W poprzednim odcinku zebraliśmy dane o pogodzie w Polsce od 1951 roku. Dzisiaj przygotujemy prognozę pogody. Ale przede wszystkim nauczymy się weryfikować modele.
Mając zgromadzone dane o pogodzie z ponad 60 lat (1951-2017) możemy pokusić się o prognozowanie temperatury w przyszłości. Wykorzystamy trzy (właściwie dwa) modele dostępne od ręki w popularnych bibliotekach R oraz zaprzęgniemy do prognozowania sieć neuronową.
Zaczniemy od potrzebnych bibliotek:
|
1 2 3 4 5 6 |
library(tidyverse) library(lubridate) library(DBI) # pobieranie danych z bazy SQLite library(forecast) # na potrzeby modeli ARIMA i ETS/STLF library(keras) # na potrzeby LSTM w TensorFlow library(corrgram) # wykres korelacji |
Na początek pobieramy dane o średniej dziennej temperaturze wszystkich stacji w latach 2000-2016. Te dane potraktujemy jako dane treningowe. Dane z 2017 roku potraktujemy jako testowe.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
# łączymy się z bazą dbase <- dbConnect(RSQLite::SQLite(), "imgw.sqlite") # dane treningowe # średnia temperatura dzienna ze wszystkich stacji, dzień po dniu - 2000-2016 mTemps_train <- dbGetQuery(dbase, "SELECT Rok, Miesiac, Dzien, AVG(MeanTemp) AS mTemp FROM imgw WHERE Rok >= 2000 AND Rok <= 2016 GROUP BY Rok, Miesiac, Dzien;") %>% # robimy sobie pole z datą mutate(data = make_date(Rok, Miesiac, Dzien)) %>% arrange(data) # dane testowe # średnia temperatura dzienna ze wszystkich stacji, dzień po dniu - 2017 mTemps_test <- dbGetQuery(dbase, "SELECT Rok, Miesiac, Dzien, AVG(MeanTemp) AS mTemp FROM imgw WHERE Rok = 2017 GROUP BY Rok, Miesiac, Dzien;") %>% # robimy sobie pole z datą mutate(data = make_date(Rok, Miesiac, Dzien)) %>% arrange(data) # odłączamy się od bazy dbDisconnect(dbase) |
Na potrzeby zbudowania modeli ARIMA i ETS potrzebujemy danych w postaci szeregu czasowego. Budujemy taki z danych treningowych:
|
1 2 3 4 |
y_ts <- ts(mTemps_train$mTemp, start = c(2000, 1, 1), # początek danych end = c(2016, 12, 31), # koniec danych frequency = 365.25) # częstotliwość szeregu - dane dzienne (0.25 ze względu na rok przestępny) |
Możemy szereg czasowy w bardzo prosty sposób obejrzeć i z grubsza przeanalizować składowe, między innymi sezonowość i trend:
|
1 |
plot(decompose(y_ts)) |
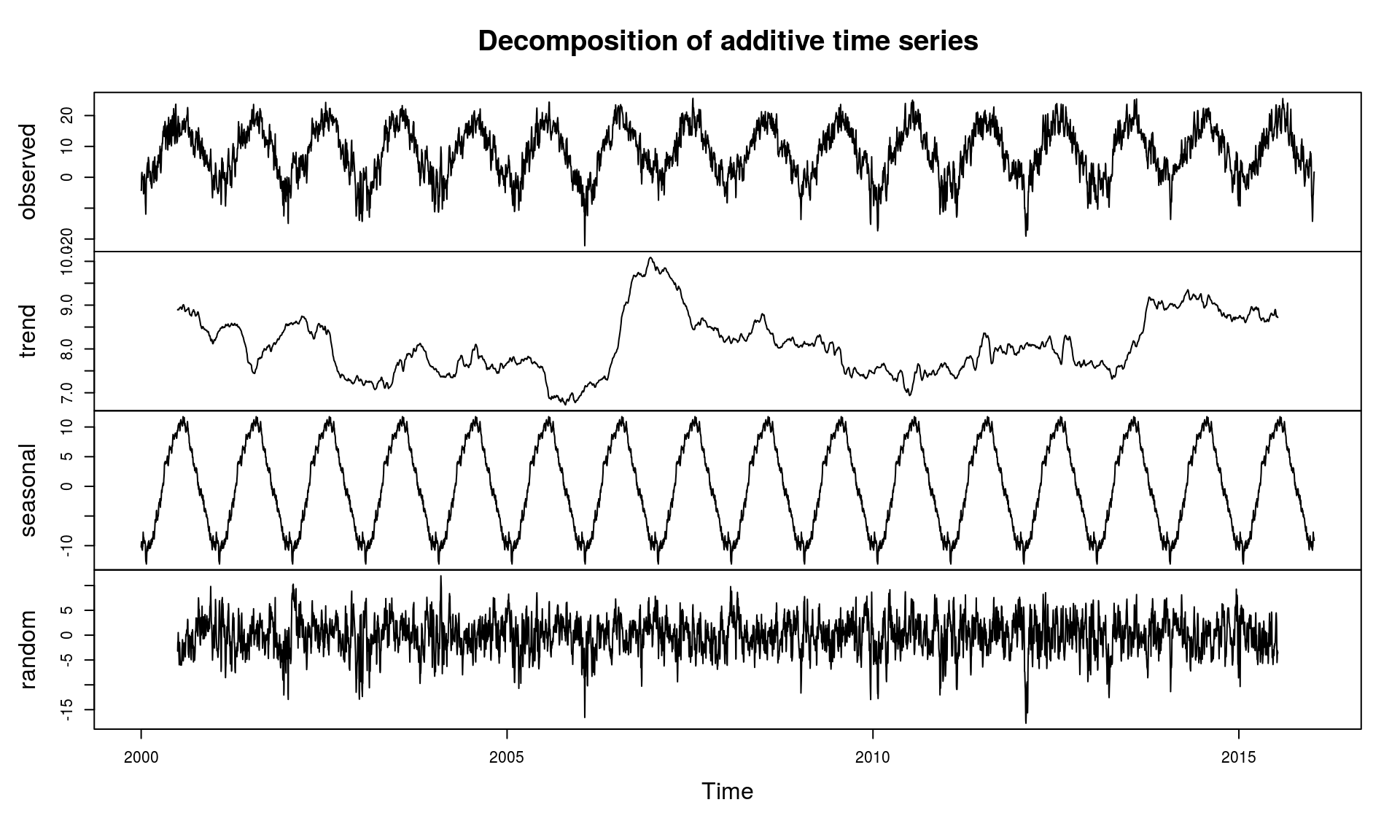
Pięknie widać sezonowość temperatury. Widać też, że w okolicy 2006 roku było zdecydowanie cieplej (składowa trendu). Można to porównać z wykresami z poprzedniej części; na tym wykresie:
oraz na tym:
Spróbujmy przewidzieć temperaturę na przyszłość, korzystając z danych historycznych. Nie jest to może najmądrzejsze podejście do prognozowania pogody, ale skoro temperaturę charakteryzuje sezonowość, to dlaczego nie?
Model ARIMA (auto)
Pierwszy będzie model typu ARIMA z automatycznie dobranymi współczynnikami. O modelu tym pisałem jakiś rok temu, przy okazji prognozowania stopy bezrobocia, który to model sprawdził się bardzo dobrze (porównajcie ówczesne prognozy z danymi o stopie bezrobocia w 2017 roku).
