Czy machine learning może pomóc w poszukiwaniu ulubionej muzyki?
Dzisiaj zajmiemy się poszukiwaniem nowej muzyki. Już kiedyś o tym było w oparciu o LastFM, dzisiaj będzie w oparciu o Spotify. Taki szybki wpis.
Na początek potrzebujemy kilku elementów:
- własnej aplikacji współpracującej z API Spotify – zbudować ją można zaczynając z dashboardu Spotify, potrzebujemy numerku
client_idiclient_secret - te numerki wpisujemy do zmiennych o tych samych nazwach i zapisujemy sobie lokalnie (żeby nie przechowywać ich w kodzie) w pliku
spotify_cred.rda. W bardzo prosty sposób:save(client_id, client_secret, file = "spotify_cred.rda") - następnie budujemy kilka funkcji, których będziemy używać. Kod jest długi, nie warto go tutaj zamieszczać – znajdziecie go na GitHubie (swoją drogą jest tam nieco więcej funkcji niż potrzeba, ale nie wszystkie skończone i działające)
Uzbrojeni w taki zestaw zaczynamy od pozyskania tokenu:
|
1 2 3 4 5 6 7 8 9 |
library(tidyverse) library(randomForest) # trochę dodatkowych pakietów jest w skrypcie z funkcjami source("spotify_functions.R") # kod na githubie load("spotify_cred.rda") # zmienne client_id i client_secret spotify_token <- getSpotifyToken() |
Kolejny krok to już praca ręczna – musimy przygotować sobie dwie listy, które posłużą do nauki modelu. Jedna z nich to lista zawierająca piosenki, które lubimy; druga – których nie lubimy. Ja skorzystałem z jakichś gotowych list. Dobrze byłoby gdyby listy były długie (dużo danych) i mniej więcej równej długości.
Trzecią listą jest lista testowa – to dla piosenek z tej listy będziemy określać czy nam się spodobają czy nie. Może to być na przykład coś z zestawień rocznych Spotify albo jakaś inna lista.
Mając takie listy zapisujemy sobie ich parametry:
|
1 2 3 4 5 6 7 8 9 10 11 |
## piosenki, które lubię: user_like <- "migueljusan" playlist_like <- "66zMURup6R6yWFVDBTdDaj" ## piosenki, których nie lubię: user_dislike <- "meemeesiko" playlist_dislike <- "3Ld8PkpgMGQQEWPH3sr3Xj" ## piosenki testowe: user_test <- "centralia" playlist_test <- "5KKBIKSTKg6rp6KiOyobOo" |
Skąd wziąć te parametry? Z jej adresu URL:

