Gdzie Polacy jadą na wakacje? Jak wyciągnąć w R informacje z PDFa? Jaki związek ma jedno z drugim?
Zgodnie z życzeniem telewidzów ;) wyrażonym w szybkiej ankiecie żebro-lajkowej kilka dni temu
- gdzie Polak jedzie na urlop?
- w ile osób jedzie?
- ile go to kosztuje?
Bo w ankiecie kciuki w górę wygrały (na obecną chwilę) 69 do 32 z serduszkami.
Na początek trochę historii. Po sukcesie wpisów o mieszkaniach na wynajem i cenach samochodów chciałem zająć się wyjazdami z biurami podróży. To byłby hicior. Nawet znalazłem miejsce, z którego trzeba wziąć dane. Takim miejscem są raporty publikowane przez Polski Związek Organizatorów Turystyki. Raporty powstają na bazie systemu rezerwacji MerlinX i to on byłby tym źródłem danych.
Same raporty nie zawierają interesujących mnie danych, na przykład:
- data zakupu wycieczki/pobytu
- data rozpoczęcia wycieczki/pobytu
- długość wycieczki (liczba dni)
- miejsce docelowe wycieczki/pobytu – tutaj może być nazwa miejscowości i kraj, okręg w danym kraju (odpowiednik NUTS3 lub NUTS2 w nomenklaturze Eurostatu byłby idealny)
- liczba takich wycieczek zakupionych danego dnia, na określoną datę wyjazdu i czas trwania i do określonego miejsca
- liczba osób dorosłych i dzieci biorących udział w wycieczce
Z tych danych można przygotować kilka przekrojowych analiz:
- gdzie jeździ najwięcej Polaków? Mapy, dużo map!
- jak długo przed wycieczką dana wycieczka jest kupowana?
- na jak długo jeździmy?
- czy rodziny z dziećmi jeżdżą w inne miejsca niż single lub osoby bezdzietne?
Niestety ani PZOT ani MerlinX nie udostępnił mi danych (obie instytucje po prostu nie odpowiedziały na miale; MerlinX na Facebooku opowiedział, że nie udostępniają takich danych nikomu oprócz PZOT). W sumie nie są to dane publiczne, więc nie mają takiego obowiązku. Ale szkoda.
Skorzystamy zatem z danych przetworzonych, czyli raportów ze strony PZOT.
Poniższy fragment możesz pominąć jeśli nie interesuje Cię jak pobrać dane. Opis pobranych danych jest w dalszej części postu.
Raporty to prezentacje zapisane w PDFach. Na szczęście istnieje coś takiego jak biblioteka pdftools, która potrafi przeczytać PDFa i wyciągnąć z niego tekst (ale nie tylko – po szczegóły odsyłam do dokumentacji). To już coś.
Zacznijmy od przygotowania miejsca na raporty:
|
1 2 3 4 5 6 7 8 9 10 11 |
library(tidyverse) library(lubridate) library(rvest) library(pdftools) # jeśli jest katalog z poprzednimi raportami - kasujemy go z całą zawartością library(fs) # przydatna biblioteka do operacji na plikach if(dir_exists("raporty_pzot")) dir_delete("raporty_pzot") # i ponownie tworzymy katalog na raporty dir_create("raporty_pzot") |
Potrzebujemy oczywiście samych raportów. Nie będziemy ich ściągać ręcznie ze strony, bo to robota głupiego. Nie będziemy ich też otwierać i przepisywać ręcznie danych (od tego są stażyści, a ja takich nie mam). Te rzeczy robią komputery, analityk ma analizować: zadawać odpowiednie pytania i szukać na nie odpowiedzi.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
# pobieramy listę plików do ściągnięcia ze strony page <- read_html("http://www.pzot.pl/index.php?module=cms/files&group=Raporty%20PZOT") # insteresują nas same urle raportów urls <- page %>% html_node("table.classFiles_default_table") %>% html_nodes("a") %>% html_attr("href") %>% .[grepl("Booking_Report", .)] # ściągamy wszystkie pliki (podane URLe) download.file(url = paste0("http://www.pzot.pl/", urls), dest = sprintf("raporty_pzot/raport_%02d.pdf", 1:length(urls))) # przyda nam się lista plików (ściągnietych) z raportami: raporty <- paste0("raporty_pzot/", list.files("raporty_pzot", pattern = ".*\\.pdf")) |
Mamy materiał badawczy, czas wyciągnąć z niego informacje do badania. Ponieważ raportów jest trochę to warto je obsłużyć tak samo, najlepiej wykorzystując jeden fragment kodu (czyli napisać odpowiednią funkcję):
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 |
# funkcja wyciągająca z raportu potrzebne nam informacje GetRankCountryTable <- function(filename) { # wczytujemy tekst z PDFa plik <- pdf_text(filename) # czy jest strona z interesującymi nas danymi? if(sum(1*grepl("Ranking of the most popular countries & destinations in", plik)) != 0) { # konkretna strona z raportu, tekst podzielony na kolejne linie strona <- which(grepl("Ranking of the most popular countries & destinations in CW", plik))[[1]] # weźmy z niej tekst podzielony na kolejne linie txt_lines <- plik[[strona]] %>% str_split("\n") %>% unlist() # z którego tygodnia są dane? tydzien <- str_sub(txt_lines[[1]], -4, -1) # w której linii jest tabelka z rankingiem państw? linia_ranking <- which(grepl("Rank Country", txt_lines)) # potrzebne jest 11 wierszy (10 pozycji w rankingu plus nagłówek tabelki) wiersze <- txt_lines[linia_ranking:(linia_ranking+15)] %>% # bierzemy z zapasem .[!is.na(.)] %>% # bez pustych linii # tabela jest z prawej strony slajdu - w drugiej połowie długości linii str_sub(., (nchar(.)/2 + 10), -1) %>% # bierzemy tą drugą część linii .[nchar(.) > 30] %>% # zostawiamy tylko odpowiednio długie linie trimws() %>% # usuwamy zbędne spacje str_flatten("\n") %>% # długi ciąg zmieniamy w pojedyncze linie read_table() %>% # z tych linii wczytujemy dane - analogicznie jak z pliku CSV na dysku set_names("Rank_Country", "Price_booking", "Price_person") %>% # nazywamy sobie kolumny filter(!is.na(Price_person), !is.na(Price_booking)) %>% # usuwamy wiersze, gdzie nie znalazły się ceny # trochę przekształceń danych: mutate(Rank = row_number(), # numer wiersza = pozycja w rankingu Country = str_sub(Rank_Country, 3, -1) %>% trimws(), # oczyszczamy kolumnę z nazwą kraju # ceny przekształcamy ze stringów na liczby Price_booking = gsub(" ", "", Price_booking) %>% trimws() %>% as.integer(), Price_person = gsub(" ", "", Price_person) %>% trimws() %>% as.integer()) %>% select(Rank, Country, Price_booking, Price_person) %>% # dodajemy numer tygodnia mutate(Week = tydzien) return(wiersze) } else { return(tibble()) } } |
Komentarze opisują dokładnie co się dzieje w kodzie. Ale aby do tego kodu dojść trzeba przejrzeć same raporty. Następnie wyciągnąć (pdf_text()) tekst z raportów. I na tym tekście już trochę pooperować. To najdłuższa część zadania. Poświęć trochę czasu i pooglądaj co wychodzi z pdf_text() dla kilku przykładowych plików – to najbardziej pouczająca część tego wpisu. Niestety raporty są (oględnie mówiąc) takie sobie (brzydkie są to przede wszystkim), stąd cała powyższa praca. Być może uda Ci się przygotować funkcję tak, aby nie brała najpopularniejszych państw a najpopularniejsze miejsca (czyli lewa strona odpowiedniego slajdu z raportu)? To będzie o wiele ciekawsza informacja. Da się to zrobić w oparciu o powyższy kod plus trochę wyrażeń regularnych.
