Mieszkałem w Krakowie, teraz w Warszawie, przez długi czas często bywałem w Poznaniu, mam znajomych z różnych części kraju – wszystkie te miejsca charakteryzują się różnymi nazwami tego samego. Jedni wychodzą na pole, inni na dwór. Jedni kupują migawkę na krańcówce, a do innych w grudniu prezenty przynosi Gwiazdor, Dzieciątko lub po prostu Mikołaj.
A jak wygląda popularność ketchupu lub majonezu?
Skąd pomysł
Ponad pół roku temu trafiłem na wpis pokazujący mapę regionalizmów w Niemczech. Jestem fanem postów z /r/MapPorn na Reddicie, w szczególności takich jak ten pokazujący od którego policzka Francuzi zaczynają całowanie podczas powitania (była też mapa o liczbie cmoknięć – nie tylko we Francji, ale w całej Europie; Polacy całują na trzy – prawda?). Wszystko to było inspiracją do zrobienia czegoś podobnego samodzielnie. Bo nauka jakiejś umiejętności to zazwyczaj powtarzanie tego, co ktoś już zrobił – w imię ja też tak potrafię. To dobre podejście, w wielu dziedzinach.
Jeśli chodzi o polskie lokalne upodobania czy nazwy tego samego (regionalizmy) to ciekawy zbiór znajdziecie na jednym fanpage’u (niestety nieco już opuszczonym) oraz w archiwum tekstów BIQData z Wyborczej.
Wszystko już było, więc potrzebowałem czegoś innego do identycznego zadania. Nie wiem czy wiecie, ale taki na przykład majonez ma zwolenników poszczególnych marek. Fani Kieleckiego nie kupią nigdy innego. Tym tropem idąc podobnie może być z ketchupem. Czy z musztardą to nie wiem – mam wrażenie, że wystarczy wszystkim sarepska (zwana saperską), a producent nie ma już takiego znaczenia. Ale z majonezem na pewno taki podział istnieje.
Mieszkając na Bieżanowie w Krakowie wiedziałem gdzie panuje Wisła, a gdzie Cracovia (bodaj ulica Teligi wyznaczała granicę). A jak to wygląda w całej Polsce? Czy kibice poszczególnych drużyn są skupieni wokół określonych regionów? Wydawałoby się, że tak. Podważać i wątpić to jednak podstawowa zasada badacza danych, zatem trzeba tezę zweryfikować.
I tutaj docieramy do końca tego przydługiego wstępu. Cel (narysowanie mapki regionalizmów) został wyposażony w przedmiot badań (majonez, ketchup i przy okazji drużyna piłkarska) i pozostała egzekucja.
Sposób zbierania danych
Aby zebrać wyniki można przygotować ankietę – na przykład w Google Forms. Szybko wyklikać i po problemie. Ale ja potrzebowałem jednej informacji, które nie uda się w Google Forms zrobić – dokładnego miejsca zamieszkania osoby ankietowanej. Można kazać odpowiadającemu wybrać powiat zamieszkania, można nawet pytać o gminę. Ale może łatwiej po prostu pokazać na mapie gdzie się mieszka? Poszedłem tym tropem, tym bardziej że kiedyś już opracowałem sposób pobierania współrzędnych wskazanych na mapie (i opisałem to w poście Shiny – punkty z mapki, gdzie zapraszam zainteresowanych).
Druga (trzecia i czwarta jednocześnie) część to wybór majonezu (ketchupu i drużyny) – tutaj mamy już gotowe listy. Skąd je wziąłem? Wyszukałem po prostu rankingi najpopularniejszych majonezów i ketchupów w jakiejś prasie. Jeśli nie ma jakiegoś majonezu lub ketchupu – to wina rankingów.
Lista drużyn to akurat łatwizna – wystarczy aktualna tabela Ekstraklasy.
Upakowałem to wszystko w prostą aplikację napisaną w Shiny (Shiny i R znakomicie się do takich szybkich aplikacyjek nadają) i umieściłem na stronie którą starałem się trochę promować w internecie (wiecie – Facebook, Wykopy, Reddity). Przez około miesiąc zebrało się jakieś 750 głosów. Kilka tysięcy byłoby świetne, bardziej miarodajne, ale już teraz widać jakieś efekty.
Technicznie – dane zbierałem w tabeli SQLowej. To też element nauki – można przetwarzać dane z Excela czy plików CSV, ale wyzwaniem (na początku) jest coś poważniejszego. A SQLa każdy data scientist powinien znać choć trochę. Serio to ułatwia życie.
Długo zastanawiałem się, czy pisać o aplikacji zbierającej dane, ale ostatecznie stwierdziłem, że sobie odpuszczę – nie ma w niej wielkiej filozofii. Ot mapka opisana tutaj, trzy elementy selectInput i jeden actionButton plus jakieś warunki sprawdzające czy odpowiednie zmienne są wypełnione. Dodatkowo połączenie do bazy MySQL i dopisanie do niej danych poprzez dbWriteTable() z parametrem append = TRUE.
Przejdźmy do wyników całego badania – tutaj już będzie trochę kodu (jak zwykle w R).
Wyniki
Dane zostały upakowane do tabeli regionalizmy przygotowanej w SQLu poprzez:
|
1 2 3 4 5 6 7 8 9 |
CREATE TABLE regionalizmy ( `timestamp` TIMESTAMP NOT NULL, `majonez` VARCHAR(15) NOT NULL, `ketchup` VARCHAR(15) NOT NULL, `ekstraklasa` VARCHAR(25) NOT NULL, `long` DOUBLE NOT NULL, `lat` DOUBLE NOT NULL ); |
timestamp w sumie jest niepotrzebny do samej analizy, ale przy okazji chciałem wiedzieć kiedy oddawane są kolejne głosy (i tym samym sprawdzać, które działania promocyjne przynoszą efekt – w połączeniu z tagowaniem linków poprzez utm_source i utm_medium).
majonez, ketchup i ekstraklasa to ciągi zawierające konkretne odpowiedzi (tak, w idealnym świecie byłyby to klucze z odpowiednich tabel słownikowych, ale – nie oszukujmy się – nie spodziewałem się milionów danych, więc nadmierna optymalizacja bazy tylko utrudniałaby życie).
long i lat to oczywiście współrzędne osoby głosującej odczytane z mapy. I znowu – idealnie byłoby pobrać te dane z lokalizacji użytkownika i nie zmuszać go do wskazywania miejsca na mapie.
Pobierzmy więc potrzebne nam dane. W dzisiejszym odcinku skorzystamy z bibliotek:
|
1 2 3 4 5 6 |
library(tidyverse) library(RMySQL) library(lubridate) library(gridExtra) library(grid) library(glue) |
Na początek łączymy się z naszą bazą. Z oczywistych względów nie podaję poniżej informacji dostępowych do bazy:
|
1 2 3 4 5 6 7 |
dbname <- "nazwa_bazy_danych" user <- "użytkownik_bazy_danych" password <- "hasło_dla_użytkownika" host <- "serwer_bazy_danych" sterownik <- dbDriver("MySQL") polaczenie <- dbConnect(sterownik, dbname = dbname, user = user, password = password, host = host) |
Teraz możemy już pobrać nasze dane. Zamiast pobierać wszystko i przetwarzać po stronie R (w pamięci) wybieramy tylko to co nam potrzebne korzystając z serwera SQL. Takie działanie jest bardziej efektywne – serwer bazodanowy zajmuje się wydobyciem i przetworzeniem odpowiednich informacji. Tutaj nie ma za dużej filozofii: ot wybieramy odpowiednie fragmenty tabeli agregując je do wartości podsumowujących odpowiednie głosy (ile razy zagłosowano na konkretny majonez?):
|
1 2 3 4 5 6 7 |
dane <- dbGetQuery(polaczenie, 'SELECT "majonez" AS typ, majonez AS nazwa, COUNT(*) AS liczba FROM regionalizmy GROUP BY majonez UNION SELECT "ketchup" AS typ, ketchup AS nazwa, COUNT(*) AS liczba FROM regionalizmy GROUP BY ketchup UNION SELECT "ekstraklasa" AS typ, ekstraklasa AS nazwa, COUNT(*) AS liczba FROM regionalizmy GROUP BY ekstraklasa UNION SELECT "wszystkie" AS typ, "wszystkie" AS nazwa, COUNT(*) AS liczba FROM regionalizmy;') |
W wyniku dostajemy stosunkowo krótką tabelę. Jedną zamiast kilku dla każdej kategorii, a kategorię (majonez, ketchup, drużyna) określa nam dodatkowa kolumna typ:
| typ | nazwa | liczba |
|---|---|---|
| majonez | Hellmann’s | 70 |
| majonez | inny | 46 |
| majonez | Kętrzyński | 24 |
| majonez | Kielecki | 217 |
| majonez | Koronny | 3 |
| majonez | Mikado | 7 |
| majonez | Mosso | 17 |
| majonez | Roleski | 13 |
| majonez | Splendido | 5 |
| majonez | ten, który jest | 96 |
| majonez | Winiary | 258 |
| ketchup | Heinz | 145 |
| ketchup | Hellmann’s | 27 |
| ketchup | inny | 62 |
| ketchup | Kamis | 5 |
| ketchup | Kotlin | 99 |
| ketchup | Krokus | 4 |
| ketchup | Pudliszki | 212 |
| ketchup | Roleski | 21 |
| ketchup | Rybak | 7 |
| ketchup | ten, który jest | 82 |
| ketchup | Włocławek | 92 |
| ekstraklasa | Arka Gdynia | 23 |
| ekstraklasa | Cracovia | 14 |
| ekstraklasa | Górnik Zabrze | 15 |
| ekstraklasa | Jagiellonia Białystok | 13 |
| ekstraklasa | Korona Kielce | 13 |
| ekstraklasa | Lech Poznań | 44 |
| ekstraklasa | Lechia Gdańsk | 18 |
| ekstraklasa | Legia Warszawa | 104 |
| ekstraklasa | Miedź Legnica | 7 |
| ekstraklasa | Piast Gliwice | 4 |
| ekstraklasa | Pogoń Szczecin | 11 |
| ekstraklasa | Śląsk Wrocław | 31 |
| ekstraklasa | Wisła Kraków | 35 |
| ekstraklasa | Wisła Płock | 3 |
| ekstraklasa | żadnej | 411 |
| ekstraklasa | Zagłębie Lubin | 7 |
| ekstraklasa | Zagłębie Sosnowiec | 3 |
| wszystkie | wszystkie | 756 |
Zwróćcie uwagę na ostatni wiersz – on stanowi podsumowanie całości i informuje nas o całkowitej liczbie zebranych głosów. Można to było policzyć inaczej (jako sumę kolumny liczba dla jednej z kategorii), ale zrobiłem tak. W sumie mamy
|
1 |
(n_glosow <- dane %>% filter(typ == "wszystkie") %>% pull(liczba)) # te zewnętrzne nawiasy przy przypisaniu do zmiennej działają jak print() dla tej zmiennej - wygodne |
756 zebranych głosów.
