Kiedyś już pisałem o filmach i danych jakie dawno temu zgromadziłem z Filmwebu. Dzisiaj zajmiemy się polecaniem filmów do obejrzenia. Czyli – systemy rekomendacji.
Dlaczego rekomendacje są ważne
W najprostszym ujęciu chodzi o sprzedaż. Albo dosłowną sprzedaż towarów, albo odsłony (czy też odtworzenia) w serwisach internetowych (i tym samym odsłony reklam). Im więcej ludziom polecisz, tym bardziej będą klikać, z tym większym prawdopodobieństwem kupią coś, czego nie mieli zamiaru kupować. O nic innego nie chodzi. Znalazłem gdzieś informację, że tego typu systemy odpowiadają za
- w Netflixie – 2/3 oglądanych filmów to wynik rekomendacji
- w Amazonie – 35% sprzedaży to produkty rekomendowane
Netflix swego (to już jakieś 10 lat… epoka wręcz) organizował konkurs Netflix Prize na poprawę swoich algorytmów.
Typy rekomendacji
Najprostszy podział to dwa rodzaje algorytmów:
- bazujący na dotychczasowych ocenach produktów
- bazujący na cechach produktów
Pierwszy z nich to Collaborative Filtering (CF) – bazujemy na założeniu, że podobni do siebie użytkownicy podobnie oceniają produkty. W związku z tym bazujemy na historycznych ocenach i szukamy podobnych użytkowników. A sama rekomendacja to wybranie produktów spełniających określone cechy (na przykład najwyższa średnia ocena wśród podobnych użytkowników). Problemem jest tutaj tak zwany “zimny start” – jeśli nie oceniłeś żadnego produktu to nie wiemy do kogo i jak bardzo jesteś podobny, w związku z tym nie możemy Ci nic polecić. Problem ten Filmweb rozwiązuje zadając na początek (przy zakładaniu konta) pytania o najpopularniejsze filmy – ocenisz kilka, to wpadniesz w jakąś grupę podobnych użytkowników. Jeśli masz niestandardowy gust – możesz nie mieć “podobnych” użytkowników w serwisie i rekomendowane produkty nie muszą dobrze do Ciebie pasować. Tym właśnie algorytmem będziemy się dzisiaj zajmować.
Druga grupa algorytmów to Content/Knowledge-based Filtering (CBF) – rekomendacje bazują na informacji o samym produkcie (content) oraz ewentualnych źródłach zewnętrznych (knowledge), nie biorą pod uwagę opinii innych użytkowników. System rekomendacyjny stara się wybrać produkty podobne do tych, którymi użytkownik był zainteresowany (kupił albo oznaczył, że go interesują czy też odwiedził strony opisujące dany produkt w sklepie). Nie ma w tym przypadku problemu zimnego startu, ale potrzebne są cechy produktów. O ile w przypadku filmów są one z jednego worka (gatunek, reżyseria, scenarzysta, występujący autorzy) o tyle w przypadku sklepów internetowych (albo agregatów typu Allegro czy Ceneo) jest już trudniej – mamy setki kategorii, w każdej inne cechy produktów (wielkość RAMu ma sens w przypadku komputerów czy telefonów, ale w przypadku ciuchów już niekoniecznie). W tym podejściu łatwiej jest podsunąć użytkownikom niestandardowym jakieś produkty. Jakaś wariacja na temat to mój wpis z czerwca, w którym (druga część) jako cech produktów użyłem średnich ocen poszczególnych osób z obsady.
Oczywiście można połączyć wyniki obu narzędzi.
Oceny filmów nadane przez użytkowników
Skoro mamy zająć się algorytmem typu collaborative filtering potrzebujemy ocen produktów. Od ręki są do zdobycia odpowiednie dane – na przykład baza MovieLens albo baza IMDb.com. Ale żeby utrudnić nieco zadanie i zdać się na polski rynek wykorzystamy Filmweb. Trochę też dlatego, że tam sam oceniam filmy i łatwiej będzie mi komentować późniejsze wyniki.
Tylko jak z Filmwebu szybko pobrać informacje o ocenach filmów? Zrobimy małe machniom i sami sobie wygenerujemy oceny. A za listę filmów posłużą nam
rankingi Filmwebu
Na stronie mamy ranking filmów z możliwością podziału go na poszczególne gatunki. I te listy (dla różnych gatunków) weźmiemy. Znowu web scrapping.
Przygotujemy odpowiednią funkcję, która:
- pobierze stronę z rankingiem dla danego gatunku
- znajdzie interesujące nas informacje
- i odda nam to czego chcemy, opakowane ładnie w tabelkę
No to wio:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
library(tidyverse) library(stringr) library(rvest) GetRanking <- function(i) { page_url <- as.character(pages[i, "url"]) gatunek <- as.character(pages[i, "gatunek"]) # strona z rankingiem danego gatunku page <- read_html(page_url) # fragment strony z tabelą lista_filmow <- page %>% html_node("div.ranking__list") %>% html_nodes("div.item") # bierzemy to co potrzebne: tmp <- data_frame( # pozycja w rankingu pozycja = lista_filmow %>% html_node("div.place__position") %>% html_text() %>% as.numeric(), # ID filmu id_filmu = lista_filmow %>% html_node(".film") %>% html_attr("data-id"), # tytuł filmu tytul = lista_filmow %>% html_node("h3.film__title") %>% html_node("a") %>% html_text() %>% trimws(), # rok produkcji rok_produkcji = lista_filmow %>% html_node("h3.film__title") %>% html_node("span.film__production-year") %>% html_text() %>% trimws() %>% gsub("\\(|\\)", "", .) %>% as.numeric(), # średnia ocena użytkowników Filmwebu ocena = lista_filmow %>% html_node("span.rate__value") %>% html_text() %>% trimws() %>% gsub(",", ".", .) %>% as.numeric() ) # dodajemy info o gatunku tmp$gatunek <- gatunek # oddajemy tabelkę :) return(tmp) } |
Teraz tylko potrzebujemy adresów stron z rankingami dla poszczególnych gatunków:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
# lista adresów stron z rankingami per gatunek pages <- list( "Akcja" = "http://www.filmweb.pl/ranking/film/Akcja/28", "Animacja" = "http://www.filmweb.pl/ranking/film/Animacja/2", "Biograficzny" = "http://www.filmweb.pl/ranking/film/Biograficzny/3", "Dokumentalny" = "http://www.filmweb.pl/ranking/film/Dokumentalny/5", "Dramat" = "http://www.filmweb.pl/ranking/film/Dramat/6", "Dreszczowiec" = "http://www.filmweb.pl/ranking/film/Dreszczowiec/46", "Erotyczny" = "http://www.filmweb.pl/ranking/film/Erotyczny/7", "Horror" = "http://www.filmweb.pl/ranking/film/Horror/12", "Katastroficzny" = "http://www.filmweb.pl/ranking/film/Katastroficzny/40", "Komedia" = "http://www.filmweb.pl/ranking/film/Komedia/13", "KomediaKryminalna" = "http://www.filmweb.pl/ranking/film/Komedia+kryminalna/58", "KomediaObyczajowa" = "http://www.filmweb.pl/ranking/film/Komedia+obycz./29", "KomediaRomantyczna" = "http://www.filmweb.pl/ranking/film/Komedia+rom./30", "Kryminał" = "http://www.filmweb.pl/ranking/film/Krymina%C5%82/15", "Obyczajowy" = "http://www.filmweb.pl/ranking/film/Obyczajowy/19", "Psychologiczny" = "http://www.filmweb.pl/ranking/film/Psychologiczny/38", "SciFi" = "http://www.filmweb.pl/ranking/film/Sci-Fi/33", "Sensacyjny" = "http://www.filmweb.pl/ranking/film/Sensacyjny/22", "Thriller" = "http://www.filmweb.pl/ranking/film/Thriller/24", "Western" = "http://www.filmweb.pl/ranking/film/Western/25", "Wojenny" = "http://www.filmweb.pl/ranking/film/Wojenny/26" ) # listę zmieniamy na data.frame - żeby w kolejnych wierszach mieć to samo co wyżej pages <- data_frame(gatunek = names(pages), url = unlist(pages)) |
Lista zamieniona na tabelę – ruch może bez sensu, ale bardzo wygodny. Wiele rzeczy w moich kodach jest bez sensu – nie trzymam się konwencji nazw zmiennych czy funkcji, zmieniam typy danych z jednego na drugi bo mi tak wygodniej, używam pętli chociaż można jakieś funkcje z pakietu purrr wykorzystać. To wynik agile’owego sposobu pisania postów ;)
Skoro mamy już dane to pooglądajmy je sobie na szybko.
|
1 |
filmy <- 1:nrow(pages) %>% map_dfr(GetRanking) |
Najpierw popatrzmy chwilę na dane. Jak zmieniały się oceny topowych filmów w poszczególnych latach?
