Jakiś czas temu była analiza ocen filmów (na podstawie bazy Filmwebu), obiecałem w różnych miejscach, że będzie też o książkach. Zatem sprawdźmy czego możemy się dowiedzieć z danych pobranych z serwisu LubimyCzytać.pl.
Przez kilka tygodni skrypt działający sobie grzecznie na serwerze pobierał stronę po stronie z serwisu, analizował zapisane na niej dane i przepisywał je sobie do lokalnego pliku (dane zgromadziłem w pliku books_total.RDS, z którego za chwilę je wczytamy).
I tutaj ciekawostka. Poprosiłem redakcję serwisu o przesłane danych, tak aby nie zapychać im serwerów. Poprosiłem jednocześnie zaznaczając, że chcę przygotować niniejszą analizę, a jeśli nie otrzymam danych – pobiorę je samodzielnie. Odmówiono mi. Żeby być miłym oszczędziłem serwery (swoje i cudze) i przed kolejnymi hitami w stronę czekałem losową liczbę sekund (od 1 do 3). Warto to robić, warto być przyzwoitym. Ale mimo wszystko nie udało się pobrać wszystkich danych (a ileż możecie czekać na nowy post?). Tak czy inaczej – mamy ponad 330 tysięcy wierszy.
Wiersze zawierają informację o tytule książki, jej autora, wydawnictwo, datę wydania (skorzystamy tylko z roku), liczbie stron i kategorii do której dana książka została przypisana w serwisie. Dodatkowo – to co najbardziej ciekawe – mamy średnią ocenę, liczbę ocen oraz liczbę każdej z ocen przyznanych przez użytkownika (od 1 do 10 gwiazdek). Gdzieś jest też znacznik w jakim języku jest książka. Fajne dane, można sobie porobić różne przekroje. I tak zrobimy.
Zaczynamy oczywiście od przygotowania środowiska – wczytanie pakietów i danych:
|
1 2 3 4 5 6 7 |
library(tidyverse) library(tidytext) library(wordcloud) books <- readRDS("books_total.RDS") theme_set(theme_minimal()) |
Od razu przystąpimy do analizy. Średnia ocena książki to 6.78 przy średniej liczbie ocen 65. A jak to wygląda według kategorii?
Średnia ocena książki według kategorii
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
books %>% # tylko książki z ocenami filter(!is.na(score_mean)) %>% # średnie oceny i liczby książek w ramach kategorii # oraz liczba książek w kategorii group_by(category) %>% summarise(mean_score = mean(score_mean), mean_score_sum = round(mean(score_sum)), n=n()) %>% ungroup() %>% # weźmy tylko kategorie w których liczba książek jest powyżej mediany tej liczby filter(n > median(n)) %>% # kolejność słupków arrange(mean_score) %>% mutate(category = factor(category, levels=category)) %>% # wykres ggplot() + geom_bar(aes(category, mean_score), stat="identity", fill="lightgreen", color="darkgreen") + geom_text(aes(category, mean_score, label=paste0("(", n, ", ", mean_score_sum, ")")), hjust=-0.3) + geom_text(aes(category, mean_score, label=round(mean_score, 2)), hjust=1.3) + ylim(0,10) + coord_flip() + labs(x="Kategoria", y="Średnia ocena (liczba tytułów, średnia liczba ocen)") |
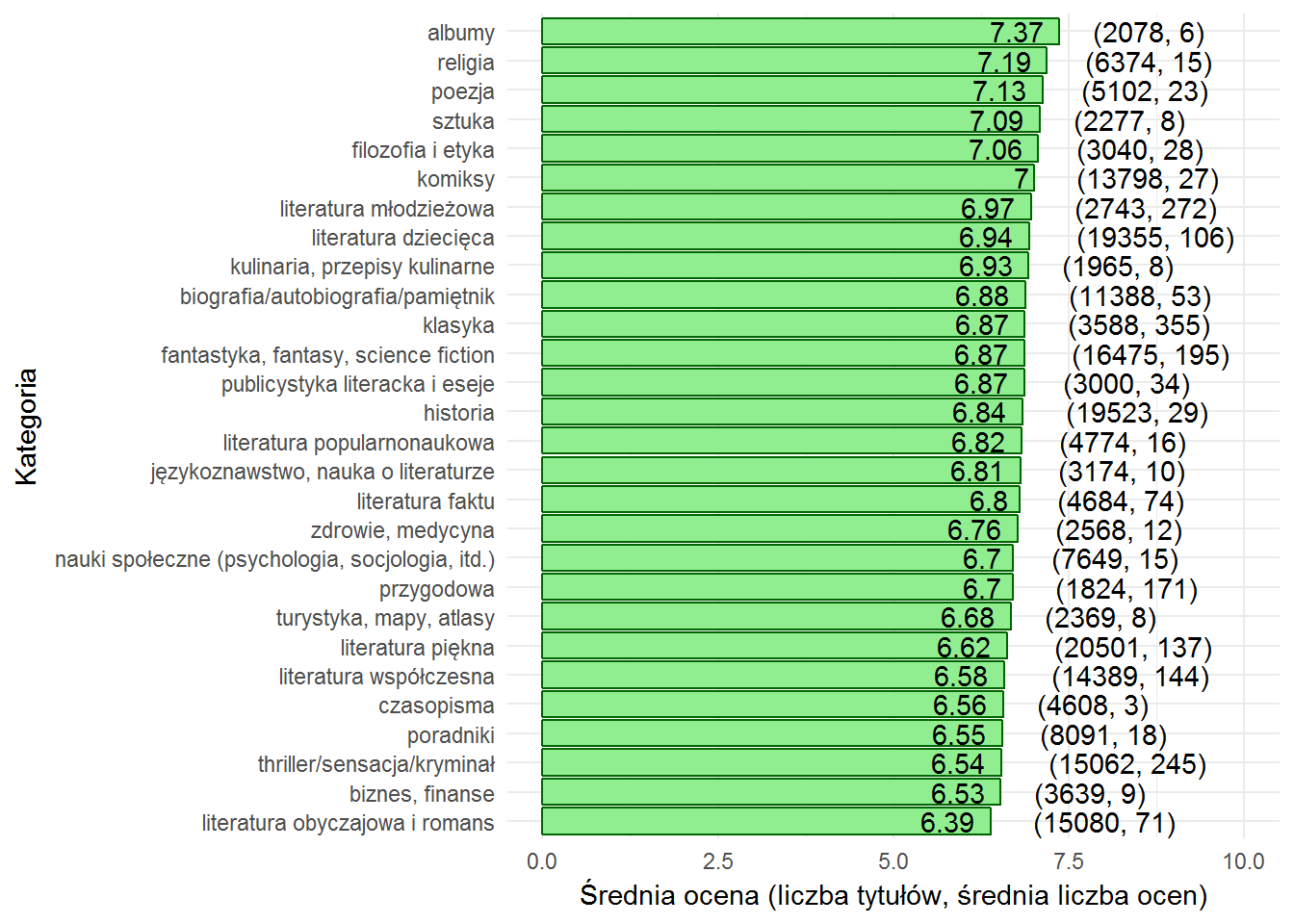
Może trochę zaskakujące? Najlepiej oceniane są książki w kategoriach album, sztuka, komiks (z tych “obrazkowych”) oraz religia i poezja.
Najgorsze według użytkowników LubimyCzytać są książki z kategorii literatura obyczajowa i romans (wiecie, że to tzw. harlequiny, prawda?).
W środku stawki, powyżej średniej oceny (6.78) mamy większość kategorii.
Ważne jest jeszcze jedno – żeby uznać średnią ocenę jako dość obiektywną powinna być zebrana z odpowiednio dużej próby. O wielkości tej próby będzie za chwilę, ale już teraz można powiedzieć, że niektóre kategorie mają za mało ocen. Takie mapy i atlasy na przykład, wspomniana sztuka czy już ewidentnie czasopisma.
Skąd zaskoczenie? Sądziłem, że to co bardziej poczytne (druga liczba w nawiasie – kategorie najpopularniejsze to: klasyka, literatura młodzieżowa, thriller/kryminał, przygodowa, fantastyka i sci-fi, literatura współczesna i piękna) będzie miało większe oceny. Ale przecież z drugiej strony – wcale najpopularniejsze nie oznacza najlepsze, wręcz może być odwrotnie (w imię eat shit, miliony much nie mogą się mylić). Zobaczymy to za chwilę.
20 najpopularniejszych książek razem z ocenami
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
books %>% top_n(20, wt = score_sum) %>% mutate(auth_title = paste0(author, " \"", title, "\"")) %>% select(auth_title, score_sum, score_mean) %>% distinct() %>% arrange(score_sum) %>% mutate(auth_title=factor(auth_title, levels=unique(auth_title))) %>% ggplot() + geom_bar(aes(auth_title, score_mean), stat="identity", fill="lightgreen", color="darkgreen") + geom_text(aes(auth_title, score_mean, label=paste0("(", score_sum, ")")), hjust=-0.2) + geom_text(aes(auth_title, score_mean, label=round(score_mean, 2)), hjust=1.2) + ylim(0,10) + coord_flip() + labs(x="Autor i tytuł książki", y="Średnia ocena (liczba głosów)") |
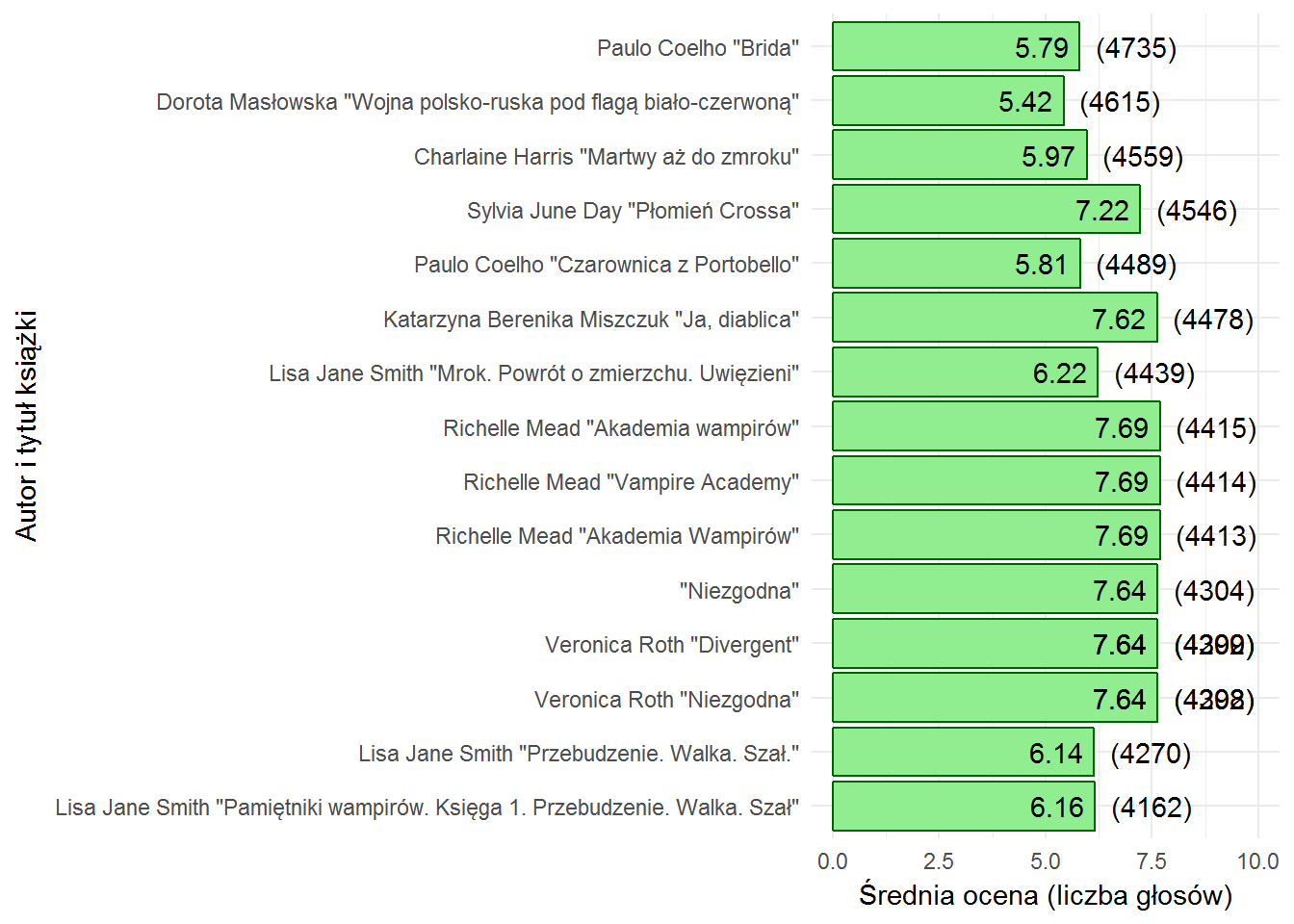
Wykres jest ułożony przewrotnie – na górze mamy te tytuły, które mają najwięcej ocen, a długość słupka odpowiada ocenie.
Moja ulubiona książka Masłowskiej to bardzo dobry przykład na (uwaga, popularne słowo) hejt w internecie. Mam wrażenie, że sporo z tych ocen to jedynki, a mało jest tych ciągnących w górę… Można by zobaczyć to bezpośrednio w danych, ale problem jest taki (i dotyczy on większości tytułów), że w bazie LubimyCzytać powtarza się bardzo dużo książek. Bo wydane są w różnych wydawnictwach, bo są wznowienia (wydania w kolejnych latach), bo chyba coś nie tak jest w bazie danych. Taka właśnie “Wojna polsko-ruska pod flagą biało-czerwoną” występuje kilka razy (linki do stron dotyczącej tej książki poniżej) i wpisy wiele się nie różnią:
| n | Strona | Ocena | Liczba ocen |
|---|---|---|---|
| 1 | Wydawnictwo: Lampa i Iskra Boża, rok: 2002 | 5.185 | 2937 |
| 2 | Wydawnictwo: Lampa i Iskra Boża, rok: 2003 | 5.184 | 2950 |
| 3 | Wydawnictwo: Świat Książki, rok: 2003 | 5.185 | 2937 |
| 4 | Wydawnictwo: Lampa i Iskra Boża, rok: 2005 | 5.184 | 2938 |
| 5 | Wydawnictwo: Code Red Tomasz Stachewicz, rok: 2015 | 5.184 | 2938 |
| 6 | Wydawnictwo: Lampa i Iskra Boża | 5.185 | 2937 |
| 7 | Wydawnictwo: Aleksandria | 5.185 | 2937 |
| 8 | Wydawnictwo: Lampa i Iskra Boża | 5.425 | 4615 |
Zobaczmy więc jaka jest średnia liczba poszczególnych ocen (liczba gwiazdek) dla tej konkretnej książki:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
books %>% # tylko konkretna książka filter(title == "Wojna polsko-ruska pod flagą biało-czerwoną") %>% # tylko potrzebne kolumny select(score_1:score_10) %>% # unpivot gather() %>% # średnia liczba głosów według oceny group_by(key) %>% summarise(value = mean(value)) %>% ungroup() %>% # wysokość słupka jako procent mutate(proc = round(100 * value/sum(value), 1)) %>% # kolejność słupków mutate(key = factor(key, levels = c(paste0("score_", 1:10)))) %>% # wykres ggplot() + geom_bar(aes(key, value), stat="identity", fill="lightgreen", color="black") + geom_text(aes(key, value, label=paste0(proc, "%")), vjust = 1.3) + labs(x="Ocena", y="Liczba ocen") |
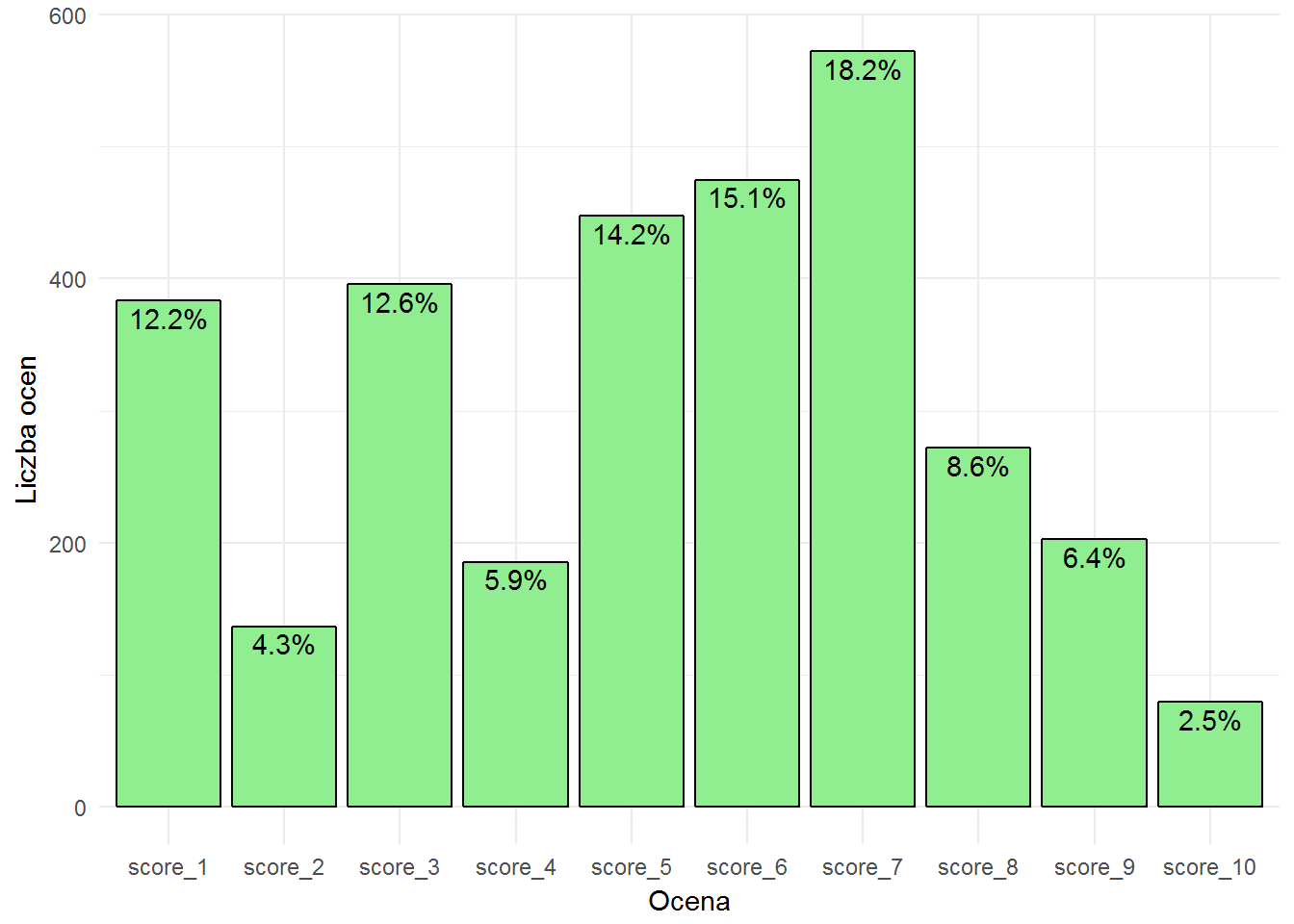
Tak jak można było podejrzewać – dużo jedynek i trójek (łącznie to 1/4 ocen), bardzo mało 10. Najwięcej szóstek i siódemek (1/3 ocen) co się zgadza z ogółem (o tym będzie za moment).
Wracając do najpopularniejszych książek – nie znam większości z tych tytułów, po tytułach wnioskuję że to czytadła pokroku “Sagi Zmierzch” dla młodzieży. Stosunkowo mało tutaj Paulo Coelho, znowu widać powtórki w tytułach, raz “Niezgodna” jest z autorem, innym razem bez, “Akademia wampirów” dwa razy… Oj, kiepska jakość bazy, kiepska.
A Coelho jest ze średnią oceną 6.43 i średnią liczbą ocen 301. Z wykresu widać też, że “Brida” to jego najpopularniejsza książka.
Liczba ocen a ocena
Czy liczba ocen ma znaczenie? Pytanie (nie bezpośrednio) padło wyżej, poszukajmy odpowiedzi:
|
1 2 3 4 5 6 |
books %>% filter(!is.na(score_mean)) %>% ggplot() + geom_point(aes(score_sum, score_mean), color="lightgreen", alpha=0.2) + geom_smooth(aes(score_sum, score_mean), se = FALSE, color="darkred", size=2) + labs(x="Liczba głosów", y="Średnia ocena") |
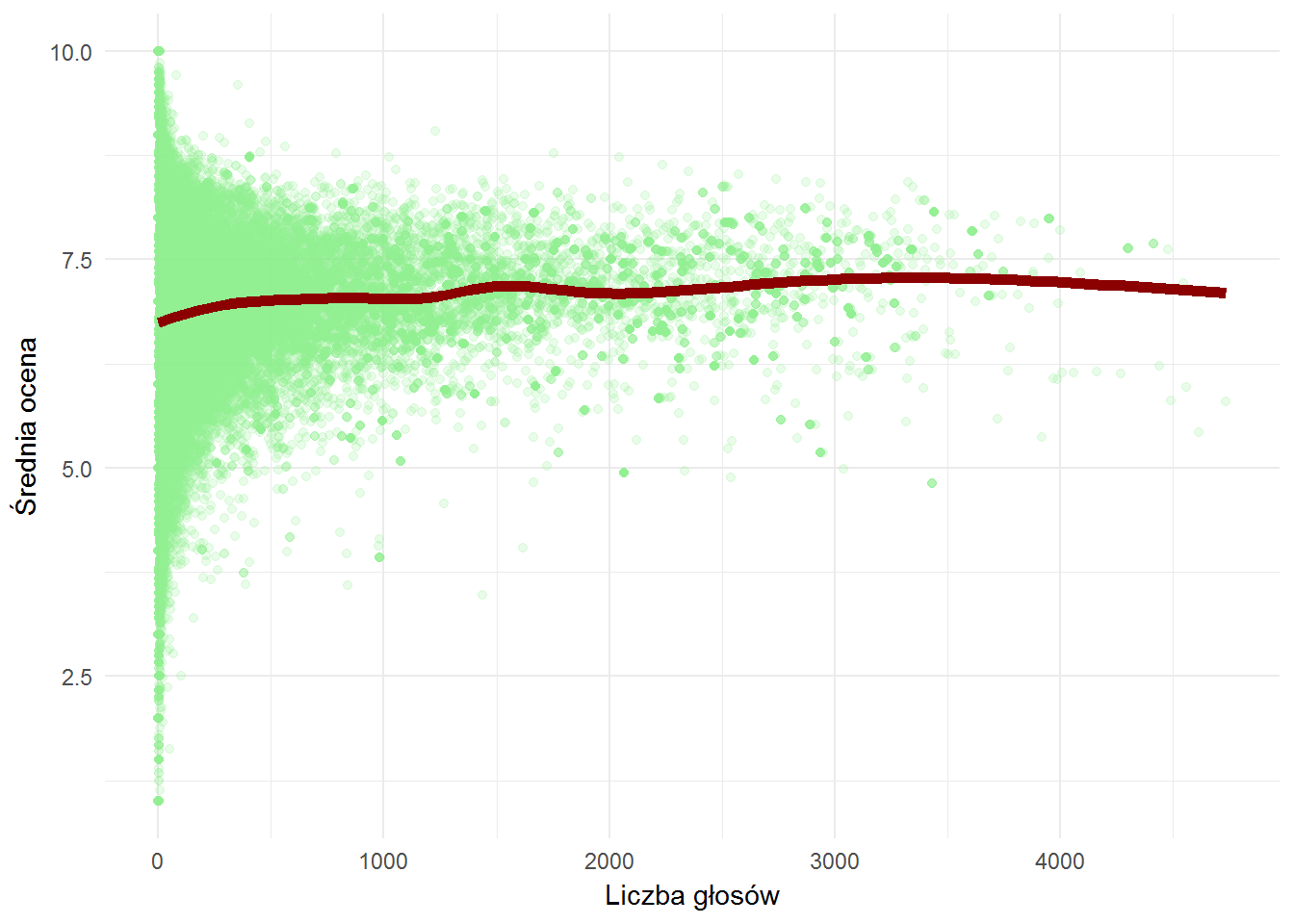
Liczba głosów nie ma znaczenia dla średniej oceny książki. Książki albo są dobre, albo złe – to czy swój głos odda 10 czy 1000 osób nie ma większego znaczenia. Poza tym, że średnia będzie coraz bliższa rzeczywistej obiektywnej oceny.
Weryfikowałem to w przypadku filmów – co 30 minut pobierałem średnią ocenę i liczbę oddanych głosów filmu, który miał premierę (zaczynał więc bez żadnej oceny). Gdzieś w okolicach 100-200 oddanych głosów średnia się ustabilizowała. Można więc przyjąć, że jeśli na daną pozycję zagłosowało 100 lub więcej osób to ocena jest wiarygodna i nie będzie się zmieniać w czasie. Oczywiście wahnięcia o ułamek punktu są możliwe. To jest między innymi przyczyna, dla której wszelakie listy Top500 na IMBd.com lub innym FilmWebie są dość stabilne.
