Google Analytics to chyba najpopularniejszy sposób mierzenia ruchu na stronach internetowych. Można bardzo dużo wyklikać w panelu, ale może zaistnieć potrzeba pobrania danych statystycznych do analiz, których GA nie daje. Dzisiaj dowiesz się jak zrobić to w języku R.
Jak większość zadań, tak samo i to ma pomocny pakiet. Jak można się podziewać pakiet nazywa się RGoogleAnalytics i dostępny jest poprzez instalację z GitHuba:
|
1 |
devtools::install_github("Tatvic/RGoogleAnalytics") |
Załadujmy więc go do R (razem z innymi pakietami) i do dzieła:
|
1 2 3 4 |
library(magrittr) library(tidyverse) library(lubridate) library(RGoogleAnalytics) |
Jak pobrać dane z Google Analytics?
Zanim zaczniemy potrzebujemy
- projektu na Google Developers
- w ramach którego włączone jest Google Analytics API
- i z którego uzyskujemy Client ID i Client Secret – identyfikatory mówiące o naszym dostępie.
Jak to zrobić opisał autor pakietu na swojej stronie – nie będę tego powielał.
Jednak ważna uwaga wcześniej. Jeśli korzystacie z R zainstalowanego na jakimś serwerze (jak takie środowisko przygotować pisałem jakiś czas temu) bez dostępu do przeglądarki warto wykonać na lokalnym komputerze autoryzację i zapisać token do pliku. Później plik ten wgrywamy na serwer i możemy działać.
Nie musimy zapisywać samego tokena, możemy zapisać coś innego. Po wykonaniu poniższej linii i poprawnej autoryzacji w przeglądarce w katalogu roboczym powstanie plik .httr-oauth – ten plik możemy skopiować na serwer. Czy to czy token – różnica niewielka.
|
1 2 |
oauth_token <- Auth(client.id = "XXXXXXXXXXXXXX.apps.googleusercontent.com", client.secret = "YYYYYYYYYYYYYY") |
Dobrze, autoryzowaliśmy się w Google API, przygotujmy kolejne narzędzia. Na początek będzie to funkcja, która sprawdzi aktualność tokena API (i ewentualnie go odświeży), przygotuje zapytanie z odpowiednimi parametrami, odpyta API o wynik i zwróci nam data.frame z tymże wynikiem:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
