Od czego zależą oceny filmów?
Jak będzie oceniony film, który dopiero powstaje?
Dawno temu, czyli gdzieś około roku, może nawet półtora temu, zebrałem z Filmwebu prawie całą ówczesną bazę danych o filmach. Wykorzystałem biblioteki napisane w PHP korzystające z (nie)oficjalnego API Filmwebu budując skrypt, który dla kolejnych ID “produktów” (produktów, bo Filmweb ma nie tylko filmy, ale również seriale i gry) i pobierał odpowiednie informacje (do ID bodaj 770 tys.): rok produkcji filmu, jego polski i oryginalny tytuł, czas trwania, gatunki, twórców i obsadę oraz liczbę ocen i średnią ocenę (na moment pobrania danych). Powstało kilka plików CSV (pliki relacyjne) z dużą ilością danych. Dzisiaj z tego skorzystamy i pooglądamy jak zmieniał się przemysł filmowy.
Pliki zgromadzone zostały w formie CSV, po wyczyszczeniu danych wpakowałem wszystko w jeden plik z danymi. Wczytajmy sobie te dane:
|
1 2 3 4 5 6 |
library(tidyverse) library(gridExtra) theme_set(theme_minimal()) load("filmweb_data.rda") |
Na początek zobaczymy jak zmieniają się oceny filmów w zależności od roku produkcji.
Aby dane o ocenie były wiarygodne potrzebujemy jakiejś próbki ocen – liczba oddanych głosów musi być znacząca, aby średnia była wiarygodna. Przyjmijmy, że jest to 70-percentyl (czyli będziemy brać pod uwagę tylko te filmy na które oddano “górne” 30% liczby głosów), co daje co najmniej 234 głosów.
|
1 2 3 4 5 6 7 8 9 10 11 |
# minimalna liczba głosów minFilmVotes <- quantile(movies$FilmVotes, 0.7, na.rm = TRUE) movies %>% filter(FilmVotes >= minFilmVotes) %>% ggplot() + geom_point(aes(filmYear, filmRate), color="lightgreen", alpha=0.1) + geom_smooth(aes(filmYear, filmRate), color="blue") + scale_x_continuous(breaks = seq(1880, 2020, 10)) + scale_y_continuous(breaks = 1:10, limits = c(0,10)) + labs(x = "Rok produkcji", y = "Ocena filmu") |
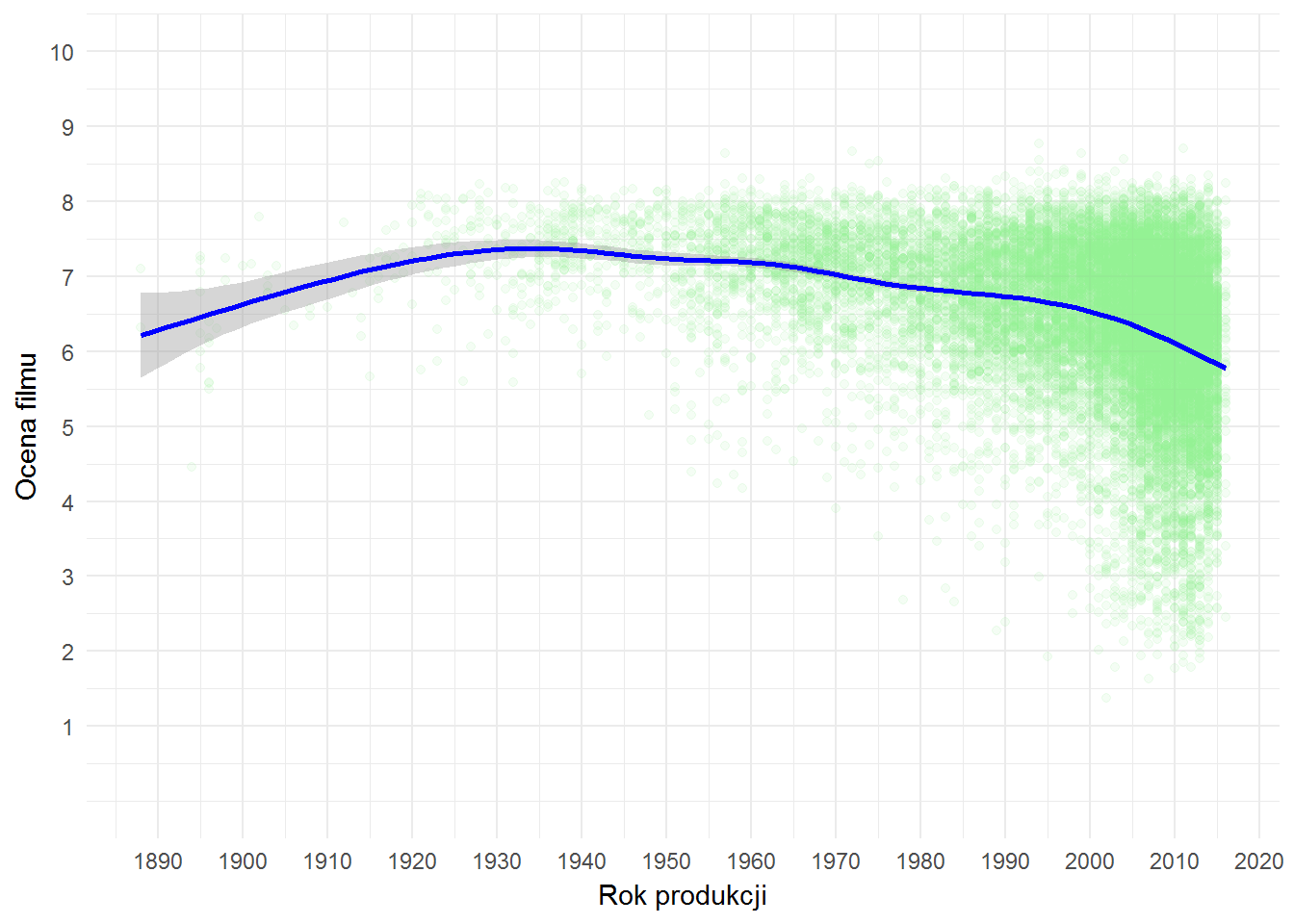
Po gęstości upakowania zielonych punktów widać, że produkuje się coraz więcej filmów. Jednocześnie widać też, że rozpiętość ocen dla tych filmów jest coraz większa – wiadomo, im więcej produkujesz tym większa szansa na arcydzieło jak i na babola. Trend jest jednak taki, że nowsze filmy są coraz niżej oceniane (średnio).
Zobaczmy jeszcze jak wygląda rozkład ocen – czyli jakie oceny nadawane są najczęściej (to trochę uproszczenie, bo mamy tylko ocenę średnią, ale przecież bierze się ona ze składowych):
|
1 2 3 4 5 6 7 8 |
movies %>% filter(FilmVotes >= minFilmVotes) %>% ggplot() + geom_histogram(aes(filmRate), fill="lightgreen", color="black", binwidth = 1) + scale_x_continuous(limits = c(0,10), breaks = 1:10) + labs(x = "Ocena filmu") |
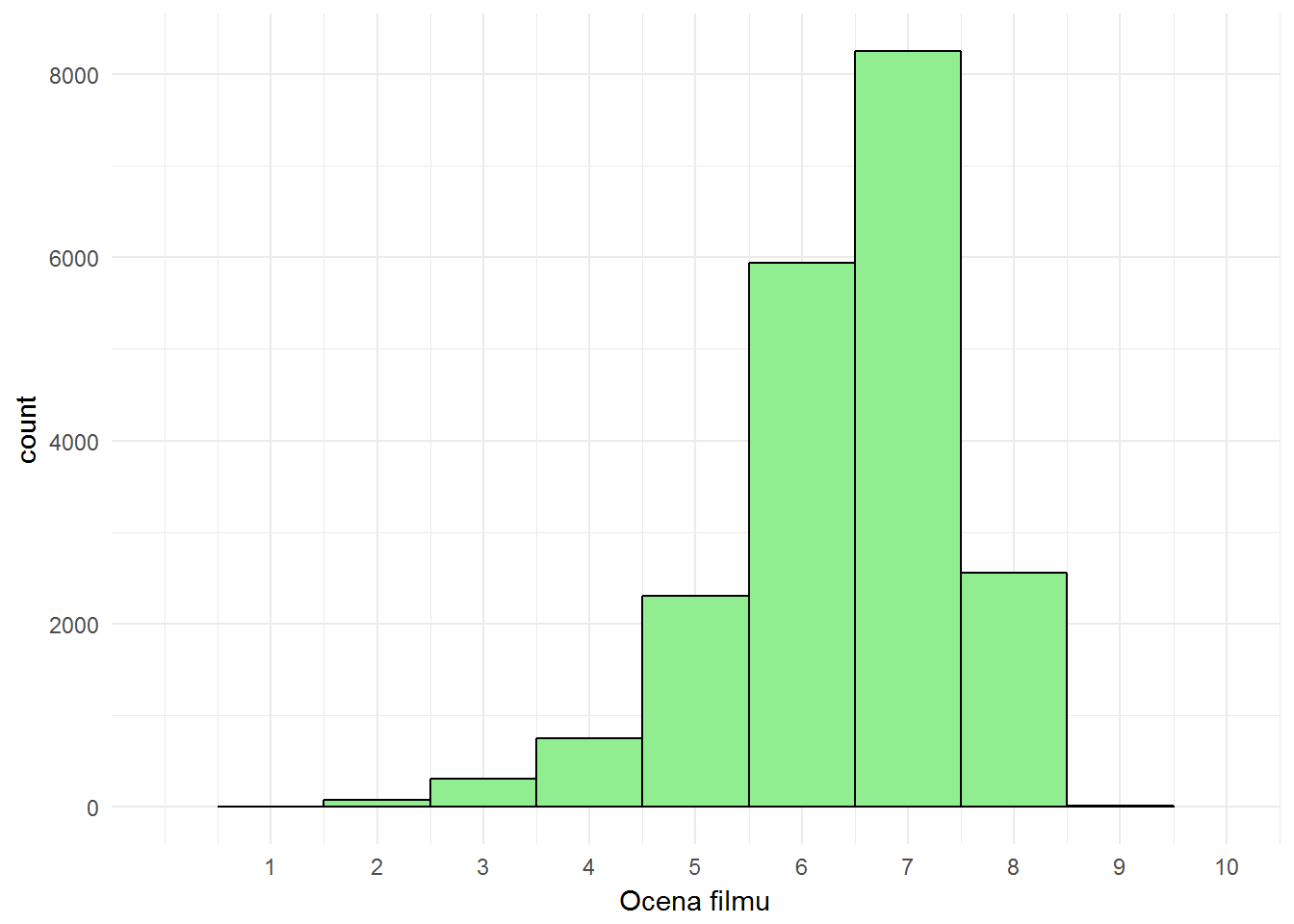
Najczęściej nadawaną oceną jest siódemka, następna w kolejności jest szóstka. Ocen skrajnych jest mało. I tak jest zawsze jeśli mamy tego typu skalę i dużo produktów do oceny. Co ciekawe – przy obliczaniu NPS (Net Promoter Score – wersja angielska tłumaczy jak liczy się ten wskaźnik) wartości 7 i 8 nie są brane pod uwagę.
Z czego może wynikać ta popularność szóstek i siódemek? Z kilku powodów:
- oceniamy filmy, które widzieliśmy, bo przecież nie będziemy marnować czasu na gnioty i wybieramy raczej coś potencjalnie wartościowego. Taki wybór nas zadowala (ocena dobra lub bardzo dobra w skali Filmwebu) stąd najwięcej ocen 6 i 7
- filmów wybitnych jest mało
- gniotów jest mało, albo ich nie oglądamy (patrz punkt pierwszy)
- w zestawieniu z ocenami zależnymi od roku produkcji może być trochę tak, że cenimy filmy stare, bo ktoś powiedział że to arcydzieła – nawet jeśli “Obywatel Kane” jest nudny (nie jest, jest rewelacyjny) to dajemy mu 8, 9 albo i 10 gwiazdek, bo to w końcu najlepszy film wszech czasów… według krytyków, Akademii i tak dalej, i tak dalej…
- druga opcja tłumacząca wyższe oceny dla starszych filmów to sentyment – film widzieliśmy dawno, niewiele pamiętamy, a to co pamiętamy to głównie emocje wokół seansu (bo byliśmy pierwszy raz w kinie, bo byliśmy młodzi i ogólnie bardziej oceniamy młodość niż sam film)
Ja dodatkowo oceniam filmy w kontekście – przede wszystkim gatunku, ale też czasu powstania filmu i tego co twórcy mieli szansę zobaczyć wcześniej. Dlatego właśnie “Obywatel Kane” jest w mojej opinii arcydziełem – przed tym filmem nie było takiego grania światłem, nie było ujęć z podłogi, a także nie było takiego sposobu prowadzenia opowieści.
Z ciekawości policzmy coś w rodzaju wskaźnika NPS dla gatunków:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
library(reshape2) NPS <- movies %>% filter(FilmVotes >= minFilmVotes) %>% mutate(filmRate=round(filmRate)) %>% left_join(movie_genres, by="filmID") %>% filter(!is.na(genreID)) %>% select(genreID, filmRate) %>% dcast(genreID ~ filmRate, length) NPS$Bad <- rowSums(NPS[, 2:6])/rowSums(NPS[,2:10]) # za złe oceny unajemy 1-5 włącznie NPS$Good <- rowSums(NPS[, 9:10])/rowSums(NPS[,2:10]) # za dobre - 8-10 NPS$NPS <- 100*(NPS$Good - NPS$Bad) NPS %>% select(genreID, NPS) %>% left_join(dict_genre, by="genreID") %>% arrange(NPS) %>% mutate(genreName = factor(genreName, levels=genreName)) %>% ggplot() + geom_bar(aes(genreName, NPS, fill = ifelse(NPS > 0, "good", "bad")), color = "black", stat = "identity", show.legend = FALSE) + geom_text(aes(genreName, y = ifelse(NPS > 0, -5, 5), label = round(NPS, 1))) + geom_hline(yintercept = 50, color = "blue") + coord_flip() + labs(x = "Gatunek", y = "NPS") + scale_fill_manual(values = c("good" = "lightgreen", "bad" = "red")) + scale_y_continuous(breaks = seq(-100, 100, 25)) |
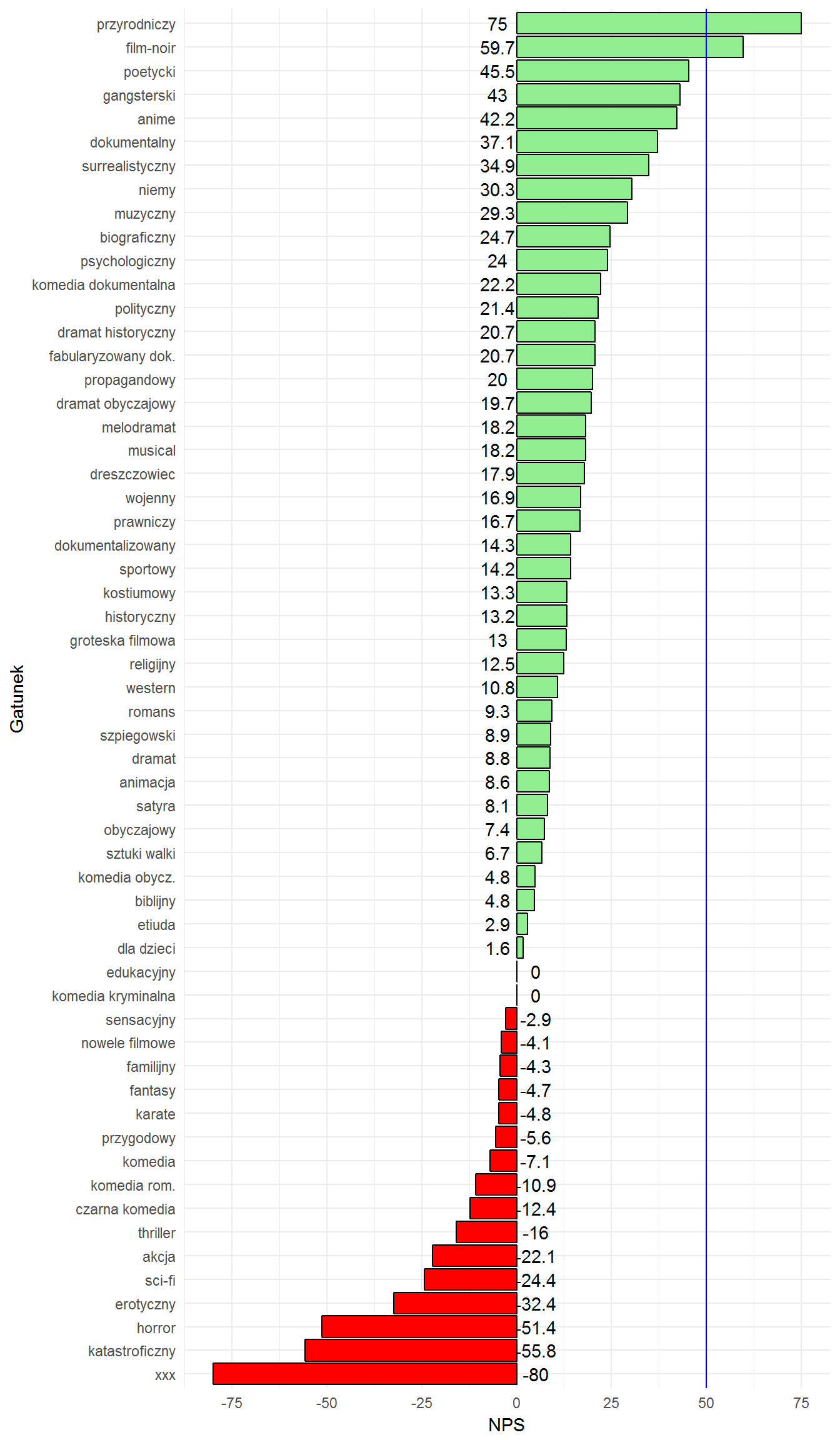
Jak czytać ten wykres? Im dłuższy zielony pasek tym większa jest przewaga ocen dobrych nad złymi. Za oceny dobre uznajemy tutaj 8 gwiazdek i więcej, za złe – do pięciu gwiazdek włącznie. Wskaźnik NPS mówi o tym jak bardzo klienci są skłonni polecać usługę lub towar znajomym (im większy tym bardziej, wartości poniżej zera to już odradzanie; wartości powyżej 50 uznawane są jako “doskonałe”). Tutaj w jakimś uproszczeniu możemy przyjąć, że filmy przyrodnicze będą polecane (jako interesujące, z ładnymi zdjęciami – na pewno mają przewagę ocen wysokich nad niższymi), a filmy z kategorii “xxx” (też można by powiedzieć, że przyrodnicze…) będą odradzane, nie należy ich oglądać. Bo są słabo oceniane, a nie ze względu na treść.