Na tak wyciągniętych danych można już narysować proste podsumowania (np. wykresy słupkowe czy kołowe), ale nie mamy informacji o lokalizacji dla poszczególnych głosów, a przecież to jest najciekawsze. Pobierzmy zatem stosowne dane z tabeli SQLowej:
|
1 2 3 |
liga <- dbGetQuery(polaczenie, 'SELECT ekstraklasa, `long`, lat FROM regionalizmy;') ketchup <- dbGetQuery(polaczenie, 'SELECT ketchup, `long`, lat FROM regionalizmy;') majonez <- dbGetQuery(polaczenie, 'SELECT majonez, `long`, lat FROM regionalizmy;') |
Na koniec pobiorę jeszcze całość danych, bo w drugiej części tego wpisu to się przyda do liczenia głosów na parę typu majonez – ketchup, a także do zobrazowania skąd pochodzą wszystkie głosy (złączenie pobranych wyżej trzech tabel nie da tego samego – liczebność punktów może się nie zgadzać):
|
1 2 3 4 |
all_data <- dbGetQuery(polaczenie, 'SELECT * FROM regionalizmy;') # i zamykamy połączenie do bazy danych dbDisconnect(polaczenie) |
Można nie wyciągać wszystkich danych tylko agregować je w SQLu, na przykład poprzez:
|
1 |
SELECT majonez, ketchup, COUNT(*) FROM regionalizmy GROUP BY majonez, ketchup; |
Tyle tylko, że takich tabelek trzeba trochę potworzyć i później je ogarnąć. Wiem, że tutaj nie ma dużo danych, więc mogę sobie pozwolić na takie działanie. Ale jeśli w bazie byłyby na przykład dziesiątki tysięcy rekordów to jednak lepiej kazać bazie policzyć te wszystkie podsumowania. W uproszczeniu:
- jeśli mamy dane w bazie danych (SQLowej, Sparkowej)
- to niech baza zajmuje się ich agregacją czy przekształceniami
- i zwraca wyniki do R
- z R niech robi część wizualną
Warto się tego nauczyć i o tym pamiętać. Dobrze napisany skrypt będzie niezależny od ilości danych (i tym samym apetyt na pamięć komputera) i bez różnicy będzie czy są to wyniki z prostej ankietki (z 756 rekordami) czy też szczegółowe dane dla na przykład wszystkich Polaków. W tym ostatnim przypadku mając bazę z kolumnami: PESEL, wiek, płeć, gmina zamieszkania dla każdego z 38 milionów Polaków bez sensu jest wciąganie wszystkiego do pamięci i liczenie chociażby ile kobiet w wieku 25 lat mieszka w każdej z gmin. Potrzebujemy pamięci na 38 mln rekordów. Można poprosić bazę o podanie gotowego wyniku – dostaniemy wtedy około 2.5 tysiąca rekordów (bo tyle mamy gmin). Jest różnica, prawda?
Pojedyncze wykresy popularności (słupki)
Dobrze, dobrze, ale do brzegu. Przygotujmy zatem podsumowania najpopularniejszych w każdej z kategorii. Na początek majonez:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
p1 <- dane %>% filter(typ == "majonez") %>% # układamy słupki na wykresie w kolejności majelącej od góry # domyślnie byłyby wg alfabetu arrange(liczba, nazwa) %>% mutate(nazwa = fct_inorder(nazwa)) %>% ggplot() + # rysujemy słupek geom_col(aes(nazwa, liczba), fill = "lightgreen") + # dodajemy liczbę głosów na słupku geom_text(aes(nazwa, liczba, label = liczba), hjust = 1) + # nazwy na osi Y a nie X coord_flip() + theme_minimal() + # tytuły wykresu i osi labs(title = "Najpopularniejszy majonez", x = "", y = "") p1 |
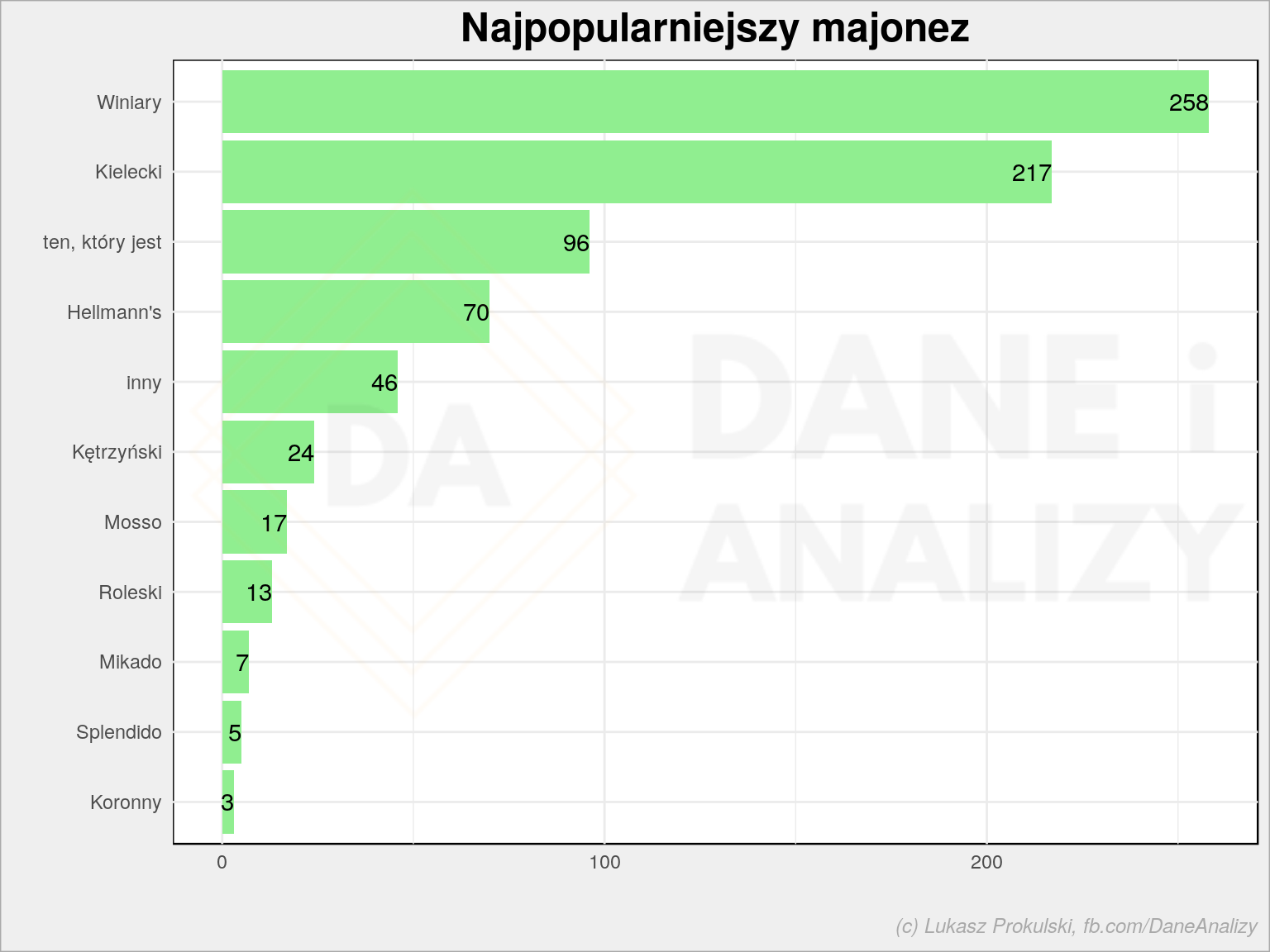
Kielecki przegrywa, cóż zrobić… Wietrzę tutaj spisek (obserwowałem co się dzieje pod pewnymi postami na Facebooku i akcje typu team Kielecki! albo Forza Winiary! ;-) To nie jest możliwe, to nie są rzeczywiste wyniki! ;) W mojej opinii najlepszy jest jednak Kielecki (nie, nie dostałem kasy za product placement).
Swoją drogą ciekawa jest dysproporcja pomiędzy dwoma liderami a resztą. Winiary i Kielecki zgarniają w sumie prawie 63% głosów. Obojętnych jest niecałe 13%, a trzecia marka w kolejności zgarnia tylko 9%. Czy to pokrywa się z wynikami sprzedaży w całym kraju?, czy ktoś z działów sprzedaży tych marek mnie słyszy i może to potwierdzić?
Opcja ten, który jest oznacza ten, który akurat mam w lodówce albo ten, który akurat wpadnie do koszyka w sklepie. Czyli jest to wybór osób, którym jest to serdecznie obojętne.
Sprawdźmy ketchup:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
p2 <- dane %>% filter(typ == "ketchup") %>% arrange(liczba, nazwa) %>% mutate(nazwa = fct_inorder(nazwa)) %>% ggplot() + geom_col(aes(nazwa, liczba), fill = "lightgreen") + geom_text(aes(nazwa, liczba, label = liczba), hjust = 1) + coord_flip() + theme_minimal() + labs(title = "Najpopularniejszy ketchup", x = "", y = "") p2 |
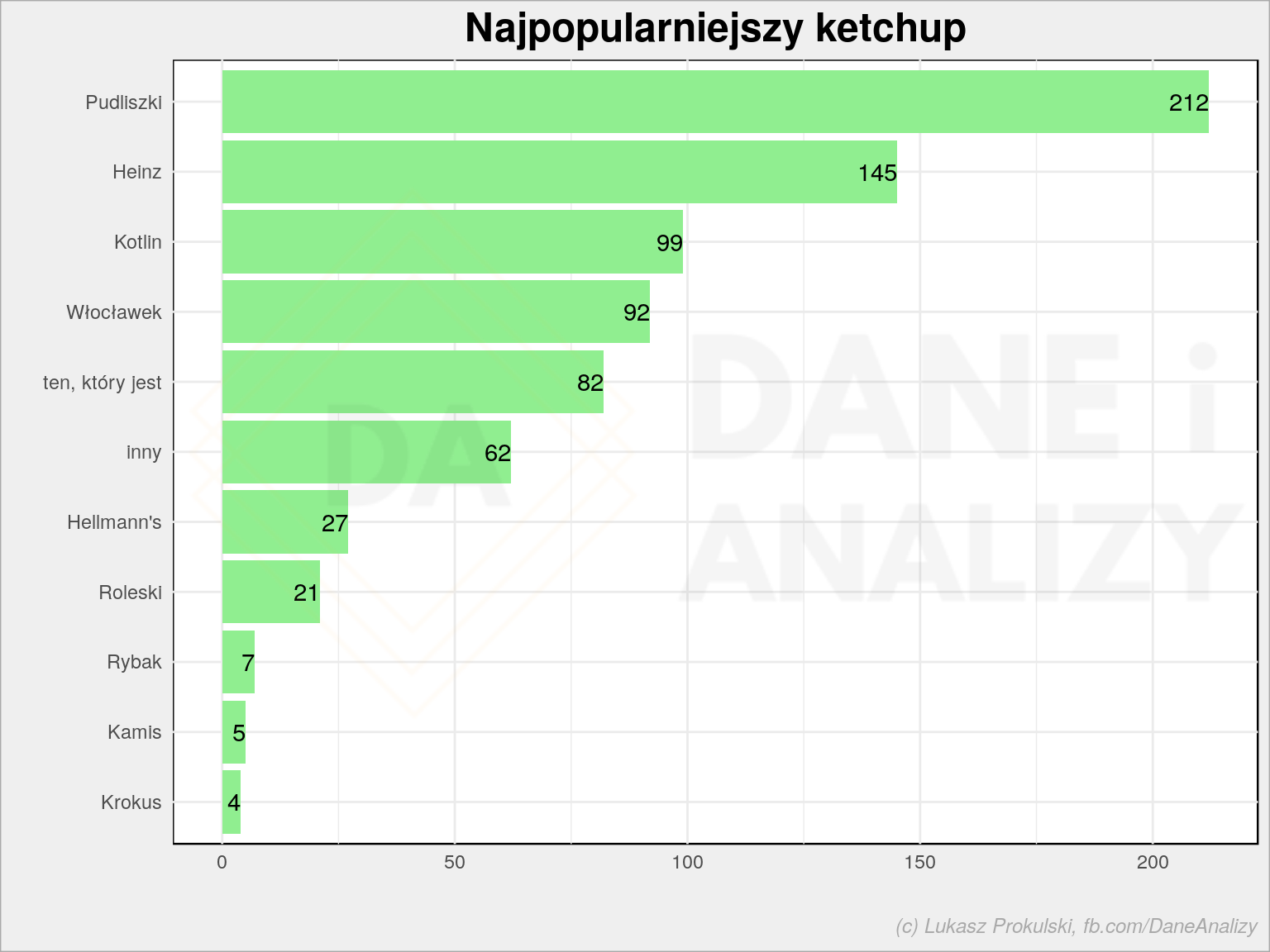
Tutaj lider (Pudliszki, nieco ponad 1/4 głosów) jest jeden i nie ma tak silnego konkurenta – Heinz daleko ma do pierwszego miejsca, ale też jego druga pozycja wydaje się nie być zagrożona. Widać raczej bitwę o trzecie miejsce (Kotlin, Włocławek).