Mając gotowe narzędzie do wyciągania danych z PDFa zastosujmy je do wszystkich plików. Cel jest taki, aby na koniec uzyskać tabelę z kolejnymi państwami, ich pozycją w rankingu w danym tygodniu oraz cenami: średnią ceną pobytu/wycieczki oraz średnią ceną na osobę.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
# dla każdego pobranego pliku PDF weź tabelę i całość zbij w długi data frame - purrr-way! holiday_countries <- raporty %>% map_df(GetRankCountryTable) %>% # usuń braki filter(Country != "", !is.na(Price_person), !is.na(Price_booking)) %>% # z tygodnia robimy datę mutate(Week = as.numeric(str_sub(Week, 3, -1))) %>% # na początek za datę raportu przymujemy 1 stycznia odpowiedniego roku # na szczęście raportów nie ma z kilku lat i numery tygodni się nie powtarzają mutate(Date = ifelse(Week <= week(now()), ymd("2018-01-01"), ymd("2017-01-01")) %>% as_date()) # datę 1 stycznia zmieniamy na odpowiednią na podstawie numeru tygodnia week(holiday_countries$Date) <- holiday_countries$Week # zapisujemy przygotowane dane na później - jeśli potrzebujemy :) saveRDS(holiday_countries, "holiday_countries.RDS") |
To nam się przyda na wykresach:
|
1 2 3 |
# zakres dat raportów do podpisu na wykresie subtitle <- paste0("Na podstawie danych z raportów PZOT za okres ", min(holiday_countries$Date), " - ", max(holiday_countries$Date)) |
Mamy wszystko! 219 wierszy z danymi. Zobaczmy czego możemy się dowiedzieć.
Analiza
Zacznimy od cen wycieczek/pobytów w zależności od kraju. Czyli ile trzeba zapłacić za osobę jadąc do danego kraju. To są ceny uśrednione, nie mamy informacji o długości pobytu, nie mamy informacji o sposobie dotarcia na miejsce (samolot, autokar, dojazd własny) a są to czynniki mające zdecydowany wpływ na cenę.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