|
1 2 3 4 5 6 7 8 |
# budujemy model model_arima <- auto.arima(y_ts) # prognozujemy na rok do przodu forecast_arima <- forecast(model_arima, h = 365) # co nam wyszło? plot(forecast_arima) |
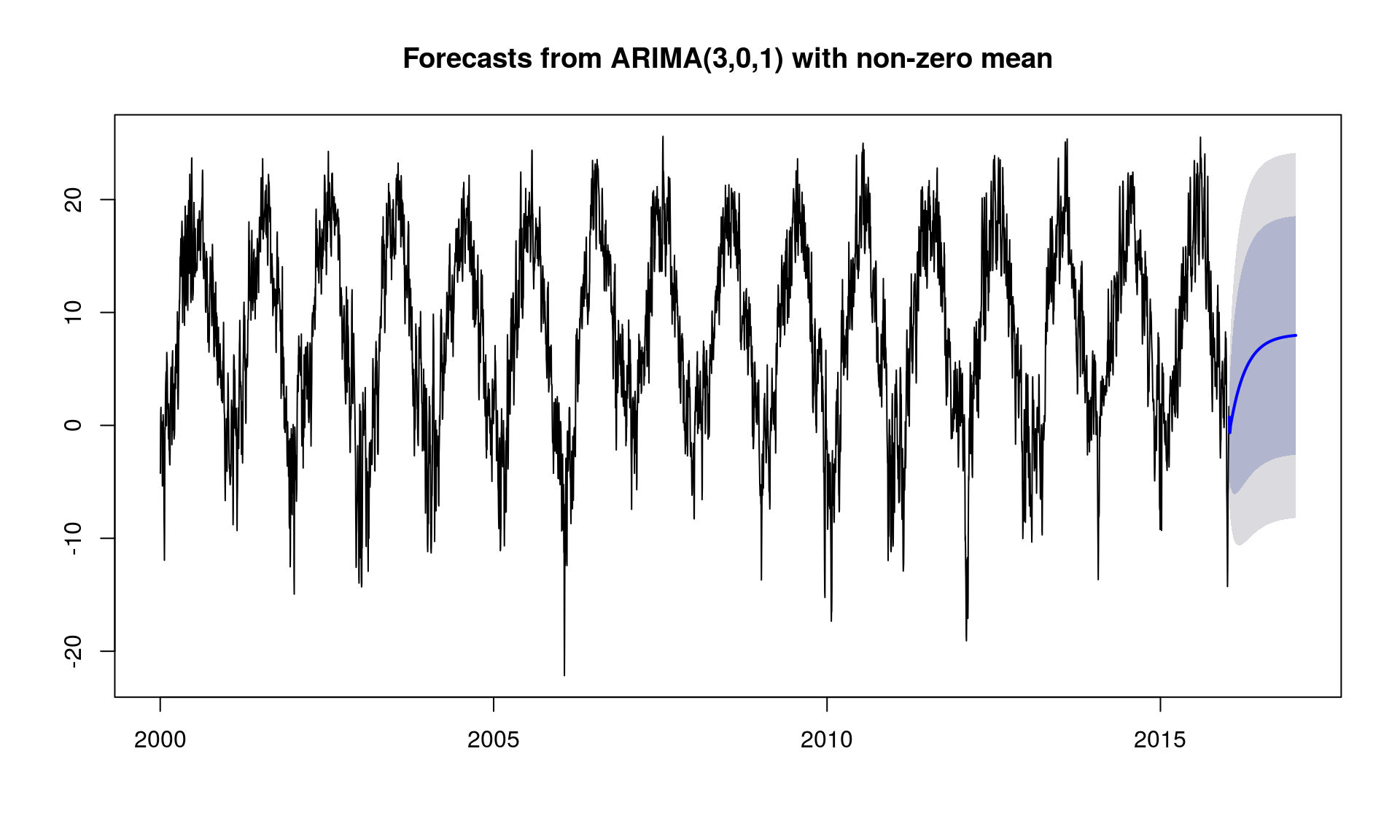
Model nie dał żadnych sensownych wyników – temperatura na początku roku urośnie, a potem będzie już stała. W naszym klimacie to bzdura (chociaż dzisiaj klikałem po nowej wersji serwisu z moją ulubioną prognozą – meteo.pl – i na przykład we Włoszech już teraz w nocy jest tak samo ciepło jak w dzień).
Model ARIMA
Należałoby dostosować parametry modelu, przede wszystkim parametr mówiący o długości okresu (sezonu) – w naszym przypadku jest to rok (365.25 dni).
|
1 2 3 4 5 6 |
model_arima_params <- Arima(y_ts, order = c(0, 1, 0), # to trochę "na pałę" seasonal = list(order = c(0, 1, 0), # to trochę "na pałę" period = 365.25)) # to ważne forecast_arima_params <- forecast(model_arima_params, h = 365) plot(forecast_arima_params) |
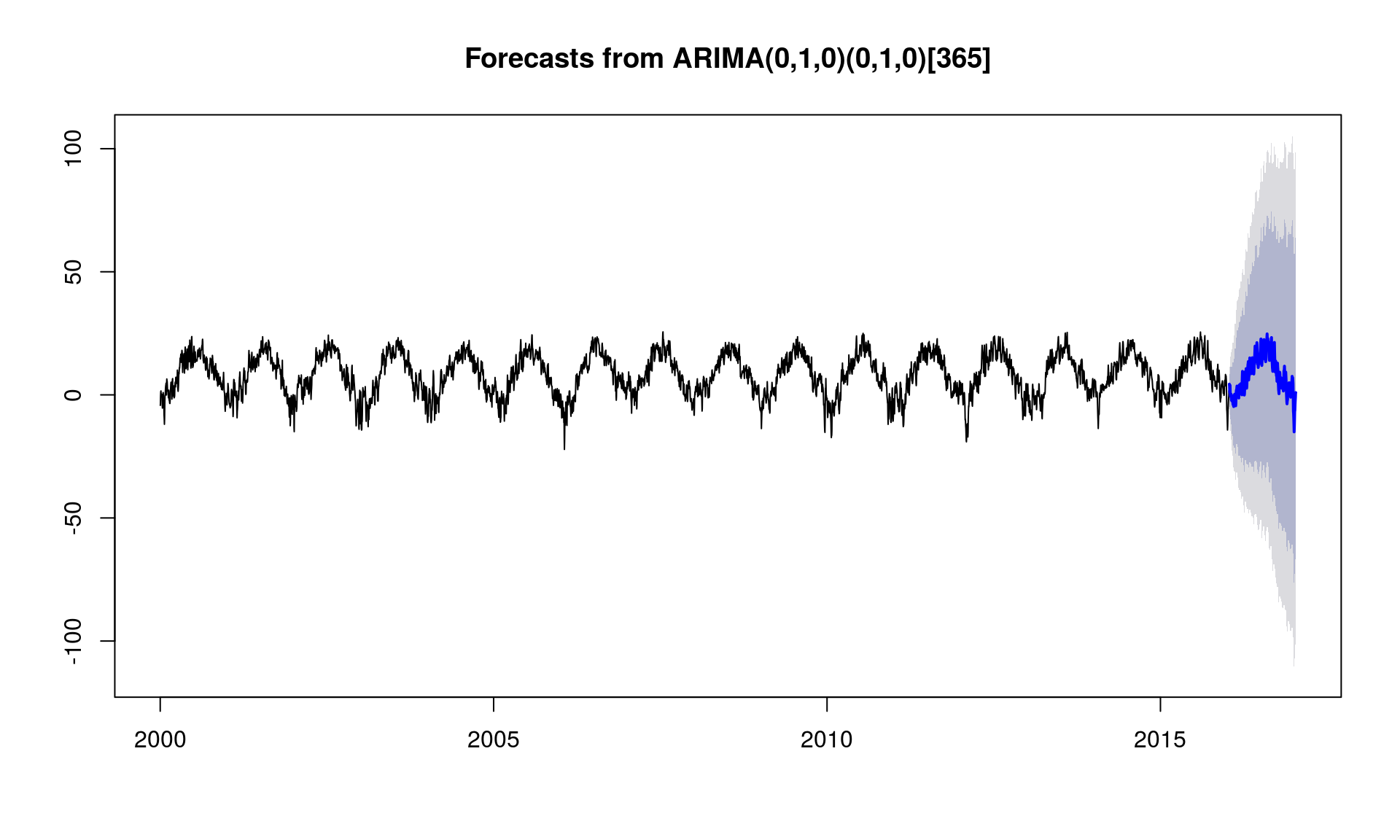
Jest zdecydowanie lepiej niż w przypadku automatycznego modelu ARIMA, widać już górkę w lecie i spadek w zimie. Linia niebieska to prognoza (i tego użyjemy do dalszych porównań), a szarości to przestrzeń w której teoretycznie temperatura może się poruszać z określonym stopniem ufności.