Na koniec tych rozważań zobaczmy najlepsze filmy według roku produkcji:
|
1 2 3 4 5 6 7 8 9 10 11 |
movies %>% filter(FilmVotes >= minFilmVotes) %>% select(filmID, filmTitle, filmYear, filmRate) %>% group_by(filmYear) %>% mutate(filmRate_max = max(filmRate)) %>% ungroup() %>% filter(filmRate == filmRate_max) %>% select(filmYear, filmTitle, filmRate) %>% arrange(filmYear) %>% mutate(filmRate = round(filmRate, 2)) %>% knitr::kable() |
| Rok | Tytuł | Ocena |
|---|---|---|
| 1888 | Roundhay Garden Scene | 7.10 |
| 1894 | Kamera Edisona rejestruje kichnięcie | 4.46 |
| 1895 | Wjazd pociągu na stację w Ciotat | 7.26 |
| 1896 | Rezydencja diabła | 6.39 |
| 1897 | Zaczarowana gospoda | 6.30 |
| 1898 | Un homme de tetes | 7.24 |
| 1900 | Człowiek orkiestra | 7.13 |
| 1901 | Człowiek z gumową głową | 7.17 |
| 1902 | Podróż na Księżyc | 7.79 |
| 1903 | Napad na ekspres | 7.01 |
| 1904 | Podróż do krainy niemożliwości | 7.14 |
| 1905 | Le Diable noir | 6.54 |
| 1906 | Humorous Phases of Funny Faces | 6.35 |
| 1908 | Fantasmagoria | 6.57 |
| 1910 | Frankenstein | 6.59 |
| 1912 | Zemsta kinooperatora | 7.71 |
| 1913 | Student z Pragi | 6.78 |
| 1914 | Gertie the Dinosaur | 6.45 |
| 1915 | Włóczęga | 7.24 |
| 1916 | Nietolerancja | 7.32 |
| 1917 | Imigrant | 7.62 |
| 1918 | Pieskie życie | 7.67 |
| 1919 | Skarb rodu Arne | 7.39 |
| 1920 | Gabinet doktora Caligari | 7.95 |
| 1921 | Brzdąc | 8.11 |
| 1922 | Doktor Mabuse | 8.08 |
| 1923 | Jeszcze wyżej | 8.02 |
| 1924 | Nibelungi: Zemsta Krymhildy | 8.03 |
| 1925 | Gorączka złota | 7.88 |
| 1926 | Generał | 8.04 |
| 1927 | Metropolis | 8.09 |
| 1928 | Męczeństwo Joanny d’Arc | 8.24 |
| 1929 | Człowiek z kamerą filmową | 8.11 |
| 1930 | Błękitny anioł | 7.76 |
| 1931 | Światła wielkiego miasta | 8.17 |
| 1932 | Jestem zbiegiem | 8.17 |
| 1933 | Królowa Krystyna | 7.80 |
| 1934 | Ich noce | 7.93 |
| 1935 | Noc w operze | 7.90 |
| 1936 | Dzisiejsze czasy | 8.14 |
| 1937 | Bohaterowie morza | 8.24 |
| 1938 | Miasto chłopców | 8.26 |
| 1939 | Burzliwe lata dwudzieste | 7.96 |
| 1940 | Pożegnalny walc | 8.17 |
| 1941 | Małe liski | 8.01 |
| 1942 | Trzy kamelie | 8.02 |
| 1943 | Kruk | 7.89 |
| 1944 | Gasnący płomień | 8.05 |
| 1945 | Komedianci | 8.14 |
| 1946 | To wspaniałe życie | 8.16 |
| 1947 | Konik Garbusek | 7.98 |
| 1948 | Czerwone trzewiki | 7.89 |
| 1949 | Dziedziczka | 8.13 |
| 1950 | Bulwar Zachodzącego Słońca | 8.16 |
| 1951 | As w potrzasku | 7.94 |
| 1952 | Zakazane zabawy | 8.00 |
| 1953 | Cena strachu | 7.98 |
| 1954 | Siedmiu samurajów | 8.04 |
| 1955 | Rififi | 8.14 |
| 1956 | Między linami ringu | 7.95 |
| 1957 | Dwunastu gniewnych ludzi | 8.64 |
| 1958 | Ballada o Narayamie | 8.14 |
| 1959 | Darby O’Gill and the Little People | 8.31 |
| 1960 | Kto sieje wiatr | 8.15 |
| 1961 | Wyrok w Norymberdze | 8.29 |
| 1962 | Forever My Love | 8.05 |
| 1963 | Niebo i piekło | 8.02 |
| 1964 | Siedem dni w maju | 8.22 |
| 1965 | Za kilka dolarów więcej | 8.09 |
| 1966 | Dobry, zły i brzydki | 8.23 |
| 1967 | Bunt | 8.30 |
| 1968 | Monterey Pop | 8.14 |
| 1969 | Butch Cassidy i Sundance Kid | 7.97 |
| 1970 | Woodstock | 8.13 |
| 1971 | Johnny poszedł na wojnę | 8.09 |
| 1972 | Ojciec chrzestny | 8.67 |
| 1973 | Ziggy Stardust and the Spiders from Mars | 8.15 |
| 1974 | Ojciec chrzestny II | 8.50 |
| 1975 | Lot nad kukułczym gniazdem | 8.54 |
| 1976 | Pieśń pozostaje ta sama | 8.26 |
| 1977 | Biurowy romans | 7.98 |
| 1978 | Łowca jeleni | 8.11 |
| 1979 | Czas Apokalipsy | 8.17 |
| 1980 | Gwiezdne wojny: Część V – Imperium kontratakuje | 8.14 |
| 1981 | Amerykańska muzyka pop | 8.17 |
| 1982 | Ściana | 8.15 |
| 1983 | Człowiek z blizną | 8.31 |
| 1984 | Dawno temu w Ameryce | 8.20 |
| 1985 | Idź i patrz | 8.14 |
| 1986 | Pluton | 8.16 |
| 1987 | Metallica: Cliff ’Em All | 8.14 |
| 1988 | Dekalog V | 8.14 |
| 1989 | 101 | 8.29 |
| 1990 | Chłopcy z ferajny | 8.33 |
| 1991 | Milczenie owiec | 8.26 |
| 1992 | Baraka | 8.20 |
| 1993 | Lista Schindlera | 8.39 |
| 1994 | Skazani na Shawshank | 8.77 |
| 1995 | Siedem | 8.32 |
| 1996 | Kiedy nadejdzie sobota | 8.36 |
| 1997 | George Wallace | 8.42 |
| 1998 | Więzień nienawiści | 8.21 |
| 1999 | Zielona mila | 8.64 |
| 2000 | Freddie Mercury, the Untold Story | 8.15 |
| 2001 | Piękny umysł | 8.29 |
| 2002 | Władca Pierścieni: Dwie wieże | 8.32 |
| 2003 | Władca Pierścieni: Powrót króla | 8.39 |
| 2004 | Rubí… La descarada | 8.56 |
| 2005 | Ashes and Snow | 8.25 |
| 2006 | Lisiczka | 8.15 |
| 2007 | Punk’s Not Dead | 8.25 |
| 2008 | House, M.D., Season Four: New Beginnings | 8.33 |
| 2009 | Iron Maiden: Flight 666 | 8.13 |
| 2010 | Incepcja | 8.28 |
| 2011 | Nietykalni | 8.71 |
| 2012 | Django | 8.29 |
| 2013 | Mandarynki | 8.08 |
| 2014 | Sól ziemi | 8.35 |
| 2015 | Pokój | 8.01 |
| 2016 | Zwierzogród | 8.24 |
A czy z postępem technologii idzie wydłużenie czasu trwania filmu?
|
1 2 3 4 5 6 7 8 9 |
movies %>% filter(!is.na(FilmDuration)) %>% filter(FilmDuration <= quantile(FilmDuration, 0.999)) %>% ggplot() + geom_point(aes(filmYear, FilmDuration), color="lightgreen", alpha=0.1) + geom_smooth(aes(filmYear, FilmDuration), color="blue") + scale_x_continuous(breaks = seq(1880, 2020, 10)) + scale_y_continuous(breaks = seq(0, 300, 30)) + labs(x = "Rok", y = "Czas trwania filmu") |
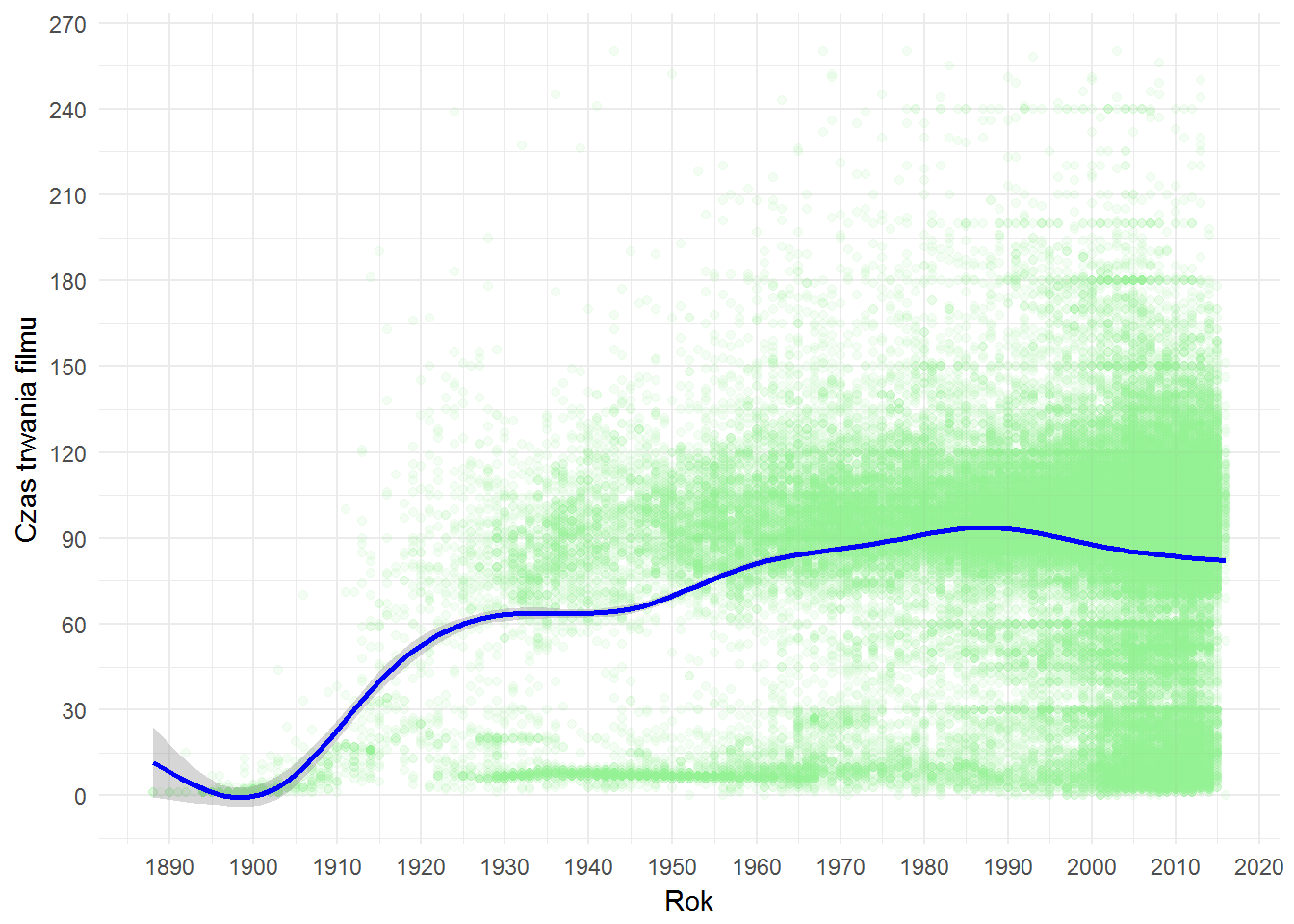
Dość przewidywalne wyniki, zależne początkowo od technologii (ciężki i grzejący się sprzęt, droga taśma), trochę pewnie też percepcji widzów szczególnie na początku XX wieku. Po II wojnie światowej ukonstytuowały się pewne standardy, między innymi około 90-110 minut czasu trwania filmu i tak już pozostało co czasów obecnych.
Mamy też smugi w okolicach 10 minut(etiudy), 30 minut (krótkie filmy dokumentalne) i 60 minut (festiwalowy limit 60 minut dla filmów krótkometrażowych).