|
1 2 3 |
ggplot(filmy) + geom_smooth(aes(rok_produkcji, ocena)) + labs(title = "Oceny filmów z rankingów gatunkowych Filmweb.pl", x = "Rok produkcji filmu", y = "Ocena") |
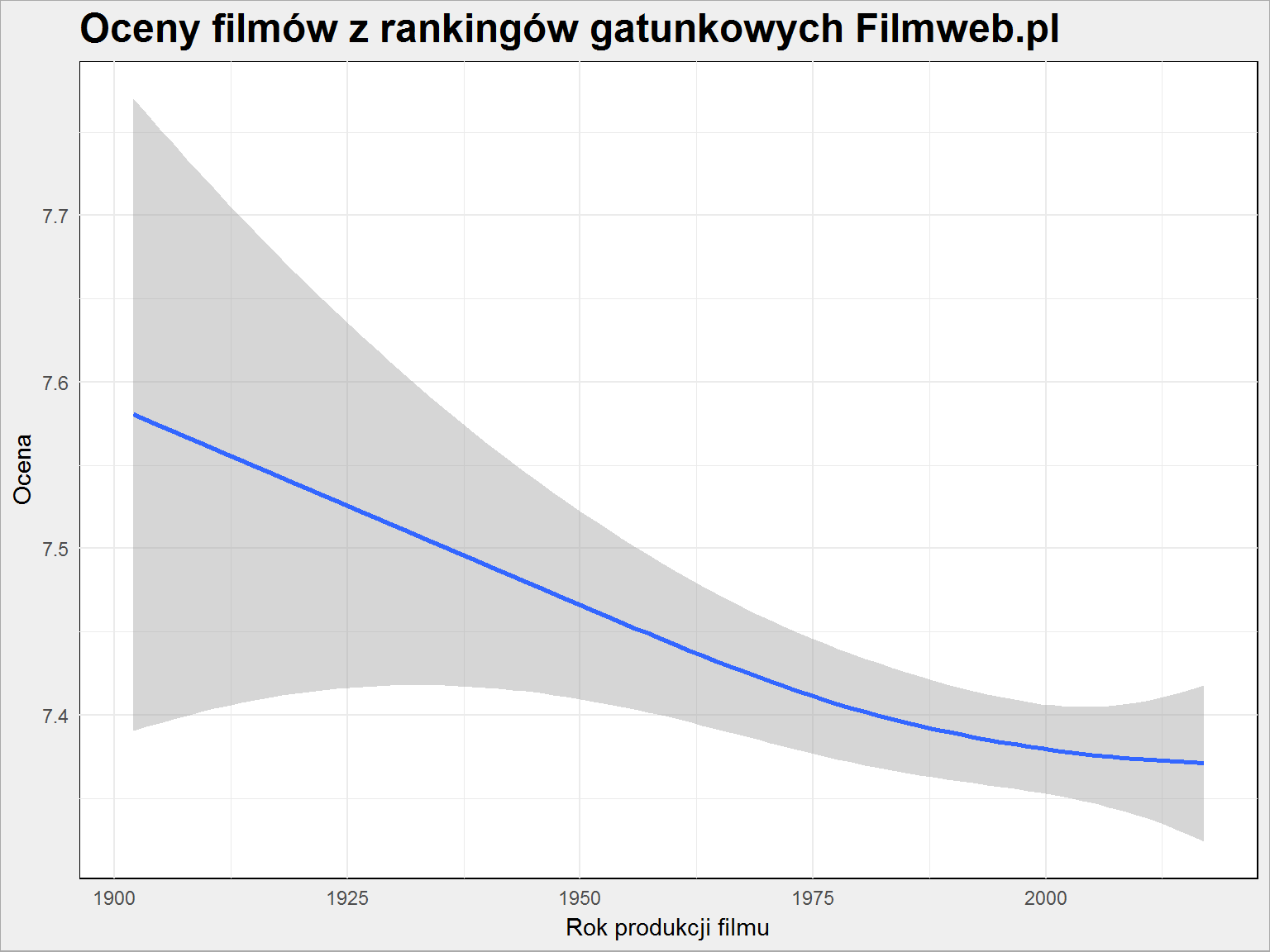
Widać, że z roku na rok oceny są coraz niższe. Co prawda zmiana jest z prawie 7.6 na nieco mniej niż 7.4, ale tendencja jest wyraźna. Ja mam na ten temat swoją teorię. Otóż kino jest coraz bardziej wtórne. Produkuje się coraz więcej i coraz więcej nowych filmów wpada do rankingów (co widać poniżej)
|
1 2 3 |
ggplot(filmy) + geom_histogram(aes(rok_produkcji), binwidth = 1, color = "gray50", fill = "lightgreen") + labs(title = "Liczba filmów z danego roku w rankingach\nwybranych gatunków", x = "Rok produkcji", y = "Liczba filmów") |
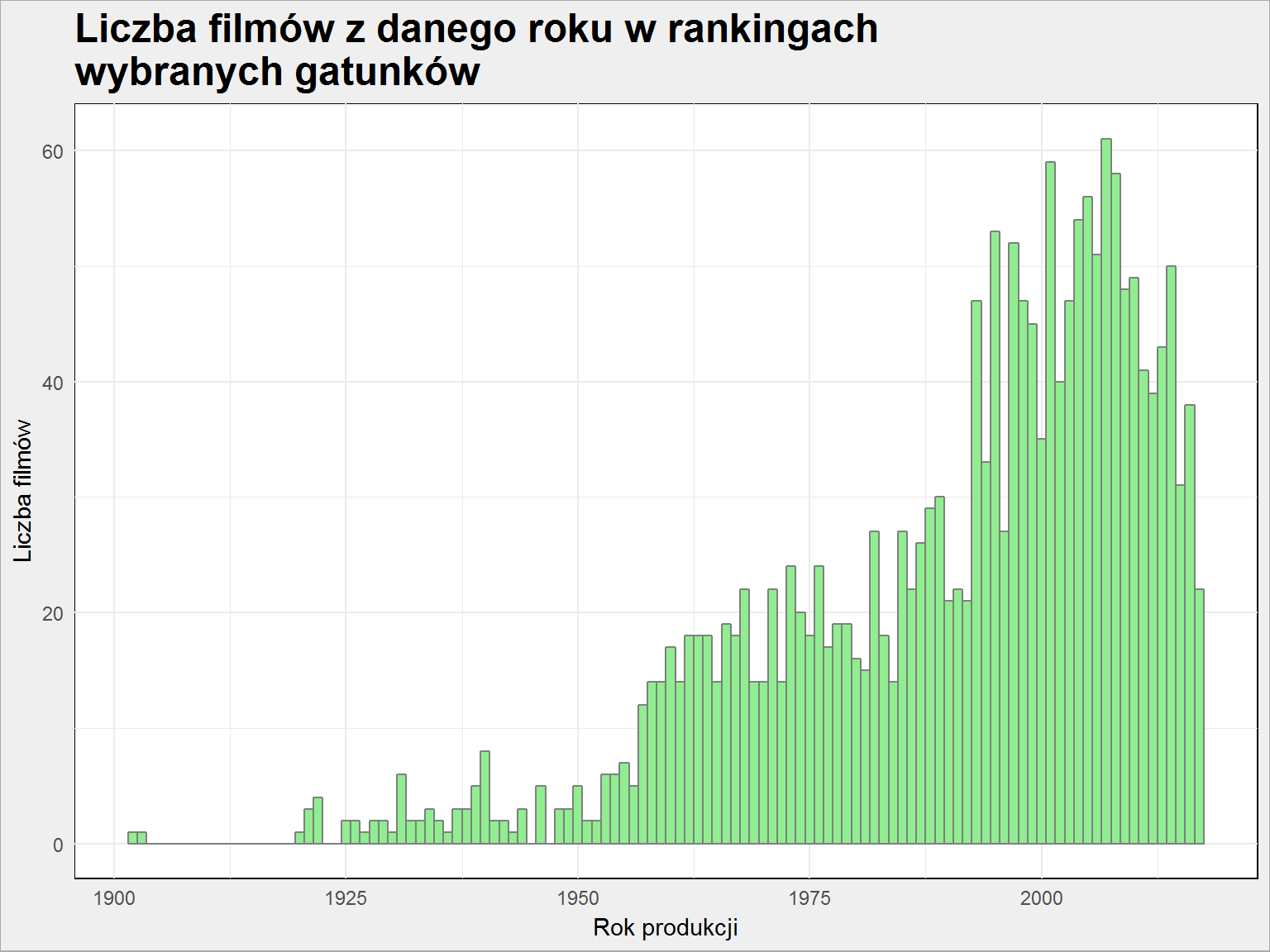
ale wcale nie znaczy to, że te filmy są coraz lepsze. Osobiście oceniam filmy w kontekście gatunku oraz tego co film wnosi do całej historii kinematografii. Obywatel Kane dostaje ode mnie wyższą ocenę niż Incepcja chociaż technicznie filmy dzieli przepaść.
A czy patrząc poprzez pryzmat gatunku widać jakieś różnice?
|
1 2 3 4 |
ggplot(filmy) + geom_smooth(aes(rok_produkcji, ocena, color = gatunek), show.legend = FALSE) + facet_wrap(~gatunek, scales = "free_y", ncol = 3) + labs(title = "Oceny filmów z rankingów gatunkowych Filmweb.pl", x = "Rok produkcji filmu", y = "Ocena") |
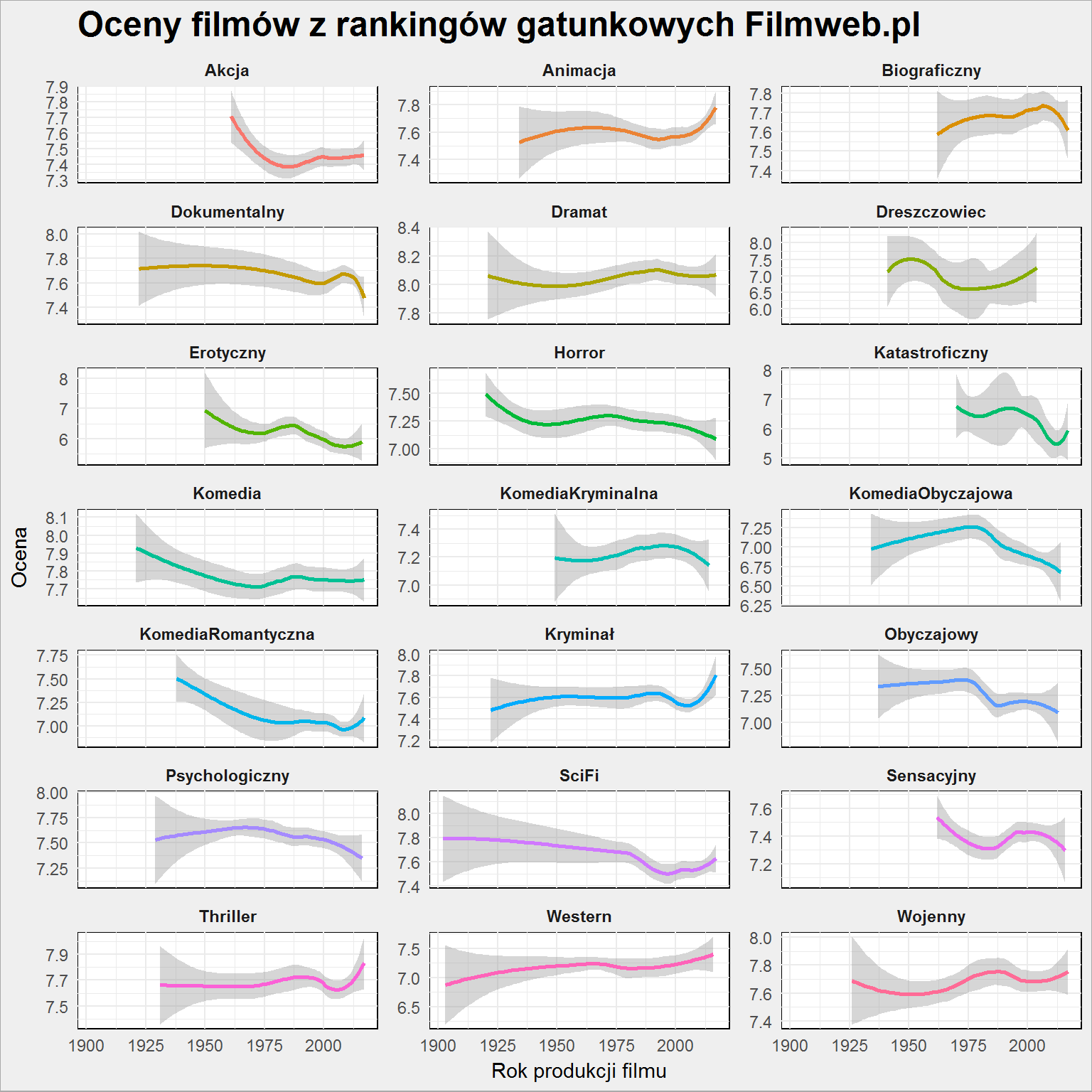
To jest ciekawe. Wszystkim właściwie spada (co jest oczywiście zbieżne z wykresem dla całej puli, bez dzielenia na gatunki), ale są gatunki gdzie (według średniego gustu użytkowników Filmwebu) jest coraz lepiej. Oczywiście coraz lepiej to dość względne pojęcie – zmiana o 0.1 (skala dla przypomnienia to 1 do 10) w średniej ocenie to nie jest przecież ogromny sukces. Ale widzimy, że powstają lepsze westerny (Django zrobiło swoje), filmy wojenne (Przełęcz ocalonych), animacje (Twój Vincent zdominował ranking – ze zwiastunów wygląda wspaniale formalnie, ale z recenzji wynika że to taki sobie film pod względem scenariusza. Czy zatem ocena nie jest zawyżona? Bo Zwierzogród zasługuje na wysokie miejsce w rankingu, chociaż formalnie nie wnosi wiele nowego po wszystkich produkcjach Pixara). Mnie cieszy zagięcie w górę przy thrillerach (i znalazłem tutaj coś czego nie widziałem – hiszpańskie Contratiempo z 2016 roku).
Jak wygląda rozkład ocen dla poszczególnych gatunków? To znaczy czy średnio rzecz biorąc horrory są lepsze niż komedie romantyczne?
|
1 2 3 4 5 |
filmy %>% ggplot() + geom_boxplot(aes(gatunek, ocena, color = gatunek), show.legend = FALSE) + coord_flip() + labs(title = "Oceny filmów z rankingów gatunkowych Filmweb.pl", x = "", y = "Ocena") |
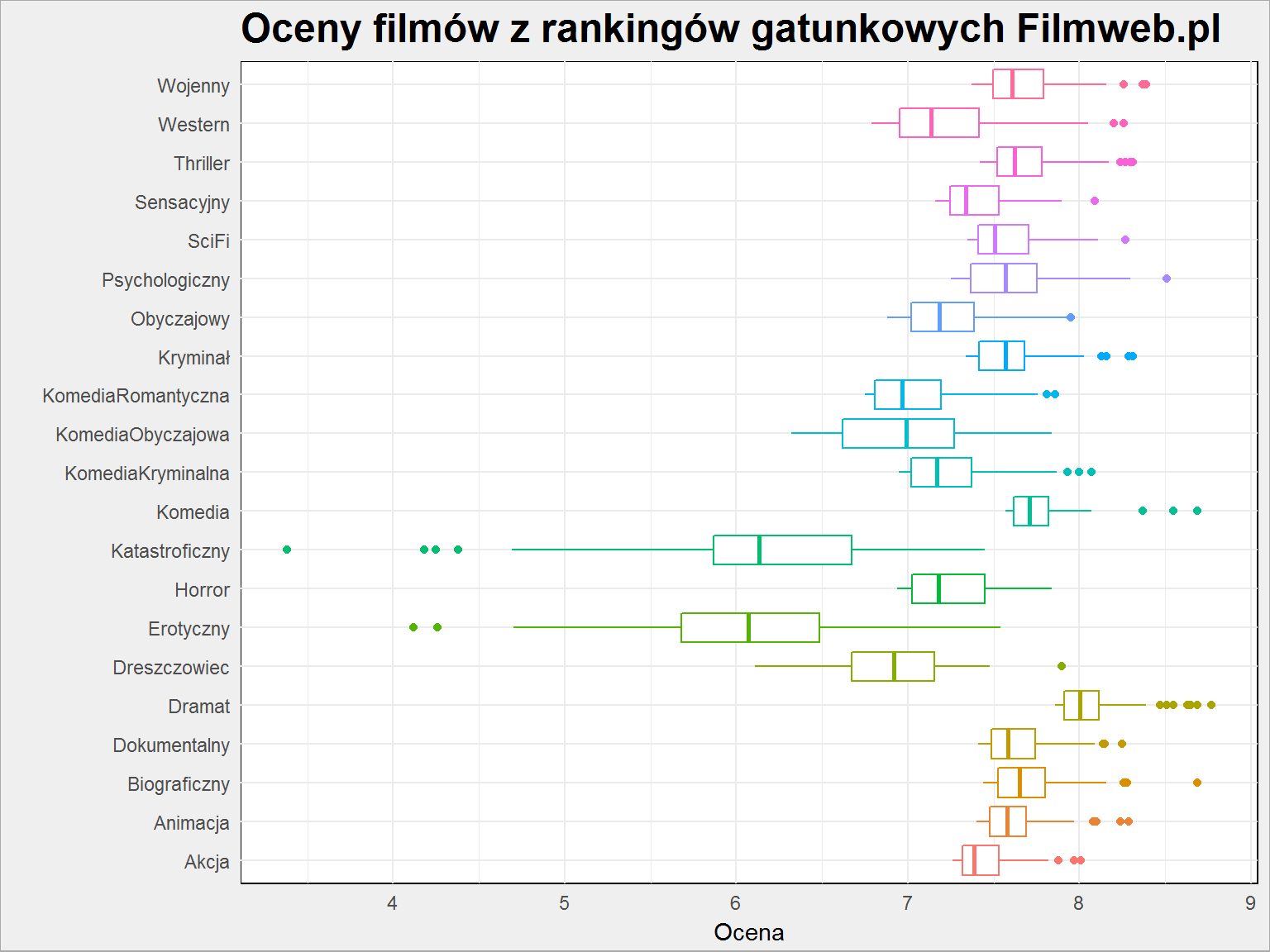
Najsłabsze są filmy erotyczne (specjalnie dodałem tę kategorię; frapuje mnie tytuł Tureckie owoce, który pierwotnie przeczytałem jako Tureckie owce…) i katastroficzne (i rzeczywiście w porównaniu do słabego w efekty kina lat ’70 XX wieku produkcje z XXI wieku nie powalają scenariuszem – drugie w rankingu Niemożliwe, hello?!)
Dobrze, mamy bazę, możemy na jej podstawie przygotować oceny filmów.
Symulacja ocen użytkowników
Zrobimy sobie funkcję, która dla użytkownika przygotuje listę filmów i ocen. Założenia:
- każdy user ogląda jakiś fragment każdego z rankingów – w przykładzie poniżej po 1/4 filmów z danego gatunku
- każdy film oceniony jest losowo, ale rozkład ocen zbliżony jest do średniego rozkładu wszystkich ocen (zobacz wykres we wspomnianym wpisie) – trochę więcej 8 i 9 (w końcu to topowe filmy), a mniej niskich ocen
- jakiś losowy gatunek jest preferowany – wtedy podbijamy oceny użytkownika dla filmów z tego gatunku o 50%
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 |
UserScores <- function(user_name) { # każdy user ocenia 25% filmów z gatunku p_filmow <- 0.25 # kazdy user ocenia losowe filmy - po losową liczbę per gatunek tmp <- filmy %>% # wybor losowych filmow group_by(gatunek) %>% sample_frac(p_filmow) %>% ungroup() %>% # ocena usera to losowa liczba w rozkładzie zbliżonym do rozkładu ocen rowwise() %>% mutate(ocena_usera = sample(1:10, 1, prob = c(2, 1, 2, 2, 4, 5, 6, 8, 9, 3))) %>% ungroup() %>% mutate(user = user_name) # jeden losowy gatunek user preferuje losowy_gatunek <- unique(filmy$gatunek) losowy_gatunek <- losowy_gatunek[sample(1:length(losowy_gatunek), 1)] tmp %>% # zawyżamy oceny w losowym gatunku o 50% mutate(ocena_usera = ifelse(gatunek == losowy_gatunek, 1.5 * ocena_usera, ocena_usera)) %>% # ocena nie może przekroczyć 10 mutate(ocena_usera = ifelse(ocena_usera >10, 10, ocena_usera)) %>% # filmy mogą być w różnych gatunkach - jeśli się powtórzy ocena tego samego filmu ale w innym gatunku to zostawiamy najwyższą group_by(id_filmu) %>% # zostawiamy te z najwyższą oceną filter(ocena_usera == max(ocena_usera)) %>% # ale dla pewności tylko jeden mutate(n = row_number()) %>% filter(n == 1) %>% select(-n) %>% ungroup() } |
Teraz jeszcze potrzebujemy losowych użytkowników i nadania przez nich ocen:
|
1 2 3 4 5 |
# losowe nazwy użytkowników users_names <- sprintf("User_%02d", 1:20) # generujemy losowe oceny filmów filmy_userzy <- users_names %>% map_df(UserScores) |
Zobaczmy jak średnio losowi użytkownicy oceniają poszczególne gatunki w porównaniu do średniej ocen gatunków zgromadzonych na Filmwebie:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
filmy_userzy %>% group_by(gatunek) %>% summarise(srednia_gatunku_all = mean(ocena), srednia_gatunku_user = mean(ocena_usera)) %>% ungroup() %>% ggplot() + geom_segment(aes(x = gatunek, xend = gatunek, y = srednia_gatunku_all, yend = srednia_gatunku_user, color = ifelse(srednia_gatunku_all > srednia_gatunku_user, "Użytkownicy oceniają\nfilm niżej", "Użytkownicy oceniają\nfilm wyżej")), size = 2) + geom_point(aes(gatunek, srednia_gatunku_user), color = "red", size = 3) + geom_point(aes(gatunek, srednia_gatunku_all), color = "blue", size = 2) + coord_flip() + labs(title = "Różnice w średniej ocenie gatunków pomiędzy\nśrednią oceną z serwisu Filmweb a oceną\nwygenerowanych użytkowników", color = "Różnica w ocenie\nużytkownik - średnia\nocena serwisu", x = "", y = "Średnia ocena") |
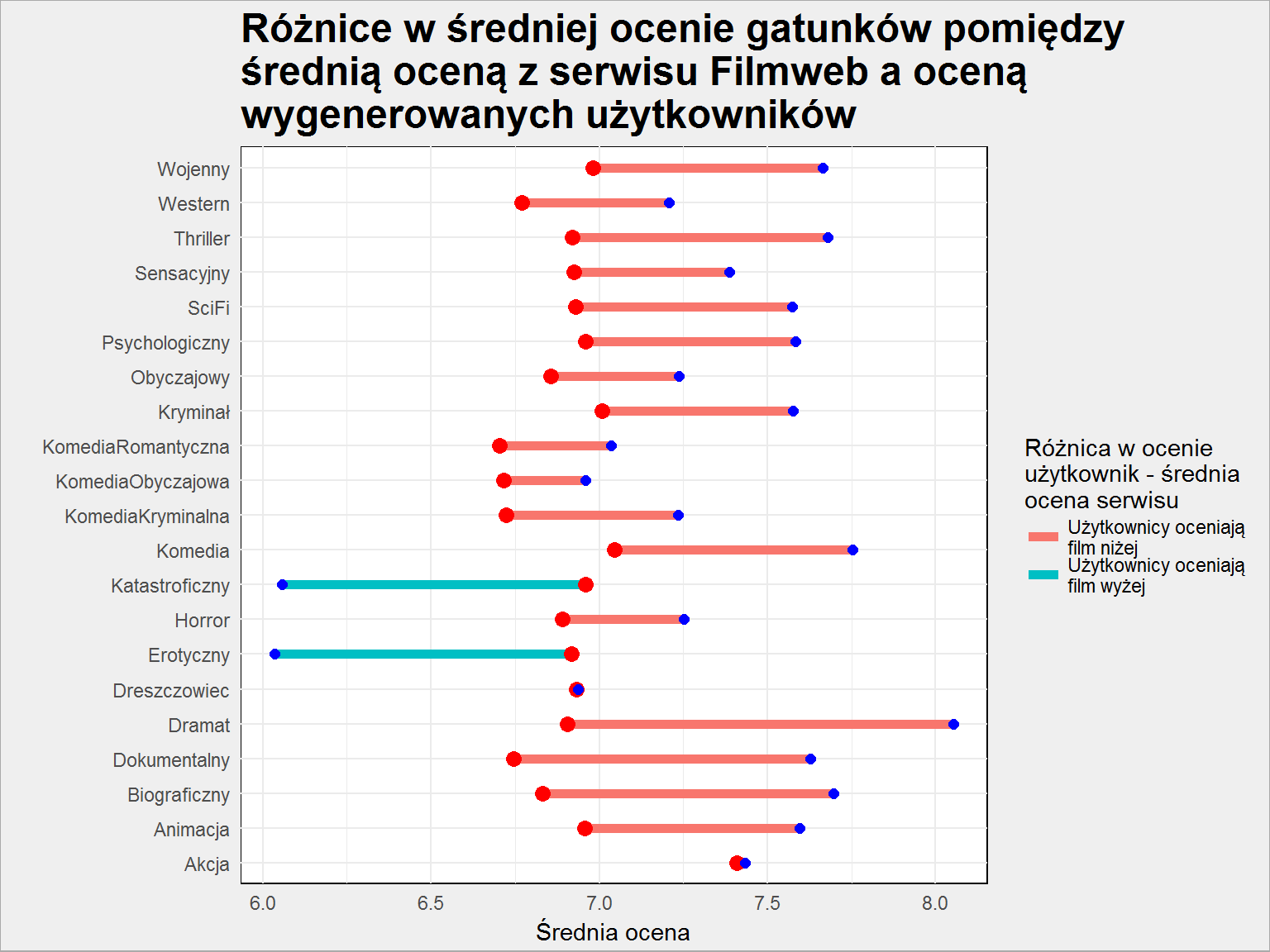
Czerwona kropka to ocena wygenerowana, niebieska – ta pochodząca z Filmwebu.
Widać, że nasze losowanie sprawiło, że w większości przypadków (poza erotykami i filmami katastroficznymi) oceny użytkowników są niższe niż te wynikające z rankingów. To dobrze, że jest taka różnica, która na poziomie użytkowników wygląda jeszcze ciekawiej:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
# per user - czy są gatunki, które lubi bardziej? filmy_userzy %>% group_by(gatunek) %>% mutate(srednia_gatunku_all = mean(ocena)) %>% ungroup() %>% group_by(gatunek, user) %>% mutate(srednia_gatunku_user = mean(ocena_usera)) %>% ungroup() %>% distinct(gatunek, user, srednia_gatunku_user, srednia_gatunku_all) %>% ggplot() + geom_segment(aes(x = gatunek, xend = gatunek, y = srednia_gatunku_all, yend = srednia_gatunku_user, color = ifelse(srednia_gatunku_all > srednia_gatunku_user, "User niżej", "User wyżej")), size = 2) + geom_point(aes(gatunek, srednia_gatunku_user), color = "red", size = 2) + geom_point(aes(gatunek, srednia_gatunku_all), color = "blue", size = 1) + facet_wrap(~user) + coord_flip() + labs(title = "Różnice w średniej ocenie gatunków pomiędzy\nśrednią oceną z serwisu Filmweb a oceną\nwygenerowanych użytkowników", color = "Różnica w ocenie\nużytkownik - średnia\nocena serwisu", x = "", y = "Średnia ocena") |

Udało się uzyskać zróżnicowanie użytkowników – niektórzy lepiej niż średnia oceniają poszczególne gatunki, inni gorzej.
Odległość między użytkownikami
Algorytm collaborative filtering polega w pierwszym kroku na znalezieniu podobnych użytkowników. Ten element jest najważniejszy i decyduje o jakości rekomendacji. Trzeba zdefiniować podobieństwo. Mamy użytkownika i bardzo dużo cech go opisujących (wszystkie filmy jakie ocenił, a właściwie wszystkie filmy w bazie). Te cechy to wektor w przestrzeni n-wymiarowej, zatem trzeba znaleźć miarę podobieństwa dwóch wektorów.
Różne miary odległości
Może to być iloczyn skalarny (wektor razy wektor daje liczbę). Może to być odległość pomiędzy punktami w n-wymiarowej przestrzeni, na przykład euklidesowa (pierwiastek sumy kwadratów różnicy) czy kosinusowa. Może to być też korelacja pomiędzy wartościami ocen i z tego skorzystamy. Nie jest to najlepsze rozwiązanie, ale wybieram je świadomie – przy okazji zobaczymy jakie błędy można popełnić i jak sobie z nimi radzić.
Aby przekształcić otrzymane współczynniki korelacji (z zakresu -1 do 1) na zakres od zera do nieskończoności dodatkowo je logarytmujemy. Dzięki temu dla najbardziej podobnych wektorów (użytkowników) odległość będzie równa zero, a dla najbardziej różnych – nieskończoność. Jeśli chcecie poćwiczyć z innymi miarami – wystarczy odpowiednio zmodyfikować poniższą funkcję:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
GetDistances <- function() { # macierz korelacji pomiędzy userami userzy_cor <- filmy_userzy %>% spread(user, ocena_usera, fill = 0) userzy_cor <- cor(userzy_cor[,7:ncol(userzy_cor)]) # odległości pomiędzy userami - mniejsza = wieksze podobieństwo return(-log(userzy_cor / 2 + 0.5)) } # macierz podobieństwa użytkowników distances <- GetDistances() |
Ważna sprawa dotycząca wydajności i ograniczeń pamięci. Funkcja cor() buduje macierz kwadratową, która swoje rozmiary ma i odpowiednio dużo zajmuje (zarówno miejsca w pamięci jak i czasu na wygenerowanie). W naszym przypadku 20 losowych użytkowników jest to macierz 20×20 elementów. Jeśli mamy miliony użytkowników jest to szalenie nieefektywne pamięciowo i trzeba szukać innych metod. Można spróbować w pętli policzyć korelację dla kolejnych par (każdy z każdym) i dane trzymać w długiej tabeli (zamiast kwadratowej macierzy) na przykład w bazie danych. W takim przypadku odpowiednio trzeba zmodyfikować funkcję powyżej oraz kolejną (GetRecommendedMovies() która będzie za moment).
Zobaczmy jeszcze co wyszło nam w macierzy podobieństwa: którzy userzy są podobni do siebie? Im bardziej czerwony tym bliższa siebie para (mniejsza odległość).
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
distances %>% as.data.frame() %>% rownames_to_column() %>% rename(UserA = rowname) %>% gather(UserB, Val, -UserA) %>% filter(UserA != UserB) %>% ggplot() + geom_tile(aes(UserA, UserB, fill = Val), color = "gray80") + scale_fill_distiller(palette = "Reds") + labs(title = "Podobieństwo użytkowników ze względu na ich oceny", subtitle = "Mniej = większe podobieństwo", fill = "Miara\npodobieństwa", x = "", y = "") + theme(axis.text.x = element_text(angle = 90, hjust = 1, vjust = 1)) |
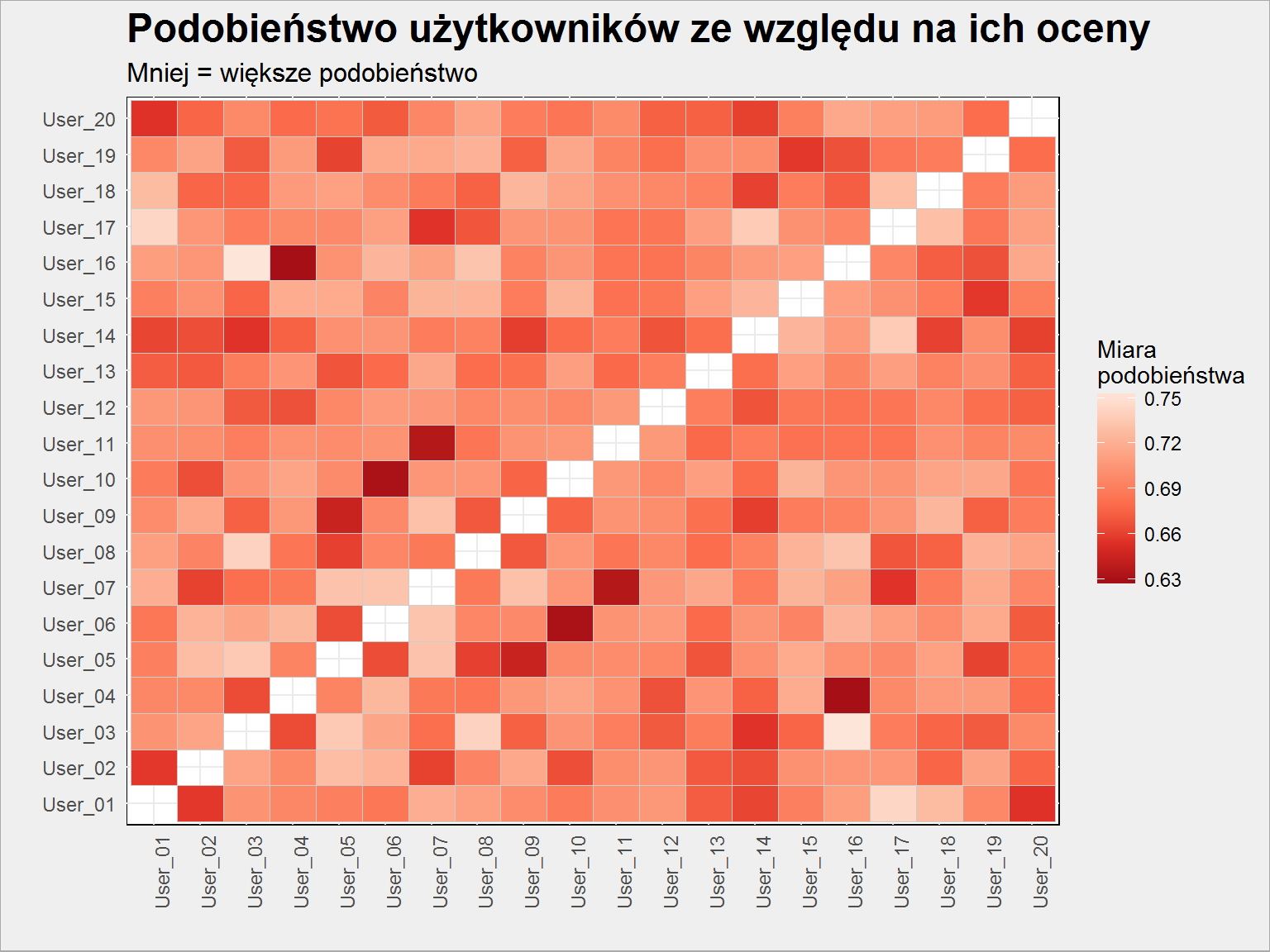
Widzimy tutaj różne odcienie czerwieni, jest więc różnorako :) Dodatkowo – generujemy losowe oceny losowym filmom, tak więc jeśli ćwiczysz to w domu to wyniki raczej nie będą powtarzalne. Można próbować ustawić generator losowy (set.seed() – ja ustawiłem go na 123456) na określoną wartość na początku. W rzeczywistości dane (oceny) się nie zmieniają (dla uruchomienia tego samego działania w bliskich odstępach czasu) i ten problem nie istnieje.
Sprawdźmy jeszcze na dendogramie jak grupują się użytkownicy i którzy są sobie najbliżsi:
|
1 |
distances %>% as.dist() %>% hclust() %>% plot() |
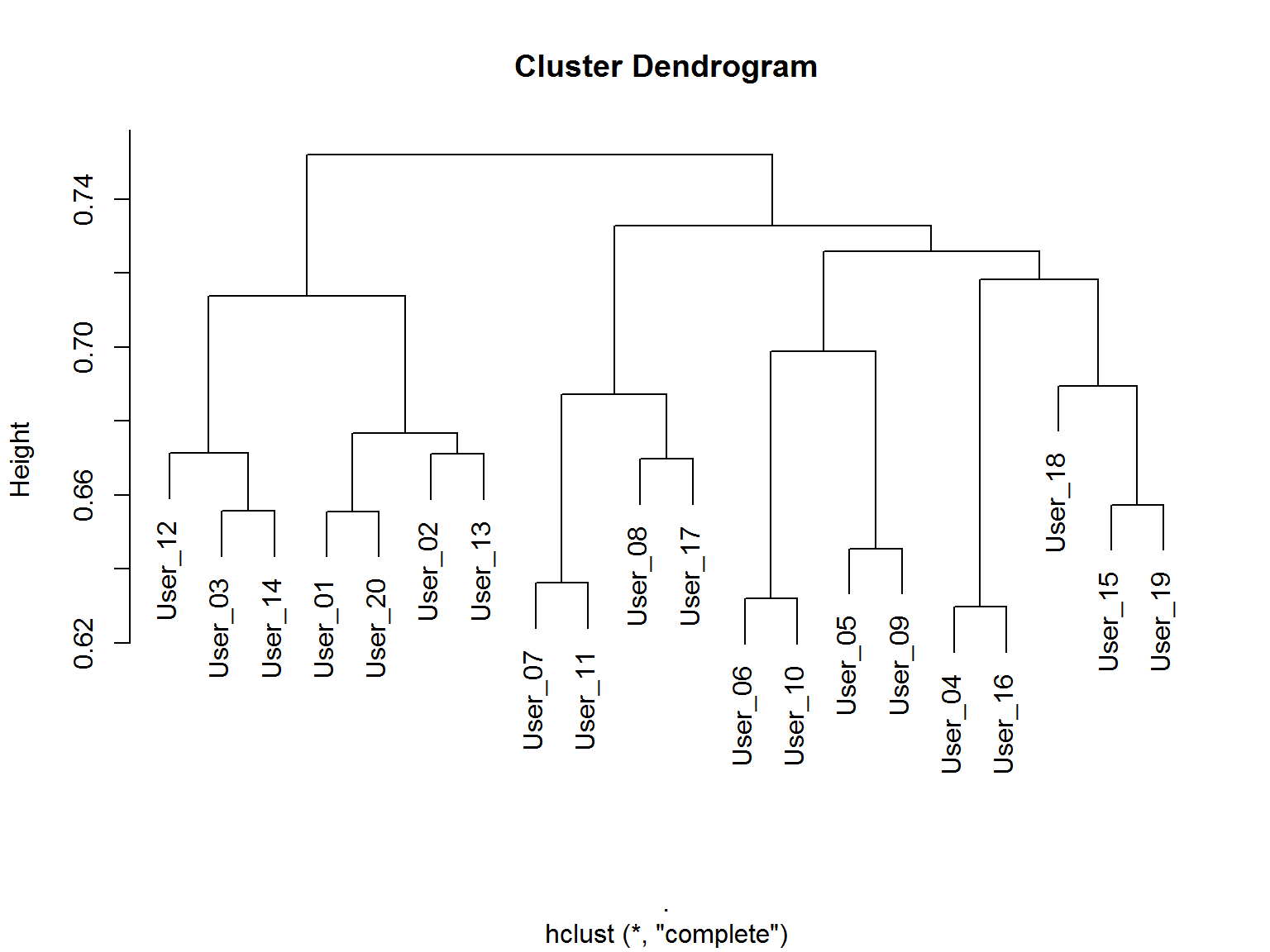
Porównajmy oba rysunki: widać podobieństwo pomiędzy parami: User_04-User_16, User_06-User_10, User_07-User_11. Zarówno są w jednej gałęzi dendrogramu jak i na heatmapie mają najbardziej czerwone kolory.
