Czy wydajność pracy w różnych krajach Europy jest jednakowa? Jak skorzystać z danych Eurostatu w R?
Jestem fanem facebookowej strony z różnymi mapkami. Na stronie tej pokazał się ostatnio obrazek z informacją o średniej liczbie godzin jaką w pracy spędzają mieszkańcy poszczególnych krajów (linkował do tego postu). Ale szczerze powiedziawszy co to za informacja? To czy siedzisz w pracy długo czy krótko nie ma (bezpośrednio) związku z tym ile wartości wypracujesz.
Sprawdźmy ile warta (w rozumieniu produktu krajowego brutto) jest godzina pracy mieszkańca poszczególnych krajów Europy.
Do tego celu skorzystamy z danych Eurostatu, tym bardziej że istnieje bardzo wygodny pakiet R, z którym takie działanie jest banalnie proste.
Na początek musimy znaleźć odpowiednie dane. Pakiet eurostat dostarcza nam odpowiednich funkcji:
|
1 2 3 4 5 6 7 |
library(tidyverse) # install.packages("eurostat") library(eurostat) # szukamy odpowiedniej tabeli - dane o średniej liczbie przepracowanych godzin search_eurostat("Average hours worked per employee") %>% select(code, title, `last update of data`) |
| code | title | last update of data |
|---|---|---|
| lc_rnum2_r2 | Average hours worked per employee, by working time, NACE Rev. 2 activity and NUTS 1 regions – LCS surveys 2008 and 2012 | 17.12.2015 |
| lc_r04num2 | Average hours worked per employee, by working time, NACE Rev. 1.1 activity and NUTS 1 regions – LCS survey 2004 | 09.03.2011 |
| lc_r00num2 | Average hours worked per employee, by working time, NACE Rev. 1.1 activity and NUTS 1 regions – LCS survey 2000 | 26.03.2009 |
Widzimy, że mamy 6 tabel z poszukiwanym ciągiem znaków (w opisie). Wykorzystamy jedną z nich zawierającą najwięcej najnowszych danych – lc_rnum2_r2:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
# pobieramy dane z tabeli lc_rnum2_r2 working_hours <- get_eurostat("lc_rnum2_r2") # agregacja (średnie) do poziomu kraju working_hours_plot <- working_hours %>% filter(worktime == "AVG_FTE", # Yearly average in full-time equivalents indic_lc == "HRS_WKD_PER_SAL") %>% # Average hours actually worked per year, per employee filter(time == max(time)) %>% mutate(country = substr(geo, 1, 2)) %>% group_by(country) %>% summarise(hours = mean(values, na.rm = TRUE)) %>% ungroup() %>% mutate(hours_per_week = 5*hours/252) |
Dane są na poziomie NUTS_1 (czyli makroregionów), ale dane o PKB są na poziomie państw – stąd agregacja (poprzez uśrednienie) stosownych wartości. W tabeli Eurostatu mamy wydzielone kilka kategorii wybieramy odpowiednią (opisane w komentarzu wyżej).
To samo robimy, aby uzyskać dane o PKB:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
# dane o PKB - szukamy tabeli search_eurostat("GDP per capita") # pobieramy tabelę pkb <- get_eurostat("nama_aux_gph") # zostawiamy tylko interesujące nas dane pkb_plot <- pkb %>% filter(time == max(working_hours$time)) %>% mutate(geo = as.character(geo)) %>% filter(nchar(geo) == 2) %>% filter(unit == "EUR_HAB", # Euro per inhabitant indic_na == "NGDPH") # Nominal Gross Domestic Product per capita |
| code | title | last update of data |
|---|---|---|
| nama_aux_gph | GDP per capita – annual Data | 27.09.2016 |
| namq_aux_gph | GDP per capita – quarterly Data | 19.09.2014 |
Pakiet eurostat umożliwia również pobranie danych geograficznych (plików SHP) – nie musimy ich więc szukać w innych serwisach.