Popatrzmy na to w inny sposób:
|
1 2 3 4 5 6 7 8 |
movies %>% filter(!is.na(FilmDuration)) %>% filter(FilmDuration <= quantile(FilmDuration, 0.999)) %>% ggplot() + geom_histogram(aes(FilmDuration), fill="lightgreen", color="black", binwidth = 5) + scale_x_continuous(breaks = seq(0, 240, 15)) + labs(x = "Czas trwania filmu") |
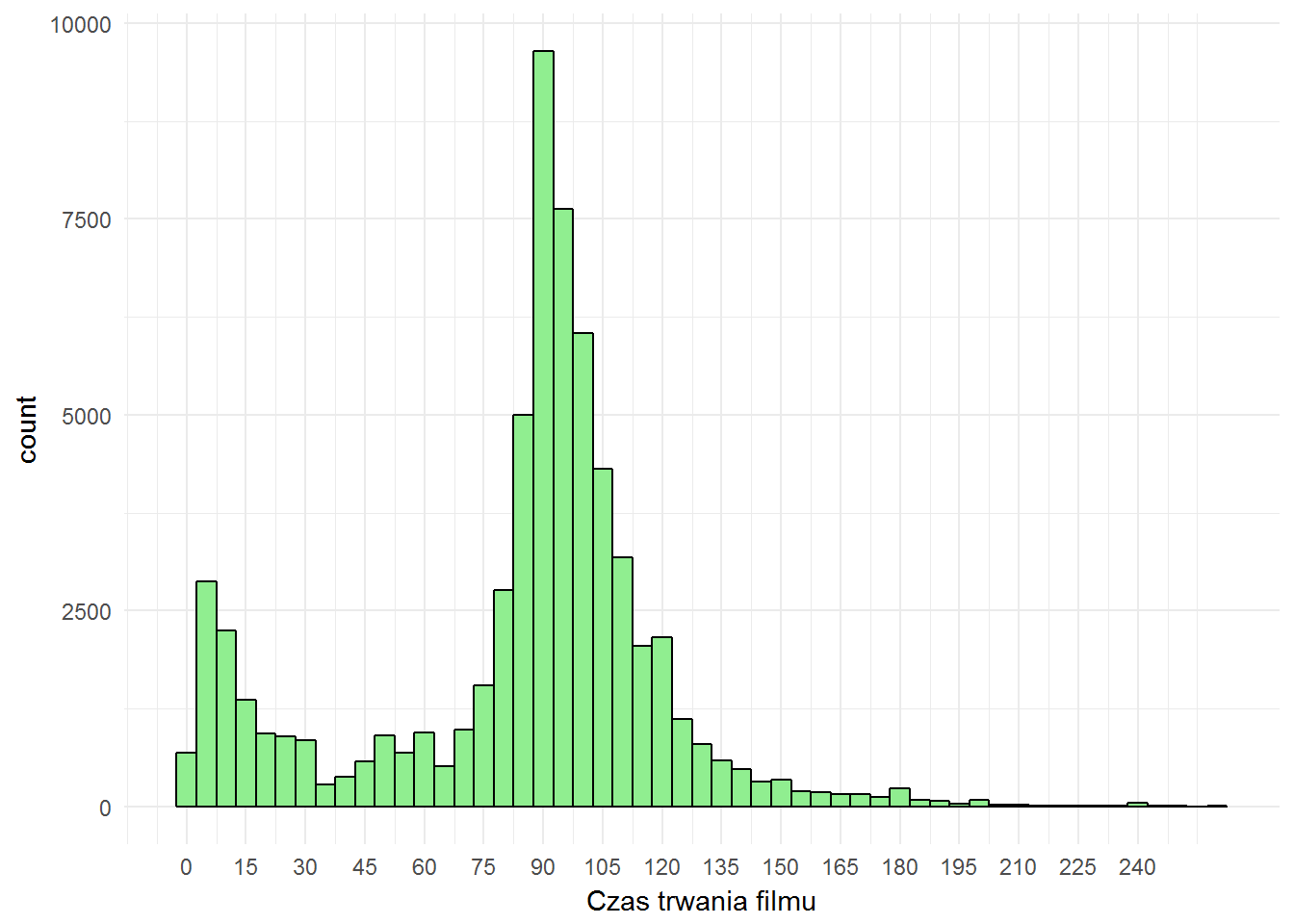
Sprawdźmy teraz czy ocena zależy od czasu trwania filmu?
|
1 2 3 4 5 6 7 8 9 10 |
movies %>% filter(!is.na(FilmDuration)) %>% filter(FilmDuration <= quantile(FilmDuration, 0.999)) %>% filter(FilmVotes >= minFilmVotes) %>% ggplot() + geom_point(aes(FilmDuration, filmRate), color="lightgreen", alpha=0.1) + geom_smooth(aes(FilmDuration, filmRate), color="blue") + scale_x_continuous(breaks = seq(0, 240, 15)) + scale_y_continuous(limits = c(0,10), breaks = 1:10) + labs(x = "Czas trwania filmu", y = "Ocena filmu") |
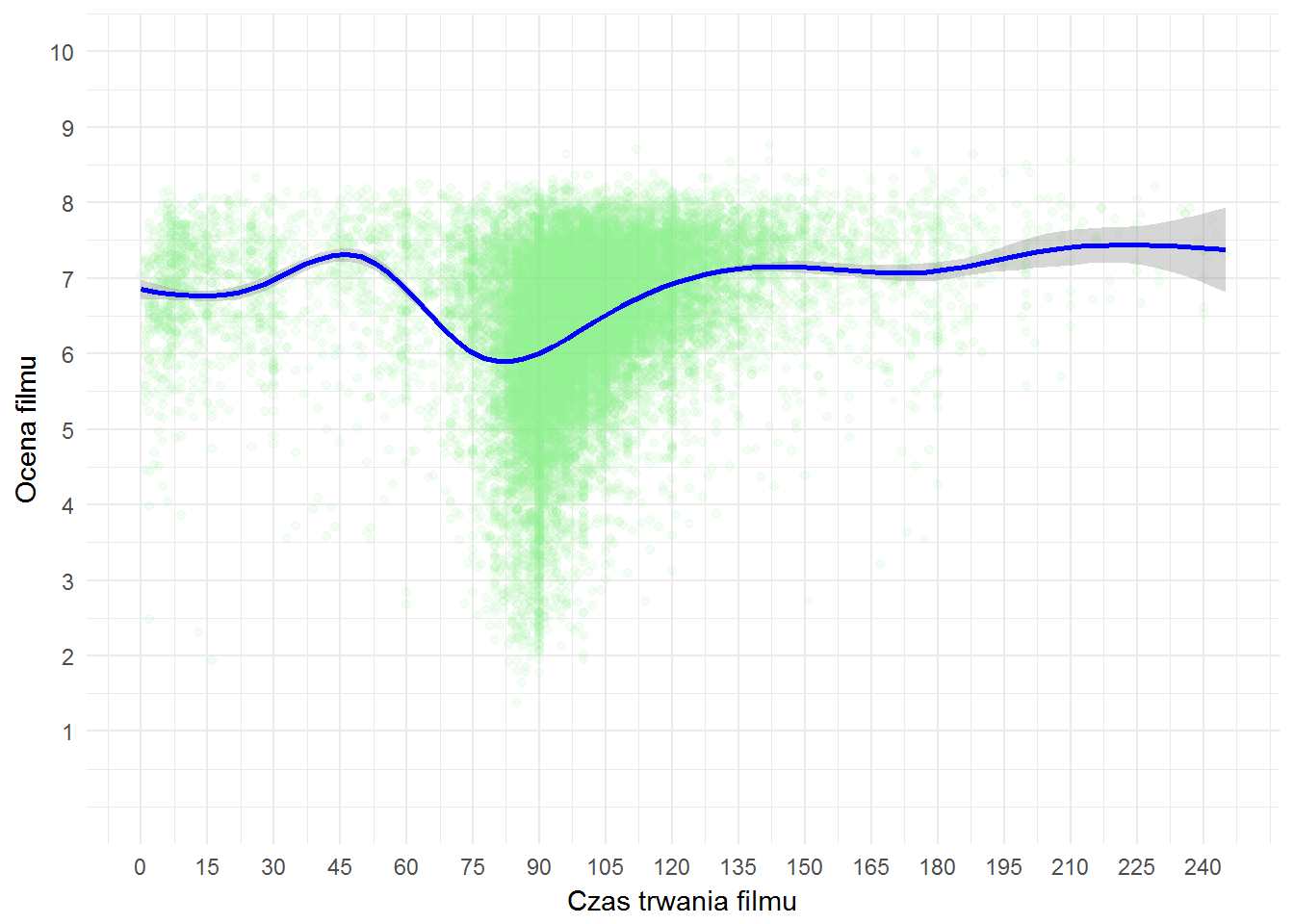
Widać spadek dla filmów dłuższych niż godzina (60-90 minut). Strzelam, że są to formaty telewizyjne (półtoragodzinny blok w programie – film plus reklamy), które są – nie ukrywajmy – słabszymi produkcjami niż filmy przeznaczone do dystrybucji kinowej. Aby potwierdzić taką tezę należałoby znaleźć te filmy i sprawdzić co to za gatunki… tyle tylko, że nie mamy gatunku “film telewizyjny” ;)
Zobaczmy teraz jak zmieniała się popularność poszczególnych gatunków z upływem czasu. Ważne jest to, co zaburza trochę wyniki – jeden film może należeć do kilku gatunków (na przykład niemy dramat wojenny sci-fi – #oglądałbym :-).
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
movies %>% select(filmID, filmYear) %>% left_join(movie_genres, by="filmID") %>% filter(!is.na(genreID)) %>% count(filmYear, genreID) %>% mutate(p = 100*n/sum(n)) %>% ungroup() %>% left_join(dict_genre, by="genreID") %>% ggplot() + geom_bar(aes(filmYear, p, fill=genreName), stat="identity", color=NA, show.legend = FALSE) + labs(x = "Rok", y = "Procent filmów") + scale_x_continuous(breaks = seq(1880, 2020, 10)) |
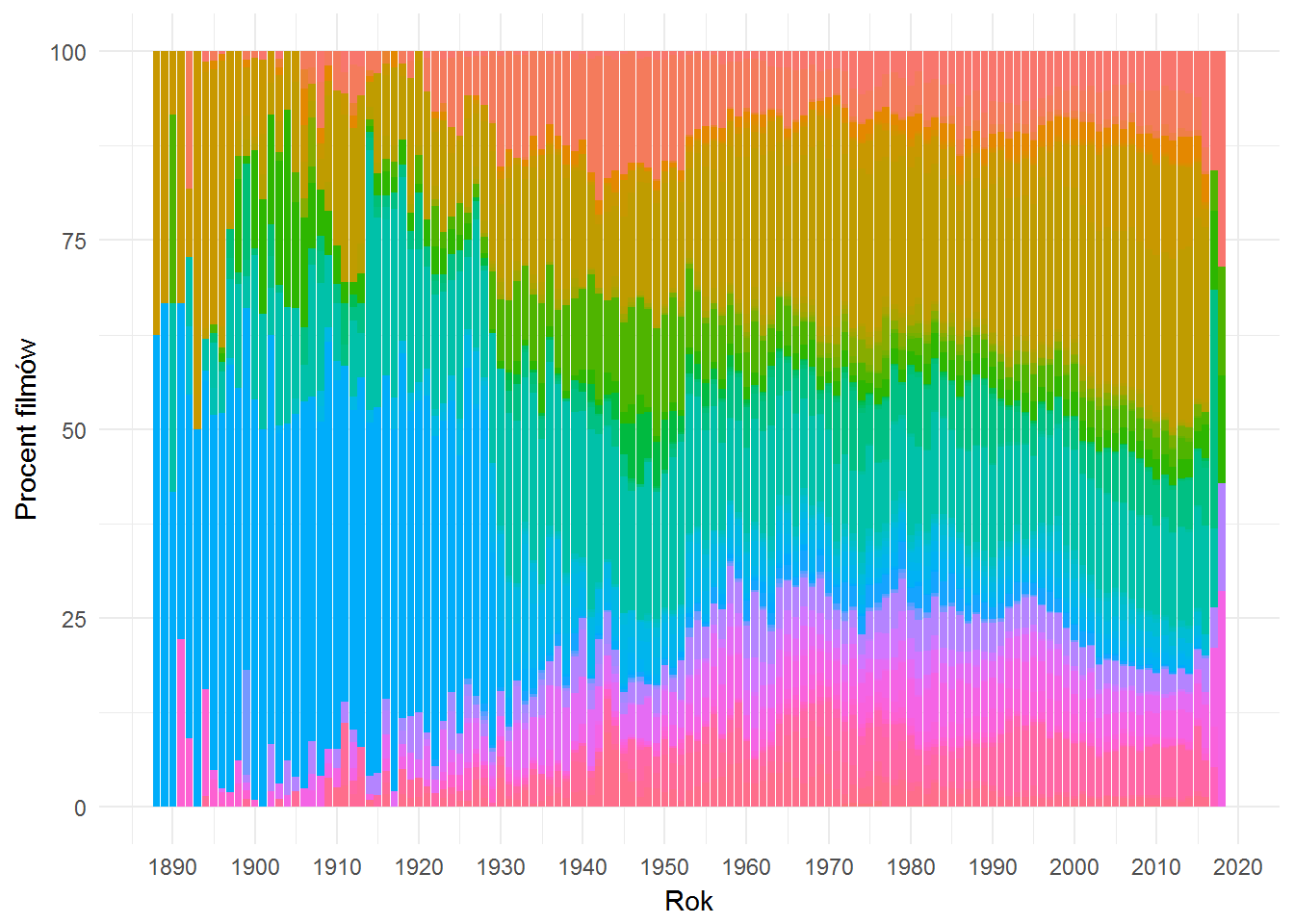
Statyczny wykres jest nieczytelny (przed skalę kolorów), zobaczmy wersję interaktywną – najedź na pasek, zobaczysz informacje w dymku:
Popatrzmy na to sumarycznie (bez rozdzielania na poszczególne lata) – jaki jest podział procentowy filmów wyprodukowanych w XXI wieku pomiędzy gatunki? Weźmy tylko 20 najpopularniejszych gatunków:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
movies %>% select(filmID, filmYear) %>% filter(filmYear >= 2000) %>% left_join(movie_genres, by="filmID") %>% filter(!is.na(genreID)) %>% count(genreID) %>% mutate(p = 100*n/sum(n)) %>% ungroup() %>% left_join(dict_genre, by="genreID") %>% top_n(20, wt = p) %>% arrange(p) %>% mutate(genreName = factor(genreName, levels=genreName)) %>% ggplot() + geom_bar(aes(genreName, p), stat="identity", fill="lightgreen", color="black") + geom_text(aes(genreName, p, label=paste0(round(p, 1), "%"), hjust = ifelse(p > 5, 1.1, -0.2))) + coord_flip() + labs(x = "Gatunek", y = "Udział procentowy gatunku") |
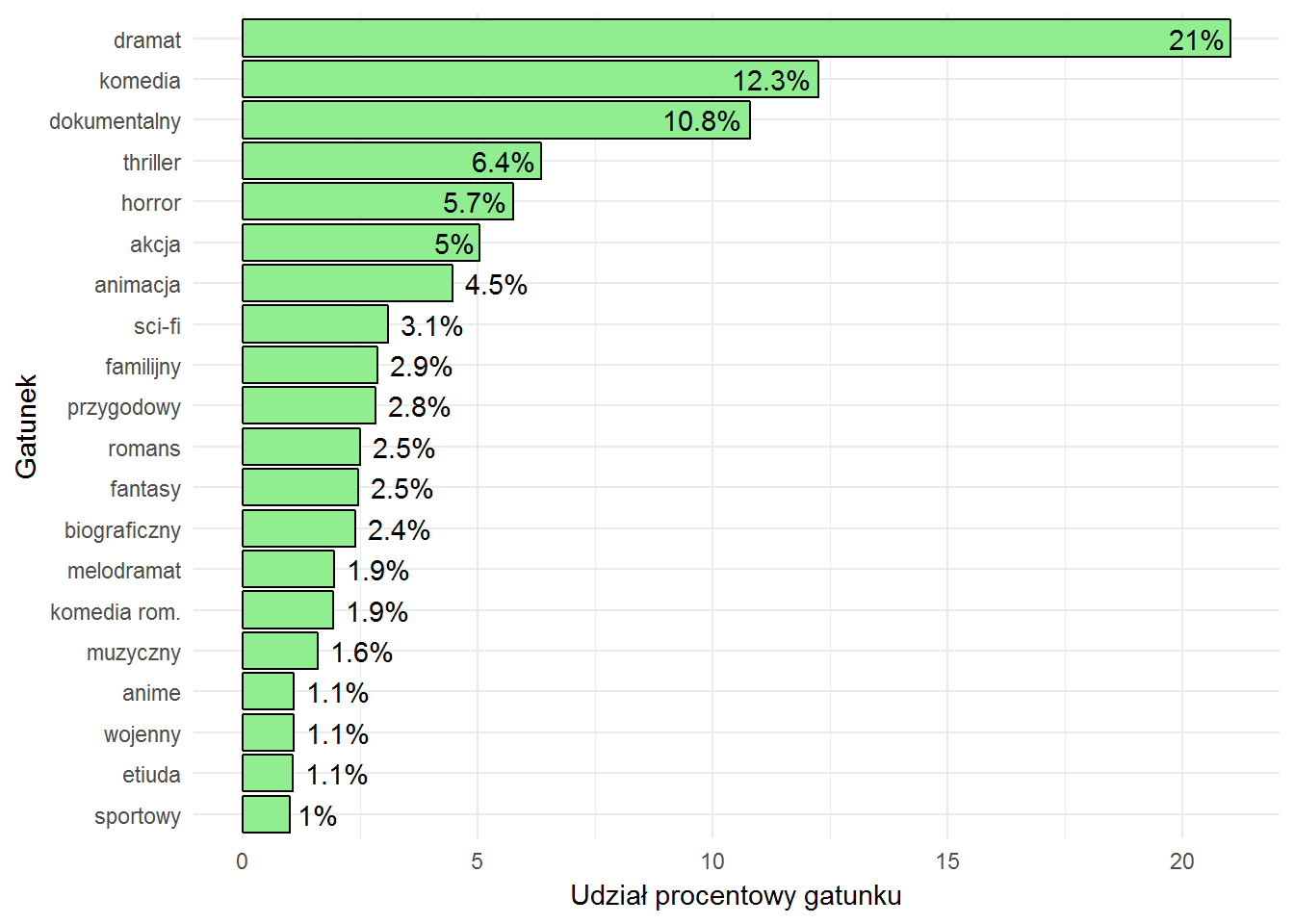
Ciekawe, ale bez odniesienia nie można wiele powiedzieć. Zobaczmy lata 1940-1970:
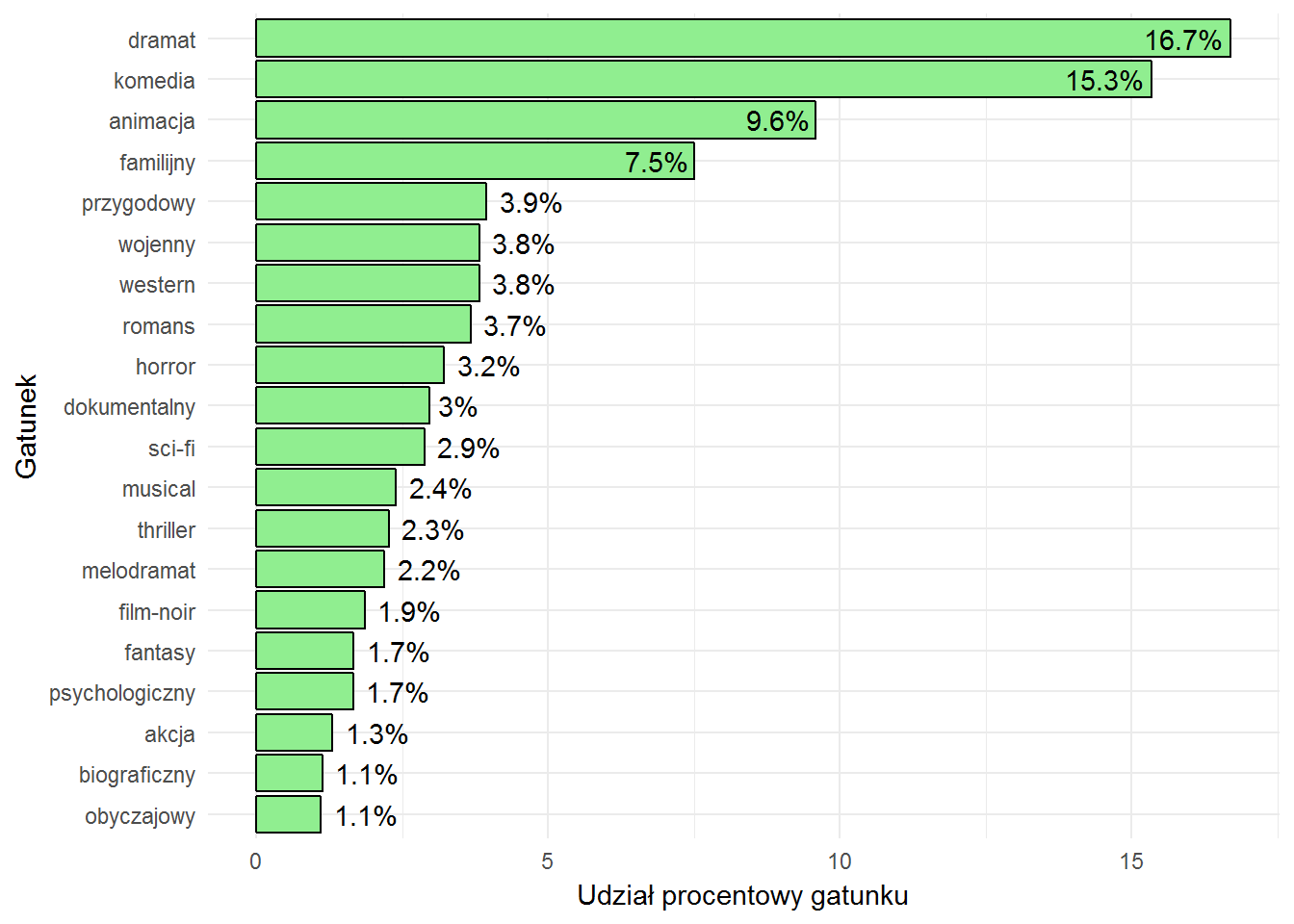
oraz podział przed 1940 rokiem:
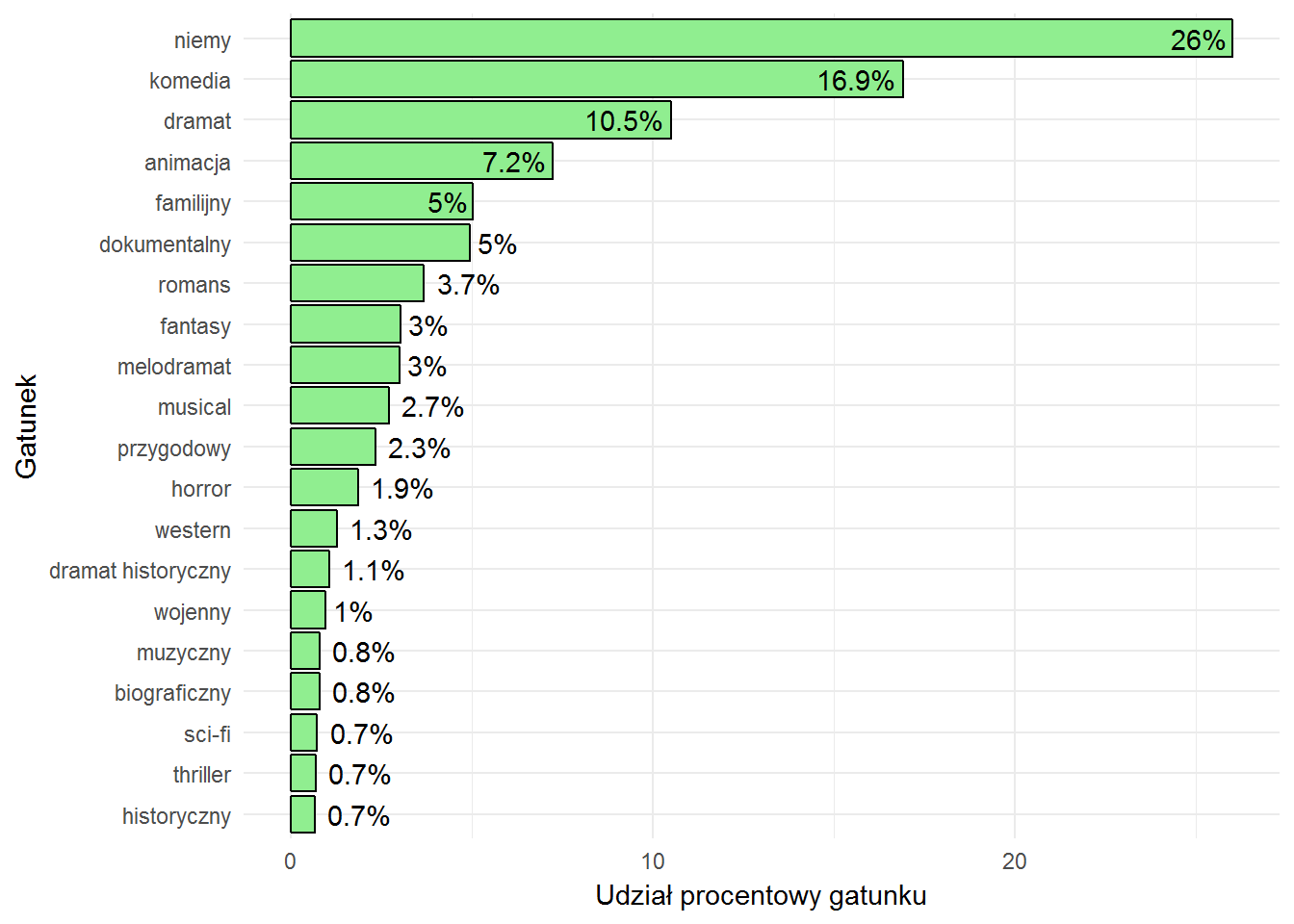
Oczywiście w pierwszej połowie XX wieku dominowały filmy nieme. Ciekawy jest spory udział animacji w latach ’40-’70. W tym samym okresie widać wzrost liczby filmów wojennych i późniejszy jej spadek. Film noir istniał w latach ’40-’50. Thriller i horror zdobywają rynek w ostatnich latach, podobnie anime – nie istniało przed 2000 rokiem (albo nie załapało się do top 20). Bez względu na okres popularne są komedie i dramaty – w końcu kino to rozrywka.
Zobaczmy teraz jak zmieniał się udział filmów dziewięciu najpopularniejszych gatunków na przestrzeni lat?
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
movies %>% select(filmID, filmYear) %>% left_join(movie_genres, by="filmID") %>% filter(!is.na(genreID)) %>% count(filmYear, genreID) %>% mutate(p = 100*n/sum(n)) %>% ungroup() %>% group_by(genreID) %>% mutate(mp = mean(p)) %>% ungroup() %>% filter(mp >= 3.5) %>% left_join(dict_genre, by="genreID") %>% ggplot() + geom_area(aes(filmYear, p, fill=genreName), show.legend = FALSE) + facet_wrap(~genreName, ncol = 3) + labs(x = "Rok", y = "Udział procentowy gatunku") |
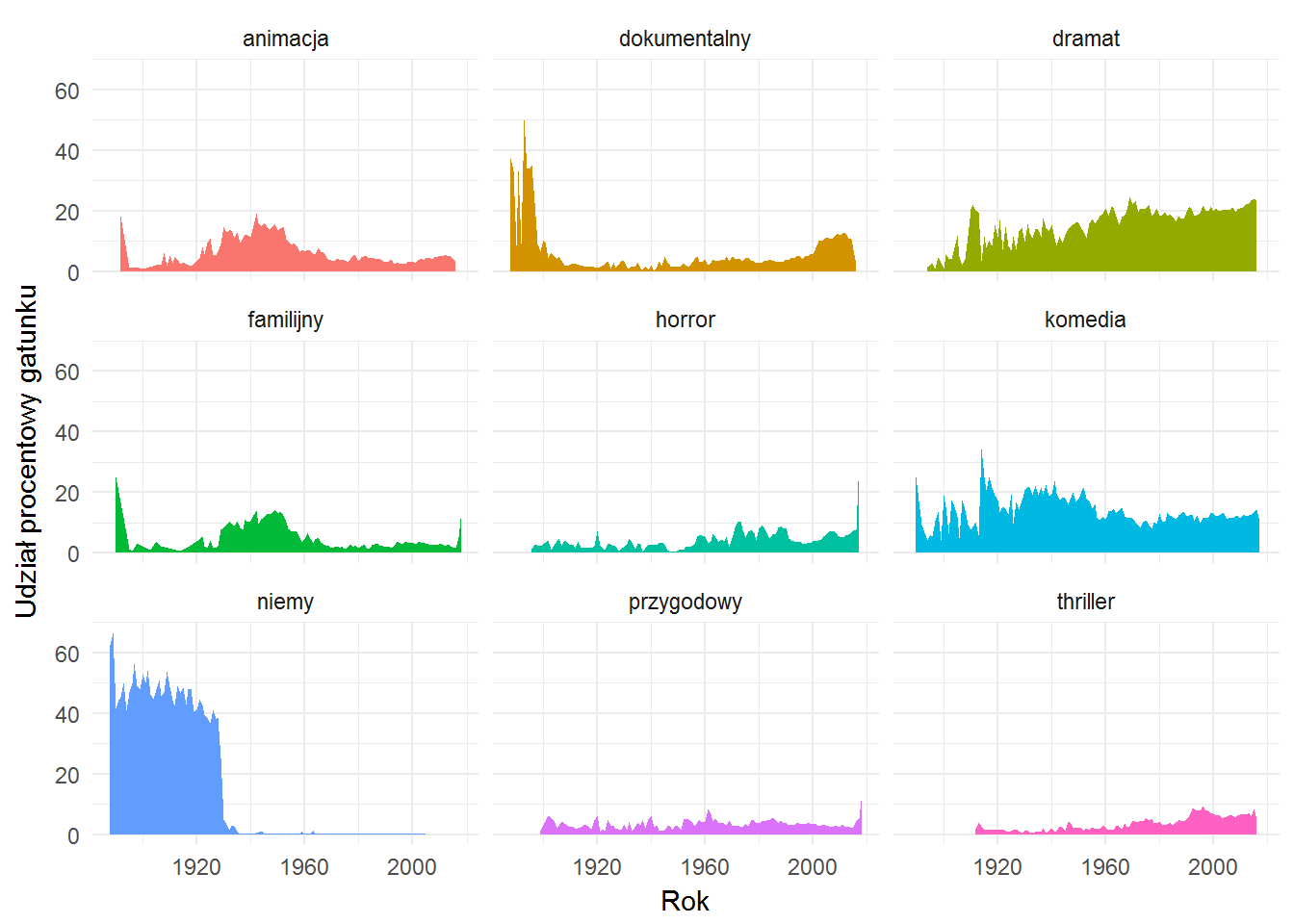
Potwierdza się to zaobserwowaliśmy wyżej przy okazji wykresów słupkowych:
- film niemy się skończył
- animacja popularna w latach 1930-1950 (Walt Disney?)