holiday_countries %>% group_by(Country) %>% summarise(mean_Price_person = mean(Price_person)) %>% ungroup() %>% arrange(desc(mean_Price_person)) %>% mutate(Country = fct_inorder(Country)) %>% ggplot() + geom_col(aes(Country, mean_Price_person), fill = "lightgreen") + geom_text(aes(Country, mean_Price_person, label = round(mean_Price_person), hjust = ifelse(mean_Price_person < 2000, -0.2, 1.2)), vjust = 0.5) + coord_flip() + labs(title = "Średnia cena wycieczki za osobę (uśredniona po wszystkich tygodniach)", subtitle = subtitle, x = "", y = "Średnia cena za osobę [zł]") |
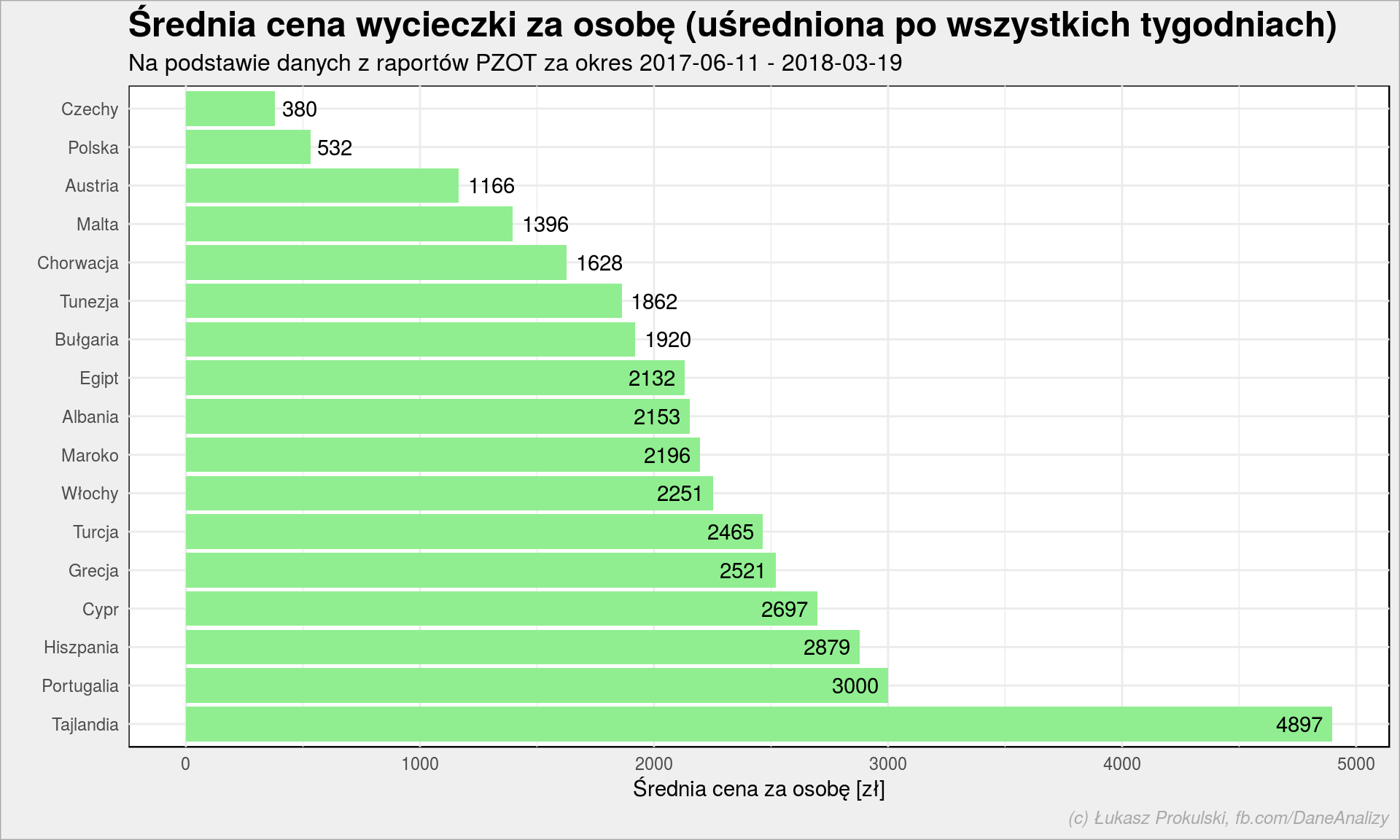
Tajlandia jest najdalej to i najdrożej (cena lotu robi swoje). Reszta jest chyba dość przewidywalna, chociaż mnie zaskoczyły ceny w Albanii, która jest porównywalna z Egiptem (a wydaje się że to biedny kraj i mniej popularny) oraz Tunezja tańsza od Bułgarii.
Zobaczmy czy ceny zmieniają się w czasie:
|
1 2 3 4 5 6 7 8 |
holiday_countries %>% ggplot() + geom_line(aes(Date, Price_booking, group = Country)) + scale_x_date(date_labels = "%Y-%m") + facet_wrap(~Country, ncol = 3) + labs(title = "Średnia cena wycieczki w kolejnych tygodniach", subtitle = subtitle, x = "", y = "Cena wycieczki [zł]") |
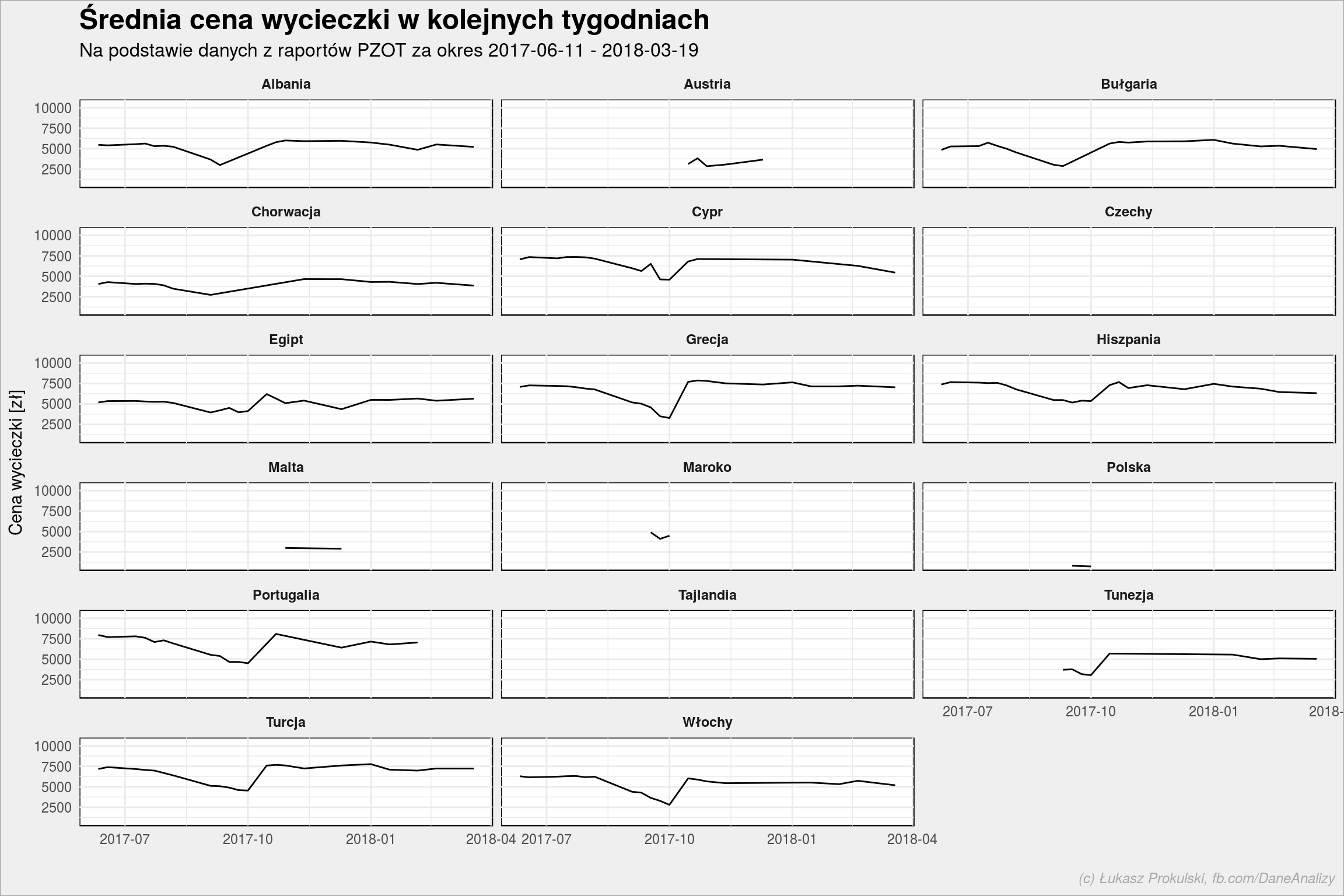
Jest mniej więcej stabilnie, nie widać dużych skoków. Widać za to dołek występujący prawie dla każdego kraju w pierwszym tygodniu października. Początkowo myślałem, że to błąd, ale prześledziłem zawartość raportów (dla tygodni 38-41 z 2017 roku) i rzeczywiście tak wyglądają liczby. Nie wiem z czego to wynika, raporty nie do końca precyzyjnie tłumaczą co zawierają.