To wynika też ze statystyki i liczności próby badawczej. Dlaczego badania przeprowadza się na reprezentatywnej próbie tysiąca Polaków? Dlatego, że tyle osób wystarczy do określenia jakie preferencje ma prawie 40 milionów. Serwisy internetowe mają mniejszą bazę użytkowników, w związku z tym liczebność próby badawczej (owe 100 ocen) jest mniejsza.
Średnia według wydawnictwa
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
books %>% # tylko to co ma ocenę i wydawcę filter(!is.na(score_mean), !is.na(publisher)) %>% # średnia ocena w ramach wydawnictwa group_by(publisher) %>% summarise(mean_score = mean(score_mean), n=n()) %>% ungroup() %>% # top 20 średnich ocen top_n(20, wt = n) %>% arrange(mean_score) %>% mutate(publisher = factor(publisher, levels=unique(publisher))) %>% # wykres ggplot() + geom_bar(aes(publisher, mean_score), stat="identity", fill="lightgreen", color="darkgreen") + geom_text(aes(publisher, mean_score, label=n), hjust=-0.2) + geom_text(aes(publisher, mean_score, label=round(mean_score, 2)), hjust=1.2) + ylim(0,10) + coord_flip() + labs(x="Wydawnictwo", y="Średnia ocena (liczba książek)") |
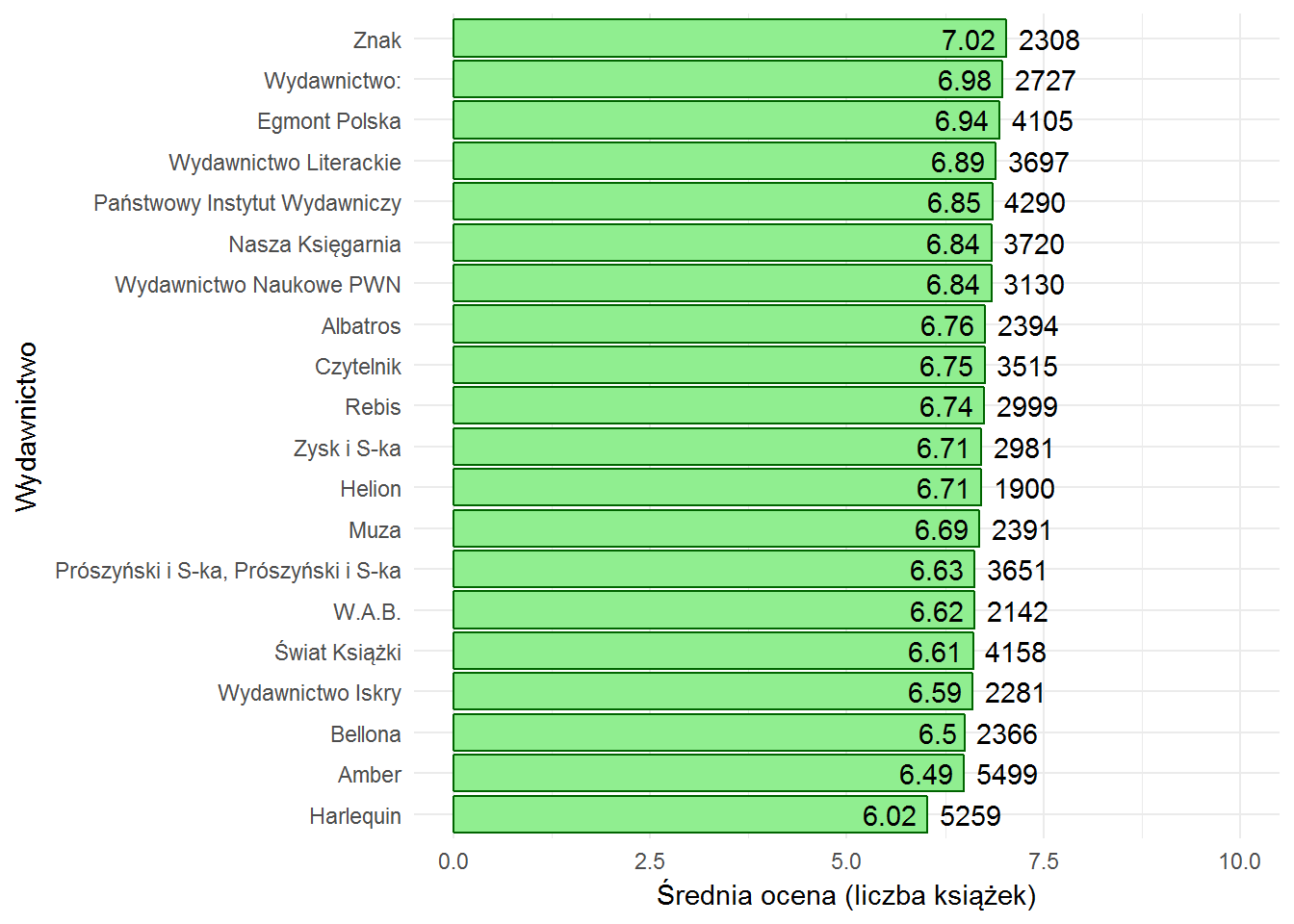
Największe wydawnictwa wydają najlepsze tytuły. Po prostu. Pozycja druga to błąd w danych (lub ich scrappingu). Widzicie Harlequina na dole wykresu? Pamiętacie kategorię literatura obyczajowa i romans? Łączy się to jakoś? Nie widać tego bezpośrednio, można to jednak udowodnić odpowiednio zestawiając dane.
Przejdźmy jednak dalej.
Rozkład liczby stron
Jak grube są książki?
|
1 2 3 4 5 6 7 8 9 |
books %>% # tylko to co ma liczbę stron :) filter(!is.na(pages)) %>% # to co ma tą liczbę poniżej 99-percentyla # to odcięcie wartości mocno odstających filter(pages <= quantile(pages, 0.99)) %>% ggplot() + geom_density(aes(pages), fill="lightgreen", color="black") + labs(x="Liczba stron", y="Gęstość prawdopodobieństwa") |
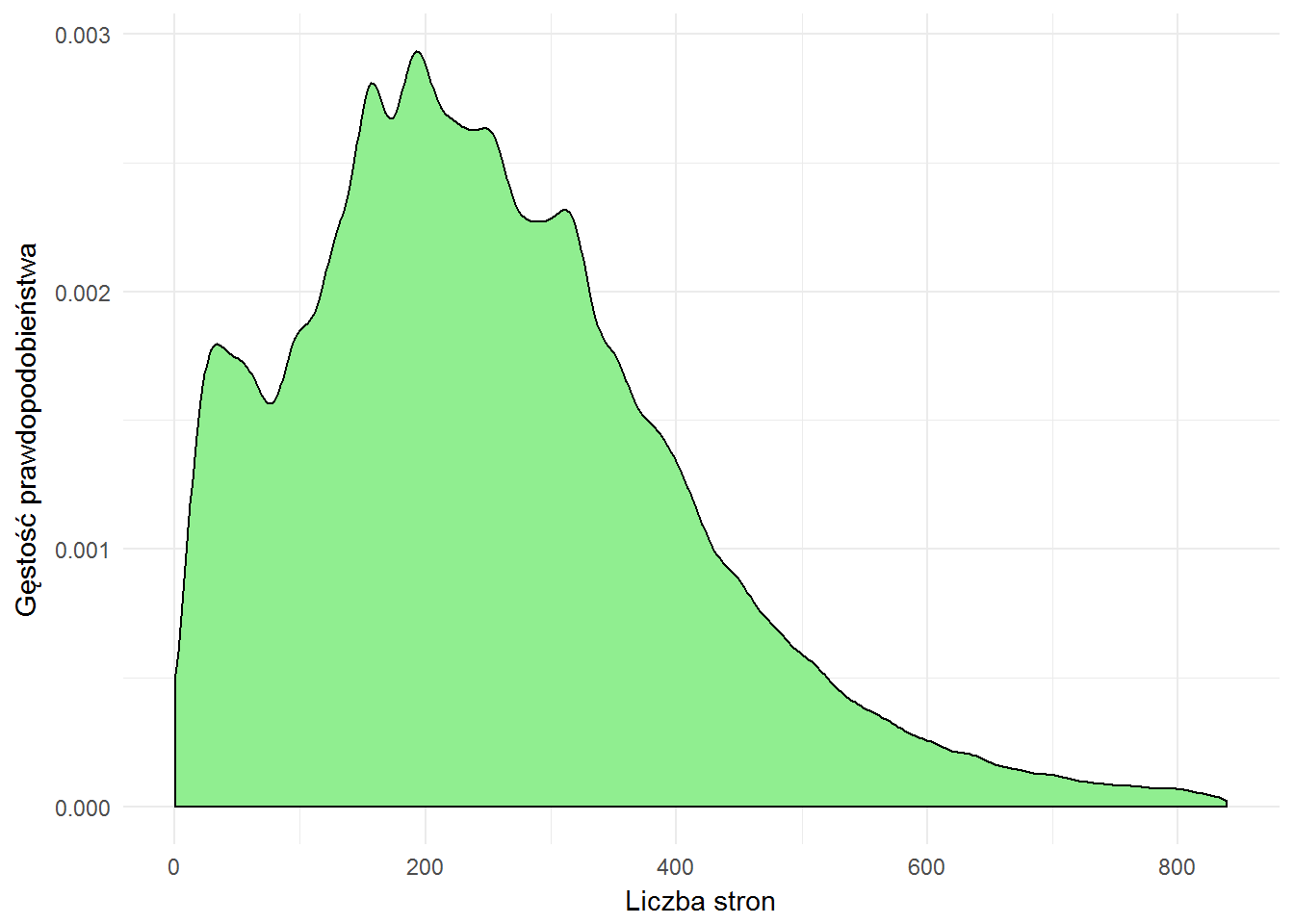
Najwięcej jest książek około 180-230 stronicowych.
Rozkład liczby ocen
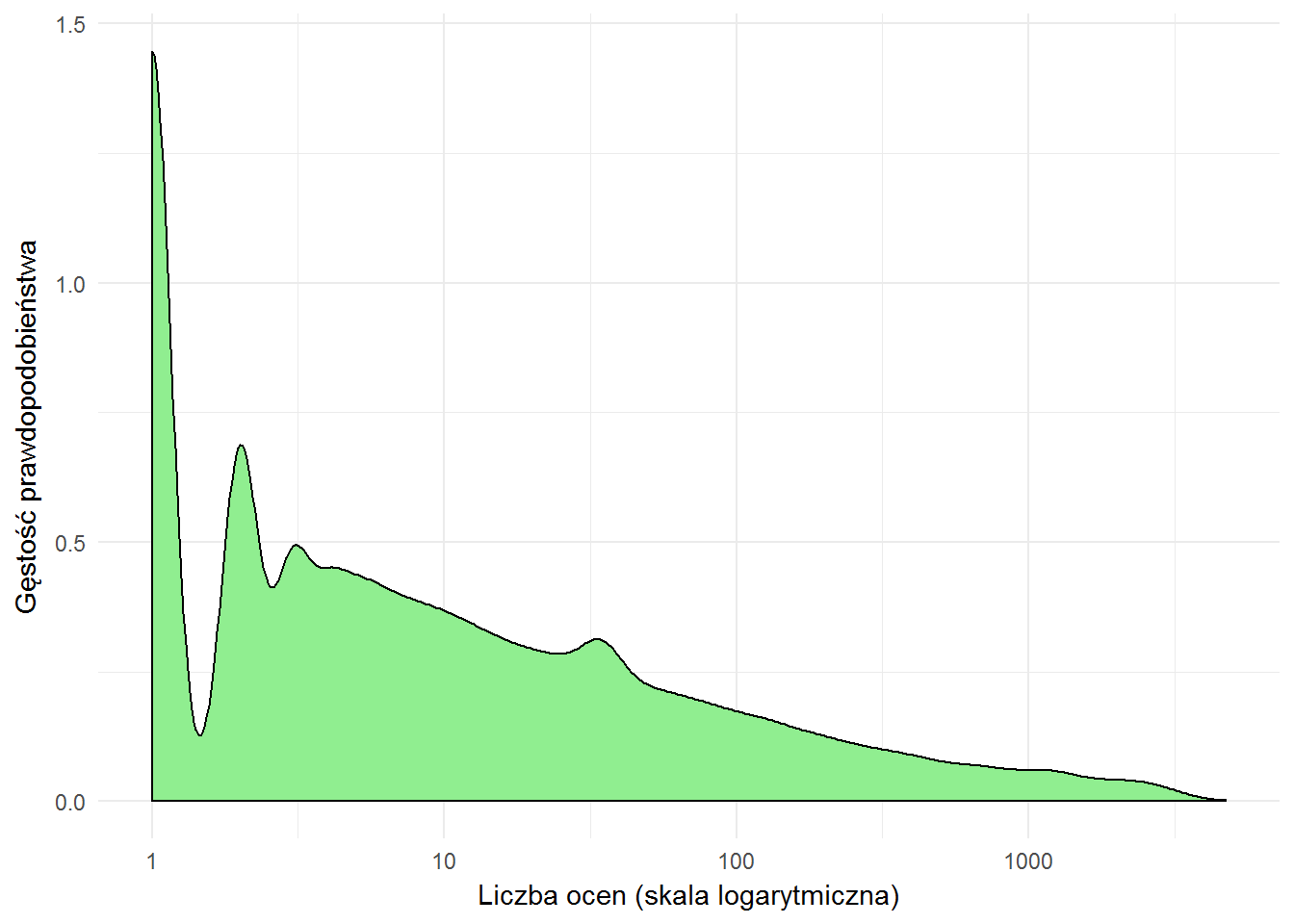
Najwięcej jest książek mających po kilka-kilkanaście ocen. Średnia liczba ocen to 65, obetnijmy więc powyższy wykres tylko do książek, które mają więcej ocen niż ich średnia:
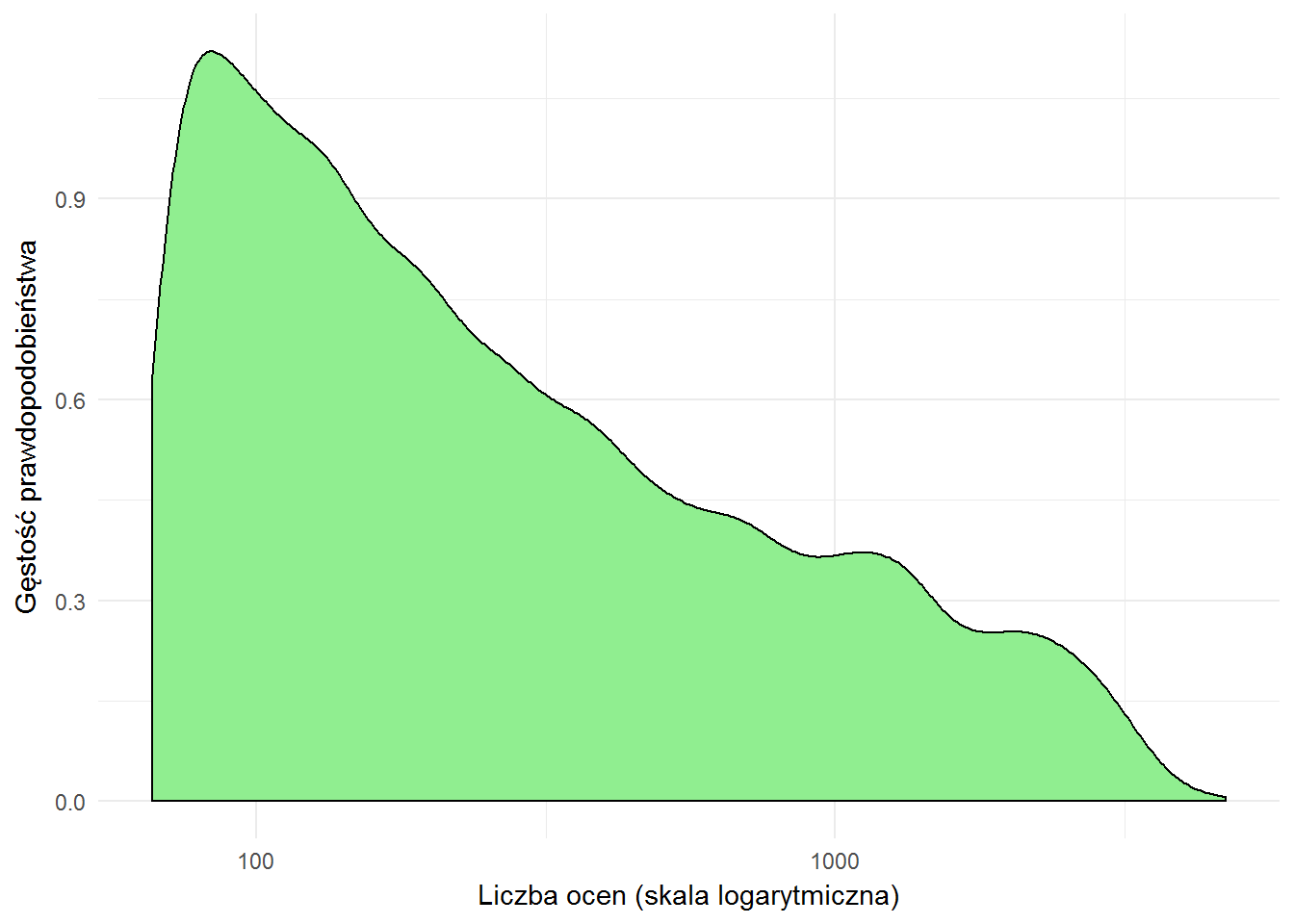
Jak widać – niewiele się zmienia, a najwięcej jest książek po około 100 ocen. Napisałem coś wyżej o stabilizacji średniej przy około 100 głosach albo o liczebności próby badawczej? Właśnie.
Rozkład ocen
Zobaczmy teraz jaka średnia ocena jest najbardziej popularna. Ale już uwzględniając te książki, które mają co najmniej 65 ocen (żeby wykluczyć książki ocenione na 10 przez jedną osobę).
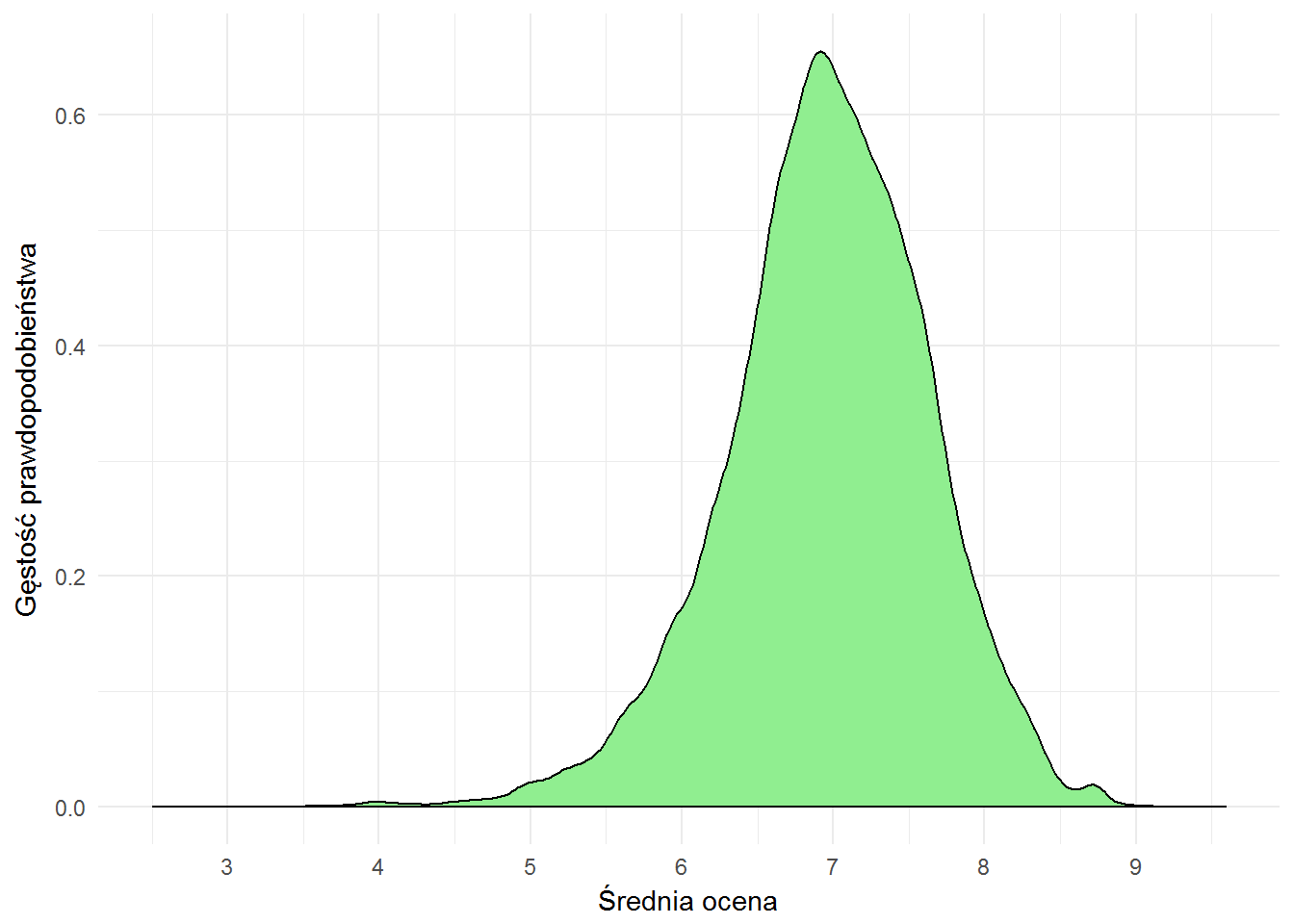
Średnio książka ma zatem ocenę bliską 7 (dokładnie 6.958) oraz medianę (połowa książek jest oceniona lepiej, a połowa gorzej) równą 6.979. Różnica pomiędzy średnią i medianą prawie żadna, a to widać już po wykresie gęstości prawdopodobieństwa – mamy tutaj rozkład taki trochę kopnięty normalny.
Jak wygląda rozkład głosów? Czyli jakie oceny przyznają użytkownicy?
Rozkład nadawanych głosów
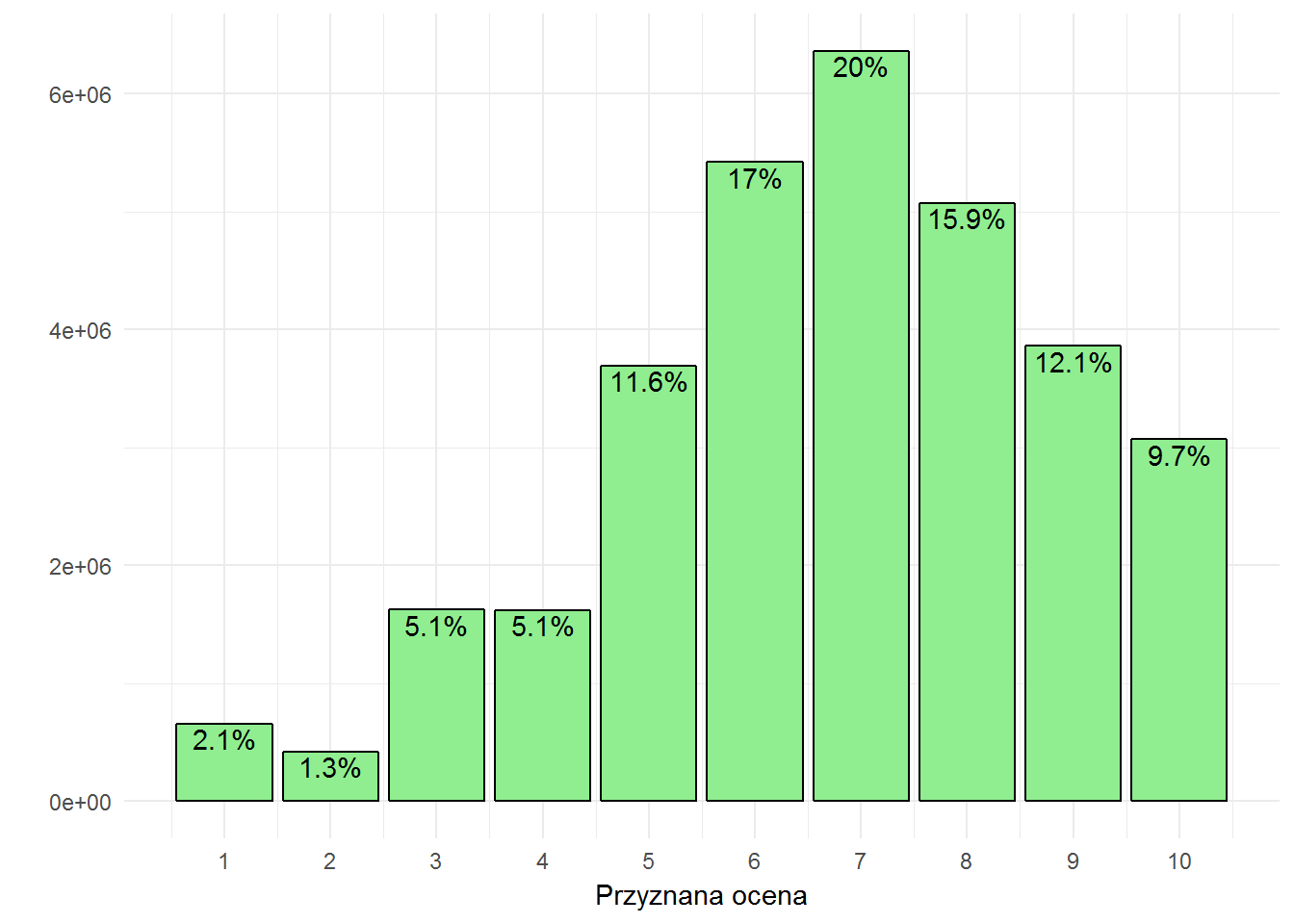
Najbardziej popularną oceną jest siódemka, następna w kolejności to szóstka (i to oczywiście powoduje średnią pomiędzy 6 a 7 – pamiętacie jeszcze oceny książki Masłowskiej?). To ciekawe spostrzeżenie, można je zauważyć w innych serwisach oceniających, na przykład filmy (sprawdź pierwszy wykres słupkowy w tekście o ocenach filmów). Może to być również przyczynek do upraszczania systemu gwiazdek – zamiast skali 10 stopniowej powinna wystarczyć na przykład trzystopniowa: zły, średni, dobry? Albo dwustopniowa: lubię lub nie lubię. Przy filmach pokusiłem się nawet o wyliczenie czegoś na kształt wskaźnika NPS.
