Jak podzielić użytkowników strony internetowej na grupy? Korzystając tylko ze statystyk ruchu.
W poprzedniej części dowiedzieliśmy się jak skorzystać z danych z Google Analytics w R. Pod koniec wpisu podałem linki do postów, które opisują jak dodać unikalne ID użytkownika wchodzącego na stronę. Dzisiaj zajmiemy się próbą przypisania każdego z użytkowników do jakiejś grupy.
Kategoryzacja klientów to jedno z podstawowych działań w biznesie. Dlaczego? Możemy zechcieć coś innego pokazać na naszej stronie różnym grupom klientów. Albo – jeśli mamy na przykład maile (z zapisów na newsletter) wysłać inne treści. Znajomość klientów i ich zachowań to podstawa.
Spróbujemy na podstawie posiadanych danych określić grupy klientów. Tymi danymi mogą być odwiedziny na stronie WWW albo wyświetlenie reklamy w aplikacji w telefonie, zakupy w rzeczywistym sklepie, udział w jakimś wydarzeniu (na przykład pójście do kina). Zwróćcie uwagę, że w każdym z wymienionych przypadków wiemy zazwyczaj nieco więcej:
- użytkownik wchodzi na stronę: wiemy dodatkowo na ile i jakie podstrony wszedł (jaką treść czytał), ile czasu spędził na stronie (nawet na każdej podstronie), skąd przyszedł (i na przykład z jakiej reklamy), jakiej używa przeglądarki, z jakiej sieci (IP, geolokalizacja) przychodzi
- wyświetlenie reklamy – większość z powyższych plus w jakiej na przykład aplikacji wyświetlił reklamę (czy to aplikacja typu gierka dla dzieci czy lista zakupów), być może jego rzeczywistą lokalizację geograficzną w momencie wyświetlenia reklamy
- wizyta w kinie – jaki to film, które to kino, ile biletów kupił, w jaki sposób (w kasie czy przez internet, jak zapłacił)
- zakupy – co kupił, ile zapłacił
Oczywiście wszystko to możemy zebrać jeśli zbieramy unikalne identyfikatory użytkowników. W internecie jest łatwiej :)
W naszym przypadku ograniczymy się do minimum, do najbardziej szczątkowych danych. Jedyne informacje jakie mamy to identyfikacja, że konkretny użytkownik (konkretne ID) wszedł na stronę w konkretnym momencie. Nic więcej. Za dane posłużą nam dane treningowe z konkursu Kaggle Google Analytics Customer Revenue Prediction – możecie ściągnąć plik train.csv.
W pierwszym kroku wczytamy nasze dane (tylko wybrane kolumny) i poprawimy zapis daty na bardziej użyteczny.
|
1 2 3 4 5 6 7 8 9 10 11 |
library(data.table) # dla fread() library(tidyverse) library(lubridate) df <- fread("data/train.csv", select = c(4,12), col.names = c("user_id", "timestamp")) df <- df %>% mutate(timestamp = as_datetime(timestamp), date = as_date(timestamp), wday = wday(timestamp, week_start = 1, label = TRUE, abbr = FALSE, locale = "pl_PL.utf8"), hour = hour(timestamp)) |
Dane wczytujemy z użyciem fread() z pakietu data.table – jest piekielnie szybka. Wybieramy tylko dwie kolumny: user_id będącą numerkiem użytkownika oraz timestamp – będącą momentem rozpoczęcia wizyty na stronie. W danych jest więcej informacji, ale dla uproszczenia (i pokazania że nawet z taką niewielką ilością danych można coś zdziałać) wykorzystamy tylko te dwie kolumny.
Podczas przygotowania modelu najlepiej zacząć od przeglądu danych. Pierwsze kroki to sprawdzenie czy mamy jakieś braki, czy są jakieś wartości odstające itd. W tym przypadku wszystkie dane są kompletne, nie musimy się tym zajmować (możecie zaufać mi na słowo).
Zobaczmy jak wyglądała liczba wizyt w czasie:
|
1 2 3 4 5 6 7 |
df %>% count(date) %>% ggplot(aes(date, n)) + geom_area(fill = "lightblue", alpha = 0.5) + geom_line(color = "blue", size = 0.2) + labs(title = "Dzienna liczba wizyt", x = "", y = "Łączna liczba wizyt") |
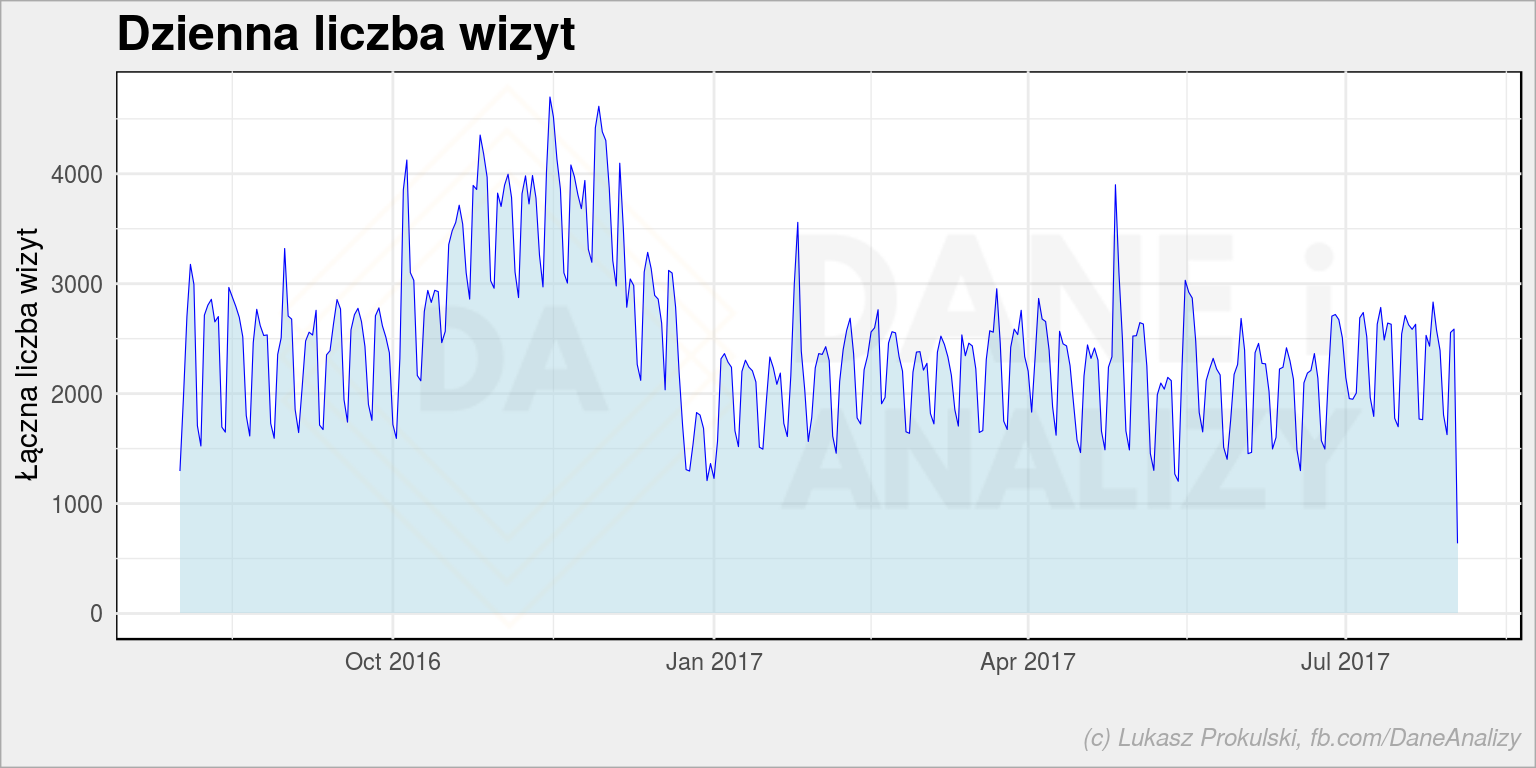
Mamy sporą górkę jesienią 2016 roku – spodziewam się, że była wtedy jakaś kampania reklamowa, stąd zwiększony ruch.