|
1 2 3 4 5 6 7 8 9 10 11 12 |
library(broom) # dla tidy() # pobranie pliku SHP geo <- get_eurostat_geospatial() map_df <- tidy(geo, region = "NUTS_ID") county_maps_df <- map_df %>% # poziom państw filter(nchar(id) == 2) %>% # odcinamy wyspy na Atlantyku filter(lat > 30) |
Mamy dane, mamy mapki – łączymy wszystko razem:
|
1 2 3 |
plot_data <- left_join(pkb_plot, working_hours_plot, by = c("geo" = "country")) %>% mutate(pkb_h = values/hours) %>% left_join(county_maps_df, by = c("geo" = "id")) |
Znajdźmy jeszcze środki państw – będzie to przydatne do pozycjonowania tekstu (napisów) na mapie:
|
1 2 3 4 5 6 |
county_maps_means_df <- plot_data %>% group_by(geo) %>% mutate(mlong = mean(long), mlat = mean(lat)) %>% ungroup() %>% select(geo, mlong, mlat, hours_per_week, values, pkb_h) %>% distinct() |
Jak wygląda mapa pobrana z Eurostatu?
|
1 2 3 4 5 6 7 8 9 |
library(ggrepel) # dla ładnego umieszczenia labelek ggplot() + geom_polygon(data = county_maps_df, aes(long, lat, group = group, fill = id), show.legend = FALSE, color = "black") + geom_label_repel(data = county_maps_means_df, aes(mlong, mlat, label = geo)) + coord_map() + labs(x = "", y ="") + theme(axis.text = element_blank()) |
Jest to jak widać Europa, a nawet Unia Europejska. Jak wyglądają częściowe dane? Najpierw PKB na głowę mieszkańca:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