gdzie:
- czerwone to nazwa użytkownika
- niebieskie to ID listy
Teraz możemy rozpocząć analizę – na początek pobierzemy utwory z playlisty lubię:
|
1 |
tracks_like <- getSpotifyUserPlaylist(user_like, playlist_like) |
a także z playlisty nie lubię:
|
1 |
tracks_dislike <- getSpotifyUserPlaylist(user_dislike, playlist_dislike) |
Łączymy obie listy (ulubionych mamy 260 utworów, nielubianych 305) z jednoczesnym oznaczeniem z której pochodzi konkretny utwór:
|
1 2 3 |
tracks <- bind_rows(tracks_like %>% mutate(liked = TRUE), tracks_dislike %>% mutate(liked = FALSE)) %>% distinct(track_id, .keep_all = TRUE) |
Mamy pełną listę 545 utworów (unikalnych; stąd suma 545 mniejsza niż suma dwóch list 260 + 305 = 565). Model oparty będzie na cechach utworów (ich opis znajdziecie w jednym z poprzednich wpisów), pobierzmy je więc ze Spotify:
|
1 |
tracks_features <- tracks$track_id %>% map_df(getSporifyTrackFeatures) |
To mogłoby wystarczyć, ale połączmy cechy z tytułami utworów (i ich wykonawcami oraz albumami z jakich pochodzą):
|
1 2 3 4 5 |
tracks_all <- left_join(tracks_features, tracks %>% select(track_id, track, artist, album, liked), by = c("id" = "track_id")) %>% select(-time_signature) %>% mutate(liked = as.factor(liked)) |
Mamy komplet, możemy sobie pooglądać jak różnią się cechy piosenek lubianych i nie:
|
1 2 3 4 5 6 7 8 9 10 11 |
tracks_all %>% select(-track, -album, -artist) %>% gather(feature, value, -id, -liked) %>% mutate(like = case_when(.$liked == TRUE ~ "liked", .$liked == FALSE ~ "disliked")) %>% select(-liked) %>% ggplot() + geom_density(aes(value, fill = like), alpha = 0.2) + facet_wrap(~feature, scales = "free") + labs(x = "", y ="", fill = "Playlista:") + theme(legend.position = "bottom") |
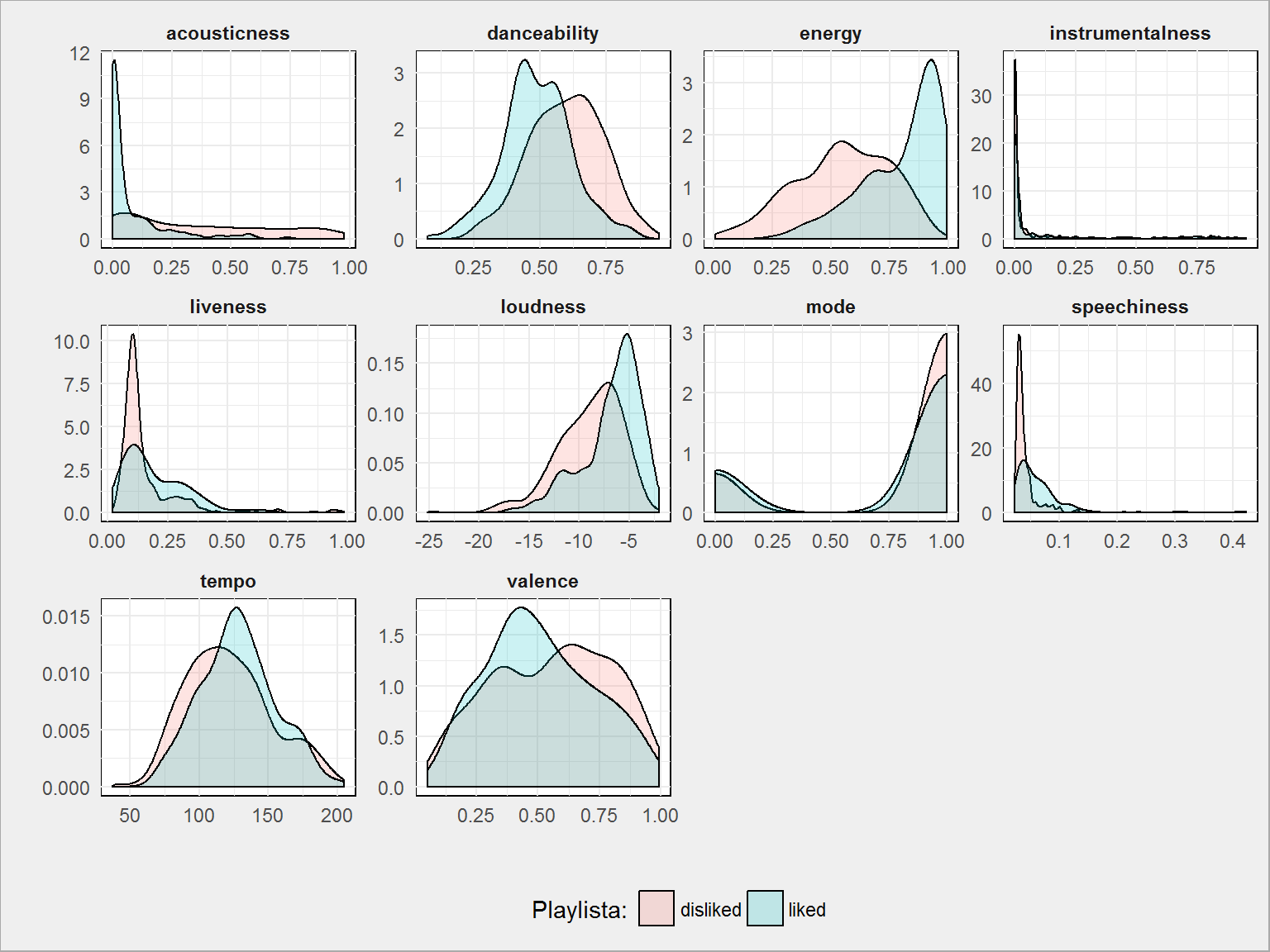
Widzimy, że największe różnice występują dla cech: danceability (lubię te, które są mniej taneczne), energy (wolę bardziej energetyczne), loudness (wolę cichsze), tempo i valence (lubiane są bardziej pozytywne – mniejsza wartość = większa pozytywność). Właściwie te pięć cech powinno wystarczyć dla naszego modelu.