Podobnie wyglądają linie dla średnich cen za osobę:
|
1 2 3 4 5 6 7 8 |
holiday_countries %>% ggplot() + geom_line(aes(Date, Price_person, group = Country)) + scale_x_date(date_labels = "%Y-%m") + facet_wrap(~Country, ncol = 3) + labs(title = "Średnia cena wycieczki za osobę w kolejnych tygodniach", subtitle = subtitle, x = "", y = "Cena za osobę [zł]") |
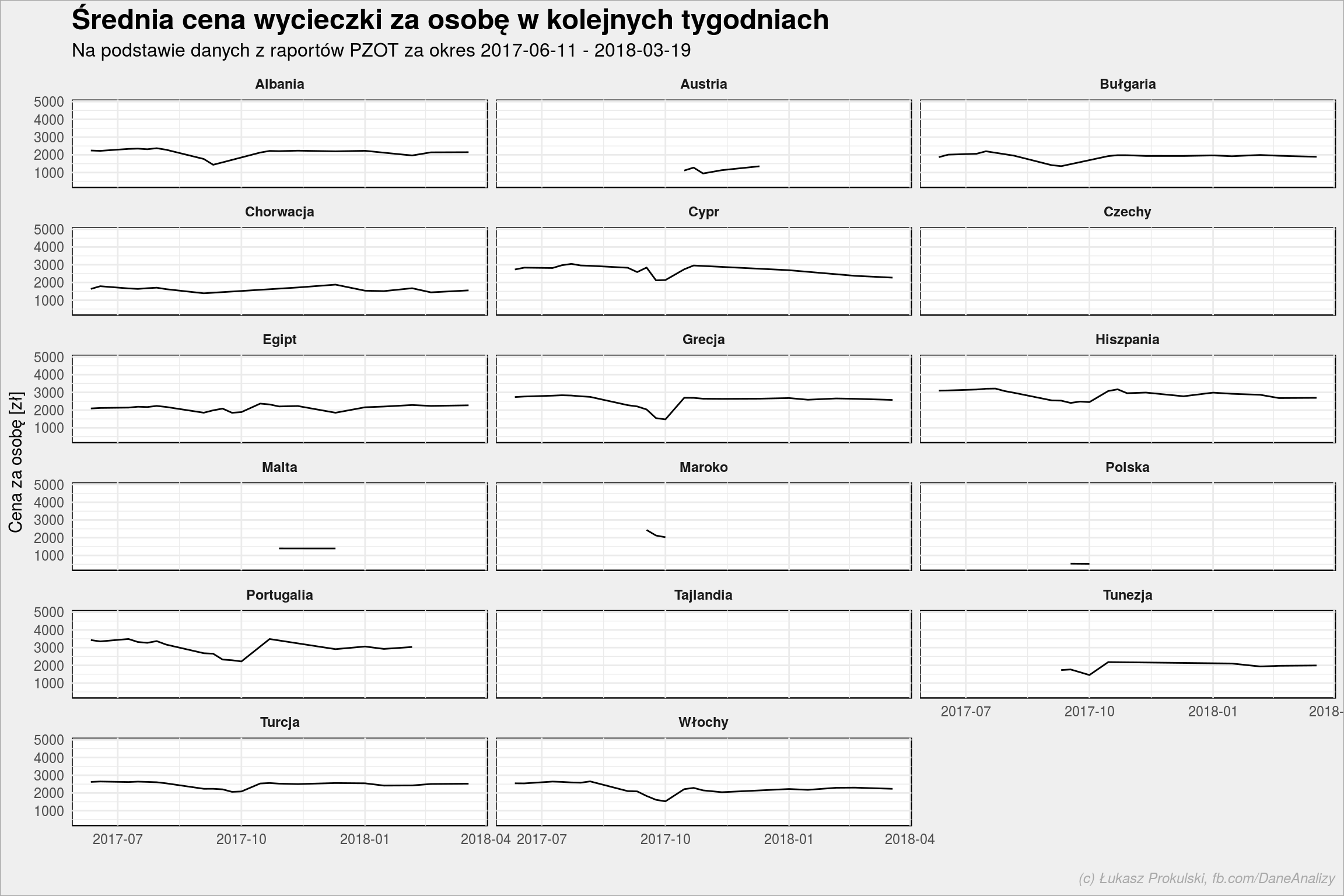
Spodziewam się, że data (tydzień) odpowiada dacie zakupu, a wycieczka (lub pobyt w hotelu) kupowana jest na przykład około 2-3 miesięcy przed wyjazdem. Licząc krakowskim targiem że to 2 i pół miesiąca, to mamy wyjazdy na połowę grudnia (przed Bożym Narodzeniem) kupowane na początku października. W połowie grudnia w takiej Grecji, Portugalii czy Tunezji nie jest jakoś super ciepło. A i pora tuż przed świętami (traktowanymi rodzinnie w Polsce) nie zachęca do wyjazdu – być może są to ceny poniżej kosztów, żeby tylko sprzedać? We Włoszech też w sumie ani ciepło ani na narty… miałoby to jakiś sens. Gdyby były to dane źródłowe być może udałoby się wyjaśnić zagadkę.