- film dokumentalny zyskuje na popularności (a może po prostu Filmweb poszerza bazę o nowe produkcje, pomijając uzupełnianie historii?), a ogromny (jak na ten gatunek) udział w początkach historii kina to wszystkie te krótkie filmy typu “Wjazd pociągu na stację” czy “Wyjście robotników z fabryki” (oczywiście upraszczając)
Poszukajmy najlepszych filmów w poszczególnych gatunkach:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
movies %>% filter(FilmVotes >= minFilmVotes) %>% select(filmID, filmTitle, filmYear, filmRate) %>% left_join(movie_genres, by="filmID") %>% filter(!is.na(genreID)) %>% distinct() %>% group_by(genreID) %>% mutate(filmRate_max = max(filmRate)) %>% ungroup() %>% filter(filmRate == filmRate_max) %>% left_join(dict_genre, by="genreID") %>% select(genreName, filmTitle, filmYear, filmRate) %>% arrange(genreName) %>% mutate(filmRate = round(filmRate, 2)) %>% knitr::kable() |
| Gatunek | Tytuł | Rok | Ocena |
|---|---|---|---|
| akcja | Straż przyboczna | 1961 | 8.08 |
| animacja | Król Lew | 1994 | 8.25 |
| anime | Grobowiec świetlików | 1988 | 8.07 |
| biblijny | Dziesięcioro przykazań | 1956 | 7.78 |
| biograficzny | Nietykalni | 2011 | 8.71 |
| czarna komedia | Cremaster 3 | 2002 | 8.02 |
| dla dzieci | Odwrócona góra albo film pod strasznym tytułem | 2000 | 7.93 |
| dokumentalizowany | Wszystko może się przytrafić | 1995 | 8.13 |
| dokumentalny | Sól ziemi | 2014 | 8.35 |
| dramat | Skazani na Shawshank | 1994 | 8.77 |
| dramat historyczny | Bunt | 1967 | 8.30 |
| dramat obyczajowy | W pogoni za szczęściem | 2006 | 8.12 |
| dreszczowiec | Człowiek, który się śmieje | 1928 | 8.01 |
| edukacyjny | Pieniądze jako dług | 2006 | 7.44 |
| erotyczny | Betty | 1985 | 7.68 |
| etiuda | Dzień babci | 2015 | 8.00 |
| fabularyzowany dok. | Uciekinier | 2006 | 7.95 |
| familijny | Darby O’Gill and the Little People | 1959 | 8.31 |
| fantasy | Władca Pierścieni: Powrót króla | 2003 | 8.39 |
| film-noir | Jestem zbiegiem | 1932 | 8.17 |
| gangsterski | Ojciec chrzestny | 1972 | 8.67 |
| groteska filmowa | Sztuka spadania | 2004 | 7.79 |
| historyczny | Wyrok w Norymberdze | 1961 | 8.29 |
| horror | Gabinet doktora Caligari | 1920 | 7.95 |
| karate | Czyniący cuda | 1989 | 7.35 |
| katastroficzny | Bez ostrzeżenia | 1994 | 7.64 |
| komedia | Nietykalni | 2011 | 8.71 |
| komedia dokumentalna | Monty Python w Hollywood | 1982 | 8.00 |
| komedia kryminalna | Żądło | 1973 | 8.09 |
| komedia obycz. | Wspomnienia Hiacynty Bukiet | 1997 | 7.94 |
| komedia rom. | Biurowy romans | 1977 | 7.98 |
| kostiumowy | Cienie zapomnianych przodków | 1964 | 8.15 |
| melodramat | Notre-Dame de Paris | 1999 | 8.33 |
| musical | Notre-Dame de Paris | 1999 | 8.33 |
| muzyczny | 101 | 1989 | 8.29 |
| niemy | Męczeństwo Joanny d’Arc | 1928 | 8.24 |
| nowele filmowe | Noc na Ziemi | 1991 | 8.01 |
| obyczajowy | Dzieci niebios | 1997 | 8.07 |
| poetycki | Ashes and Snow | 2005 | 8.25 |
| polityczny | George Wallace | 1997 | 8.42 |
| prawniczy | Zabić drozda | 1962 | 7.93 |
| propagandowy | The Union: The Business Behind Getting High | 2007 | 7.94 |
| przygodowy | Władca Pierścieni: Powrót króla | 2003 | 8.39 |
| przyrodniczy | Earth | 2007 | 8.17 |
| psychologiczny | Lot nad kukułczym gniazdem | 1975 | 8.54 |
| religijny | Duch | 2008 | 7.90 |
| romans | Światła wielkiego miasta | 1931 | 8.17 |
| satyra | Dr Strangelove, czyli jak przestałem się martwić i pokochałem bombę | 1964 | 8.08 |
| sci-fi | Incepcja | 2010 | 8.28 |
| sensacyjny | Gorączka | 1995 | 8.10 |
| sportowy | Kiedy nadejdzie sobota | 1996 | 8.36 |
| surrealistyczny | Incepcja | 2010 | 8.28 |
| szpiegowski | Północ – północny zachód | 1959 | 7.81 |
| sztuki walki | Ip Man | 2008 | 7.93 |
| thriller | Siedem | 1995 | 8.32 |
| western | Django | 2012 | 8.29 |
| wojenny | Lista Schindlera | 1993 | 8.39 |
| xxx | Kaligula | 1979 | 6.09 |
Wiemy już jak wygląda popularność poszczególnych gatunków, jak zmieniała się ocena wszystkich filmów w czasie, a czy takie same zmiany są w ramach gatunków? Przygotujemy fukncję, która po podaniu w parametrze nazwy gatunku narysuje nam stosowny wykres:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
RatesByGenre <- function(gatunek) { # ID gatunku gatunek_id <- dict_genre %>% filter(genreName == gatunek) %>% .[1, 1] %>% as.integer() # lista filmów gatunku movies_ids <- movie_genres %>% filter(genreID == gatunek_id) %>% select(filmID) %>% .$filmID plot <- movies %>% filter(filmID %in% movies_ids, FilmVotes >= minFilmVotes) %>% ggplot() + geom_point(aes(filmYear, filmRate), color="lightgreen", alpha=0.3) + geom_smooth(aes(filmYear, filmRate), color="blue") + labs(title=paste("Oceny filmów z gatunku:", gatunek), x="Rok", y="Ocena filmu") + scale_x_continuous(breaks = seq(1880, 2020, 10)) + scale_y_continuous(breaks = 1:10, limits = c(0,10)) return(plot) } |
