Czy da się napisać tekst za pomocą sieci neuronowych?
Skorzystamy (podobnie jak w przypadku sieci CNN w poprzednich częściach) z TensorFlow opakowanego w Keras. Załadujmy wiec potrzebne pakiety i ustalmy kilka stałych dla kolejnych elementów kodu:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
library(tidyverse) library(keras) library(stringr) library(tokenizers) ## stałe # tekst źródłowy book_path <- "Mroz-Kasacja.txt" # sterowanie poniższymi parametrami może poprawić model (im więcej tym lepiej), # na pewno ma wpływ na zapotrzebowanie na pamięć i czas # parametry zbioru treningowego maxlen <- 30 # wielkość okna max_lines <- 2000 # ile linii tekstu bierzemy do treningu? # parametry sieci # co najmniej 20 epochów daje sensowne wyniki EPOCHS <- 20 # liczba neuronów w sieci LSTM - co najmniej 128 daje fajne wyniki, 256 jeszcze fajniejsze lstm_neurons <- 128 |
Za dane treningowe posłuży nam tekst jednej z książek Remigiusza Mroza o Chyłce i Zordonie (o poprzedniego wpisu gdzie analizowałem te książki zdążyłem przeczytać wszystkie części, a już za chwile kolejna część :) – Kasacja. Aby przyspieszyć cały proces wybierzemy tylko cześć tekstu (max_lines powyżej), co jednocześnie pozwoli na ograniczenie potrzebnej ilości pamięci.
Przygotowanie danych
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
# wczytanie tekstu book <- read_lines(book_path) # pozbywamy się pustych linii book <- book[nchar(book) != 0] # pierwsze 19 linii to info o wydaniu, wydawnictwie itp - usuwamy book <- book[20:length(book)] # ostatnie linie to spis treści, reklamy innych książek plus wyimki z recenzji - usuwamy book <- book[1:5013] # jeśli masz dużo pamięci możesz zakomentować poniższe linie book <- book[nchar(book) >= 20] # bierzemy tylko dłuższe linie, żeby było więcej znaków # gdybyśmy chcieli wybrać więcej linii niż ma tekst if(max_lines > length(book)) max_lines <- length(book) book <- book[sample(1:length(book), max_lines)] # bierzemy losowo wybrane linie text <- book %>% # zamiana na małe literki str_to_lower() %>% # usuwamy wielokrotne spacje gsub("[ ]+", " ", .) %>% # złączenie wszystkich linii w jeden dlugi ciag str_c(collapse = "\n") %>% # rozbicie tekstu na literki tokenize_characters(strip_non_alphanum = FALSE, simplify = TRUE) |
Mamy tekst o długości 294902 znaków. Sensowne wyniki zaczynają się przy rozmiarze co najmniej 100 tysięcy znaków – im więcej tym lepiej :)
|
1 2 |
# budujemy posortowaną listę unikalnych znaków chars <- sort(unique(text)) |
Unikalnych znaków mamy zaś 61. W kolejnym kroku podzielimy tekst na okna i budujemy listę ciąg – następny znak.
Jakie okna? Dla przykładowego ciągu ala ma kota i okna o szerokości pięciu znaków mamy kolejno:
- w oknie pierwszym: ala m i następny znak a
- w oknie drugim: la ma i następny znak to spacja
- w oknie trzecim: a ma (spacja na końcu) i k jako następny znak
- i tak dalej
|
1 2 3 4 5 6 |
dataset <- map( # okno przeskakuje co 3 znaki - zmniejsza to wielkość danych, a jednocześnie zachowuje cechy języka seq(1, length(text) - maxlen - 1, by = 3), # lista ciag - nastepny znak ~list(sentece = text[.x:(.x + maxlen - 1)], next_char = text[.x + maxlen]) ) |
Przykładowe wyniki całej tej transformacji wyglądają następująco:
|
1 |
dataset[50:53] |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 |
## [[1]] ## [[1]]$sentece ## [1] "z" "a" "p" "y" "t" "a" "ł" " " "h" "a" "r" "r" "y" " " "b" "e" "z" ## [18] " " "p" "r" "z" "e" "k" "o" "n" "a" "n" "i" "a" "." ## ## [[1]]$next_char ## [1] "\n" ## ## ## [[2]] ## [[2]]$sentece ## [1] "y" "t" "a" "ł" " " "h" "a" "r" "r" "y" " " "b" "e" "z" ## [15] " " "p" "r" "z" "e" "k" "o" "n" "a" "n" "i" "a" "." "\n" ## [29] "w" "y" ## ## [[2]]$next_char ## [1] "ł" ## ## ## [[3]] ## [[3]]$sentece ## [1] "ł" " " "h" "a" "r" "r" "y" " " "b" "e" "z" " " "p" "r" ## [15] "z" "e" "k" "o" "n" "a" "n" "i" "a" "." "\n" "w" "y" "ł" ## [29] "u" "s" ## ## [[3]]$next_char ## [1] "z" ## ## ## [[4]] ## [[4]]$sentece ## [1] "a" "r" "r" "y" " " "b" "e" "z" " " "p" "r" "z" "e" "k" ## [15] "o" "n" "a" "n" "i" "a" "." "\n" "w" "y" "ł" "u" "s" "z" ## [29] "c" "z" ## ## [[4]]$next_char ## [1] "y" |
Wektoryzacja
O co w tym chodzi?