Widać też regularne dołki w równych odstępach czasu – to zapewne weekendy. Możemy to sprawdzić rysując heatmapę dzień tygodnia – godzina:
|
1 2 3 4 5 6 7 8 |
df %>% count(wday, hour) %>% ggplot() + geom_tile(aes(wday, hour, fill = n), color = "gray50") + scale_y_reverse() + scale_fill_distiller(palette = "Greens", direction = 1) + labs(title = "Łączna liczba wizyt na stronie\nw zależności od dnia tygodnia i godziny", x = "", y = "Godzina", fill = "Łączna liczba\nwizyt na godzinę") |
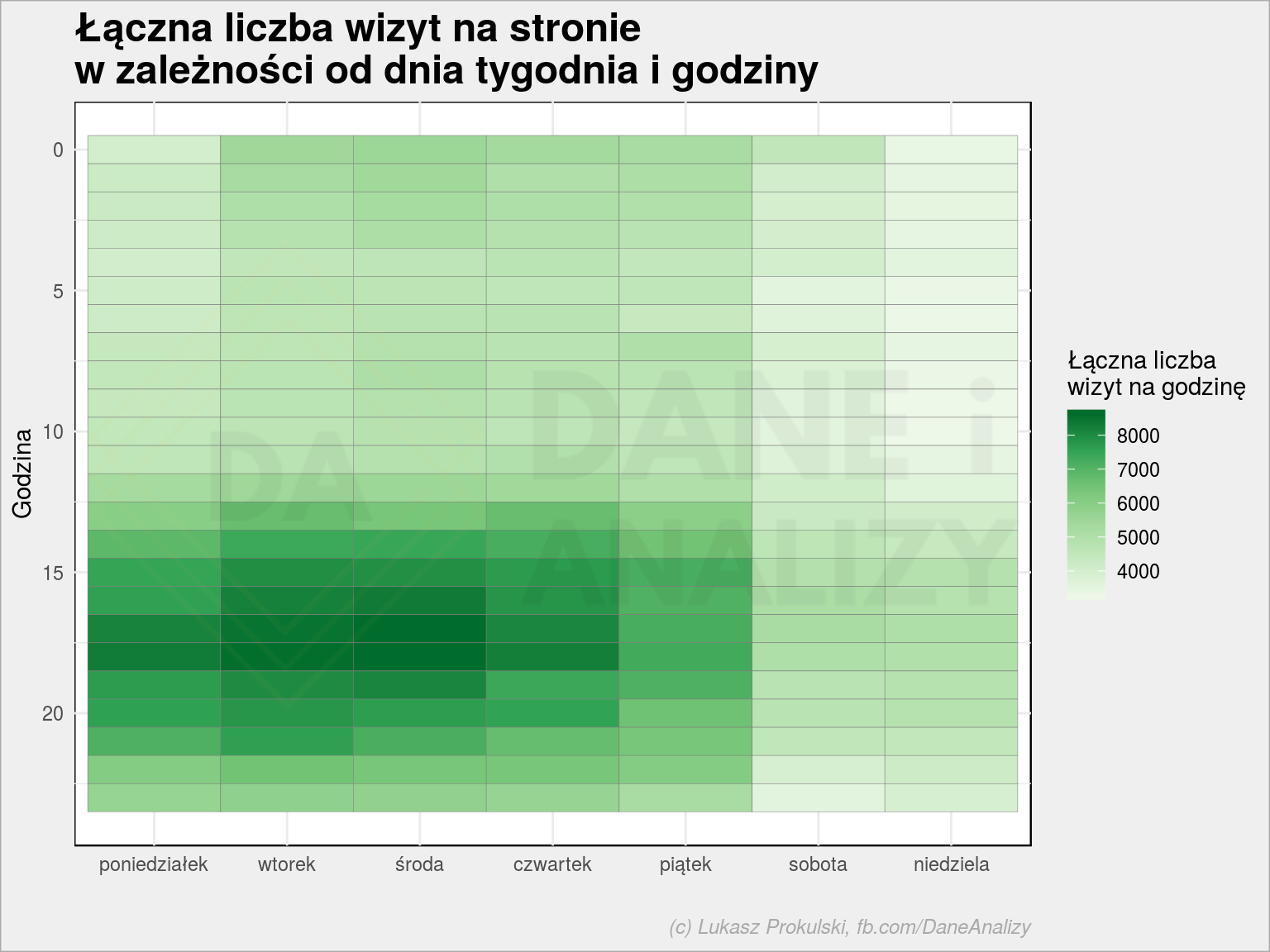
I przypuszczenia się potwierdzają: większy ruch jest w godzinach popołudniowych w dni robocze. Jest tutaj coś, co wprawne oko zauważy, ale niech to na chwilę będzie niewiadomą.
Policzmy teraz ile razy dany użytkownik (czyli unikalny user_id) odwiedzał stronę:
|
1 2 3 4 5 6 7 |
df %>% count(user_id) %>% ggplot() + geom_density(aes(n), fill = "lightblue", color = "blue", size = 0.2) + scale_x_log10() + labs(title = "Rozkład liczy wizyt użytkownika na stronie", x = "Liczba wizyt użytkownika", y = "Gęstość prawdopodobieństwa") |
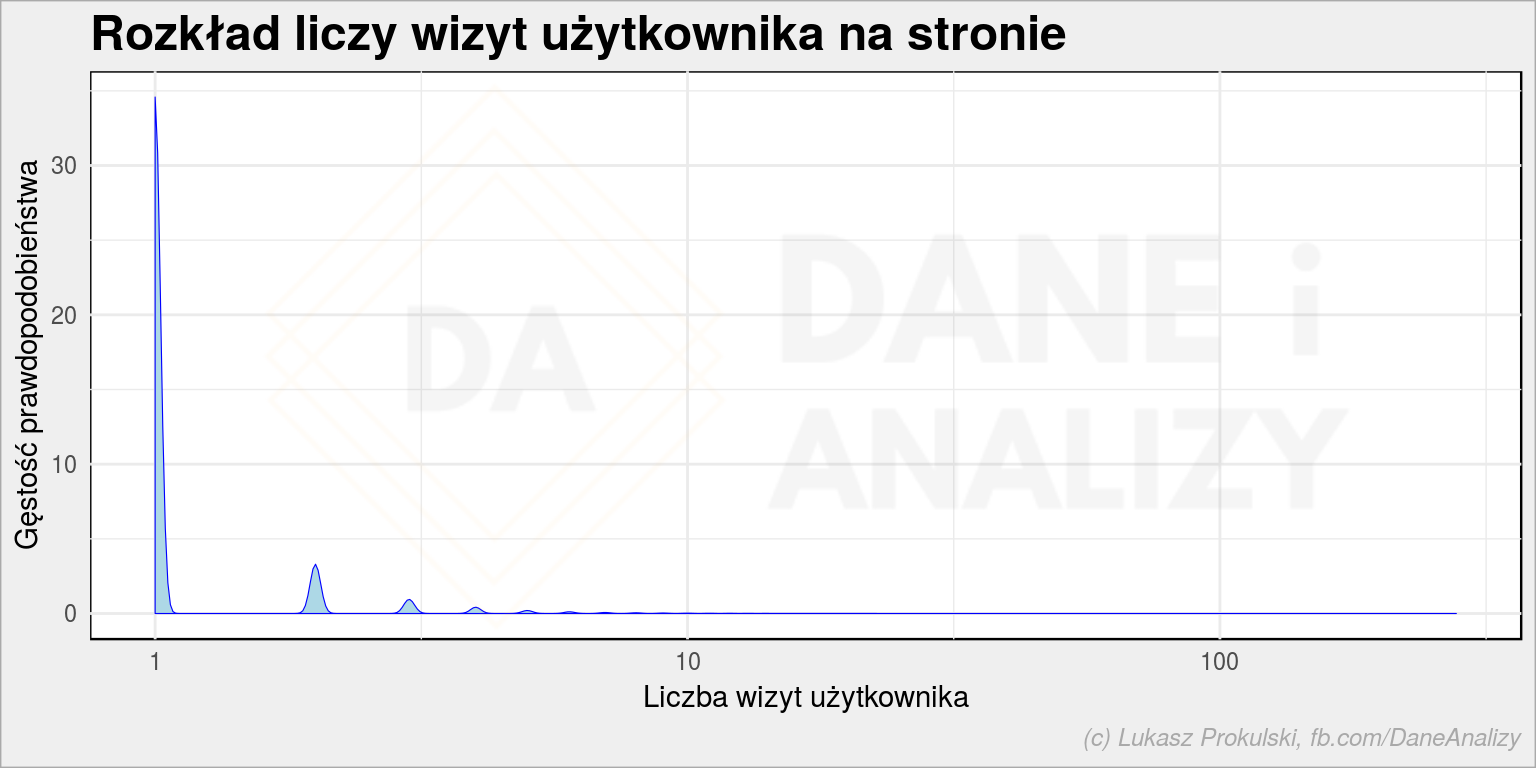
Wielka szpila dla pojedynczych odwiedzin, a później coraz niższe górki dla kolejnych. Powyżej 10 razy prawie nikt nie odwiedzał strony. Skorzystamy z tej informacji.
