Czy zmiany w Polsce (koniec PRL, wstąpienie do NATO i UE) mają odzwierciedlenie w głosowaniu w Zgromadzeniu Ogólnym Organizacji Narodów Zjednoczonych? Kto jest (a kto był) naszym przyjacielem a z kim nam nie jest po drodze?
Dzisiejszy wpis to sporo kodu (dość prostego, często powtórzonego – nie programujcie w ten sposób!), a całość podzielić można na kilka części:
- opis użytych narzędzi – dwa nowe (na blogu) pakiety:
widyrorazunvotes - przygotowanie danych do dalszej pracy
Właściwa analiza zaczyna się od
- porównania podobieństwa głosów Polski z innymi krajami (NATO, Układu Warszawskiego i nie tylko) w zależności od tego czy Polska była członkiem NATO czy nie
- analogicznego porównania w zależności od naszej przynależności do Unii Europejskiej
- oraz na koniec poszukiwania podobieństw pomiędzy państwami UE
Klikając w odpowiednie linki wyżej możesz dotrzeć do interesujących Cię części. Bo jeśli nie masz pojęcia o programowaniu, R i nie masz ochoty na czytanie kodów źródłowych (które są w moim założeniu istotą tego bloga) to po co masz się męczyć?
Opis narzędzi
Zanim zaczniemy przyglądać się danym potrzebujemy oczywiście odpowiednich pakietów ułatwiających pracę. Standardowych:
|
1 2 |
library(tidyverse) library(lubridate) |
oraz dwóch ciekawych:
|
1 2 |
library(widyr) # instalacja z CRAN lub poprzez devtools::install_github("dgrtwo/widyr") library(unvotes) # instalaja z GitHuba devtools::install_github("dgrtwo/unvotes") (CRAN też wchodzi w grę) |
Pierwszy widyr to świetne narzędzie, które pozwala dane upakowane w tidy-way przetworzyć metodami dobrze działającymi na macierzach, a później upakować je z powrotem w wersję tidy. Na przykład kiedy w danych mamy każdą obserwację w oddzielnym wierszu (to clue tidy) możemy policzyć korelację każdy z każdym (w efekcie dostalibyśmy dużą kwadratową macierz gdzie każdy element jest w wierszach i kolumnach, a na przecięciu jest współczynnik korelacji), a później ułożyć ją w długą tabelę z trzema kolumnami: element A, element B i współczynnik korelacji między nimi. Polecam lekturę dokumentacji pakietu – moje tłumaczenie z angielskiego jest kulawe, a też nie o ten pakiet tutaj chodzi. Korelacja to nie jedyna rzecz, którą widyr potrafi.
Interesuje nas bardziej zawartość unvotes – to w sumie same dane. Opisują one głosowania w ONZ. Mamy w pakiecie trzy tabelki:
un_votes zawierającą informacje o numerze głosowania, kraju i głosie jaki został oddany – pierwsze kilka wierszy poniżej:
| rcid | country | country_code | vote |
|---|---|---|---|
| 3 | United States of America | US | yes |
| 3 | Canada | CA | no |
| 3 | Cuba | CU | yes |
| 3 | Haiti | HT | yes |
| 3 | Dominican Republic | DO | yes |
| 3 | Mexico | MX | yes |
| 3 | Guatemala | GT | yes |
| 3 | Honduras | HN | yes |
| 3 | El Salvador | SV | yes |
| 3 | Nicaragua | NI | yes |
To najważniejsze dla nas dane – kto jak głosował (i kiedy).
un_roll_calls z danymi o sprawie, nad którą głosowano, a kolumny mówią nam o:
- numerze głosowania (to klucz łączący temat z głosami),
- numerze sesji Zgromadzenia ONZ (dotychczas sesji było 72, dane mamy tylko do 70 sesji włącznie),
- dacie głosowania (może być kilka dni na sesję)
- tytule sprawy jakiej dotyczyło głosowanie i nieco szerszym opisie
- plus inne pierdoły, które nie będą nam do niczego potrzebne (kolumny unres, amend i para)
| rcid | session | important vote | date | unres | amend | para | short | descr |
|---|---|---|---|---|---|---|---|---|
| 3 | 1 | 0 | 1946-01-01 | R/1/66 | 1 | 0 | AMENDMENTS, RULES OF PROCEDURE | TO ADOPT A CUBAN AMENDMENT TO THE UK PROPOSAL REFERRING THE PROVISIONAL RULES OF PROCEDURE AND ANY AMENDMENTS THEREOF TO THE 6TH COMMITTEE, SAID AMENDMENT PRESCRIBING A 1-WEEK TIME LIMIT WITHIN WHICH THE 6TH COMM. MUST SUBMIT ITS REPORT ON THE |
| 4 | 1 | 0 | 1946-01-02 | R/1/79 | 0 | 0 | SECURITY COUNCIL ELECTIONS | TO ADOPT A USSR PROPOSAL ADJOURNING DEBATE ON AND POSTPONINGELECTIONS OF THE NON-PERMANENT MEMBERS OF THE SECURITY COUNCIL, TO THE FOLLOWING WEEK. |
| 5 | 1 | 0 | 1946-01-04 | R/1/98 | 0 | 0 | VOTING PROCEDURE | TO ADOPT THE KOREAN PROPOSAL THAT INVALID BALLOTS BE INCLUDED IN THE TOTAL NUMBER OF PRESENT AND VOTING\, IN CALCULATING THE MAJORITY VOTE.”” |
| 6 | 1 | 0 | 1946-01-04 | R/1/107 | 0 | 0 | DECLARATION OF HUMAN RIGHTS | TO ADOPT A CUBAN PROPOSAL (A/3-C) THAT AN ITEM ON A DECLARATION OF THE RIGHTS AND DUTIES OF MAN BE TABLED. |
| 7 | 1 | 0 | 1946-01-02 | R/1/295 | 1 | 0 | GENERAL ASSEMBLY ELECTIONS | TO ADOPT A 6TH COMMITTEE AMENDMENT (A/14) TO THE PROVISIONAL RULES OF PROCEDURE, WHICH AMENDMENT PROVIDES THAT RULE 73 SHOULD END WITH:SHALL BE NO NOMINATIONS.\” 0 0 0 0 0 0 |
Z tej tabeli będziemy korzystać tylko dla określenia dat głosowań.
Ostatnia tabela – un_roll_call_issues – mówi o podziale głosowań na grupy sześciu obszarów:
- Palestinian conflict
- Nuclear weapons and nuclear material
- Arms control and disarmament
- Human rights
- Colonialism
- Economic development
Nie będziemy jej używać, ale ciekawe może być prześledzenie jak w określonych obszarach głosowały poszczególne kraje.
Przygotowanie danych
Do wygodnej pracy potrzebujemy jeszcze kilku list państw:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
# kraje starej Unii Europejskiej UE_countries_1 <- c("Austria", "Belgium", "Cyprus", "Denmark", "Finland", "France", "Germany", "Greece", "Ireland", "Italy", "Luxembourg", "Malta", "Netherlands", "Portugal", "Spain", "Sweden", "United Kingdom of Great Britain and Northern Ireland") # kraje nowej Unii Europejskiej UE_countries_2 <- c(UE_countries_1, "Bulgaria", "Croatia", "Czech Republic", "Estonia", "Hungary", "Latvia", "Lithuania", "Romania", "Slovakia", "Slovenia") # kraje NATO - przed przystąpieniem Polski NATO_countries_1 <- c("Belgium","Canada", "Denmark", "France", "Greece", "Iceland", "Italy", "Luxembourg", "Netherlands", "Norway", "Portugal", "Spain", "United Kingdom of Great Britain and Northern Ireland", "United States of America", "Turkey", "Federal Republic of Germany", "Germany") # kraje NATO - obecnie NATO_countries_2 <- c(NATO_countries_1, "Czech Republic", "Hungary", "Bulgaria", "Estonia", "Latvia", "Lithuania","Romania", "Slovakia", "Slovenia", "Albania", "Croatia", "Montenegro") # kraje Układu Warszawskiego WarsawPact_countries <- c("Albania", "Bulgaria", "Czechoslovakia", "German Democratic Republic", "Hungary", "Romania", "Russian Federation") # pozostałe kraje, które mogą być ciekawe przy porównaniu other_countries <- c("Afghanistan", "Argentina", "Australia", "Brazil", "China", "Cuba", "Democratic People's Republic of Korea", "India", "Iran (Islamic Republic of)", "Iraq", "Israel", "Japan", "Kuwait", "Libya", "Madagascar", "Mexico", "Mongolia", "Morocco", "Mozambique", "New Zealand", "Pakistan", "Republic of Korea", "Saudi Arabia", "South Africa", "Switzerland", "Turkey", "Yugoslavia") |
W porzyższych listach nie wymieniamy Polski, bo będziemy ją podawać explicite. Uff. Czas na scalenie odpowiednich danych (łączymy informacje o oddanych głosach z datami głosowań):
|
1 2 3 4 |
# wszystkie głosowania uzupełnione o datę un_votes_date <- inner_join(un_votes %>% select(-country_code), un_roll_calls %>% select(rcid, date), by = "rcid") |
Chcemy sprawdzić jak zmieniło się podobieństwo głosów oddanych przez Polskę do innych państw w zależności od okresu w jakim była Polska – czy był to Układ Warszawski (i PRL), czy byliśmy w NATO oraz czy byliśmy w Unii. Miarą podobieństwa będzie korelacja głosów – każdy głos (tak, nie, głos wstrzymujący się) będzie przekształcony na liczbę, a później policzymy współczynnik korelacji pomiędzy liczbami dla każdego z państw. Można użyć innych metod (np. policzyć procent zgodnych głosów), ale korelacja też się sprawdzi, a poza tym łatwo ją policzyć z użyciem widyr właśnie.