getGAData <- function(start, end = Sys.Date(), dimensions, metrics, page_id, oauth_token) { # aktualizacja tokena ValidateToken(oauth_token) # początek i koniec okresu z jakiego pobieramy dane start <- format(start, "%Y-%m-%d") end <- format(end, "%Y-%m-%d") # budowa zapytania do API query <- Init(start.date = start, end.date = end, dimensions = dimensions, metrics = metrics, max.results = 20000, # liczba ustalona doświadczalnie ;) table.id = page_id) ga_query <- QueryBuilder(query) # wywołanie API dataset <- GetReportData(ga_query, oauth_token) # oddajemy wynik return(dataset) } |
ID strony
Pytając Google Analytics API o dane musimy podać numer identyfikacyjny strony. Oczywiście musi to być numer strony, do której mamy dostęp w samym GA. Jego uzyskanie jest proste:
- wchodzimy do Google Analytics
- wybieramy interesującą nas stronę (jeśli mamy ich kilka), a właściwie konto
- patrzymy na adres URL otwartej aplikacji GA i z niego pobieramy ciąg liczb z końca, po literce p
U mnie jest to 7093365 i chyba nie ma problemu, że Wam go zdradzam? :) Zresztą za chwilę zobaczycie statystyki ruchu na niniejszej stronie.
Analiza danych z GA
Tutaj mamy pełną dowolność. Przygotowujemy odpowiednie zapytanie wykorzystując wymiary (dimensions) i miary (metrics) jakich potrzebujemy i przetwarzamy dane jak chcemy. Opis miar i wymiarów znajdziecie w dokumentacji Google Analytics
Historyczny ruch dzień po dniu
Zacznijmy od czegoś prostego – liczy odsłon (pageviews) dzień po dniu:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
# prosimy o dane z ostatnich 3 lat ga_data <- getGAData(Sys.Date() - years(3), Sys.Date(), "ga:date", "ga:pageviews", "ga:7093365", oauth_token) # poprawiamy nieco zapis daty ga_data %<>% mutate(date = ymd(date)) # rysujemy wykresik liniowy ggplot(ga_data, aes(date, pageviews)) + geom_line() + labs(title = "Dzienna liczba odsłon na stronie prokulski.net", subtitle = "Dane za okres 3 ostatnich lat", x = "", y = "Liczba odsłon") |
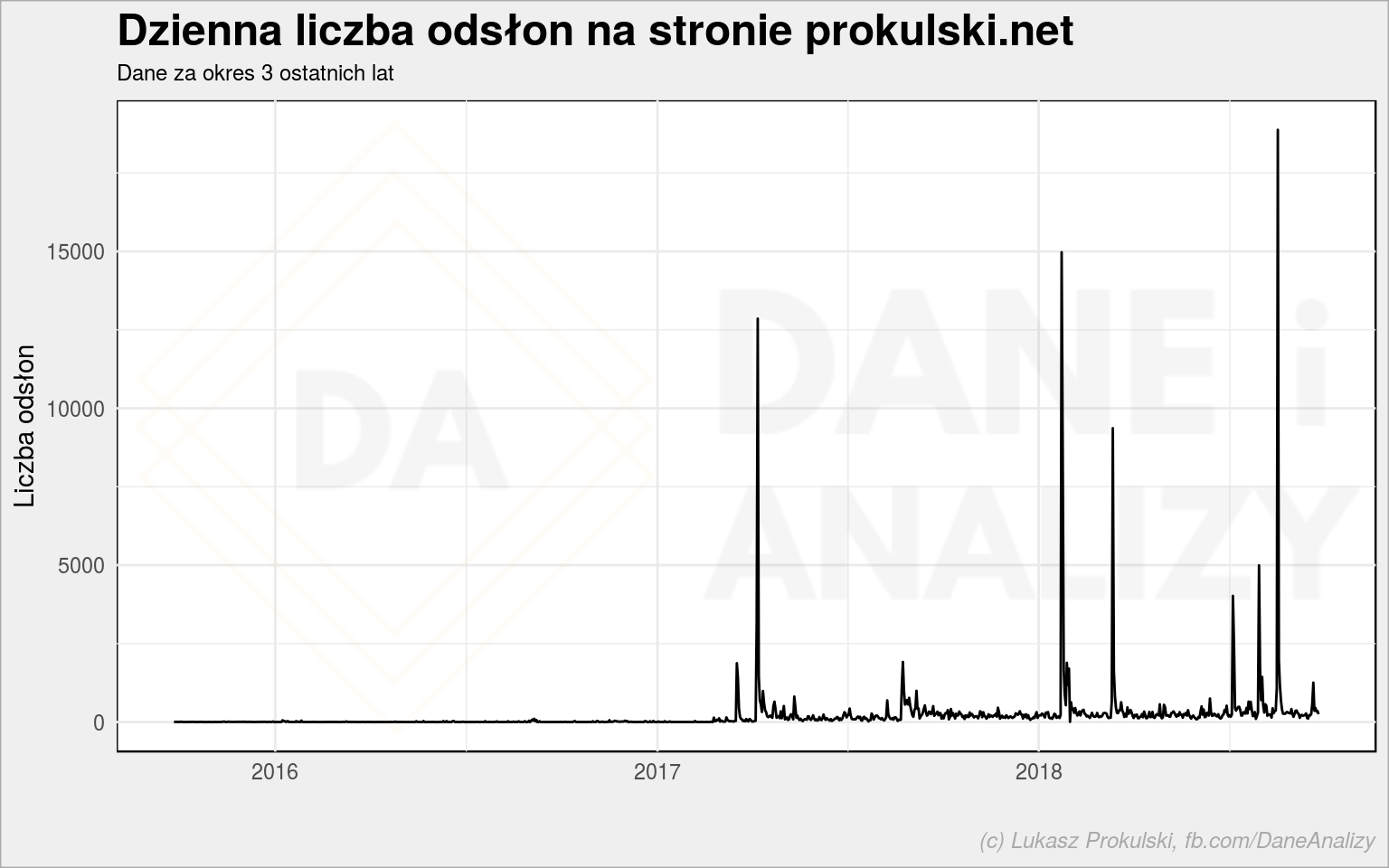
Te szpilki to Wykop efekt dla kilku tekstów. Ale interesuje nas bardziej to co jest niskie – ruch ze średnich dni, bez żadnych ekstremów. Takie wykresy warto spłaszczyć logarytmując wartości (oś Y). W R (ggplot2) to proste:
|
1 2 3 4 5 6 |
ggplot(ga_data, aes(date, pageviews+1)) + geom_line() + scale_y_log10() + labs(title = "Dzienna liczba odsłon na stronie prokulski.net", subtitle = "Dane za okres 3 ostatnich lat", x = "", y = "Liczba odsłon (skala logarytmiczna)") |
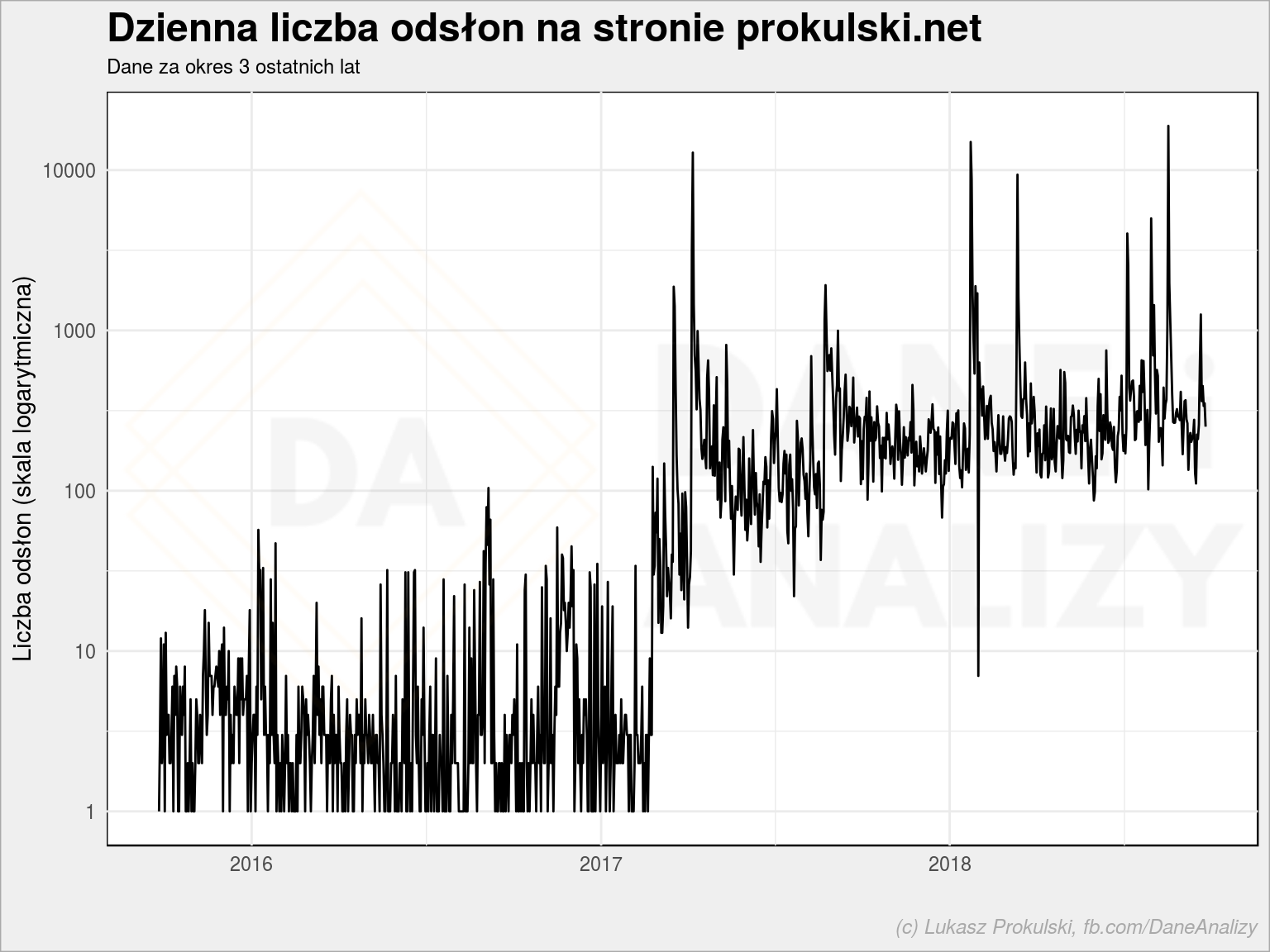
Już jest lepiej. Widzimy tutaj przede wszystkim dwie rzeczy.
Po pierwsze – przed 2017 rokiem właściwie niczego na blogu nie pisałem, nigdzie go nie promowałem, ruch był sporadyczny. Po drugie – od 2017 roku zacząłem pisać o R, w połowie 2017 roku założyłem fanpage’a Dane i analizy na Facebooku – pojawił się ruch. I jest on na poziomie około 200-300 PV dziennie.
Za chwilę będziemy analizować te dane nieco inaczej, ale aby pokazać średni obraz będziemy musieli pozbyć się outlinerów (wartości odstających) – w tym wypadku efektu Wykopu. Zobaczmy jaka jest średnia (licząc wszystkie dni, nawet te szpilki) i odchylenie standardowe. Nałóżmy te wartości na wykres (i trochę go upiększmy):
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
PV_mean <- mean(ga_data$pageviews) PV_sd <- sd(ga_data$pageviews) ggplot(ga_data, aes(date, pageviews+1)) + geom_area(fill = "lightblue", alpha = 0.5) + geom_line(color = "blue", size = 0.2) + geom_hline(yintercept = PV_mean, color = "red") + geom_hline(yintercept = PV_mean + PV_sd, color = "red", alpha = 0.6) + geom_hline(yintercept = PV_mean + 2 * PV_sd, color = "red", alpha = 0.3) + geom_hline(yintercept = PV_mean + 3 * PV_sd, color = "red", alpha = 0.3) + scale_y_log10() + scale_x_date(date_breaks = "3 months") + theme(axis.text.x = element_text(angle = 45, hjust = 1)) + labs(title = "Dzienna liczba odsłon na stronie prokulski.net", subtitle = "Dane za okres 3 ostatnich lat", x = "", y = "Liczba odsłon (skala logarytmiczna)") |
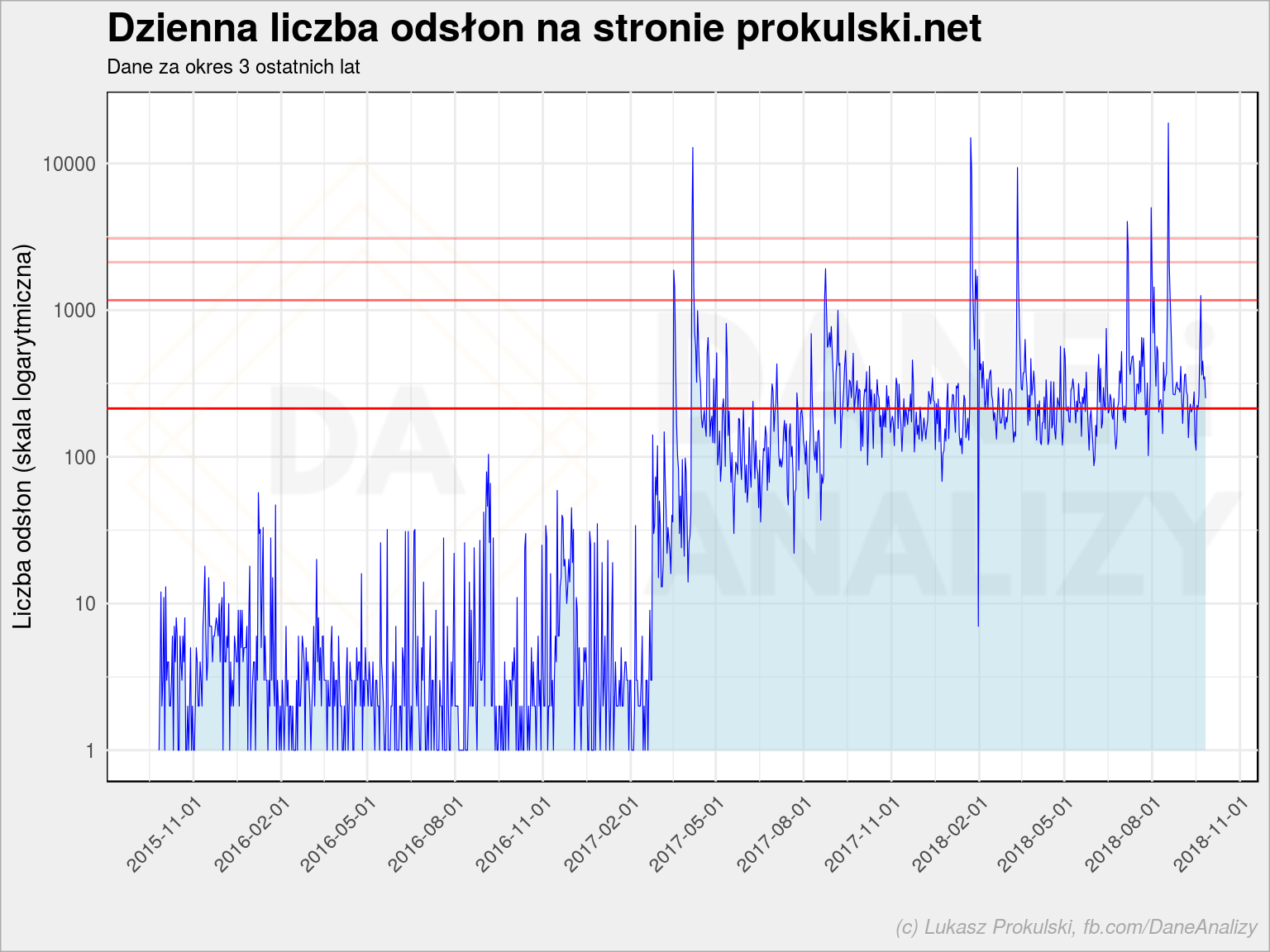
Czerwone poziome linie to kolejno od dołu:
 czyli średnia ze wszystkich dni
czyli średnia ze wszystkich dni czyli średnia plus odchylenie standardowe (poniżej niej jest około 80% przypadków)
czyli średnia plus odchylenie standardowe (poniżej niej jest około 80% przypadków) czyli średnia plus dwa odchylenia standardowe (poniżej jest około 97% przypadków)
czyli średnia plus dwa odchylenia standardowe (poniżej jest około 97% przypadków) czyli średnia plus trzy odchylenia standardowe (poniżej jest około 99.7% przypadków i to wycina nam pojedyncze szpilki)
czyli średnia plus trzy odchylenia standardowe (poniżej jest około 99.7% przypadków i to wycina nam pojedyncze szpilki)
Kiedy jest największy ruch w tygodniu?
Sprawdźmy kiedy użytkownicy pojawiają się na stronie – w zależności od pory dnia i dnia tygodnia.
Pobieramy dane na nowo – dodając podział godzinowy:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
ga_data <- getGAData(Sys.Date() - years(3), Sys.Date(), "ga:date,ga:hour", "ga:pageviews", "ga:7093365", oauth_token) # poprawiamy daty ga_data %<>% mutate(date = ymd(date), datetime = make_datetime(year(date), month(date), day(date), as.integer(hour))) ga_data %>% # usunięcie dni z outlinerami # dolne ~97% wartości group_by(date) %>% mutate(PV_day = sum(pageviews)) %>% ungroup() %>% filter(PV_day <= mean(PV_day) + 2*sd(PV_day)) %>% # rozbicie na dzień tygodnia i godzinę mutate(w = wday(datetime, week_start = 1, label = TRUE, abbr = FALSE, locale = "pl_PL.utf8"), h = as.integer(hour)) %>% group_by(w, h) %>% summarise(w_PV = mean(pageviews)) %>% ungroup() %>% ggplot(aes(w, h, fill = w_PV)) + geom_tile(color = "gray50") + scale_y_reverse() + scale_fill_distiller(palette = "Greens", direction = 1) + labs(title = "Średnia liczba odsłon na stronie prokulski.net\nw zależności od dnia tygodnia i godziny", subtitle = "Dane za okres 3 ostatnich lat", x = "", y = "", fill = "Średnia liczba odsłon w godzine") + theme(legend.position = "bottom") |
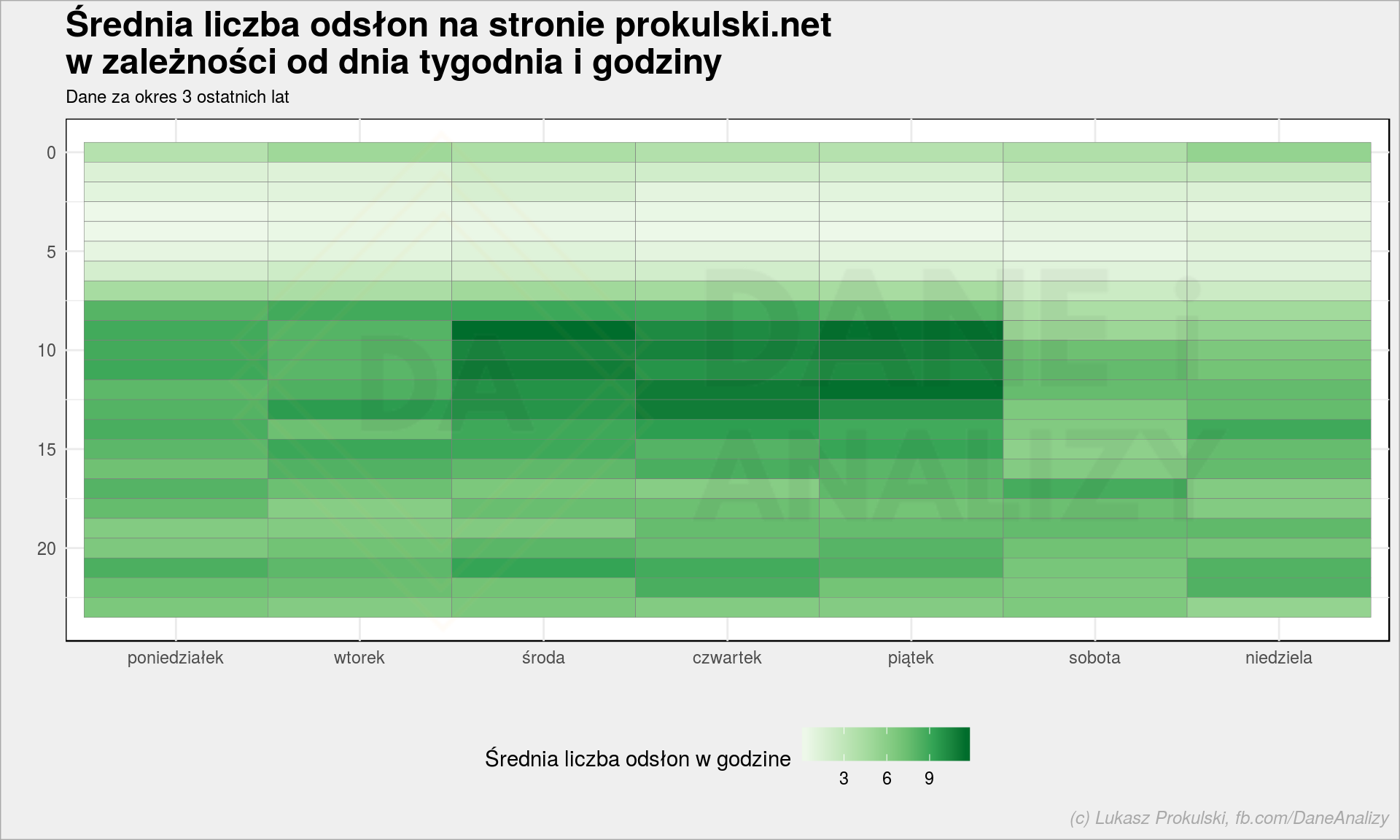
Powyżej odsialiśmy wartości odstające kryterium i uśredniliśmy wartości dla poszczególnych dni tygodnia i godzin. Rozkład nie zaskakuje i widać, że publikuję (albo promuję) kolejne posty w środę lub piątek rano.
Skąd pochodzą użytkownicy?
Przygotujmy inny zestaw danych z Google Analytics – skąd i w jakim wieku (to już określa Google) są użytkownicy? Pobieramy dane w rozbiciu na datę (jest ona tylko po to, aby usunąć outlinery), miasto i kraj pochodzenia użytkownika (określony na podstawie geolokalizacji adresu IP z jakiego użytkownik wchodzi na stronę – robi to Google) oraz grupę wiekową.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
ga_data <- getGAData(Sys.Date() - years(3), Sys.Date(), "ga:date,ga:city,ga:country,ga:userAgeBracket", "ga:pageviews", "ga:7093365", oauth_token) ga_data %<>% mutate(date = ymd(date)) %>% # usunięcie dni z outlinerami group_by(date) %>% mutate(PV_day = sum(pageviews)) %>% ungroup() %>% filter(PV_day <= mean(PV_day) + 2*sd(PV_day)) ga_data %>% filter(country != "Poland") %>% group_by(country) %>% summarise(PV = sum(pageviews)) %>% ungroup() %>% top_n(5, PV) %>% mutate(country = reorder(country, PV)) %>% ggplot() + geom_col(aes(country, PV)) + coord_flip() + labs(title = "Łączna liczba odsłon na stronie prokulski.net w zależności od kraju", subtitle = "Dane za okres 3 ostatnich lat, bez Polski", x = "", y = "Łączna licza odsłon") |
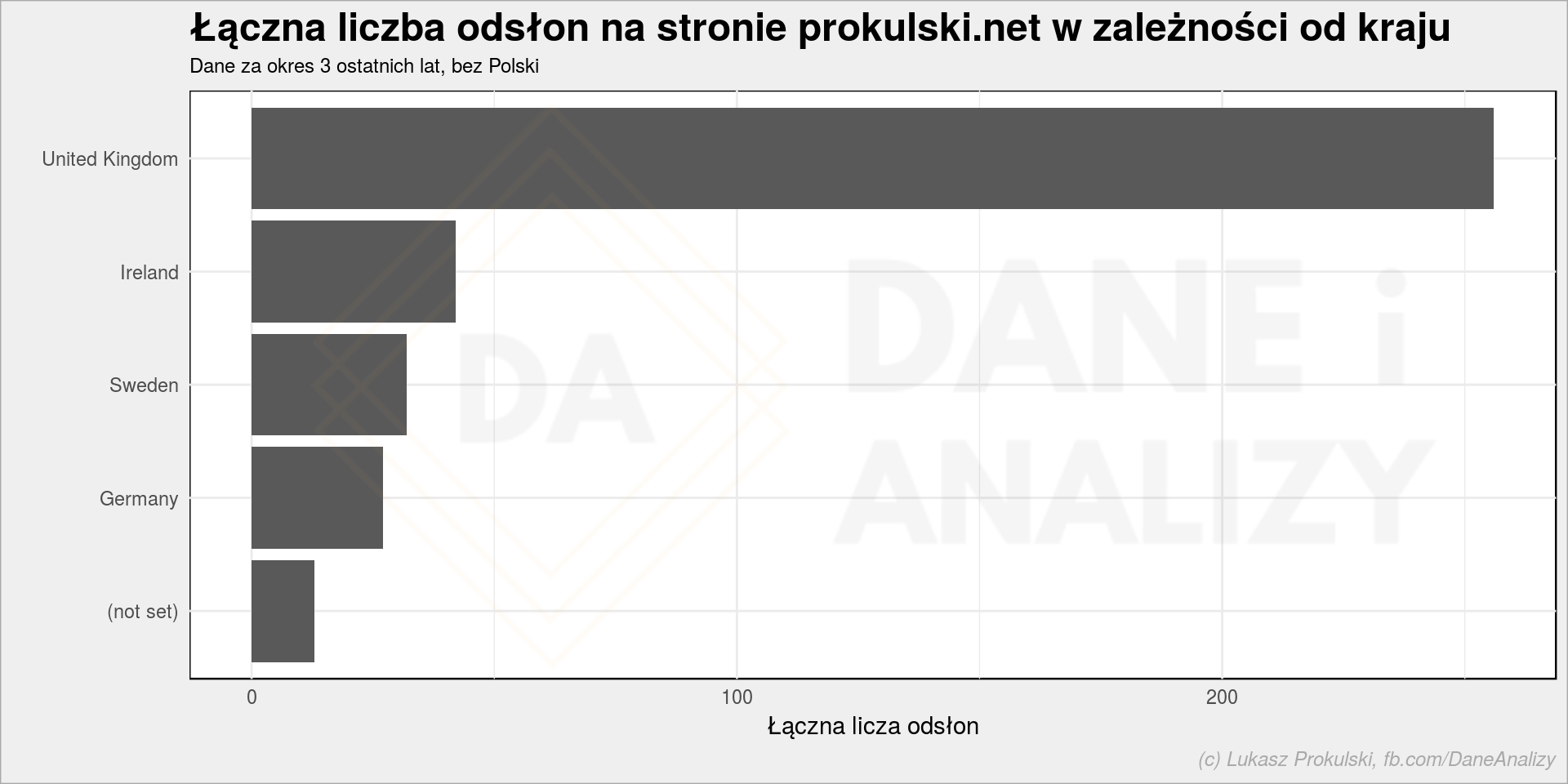
Na powyższym wykresie specjalnie usunąłem Polskę – słupek Polski miażdży resztę. A ciekawy jest ruch spoza naszego nadwiślańskiego kraju. Dla mnie osobiście ciekawa jest Szwecja… Jesteś w Szwecji i czytasz? Zostaw komcia! UK i Irlandię można wytłumaczyć obecnością tamże Polaków (w końcu strona jest po polsku, to wymagające). Zwróćcie jednak uwagę, że te 250 PV przez 3 lata to żaden właściwie ruch.
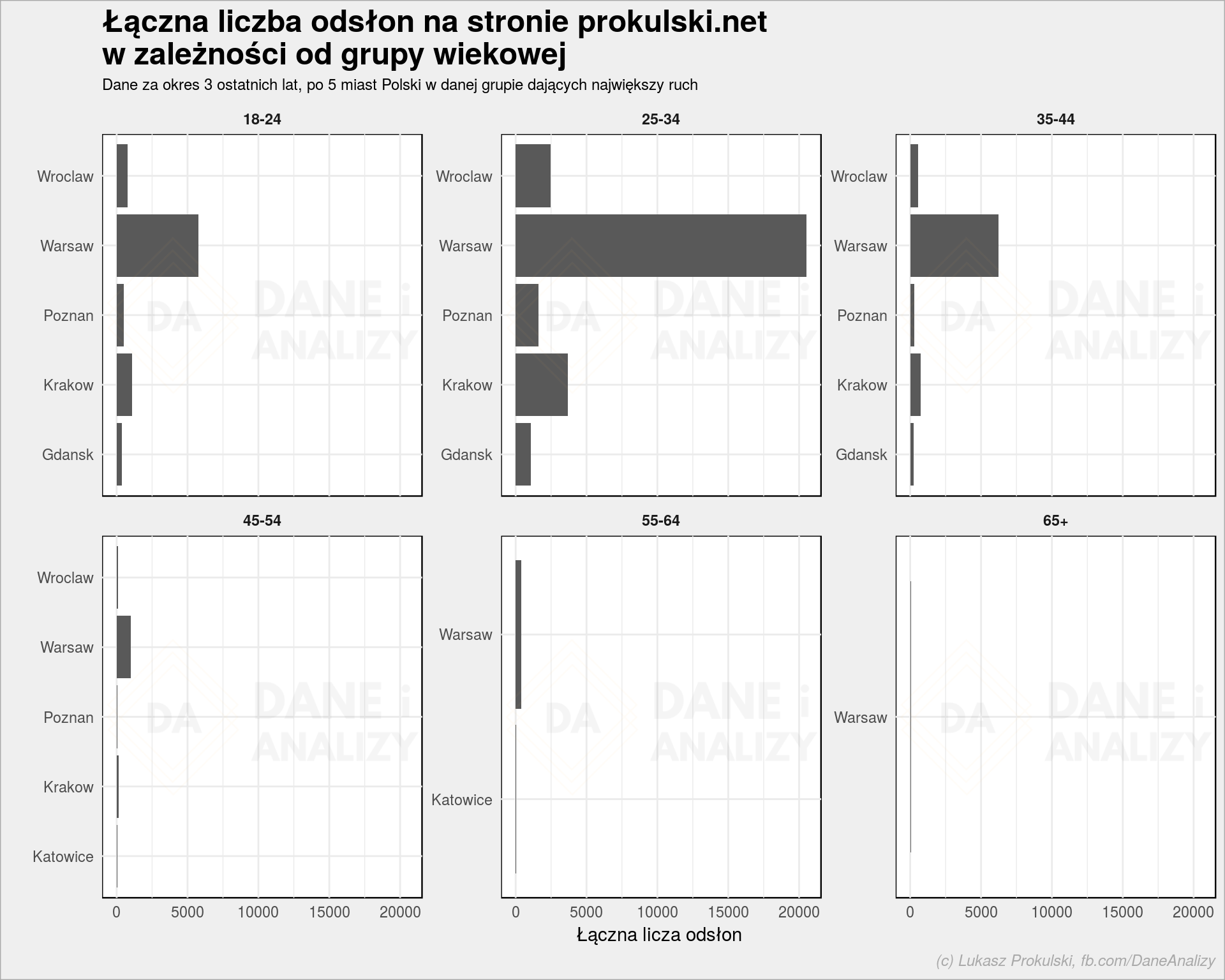
Weźmy teraz tylko Polskę, tylko największe (w sensie dowożenia ruchu) pięć miast z każdej grupy wiekowej:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
ga_data_city_age <- ga_data %>% filter(country == "Poland") %>% # grupujemy po mieście i wieku group_by(city, userAgeBracket) %>% summarise(PV = sum(pageviews)) %>% ungroup() %>% group_by(userAgeBracket) %>% top_n(5, PV) %>% ungroup() ga_data_city_age %>% ggplot() + geom_col(aes(city, PV)) + coord_flip() + facet_wrap(~userAgeBracket, scales = "free_y") + labs(title = "Łączna liczba odsłon na stronie prokulski.net\nw zależności od grupy wiekowej", subtitle = "Dane za okres 3 ostatnich lat, po 5 miast Polski w danej grupie dających największy ruch", x = "", y = "Łączna licza odsłon") |
Każdy zarząd lubi wykresy, a mapki to już w ogóle sikanie po nogach jest. W R to proste. Znamy miasto (nazwę), znamy liczbę PV. Do narysowania mapki potrzebujemy wiedzieć gdzie zaznaczyć miasto na mapie. No i samą mapę (kontury).
Użyjemy danych zapisanych w pakiecie maps (poniżej wczytywany ggmap importuje maps) do narysowania konturów kraju, oraz funkcji geocode() do znalezienia współrzędnych geograficznych:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
library(ggmap) # konruty Polski poland_map <- map_data("world", region = "Poland") # lokalizacje miast, source może być równie dobrze równe "google" geocode_df <- geocode(paste0(unique(ga_data_city_age$city), ", Poland"), source = "dsk") %>% mutate(city = unique(ga_data_city_age$city)) # łączymy lokalizację z danymi ga_data_city_age <- left_join(ga_data_city_age, geocode_df, by = "city") # mapki wg grup wiekowych ggplot() + geom_polygon(data = poland_map, aes(long, lat, group = group), fill = "white", color = "red", size = 0.5) + geom_point(data = ga_data_city_age, aes(lon, lat, size = PV, color = city)) + scale_size_continuous(range = c(4, 9)) + coord_quickmap() + facet_wrap(~userAgeBracket) + labs(title = "Łączna liczba odsłon na stronie prokulski.net\nw zależności od grupy wiekowej", subtitle = "Dane za okres 3 ostatnich lat, po 5 miast Polski w danej grupie dających największy ruch", x = "", y = "", color = "", size = "Łączna liczba odsłon") + theme(legend.position = "bottom", axis.text = element_blank()) |
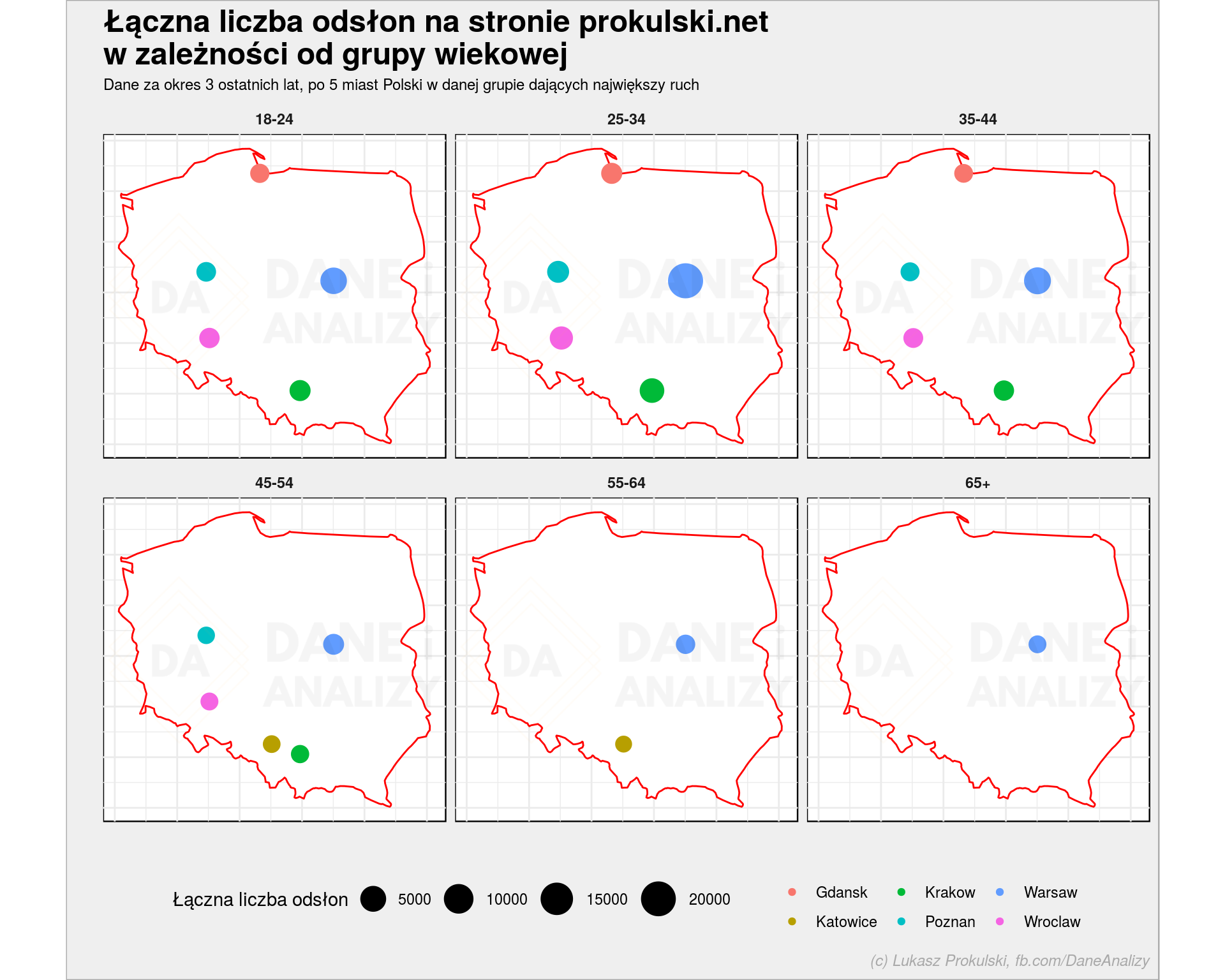
Pięknie, prawda? W kilku linijkach kodu. Weź to wszystko ogarnij w Excelu… W Tableau czy innym PowerBI to jeszcze łatwo…
Jak do Google Analytics dodać UserID?
Cały pomysł na wpis wziął się z potrzeby zdobycia pewnych danych. Załóżmy, że chcemy kategoryzować użytkowników naszej strony. Nie wiemy o nich nic poza to co znajdziemy w Google Analytics. Jak dobrać się do danych z GA już wiemy, ale jak powiązać to z konkretnym użytkownikiem? Przydałby się jakiś UserID unikalny dla każdego odwiedzającego, ale jednocześnie dający możliwość sprawdzenia, że ten sam użytkownik odwiedza stronę kilka razy (w roku na przykład).
Co może być UserID? Może to być login (albo numer) klienta, jakaś nazwa jego konta. Ale żeby nie przekazywać Google za dużo danych o naszych klientach (oni w Google i tak swoje wiedzą i mają na to inne sposoby; poza tym może nie być kont na stronie i co wtedy?) możemy przyjąć zasadę, że do każdej wizyty przypisujemy cookie z unikalnym ID. Działamy wówczas według prostego algorytmu:
Jeśli użytkownik wchodzi na stronę to:
- sprawdzamy czy ma nasze ciasteczko
- jeśli nie ma (czyli pojawia się na stronie po raz pierwszy) – dostaje w naszym unikalnym cookie kolejny numerek (pierwszy wolny)
I tyle. Wartość tego ciasteczka przekazujemy do Google Analytics. W dobrym przykładzie opisującym tego typu podejście ustawiane jest dodatkowe pole dimension1, które później w zapytaniu możemy pobrać dodając ga:dimension1 do parametrów Init() w części “dimensions” (albo do naszej funkcji getGAData()).
Jeżeli używasz strony na WordPressie to szczegółową instrukcję ustawiania swojego własnego cookie znajdziesz tutaj
Niestety ja takich danych nie mam na swojej stronie. Trochę szkoda, więcej wiedziałbym o Was.
Sięgniemy więc po inne. Ale to w drugiej części, za kilka dni. Mam nadzieję, że ten kawałek (dość technicznej, przyznaję) wiedzy jest coś dla Ciebie wart i jeśli Ci się przyda możesz postawić dużą kawę (albo po prostu dobre piwo z marketu).
Co do miejsca skąd pochodzi ruch to mam wrażenie, że google jednak zakłamuje trochę i często przypisuje ruch do Warszawy mimo, że pochodzi on z innej miejscowości (stolica tak czy tak będzie wygrywać, ale może trochę mniej).
A co do obsługi GA to wygodnie jest wyciągać sobie dane do arkuszów google i tam je obrabiać (przy okazji można łączyć je z innymi, np. pobieranymi z wikpedii (ruch podzielony przez liczbę mieszkańców – bo ciężko, żeby Pcim był wyżej niż Warszawa biorąc pod uwagę liczbę osób, która mieszka w danym miejscu).
Tak to prawda dane o loklizacji w GA są zakłamane dawno temu cały mobile był w WWA, a teraz np. w moim przypadku i sieci play jestem w Poznaniu a pokazuje od długiego czasu ze niby jestem z Wrocławia. Więc dane o lokalizacji powinno traktować się poglądowo.
Jaka funkcja w ggplot’cie daje możliwość „podpisania” się pod wykresem?
Parametr caption w labs(). W kodzie widocznym w postach nie zawsze jest wszystko dające widoczny efekt, np te podpisy.