Każdy znak zapisujemy jako one-hot-encoder – czyli za każdym razem, dla każdego znaku trzymamy wektor długości liczby unikalnych znaków z zapalonym odpowiednim znakiem. Obrazek wyjaśnia to chyba najlepiej:
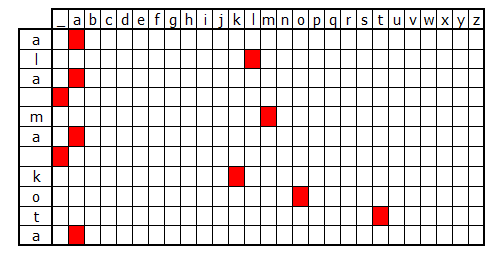
Potrzebujemy w ten sposób zakodować wszystkie dane: zarówno cechy (X) jak i odpowiedzi (Y).
Na obrazku poniżej mamy okno 5-znakowe i na tym się skupmy na chwilę. Dla każdego ciągu znaków wybranego przez okno przygotowujemy macierz pięciu wierszy i 27 kolumn (litery a-z plus spacja) będącą cechą. W macierzy tej w sposób opisany wyżej kodujemy kolejne literki z okna. Odpowiedzią jest jedna litera – również zakodowana (w wektorze 27-elementowym).

Odpowiedni kod przygotowujący macierze X i Y poniżej:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
dataset <- transpose(dataset) # wektoryzacja - robimy miejsce na cechy X i odpowiedzi Y x <- array(0, dim = c(length(dataset$sentece), maxlen, length(chars))) y <- array(0, dim = c(length(dataset$sentece), length(chars))) # dla każdego okna uzupełnij cechy i odpowiedzi for(i in 1:length(dataset$sentece)){ # cechy = macierz wielkości liczba unikalnych znaków x liczba znaków w oknie x[i,,] <- sapply(chars, function(x) { as.integer(x == dataset$sentece[[i]]) }) # odpowiedz = one-hot-encoder wektor długości liczby unikalnych znaków y[i,] <- as.integer(chars == dataset$next_char[[i]]) } # sprzątamy śmieci dla oszczędzenia pamięci rm(dataset, book, text) |
Można napisać to na wiele sposobów. Sieci neuronowe jednak najlepiej działają ze zmiennymi typu one-hot-encoder (a więc wektorami z zapalonymi poszczególnymi wartościami) stąd taki układ. Mniej pamięciożerne byłoby zapisanie chociażby w odpowiedzi numeru literki, ale tak sieć nie zadziała :) Zadziała jakieś drzewo czy las losowy.
Dobra, budujmy ten model!
Model 1
Na początek krótkie wprowadzenie – co robi siec rekurencyjna (RNN) typu LSTM (Long Short Term Memory)? Świetne wytłumaczenia znajdziecie w dwóch postach (angielskich):
W dużym uproszczeniu siec bierze do obliczenia wag nie tylko stan (cechy i odpowiedz na nie) w chwili Xt0 oraz Yt0 (aktualnej) ale tez w chwilach poprzednich Xt-1 oraz Tt-1. Ile tych poprzednich chwil jest brane pod uwagę?