Wiecie ile się naszukałem ketchupu z Biedronki Słodka Ania albo Krzepki Radek? Społeczność na Wykopie domagała się, a w wyniku – marka Rybak to tylko 7 głosów (niecały jeden procent).
Została nam na koniec drużyna piłkarska z Ekstraklasy – zobaczmy tylko te, które dostały jakieś głosy:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
p3 <- dane %>% filter(typ == "ekstraklasa", nazwa != "żadnej") %>% arrange(liczba, nazwa) %>% mutate(nazwa = fct_inorder(nazwa)) %>% ggplot() + geom_col(aes(nazwa, liczba), fill = "lightgreen") + geom_text(aes(nazwa, liczba, label = liczba), hjust = 1) + coord_flip() + theme_minimal() + labs(title = "Najpopularniejsza drużyna Ekstraklasy", x = "", y = "") p3 |
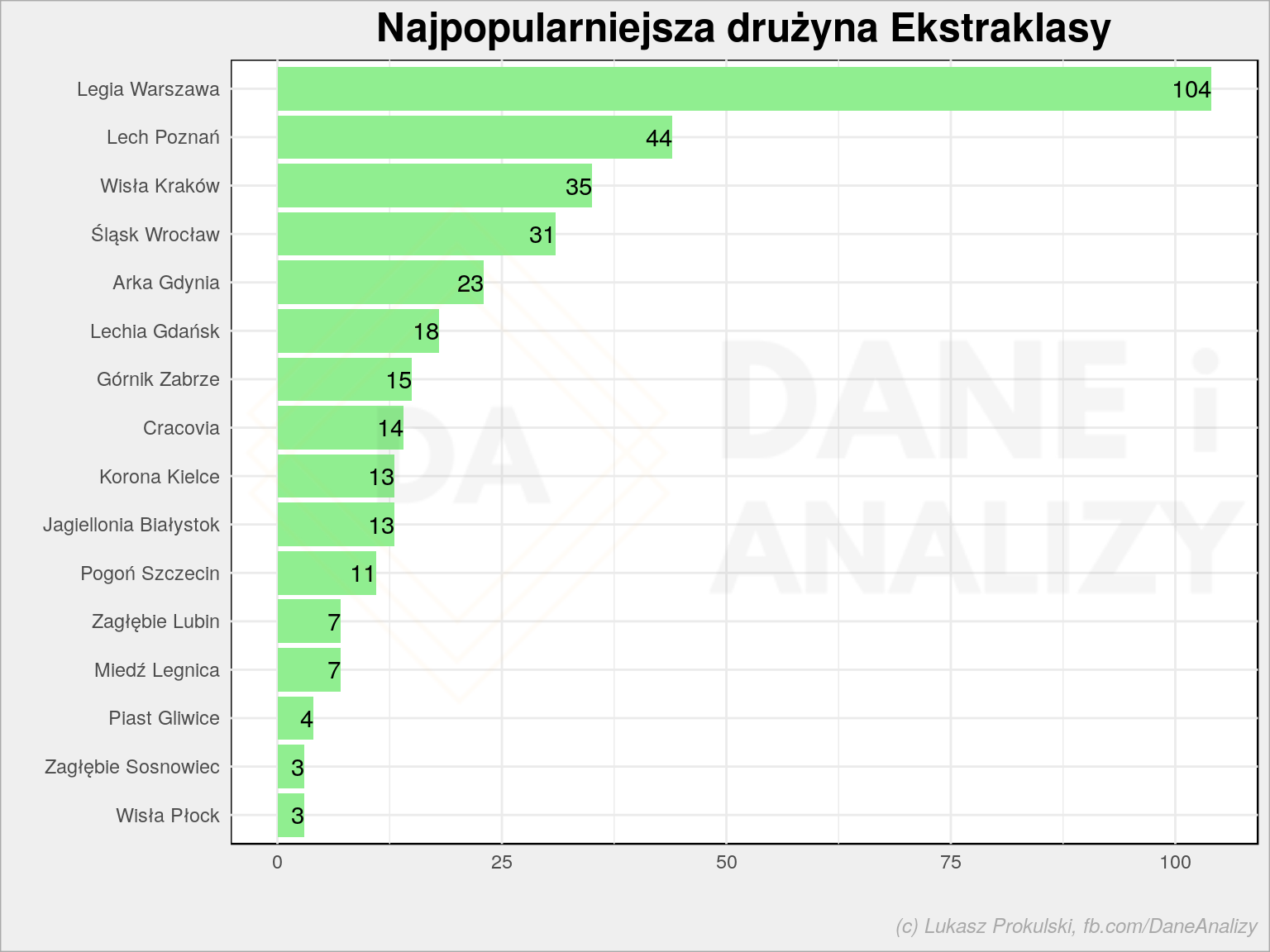
Kolejność chyba pokrywa się z wynikami poszczególnych drużyn w lidze. Wpadamy tutaj jednak w pewną pułapkę zwaną niezbilansowany zbiór danych (ang. imbalanced dataset) – jak zobaczymy za chwilę na mapie najwięcej głosów jest z dużych miast, najwięcej chyba z Warszawy. Niezbilansowane dane to typowe zjawisko i trzeba sobie z nim jakoś radzić. W niniejszym tekście metodą jest… olanie problemu. Jeśli chcecie o tym problemie dowiedzieć się więcej to dobrym startem będzie artykuł 8 Tactics to Combat Imbalanced Classes in Your Machine Learning Dataset.
Zwróćcie uwagę, że wyłączona z wykresu została drużyna żadnej. Ta gromadzi 54% głosów. I albo jest tak, że ankietę wypełniły osoby mające gdzieś piłkę nożną, albo mające gdzieś polską ligę.
Lokalizacje
Przed chwilą wspomniałem, że najwięcej głosów jest najprawdopodobniej z Warszawy. Zobaczmy zatem skąd są wszystkie głosy (o ile zmieściły się w prostokącie współrzędnych opisującym Polskę). Weźmy mapę Polski (kontury) i zaznaczmy na niej punkty wybierane przez ankietowanych na mapie:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
# kontury Polski poland_map <- map_data('world') %>% filter(region == "Poland") p4 <- ggplot() + geom_polygon(data = poland_map, aes(long, lat, group=group), fill = "white", color = "black") + geom_point(data = all_data %>% # prostokąt opisany na Polsce filter(long >= min(poland_map$long), long <= max(poland_map$long), lat >= min(poland_map$lat), lat <= max(poland_map$lat)), aes(long, lat), alpha = 0.5, color = "red") + coord_quickmap() + theme_void() + labs(title = "Skąd pochodzą głosy?", x = "" , y = "") p4 |
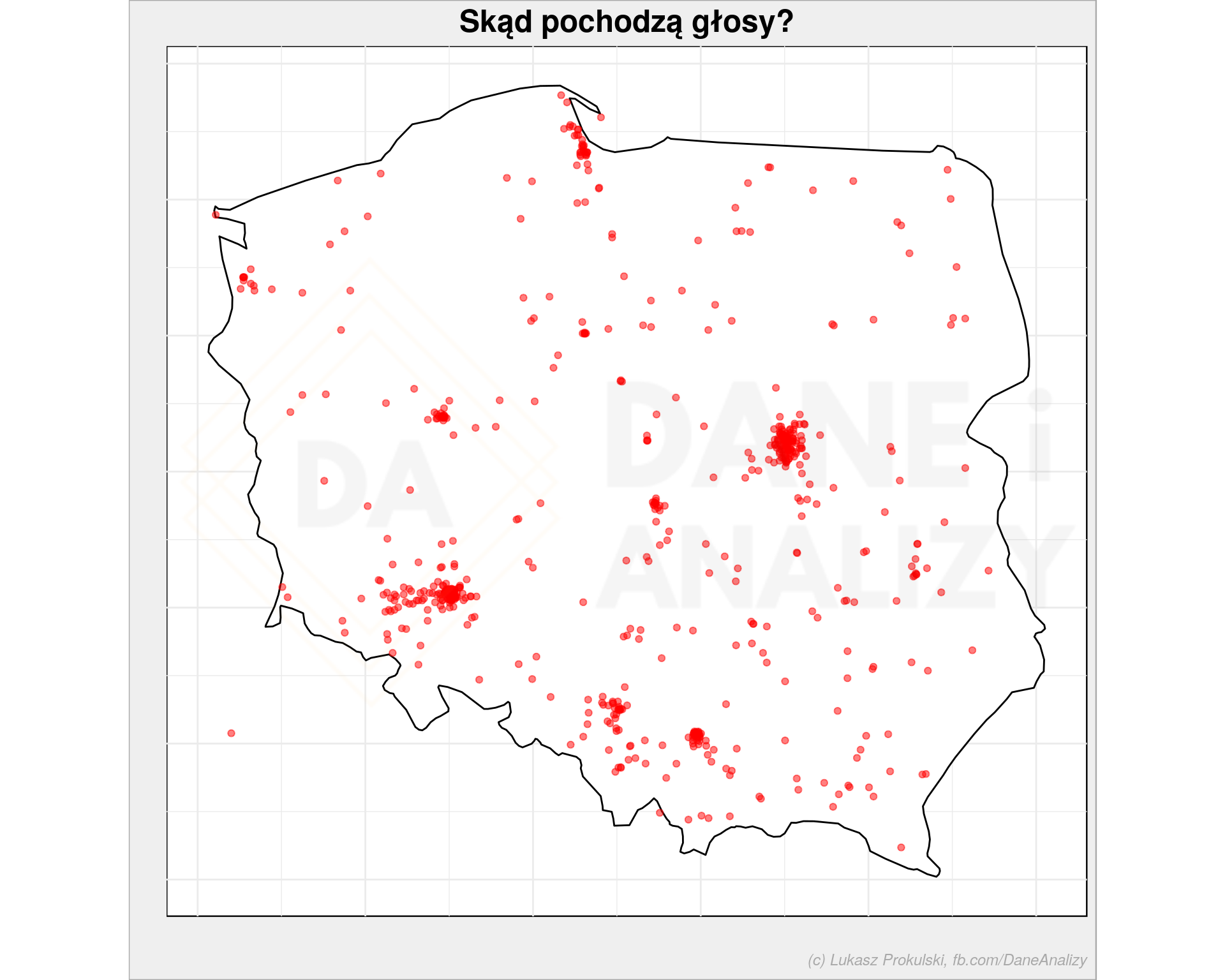
Zgodnie z zapowiedzią – najwięcej głosów jest tam, gdzie jest najwięcej internautów i tym samym najwięcej mieszkańców. Wyraźnie widać Warszawę, Kraków, Wrocław, Trójmiasto, Poznań i Górny Śląsk. Po wejściu na stronę z ankietą punktem domyślnym na mapie był środek kraju – widać, że mało jest wskazań w tym miejscu, co oznacza że ludkowie przestawiali pinezkę. Zresztą – mechanizm napisany został tak, że trzeba było gdzieś kliknąć na mapie aby dało się oddać głos – to zapewne uchroniło zebrane dane przed zaburzeniem (jeśli chodzi o lokalizację).