Nie mamy również danych o liczbie wyjeżdżających osób, ale możemy spróbować to oszacować – ot dzieląc średnią cenę całego zakupionego pakietu przez średnią cenę na osobę. Powinna wyjść liczba osób (średnia):
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
holiday_countries %>% mutate(p = Price_booking/Price_person) %>% # poniższy zabieg tylko po to, aby ładnie ułożyć paseczki ;) group_by(Country) %>% mutate(a = median(p)) %>% ungroup() %>% arrange(desc(a)) %>% mutate(Country = fct_inorder(Country)) %>% # koniec zabiegu :) ggplot() + geom_boxplot(aes(Country, p)) + coord_flip() + labs(title = "Liczba osób na wycieczce", subtitle = subtitle, x = "", y = "Liczba osób") |
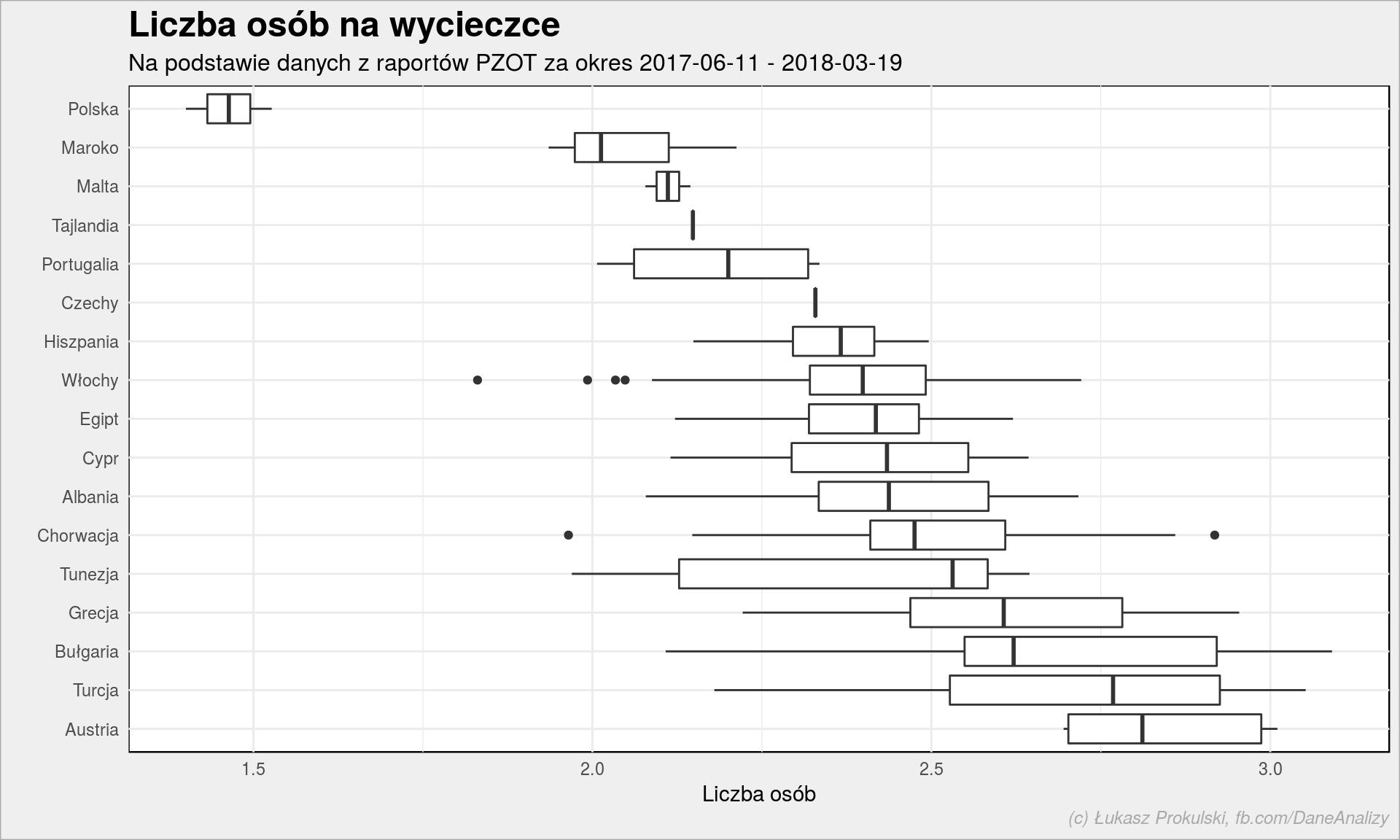
Od razu w oczy rzuca się Polska z najniższą liczbą osób. Polska w rankingu pojawia się bodaj w dwóch tygodniach (17.09 i 1.10) – można przypuszczać, że są to wyjazdy na ferie zimowe (zakładając wspomniane trzymiesięczne wyprzedzenie kupna w stosunku do pobytu), co miałoby ręce i nogi. Średnio prawie 1.5 osoby to dzieci (jedno lub dwoje) wysyłane na kolonie? Zgaduję, ale czy bardzo się mylę?
Pozgadujmy jeszcze trochę:
- do Maroko jeździ się przeważnie (mediana = paseczek w prostokącie) we dwójkę – bo gorąco, bo może mniej bezpiecznie
- Austria (narty?) to już prawie (średnio) 3 osoby – wyjazdy z dziećmi lub na przykład w dwie pary?
- tam gdzie ciepło, popularnie, w betonowym hotelu z basenem, czyli Turcja, Grecja, Tunezja – średnia krąży wokół 2.75, zatem rodzina z dzieckiem (trzy osoby)
- podobnie wygląda w innych krajach, z tendencją ku dwójce w miejscach, które mi osobiście kojarzą się bardziej ze zwiedzaniem a nie leżeniem na plaży (Portugalia, Malta, Tajlandia – tutaj dodatkowo istotny jest długi lot). Dzieci (zasadniczo) nie bardzo lubią zwiedzać i nie widzą w tym wiele ciekawego, zatem rodzice jadą sami. Albo zanim te dzieci sobie zrobią. Można również jechać i robić na miejscu – podróże temu sprzyjają.
Swoją drogą ciekawe byłoby porównanie liczby zakupionych wycieczek w miejsca, w których doszło do niebezpiecznych incydentów (zamachy terrorystyczne, przewroty polityczne – Turcja swego czasu, czy też związanych z pogodą) w tygodniach kiedy owe incydenty miały miejsce. Czy Polacy boją się i od razu kupują mniej? Tego z posiadanych danych się nie dowiemy.