Rozkład ocen według kategorii
Jak wyglądają oceny w ramach kategorii? Czy jedne kategorie mają więcej ocen dobrych niż inne? Czyli czy po prostu książki z danej kategorii są lepiej oceniane?
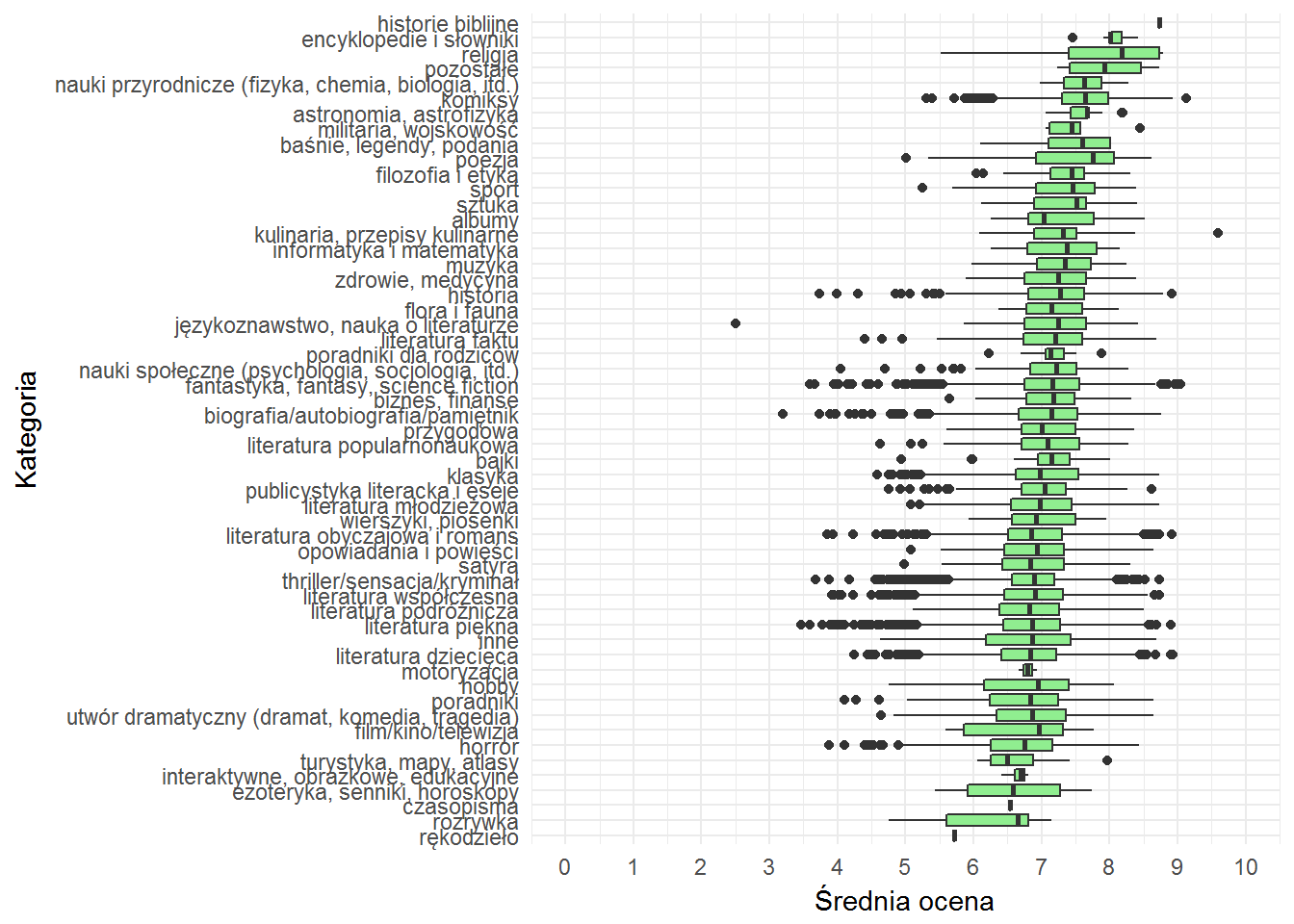
To bardziej precyzyjny obraz niż średnia ocena według kategorii – tutaj widać zróżnicowanie. Im szerszy słupek tym większy rozrzut. I na przykład taka motoryzacja jest w miarę zwarta. Jak bardzo? Ano:
|
1 2 3 4 |
books %>% filter(category == "motoryzacja", # jest w kategorii motoryzacja !is.na(score_mean)) %>% select(score_mean) %>% # i ma ocenę summary() |
|
1 2 3 4 5 6 7 |
## score_mean ## Min. : 3.000 ## 1st Qu.: 6.700 ## Median : 7.147 ## Mean : 7.129 ## 3rd Qu.: 7.756 ## Max. :10.000 |
Widać, że 1 i 3 kwartyl nie są tak bardzo od siebie oddalone.
Czas na najciekawsze pytanie:
Jakie są najlepsze książki (według kategorii)?
Ano takie:
|
1 2 3 4 5 6 7 8 9 10 |
# górne 30% liczby ocen brane pod uwagę books %>% filter(score_sum >= quantile(score_sum, 0.7, na.rm=TRUE)) %>% group_by(category) %>% mutate(cat_max_score = max(score_mean)) %>% ungroup() %>% filter(score_mean == cat_max_score) %>% select(category, title, author, score_mean) %>% mutate(score_mean = round(score_mean, 2)) %>% arrange(category) |
| Kategoria | Tytuł | Autor | Ocena |
|---|---|---|---|
| albumy | Witold Pilecki. Fotobiografia | Maciej Sadowski | 9.42 |
| astronomia, astrofizyka | Nasz matematyczny Wszechświat. W poszukiwaniu prawdziwej natury rzeczywistości | Max Tegmark | 8.56 |
| bajki | Baśnie braci Grimm | Ruth Brocklehurst | 8.80 |
| baśnie, legendy, podania | Baśnie Andersena | Hans Christian Andersen | 8.60 |
| biografia/autobiografia/pamiętnik | Dziennik 1943-1948 | Sándor Márai | 9.36 |
| biznes, finanse | Dzieła zebrane. T. 1 | Frédéric Bastiat | 9.29 |
| czasopisma | Teraz Rock. Kolekcja ‘po całości’, nr 8. Guns N’ Roses | Redakcja magazynu Teraz Rock | 8.40 |
| encyklopedie i słowniki | Moja pierwsza encyklopedia zwierząt | Marta Kotecka | 8.77 |
| ezoteryka, senniki, horoskopy | Przywracanie zdrowia | David R. Hawkins | 9.40 |
| fantastyka, fantasy, science fiction | Wojownicy. Cisza przed burzą | Erin Hunter | 9.22 |
| film/kino/telewizja | 33 x Trójka | Wiesław Weiss | 8.43 |
| filozofia i etyka | Boża Opatrzność | Catalina Rivas | 9.44 |
| flora i fauna | Ptaki. Przewodnik Collinsa | Lars Svensson | 9.32 |
| historia | Getto Warszawskie. Przewodnik po nieistniejącym mieście. | Barbara Engelking, Jacek Leociak | 9.30 |
| historia | Narodziny cywilizacji Wysp Brytyjskich | Wojciech Lipoński | 9.30 |
| historie biblijne | Biblia | 8.73 | |
| historie biblijne | Biblia to jest Pismo Święte Starego i Nowego Testamentu z Apokryfami | autor nieznany | 8.73 |
| hobby | Inwazja bazgrołów. Książka do kolorowania | Zifflin, Kerby Rosanes | 8.90 |
| horror | The Whisperer in Darkness: Collected Stories Volume I | Howard Phillips Lovecraft | 8.45 |
| informatyka i matematyka | Kod doskonały. Jak tworzyć oprogramowanie pozbawione błędów | Steve McConnell | 9.06 |
| inne | Co chatka to zagadka | Andrzej Setman | 9.71 |
| interaktywne, obrazkowe, edukacyjne | Mieszkamy w książce! | Mo Willems | 9.21 |
| językoznawstwo, nauka o literaturze | Gwara warszawska dawniej i dziś | Bronisław Wieczorkiewicz | 8.67 |
| klasyka | herodot: dzieje | 9.17 | |
| komiksy | Życie i czasy Sknerusa McKwacza | Don Rosa | 9.24 |
| kulinaria, przepisy kulinarne | Najwyższa jakość | NA | 9.59 |
| literatura dziecięca | We mgle | Walt Disney, Kiki Thorpe | 9.33 |
| literatura faktu | Fotograf z Auschwitz | Anna Dobrowolska | 9.03 |
| literatura młodzieżowa | Elena. Tajemnica stadniny | Nele Neuhaus | 9.11 |
| literatura obyczajowa i romans | Ilium | Josephine Angelini | 9.06 |
| literatura piękna | Siedem grzechów głuchych | Kaja Kowalewska | 9.60 |
| literatura podróżnicza | Amazonia – piekielne piękno. Kiedy przygoda zderza się z życiem | 9.25 | |
| literatura popularnonaukowa | Biologia | Neil A. Campbell | 9.28 |
| literatura współczesna | Play listy, czyli nie wszystkie fobie są o miłości | Kaja Kowalewska | 9.28 |
| militaria, wojskowość | Pamiętnik (1941 -maj 1949) | Zdzisław Broński | 8.96 |
| motoryzacja | Gawędy motocyklowe | praca zbiorowa | 8.23 |
| muzyka | Tysiąc i jedna opera | Piotr Kamiński | 9.27 |
| nauki przyrodnicze (fizyka, chemia, biologia, itd.) | Feynmana wykłady z fizyki t. 1-3 | Richard Phillips Feynman | 8.94 |
| nauki społeczne (psychologia, socjologia, itd.) | Nowa Psychocybernetyka | Maxwell Maltz | 9.33 |
| opowiadania i powieści | American Daydream | Justyna Gaworska | 8.95 |
| poezja | nieskończoność M.YŚLI | Magdalena Joanna Wojciechowska | 9.70 |
| poradniki | Światło jogi | B. K. S. Iyengar | 9.15 |
| poradniki dla rodziców | Mama alergika gotuje tradycyjnie | Katarzyna Jankowska | 8.25 |
| pozostałe | Biblia | 8.73 | |
| przygodowa | Danzig Breslau Danzig | Amos Oskar Ajchel | 9.20 |
| publicystyka literacka i eseje | Listy z Rzymu | Zbigniew Kadłubek | 9.36 |
| religia | Mądrość Ewangelii | Francesco Bersini | 9.60 |
| rękodzieło | Cuda z modeliny. Techniki, materiały, pomysły | Sue Heaser | 8.24 |
| rozrywka | Niesamowicie rozkoszne koty | Stuart Macfarlane | 8.89 |
| satyra | Jarek Patriota: Bóg, honor i włoszczyzna | Artur Pruziński | 8.46 |
| sport | The Book of Basketball | Bill Simmons | 9.50 |
| sztuka | Hiroshige: Sto Słynnych Widoków Edo | Bichler Lorenz, Trede Melanie | 9.75 |
| teatr | Performatyka: wstęp | Richard Schechner | 9.00 |
| technika | Typografia książki. Podręcznik projektanta | Michael Mitchell, Susan Wightman | 8.67 |
| thriller/sensacja/kryminał | Pretty Lost Dolls | Ker Dukey | 9.44 |
| turystyka, mapy, atlasy | Polska egzotyczna. Tom 2 | Grzegorz Rąkowski | 8.67 |
| utwór dramatyczny (dramat, komedia, tragedia) | Tragedie i kroniki | William Shakespeare | 9.47 |
| wierszyki, piosenki | Gupik ma szczęście! | Tomek Nowaczyk | 8.94 |
| zdrowie, medycyna | Zapalenie Tarczycy Hashimoto | Izabella Wentz MD, Marta Nowosadzka MD | 9.06 |
To jeszcze sprawdźmy jacy są
najlepsi autorzy (według kategorii)
|
1 2 3 4 5 6 7 8 9 10 11 12 |
# górne 30% liczby ocen brane pod uwagę books %>% filter(score_sum >= quantile(score_sum, 0.7, na.rm=TRUE)) %>% group_by(category, author) %>% summarise(group_mean_score = mean(score_mean), n=n()) %>% ungroup() %>% group_by(category) %>% filter(group_mean_score == max(group_mean_score)) %>% ungroup() %>% select(category, author, mean_score=group_mean_score) %>% mutate(mean_score = round(mean_score, 2)) %>% arrange(category) |
| category | author | mean_score |
|---|---|---|
| albumy | Maciej Sadowski | 9.42 |
| astronomia, astrofizyka | Max Tegmark | 8.56 |
| bajki | Ruth Brocklehurst | 8.80 |
| baśnie, legendy, podania | Małgorzata Sobczak | 8.58 |
| biografia/autobiografia/pamiętnik | Jan Rossman, Anna Zawadzka | 9.14 |
| biznes, finanse | Bernard Fruga | 8.67 |
| biznes, finanse | Oskar Jażdżyk | 8.67 |
| czasopisma | Redakcja pisma Trans/wizje | 8.07 |
| encyklopedie i słowniki | Marta Kotecka | 8.77 |
| ezoteryka, senniki, horoskopy | David R. Hawkins | 9.40 |
| fantastyka, fantasy, science fiction | S.L. Leśna | 9.12 |
| film/kino/telewizja | Wiesław Weiss | 8.43 |
| filozofia i etyka | Catalina Rivas | 9.44 |
| flora i fauna | Lars Svensson | 9.32 |
| historia | Barbara Engelking, Jacek Leociak | 9.30 |
| historie biblijne | autor nieznany | 8.73 |
| hobby | Zifflin, Kerby Rosanes | 8.90 |
| horror | Michael Sims | 8.10 |
| informatyka i matematyka | Steve McConnell | 9.06 |
| inne | Andrzej Setman | 9.07 |
| interaktywne, obrazkowe, edukacyjne | Mo Willems | 9.21 |
| językoznawstwo, nauka o literaturze | Bronisław Wieczorkiewicz | 8.67 |
| klasyka | John Milton | 8.71 |
| komiksy | Sergio Cariello, Doug Mauss | 9.00 |
| komiksy | Steve Lieber, Matt Fraction i inni… | 9.00 |
| kulinaria, przepisy kulinarne | NA | 9.59 |
| literatura dziecięca | Tony Wolf, Jane Brierley i inni… | 9.28 |
| literatura faktu | Anna Dobrowolska | 9.03 |
| literatura młodzieżowa | Nele Neuhaus | 8.93 |
| literatura obyczajowa i romans | Josephine Angelini | 9.06 |
| literatura piękna | Kaja Kowalewska | 9.60 |
| literatura podróżnicza | Rafał Urbanelis | 9.00 |
| literatura popularnonaukowa | Neil A. Campbell | 9.28 |
| literatura współczesna | Kaja Kowalewska | 9.28 |
| militaria, wojskowość | Zdzisław Broński | 8.96 |
| motoryzacja | Witold Rychter | 7.88 |
| muzyka | Piotr Kamiński | 9.27 |
| nauki przyrodnicze (fizyka, chemia, biologia, itd.) | Roger Penrose | 8.77 |
| nauki społeczne (psychologia, socjologia, itd.) | Maxwell Maltz | 9.33 |
| opowiadania i powieści | Justyna Gaworska | 8.95 |
| poezja | Magdalena Joanna Wojciechowska | 9.70 |
| poradniki | B. K. S. Iyengar | 9.15 |
| poradniki dla rodziców | Katarzyna Jankowska | 8.25 |
| pozostałe | Agnieszka Kossowska | 8.65 |
| przygodowa | Amos Oskar Ajchel | 8.79 |
| publicystyka literacka i eseje | Zbigniew Kadłubek | 9.36 |
| religia | Francesco Bersini | 9.60 |
| rękodzieło | Sue Heaser | 8.24 |
| rozrywka | Stuart Macfarlane | 8.89 |
| satyra | Artur Pruziński | 8.46 |
| sport | Bill Simmons | 9.50 |
| sztuka | Bichler Lorenz, Trede Melanie | 9.75 |
| teatr | Richard Schechner | 9.00 |
| technika | Michael Mitchell, Susan Wightman | 8.67 |
| thriller/sensacja/kryminał | Ker Dukey | 9.44 |
| turystyka, mapy, atlasy | Grzegorz Rąkowski | 8.62 |
| utwór dramatyczny (dramat, komedia, tragedia) | Jarosław Borszewicz | 8.64 |
| wierszyki, piosenki | Tomek Nowaczyk | 8.94 |
| zdrowie, medycyna | Izabella Wentz MD, Marta Nowosadzka MD | 9.06 |
Nazwiska powinny się pokrywać z tabelą najlepszych książek. Chociaż nie musi oczywiście tak być.
Przejdźmy do dziedziny czasu.
Książki według daty wydania
|
1 2 3 4 5 6 |
books %>% filter(date >= 1950, date <= 2017) %>% ggplot() + geom_histogram(aes(date), binwidth = 1, fill="lightgreen", color="black") + labs(x="Rok", y="Liczba książek") + scale_x_continuous(breaks = seq(1950, 2020, 5)) |
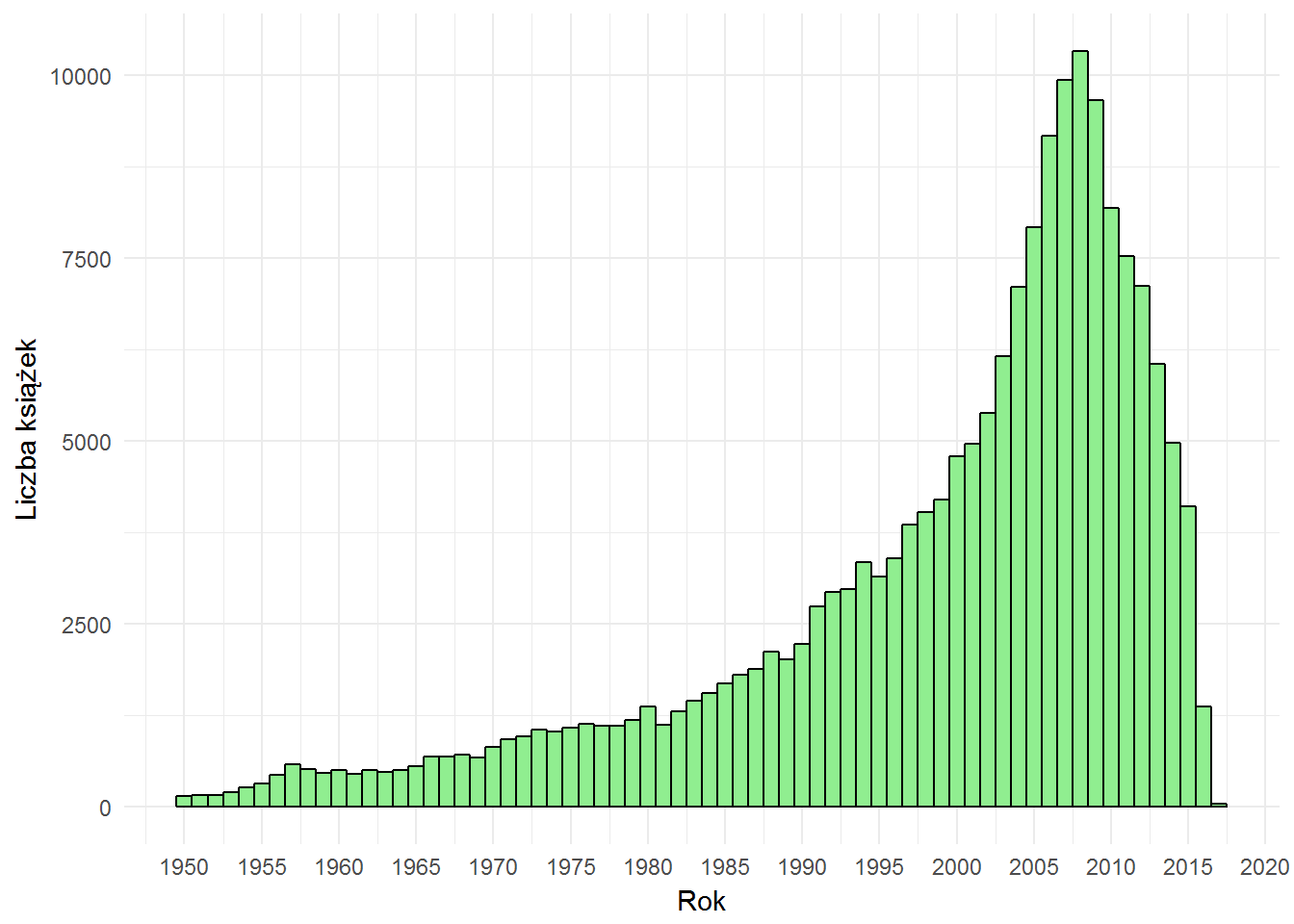
Serwis LubimyCzytać.pl istnieje od jakiegoś czasu i zapewne jest tak, że stara się mieć w bazie najnowsze książki (o nowościach dyskutuje się najchętniej) – stąd im bliżej “dzisiaj” tym więcej książek. Brakuje kompletu danych z lat 2015-2017, bo ich najzwyczajniej w świecie nie pobrałem (ileż można czekać…). Widać jednak wyraźną tendencję i sądzę, że w kolejnych latach słupki są po prostu wyższe (no, 2017 może być jeszcze niższy niż 2016 – w końcu rok jeszcze trwa).