Użyjemy jednak wszystkich, a model będzie typu lasu losowego dla klasyfikacji. Zbudowanie go w R jest banalne:
|
1 2 3 4 5 |
model_rf <- randomForest(liked ~ ., data = tracks_all[, -c(1, 12:14)], importance=TRUE) model_rf |
|
1 2 3 4 5 6 7 8 9 10 11 12 |
## ## Call: ## randomForest(formula = liked ~ ., data = tracks_all[, -c(1, 12:14)], importance = TRUE) ## Type of random forest: classification ## Number of trees: 500 ## No. of variables tried at each split: 3 ## ## OOB estimate of error rate: 17.93% ## Confusion matrix: ## FALSE TRUE class.error ## FALSE 278 25 0.08250825 ## TRUE 65 134 0.32663317 |
Widzimy, że błąd klasyfikacji to około 18% (na danych uczących). Dość dużo. Zobaczmy jak zmienia się błąd w zależności od liczby drzew w lesie:
|
1 |
plot(model_rf) |
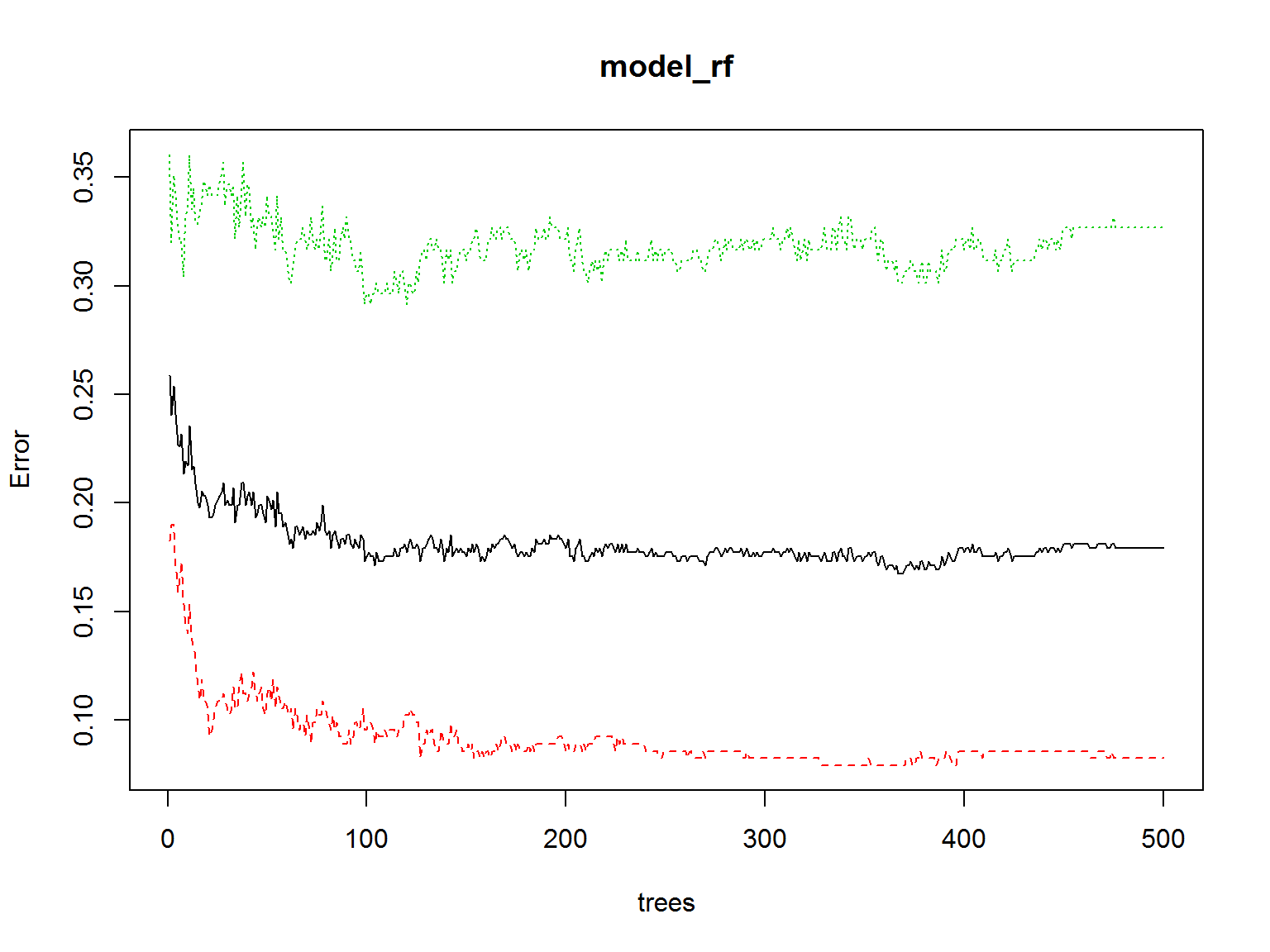
- czarne to błąd łączny