plot_data %>% select(geo, values) %>% distinct() %>% arrange(values) %>% mutate(geo = factor(geo, levels = geo)) %>% ggplot() + geom_col(aes(geo, values, fill = ifelse(geo == "PL", "PL", "other")), color = "black", show.legend = FALSE) + scale_fill_manual(values = c("PL" = "orange", "other" = "lightgreen")) + labs(title = "Produkt krajowy brutto na głowę mieszkańca", subtitle = "Na podstawie danych Eurostat, stan na koniec 2011 roku", x = "", y = "PKB per capita (w €)") |
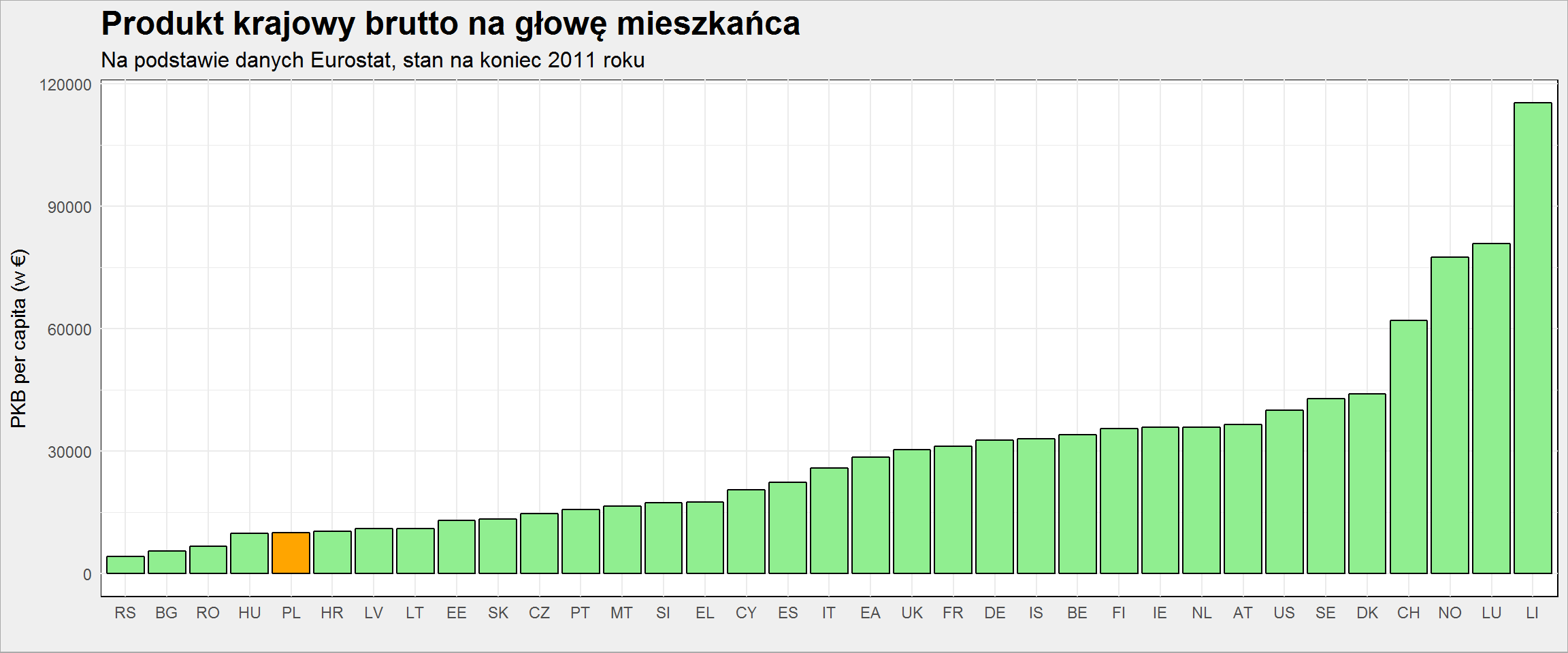
Słupki są ok, ale mapki są ładniejsze:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
ggplot() + geom_polygon(data = plot_data, aes(long, lat, group = group, fill = values), color = "black", show.legend = FALSE) + geom_label_repel(data = county_maps_means_df, aes(mlong, mlat, label = paste0(geo, ": ", values, " €"))) + coord_map() + scale_fill_gradient(low = "darkred", high = "yellow", na.value = "gray80") + labs(title = "Produkt krajowy brutto na głowę mieszkańca", subtitle = "Na podstawie danych Eurostat, stan na koniec 2011 roku", x = "", y = "") + theme(axis.text = element_blank()) |
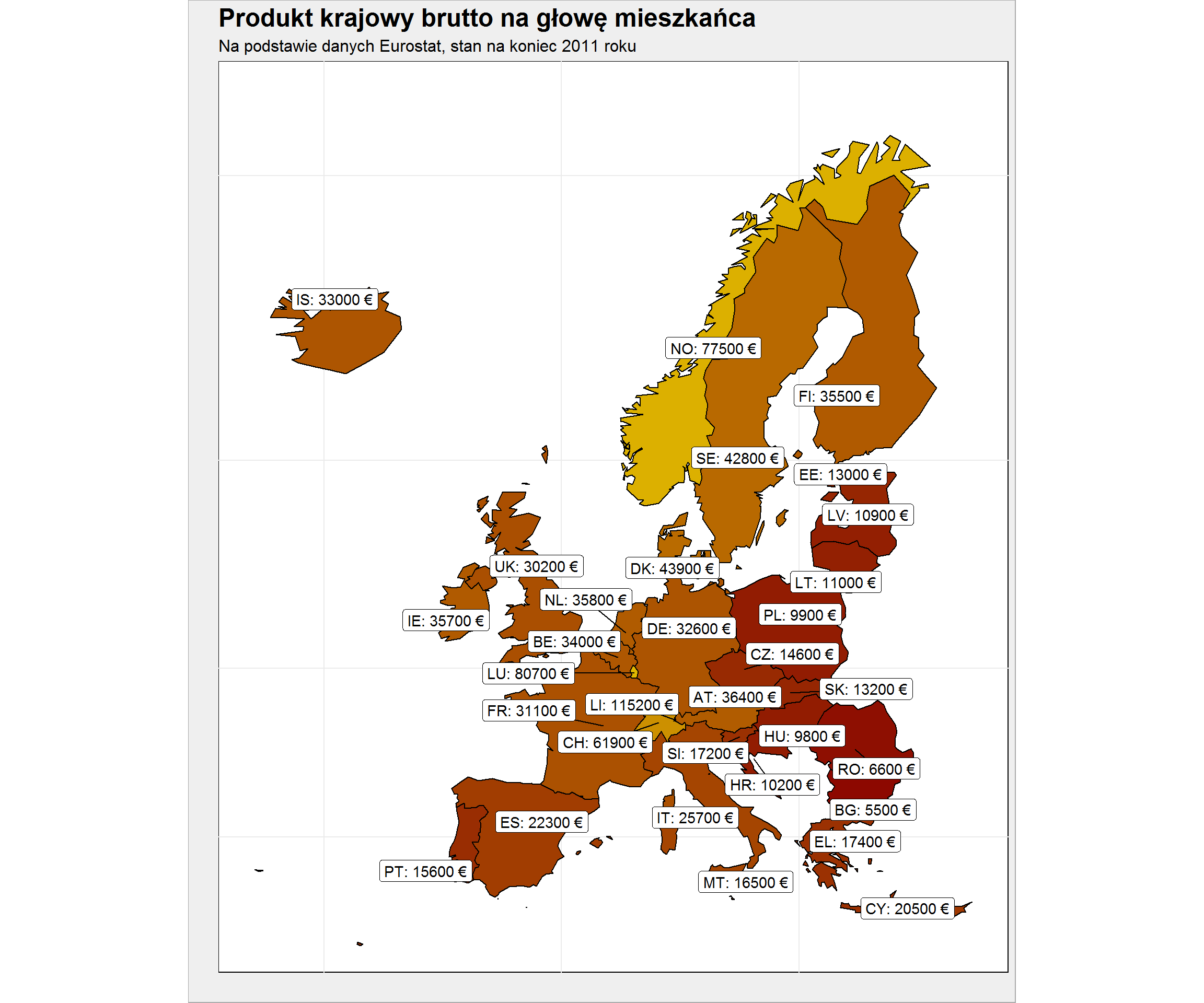
Widać wyraźnie dawny podział na Europę Zachodnią i blok post-sowiecki. Najbogatsze kraje to Norwegia, Szwajcaria (tak wiem – nie jest w UE, ale znalazła się w danych o PKB) i Szwecja. Druga strona skali to Bułgaria, Rumunia, Węgry i Polska. Pamiętajcie, że dane są na koniec 2011 roku (to dość dawno – ale takie dane są w Eurostacie o liczbie przepracowanych godzin, a przecież porównywać należy jabłka z jabłkami).
Jak zatem wyglądała średnia liczba przepracowanych w roku godzin na pracownika?
Najpierw słupki:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
plot_data %>% select(geo, hours_per_week) %>% distinct() %>% filter(!is.na(hours_per_week)) %>% arrange(hours_per_week) %>% mutate(geo = factor(geo, levels = geo)) %>% ggplot() + geom_col(aes(geo, hours_per_week, fill = ifelse(geo == "PL", "PL", "other")), color = "black", show.legend = FALSE) + geom_text(aes(geo, hours_per_week, label = sprintf("%.1f h", hours_per_week)), vjust = 1.2) + scale_fill_manual(values = c("PL" = "orange", "other" = "lightgreen")) + labs(title = "Średnia liczba godzin przepracowanych w tygodniu przez pracownika", subtitle = "Na podstawie danych Eurostat, stan na koniec 2011 roku", x = "", y = "") |
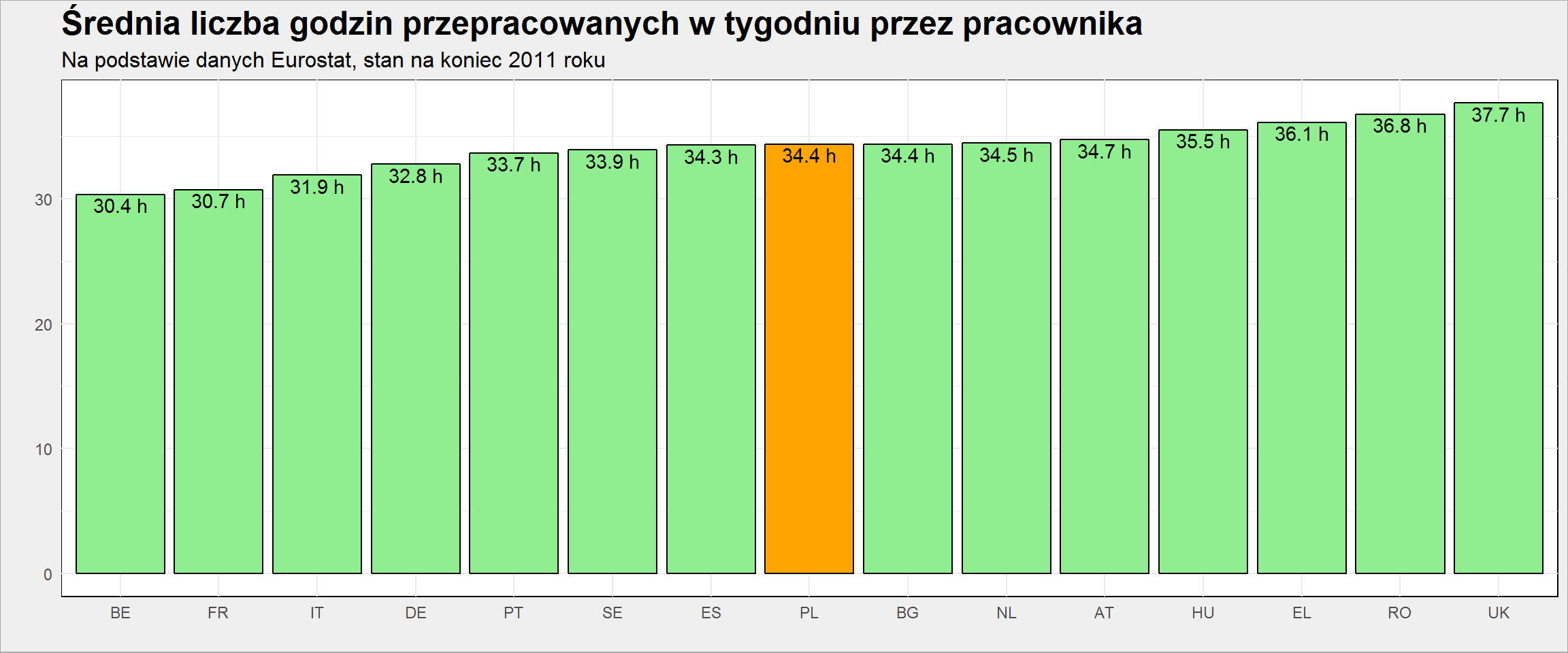
i jeszcze mapa (od czego się zaczęło – post z facebooka):
|
1 2 3 4 5 6 7 8 9 10 11 12 |