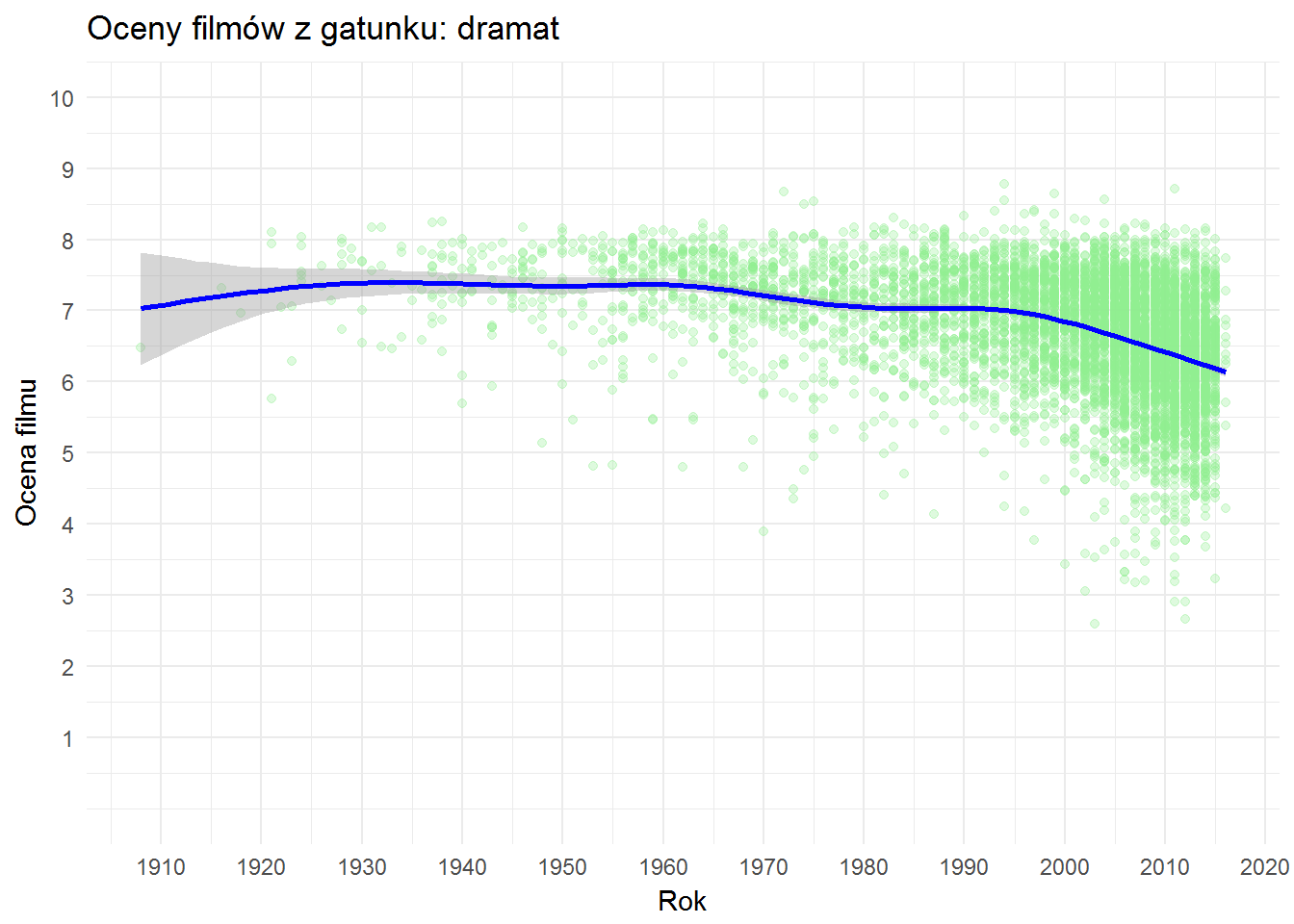
Teraz z wykorzystaniem tej funkcji zobaczmy czy thrillery są coraz lepsze czy coraz gorsze?
|
1 |
RatesByGenre("thriller") |

Coraz więcej i coraz gorzej… niestety. To pewnie dlatego nic nie jest w stanie mnie zaskoczyć. A najlepsze filmy z tego gatunku to:
|
1 2 3 4 5 |
RatesByGenre("thriller")$data %>% select(filmTitle, filmYear, filmRate) %>% top_n(10, wt = filmRate) %>% arrange(desc(filmRate)) %>% mutate(filmRate = round(filmRate, 2)) |
| Tytuł | Rok | Ocena |
|---|---|---|
| Siedem | 1995 | 8.32 |
| Podziemny krąg | 1999 | 8.30 |
| Incepcja | 2010 | 8.28 |
| Milczenie owiec | 1991 | 8.26 |
| Siedem dni w maju | 1964 | 8.22 |
| Wyspa tajemnic | 2010 | 8.16 |
| Prestiż | 2006 | 8.13 |
| Dziura | 1960 | 8.12 |
| Noc i miasto | 1950 | 8.10 |
| Doktor Mabuse | 1922 | 8.08 |
Większość już widziałem (poza ostatnimi trzema i “Siedem dni w maju”). Rzeczywiście “Siedem” jest chyba najlepszy, a “Incepcji” do thrillerów bym nie zaliczał.
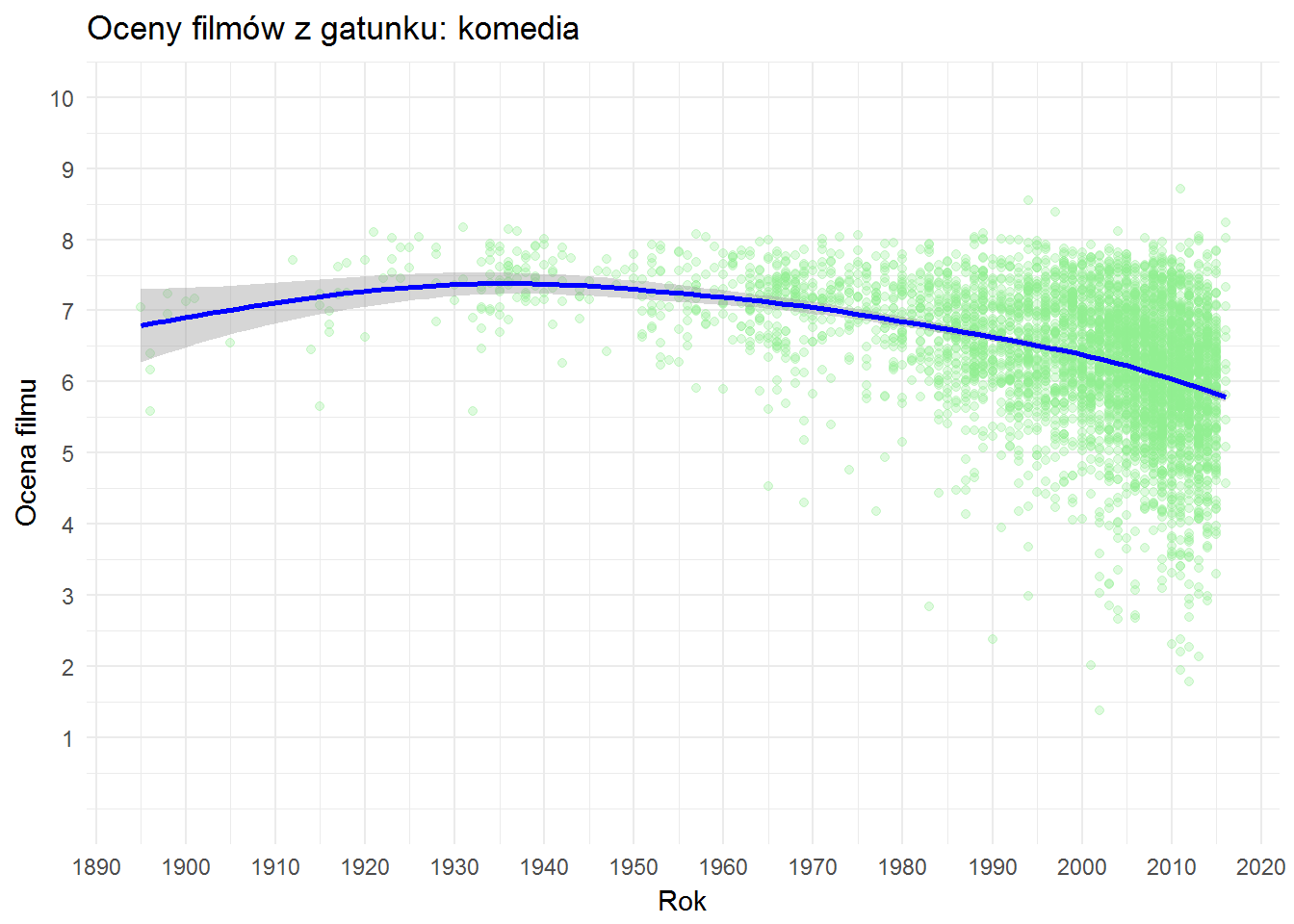
Zobaczmy to samo dla kilku innych gatunków:
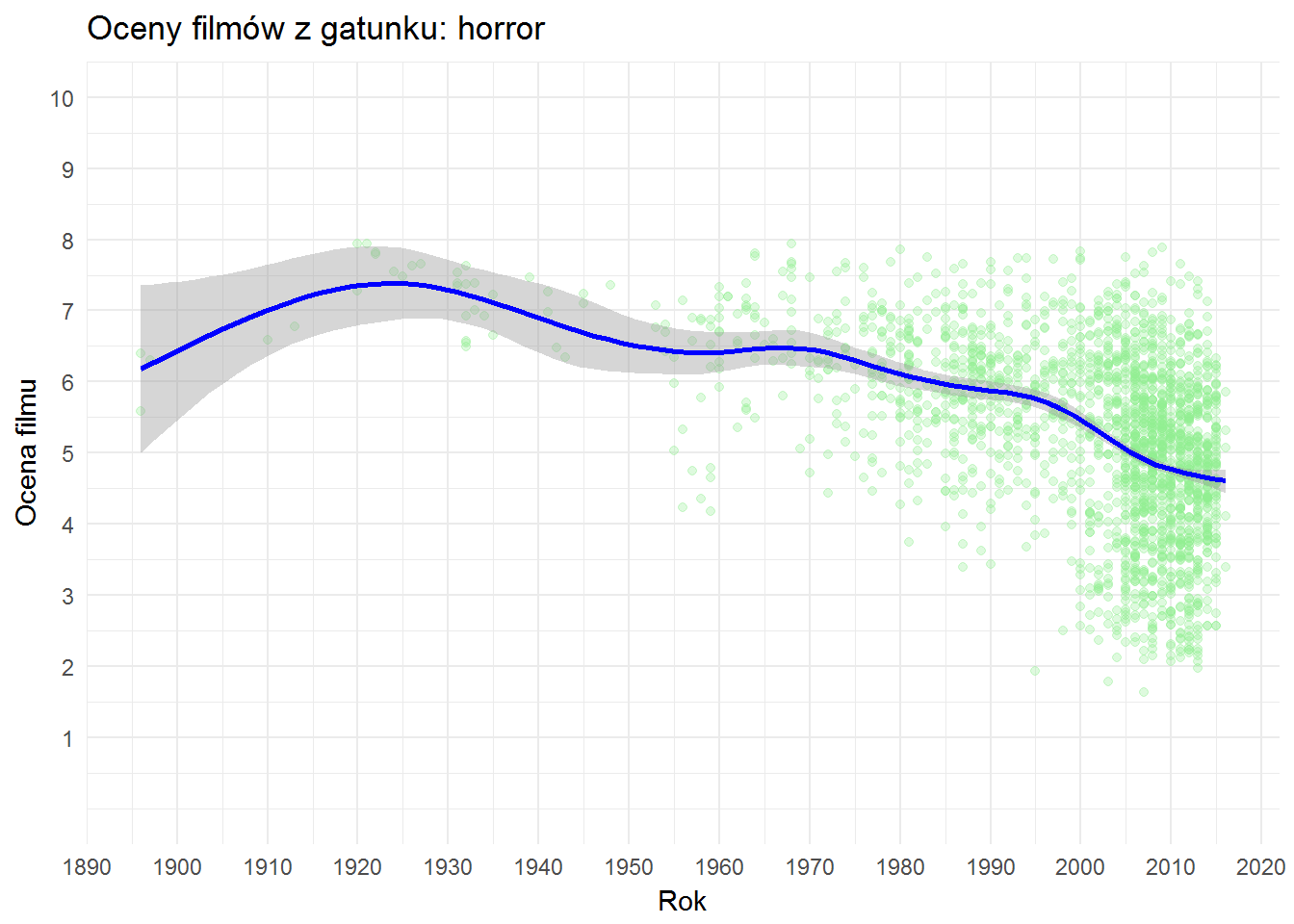
| Tytuł | Rok | Ocena |
|---|---|---|
| Gabinet doktora Caligari | 1920 | 7.95 |
| Palacz zwłok | 1968 | 7.94 |
| Furman śmierci | 1921 | 7.94 |
| Kara no Kyokai: Satsujin Kosatsu (Go) | 2009 | 7.89 |
| Lśnienie | 1980 | 7.86 |
| Sleepy Hollow: Behind the Legend | 2000 | 7.83 |
| Kara no Kyokai: Tsukaku Zanryu | 2008 | 7.82 |
| Czarownice | 1922 | 7.82 |
| Kobieta-diabeł | 1964 | 7.81 |
| Nosferatu – symfonia grozy | 1922 | 7.79 |
| Tytuł | Rok | Ocena |
|---|---|---|
| Skazani na Shawshank | 1994 | 8.77 |
| Nietykalni | 2011 | 8.71 |
| Ojciec chrzestny | 1972 | 8.67 |
| Zielona mila | 1999 | 8.64 |
| Rubí… La descarada | 2004 | 8.56 |
| Forrest Gump | 1994 | 8.55 |
| Lot nad kukułczym gniazdem | 1975 | 8.54 |
| Ojciec chrzestny II | 1974 | 8.50 |
| George Wallace | 1997 | 8.42 |
| Lista Schindlera | 1993 | 8.39 |
| Tytuł | Rok | Ocena |
|---|---|---|
| Nietykalni | 2011 | 8.71 |
| Forrest Gump | 1994 | 8.55 |
| Życie jest piękne | 1997 | 8.38 |
| Zwierzogród | 2016 | 8.24 |
| Światła wielkiego miasta | 1931 | 8.17 |
| Dzisiejsze czasy | 1936 | 8.14 |
| The Trailer Park Boys Christmas Special | 2004 | 8.11 |
| Piętro wyżej | 1937 | 8.11 |
| Brzdąc | 1921 | 8.11 |
| Skeczu z papugą nie będzie | 1989 | 8.08 |
A na koniec coś, dla czego (oprócz kotów) powstał internet – pornoski:
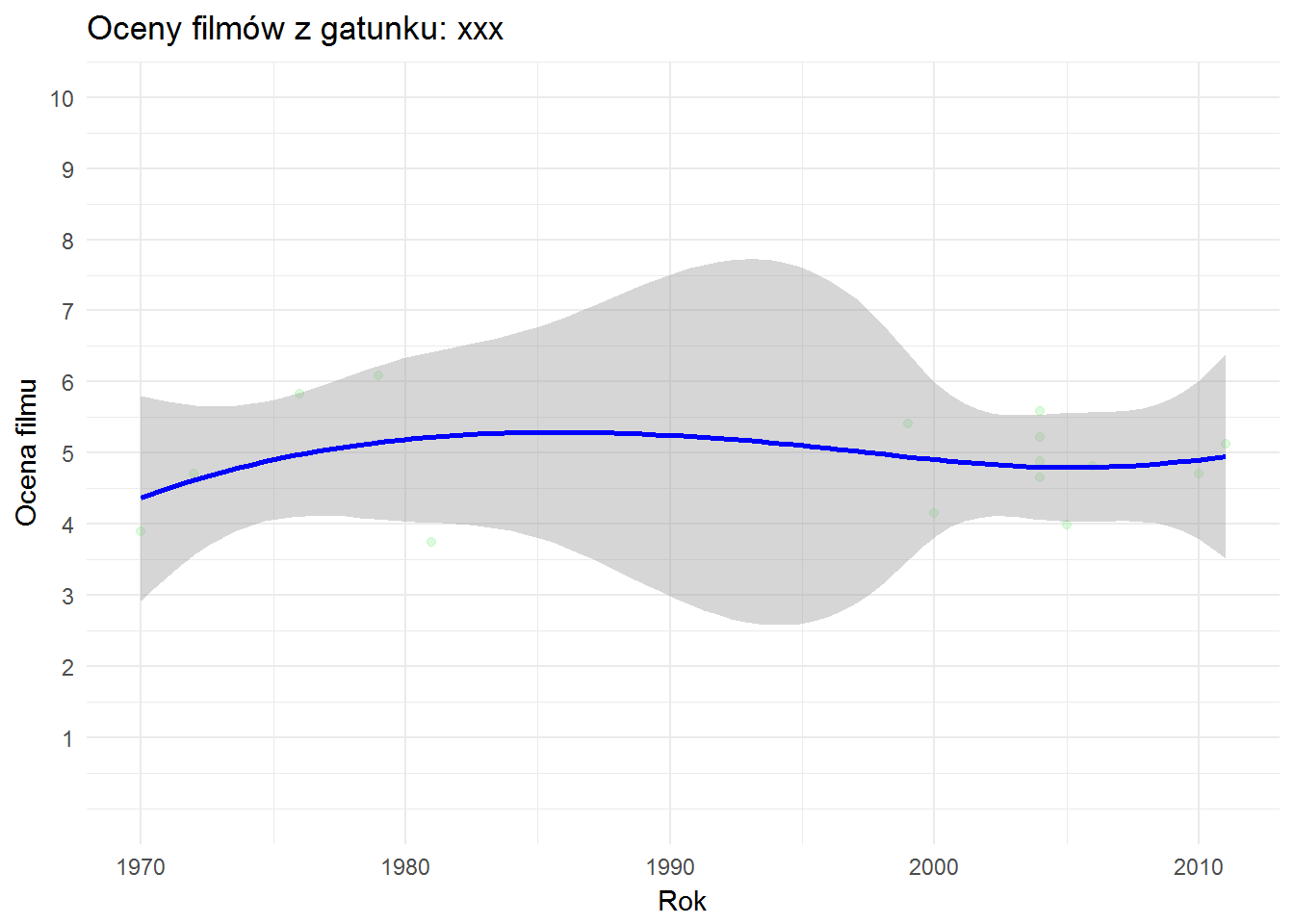
Wiele ich nie ma, trzymają stały poziom. 10 najlepszych pornosów to:
| Tytuł | Rok | Ocena |
|---|---|---|
| Kaligula | 1979 | 6.09 |
| Alicja w Krainie Czarów | 1976 | 5.84 |
| Dziura w sercu | 2004 | 5.58 |
| Romans | 1999 | 5.41 |
| The Raspberry Reich | 2004 | 5.22 |
| Q | 2011 | 5.13 |
| Anatomia piekła | 2004 | 4.88 |
| Destricted | 2006 | 4.81 |
| Srpski film | 2010 | 4.71 |
| Głębokie gardło | 1972 | 4.70 |
Teraz przygotujmy podobną funkcję, ale przyglądać będziemy się dokonaniom poszczególnych twórców (lub aktorów – nie bierzemy w poniższej funkcji pod uwagę roli w jakiej występuje dana osoba – czy jest reżyserem czy aktorem).
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
RatesByPerson <- function(osoba) { # ID osoby person_id <- persons %>% filter(personName == osoba) %>% .[1, 1] %>% as.integer() # lista filmów z osobą movies_ids <- persons_in_movies %>% filter(personID == person_id) %>% select(filmID) %>% .$filmID plot <- movies %>% filter(filmID %in% movies_ids, FilmVotes >= minFilmVotes) %>% ggplot() + geom_point(aes(filmYear, filmRate), color="darkgreen") + geom_smooth(aes(filmYear, filmRate), color="blue", se = FALSE) + labs(title=paste("Oceny filmów z:", osoba), x="Rok", y="Ocena filmu") + scale_x_continuous(breaks = seq(1880, 2020, 10)) + scale_y_continuous(breaks = 1:10, limits = c(0,10)) return(plot) } |
Na początek mój ulubiony reżyser (i scenarzysta, i aktor) – Woody Allen:
|
1 |
RatesByPerson("Woody Allen") |
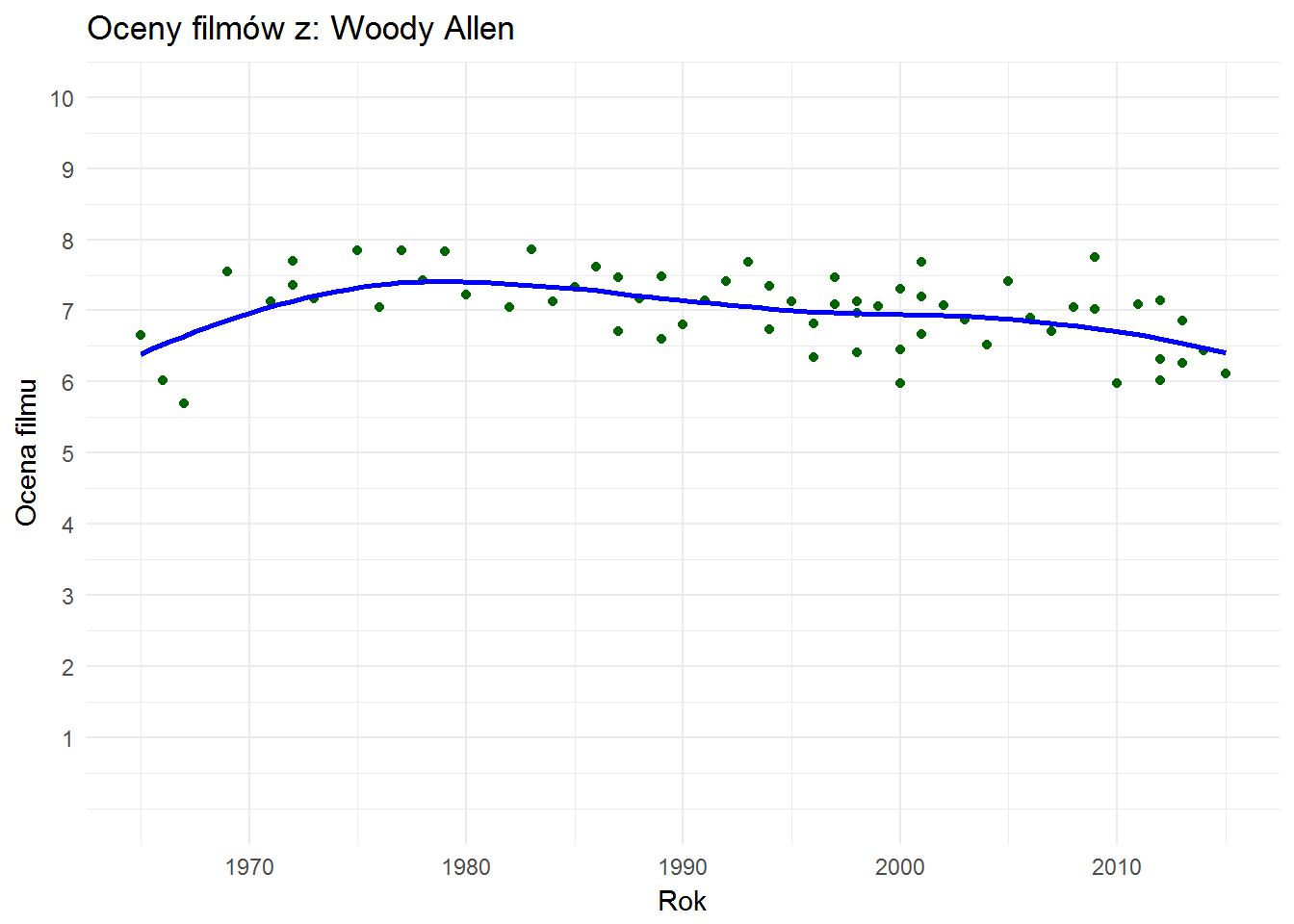
i jego (lub z nim) najlepsze filmy:
|
1 2 3 4 5 |
RatesByPerson("Woody Allen")$data %>% select(filmTitle, filmYear, filmRate) %>% top_n(10, wt = filmRate) %>% arrange(desc(filmRate)) %>% mutate(filmRate = round(filmRate, 2)) |
| Tytuł | Rok | Ocena |
|---|---|---|
| Zelig | 1983 | 7.86 |
| Annie Hall | 1977 | 7.85 |
| Miłość i śmierć | 1975 | 7.85 |
| Manhattan | 1979 | 7.83 |
| Chwilami życie bywa znośne | 2009 | 7.75 |
| Zagraj to jeszcze raz, Sam | 1972 | 7.69 |
| Tajemnica morderstwa na Manhattanie | 1993 | 7.69 |
| Stanley Kubrick: Życie w Obrazach | 2001 | 7.68 |
| Hannah i jej siostry | 1986 | 7.62 |
| Bierz forsę i w nogi | 1969 | 7.55 |
Osobiście bardziej cenię “Annie Hall”, ale pierwsza czwórka to rzeczywiście szczyt formy Allena. Jak widać są to lata ’70, później było z górki (ale nie tak bardzo).
Poptarzmy też na innych reżyserów – Oliver Stone zalicza coraz gorsze filmy:
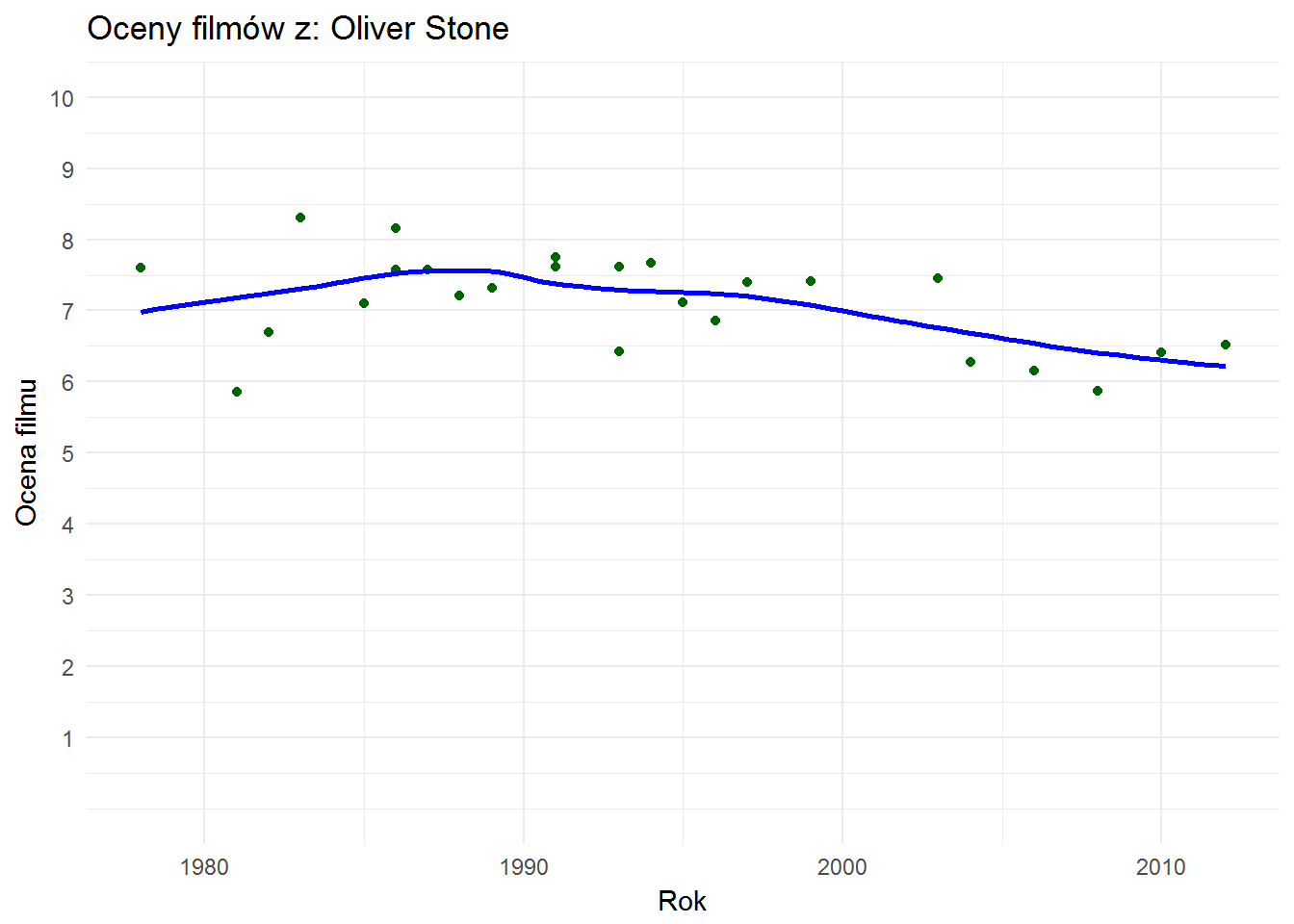
| Tytuł | Rok | Ocena |
|---|---|---|
| Człowiek z blizną | 1983 | 8.31 |
| Pluton | 1986 | 8.16 |
| JFK | 1991 | 7.74 |
| Urodzeni mordercy | 1994 | 7.67 |
| The Doors | 1991 | 7.62 |
| Pomiędzy niebem a ziemią | 1993 | 7.61 |
| Midnight Express | 1978 | 7.60 |
| Salwador | 1986 | 7.58 |
| Wall Street | 1987 | 7.57 |
| Bez granic | 2003 | 7.45 |
Zaś Tarantino trzyma równy poziom:
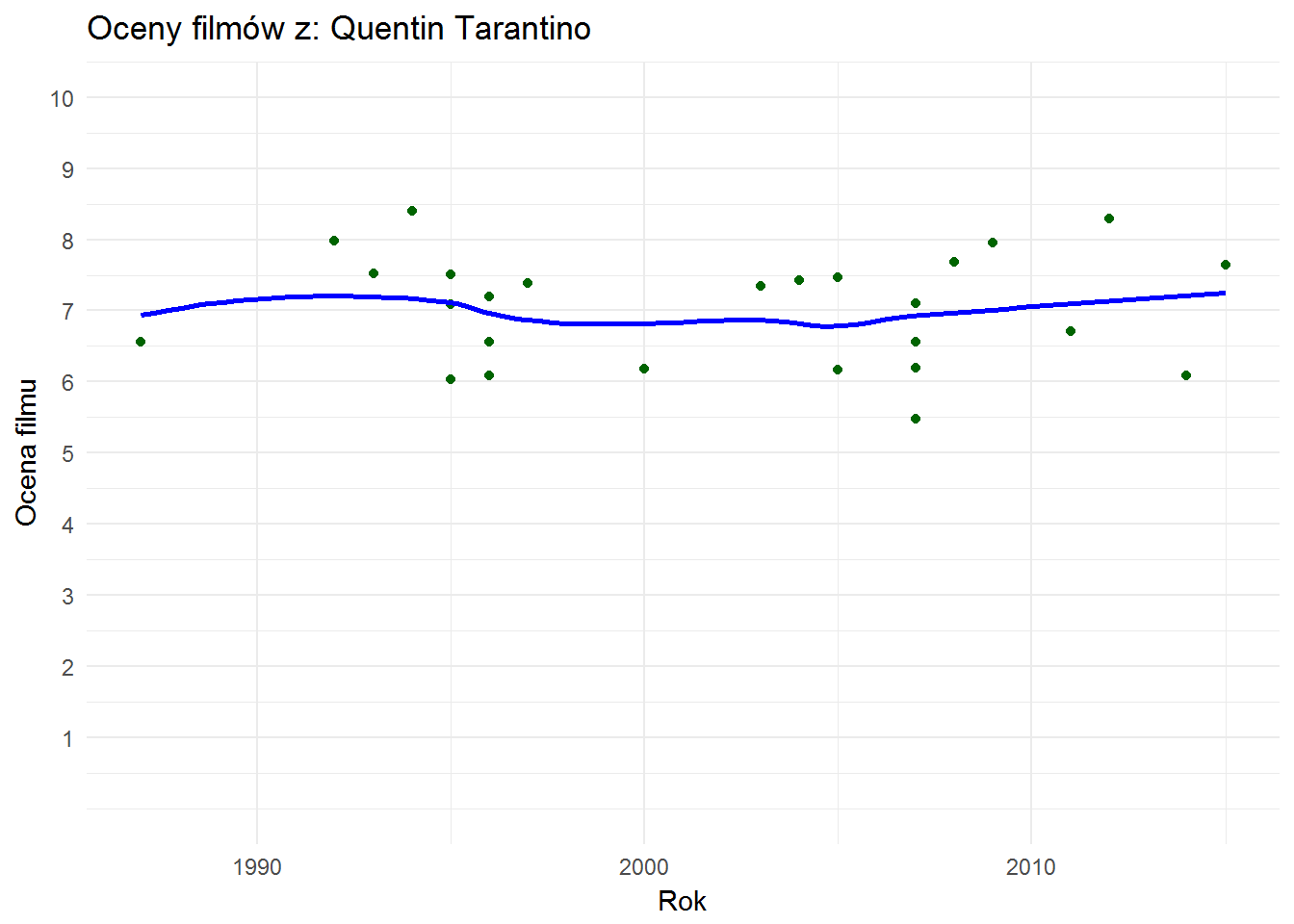
| Tytuł | Rok | Ocena |
|---|---|---|
| Pulp Fiction | 1994 | 8.39 |
| Django | 2012 | 8.29 |
| Wściekłe psy | 1992 | 7.98 |
| Bękarty wojny | 2009 | 7.95 |
| Niezupełnie Hollywood | 2008 | 7.68 |
| Nienawistna ósemka | 2015 | 7.65 |
| Prawdziwy romans | 1993 | 7.52 |
| Cztery pokoje | 1995 | 7.51 |
| Sin City – Miasto grzechu | 2005 | 7.47 |
| Kill Bill 2 | 2004 | 7.42 |
Podobnie było z Kubrickiem:
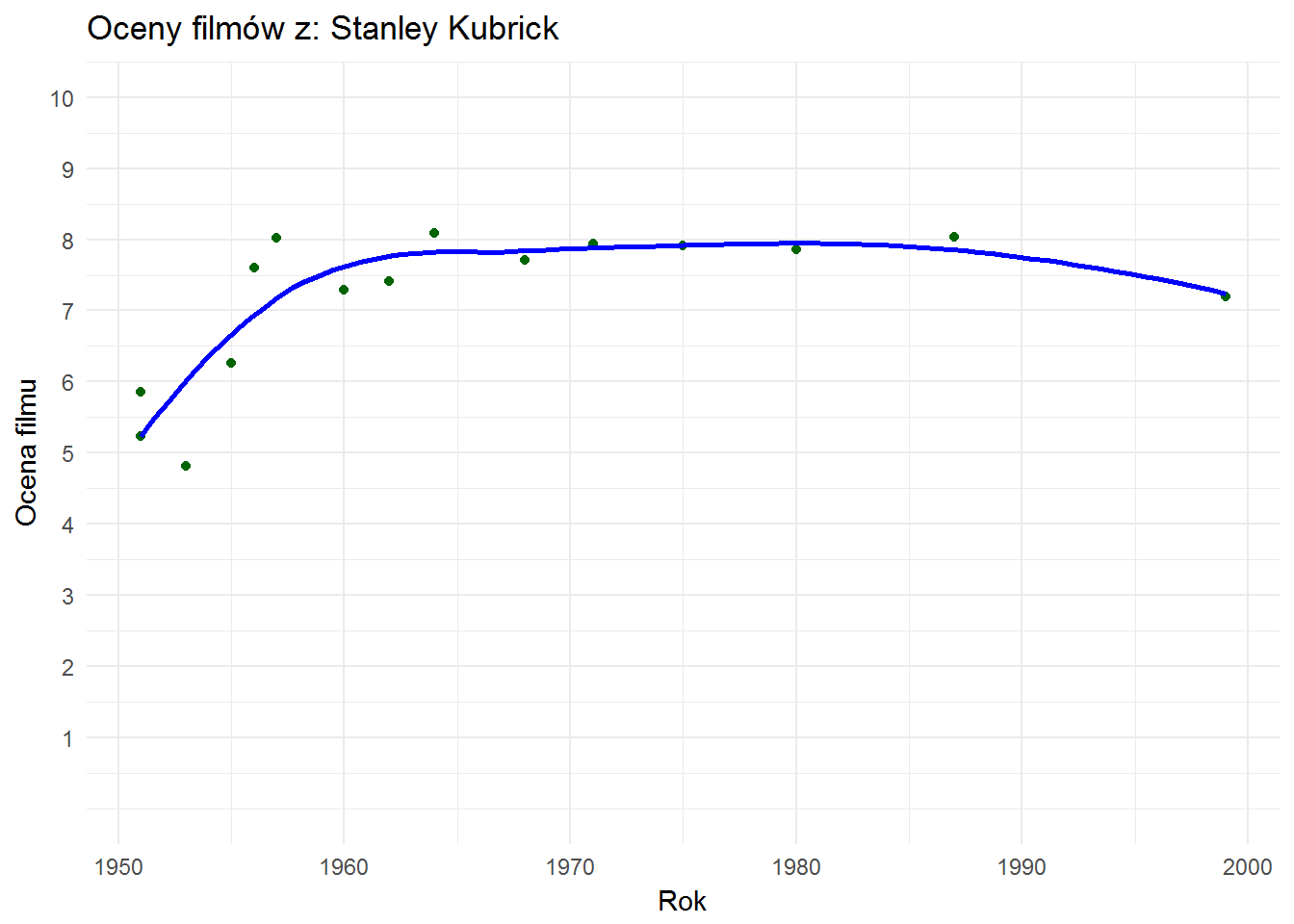
| Tytuł | Rok | Ocena |
|---|---|---|
| Dr Strangelove, czyli jak przestałem się martwić i pokochałem bombę | 1964 | 8.08 |
| Full Metal Jacket | 1987 | 8.03 |
| Ścieżki chwały | 1957 | 8.02 |
| Mechaniczna pomarańcza | 1971 | 7.93 |
| Barry Lyndon | 1975 | 7.92 |
| Lśnienie | 1980 | 7.86 |
| 2001: Odyseja kosmiczna | 1968 | 7.71 |
| Zabójstwo | 1956 | 7.61 |
| Lolita | 1962 | 7.41 |
| Spartakus | 1960 | 7.29 |
Jeśli nie widzieliście “Zabójstwa” w reżyserii tego pana to koniecznie musicie nadrobić – film z połowy lat ’50, a wyprzedził to co oglądamy teraz o jakieś 40-50 lat. Geniusz.
Zobaczmy na dwie aktorskie gwiazdy drugiej połowy XX wieku:
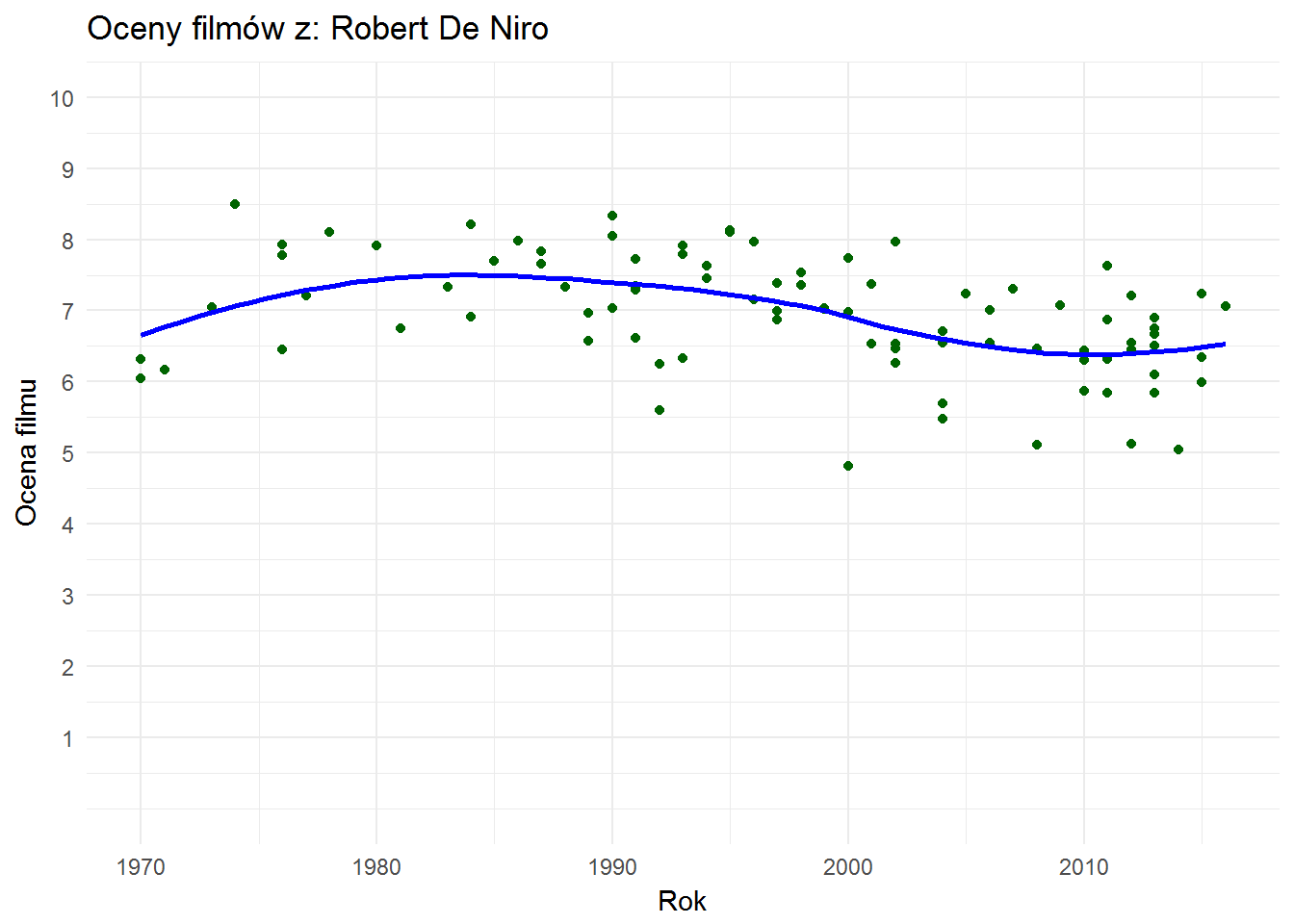
| Tytuł | Rok | Ocena |
|---|---|---|
| Ojciec chrzestny II | 1974 | 8.50 |
| Chłopcy z ferajny | 1990 | 8.33 |
| Dawno temu w Ameryce | 1984 | 8.20 |
| Kasyno | 1995 | 8.12 |
| Łowca jeleni | 1978 | 8.11 |
| Gorączka | 1995 | 8.10 |
| Przebudzenia | 1990 | 8.05 |
| Misja | 1986 | 7.98 |
| Uśpieni | 1996 | 7.96 |
| 9/11 | 2002 | 7.96 |
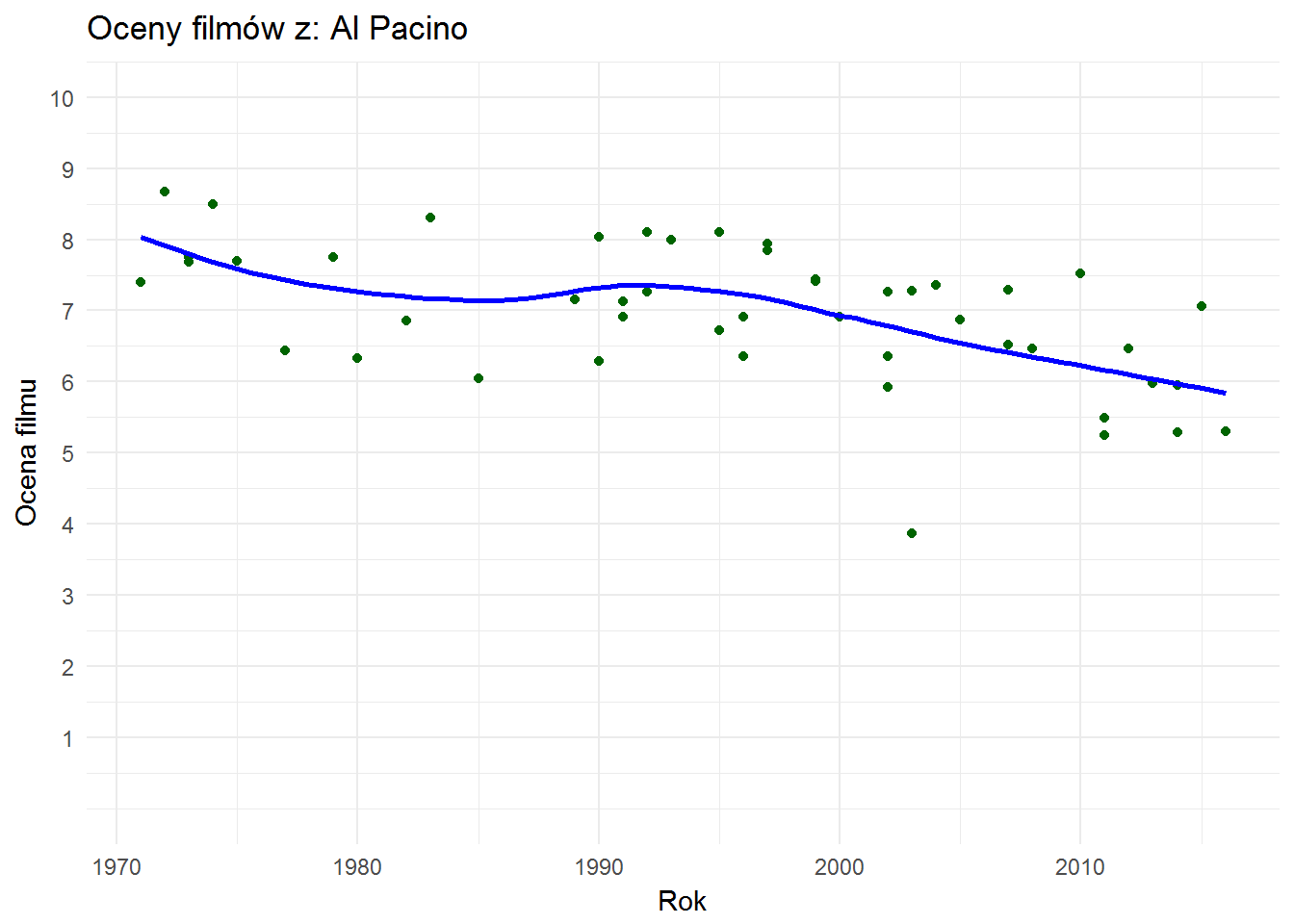
| Tytuł | Rok | Ocena |
|---|---|---|
| Ojciec chrzestny | 1972 | 8.67 |
| Ojciec chrzestny II | 1974 | 8.50 |
| Człowiek z blizną | 1983 | 8.31 |
| Gorączka | 1995 | 8.10 |
| Zapach kobiety | 1992 | 8.10 |
| Ojciec chrzestny III | 1990 | 8.03 |
| Życie Carlita | 1993 | 7.99 |
| Adwokat diabła | 1997 | 7.95 |
| Donnie Brasco | 1997 | 7.85 |
| Serpico | 1973 | 7.75 |
Teraz zajmiemy się przewidywaniami. To najciekawsza rzecz w dzisiejszym wpisie. Poniższa funkcja znajduje wszystkie filmy z podaną osobą w określonej roli i zwraca średnią ocen filmów oraz wykres ze średnią. Dzięki temu możemy skomponować dowolną grupę twórców i na podstawie średnich ocen z dotychczasowych dokonań poszczególnych osób policzyć średnią wynikową dla tak “przygotowanego” filmu.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
GetMovieMean <- function(osoba_name, osoba_rola) { id_osoby <- persons %>% filter(personName == osoba_name) %>% .[1,1] %>% as.integer() id_roli <- dict_roles %>% filter(roleName == osoba_rola) %>% .[1,1] %>% as.integer() movie_list <- persons_in_movies %>% filter(personID == id_osoby, roleID == id_roli) %>% select(filmID) movie_list <- inner_join(movie_list, movies, by="filmID") movie_mean <- mean(movie_list$filmRate, na.rm=TRUE) plot <- movie_list %>% ggplot() + geom_point(aes(filmYear, filmRate), color="lightgreen") + geom_smooth(aes(filmYear, filmRate), color="blue", se = FALSE) + labs(title = paste0(osoba_rola, ": ", osoba_name), subtitle = paste("Średnia", round(movie_mean, 2)), x = "Rok produkcji", y = "Średnia ocena") + scale_x_continuous(breaks = seq(1880, 2020, 10)) + scale_y_continuous(breaks = 1:10, limits = c(0,10)) return(list(movie_mean, plot)) } |
Sprawdźmy jaki wynik da wymyślony film:
- reżyseria Quentin Tarantino
- zdjęcia Emmanuel Lubezki
- scenariusz Charlie Kaufman
- obsada: Jack Nicholson, Leonardo DiCaprio, Cate Blanchett, Charlize Theron
(powyższe nazwiska to osoby z top w poszczególnych kategoriach według Filmwebu)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
# przygotowanie obsady i twórców: movie_cast <- data.frame(matrix(c("Quentin Tarantino", "reżyser", "Charlie Kaufman", "scenarzysta", "Emmanuel Lubezki", "zdjęcia", "Jack Nicholson", "aktor", "Leonardo DiCaprio", "aktor", "Cate Blanchett", "aktor", "Charlize Theron", "aktor"), ncol = 2, byrow = TRUE), stringsAsFactors = FALSE) # dla każdego wiersza tabeli wywołaj funkcję biorącą średnie t <- mapply(GetMovieMean, movie_cast$X1, movie_cast$X2) |
Wypadkowa ocena końcowa:
|
1 |
mean(unlist(t[1, ])) |
7.040453
A wszystkie wykresy historii ocen poszczególnych osób:
|
1 |
grid.arrange(arrangeGrob(grobs=t[2,], ncol = 2)) |
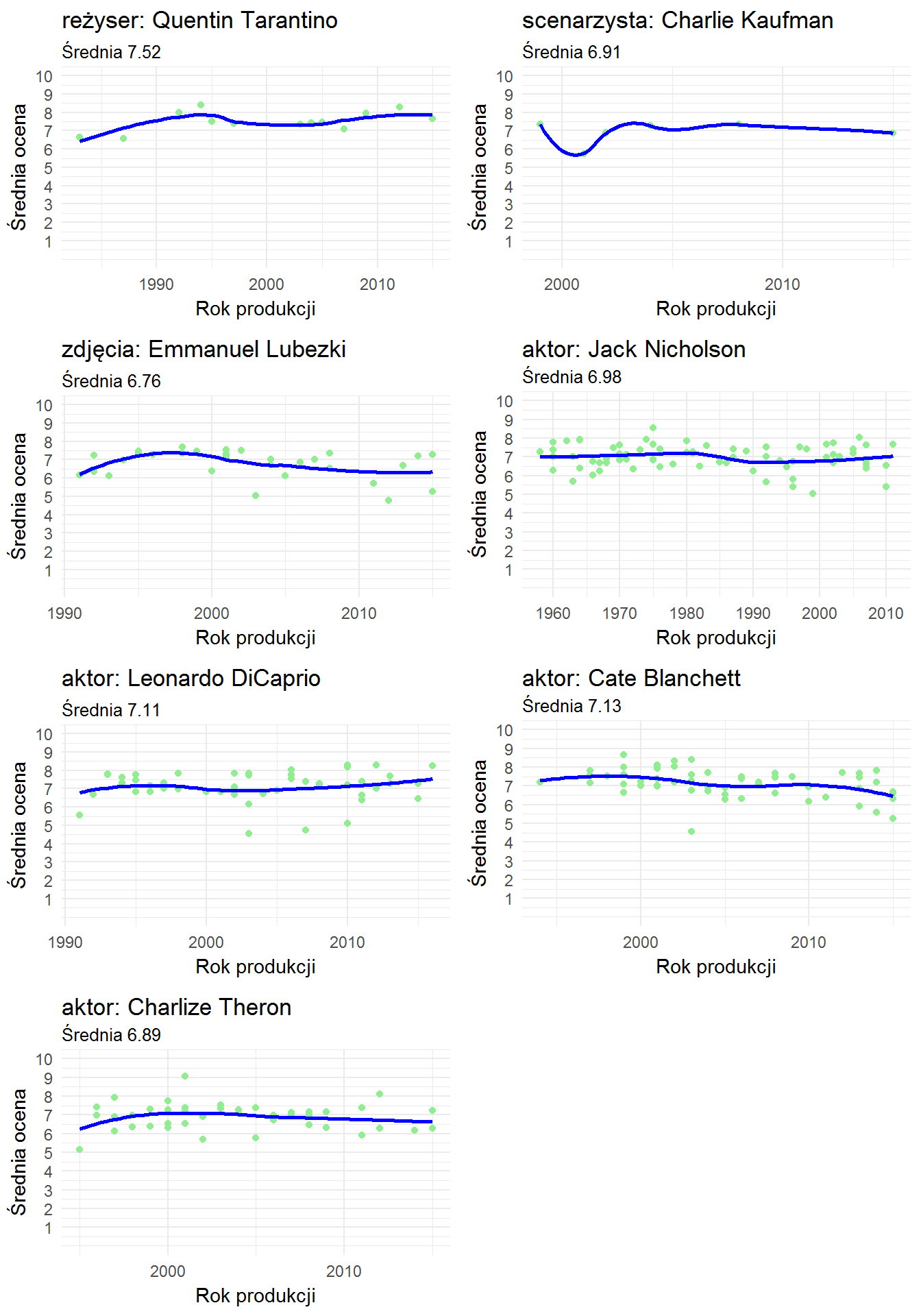
Wychodzi jakiś tam wynik (całkiem niezły – średnia 7.04 plus twórcy i obsada zachęciłaby do oglądania). A co się stanie, jak wymienimy scenarzystę? Niech Tarantino napisze również scenariusz:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
movie_cast <- data.frame(matrix(c("Quentin Tarantino", "reżyser", "Quentin Tarantino", "scenarzysta", "Emmanuel Lubezki", "zdjęcia", "Jack Nicholson", "aktor", "Leonardo DiCaprio", "aktor", "Cate Blanchett", "aktor", "Charlize Theron", "aktor"), ncol = 2, byrow = TRUE), stringsAsFactors = FALSE) t <- mapply(GetMovieMean, movie_cast$X1, movie_cast$X2) mean(unlist(t[1, ])) |
Widzimy, że średnia 7.1 jest wyższa. Czyli jeszcze bardziej zachęca :)
Teraz weźmy hipotetyczny polski film – znowu nazwiska dobrane według top Filmwebu:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
movie_cast <- data.frame(matrix(c("Wojciech Smarzowski", "reżyser", "Krzysztof Kieślowski", "scenarzysta", "Piotr Sobociński Jr.", "zdjęcia", "Tomasz Kot", "aktor", "Janusz Gajos", "aktor", "Maja Ostaszewska", "aktor", "Agata Kulesza", "aktor"), ncol = 2, byrow = TRUE), stringsAsFactors = FALSE) t <- mapply(GetMovieMean, movie_cast$X1, movie_cast$X2) mean(unlist(t[1, ])) |
6.62 to niewiele, nawet jak na polskie warunki. Widocznie ktoś tutaj zaniża wynik:
|
1 |
grid.arrange(arrangeGrob(grobs=t[2,], ncol = 2)) |
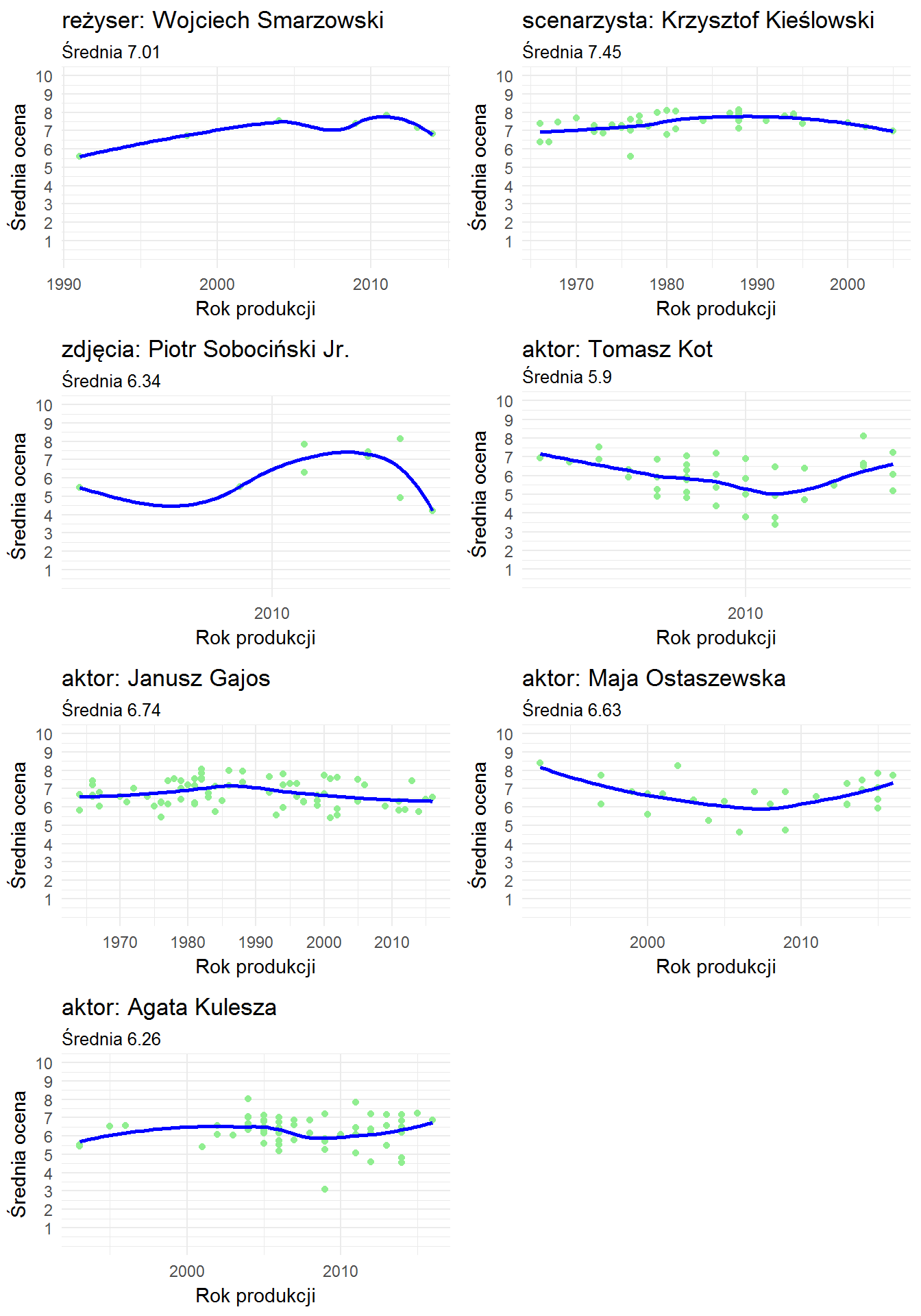
Tomasz Kot jest temu winny – miał w swojej karierze kilka słabych filmów (ten dołek po 2010), chociaż to świetny aktor.
Sprawdźmy jak nasze przewidywania sprawdzają się w przypadku nowego filmu. Weźmy jakiś film z 2016 roku, którego nie mamy w danych, a który ma już ocenę – na przykład ostatni Allen. Znamy obsadę, zobaczymy czy ta prosta metoda się sprawdza. Ten film to Śmietanka towarzyska. Co wiemy o twórcach i obsadzie? Scenariusz i reżyseria – Woody Allen, zdjęcia – Vittorio Storaro, obsada: Jesse Eisenberg, Kristen Stewart, Steve Carell, Blake Lively.
Uzupełniając odpowiednio dane i wywołując GetMovieMean() otrzymamy przewidywaną średnią ocenę 6.63, zaś na Filmwebie jest to aktualnie 6.3 (sam dałem 5 gwiazdek z komentarzem “Allen ma już swoje lata. Jessie pasuje, są żarty o Żydach, jest sposób opowiadania jak zawsze, ale nie ma pazura. Pretensjonalne w sumie”). Nasz wynik jest wyższy (te 0.3 punktu to całkiem sporo, chociaż z drugiej strony jest to tylko 3% skali 0-10).
Taki uproszczony model ma jedną podstawową wadę: nie bierze pod uwagę ostatnich dokonań osoby (czy jest na fali i w świetnej formie czy też “skończył się i utył”), a całą historię. Nie bierzemy też pod uwagę oceny osoby w filmie a ocenę całego filmu. Zdażają się przypadki kiedy dobra obsada jest zmarnowana przez słaby scenariusz albo kiepską reżyserię. Wtedy nawet dobry aktor nie uciągnie całego filmu – tak jest w przypadku wspomnianego już Tomasza Kota w jakichś “Jak się pozbyć cellulitu” czy też w filmach, którym osobiście dałem “jedynkę” (a rzadko to robię): “Wyjazdach integracyjnych” i “Ciacho”.
Jak można ulepszyć model? Być może model powinien odrzucać wartości odstające. Być może powinien brać po uwagę tylko kilka ostatnich filmów. Warto też pomyśleć o jakichś wagach dla poszczególnych “ról” w przygotowaniu filmu (reżyseria, scenariusz, obsada). Pytanie tylko co jest ważniejsze: reżyseria czy scenariusz? A może zdjęcia? Aby dobrać takie wagi można zastosować trick polegający na uczeniu modelu. Proces wyglądać powinien następująco:
- bierzemy jakiś losowy film
- sprawdzamy kto go tworzył
- zbieramy średnie z dokonań twórców, ale bez badanego filmu, być może też bez późniejszych filmów (czyli bierzemy tylko dokonania przed produkcją badanego filmu)
- powyższe kroki powtarzamy na przykład tysiąc razy. Albo sto tysięcy. Najlepiej 70-80 procent bazy (czyli w naszym przypadku jakieś 47 do 53 tysięcy filmów)
- z tak zgromadzonych danych (zmienne niezależne) w zestawieniu z prawdziwą oceną filmu (zmienna zależna) budujemy model – na przykład najprostrzą regresję liniową dla wielu zmiennych
- w modelu otrzymamy wagi poszczególnych ról, które możemy zastosować w przyszłości
Kto się pokusi? Zapraszam do dyskusji i prezentacji swoich dokonań – podrzućcie linki w komentarzach!
Pingback: Przewidywanie oceny filmu: wybór modelu | Łukasz Prokulski
Wrzuciłem dane, które były wykorzystane w obliczeniach. Niestety pochodzą z innego komputera, na którym powstał wpis więc mogą być jakieś braki lub błędy, a kolumny mogą być błędnie nazwane… na początek lepsze to niż ściąganie wszystkiego raz jeszcze :)
Plik *.Rdata ma około 42 MB, znajduje się w archiwum
Pingback: Lubimy czytać | Łukasz Prokulski
Dzień dobry, czy mógłby Pan ponownie załadować plik z danymi z Filmwebu?
Powyższy link, który kieruje do archiwum już nie działa :(
Z góry dziękuję :)
Jest szansa, że link już zadziała :)
Wszystko działa, dziękuję bardzo! :)
Hej, czy można prosić o załadowanie pliku filmweb ;)? Z góry dziękuje!
Cudowne analizy. Podziwiam i dziękuję, że dzieli się Pan swoją ogromną wiedzą. Fascynujący blog. Ukłony i pozdrowienia.