Ocena w zależności od daty wydania
Czy data wydana książki ma wpływ na jej ocenę?
|
1 2 3 4 5 6 7 8 9 |
books %>% filter(date >= 1950, date <= 2017, !is.na(score_mean)) %>% filter(score_sum >= quantile(score_sum, 0.1)) %>% ggplot() + geom_jitter(aes(date, score_mean), color="lightgreen", height = 0, width = 0.25, alpha=0.2) + geom_smooth(aes(date, score_mean), se = FALSE, color="darkred", size=2) + labs(x="Rok", y="Średnia ocena") + scale_x_continuous(breaks = seq(1950, 2020, 10)) |
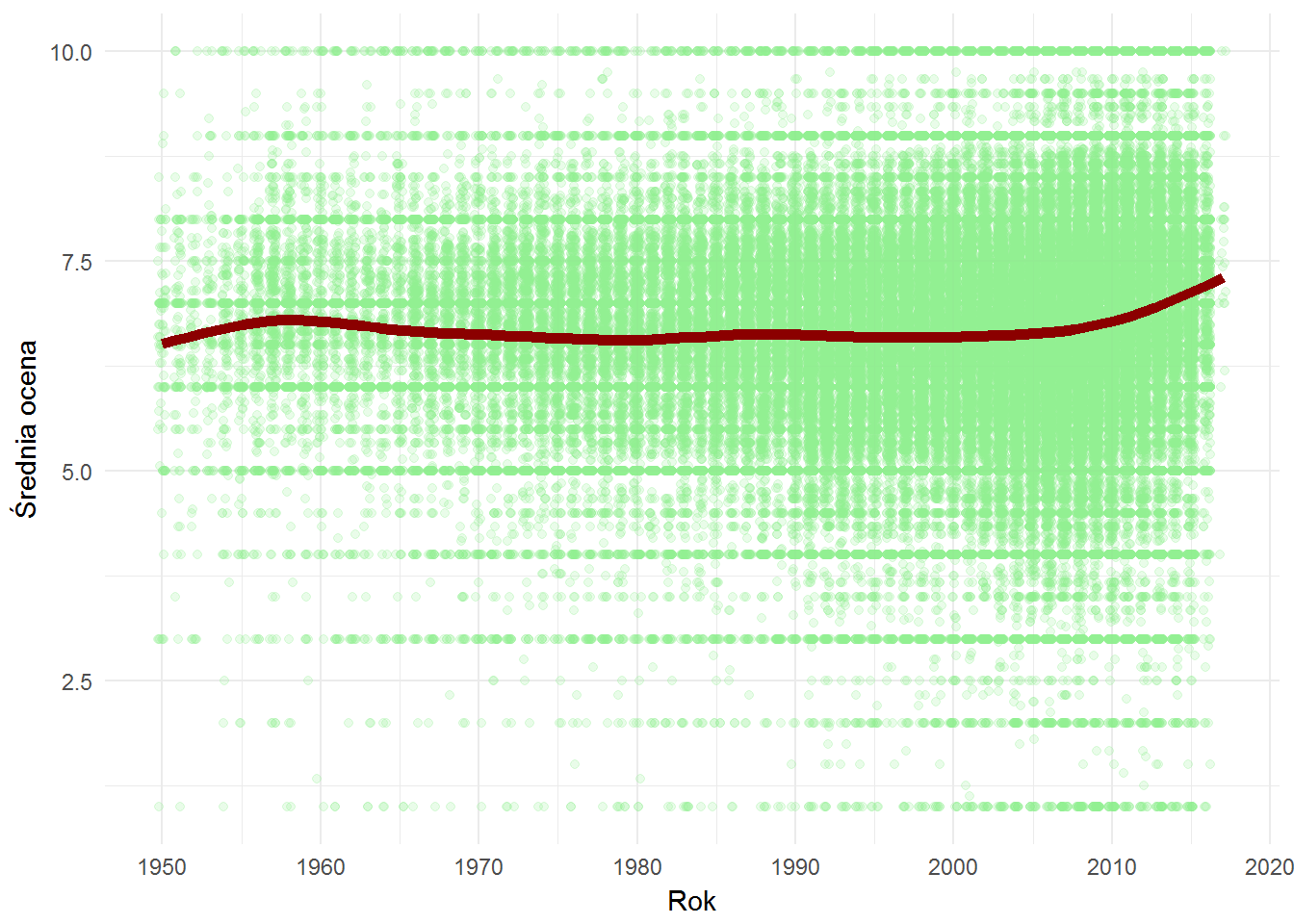
W zasadzie nie, chociaż dla najnowszych książek linia zawija się wyraźnie ku górze. Być może znaczenie ma liczba ocen?
Liczba ocen w zależności od daty wydania
|
1 2 3 4 5 6 7 8 9 10 |
books %>% filter(date >= 1950, date <= 2017, score_sum > 0) %>% filter(score_sum >= quantile(score_sum, 0.1)) %>% ggplot() + geom_jitter(aes(date, score_sum), color="lightgreen", height = 0, width = 0.25, alpha=0.2) + geom_smooth(aes(date, score_sum), se = FALSE, color="darkred", size=2) + scale_y_log10() + labs(x="Rok", y="Liczba ocen") + scale_x_continuous(breaks = seq(1950, 2020, 10)) |
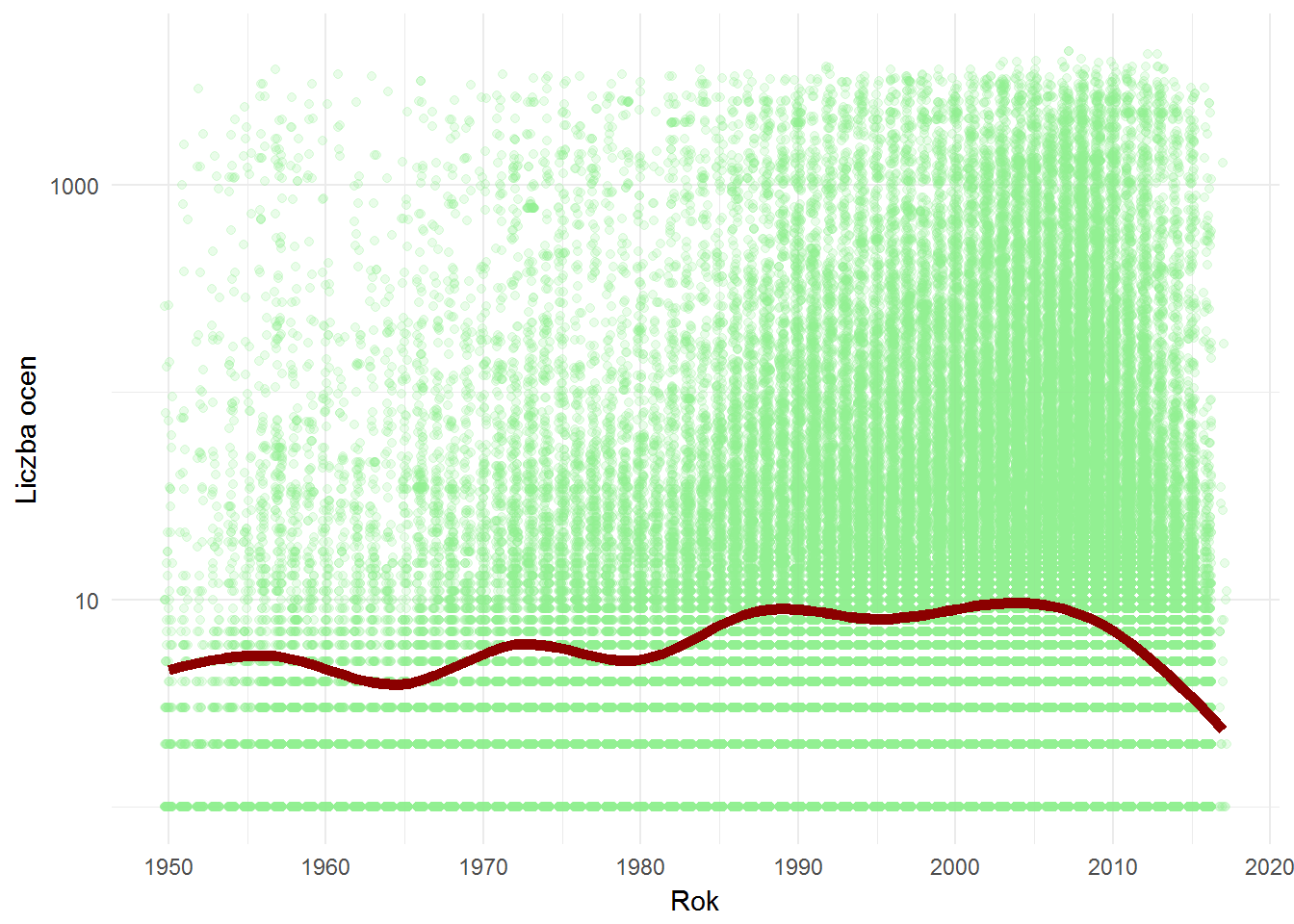
Z linii trendu tego nie widać (ot, faluje sobie jakoś), ale kiedy popatrzymy na zagęszczenie punktów to wyraźnie dla nowszych książek jest więcej ocen. To może potwierdzać strategię serwisu (lub po prostu ludzką natruę) – chętniej dyskutujemy czy oceniamy nowości. A ci, którzy czytają dużo na pewno przeczytali klasykę, a teraz czytają na bieżąco to co ukazuje się na rynku. I na bieżąco oceniają nie pamiętając aby uzupełnić oceny książek, które dawno temu przeczytali (to mój problem na Filwebie – mimo pewnie już prawie dwóch tysięcy ocenionych filmów ciągle są takie, które widziałem dawno temu, a ich nie oceniłem).
Oczywiście linia trendu spada po prawej stronie – brakuje nam danych to raz, a dwa – nie wszyscy przeczytali jeszcze te najnowsze książki. W końcu poziom czytelnictwa spada z roku na rok…
A czy grube książki są lepsze?
Liczba stron a ocena
|
1 2 3 4 5 6 7 |
books %>% filter(!is.na(pages), !is.na(score_mean)) %>% filter(pages <= quantile(pages, 0.99), score_sum >= quantile(score_sum, 0.1)) %>% ggplot() + geom_point(aes(pages, score_mean), color="lightgreen", alpha=0.2) + geom_smooth(aes(pages, score_mean), se = FALSE, color="darkred", size=2) + labs(x="Liczba stron", y="Średnia ocena") |
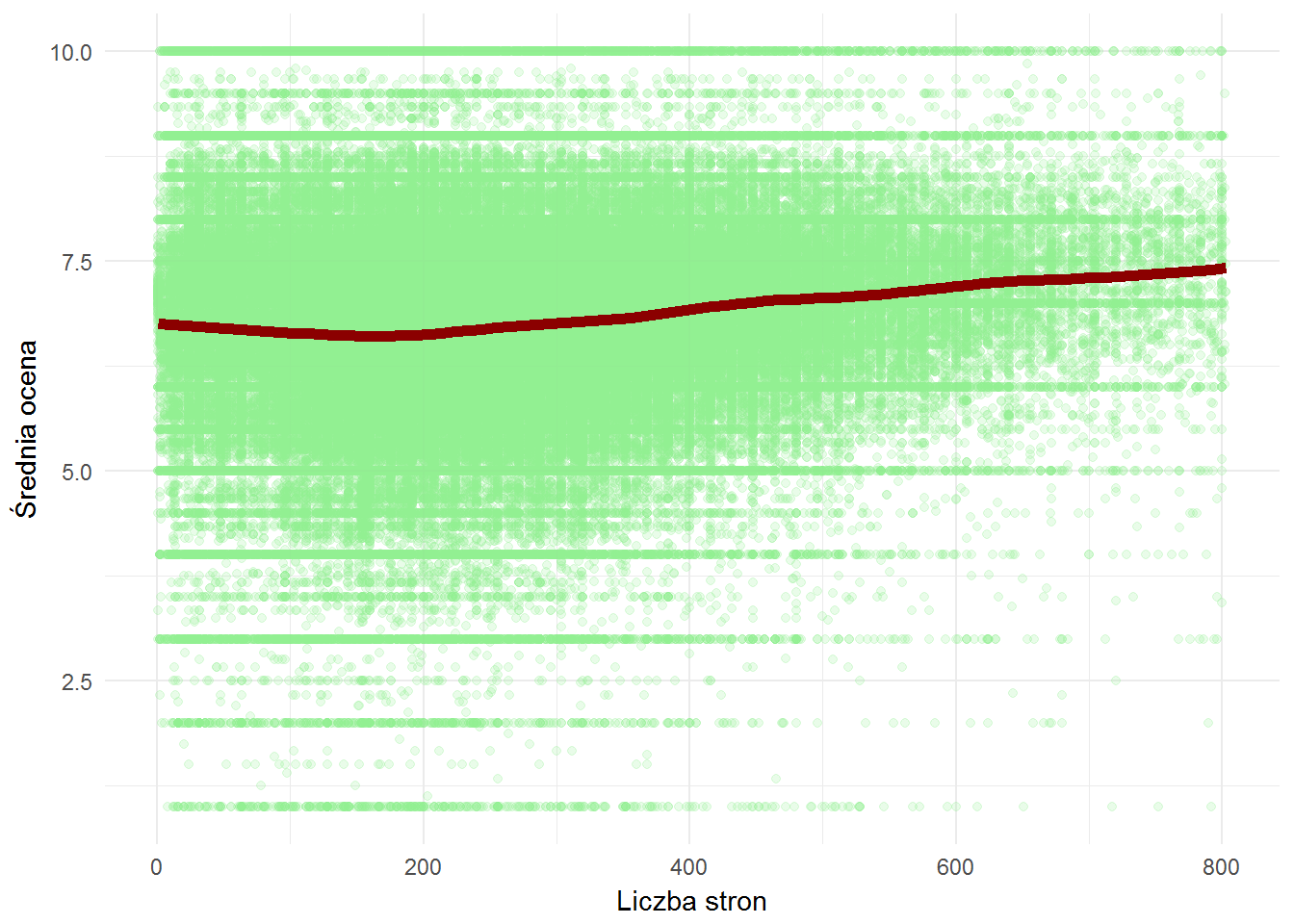
Liczba stron nie ma bardzo dużego znaczenia dla oceny książki, ale jakieś ma. Im grubsza książka tym wyższa ocena. Delikatnie, ale jednak. Troszeczkę. Nie bardzo. W sumie wokół średniej.
Liczba stron a liczba ocen
Czyli odpowiedź na pytanie czy wolimy czytać grube książki?
|
1 2 3 4 5 6 7 8 |
books %>% filter(!is.na(pages), score_sum > 0) %>% filter(pages <= quantile(pages, 0.99), score_sum >= quantile(score_sum, 0.1)) %>% ggplot() + geom_point(aes(pages, score_sum), color="lightgreen", alpha=0.2) + geom_smooth(aes(pages, score_sum), se = FALSE, color="darkred", size=2) + scale_y_log10() + labs(x="Liczba stron", y="Liczba ocen") |
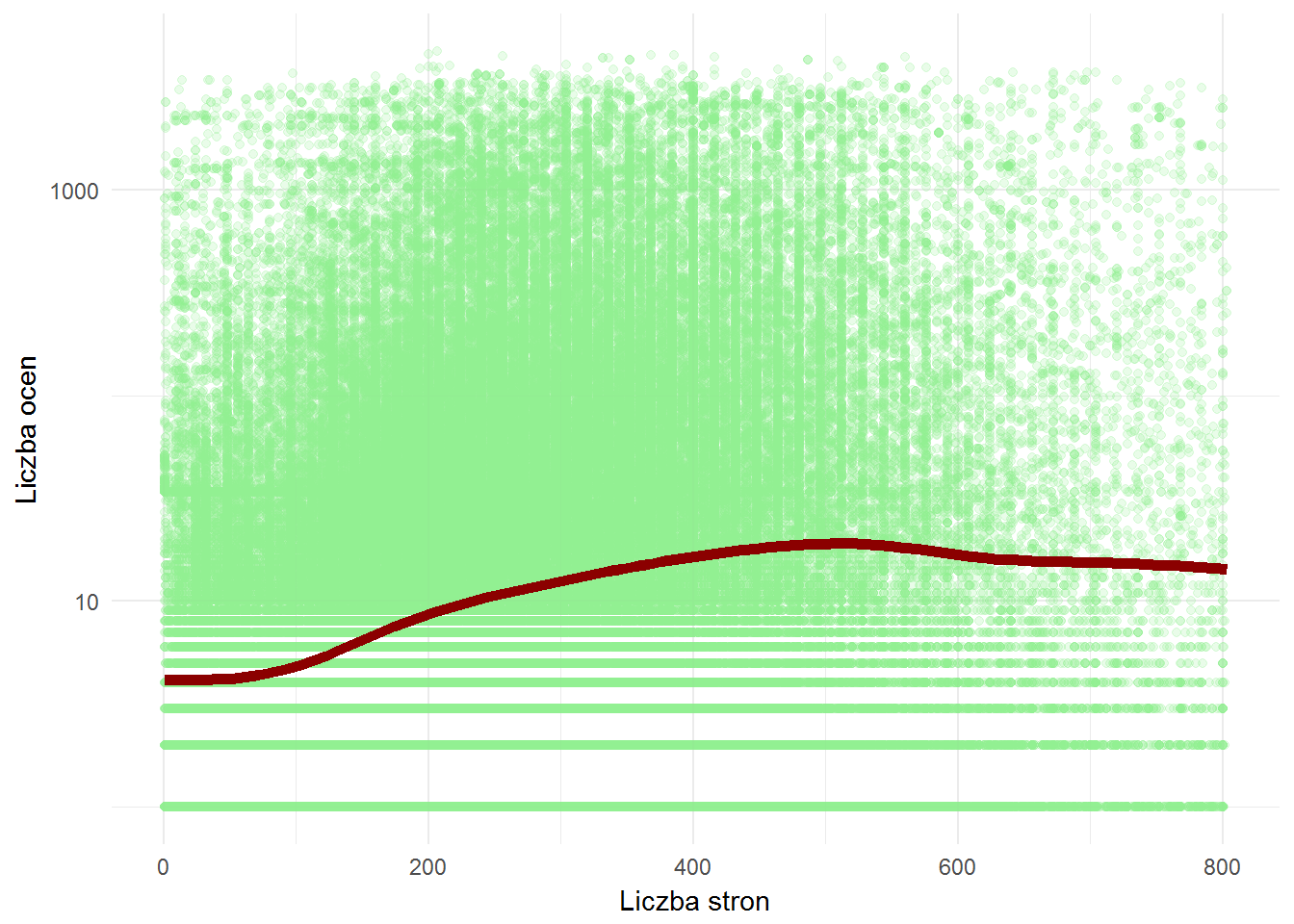
Dla liczby ocen znaczenie ma już liczba stron. Znowu trend tego nie pokazuje tak mocno jak gęstość punktów. Najwięcej ocen mają książki po 200-300 stron. Czyli te najpopularniejsze.
Co ciekawe – kiedy narysujemy macierz ze współczynnikami korelacji to zależności pomiędzy rokiem (date), liczbą stron (pages), liczbą ocen (score_sum) i średnią oceną (score_mean) nie są zbyt mocne:
|
1 2 3 4 5 6 7 |
library(corrgram) books %>% select(date, pages, score_mean, score_sum) %>% filter(date >= 1950, date <= 2017, score_sum >= mean(score_sum, na.rm = TRUE), pages <= quantile(pages, 0.99, na.rm = TRUE)) %>% corrgram(lower.panel = panel.shade, upper.panel = panel.cor) |
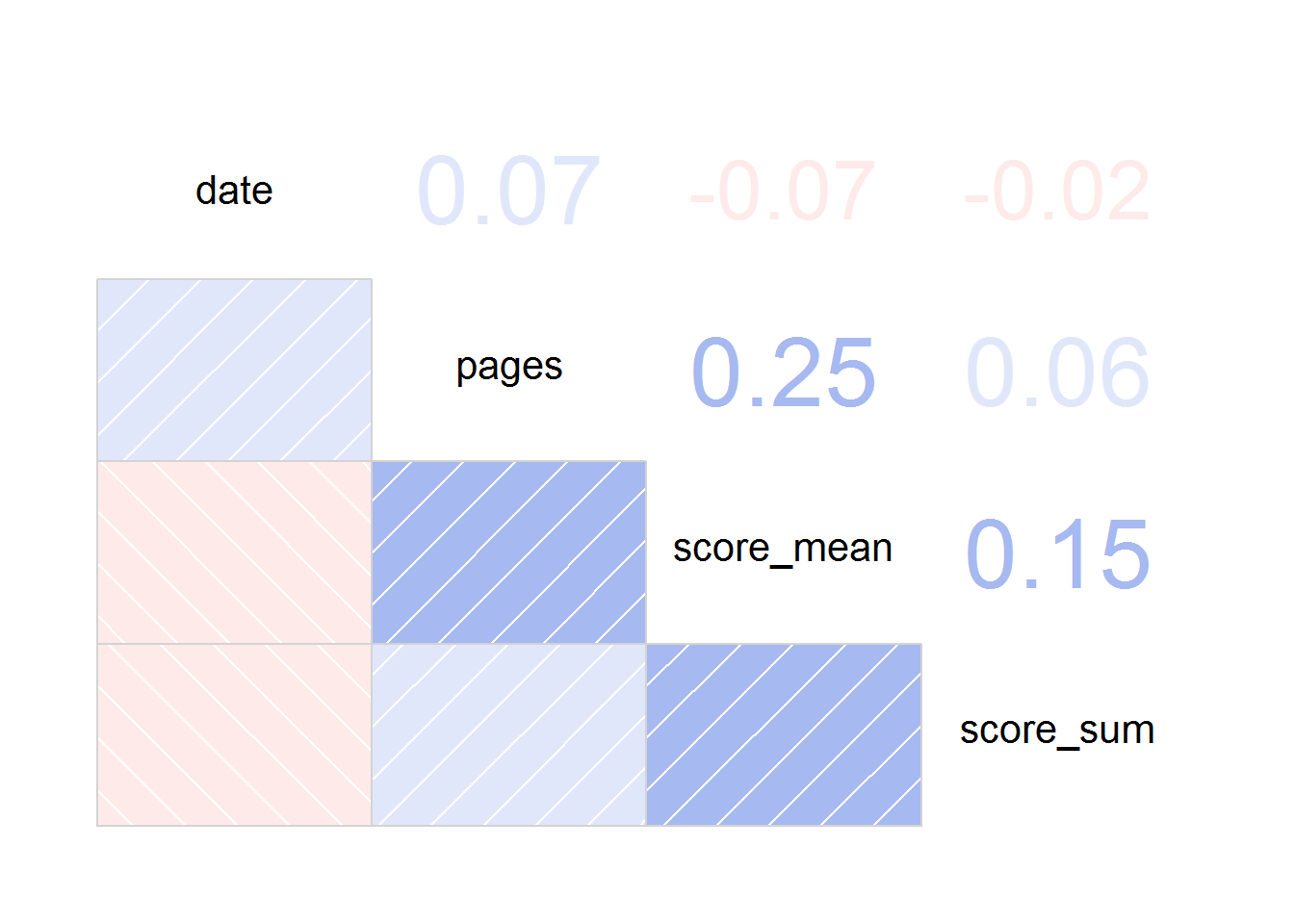
Najsilniejsza zależność wiąże liczbę stron i średnią ocenę, co już widzieliśmy na wykresach z liniami trendu.
Najbardziej płodni autorzy
Czyich książek mamy najwięcej?
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
books %>% filter(!author %in% c("praca zbiorowa", "autor nieznany", "")) %>% select(author, title) %>% distinct() %>% count(author) %>% ungroup() %>% top_n(20, wt = n) %>% arrange(n) %>% mutate(author=factor(author, levels=unique(author))) %>% ggplot() + geom_bar(aes(author, n), stat="identity", color="black", fill="lightgreen") + geom_text(aes(author, n, label=n), hjust=1.2) + coord_flip() + theme(legend.position = "bottom") + labs(x="Autor", y="Liczba książek") |
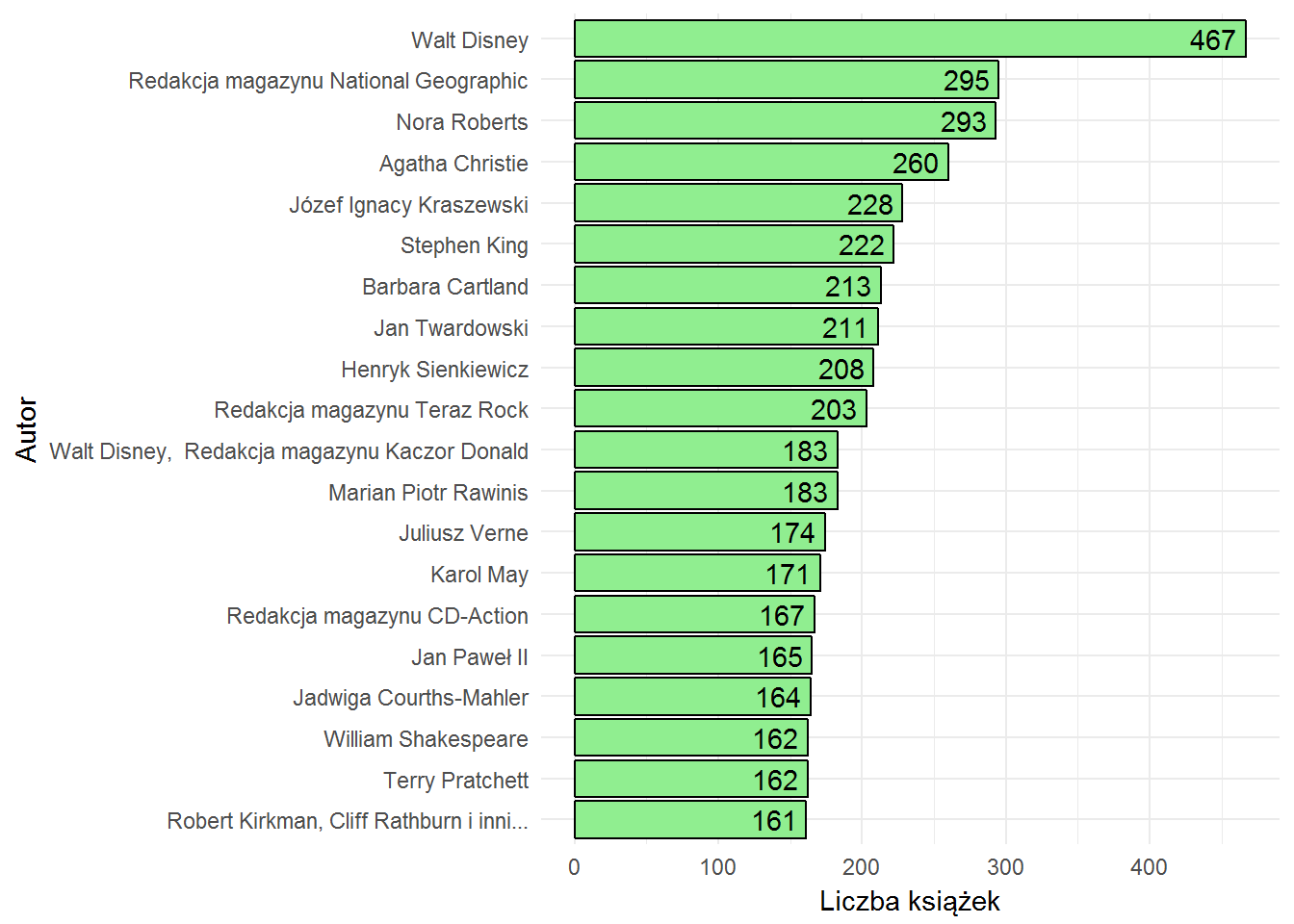
I tutaj niespodzianka. Walt Disney jako autor książek? Redakcja magazynu National Geographic naprowadza na trop (zerknięcie w kategorie też) – są to książeczki z komiksami dla dzieci, kolorowankami i innymi wydawnictwami tego typu. LubimyCzytać ma po prostu w bazie nie tylko książki (powieści, poezje i albumy) ale też czasopisma i inne periodyki.