Model ETS
W prognozowaniu bezrobocia świetnie sprawdził się model ETS, ale dla tak dużej częstotliwości szeregu czasowego przy wywołaniu funkcji ets() dostajemy komunikat, że to jednak przesada (z tą częstotliwością) i należy użyć stlf(). No to proszę bardzo:
|
1 2 3 |
model_stlf <- stlf(y_ts) forecast_stlf <- forecast(model_stlf, h = 365) plot(forecast_stlf) |
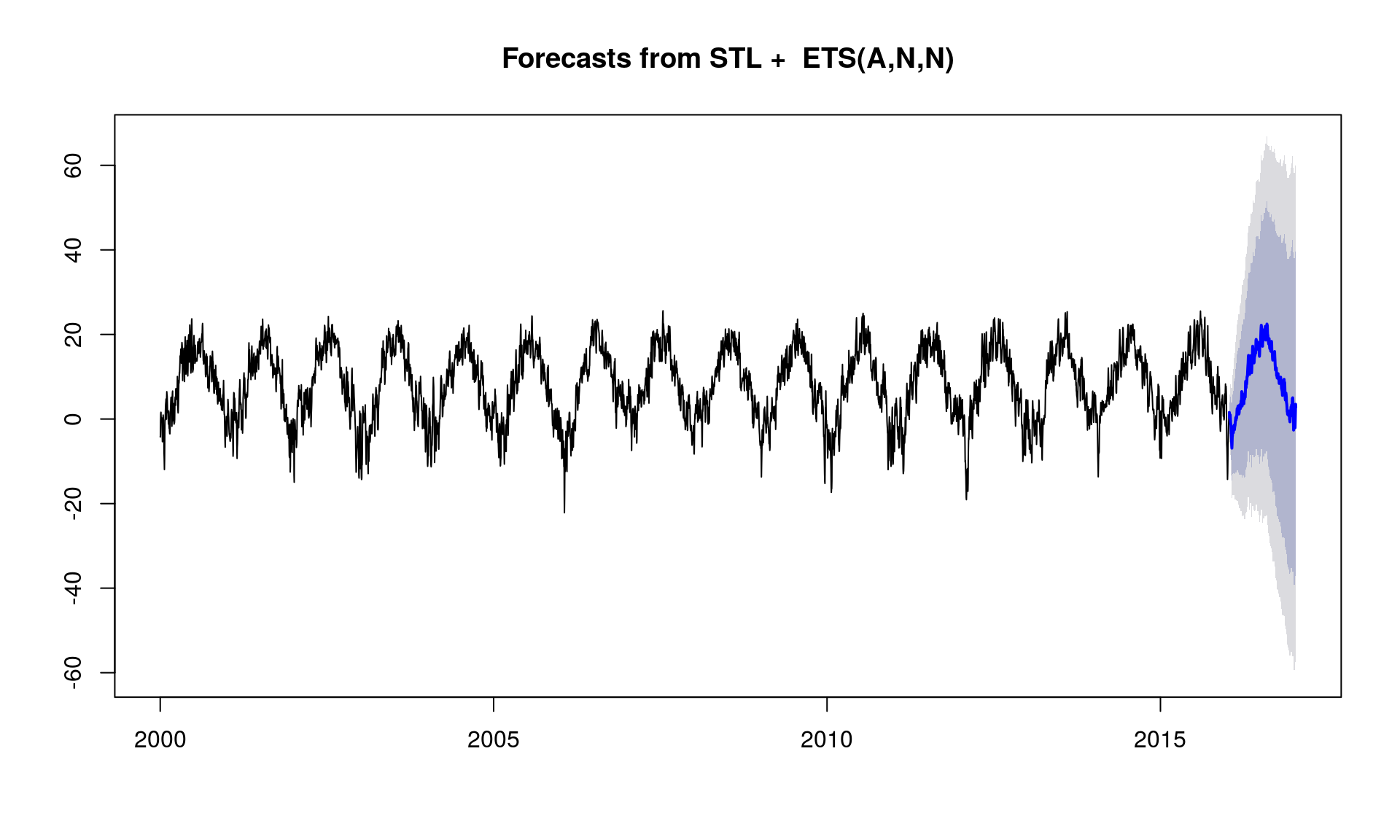
Na pierwszy rzut oka też jest dobrze. Co ciekawe – prognozy przeliczyły się zdecydowanie szybciej niż paramteryzowana Arima.
Przygotujmy sobie tabelkę z wartościami prognozowanymi przez kolejne modele – przyda się za chwilę do porównania który model daje najlepsze predykcje.
|
1 2 3 4 5 |
modele_podsumowanie <- tibble(date = seq(as_date("2017-01-01"), as_date("2017-12-31"), by = "1 day"), org = mTemps_test$mTemp) %>% mutate(arima = as.numeric(forecast_arima$mean), arima_params = as.numeric(forecast_arima_params$mean), stlf = as.numeric(forecast_stlf$mean)) |
Sieć LSTM
Ostatnim modelem będzie model zbudowany w oparciu o sieć neuronową typu LSTM. Zadziałamy podobnie jak w przypadku przewidywania tekstu: podzielimy historię na serię okien (tutaj o długości 30 dni) i wytrenujemy sieć tak, aby nauczyła się odpowiadać na wektor 30-elementowy jedną liczbą (temperaturą z kolejnego dnia).
Pierwszy krok to przygotowanie danych w odpowiedniej dla TensorFlow (w tym przypadku opakowany w bibliotekę Keras) formie:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
# rozmiar okna window_size <- 30 # miejsce na dane treningowe - cechy X (historyczne temperatury) i odpowiedź Y (temperatura kolejnego dnia) lstm_x <- array(0, dim = c(nrow(mTemps_train)-window_size, window_size, 1)) lstm_y <- array(0, dim = c(nrow(mTemps_train)-window_size, 1)) # budujemy 30-dniowe wektory X i zapamiętujemy odpowiedź Y for(i in 1:(nrow(mTemps_train)-window_size)) { lstm_x[i,,] <- mTemps_train$mTemp[(i+1):(i+window_size)] lstm_y[i,] <- mTemps_train$mTemp[i] } |
Teraz czas na stosowny model. Próbowałem kilku architektur sieci, ta daje dobre wyniki przy niewielkim czasie obliczeń.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
model <- keras_model_sequential() model %>% layer_lstm(256, input_shape = c(window_size, 1)) %>% layer_dense(512) %>% layer_dense(1) %>% # w odpowiedzi potrzebujemy jednej, niezmienionej przez funkcje aktywacji liczby layer_activation("linear") model %>% compile( loss = "mse", metrics = "mse", optimizer = "adam" ) |
Podsumowanie modelu (architektura sieci) wygląda następująco:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
summary(model) ## ___________________________________________________________________________ ## Layer (type) Output Shape Param # ## =========================================================================== ## lstm_1 (LSTM) (None, 256) 264192 ## ___________________________________________________________________________ ## dense_1 (Dense) (None, 512) 131584 ## ___________________________________________________________________________ ## dense_2 (Dense) (None, 1) 513 ## ___________________________________________________________________________ ## activation_1 (Activation) (None, 1) 0 ## =========================================================================== ## Total params: 396,289 ## Trainable params: 396,289 ## Non-trainable params: 0 ## ___________________________________________________________________________ |
Mamy prawie 400 tysięcy parametrów do określenia. Zatem do dzieła, licz komputerku, licz!