Znamy orientacyjne ceny, znamy liczbę osób, ale nadal nie wiemy gdzie Polak jedzie. W raportach korzystaliśmy z rankingów – zakładam, że zostały ułożone według popularności kraju. Zatem policzmy średnią pozycję w rankingach z kolejnych tygodni. To powinno powiedzieć nam która destynacja jest najbardziej popularna:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
holiday_countries %>% group_by(Country) %>% summarise(mRank = mean(Rank)) %>% ungroup() %>% arrange(desc(mRank)) %>% mutate(Country = fct_inorder(Country)) %>% ggplot() + geom_col(aes(Country, mRank), fill = "lightgreen") + geom_text(aes(Country,mRank, label = round(mRank, 1)), hjust = 1.2, vjust = 0.5) + coord_flip() + labs(title = "Najpopularniejsze destynacje (państwa)", subtitle = subtitle, x = "", y = "Średnia pozycja w rankingu") |
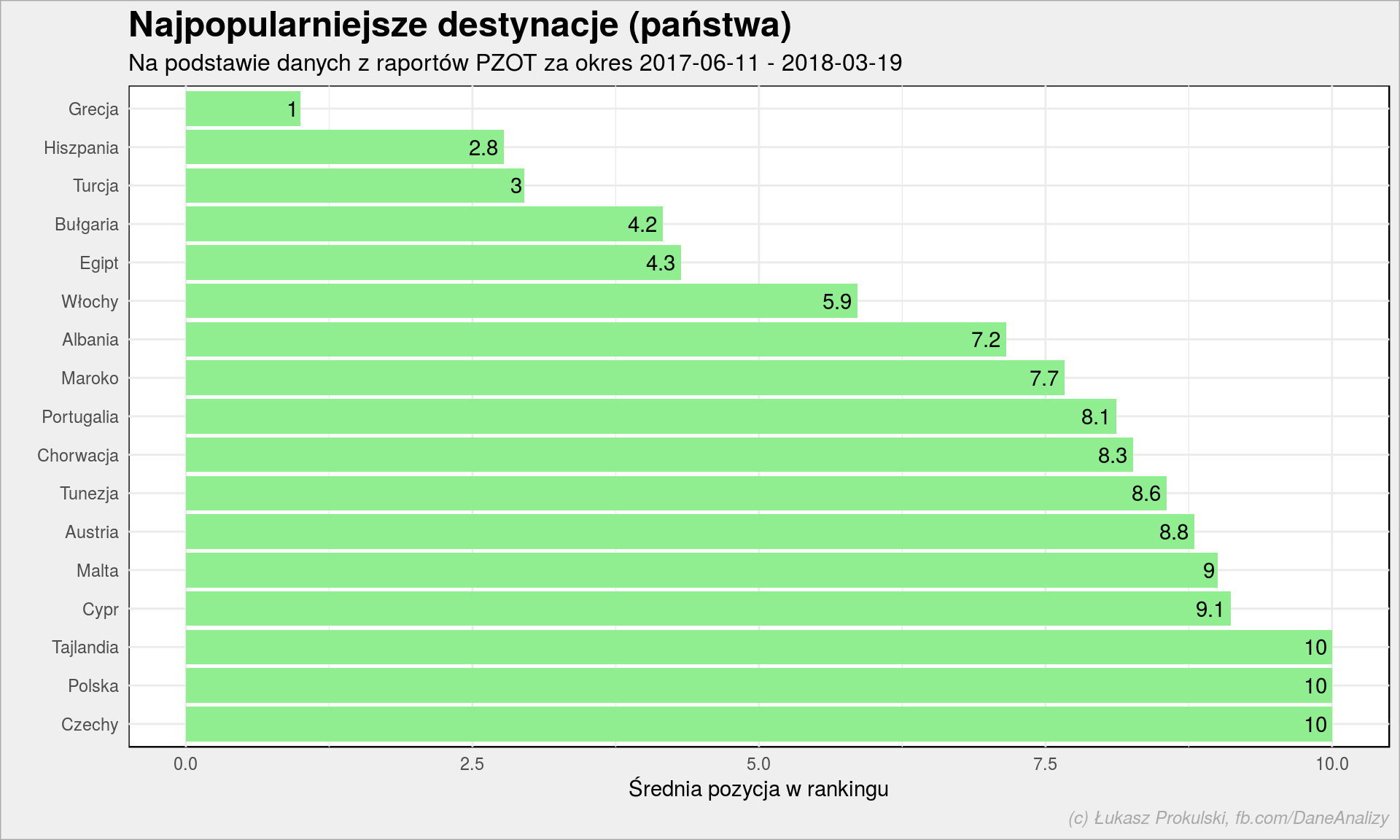
Króluje Grecja. Średnio zawsze jest na szczycie. Druga w kolejności jest Hiszpania. Sądziłem, że Egipt będzie na podium i się pomyliłem.
Zobaczmy jak to wygląda w detalach – ile razy dany kraj zajmował konkretne miejsce?