To ustalamy w parametrach warstwy:
layer_lstm(hidden_nodes, input_shape = (timesteps, input_dim)))
gdzie:
- hidden_nodes określa liczbę neuronów w warstwie LSTM. Im większa liczba neuronów tym silniejsza siec. Oczywiście rośnie też czas trenowania sieci
- timesteps – liczba kroków czasowych, które chcemy uwzględnić. Na przykład jeśli chcemy sklasyfikować zdanie, będzie to liczba słów w zdaniu. W naszym wypadku jest to liczba znaków (rozmiar okna)
- input_dim określa liczbę cech – na przykład długość wektora w którym zapisujemy słowo (w naszym przypadku tyle ile mamy unikalnych znaków w danych treningowych – 61)
Upakujmy więc to w model:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
# model typu sekwencyjnego model <- keras_model_sequential() # architektura sieci - kolejne warstwy model %>% layer_lstm(lstm_neurons, input_shape = c(maxlen, length(chars))) %>% layer_dense(length(chars)) %>% layer_activation("softmax") # kompilujemy model model %>% compile( loss = "categorical_crossentropy", optimizer = optimizer_rmsprop(lr = 0.01) ) # podsumowanie summary(model) |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
## ___________________________________________________________________________ ## Layer (type) Output Shape Param # ## =========================================================================== ## lstm_1 (LSTM) (None, 128) 97280 ## ___________________________________________________________________________ ## dense_1 (Dense) (None, 61) 7869 ## ___________________________________________________________________________ ## activation_1 (Activation) (None, 61) 0 ## =========================================================================== ## Total params: 105,149 ## Trainable params: 105,149 ## Non-trainable params: 0 ## ___________________________________________________________________________ |
Trenujemy model i patrzymy na jego osiągi:
|
1 2 3 4 5 6 7 8 |
history <- model %>% fit( x, y, batch_size = 128, validation_split = 0.1, epochs = EPOCHS, verbose = 1 ) |
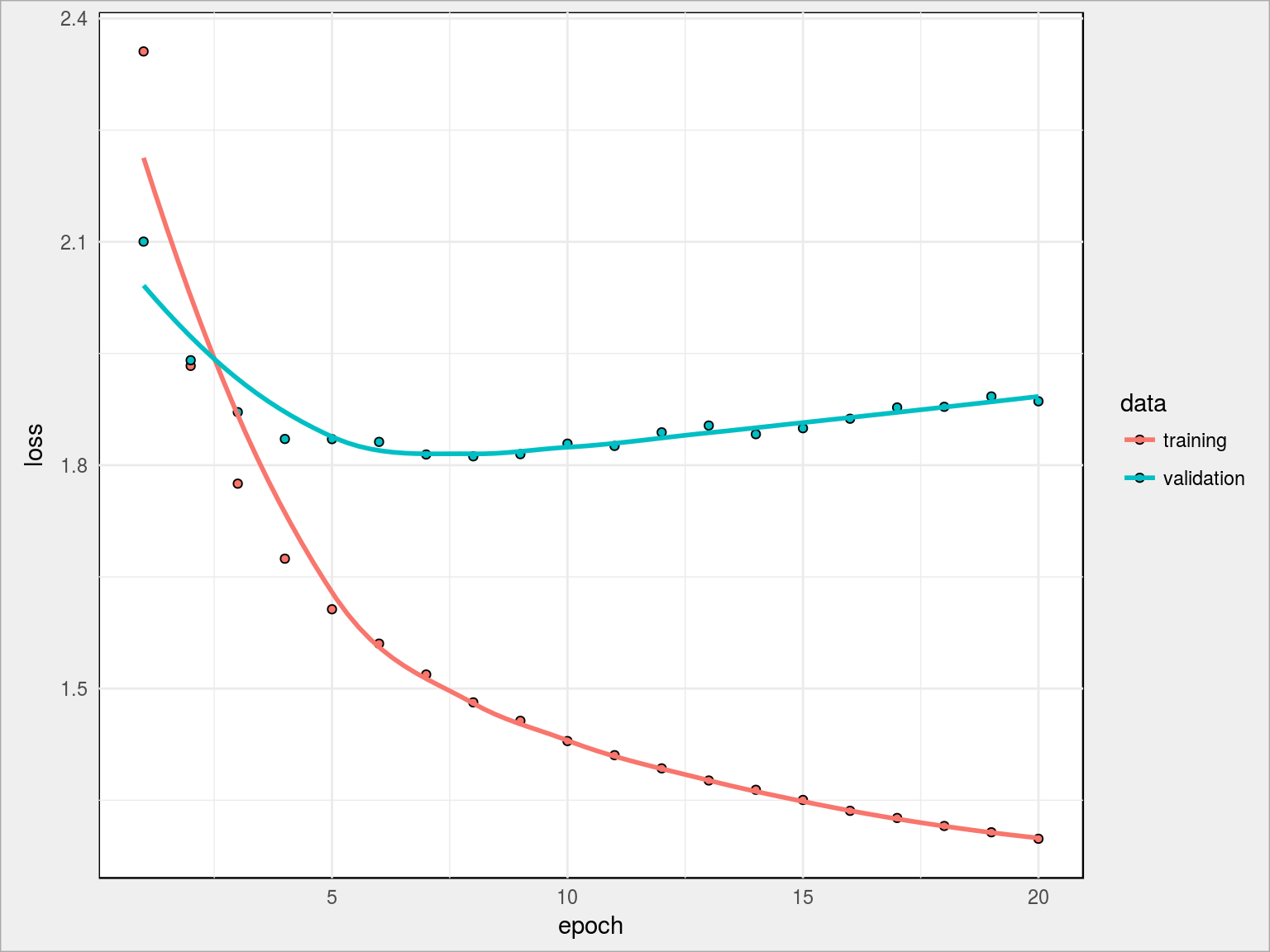
Wynik treningu sieci:
- loss na koniec: 1.2982
- val_loss na koniec: 1.8858