Powtórka z historii najnowszej:
- PRL kończy się 4 czerwca 1989 roku (chociaż poprawniej byłoby liczyć to od końca 1989 roku)
- Polska jest członkiem NATO od 12 marca 1999 r.
- Polska jest członkiem Unii Europejskiej od 1 maja 2004 r.
To będą nasze daty graniczne. Przypisujemy więc dla nich odpowiednie znaczniki do naszej podstawowej tabeli z danymi:
|
1 2 3 4 |
un_votes_date <- un_votes_date %>% mutate(prl = date <= as_date("1989-06-04"), nato = date >= as_date("1999-03-12"), ue = date >= as_date("2004-05-01")) |
Zobaczmy te przypisane daty na osi czasu:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
un_votes_date %>% select(date:ue) %>% group_by(date) %>% distinct() %>% ungroup() %>% gather("key", "val", -date) %>% mutate(key = factor(toupper(key), levels = rev(c("PRL", "NATO", "UE")))) %>% ggplot(aes(date, key)) + geom_point(aes(color = val), show.legend = FALSE) + geom_vline(xintercept = as_date(c("1989-06-04", "1999-03-12", "2004-05-01"))) + annotate("label", x = as_date(c("1989-06-04", "1999-03-12", "2004-05-01")), y = c(3.3, 2.3, 1.3), label = c("Wybory 1989", "Polska w NATO", "Polska w UE"), color = "gray40", size = 3) + scale_color_manual(values = c("TRUE" = "#006837", "FALSE" = "#d73027"), labels = c("TRUE" = "tak", "FALSE" = "nie")) + labs(x = "", y = "", color = "") |
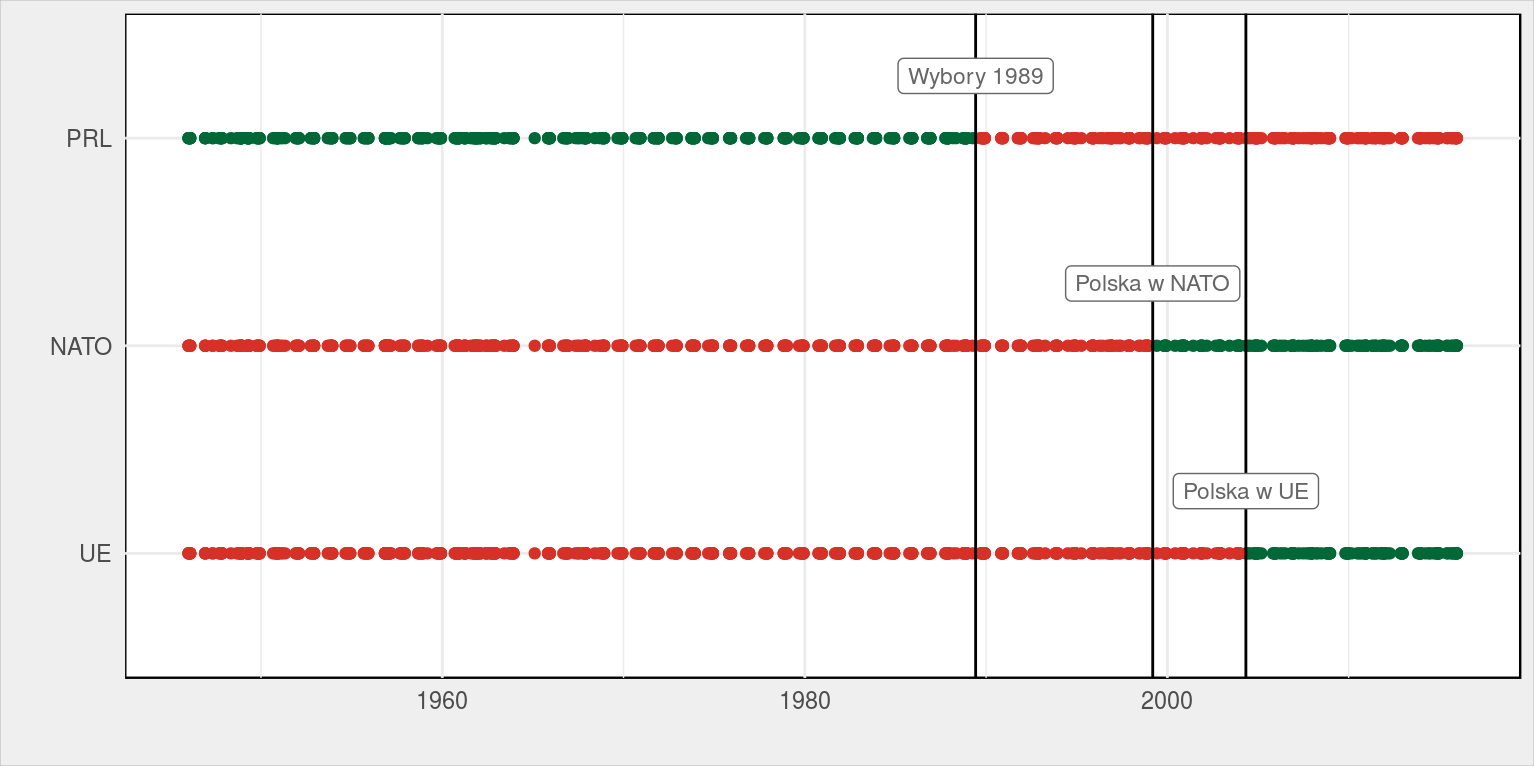
Wszystko się zgadza, zacznijmy zatem od
POLSKA vs NATO
Jak głosowaliśmy w PRL? Czy byliśmy bliżej Układu Warszawskiego czy NATO?
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 |
# wybieramy kraje z NATO (przed przystąpieniem Polski) i Układu Warszawskiego prl_nato <- un_votes_date %>% # tylko głosowania, kiedy istniał PRL: filter(prl) %>% filter(country %in% c(NATO_countries_1, WarsawPact_countries, other_countries , "Poland")) %>% # odrzucamy dla pewności zjednoczone Niemcy: filter(country != "Germany") %>% # głosy (factory) zamieniamy na liczby - nie ma znaczenia jakie, ważne żeby różne mutate(vote = as.numeric(vote)) %>% # liczymy współczynniki korelacji każdy kraj z każdym krajem: pairwise_cor(country, rcid, vote, sort = TRUE, upper = FALSE) # z powstałej tabeli bierzemy tylko wiersze z Polską: prl_nato <- bind_rows( prl_nato %>% filter(item1 == "Poland") %>% select(country = item2, correlation), prl_nato %>% filter(item2 == "Poland") %>% select(country = item1, correlation) ) %>% # dla przyszłej legendy wykresu oznaczamy odpowiednio państwa mutate(nato = case_when( country == "Russian Federation" ~ "Rosja", country %in% NATO_countries_1 ~ "NATO", country %in% WarsawPact_countries ~ "Układ Warszawski", TRUE ~ "inne")) # i rysujemy całość w postaci wykresu słupkowego prl_nato %>% # odpowiednia kolejność na wykresie: mutate(country = reorder(country, correlation)) %>% # odpowiednia kolejność w legendzie: mutate(nato = factor(nato, levels = c("NATO", "Rosja", "Układ Warszawski", "inne"))) %>% # wykres słupkowy: ggplot(aes(country, correlation)) + geom_col(aes(fill = nato), color = "gray30", size = 0.1) + # paleta kolorów dla słupków: scale_fill_manual(values = c("NATO" = "#4575b4", "Układ Warszawski" = "#fdae61", "inne" = "#a6d96a", "Rosja" = "#d73027")) + # obracamy osie coord_flip() + # zmieniamy położenie legendy theme(legend.position = "bottom") + # i dodajemy tytuły labs(title = "Podobieństwo Polski do innych państw\nwedług głosowania w ONZ", subtitle = "W czasach PRL", x = "", y = "współczynnik korelacji głosowań", fill = "", caption = "(c) Łukasz Prokulski, fb.com/DaneAnalizy") |
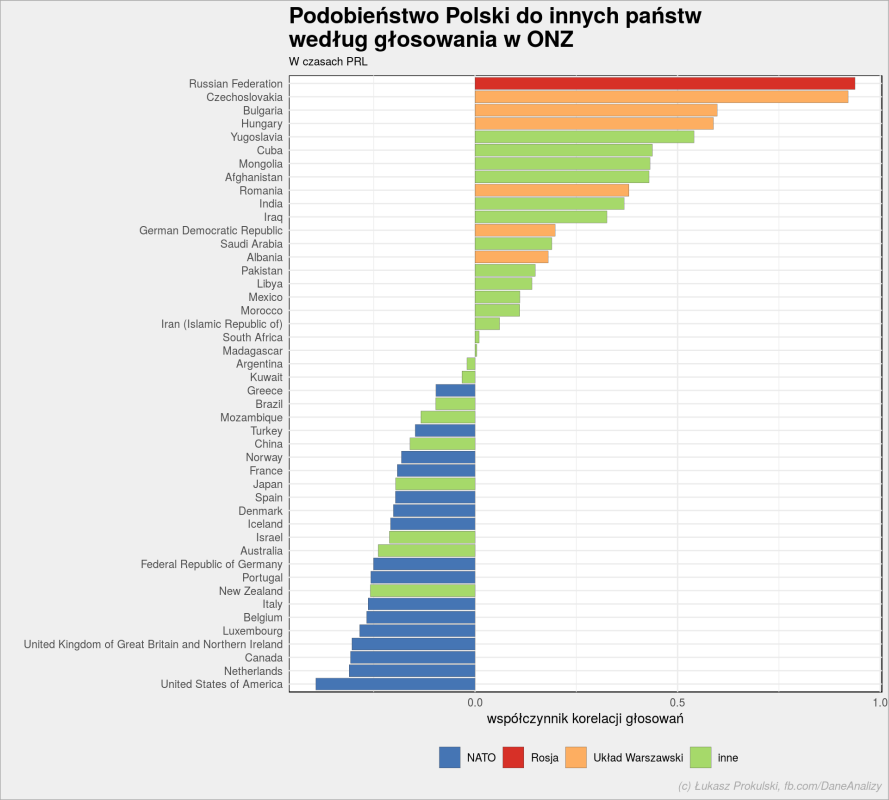
Widzimy, że byliśmy zgodni z naszymi przyjaciółmi z Europy Wschodniej, a najbardziej z naszym wielkim bratem ze wschodu. Dla wszystkich krajów Układu Warszawskiego mamy dodatnią korelację – zatem zgodność. Z kolei wszystkie kraje (wówczas) należące do NATO są po ujemnej stronie korelacji. Można w dużym uproszczeniu powiedzieć, że kiedy my głosowaliśmy na tak to zazwyczaj razem z nami głosował tak samo Układ Warszawski, a na nie głosowało NATO. Uwaga – w danych bierzemy pod uwagę również głosy wstrzymujące się – spodziewam się, że po ich odrzuceniu wyniki byłyby nawet bardziej spolaryzowane.