|
1 2 3 4 5 6 7 |
history <- model %>% fit( lstm_x, lstm_y, batch_size = 128, epochs = 20, validation_split = 0.8, verbose = TRUE ) |
W przypadku sieci zawsze warto sprawdzić jak wyglądają krzywe błędów:
|
1 |
plot(history) |
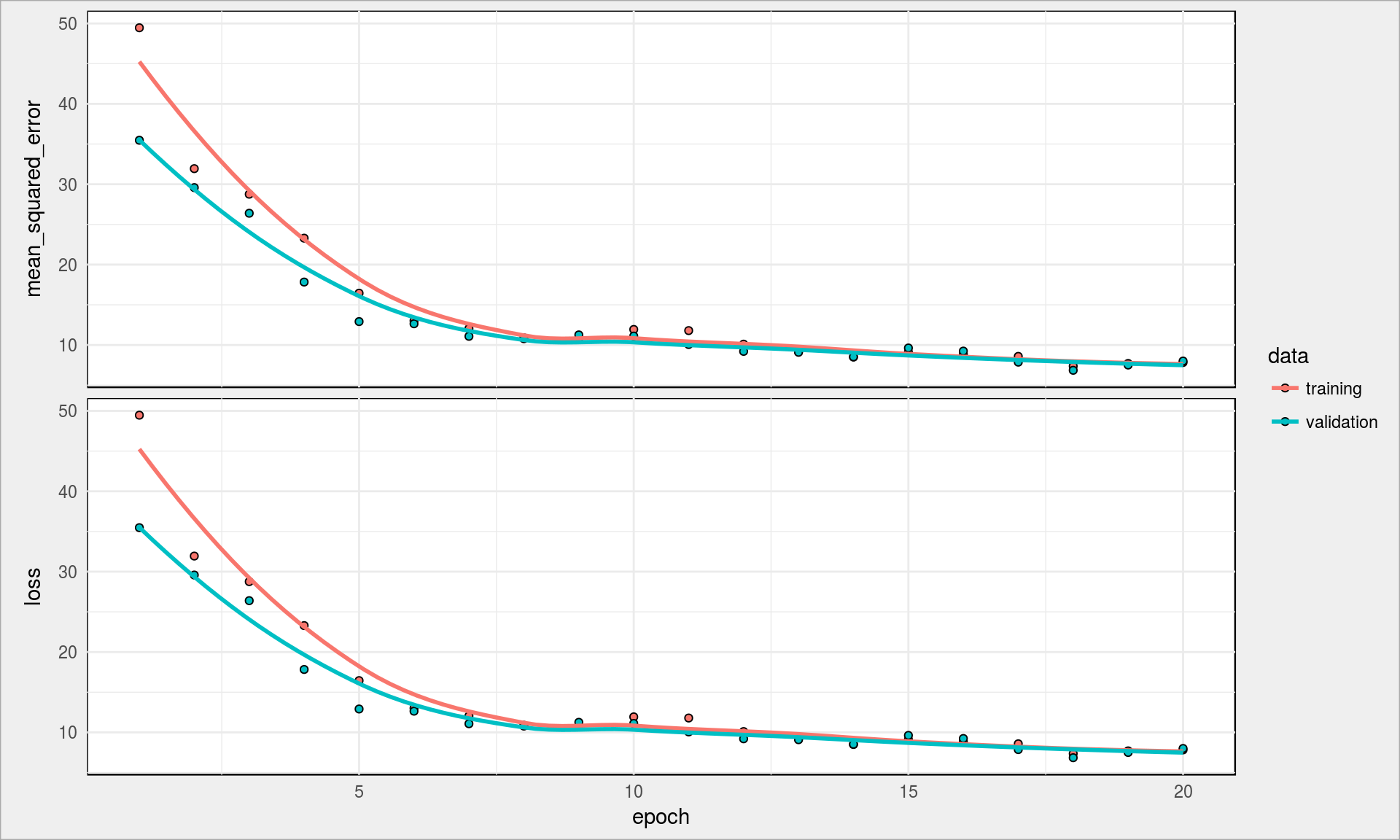
Wygląda to dobrze, krzywe spadają z liczą epochów, a w dodatku są ze sobą zbieżne – nie ma więc mowy o przeuczeniu sieci. Możecie popróbować zmienić liczbę epochów oraz węzłów sieci.
Policzmy więc temperaturę dla 2017 roku. Przygotujmy dane w odpowiedniej formie:
|
1 2 3 4 5 |
lstm_x_test <- array(0, dim = c(nrow(mTemps_test)-window_size, window_size, 1)) for(i in 1:(nrow(mTemps_test)-window_size)) { lstm_x_test[i,,] <- mTemps_test$mTemp[(i+1):(i+window_size)] } |
i sprawdźmy wynik:
|
1 |
lstm_y_pred <- predict(model, lstm_x_test) |
Teraz do zestawienia wszystkich prognoz dodajemy te z modelu LSTM. Ważna sprawa – okno 30-dniowe sprawia, że nie mamy pełnego roku, zatem aby nie było problemów część danych z poprzednich modeli sobie po prostu usuniemy. To szkoła jest, a nie poważny instytut meteo, więc możemy :)
|
1 2 3 4 5 6 |
modele_podsumowanie <- modele_podsumowanie %>% arrange(date) %>% mutate(n = row_number()) %>% filter(n <= length(lstm_y_pred)) %>% select(-n) %>% mutate(lstm = as.numeric(lstm_y_pred)) |
Porównanie wyników
Zobaczmy jak według poszczególnych modeli miała wyglądać temperatura w 2017 roku. Oczywiście w zestawieniu z tą prawdziwą – inaczej test nie miałby większego sensu.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
modele_podsumowanie_gather <- modele_podsumowanie %>% gather(key = key, value = val, -date) ggplot() + # punkty = predykcje geom_point(data = modele_podsumowanie_gather %>% filter(key != "org"), aes(date, val, color = key), size = 2, alpha = 0.8) + # linia = rzeczywistość geom_line(data = modele_podsumowanie_gather %>% filter(key == "org"), aes(date, val), color = "red", size = 1) + scale_color_manual(values = c("arima" = "#1a9641", "arima_params" = "#a6d96a", "lstm" = "#d7191c", "stlf" = "#fdae61")) + theme(legend.position = "bottom") + labs(title = "Średnia dzienna temperatura według poszczególnych modeli", x = "", y = "Średnia temperatura dzienna", color = "Model") |
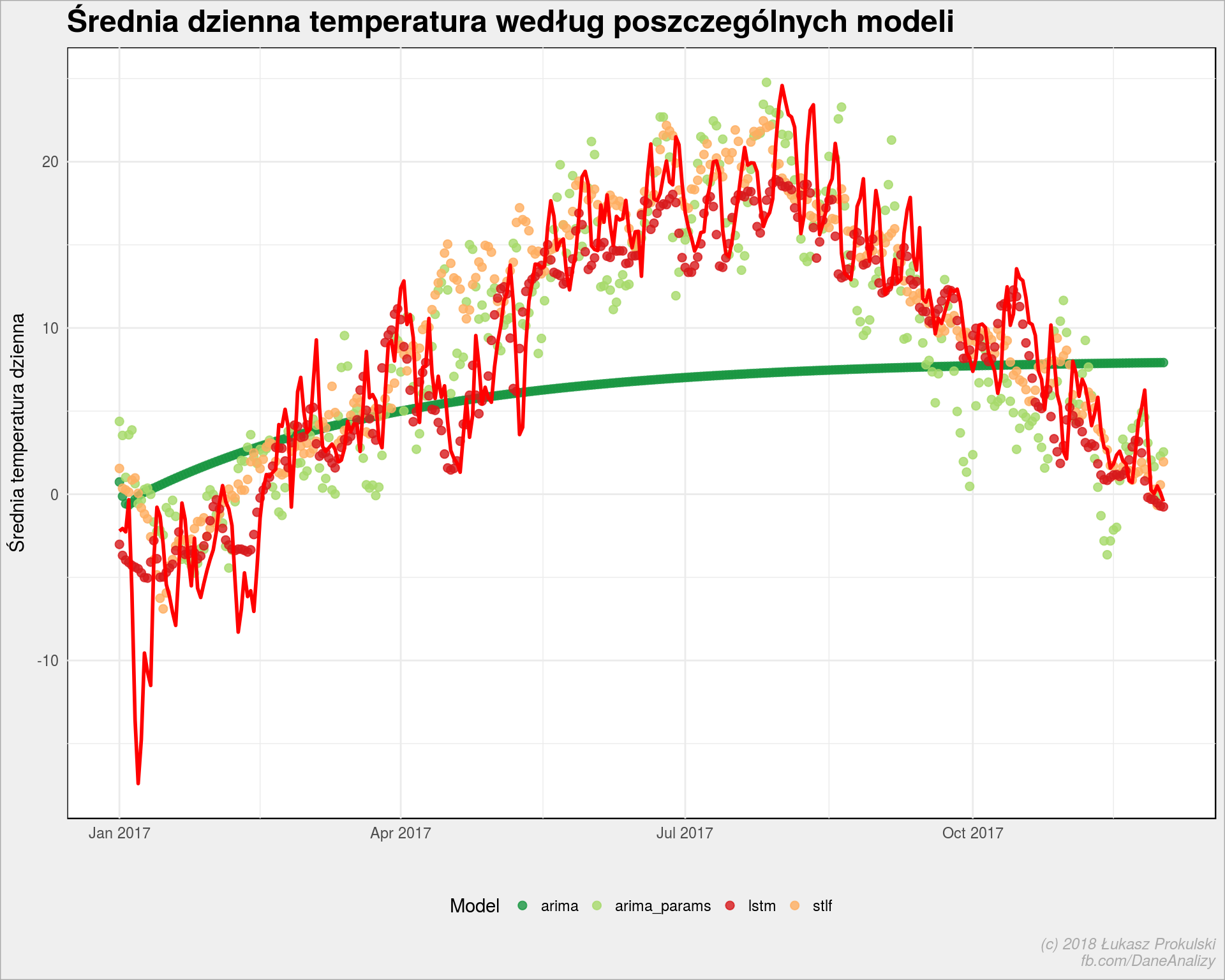
Czerwona linia to rzeczywiste średnie dzienne temperatury z 2017, punkty – temperatury według kolejnych modeli.
Automatyczna Arima dała ciała, co wiemy już od początku. Cała reszta leży mniej więcej w okolicach rzeczywistości. Ciekawe są czerwone punkty – odpowiadające za model LSTM. Wyglądają trochę jak średnia ruchoma.
Ale miarą poprawności nie jest mniej więcej a rzeczywiste różnice od prawdziwych wartości. Matematycznie zwie się to residua. Policzmy residua, a dodatkowo na jednym wykresie pokażmy jak układają się wartości obliczone przez model w porównaniu z wartościami rzeczywistymi.
|
1 2 3 4 5 6 7 |
modele_podsumowanie_res <- modele_podsumowanie %>% mutate(arima_res = org - arima, arima_params_res = org - arima_params, lstm_res = org - lstm, stlf_res = org - stlf) pairs(modele_podsumowanie_res[,2:6], cex = .1) |
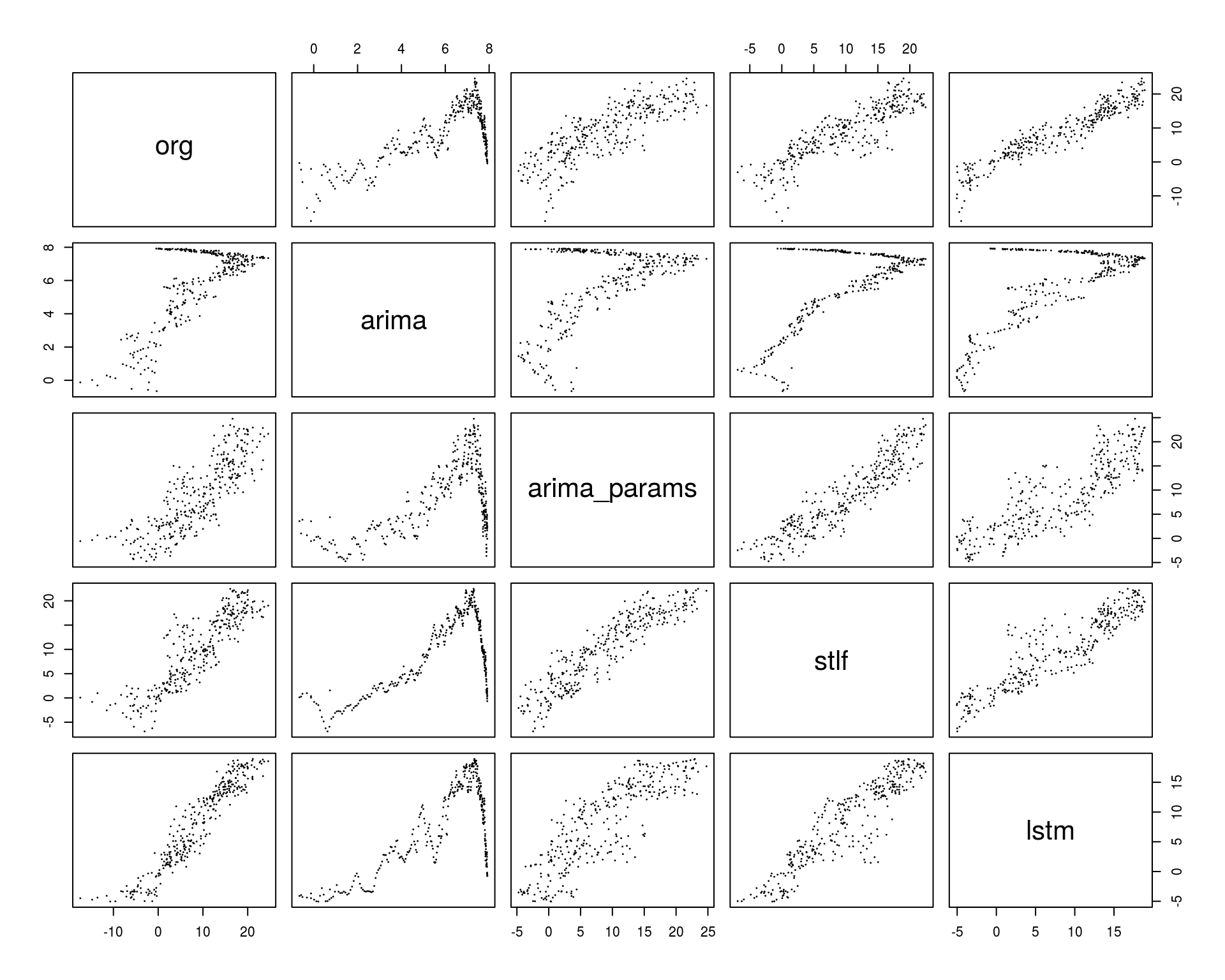
Na powyższym wykresie interesuje nas tak na prawdę pierwszy wiersz (albo pierwsza kolumna). To są wykresy typu Q-Q plot – w idealnym modelu punkty ułożyłyby się na linii prostej (takiej na ukos, z równaniem y=x). Widać, że najmniejszy rozrzut wokół prostej jest dla pary org – lstm, co może prowadzić do wniosku, że model LSTM dał najmniejsze błędy.
RMSE
Czy tak jest również można policzyć – używając na przykład miary RMSE (root mean square error – błąd średnio kwadratowy), czyli pierwiastka z sumy kwadratów odchyłek (residuów). RMSE dla kolejnych modeli to:
- ARIMA (auto): 133.4418
- ARIMA (parametryzowana): 85.377
- STLF: 73.9815
- LSTM: 50.6776
Mamy potwierdzenie, że LSTM dał najmniejsze odchyłki.
Można to też sprawdzić poprzez współczynniki korelacji danych obliczonych z rzeczywistymi – w tabelce:
|
1 |
cor(modele_podsumowanie_res[,2:6]) |
| org | arima | arima_params | stlf | lstm | |
|---|---|---|---|---|---|
| org | 1.000 | 0.716 | 0.822 | 0.878 | 0.948 |
| arima | 0.716 | 1.000 | 0.552 | 0.639 | 0.693 |
| arima_params | 0.822 | 0.552 | 1.000 | 0.919 | 0.850 |
| stlf | 0.878 | 0.639 | 0.919 | 1.000 | 0.917 |
| lstm | 0.948 | 0.693 | 0.850 | 0.917 | 1.000 |
albo na wykresie:
|
1 |
corrgram(modele_podsumowanie_res[,2:6], upper.panel = panel.ellipse, lower.panel = panel.cor) |
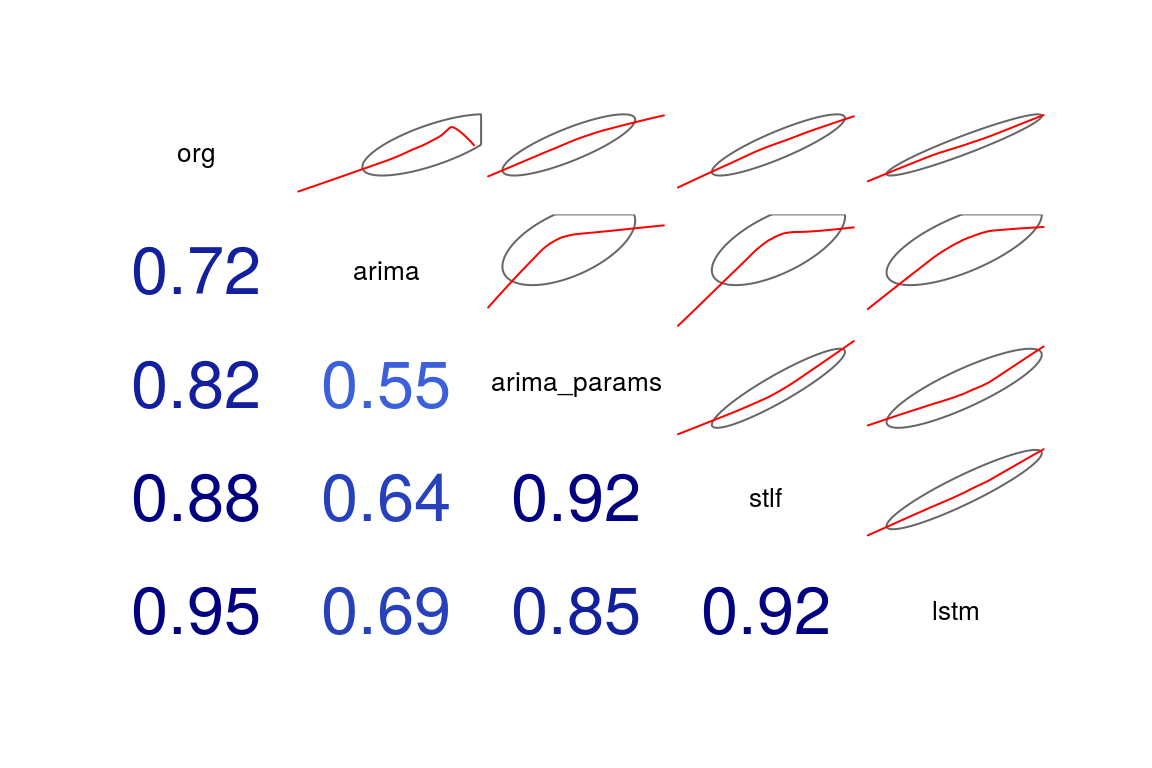
Znowu – interesuje na pierwszy wiersz lub pierwsza kolumna. Widzimy, że współczynnik korelacji pomiędzy org a lstm jest największy. Bardzo fajnie widać to na miniaturkach (obrazują to co pairs() wyżej).
Różnice dzień po dniu
Na koniec sprawdźmy jak bardzo dla każdego dnia modele rozbiegały się z rzeczywistością.
|
1 2 3 4 5 6 7 8 9 10 11 |
modele_podsumowanie_res %>% select(date, arima_res, arima_params_res, lstm_res, stlf_res) %>% gather(key = key, value = val, -date) %>% ggplot() + geom_col(aes(date, val, fill = key)) + facet_wrap(~key, ncol = 1) + scale_fill_manual(values = c("arima_res" = "#1a9641", "arima_params_res" = "#a6d96a", "lstm_res" = "#d7191c", "stlf_res" = "#fdae61")) + theme(legend.position = "bottom") + labs(title = "Residua dla poszczególnych modeli", x = "", y = "Srednia temperatura dzienna\n(odchyłki od wartosci rzeczywistej)", fill = "Model") |
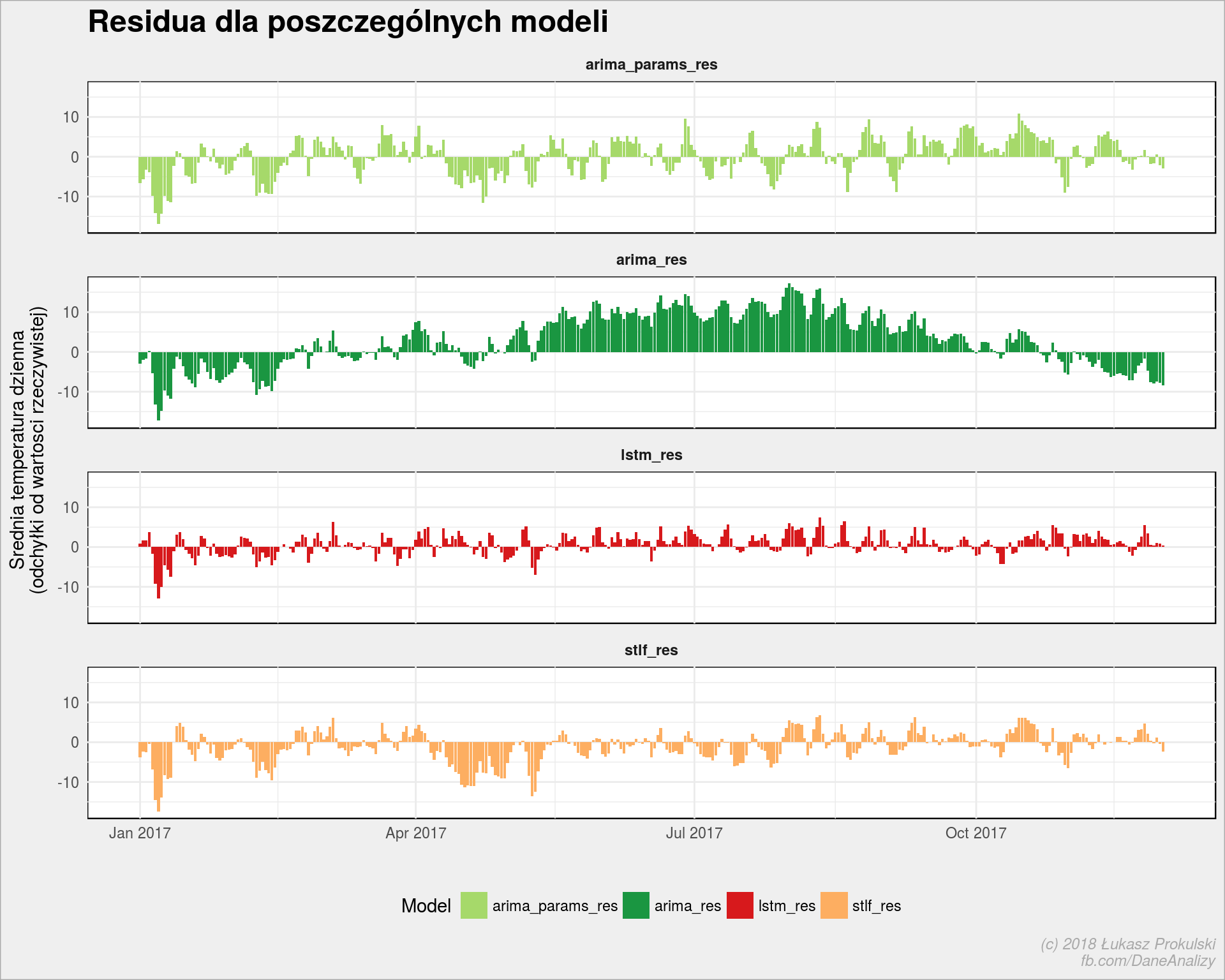
Warto zwrócić uwagę na kierunek słupków na poszczególnych wykresach w konkretnych dniach (albo okresach) – z reguły modele mylą się w tą samą stronę – czyli albo wszystkie prognozują temperaturę za wysoką w porównaniu z rzeczywistością, albo za niską. To daje jakieś spojrzenie na anomalia temperatury (rzeczywistej) w danym dniu na przestrzeni wielu lat.
Rozkład residuów
Sprawdźmy czy różnice rozkładają się równomiernie na plus i na minus.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
modele_podsumowanie_res %>% select(date, arima_res, arima_params_res, lstm_res, stlf_res) %>% gather(key = key, value = val, -date) %>% ggplot() + geom_density(aes(val, fill = key), alpha = 0.5) + geom_vline(xintercept = 0, color = "black") + scale_fill_manual(values = c("arima_res" = "#1a9641", "arima_params_res" = "#a6d96a", "lstm_res" = "#d7191c", "stlf_res" = "#fdae61")) + theme(legend.position = "bottom") + labs(title = "Rozkład residuów dla poszczególnych modeli", y = "Gestosc prawdopodobienstwa", x = "Srednia temperatura dzienna\n(odchyłki od wartosci rzeczywistej)", fill = "Model") |
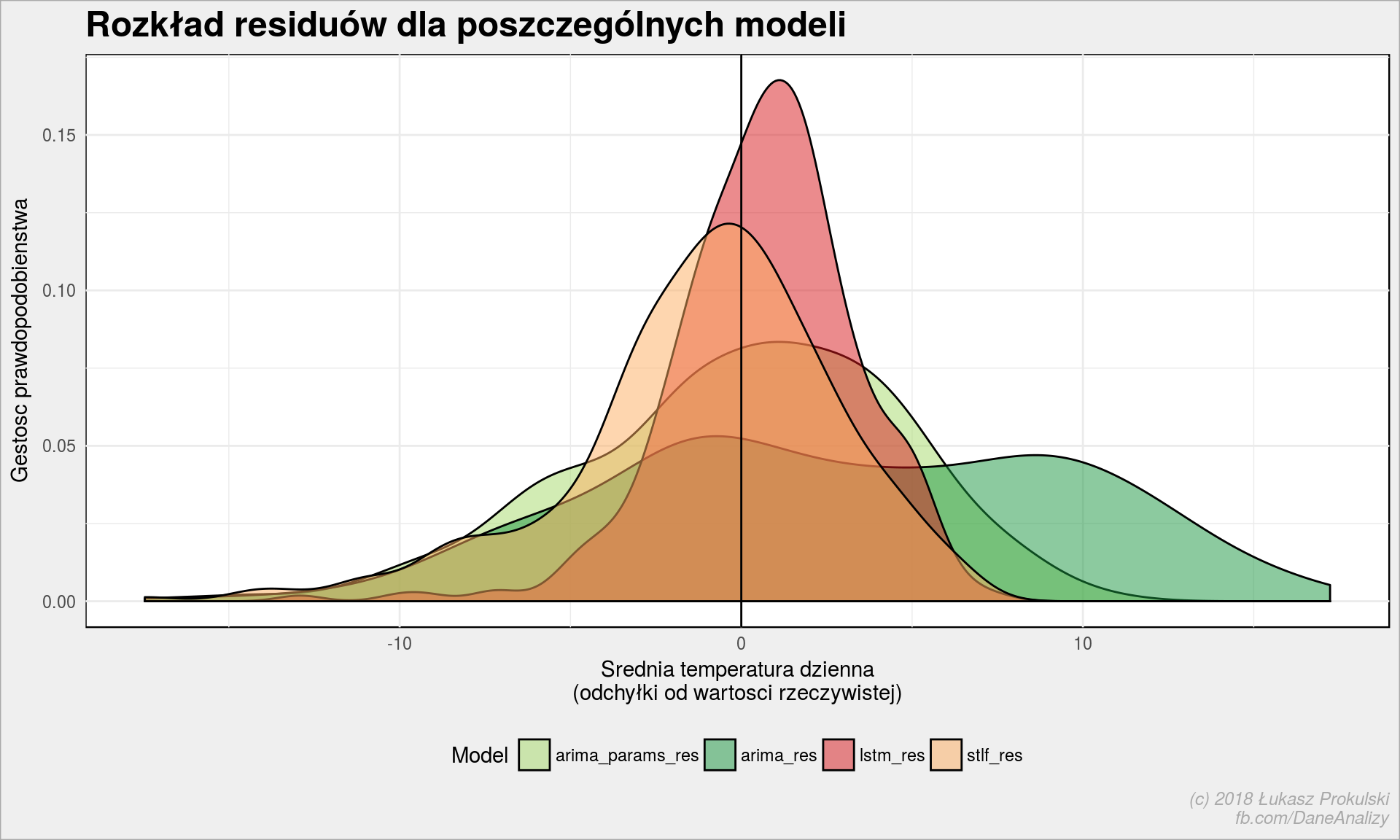
Im bardziej smukła krzywa i jej wierchołek bliżej zera tym lepiej. Bardzo dobrze wygląda tutaj rozkład residuów dla modelu lstm – po raz kolejny wygrywa. Zielona arima_res już na tym wykresie wygląda nieciekawie i możemy sądzić, że jest nieprzydatna. Zweryfikujmy to przy pomocy testu t-Studenta.
Zazwyczaj dwie średnie z różnych od siebie grup będą się różnić. Test t-Studenta powie nam czy te różnice są istotne statystycznie. O co chodzi? Dla tych, którzy niewiele pamiętają ze statystyki prostu przykład – czy kobiety i mężczyźni palą tyle samo (średnio)? Stawiamy dwie przeciwne hipotezy – H0 oraz H1.
Hipoteza zerowa takiego testu będzie brzmiała:
- H0: Średnia liczba wypalanych papierosów w grupie mężczyzn jest taka sama jak średnia liczba wypalanych papierosów w grupie kobiet.
Hipoteza alternatywna z kolei jest przeciwna:
- H1: Kobiety będą różnić się od mężczyzn pod względem liczby wypalanych papierosów w ciągu miesiąca (licząc średnią).
Jeśli wynik testu t-Studenta będzie istotny na poziomie p < 0.05 możemy odrzucić hipotezę zerową na rzecz hipotezy alternatywnej (H0 jest nieprawdziwe, a z tego wynika, że H1 jest prawdziwe). Czyli mężczyźni różnią się istotnie od kobiet jeśli chodzi o liczbę wypalanych papierosów. Patrząc na średnie w obu grupach dowiemy się kto pali więcej.
Wróćmy do naszych danych o pogodzie. Porównamy średnie temperatury uzyskane różnymi modelami ze średnią temperaturą zarejestrowaną rzeczywiście. Tutaj porównujemy dane (średnie) z całego roku, ale warto rozbić te porównania na poszczególne pory roku albo miesiące. Później na takich grupach policzyć na przykład ile razy hipoteza H0 została odrzucona dla danego modelu. Tam, gdzie ta wartość (liczba grup z odrzuconą hipotezą H0) jest większa mamy gorszy model.
Spróbujmy najpierw rozpatrzyć średnią z temperatur dla całego roku, bez dzielenia na grupy:
ARIMA (auto):
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
t.test(modele_podsumowanie_res$org, modele_podsumowanie_res$arima) ## ## Welch Two Sample t-test ## ## data: modele_podsumowanie_res$org and modele_podsumowanie_res$arima ## t = 6.346, df = 385, p-value = 6.216e-10 ## alternative hypothesis: true difference in means is not equal to 0 ## 95 percent confidence interval: ## 2.015153 3.824383 ## sample estimates: ## mean of x mean of y ## 8.793123 5.873356 |
Wartość p jest mniejsza od 0.05, a więc odrzucamy H0 (średnia roczna temperatura jest różna dla danych z modelu i danych rzeczywistych).
- ARIMA (parametryzowana): p = 0.9791, a więc nie odrzucamy H0
- STLF: p = 0.069, a więc nie odrzucamy H0
- LSTM: p = 0.2315, a więc nie odrzucamy H0
Model LSTM wydaje się być jak na razie najlepszy, gdyż:
- nie możemy odrzucić hipotezy zerowej H0, a więc średnia roczna według modelu nie różni się statystycznie od średniej zaobserwowanej
- model ten ma największy współczynnik korelacji z danymi rzeczywistymi (co łączy się bezpośrednio z punktem wyżej – być może nawet jest na to jakiś dowód matematyczny, albo jedno wynika z drugiego?)
- model ten ma najniższą wartość RMSE
Na (kolejny już) pierwszy rzut oka jest zwycięzca. Spróbujmy jeszcze przeprowadzić test t-Studenta na grupach dla poszczególnych miesięcy.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
# wartości p dla kolejnych miesięcy pvals_lstm <- modele_podsumowanie_res %>% # bierzemy miesiąc z daty mutate(miesiac = month(date)) %>% # usuwamy grudzien - mamy tam tylko 1 dzień ze względu na 30-dniowe okno, # a t.test() potrzebuje więcej danych filter(miesiac != 12) %>% # dzielimy dane na miesiące split(.$miesiac) %>% # dla każdej grupy liczymy t.test() z którego potrzebujemy tylko p.value map_dbl(~ t.test(.x$org, .x$lstm)$p.value) # ile mamy miesięcy z p > 0.05 (H0 nie jest odrzucona)? length(pvals_lstm[pvals_lstm > 0.05]) |
Mamy 6 miesięcy (z 11) dla których hipoteza o równości średnich (miesięcznych) z modelu LSTM i rzeczywistych jest prawdziwa. Tutaj wynik jest różny i może być losowy. Warto ustawić na początek generator liczb losowych na stałą wartość (przez set.seed())
Dla pozostałych modeli H0 jest prawdziwe w przypadku
- ARIMA (auto): 3 miesięcy
- ARIMA (parametryzowana): 4 miesięcy
- STLF: 5 miesięcy
Znowu LSTM wydaje się być najlepszym.
Pięknie, pięknie ale jest tutaj jeden poważny błąd. Jaki?
