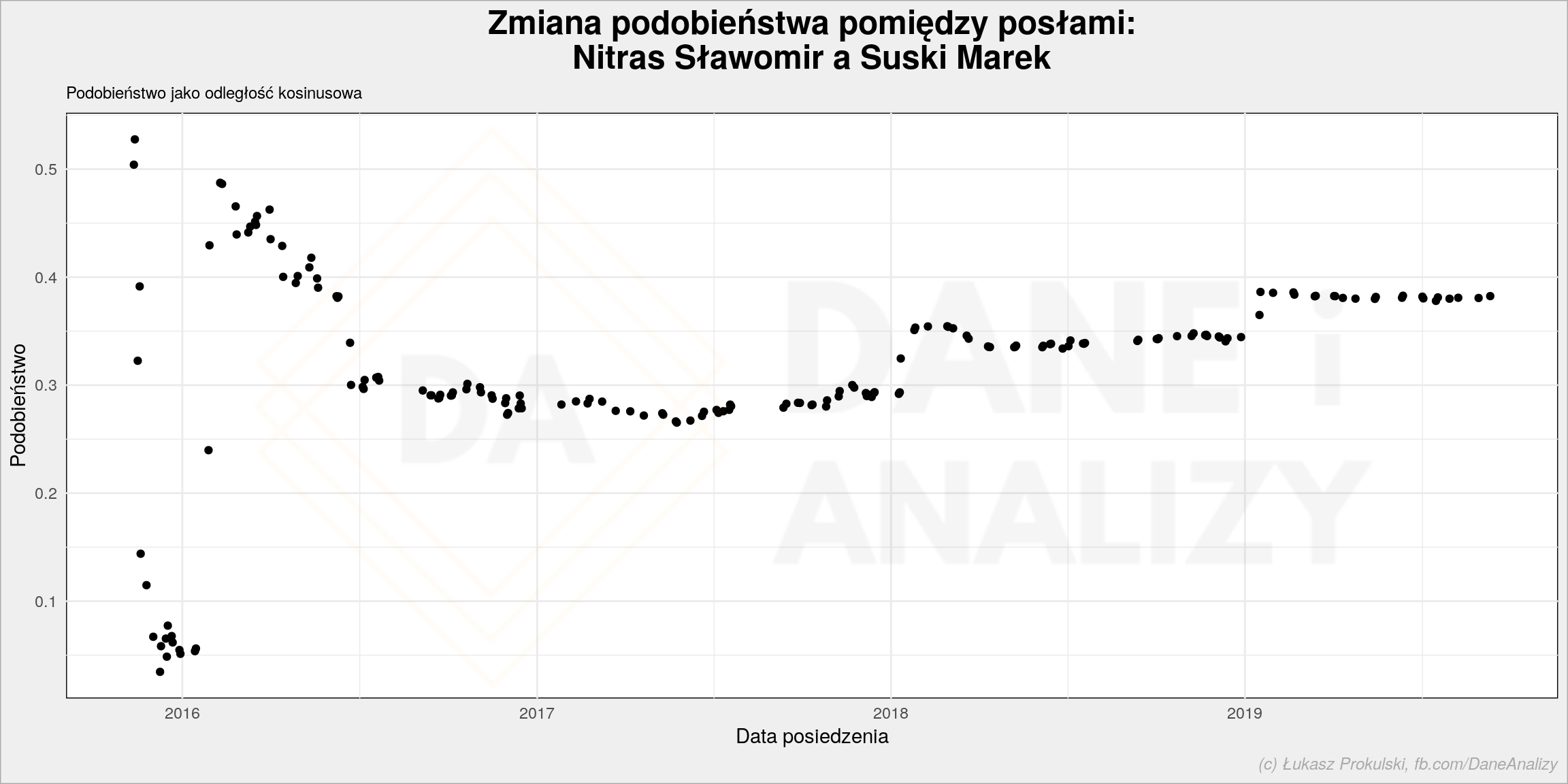
Zmiany widoczne są w podobnych miejscach, różnica jest w znaczeniu wartości z osi Y.
Przygotowanie tego wpisu kosztowało mnie jakiś tydzień pracy, z czego najdłużej trwało zbieranie danych (i doglądanie czy skrypt działa czy z jakiegoś powodu się zatrzymał). Sama analiza jest już prosta, o ile wie się co chce się zrobić. I ma się do tego opanowany warsztat.
Miło będzie jeśli docenisz trud autora stawiając dużą kawę. Wpadnij też na Dane i Analizy na Facebooku i daj lajka, tam więcej takich smaczków (szczególnie dla praktyków) i zdecydowanie częściej. Jest też newsletter w którym co jakiś czas duża ilość tekstów wartych uwagi – zapraszam do subskrypcji!
Prof. Marian Zembala zdaje się miał także problemy zdrowotne, pewnie stąd tak duża absencja.