Rozłóżmy mapę wszystkich głosów na poszczególne kategorie i na mniejsze mapki pokazujące gdzie wybierano daną markę. Do tego celu dążyliśmy.
Czy majonez Kielecki kupowany jest tylko w okolicach Kielc?
|
1 2 3 4 5 6 7 8 9 10 11 |
ggplot() + geom_polygon(data = poland_map, aes(long, lat, group=group), fill = "white", color = "black") + geom_point(data = majonez %>% filter(!majonez %in% c("ten, który jest", "inny")) %>% filter(long >= min(poland_map$long), long <= max(poland_map$long), lat >= min(poland_map$lat), lat <= max(poland_map$lat)), aes(long, lat, color = majonez), show.legend = FALSE) + coord_quickmap() + facet_wrap(~majonez, ncol = 3) + labs(title = "Popularność majonezu w regionach", x = "", y = "") + theme_void() |
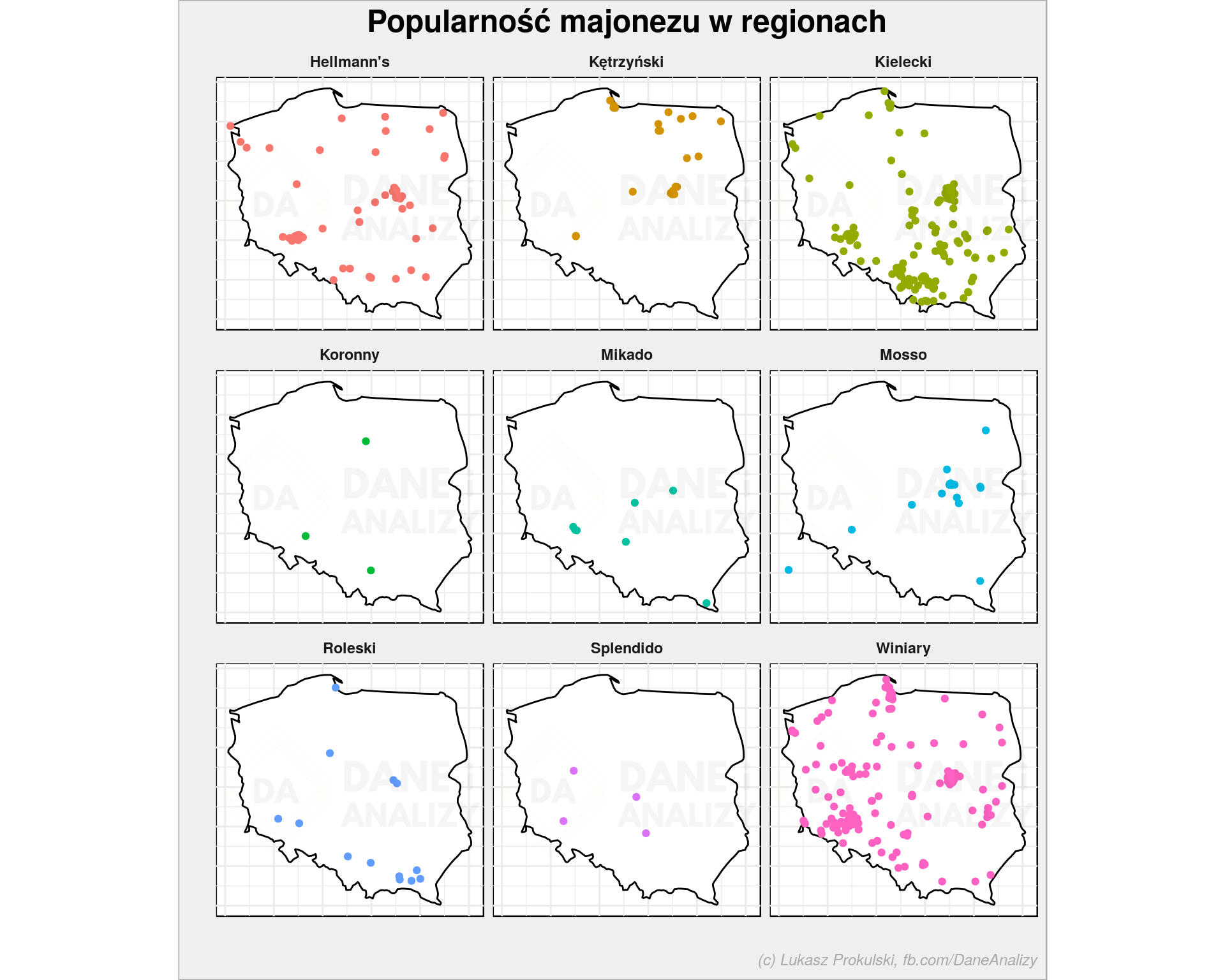
Widać regionalizację, ale właściwie tylko dla Kieleckiego i Kętrzyńskiego. Rzeczywiście w Małopolsce majonez Kielecki jest najbardziej popularny. O całej reszcie marek chyba nie można za wiele powiedzieć.
|
1 2 3 4 5 6 7 8 9 10 11 |
ggplot() + geom_polygon(data = poland_map, aes(long, lat, group=group), fill = "white", color = "black") + geom_point(data = ketchup %>% filter(!ketchup %in% c("ten, który jest", "inny")) %>% filter(long >= min(poland_map$long), long <= max(poland_map$long), lat >= min(poland_map$lat), lat <= max(poland_map$lat)), aes(long, lat, color = ketchup), show.legend = FALSE) + coord_quickmap() + facet_wrap(~ketchup, ncol = 3) + labs(title = "Popularność ketchupu w regionach", x = "", y = "") + theme_void() |
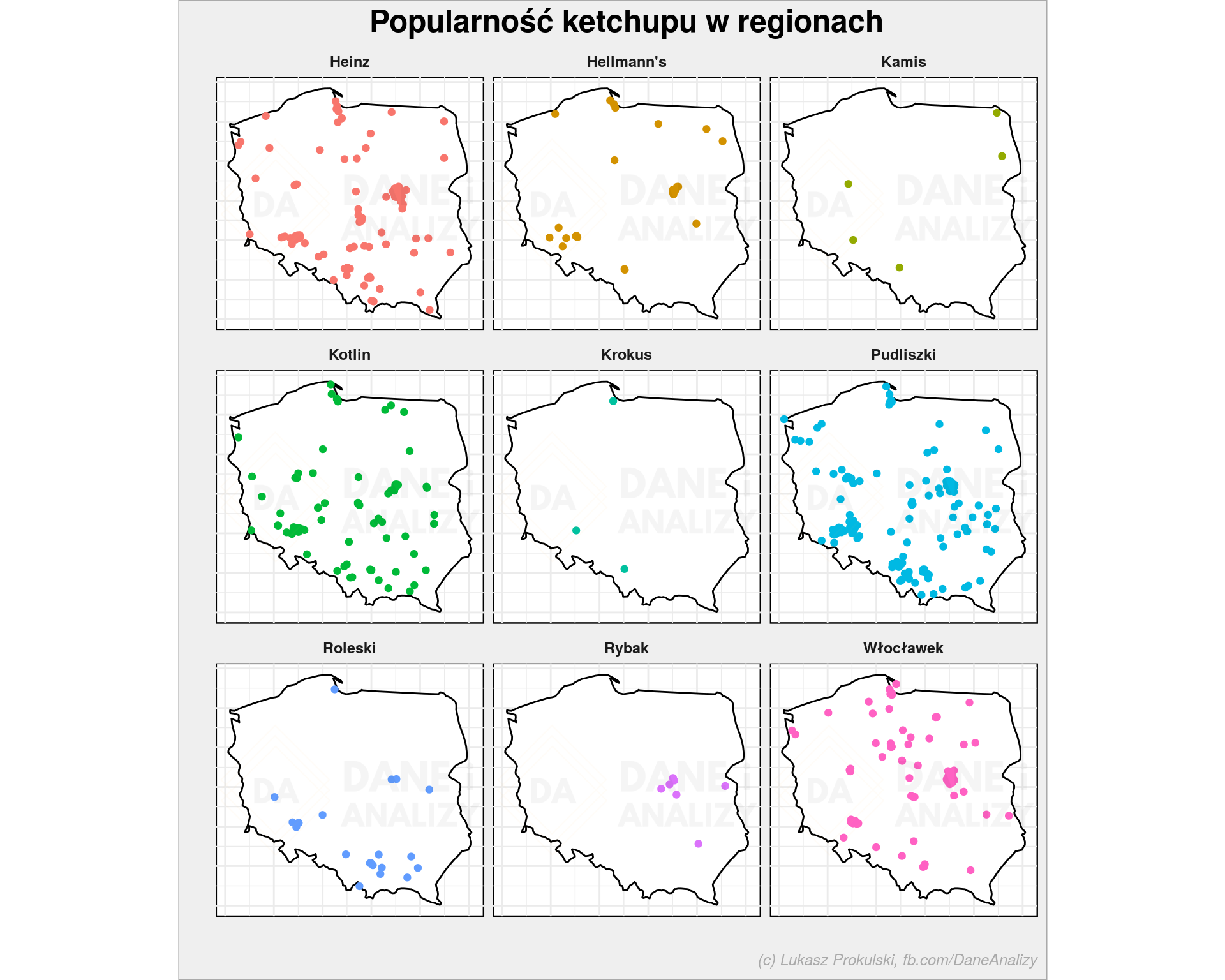
Jeśli chodzi o ketchup – ja nie widzę jakiegoś specjalnego zróżnicowania. Może Roleski jest bardziej popularny na południu niż na północy (mamy sporo głosów z Pomorza, a wiele punktów Roleski na mapie tam nie zaznacza). Można próbować udowadniać, że do Włocławka należy bardziej północna część kraju, a do Pudliszek południowa ale czy to nie będzie na siłę?