Ano taki, ze przewidujemy wartości w LSTM korzystając z wartości prawdziwych. Bierzemy wektor (jedno okno) wartości przewdziwych, obliczamy jedną wartość przewidywaną. Później bierzemy kolejne okno i znowu przewidujemy jedną wartość. Zapamiętujemy wartości przewidziane na podstawie wartości prawdziwych. Robimy więc trochę taką prognozę krótkoterminową i tę prognozę porównujemy z rzeczywistością.
W przypadku modeli zbudowanych na szzeregach czasowych (ARIMA i STFL) przewidujemy temperaturę na cały 2017 rok od razu. Czy zatem można porównywać w ten sposób modele?
Może w modelu LSTM trzeba przewidywać kolejne dni na podstawie już przewidzianych? To brzmi sensowniej. Trochę gimnastyki i z tym sobie poradzimy:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
# inicjalne dane - ostatnie 30 dni z danych treningowych lstm_predict <- mTemps_train$mTemp[(nrow(mTemps_train)-window_size):nrow(mTemps_train)] # miejsce na dane, do których zastosujemy model lstm_predict_array <- array(0, dim = c(1, window_size, 1)) for(i in 1:365) { # ostatnie 30 wartości z danych przewidzianych lstm_predict_array[1,,] <- lstm_predict[(length(lstm_predict)-window_size+1):length(lstm_predict)] # przewidujemy "temperaturę na jutro" temp_next_day <- as.numeric(predict(model, lstm_predict_array)) # doklejamy ją na koniec do już przewidzianych lstm_predict <- c(lstm_predict, temp_next_day) # powtarzamy proces } # co nam wyszło? bez 30 pierwszych inicjujących dni plot(lstm_predict[30:length(lstm_predict)]) |
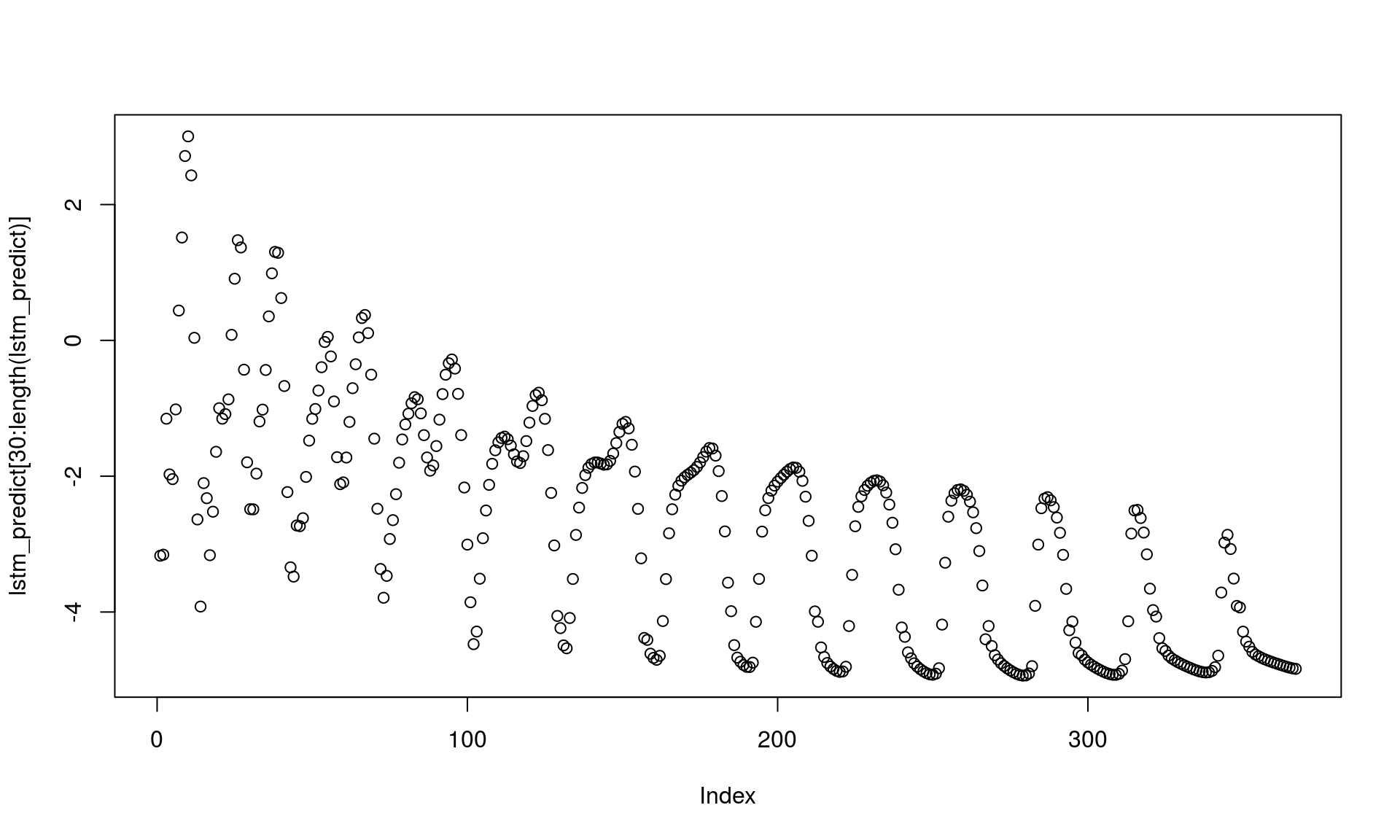
Uuuu – trochę bullshit! Nie widać lata (powinno być w górę w okolicach 100-200, później znowu w dół). W przewidywaniu tekstu mięliśmy podobny problem, pomogła zmiana architektury sieci. Tutaj problem może wynikać z tego, że za początkowe (lstm_predict ustalane na początku) dane bierzemy temperatury z grudnia 2016 (gdzie raczej robiło się coraz chłodniej – stąd coraz niższe przewidywania). Być może zaczynając od czerwca wynik byłby odwrotny. Pomóc też może wcześniejsze (przed trenowaniem) skalowanie danych. Dla zainteresowanych polecam post Using LSTMs to forecast time-series – tam znajdziecie podejście do tematu z przykładowym kodem w Pythonie. A może po prostu nie można prognozować tak daleko do przodu?
Na zakończenie podsumujmy, czego nauczyliśmy się dzisiaj:
- Do prognozowania szeregów czasowych przydatny jest pakiet forecast
- Po przygotowaniu predykcji warto przeanalizować wyniki na próbce testowej – szczególnie residua, ich rozkład. Przydatne mogą być współczynniki korelacji i test t-Studenta. I to jest najważniejsze w dzisiejszym poście.
- Sieć neuronowa typu LSTM też może być przydatna, szczególnie jeśli przewidujemy krótkie okresy (a nie cały rok)
Uwagi? Komentarze? Zapraszam do dyskusji poniżej oraz na fanpage Dane i analizy.
Świetnie wszystko wytłumaczone, na pewno mi się przyda , bardzo dziękuję! Czekam na więcej podobnych wpisów.
Łukasz, super wpis :) Dzięki wielkie, bo świetnie się czyta. Fajnie, że poruszyłeś ten temat, bo sam ostatnio sporo siedzę w tym i testowałem różne metody na przykładach związanych z giełdą i sektorem finansowym :) Bardzo mi się spodobał pomysł z testowaniem średnich.
Jeśli można, to mam pytania co do LSTM i kolejnych wykonywanych kroków:
1. Sieć w tym wypadku dostaje dane z 30-dniowego okna (dni 1-30) i odpowiada jedną wartością: temperaturą na kolejny dzień, po wskazanych 30 dniach. Dobrze zrozumiałem?
2. Kolejnym krokiem jest wyznaczenie następnego okna (dni 2-31), w którym temperaturą z dnia numer 31 jest temperatura wyznaczona w kroku pierwszym i teraz wyznaczasz temperaturę na dzień numer 32, tak?
3. W sposób iteracyjny powtarzasz krok 2, wyznaczając kolejne okna: (dni 3-32) – dzień 31 został wyznaczony w kroku 1, dzień 32 został wyznaczony w kroku 2, tak? :)
Powinno być tak jak napisałeś, ale mój kod robi przewidywania dla kolejnych dni na bazie historii. Czyli nie bierze pod uwagę przewidzianej wartości… To jest błąd i zdaję sobie sprawę z tego.
Z tego co pamiętam to podlinkowany tekst z kodem w Pythonie robi to poprawnie.
Ok, dzięki :)