|
1 2 3 4 5 6 7 8 9 10 11 12 |
holiday_countries %>% count(Rank, Country) %>% arrange(desc(Rank)) %>% mutate(Country = fct_inorder(Country)) %>% ggplot() + geom_tile(aes(as.factor(Rank), Country, fill = n), color = "gray50") + geom_text(aes(as.factor(Rank), Country, label = n)) + scale_fill_distiller(palette = "YlOrRd", direction = 1) + labs(title = "Najpopularniejsze destynacje (państwa)", subtitle = subtitle, x = "Pozycja w rankingu", y = "", fill = "Ile razy na danej pozycji?") + theme(legend.position = "bottom") |
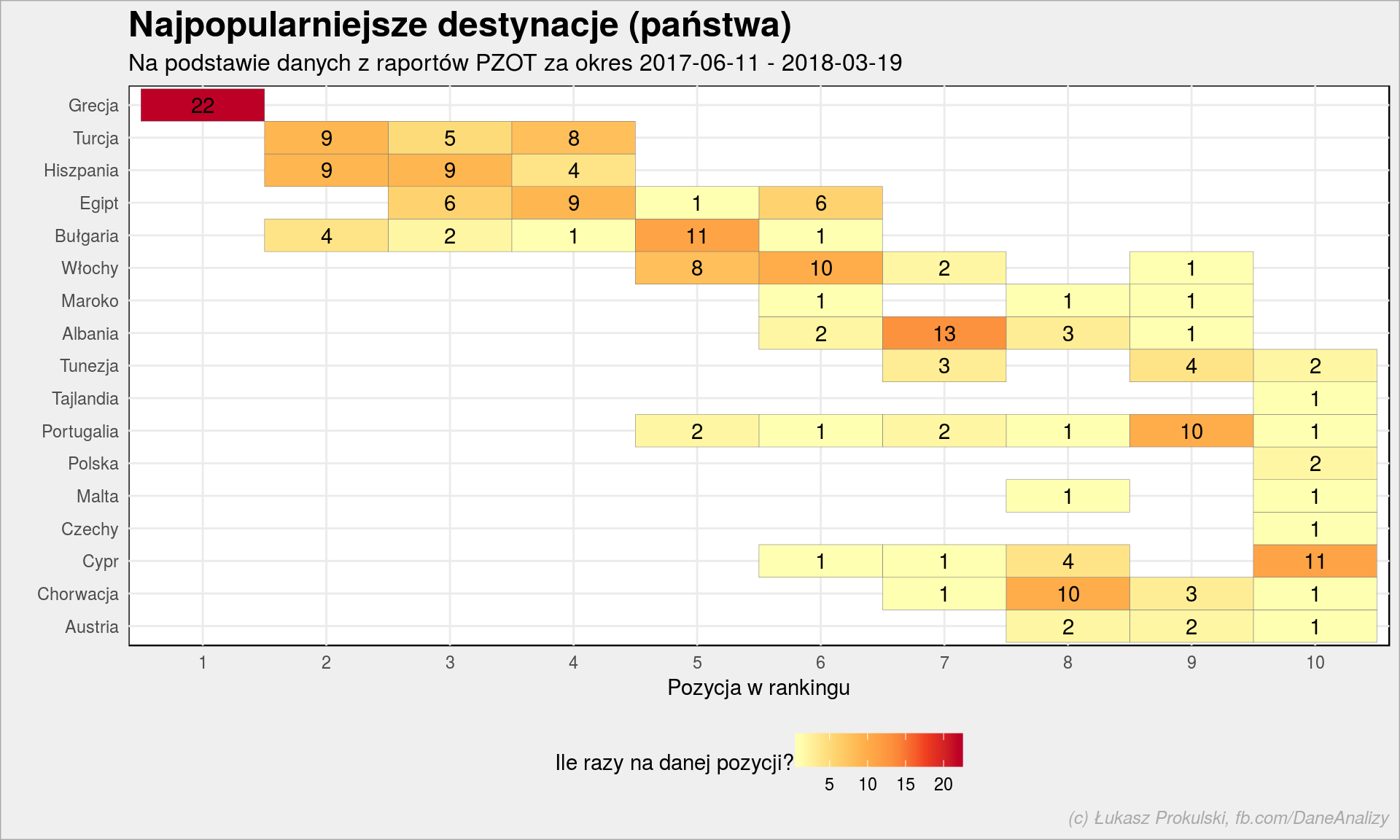
Grecja jest najpopularniejszym krajem odwiedzanym przez Polaków (tak przynajmniej było dla wszystkich rankingów jakie mamy). Turcja i Hiszpania zajmowały drugie miejsce tak samo często, jednakże ostatecznie Hiszpania wygrywa (częściej była na 3 miejscu).
Jak zmieniała się pozycja na szczycie? Weźmy kraje, które były w rankingach na miejscu piątym lub wyżej i zobaczmy jakie miejsca zajmowały w kolejnych tygodniach. Oczywiście Grecja będzie stale na szczycie, ale co niżej?
|
1 2 3 4 5 6 7 8 9 10 11 |
holiday_countries %>% filter(Rank <= 5) %>% ggplot() + geom_line(aes(Date, Rank, color = Country)) + geom_point(aes(Date, Rank, color = Country), size = 3) + scale_x_date(date_labels = "%Y-%m") + scale_y_reverse() + labs(title = "Najpolularniejsze destynacje (państwa) - zmiany na podiumn", subtitle = subtitle, x = "", y = "Pozycja w rankingu", color = "Kraj") + theme(legend.position = "bottom") |
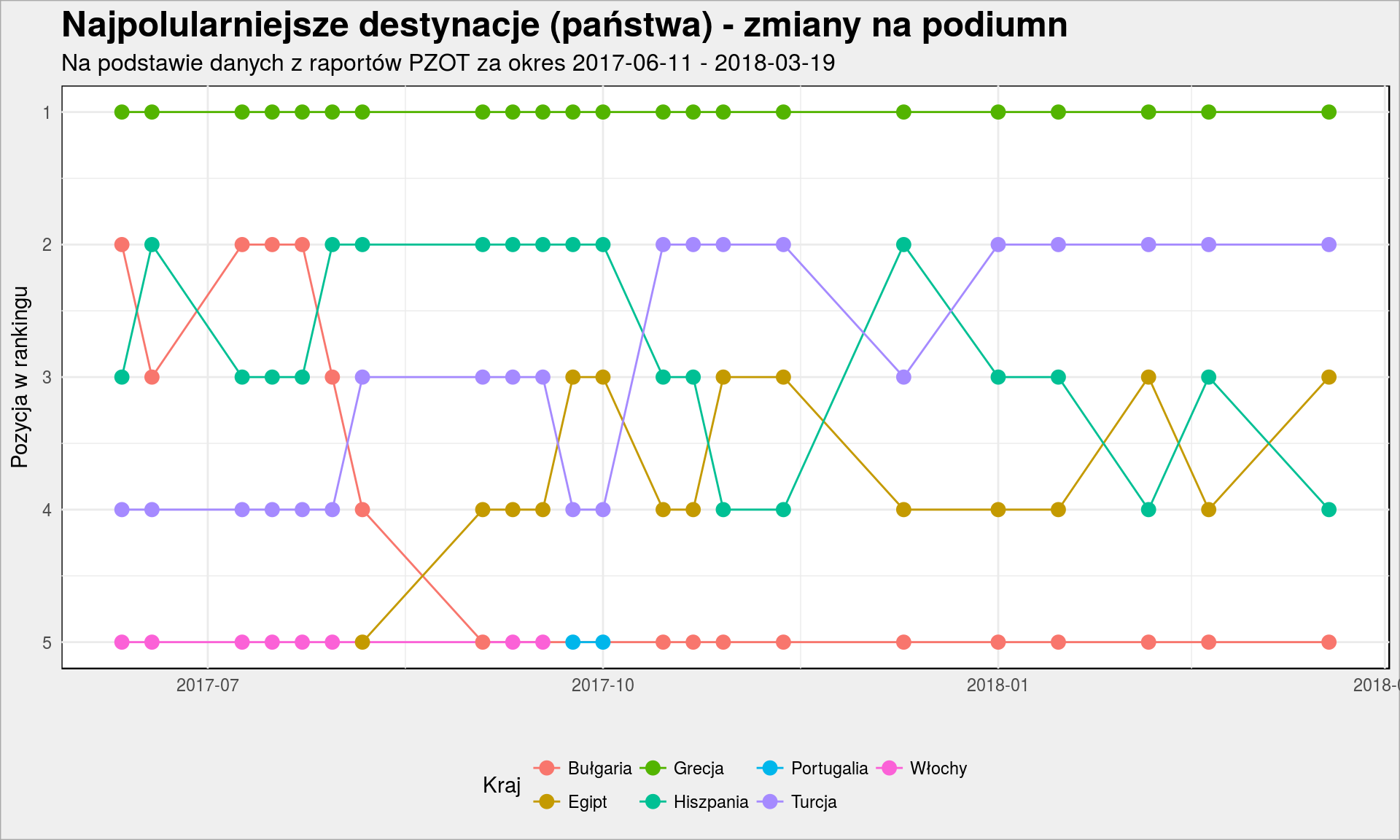
Mamy standardową mijankę na 2-4 miejscu co może znaczyć tylko tyle, że kraje te (Turcja, Hiszpania, Egipt) są tak samo popularne. Z ciekawostek:
- Włochy pod koniec września wypadły z Top 5, co ciekawe nie wróciły przed rozpoczęciem sezonu narciarskiego (wróciły, ale na szóste miejsce czego już nie widać na wykresie). Pamiętajmy, że Włochy to też Sycylia – to pewnie ona waży najwięcej we włoskim kawałku tortu
- Bułgaria z 2-3 miejsca spadła z końcem lata (oferty last-minute? już nie ma tyle słońca?) na miejsce piąte
- w tym samym czasie Egipt zyskał na znaczeniu. Wyższe temperatury jesienią są dostępne bardziej na południu, a różnica w cenie między Bułgarią a Egiptem stosunkowo niewielka (około 200 zł na osobę) – to może być wytłumaczenie zmiany