Z piłką nożną jest najprościej:
|
1 2 3 4 5 6 7 8 9 10 11 |
ggplot() + geom_polygon(data = poland_map, aes(long, lat, group=group), fill = "white", color = "black") + geom_point(data = liga %>% filter(ekstraklasa != "żadnej") %>% filter(long >= min(poland_map$long), long <= max(poland_map$long), lat >= min(poland_map$lat), lat <= max(poland_map$lat)), aes(long, lat, color = ekstraklasa), show.legend = FALSE) + coord_quickmap() + facet_wrap(~ekstraklasa, ncol = 4) + labs(title = "Popularność drużyny piłkarskiej w regionach", x = "", y = "") + theme_void() |
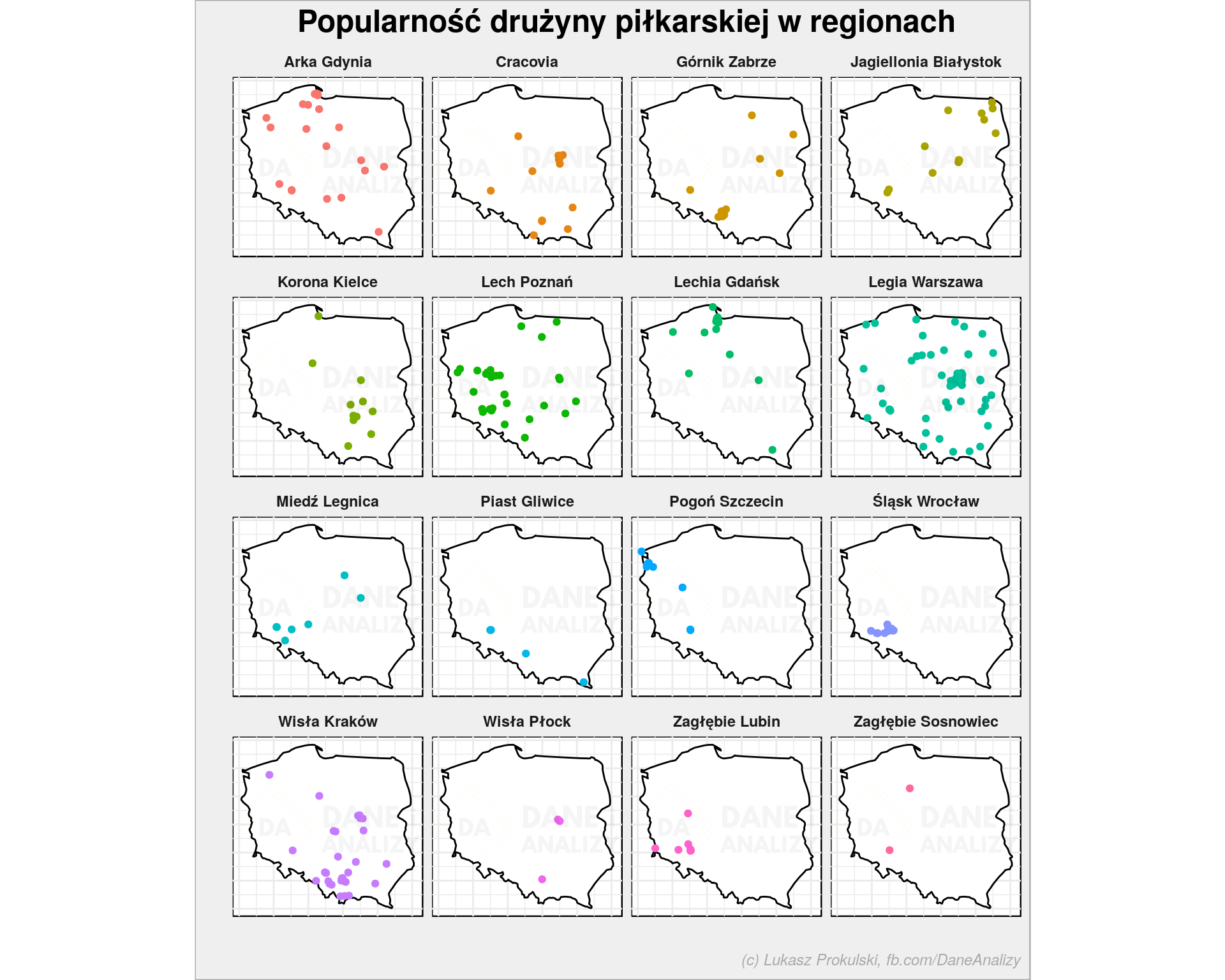
Każdy rejon ma w przybliżeniu swoją drużynę. Ale do tej mapki jeszcze wrócimy.
Dobór w pary
Sprawdźmy na koniec czy kibicowanie danej drużynie piłkarskiej wiąże się w jakikolwiek sposób z preferencjami dotyczącymi majonezu lub ketchupu. Tutaj znowu wraca sprawa niezbilansowanych danych. Chcę zaznaczyć, że błędne jest poniższej prezentowane podejście, a mimo to prezentuję je z premedytacją. Dla dobra poszerzania Waszej wiedzy.
Wiedząc, że mamy nierównomierny rozkład głosów na terenie całego kraju możemy spodziewać, że coś nie tak będzie z wynikiem. I tak mając dużo głosów z Warszawy (preferującej jeden klub piłkarski i jeden rodzaj majonezu) para majonez – ketchup może być zachwiana preferencjami Warszawiaków. Jak się przed tym uchronić? Możemy policzyć procent głosów oddanych na dany klub, majonez czy ketchup w danym województwie i porównywać te względne (procentowe) wartości. Na poniższych wykresach wynik byłby bardziej zbliżony do prawdy gdybyśmy policzyli na przykład procentowy rozkład poszczególnych wartości w ramach wiersza. Czyli ile procent zwolenników Legii wybrało Kielecki a ile Winiary? Jednak nawet na tak (jak poniżej) zaprezentowanych danych widać pewne zależności.
Złudne jest też to, że porównujemy dwie wartości, które są skorelowane z położeniem geograficznym. Może są skorelowane bezpośrednio ze sobą, ale czy na pewno? Czy korelacja pośrednia (poprzez lokalizację) nie powoduje tej bezpośredniej? Zastanówcie się nad tym. I dajcie znać w komentarzu jak poradzić sobie z tym problemem.
Wracając – jak wygląda współwybór (o ile można tak powiedzieć) klubu i majonezu? Może dana marka powinna sponsorować któryś z klubów? Żart taki, z tych czerstwych.
|
1 2 3 4 5 6 7 8 9 10 |
all_data %>% filter(ekstraklasa != "żadnej", majonez != "ten, który jest") %>% count(ekstraklasa, majonez) %>% ggplot() + geom_tile(aes(ekstraklasa, majonez, fill = n), color = "gray50", show.legend = FALSE) + geom_text(aes(ekstraklasa, majonez, label = n)) + coord_flip() + scale_fill_distiller(palette = "Greens", direction = 1) + theme_minimal() + labs(title = "Majonez a drużyna piłkarska", x = "", y = "") |
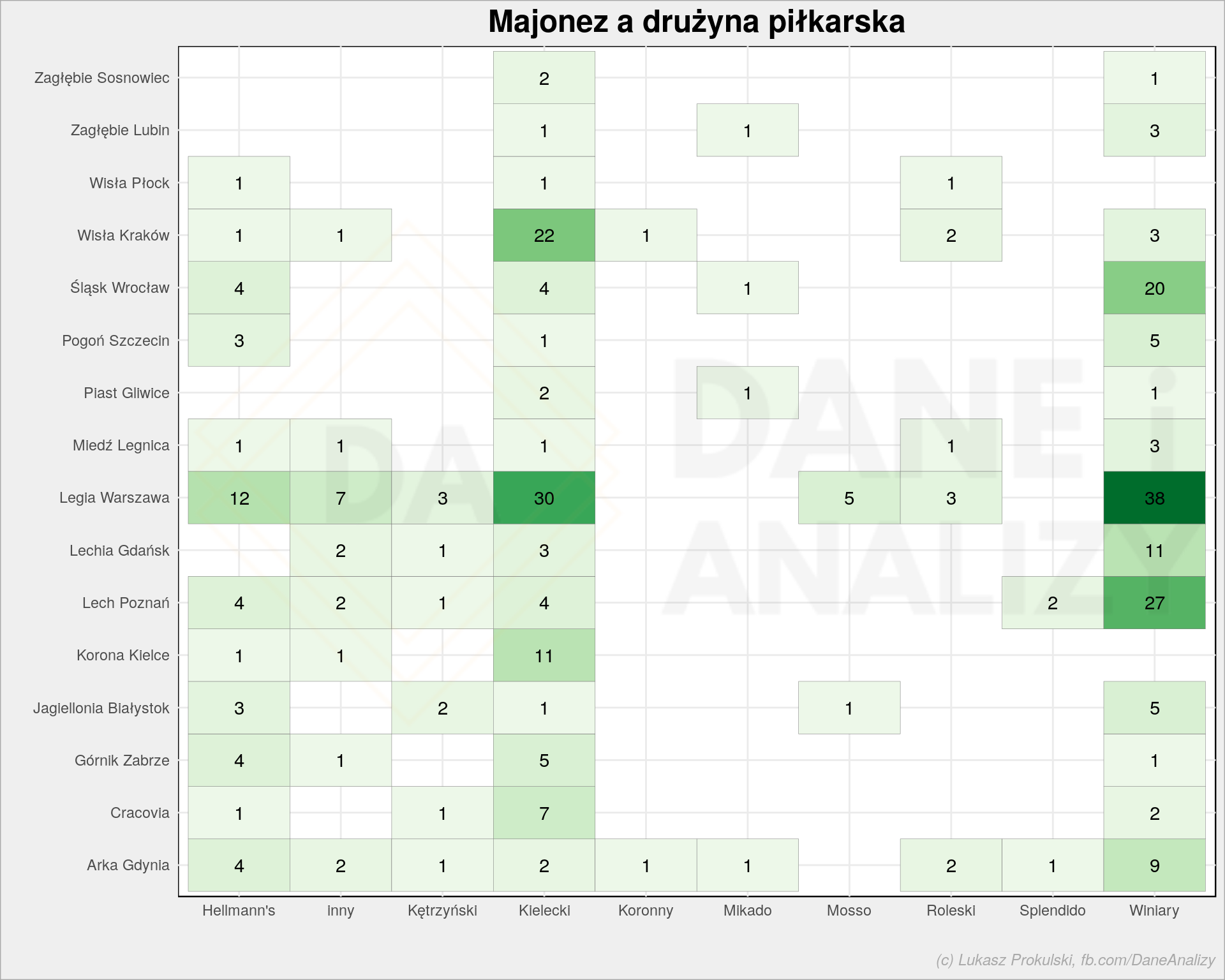
Na przykładzie Wisły Kraków widać wspomnianą korelację pośrednią. Kibicujemy Wiśle, bo mieszkamy niedaleko Krakowa (porównaj z mapą wyżej) – to ma sens. Jemy majonez Kielecki, bo mieszkamy blisko Kielc – to też ma sens. Ale czy jemy Kielecki bo kibicujemy Wiśle? A może kibicujemy Wiśle, bo jemy Kielecki? Correlation does not imply causation.
|
1 2 3 4 5 6 7 8 9 10 |
all_data %>% filter(ekstraklasa != "żadnej", ketchup != "ten, który jest") %>% count(ekstraklasa, ketchup) %>% ggplot() + geom_tile(aes(ekstraklasa, ketchup, fill = n), color = "gray50", show.legend = FALSE) + geom_text(aes(ekstraklasa, ketchup, label = n)) + coord_flip() + scale_fill_distiller(palette = "Greens", direction = 1) + theme_minimal() + labs(title = "Ketchup a drużyna piłkarska", x = "", y = "") |
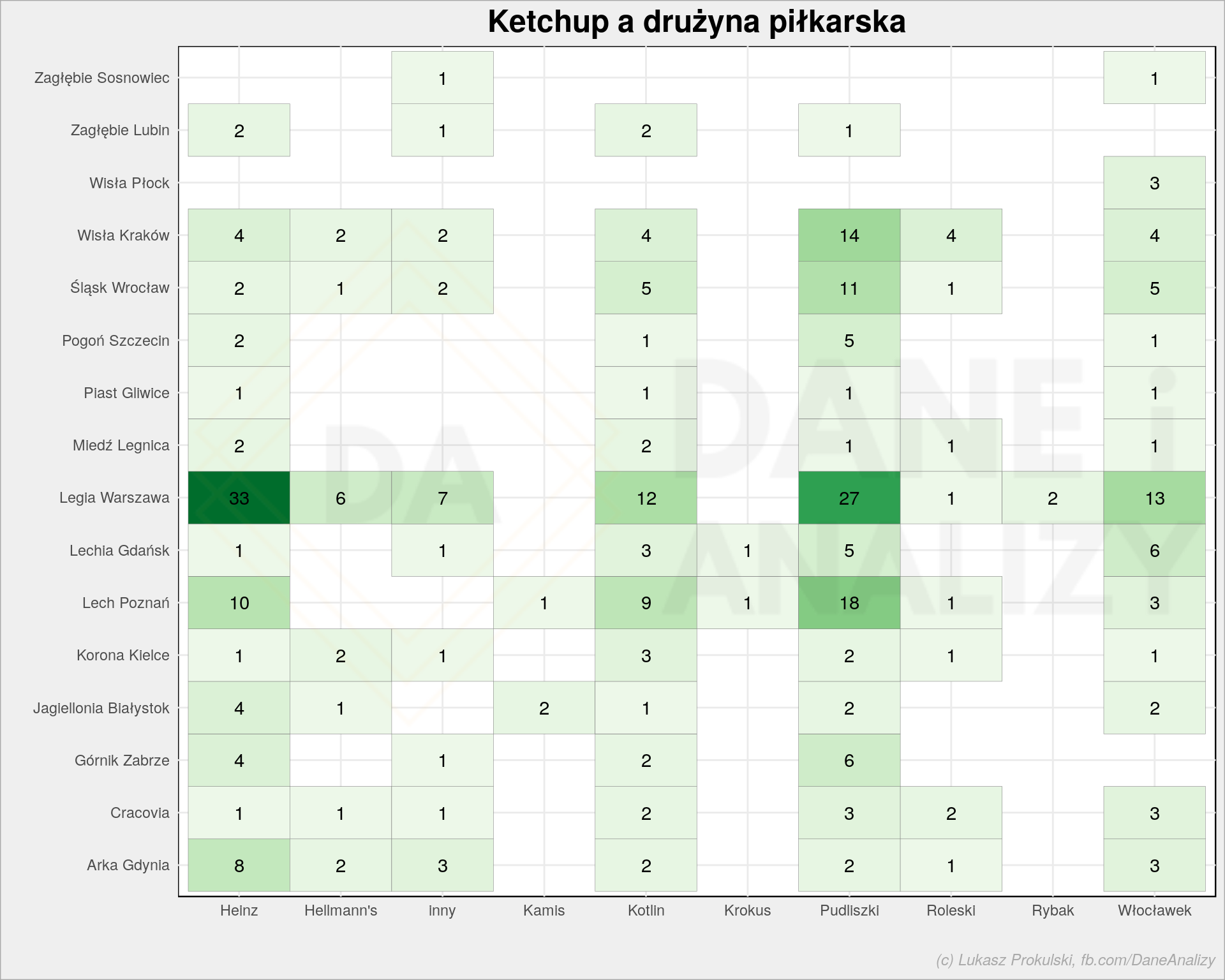
Tutaj mamy podobnie. Kibice Legii wybierają Heinz? To tylko fragment danych – wynika z niego, że około 32.7% kibiców Legii wskazało Heinza.
Ale może w okolicach Warszawy jest bardzo dużo głosów nie wskazujących żadnej ulubionej drużyny albo żadnego konkretnego ketchupu? Pamiętajcie, żeby nie wnioskować zbyt łatwo na podstawie tylko części danych. Po usunięciu filtrów mamy podobne liczby i podobny wynik (31.7% dla Heinza wśród Legionistów), ale różnica jednak istnieje.
Patrząc odwrotnie – miłośnicy Heinza w 44% to kibice Legii (i to najlepszy wynik). Tak jest jeśli odrzucimy nie-kibiców. Ale razem z osobami nieinteresującymi się piłką nożną (tak ich roboczo nazwijmy) – Legioniści to już tylko niecałe 23% fanów Heinza. Największą grupę (wśród klientów tej marki ketchupu) stanowią Ci, którzy nie kibicują żadnej drużynie (niespełna 48%). I na kogo wydasz swój budżet marketingowy, marketerze z Heinz – na kibiców czy na nie-kibiców? Właśnie.
Na koniec tej części coś co jest chyba najbardziej prawdziwe (co nie znaczy, że wszystko wyżej jest nieprawdziwe) – para ketchup i majonez:
|
1 2 3 4 5 6 7 8 9 10 11 |
p5 <- all_data %>% count(majonez, ketchup) %>% ggplot() + geom_tile(aes(majonez, ketchup, fill = n), color = "gray50", show.legend = FALSE) + geom_text(aes(majonez, ketchup, label = n)) + scale_fill_distiller(palette = "Greens", direction = 1) + theme_minimal() + labs(title = "Ketchup a majonez") + theme(axis.text.x = element_text(angle = 45, vjust = 0.6)) p5 |
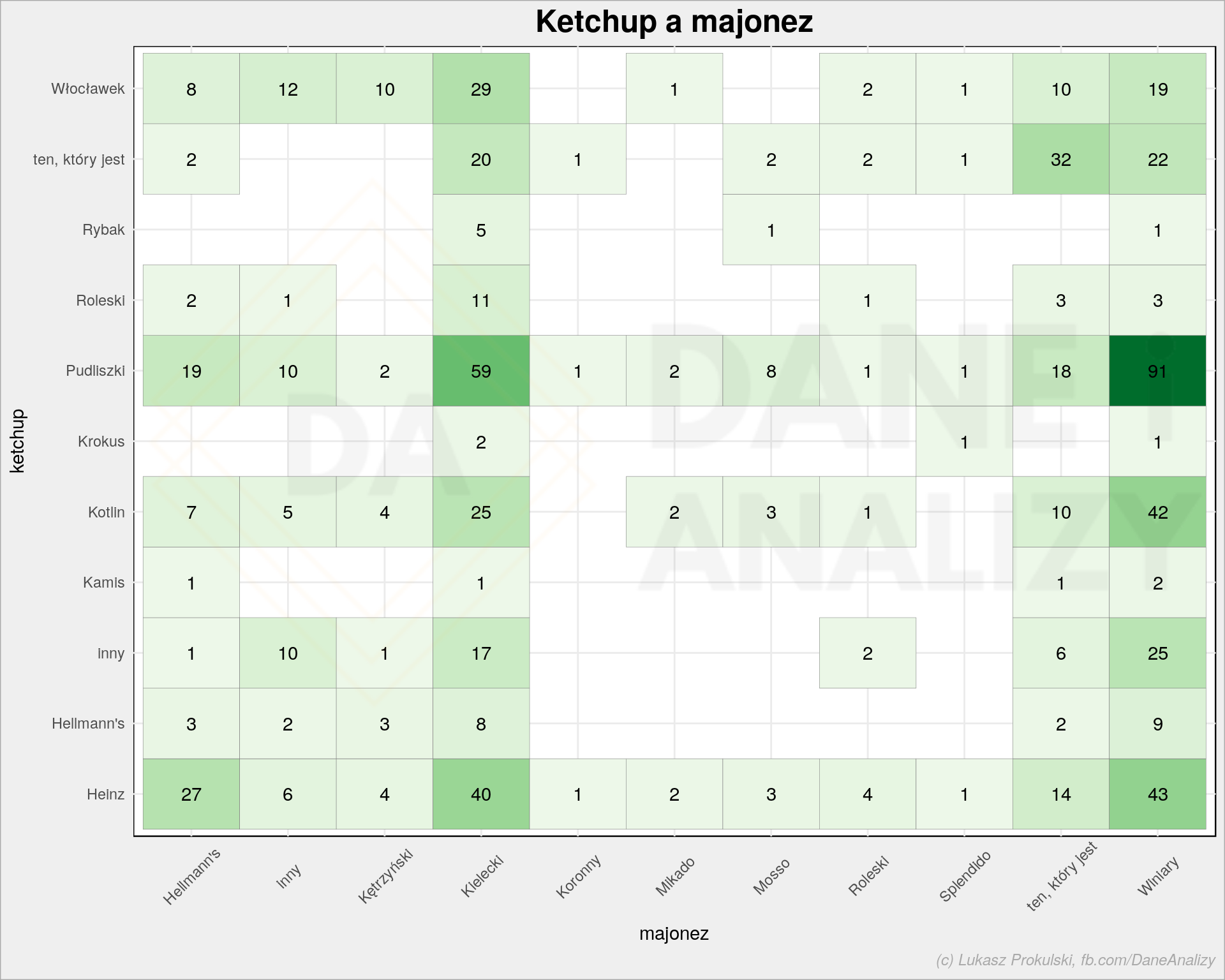
Najczęściej w koszyku sklepowym razem występuje majonez Winiary i ketchup Pudliszki (12% takich głosów). Ale 4.25% to odpowiedzi typu wszystko jedno. W sondażach politycznych owo wszystko jedno jest najbardziej kluczowe czasami, o te głosy odbywa się walka. Zakładam, że producenci wszystkich tych majonezów i ketchupów mają o wiele bardziej prawdziwe dane pochodzące chociażby z paragonów.