- zielone – błąd dla utworów klasyfikowanych jako lubiane
- czerwone – błąd dla utworów klasyfikowanych jako nielubiane
Sprawdźmy które cechy mają największe znaczenie:
|
1 |
varImpPlot(model_rf) |
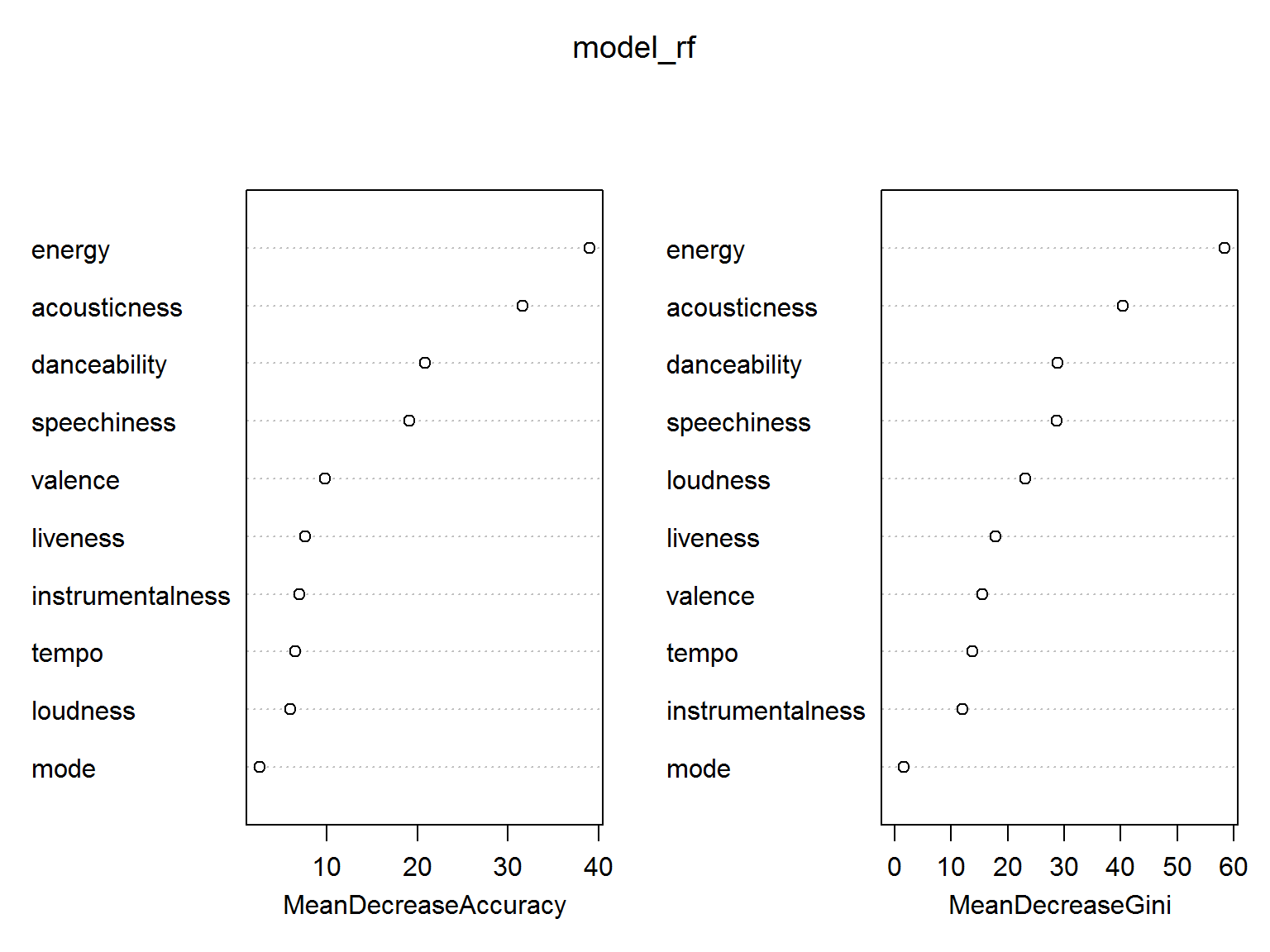
W większości pokrywa się to z tym, co wywnioskowaliśmy z wykresów rozkładu cech powyżej.
Przeprowadźmy teraz klasyfikację na nieznanym zbiorze – czyli bierzemy playlistę testową:
|
1 |
tracks_test <- getSpotifyUserPlaylist(user_test, playlist_test) |
pobieramy cechy utworów z tej listy:
|
1 |
tracks_test_features <- tracks_test$track_id %>% map_df(getSporifyTrackFeatures) |
i przewidujemy czy utwory będą się podobać czy nie:
|
1 |
tracks_test_features$like <- predict(model_rf, newdata = tracks_test_features %>% select(-time_signature)) |
Dla czytelności obrazu łączymy przewidywania z tytułami piosenek:
|
1 2 3 |