Druga sprawa: czy Verne napisał 174 książki? No raczej nie. Ale jego książki są:
- wydawane przez różne wydawnictwa
- wydawane w różnych językach
- wydawane pod delikatnie różniącymi się tytułami (20000 mil – 8 sztuk, 20 000 mil – 7 sztuk, 20.000 mil – trzy sztuki, a to tylko przykład dla fragmentu jednego tytułu!)
- wydawane w postaci całości lub podzielonej na tomy (Tom 1 albo część 1 albo cz.1 – super, co?)
Tutaj znowu kłania się porządek w danych i porządne słowniki. Czyli ta najbardziej upierdliwa rzecz w analityce, którą tutaj rozmyślnie odpuściłem. Ale to pokazuje też problem LubimyCzytać.pl (tylko czy oni potrzebują mieć to uporządkowane?).
W jakim języku są książki?
|
1 2 3 4 5 6 7 8 9 |
table(books$language) %>% as.data.frame() %>% mutate(p=100*Freq/sum(Freq)) %>% ggplot() + geom_bar(aes(Var1, p), stat="identity", fill="lightgreen", color="black") + geom_text(aes(Var1, p, label=paste(Freq, "egz.")), hjust=-0.1) + labs(x="Język", y="% zbioru") + scale_y_continuous(breaks = c(0,25,50,75,100), limits = c(0, 110)) + coord_flip() |
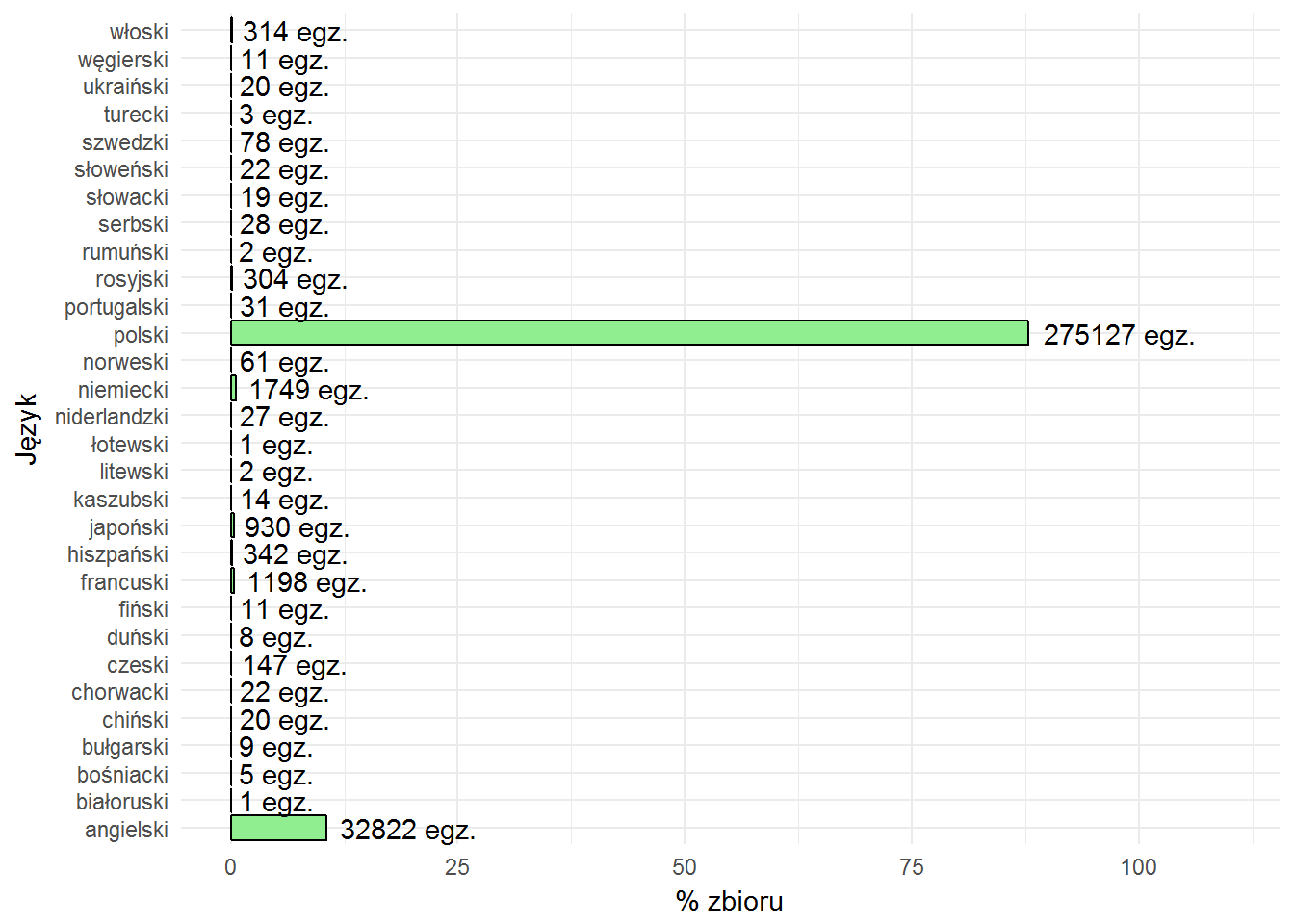
Oczywiście w polskim serwisie jest najwięcej książek polskojęzycznych.
Powtarzające się tytuły
Czy są tytuły (całe, a nie fragmenty), które się powtarzają? Zobaczmy 20 najpopularniejszych:
|
1 2 3 4 5 |
books %>% count(title) %>% ungroup() %>% top_n(20) %>% arrange(desc(n)) |
| title | n |
|---|---|
| Poezje | 178 |
| Opowiadania | 129 |
| Poezje wybrane | 113 |
| Wiersze | 105 |
| Wiersze wybrane | 83 |
| Baśnie | 81 |
| Wybór poezji | 71 |
| Bajki | 66 |
| Wspomnienia | 61 |
| Pan Tadeusz | 56 |
| Pamiętniki | 55 |
| Mały Książę | 52 |
| Przebudzenie | 52 |
| Tajemniczy ogród | 51 |
| Ania z Zielonego Wzgórza | 50 |
| Dziedzictwo | 49 |
| Listy | 49 |
| Powrót | 49 |
| Kopciuszek | 48 |
| Pinokio | 46 |
| W pustyni i w puszczy | 46 |
Odpowiedź brzmi: są. I są to mało zaskakujące tytuły. Zaskoczeniem może jedynie jest skala – Pan Tadeusz wydany w 56 wersjach, u-la-la!
Pozostając przy tytułach zobaczmy czy są jakieś słowa, które w ramach danej kategorii są najbardziej popularne (w ramach tutułów)? To jest ciekawe! I jest duużo obrazków!
Najpopularniejsze słowa w tytułach – według kategorii
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
stop_words <- read_lines("../TwitterTrends_Raport/polish_stopwords.txt") # rozbicie tytułów na poszczególne słowa, w ramach kategorii words_by_cat <- books %>% # tytlko unikalna kombinacja tytuł-kategoria select(category, title) %>% distinct() %>% unnest_tokens(words, title, token="words") %>% # słowa dłuższe niż 2 znaki (eliminuje spójniki) filter(nchar(words) > 2) %>% count(category, words) %>% ungroup() %>% # wyrzucamy słowa nic nie znaczące, których jest bardzo dużo (głównie angielskie) filter(!words %in% c("the", "and", "tom", "vol", "volume", "part", "cz", "in", "for")) %>% # oraz polskie stop-words filter(!words %in% stop_words) # dla każdej kategorii generujemy chmurkę max 50 słów by(words_by_cat, words_by_cat$category, function(x) { wordcloud(x$words, x$n, max.words = 50, min.freq = median(x$n), scale = c(3.2, 0.5), colors = RColorBrewer::brewer.pal(9, "Greens")[4:9]) text(0.05, 0.95, unique(x$category), col="darkred", cex=1.3, adj=c(0,0)) cat("\n") } ) |












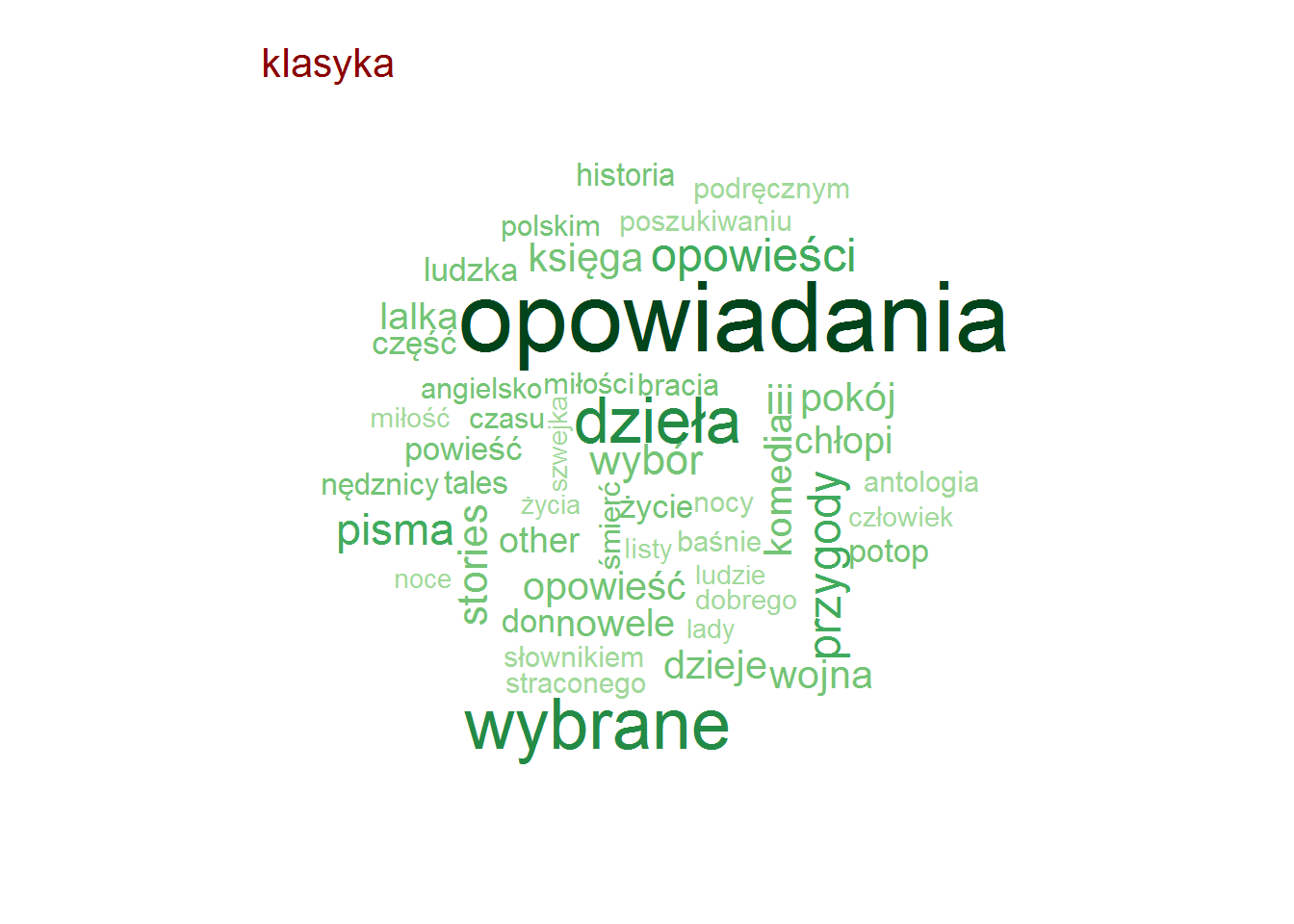
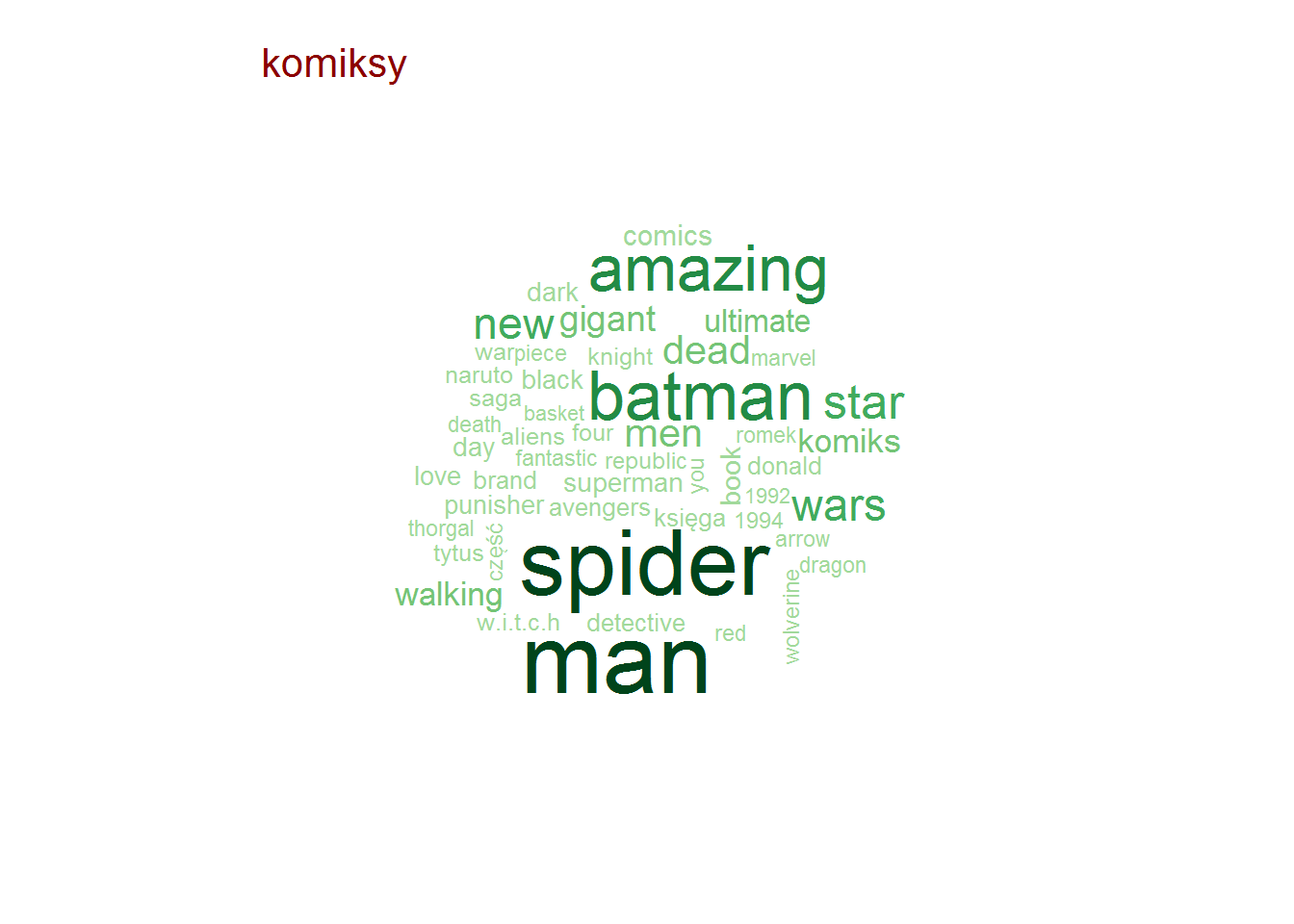



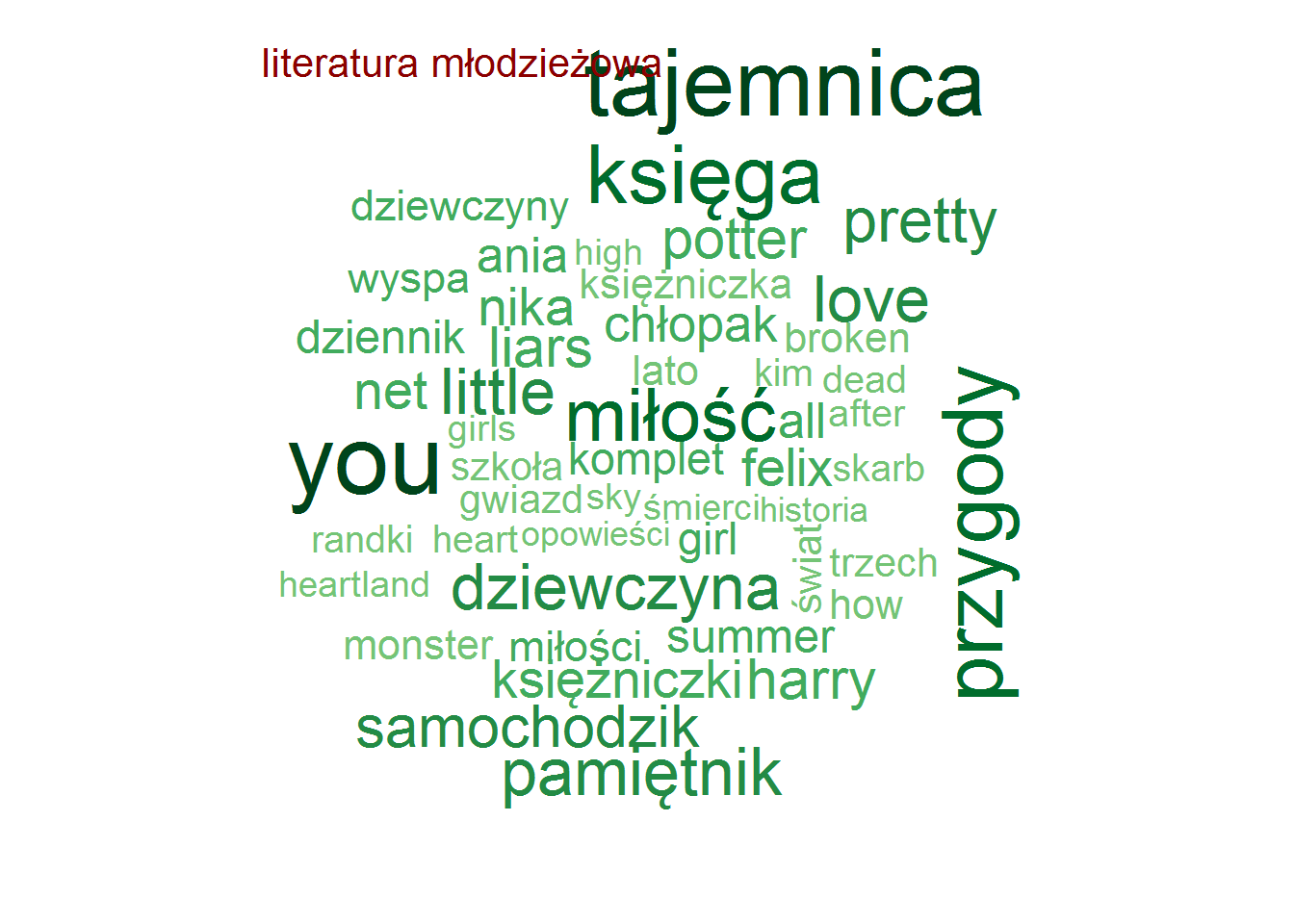
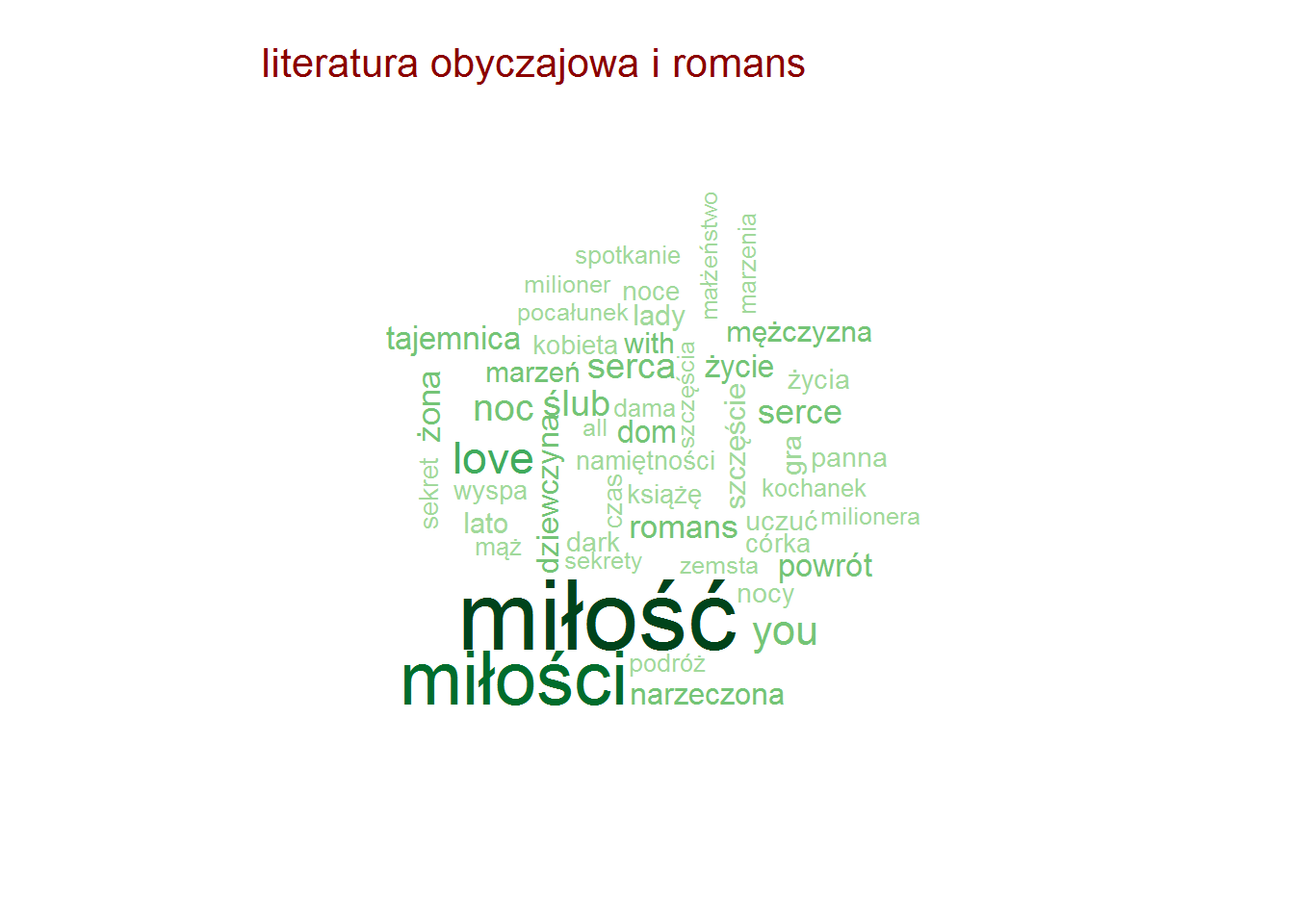