Tak, są firmy, które robią takie badania. Dodatkowo nasze Ministerstwo Finansów wprowadziło obowiązek jakichś kas fiskalnych działających online i łączących się z serwerami MF. Wiecie co będzie wynikiem? Każdy zakupiony towar wpadnie do bazy, razem z informacją gdzie (numer ID sklepu/kasy) i kiedy (data oraz czas wydania paragonu) został zakupiony. Każdy.
A jeśli dwa produkty były na jednym paragonie to znaczy, że zostały kupione razem. Teraz tylko jedna kwerenda wystarczy aby dowiedzieć się jak często taki czy inny majonez kupowany jest z takim czy innym ketchupem. Gdyby do tego dodać numer karty kredytowej… to wiadomo kto, gdzie, kiedy i jak dużo kupuje na przykład piwa i czipsów. Wiadomo jaki ma PESEL (z banku po numerze karty), wiadomo gdzie pracuje (z ZUSu po PESELu), wiadomo gdzie mieszka (z urzędu gminy, też po PESELu). Wielki Brat? Nie, Polska. Polskie państwo zdaje się po 2019 roku. Czy mam coś przeciwko? Tak – to, że nie mam tych danych i nie mogę ich sprzedawać…
Złożenie wykresów w całość (infografika)
Na koniec przygotujmy coś co super się sprzedaje w dzisiejszych czasach – infografikę. Mamy wszystkie niezbędne elementy, a nawet przygotowaliśmy stosowne wykresy. Teraz wystarczy je ułożyć jakoś sensownie razem. W R poskładać kilka wykresów razem możemy przy pomocy pakietów grid i gridExtra. Wystarczy każdy z wykresów składowych przypisać do zmiennej (nie bez powodu było to robione wyżej) i później ułożyć je na jednym dużym, o tak:
|
1 2 3 4 5 6 7 8 9 10 |
grid.arrange(p1, p2, p3, p4, p5, # lista wykresów "składowych" # układ wykresów - numerki to kolejność z listy layout_matrix = rbind(c(1,2,3), c(4,4,4), c(4,4,4), c(5,5,5)), # tytuł na górze top = "Majonez, ketchup i klub piłkarski", # podpis na dole bottom = glue("Dane zebrane z {n_glosow} głosów oddanych w ankiecie na stronie https://shiny.prokulski.science/regiony/")) |
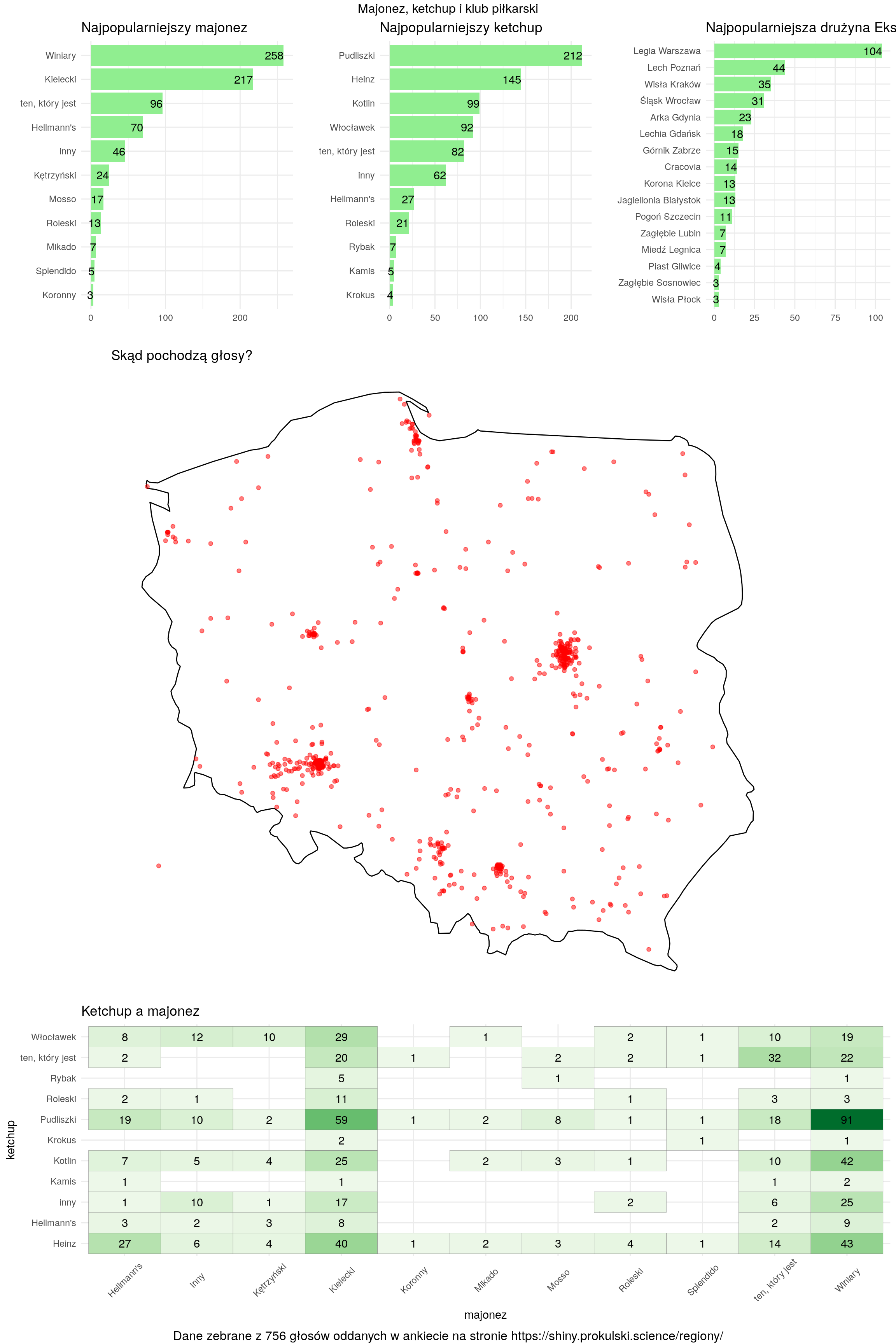
Na koniec można to obrobić w Photoshopie, pododawać jakieś logotypy i kolorki… Ale to już nie ja, nie z moimi zdolnościami graficznymi ;-).
Uogólnienie na cały kraj – kknn
Na koniec zostawiłem to, co najbardziej podobało mi się we wspomnianych na początku wpisach czy grafikach dotyczących Niemiec lub Francji. Ćwiczyliśmy to już przy okazji budowania animowanych mapek z pogodą, we wpisie Lato było cieplejsze (gdzieś tak po połowie tamtego wpisu).
Przydatna będzie biblioteka kknn:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 |
library(kknn) liga <- liga %>% filter(ekstraklasa != "żadnej") %>% filter(long >= min(poland_map$long), long <= max(poland_map$long), lat >= min(poland_map$lat), lat <= max(poland_map$lat)) %>% mutate(ekstraklasa = as.factor(ekstraklasa)) # siatka punktów w Polsce poland_grid <- expand.grid(long = seq(min(poland_map$long), max(poland_map$long), 0.05), lat = seq(min(poland_map$lat), max(poland_map$lat), 0.05)) # zbudowanie modelu model <- kknn(ekstraklasa~., liga, poland_grid, distance = 1, kernel = "gaussian") # zapełnienie siatki na podstawie modelu poland_grid <- poland_grid %>% mutate(fit = fitted(model)) # paleta wygenerowana na https://sashat.me/2017/01/11/list-of-20-simple-distinct-colors/ paleta_kolorow <- c("#e6194B", "#3cb44b", "#ffe119", "#4363d8", "#f58231", "#42d4f4", "#f032e6", "#fabebe", "#469990", "#e6beff", "#9A6324", "#fffac8", "#800000", "#aaffc3", "#000075", "#a9a9a9") # seria mapek ggplot() + geom_point(data = poland_grid, aes(long, lat, color = fit), alpha = 0.6, size = 0.1, show.legend = FALSE) + geom_polygon(data = poland_map, aes(long, lat, group=group), fill = NA, color = "black") + scale_color_manual(values = paleta_kolorow) + coord_quickmap() + theme_minimal() + theme(axis.text = element_blank()) + facet_wrap(~fit) + labs(title = "Popularność drużyn Ekstraklasy na terenie Polski", x = "", y = "") |
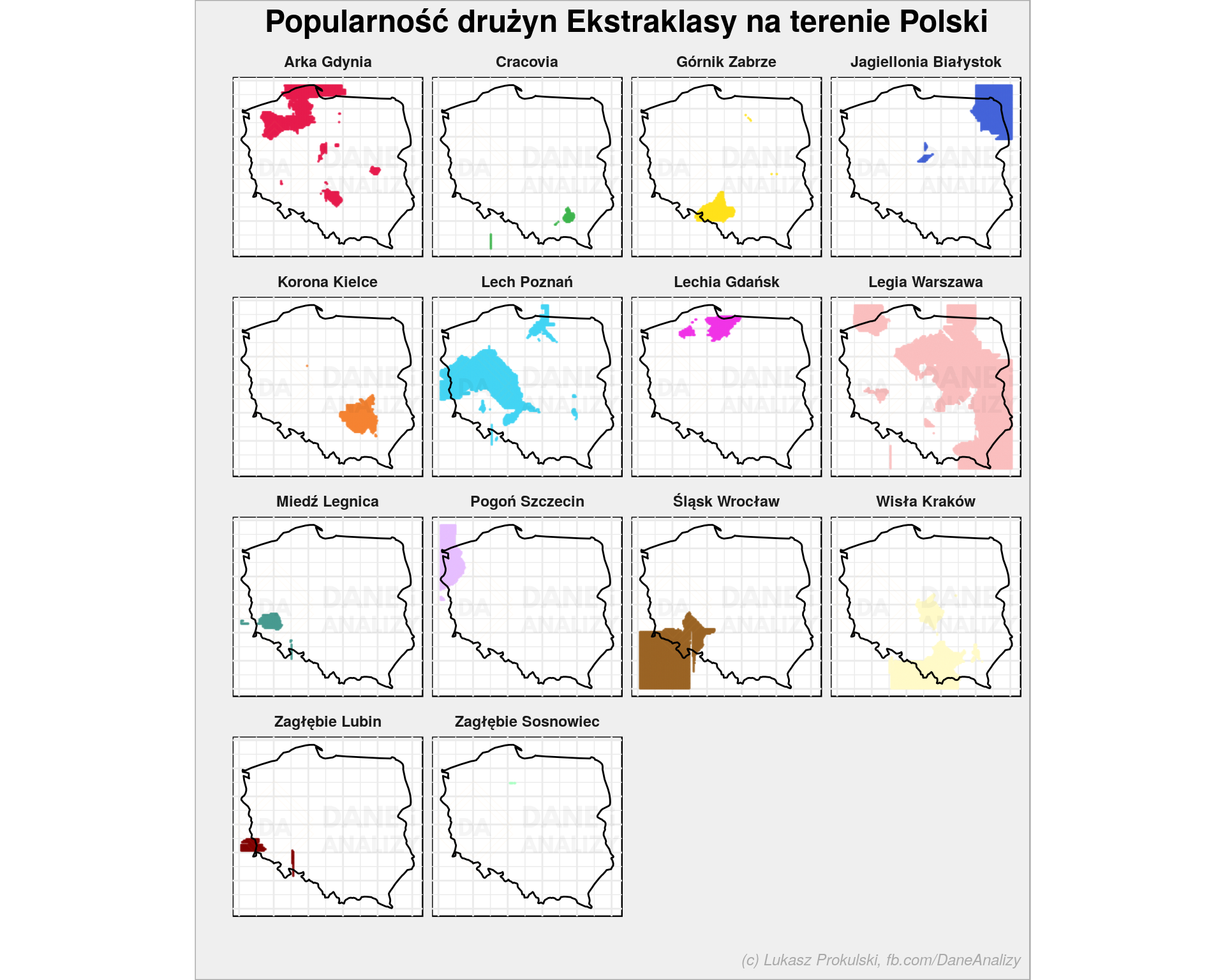
Jak to działa? W pierwszej kolejności budujemy sobie model (model <- kknn(..)), który w dużym uproszczeniu jest modelem typu k najbliższych sąsiadów (knn) i szuka dla każdej z klas centrum, czyli punktu do którego wszystkie elementy klasy mają najbliżej (łącznie, a nie każdy z osobna). W drugim kroku siatkę wszystkich punktów pokrywających Polskę (tutaj z jakimiś odstępami pomiędzy tymi punktami) traktujemy tym modelem: dla każdego z punktów siatki sprawdzane jest, które z centrów jest najbliżej i to, które centrum jest najbliżej oznacza przypisanie punktu na siatce do klasy. Dość prosty sposób, ale wymagający dużej liczby obliczeń. W R z użyciem kknn jedna linijka.