Rekomendacje
Proces wyboru produktów rekomendowanych polega na:
- wybraniu określonej liczby podobnych użytkowników, im większa ich liczba tym teoretycznie lepsze rekomendacje
- wybraniu spośród ocenianych przez nich produktów tych, które mają na przykład najwyższą ocenę (średnią ocen wśród podobnych użytkowników)
- w drugim punkcie warto odrzucić produkty, które użytkownik dla którego przygotowujemy rekomendację już ocenił (po co polecać coś, co ktoś już zna?)
Przygotujemy do tego funkcję, która znajdzie podobnych użytkowników (tych, których odległości są najmniejsze) i na tej podstawie przygotuje rekomendacje, ale nie tylko. Co się dzieje wewnątrz opisują komentarze, ale też dalszy tekst. W kodzie funkcji wszystkie kroki są rozbite i liczone od początku. Można wszystko zrobić na jednej tabeli, ale chciałem zachować czytelność działań.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 |
GetRecommendedMovies <- function(user_search, k = 2) { # k najbardziej podobnych do usera (mniej = lepiej) # od 2 wyniku, bo pierwszy będzie user - sam jest najbardziej do siebie podobny users_knn <- sort(distances[user_search, ])[2:(k+1)] # to samo w formie tabelki nam się przyda za chwilę users_knn_tab <- users_knn %>% as.data.frame() %>% set_names("dist") %>% rownames_to_column() # oceny wspólnie oglądanych filmów wspolnie_oceniane <- filmy_userzy %>% filter(user %in% names(users_knn)) %>% spread(user, ocena_usera) %>% # usuwamy wiersze gdzie brakuje chociaż jednej oceny na.omit() # średnia współoglądających wspolnie_oceniane$sr_ocena_podobnych <- apply(wspolnie_oceniane[, 7:ncol(wspolnie_oceniane)], 1, mean, na.rm = TRUE) # wybrany user widział filmy... user_search_widzial <- filmy_userzy %>% filter(user == user_search) %>% .$tytul # wybierz te filmy, które są ocenione przez podobnych userów wybrane_filmy <- filmy_userzy %>% # i których user nie widzial filter(!tytul %in% user_search_widzial) %>% # podobni ocenili (chociaż jeden z podobnych) filter(user %in% names(users_knn)) %>% spread(user, ocena_usera) # średnia ocena podobnych użytkowników wybrane_filmy$sr_ocena_podobnych <- apply(wybrane_filmy[, 7:ncol(wybrane_filmy)], 1, mean, na.rm = TRUE) # ilu podobnych widziało film? liczba wyrażona jako procent wybrane_filmy$l_ocena_podobnych <- apply(wybrane_filmy[, 7:(ncol(wybrane_filmy)-1)], 1, function(x) sum(!is.na(x))/k) # przewidywana ocena przewidywane <- filmy_userzy %>% # user nie widzial filter(!tytul %in% user_search_widzial) %>% # podobni ocenili (chociaz jeden z nich) filter(user %in% names(users_knn)) %>% # tabela z podobieństwami, które traktujemy jak wagi left_join(users_knn_tab, by = c("user" = "rowname")) %>% # przygotowanie wagi - odejmowanie, bo mniejsza odległość oznacza większą bliskość (czyli większą wagę) mutate(dist = max(dist) - dist) %>% # dla każdego filmu liczymy ważoną ocenę przewidywaną - tylko z ocen podobnych userów! group_by(id_filmu) %>% mutate(ocena_pred = sum(ocena_usera*dist)/sum(dist)) %>% ungroup() %>% select(gatunek, id_filmu, tytul, rok_produkcji, ocena, ocena_pred) %>% # dodajemy informację o tym ilu podobnych oceniało film left_join(wybrane_filmy %>% select(id_filmu, l_ocena_podobnych), by = "id_filmu") %>% # dla każdego filmu zostawiamy distinct() return(list(rekomendacje = wybrane_filmy, wspolne = wspolnie_oceniane, przewidywane = przewidywane)) } |
Używając tej funkcji możemy przeanalizować przykładowego losowego usera – weźmy pod lupę User_04 i zobaczmy jak działa nasza funkcja. Zobaczmy co dostaniemy w wyniku dla User_04 przy 5 podobnych użytkownikach:
|
1 |
wynik <- GetRecommendedMovies("User_04", 5) |
Funkcja na początku wybiera k najbardziej podobnych użytkowników. W drugim kroku szuka filmów ocenionych przez tych podobnych i pozostawia te, które widzieli wszyscy. Dla każdego z filmu liczy średnią ocenę wystawioną przez podobnych. Efekt:
Wspólnie oceniane
|
1 2 3 |
wynik$wspolne %>% arrange(gatunek, desc(sr_ocena_podobnych), desc(ocena)) %>% select(gatunek, tytul, rok_produkcji, sr_ocena_podobnych, ocena) |
| Gatunek | Tytuł | Rok produkcji | Średnia ocena podobnych użytkowników | Ocena z Filmweb |
|---|---|---|---|---|
| KomediaObyczajowa | Życie | 1999 | 4.6 | 7.34 |
| Thriller | Karmazynowy przypływ | 1995 | 5.3 | 7.54 |
Im więcej podobnych użytkowników będziemy brać pod uwagę tym ta lista będzie krótsza – prawdopodobnieństwo, że wszyscy widzieli dany film maleje z liczbą owych wszystkich. Oczywiście w realnym świecie są filmy, które widziało i oceniło bardzo dużo użytkowników.
Rekomendacje
Kolejny krok funkcji to wybór filmów, które użytkownik już ocenił – ich nie będziemy rekomendować, więc odrzucamy je z listy wszystkich ocenionych filmów. Dla całej reszty liczymy średnią z ocen podobnych użytkowników oraz liczymy jaki procent podobnych oceniło dany film (im więcej tym rekomendacja powinna być pewniejsza).
Co zatem jest rekomendowane dla użytkownika?
|
1 2 3 4 5 6 7 8 9 |
wynik$rekomendacje %>% # co najmniej 30% podobnych oceniło film filter(l_ocena_podobnych >= 0.3) %>% # tylko najlepiej oceniane przez podobnych filmy w ramach gatunku - dla zmniejszenia listy wyników group_by(gatunek) %>% top_n(1, sr_ocena_podobnych) %>% ungroup() %>% arrange(gatunek) %>% select(gatunek, tytul, rok_produkcji, sr_ocena_podobnych, l_ocena_podobnych) |
| Gatunek | Tytuł | Rok produkcji | Średnia ocena podobnych użytkowników | Liczba ocen podobnych użytkowników |
|---|---|---|---|---|
| Akcja | Brat | 1997 | 9.750000 | 0.8 |
| Animacja | Starsza pani i gołębie | 1998 | 9.500000 | 0.4 |
| Biograficzny | Jak zostać królem | 2010 | 9.500000 | 0.4 |
| Dokumentalny | Takiego pięknego syna urodziłam | 1999 | 9.000000 | 0.4 |
| Dramat | Piękny umysł | 2001 | 9.000000 | 0.4 |
| Dramat | Ray | 2004 | 9.000000 | 0.4 |
| Dreszczowiec | Wetherby | 1985 | 7.000000 | 0.4 |
| Erotyczny | Nigdy nie rozmawiaj z nieznajomym | 1995 | 9.333333 | 0.6 |
| Horror | Obcy 3 | 1992 | 9.500000 | 0.4 |
| Katastroficzny | Epicentrum | 2002 | 10.000000 | 0.4 |
| Komedia | Gorączka złota | 1925 | 9.500000 | 0.4 |
| KomediaKryminalna | Kingsman: Tajne służby | 2014 | 9.500000 | 0.4 |
| KomediaKryminalna | 8 kobiet | 2002 | 9.500000 | 0.4 |
| KomediaKryminalna | Trailer Park Boys: Countdown to Liquor Day | 2009 | 9.500000 | 0.4 |
| KomediaObyczajowa | Grzeszny żywot Franciszka Buły | 1980 | 9.000000 | 0.4 |
| KomediaRomantyczna | Cocktail | 2012 | 9.000000 | 0.4 |
| Kryminał | 25. godzina | 2002 | 9.000000 | 0.4 |
| Kryminał | Infernal Affairs: Piekielna gra | 2002 | 9.000000 | 0.4 |
| Kryminał | Do utraty tchu | 1960 | 9.000000 | 0.4 |
| Obyczajowy | Światła sceny | 2000 | 9.333333 | 0.6 |
| Psychologiczny | Przekleństwa niewinności | 1999 | 9.000000 | 0.4 |
| Psychologiczny | Salto | 1965 | 9.000000 | 0.4 |
| Psychologiczny | Służący | 1963 | 9.000000 | 0.4 |
| SciFi | Gwiezdne wojny: Część III – Zemsta Sithów | 2005 | 9.000000 | 0.4 |
| Sensacyjny | Wydział pościgowy | 1998 | 9.000000 | 0.4 |
| Sensacyjny | Firma | 1993 | 9.000000 | 0.4 |
| Sensacyjny | Diamenty są wieczne | 1971 | 9.000000 | 0.4 |
| Sensacyjny | Bullitt | 1968 | 9.000000 | 0.4 |
| Thriller | Blue Velvet | 1986 | 10.000000 | 0.4 |
| Western | Człowiek zwany Koniem | 1970 | 8.500000 | 0.4 |
| Western | Samuraje i kowboje | 1971 | 8.500000 | 0.4 |
| Wojenny | Eroica | 1957 | 8.500000 | 0.4 |
| Wojenny | Lawrence z Arabii | 1962 | 8.500000 | 0.4 |
| Wojenny | Na Zachodzie bez zmian | 1930 | 8.500000 | 0.4 |
Przewidywanie oceny
Ostatni krok to policzenie przewidywanej oceny. Najprościej jest wziąć filmy, które widzieli użytkownicy podobni, policzyć średnią ważoną ich ocen gdzie wagą jest miara podobieństwa do użytkownika dla którego wykonujemy predykcję.
|
1 2 3 4 5 6 7 8 9 |
wynik$przewidywane %>% # co najmniej 30% podobnych oceniło film filter(l_ocena_podobnych >= 0.3) %>% # po jednym filmie na gatunek z najwyższą przewidywalną oceną group_by(gatunek) %>% top_n(1, ocena_pred) %>% ungroup() %>% arrange(gatunek) %>% select(gatunek, tytul, rok_produkcji, ocena_pred, ocena) |
| Gatunek | Tytuł | Rok produkcji | Przewidywana ocena | Ocena na Filmweb |
|---|---|---|---|---|
| Akcja | Baby Driver | 2017 | 10.000000 | 7.29 |
| Animacja | Stalowy gigant | 1999 | 9.256047 | 7.66 |
| Biograficzny | Jak zostać królem | 2010 | 9.784397 | 7.79 |
| Dokumentalny | Kokainowi kowboje | 2006 | 8.778561 | 7.80 |
| Dokumentalny | Międzynarodowe Centrum Szczęśliwych Ludzi | 1998 | 8.778561 | 7.42 |
| Dramat | Wołyń | 2016 | 9.507961 | 7.94 |
| Dreszczowiec | Krzyk strachu | 1961 | 6.665182 | 6.83 |
| Erotyczny | Nigdy nie rozmawiaj z nieznajomym | 1995 | 9.221439 | 6.31 |
| Horror | Kara no Kyokai: Tsukaku Zanryu | 2008 | 9.335684 | 7.26 |
| Katastroficzny | Epicentrum | 2002 | 10.000000 | 5.54 |
| Komedia | Gorączka złota | 1925 | 9.745070 | 7.79 |
| Komedia | Forrest Gump | 1994 | 9.745070 | 8.55 |
| KomediaKryminalna | 8 kobiet | 2002 | 10.000000 | 7.05 |
| KomediaKryminalna | Szajka z Lawendowego Wzgórza | 1951 | 10.000000 | 7.02 |
| KomediaObyczajowa | Grzeszny żywot Franciszka Buły | 1980 | 9.000000 | 7.02 |
| KomediaRomantyczna | Wiele hałasu o nic | 1993 | 9.000000 | 7.48 |
| KomediaRomantyczna | Cocktail | 2012 | 9.000000 | 6.86 |
| KomediaRomantyczna | Jak stracić chłopaka w 10 dni | 2003 | 9.000000 | 6.79 |
| Kryminał | Zagadka zbrodni | 2003 | 10.000000 | 7.54 |
| Obyczajowy | Zabić drozda | 1962 | 10.000000 | 7.87 |
| Obyczajowy | Dobry rok | 2006 | 10.000000 | 7.25 |
| Obyczajowy | Dobosz | 2002 | 10.000000 | 6.95 |
| Psychologiczny | Noc | 1961 | 9.490139 | 7.52 |
| SciFi | Gwiezdne wojny: Część III – Zemsta Sithów | 2005 | 9.854983 | 7.64 |
| Sensacyjny | Bułgarski pościkk | 2001 | 10.000000 | 7.19 |
| Thriller | Blue Velvet | 1986 | 10.000000 | 7.56 |
| Thriller | Obłęd | 2005 | 10.000000 | 7.55 |
| Thriller | Gra | 1997 | 10.000000 | 7.88 |
| Thriller | Zaginiona dziewczyna | 2014 | 10.000000 | 7.81 |
| Western | Człowiek zwany Koniem | 1970 | 10.000000 | 7.14 |
| Wojenny | Życie jest cudem | 2004 | 9.709966 | 7.62 |
Zwróćcie uwagę na coś ciekawego: w ramach Dramatów rekomendowany były Piękny umysł oraz Ray (średnia ocena podobnych użytkowników to w obu przypadkach 9, 40% z nich oceniło każdy z filmów). A najwyższą przewidywaną ocenę ma Wołyń. Dlaczego tak się dzieje? Przecież na zdrowy rozum w obu przypadkach na pierwszym miejscu powinien być ten sam film. Spróbujmy to wyjaśnić.
Zaczniemy od sprawdzenia jakie informacje o tych filmach zwraca nam funkcja w obu tabelach.
Rekomendacje:
|
1 2 3 4 |
wynik$rekomendacje %>% filter(tytul %in% c("Wołyń", "Ray", "Piękny umysł")) %>% arrange(tytul) %>% select(-pozycja, -id_filmu, - rok_produkcji, -ocena) |
| Tytuł | Gatunek | User_03 | User_12 | User_14 | User_16 | User_20 | Średnia ocena podobnych użytkowników | Liczba ocen podobnych użytkowników |
|---|---|---|---|---|---|---|---|---|
| Piękny umysł | Dramat | – | 9 | – | 9 | – | 9.000000 | 0.4 |
| Piękny umysł | Biograficzny | – | – | – | – | 9 | 9.000000 | 0.2 |
| Ray | Dramat | – | 9 | – | – | 9 | 9.000000 | 0.4 |
| Wołyń | Dramat | 9 | – | 5 | – | 9 | 7.666667 | 0.6 |
| Wołyń | Wojenny | – | – | – | 10 | – | 10.000000 | 0.2 |
Przewidywane oceny:
|
1 2 3 4 |
wynik$przewidywane %>% filter(tytul %in% c("Wołyń", "Ray", "Piękny umysł")) %>% arrange(tytul) %>% select(-id_filmu, -rok_produkcji, -ocena) |
| Gatunek | Tytuł | Przewidywana ocena | Liczba ocen podobnych użytkowników |
|---|---|---|---|
| Dramat | Piękny umysł | 9.000000 | 0.4 |
| Dramat | Piękny umysł | 9.000000 | 0.2 |
| Biograficzny | Piękny umysł | 9.000000 | 0.4 |
| Biograficzny | Piękny umysł | 9.000000 | 0.2 |
| Dramat | Ray | 9.000000 | 0.4 |
| Dramat | Wołyń | 9.507961 | 0.6 |
| Dramat | Wołyń | 9.507961 | 0.2 |
| Wojenny | Wołyń | 9.507961 | 0.6 |
| Wojenny | Wołyń | 9.507961 | 0.2 |
Widzicie gdzie jest problem? Piękny umysł i Wołyń należą jednocześnie do dwóch gatunków. W związku z tym gdzieś po drodze są liczone oddzielnie, trochę jak dwa różne filmy. Widać to szczególnie w przypadku filmu Smarzowskiego – raz ma średnią ocenę wśród podobnych 7.66 a innym razem 10.
Dzieje się to w funkcji GetRecommendedMovies(), tam gdzie powstaje tabelka wybrane_filmy. Tabelka ta ma więcej wierszy niż wybranych filmów – w przypadku naszej trójki filmów powstaje pięć wierszy zamiast trzech. Należy odpowiednio przebudować ten fragment, tak aby funkcja spread dostała tylko trzy kolumny: film (jego tytuł, a bezpieczniej ID filmu – tytuły mogą się powtórzyć), nazwę użytkownika oraz jego ocenę. Poprawiona wersja wygląda tak (w komentarzach oznaczyłem zmiany):
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 |
GetRecommendedMovies_v2 <- function(user_search, k = 2) { users_knn <- sort(distances[user_search, ])[2:(k+1)] users_knn_tab <- users_knn %>% as.data.frame() %>% set_names("dist") %>% rownames_to_column() wspolnie_oceniane <- filmy_userzy %>% filter(user %in% names(users_knn)) %>% spread(user, ocena_usera) %>% na.omit() wspolnie_oceniane$sr_ocena_podobnych <- apply(wspolnie_oceniane[, 7:ncol(wspolnie_oceniane)], 1, mean, na.rm = TRUE) user_search_widzial <- filmy_userzy %>% filter(user == user_search) %>% .$tytul wybrane_filmy <- filmy_userzy %>% filter(!tytul %in% user_search_widzial) %>% filter(user %in% names(users_knn)) %>% # dodane poniższe dwie linie select(id_filmu, user, ocena_usera) %>% distinct() %>% spread(user, ocena_usera) # zmieniony poniżej numer kolumny z 7 na 2 wybrane_filmy$sr_ocena_podobnych <- apply(wybrane_filmy[, 2:ncol(wybrane_filmy)], 1, mean, na.rm = TRUE) # zmieniony poniżej numer kolumny z 7 na 2 wybrane_filmy$l_ocena_podobnych <- apply(wybrane_filmy[, 2:(ncol(wybrane_filmy)-1)], 1, function(x) sum(!is.na(x))/k) # musimy dodać informacje, które usunęliśmy wcześniej - m.in. tytuł i gatunek filmu wybrane_filmy <- wybrane_filmy %>% left_join(filmy %>% select(-pozycja), by = "id_filmu") przewidywane <- filmy_userzy %>% filter(!tytul %in% user_search_widzial) %>% filter(user %in% names(users_knn)) %>% left_join(users_knn_tab, by = c("user" = "rowname")) %>% mutate(dist = max(dist) - dist) %>% group_by(id_filmu) %>% mutate(ocena_pred = sum(ocena_usera*dist)/sum(dist)) %>% ungroup() %>% select(gatunek, id_filmu, tytul, rok_produkcji, ocena, ocena_pred) %>% left_join(wybrane_filmy %>% select(id_filmu, l_ocena_podobnych), by = "id_filmu") %>% distinct() return(list(rekomendacje = wybrane_filmy, wspolne = wspolnie_oceniane, przewidywane = przewidywane)) } |
Jak teraz wyglądają rekomendacje i przewidywane oceny dlanaszej trójki?
Rekomendacje:
|
1 2 3 4 5 6 7 |
# wywołujemy zmodyfikowaną funkcję: wynik_v2 <- GetRecommendedMovies_v2("User_04", 5) wynik_v2$rekomendacje %>% filter(tytul %in% c("Wołyń", "Ray", "Piękny umysł")) %>% arrange(tytul) %>% select(-id_filmu, -rok_produkcji, -ocena) |
| User_03 | User_12 | User_14 | User_16 | User_20 | Średnia ocena podobnych użytkowników | Liczba ocen podobnych użytkowników | Tytuł | Gatunek |
|---|---|---|---|---|---|---|---|---|
| – | 9 | – | 9 | 9 | 9.00 | 0.6 | Piękny umysł | Dramat |
| – | 9 | – | 9 | 9 | 9.00 | 0.6 | Piękny umysł | Biograficzny |
| – | 9 | – | – | 9 | 9.00 | 0.4 | Ray | Dramat |
| – | 9 | – | – | 9 | 9.00 | 0.4 | Ray | Biograficzny |
| 9 | – | 5 | 10 | 9 | 8.25 | 0.8 | Wołyń | Wojenny |
| 9 | – | 5 | 10 | 9 | 8.25 | 0.8 | Wołyń | Dramat |
Przewidywane oceny:
|
1 2 3 4 |
wynik_v2$przewidywane %>% filter(tytul %in% c("Wołyń", "Ray", "Piękny umysł")) %>% arrange(tytul) %>% select(-id_filmu, -rok_produkcji, -ocena) |
| Gatunek | Tytuł | Przewidywana ocena | Liczba ocen podobnych użytkowników |
|---|---|---|---|
| Dramat | Piękny umysł | 9.000000 | 0.6 |
| Biograficzny | Piękny umysł | 9.000000 | 0.6 |
| Dramat | Ray | 9.000000 | 0.4 |
| Dramat | Wołyń | 9.507961 | 0.8 |
| Wojenny | Wołyń | 9.507961 | 0.8 |
Dalej filmy są rozbite na gatunki, ale liczby im towarzyszące już są stale takie same. Wołyń nadal nie będzie rekomendowany – średnia ocena wśród podobnych użytkowników jest mniejsza niż ta dla Pięknego umysłu czy Raya. Średnia ocena nie jest oceną ważoną, a jedynie arytmetyczną.
Przewidywana ocena zależy zaś od podobieństwa użytkowników – widocznie piątka od User_14 nie ma tak wielkiego wpływu jak 10 od User_16. I rzeczywiście tak jest: najbardziej podobnym do naszego badanego User_04 był właśnie User_16, tak więc jego ocena ma największą wagę.
Cały ten wywód był po to, aby pokazać jak nawet drobne zmiany (albo przeoczenia) wpływają na wynik rekomendacji. Który z trzech filmów polecić User_04 do obejrzenia? Patrząc na najlepsze według niego dramaty:
|
1 2 3 4 5 |
filmy_userzy %>% filter(gatunek == "Dramat", user == "User_04") %>% top_n(10, ocena_usera) %>% arrange(desc(ocena_usera), tytul) %>% select(tytul, rok_produkcji, ocena_usera) |
| Tytuł | Rok produkcji | Ocena użytkownika |
|---|---|---|
| Amarcord | 1973 | 9 |
| Kasyno | 1995 | 9 |
| Krótki film o zabijaniu | 1987 | 9 |
| Leon zawodowiec | 1994 | 9 |
| Przesłuchanie | 1982 | 9 |
| Rękopis znaleziony w Saragossie | 1964 | 9 |
| Ścieżki chwały | 1957 | 9 |
| Bulwar Zachodzącego Słońca | 1950 | 8 |
| Dawno temu w Ameryce | 1984 | 8 |
| Dom z małych kostek | 2008 | 8 |
| Filadelfia | 1993 | 8 |
| Lista Schindlera | 1993 | 8 |
| Nietykalni | 2011 | 8 |
| Pętla | 1957 | 8 |
| Skazani na Shawshank | 1994 | 8 |
| Tam, gdzie rosną poziomki | 1957 | 8 |
w pierwszej kolejności poleciłbym jednak to co wyszło z rekomendacji (Piękny umysł i Ray), a Wołyń… to zależy od oceny Idź i patrz (dlaczego akutat ten film? trzeba go zobaczyć i porównać z Wołyniem) oraz pozostałych filmów Smarzowskiego:
|
1 2 3 4 |
filmy_userzy %>% filter(user == "User_04") %>% filter(tytul %in% c("Idź i patrz", "Wesele", "Dom zły", "Róża", "Drogówka", "Pod Mocnym Aniołem")) %>% select(tytul, rok_produkcji, ocena_usera) |
| Tytuł | Rok produkcji | Ocena użytkownika |
|---|---|---|
| Idź i patrz | 1985 | 6 |
| Drogówka | 2013 | 9 |
Wyliczone 9.5 to chyba za dużo…
Pamiętajmy jednak, że to tylko symulacja.
Dane rzeczywiste
Bardziej sensowne i prawdopodobne wyniki wyjdą nam, kiedy na warsztat weźmiemy dane rzeczywiste i tym samym rzeczywisty gust poszczególnych osób. Tylko skąd pobrać dane o ocenach rzeczywistych użytkowników?
Rozwiązania są dwa. Jedno w R, drugie z użyciem mechanizmów oddzielnych.
W R po prostu wczytamy sobie stronę i wyciągniemy z niej informacje. Niestety – bez zalogowania dostaniemy tylko kilkadziesiąt ostatnich ocen danego użytkownika. Funkcja wygląda tak jak poniżej i jako parametru potrzebuje ciągu z nickiem:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 |
GetUserVotes <- function(user_name) { page <- read_html(paste0("http://www.filmweb.pl/user/", user_name, "/films")) user_oceny <- data_frame( # film (ID) film_id = page %>% html_node("div#userFilmVotesContainer") %>% html_nodes("div.votePanel") %>% html_node("div.voteFilmTitle") %>% html_node("a") %>% html_attr("href") %>% map(str_match, "\\/film\\/(.*)-(.*)-(.*)") %>% # to na pewno można zrobic lepiej :) do.call(rbind, .) %>% .[,4], # ocena ocena = page %>% html_node("div#userFilmVotesContainer") %>% html_nodes("div.votePanel") %>% html_node("div.votingPanel") %>% html_node("div.rateText") %>% html_node("span") %>% html_text(), # tytul tytul = page %>% html_node("div#userFilmVotesContainer") %>% html_nodes("div.votePanel") %>% html_node("div.voteFilmTitle") %>% html_node("a") %>% html_text(), user = user_name) user_oceny <- user_oceny %>% filter(!is.na(film_id)) return(user_oceny) } |
Ja jakiś czas temu skorzystałem ze skryptu, jaki znalazłem na forum Filmwebu, pobrałem dane o kilku użytkownikach i wpakowałem do pliku CSV. Ten plik i wszystkie przygotowane wcześniej funkcje za chwilę wykorzystamy.
Przy okazji: jeśli używacie IMDB i tam oceniacie filmy to jest też ciekawa wtyczka do Chrome
Wyniki dla danych rzeczywistych
|
1 2 3 4 5 6 7 |
# wczytujemy dane zapisane lokalnie znajomi <- read_csv2("oceny_znajomych.csv") # budujemy tabelę ocen i informacji o filmach filmy_userzy <- left_join(znajomi %>% mutate(id_filmu = as.character(id)), filmy, by = "id_filmu") %>% select(pozycja, id_filmu, tytul, rok_produkcji, ocena, gatunek, ocena_usera = vote, user) %>% na.omit() |
Zobaczmy jakie moje oceny znajdziemy, może same 10-tki (wszystkich moich ocen w tym archiwum jest 598, a jest to może 1/3 aktualnego stanu – ten plik jest bardzo stary…):
|
1 2 3 4 5 |
filmy_userzy %>% filter(user == "lemur78", ocena_usera == 10) %>% select(gatunek, tytul, ocena_usera) %>% distinct(tytul, ocena_usera, .keep_all = TRUE) %>% arrange(gatunek, desc(ocena_usera), tytul) |
| Gatunek | Tytuł | Ocena użytkownika |
|---|---|---|
| Akcja | Batman | 10 |
| Dramat | Dawno temu w Ameryce | 10 |
| Dramat | Ojciec chrzestny | 10 |
| Dramat | Ojciec chrzestny II | 10 |
| Dramat | Skazani na Shawshank | 10 |
| Horror | Dziecko Rosemary | 10 |
| Horror | Lśnienie | 10 |
| Komedia | Kawa i papierosy | 10 |
| Komedia | Kawa i papierosy III | 10 |
| Komedia | Zelig | 10 |
| Komedia | Żywot Briana | 10 |
| KomediaObyczajowa | Annie Hall | 10 |
| Kryminał | Dzikość serca | 10 |
| Obyczajowy | Ziemia obiecana | 10 |
| Psychologiczny | Lot nad kukułczym gniazdem | 10 |
| Psychologiczny | Nóż w wodzie | 10 |
| Psychologiczny | Truposz | 10 |
| Psychologiczny | Wstręt | 10 |
| SciFi | 2001: Odyseja kosmiczna | 10 |
| SciFi | Metropolis | 10 |
| Thriller | 21 gramów | 10 |
| Thriller | Fargo | 10 |
| Thriller | Lokator | 10 |
| Thriller | Urodzeni mordercy | 10 |
| Thriller | Zagubiona autostrada | 10 |
Potrzebujemy oczywiście macierzy podobieństw:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
distances <- GetDistances() # kto do kogo podobny? distances %>% as.data.frame() %>% rownames_to_column() %>% rename(UserA = rowname) %>% gather(UserB, Val, -UserA) %>% filter(UserA != UserB) %>% ggplot() + geom_tile(aes(UserA, UserB, fill = Val), color = "gray80") + scale_fill_distiller(palette = "Reds") + labs(title = "Podobieństwo użytkowników ze względu na ich oceny", subtitle = "Mniej = większe podobieństwo", fill = "Miara\npodobieństwa", x = "", y = "") + theme(axis.text.x = element_text(angle = 90, hjust = 1, vjust = 1)) |
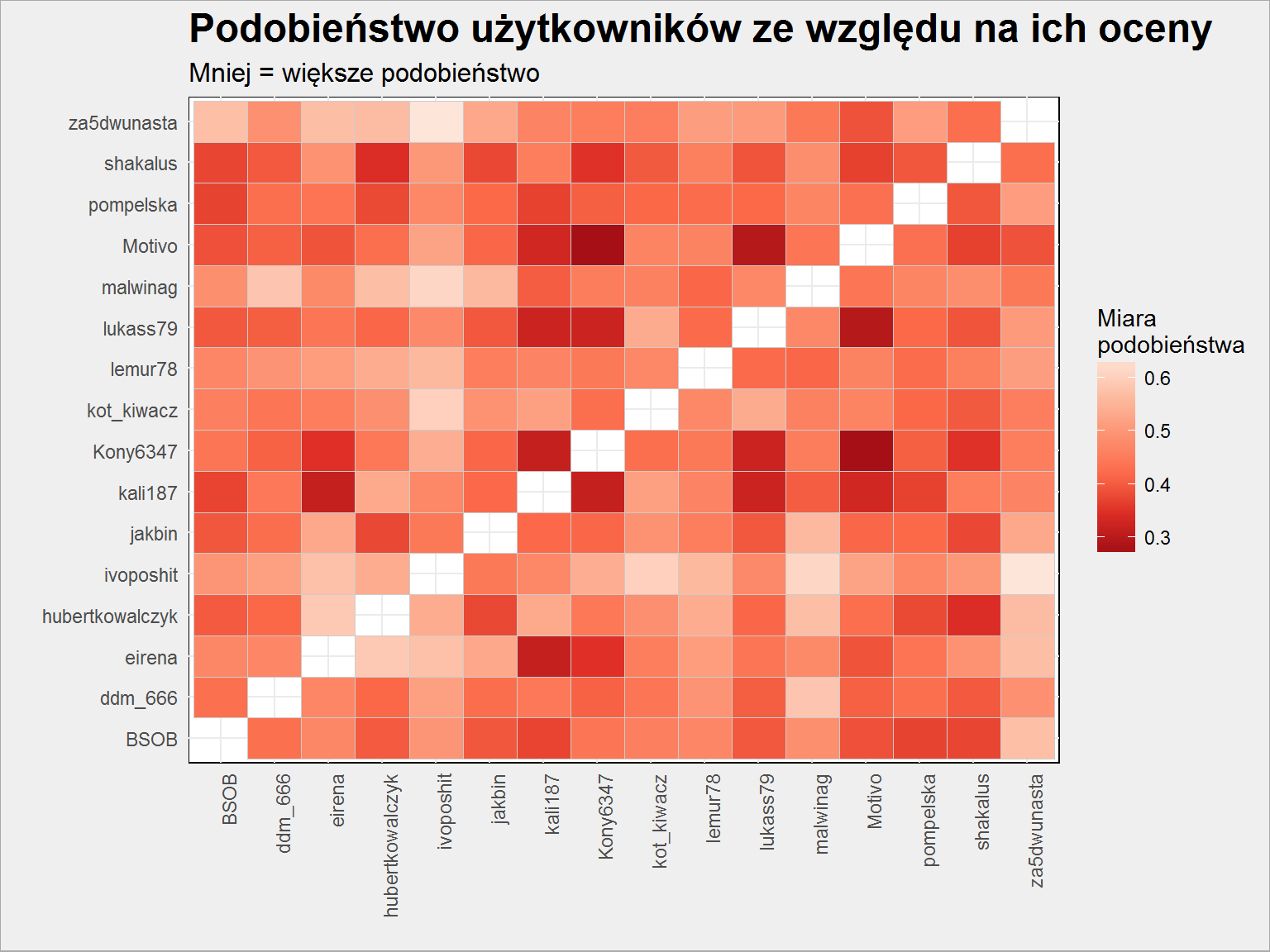
Mało jest podobnych do mnie użytkowników w tej bazie. Z dendrogramu
|
1 |
distances %>% as.dist() %>% hclust() %>% plot() |
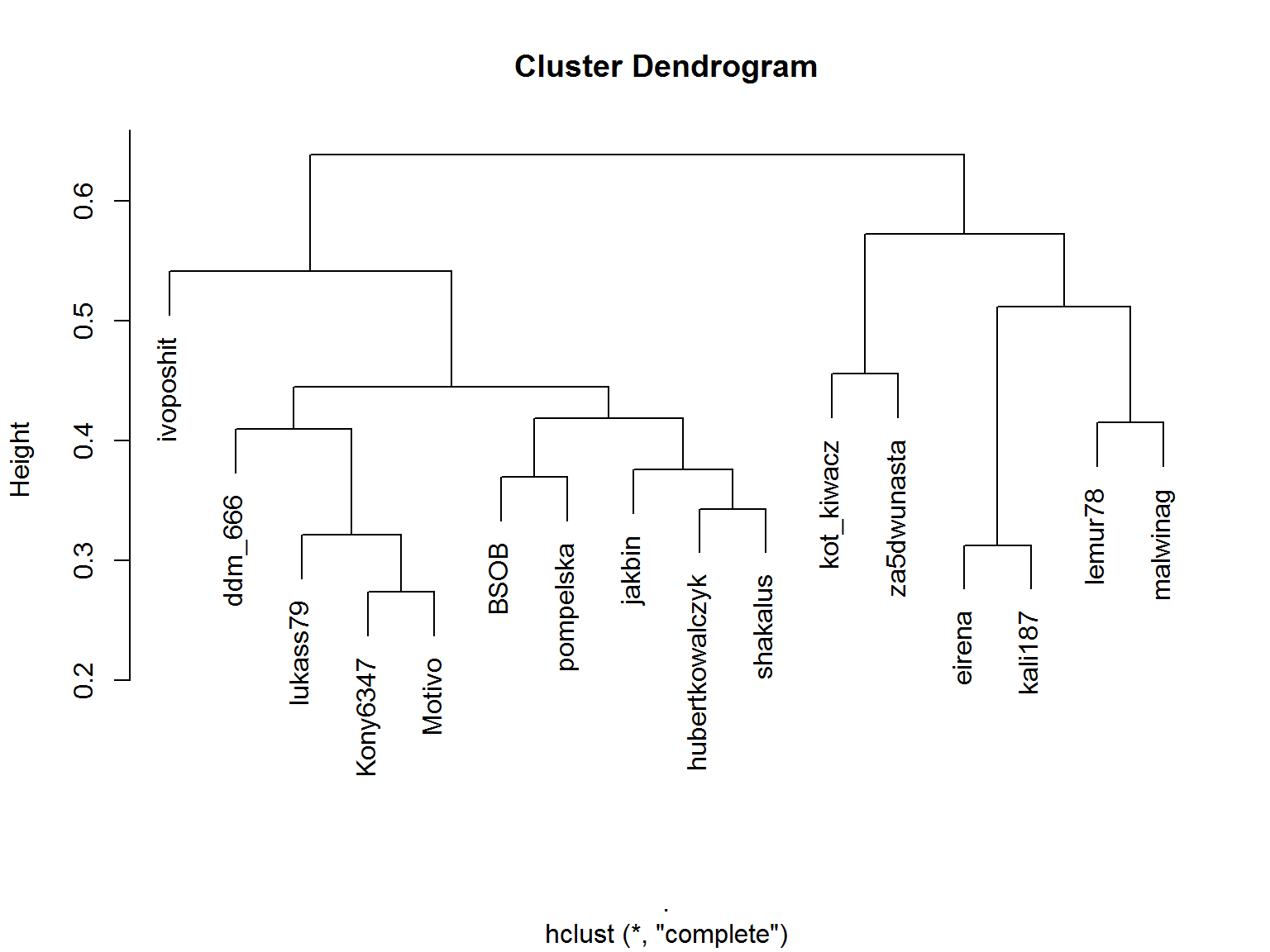
wynika, że MalwinaG powinna być najbliżej. Znam Malwinę i znam jej oceny – zgadza się.
Zobaczmy co rekomenduje maszyneria:
|
1 2 3 4 5 6 7 8 9 |
# wyniki na podstawie 7 najbardziej podobnych wynik_lemur78 <- GetRecommendedMovies_v2("lemur78", 7) wynik_lemur78$rekomendacje %>% # bierzemy pod uwagę filmy ocenione przez co najmniej 3 z 7 osób filter(l_ocena_podobnych >= 3/7) %>% select(tytul, rok_produkcji, sr_ocena_podobnych, ocena) %>% distinct() %>% arrange(desc(sr_ocena_podobnych)) |
| Tytul | Rok produkcji | Średnia ocena podobnych użytkowników | Ocena na Filmweb |
|---|---|---|---|
| Święci z Bostonu | 1999 | 8.666667 | 7.84 |
| Imperium Słońca | 1987 | 8.333333 | 7.80 |
| Gran Torino | 2008 | 7.833333 | 8.21 |
| Sugar Man | 2012 | 7.666667 | 7.74 |
| Człowiek w ogniu | 2004 | 7.250000 | 7.90 |
| Helikopter w ogniu | 2001 | 7.250000 | 7.79 |
| W pogoni za szczęściem | 2006 | 7.000000 | 8.10 |
| Gwiezdne wojny: Przebudzenie Mocy | 2015 | 7.000000 | 7.47 |
| Tańczący z wilkami | 1990 | 6.666667 | 7.76 |
| Monachium | 2005 | 6.666667 | 7.40 |
| To właśnie miłość | 2003 | 6.666667 | 7.60 |
| Wszystko za życie | 2007 | 6.333333 | 7.92 |
Wśród powyższych rekomendowanych filmów część widziałem i nie były to gnioty, nie jest więc źle. A co z proponowanymi ocenami?
|
1 2 3 4 5 |
wynik_lemur78$przewidywane %>% filter(l_ocena_podobnych >= 3/7) %>% select(tytul, rok_produkcji, ocena_pred, ocena) %>% distinct() %>% arrange(desc(ocena_pred), desc(ocena)) |
| Tytuł | Rok produkcji | Przewidywana ocena | Ocena na Filmweb |
|---|---|---|---|
| Święci z Bostonu | 1999 | 8.799850 | 7.84 |
| Gran Torino | 2008 | 8.562072 | 8.21 |
| Imperium Słońca | 1987 | 8.439186 | 7.80 |
| Wszystko za życie | 2007 | 7.505476 | 7.92 |
| Sugar Man | 2012 | 7.272766 | 7.74 |
| W pogoni za szczęściem | 2006 | 7.000000 | 8.10 |
| To właśnie miłość | 2003 | 6.930428 | 7.60 |
| Człowiek w ogniu | 2004 | 6.768800 | 7.90 |
| Helikopter w ogniu | 2001 | 6.545532 | 7.79 |
| Tańczący z wilkami | 1990 | 6.300580 | 7.76 |
| Monachium | 2005 | 6.132817 | 7.40 |
| Gwiezdne wojny: Przebudzenie Mocy | 2015 | 5.775787 | 7.47 |
Z tego co widziałem i pamiętam w tym momencie:
- Gran Torino mnie wynudził, nie przepadam za filmami Eastwooda i zawsze oceniam niżej niż znajomi
- To właśnie miłość – prawie siódemka… tak, zgadzam się – dałbym temu filmowi 7/10, bo to dobrze zrobiona komedia romantyczna (chociaż prosta w konstrukcji)
- Helikopter w ogniu – chyba nie obejrzałem do końca, ale byłaby to co najmniej 7/10
- Tańczący z wilkami – ten film widziałem tak bardzo dawno temu, że nie podejmuję się go oceniać w tym momencie
- Monachium z nieco ponad 6? Pamiętam, że mnie wcale nie wzięło, wynudziłem się. Byłaby to 5 albo 6
- Przebudzenie Mocy – to te przeodstatnie? Bardziej piątka niż szóstka. Ale wielkim fanem Star Wars nie jestem, a jeśli już to wolę pierszą (w kolejności kręcenia) trylogię
- Święci z Bostonu – tego filmu nie widziałem i kiedyś wreszcie muszę nadrobić, bo często ten tytuł się przewija przed moimi oczami jako pasujący do mojego gustu
Warto przeczytać
Na koniec dwa linki, które warto prześledzić jeśli chcecie dowiedzieć się czegoś więcej o systemach rekomendacyjnych (oba dotyczą problemu rekomendacji filmów).
- Pierwszy to nieprzebrane źródło wiedzy jakim jest Kaggle.com – jest tam zestaw danych The Movies Dataset i kernele do niego podczepione opisują co i jak – zarówno w R jak i w Pythonie.
- Drugi, według mnie bardzo ciekawy wpis to Silnik rekomendacji filmów na blogu Mateusza Grzyba. Mateusz zaprezentował opisany materiał na Meetupie, z którego materiały znajdziecie tutaj.
Spośród listy artykułów na RSS mój wzrok w ciągu sekundy dostrzegł frazę „Jaki film obejrzeć” :) Zapisuję na rano do kawy :)
Napisałem sobie kiedyś rekomendacje dla serwisu książkowego i algorytm był mniej więcej podobny. :) Ale jest parę pułapek, na które trzeba uważać.
1. Jeśli użytkownik ocenił wszystkie filmy na tą sama ocenę (np. tylko 10, albo tylko 1), to nie da się policzyć korelacji z nim. Z drugiej strony taki użytkownik jest mało wiarygodny i pewnie nic nie wnosi do rekomendacji. Nie jest to jednak przypadek wydumany. W bazie widziałem użytkowników, którzy książki pewnych kategorii hurtowo oceniali na MIN lub MAX. Najczęściej była to kategoria „religijne”.
2. Zero ma wartość liczbową i mocno psuje liczenie korelacji. Przykład:
User_01”, który ocenił 10 filmów (przyjmijmy, że filmów jest 100) ma lepszą korelację z użytkownikiem, „User_02”, który ocenił te same 10 filmów zupełnie inaczej, niż z użytkownikiem „User_03”, który ocenił 90 filmów, w tym wszystkie 10 tak samo jak „User_01”
Korelację warto by liczyć tylko dla wspólnie ocenionych filmów i jeszcze wprowadzić jakieś minimum. Pewnie nie da się tego zrobić jedna zgrabną instrukcją, ale zawsze możne pętlą. Próbowałem nieocenione ustawiać na NA i różnych argumentów „use” dla funkcji cor(), ale to chyba nie pomoże.
3. Korelacja daje czasami nieintuicyjne wyniki.
Np. jeśli „User_01” oceni tylko jeden film np. na 1, a „User_02” oceni tylko ten jeden film na 10, to korelacja jest 1. (Takich użytkowników jest sporo. Wpadnie na chwilę, oceni kilka pozycji i już nie wraca)
Inny przykład dla 10 filmów:
„User_01” ocenił filmy kolejno na 1 3 1 2 0 0 0 9 8 9
„User_02” ocenił filmy kolejno na 8 10 8 9 1 2 2 0 0 0
Korelacja na podstawie pierwszych czterech jest 1. Czy to źle? Nie! Bo zgodnie oceniają film 2 najlepiej, a filmy 1 i 3 najgorzej. Ale dla jednego są to filmy najgorsze, a dla drugiego najlepsze. Taka korelacja niesie nam sporo informacji, ale pewnie trzeba by to jakoś sensownie użyć. Na oko wydaje się, że przy liczeniu korelacji należy uwzględniać tylko wspólnie ocenione filmy, ale odchylenie liczyć od średniej ze wszystkich ocen użytkownika.
4. Nie musimy liczyć korelacji każdy z każdym. Jeśli liczymy rekomendacje dla „User_01” to wystarczy policzyć N-1 korelacji z użytkownikami „User_02”-„User_N”. Być może pełna macierz korelacji była by przydatna jeśli liczenie korelacji jest kosztowne. Dla serwisu książkowego liczenie na żądanie korelacji jednego użytkownika z pozostałymi(>50000) przy ograniczeniu tylko do wspólnie ocenionych książek było bardzo szybkie. (średnio wspólne było około kilkanaście-kilkadziesiąt książek z bazy ponad 100000)
5. Przy wyliczaniu przewidywanych ocen warto wziąć też pod uwagę jaka jest średnia ocen osoby, która nam poleca filmy. Np. 10 od osoby, której średnia jest około 7, może oznaczać film dla niej wybitny, z kolei u osoby której średnia ocen jest około 9, ocena 10 dla filmu jest pewnie prawie normą. (Ale tez może się okazać, że ta pierwsza jest krytykiem filmowym, który zawodowo musi oglądać wiele gniotów ;) ). W moim algorytmie podciągałem oceny o procentowe odchylenie oceny filmu od średniej dla tej osoby. W efekcie przewidywana ocena czasami wyskakiwała ponad MAX, ale informacja, że dany film będzie się podobał na 11,5 też jest interesująca.
6. Wiem, że dla czytelności są pewne uproszczenia, ale też nigdy nie zaszkodzi przypomnieć, że gdyby ktoś chciał pociągnąć temat to technicznie lepiej w tabelach mieć identyfikatory filmów i użytkowników, zamiast ciągnąć ze sobą pełne tytuły i nazwy. Być może R sobie poradzi z wydajnością operacji na takich pełnych tabelach, ale nigdy nie zaszkodzi samemu oszczędzić na pamięci. (to takie moje skrzywienie dotyczące optymalizacji i trzeciej postaci normalnej ;) )
W moim algorytmie dałem trzy parametry. Minimalna liczba wspólnie ocenionych książek, minimalne podobieństwo osób branych pod uwagę i minimalna liczba podobnych osób polecających daną pozycję. Żonglując wartościami można dostosować specyfikę algorytmu, np. żeby polecał książki w sposób bardziej bezpieczny (duże podobieństwo, dużo poleceń), lub bardziej ryzykancki (mniej wspólnych ocen, mniej poleceń, duże podobieństwo). Wyniki były całkiem ciekawe. :) Niestety taki algorytm jest jednak dosyć prosty i nie zawsze dobrze działa. Daje radę dla użytkowników z rozsądnie niewielką liczbą ocen i dla bardziej bezpiecznych ustawień. (Ale równie dobrze można by wtedy brać topowe pozycje z rankingów). Dla maniaków z tysiącami ocen i specyficznym guście już jest gorzej. Chciałem kiedyś poprawić i przepisać algorytm (z C). R wygląda całkiem nieźle do tego celu, tylko muszę się jeszcze trochę podszkolić.
Dzięki za świetny komentarz – wszystko się zgadza, a dotyczy głównie korelacji jako miary podobieństwa. Tak jak napisałem w poście – nie jest to najlepsza miara, lepszą jest chociażby odległość kosinusowa.
Swoją drogą – odnośnie punktu 3:
> User_01 = c(1, 3, 1, 2, 0, 0, 0, 9, 8, 9)
> User_02 = c(8, 10, 8, 9, 1, 2, 2, 0, 0, 0)
> cor(User_01, User_02) # korelacja
[1] -0.4706835
> lsa::cosine(User_01, User_02) # odległość kosinusowa
[,1]
[1,] 0.2311841
;)
Jeśli chodzi o wydajność – R jest wolny. Lepsze efekty są w Pythonie. Oczywiście masz rację – wystarczą same IDki filmów. Liczenie całych macierzy odległości dla użytkowników każdy z każdym też jest wątpliwe, ale… może się okazać lepszym rozwiązaniem przeliczenie całości raz na dobę zamiast w locie.
Filmweb pokazuje procent, że dany film mi się spodoba – tego nie może robić w locie, maszyny by umarły. Swoją drogą średnią ocenę filmu też przeliczają co jakiś czas (badałem jak się ona zmienia w czasie i są wyraźne skoki)
Uwielbiam oglądać filmy i z chęcią bym sobie teraz coś włączyła, ale niestety nie mam jeszcze kupionych złącz antenowych. Gdy tylko je zamówię to w końcu będę mogła oglądać telewizję, a jest to moja ulubiona rozrywka.