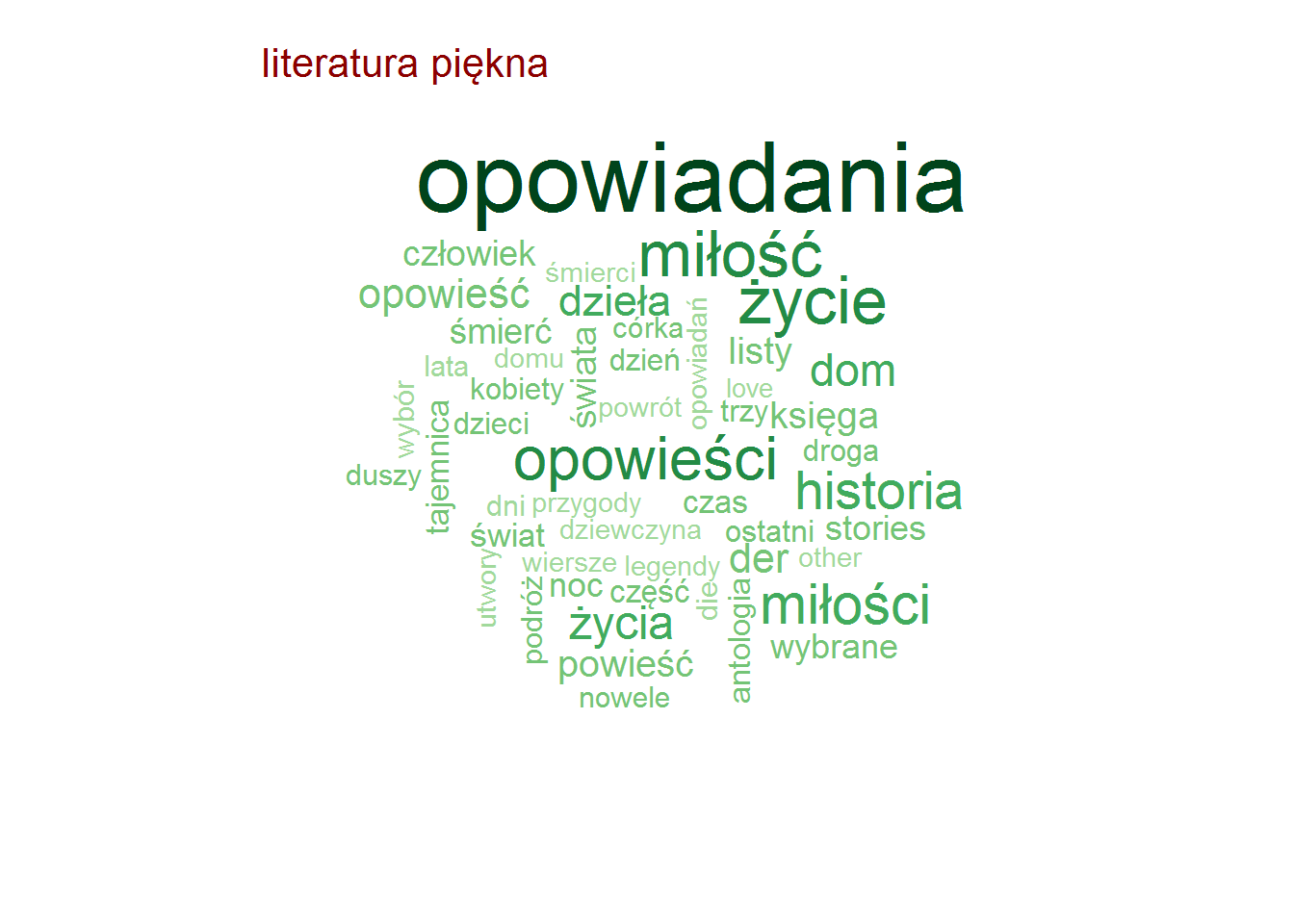

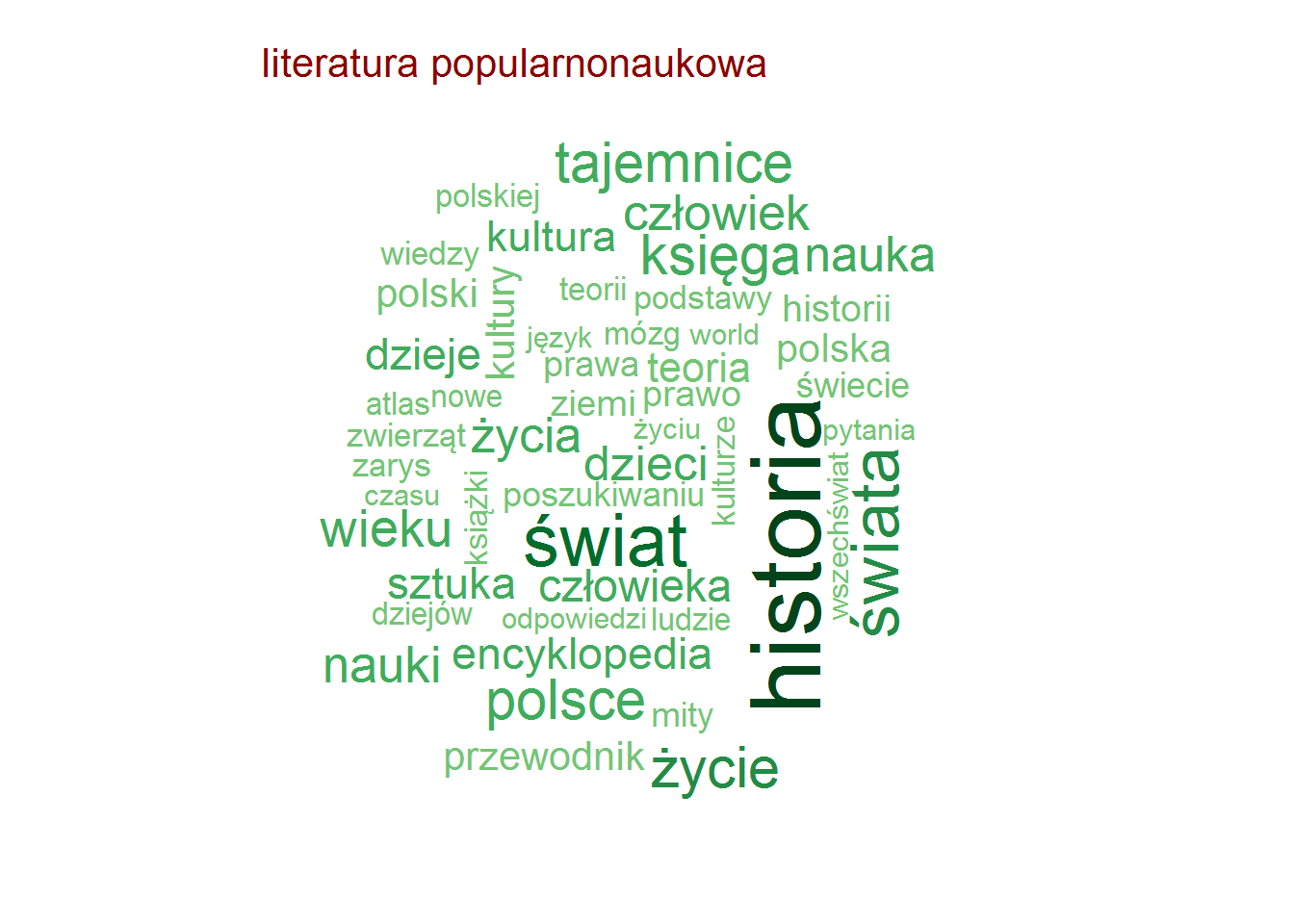
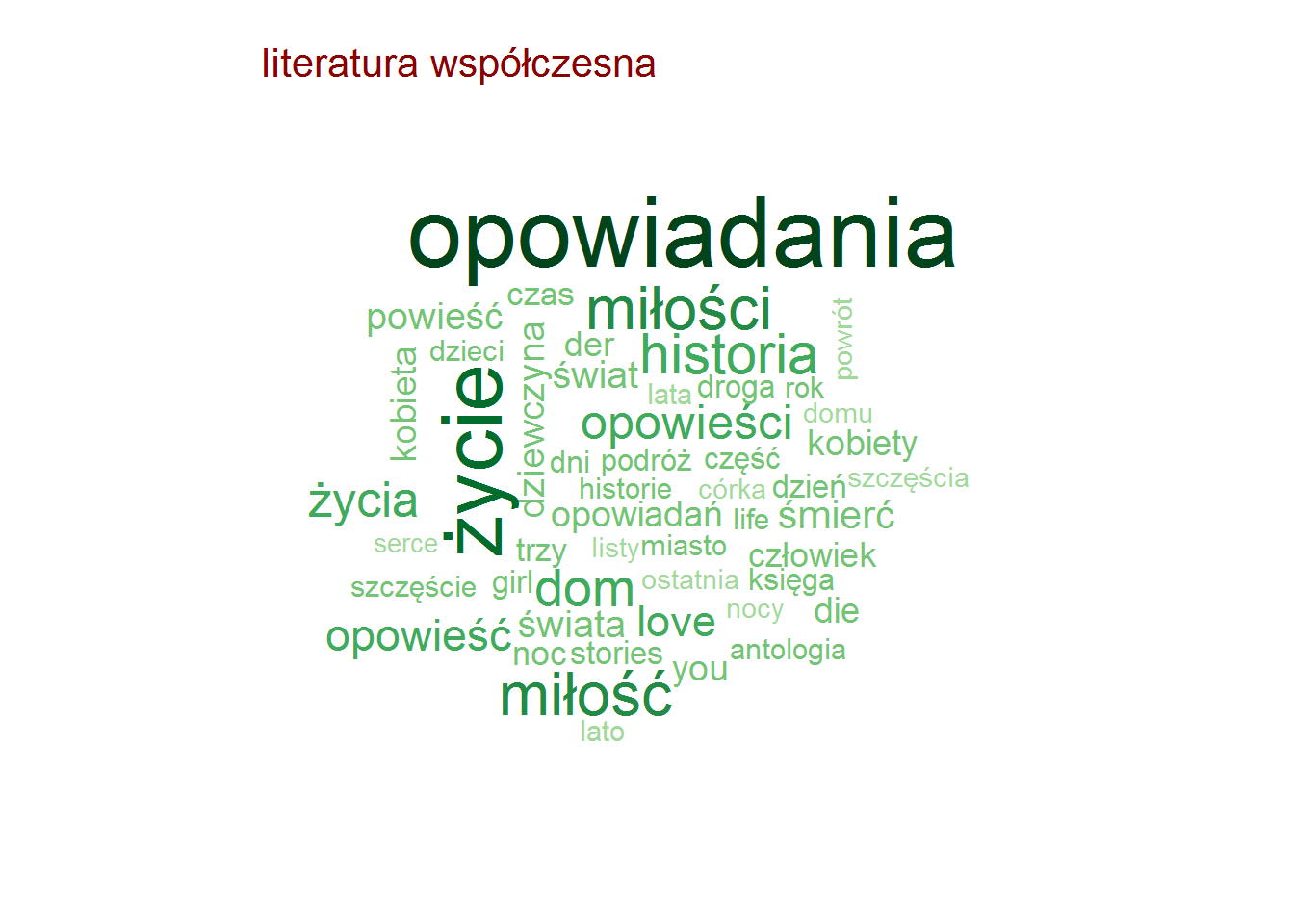

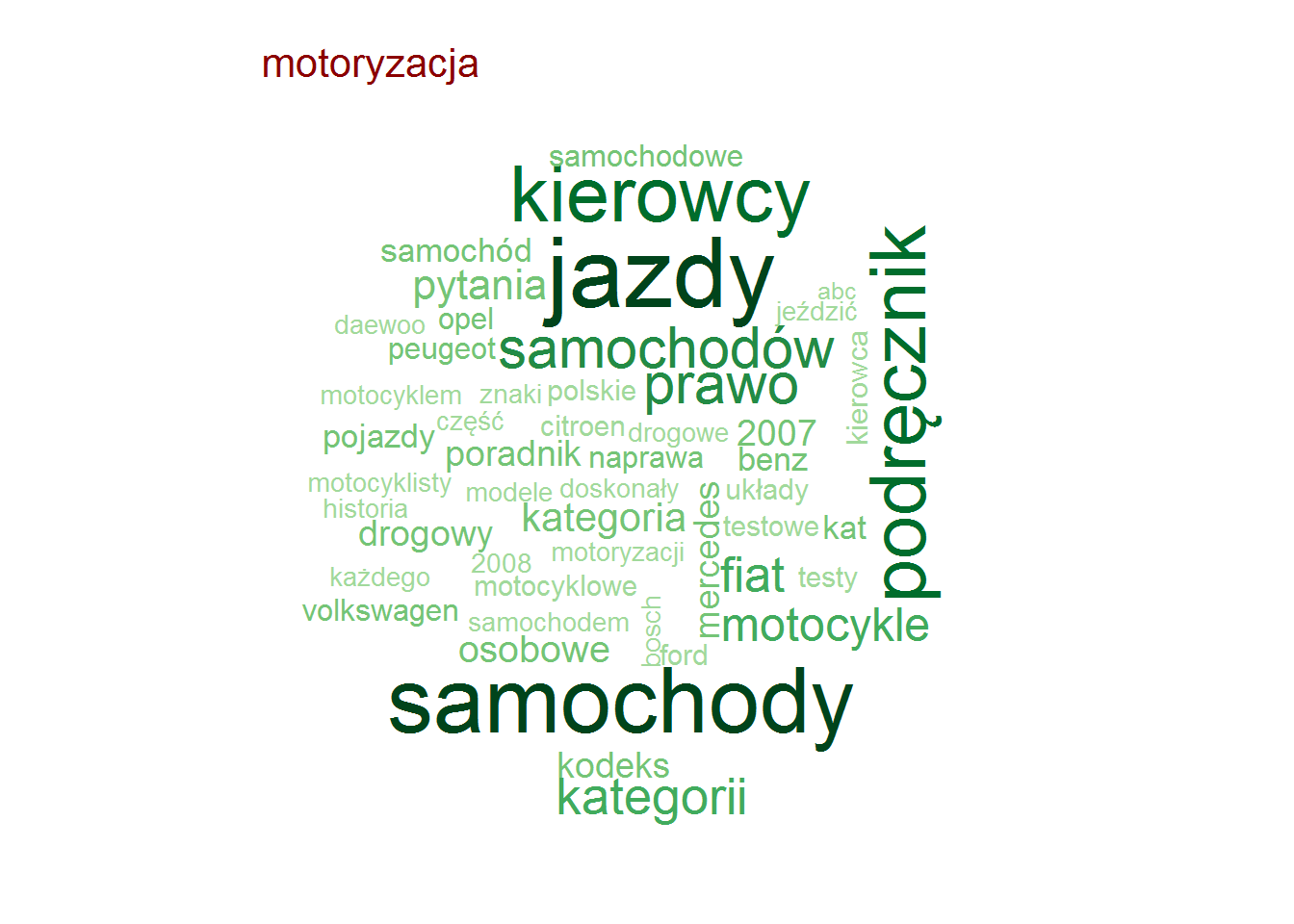

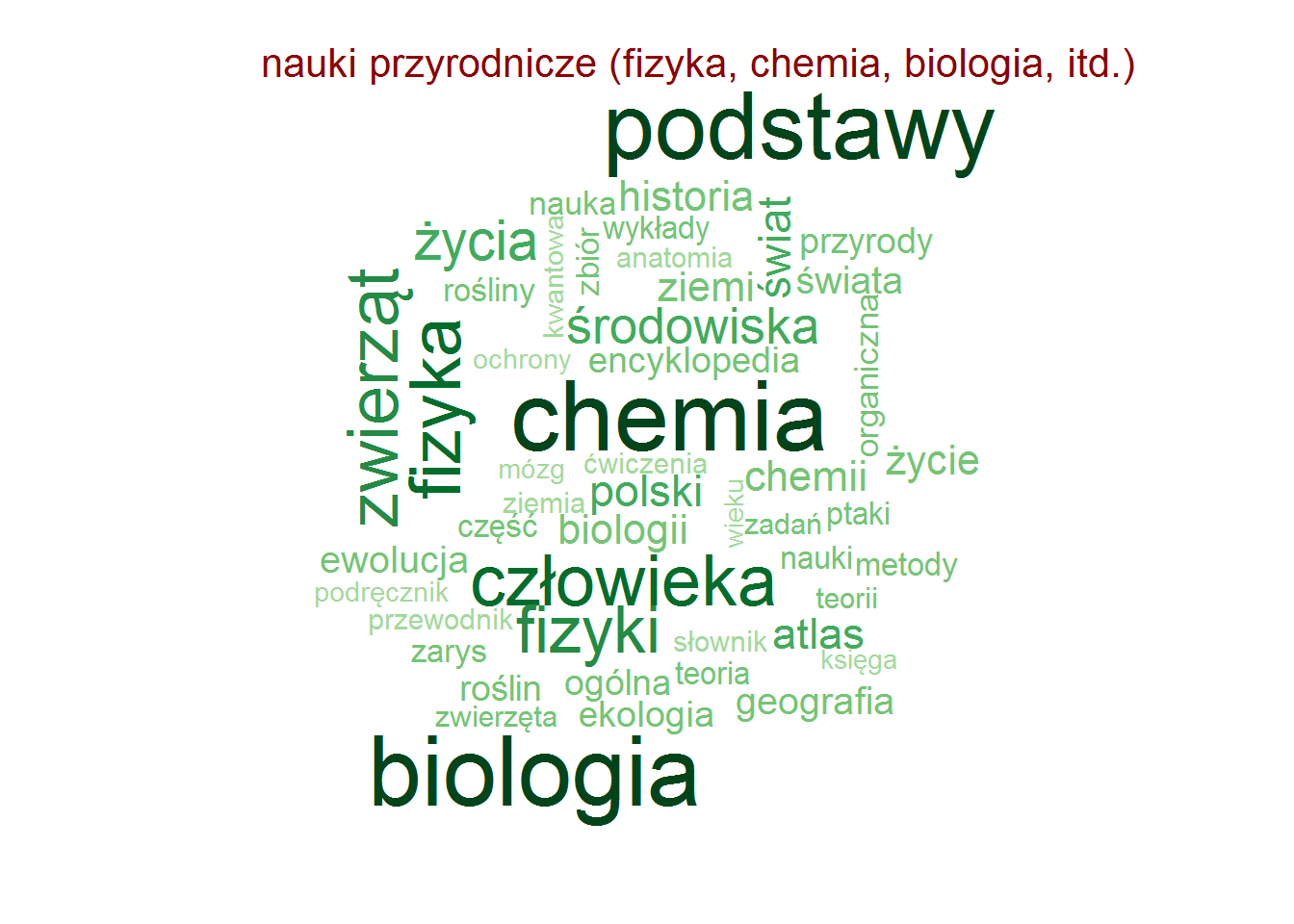

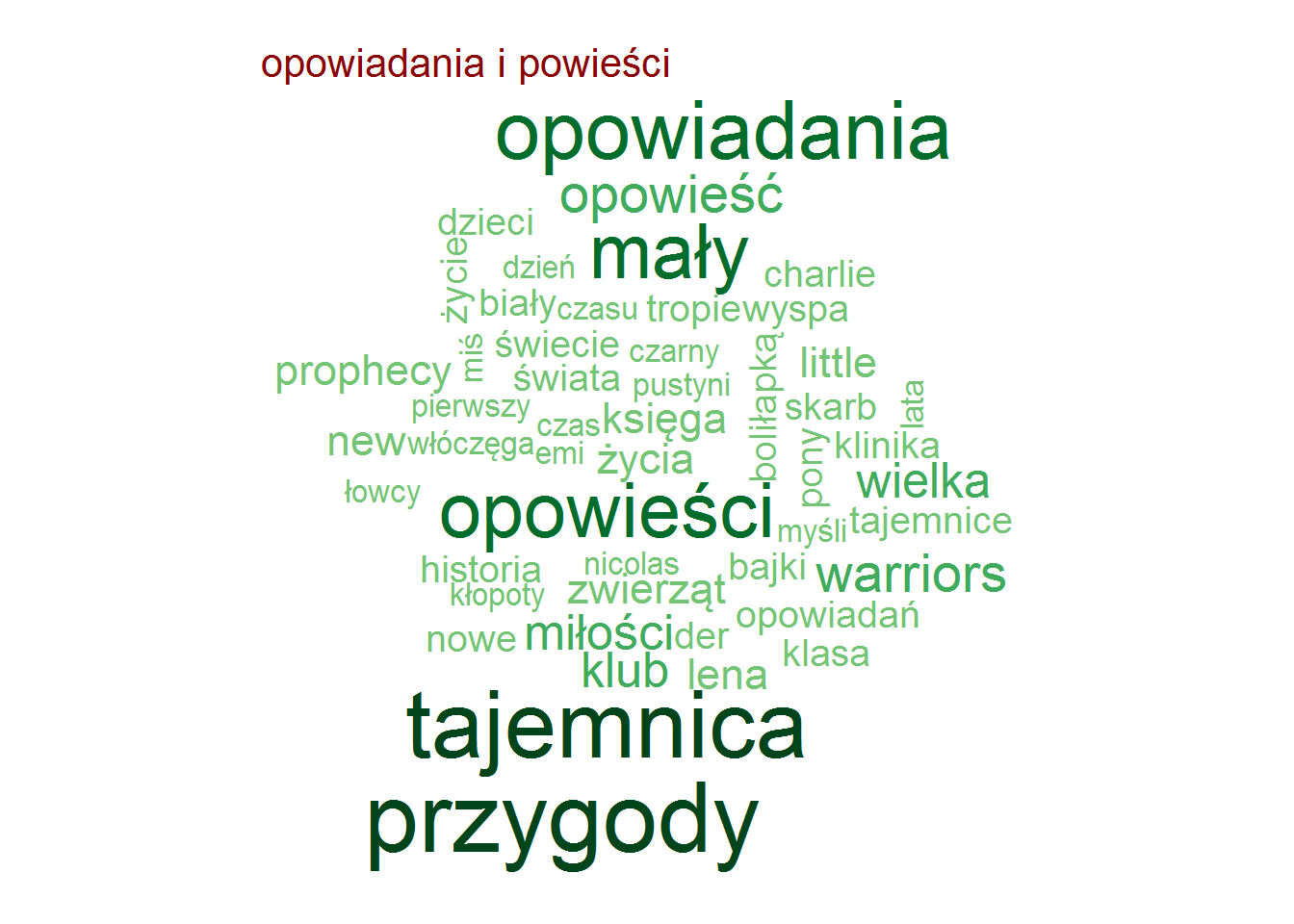

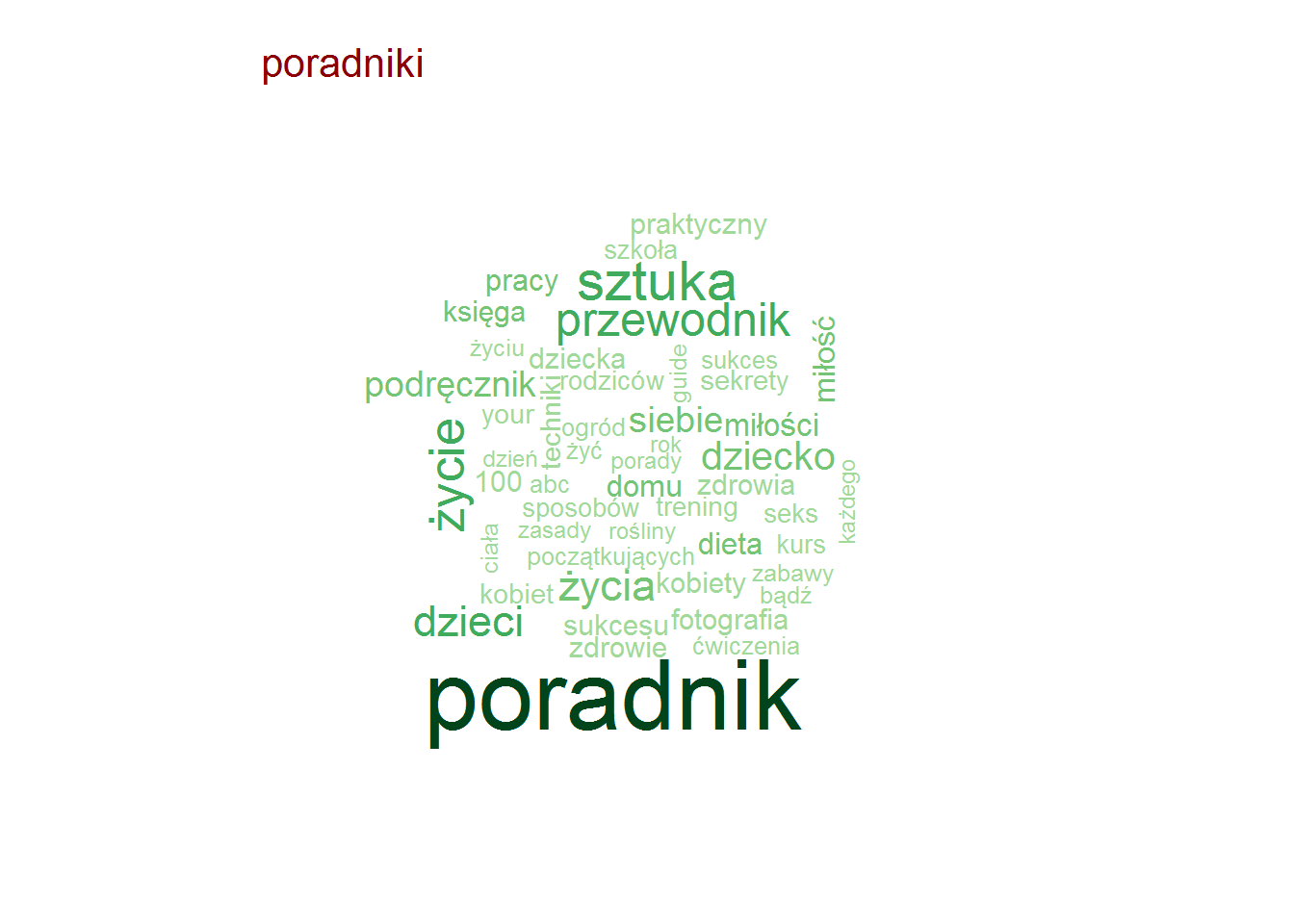

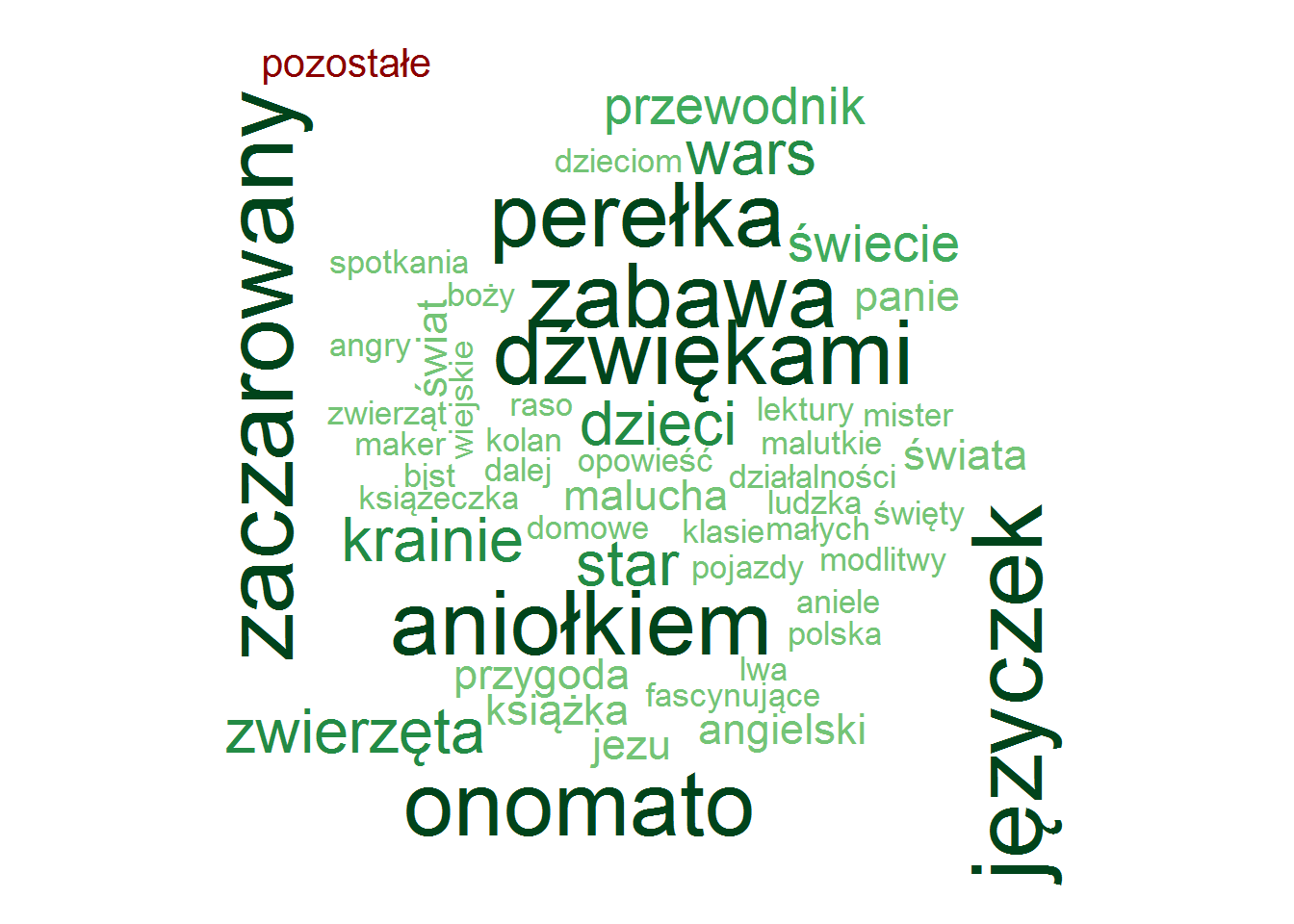


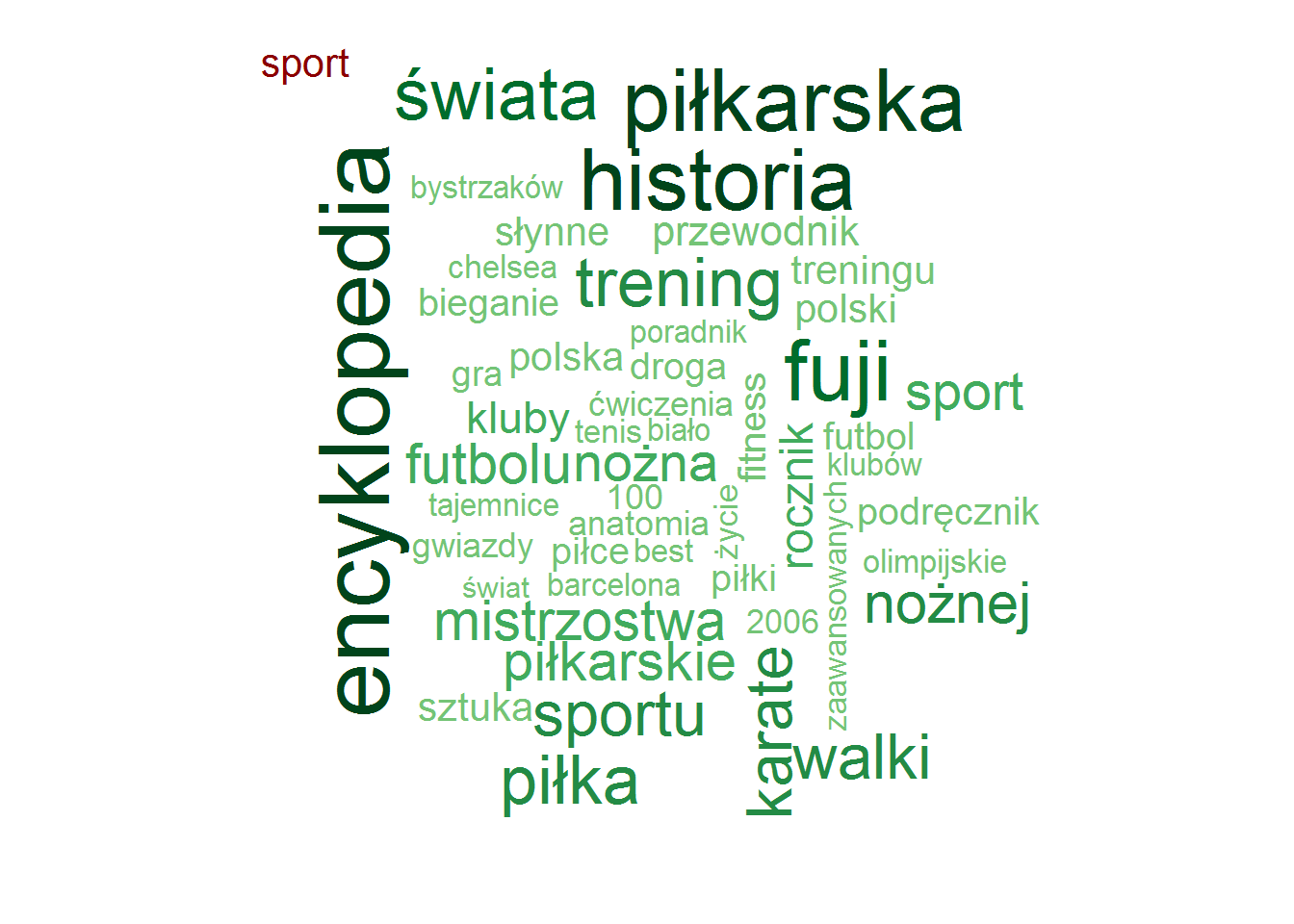
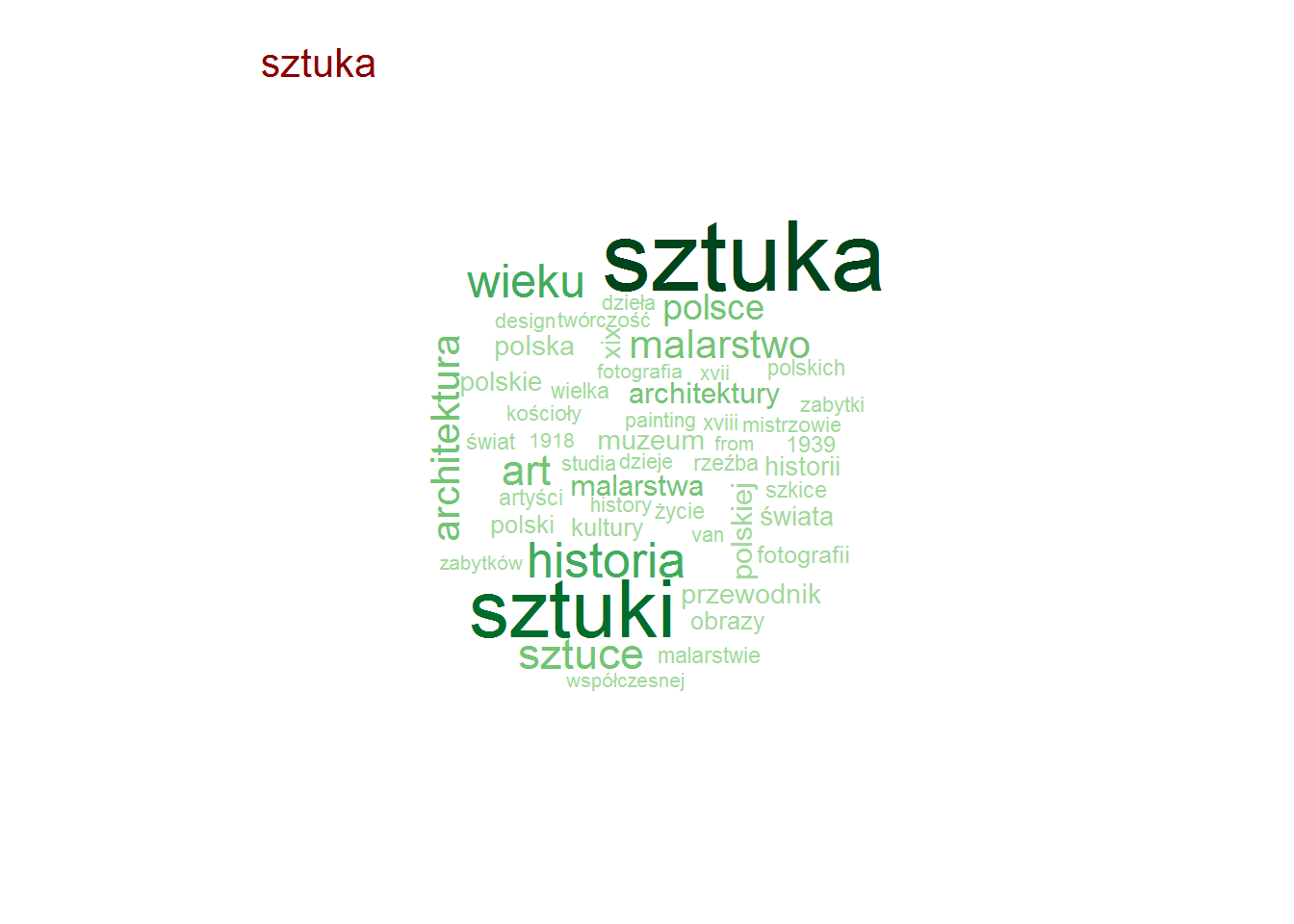

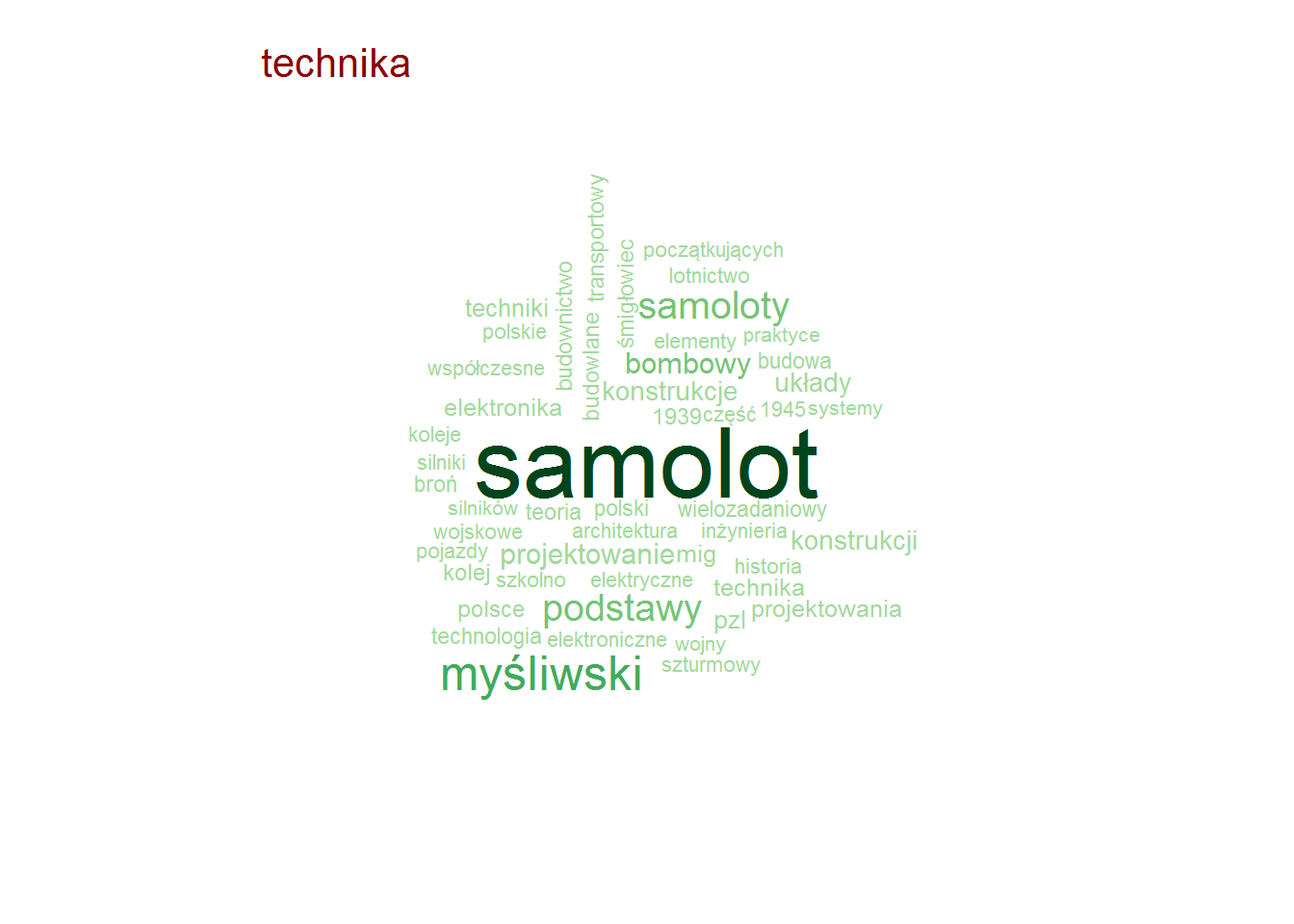

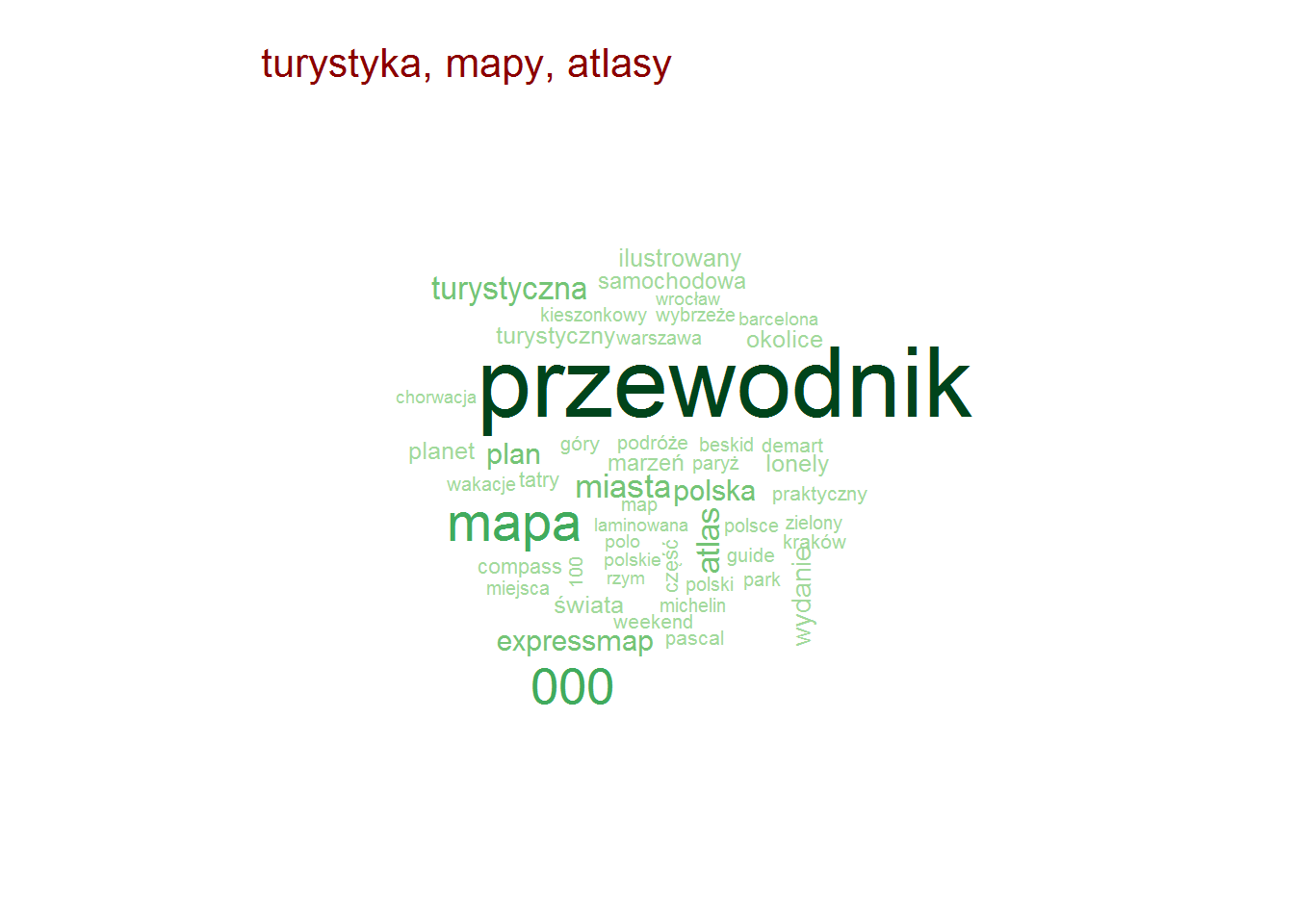

Zero zaskoczenia, całkowite zero.
Wszystkie kategorie
A jak wyglądają najpopularniejsze słowa, bez względu na kategorię? Wystarczy zagregować to co już mamy podzielone po kategoriach:
|
1 2 3 4 5 6 7 8 9 10 11 |
words_total <- words_by_cat %>% filter(n >= 3) %>% group_by(words) %>% summarise(n = sum(n)) %>% ungroup() # chmurka słów - max 50 słów wordcloud(words_total$words, words_total$n, scale = c(3.2, 0.5), max.words = 50, colors = RColorBrewer::brewer.pal(9, "Greens")[4:9]) |
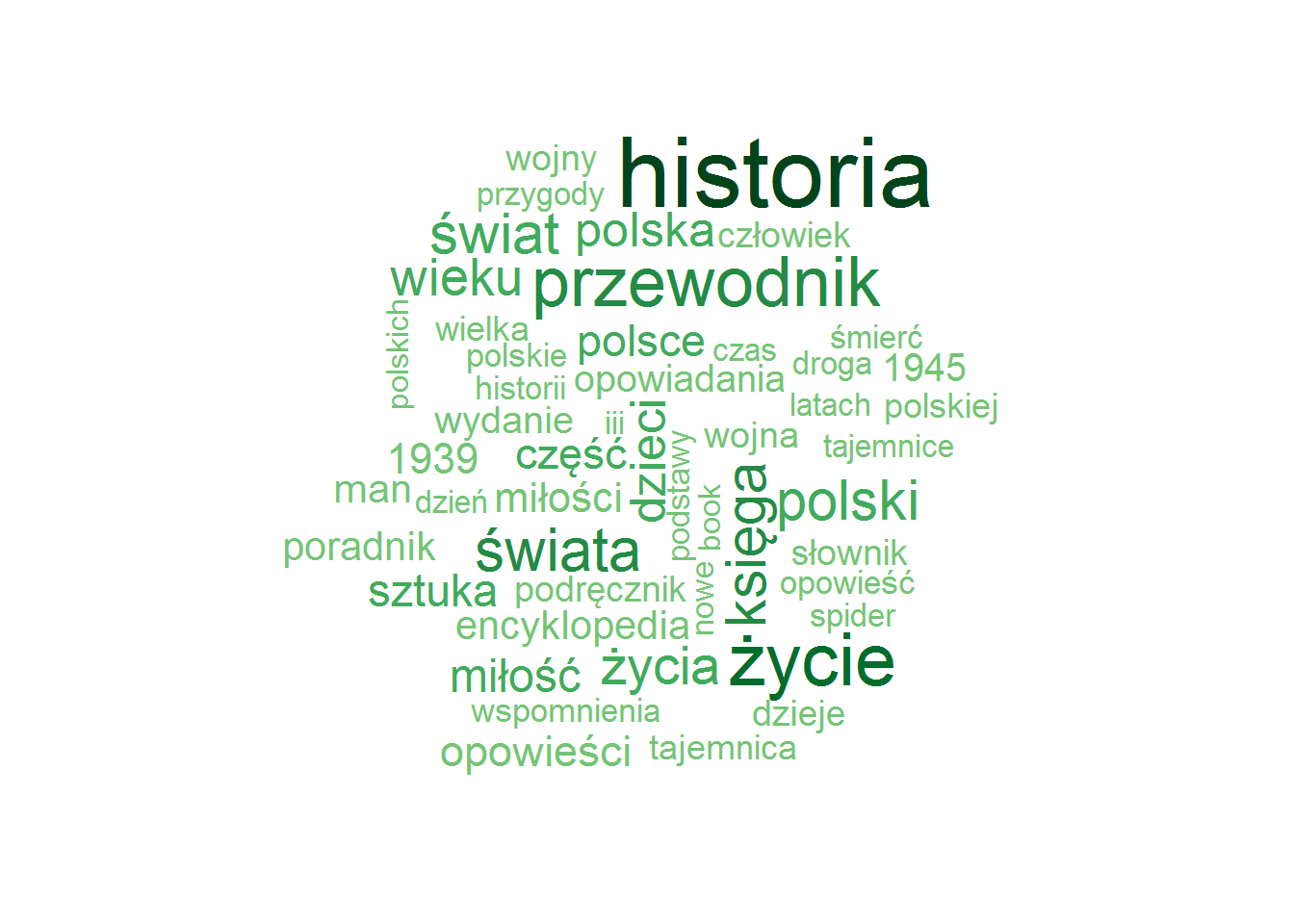
Tutaj mam pewne wątpliwości – czy rzeczywiście historia to najbardziej popularne słowo w tytułach wśród 330 tysęcy książek? Według obliczeń występuje ono 4036 razy, a więc w 1.22% książek. Bardzo dużo, ja jestem szczerze zaskoczony.
Ale może być tak, że w (pobranej) bazie serwisu jest jakaś nadreprezentacja danej kategorii. Być może serwis jest delikatnie ukierunkowany w stronę konkretnych odbiorców (piszemy trochę więcej o książkach historycznych, tak jak w jednej telewizji na abonament mówi się więcej o sukcesach rządu, a w takiej na reklamy – o jego wpadkach)? Tak czy inaczej – przydałaby się pełna, oczyszczona baza. Wówczas nasze analizy byłyby kompletne i nieco bardziej wiarygodne.