Jak to się zmieniło po naszym wstąpieniu do NATO?
Kod jest analogiczny, już bez komentarzy:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
polska_nato <- un_votes_date %>% filter(nato) %>% filter(country %in% c(NATO_countries_2, WarsawPact_countries, other_countries , "Poland")) %>% mutate(vote = as.numeric(vote)) %>% pairwise_cor(country, rcid, vote, sort = TRUE, upper = FALSE) polska_nato <- bind_rows( polska_nato %>% filter(item1 == "Poland") %>% select(country = item2, correlation), polska_nato %>% filter(item2 == "Poland") %>% select(country = item1, correlation) ) %>% mutate(nato = case_when( country == "Russian Federation" ~ "Rosja", country %in% NATO_countries_1 ~ "NATO", country %in% WarsawPact_countries ~ "dawny Układ Warszawski", TRUE ~ "inne")) polska_nato %>% mutate(country = reorder(country, correlation)) %>% mutate(nato = factor(nato, levels = c("NATO", "Rosja", "dawny Układ Warszawski", "inne"))) %>% ggplot(aes(country, correlation)) + geom_col(aes(fill = nato), color = "gray30", size = 0.1) + scale_fill_manual(values = c("NATO" = "#4575b4", "dawny Układ Warszawski" = "#fdae61", "inne" = "#a6d96a", "Rosja" = "#d73027")) + coord_flip() + theme(legend.position = "bottom") + labs(title = "Podobieństwo Polski do innych państw\nwedług głosowania w ONZ", subtitle = "W okresie po wstąpieniu Polski do NATO", x = "", y = "współczynnik korelacji głosowań", fill = "Czy państwo było w:", caption = "(c) Łukasz Prokulski, fb.com/DaneAnalizy") |
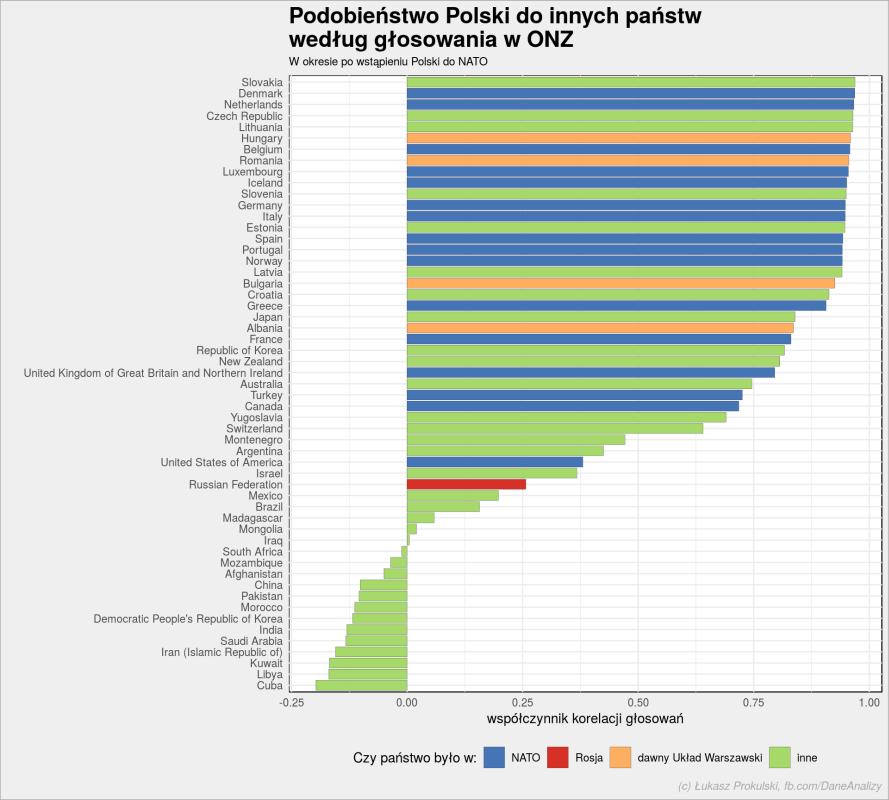
Przede wszystkim już nie jesteśmy tak podobni w swoich głosach do Rosji. Okolice 0.25 to korelacja dodatnia (a więc zgodność), ale słaba. Interesujące może być sprawdzenie w jakich kategoriach jesteśmy zgodni, a w jakich nie (dla zainteresowanych – trzeba wykorzystać tabelę un_roll_call_issues).
Jesteśmy teraz zgodni z NATO i nadal z dawnym Układem Warszawskim (bez Rosji). To drugie chyba nie powinno dziwić – w końcu to kraje z naszego regionu świata, obecnie też należące do NATO.
Ciekawe jest porównanie najbardziej podobnych z obu okresów: Czechosłowacja i obecne Czechy oraz Słowacja; blisko nam również do Węgrów, Litwy czy Rumunii. Zatem nic się nie zmieniło. Ale spójrzcie jak oddaliliśmy się od Kuby, Mongolii, Afganistanu, Iraku czy Arabii Saudyjskiej – to niejako opozycja do współczesnego świata zachodu. Ciekawe mogłoby być porównanie tych państw z USA.
Gdzie zaszła największa zmiana?