Na koniec całą siatkę dzielimy sobie na grupy i te grupy rysujemy na oddzielnych mapkach.
Wynik pokazuje nam regionalne upodobania dla konkretnych drużyn. Zaskoczenia tutaj nie ma chyba żadnego. Zwróćcie jednak uwagę, że tutaj mamy 14 drużyn (brakuje Piasta Gliwice oraz Wisły Płock) a na mapce wyżej było ich 16. Dlaczego? Bo dla brakujących drużyn było mało punktów pomiarowych (oddanych głosów – dla Piasta 4, dla Wisły Płock – 3) oraz (to przede wszystkim) nie znalazł się ani jeden punkt na siatce, który zostałby przypisany do tych drużyn.
Złóżmy to w jedną mapkę – tym razem dodając dodatkowo prawdopodobieństwo przynależności do odpowiedniej grupy, które mamy wprost z modelu (w macierzy model$prob):
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
dither_map <- bind_cols(poland_grid %>% select(long, lat), # siatka z przypisanymi klasami model$prob %>% as_data_frame()) %>% # prawdopodobieństwa przynależności do klas gather(key = "druzyna", val = "prob", -long, -lat) %>% # zmieniamy tabelkę szeroką w długą - na potrzeby ggplot() filter(prob != 0) # żeby tabela była krótsza usuwamy wiersze z zerowym prawdopodobieństwem, # które i tak niczego nie wnoszą ggplot() + # _jitter a nie _point aby punkty z siatki się nie nakładały na siebie geom_jitter(data = dither_map, aes(long, lat, # kolor określa przynależność do klasy color = druzyna, # przeźroczystość zależna jest od prawdopodobieństwa alpha = prob)) + # konruty mapki geom_polygon(data = poland_map, aes(long, lat, group=group), fill = NA, color = "black") + scale_alpha_continuous(range = c(0, 0.7)) + scale_color_manual(values = paleta_kolorow) + coord_quickmap() + theme_minimal() + labs(title = "Popularność drużyn Ekstraklasy na terenie Polski", x = "", y = "") |
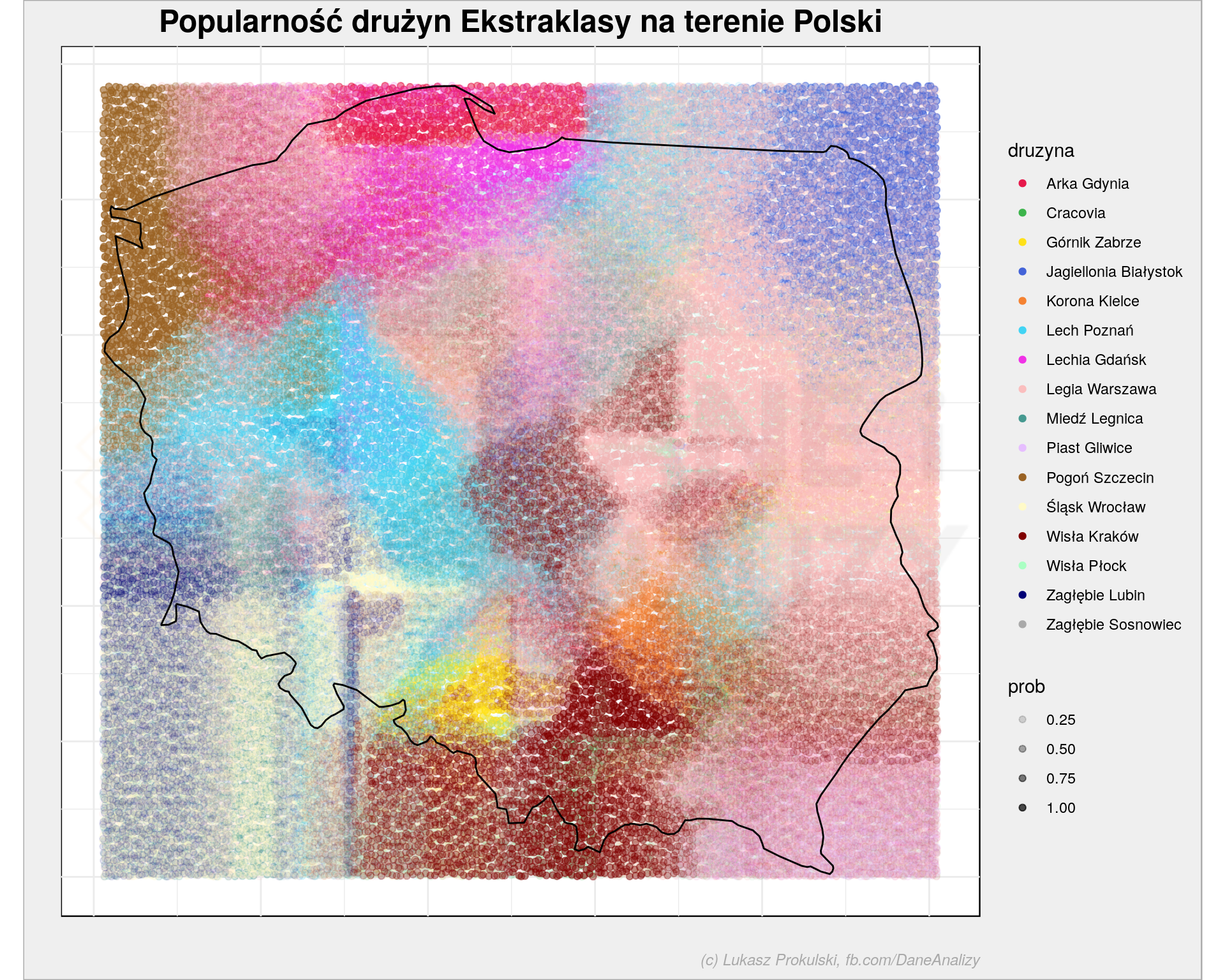
Jak widzicie (głównie po legendzie) tutaj Wisła Płock i Piast Gliwice) już się pojawiają. Bo istnieją punkty na siatce z niezerowym prawdopodobieństwem. Ale nie było ono największe w tych punktach (dla innych klas było większe), stąd nie było ich na poprzedniej mapie.
Dlaczego ta mapka jest taka nieczytelna? Bo klas mamy za dużo i jednocześnie za mało zwarte obszary. Wyraźnie widać Lecha Poznań w Wielkopolsce, trochę Koronę w pobliżu Kielc czy Górnika na Górnym Śląsku. Dużo głosów rozsianych po dużej części kraju (patrz wcześniejsza mapka) jest na rzecz Legii i to zaciemnia obraz.
Oczywiście dokładnie to samo można zrobić dla majonezu i ketchupu – spróbujcie w domu!
Podsumowanie
Z prostej ankiety udało nam się wydobyć trochę informacji, być może cennych dla producentów majonezu i ketchupu. Dowiedzieliśmy się, że
- dwie najpopularniejsze marki majonezu zagarniają łącznie prawie 2/3 rynku,
- zaś najpopularniejszy ketchup zgarnia nieco ponad 1/4
i to bez sięgania po informacje o rzeczywistych wynikach sprzedaży.
Badanie na grupie 756 może nie jest idealne, ale wydaje się być reprezentatywne. Możesz dorzucić swoje głosy w ankiecie, która ciągle działa i w dodatku na końcu pokazuje kawałek wyników. Wystarczy wejść na stronę z aplikacją i oddać swój głos.
Przy okazji zobaczyliśmy jak z poziomu R dostać się do bazy danych (tutaj MySQL, ale w sumie bardzo podobnie jest z PostgreSQL czy np. SQLite). Jeśli chcesz pogłębić wiedzę na ten temat to przeczytaj Databases using R. Można nawet zbudować model (regresję lm() ale i las losowy randomForest()), przetłumaczyć go na zapytanie SQL i już na bazie wykonać – interesujący do tego celu wydaje się być pakiet tidypredict.
Dowiedzieliśmy się też jak uogólnić na cały kraj dane z części lokalizacji (metodą kknn).
Mam jednak nadzieję, że przede wszystkim pobudziłem Cię do myślenia. Czy warto wierzyć takim danym? Gdzie może być haczyk, który wywraca wszystko do góry nogami? A może go wcale nie ma i jest tak jak widzieliśmy na powyższych wykresach? Mój blog to nie tylko R, ale też pobudzanie do myślenia (mam nadzieję, że tak jest), inspirowanie do zadawania własnych pytań i szukania dla nich odpowiedzi. Jeśli prowadzisz biznes i zadajesz sobie jakieś pytania to może mogę Ci pomóc? Trochę już w swoim życiu danych przerzuciłem w różne strony, trochę pytań zadałem. I projektów zrobiłem.
A jeśli nie prowadzisz biznesu to daj na majonez albo ketchup ;P. Wszystkiego też sam nie napiszę, a dużo jest do poczytania – zapraszam więc do śledzenia fanpage’a Dane i Analizy, bo tam do czytania znajdziesz dużo.
Kętrzyński jak zwykle niedoceniany…
Dokładnie. Kętrzyński jest najlepszy.
Mój ulubiony to Kotlin. Jemy go od lat <3