Na początek przygotujmy trzy funkcje, które ułatwią nam pracę.
Pierwsza z nich z całości danych wybierze tylko ich fragment. W przemysłowych warunkach może okazać się zbędna. Tutaj wybieramy tylko użytkowników, którzy odwiedzili stronę co najmniej dwa razy.
|
1 2 3 4 5 6 7 8 9 10 |
select_data <- function(source_df) { # znajdź ID użytkowników z co najmniej 2 wizytami users_more_than_once <- count(source_df, user_id) %>% filter(n >= 2) %>% pull(user_id) # wybierz tylko tych użytkowników z całości danych df_more_than_once <- filter(source_df, user_id %in% users_more_than_once) return(df_more_than_once) } |
Większość modeli lepiej działa jeśli dane liczbowe będące cechami do uczenia modelu są przeskalowane do zakresu <0;1>. Zatem przygotujmy odpowiednią funkcyjkę skalującą:
|
1 2 3 |
scale_num <- function(x) { return( (x - min(x)) / (max(x) - min(x)) ) } |
I na koniec funkcja najważniejsza: przygotowanie cech, których użyje model. Ten kod robi kilka rzeczy:
- liczy ile razy użytkownik odwiedził stronę (w całym badanym czasie) – ta informacja trafia do zmiennej n_times
- rozdziela datę na kolejne dni tygodnia – dodając zmienną dw z wartością w1 do w7; literka w upraszcza późniejsze problemy z nazwami kolumn
- w zmiennej w określa czy dana data to sobota lub niedziela (1 jeśli tak, 0 jeśli nie); przy podejściu bardziej kompleksowym warto uwzględnić też inne dni wolne od pracy (święta, w sklepach stacjonarnych wolne niedziele niehandlowe)
- następnie funkcja sumuje liczbę wystąpień poszczególnych zmiennych dla każdego użytkownika w kolejnych godzinach
- na koniec rozsmarowuje długą tabelę na tabelę szeroką, gdzie w kolejnych wierszach mamy informacje dla kolejnych numerów user_id odwiedzających stronę w kolejnych godzinach (w najbardziej skrajnym przypadku może być więc 24 wierszy dla jednego user_id), a w kolumnach: liczbę wizyt w danym dniu tygodnia i w weekendy oraz łączną liczbę wizyt użytkownika w całym badanym czasie
- na koniec skalujemy kolumny z łączną liczbą odwiedzin i godziną konkretnej wizyty do przedziału <0;1>
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
prepare_data <- function(source_df) { source_df %>% # łączna liczba wizyt na użytkownika group_by(user_id) %>% mutate(n_times = n()) %>% ungroup() %>% # cechy oparte na dacie mutate(dw = sprintf("w%d", wday(timestamp, week_start = 1)), # dzień tygodnia h = hour(timestamp), # godzina w = 1*(wday(timestamp, week_start = 1) %in% c(6, 7))) %>% # czy weekend? # zliczamy liczbę wizyt w danym dniu tygodnia i o określonej godzinie dla każdego z użytkowników count(user_id, n_times, w, h, dw) %>% # przechodzimy na szeroką tabelę - takie nieco one-hot-encoder dla dni tygodnia i weekendów spread(dw, n, fill = 0) %>% # skalowanie godzin i łącznej liczby odwiedzin mutate_at(.vars = c("h", "n_times"), .funs = scale_num) } |
Odpalmy zatem naszą maszynę. Najpierw wybieramy interesujące nas dane z całości – czyli tych użytkowników, którzy byli na stronie co najmniej dwa razy (zgodnie z select_data()):
|
1 |
df_train <- select_data(df) |
Ostatecznie będziemy działać na 31% danych – bo tyle mamy użytkowników powracających. Zobaczmy jak wyglądała liczba wizyt dla wszystkich użytkowników (czerwone) i dla tych wybranych w poszczególnych dniach (zielone):
|
1 2 3 4 |
ggplot() + geom_line(data = df_train %>% count(date), aes(date, n), color = "green") + geom_line(data = df %>% count(date), aes(date, n), color = "red") + labs(x = "", y = "Liczba wizyt danego dnia") |
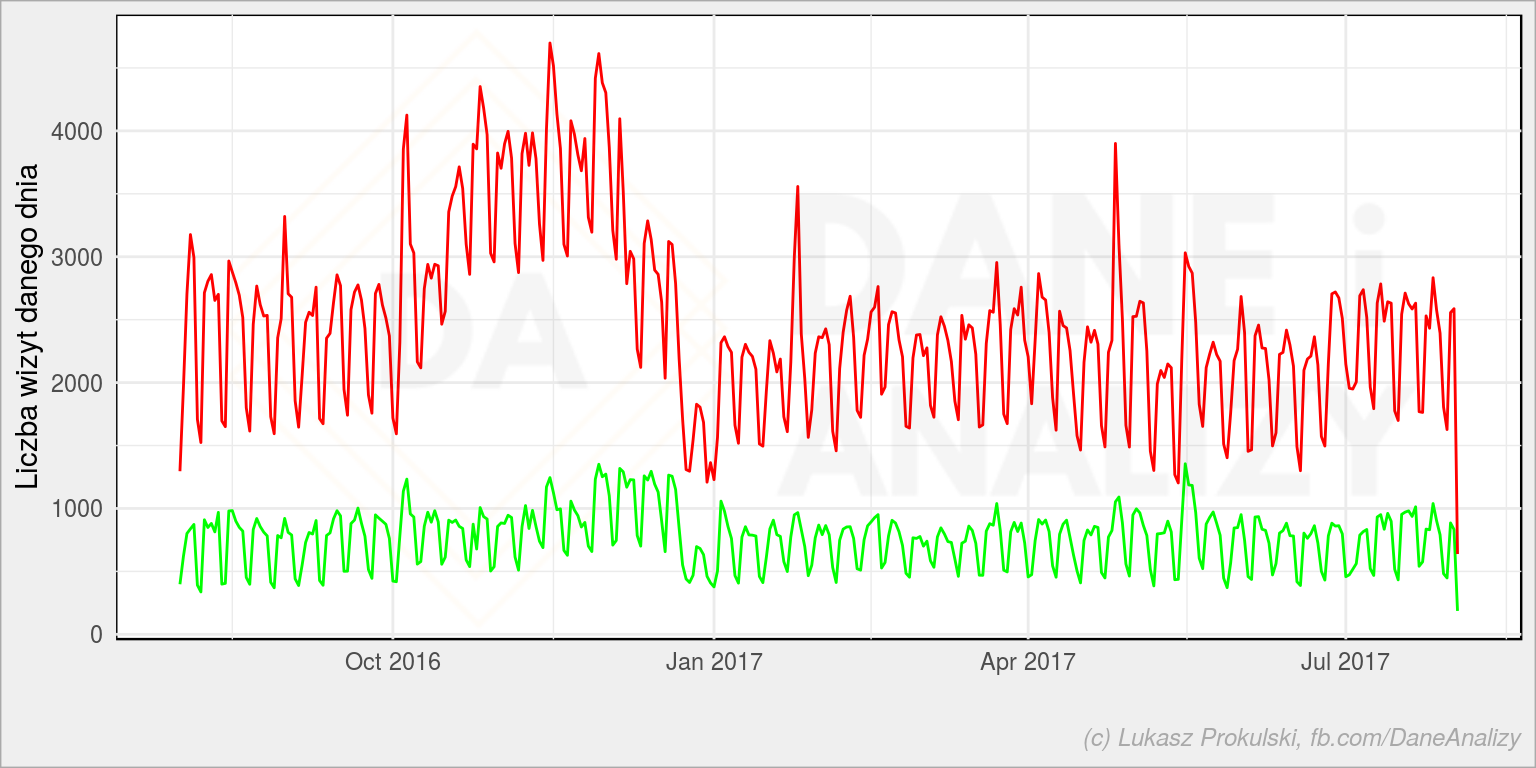
Czerwone to wszyscy i tutaj jesienna górka z 2016 roku pozostała. Na zielonym jest mniej więcej stabilnie. Wniosek z kampanią reklamową wydaje się być słuszny. Możemy szybko sprawdzić udział powracających do wszystkich:
|
1 2 3 4 5 6 7 8 |
left_join(df %>% count(date) %>% set_names(c("date", "n_all")), df_train %>% count(date) %>% set_names(c("date", "n_train")), by = "date") %>% mutate(ratio = 100*n_train/n_all) %>% ggplot() + geom_line(aes(date, ratio)) + labs(title = "Udział procentowy użytkowników powracających", x = "", y = "% użytkowników powracających") |
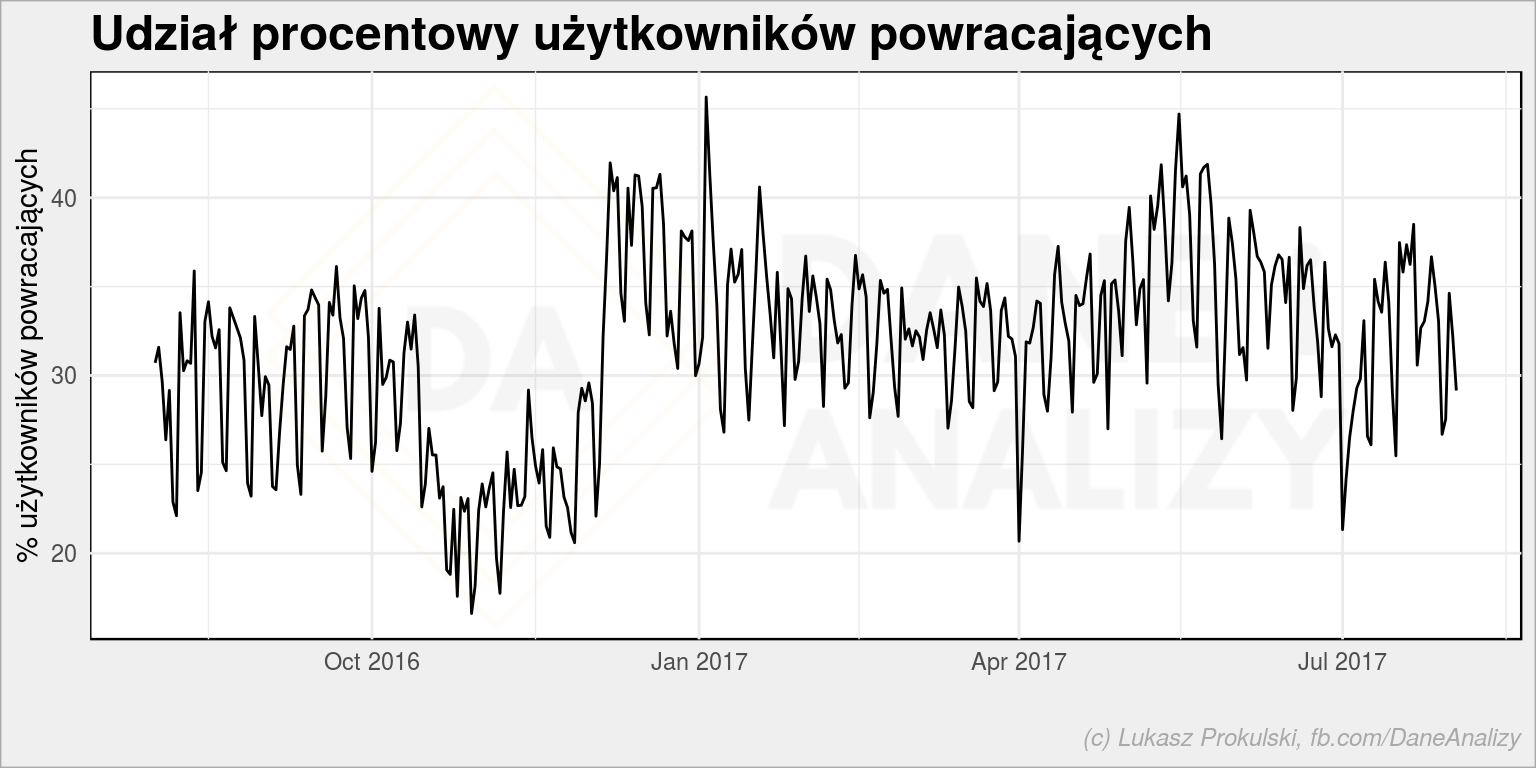
Uwaga – powyższy wykres jest fałszywy. Dlaczego? Bo jako powracającego bierzemy każdego użytkownika, który w całym badanym okresie zrobił co najmniej dwie wizyty. Czyli tego, który odwiedził stronę we wrześniu 2016 i w lipcu 2017. Dla ostatniego dnia będzie już powracającym, ale dla np. stycznia 2017 jeszcze nie (bo nie zrobił swojej kolejnej wizyty). Ale to tylko uproszczenie, które znowu pokazuje nam, że jesienią 2017 mamy więcej jednorazowych strzałów (mniejszy udział powracających), zatem po raz kolejny mamy (prawdopodobne) potwierdzenie kampanii reklamowej.
W kolejny kroku przygotowujemy nasze dane na potrzeby modelu:
|
1 |
wide_mat <- prepare_data(df_train) |
i wybieramy same unikalne wartości i tylko cechy (bez numerów user_id):
|
1 2 3 |
wide_mat_dist <- wide_mat %>% select(-user_id) %>% distinct() |
Dlaczego tylko unikalne? Dlatego, żeby późniejsze przypisanie klas i sam model nie spowodowało, że takiej samej kombinacji przypisujemy inną klasę. Jest to trochę dmuchanie na zimne i jednocześnie zmniejsza nam wielkość danych – mamy 15597 unikalnych wierszy spośród 241672 (czyli 15.5 razy mniej) – co przyspiesza obliczenia.
Taką tablicę możemy podzielić na przykład na trzy grupy korzystając z algorytmu k-means.
|
1 2 3 4 5 |
# kmeans do określenia kategorii usera km <- kmeans(wide_mat_dist, centers = 3) # przypisujemy klasy do danych treningowych wide_mat_dist$cluster <- as.factor(km$cluster) |
Czy k-means to najlepszy sposób? To jeden z elementów przygotowania modelu, zatem warto poświęcić mu więcej czasu. Jeśli mamy jakiekolwiek cechy, które pozwolą przypisać użytkownika do grupy – powinniśmy z tego skorzystać. W tym przypadku mamy tylko datę wizyty, dlatego zastosowałem uczenie nienadzorowane. Każda inna metoda może być dobra (hierarchical clustering chociażby). Każda inna liczba grup też może być dobra. K-means i trzy grupy to tylko przykład!
W ramach ciekawostki możemy zrzutować naszą wielowymiarową przestrzeń na płaszczyznę – zwykle robi się to przy użyciu algorytmu PCA albo t-SNE. Dzisiaj ten drugi:
|
1 2 3 4 5 6 7 |
# sprawdźmy czy tworzą się jakieś klastry library(Rtsne) tsne <- Rtsne(wide_mat_dist, initial_dims = ncol(wide_mat_dist)) tsne_df <- as.data.frame(tsne$Y) ggplot(tsne_df, aes(V1, V2)) + geom_point() |
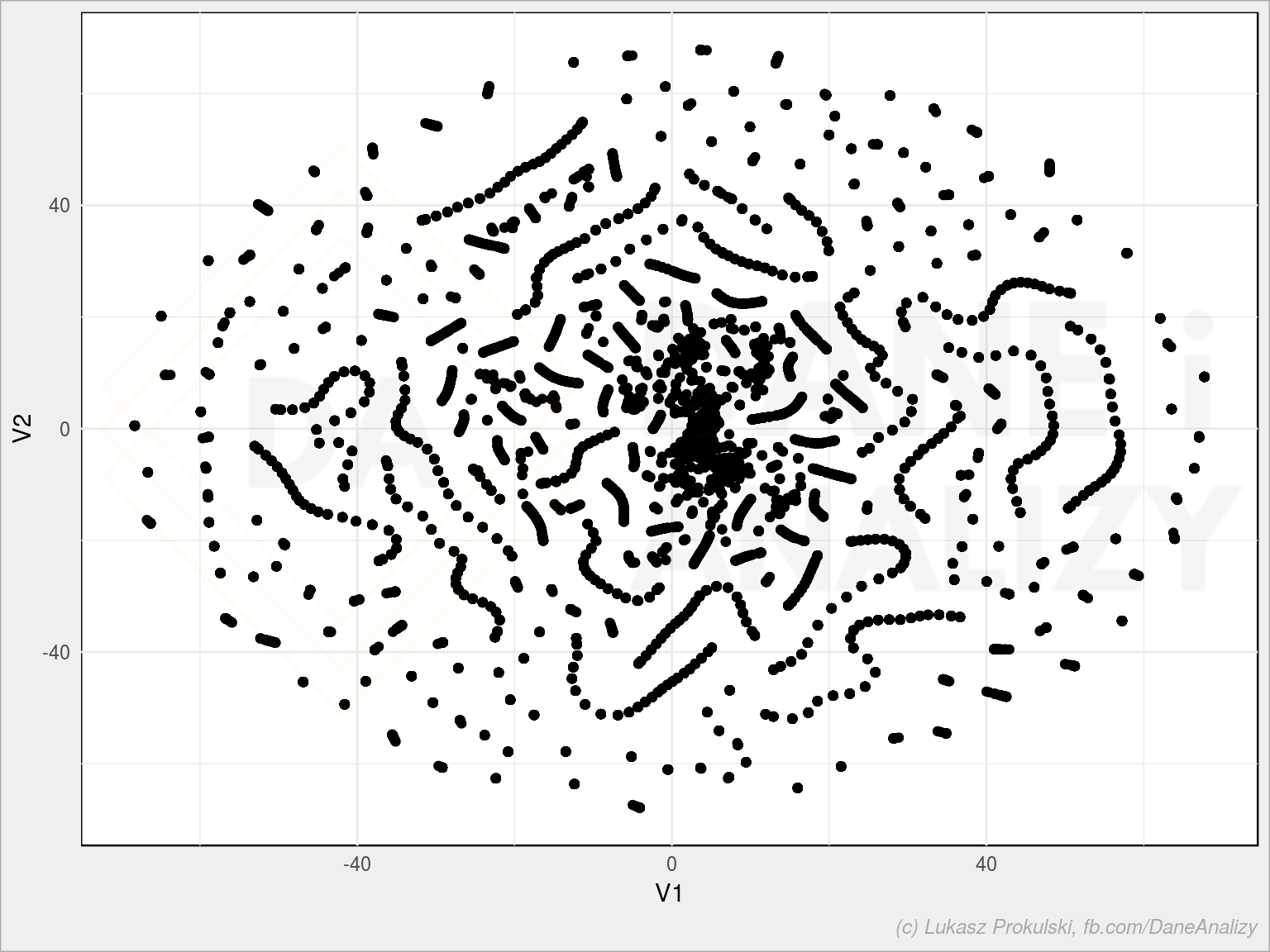
Widać jakieś grupy. Wiele ich. Można je wykorzystać do klasteryzacji (i dopiero tutaj nadawać klasy). My zrobiliśmy ją wcześniej, więc zobaczmy jak wyglądają te grupy na obrazie z t-SNE:
|
1 2 3 |
tsne_df$cluster <- as.factor(km$cluster) ggplot(tsne_df, aes(V1, V2, color = cluster)) + geom_point() |
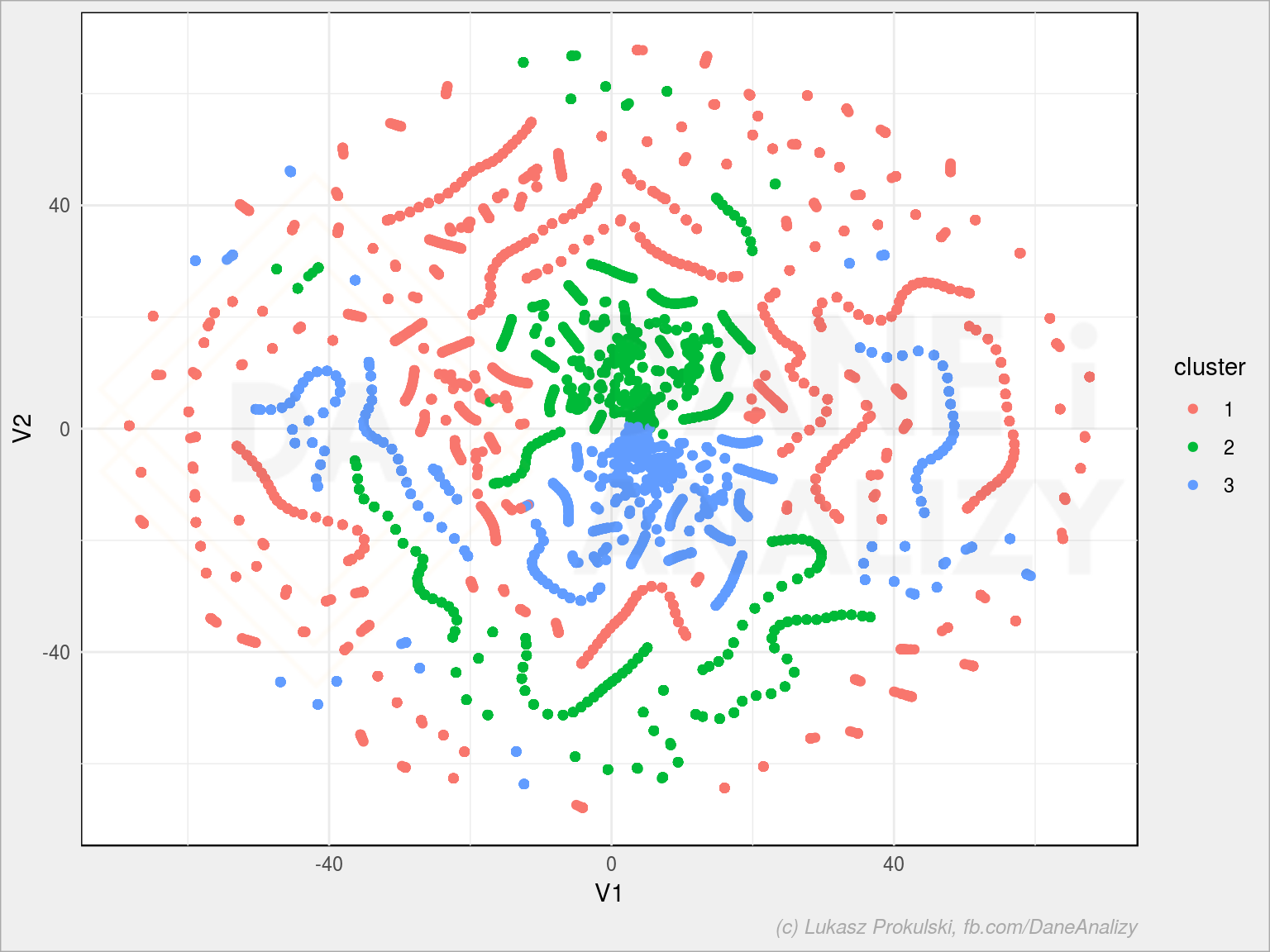
Ależ pięknie wyszło! Nie jest źle – poszczególne skupiska są w jednym kolorze. Gdyby było inaczej warto byłoby sprawdzić inną liczbę klastrów albo inny model klasteryzacji). Albo dzielić na klastry to co mamy po t-SNE (albo PCA).
Albo (co wydaje się nawet sensowniejsze) cofnąć się jeszcze bardziej i spróbować wyłuskać inne cechy z danych (przebudować funkcję prepare_data()), może dorzucić jakieś dane? Nasze wyłuskane cechy są dość banalne, co zobaczymy za chwilę.
Przygotujemy teraz model, tak aby dla nowych danych potrafił przypisać klasy. Może to być dowolny model kategoryzujący: od np. SVM, przez drzewa decyzyjne, las losowy (którego użyjemy), XGBoost, sieci neuronowe (FF pewnie najbardziej, można spróbować z CNN). Proste algorytmy opisałem dawno temu.
|
1 2 3 4 |
library(randomForest) model <- randomForest(cluster ~ ., data = wide_mat_dist, importance = TRUE) |
Las losowy wybrałem nieprzypadkowo – przede wszystkim jest stosunkowo szybki (jak na taką ilość danych), ale co ważniejsze – w prosty sposób możemy sprawdzić jakie cechy są najważniejsze dla modelu (stąd włączony parametr importance). Wszystkie parametry zostawiłem domyślne, aby już nie komplikować za bardzo.
|
1 |
varImpPlot(model) |
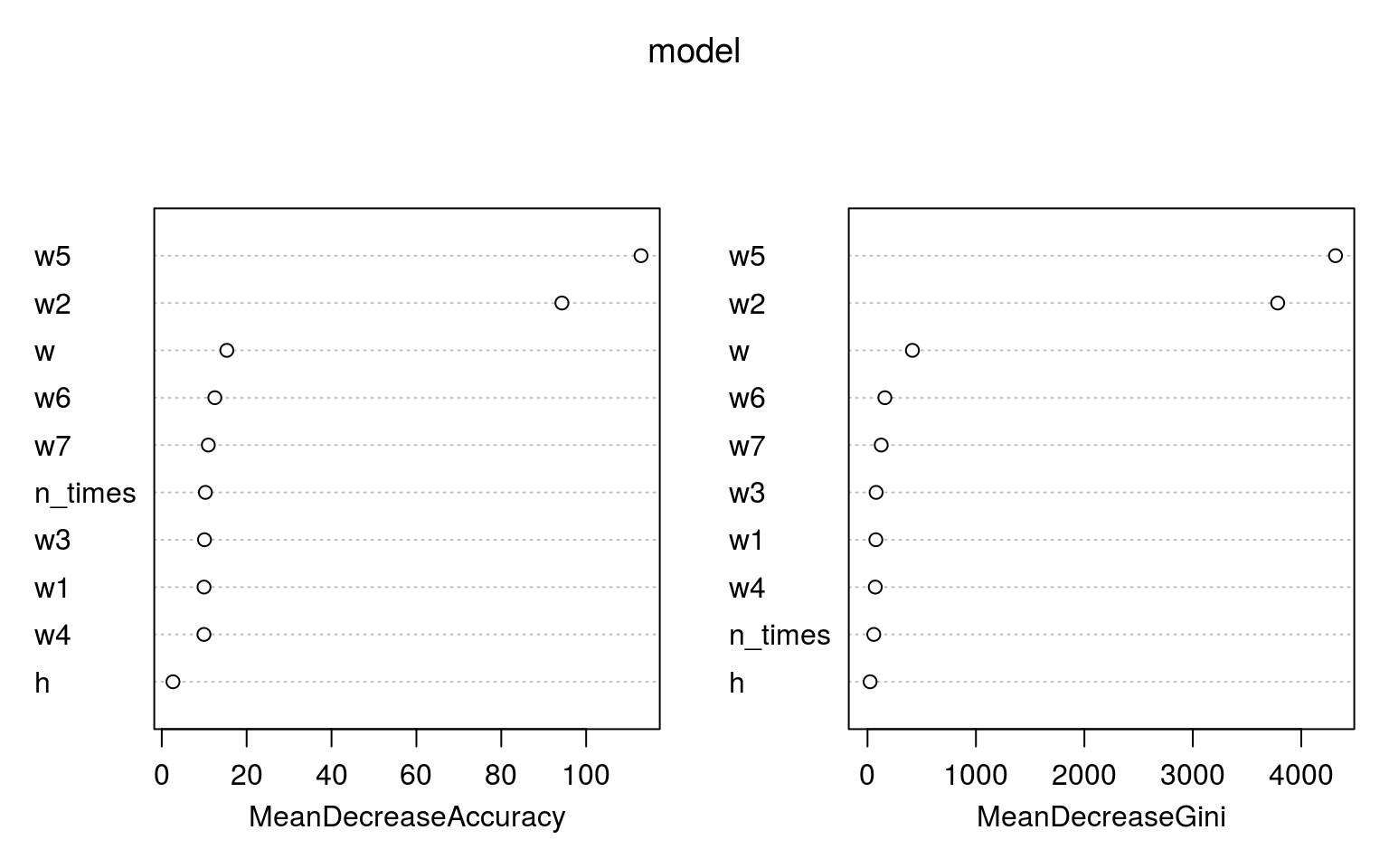
I co tutaj widzimy? Że najważniejsze jest to w jakim dniu tygodnia była wizyta – czy był to weekend (cecha w) czy któryś z dni poniedziałek – piątek (cechy w1 do w5 – szczególnie wtorek w2 i piątek w5). Godzina (cecha h) ma najmniejsze znaczenie, ważniejsza jest krotność powrotów (cecha n_times). Z godziną można sobie poradzić (próbować) – zamiast brać konkretną godzinę możemy podzielić dobę na kilka części (noc, rano, południe, popołudnie i wieczór) i albo użyć tego podziału w jednej zmiennej albo zrobić z niej kilka (one hot encoding).
|
1 2 3 4 5 6 7 |
# dopisujemy klasy do szerokiej tabeli z user_id wide_mat$cluster <- predict(model, wide_mat) # mając przypisanie user_id do klas możemy dodać klasy do danych źródłowych df_train_clusters <- left_join(df_train, select(wide_mat, user_id, cluster), by = "user_id") |
Zakładamy w tym momencie, że nasz model działa poprawnie i jakoś dzieli odwiedzających. Sprawdźmy jak rozkłada się ruch w poszczególnych klasach.
Na początek ruch dzień po dniu (tutaj dla czytelności obrazu wybieram jeden miesiąc). Na tym i kolejnych wykresach liczba wizyt w danum dniu jest zeskalowana do przedziału <0;1> aby sprowadzić wartości do jednej miary i uniezależnić od ewentualnych pików dla którejś z grup.
|
1 2 3 4 5 6 7 8 9 10 |
df_train_clusters %>% filter(year(date) == 2017, month(date) == 4) %>% count(cluster, date) %>% group_by(cluster) %>% mutate(n_scaled = scale_num(n)) %>% ungroup() %>% ggplot() + geom_area(aes(date, n_scaled, fill = cluster), alpha = 0.5, position = position_identity()) + geom_line(aes(date, n_scaled, color = cluster)) + labs(title = "Znormalizowana liczba wizyt", x = "", y = "") |
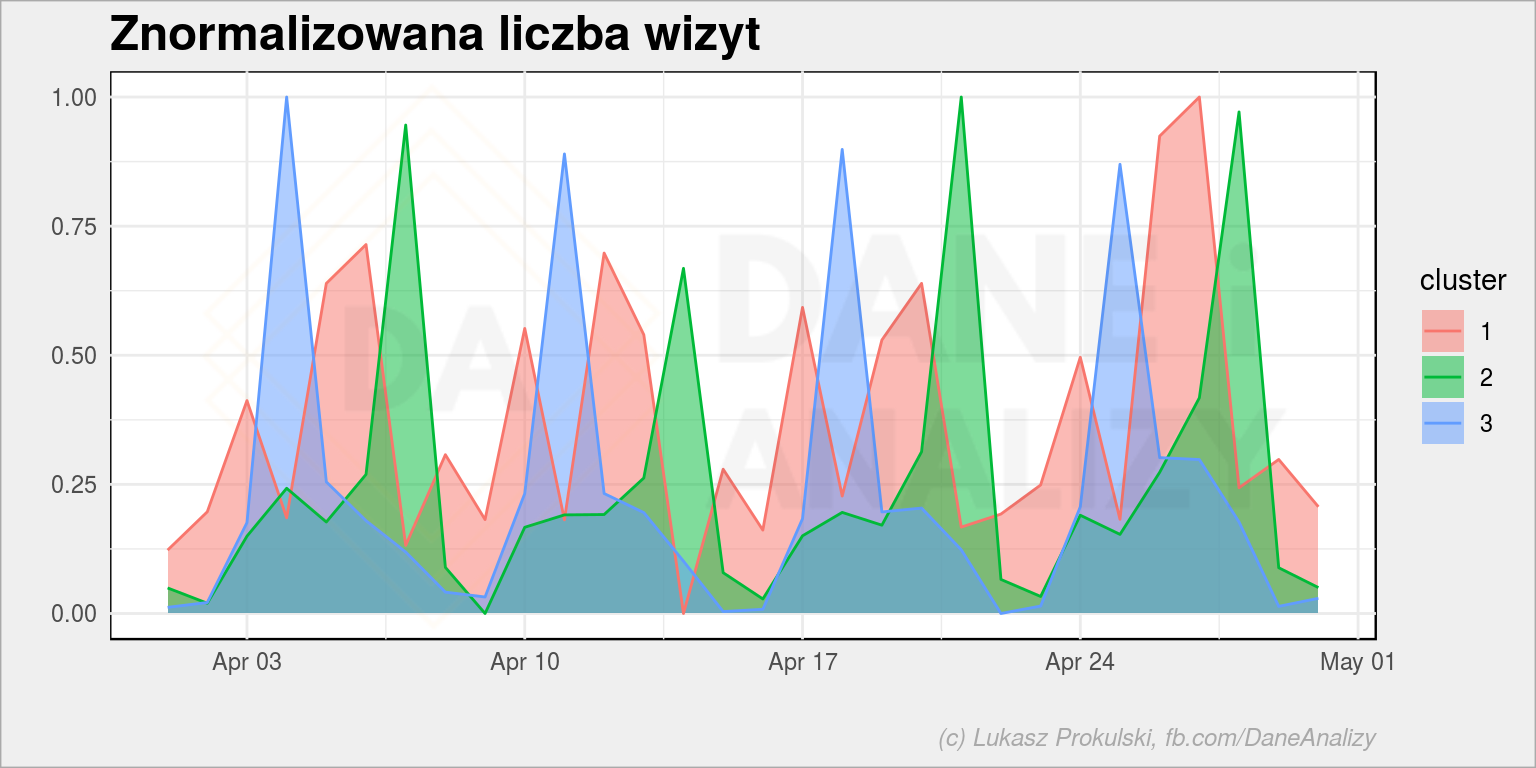
Coś widać. Szpilki są poprzesuwane względem siebie. Zobaczmy ruch według dni tygodnia:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
df_train_clusters %>% count(cluster, wday) %>% group_by(cluster) %>% mutate(n_scaled = scale_num(n)) %>% ungroup() %>% mutate(wday = fct_rev(wday)) %>% ggplot() + geom_col(aes(wday, n_scaled, fill = cluster)) + coord_flip() + facet_wrap(~cluster, scales = "free_y") + labs(title = "Znormalizowana liczba wizyt według grupy i dnia tygodnia", x = "", y = "", fill = "Grupa") + theme(legend.position = "bottom") |
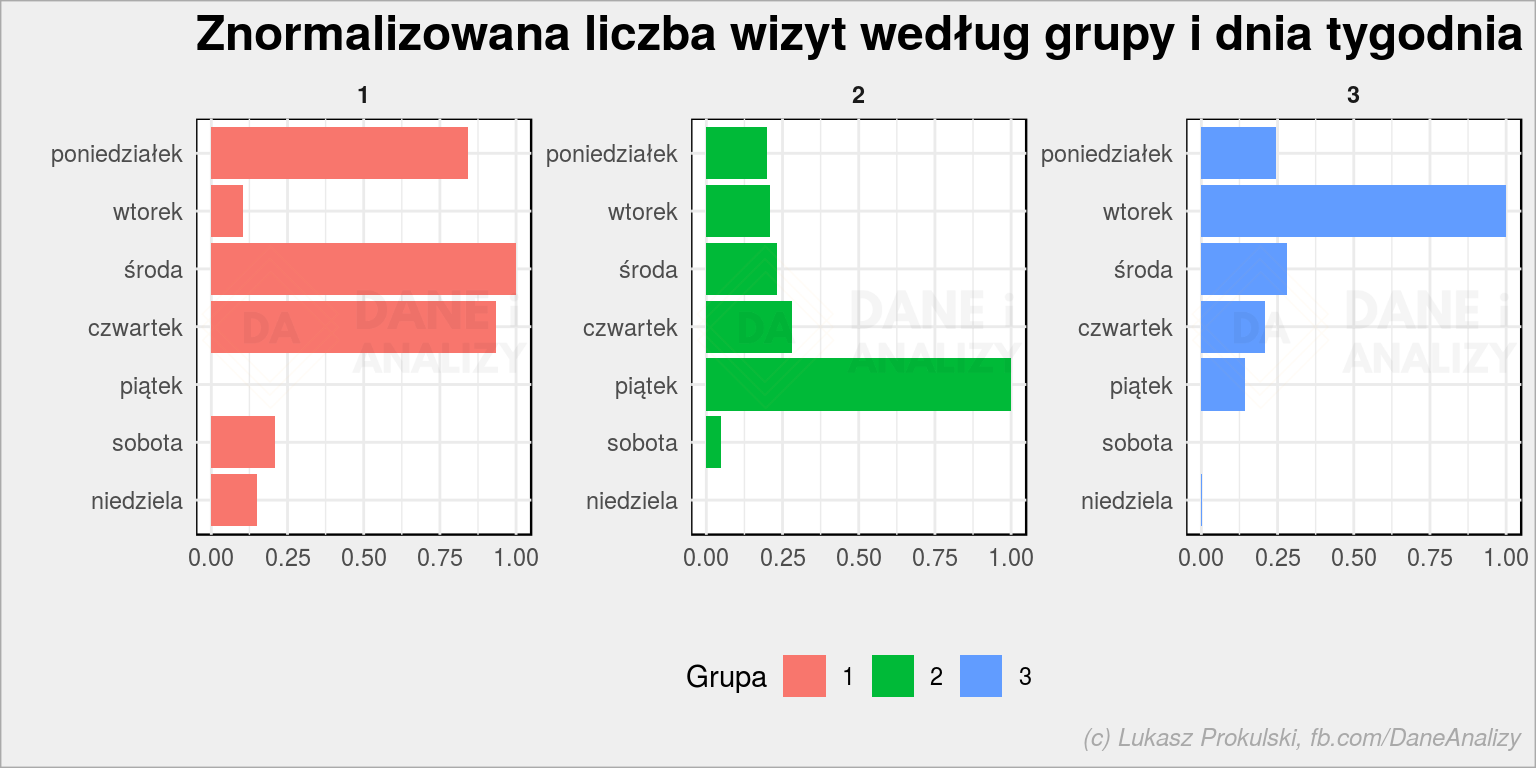
Tutaj już wyraźniej widać użytkowników weekendowych (i jednocześnie poniedziałkowych, środowych i czwartkowych) i z konkretnych dni (część lubuje się we wtorkach, inni – w piątek; pamiętacie kilka obrazków wyżej ważność cech w2 i w5?). A jak to się ma w podziale na godziny:
|
1 2 3 4 5 6 7 8 9 10 |
df_train_clusters %>% count(cluster, hour) %>% group_by(cluster) %>% mutate(n_scaled = scale_num(n)) %>% ungroup() %>% ggplot() + geom_col(aes(hour, n_scaled, fill = cluster)) + facet_wrap(~cluster, scales = "free_y") + labs(title = "Znormalizowana liczba wizyt według grupy i godziny", x = "", y = "", fill = "Grupa") + theme(legend.position = "bottom") |
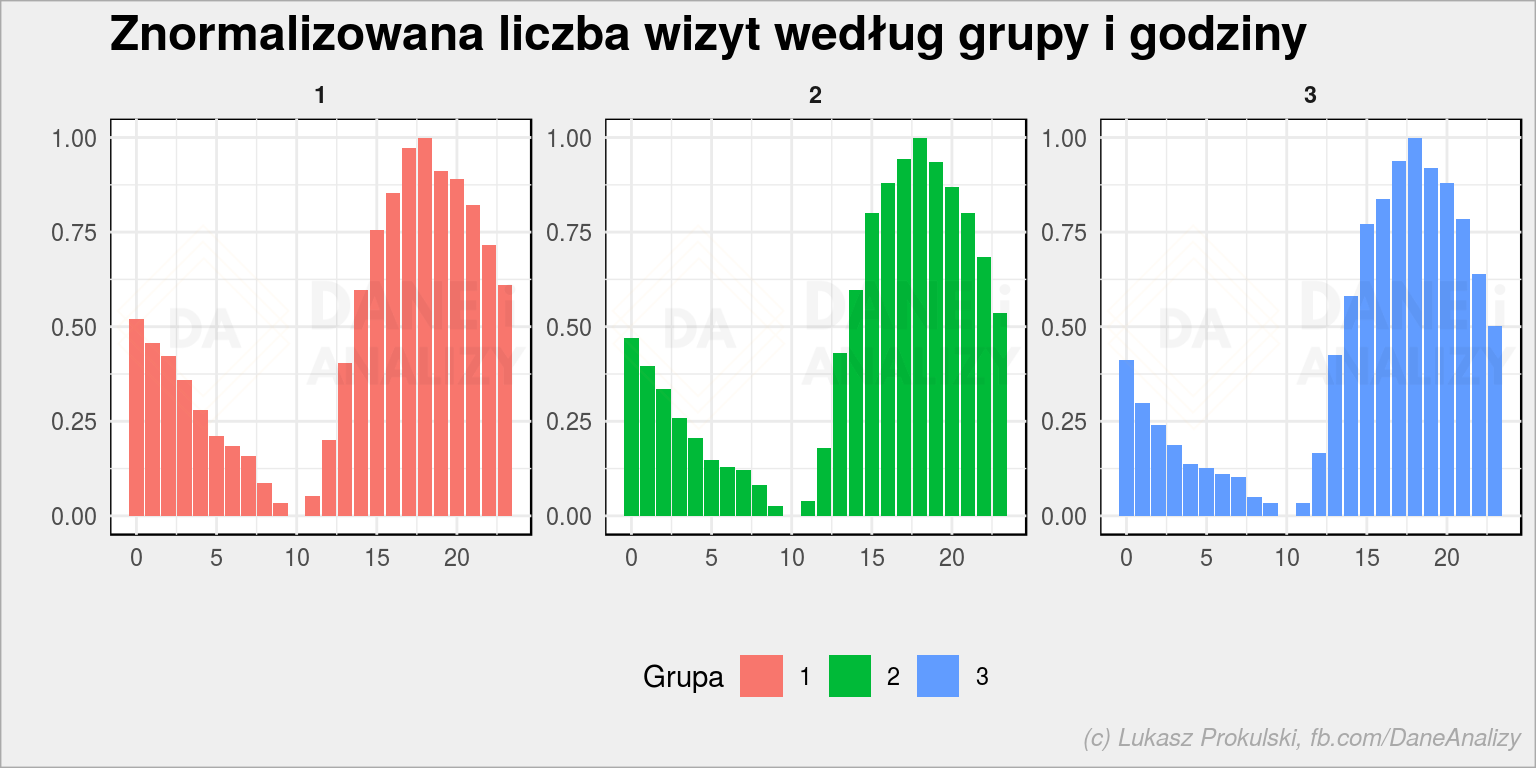
Szczerze mówiąc ma się nijak, chociaż nienaturalny wydaje się dołek w okolicach przedpołudniowych. Wiecie dlaczego tak jest? Bo to dane z amerykańskiej strony, a czas polski – w takim Nowym Jorku o naszej 10 rano jest środek nocy (4 rano) – stąd ten dołek.