Sprawdźmy więc czy jest nadreprezentacja którejś kategorii?
|
1 2 3 4 5 6 7 8 9 10 |
table(books$category) %>% prop.table() %>% as.data.frame() %>% mutate(Freq = 100 * Freq) %>% arrange(Freq) %>% mutate(Var1=factor(Var1, levels=Var1)) %>% ggplot() + geom_bar(aes(Var1, Freq), stat="identity", fill="lightgreen", color="black") + coord_flip() + labs(x="Kategoria", y="Udział procentowy w bazie") |
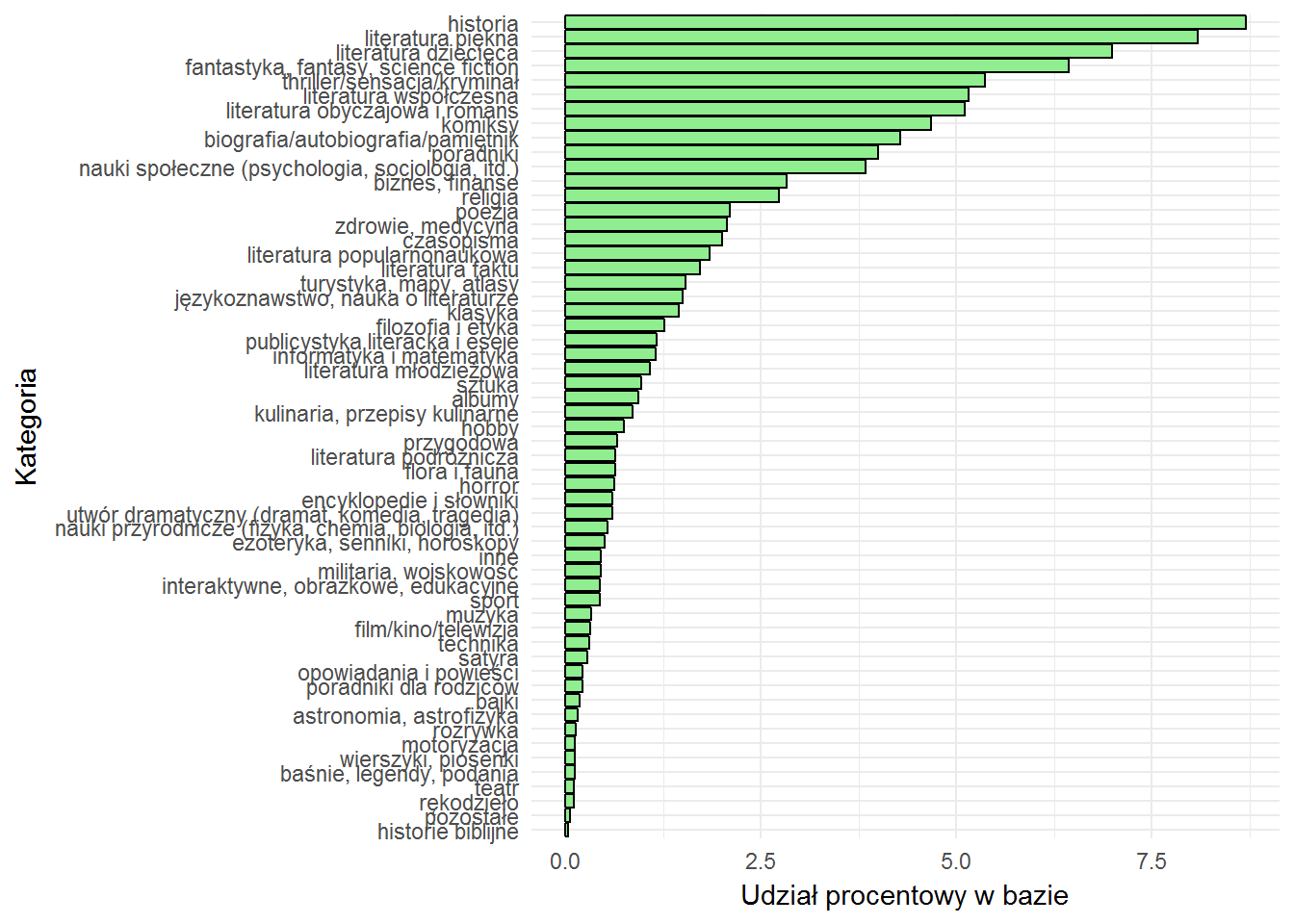
No niestety jest… i to właśnie tej odpowiedzialnej za historię. Ale może tak właśnie wygląda rynek wydawniczy?
W dalszych rozważaniach pominiemy tę kwestię, ale można pokusić się o znormalizowanie wartości zgodnie z powyższym wykresem – na przykład najprościej mnożąc liczbę słów przez liczbę, która określa jaką część stanowi kategoria (jeśli kategoria to 10% wszystkich książek – mnożymy prze 10, jeśli 5% – przez dwadzieścia. Krótko mówiąc: mnożymy przez 100/x).
Co jeszcze można zrobić? Można przygotować chmurki najpopularniejszych bigramów (zbitek dwuwyrazowych) albo zrobić z bigramów graf, aby sprawdzić jakie słowa łączą się ze sobą, jak często i czy są kategorie gdzie dane połączenia są bardziej popularne. Wcześniej można oczyścić słowa z przypadków (sprowadzić je do mianowników) – pomocna może być hunspell_stem() z biblioteki hunspell (jest pakiet hunspell w CRAN).
Można pokusić się o sprawdzenie czy popularność określonych słów w tytule zmienia się w zależności od daty wydania książki. To brzmi ciekawie, sprawdźmy więc!
|
1 2 3 4 5 6 7 8 9 10 11 |
words_by_year <- books %>% select(date, title) %>% # tylko przedział lat filter(date >= 1950, date <= 2017) %>% unnest_tokens(words, title, token="words") %>% count(date, words) %>% ungroup() %>% filter(nchar(words) > 2) %>% filter(!words %in% c("the", "and", "tom", "vol", "volume", "part", "cz", "in", "for")) %>% filter(!words %in% stop_words) |
Mamy przygotowane dane, zobaczmy liczbę książek ze słowem historia w tytule – jak zmieniała się w poszczególnych latach?
|
1 2 3 4 5 6 |
words_by_year %>% filter(words=="historia") %>% ggplot() + geom_bar(aes(date, n), stat="identity", fill="lightgreen", color="black") + labs(x="Rok", y="Liczba książek ze słowem \"historia\" w tytule") + scale_x_continuous(breaks = seq(1950, 2020, 5)) |
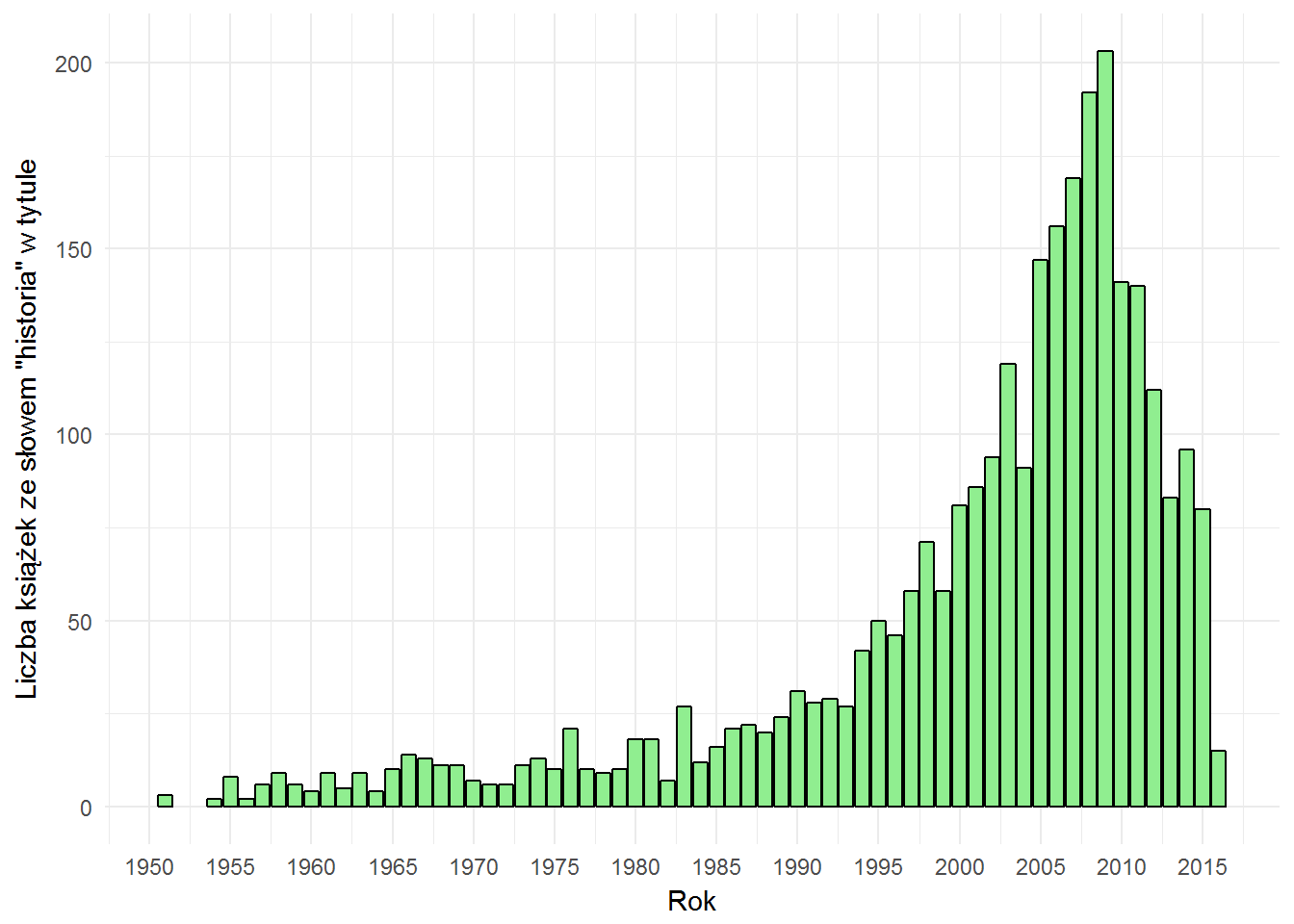
To są wartości bezwzględne co nie daje nam obrazu czy udział książek z historią w tytule rośnie czy nie. Wykes wygląda zresztą podobnie do tego z liczbą książek w poszczególnych latach. Zderzmy więc obie dane ze sobą i określmy procent książek z danym tytułem zamiast liczby bezwzględnej.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
# liczba książek w roku books_by_year <- books %>% count(date) %>% ungroup() %>% filter(date >= 1950, date <= 2017) # łączymy liczbę słów w roku z liczbą książek w roku i liczymy procent words_by_year_prop <- left_join(words_by_year, books_by_year, by="date") %>% mutate(prop = 100*n.x/n.y) %>% select(date, words, prop) # wykres dla słowa "historia" words_by_year_prop %>% filter(words=="historia") %>% ggplot() + geom_bar(aes(date, prop), stat="identity", fill="lightgreen", color="black") + labs(x="Rok", y="Liczba książek ze słowem \"historia\" w tytule") + scale_x_continuous(breaks = seq(1950, 2020, 5)) |
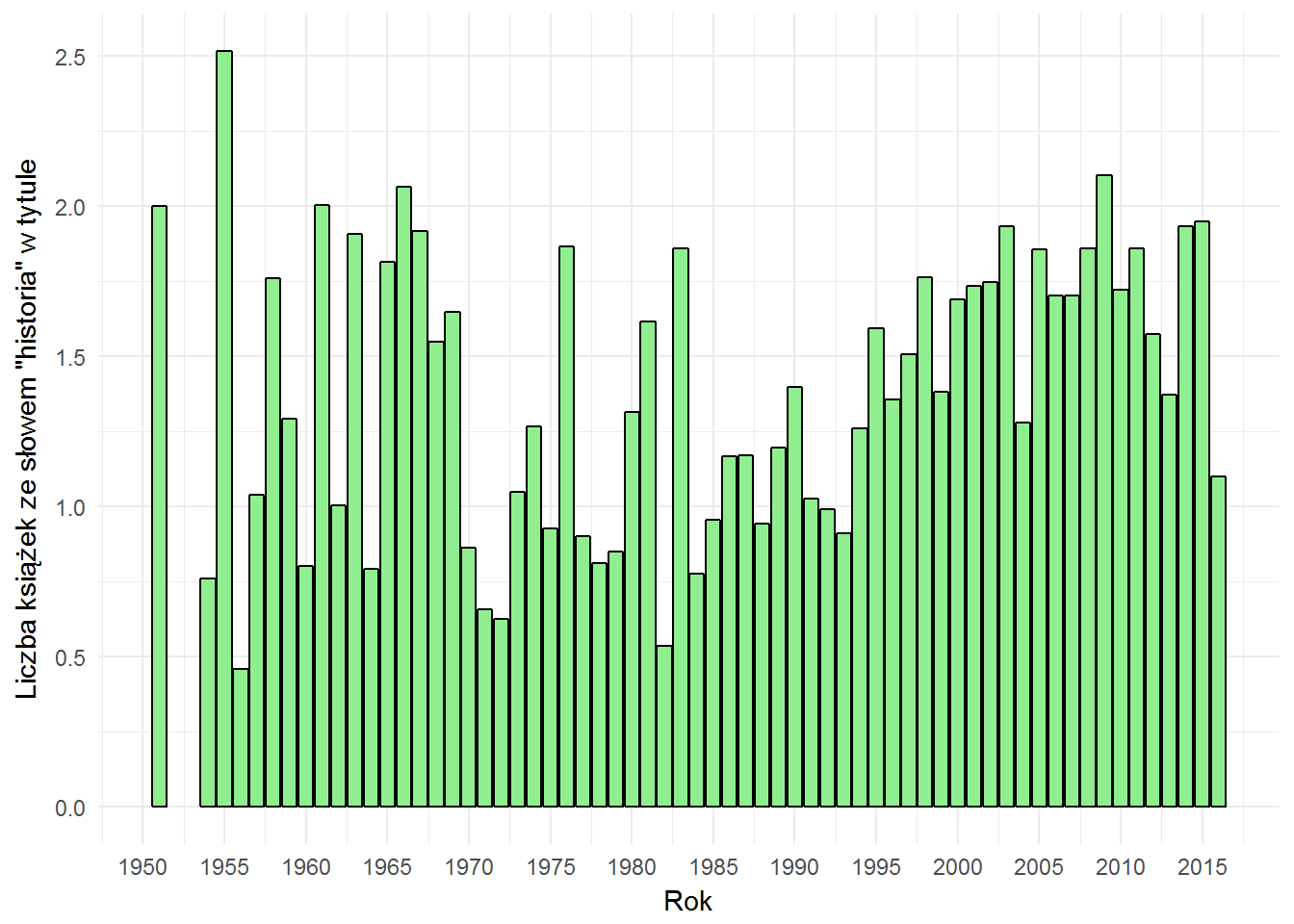
Jak widać proporcjonalnie książek ze słowem historia w tytule nie przybywa (i nie ubywa) jakoś bardzo, a różnice są na poziomie dziesiętnych części punktu procentowego. Tym bardziej jestem zaskoczony popularnością tego słowa (ale widząc nadreprezentację kategorii już mniej).
Na koniec zobaczmy zatem sześć (akurat tyle, bo łatnie wygląda układ wykresów) najpopularniejszych słów w tytułach i ich zmianę w czasie:
|
1 2 3 4 5 6 7 8 9 10 11 |
# 6 najpopularniejszych słów top_title_words <- words_total %>% top_n(6, wt=n) %>% .$words words_by_year_prop %>% filter(words %in% top_title_words) %>% ggplot() + geom_bar(aes(date, prop, fill=words), stat="identity", color="black", show.legend = FALSE) + labs(x="Rok", y="Liczba książek z danym słowem w tytule") + scale_x_continuous(breaks = seq(1950, 2020, 10)) + facet_wrap(~words, ncol=2) |
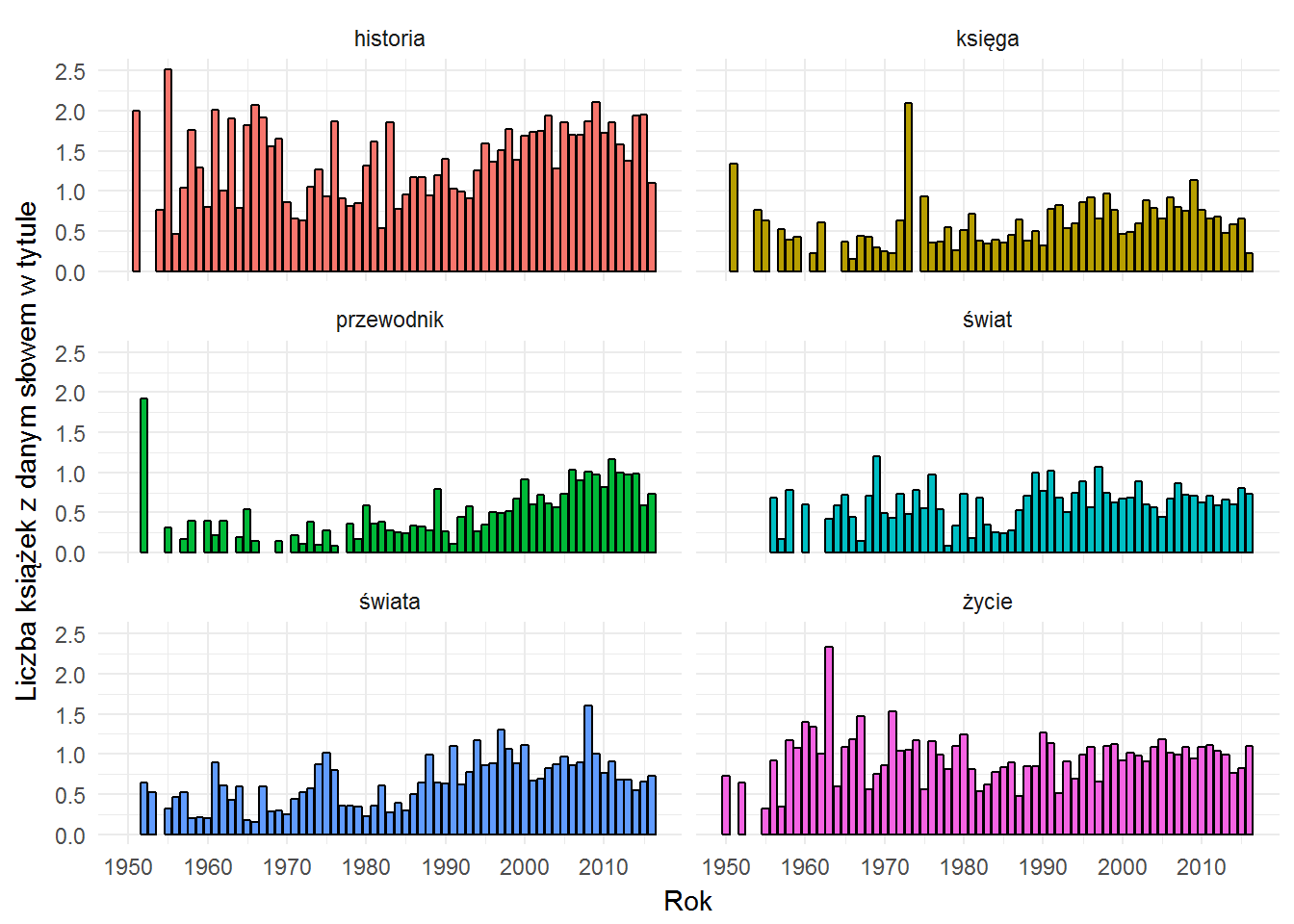
Najwyraźniej widać wzrost liczby przewodników. Dobierając odpowiednie słowa można znaleść też inne ciekawostki. Weźmy kilka słów: opowiadania, spider man (jako oddzielne słowa), prawo, ludzie, zarządzanie oraz star wars (też oddzielnie):
|
1 2 3 4 5 6 7 8 9 |
words_by_year_prop %>% filter(words %in% c("opowiadania", "spider", "man", "prawo", "ludzie", "zarządzanie", "star", "wars")) %>% ggplot() + geom_bar(aes(date, prop, fill=words), stat="identity", color="black", show.legend = FALSE) + labs(x="Rok", y="Liczba książek z danym słowem w tytule") + scale_x_continuous(breaks = seq(1950, 2020, 10)) + facet_wrap(~words, ncol=2) |
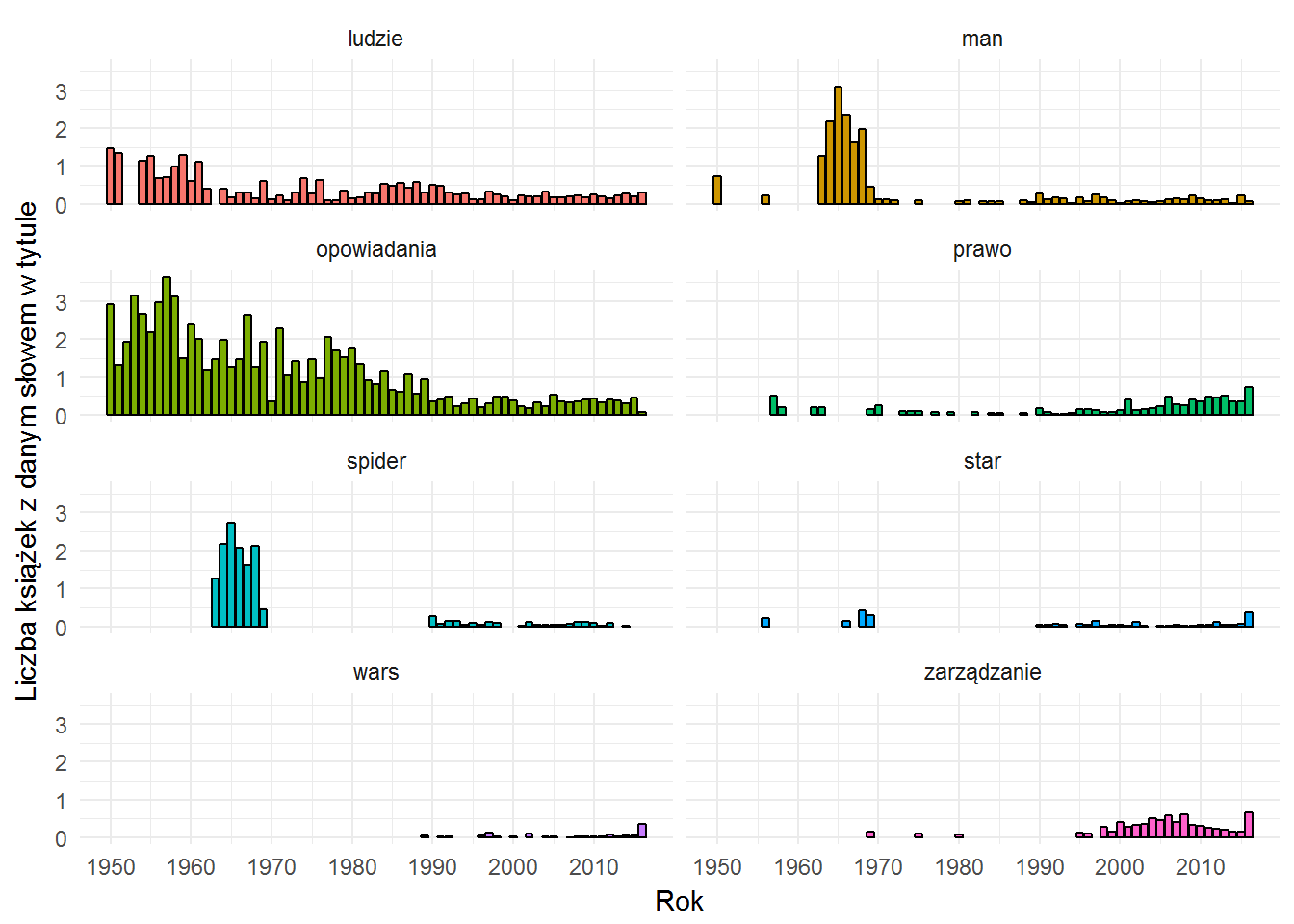
Tutaj widać wzrost od początku lat dwutysięcznych wydawnictw związanych z zarządzaniem, spada liczba książek ze zbiorem opowiadań (tak można wnioskować po wystąpieniach tego słowa w tytułach), widać wyraźną zbieżność słów spider i man (w latach 1960-1970 to pewnie komiksy, po roku 1990 to książeczki dla dzieci), podobnie dla Star Wars.
Podobnie można prześledzić popularność poszczególnych autorów lub wydawnictw (ile tytułów zostało wydanych przez dane wydawnictwo w poszczególnych latach). Zestawiając dane o popularności wydawnictw z ich przychodami (o ile są dostępne na rynku, na przykład w raportach okresowych spółek) można próbować dobierać odpowiednie książki, które powinny być wydane aby zapewnić zysk. Oczywiście to bardzo uproszczone rozumowanie – w końcu nie oceniamy książek po okładce tytule.
Może ktoś z Was ma pomysł? Podzielcie się w komentarzach!
Analiza bardzo dobra, choć wiele z niej nie wynika, ot dowiedzieliśmy się że grubość książki nie ma znaczenia na jej treść.
Co do stanu bazy danych LubimyCzytać.pl to jak najbardziej się zgadzam: jest tragicznie. Portal jest popularny dlatego że jest popularny, takiemu filmweb’owi do pięt nie dorasta.
Wspominałeś coś w poście, że skrypt zbierający dane umieściłeś na serwerze. Co to za serwer i jak duże są koszty utrzymania przy masowym poborze danych z internetu?
Serwer to AWS EC2. Zero złotych. Jak się znajdzie odpowiedni obraz to jest R, Rstudio, Python i Shiny. Szukać trzeba RStudio_AMI.
A czy mógłbym prosić o kierunek w którym należy szukać informacji o budowie własnego crawlera do takiego zbierania ?
Pingback: Analiza twórczości J.K.Rowling | Łukasz Prokulski
Witam,
czy jest szansa na udostępnienie danych do odtworzenia Twojej analizy ?
Nie chce męczyć serwera puszczaniem :(
No danych sprzed trzech lat nie trzymam…