Widzimy przede wszystkim, że val_loss jest stabilne (lub rośnie) kiedy loss spada – to oznacza przeuczenie sieci. Za chwilę spróbujemy zbudować inna architekturę i poradzić sobie z tym problemem. Wcześniej jednak
Przewidywanie tekstu
Na początek zbudujemy funkcję, która na podstawie podanego ciągu znaków przewidzi kolejne n-znaków zgodnie z modelem.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
predictText <- function(test_string, nchars) { # "przewidziany" początkowo tekst to pierwsze 'maxlen' znaków z parametru, # zamieniony na małe litery pred_string <- test_string %>% str_sub(1, maxlen) %>% str_to_lower() # przewidujemy 100 kolejnych znaków for(nround in seq_len(nchars)) { test <- pred_string %>% # bierzemy ostatnie 'maxlen' znaków z całego przewidzianego ciągu str_sub(-maxlen, -1) %>% # rozbicie tekstu na literki tokenize_characters(strip_non_alphanum = FALSE, simplify = TRUE) # wektoryzacja test_x <- sapply(chars, function(x) { as.integer(x == test) }) # przekształcenie macierzy na rozmiar taki jak w modelu test_x <- array_reshape(test_x, c(1, dim(test_x))) # predykcja - jaki będzie następny znak? preds <- predict_classes(model, test_x) + 1 # dodajemy go na koniec ciągu pred_string <- str_c(pred_string, chars[preds], collapse = "") # i powtarzamy przewidywanie od początku już na nowym ciągu } # co nam wyszło? return(pred_string) } |
Przewidujemy przykładowy tekst – 100 nowych znaków:
|
1 |
cat(predictText("Joanna wpadła na kawę do Zordona", 100)) |
|
1 2 3 |
## joanna wpadła na kawę do zordonu. chyłka. ## – nie ma cię to miejsce zaczęło się do przekomanie spotkanie. ## – nie ma cię to miejsce za |
Spróbujmy z innym tekstem początkowym:
|
1 |
cat(predictText("Na wysokiej górze stoi dom z cegły", 100)) |
|
1 2 |
## na wysokiej górze stoi dom z czy od przekońcjował się do przekomanie spotkanie. ## – nie ma cię to miejsce zaczęło się do przekomanie |
Co ciekawe – ciąg wejściowy może być całkowicie bzdurny, po kilku literach tekst prostuje się sam:
|
1 2 3 4 5 |