Dla wszystkich grup rozkłady wyglądają podobnie. To kolejny kamyczek (po sprawdzeniu ważności zmiennych) do ogródka nie należy brać godziny jako cechę do modelu.
Na koniec możemy złożyć wykres tygodniowy i godzinowy w heat mapę:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
df_train_clusters %>% count(cluster, wday, hour) %>% group_by(cluster) %>% mutate(n_scaled = scale_num(n)) %>% ungroup() %>% mutate(wday = fct_rev(wday)) %>% ggplot() + geom_tile(aes(wday, hour, fill = n_scaled), color = "gray50", show.legend = FALSE) + facet_wrap(~cluster) + scale_fill_distiller(palette = "Greens", direction = 1) + coord_flip() + labs(title = "Znormalizowana liczba wizyt według grupy, dnia tygodnia i godziny", x = "", y = "") |
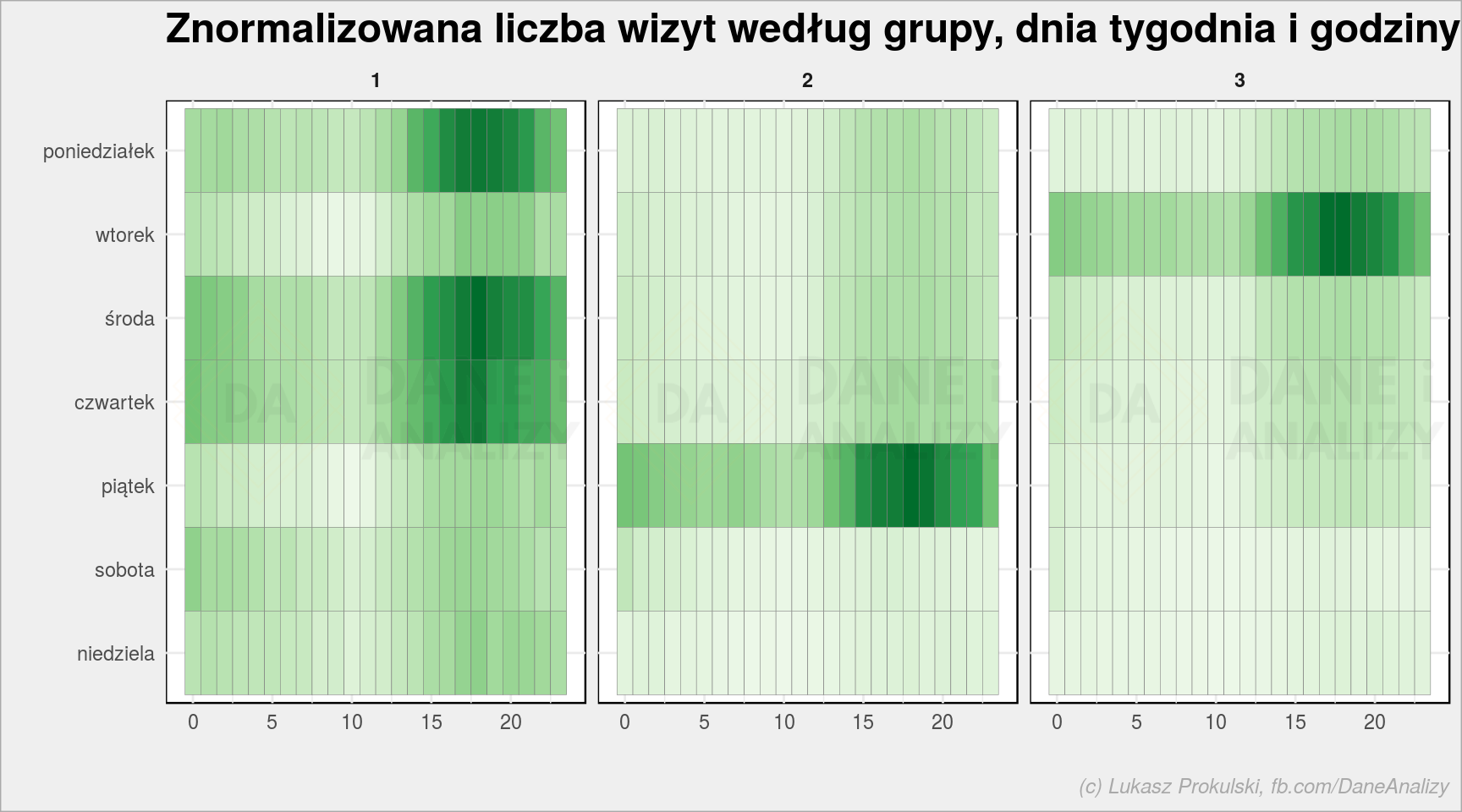
Gdyby godzina miała znaczenie dla przypisania do grup uzyskalibyśmy tutaj bardziej nasycone placki na przykład we wtorki rano w jednej grupie i w weekendy po południu w drugiej.
Gdybyśmy mieli więcej danych to byłoby łatwiej. W naszym przykładzie ograniczyliśmy się do minimum. Zapewne wystarczyłoby dorzucić informacje o pohodzeniu użytkownika i przeglądarce z jakiej korzysta. Dostalibyśmy na przykład grupy weekendowych wieczornych przeglądaczy na telefonie albo tych co szukają informacji podczas pracy korzystając z desktopów. Zerknijcie na kernele do konkursu Kaggle, z którego pobraliśmy dane – tam znajdziecie pełno EDA jak i samych modeli.
Dla przychodzących do kina moglibyśmy dodać gatunek filmu, dla przychodzących do klubu fitness – zajęcia czy ćwiczenia z jakich korzysta, w jakie dni, w jakich porach (po pracy, przed pracą), czy są to konkretne kluby czy losowo wybrane, a może takie które z jakiegoś powodu (duży parking? po drodze z pracy do domu?) są lepsze czy wygodniejsze dla konkretnego użytkownika.
Dane są wszędzie, trzeba tylko wiedzieć o chce się zmierzyć i odpowiednio je dobrać. Jeśli ich nie ma – może czas zacząć mierzyć? Jeśli prowadzisz biznes i zastanawiasz się jak skorzystać z posiadanych danych (albo jakie zacząć zbierać) – skontaktuj się ze mną, być może pomogę. A trochę już w swoim życiu danych przerzuiłem w różne strony.
Ta górka na pierwszym wykresie to ruch przedświąteczny.