ggplot() + geom_polygon(data= plot_data, aes(long, lat, group = group, fill = hours_per_week), color = "black", show.legend = FALSE) + geom_label_repel(data = county_maps_means_df %>% filter(!is.na(hours_per_week)), aes(mlong, mlat, label = paste0(geo, ": ", round(hours_per_week, 1), " h"))) + coord_map() + scale_fill_gradient(low = "darkred", high = "yellow", na.value = "gray80") + labs(title = "Średnia liczba godzin przepracowanych w tygodniu", subtitle = "Na podstawie danych Eurostat, stan na koniec 2011 roku", x = "", y = "") + theme(axis.text = element_blank()) |
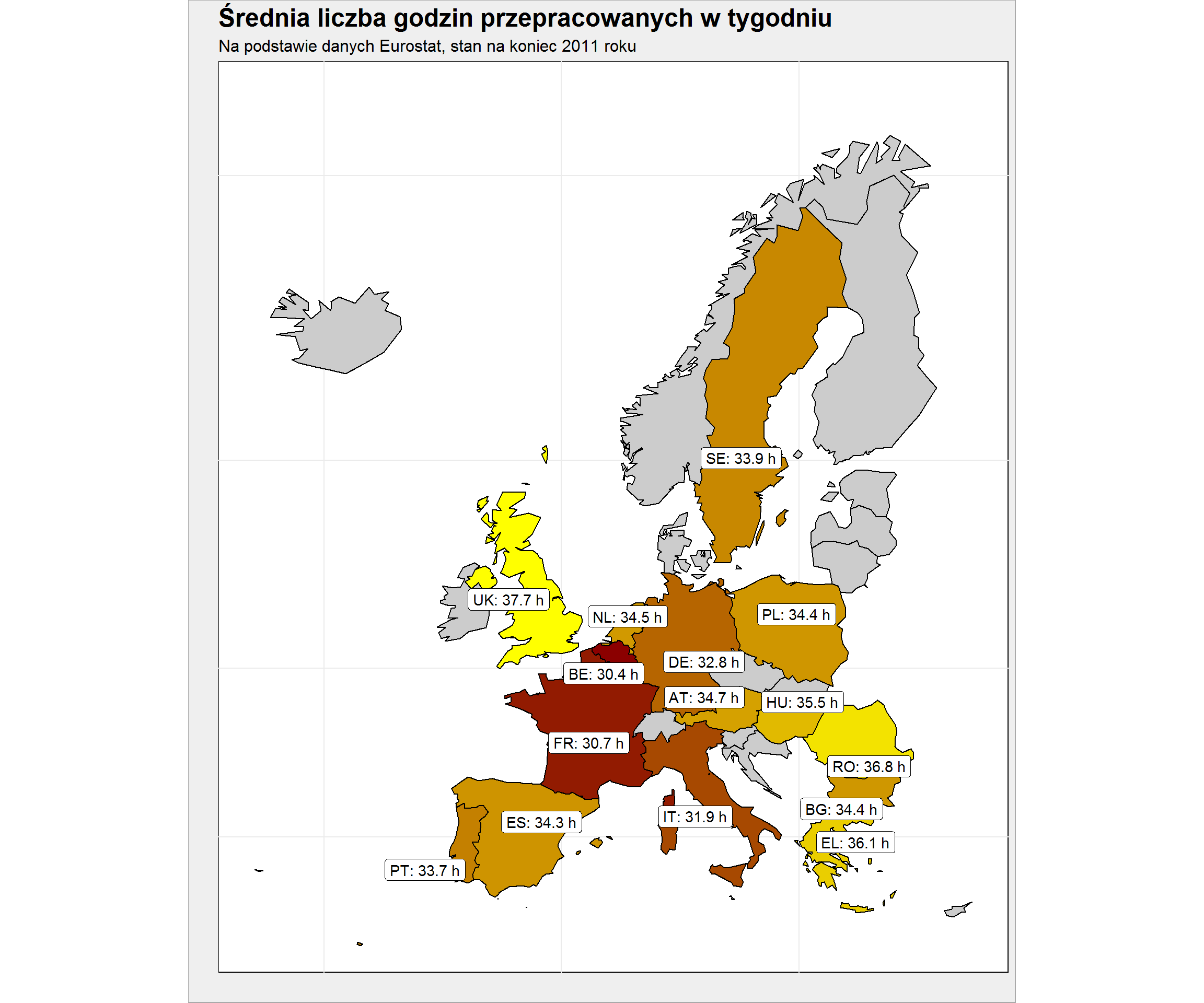
Widać różnice w stosunku do wspomnianego postu, a wynikają one z innego źródła danych (ja użyłem Eurostat, Jakub tabel z OECD) jak i okresu (2011 vs 2016). Inne dane również braliśmy pod uwagę (pracownicy na pełny etat i pracownicy na część etatu). Tutaj zabrakło również kilku państw (nie ma Czechów i Słowaków, nie ma krajów nadbałtyckich, a najbardziej mi brak Norwegii).
Co widzimy już teraz? Zachodnia Europa pracuje nieco mniej niż część wschodnia, ale jak pamiętamy z poprzedniej mapki – PKB jest ułożone odwrotnie! Policzmy zatem ile euro do PKB wypracowuje średni pracownik w czasie jednej godziny:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
ggplot() + geom_polygon(data= plot_data, aes(long, lat, group = group, fill = pkb_h), color = "black", show.legend = FALSE) + geom_label_repel(data = county_maps_means_df %>% filter(!is.na(pkb_h)), aes(mlong, mlat, label = paste0(geo, ": ", round(pkb_h, 1), " €/h"))) + coord_map() + scale_fill_gradient(low = "darkred", high = "yellow", na.value = "gray80") + labs(title = "Kto pracuje najbardziej efektywnie w Europie?", subtitle = "PKB na osobę wypracowany przez godzinę\nNa podstawie danych Eurostat, stan na koniec 2011 roku", x = "", y = "", fill = "PKB na osobę wypracowany przez godzinę") + theme(axis.text = element_blank()) |
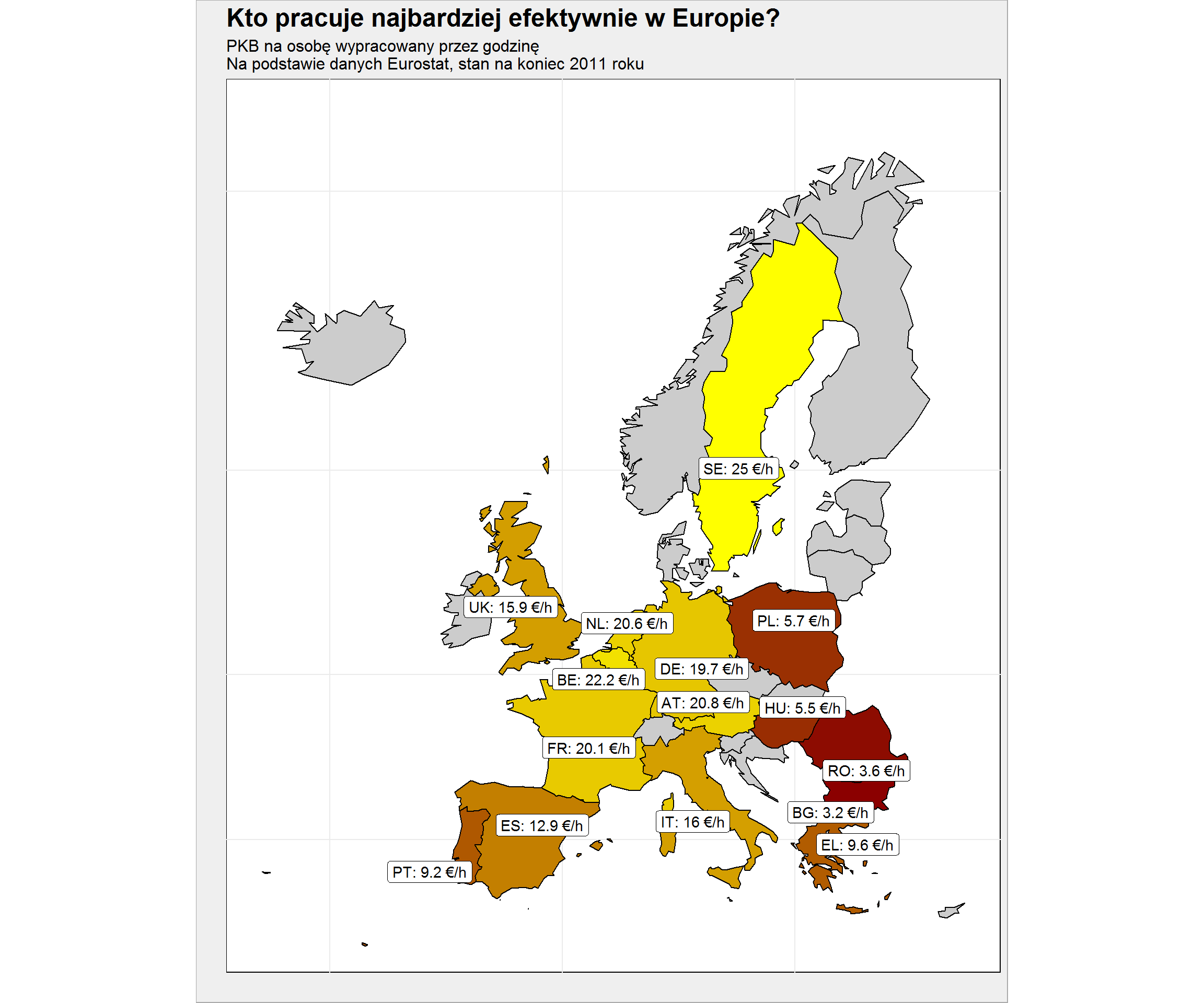
Jest to swoista miara wydajności pracy. Oczywiście PKB nie bierze się tylko z samej pracy (pod uwagę brane są inwestycje, konsumpcja).
Zestawienie samo w sobie jest ciekawe. A przepis powyżej pozwoli Wam na opracowania swoich, właściwie dowolnych, wskaźników na bazie danych z Eurostat. Oprócz pakietu eurostat istnieje analogiczny dla danych z OECD.
Zobaczmy jeszcze jak wygląda czas pracy w poszczególnych częściach Polski. Wszystkie dane mamy już pobrane
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
left_join( map_df %>% filter(substr(id, 1, 2) == "PL", nchar(id) == 3), working_hours %>% filter(worktime == "AVG_FTE", # Yearly average in full-time equivalents indic_lc == "HRS_WKD_PER_SAL") %>% # Average hours actually worked per year, per employee filter(time == max(time)) %>% filter(substr(geo, 1, 2) == "PL") %>% group_by(geo) %>% summarise(work = round(5*mean(values, na.rm = TRUE)/252, 2)) %>% ungroup() %>% mutate(geo = as.character(geo)), by = c("id" = "geo")) %>% ggplot() + geom_polygon(aes(long, lat, group = group, fill = as.factor(work)), color = "black") + coord_map() + scale_fill_brewer(palette = "YlOrRd", direction = -1) + labs(title = "Kto pracuje najdłużej w Polsce?", subtitle = "Na podstawie danych Eurostat, stan na koniec 2011 roku", x = "", y = "", fill = "Średnia liczba godzin pracy w tygodniu") + theme(axis.text = element_blank()) |
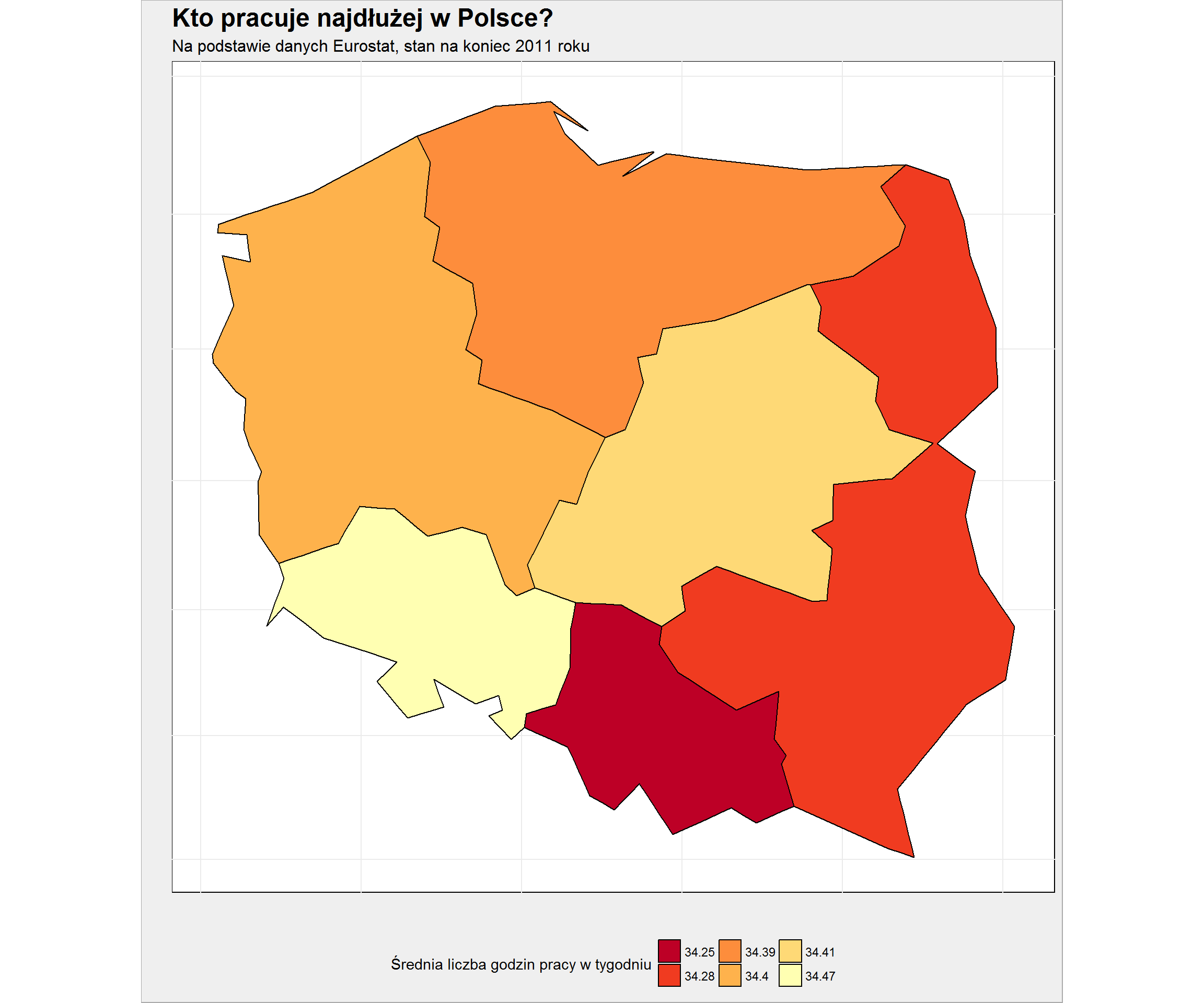
O dziwo wcale Mazowsze (z Warszawą na czele) nie pracuje najwięcej. Jak wdać Małopolska ma najwięcej luzu (idealnie pasuje tutaj Kraków – Ocean wolnego czasu Maanamu).
Pod pierwszą mapką napisałeś „Jest to jak widać Europa, a nawet Unia Europejska” – ale mapka jest nieco szersza i zawiera kraje spoza UE (Norwegia, Szwajcaria, Islandia, Turcja, Macedonia (?), Czarnogóra (?)). Teoretycznie Eurostat zajmuje się UE+EFTA, ale to wyjaśnia tylko pierwsze trzy…
Analiza bardzo fajna ale jestem szalenie ciekaw jak wygląda to dzisiaj. Sporo się wydarzyło od 2011 roku i mam wrażenie że dziś Polska wypada nieco lepiej :)
Też chciałem zobaczyć jak to wygląda teraz, ale niestety Eurostat nie ma tak nowych danych :(
Może dane są w OECD – szczerze mówiąc nie szukałem tam.