# losowy ciąg 30 znaków ze słownika liter paste(chars[sample(length(chars), 30, replace = TRUE)], collapse = "") %>% # generujemy tekst 1000 znaków predictText(1000) %>% cat() |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
## ęź„ćd.ádop…’?m-!!f.(&t;ó„11ad4owało się do przekomanie spotkanie. ## – nie ma cię to miejsce zaczęło się do przekomanie spotkanie. ## – nie ma cię to miejsce zaczęło się do przekomanie spotkanie. ## – nie ma cię to miejsce zaczęło się do przekomanie spotkanie. ## – nie ma cię to miejsce zaczęło się do przekomanie spotkanie. ## – nie ma cię to miejsce zaczęło się do przekomanie spotkanie. ## – nie ma cię to miejsce zaczęło się do przekomanie spotkanie. ## – nie ma cię to miejsce zaczęło się do przekomanie spotkanie. ## – nie ma cię to miejsce zaczęło się do przekomanie spotkanie. ## – nie ma cię to miejsce zaczęło się do przekomanie spotkanie. ## – nie ma cię to miejsce zaczęło się do przekomanie spotkanie. ## – nie ma cię to miejsce zaczęło się do przekomanie spotkanie. ## – nie ma cię to miejsce zaczęło się do przekomanie spotkanie. ## – nie ma cię to miejsce zaczęło się do przekomanie spotkanie. ## – nie ma cię to miejsce zaczęło się do przekomanie spotkanie. ## – nie ma cię to miejsce zaczęło się do przekomanie spotkanie. ## – nie ma cię to miejsce zaczęło si |
Znaczenie ma całkowity układ liter, nie tylko na przykład ostatni znak – porównajcie:
|
1 |
cat(predictText("Tam na wysokiej górce stoi dom", 50)) |
|
1 2 |
## tam na wysokiej górce stoi domfacja zaczęła się do przekomanie spotkanie. ## – nie |
|
1 |
cat(predictText("Tam na wysokiej górce stoi don", 50)) |
|
1 |
## tam na wysokiej górce stoi donież czardiarza na tem zaczęła się do przekomanie s |
|
1 |
cat(predictText("Tam na wysokiej górce stoi dam", 50)) |
|
1 |
## tam na wysokiej górce stoi dam na temat na to przychodziła się z przekonanie się |
|
1 |
cat(predictText("Tam na wysokiej górce stoi Tom", 50)) |
|
1 2 |
## tam na wysokiej górce stoi tomientował się do przekomanie spotkanie. ## – nie ma ci |
Widzimy tutaj ciekawa rzecz: po kilku nowych literach tekst zaczyna się powtarzać. Oznacza to, że siec sobie trochę nie poradziła i zapętliła się. Można przygotować model jeszcze raz, tym razem zamiast neuronów dać ich na przykład dwa razy więcej.
Model 2
Dodajmy jeszcze jedna warstwę Dense oraz zmieńmy funkcję optymalizującą (nie powinno się tego robić jednocześnie – nie wiadomo która zmiana wpłynie na wyniki).