Osobiście raz byłem na wyjeździe z biurem podróży. W sumie tylko dlatego, że przelot plus hotel wychodziły taniej niż organizowanie tego na własną rękę. Więcej nie pojadę. Jesteśmy z żoną zwolennikami wyjazdów zorganizowanych samodzielnie. Daliśmy radę w Chinach kilka lat temu, to damy radę wszędzie! Wyszukiwarki lotów, AirBNB i w trasę.
Ale co kto lubi. W naszym wariancie pretensje można mieć tylko do siebie i własnych wyborów.
A co jeśli wycieczka się nie udała i urlop zmarnowany? Zawsze można spróbować odzyskać pieniądze. Pomocna może być na przykład kancelaria Kempa i Wspólnicy, która specjalizuje się w takich sprawach. Polecam serdecznie ich ekspercki blog, na którym radca prawny Bartosz Kempa i jego ekipa z serwisu ZmarnowanyUrlop.pl opisują co robić aby nie zmarnować urlopu oraz co robić jak już szlag Cię trafił i zamiast leżenia nad basenem z drinkiem z palemką w ręce trzeba było użerać się z hotelem i biurem podróży. Śledźcie ich fanpage, tam więcej o wakacjach z biurem podróży, bez stresu.
Podsumowując dzisiejszy wpis:
- lubimy jeździć tam gdzie jest ciepło i stosunkowo tanio
- jak ciepło odchodzi (ze zmianą roku) na południe to jedziemy za nim
- z dziećmi jeździmy tam, gdzie można posiedzieć nad basenem
- zwiedzanie (przykład Portugalii czy Tajlandii) raczej w parach (czyli bez dzieci)
- miejsca w Polsce wybieramy raczej samodzielnie (nie ma Polski w rankingach), a jeśli korzystamy z biura podróży to zapewne chodzi o kolonie dla dzieci (może też wyjazdy na Boże Narodzenie?)
Podobało się? Rzuć piątaka na kolejny wyjazd (no dobra: na serwer). Polub też Dane i Analizy – nie przegapisz następnej żebro-lajkowej ankietki o temacie kolejnego wpisu. Oczywiście możesz też zaproponować coś od siebie!
Fajny wpis :)
ale jakbym nie próbowała to ściąga mi się pusty pdf, nawet jak wpisze na sztywno ścieżkę pliku
download.file(url=”http://www.pzot.pl/index.php?module=cms/files/download&name=00000000333DWOQK76V60GZ1C2H56771_Booking_Report_12_2018.pdf”, destfile = „raporty_pzot/raport_1.pdf”)
A inne (z innego serwera, dowolne) pliki działają? Ten konkretny plik istnieje i nie jest pusty (sprawdziłem właśnie w przeglądarce).
Być może to coś z Twoim łączem (proxy? Zobacz stack overflow) albo samym R.
Miałem podobny problem, i wystarczyło dodać parę argumentów do funkcji download.file:
download.file(url = paste0(„http://www.pzot.pl/”, urls),
destfile = sprintf(„raporty_pzot/raport_%02d.pdf”, 1:length(urls)), mode = „wb”,method=”libcurl”, quiet=TRUE)
Kod powinien teraz działać. Pozdrawiam