|
1 2 3 4 5 6 |
nato_delta <- inner_join(prl_nato, polska_nato, by = c("country")) %>% mutate(delta = correlation.y - correlation.x) %>% select(country, prl_nato = correlation.x, pl_nato = correlation.y, delta) %>% arrange(delta) nato_delta |
| country | prl_nato | pl_nato | delta |
|---|---|---|---|
| Russian Federation | 0.9378376 | 0.2571535 | -0.6806841 |
| Cuba | 0.4375991 | -0.1972846 | -0.6348837 |
| India | 0.3681376 | -0.1303505 | -0.4984881 |
| Afghanistan | 0.4293974 | -0.0500393 | -0.4794367 |
| Mongolia | 0.4318937 | 0.0204369 | -0.4114568 |
| Saudi Arabia | 0.1894611 | -0.1325140 | -0.3219751 |
| Iraq | 0.3254869 | 0.0051074 | -0.3203796 |
| Libya | 0.1404392 | -0.1692990 | -0.3097383 |
| Pakistan | 0.1486058 | -0.1039250 | -0.2525308 |
| Morocco | 0.1100057 | -0.1131046 | -0.2231103 |
Kolumna prl_nato to współczynnik korelacji z państwem z kolumny country w czasach PRLu, pl_nato – w czasach Polski w NATO, zaś delta to różnica. Im różnica bardziej ujemna tym bardziej spadło nasze podobieństwo (im bardziej dodatnia – tym bardziej staliśmy się podobni). W tabelce wyżej tylko 10 pierwszych wierszy (czyli te państwa, od których się oddaliliśmy), zobaczmy całość na wykresie:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
nato_delta <- nato_delta %>% mutate(country = fct_inorder(country)) %>% gather("key", "value", -country) ggplot() + geom_col(data = nato_delta %>% filter(key == "delta"), aes(country, value), fill = "lightgreen") + geom_point(data = nato_delta %>% filter(key != "delta"), aes(country, value, color = key)) + geom_segment(data = nato_delta %>% filter(key != "delta") %>% spread(key, value) %>% filter(pl_nato > prl_nato), aes(y = pl_nato, yend = prl_nato, x = country, xend = country), arrow = arrow(length = unit(0.015, "npc"), ends = "first", type = "closed"), arrow.fill = "gray50", color = "gray50") + geom_segment(data = nato_delta %>% filter(key != "delta") %>% spread(key, value) %>% filter(pl_nato < prl_nato), aes(y = prl_nato, yend = pl_nato, x = country, xend = country), arrow = arrow(length = unit(0.015, "npc"), ends = "last", type = "closed"), arrow.fill = "gray30", color = "gray50") + scale_color_manual(values = c("pl_nato" = "red", "prl_nato" = "blue"), labels = c("pl_nato" = "Polska w NATO", "prl_nato" = "PRL")) + coord_flip() + theme(legend.position = "bottom") + labs(title = "Zmiana podobieństwo Polski do innych państw\nwedług głosowania w ONZ", subtitle = "W okresie po wstąpieniu Polski do NATO", x = "", y = "Współczynnik korelacji (punkty) oraz jego zmiana (paski)", color = "", caption = "(c) Łukasz Prokulski, fb.com/DaneAnalizy") |
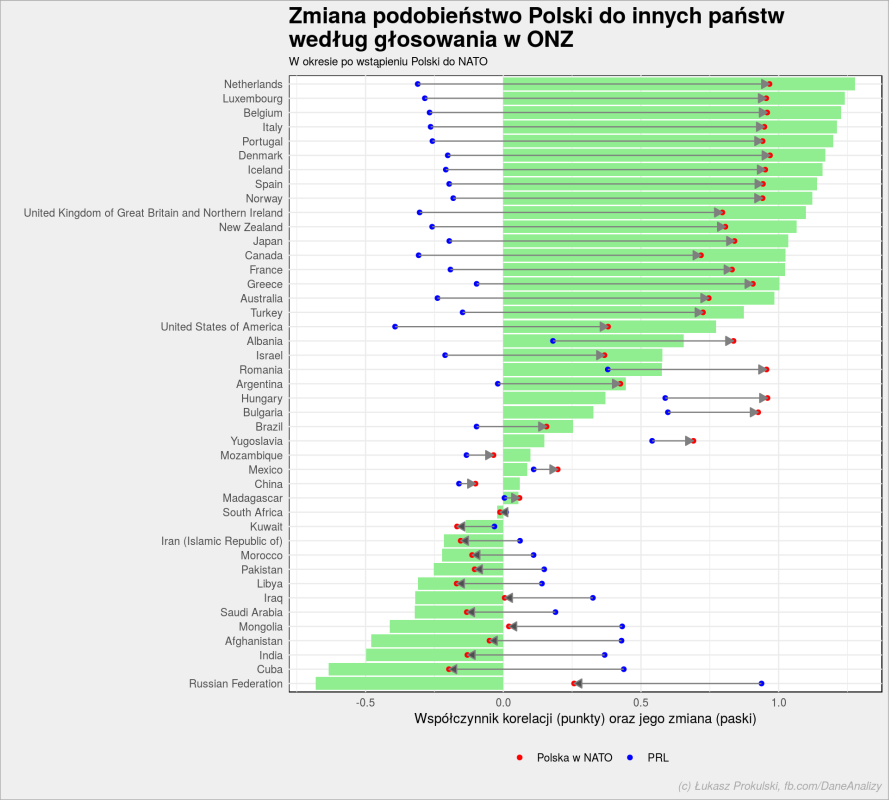
Widzimy, że państwa, które były w NATO przed nami (zgniły, imperialistyczny zachód jeśli użyć dawnych określeń) zyskały najwięcej na podobieństwie (najdłuższe zielone paski, kropki niebieskie były po ujemnej stronie, czerwone są po dodatniej).
Zobaczmy jeszcze podobieństwo głosów oddanych przez inne państwa do naszych głosów (już po wstąpieniu do NATO) na mapie:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 |
# wybieramy dane z okresu kiedy byliśmy w NATO polska_nato_2 <- un_votes_date %>% filter(nato) %>% mutate(vote = as.numeric(vote)) %>% pairwise_cor(country, rcid, vote, sort = TRUE, upper = FALSE) plot_data <- bind_rows( polska_nato_2 %>% filter(item1 == "Poland") %>% select(country = item2, correlation), polska_nato_2 %>% filter(item2 == "Poland") %>% select(country = item1, correlation) ) # przygotowujemy mapę świata world_map <- map_data("world") %>% # zmieniamy kilka nazw, tak aby były zgodne z tym co mamy w danych o głosowaniu: mutate(region = case_when( region == "Bolivia" ~ "Bolivia (Plurinational State of)", region == "Republic of Congo" ~ "Congo", region == "UK" ~ "United Kingdom of Great Britain and Northern Ireland", region == "Iran" ~ "Iran (Islamic Republic of)", region == "South Korea" ~ "Republic of Korea", region == "Laos" ~ "Lao People's Democratic Republic", region == "Moldova" ~ "Republic of Moldova", region == "Macedonia" ~ "The former Yugoslav Republic of Macedonia", region == "North Korea" ~ "Democratic People's Republic of Korea", region == "Russia" ~ "Russian Federation", region == "Syria" ~ "Syrian Arab Republic", region == "USA" ~ "United States of America", region == "Venezuela" ~ "Venezuela, Bolivarian Republic of", TRUE ~ region )) # łączymy dane mapy z danymi o głosach - kluczem jest nazwa państwa (stąd powyższe zmiany) plot_data <- left_join(world_map, plot_data, by = c("region" = "country")) %>% # podzielmy jeszcze współczynnik korelacji na kilka przedziałów - narysujemy za chwię drugą mapę mutate(correlation_cluster = cut(correlation, c(-2, -0.75, 0, 0.75, 2))) # rysujemy mapkę plot_data %>% ggplot() + # granice państw, wypełnienie jest zależne od współczynnika korelacji geom_polygon(aes(long, lat, group = group, fill = correlation), color = "gray30", size = 0.1) + # paleta dla wypełnienia scale_fill_distiller(palette = "RdYlGn", na.value = "white") + # poprane (mniej więcej) odwzorowanie kształtów państw coord_quickmap() + # trochę zmieniamy wygląd osi, miejsce legendy i dodajemy niebieską wodę ;) theme(panel.background = element_rect(fill = "#abd9e9"), axis.text = element_blank(), legend.position = "bottom") + # oraz tytuły na wykresie labs(title = "Podobieństwo Polski do innych państw w głosowaniach w ONZ", subtitle = "W okresie po wstąpieniu Polski do NATO", x = "", y = "", fill = "Współczynnik korelacji głosowań:", caption = "(c) Łukasz Prokulski, fb.com/DaneAnalizy") |
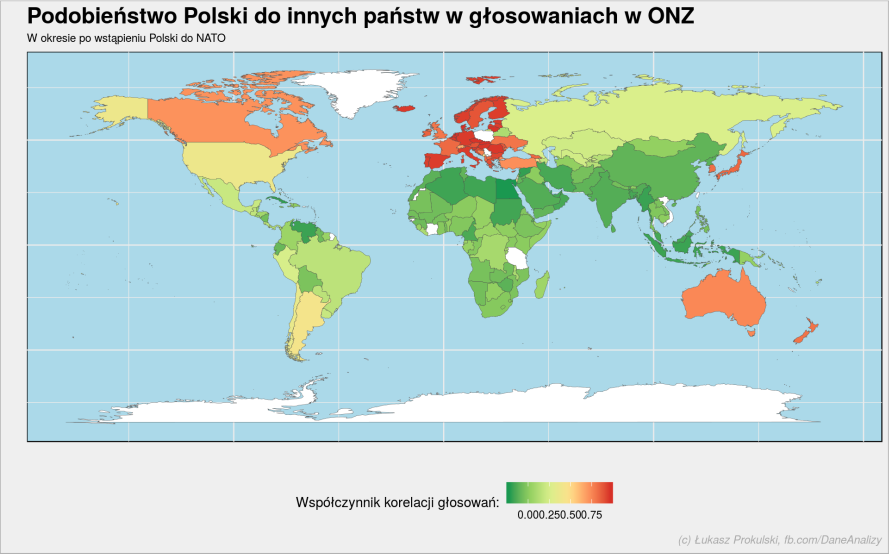
Tutaj wyraźnie widzimy do jakiej części świata należymy – jesteśmy podobni do właściwie całej Europy. Co może być ciekawe – nasz nowy wielki brat, Stany Zjednoczone – nie jest tak blisko jak na przykład Kanada, Australia czy Japonia.
Dla porównania mapa z czasów PRL:
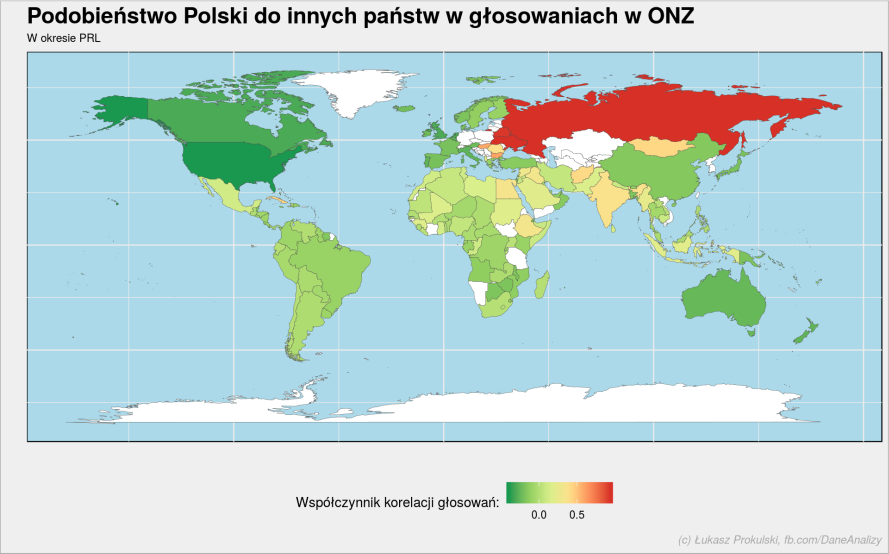
W kodzie powyżej pogrupowaliśmy państwa według kilku przedziałów współczynnika korelacji. Możemy też to pokazać – dane mamy gotowe, wystarczy je narysować. Dla analizujących kod – zwróćcie uwagę na inny sposób przygotowania palety: tutaj są wartości dyskretne, wyżej były ciągłe.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
plot_data %>% ggplot() + geom_polygon(aes(long, lat, group = group, fill = correlation_cluster), color = "gray30", size = 0.1) + scale_fill_manual(values = c("(-0.75,0]" = "#1a9850", "(0,0.75]" = "#fee08b", "(0.75,2]" = "#d73027", "NA" = "white"), na.value = "white") + coord_quickmap() + theme(panel.background = element_rect(fill = "#abd9e9"), axis.text = element_blank(), legend.position = "bottom") + labs(title = "Podobieństwo Polski do innych państw w głosowaniach w ONZ", subtitle = "W okresie po wstąpieniu Polski do NATO", x = "", y = "", fill = "Współczynnik korelacji głosowań:", caption = "(c) Łukasz Prokulski, fb.com/DaneAnalizy") |
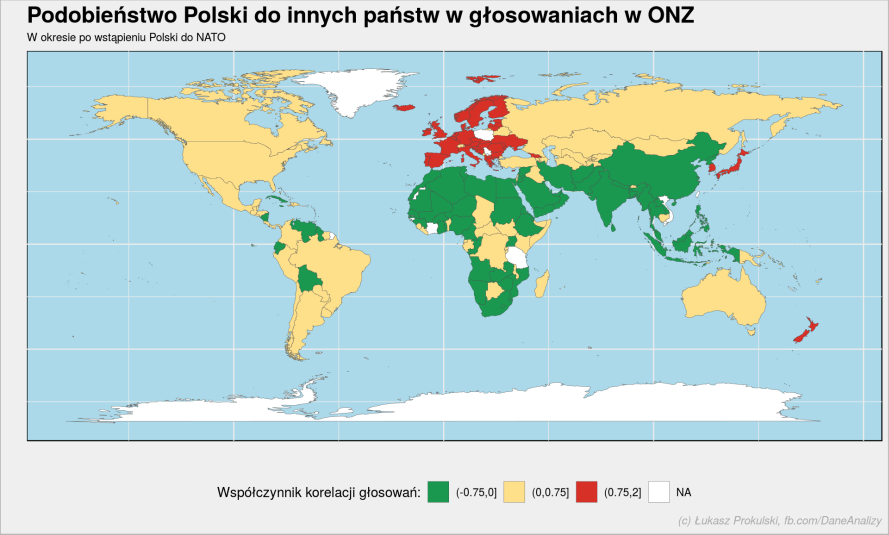
Tutaj podobieństwo z poprzedniego akapitu widać jeszcze bardziej. Tworzymy jedną rodzinę z całą Europą, Japonią, Nową Zelandią i co ciekawe Koreą Południową. Państwa islamu (Bliski Wschód, północna Afryka) są po przeciwnej stronie. Jednak warto zwrócić uwagę na granice przedziałów: na zielono mamy wszystko co ma ujemną korelację (nie ważne czy silną czy słabą), ale granica pomiędzy żółtym i czerwonym to współczynnik korelacji 0.75. Trochę więc jak umowna granica pomiędzy korelacją słabą (żółte) i silną (czerwone).
Jak zmieniało się podobieństwo w czasie? Widzieliśmy zagregowane wyniki dla poszczególnych okresów, widzieliśmy różnice. Ale czy możemy zobaczyć od kiedy zbliżaliśmy się do USA czy Niemiec, a oddalaliśmy się od Rosji? Zobaczmy to na osi czasu.
Policzymy współczynniki korelacji głosów oddanych przez Polskę z USA, Niemcami i Rosją dla kolejnych sesji Zgromadzenia ONZ. Później tym sesjom przypiszemy datę i w formie wykresu liniowego obejrzymy wyniki.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 |
# tym razem dane o głosach łączymy z sesjami ale nie tylko z datą ale również numerem sesji (po niej będziemy grupować) un_votes_session <- inner_join(un_votes %>% select(-country_code), un_roll_calls %>% select(rcid, session, date), by = "rcid") # przygotowujemy wyniki: un_votes_session %>% # bierzemy tylko głosy czterech państw filter(country %in% c("United States of America", "Russian Federation", "Germany", "Federal Republic of Germany", "Poland")) %>% # upraszczamy nazwy i RFN traktujemy jak zjednoczone Niemcy mutate(country = case_when( country == "United States of America" ~ "USA", country == "Russian Federation" ~ "Russia", country == "Federal Republic of Germany" ~ "Germany", TRUE ~ country)) %>% mutate(vote = as.numeric(vote)) %>% spread(country, vote) %>% # usuwamy głosowania, w których nie brał udziału co najmniej jeden kraj na.omit() %>% # grupujemy po sesjach group_by(session) %>% # liczymy korelacje głosów Polski z pozostałymi krajami summarise(date = min(date), # data sesji to pierwszy dzień sesji cor_USA = cor(Poland, USA), cor_Germany = cor(Poland, Germany), cor_Russia = cor(Poland, Russia)) %>% ungroup() %>% # rysujemy wykres ggplot() + # wyraźniejsze oznaczenie poziomów dla wsp. korelacji -0.5, 0 i 0.5 geom_hline(yintercept = c(-0.5, 0, 0.5), color = "gray40") + # linie dla poszczególnych państw geom_line(aes(date, cor_USA), color = "blue", size = 2) + geom_line(aes(date, cor_Germany), color = "green", size = 2) + geom_line(aes(date, cor_Russia), color = "red", size = 2) + # daty graniczne z naszej historii geom_vline(xintercept = as_date(c("1989-06-04", "1999-03-12", "2004-05-01")), color = "gray40") + # labelki oznaczające daty z naszej historii annotate("label", x = as_date(c("1989-06-04", "1999-03-12", "2004-05-01")), y = c(-0.5, -0.5, -0.5), label = c("Wybory 1989", "Polska w NATO", "Polska w UE"), color = "gray40", size = 3) + # labelki na wykresie odpowiadające liniom z wsp. korelacji annotate("label", x = as_date(rep("1973-12-02", 3)), y = c(0.95, -0.4, -0.05), label = c("Rosja", "Niemcy", "USA"), color = c("red", "green", "blue")) + # opis wykresu - osie, tytuły labs(title = "Zmiana podobieństwa głosów oddanych przez Polskę\nwedług głosowań w ONZ", x = "", y = "Współczynnik korelacji", caption = "(c) Łukasz Prokulski, fb.com/DaneAnalizy") |
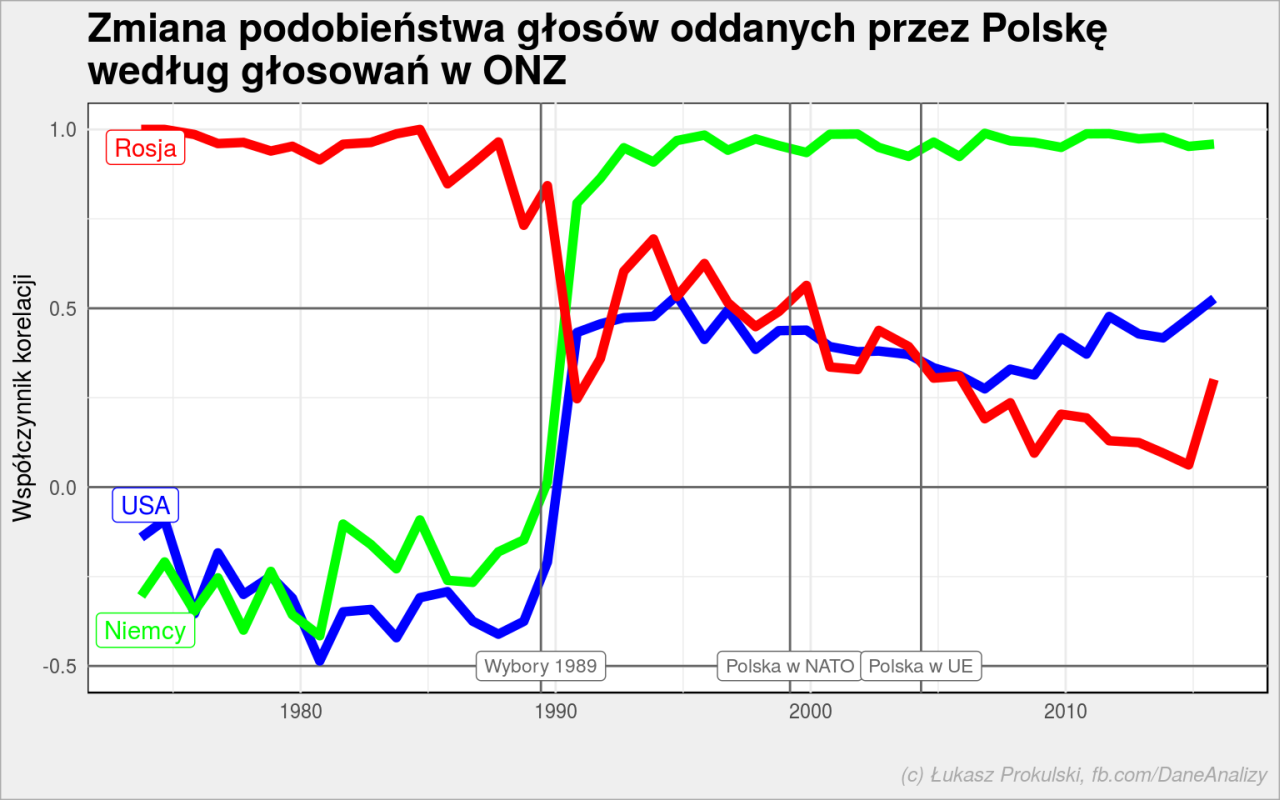
Z powyższego wykresu widzimy, że swego rodzaju przełom nastąpił w 1989 roku (właściwie już w 1990), a nie po wstąpieniu do NATO. Możemy zatem uznać, że:
- wyswobodziliśmy się spod nadzoru Rosji i zaczęliśmy samodzielnie głosować, bez oglądania się na wschód
- lub też: postanowiliśmy głosować tak jak mocarstwa z drugiej strony żelaznej kurtyny, być może aby się im przypodobać?
Od tego wykresu zaczął się ten wpis. A właściwie od rozmowy przy piwie na temat tych danych (tak, badam sobie różne dane, niekoniecznie dobrane pod wpisy – wpisy rodzą się jeśli badania są interesujące). Oba punkty wyżej to nieco przeciwstawne opinie: albo idziemy na swoje albo przymilamy się do drugiej strony. Którą opcję wybierzemy zależy od naszych poglądów politycznych, naszego poglądu na to czy Polska jest samodzielnym krajem czy też potrzebuje silniejszego sojusznika. Z tym pozostawię Was samych i przede do innego aspektu:
POLSKA vs Unia Europejska
Analogiczne ćwiczenie przeprowadzimy dla rozpoznania różnic i podobieństw w okresach przed i po przystąpieniu Polski do UE. Będziemy brać do porównania kraje z obecnej Unii oraz Rosję.
Podobieństwo w głosowaniu przed przystąpieniem do UE
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
# wybieramy kraje z obecnego UE plus Rosja prl_ue <- un_votes_date %>% filter(!ue) %>% filter(country %in% c(UE_countries_2, "Poland", "Russian Federation")) %>% mutate(vote = as.numeric(vote)) %>% pairwise_cor(country, rcid, vote, sort = TRUE, upper = FALSE) bind_rows( prl_ue %>% filter(item1 == "Poland") %>% select(country = item2, correlation), prl_ue %>% filter(item2 == "Poland") %>% select(country = item1, correlation) ) %>% # oznaczamy kraje starej i nowej Unii mutate(ue = case_when( country == "Russian Federation" ~ "Rosja", country %in% UE_countries_1 ~ "stare UE", country %in% UE_countries_2 ~ "nowe UE", TRUE ~ "poza UE")) %>% mutate(country = reorder(country, correlation)) %>% mutate(ue = factor(ue, levels = c("stare UE", "nowe UE", "poza UE", "Rosja"))) %>% ggplot(aes(country, correlation)) + geom_col(aes(fill = ue), color = "gray30", size = 0.1) + scale_fill_manual(values = c("stare UE" = "#4575b4", "nowe UE" = "#abd9e9", "poza UE" = "#fee090", "Rosja" = "#d73027")) + coord_flip() + theme(legend.position = "bottom") + labs(title = "Podobieństwo Polski do innych państw\nwedług głosowań w ONZ", subtitle = "W okresie przed wstąpieniem Polski do UE", x = "", y = "współczynnik korelacji", fill = "", caption = "(c) Łukasz Prokulski, fb.com/DaneAnalizy") |
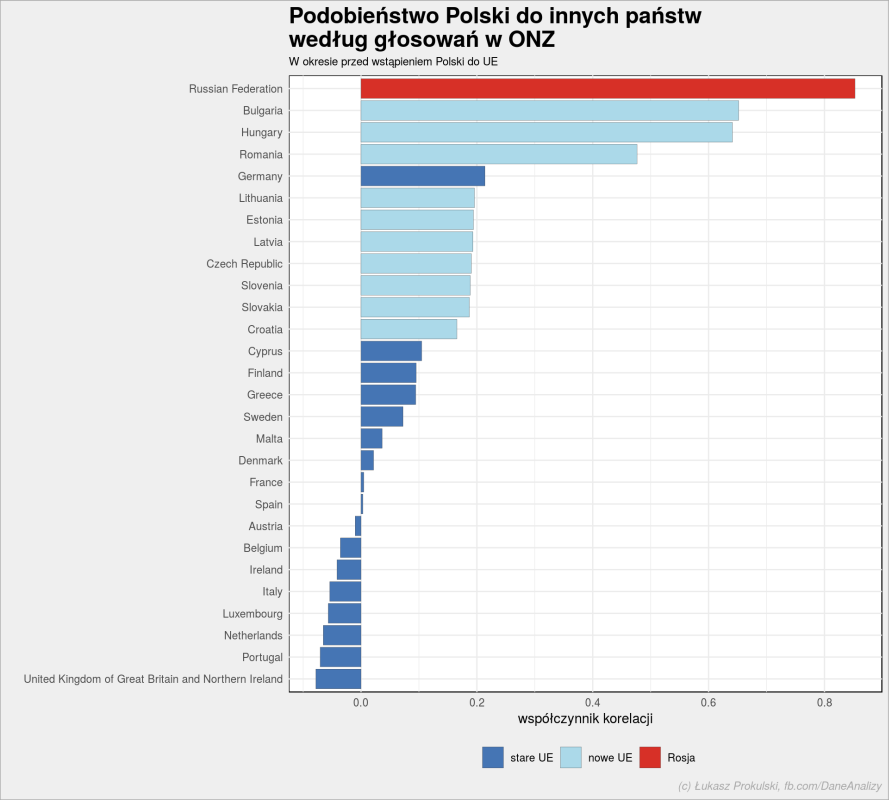
Liczby oczywiście (z mniejszą bądź większą dokładnością – granica jest o kilka lat później niż wstąpienie do NATO czy koniec PRLu) się powtarzają. Wnioski również – byliśmy blisko Rosji, a teraz…
Podobieństwo w głosowaniu po przystąpieniu do UE
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
polska_ue <- un_votes_date %>% filter(ue) %>% filter(country %in% c(UE_countries_2, "Poland", "Russian Federation")) %>% mutate(vote = as.numeric(vote)) %>% pairwise_cor(country, rcid, vote, sort = TRUE, upper = FALSE) bind_rows( polska_ue %>% filter(item1 == "Poland") %>% select(country = item2, correlation), polska_ue %>% filter(item2 == "Poland") %>% select(country = item1, correlation) ) %>% mutate(ue = case_when( country == "Russian Federation" ~ "Rosja", country %in% UE_countries_1 ~ "stare UE", country %in% UE_countries_2 ~ "nowe UE", TRUE ~ "poza UE")) %>% mutate(country = reorder(country, correlation)) %>% mutate(ue = factor(ue, levels = c("stare UE", "nowe UE", "poza UE", "Rosja"))) %>% ggplot(aes(country, correlation)) + geom_col(aes(fill = ue), color = "gray30", size = 0.1) + scale_fill_manual(values = c("stare UE" = "#4575b4", "nowe UE" = "#abd9e9", "poza UE" = "#fee090", "Rosja" = "#d73027")) + coord_flip() + theme(legend.position = "bottom") + labs(title = "Podobieństwo Polski do innych państw\nwedług głosowań w ONZ", subtitle = "W okresie po wstąpieniu Polski do UE", x = "", y = "współczynnik korelacji", fill = "", caption = "(c) Łukasz Prokulski, fb.com/DaneAnalizy") |
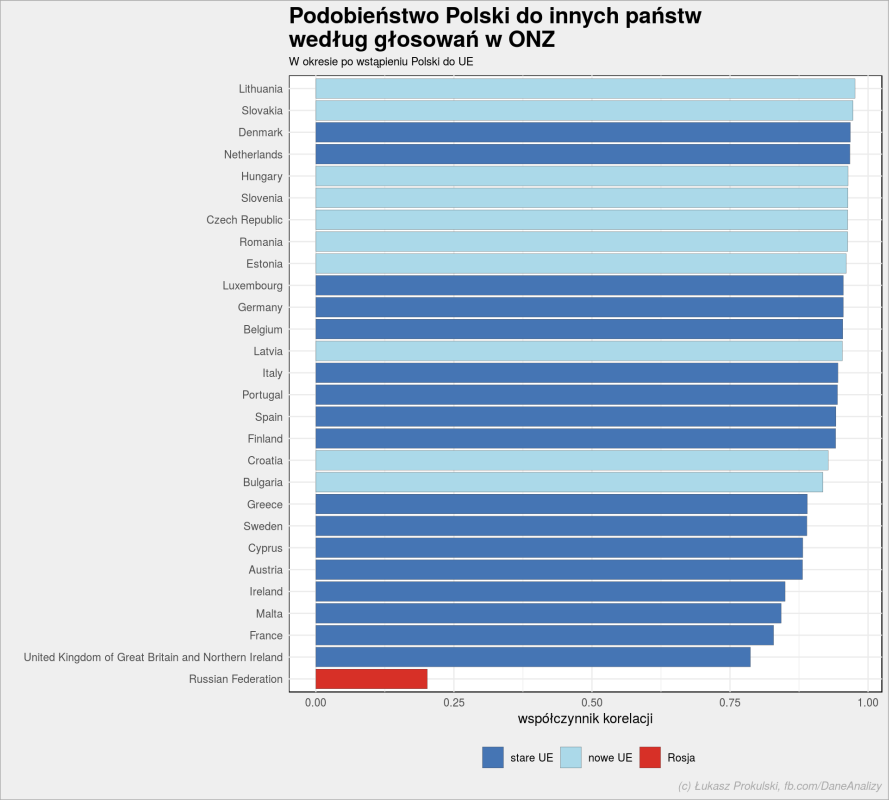
…Rosja jest najdalej spośród krajów branych pod uwagę (UE i Rosja). Oczywiście trzymamy się blisko państw, które mają podobną historię (tą po II wojnie światowej) i wstąpiły do UE w podobnym okresie. Stąd też zapewne (oraz z geografii) wywodzi się idea Trójmorza.
Czy państwa UE różnią się od siebie?
Do porównania weźmiemy głosy oddane w ONZ już po przystąpieniu Polski do UE. Tym razem odrzucamy też głosy wstrzymujące się (linijka filter(vote != "abstain") w poniższym kodzie), co wyostrza różnice.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
ue_votes <- un_votes_date %>% filter(ue) %>% filter(vote != "abstain") %>% filter(country %in% c(UE_countries_2, "Poland")) %>% # uproścmy nazwę Wielkiej Brytanii mutate(country = if_else(country == "United Kingdom of Great Britain and Northern Ireland", "UK", country)) %>% mutate(vote = as.numeric(vote)) %>% pairwise_cor(country, rcid, vote) ue_votes %>% mutate(item2 = factor(item2, levels = sort(unique(item2), decreasing = TRUE))) %>% ggplot() + geom_tile(aes(item1, item2, fill = correlation), color = "gray30", size = 0.1) + scale_fill_distiller(palette = "RdYlGn", na.value = "white") + theme(axis.text.x = element_text(angle = 90), legend.position = "bottom") + labs(title = "Podobieństwo państw UE w głosowaniach w ONZ", subtitle = "W okresie po wstąpieniu Polski do UE", x = "", y = "", fill = "współczynnik korelacji", caption = "(c) Łukasz Prokulski, fb.com/DaneAnalizy") |
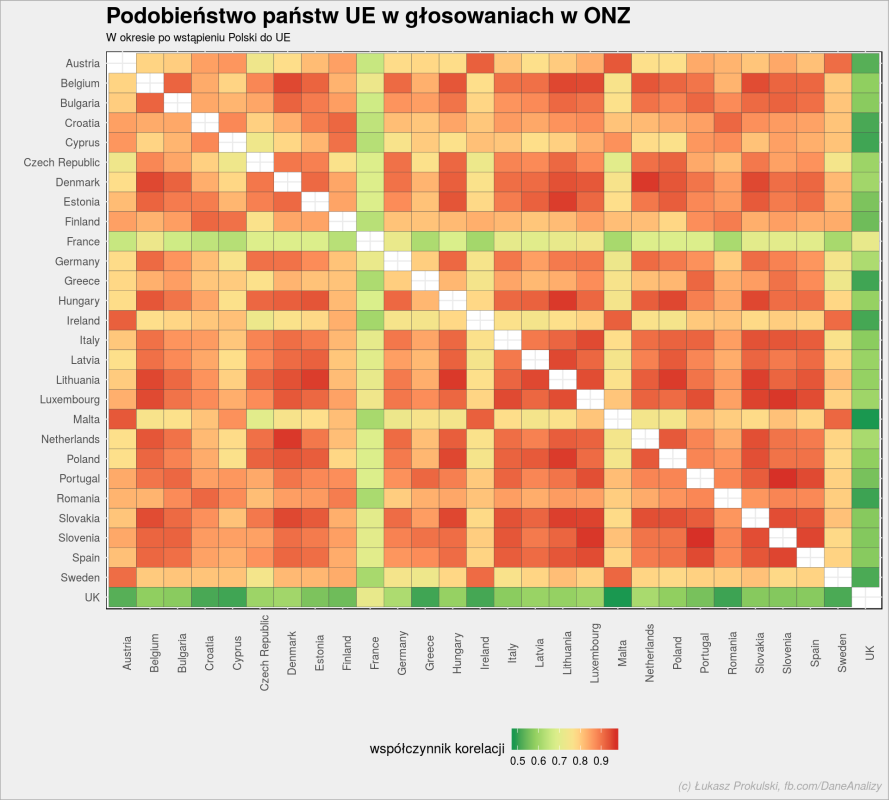
Pierwsze co rzuca się w oczy to zielona (bo niska korelacja) Wielka Brytania. Brexit, anybody? Coś w tym jest… Ciekawe jak wygląda podobieństwo UK-USA? Zrobiłem test: po dodaniu USA UK wypada żółto, a USA – zielono. Korelacja pomiędzy UK a USA jest na poziomie 0.27.
Odmienna od reszty Europy jest też nieco Francja i już mniej Malta. Zobaczmy
które państwa UE są najbardziej podobne do siebie?
Z powyższej heat-mapy można to wyczytać, ale odcienie czerwonego są tak blisko siebie, że nie widać od razu do kogo najbliżej na przykład Węgrom. Poszukajmy więc dla każdego państwa tego, które ma największy współczynnik korelacji:
|
1 2 3 4 5 |
ue_votes %>% group_by(item1) %>% filter(correlation == max(correlation)) %>% ungroup() %>% arrange(item1) |
| Państwo | Najbardziej podobne państwo | Współczynnik korelacji |
|---|---|---|
| Austria | Malta | 0.9334059 |
| Belgium | Lithuania | 0.9501855 |
| Bulgaria | Slovenia | 0.9216189 |
| Croatia | Finland | 0.9170618 |
| Cyprus | Finland | 0.9050580 |
| Czech Republic | Poland | 0.9211749 |
| Denmark | Netherlands | 0.9629506 |
| Estonia | Lithuania | 0.9588502 |
| Finland | Croatia | 0.9170618 |
| France | Luxembourg | 0.7380901 |
| Germany | Hungary | 0.9153014 |
| Greece | Portugal | 0.9172528 |
| Hungary | Lithuania | 0.9626541 |
| Ireland | Austria | 0.9246736 |
| Italy | Luxembourg | 0.9471139 |
| Latvia | Lithuania | 0.9489628 |
| Lithuania | Hungary | 0.9626541 |
| Luxembourg | Slovenia | 0.9645315 |
| Malta | Austria | 0.9334059 |
| Netherlands | Denmark | 0.9629506 |
| Poland | Lithuania | 0.9605076 |
| Portugal | Slovenia | 0.9695714 |
| Romania | Croatia | 0.9161638 |
| Slovakia | Lithuania | 0.9575021 |
| Slovenia | Portugal | 0.9695714 |
| Spain | Slovenia | 0.9516218 |
| Sweden | Malta | 0.9172435 |
| UK | France | 0.7155979 |
A gdyby tak podzielić jakoś państwa na grupy? Na przykład pary na podstawie korelacji między państwami podzielić w prosty sposób (algorytmem k-means) na sześć grup, a później poszukać do której grupy każde z państw wpada najczęściej. Da nam to jakiś podział, nie do końca wiem czy sensowny i co znaczący, ale sprawdźmy:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
# przypisujemy pary państw do jednej z grup # 6 grup, bo bierzemy pierwastek z liczby państw zaokrąglony do góry ue_votes$km <- kmeans(ue_votes$correlation, 6)$cluster ue_votes_clusters <- ue_votes %>% # dla każdego z państw group_by(item1) %>% # liczymy ile razy było w danej grupie count(km) %>% # liczymy jaki to procent mutate(p = 100*n/sum(n)) %>% ungroup() %>% # bierzemy tylko te największe procenty group_by(item1) %>% top_n(1, n) %>% ungroup() |
Zobaczmy jaki jest wynik podziału:
|
1 2 3 |
ue_votes_clusters %>% select(km, item1, p) %>% arrange(km, item1) |
| Grupa | Państwo | Dopasowanie do grupy |
|---|---|---|
| 1 | Czech Republic | 33.3% |
| Estonia | 33.3% | |
| Germany | 37.0% | |
| Portugal | 37.0% | |
| Romania | 48.1% | |
| 2 | Belgium | 55.6% |
| Bulgaria | 37.0% | |
| Denmark | 55.6% | |
| Estonia | 33.3% | |
| Hungary | 55.6% | |
| Italy | 40.7% | |
| Latvia | 33.3% | |
| Lithuania | 55.6% | |
| Luxembourg | 51.9% | |
| Netherlands | 44.4% | |
| Poland | 48.1% | |
| Portugal | 37.0% | |
| Slovakia | 55.6% | |
| Slovenia | 48.1% | |
| Spain | 48.1% | |
| 3 | Austria | 33.3% |
| Croatia | 44.4% | |
| Cyprus | 33.3% | |
| Finland | 55.6% | |
| Greece | 48.1% | |
| 4 | France | 74.1% |
| 5 | Austria | 33.3% |
| Ireland | 59.3% | |
| Malta | 51.9% | |
| Sweden | 44.4% | |
| 6 | UK | 96.3% |
Samotne w swoich grupach są Wielka Brytania i Francja. Oprócz suchej tabelki możemy zobaczyć na mapie podział na grupy:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
left_join(world_map, ue_votes_clusters %>% mutate(item1 = if_else(item1 == "UK", "United Kingdom of Great Britain and Northern Ireland", item1)), by = c("region" = "item1")) %>% ggplot(aes(long, lat, group = group)) + geom_polygon(aes(fill = as.factor(km)), color = "black", size = 0.1, show.legend = FALSE) + scale_fill_viridis_d(option = "D", na.value = "gray80") + coord_quickmap(xlim = c(-15,40), ylim = c(35, 71)) + theme(panel.background = element_rect(fill = "#abd9e9"), axis.text = element_blank()) + labs(title = "Podobieństwo krajów UE do siebie", subtitle = "Na podstawie głosowań w ONZ, w okresie po wstąpieniu Polski do UE", x = "", y = "", caption = "(c) Łukasz Prokulski, fb.com/DaneAnalizy") |
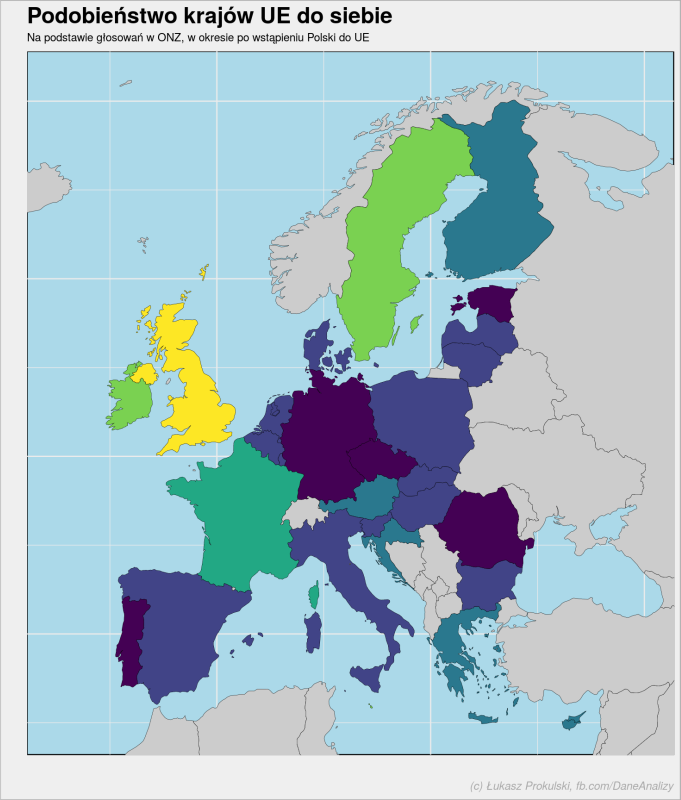
Trzeba pamiętać, że algorytm k-means jest losowy, więc jeśli sami śledzicie kod krok po kroku może się okazać, że wyniki nie będą powtarzalne. Pamiętać należy też, że każde z państw należy do kilku grup, a tabela i mapa powyżej to wynik znalezienia tej w której kraj znalazł się najczęściej. Zresztą jak możemy zobaczyć:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
ue_votes %>% group_by(item1) %>% count(km) %>% mutate(p = 100*n/sum(n)) %>% ungroup() %>% mutate(item1 = factor(item1, levels = sort(unique(item1), decreasing = TRUE))) %>% ggplot() + geom_tile(aes(item1, as.factor(km), fill = p)) + coord_flip() + scale_fill_distiller(palette = "RdYlGn", na.value = "white") + labs(x = "", y = "Grupa", fill = "Prawdopodobieństwo przynależności do grupy") + theme(legend.position = "bottom") |
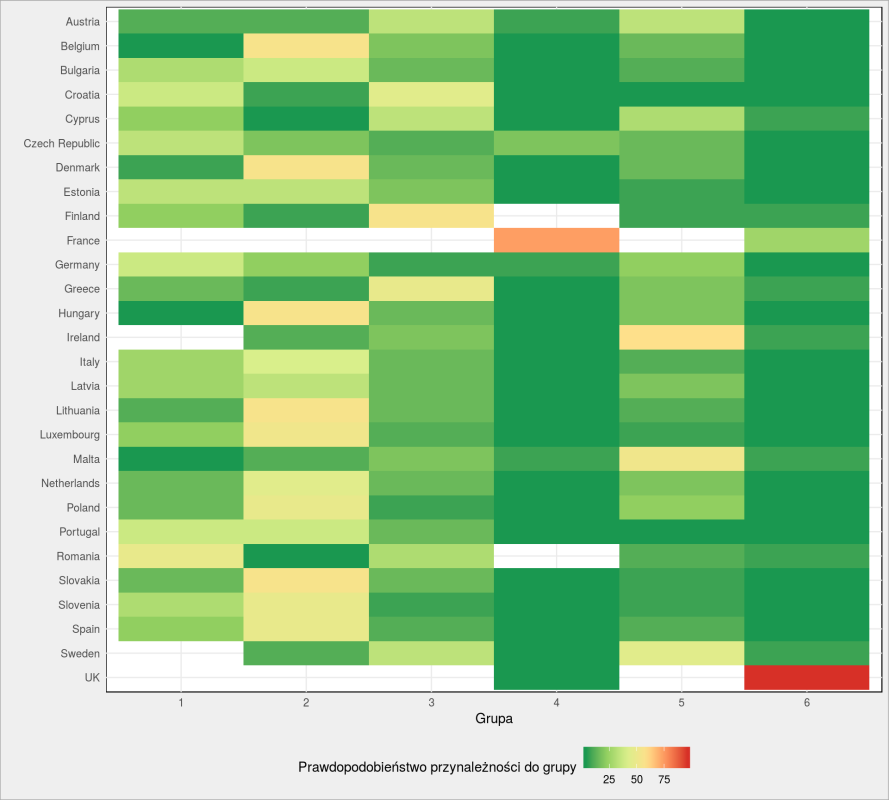
stosunkowo pewne są Wielka Brytania i Francja.
Niestety zbiór danych jakie zawarte są w pakiecie unvotes nie zawiera wyników głosowania po 2015 roku. Nie możemy zatem sprawdzić jak zmieniło się podobieństwo między Polską a resztą świata po objęciu rządów przez PiS. A to byłoby bardzo interesujące… Interesująca byłoby również analiza analogicznych danych pochodzących z głosowań w samej Unii Europejskiej – czy to w Parlamencie Europejskim czy też innych organach (pamiętne 27:1). Może ktoś z Was zna takie źródła danych? Albo sam analizował i podrzuci w komentarzu link? To drugie rozwiązanie podoba mi się bardziej.
Na dzisiaj to wszystko. Polecam również dwa teksty związane z omawianymi danymi:
- opracowanie Erika Voetena “Data and Analyses of Voting in the UN General Assembly”
- wpis United Nations General Assembly u Błażej Mrozińskiego
Nie jestem politologiem i w związku z tym powstrzymałem się od komentowania wyników. Ale jeśli masz ochotę – zapraszam, pole na komentarz jest tuż poniżej :)
Możesz postawić średnie latte autorowi jeśli masz ochotę. Jeżeli potrzebujesz przygotowania analizy lub modelu – zerknij na odpowiednią stronę. Oczywiście wpadnij też na Dane i Analizy na Facebooku – tam więcej takich smaczków (szczególnie dla praktyków).
CZYli w megaskrócie przeszliśmy sobie z kołchozu ruskiego do niemieckiego, i widać ze już zrozumieliśmy ze trzeba robić to co wielki brat niezależnie od tego czy nosi on wąsy czy brodę….
bardzo fajne zestawienie!
W bloku sowieckim, nie blisko było nam z nimi,
a w bloku nato daleko jesteśmy od sprzymierzeńców.
Dziwny ten Naród;)
Kawał solidnej pracy. Bardzo ciekawe, szczególnie wnioski w UE.
Technicznie dziwi mnie dobór kolorów – intuicyjnie zielony powinien pokazywać większą korelację, a czerwony mniejszą. Jeśli to miało być korelacyjny heat-map, to lepiej zamiast zielonego dawać chłodne niebieskie i przy wzroście korelacji iść w cieplejsze barwy aż do pomarańczowego / czerwonego.
Anyways, zawsze miło poczytać.
Super… ciekawe byłoby wzięcie pod uwagę sąsiedztwa w analizie.
Widzialem coś takiego w kursie geostatistics na data.camp, gdzie fakt sąsiadowania ze sobą poszczególnych krajów był kodowany do dummy variables a następnie użyta była chyba regresja, muszę to odgrzebać,bo byłoby fajne np. przy analizach zachorowań w gminach czy … czy głosach (np. nieważnych, tzw 'spoiled votes) w wyborach.