|
1 2 3 4 5 6 7 8 9 10 11 12 |
model <- keras_model_sequential() %>% layer_lstm(lstm_neurons, input_shape = c(maxlen, length(chars))) %>% layer_dense(2*length(chars)) %>% layer_dropout(0.25) %>% layer_dense(length(chars)) %>% layer_activation("softmax") %>% compile( loss = "categorical_crossentropy", optimizer = optimizer_adam() ) summary(model) |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
## ___________________________________________________________________________ ## Layer (type) Output Shape Param # ## =========================================================================== ## lstm_2 (LSTM) (None, 128) 97280 ## ___________________________________________________________________________ ## dense_2 (Dense) (None, 122) 15738 ## ___________________________________________________________________________ ## dropout_1 (Dropout) (None, 122) 0 ## ___________________________________________________________________________ ## dense_3 (Dense) (None, 61) 7503 ## ___________________________________________________________________________ ## activation_2 (Activation) (None, 61) 0 ## =========================================================================== ## Total params: 120,521 ## Trainable params: 120,521 ## Non-trainable params: 0 ## ___________________________________________________________________________ |
Trenujemy model:
|
1 2 3 4 5 6 7 8 |
history <- model %>% fit( x, y, batch_size = 128, validation_split = 0.1, epochs = EPOCHS, verbose = 1 ) |
Wynik treningu sieci:
- loss na koniec: 1.5042
- val_loss na koniec: 1.8949
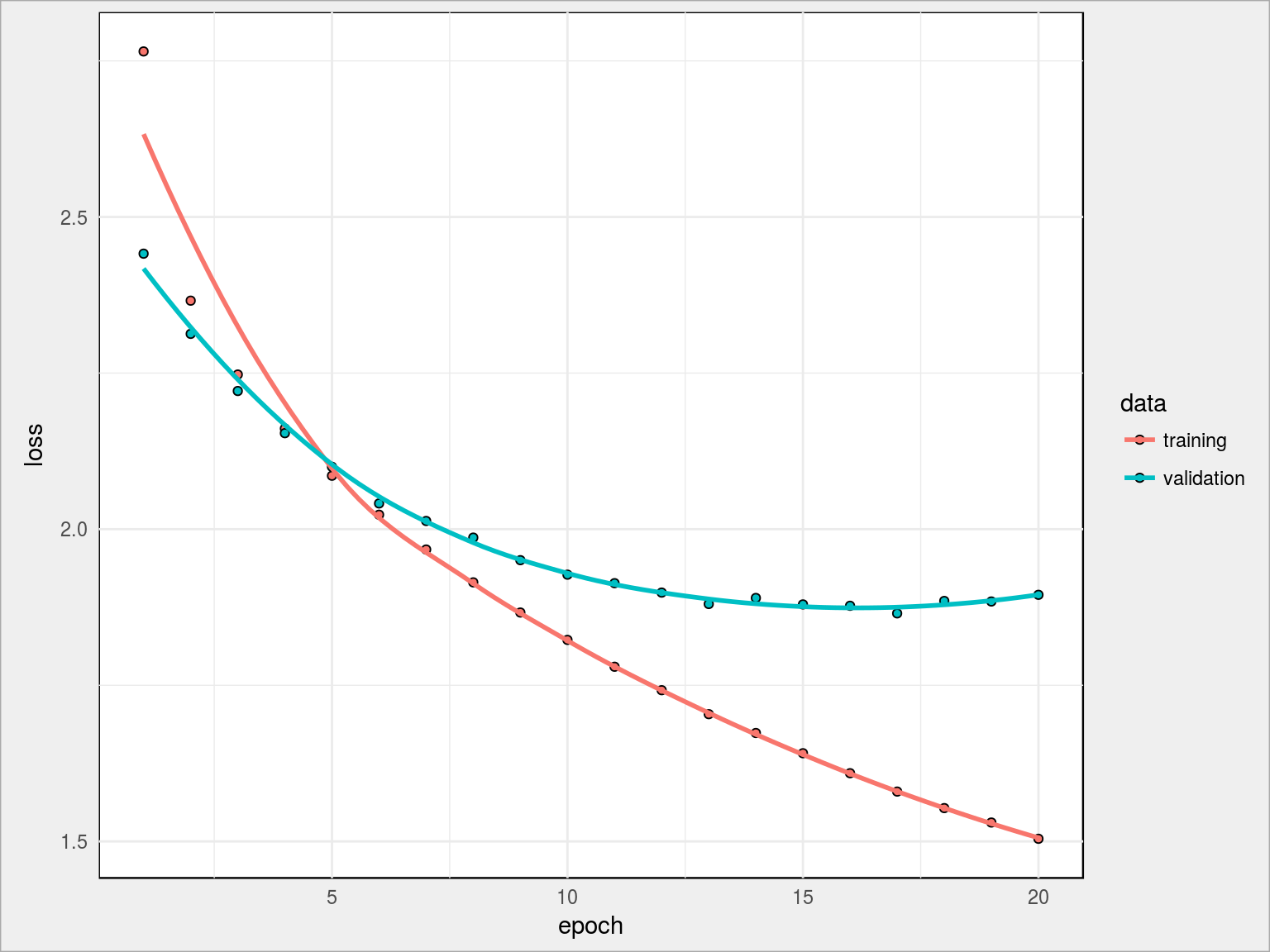
Jak widać linie loss i val_loss są teraz nieco bardziej zbieżne, ale w dalszym ciągu nie pozbyliśmy się overfittingu. Można próbować z innymi wartościami dla dropout (dobrze wypadło 0.5) lub innym rozmiarem warstw dense. Zostańmy przy tym co mamy – w końcu chodzi o ideę.