tracks_predicted_to_like <- left_join(tracks_test_features %>% select(id, like), tracks_test %>% select(track_id, track, artist, album), by = c("id" = "track_id")) |
Wszystkie 115 utworów nasz model podzielił:
|
1 |
table(tracks_predicted_to_like$like) |
| nie lubię | lubię |
|---|---|
| 83 | 34 |
Na koniec przygotujmy wykresy tak jak na początku – rozkład cech utworów lubianych, nie lubianych i przewidzianych do lubienia oraz nielubienia. Łączymy więc wszystkie dane znane (listy lubię i nie lubię) oraz dane testowe:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
tracks_all_long <- bind_rows( tracks_all %>% select(-track, -album, -artist) %>% gather(feature, value, -id, -liked) %>% mutate(like = case_when(.$liked == TRUE ~ "liked", .$liked == FALSE ~ "disliked")) %>% select(-liked), tracks_test_features %>% select(-time_signature) %>% gather(feature, value, -id, -like) %>% mutate(like = case_when(.$like == TRUE ~ "pred like", .$like == FALSE ~ "pred dislike")) ) |
I rysujemy sobie wykresik:
|
1 2 3 4 5 6 7 |
tracks_all_long %>% mutate(like = factor(like, levels = c("liked","pred like", "disliked", "pred dislike"))) %>% ggplot() + geom_violin(aes(like, value, fill = like)) + facet_wrap(~feature, scales = "free") + theme(legend.position = "bottom") + labs(x = "", y = "", fill = "") |
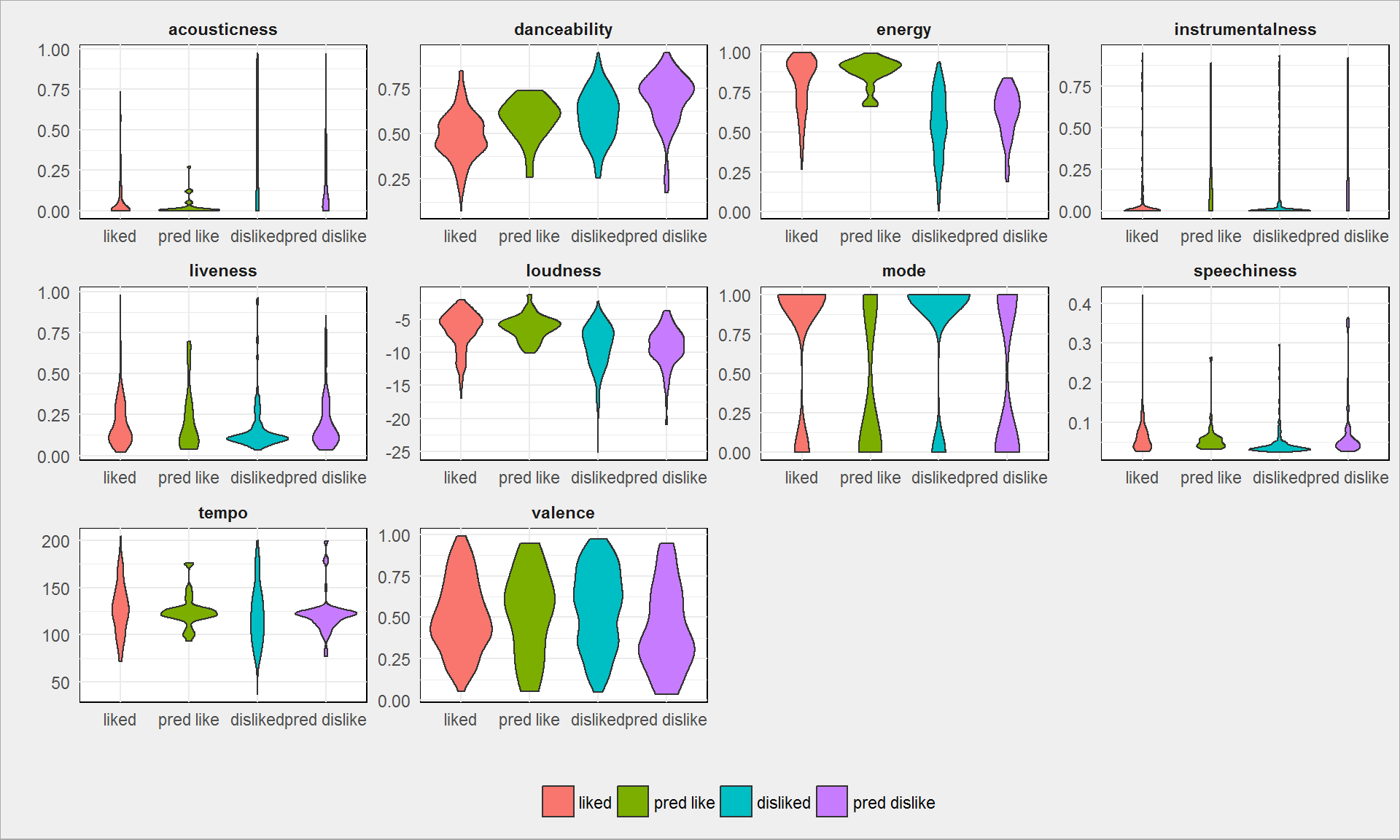
Wyraźne podobieństwo przewidywań i rzeczywistości widać dla cech energy, loudness. Jeśli uśrednimy wartości dla poszczególnych kategorii:
|
1 2 3 4 5 6 7 8 9 10 |
tracks_all_long %>% mutate(like = factor(like, levels = c("liked","pred like", "disliked", "pred dislike"))) %>% group_by(feature, like) %>% summarise(m_val = mean(value)) %>% ungroup() %>% ggplot() + geom_point(aes(like, m_val, color = like), size = 5) + facet_wrap(~feature, scales = "free") + theme(legend.position = "bottom") + labs(x = "", y = "", color = "") |
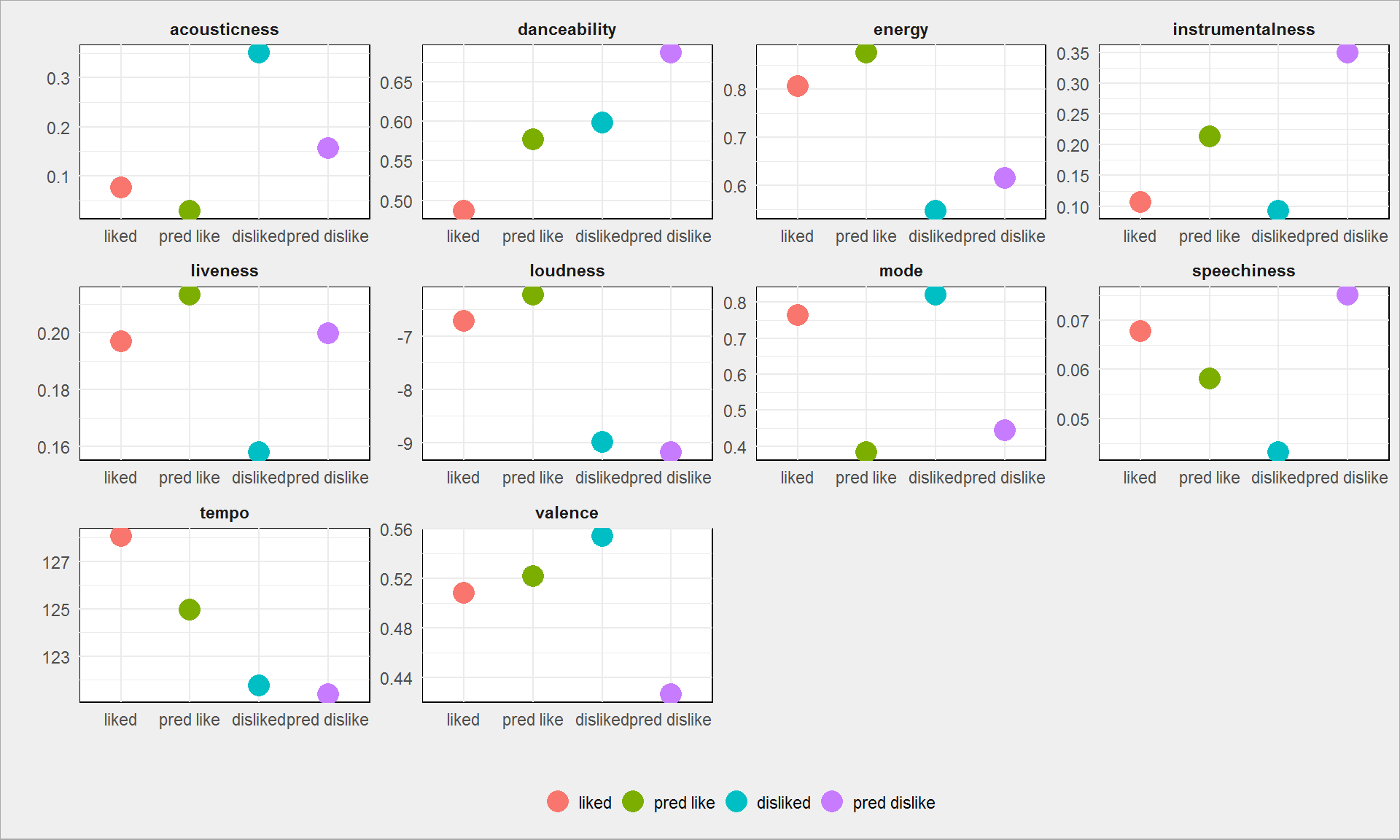
można zauważyć granice pomiędzy lubię i nie lubię:
- acousticness w okolicach 0.13 (mniejsze lubię)
- danceability – 0.58 (mniejsze lubię)
- energy 0.7 (większe lubię)
- loudness -8 (większe, czyli bliższe zera – lubię)
- valence na poziomie około 0.5 lubię, inne – nie
To znaczne uproszczenie, prowadzące właściwie do modelu drzewa (zamiast lasu drzew).
Kolejnym krokiem może być zbudowanie nowej listy (da się to zrobić przez API), dodanie do niej utworów, które powinny się podobać i… przesłuchanie jej. Ciekawe jak się sprawdzi? Wszystko zależy od tego jak bardzo różnorodnej muzyki słuchacie i jak bardzo różnorodne są playlisty uczące.