Przewidujemy przykładowy tekst – weźmy te same ciągi co poprzednio, tym razem może trochę więcej znaków?
|
1 |
cat(predictText("Joanna wpadła na kawę do Zordona", 200)) |
|
1 2 |
## joanna wpadła na kawę do zordował się po czym po czym przekontania – zapytała chyłka. ## – nie miał potrzyć na spokojnie powiedziała w kordianki i przypadkuje było jeszcze na się zarzymanta. – zapewnie się zastarała się z krzeście z |
Spróbujmy z innym tekstem początkowym i większa długością przewidywanego tekstu:
|
1 |
cat(predictText("Na wysokiej górze stoi dom z cegły", 500)) |
|
1 2 3 4 |
## na wysokiej górze stoi dom z czym przypadku teraz na staną się do niego zastanie spojrzała na kordiana. ## – nie miał potrzyła się na kormak. – zapytał oryński. ## – chciała pomyślił o po czym podeszła się do niego zaszym kordian. ## – chciała pomiedział o niego powiedzieć, że nie miał z klienta z powiedziała w kordianki i przypadkuje było jeszcze na się zarzymanta. – zapewnie się zastarała się z krzeście z powiedziała w kordianki i przypadkuje było jeszcze na się zarzymanta. – zapewnie się zastarała się z krzeście z powiedziała w ko |
Znowu widzimy zapętlenie po kilkudziesięciu znakach.
Możemy zamiast przewidywać kolejne litery przewidywać całe słowa. Wówczas całe przygotowanie danych trzeba przeprowadzić inaczej – rozbić tekst na unikalne słowa (i to będzie baza). Słów mamy więcej niż znaków – długość wektora (matematycznie mówiąc: wymiar przestrzeni w której opisujemy wektor) będzie odpowiednio dłuższa. W wyniku przewidywania kolejnych slow nie dostaniemy czegoś co wygląda podobnie do slow (jak w powyższych przykładach) a konkretne słowa. Czy sensownie powiązane ze sobą? Zapewne nie do końca, szczególnie dla bardziej złożonych zdań. Warto tez taka siec trenować ogromna ilością danych (tak, aby było jak najwięcej kombinacji rożnych slow ze sobą).
Przewidywanie znaków daje w wyniku pozorny tekst w naszym języku – siec odpowiada kolejnymi znakami, ale nie wie czy utworzone ciągi coś znaczą. To tylko zbitki liter (i dodatkowo znaków specjalnych typu spacje czy znaki przestankowe). W przypadku przewidywania słów mielibyśmy prawdziwe słowa, ale zapewne bezsensowny ich układ, nie dający sensownych zdań. Może ktoś z Was trenował tego typu sieci o większej architekturze i zechce podzielić się wynikami?
Inne podejście do tego samego problemu to łańcuchy Markova. Idea polega mniej więcej na tym samym:
- dla każdego ciągu znaków (lub słów) w oknie sprawdzamy jaki znak (lub jakie słowo) występuje jako kolejny
- dla każdego identycznego ciągu w oknie mamy rożne prawdopodobieństwa następników
- przy generowaniu następnika bierzemy odpowiedni, według prawdopodobieństwa
- nowym oknem jest ciąg uzupełniony o dodany znak (lub słowo)
Problemem jest sytuacja w której nie mamy odpowiednika w danych treningowych – w łańcuchu Markova nie wiemy co zrobić (nie było takiego przypadku w danych treningowych), siec LSTM jakoś sobie z tym radzi (automagicznie).
Do czego można jeszcze wykorzystać sieć LSTM? Do przewidywania w szeregach czasowych (na przykład notowań na giełdzie). Działamy podobnie jak w przypadku odgadywania kolejnych liter: bierzemy wektor wartości (kilku, kilkunastu) do chwili t-1 jako cechy (X) i kolejna wartość z chwili t0 jako odpowiedź. Przesuwamy takie okno przez cały szereg i z tak zbudowanych danych trenujemy sieć. Kilka zastosowań znajdziecie pod linkami: